![AI Data Center Infrastructure Upgrades: The Engineering Boom [2025]](https://tryrunable.com/blog/ai-data-center-infrastructure-upgrades-the-engineering-boom-/image-1-1768563442298.jpg)
AI Data Center Infrastructure Upgrades: The Engineering Boom [2025]
The AI boom isn't just changing how we work. It's reshaping the physical infrastructure that makes AI possible in the first place.
Data centers built five years ago? Obsolete. The ones being designed today are being built for tomorrow's challenges, not today's requirements. And the gap between what we have and what we need is growing faster than anyone anticipated.
Here's what's really happening: hyperscalers like OpenAI, Google, and Meta are pushing data center infrastructure to extremes that conventional operations never contemplated. We're talking about facilities that consume the equivalent of a small city's electricity. Cooling systems that require completely new engineering approaches. Network connectivity demands that strain global supply chains.
The result is a defining moment for infrastructure: companies that can move fast and execute flawlessly are capturing enormous market share. Those that can't are watching opportunities slip away to newer, more agile competitors.
This isn't just a technical story. It's a business story. It's a geopolitical story. And it directly impacts which countries, companies, and teams will lead AI development for the next decade.
Let me walk you through exactly what's changing, why it matters, and what the constraints are that everyone's running into right now.
TL; DR
- The Scale is Unprecedented: Data center spending is projected to hit $6.7 trillion by 2030, with the majority dedicated to AI infrastructure.
- Power Density Exploded: GPU clusters require 5-10 times higher power density than traditional data centers, forcing complete redesigns.
- Liquid Cooling is Mandatory: Direct-to-chip cooling systems are no longer optional for AI facilities—they're a baseline requirement.
- Supply Chain Bottlenecks: GPU, interconnect, and specialty component shortages are delaying projects and creating competitive advantages for those who move fast.
- Neoclouds are Disrupting Everything: Purpose-built GPU providers are moving faster than legacy operators and capturing market share at scale.
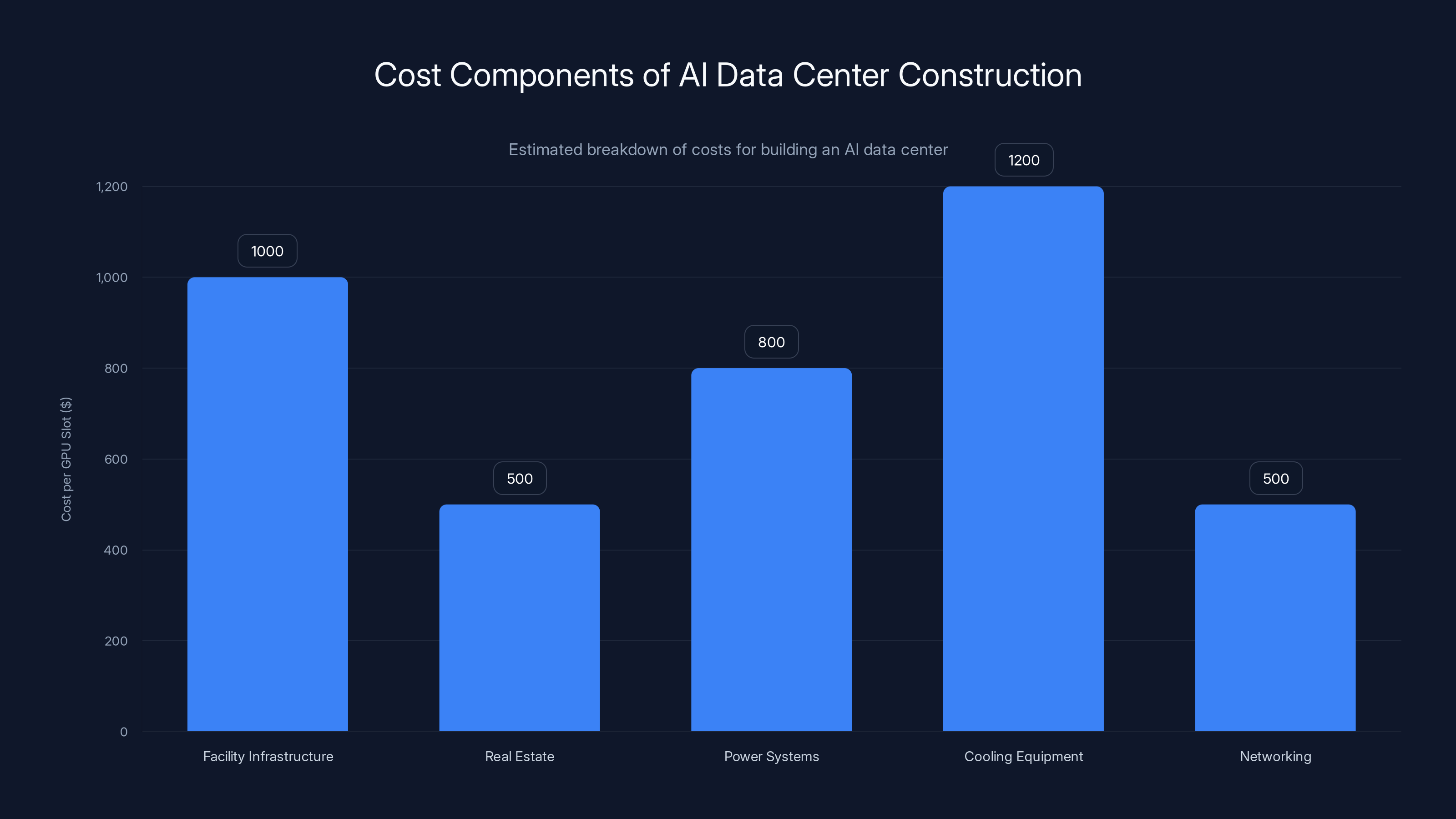
Building an AI data center involves significant costs, with cooling equipment and facility infrastructure being the largest expenses. Estimated data.
The Scale of Investment Driving the AI Infrastructure Boom
Let's start with numbers because they illustrate the magnitude of this moment.
Data center infrastructure spending isn't just growing—it's exploding. We're looking at facilities being built right now that will cost billions of dollars. Single buildings housing tens of thousands of GPUs. Projects in Norway, Iceland, Scandinavia, and North America designed from the ground up for AI workloads.
The global investment picture is staggering. By 2030, we're looking at $6.7 trillion in cumulative data center spending globally. That's not a typo. The majority of this capital is being funneled into facilities engineered specifically for AI and large-scale model training.
Why the rush? Because the demand for generative AI capacity is growing faster than supply can be deployed. Companies like CoreWeave are expanding from modest operations to tens of thousands of GPUs in months. Microsoft is signing multi-billion-dollar agreements with GPU infrastructure providers. OpenAI is raising capital at a scale that would have been unthinkable three years ago, much of it going straight to data center expansion.
Nations are watching this closely. Countries capable of deploying AI infrastructure at speed stand to attract tech investment, talent, and the economic opportunities that come with being a hub for AI development. Those that move too slowly risk watching opportunities migrate elsewhere.
This creates a competitive dynamic unlike anything we've seen before. Infrastructure is no longer a supporting function—it's a strategic asset. Which facilities are built first, how quickly they're deployed, and which countries host them determines who gets access to the computing resources that train the next generation of AI models.
For enterprise teams and startups, this translates directly into cost and accessibility. If you can't get GPU allocation, you can't train your models. If you're paying 3x what competitors pay for compute, you're at a disadvantage. Infrastructure constraints are becoming business constraints, not just technical ones.
