A/B Testing vs Multivariate Testing: The Complete Guide to Website Optimization in 2025
Introduction: Understanding the Two Pillars of Website Optimization
Website optimization has become the cornerstone of digital success, yet many organizations still operate without a structured approach to testing and improving their digital experiences. The difference between companies that systematically test changes and those that rely on intuition can amount to millions in lost or gained revenue annually. According to industry benchmarks, companies implementing proper testing methodologies see conversion rate improvements ranging from 15% to 300% depending on their starting point and testing rigor.
Within the landscape of experimentation, two methodologies dominate: A/B testing and multivariate testing (MVT). While these terms are sometimes used interchangeably by those unfamiliar with testing strategies, they represent fundamentally different approaches to understanding user behavior and optimizing digital experiences. Understanding when and how to deploy each method is critical for anyone responsible for website performance, user experience, or conversion optimization.
The confusion surrounding these two methodologies creates a real problem. Teams often select the wrong testing approach for their specific challenge, leading to wasted resources, incomplete insights, or delayed implementation of winning variations. Some organizations default to A/B testing for everything, missing opportunities to understand complex interactions between page elements. Others attempt multivariate tests on pages with insufficient traffic, resulting in statistically insignificant results that waste months of testing time.
This comprehensive guide cuts through that confusion by providing a deep dive into both testing methodologies. We'll explore the fundamental differences, examine when each approach shines, walk through real-world implementation scenarios, and provide a framework for deciding which methodology best serves your specific optimization goals. Whether you're optimizing e-commerce product pages, Saa S landing pages, or conversion funnels, understanding these testing approaches will transform how you make decisions about your website.
By the end of this guide, you'll understand not just what these testing methodologies are, but exactly how to deploy them strategically in your organization. You'll have clarity on sample size requirements, timeline expectations, and the specific insights each methodology can deliver. Most importantly, you'll be equipped to make faster, more confident decisions about your website optimizations based on solid data rather than guesswork or stakeholder opinions.
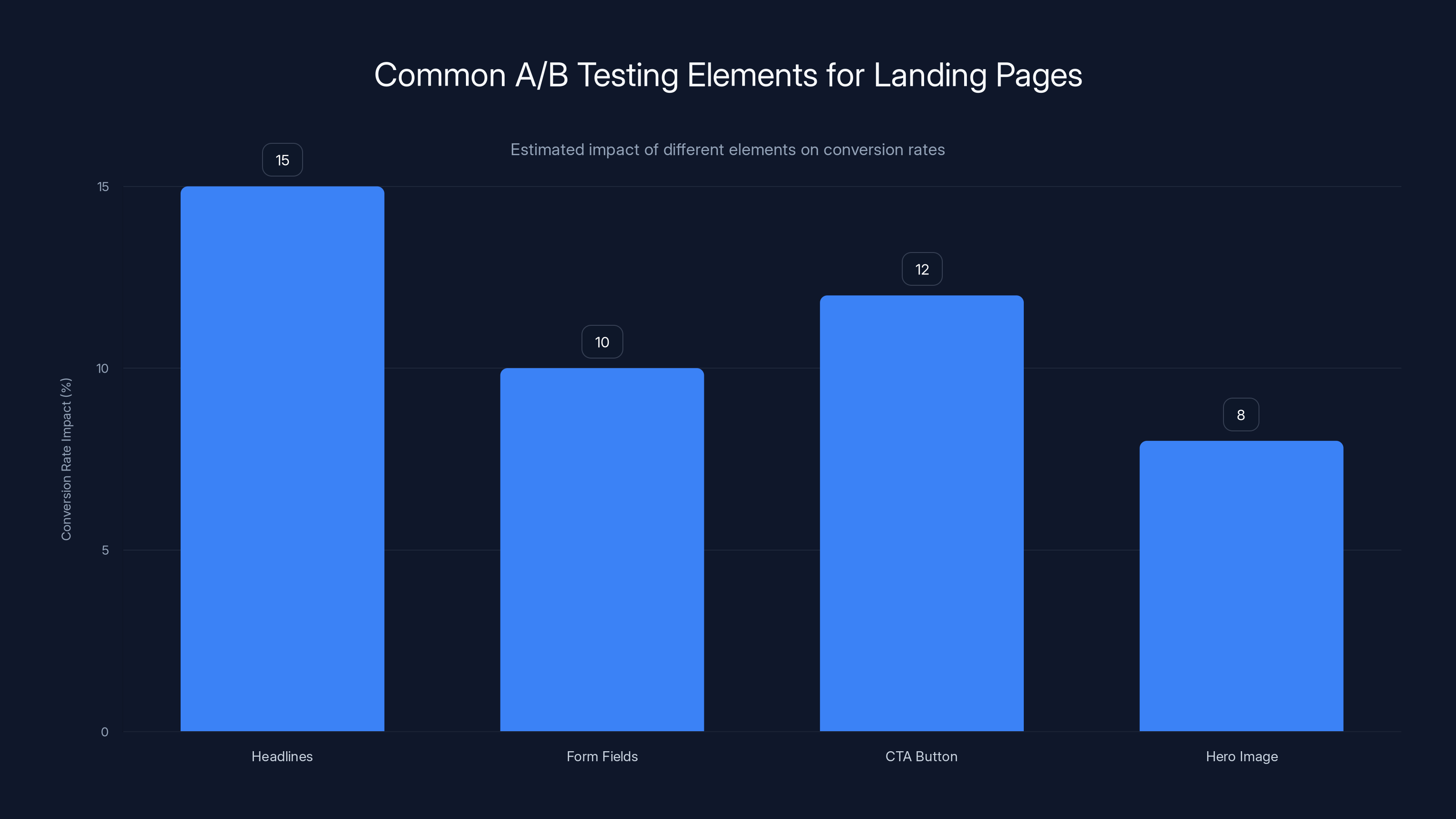
Estimated data shows that headline testing can have the highest impact on conversion rates, followed by CTA button design and form field optimization.
Chapter 1: Foundational Concepts – What Are A/B Testing and Multivariate Testing?
The Core Definition of A/B Testing
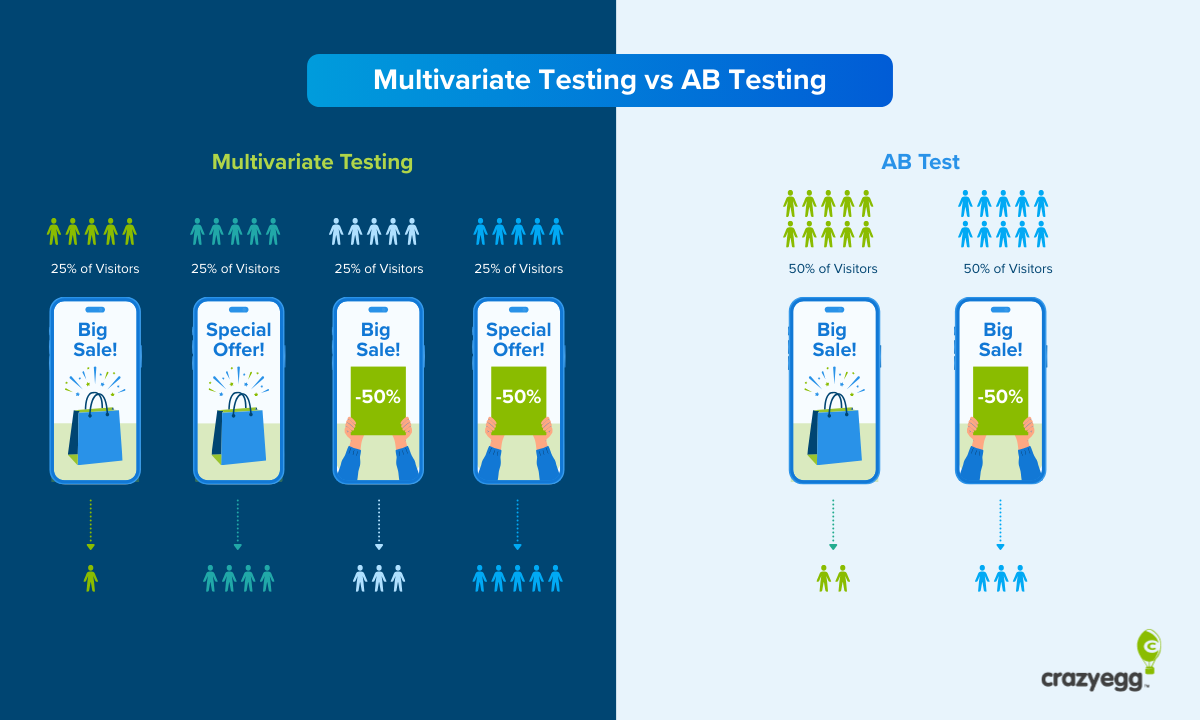
A/B testing, also called split testing or controlled experimentation, is a method where two versions of a webpage or digital element are shown to different segments of your audience simultaneously, and their performance is compared to determine which performs better against your defined success metrics. The methodology is elegantly simple: divide traffic evenly between version A (the control, or existing state) and version B (the variation, containing a single change), measure the outcomes, and determine which version achieved superior results.
The power of A/B testing lies in its clarity. Because only one element differs between the two versions, you can confidently attribute any performance difference to that specific change. If your new headline increases signups by 23%, you know with statistical certainty that the headline change caused that improvement. This direct causality makes A/B testing the gold standard for testing individual elements and understanding how specific changes impact user behavior.
A/B testing works because it applies the scientific method to digital optimization. You develop a hypothesis about how a change will impact user behavior, design an experiment to test that hypothesis, collect data from a representative sample of your audience, and then analyze results to confirm or refute your hypothesis. The methodology controls for variables so that the only difference between groups is the element you're testing.
The Core Definition of Multivariate Testing
Multivariate testing (MVT) is an advanced experimentation methodology where multiple elements on a page are changed simultaneously, and traffic is distributed across all possible combinations of those elements. If you're testing two headlines, two images, and two call-to-action button colors, the test would expose users to all eight possible combinations (2 × 2 × 2 = 8 variations), measuring how each combination performs.
Multivariate testing allows you to test element interactions and discover which combination of changes produces the optimal result. Rather than testing changes in isolation, you're exploring a multidimensional testing space where you can identify not just winning individual elements, but winning combinations that may perform synergistically better than expected. The complexity of multivariate testing is intentional—it's designed to answer more nuanced questions about how different page elements work together.
While A/B testing answers "Does this change work better?" multivariate testing answers "Which combination of changes works best?" and more importantly, "How do these elements interact with each other?" This distinction is crucial because in real-world optimization, user perception and behavior often involve interactions between elements. A strong headline might pair perfectly with one image but clash with another, and multivariate testing captures these synergistic effects.
The Statistical Foundation Underlying Both Methods
Both testing methodologies rest on the foundation of statistical hypothesis testing. When you run an A/B test or multivariate test, you're conducting an experiment designed to determine whether observed differences in performance metrics are real and reproducible, or simply the result of random variation in your sample.
