AI Gross Margins & Compute Costs: The Real Math Behind 70% Margins [2025]
Introduction: The Margin Mirage That's Reshaping AI Economics
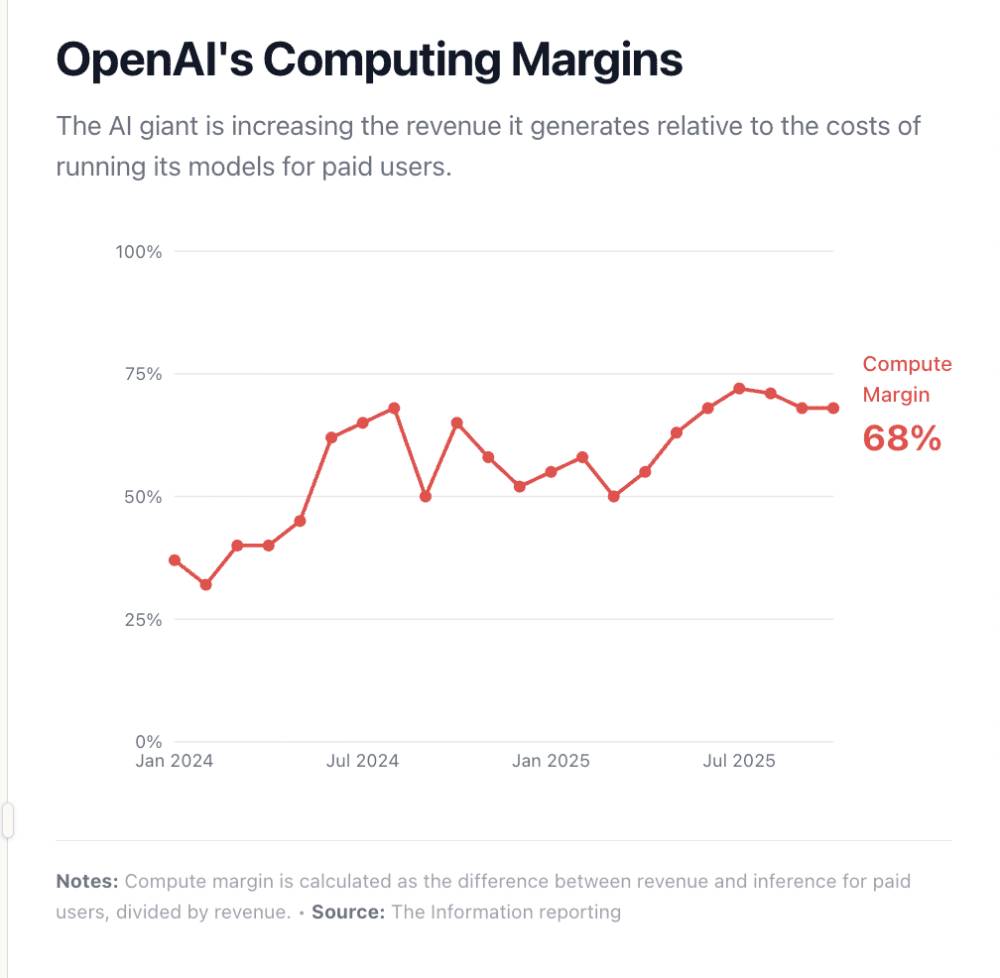
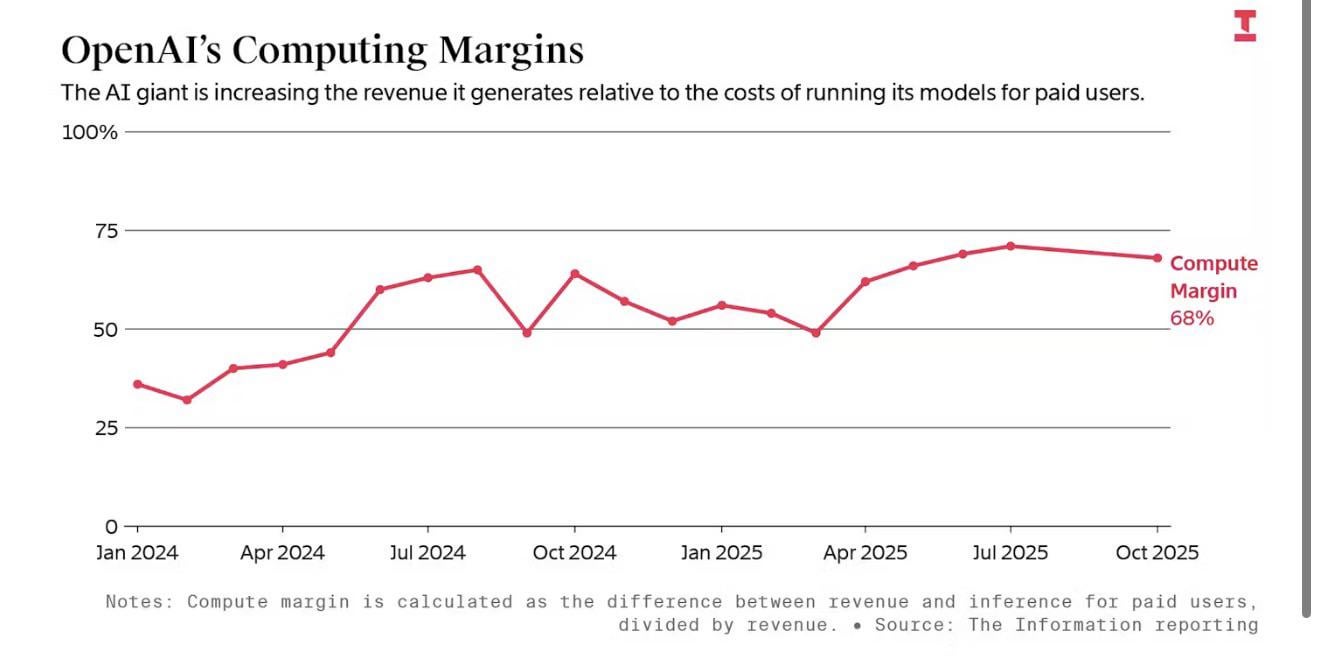
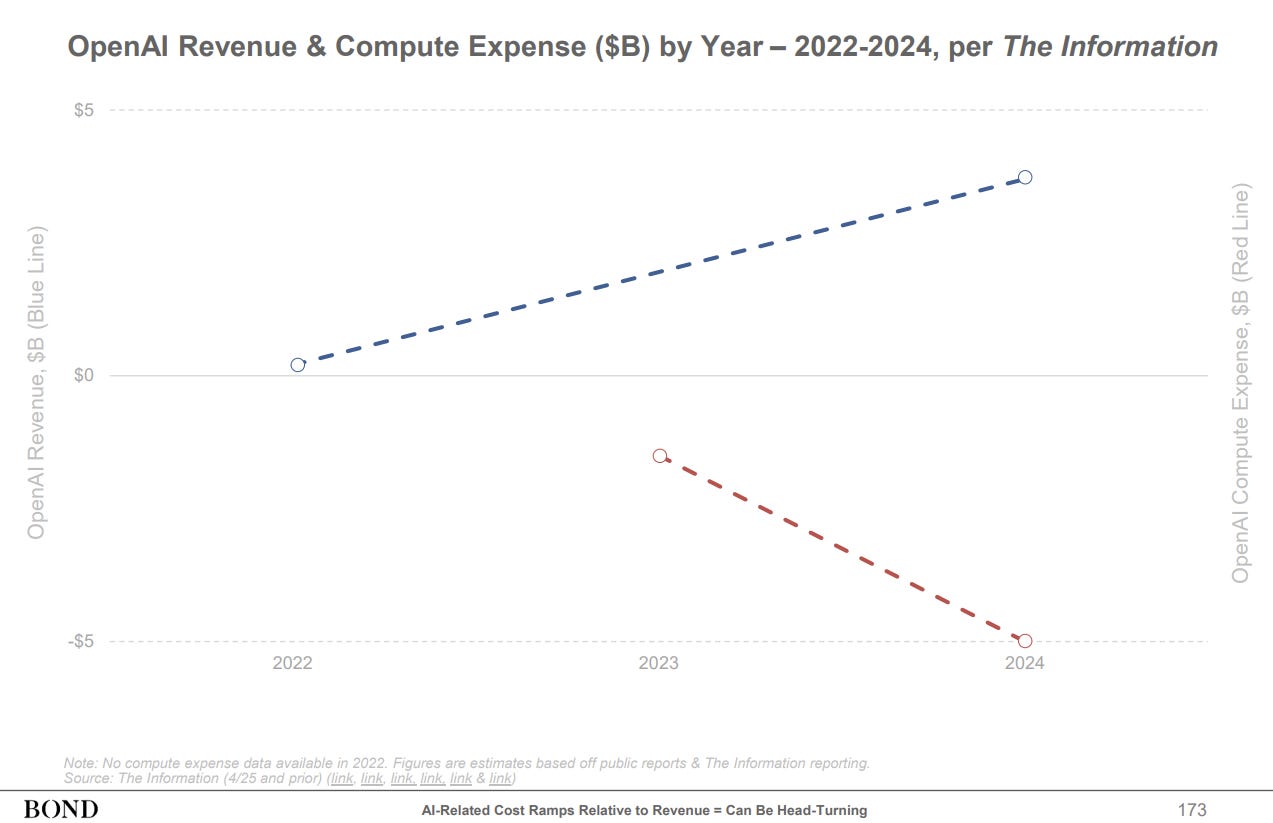
When OpenAI announced in December 2025 that their compute margins had climbed to approximately 70% — nearly double the 35% they reported in early 2024 — the AI industry erupted. This wasn't just a number; it was validation that the economics of artificial intelligence were finally maturing. For a moment, the narrative seemed clear: AI was transitioning from a money-losing research experiment into genuine, profitable software.
But dig deeper, and the story becomes far more nuanced and far more revealing about the divergence between foundation model providers and the B2B startups trying to build applications on top of them.
This paradox sits at the heart of modern AI economics: while the companies building and training foundational large language models are experiencing genuine margin expansion, the startups embedding these models into customer-facing products are caught on an increasingly brutal treadmill. The cost-per-token may be falling, but the tokens-per-task are rising even faster. Better models require more computational resources for reasoning. Competitive pressure demands better results. And better results demand more expensive models.
This comprehensive analysis examines the real mathematics behind AI margins, explores why foundation model efficiency hasn't translated to application-layer profitability, and reveals the structural dynamics that are reshaping how B2B companies think about unit economics in 2025 and beyond.
The implications extend far beyond accounting spreadsheets. They fundamentally reshape how founders should think about pricing, how they should architect their products, and crucially, what this means for the viability of an entire category of AI-native startups built on the assumption that compute costs would simply continue declining indefinitely.