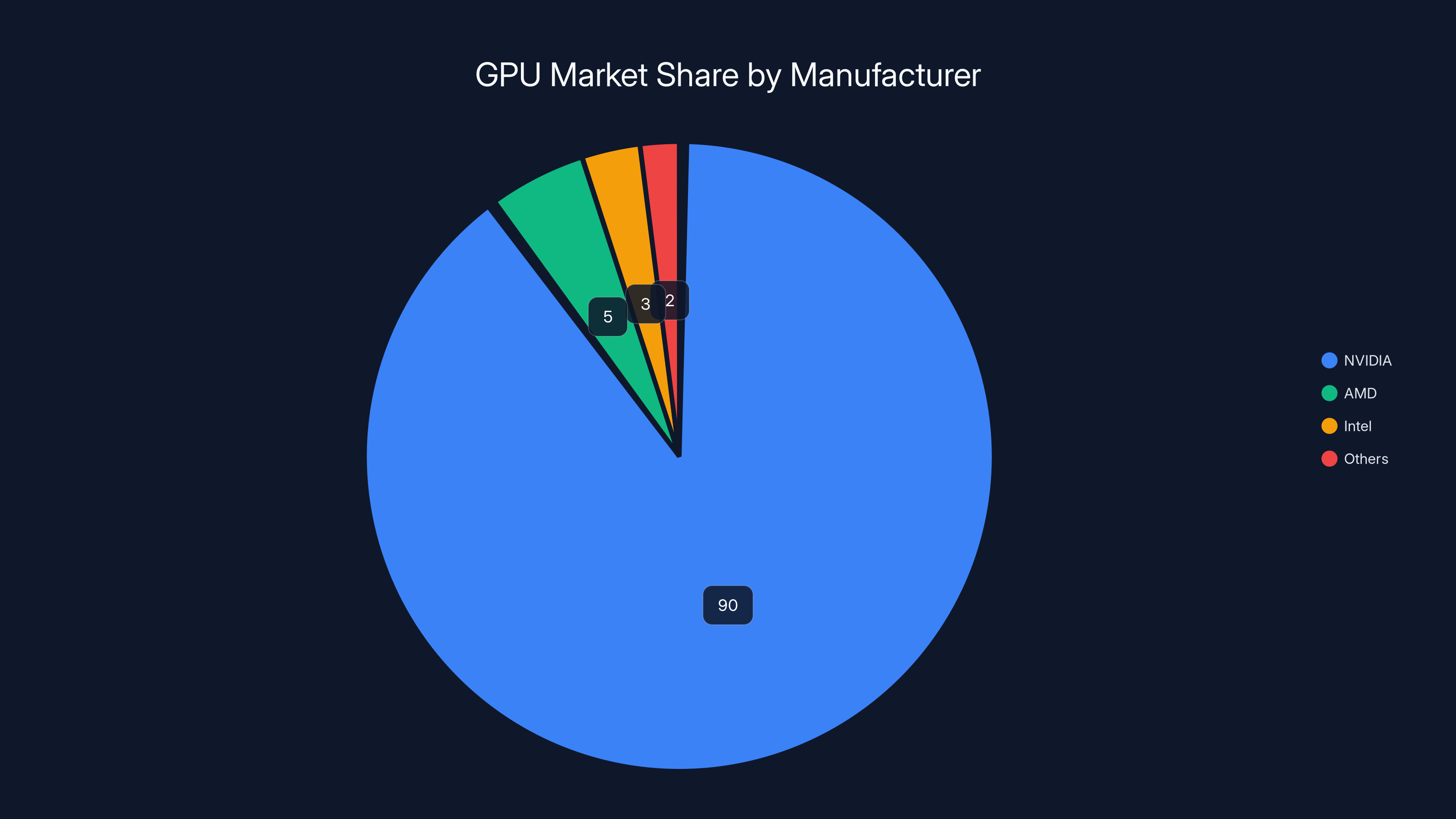
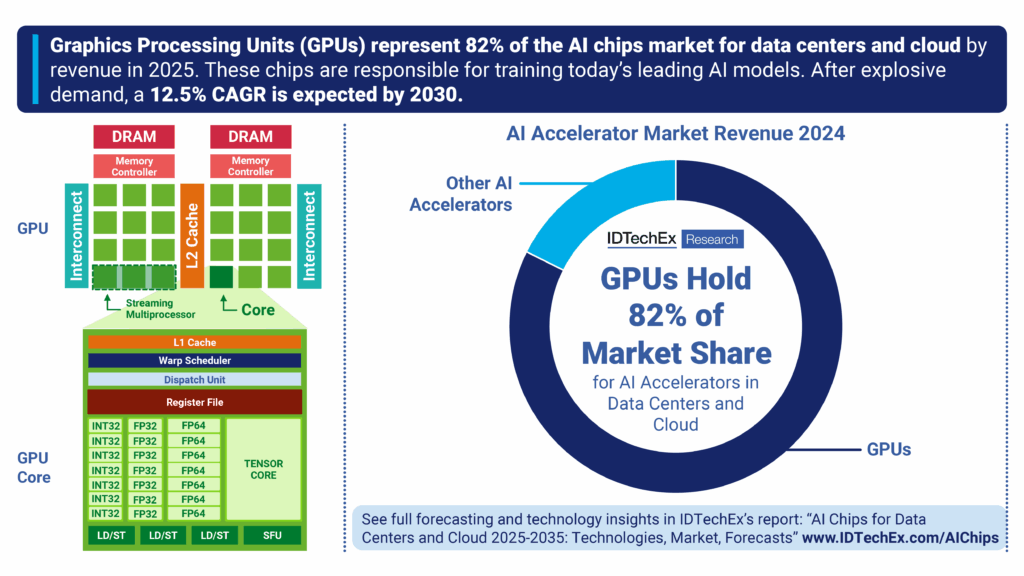
NVIDIA dominates the discrete AI accelerator market with an estimated 90% share, while AMD and Intel are ramping up but still lag behind significantly. (Estimated data)
Power Density: The First Fundamental Constraint
Here's where the engineering gets real.
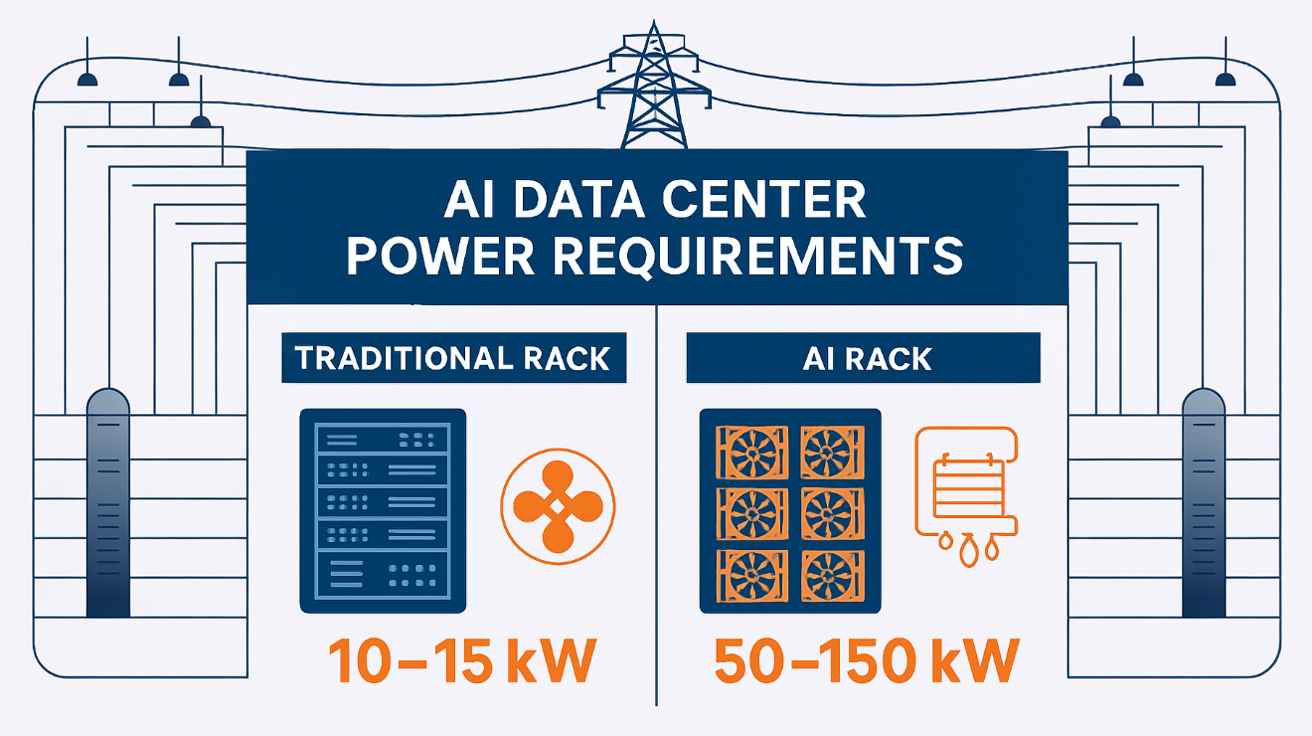
Traditional data centers operate at power densities of roughly 5-15 kilowatts per rack. This was the standard for the last 20 years. Well-designed cooling systems, standard electrical infrastructure, and conventional power distribution could handle it.
