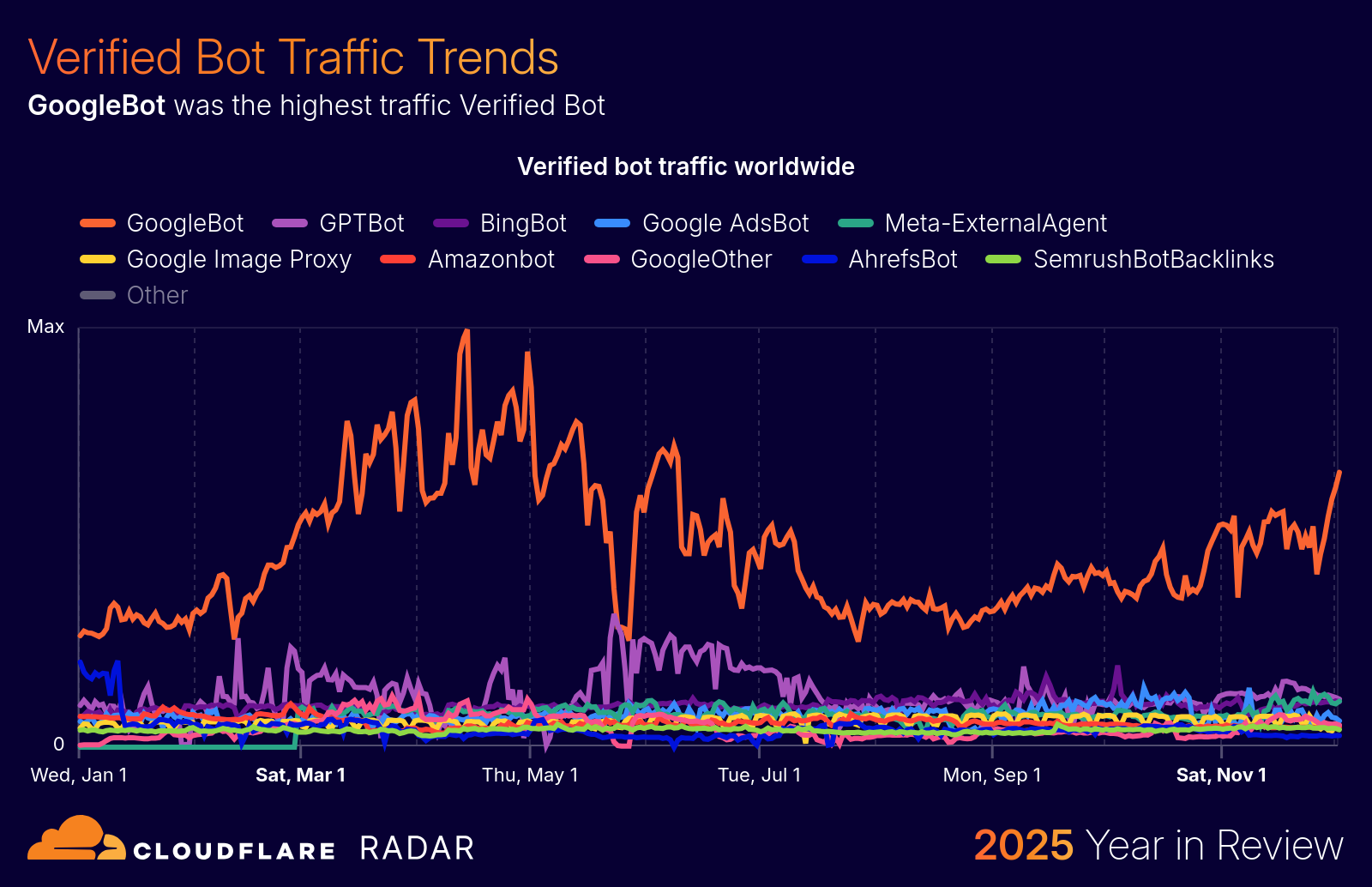
![AI Bot Web Traffic vs Human Usage: What It Means for Your Site [2025]](https://tryrunable.com/blog/ai-bot-web-traffic-vs-human-usage-what-it-means-for-your-sit/image-1-1770315125637.jpg)
AI Bot Web Traffic vs Human Usage: What It Means for Your Site [2025]
Last year, something quietly seismic happened on the internet. For the first time in the web's history, artificial intelligence bots didn't just share the road with human users—they started looking like they might take it over entirely.
We're not talking about some distant future scenario. This is happening right now. The data is stark: at the end of 2024, there was roughly one AI bot visit for every 31 human visits. Now we're seeing that ratio compress dramatically. Meanwhile, human web traffic itself is dropping. People are starting their searches in Chat GPT instead of Google. They're asking Claude instead of opening their browser. The infrastructure that powered the internet for the last 25 years is getting quietly obsolete.
For website owners, this creates a genuine crisis. Your content is being consumed by machines at rates you can't control or measure properly. Publishers are watching click-through rates collapse. And the mechanisms that were supposed to protect intellectual property—the ones built into the very foundations of the web—aren't working anymore.
Here's what you need to understand about this shift, why it matters, and what you should actually do about it.
TL; DR
- AI bot traffic exploded: One AI bot visit per 31 human visits by end of 2024, up from 1:200 at start of 2024
- Human traffic is falling: Web traffic from actual people dropped about 5% in just one quarter as users shift to AI chatbots
- robots.txt is dead: These instructions are ignored 30-42% of the time by major AI crawlers, making intellectual property protection nearly impossible
- Publishers are getting crushed: Click-through rates dropped 3x for sites without AI licensing deals, threatening ad revenue and sustainability
- RAG and search indexing bots surged: Training crawlers declined 15%, but retrieval-augmented generation bots jumped 33% and search indexers rose 59%
- The internet is reorganizing: The shift to agentic AI means websites need to prepare for AI as their primary audience, not humans

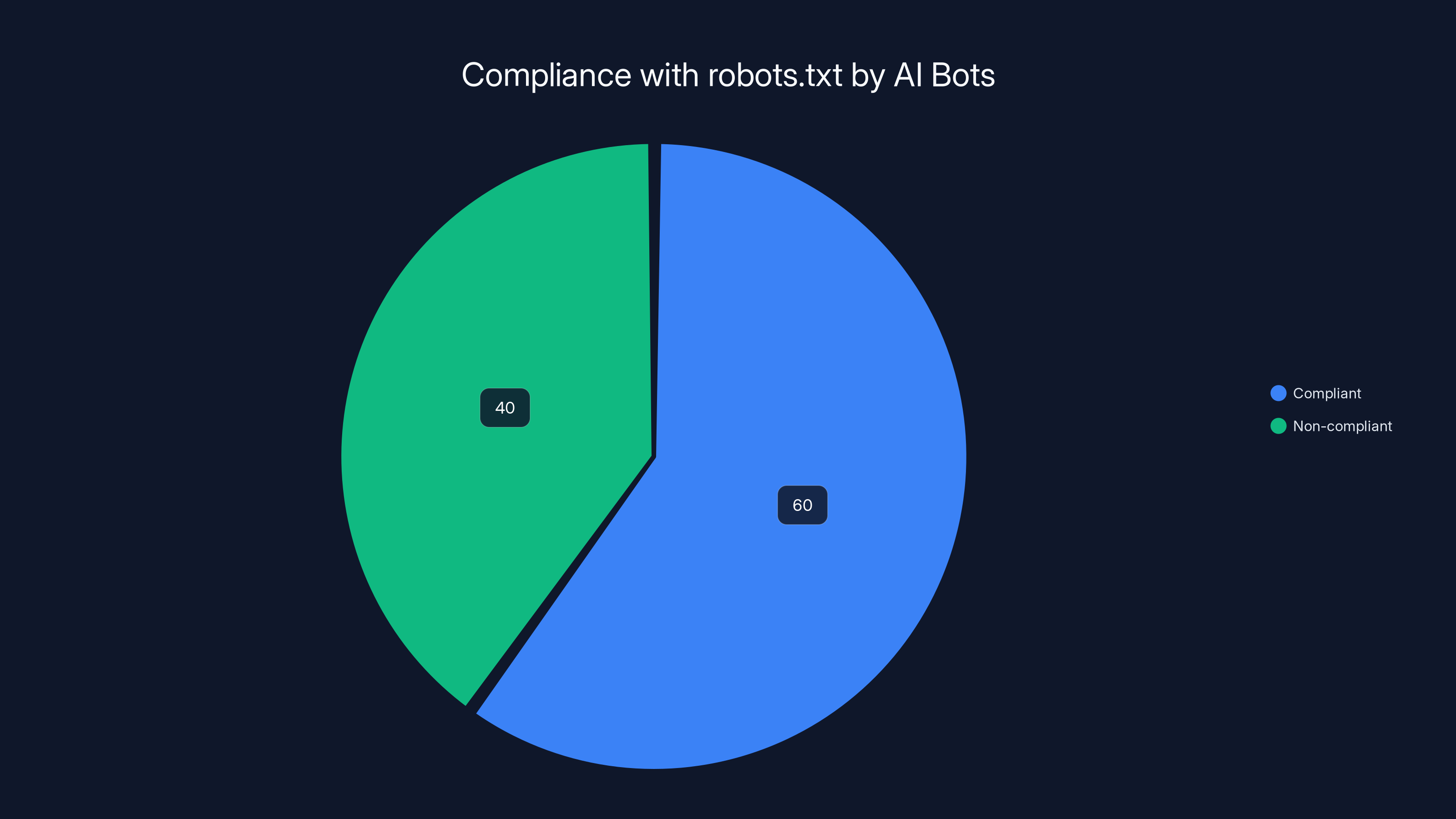
An estimated 40% of AI bots ignore robots.txt directives, highlighting the challenge of controlling automated access to website content. Estimated data.