At the heart of both methodologies is the concept of statistical significance. This represents the confidence level that an observed difference between variations is genuine and not attributable to chance. The industry standard significance level is 95%, meaning you want to be 95% confident that the observed difference would occur again if you repeated the experiment. Mathematically, this is expressed as a p-value less than 0.05 (
The calculation of statistical significance depends on several factors: the baseline conversion rate of your control, the size of the improvement you're trying to detect, and the number of visitors exposed to each variation. These factors interrelate in complex ways, which is why tools and calculators are essential for determining appropriate sample sizes before launching tests.
Chapter 2: The Critical Differences Between A/B Testing and Multivariate Testing
Scope and Complexity: Single Element vs. Multiple Elements
The most fundamental difference between A/B testing and multivariate testing is scope. A/B testing isolates a single variable—one element changes between the control and variation. This could be a headline, button color, form field length, image, or any single component. The constraint of testing one element at a time is actually a feature, not a limitation, because it provides absolute clarity about what caused any observed changes in user behavior.
Multivariate testing, by contrast, is fundamentally designed to test multiple elements simultaneously. Instead of changing one headline, you change the headline and the image and the button copy all at once, then measure how each combination of these changes affects performance. This approach generates more data points from the same volume of traffic because each visitor experiences one specific combination of all the elements you're testing.
Consider a practical example: You operate an e-commerce product page and want to optimize your checkout abandonment. With A/B testing, you might test whether a new headline ("Complete Your Purchase in 60 Seconds" vs. "Secure Checkout") increases completed purchases. With multivariate testing, you could simultaneously test that headline variation, two different product images, and two different trust badges, examining how all these elements interact to influence the decision to proceed with checkout.
The complexity implications are substantial. An A/B test comparing two versions is straightforward to set up and analyze. A multivariate test with six elements testing two variations each (creating 64 possible combinations) requires significantly more traffic to achieve statistical significance, more sophisticated analysis tools, and greater expertise to interpret results correctly.
Sample Size Requirements and Time-to-Significance
One of the most practical differences between these methodologies is how traffic volume impacts your ability to reach conclusive results. A/B testing is remarkably efficient with traffic. To achieve statistical significance on a typical A/B test improving conversion rates, you might need 1,000 to 10,000 visitors total, depending on your baseline conversion rate and the improvement magnitude. For many websites, this translates to one to four weeks of testing time.
Multivariate testing demands substantially more traffic because you're distributing your audience across more variations. If you're testing six elements with two variations each (64 combinations), you need approximately 16 times more traffic than an equivalent A/B test to reach the same statistical significance level for each individual combination. This mathematical reality is often overlooked by teams new to multivariate testing, leading to tests that run for months without reaching statistical significance.
The formula for sample size calculation reflects this reality. For A/B testing:
Where:
- andare critical values for significance level and power
- is the standard deviation
- represents the mean conversion rate
Multivariate testing requires multiplying this by the number of combination variations to determine traffic needs. For websites with modest traffic (under 1,000 daily visitors), this difference is often prohibitive, making A/B testing the only practical option.
Question Types Each Methodology Answers
A/B testing is optimized for answering specific, focused questions: "Does this change work?" "Which of these two approaches performs better?" "Should we implement this change?" These binary or binary-like questions naturally align with testing a single change in isolation.
Multivariate testing excels at answering more complex questions that involve combinations: "Which combination of these elements works best?" "How do these elements interact with each other?" "What is the optimal configuration of our page?" These questions require examining multiple elements in relationship to each other, not in isolation.
The difference manifests in real-world scenarios. If you're testing a new checkout flow, A/B testing would answer "Does our new three-step flow convert better than the current five-step flow?" Multivariate testing could explore "Which combination of step count, form field visibility, and progress indicator style produces the highest conversion rate?"
Statistical Power and Interaction Detection
One sophisticated advantage of multivariate testing is its ability to detect interactions between variables. An interaction occurs when the effect of one variable depends on the level of another variable. For instance, perhaps a particular headline is highly effective with one product image but mediocre with another. Multivariate testing reveals these interactions; A/B testing cannot because it never presents these combinations together.
However, this advantage comes with a caveat: multivariate testing requires substantially more traffic to detect interactions with adequate statistical power. If you lack sufficient traffic to detect main effects (individual element impacts), detecting interactions becomes even more challenging. This is why many organizations never reach the statistical power necessary to confidently claim interaction effects in their multivariate tests.

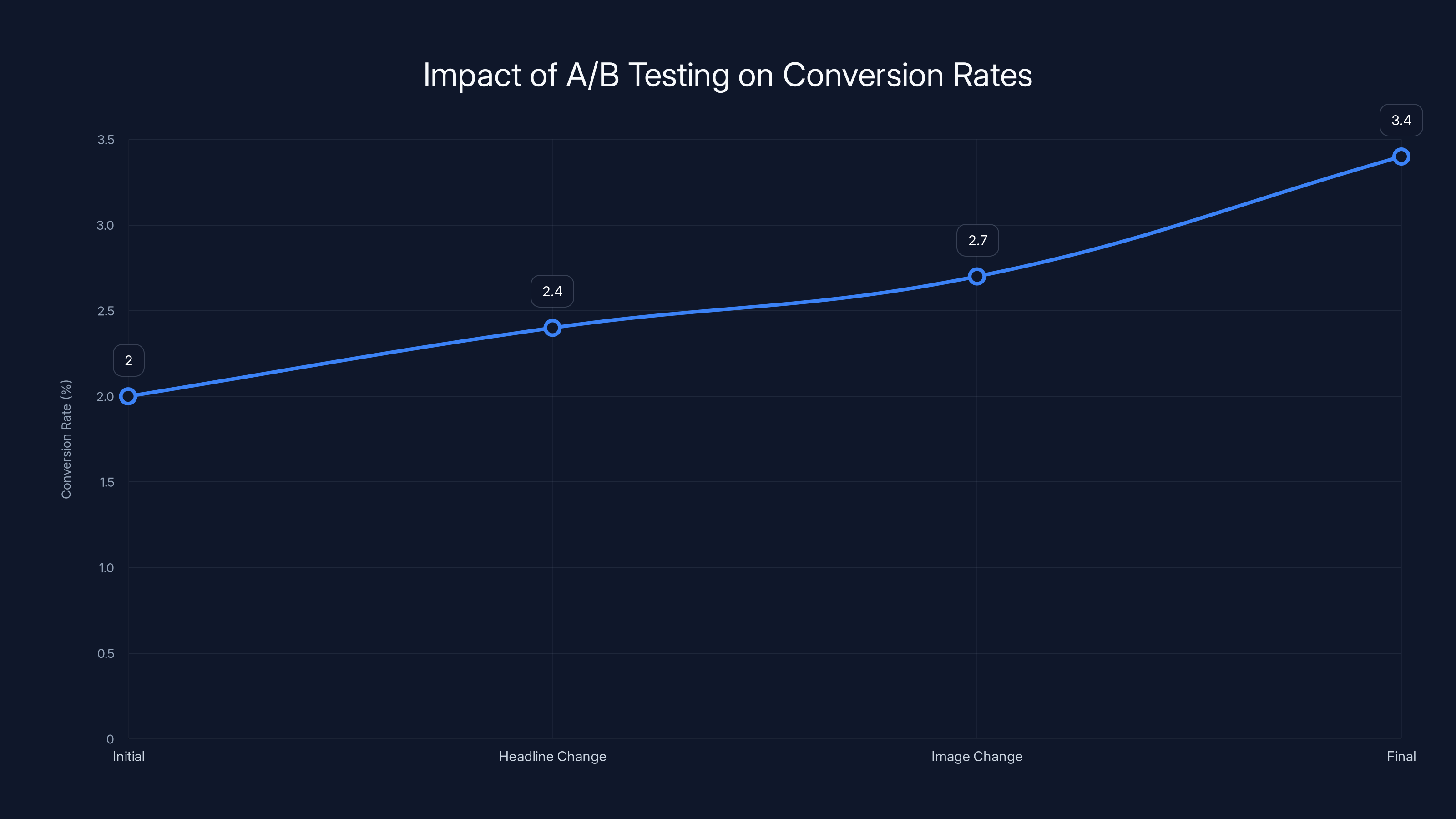
Sequential A/B testing improved the conversion rate from 2.0% to 3.4%, a 70% relative improvement, resulting in significant revenue gains. Estimated data.
Chapter 3: When to Use A/B Testing – Scenarios and Applications
A/B Testing for Landing Page Optimization
Landing pages are prime candidates for A/B testing because they typically receive substantial traffic, have clearly defined conversion goals, and involve discrete elements that can be tested individually. A typical landing page optimization sequence might involve:
Headlines and Value Propositions: Testing whether a value-focused headline ("Save 10 Hours Per Week") outperforms a benefit-focused headline ("The Smart Way to Manage Your Time") helps clarify your messaging. Saa S companies particularly benefit from this testing because headline effectiveness directly impacts qualified lead capture.
Form Field Optimization: A/B testing the number of form fields on a lead generation page frequently reveals substantial conversion improvements. Testing a two-field form (Name, Email) against a four-field form (Name, Email, Company, Phone) directly measures the friction cost of each additional field.
Call-to-Action Button Text and Design: The specific wording and visual prominence of your CTA button impacts conversion rates. Testing "Start Free Trial" vs. "Get Started Now" or testing bright orange versus muted blue button colors provides definitive answers about what drives clicks.
Hero Image Selection: Testing different hero images to determine which drives stronger engagement and conversion. A corporate headshot might outperform an abstract image, or vice versa, depending on your audience and value proposition.
The advantage in landing page testing is that changes are discrete, audience expectations are clear, and the traffic volume is typically sufficient to reach significance quickly. Most organizations can run multiple sequential landing page A/B tests monthly, progressively improving performance.
A/B Testing for Email Marketing Optimization
Email represents another domain where A/B testing excels. The inherent A/B structure of email (send time, subject line, content, CTA) makes A/B testing natural and efficient. Common email A/B tests include:
Subject Line Testing: Whether a personalized subject line ("[Name], here's your custom recommendation") outperforms a generic subject line ("Check out these products"). Subject line impacts open rates, the first critical metric in the email funnel.
Send Time Optimization: Testing whether sending emails at 9 AM on Tuesday produces higher open and click rates than 2 PM on Wednesday. This varies dramatically by audience segment and industry.
CTA Button Text: Testing whether "View Offer" or "Claim Discount" produces more clicks reveals what messaging resonates with your audience.
Email Length and Format: Testing whether long-form narrative emails outperform short, punchy emails with multiple CTAs provides insights into content preferences.
Email testing is efficient because you're working with very large sample sizes (most email campaigns reach thousands of subscribers), making it easy to achieve statistical significance. Many email marketing platforms have built-in A/B testing functionality, making implementation straightforward.
A/B Testing in E-Commerce Product Pages
Product pages handle massive traffic volumes and directly influence purchasing decisions, making them ideal for A/B testing. Typical e-commerce A/B tests include:
Product Images and Zoom Functionality: Testing whether multiple detailed product images increase conversion compared to a single lifestyle image. Some audiences respond better to technical specifications visualized, others to lifestyle aspirational imagery.