AI data centers? We're talking 50-100+ kilowatts per rack, sometimes more with densely packed GPU clusters. That's a 5-10x increase from what was considered cutting-edge efficiency just a few years ago.
Let me be specific about why this matters. When you're drawing that much power into a single rack, the heat generation becomes the limiting factor. Electricity flows in. Computations happen. Heat flows out. If you can't move that heat away fast enough, the GPUs throttle themselves or shut down to prevent damage. Your multi-million-dollar hardware becomes a space heater, and your compute capacity evaporates.
The naive approach—just build a bigger cooling system—doesn't work. You can't just add more air conditioning units. The thermodynamic efficiency falls apart. You need fundamentally different approaches.
This is where power infrastructure planning becomes as critical as the GPU selection itself. Many operators initially underestimated this challenge. They thought about computing power. They didn't think carefully enough about electrical delivery, voltage distribution, and the infrastructure required to get electricity into racks safely and efficiently.
Resulting problem: buildings designed and constructed five years ago, retrofitted with modern GPU clusters, now face electrical constraints that prevent them from reaching their intended capacity. The power infrastructure can't handle it. Upgrades cost millions and take months.
The smarter operators are designing from scratch, starting with power requirements and building the facility around them. This means:
- Dedicated electrical substations on or adjacent to the data center
- High-voltage distribution running directly to rack levels
- Advanced power monitoring systems that can detect faults in milliseconds
- Redundant feeds ensuring that a single failure doesn't cascade into a facility-wide outage
- Voltage regulation at the local level to prevent fluctuations that damage equipment
None of this is cheap. But the alternative—facility downtime, equipment damage, or inability to deploy GPUs at intended density—is worse.
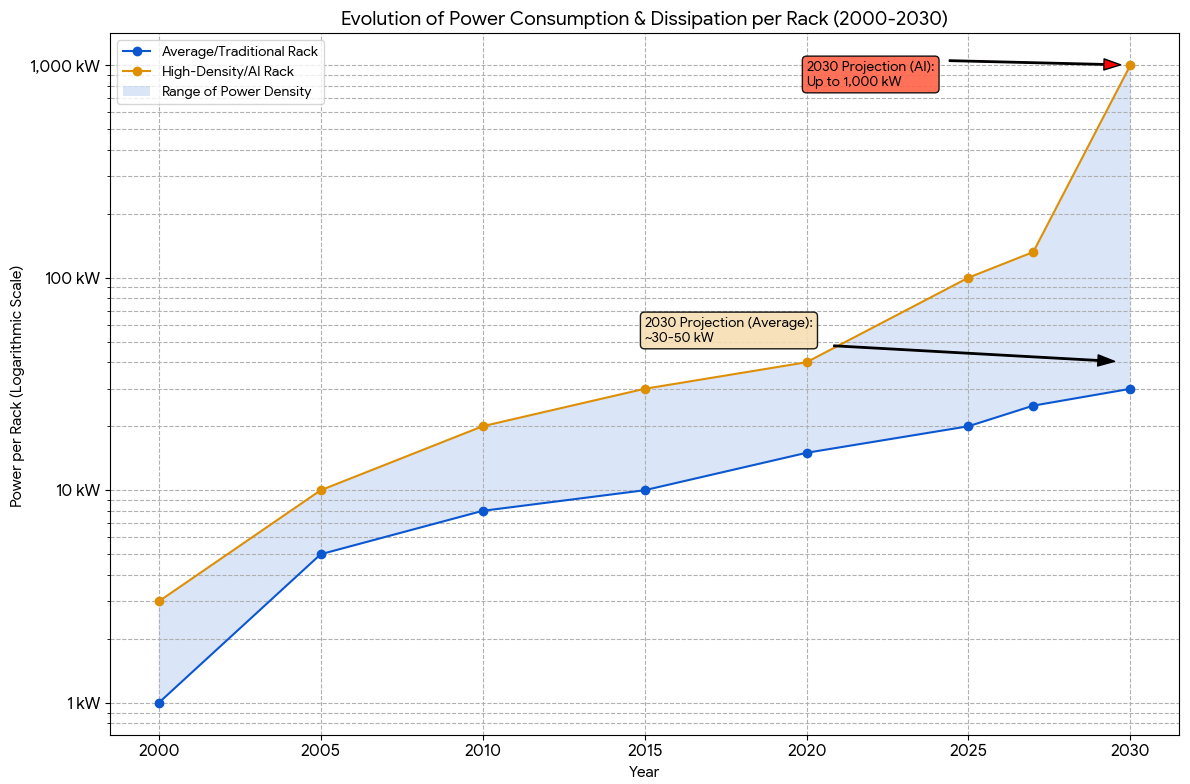
The Thermal Management Revolution: Liquid Cooling Becomes Mandatory
Air cooling is dead for AI data centers. That might sound dramatic, but operationally it's true.
Traditional data centers use hot-aisle/cold-aisle designs with massive CRAC and CRAH units (computer room air conditioner/handler). Cold air blows across equipment. Hot air is extracted and cooled, then recirculated. It works. It's standardized. Thousands of facilities run this way.
But at 50-100+ kilowatts per rack, air cooling becomes thermodynamically inefficient and economically nonsensical. You're moving enormous volumes of air, burning massive amounts of electricity just to move air around, and you still end up with thermal hotspots where components overheat.
Direct-to-chip liquid cooling flips the equation. Instead of cooling air that surrounds equipment, you cool the equipment directly. A liquid (usually water with additives to prevent corrosion) runs through channels on GPU dies and other hot components, extracting heat at the source.
The efficiency gains are dramatic. You move less fluid, consume less electricity for cooling, and maintain tighter temperature control on components. The trade-off is complexity.
Liquid cooling systems require entirely new facility considerations:
Fluid Distribution Infrastructure You need tubing routed to every rack, every GPU, every hot component. This isn't simple piping. Modern AI data centers use closed-loop systems with:
- Chilled water supplies and return lines
- Filtration systems to keep particles out of components
- Pressure regulators to prevent overpressure
- Leak detection sensors throughout
- Redundant circulation pumps
Containment and Safety If a water line ruptures in a traditional facility, water spills on expensive equipment. In a liquid-cooled AI data center, you've got higher pressures and volumes. Containment becomes critical:
- Sealed racks with catch basins
- Rapid-shutoff valves
- Moisture detection sensors
- Sealed, monitored connectors
Heat Removal at Facility Scale The heat extracted from GPUs has to go somewhere. You need cooling towers, chilled water loops, or in the best cases, you exhaust it to the environment directly. Some operators in cold climates (Scandinavia, Canada, Iceland) can exhaust hot water and effectively eliminate their cooling energy costs.
Water Treatment Keeping cooling fluid clean and at the right pH requires ongoing management. Mineral buildup, algae growth, and corrosion all damage equipment. Water treatment becomes an operational process as critical as power management.
The result? Facilities built for liquid cooling cost more upfront. But operational costs drop significantly—cooling electricity can be 30-40% lower than air-cooled equivalents. Over the 10-15 year lifespan of a data center, that difference compounds into hundreds of millions of dollars.
But here's the catch: not all GPUs are designed for direct liquid cooling. NVIDIA's recent systems support it. Older generations don't. Intel's data center GPUs are adding liquid cooling support. AMD's MI series supports it. But the transition isn't universal. If you've invested in GPU inventory that doesn't support liquid cooling, you're stuck with suboptimal facility designs for those assets.
This creates another competitive dynamic. Operators who standardize early on liquid-compatible hardware gain efficiency advantages that persist for years.