The Numbers Tell a Story Nobody Expected
Let's start with what the data actually shows, because the trend lines are genuinely alarming if you depend on web traffic for income.
Twelve months ago, if an AI bot hit your website, it was relatively rare. You might get 200 human visitors and 1 bot visitor. That was the baseline. It didn't feel like a threat. Most websites weren't even tracking bot traffic with any precision.
Fast forward to the final months of 2024, and that ratio inverted in ways that caught most of the industry off-guard. Now you're looking at roughly 31 bot visits for every single human visitor. That's a 62x increase in the bot-to-human ratio in less than a year.
But the numbers get more complicated when you break down what types of bots we're talking about. Training crawlers—the bots that scrape content to build AI models—actually declined. We're talking a 15% drop between Q2 and Q4 of 2024. That's counterintuitive. You'd expect those to spike.
What actually exploded were two other categories. RAG bots, which fetch content to feed into retrieval-augmented generation systems, jumped 33%. And search indexing bots rose 59%. These aren't bots that come once and process your entire site. They're bots that keep coming back, again and again, pulling fresh information.
The business logic here is actually clear when you think about it. Companies like Open AI and Meta aren't trying to build bigger training datasets anymore. They already have massive model checkpoints. What they need is fresh, real-time information to power their products. That's what RAG bots do—they're the intelligence-gathering apparatus for products you're already using every day.
In parallel, something else shifted in user behavior that's making the bot problem even worse. A survey found that 37% of active AI users now start searches with artificial intelligence directly. They type into Chat GPT, or Gemini, or Claude. They don't go to Google anymore. They don't visit publisher websites. They ask the AI, the AI hits your site through a bot, extracts what it needs, and the human user gets an answer without ever seeing where the information came from.
This matters because it means bot traffic isn't evenly distributed. Open AI has one bot scraping your site. Meta has another. Google has another. Perplexity has another. Each one is making independent requests, and they're not coordinating. Your server is getting hammered by multiple bots, all pulling the same content.
Why Human Traffic Is Actually Declining
This is the part that should worry every publisher and content creator reading this.
Human web traffic dropped about 5% between Q3 and Q4 of 2024. That might not sound catastrophic until you realize what that means. For a typical news site or content publisher, a 5% drop in human traffic translates directly to roughly 5% less ad revenue. For subscription-based models, it's roughly 5% fewer potential customers. For e-commerce, it's 5% fewer potential sales.
That's not a rounding error. That's a material business impact.
Why is human traffic falling? The answer isn't that people are using the internet less. They're using it differently. Instead of going to websites, they're interacting with AI interfaces. They're asking Chat GPT instead of Googling. They're chatting with Gemini instead of browsing.
This represents a fundamental shift in how people access information online. The website, which has been the atomic unit of the internet for decades, is starting to feel like a legacy system. Why click through to a news site if you can get the summary from an AI? Why browse an e-commerce site if you can describe what you want and have Chat GPT recommend products?
The irony is that all of this AI functionality is built on your content. Open AI trained Chat GPT on web text. Meta trained Llama on web text. The value these companies are creating comes directly from the intellectual property that publishers and creators built over years.
And yet, when those companies' bots come to your site to pull fresh content, there's almost no mechanism to stop them or compensate you for the value they're extracting.
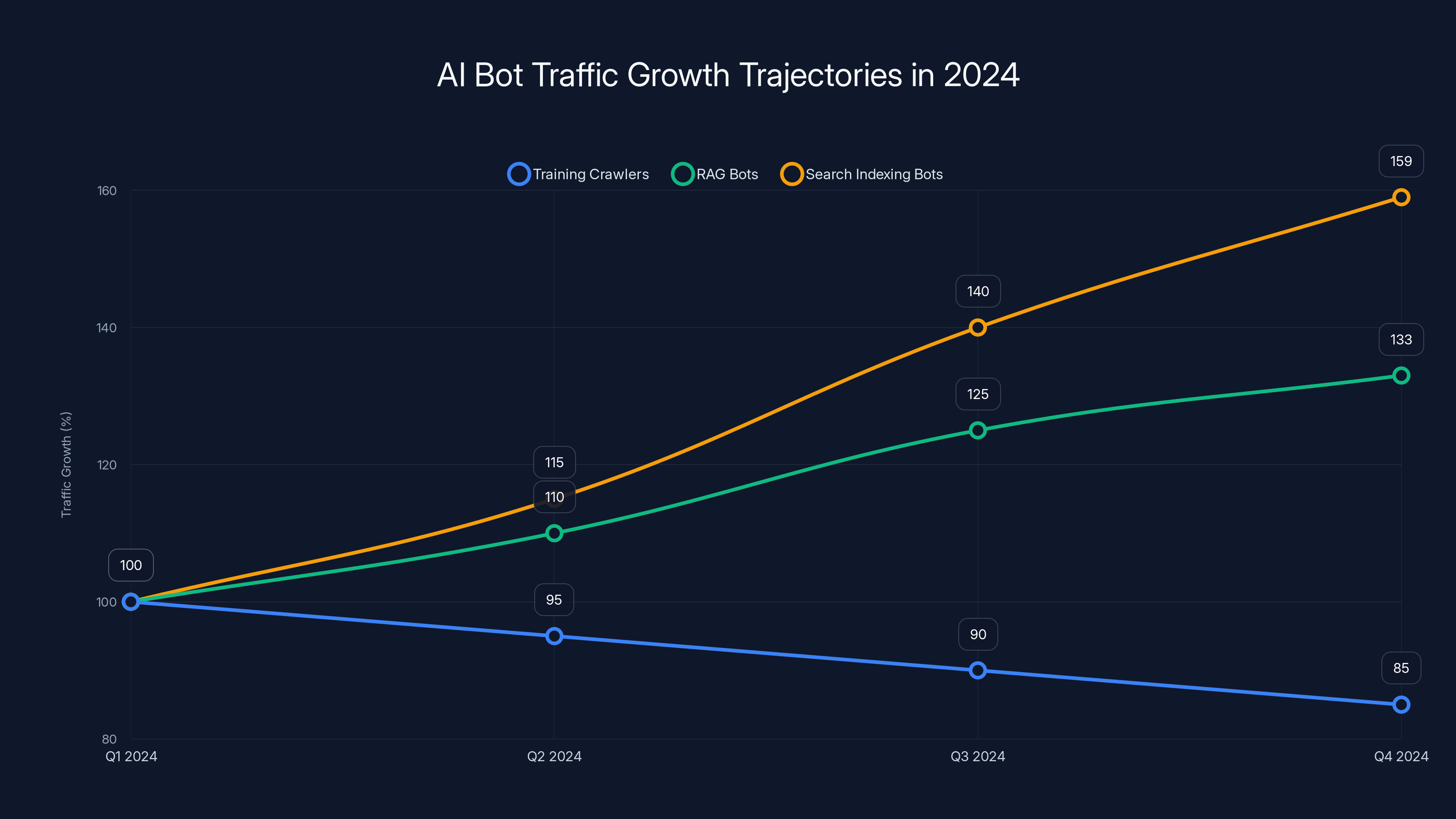
RAG bots and search indexing bots showed significant growth, with increases of 33% and 59% respectively, while training crawlers declined by 15% in 2024. Estimated data based on observed trends.