Product Description Length and Format: Testing whether bullet-point specifications outperform narrative product descriptions, or whether including video reviews impacts purchase likelihood.
Pricing Display and Options: Testing whether showing the price prominently at the top of the fold versus making users scroll to find it affects engagement. Testing whether showing "3 payments of
Trust Elements: Testing the placement and presentation of reviews, ratings, trust badges, and guarantees. The specific positioning of a "30-day money-back guarantee" statement might impact conversion rates differently than the same guarantee shown as a badge.
Shipping and Return Information: Testing whether prominently displaying free shipping information above the fold increases conversion compared to hiding it until checkout.
E-commerce A/B testing typically yields rapid insights because of high traffic volumes. Major e-commerce platforms can identify winning variations in days rather than weeks.
A/B Testing for UI/UX Changes
When making significant interface changes—like redesigning navigation, restructuring page layout, or changing button placements—A/B testing ensures changes improve rather than harm user behavior. Common UI/UX A/B tests include:
Navigation Structure: Testing a traditional horizontal navigation against a newer sidebar navigation, or testing a mega-menu against a standard dropdown menu. The choice impacts not just initial clicks but downstream behavior.
Page Layout and Content Hierarchy: Testing a single-column layout against a multi-column layout, or testing content reordering to determine optimal information hierarchy.
Search Functionality: Testing whether adding a prominent search box to your page increases engagement, or whether predictive search suggestions improve search success rates.
Filter and Sort Options: For content-heavy pages, testing different filtering and sorting approaches helps users find relevant content faster.
UI/UX testing is valuable because it measures actual user behavior impact, preventing misguided redesigns based on designer preferences rather than user preferences. A beautiful new design might actually decrease conversions if it makes key information harder to find.
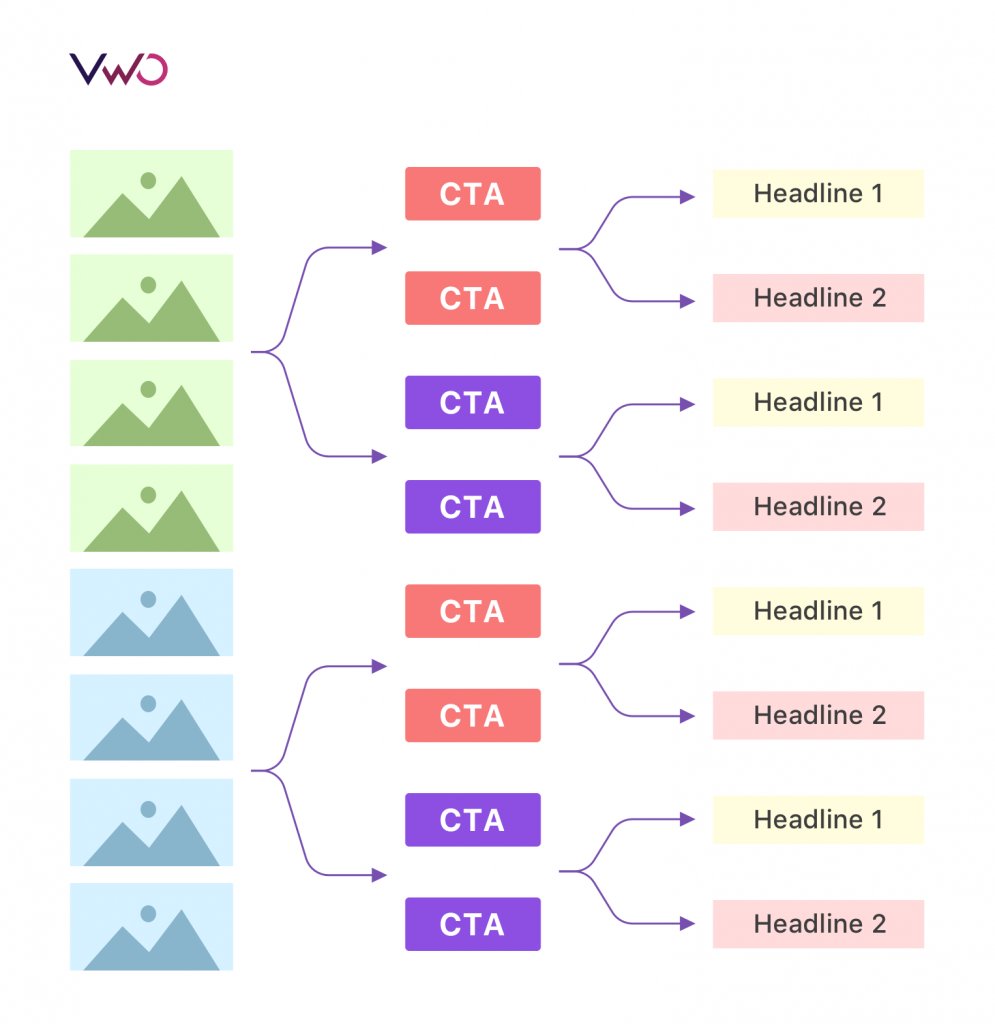
Chapter 4: When to Use Multivariate Testing – Advanced Scenarios
Multivariate Testing When You Have Abundant Traffic
The primary constraint of multivariate testing is traffic volume. Websites receiving 50,000+ daily visitors can run multivariate tests where websites receiving 5,000 daily visitors cannot. With abundant traffic, multivariate testing becomes practical because you can distribute visitors across numerous combinations without extending test duration excessively.
A major e-commerce retailer might have sufficient traffic to simultaneously test three different product images, two different headline variations, and two different CTA button colors (12 combinations total). With sufficient traffic, this test might reach statistical significance in one to two weeks, whereas the same test at lower traffic volumes might require two to three months.
The advantage is that you gather multi-dimensional optimization data in the time it would take to run several sequential A/B tests. You discover not just which individual elements work best, but how they work together. This is particularly valuable when you suspect that element interactions significantly influence performance.
Multivariate Testing for Complex Page Elements
Some pages involve inherent complexity that makes multivariate testing logical. Landing pages for complex B2B products, high-involvement purchases, or services with multiple value propositions sometimes benefit from multivariate testing because the value proposition itself is multifaceted.
Consider a Saa S platform selling to enterprises. The value proposition involves multiple dimensions: security, scalability, integration capabilities, support quality, and cost efficiency. A multivariate test might explore different ways to emphasize and present these multiple value dimensions. Testing different headline pairings, image selections, and social proof elements simultaneously reveals which combination most resonates with your target buyer.
Similarly, pages targeting multiple audience segments simultaneously (like a product page appealing to both technical users and business decision-makers) might benefit from multivariate testing to optimize for diverse needs. One headline and image combination might appeal more to technical users while another appeals to business buyers.
Multivariate Testing for Interaction Hypothesis Validation
When you have a specific hypothesis about how page elements interact, multivariate testing can be designed to validate that hypothesis. For instance, you might hypothesize that a particular image style works best with a certain headline tone, but poorly with another headline tone.
To test this interaction hypothesis, you'd design a multivariate test specifically to measure how these two elements work together. If the test confirms the interaction (that element A only works well with element B, but not with element C), you've gained valuable insight that guides future optimization efforts. Sequential A/B tests couldn't surface this insight because you'd never test these combinations together.
This is the genuine power of multivariate testing—it's not about testing more things simultaneously for efficiency's sake, but about measuring specific interactions you believe significantly influence performance. When you have traffic to support it and a clear hypothesis about interactions, multivariate testing provides unique value.
Multivariate Testing for Experience Optimization
Beyond testing individual page elements, multivariate testing can optimize entire experiences or user journeys. A company might multivariate test different onboarding sequences, testing variations in step order, content, timing, and interaction styles simultaneously to identify the optimal onboarding experience.
For example, a Saa S product might test whether onboarding should progress: (1) Setup-first (configure your workspace) then learn, or (2) Learn-first (understand features) then setup; (3) whether progress indicators are helpful or anxiety-inducing; (4) whether video tutorials are helpful or overwhelming. These four dimensions create 8 variations of the onboarding experience. With sufficient traffic, measuring which complete onboarding approach produces the highest activation rate provides more holistic optimization insight than testing individual elements sequentially.
Chapter 5: Sample Size and Traffic Requirements – The Practical Reality
Calculating A/B Test Sample Size
Determining adequate sample size is critical to ensure test results are statistically valid. Too small a sample and you risk drawing conclusions from random variation. The necessary sample size depends on four factors:
Baseline Conversion Rate: Your starting conversion rate. If 10% of visitors convert, you need more samples than if 50% convert, because lower conversion rates create more variability.
Minimum Detectable Effect: The smallest improvement you want to reliably detect. Do you want to detect a 5% relative improvement? 10%? 25%? Smaller improvements require larger samples. If your baseline is 10% conversion and you want to detect a 1% absolute improvement (10% → 11%, or 10% relative improvement), you need considerably more visitors than if you want to detect a 5% absolute improvement (10% → 15%, or 50% relative improvement).
Statistical Significance Level: The confidence level you want in your results. The industry standard is 95% confidence (p < 0.05). Some organizations use 90% or 99%, affecting sample size requirements.
Statistical Power: The probability of detecting an effect if one truly exists. The standard is 80% power, meaning if a real effect exists, you'll detect it 80% of the time. Higher power requirements increase sample size.
For a typical A/B test with a 10% baseline conversion rate, testing for a 1% absolute improvement (10% to 11%) with 95% significance and 80% power, you'd need approximately 14,000 visitors total (7,000 per variation). For a 2% absolute improvement, you'd need approximately 3,500 visitors total.
Most A/B testing calculators use this formula or variants:
Where
Calculating Multivariate Test Sample Size
Multivariate testing requires substantially more traffic. If you're testing six elements with two variations each, creating 64 combinations, you roughly need 64 times the visitors of an equivalent A/B test. This isn't a strict multiplier—the exact requirement depends on whether you're powering main effects or interactions—but it illustrates the traffic multiplier effect.
With the same baseline and effect assumptions requiring 14,000 visitors for an A/B test, a 64-combination multivariate test would need approximately 896,000 visitors to achieve comparable statistical power on each combination. This would require 3-6 months of testing for most websites.
This reality explains why multivariate testing is only practical for high-traffic websites. A website with 5,000 daily visitors can run dozens of A/B tests yearly. The same website can realistically run only one or two multivariate tests annually due to traffic constraints.
Traffic Velocity and Time-to-Results
Beyond absolute visitor counts, traffic velocity—how quickly you accumulate visitors—determines how long a test must run. A website with 10,000 daily visitors running an A/B test needing 14,000 visitors would run for approximately 7 days. The same website running a multivariate test needing 896,000 visitors would run for approximately 6 months.
This timeline difference is crucial because the longer a test runs, the greater the risk of:
Novelty Effects: User behavior may change once the novelty of a new design wears off, or conversely, the new version may initially seem strange to users.
External Variables: Market conditions, seasonality, competitor actions, and other external factors may change during the test period, confounding results.
Traffic Source Changes: The composition of your traffic may shift during a long test period, meaning you're not testing against a consistent audience.
Testing Integrity Issues: Longer tests are more prone to multiple comparison problems if you peek at interim results.