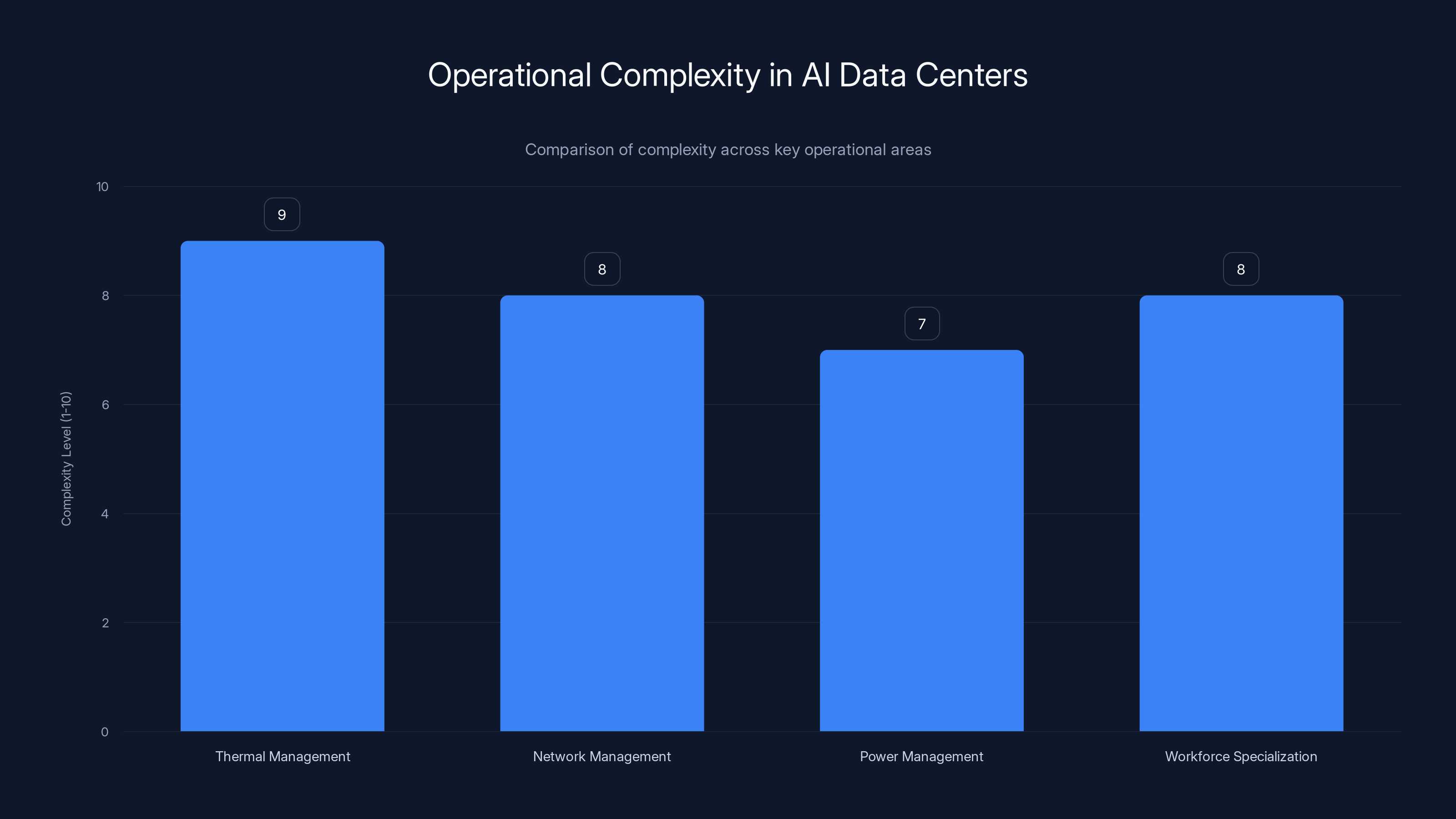
AI data centers face high complexity in thermal, network, power management, and workforce specialization, with thermal management being the most complex. Estimated data.
Network Connectivity: The Bandwidth Bottleneck
Power and cooling get the attention. Connectivity is where projects actually fail.
Modern AI workloads generate enormous volumes of traffic between GPUs. Training large language models involves:
- Forward passes where data flows from input through distributed layers across dozens or hundreds of GPUs
- Backward passes where gradients flow back through the network
- Synchronization where GPUs coordinate on results
- Gradient aggregation where individual GPU gradients are combined
All of this happens continuously, generating east-west traffic—traffic flowing laterally within the facility between GPUs, not north-south traffic flowing in and out to external networks.
The scale is staggering. Modern distributed training frameworks might push terabits per second of traffic through data center networks during peak computation. That's not megabits. Not gigabits. Terabits.
Supporting this requires:
Advanced Interconnect Technologies
- InfiniBand (primarily HDR 200 Gbps and NDR 400 Gbps) dominates high-performance AI clusters
- Ethernet is improving (25/50/100/200/400 Gbps variants) but historically lagged in latency-sensitive AI workloads
- Proprietary interconnects (NVIDIA NVLink for multi-GPU systems) provide extreme bandwidth within physical proximity
Complex Network Architecture AI data centers need network designs that minimize latency and maximize bisection bandwidth. This typically means:
- High-radix switches (switches with many ports)
- Fat-tree or similar topologies that prevent bottlenecks
- Custom-built networks, not off-the-shelf configurations
- Redundancy to prevent single points of failure
Physical Cabling This is where it gets real. Running high-speed fiber or copper to every GPU in a dense cluster requires:
- Precision installation: Fiber optics are fragile. Bends exceed critical angles and signals fail silently
- Specialized technicians: Installing and terminating fiber at density requires expertise that's in short supply
- Cable management: In a dense cluster, the sheer volume of cabling is overwhelming. Poor management creates thermal pockets and makes maintenance impossible
- Documentation: Every connection needs to be tracked. In a cluster with 10,000 connections, manual tracking is impossible
Component Supply Constraints Here's the bottleneck nobody talks about enough: specialty network components are supply-constrained globally.
HDR 400 Gbps InfiniBand components? Limited supply. Custom network adapters? Backordered. High-radix switches from optical vendors? Wait times measured in quarters.
Operators are literally waiting for components to become available before they can complete facilities. This creates a cascading effect: facility shell is built and ready, power is installed, cooling is live, but GPUs are sitting idle because network components haven't arrived yet.
Some operators resort to workarounds that compromise performance. Others pay premiums for expedited procurement. The most sophisticated ones maintain relationships with component vendors and get early allocation in exchange for committed volume.
GPU Supply Chain: The Constraint That Defines Market Access
You can build the most sophisticated facility in the world. If you can't get GPUs to fill it, you've built an empty shell.
GPU supply is the hard constraint on data center expansion. NVIDIA dominates the market (roughly 90%+ of discrete AI accelerators). AMD and Intel are ramping up, but supply lags significantly behind demand.
Here's the fundamental problem: NVIDIA's manufacturing capacity is bottlenecked at TSMC (Taiwan Semiconductor Manufacturing Company). TSMC can only produce so many advanced chips per quarter. NVIDIA has massive demand from hyperscalers, cloud providers, enterprises, and startups all trying to secure allocation.
The allocation process is deliberate and strategic:
- Tier 1 customers (Google, Microsoft, Meta, OpenAI) get priority allocation
- Established cloud providers (AWS, Azure, GCP) get significant volume
- Everyone else gets what's left, with wait times measured in months
This creates a market dynamic where:
- Large players with existing relationships get larger: They can secure GPU allocation and expand faster than competitors
- Startups and new entrants are constrained: Trying to launch a competing AI infrastructure provider without GPU allocation is nearly impossible
- Used GPU markets emerge: Companies liquidating equipment or reallocating resources sell into secondary markets where buyers pay premiums for immediate availability
- Geographic arbitrage happens: Countries or regions with access to GPU inventory can offer competitive pricing; others face scarcity
Some operators try to hedge by diversifying across NVIDIA, AMD, and Intel GPUs. The problem: different GPUs require different software optimization, different interconnect technologies, and different operating procedures. They're not interchangeable.
The long-term implication: GPU supply constraints will ease as:
- TSMC increases output
- Intel's facilities come online
- Samsung and other foundries gain advanced process capability
- Companies like AMD scale manufacturing
But for 2025-2026, supply is constrained. Operators who secured allocation 18 months ago are deploying now. Those trying to secure GPUs today are competing for scraps.