The robots.txt Problem: Your Copyright Protection Is Broken
Imagine if, 25 years ago, someone invented a universal "Do Not Copy" sign for buildings. And everybody agreed to respect it. It was built into how commerce worked. You'd paste this sign on your door, and thieves would mostly walk past.
That's what robots.txt was supposed to be for the internet.
robots.txt is a simple text file that websites can create. It tells automated bots which parts of your site they can and cannot crawl. It's been the standard since the mid-1990s. Google respects it. Bing respects it. Most legitimate bots respect it.
But here's what's happening now: AI companies' bots are ignoring it.
The data shows that robots.txt instructions are being violated about 30% of the time on average. For Open AI's Chat GPT-User bot specifically, that number jumps to 42%. Forty-two percent of the time, it's ignoring explicit instructions not to crawl a site.
That's not a small violation rate. That's a wholesale rejection of the one mechanism publishers have to protect their intellectual property.
Why is this happening? Part of it is philosophical. AI companies argue they're doing important work—building systems that benefit everyone—and that should take precedence over individual publisher requests. Part of it is technical. Some bots might genuinely be misconfigured. Part of it is probably just indifference.
But the end result is the same: the copyright protection mechanism is broken. It's effectively obsolete.
One publishing executive described it bluntly: robots.txt has been "deemed effectively obsolete." Not because it doesn't work technically. It works fine. But because it's being systematically ignored, and there's no legal or technical way to enforce it.
This creates a perverse incentive structure. If a site respects robots.txt and blocks an AI bot, that bot just gets its content from other sites. Meanwhile, the respectful site gets less bot traffic—which might seem good until you realize that bot traffic is increasingly what drives content value and discoverability.
Publishers are starting to face a genuine catch-22. Block AI bots and lose potential traffic and partnership opportunities. Allow AI bots and watch them extract your content without compensation and without any obligation to link back or credit you.
The Click-Through Rate Collapse
This is where the economic impact becomes crystal clear.
When an AI bot crawls your site and extracts information, and then an AI model uses that information to answer a user's question, the human never has to click through to your site. They get their answer directly from the AI interface. From a business perspective, that's a total loss. You created the content. You paid for the hosting. You maintained the site. And you get zero traffic credit and zero revenue.
The data on this is damning. Sites without direct AI licensing deals saw their click-through rates drop approximately 3x (that's a 3x reduction, or a 66% drop) between Q2 and Q4 of 2024. In practical terms, if a publisher was getting 1,000 clicks a day from AI sources in Q2, they'd be down to maybe 330 by Q4.
Even sites that negotiated licensing deals with AI companies aren't immune. Their click-through rates dropped too, just not as severely. Which suggests that even "fair" compensation arrangements are still making the traffic picture worse for publishers.
Let's put this in concrete terms. A mid-sized news site might generate 50,000 human visits per day. If they monetize through ad networks, they might make
Now imagine 150,000 bot visits per day (the 31:1 ratio we discussed). Even if those bot visits generated some revenue—and they don't, typically—they're creating server load and infrastructure costs. Meanwhile, the human click-through rate is dropping. That same site might now be down to 47,500 human visits, losing $75 per day in revenue.
Multiply that across a publishing company with hundreds of sites, and you're looking at meaningful losses.
Now here's the strategic problem: there's no way for individual publishers to "solve" this. One site blocking AI bots won't matter. AI companies will just get that content from other sites. The only solution requires coordination at industry level, or regulation, or both. And neither of those things is happening fast enough.
Open AI's Dominance in the Bot Ecosystem
If the bot traffic problem were evenly distributed, it would be complicated but manageable. Different bots, different purposes, shared impact.
But it's not evenly distributed. It's heavily concentrated, with one company extracting far more value than anyone else.
Open AI's Chat GPT-User bot is roughly 5x more active than Meta's most active crawler and about 16x more active than Perplexity's. In a highly concentrated ecosystem, Open AI is operating at a different scale entirely.
This creates interesting dynamics. Open AI has so much leverage that they can essentially set the terms for how AI companies interact with the web. If Open AI ignores robots.txt, other companies can argue they need to as well to remain competitive. If Open AI starts making licensing deals with publishers, others might follow.
But right now, Open AI's approach seems to be: crawl aggressively, ask permission later if at all.
The dominance also means that Open AI's business model is essentially extracting value from publisher content at scale. Chat GPT makes money through subscriptions and API access. A significant portion of that product value comes from information pulled from publisher sites. Yet publishers see almost no direct revenue from Open AI.
Some AI companies have started offering publishing licensing programs. But these are typically structured as: "We'll pay you some money, and in return, we can freely crawl your site and use your content in our products." The payment is usually a small fraction of what traffic-based advertising would have generated.
This is where regulatory intervention becomes almost inevitable. The current situation—where AI companies extract value without permission or compensation—simply cannot persist indefinitely. Either publishers will organize and demand change, or regulators will step in and require it.
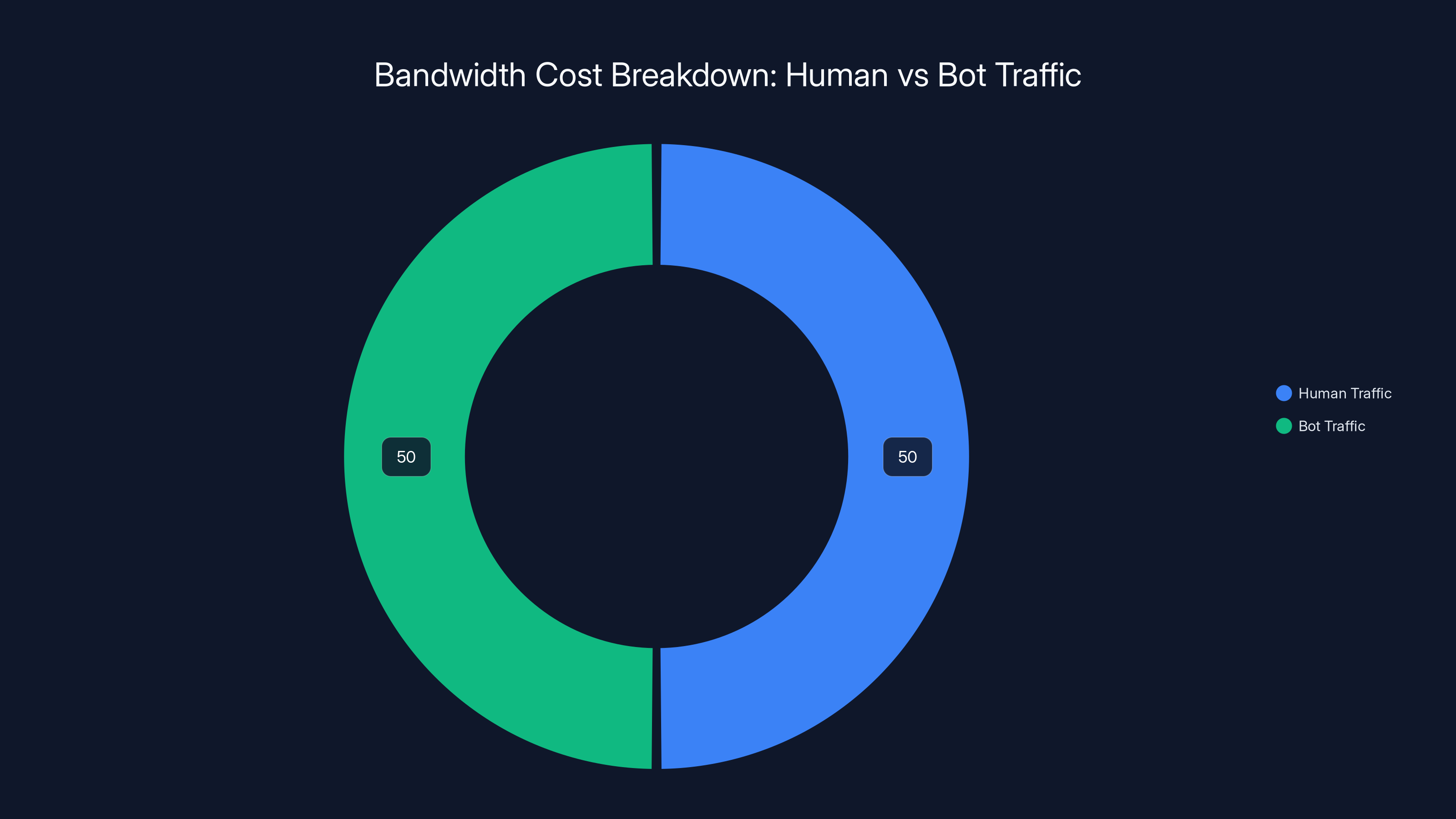
Estimated data suggests that bot traffic can account for up to 50% of bandwidth costs on medium-sized news sites, despite representing only a small portion of total visits.