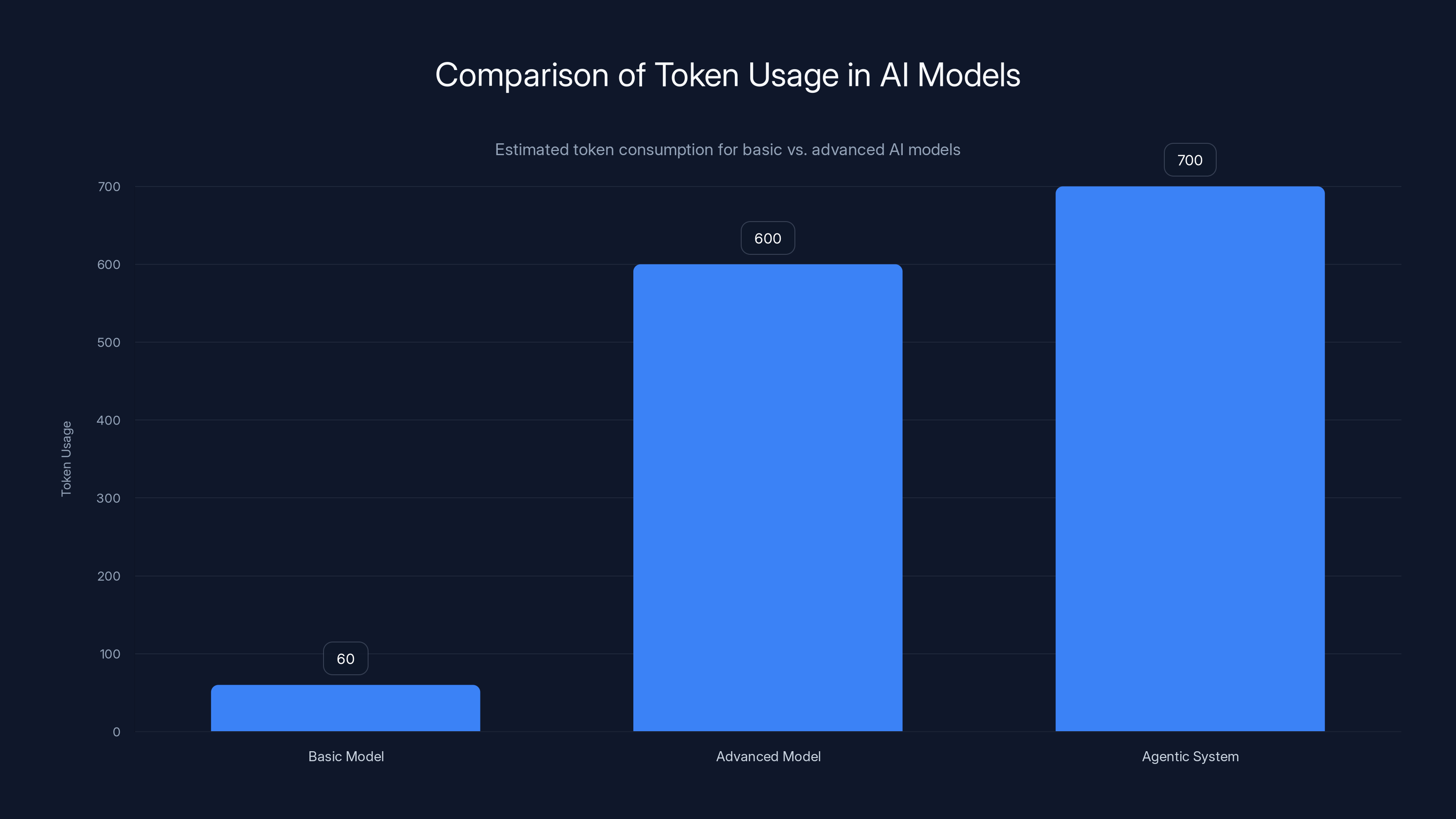
Advanced and agentic AI models consume significantly more tokens per task compared to basic models, increasing per-task costs despite lower per-token costs. Estimated data.