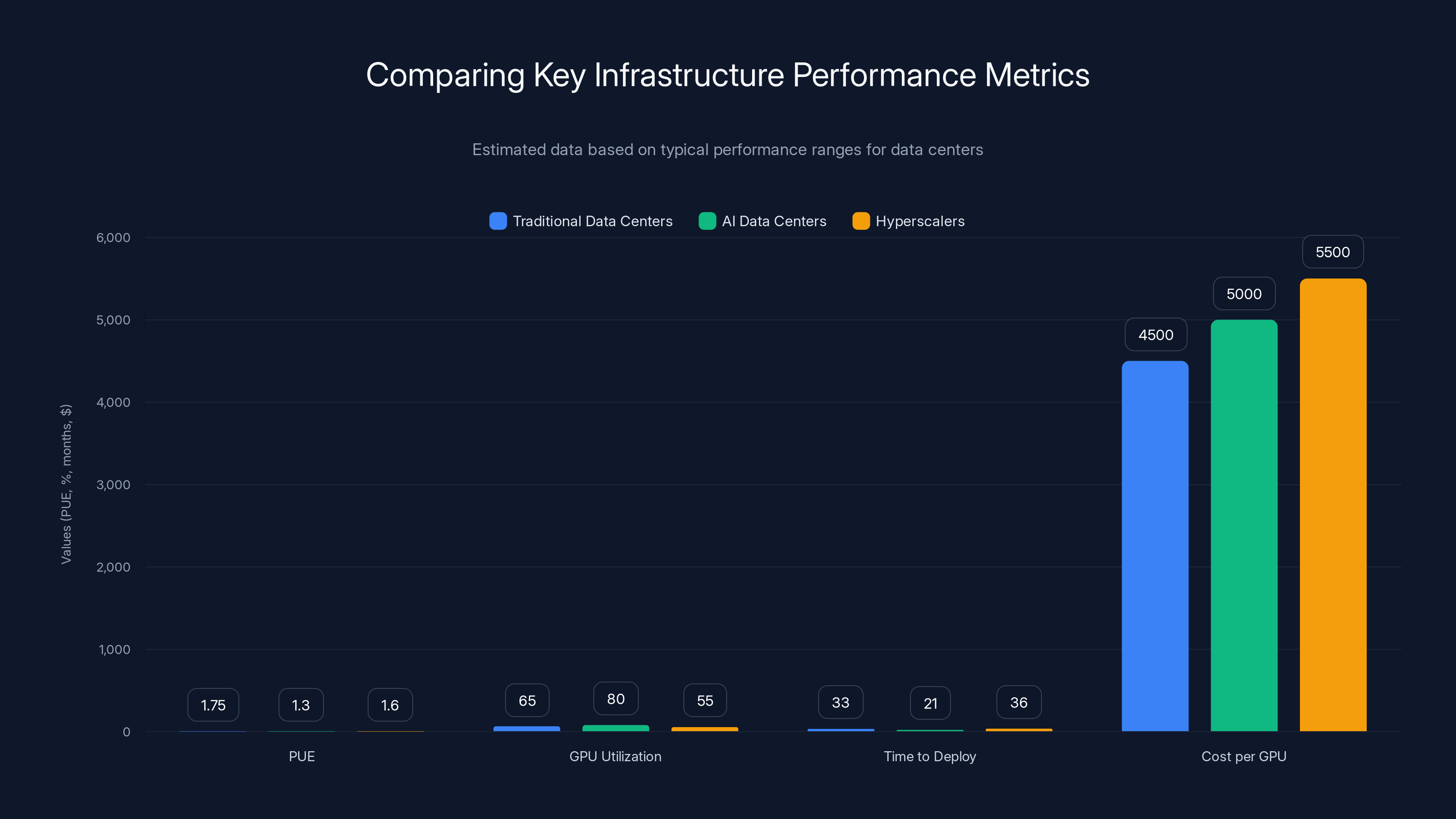
AI data centers generally achieve better PUE and GPU utilization rates compared to traditional and hyperscaler data centers. They also have a faster time to deploy, although costs per GPU are slightly higher. Estimated data based on typical performance ranges.
The Rise of Neoclouds: Purpose-Built GPU Infrastructure Providers
This constraint created an opportunity. Enter the "neocloud" providers.
Neoclouds are data center companies built entirely around GPU acceleration. Unlike traditional hyperscalers (AWS, Google, Microsoft) which must balance AI capacity against broader cloud computing demands, or traditional data center operators focused on renting generic compute, neoclouds design everything around GPUs.
They started small. CoreWeave, Lambda Labs, Crusoe Energy, and others began as GPU compute providers serving AI researchers. They rented access to GPU clusters on an hourly or monthly basis.
What happened next was unexpected. They grew. Fast.
CoreWeave went from tens of thousands of GPUs to hundreds of thousands in deployment or under contract. They're expanding globally—North America, Europe, Asia. They've attracted major venture capital and strategic investment. Why? Because they identified a market gap:
Hyperscalers needed to expand GPU capacity but were constrained by their own infrastructure complexity and competing demands. Neoclouds could build facilities focused exclusively on GPU utilization, achieving higher utilization rates and offering compute at competitive pricing.
The business model is deceptively simple:
- Identify locations with power and cooling advantage: Often places with cheap electricity (renewable-powered regions) or natural cooling (cold climates)
- Build facilities optimized for GPU density: No compromises for other workload types
- Secure GPU allocation (harder than it sounds; requires relationships and credibility)
- Operate the facility at maximum utilization: Sell capacity to researchers, enterprises, and other AI infrastructure consumers
- Expand to new locations and repeat
The competitive advantages are real:
- Single focus: Everything is optimized for GPUs. Network design, power distribution, cooling architecture—all purpose-built
- Speed to deployment: Less organizational complexity means faster builds
- Utilization rates: Because they only serve GPU workloads, utilization is typically higher than hyperscalers managing diverse workload types
- Pricing flexibility: Can offer compute at different price points for different customer types
The disruption is significant. Traditional data center operators are watching market share shift. Hyperscalers are increasingly turning to neoclouds for overflow capacity rather than building everything internally. Enterprises that would have gone to AWS for GPU compute are now comparing prices with neocloud providers and finding competitive alternatives.
NScale is building a 230-megawatt facility in Norway explicitly designed for 100,000 GPUs by 2026. That's powered entirely by renewable energy. The facility doesn't exist yet, but the commitment is real.
Nebius, a Russian-backed infrastructure company, signed a multi-billion-dollar agreement with Microsoft for GPU infrastructure. Instantly transformed its market position.
These aren't hypothetical companies with aspirational projections. They're deploying at scale, securing major partnerships, and reshaping market dynamics.
The long-term implication: the data center infrastructure market is consolidating around specialists. Generic compute is becoming commoditized. GPU infrastructure is becoming premium, specialized, and concentrated among players who can move fast and execute complex builds.

Engineering Challenges: Operational Complexity at Scale
Building a facility is one thing. Operating it at sustained high utilization is another.
AI data centers operate with fundamentally higher complexity than conventional facilities:
Thermal Management Complexity Liquid cooling systems require continuous monitoring and adjustment. You're managing:
- Chilled water loops with multiple zones and demand variations
- Temperature sensors reporting continuously
- Automated valve adjustments based on load
- Predictive maintenance to catch failures before they happen
A cooling system failure in a traditional data center might cause a few servers to overheat. In a GPU cluster, it might cost $10 million in compute throughput lost, not counting equipment damage.
Network Complexity Managing and debugging terabit-scale networks is not straightforward. When traffic is congested, it's often unclear where the bottleneck is. Is it a switch? A link? Oversubscribed connections? Solving these problems requires:
- Deep expertise in network architecture
- Advanced telemetry and monitoring
- Willingness to make infrastructure changes on the fly
- Testing methodologies to validate changes without disrupting workloads
Power Management at Scale When a single facility is drawing multiple hundreds of megawatts, small inefficiencies become visible at facility economics. A 1% improvement in power efficiency might save $1 million per year. But achieving that improvement requires:
- Detailed monitoring of power consumption
- Analysis of load patterns
- Iterative optimization
- Hardware and software changes that might affect other systems
Workforce Specialization Conventional data center work is standardized. You can hire a technician, train them in a few weeks, and they're productive. AI data center work is different.
You need specialists in:
- Fiber optics: Installation, termination, and diagnostics
- High-power electrical systems: Safety protocols, testing, troubleshooting
- Liquid cooling systems: Installation, maintenance, troubleshooting
- GPU cluster configuration: Drivers, firmware, performance tuning
- Distributed systems: Coordinating across thousands of machines
These specialists are in short supply globally. Training them takes time. Getting experienced people to relocate is expensive.
Many AI data center projects routinely require several times the manpower of conventional builds. A traditional data center expansion might require 100 technicians over 6 months. An AI facility upgrade might require 300-500 specialized workers, coordinating across disciplines, executing under tight timelines.
Coordinating these teams while maintaining quality, safety, and schedule is a logistics problem as much as an engineering problem.