The Death of Search as We Know It
For decades, Google's search results were the primary way people discovered content on the internet. You wanted to know something, you searched, you clicked through. Google became the internet's dominant company because they controlled that discovery mechanism.
Now that's changing in ways that Google itself is struggling to adapt to.
37% of AI users now start searches in AI systems rather than traditional search engines. That percentage is growing. And as it grows, the entire discovery ecosystem breaks down.
Traditional search engines use click-through data to understand which sites have valuable content. The more clicks a site gets for a particular topic, the higher it ranks. This created a virtuous cycle: good content gets ranked, users click through, traffic validates the quality, more traffic comes, site becomes more authoritative.
AI-mediated search breaks this feedback loop. An AI crawls your site, gets the information, answers the user's question, and the user never clicks through. No click data. No traffic validation. No signal that your content was valuable.
This is particularly devastating for long-tail content creators. A science writer might create incredible content on a niche topic. In the traditional search model, if that content is good, it'll eventually rank well, and the writer benefits from traffic and potential monetization.
In the AI model, that content just becomes training data. The writer's name might not even appear. The AI will synthesize information from dozens of sources and present it as a single coherent answer, with attribution muddled or lost entirely.
The long-term effect is that the economic incentive to create content might decline significantly. If you can't rely on traffic from search, and AI companies don't pay fairly for content, why spend months researching and writing detailed articles?
The irony is that this undermines the AI companies themselves. They depend on high-quality human-created content. If the economic incentives to create that content disappear, the AI systems will eventually have less good training data and less fresh information to work with.
Training Crawlers Declined, but RAG Bots Exploded
Here's a detail that reveals something important about AI companies' strategy.
Training crawlers—the bots that scrape content to build foundational AI models—actually declined 15% between Q2 and Q4 of 2024. This might seem contradictory to the idea that AI is becoming more dominant. If AI is growing, shouldn't training crawlers be growing?
The answer is nuanced. Most major AI companies have already built their foundational models. They have massive transformer models trained on internet-scale data. They don't need to keep scraping at the same intensity they did in 2021-2023.
What they need now is different: they need fresh, real-time information to feed into their production systems.
That's what RAG bots do. RAG stands for Retrieval-Augmented Generation. The idea is simple: instead of only using information from the model's training data (which becomes stale), you fetch current information from the web whenever a user asks a question.
RAG bots jumped 33% in activity. They're the systems that power Chat GPT's "Web Search" feature, Perplexity's real-time search, and Google's integration of AI results into search.
This is actually worse for publishers than training crawlers in some ways. Training crawlers come, scrape, and then stop. They're one-time events. RAG bots are continuously hitting your site, over and over, pulling the latest information.
Search indexing bots rose 59%. These are similar to RAG bots but focused specifically on search functionality. Every time you search in Chat GPT for current information, an indexing bot is hitting websites to build search results.
The pattern is clear: AI companies are transitioning from "we need to download the internet once" to "we need continuous access to the internet." And they're building infrastructure to make that continuous access automatic and efficient.
The RAG Bot Problem: Efficiency at Scale
There's a technical problem here that's worth understanding, because it affects how heavily bot traffic will impact your infrastructure.
When a user asks Chat GPT a question, and Chat GPT needs fresh information, it uses a RAG bot to search your site. In an ideal world, it would ask Chat GPT to retrieve information efficiently, caching results to avoid hammering your server.
In practice, here's what happens: Chat GPT might spawn 5, 10, or even 20 parallel requests to your site. If multiple users are asking related questions, that multiplies. If the RAG system is trying to verify information or compare data across multiple pages, it keeps requesting.
From your server's perspective, it looks like a distributed denial-of-service attack. The requests are legitimate (they're really from Open AI), but the volume is intense and uncontrolled.
Some websites are already reporting that bot traffic has taken up 50-60% of their server capacity. They're paying for infrastructure to serve machines, not humans.
The infrastructure cost problem is particularly bad for smaller publishers. A major news outlet might have servers that can handle bot traffic spikes. A small publisher running on standard shared hosting might see their site slow down or go down when a popular RAG bot hits them.
This creates a hidden cost of the bot internet that nobody's really accounting for yet. You're not just losing revenue from clicks that don't happen. You're also paying more for infrastructure to serve bots.
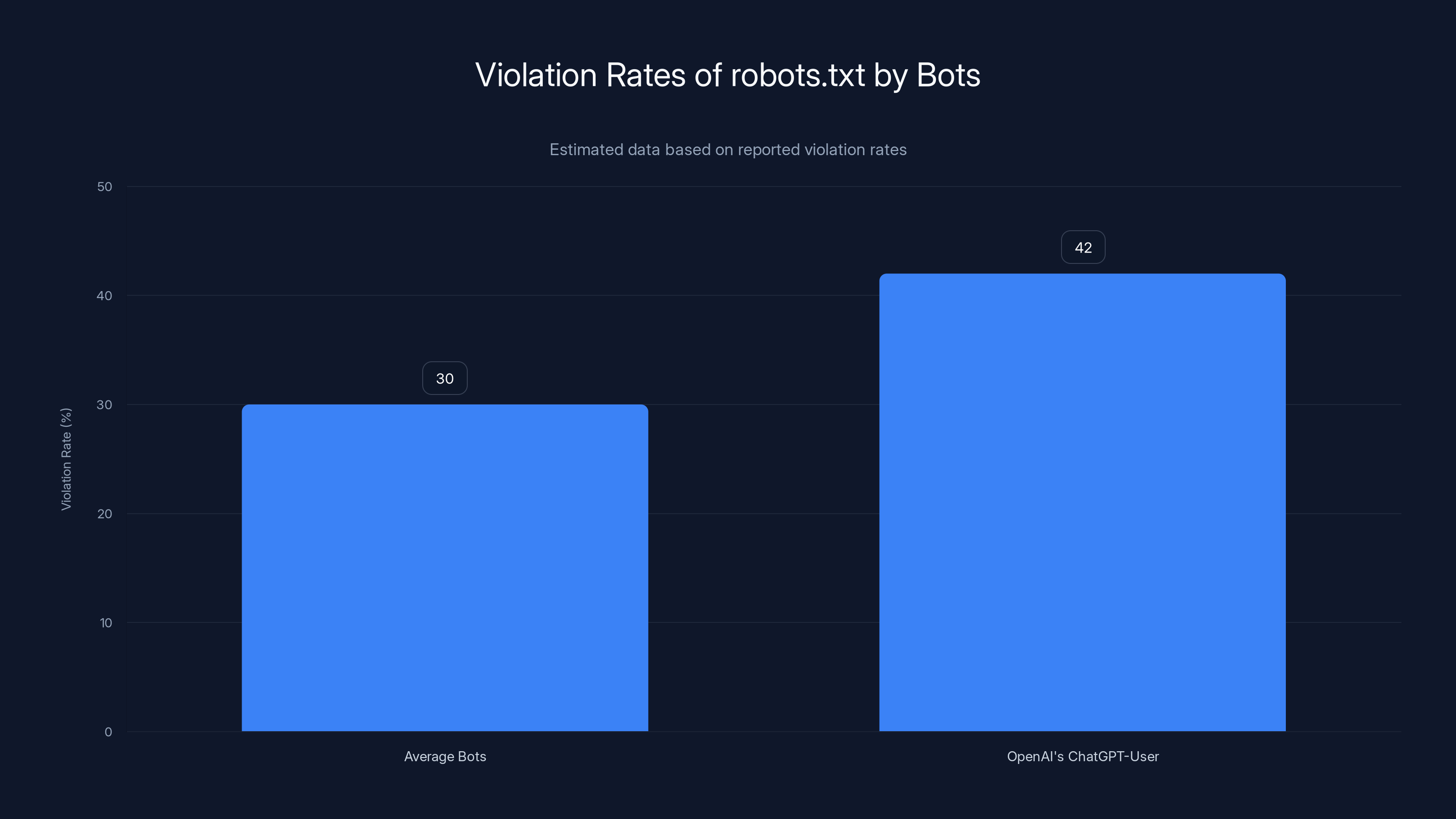
OpenAI's ChatGPT-User bot ignores robots.txt instructions 42% of the time, significantly higher than the average bot violation rate of 30%. Estimated data.