These considerations suggest that shorter tests are preferable when possible. This is another argument for A/B testing sequential elements rather than attempting comprehensive multivariate tests, when traffic volume permits.
Traffic Requirements by Conversion Rate and Website Type
Different websites have dramatically different baseline conversion rates and traffic volumes:
E-Commerce Websites typically have 1-5% conversion rates and 10,000+ daily visitors. Sample size needs are approximately 5,000-20,000 visitors per element for standard improvements. Timeline: 1-4 weeks.
B2B Saa S Websites typically have 2-10% conversion rates (free trial signups) but might have 1,000-5,000 daily visitors. Sample size needs are approximately 2,000-10,000 visitors per element. Timeline: 2-8 weeks.
Lead Generation Websites typically have 5-20% conversion rates and variable traffic. With good traffic, sample needs are 1,000-5,000 visitors. Timeline: 1-4 weeks.
Low-Traffic Websites (under 1,000 daily visitors) struggle with A/B testing on smaller improvement margins (under 20% relative improvement) and should avoid multivariate testing entirely.

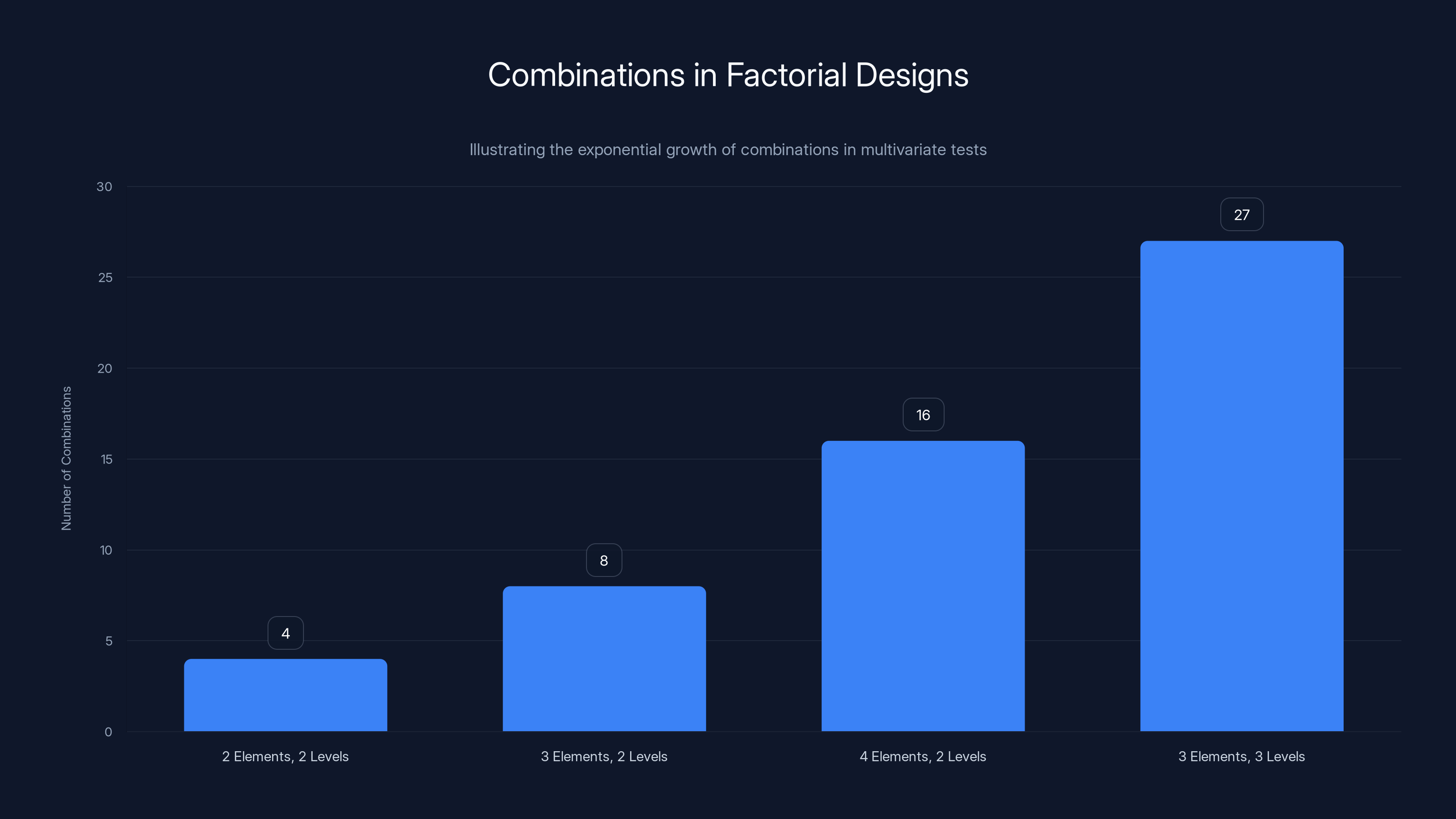
The number of combinations in factorial designs grows exponentially with more elements and levels. For example, 4 elements at 2 levels result in 16 combinations, while 3 elements at 3 levels result in 27 combinations.
Chapter 6: Implementation Deep Dive – How to Run A/B Tests Effectively
Pre-Test Planning and Hypothesis Development
Successful A/B testing begins long before you launch the test. The pre-test phase establishes the foundation for meaningful results. Start by conducting a hypothesis workshop with your team:
Define the Problem: What metric are you trying to improve? Identify the specific user behavior you want to change. Are you trying to increase form submissions, product purchases, email signups, time on page, or something else? Clarity on the metric eliminates ambiguity later.
Develop Hypotheses: Based on user research, analytics, user testing, and stakeholder input, generate multiple hypotheses about what might improve that metric. Rather than testing a single idea, develop 3-5 distinct hypotheses. For a signup form, you might hypothesize that a shorter form increases submissions, that social proof increases trust and submissions, or that emphasizing time-to-value increases submissions.
Prioritize Hypotheses: Not all hypotheses are equally valuable. Prioritize based on (1) expected impact magnitude, (2) likelihood of success based on evidence, and (3) cost and effort to implement. High-impact, high-probability hypotheses should be tested first.
Define Success Metrics: Beyond your primary metric, define secondary metrics and guardrail metrics. Primary metrics measure your main objective. Secondary metrics measure other valuable impacts (engagement, retention, customer satisfaction). Guardrail metrics ensure you don't improve the primary metric while harming other important metrics (conversion rate increases while average order value decreases).
Test Design and Creative Development
Once you've selected a hypothesis to test, design the variation thoughtfully. The variation should isolate the single change you're testing while keeping everything else constant.
Develop Compelling Variations: The variation shouldn't be a slight modification; it should represent a meaningfully different approach. If testing headlines, the variation shouldn't be a minor word change but a fundamentally different headline approach (benefit-focused vs. urgency-focused, for instance).
Maintain Design Consistency: Beyond the element you're changing, the variation should maintain consistent design, branding, and functionality. The goal is to isolate the impact of your change, not introduce multiple confounding variables.
Control for Novelty: Be aware that users often respond differently to new designs simply because they're new. This novelty effect fades over time. Running tests longer helps distinguish true preference from novelty effect.
Technical Implementation and Traffic Allocation
Technically implementing your test requires careful setup to ensure valid results. Your testing platform (Optimizely, VWO, Google Optimize, or another solution) handles traffic allocation and variation assignment.
Random Visitor Assignment: Traffic allocation must be truly random. Avoid assigning the first half of daily visitors to the control and the second half to the variation, as daily traffic composition may change. Truly random assignment ensures each visitor has equal probability of seeing either variation, eliminating bias.
Sufficient Randomization Period: During the first 24-48 hours of testing, don't trust results. Let traffic allocation run long enough to smooth daily variations in visitor composition, traffic sources, and behavior. Only begin monitoring results after this period.
Cross-Browser and Device Testing: Before launching to all traffic, manually test your variation across browsers (Chrome, Firefox, Safari, Edge) and devices (desktop, tablet, mobile) to ensure technical functionality. A broken variation biases results toward the control.
Monitoring and Analysis
Once launched, resist the temptation to peek at results constantly. Frequent peeking introduces multiple comparison problems—if you check results every day and stop the test when you see statistical significance, you're essentially running dozens of mini-tests, inflating false positive rates.
Set a Pre-Planned Duration: Before launching, determine your sample size requirement and calculate how long the test must run. Commit to running the test for that duration regardless of interim results.
Monitor for Technical Issues: While respecting the no-peeking principle, do monitor for technical problems. If your variation has a broken checkout flow, crashes on mobile, or experiences other technical failures, pause and fix before resuming.
Analyze When Complete: Once the test reaches your pre-planned sample size, conduct proper statistical analysis. Calculate the relative uplift in your primary metric, the confidence interval around that estimate, and the statistical significance (p-value).
Chapter 7: Implementation Deep Dive – How to Run Multivariate Tests Effectively
Pre-Test Analysis and Factorial Design
Multivariate testing requires more sophisticated pre-test analysis. You must decide which elements to test and how many variations of each element to include.
Element Selection: Select only elements where you have genuine hypotheses about individual impact and potential interactions. If you're testing six elements, you need clear reasoning for each. Random element selection creates confusing results that don't guide future optimization.
Variation Levels: For each element, determine how many variations to test. Two variations per element creates a "2-level factorial design." A test with four elements at two levels creates
Factorial Design Considerations: Full factorial designs (testing all combinations) are most common but extremely traffic-intensive. Fractional factorial designs test a subset of combinations, reducing traffic requirements but sacrificing some information. For instance, a "quarter-factorial" design tests only 1/4 of combinations. This works if you're willing to assume certain interactions don't exist, but requires careful design.
Pre-Test Traffic Modeling
Before launching a multivariate test, rigorously model whether you have sufficient traffic to reach statistical significance. This is often where MVT efforts founder—teams launch tests, run them for months, then discover they lack sufficient traffic for any conclusive results.
Sample Size Calculation for Interactions: If you're specifically powering the test to detect interaction effects (not just main effects), sample size requirements increase substantially. Detecting main effects requires one multiplier; detecting interactions requires a larger multiplier.
Conservative Assumptions: When estimating whether you have sufficient traffic, use conservative assumptions. Rather than assuming your best-case scenario traffic and best-case scenario effect size, use expected traffic and modest effect estimates. This prevents launching tests you can't actually complete successfully.
Pre-Planning Element Combinations: Specify in advance which combinations you're specifically powering. Are you powering all combinations equally? Are you focusing on detecting main effects (individual element impacts)? Are you specifically interested in particular interactions? This determines sample size requirements.
Multivariate Test Execution
Executing multivariate tests requires greater technical sophistication than A/B testing. Most MVT tests use testing platforms' built-in multivariate functionality to handle the complexity of combination assignment and analysis.
Combination Assignment and Tracking: Your testing platform assigns each visitor to one specific combination of all tested elements and tracks their behavior against that combination. This assignment must be consistent (if a visitor returns, they see the same combination), random, and properly balanced across combinations.