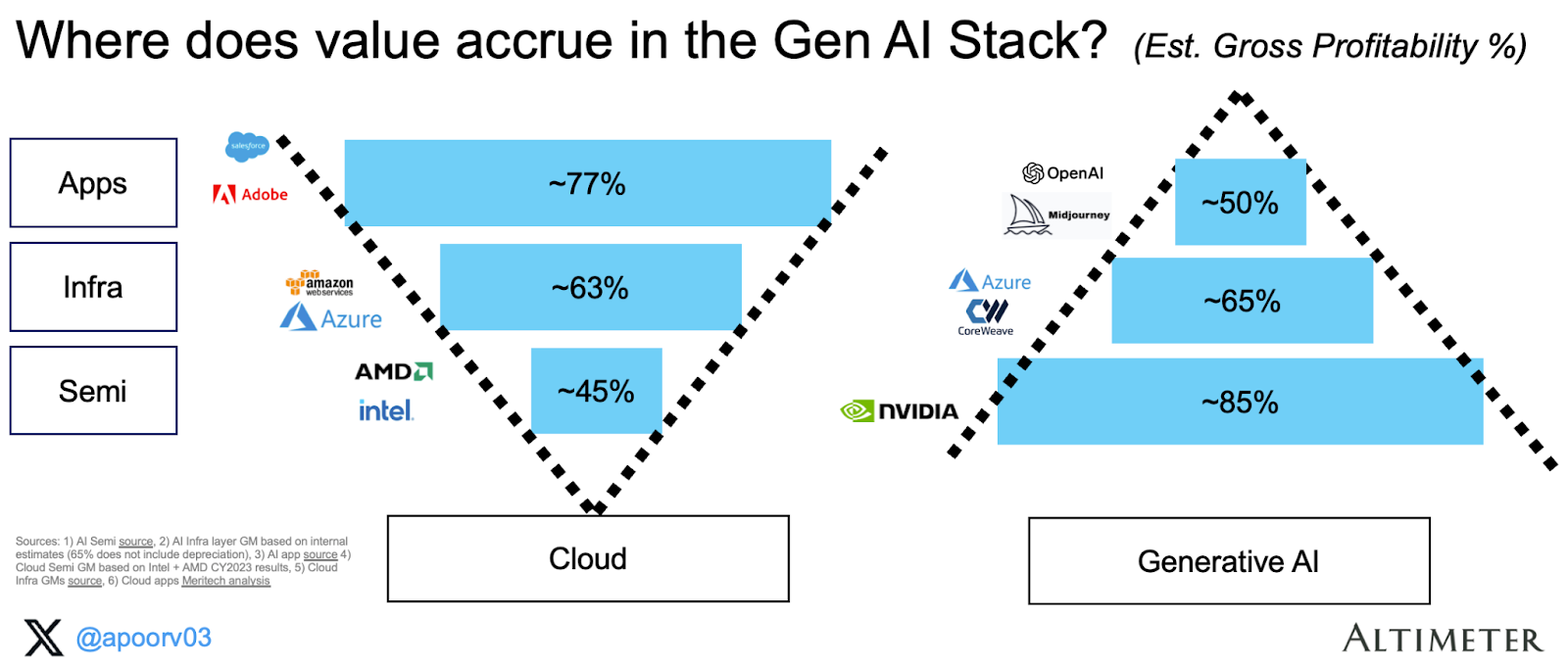
The Foundation Model Economics Revolution: From Negative Margins to Genuine Profitability
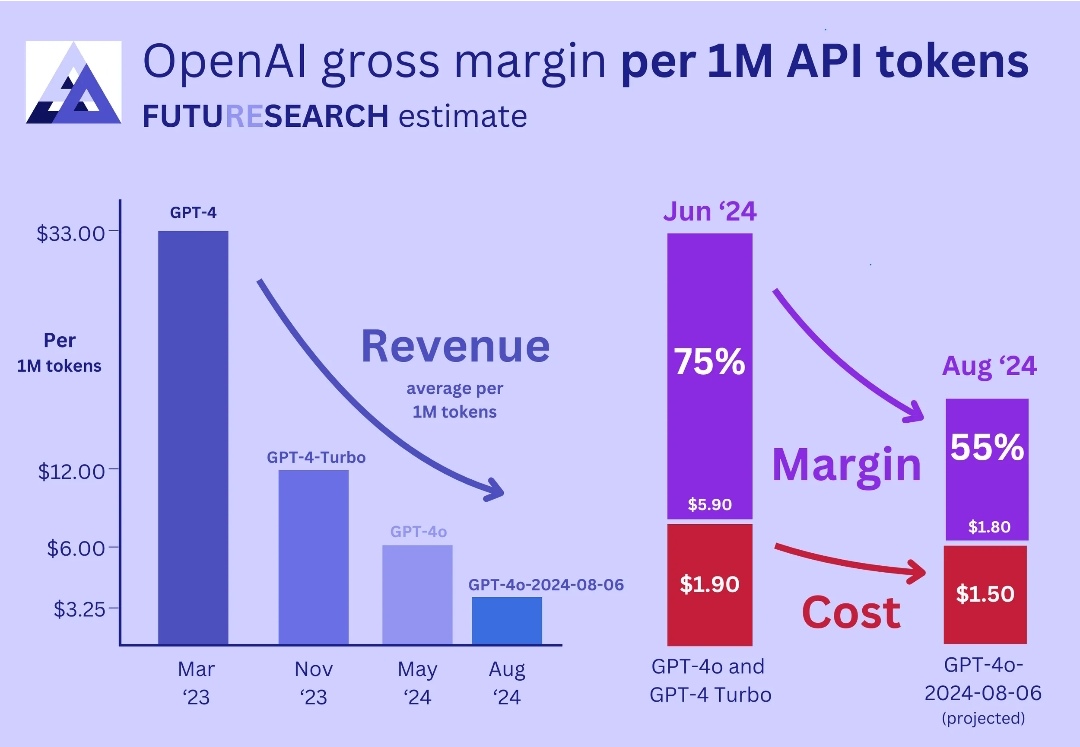
OpenAI's Stunning Margin Expansion Explained
OpenAI's journey from 35% to 70% compute margins in less than two years represents one of the fastest margin expansion trajectories in technology history. This wasn't achieved through price increases alone — in fact, Chat GPT Plus pricing remained largely stable at $20/month throughout this period. Instead, it reflects a cascade of interconnected efficiency gains across the entire inference stack.
First, there were hardware efficiency improvements. The transition from H100 GPUs to H200 and eventually to more specialized inference-optimized processors reduced the computational cost of running inference operations. A single GPU can now serve more concurrent users through improved batching algorithms and attention optimization techniques. These weren't revolutionary breakthroughs — they were evolutionary improvements in how effectively compute resources were utilized.
Second, model quantization and distillation techniques allowed OpenAI to serve many queries using smaller, faster models while reserving larger models for genuinely complex tasks. This tiered approach means that approximately 60-70% of queries could be answered by more efficient variants, fundamentally reducing average inference cost per user. This architectural shift is invisible to users but economically transformative for providers.