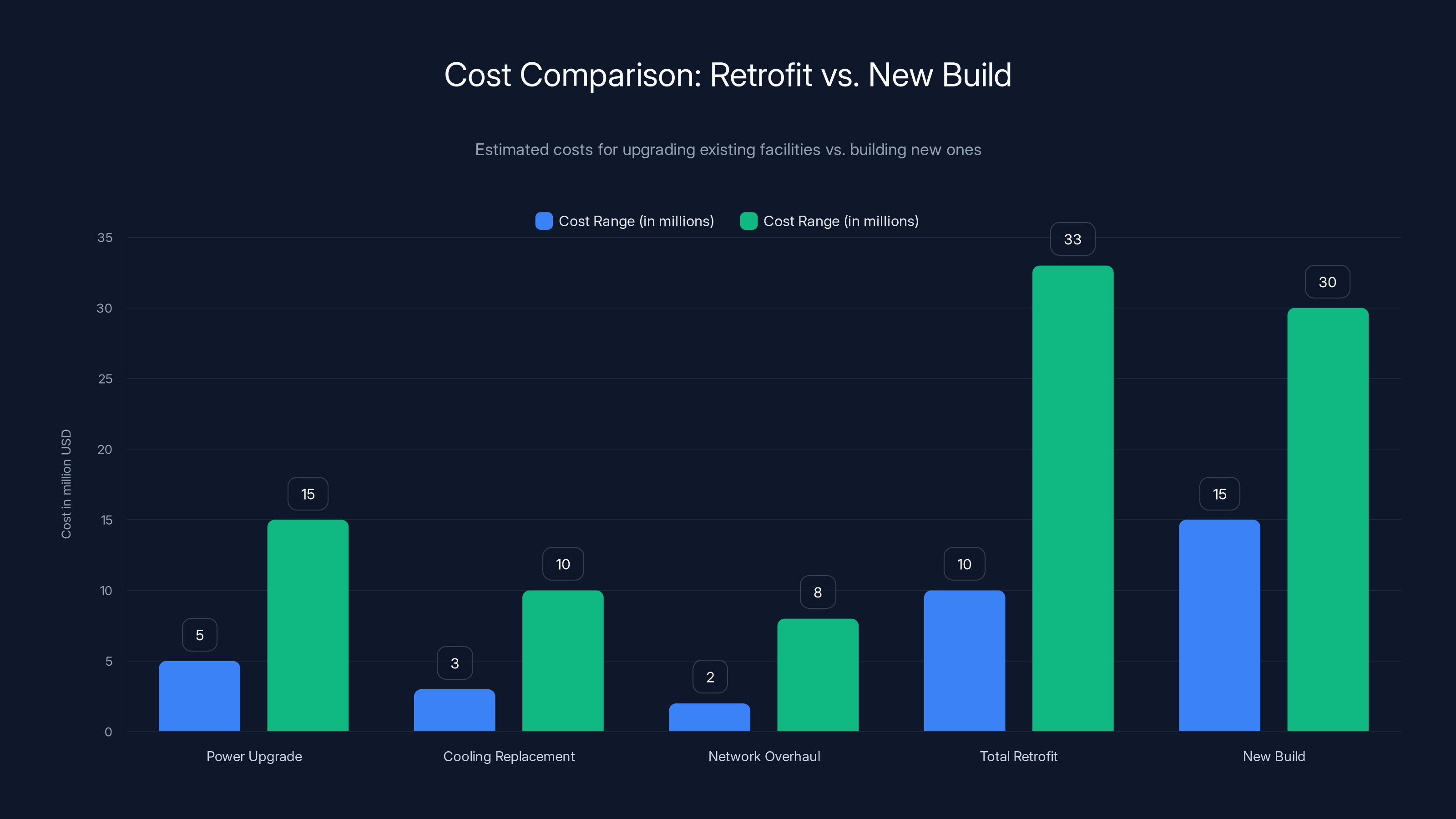
Retrofitting existing facilities can cost between
Site Selection: Geography as Infrastructure
Where you build a data center matters more for AI workloads than it does for conventional compute.
Traditional data center site selection considers:
- Proximity to fiber backbone (for network latency to users)
- Local real estate costs
- Tax incentives
- Disaster recovery proximity
AI data center site selection adds critical criteria:
Power Availability and Cost AI facilities consume massive amounts of electricity. A 100-megawatt facility operating at 70% utilization consumes roughly 600 gigawatt-hours per year. At
The difference between cheap power and expensive power is operational margin. This explains why:
- Iceland is attracting data center operators (geothermal and hydroelectric energy)
- Scandinavia (Norway, Sweden, Finland) is growing as a hub (renewable energy and natural cooling)
- Parts of North America (regions with hydroelectric power) are popular
- Coal-heavy regions are less attractive (high costs, environmental concerns)
Some operators are co-locating facilities near power generation plants. Microsoft is experimenting with data centers near renewable energy sources and even exploring cooling solutions that use ambient water temperature.
Cooling Advantage Climate matters. If ambient temperatures are cold most of the year, cooling costs drop dramatically. You can use free-air cooling (pulling in outside air) or minimal mechanical cooling.
This is why Scandinavia is attractive. Winter temperatures mean cooling costs are minimal for much of the year. Iceland's natural cooling resources (cold water from glacial sources) are valuable.
Conversely, building a massive GPU facility in Arizona or Texas requires aggressive cooling architectures and ongoing energy cost.
Geopolitical Considerations Increasingly, geographic location is a geopolitical decision.
Countries view AI infrastructure as strategic. China has restrictions on where international AI infrastructure can be built. The U.S. has export controls on advanced GPUs and interconnect technologies. European countries are discussing regulations on data center power consumption.
Companies operating globally are increasingly building distributed infrastructure to navigate these constraints:
- U.S.-based operators for North American workloads
- EU-based infrastructure for European operations
- Asia-specific regions for Asian operations
This geographic distribution adds complexity but reduces geopolitical risk.
Water Availability Whether you're cooling with liquid circulation or needing water for cooling towers, water availability matters. Regions with water scarcity might face restrictions or political pressure during droughts.
Operators are increasingly considering water consumption as part of their site selection criteria. Some are moving toward air-cooled systems or closed-loop water recirculation to reduce consumption.

Retrofitting Existing Facilities: The Economics of Upgrade vs. Rebuild
Many operators don't have the luxury of building from scratch. They have existing data centers designed for conventional workloads, and they're trying to retrofit them for AI.
The retrofit equation is brutal.
A facility designed in 2018 for 15 kilowatts per rack maximum might have:
- Electrical infrastructure rated for 15kW per rack
- Air cooling designed for 15kW per rack
- Network designed for conventional east-west traffic patterns
- Racks and power distribution rated for conventional density
Converting to 50+ kilowatts per rack requires:
Power Infrastructure Upgrade
- New electrical feeds from the substation
- New transformers
- New distribution at the rack level
- Cost: $5-15 million depending on scale
- Timeline: 6-12 months
Cooling System Replacement
- Removal of existing air cooling units
- Installation of liquid cooling infrastructure
- Connection of chilled water loops
- Cost: $3-10 million
- Timeline: 6-12 months, potentially longer if facility must remain partially operational
Network Infrastructure Overhaul
- Replacement of switches and interconnects
- Installation of new fiber
- Removal of old cabling
- Cost: $2-8 million
- Timeline: 3-6 months
Total Retrofit Cost: $10-33 million or more for a facility with 100-200 racks
Compare that to the cost of building a new facility from scratch at similar capacity: $15-30 million for a greenfield build.
The numbers are surprisingly close. The difference? Retrofit projects face additional constraints:
- Must maintain partial operations: You can't shut down the entire facility while upgrading. You must carefully plan which sections go offline when, managing customer workloads and SLAs
- Physical constraints: Existing buildings have layouts, column placements, and spatial constraints that new builds don't face
- Unexpected surprises: Once you tear into old infrastructure, you discover things that weren't documented. That increases costs and timelines
- Regulatory approval: Modifying existing facilities requires more compliance reviews than building new ones
The result: many retrofit projects end up costing 20-40% more than originally budgeted and taking 20-40% longer to complete.
Smarter operators are making the financial case to rebuild: "Yes, it's more capital upfront, but we avoid retrofit complexity, we get higher utilization, and we deliver to customers faster."
Newer cloud providers and neoclouds have an advantage here. They don't have legacy infrastructure to retrofit. They build new, purpose-built from the start.


Power infrastructure and securing GPU allocation are rated highest in importance for successful AI infrastructure deployment. Estimated data based on shared patterns.
Supply Chain Bottlenecks: The Hidden Constraints
If you list the top 10 reasons AI data center projects run late, at least 7 are supply chain related.
GPU Allocation (already discussed, but worth emphasizing) GPU supply is the hard constraint. Everything else is secondary.