Guardrail Metrics and Stopping Rules: Multivariate tests require careful monitoring because combinations might significantly underperform the control. Some testing methodologies involve stopping rules—if a combination drops conversion rate by 25% or more, remove that combination from the test and reallocate traffic to remaining combinations.
Interim Analysis Caution: Multivariate tests are even more vulnerable to multiple comparison problems than A/B tests. With 16 combinations, if you analyze results after each is seen 1,000 times, you're conducting 16 comparisons, inflating false positive rates. Use appropriate statistical corrections if conducting interim analysis (Bonferroni correction, for instance).
Multivariate Analysis and Interaction Interpretation
Analyzing multivariate results requires more sophisticated statistical methods than A/B test analysis. Rather than simple comparison between two groups, you're analyzing how each element impacts the outcome and whether elements interact.
Main Effects Analysis: Calculate the performance impact of each individual element across all combinations. For instance, across all 16 combinations, does element A perform better at level 1 or level 2? This is the main effect for element A.
Interaction Analysis: Determine whether the impact of element A depends on which level of element B you're testing. If element A performs better at level 1 when element B is level 1, but element A performs better at level 2 when element B is level 2, that's an interaction effect.
Implementation Decisions: Translating multivariate results into implementation decisions requires judgment. You can't always implement every high-performing element in every combination; you might only be able to implement one set of changes. Decide whether to implement the single best-performing combination, or whether to implement combinations of the top-performing individual elements.

Chapter 8: Statistical Significance, Power, and Common Mistakes
Understanding Statistical Significance
Statistical significance means you're confident that an observed difference between variations is real and not due to random variation. The industry standard is 95% confidence, denoted as p < 0.05. This means there's less than a 5% probability that the observed difference occurred by chance.
Critically, statistical significance does not mean the difference is practically important. A 0.5% relative improvement might be statistically significant with large sample sizes but practically negligible if it doesn't offset the effort to implement. Conversely, a 5% improvement might not reach statistical significance with small sample sizes but could be practically important if you implement it.
P-values and Confidence Intervals: Rather than just reporting "p < 0.05," report confidence intervals around your estimate. If an A/B test shows a 15% relative improvement with a 95% confidence interval of 8% to 22%, you know the true improvement is likely between these bounds. This communicates uncertainty in your estimate.
Type I and Type II Errors in Testing
Two types of errors can occur when analyzing test results:
Type I Error (False Positive): Concluding there's a difference when none exists. This is the risk controlled by significance level (5% at p < 0.05). You incorrectly implement a change thinking it's an improvement when it actually has no effect.
Type II Error (False Negative): Concluding there's no difference when one actually exists. This is controlled by statistical power (typically 80%). You miss a true improvement because your sample size was insufficient.
These errors have different consequences. A false positive might lead to implementing a meaningless change. A false negative might lead to abandoning a promising change prematurely. Both are costly, but in different ways.
Common Statistical Mistakes in Testing
Peeking and Multiple Comparisons: Perhaps the most common mistake is analyzing test results before reaching the pre-planned sample size. Each interim analysis inflates false positive rates. If you peek daily and stop when you see significance, you're increasing false positive rate from 5% to potentially 30% or higher.
Ignoring Sample Size Requirements: Launching tests without calculating adequate sample size leads to underpowered tests that can't detect real effects. Running a test to "see what happens" without statistical planning is poor methodology.
Segmentation Without Adjustment: Analyzing your test results across multiple segments (by geography, traffic source, device) without statistical adjustment for multiple comparisons inflates false positive rates. Each additional segment comparison increases the chance of finding spurious significance.
Novelty Effect Confusion: Launching a test for too short a duration and mistaking novelty effects for true preference differences. Some users respond positively to change simply because it's new. Running tests longer helps distinguish genuine preference from novelty.
Assuming Causality Without Controls: Without proper experimental control (random assignment, sufficient sample size, statistical analysis), you can't claim causality. Observational data might show correlation, but only proper experimentation establishes cause-and-effect.

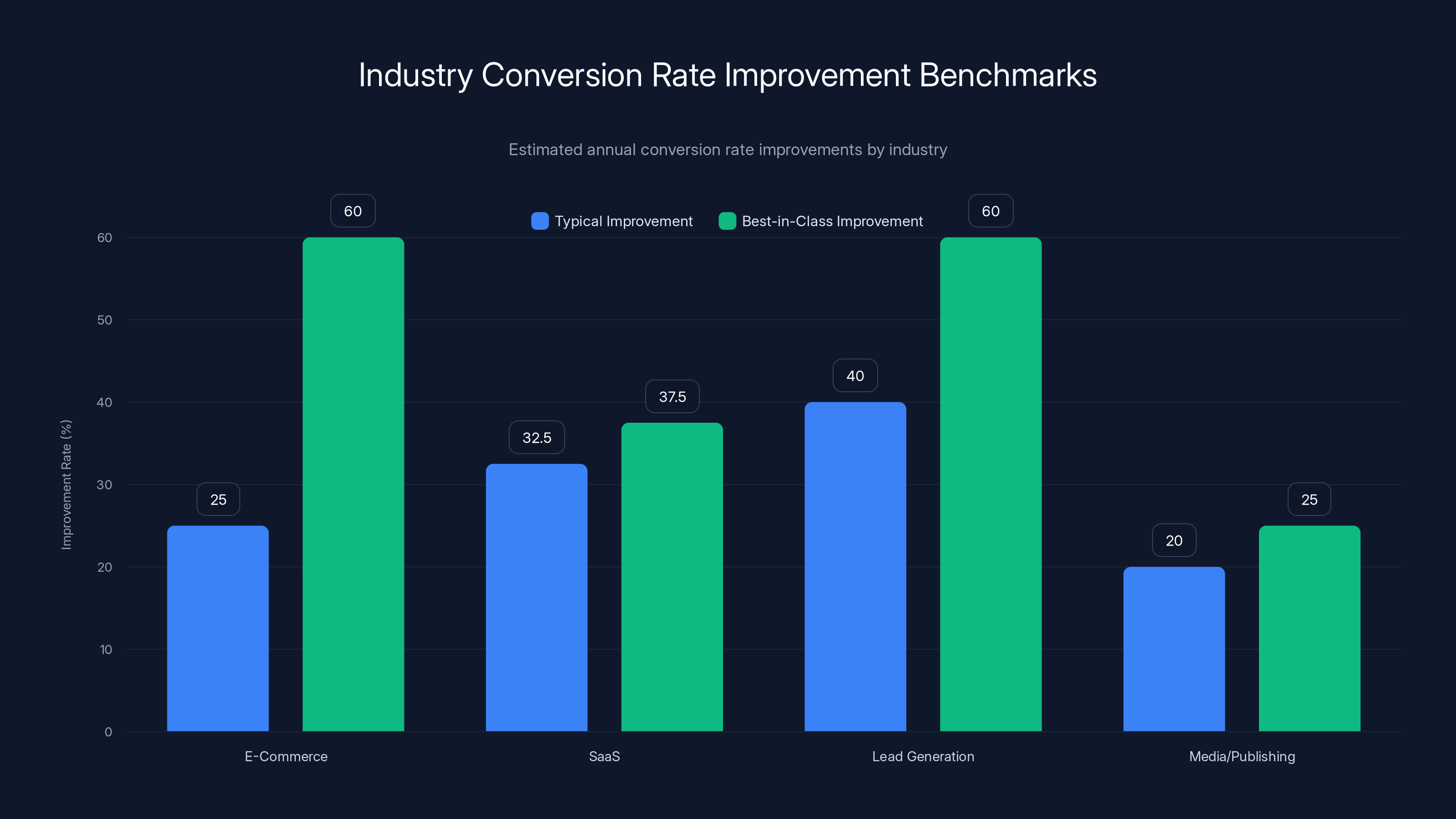
E-Commerce and Lead Generation industries show the highest potential for conversion rate improvements, with best-in-class organizations achieving up to 80% and 60% improvements respectively. (Estimated data)
Chapter 9: Real-World Case Studies and Performance Impact
E-Commerce Case Study: Product Page Optimization
A mid-size e-commerce retailer received 25,000 daily visitors but had a 2% product page conversion rate to purchase. The company wanted to increase conversions but wasn't sure which changes would impact the metric.
Using A/B testing methodology, the team tested headline changes first. The original headline was "Premium Quality Product from Trusted Brand." The variation tested "Free Shipping on Orders Over $50 + 30-Day Returns." This shift from quality positioning to value positioning increased conversion rate from 2.0% to 2.4%—a 20% relative improvement.
With that learning, they tested a second element: product images. The original used lifestyle images showing the product in context. The variation tested close-up product detail images. This change increased conversion from 2.4% to 2.7%—an additional 12.5% relative improvement.
Through sequential A/B testing over three months, testing seven different elements, the company improved product page conversion rate from 2.0% to 3.4%—a 70% relative improvement. This translated to 300+ additional daily purchases, approximately **
This case illustrates the power of systematic testing. Each individual test improved conversion by 10-20%. Combined, these improvements were multiplicative, not additive, demonstrating how optimization is an iterative process rather than a one-time effort.
Saa S Case Study: Landing Page Multivariate Testing
A B2B Saa S platform targeting two distinct user personas (IT security teams and compliance officers) received 5,000 daily visitors to their main landing page. The page had a 5% free trial signup rate, and the company wanted to increase it to 7%+.
The team hypothesized that different headlines, value propositions, and social proof resonated with their two personas. Rather than running sequential A/B tests (which would take months given the traffic level), they designed a multivariate test:
Element 1 - Headline: Persona-specific ("For IT Security Teams" vs. "For Compliance Officers") vs. universal ("Secure Your Systems, Simplify Compliance")
Element 2 - Value Proposition: Security-focused vs. compliance-focused vs. efficiency-focused
Element 3 - Social Proof: Customer logos vs. customer testimonials vs. certification badges
This 3×3×3 multivariate test created 27 combinations. With 5,000 daily visitors, the test required approximately 45,000 total visitors, or about 9 days of traffic.
Results revealed a significant interaction effect: persona-specific headlines worked well with persona-matched value propositions, but poorly with mismatched propositions. The IT Security Personas + IT Security Value Prop + Certification Badges combination achieved 7.8% conversion—a 56% relative improvement. However, the Compliance Officers persona + Security Value Prop + Logos combination dropped to 3.2%, a 36% relative decrease.
This interaction effect wouldn't have been discovered through sequential A/B testing. The company implemented the winning combination, increasing overall signup rate to 7.2%. The multivariate approach revealed insights that guided all future optimization efforts.
Email Marketing Case Study: Subject Line and Send Time Testing
An e-commerce platform with 500,000 email subscribers wanted to optimize open rates on its weekly promotional email. The baseline open rate was 18%.
The marketing team ran a series of A/B tests over eight weeks:
Week 1-2: Subject Line Testing: Tested "Save 25% This Weekend" vs. "Last Chance: 25% Off Sale" (personalized subject with recipient name). The personalized version achieved 22% open rate (+22% relative improvement).
Week 3-4: Send Time Testing: Tested Tuesday 9 AM vs. Thursday 2 PM. Thursday 2 PM achieved 24% open rate (+9% relative improvement over Tuesday).