The Agentic Internet Is Coming: Are You Ready?
All of this bot activity is leading to something larger: an internet increasingly designed for AI agents rather than human users.
Right now, when you visit a website, you see it in a browser. It's formatted for human eyeballs. Text is readable, images are placed for visual impact, CTAs are prominent.
AI bots don't care about any of that. They want structured data, clean markup, consistent formats. And websites are starting to optimize for bot consumption rather than human consumption.
This creates a subtle but important shift. Web developers might start prioritizing bot accessibility over human readability. Publishers might restructure content in ways that make it easier for AI to parse, even if it makes it harder for humans to enjoy.
You can already see this happening. Some news sites are adding machine-readable summaries above articles. Some publishers are restructuring content to be more modular and AI-friendly.
The logical endpoint of this is an internet where most content is primarily designed for machine consumption, and human users are just getting summaries from AI systems.
For businesses, preparing for the agentic internet means:
- Structured data: Using schema markup, JSON-LD, and other structured formats so AI systems can easily understand your content
- Bot-friendly infrastructure: Making sure your site can handle bot traffic without degradation
- Direct AI relationships: Negotiating licensing deals or partnerships with major AI companies rather than hoping to be discovered through human search
- API-first thinking: Providing APIs and feeds that AI systems can easily integrate with
- New monetization models: Moving beyond ad-dependent models to direct licensing, subscriptions, and partnership revenue
The companies that thrive in this new internet will be the ones that adapt fastest. The companies that assume the human web will continue to work the way it did in 2020 will struggle.
What Regulators Are Starting to Do (And Why It Matters)
The current situation—where AI companies extract value from publisher content without permission or fair compensation—is not stable. Regulators are beginning to notice.
Several approaches are emerging:
Licensing mandates: Some jurisdictions are exploring rules that require AI companies to license content from publishers or compensate them for scraping.
Transparency requirements: Regulators are asking why AI companies are violating robots.txt and demanding better disclosure of how much publisher content is being used.
Copyright enforcement: There are ongoing legal cases exploring whether scraping for AI training violates copyright law. The outcomes could reshape the entire industry.
Bot identification standards: Some discussions are focused on standardizing how bots identify themselves and their purpose, making it easier for publishers to allow some bots while blocking others.
The challenge for regulators is that AI is distributed globally and moves fast. By the time a regulation is drafted and implemented, the technology and industry have already evolved past it.
But momentum is building. Publishers are organizing. Regulators are taking notice. The question isn't whether the current situation will change—it will. The question is how, and how quickly.
Building a Monetization Strategy for the Bot Internet
If you're a content creator or publisher, the bot traffic shift isn't something to just endure. It's something to capitalize on strategically.
Direct licensing deals: Reach out to major AI companies and offer to license your content. The payments might be modest compared to historical traffic revenue, but it's better than nothing. More importantly, exclusive licensing deals give you leverage.
Structured data optimization: Make sure your content is easily machine-readable. Use proper heading hierarchies, schema markup, clear metadata. RAG systems will prefer to cite well-structured content.
Bot traffic analytics: Start tracking bot traffic separately from human traffic. Understand which bots are hitting you, how often, and what content they're interested in. This data is valuable for negotiations.
Subscription or membership models: As ad revenue declines due to lost click-through traffic, recurring revenue models become more important. Build direct relationships with your audience.
API offerings: Some AI companies might be willing to pay for direct API access to your content rather than scraping it. This is more efficient for them and gives you better control.
Content differentiation: Focus on content that's valuable but hard to scrape or synthesize. Deep investigations, original research, exclusive interviews. These have higher inherent value.
The companies that are thriving through this transition are the ones that aren't fighting it—they're adapting to it. They're negotiating, structuring content for AI discovery, and building new revenue streams.
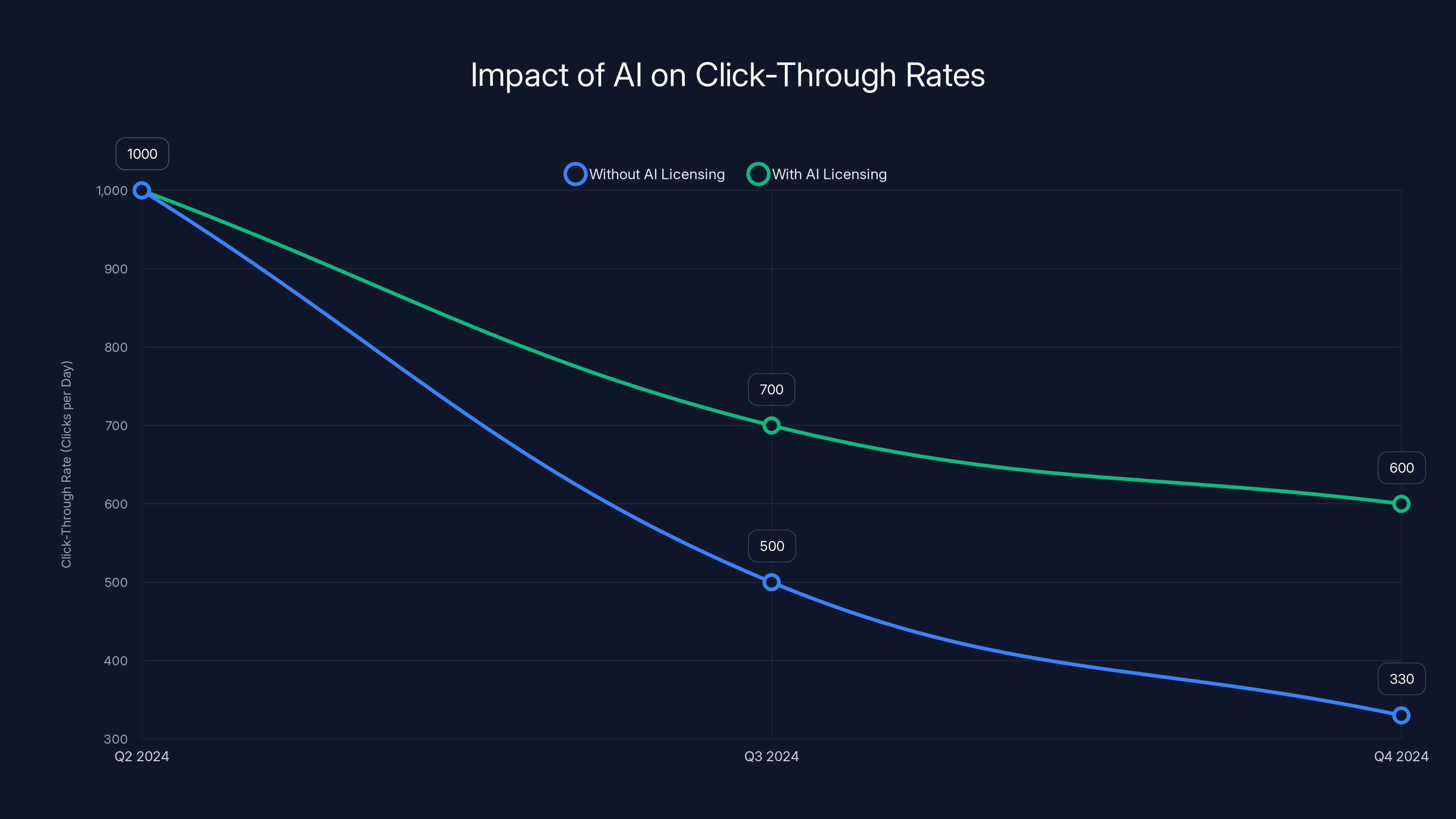
Sites without AI licensing deals saw a 66% drop in click-through rates from Q2 to Q4 2024, while those with deals experienced a less severe decline. Estimated data highlights the economic impact of AI on web traffic.
The Infrastructure Challenge Nobody's Talking About
Here's something that most analyses of the bot traffic problem miss: the infrastructure cost.
Serving bot traffic is expensive. Bots generate reads, not just clicks. Each RAG request from Chat GPT hits your server, downloads the HTML, parses it, extracts information, and moves on. If you're paying per gigabyte of bandwidth, per server request, or per database query, bot traffic is expensive.