Interconnect Component Shortages Specialized network components for InfiniBand and high-speed Ethernet are constrained:
- HDR/NDR adapters from Mellanox/NVIDIA
- Custom optical components
- High-port-count switches
- Specialty cables and connectors
Wait times are measured in quarters. Some components have 6+ month lead times.
Power Distribution Components
- High-capacity transformers: constrained
- Advanced switchgear: constrained
- Custom power monitoring systems: made-to-order
Fiber Optic Cabling and Installation Services Not just the cable (though it's constrained), but the installation services. Quality fiber installation is an art. Specialists are fully booked. Many projects wait months for installation availability.
Cooling System Components Chilled water manifolds, high-performance pumps, specialized valves: all in limited supply.
Labor and Specialized Trades Less of a supply chain issue and more of a labor market issue, but the constraint is real. Operators can't move faster than they can source qualified labor.
The sophisticated players manage these constraints through:
- Early procurement: Starting supply chain processes 12-18 months before facility completion
- Strategic relationships: Maintaining ongoing relationships with suppliers and manufacturers for priority allocation
- Design flexibility: Using multiple component options so that supply constraints don't block progress
- Buffer inventory: Maintaining strategic inventory of critical components
- Geographic diversification: Sourcing from multiple regions to reduce single-source risk
Companies that underestimate supply chain complexity often miss project timelines by 6-12 months.

The Role of Technology Partners in Execution
No operator, regardless of size, can shoulder the full burden of AI data center buildout alone.
The complexity spans:
- Electrical engineering
- Mechanical engineering
- Network engineering
- Software and automation
- Project management
- Regulatory compliance
- Supply chain management
- Labor coordination
Successful operators partner with technology companies that bring:
Deep Technical Expertise
- Understanding of high-density cabling architectures
- Experience with advanced cooling solutions
- Familiarity with GPU cluster integration and optimization
- Knowledge of network design patterns that work at scale
Operational Experience
- Having built and operated similar facilities
- Understanding what works and what doesn't from firsthand experience
- Ability to anticipate problems and propose solutions
Supply Chain Access
- Relationships with component manufacturers
- Priority allocation agreements
- Ability to expedite procurement
- Alternative sourcing for constrained components
Project Execution Capability
- Mobilizing large, skilled teams rapidly
- Coordinating across specialized disciplines
- Managing timeline and budget constraints
- Ensuring quality and safety
Regulatory and Compliance Navigation
- Understanding local permitting and regulatory requirements
- Managing environmental impact assessments
- Coordinating with local authorities
- Ensuring compliance with evolving regulations
The operators who move fastest are those who found partners they trust and gave them significant latitude to execute. Operators who try to do everything internally or manage partners too tightly typically move slower.

Future Outlook: What's Coming Next
The infrastructure buildout we're seeing now is just the beginning.
Next-Generation GPU Architectures NVIDIA's Blackwell, and subsequent generations, will have even higher power density and connectivity demands. Each generation increases the challenge.
Distributed AI Training at Planetary Scale We're moving toward AI systems trained across multiple data centers in different geographic regions. This requires global connectivity infrastructure, federated training frameworks, and monitoring systems that span continents. The networking and operational complexity multiplies.
Specialized Chip Development More companies are building custom chips optimized for specific workloads. Google TPUs, NVIDIA Hopper/Blackwell variants, AMD MI series, Intel data center GPUs, startups building specialized inference accelerators. This increases the diversity of equipment that data centers must support, complicating operational standards.
Renewable Energy Mandates Countries and companies are increasingly requiring that data center expansion be powered by renewable energy. This drives geographic concentration toward favorable locations and creates competitive pressure around power sourcing.
Power and Efficiency Limits There's a physical ceiling to how much power can be distributed through traditional data center architectures. We're approaching those limits. Next-generation approaches might involve:
- Distributed clusters spread across multiple smaller facilities
- Modular data center designs that can be shipped and deployed
- Hybrid approaches combining on-site power generation with grid power
Automation and AI Operations Data centers themselves are starting to use AI for operational optimization. Predicting failures, optimizing cooling, balancing workloads, managing thermal zones. The operational intelligence layer is becoming as important as the physical infrastructure.
Key Operational Metrics: How to Measure Infrastructure Performance
Data center operators track specific metrics to understand facility performance and identify optimization opportunities.
Power Usage Effectiveness (PUE) Formula:
Traditional data centers aim for PUE of 1.5-2.0 (meaning they consume 1.5-2.0 watts of total facility power for every watt of IT equipment power).
AI data centers with advanced cooling and power management achieve PUE of 1.2-1.4. The best operators exceed 1.1.
A 0.1 improvement in PUE might reduce annual energy costs by millions for a large facility.
GPU Utilization Rate What percentage of GPU capacity is actually being used for workloads?
Traditional cloud providers achieve 60-70% utilization. Neoclouds with AI-focused customers achieve 75-85%. Hyperscalers with diversified workloads sometimes achieve 50-60%.
Higher utilization means better returns on infrastructure investment.
Network Latency and Throughput How fast can GPUs communicate? What's the latency between nodes? What's the sustained bandwidth?
Modern AI data centers measure latency in microseconds and track whether communication latency creates training bottlenecks.
Time to Deploy (TDD) How long between securing a facility location and beginning customer workloads?
Aggressive operators achieve 18-24 months from site selection to initial deployment. Average operators take 30-36 months. Slow operators take 3+ years.
Faster time to deployment means revenue generation earlier, which helps fund subsequent builds.
Cost per GPU Total facility cost (construction, equipment, land, permitting) divided by GPU slots.
This varies significantly by location and design, but ballpark figures are $3,000-6,000 per GPU for greenfield builds, more for retrofits.

Comparing Infrastructure Approaches: Trade-offs and Strategies
Different operators make different choices based on their constraints and priorities.
| Approach | Pros | Cons | Best For |
|---|---|---|---|
| Greenfield Build | Purpose-built, optimized from start, high efficiency, modern systems | High upfront capital, long timeline, site selection constraints | Neoclouds, hyperscalers expanding aggressively |
| Facility Retrofit | Leverages existing real estate, faster time to revenue, lower initial capital | Complex execution, constraints from existing design, potentially suboptimal | Traditional operators with existing portfolio |
| Distributed Small Clusters | Flexibility, reduced single-point-of-failure risk, easier to start small | Operational complexity multiplies, less efficiency, higher per-GPU costs | Emerging operators, geographic diversity needs |
| Partnerships with Neoclouds | Immediate capacity access, no build responsibility, flexible scaling | Less control, dependent on partner's availability and pricing | Enterprise customers, research institutions, startups |

The Geopolitical Dimension: Infrastructure as Strategic Asset
Data center infrastructure is increasingly viewed as a strategic asset on the national level.
United States Has GPU manufacturing advantage (NVIDIA, high performance computing ecosystem, favorable regulations). Disadvantage: competition for land, relatively high labor costs.
Taiwan Controls manufacturing of most advanced GPUs through TSMC. Strategic importance is high. Geopolitical risk is significant.
European Union Attractive for renewable energy resources, specialized engineering talent, and regulatory alignment. Less mature GPU ecosystem, more stringent energy regulations.
China Building significant domestic GPU capacity (Huawei, Alibaba). Restricted from importing advanced NVIDIA/AMD GPUs due to U.S. export controls. Developing self-sufficient GPU ecosystem.
Middle East and Gulf States Investing heavily in AI infrastructure with capital from sovereign wealth funds. Building clusters in UAE, Saudi Arabia, Qatar.
These geopolitical dynamics affect which companies can source GPUs, where they can build facilities, and what regulatory frameworks they must navigate.
For global organizations, this creates operational complexity: they must maintain infrastructure in multiple regions to navigate export controls, latency requirements, and regulatory constraints.

Lessons Learned: What Actually Works
Operators who have successfully deployed large-scale AI infrastructure share common patterns:
1. Start with Power First Design the electrical infrastructure to support your target density. Everything else follows from power capacity. Operators who tried to optimize other things first, then added power, consistently underperformed.
2. Choose Your Cooling Strategy Early Liquid cooling vs. air cooling is a foundational decision. Don't try to have both in the same facility—the operational complexity is untenable. Commit to a direction and optimize around it.
3. Invest in Network Design Network design decisions made during facility planning determine achievable performance for years. Overconstrain the network and you'll never reach your utilization targets. Invest in quality design and expert installation.