Week 5-6: Length Testing: Tested long-form promotional emails (5 products featured) vs. short-form (single highest-value product featured). Short-form achieved 23% click-through rate vs. 19% for long-form (+21% relative improvement in clicks).
Week 7-8: CTA Button Testing: Tested "Shop Sale" vs. "Unlock Offer" button text. "Unlock Offer" achieved 25% click-through rate vs. 23% for "Shop Sale" (+9% relative improvement).
Final email (combining all winning elements) achieved 26% open rate and 26% click-through rate, representing 44% open rate improvement and 37% click-through improvement over baseline. Given the massive email list, this translated to approximately 39,000 additional clicks weekly to promotional content, driving significant incremental revenue.
This case illustrates the iterative power of sequential A/B testing. Each test revealed one piece of optimization, and combined improvements were substantial.

Chapter 10: Tools and Platforms for Testing
A/B Testing Platforms: Capabilities and Selection
Modern A/B testing platforms range from simple to sophisticated, each with tradeoffs:
Google Optimize (Deprecated): Integrated with Google Analytics, Google Optimize was the free option for Google users but was discontinued and migrated to Google Analytics 4. For some organizations, this represents the lowest-cost entry point, though it had limitations compared to dedicated testing platforms.
Optimizely: Enterprise-grade platform with sophisticated targeting, multivariate testing, personalization, and integration capabilities. Pricing scales with traffic and features, making it expensive for small organizations but offering comprehensive functionality for enterprises.
VWO (Visual Website Optimizer): Mid-market platform offering A/B testing, multivariate testing, heat mapping, and session recording. Pricing is more accessible than Optimizely, and the interface is highly usable, making it popular with growing companies.
Convert: Dedicated A/B testing platform (no page builder or personalization features) with strong statistical methodology, detailed experiment reports, and high reliability. Attracts organizations prioritizing statistical rigor and data privacy.
Unbounce: Landing page builder with built-in A/B testing, popular for quick landing page optimization without coding. Limited for testing existing website pages.
Platform selection should consider your technical capabilities, traffic volume, budget, integration needs, and required features. Teams with engineering resources might use lightweight tools like Convert and handle targeting themselves. Non-technical teams might prefer visual builders like Unbounce.
Analytics Platforms and Data Integration
A/B testing platforms must integrate with your analytics infrastructure to measure test results. Integration approaches include:
Native Integrations: Testing platforms with built-in integrations to Google Analytics, Adobe Analytics, or Mixpanel automatically send test assignment data to your analytics platform, enabling test analysis within your existing analytics interface.
Custom Event Tracking: For platforms lacking native integrations, custom event tracking sends test data to your analytics platform via manual code implementation. This requires engineering resources but offers maximum flexibility.
Data Warehouse Integration: Advanced organizations send testing data to data warehouses (Snowflake, Big Query, Redshift) for analysis alongside other business data. This enables sophisticated cross-functional analysis but requires data engineering capabilities.
Statistical Analysis Tools and Sample Size Calculators
Beyond testing platforms, several statistical tools support rigorous test analysis:
ABBA: A free Bayesian approach to A/B testing that allows continuous monitoring and early stopping, eliminating the need for pre-planned sample sizes. Useful when conventional frequentist approaches are overly conservative.
Evan Miller's Sample Size Calculator: Online calculator for determining A/B test sample size based on baseline conversion, minimum detectable effect, significance level, and power. Quick and reliable.
Python and R Libraries: For organizations with data science capabilities, scipy and other libraries enable custom statistical analysis, simulations, and sensitivity analyses. Necessary for multivariate analysis.
Power Analysis Tools: G*Power and other tools perform complex power analyses for various statistical tests and designs.

Chapter 11: Advanced Testing Strategies and Considerations
Sequential Testing and Fixed Horizon Design
Two philosophical approaches to testing design exist:
Fixed Horizon: Pre-determine sample size and test duration, run the test to completion, then analyze. This approach is simple and avoids multiple comparison problems but requires waiting until the pre-planned sample is collected, even if results are clearly conclusive early.
Sequential Testing: Conduct interim analysis at predetermined points, deciding whether to stop early for conclusive results, continue testing, or stop for futility (lack of evidence for effect). This approach is efficient—stopping early when results are conclusive—but requires statistical adjustment for multiple comparisons.
Most organizations use fixed horizon testing due to its simplicity, but sequential testing is increasingly accessible through tools like ABBA.
Segmentation and Heterogeneous Treatment Effects
Tests often show different results for different user segments. Perhaps your headline variation works better for new visitors but worse for returning customers. Or it works better on mobile but worse on desktop.
Powered Segmentation: If you specifically want to detect treatment effects within segments, you must power your test for segment-level analysis, requiring 3-4 times more traffic than powering for overall effect.
Post-Hoc Segmentation: Analyzing test results within segments after the fact, without powering for that analysis, increases false positive rate due to multiple comparisons. If you look at 10 segments, you've conducted 10 comparisons, and at least one is likely significant by chance.
Subgroup Analysis Caution: The most dangerous testing mistake is running an A/B test, finding no overall effect, then diving into segments, finding one segment with an effect, and concluding that segment responds differently. This is often false positive—you're conducting multiple comparisons without adjustment.
Interaction Effects and Synergy
Beyond the formal multivariate testing approach, understanding how changes interact is important:
Positive Interaction (Synergy): Two elements together produce a larger effect than the sum of individual elements. A strong headline paired with a persuasive image might convert 5% better than individual headline improvement (3%) plus individual image improvement (1.5%).
Negative Interaction (Cannibalization): Two elements together produce a smaller effect than the sum of individual elements. Perhaps a strong headline and multiple testimonials together create skepticism, converting worse than individual improvements combined.
Identifying interactions requires either multivariate testing or carefully designed sequential experiments. Once identified, interactions guide implementation strategy—prioritizing synergistic pairs and avoiding detrimental combinations.
Personalization vs. Optimization
A/B testing optimizes for the average user. Personalization tailors experiences to individual users. While distinct, these approaches complement each other:
Test-Informed Personalization: A/B tests identify what works for different audiences. Then personalization delivers the right experience to each user based on their characteristics. Test first to understand what works, then personalize implementation.
Personalization Context: If you personalize based on user attributes (new vs. returning, mobile vs. desktop), you're essentially running multiple A/B tests simultaneously—one for each segment. This requires substantially more traffic to achieve statistical significance for each segment.
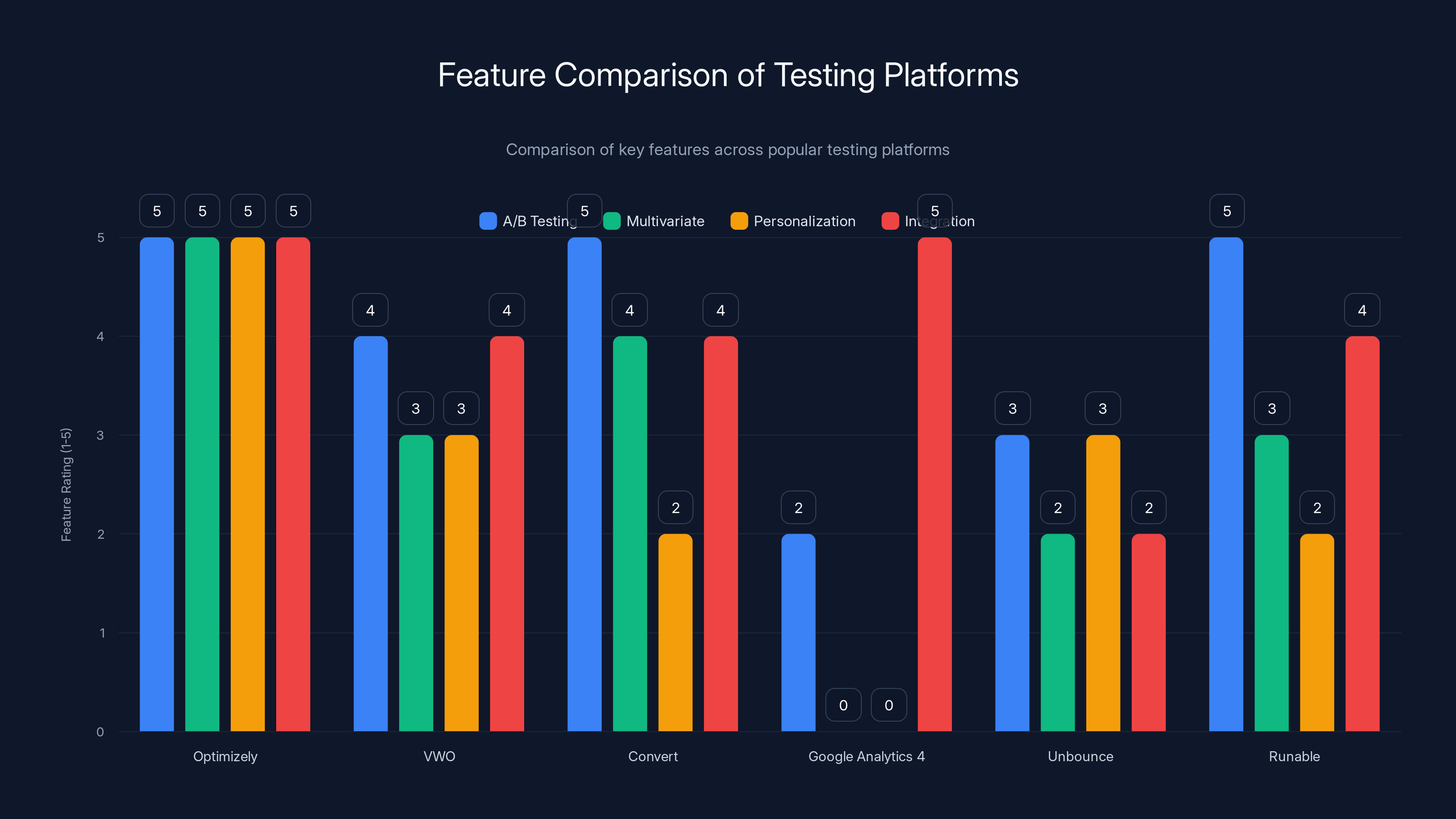
Optimizely excels across all features, making it ideal for enterprise needs, while Google Analytics 4 is limited in testing capabilities but integrates well within the Google ecosystem. Estimated data based on typical feature ratings.
Chapter 12: Common Pitfalls and How to Avoid Them
The Novelty Effect
The Problem: Users respond differently to new designs simply because they're new. A fresh layout that initially seems confusing might become preferred once users learn it, or conversely, might lose its initial appeal once novelty wears off.
The Impact: Tests run for too short a duration might conclude a change is positive (or negative) when the effect is purely novelty-driven. A 10-day test might show higher engagement with a new layout due to novelty, but this engagement drops once users adjust.
The Solution: Run tests long enough for the novelty effect to wear off. For design changes, this typically requires 2-4 weeks. For daily visitor behavior, novelty usually stabilizes within 7-10 days. Specify this in your test planning.
Traffic Composition Changes
The Problem: If your traffic composition changes substantially during a test, you're no longer testing the same population. Perhaps seasonal changes, marketing campaign shifts, or external events change your visitor composition.