A medium-sized news site might find that bot traffic accounts for 40-50% of their total bandwidth costs, even if bots are only driving 5% of human visits.
There are some technical solutions emerging:
Bot-specific caching: Serving bots from cache rather than generating fresh pages saves compute resources
Rate limiting: Some publishers are experimenting with rate limits on bot traffic. If a bot makes more than X requests per second, responses slow down until traffic normalizes
Bot detection and filtering: Identifying bot traffic and serving it lower-quality content (stripped of ads, simplified formatting) can reduce bandwidth costs
CDN optimization: Using content delivery networks specifically optimized for bot traffic patterns can reduce costs
Server-side rendering optimization: Simplifying pages for bot consumption (no heavy Java Script, streamlined assets) reduces per-request costs
The irony is that all of these optimizations benefit bots at the expense of humans. A site might end up faster for AI crawlers and slower for human users, because human traffic is what's driving profitability pressure.
Long-term, this is probably unsustainable. Either publishers will successfully negotiate bot licensing that covers infrastructure costs, or publishers will find technical ways to make bots more expensive to scrape, or regulators will force AI companies to compensate fairly.
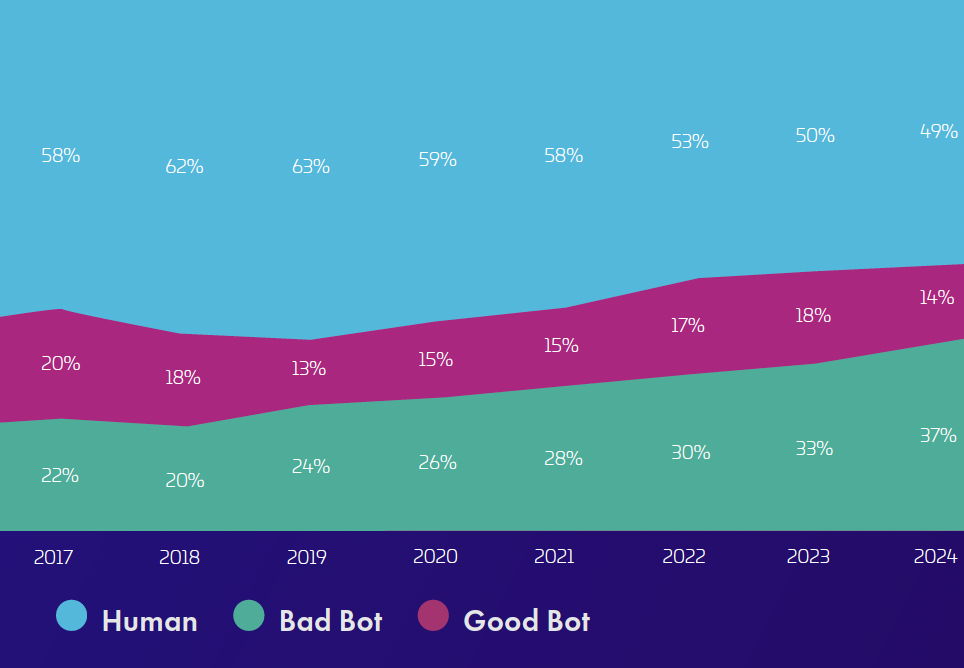
Will Your Content Survive the Bot Era?
There's an existential question lurking under all of this: what happens to content creation when the economic incentive structure breaks down?
For most of the web's history, the incentive has been clear. Create good content, rank in search, get traffic, monetize traffic (through ads, subscriptions, or sales). The system wasn't perfect, but it worked.
In the bot era, the incentive is murkier. Create good content, AI bots find it, humans never see it, no traffic, no direct monetization. Unless you've negotiated a licensing deal, you just created valuable content for free.
Over time, this could lead to a decline in original content creation. Why invest in research if you don't benefit from it? Why write detailed explainers if they just become training data for AI systems?
The AI industry's counterargument is that AI products make content more accessible and usable. Instead of everyone having to visit individual sites, they can ask an AI question and get a synthesized answer. This is genuinely useful for users.
But utility for users doesn't automatically translate to compensation for creators. And creators need to eat.
The most likely outcome is that the content ecosystem will bifurcate. Premium, original content created by well-funded organizations (major news outlets, universities, research institutions) will survive through licensing deals and institutional support. Commodity content (list articles, general information, rehashed takes) will become increasingly valuable only as training data for AI systems.
The middle—independent creators, small publishers, niche publications—will have the hardest time adapting. They don't have the bargaining power for licensing deals, they can't survive on reduced traffic, and they can't afford to lose all ad revenue.
The 2025 Perspective: Bot Traffic Has Already Won
It's worth being clear about where we are in this timeline. This isn't a prediction about some future internet. This is happening now.
Bot traffic already exceeds human traffic significantly. The ratio is compressing constantly. Within a year or two, there will likely be more bot visits to the average website than human visits.
Some implications of that:
Search traffic will continue to decline: As more people use AI search directly, Google and Bing traffic will decrease. Publisher sites that depend on search traffic will see revenue decline.
Ad networks will face pressure: Fewer human pageviews means less ad inventory. Ad rates might increase to compensate, but they'll also become more fragmented as publishers compete harder for remaining human traffic.
Licensing will become essential: Publishers that haven't negotiated with AI companies will face increasingly difficult economics. Licensing won't fully replace lost ad revenue, but it'll be necessary to remain sustainable.
Infrastructure costs will increase: Every publisher will need to invest in understanding and managing bot traffic. This is a new operational cost that didn't exist five years ago.
Content structure will change: Websites will increasingly optimize for bot consumption because that's where volume is. Human-first design will be for premium, directly-monetized properties.
The open web will become more closed: More content will be paywalled or restricted. Free content will be increasingly designed for bots, not humans.
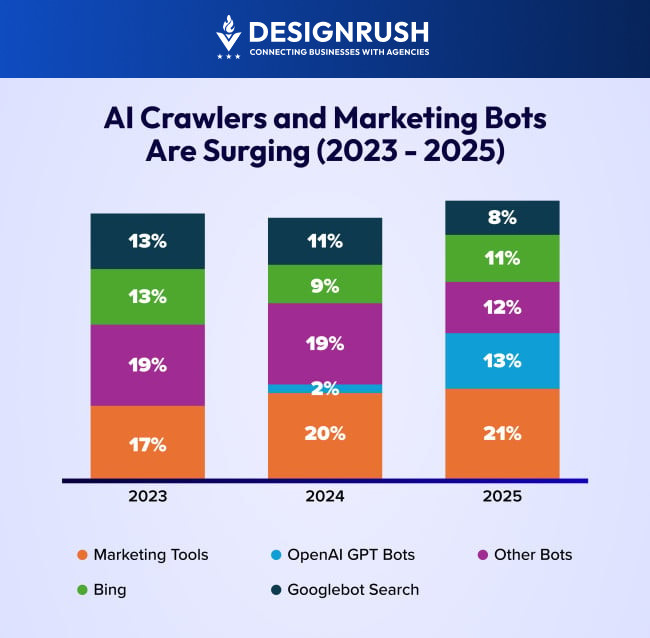

Estimated data shows bot traffic can consume up to 55% of server capacity, leaving only 45% for human users. This highlights the significant impact of bot traffic on infrastructure costs.
What You Can Do Right Now
If you operate a website or content platform, here's the practical checklist:
1. Instrument your analytics: Set up bot traffic tracking separately from human traffic. Understand what bots are hitting you, when, and why. Most standard analytics tools bucket this together, so you might need to add custom tracking or use security tools that separate bot traffic.
2. Audit your robots.txt: See what you're currently blocking. Consider whether your current restrictions are achieving what you intend, or whether you should be more permissive (to get bot traffic credit and licensing potential) or more restrictive (to reduce server load).
3. Implement structured data: Add JSON-LD schema markup, proper heading hierarchies, and metadata to your content. Make it easy for AI systems to understand and cite your content properly.
4. Document your value: Start collecting data on how much bot traffic you're receiving. If you're getting scraped by major AI companies, quantify it. This becomes leverage in licensing negotiations.
5. Research licensing options: Reach out to Anthropic, Open AI, and other AI companies. Ask whether they have content licensing programs. Even if they don't have formal programs yet, having the conversation positions you for future deals.
6. Optimize your infrastructure: Talk to your hosting provider about bot traffic management. Consider CDN improvements, caching strategies, and rate limiting options.