4. Secure GPU Allocation Before Building Don't build a facility hoping to fill it with GPUs later. Secure allocation commitments before breaking ground. The facilities sitting empty waiting for GPU inventory are expensive lessons in execution sequence.
5. Recruit Specialist Teams Early Start recruiting specialized technicians 12-18 months before facility completion. The bottleneck won't be materials—it'll be people who know how to install and operate the systems.
6. Plan for 50% Cost and Timeline Overruns If your budget is
7. Partner with Experts Don't try to do everything yourself. Partner with organizations that have built similar facilities and learn from their experience. The premium you pay for experienced partners is recovered in faster execution and avoided mistakes.
8. Automate Operations from Day One Build monitoring, alerting, and automation systems as part of the facility deployment, not as an afterthought. Understanding facility behavior through data from day one enables faster optimization.

The Business Case: Why This Matters Beyond Infrastructure
Why does any of this matter to people not building data centers?
Because data center infrastructure constraints directly affect AI access and cost.
If GPUs are scarce and expensive, AI development is restricted to well-funded organizations. If infrastructure is abundant and competitive, more researchers, enterprises, and startups can participate in AI development.
Infrastructure directly determines:
- Cost of AI development: Do you pay 0.10/hour for GPU compute?
- Speed of iteration: Can you run experiments immediately or do you wait weeks for compute access?
- Ability to serve AI applications: Can you deploy large language models at scale or are you limited by available resources?
- Market competition: Can new entrants compete or are they locked out by infrastructure costs?
The operators who build efficient, cost-effective infrastructure aren't just optimizing facilities. They're democratizing AI access and enabling new categories of AI innovation.
Conversely, if infrastructure is constrained and expensive, we see a concentration of AI development among a small number of well-capitalized organizations. Valuable ideas get locked out because their developers can't access the compute they need.

Conclusion: The Infrastructure Arms Race
We're in the middle of the largest infrastructure buildout in computing history.
During the internet boom of the late 1990s, companies raced to build data centers. Most of that infrastructure became worthless. Billions were wasted on facilities that never achieved utilization.
The AI infrastructure boom is different. The demand is real, quantified, and growing faster than supply can keep up. Every megawatt of capacity deployed is spoken for within weeks.
But the challenge is immense. Operating at 50-100+ kilowatts per rack requires rethinking everything from power distribution to cooling to networking. Operators who nail this achieve competitive advantages that compound for years. Those who get it wrong watch competitors move faster and capture market share.
The next phase of this story will be determined by infrastructure. The companies and countries that can deploy capacity at scale, efficiently, and reliably will lead AI development for the next decade.
For people building AI infrastructure: focus on power first, choose cooling strategy early, invest in network design, secure GPU allocation before building, and partner with experts. Execution matters more than vision.
For people developing AI: understand that your cost of compute and access to resources is directly determined by this infrastructure buildout. Better infrastructure means cheaper compute means more innovation means more opportunity for you.
The era of "let's build it and see what happens" is over. The era of purposeful, sophisticated, competitive infrastructure is just beginning. And it's only going to get more intense from here.
FAQ
What is AI data center infrastructure?
AI data center infrastructure refers to the specialized facilities, electrical systems, cooling mechanisms, and networking equipment designed to house and operate large numbers of GPUs and other AI accelerators. These facilities are engineered specifically to handle the extreme power density, thermal load, and network bandwidth requirements of modern AI training and inference workloads.
Why is liquid cooling necessary in AI data centers?
Liquid cooling is necessary because air cooling becomes thermodynamically inefficient and economically unfeasible at the power densities required for AI workloads (50-100+ kilowatts per rack). Direct-to-chip liquid cooling extracts heat at the source, reduces facility cooling energy consumption by 30-40%, maintains tighter temperature control on components, and allows operators to achieve higher GPU density within the same physical space.
What are the main bottlenecks preventing faster AI data center deployment?
The primary bottlenecks are GPU supply constraints from limited TSMC manufacturing capacity, shortage of specialized network components (InfiniBand adapters, high-speed switches), lack of specialized technicians with fiber optics and liquid cooling expertise, extended lead times for custom electrical infrastructure components, and the logistics complexity of coordinating multiple specialized trades simultaneously across large facilities.
How much does it cost to build an AI data center?
Greenfield AI data center builds typically cost
What is a neocloud and why are they disrupting the market?
Neoclouds are companies that build data centers exclusively for GPU infrastructure, unlike traditional cloud providers that balance AI capacity with broader computing demands. They move faster, achieve higher utilization rates, and offer competitive GPU compute pricing. Companies like CoreWeave, NScale, and Nebius are reshaping the market by focusing entirely on GPU acceleration and deploying at unprecedented speed and scale.
How do geographic location and power costs affect data center site selection?
Power availability and cost are the dominant factors in AI data center site selection because facilities consume enormous electricity (600+ gigawatt-hours annually for a 100-megawatt facility). The difference between
What is PUE and why does it matter?
PUE (Power Usage Effectiveness) is calculated as total facility power divided by IT equipment power. Traditional data centers achieve PUE of 1.5-2.0, while advanced AI data centers achieve 1.2-1.4. A 0.1 improvement in PUE can reduce annual energy costs by millions for large facilities. Lower PUE indicates more efficient facility design and operations.
How do supply chain constraints affect project timelines?
Supply chain bottlenecks are responsible for the majority of AI data center project delays. GPU allocation takes months or quarters to secure, specialized network components have 6+ month lead times, fiber optic installation services are fully booked, and custom electrical components are made-to-order. Sophisticated operators manage these constraints through early procurement (12-18 months before facility completion), strategic supplier relationships, and design flexibility using multiple component options.
What skills and expertise are required to operate AI data centers?
AI data centers require specialists in fiber optics installation and diagnostics, high-power electrical systems and safety protocols, liquid cooling system installation and troubleshooting, GPU cluster configuration and performance tuning, and distributed systems management. These specialists are in short supply globally, and training them takes significant time. Many AI facility projects require 3-5 times the personnel of conventional data center builds.
How does geopolitics affect AI infrastructure development?
Geopolitical factors increasingly determine where AI infrastructure can be built and which organizations can access it. U.S. export controls restrict GPU sales to China, European regulations are becoming more stringent around energy consumption, and countries view AI infrastructure as strategic assets affecting national competitiveness. Companies operating globally must now maintain infrastructure across multiple regions to navigate export controls, latency requirements, and regulatory constraints.
Want to streamline your operations or automate reporting on data center performance and infrastructure metrics? Consider how AI-powered automation tools can help. Runable offers AI-powered solutions for creating reports, presentations, and documentation—perfect for documenting facility designs, generating infrastructure audit reports, or automating performance dashboards. Check out Runable starting at just $9/month.

Key Takeaways
- AI data center infrastructure spending will reach $6.7 trillion by 2030, with the majority dedicated to GPU-optimized facilities.
- Power density in AI data centers has grown 20x in a decade, forcing fundamental shifts to liquid cooling and advanced electrical infrastructure.
- GPU supply constraints from TSMC manufacturing capacity are the hard bottleneck limiting facility deployment, more than any other factor.
- Liquid cooling systems reduce energy costs by 30-40% compared to air cooling, but require specialized infrastructure, expertise, and ongoing management.
- Neocloud providers are disrupting traditional data center operators by building facilities exclusively for GPU workloads at higher efficiency and faster velocity.
- Site selection is increasingly driven by power costs and renewable energy availability rather than proximity to users.
- Retrofit projects cost 20-40% more and take 20-40% longer than greenfield builds, making new facility construction competitive despite higher upfront capital.
- Network bandwidth and latency constraints are now as critical as compute capacity—poorly designed networking severely limits achievable performance.
- Specialized labor (fiber technicians, cooling specialists, electrical engineers) is the bottleneck slowing operational deployment, requiring 12-18 month lead times for hiring.
- Infrastructure constraints directly determine AI accessibility and cost, affecting which organizations can participate in AI development.
Related Articles
- Galaxy's Edge Timeline Expansion: What Fans Need to Know [2025]
- How to Watch Molly-Mae: Behind It All Online [2025]
- Anthropic's India Play: Inside the $100B AI Race in Bengaluru [2025]
- OpenAI vs. Elon Musk: Silicon Valley's Biggest Legal Battle Headed to Trial [2025]
- Altra Running Shoes Promo Codes & Deals: Save 50% [2025]
- Best Adidas Promo Codes & Coupons: Save Up to 40% [January 2025]