The Impact: If your new variation is better for mobile but worse for desktop, and your mobile traffic percentage increased during the test period, results are biased toward the variation.
The Solution: Monitor traffic composition daily. If sources or device breakdown change significantly, extend the test to smooth these variations, or potentially restart the test if changes are substantial.
Guardrail Metric Neglect
The Problem: Focusing exclusively on your primary metric (conversion rate) while ignoring secondary metrics creates blind spots. Your variation might increase conversions while decreasing average order value, or increasing signups while decreasing subsequent engagement.
The Impact: You implement an "improvement" that optimizes for short-term conversion but harms overall business metrics.
The Solution: Define guardrail metrics before launching the test. These might include average order value, engagement metrics, customer lifetime value, or other important outcomes. Monitor these alongside your primary metric and be willing to reject a variation that improves the primary metric but harms guardrails.
Sample Ratio Mismatch
The Problem: Traffic isn't actually split 50/50 between control and variation. Perhaps your randomization logic is flawed, or your test platform has a bug. Traffic might be split 48/52 or even 30/70.
The Impact: Unequal traffic allocation reduces statistical power. You're not getting full benefit from your visitor volume.
The Solution: Check the sample ratio in your test setup. Most platforms display it clearly. If it's significantly different from your expectation, investigate why. Usually, there's nothing wrong, but sample ratio mismatches can indicate randomization issues.
Implementation without Validation
The Problem: Implementing test results without validating them in real production conditions. A test result might be valid for the test traffic but not generalize to the production population.
The Impact: You implement a winning variation and conversion rate doesn't improve, or even decreases. The test result was real, but implementation failed, or the production population differs from test population.
The Solution: After implementing a test-winning variation, validate in production. Monitor conversion rate post-implementation to ensure the expected improvement materializes. If it doesn't, investigate whether implementation differs from the test setup.
Chapter 13: Roadmap Development and Testing Prioritization
Creating an Optimization Roadmap
Systematic organizations develop testing roadmaps rather than testing randomly. A roadmap ensures testing efforts focus on highest-impact opportunities.
Phase 1 - Research and Discovery: Conduct user research, analytics analysis, and user testing to identify optimization opportunities. Where do users struggle? What do they want? Where is the biggest gap between user intent and current experience?
Phase 2 - Hypothesis Generation: Generate multiple hypotheses about how to address identified problems. Prioritize by expected impact and implementation effort.
Phase 3 - Quick Wins: Test highest-priority, low-effort hypotheses first. Early wins build momentum and budget support for testing.
Phase 4 - Strategic Improvements: Move to more complex tests addressing core problems or opportunities.
Phase 5 - Continuous Refinement: Establish ongoing testing cadence focused on continuous incremental improvement.
Estimating Testing Impact
Before committing significant resources to a testing initiative, estimate potential impact:
Opportunity Sizing: What's the potential uplift if you solve this problem? If your signup form has 30% abandonment and you reduce it to 25%, how many additional signups does that represent? Apply this to revenue or business outcomes.
Achievability Assessment: How realistic is the estimated improvement? Base this on comparable optimizations, industry benchmarks, and user research. Be conservative.
Expected Timeline: How long will discovering and implementing the improvement require? Faster improvements should be prioritized.
Testing Maturity Level: New testing organizations might achieve larger improvements quickly (low-hanging fruit). Mature testing organizations (having already optimized most obvious elements) might achieve smaller improvements with more effort.
Building Organizational Testing Capability
Successful testing isn't about a single test; it's about building organizational capability to run tests continuously.
People: Hire or develop a team with testing expertise. This includes product managers, data analysts, marketers, and UX specialists who understand testing methodology.
Processes: Establish standard processes for hypothesis generation, test design, analysis, and implementation. Consistency enables faster learning.
Technology: Invest in testing platforms, analytics infrastructure, and statistical tools. The right technology accelerates testing velocity.
Culture: Foster a culture that values experimentation over intuition. Leaders should reward learning from tests, not just winning results.

Chapter 14: Integration with Product Development and Design
Experimentation as Core to Product Development
The most mature organizations treat experimentation as central to product development, not peripheral.
Experiment-Driven Product Decisions: Rather than debating whether a feature will improve user experience, test it. Ship a small variation, measure impact, iterate based on results.
Reducing Implementation Risk: By testing changes before full rollout, organizations reduce implementation risk. Changes proven effective in A/B tests have higher success probability in production.
Enabling Fast Iteration: Organizations running dozens of tests monthly can iterate on products much faster than competitors running tests quarterly.
Design and Testing Collaboration
Product design and testing can sometimes create tension. Designers want creative freedom; testers want statistical rigor. Resolving this tension requires collaboration:
Designing for Testing: Designing variations that are testable. Some of the most innovative designs aren't testable because they change too many elements simultaneously.
Test-Informed Design: Using test results to inform future design direction. What design patterns consistently win? What resonates with your audience?
Challenging Assumptions Through Testing: Sometimes tests overturn design assumptions. Users might prefer minimalist design over feature-rich design, or conversely. Testing reveals what actually works rather than what designers hypothesized.

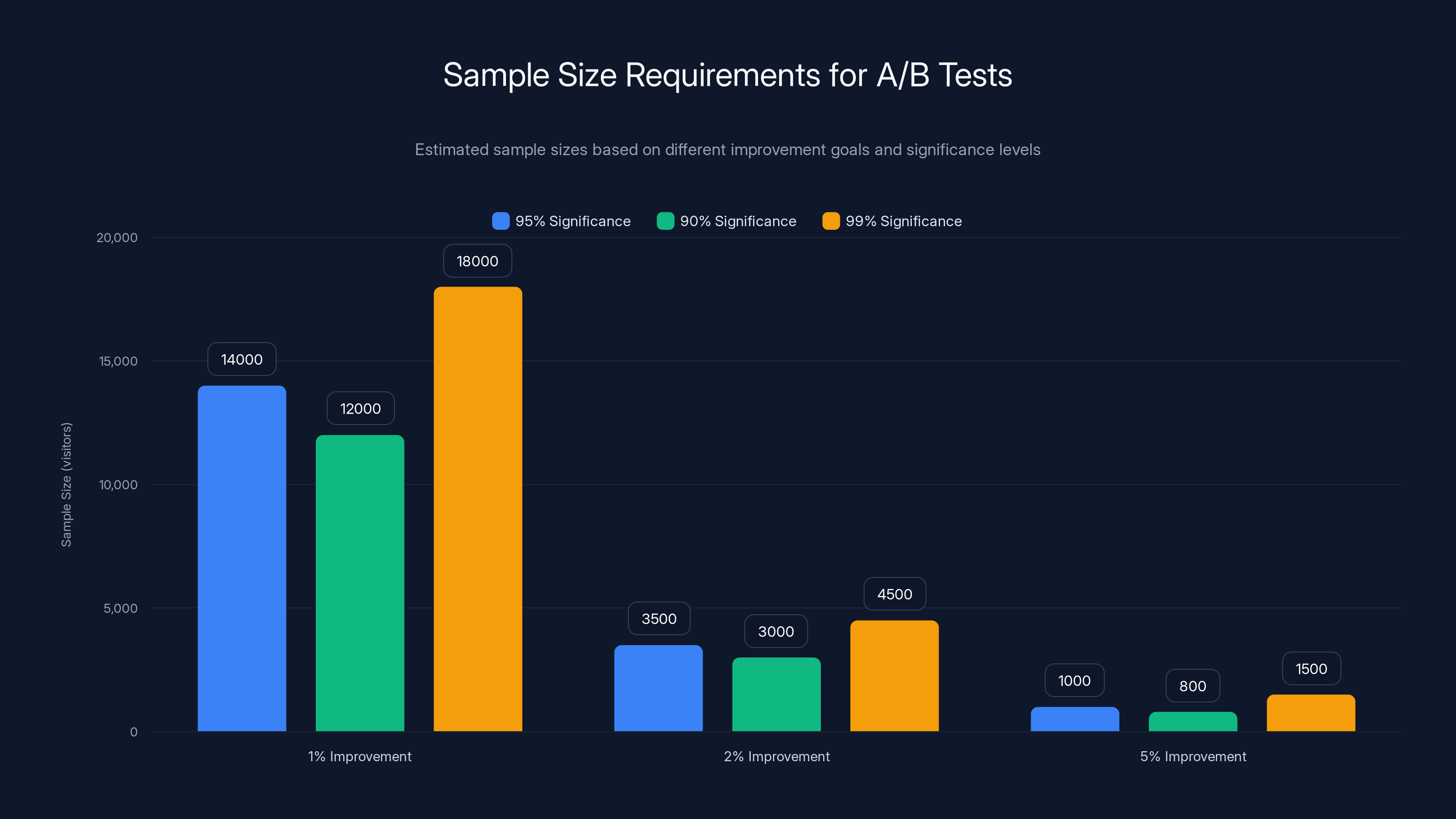
Estimated sample sizes for A/B tests vary significantly based on the desired improvement and statistical significance level. Higher significance levels and smaller improvements require larger sample sizes.
Chapter 15: Advanced Topics and Future Directions
Bayesian vs. Frequentist Testing Approaches
Traditional A/B testing uses frequentist statistics (the p-value approach). Bayesian approaches are increasingly used for online experiments.
Frequentist Approach: Tests whether observed data are consistent with the null hypothesis (no difference between control and variation). If p < 0.05, reject the null hypothesis and conclude there's a difference. This approach is rigid about multiple comparisons and sample size.
Bayesian Approach: Estimates the probability that the variation is better than the control given the observed data. This allows continuous monitoring and dynamic stopping without the multiple comparison problems of frequentist sequential testing. Bayesian approaches are more flexible but require defining prior distributions.
Many organizations are moving toward Bayesian approaches for online experiments because they're more intuitive and better support continuous testing.
Contextual Bandits and Reinforcement Learning
Beyond traditional A/B testing, machine learning approaches are gaining prominence:
Contextual Bandits: Algorithms that balance exploration (trying different variations to learn what works) and exploitation (showing the variation most likely to succeed). Unlike traditional A/B tests that use all traffic equally to compare variations, contextual bandits shift traffic toward better-performing variations over time.
Advantages: Higher expected conversion rate during the experiment itself—you're not wasting traffic showing visitors clearly inferior variations.
Challenges: Requires significant machine learning expertise and sophisticated implementation. Results are harder to interpret than traditional A/B test results.
Real-Time Personalization at Scale
Future testing might not focus on comparing static variations, but on dynamically personalizing each user's experience based on their characteristics and real-time behavior.
Edge Computing and Client-Side Optimization: Rather than centralizing optimization decisions server-side, optimizations happen client-side at the edge, enabling microsecond-level personalization.
Real-Time Data and Feedback Loops: Personalization systems rapidly incorporate feedback, adjusting personalization rules as new behavior data arrives.

Chapter 16: Industry Benchmarks and Performance Data
Conversion Rate Improvement Benchmarks by Industry
Different industries achieve different improvement ranges through testing:
E-Commerce: Typical improvements range from 10-40% annually through systematic testing. Best-in-class e-commerce organizations achieve 40-80% annual improvements.