7. Diversify your revenue: Stop relying solely on ad-based monetization from human traffic. Add subscriptions, memberships, licensing deals, or affiliate revenue.
8. Create valuable content: The content that survives the bot era is content that's expensive to create and hard to synthesize. Original reporting, deep research, unique perspectives. Don't compete on commodity content with AI.
The Long Game: What the Internet Looks Like in 2027
Projecting forward a couple of years, several scenarios are plausible:
Scenario 1: Regulatory intervention: Regulators force AI companies to license content more fairly or compensate publishers through copyright law changes. Publishers receive meaningful revenue, bot traffic becomes a feature rather than a threat. This requires coordinated action and is probably 12-24 months out.
Scenario 2: Market consolidation: Smaller publishers and creators don't survive the transition. The internet becomes dominated by well-capitalized publishers who can negotiate licensing deals. Niches and long-tail content disappear. This is already happening.
Scenario 3: Technical arms race: Publishers get better at detecting and blocking bots. AI companies get better at evading detection. The internet becomes increasingly adversarial, with significant technical overhead on both sides.
Scenario 4: API-first internet: Most high-value content becomes available through APIs that AI systems can access with billing and authentication. This creates a new standard for how AI accesses information. More efficient, more fair, better controlled.
The most likely outcome is probably a combination of these. Regulators will push licensing. Technology will evolve. Market consolidation will happen. The internet will become simultaneously more controlled (through APIs and authentication) and more AI-native (structured for machine consumption).
For content creators and publishers, the strategic imperative is clear: understand the new rules now, adapt your infrastructure and business model, and build direct relationships with AI platforms rather than hoping to be discovered through traditional search.
The old internet rules still apply for now. But they're expiring fast.
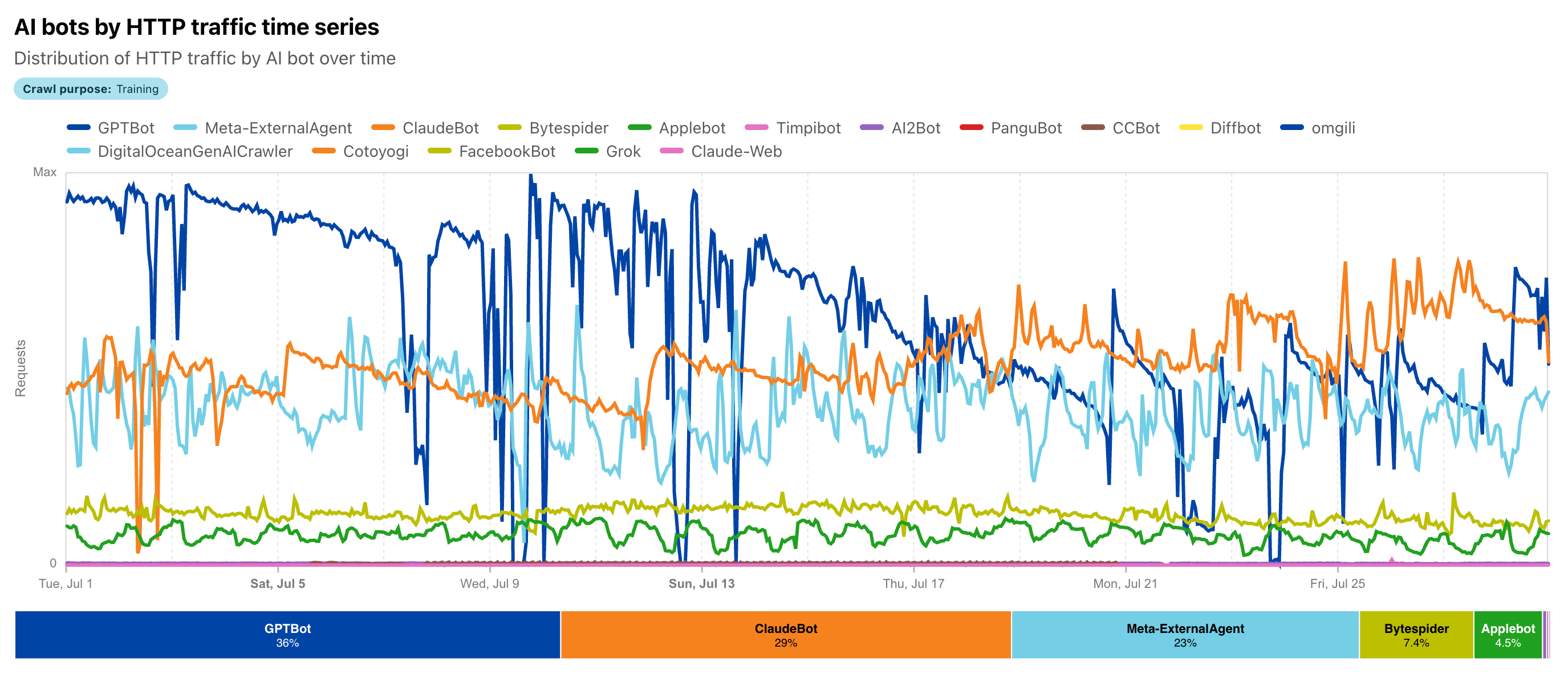
How to Prepare Your Website for the Bot-Dominated Internet
Beyond the strategic considerations, there are concrete technical steps you can take today.
Content architecture for AI parsing: Use consistent heading structures, clear sections, and descriptive subheadings. AI systems parse documents hierarchically, and a well-structured document is much easier to accurately summarize and cite.
Microdata and schema markup: Add structured data that explicitly identifies who wrote something, when it was published, what it's about. Use schema.org vocabulary consistently.
Clear citations and sourcing: If you're aggregating information from other sources, cite them clearly. AI systems that want to provide accurate citations will find it easier to credit your sources correctly if you've done the work first.
Metadata optimization: Write clear meta descriptions. Include author information. Add publication dates. These signals help AI systems understand and properly attribute content.
Performance optimization: Bot traffic is read-only traffic, but it still impacts your server load. Optimize for fast page loads, efficient database queries, and responsive infrastructure.
API endpoints: If you have high-value content, consider providing API access for authorized AI systems. This is more efficient than web scraping and gives you control.
Content freshness signals: Update timestamps on content that's still accurate. Add "updated" dates. AI systems are increasingly looking for fresh information, and being clear about freshness improves your content's value.
Provenance and authorship: Make it extremely clear who created each piece of content. AI systems are being trained to respect attribution. Clear authorship information makes proper citation more likely.
The Human Element: Why This Matters Beyond Economics
This isn't just an economic story. There's something deeper happening to how humans and machines interact with information.
For decades, the internet was a place where humans published and humans consumed. Websites were written by people for people. Search engines helped humans navigate. Algorithms ranked content based on human engagement.
Now, an increasingly large portion of the internet is being written by humans and consumed by machines. The machines are then synthesizing information and presenting it to humans through an interface that might not even tell you where the information came from.
This changes how information gets valued, preserved, and understood. It changes how attribution and reputation work. It changes the incentive structure for creating knowledge.
If you spend months researching and writing a comprehensive guide to some topic, and an AI system scrapes that guide, synthesizes it with 10 other sources, and presents it as a single answer without mentioning you—you don't just lose traffic revenue. You lose credit. You lose reputation. You lose the ability to build an audience.
Multiply that across millions of creators and millions of pieces of content, and you get a system where original work is extracted at scale without acknowledgment or compensation.
The internet of the future could be more efficient and more accessible. Or it could be more extractive and less rewarding for creators. Or some combination of both. But it will definitely be different.
FAQ
What exactly is an AI bot, and how is it different from a search engine crawler?
AI bots are automated programs that crawl websites to retrieve content for AI systems. Search engine crawlers (like Googlebot) index content to build a searchable index, and they mostly respect robots.txt restrictions. AI bots, particularly RAG bots and search indexers used by AI companies, retrieve content to feed into language models and answer user queries directly without necessarily maintaining a searchable index. The key difference is that AI bots are designed to extract information for processing by AI models, while search crawlers are designed to understand and rank content for human discovery.
Why would my website want bot traffic if it doesn't generate revenue?
Bigger question: does it? Current bot traffic typically generates zero direct revenue unless you've negotiated a licensing deal with an AI company. However, some websites might benefit from having their content appear in AI responses, as this provides a form of visibility. The tradeoff is that visibility in AI responses often means users never visit your actual site. Increasingly, websites are trying to negotiate licensing deals where the AI company pays for access to content, but these deals are still relatively rare and don't compensate for lost human traffic.