Saa S: Free trial signup rate improvements of 15-50% are common. Paid conversion improvements (trial to paid) range from 5-25%.
Lead Generation: Form completion rate improvements of 20-60% are achievable. Cost-per-qualified-lead improvements often exceed form completion improvements due to segmentation and targeting improvements.
Media/Publishing: Subscription and registration improvements of 10-30% are typical. Engagement metrics (time on site, return visits) often improve 15-40%.
These benchmarks illustrate that optimization opportunity varies significantly by industry and business model. Saa S businesses with smaller conversion rates often achieve larger percentage improvements than e-commerce (which operates with higher baseline conversion rates).
Testing Velocity Benchmarks
High-Traffic E-Commerce Sites: Can run 4-8 A/B tests monthly, completing each test in 1-2 weeks.
Mid-Market Saa S: Can run 2-4 A/B tests monthly, each requiring 2-4 weeks.
Growing Startups: Often run 1-2 A/B tests monthly while building testing capability.
Enterprise: Despite high traffic, enterprise sites often run fewer tests (1-3 monthly) due to approval processes and implementation timelines.
Testing velocity compounds over time. An organization running 4 tests monthly with 20% average improvement will achieve 107% annual improvement (compounding), while an organization running 1 test quarterly achieves only 21% annual improvement.
Chapter 17: Building Testing into Your Organization
Structuring Testing Teams
Centralized Testing: A dedicated testing team runs all organizational tests. Advantages: consistency, statistical rigor, efficiency. Disadvantages: bottleneck, distance from product teams.
Decentralized Testing: Individual teams (product, marketing, design) run their own tests with guidelines from a testing center of excellence. Advantages: speed, ownership, contextual understanding. Disadvantages: inconsistency, statistical rigor challenges.
Hybrid Model: Central testing team handles complex multivariate and infrastructure testing; individual teams run A/B tests with tooling and guidance from the central team. Most mature organizations use this model.
Training and Capability Building
Building testing capability requires investment in training:
Statistical Literacy: Team members need to understand statistical concepts: sample size, significance, power, confidence intervals. Not everyone needs Ph D-level expertise, but functional understanding is critical.
Experimentation Methodology: Understanding how to design experiments, avoid common pitfalls, and interpret results.
Tool Proficiency: Hands-on experience with testing platforms and analytics tools.
**Tool training and workshops accelerate capability development. Monthly testing workshops where the team discusses recent results and methodology reinforce learning.
Establishing Quality Standards
Pre-Launch Checklist: Standardized checklist ensuring tests are properly designed before launch. Does the test have adequate sample size? Are the metrics appropriate? Are hypotheses clear? Does the variation load properly across browsers and devices?
Documentation Requirements: Standardized documentation of test hypotheses, design, results, and learnings. This creates institutional knowledge and prevents repeating tests.
Statistical Rigor Standards: Minimum significance level (95% confidence), minimum power (80%), minimum effect size detection expectations.

Chapter 18: Tools, Platforms, and Technology Stack
Comprehensive Testing Platform Comparison
| Platform | Pricing | A/B Testing | Multivariate | Personalization | Integration | Best For |
|---|---|---|---|---|---|---|
| Optimizely | Enterprise | Excellent | Excellent | Excellent | Extensive | Enterprise scale, complex needs |
| VWO | Mid-market | Very Good | Good | Good | Broad | Growing companies, visual testing |
| Convert | Mid-market | Excellent | Very Good | Limited | Flexible | Statistics-first organizations |
| Google Analytics 4 | Free | Basic | No | No | Basic testing, Google ecosystem | |
| Unbounce | SMB | Good | Basic | Good | Limited | Landing page testing |
| Runable | Startup | Excellent for AI workflows | Good | Fair | Seamless | Teams building automated content generation workflows alongside optimization |
Analytics Integration Architecture
A modern testing organization needs:
Event Tracking Infrastructure: Ability to track relevant user events (form submissions, purchases, engagement metrics) consistently across platforms.
Data Warehouse: Centralized location for all experimental and behavioral data enabling sophisticated analysis.
Visualization Tools: Dashboards and reports for communicating test results and trends.
Statistical Analysis Tools: Capabilities for computing confidence intervals, significance tests, and complex analyses.
Conclusion: Choosing Your Testing Strategy and Moving Forward
A/B testing and multivariate testing represent two distinct approaches to website optimization, each with specific applications, strengths, and limitations. Understanding these differences and applying the right methodology to the right problem is the foundation of effective optimization.
A/B testing is your primary tool. Its simplicity, statistical clarity, and efficiency make it suitable for most optimization challenges. Most organizations should prioritize mastering A/B testing before attempting multivariate testing. Start with sequential A/B tests on your highest-impact pages and elements. Test hypotheses grounded in user research and analytics insight. Let test results guide implementation decisions rather than stakeholder opinions or design preferences.
Multivariate testing is your advanced tool. Pursue multivariate testing only when you have abundant traffic supporting it and clear hypotheses about element interactions. Rather than testing more elements simultaneously for efficiency, use multivariate testing to answer specific questions about how elements work together. When properly deployed, multivariate testing reveals insights that sequential A/B testing cannot, but this requires the traffic volume and planning discipline to execute correctly.
Your testing roadmap should evolve with organizational maturity. New testing organizations should focus on quick wins—testing high-impact, low-effort improvements to build momentum. As testing capability matures, move toward strategic optimization addressing core friction and experience problems. Establish standard processes, invest in team development, and build testing into core product and marketing practices.
Implementation and follow-through matter as much as testing methodology. A perfectly designed test reveals nothing if the winning variation isn't implemented or if implementation doesn't match test conditions. Establish processes ensuring test winners move efficiently into production and that post-implementation monitoring confirms expected results materialize.
Testing is iterative and continuous. Individual test results guide next steps. A headline test reveals what messaging resonates; use this insight to inform future messaging tests. An image test reveals visual preferences; apply this to future design decisions. Organizations that approach testing as a continuous learning process rather than one-off experiments achieve compounding improvements.
As you move forward with testing:
- Start with A/B testing. Master this methodology before advancing to multivariate testing.
- Ground tests in research. Let user research, analytics, and user behavior guide hypothesis development.
- Design for statistical rigor. Calculate appropriate sample sizes and commit to running tests to completion.
- Avoid common pitfalls. Resist peeking at interim results, monitor guardrail metrics, and account for novelty effects.
- Build organizational capability. Invest in team training, establish standard processes, and foster a culture valuing experimentation.
- Measure and iterate. Let test results guide decisions, and learn from both winning and losing tests.
Website optimization through systematic testing isn't a destination—it's a practice. Organizations that institutionalize experimentation and continuously test and improve their digital experiences compound small gains into massive improvements over months and years. Your competitive advantage comes not from a single test, but from systematic application of testing methodology across your organization.

FAQ
What is the main difference between A/B testing and multivariate testing?
A/B testing compares two versions of a webpage where only one element differs, allowing you to isolate the impact of that specific change. Multivariate testing simultaneously tests multiple elements with variations, measuring how different combinations of elements perform together. The key distinction is scope: A/B testing isolates single variables, while multivariate testing examines element interactions.
How much traffic do I need for A/B testing versus multivariate testing?
A/B testing requires relatively modest traffic—typically 1,000 to 20,000 total visitors depending on your baseline conversion rate and minimum detectable effect size. Most tests complete in 1-4 weeks. Multivariate testing requires substantially more traffic; a test with six elements and two variations each requires roughly 16 times more visitors than an equivalent A/B test. This translates to 3-6 months of testing for many organizations.
When should I use multivariate testing instead of A/B testing?
Use multivariate testing when you have abundant traffic (50,000+ daily visitors), a clear hypothesis about how specific elements interact, and need to answer complex questions about element combinations. For most organizations with less traffic, sequential A/B testing is more practical. Multivariate testing is the right choice when you specifically need to understand interactions or optimize multiple dimensions simultaneously.
What is statistical significance and why does it matter in testing?
Statistical significance indicates confidence that an observed difference between test variations is real and not due to random chance. The industry standard is 95% confidence (p-value < 0.05). This means there's less than 5% probability the observed difference occurred by chance. Significance matters because it determines whether test results are reliable enough to guide implementation decisions. Without adequate significance, you might implement changes that have no real impact.
How long should I run an A/B test before analyzing results?
You should run an A/B test until you reach your pre-calculated sample size requirement, which depends on baseline conversion rate, minimum detectable effect, desired significance level, and statistical power. Don't analyze results before reaching this sample size, as peeking at interim results inflates false positive rates. Running the test to completion typically requires 1-4 weeks depending on traffic volume and effect size. Resist the temptation to stop early when you see significant results.
What are guardrail metrics and why should I track them?
Guardrail metrics are important secondary metrics you monitor alongside your primary test metric. While testing to improve conversion rate, you might track average order value, customer satisfaction, or engagement metrics as guardrails. A variation might improve your primary metric while harming guardrail metrics, indicating you shouldn't implement it. Tracking guardrails prevents optimizing for one metric while inadvertently damaging others.
Can I segment my test results by user type (new vs. returning visitors, device type, etc.)?
You can examine how test results vary across segments, but analyzing multiple segments without statistical adjustment inflates false positive rates. If you specifically want to power your test to detect segment-level differences, you need additional traffic (typically 3-4 times more). If examining segments post-hoc, treat findings as exploratory rather than conclusive and validate in follow-up tests.
What is the novelty effect and how does it impact my test results?
The novelty effect occurs when users respond differently to new designs simply because they're new. Users might interact more with a redesigned interface due to curiosity, not genuine preference. This effect fades as users adjust to the new design. To account for novelty, run tests for sufficient duration (typically 2-4 weeks for design changes) so the effect stabilizes. Tests shorter than this might show spurious results driven by novelty rather than true performance differences.
How should I prioritize which elements to test?
Prioritize tests based on three factors: expected impact magnitude (how much could improvement matter to business results), likelihood of success (how confident are you the change will work), and implementation effort/cost. Test high-impact, high-probability hypotheses first. Sequence tests so results from initial tests inform subsequent hypotheses. Let user research, analytics, and user feedback guide hypothesis generation rather than testing random ideas.
What should I do with test results after the experiment is complete?
First, determine if results reached statistical significance and the practical magnitude of improvement. If the variation won, implement it in production. After implementation, monitor actual results to confirm expected improvements materialize (sometimes implementation differs from test conditions). Document test methodology, results, and learnings for institutional knowledge. Use winning test insights to inform future optimization efforts—let successful approaches guide next hypothesis development.
How do I know if I have enough traffic to run a multivariate test?
Calculate the number of combinations you're testing (multiply the number of variations for each element). Multiply your A/B test sample size requirement by this number to estimate multivariate test requirements. If this exceeds your expected traffic for a reasonable test duration (2-4 weeks), you lack sufficient traffic for multivariate testing. For example, six elements at two variations each creates 64 combinations. If your A/B test needs 14,000 visitors, a multivariate test would need approximately 896,000 visitors—about 6 months for a site with 5,000 daily visitors.