What does "robots.txt" do, and why does it matter if it's being ignored?
robots.txt is a file websites create to tell bots which areas of the site they can and cannot crawl. For decades, it was the primary tool for controlling automated access. However, robots.txt is entirely voluntary—there's no enforcement mechanism if a bot chooses to ignore it. It's being ignored 30-42% of the time by major AI bots, which means publishers have essentially lost their primary tool for protecting content from automated scraping. This is why some legal scholars are predicting robots.txt will become obsolete and why regulation is probably necessary to protect publisher content.
Is my website going to lose traffic to AI bots? How much should I expect to lose?
Likely yes, though the amount varies by industry and content type. Sites that depend on people searching for information and clicking through are already seeing 3x drops in click-through rates. Sites with more direct audience relationships (subscription-based, email lists, social media) are less affected. News sites, educational content, reference materials, and information-heavy content are being hit hardest. The typical range is 20-50% reduction in organic search traffic as users shift to AI-based searching, depending on your content category.
Should I block AI bots from my website?
It depends on your business model and traffic sources. Blocking AI bots through robots.txt reduces your infrastructure load but doesn't generate revenue and potentially reduces visibility. Some high-value content sites are experimenting with blocking bots and relying on direct audience relationships instead. Others are negotiating licensing deals. The pure blocking strategy only works if you have alternative revenue sources and don't rely on search traffic discovery. For most publishers, a mixed approach makes more sense: allow some bots, license content to key players, and optimize infrastructure to handle bot traffic efficiently.
What's the difference between RAG bots and search indexing bots?
Both are bots that continuously crawl the web, but for slightly different purposes. RAG (Retrieval-Augmented Generation) bots fetch information in response to specific user queries—when someone asks Chat GPT a question, a RAG bot searches websites for relevant information to include in the answer. Search indexing bots are broader, continuously cataloging content to maintain an index that can be searched. RAG bots are more intensive and targeted, while search indexers are more systematic and continuous. Both are growing rapidly as AI companies build more sophisticated real-time information access.
Can I negotiate with AI companies to license my content fairly?
Some AI companies have content licensing programs or are open to discussions about them, but the market is still developing. Open AI, Anthropic, and others do engage with publishers, though the terms are often less generous than you might hope. The leverage you have depends on the value and uniqueness of your content. News organizations and specialized publishers (financial information, legal research, medical data) have more negotiating power than general-purpose websites. It's worth reaching out to major AI companies to understand what options exist, but don't expect these agreements to fully replace lost ad revenue.
What's the most important thing I should do immediately to prepare for increased bot traffic?
Start tracking your bot traffic separately from human traffic. Most analytics tools don't distinguish, so you might need custom implementation or a separate tool. Understanding which bots are hitting you, how often, and what they're accessing is crucial information for both operational decisions (infrastructure planning, rate limiting) and business decisions (licensing negotiations, content strategy). This data also becomes valuable if you ever need to make a case about copyright violations or in regulatory proceedings.
Will traditional search engines like Google be affected by AI bot traffic?
Google itself is adapting to this shift. Google Search is integrating AI-generated summaries, which means Google is now part of the bot traffic ecosystem rather than just the gateway to organic traffic. This is actually accelerating the decline in click-through rates to publisher sites, since Google is now answering questions directly instead of sending people to websites. Other search engines (Bing, Duck Duck Go) are following similar paths. The long-term impact is that traditional search, which was the primary traffic driver for decades, becomes less relevant as AI search (Chat GPT, Perplexity, etc.) takes share.
What's the economic impact of bot traffic on a typical publisher?
For a mid-sized news site with 50,000 human daily visitors and
Conclusion: The Internet Is Reorganizing
Let's be clear about what's happening. The internet that worked for the last 25 years is reorganizing. The mechanisms that protected intellectual property are failing. The incentive structures that funded content creation are breaking down. The discovery mechanism that drove human traffic is being bypassed.
This isn't a small change. It's a fundamental shift in how information flows online.
For website owners and publishers, the strategy can't be to fight this shift. That's already lost. Instead, the strategy is to adapt faster than your competition, understand the new rules before everyone else figures them out, and build business models that work in the bot-mediated internet.
Some concrete steps that matter immediately:
First, instrument your infrastructure to understand what you're actually dealing with. What percentage of your traffic is bots? Which bots? What are they accessing? How much infrastructure load are they creating? You can't strategize without data.
Second, reach out to major AI companies and start conversations about licensing. Whether or not a deal makes sense for you, understanding what they're offering and what they're willing to pay tells you about the broader market. These conversations are how you find negotiating leverage.
Third, optimize your content for both human consumption and bot consumption. Use clear structure, explicit markup, strong attribution. Content that's easy for AI systems to understand and properly cite will get more valuable in this environment.
Fourth, diversify your revenue away from traffic-based monetization. Subscriptions, memberships, licensing deals, direct relationships with AI companies. The age of pure ad-based revenue from search traffic is ending.
Fifth, focus on creating content that's genuinely valuable and hard to synthesize. Commodity information will become increasingly worthless as AI handles it. Original research, unique perspectives, and specialized knowledge will be what survives.
The internet of the future won't be worse because of AI. But it will be different. And the companies that thrive will be the ones that understand the difference and adapt accordingly.
The bots aren't going away. The question is whether you're prepared for them to be your primary audience.
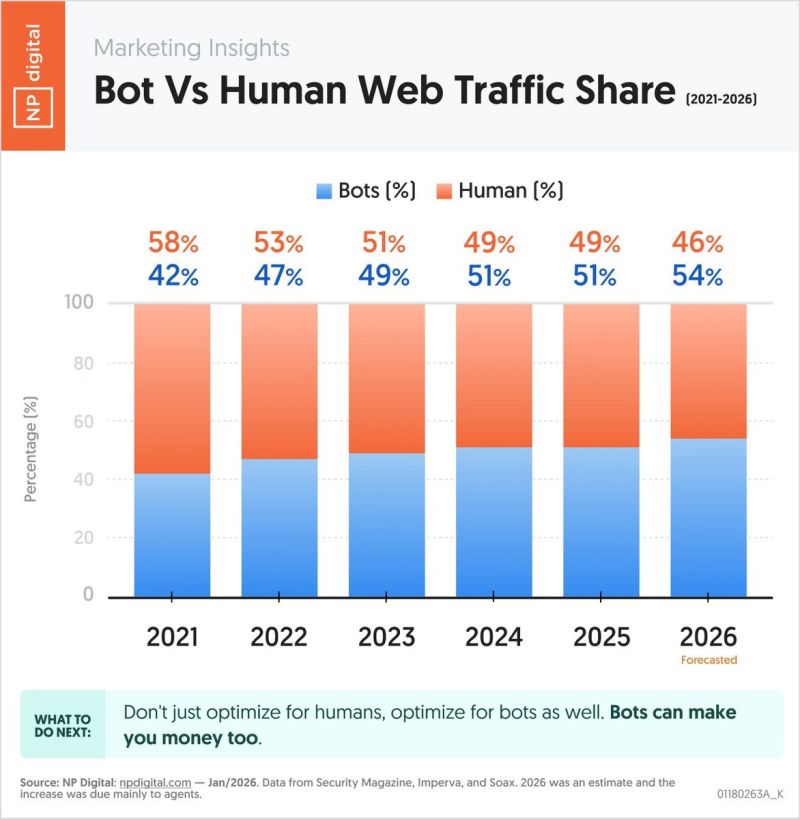
Key Takeaways
- AI bot traffic reached 1 visit per 31 human visits by end of 2024, up from 1:200 at the start of the year—a 62x increase in less than 12 months
- Human web traffic dropped 5% in Q4 as users shifted directly to AI systems like ChatGPT for search rather than visiting websites
- robots.txt is effectively dead: AI bots ignore these copyright protection instructions 30-42% of the time, with no enforcement mechanism
- Publishers without AI licensing deals saw click-through rates collapse 3x (66% reduction), destroying ad-based revenue models
- The internet is reorganizing around AI consumption: RAG bots (+33%) and search indexers (+59%) surged while training crawlers declined 15%
- OpenAI dominates the bot ecosystem, with its ChatGPT-User bot 5x more active than Meta's bots and 16x more than Perplexity's
- Content creators must negotiate direct licensing deals, optimize infrastructure for bot traffic, and move beyond pure ad-based monetization
- The long-term survival of original content creation is threatened as economic incentives break down