Third, and perhaps most important, OpenAI dramatically improved their algorithmic efficiency. Speculative decoding — a technique where smaller models predict what larger models will generate, then verify predictions — reduced the number of forward passes required for many requests. Prompt caching meant that documents or code samples used repeatedly didn't require full re-processing. These optimizations compressed the computational footprint of serving identical functionality.
The mathematics behind this expansion are revealing. If OpenAI's revenue per user increased by 15% while compute costs decreased by 40%, the improvement in compute margins from 35% to 70% becomes mathematically inevitable. The formula is straightforward:
Compute Margin = (Revenue - Compute Costs) / Revenue
Moving from 35% to 70% means compute costs fell from 65% of revenue to 30% of revenue — a nearly 50-percentage-point improvement. Over billions of queries monthly, even marginal efficiency gains compound dramatically.
The Broader Picture: Anthropic's Path to Profitability
While OpenAI captured headlines, Anthropic's margin trajectory may be even more instructive. In 2024, Anthropic reported gross margins as low as -94% to -109% — meaning they lost more than a dollar on infrastructure for every dollar of revenue earned. This wasn't a sign of failure; it was the expected outcome of a scaling phase where user growth was prioritized over profitability.
By 2025, Anthropic's leadership publicly guided toward 50% gross margins in 2025 and 77% gross margins by 2028. This forecast suggests that Anthropic is experiencing similar efficiency gains to OpenAI, compressed into a shorter timeframe. For a company with a fraction of OpenAI's scale in late 2023, reaching 50% margins represents extraordinary progress.
The structural reason is simple: the economics of inference are subject to extraordinary scale advantages. The first 1 billion queries require enormous infrastructure investment. The second billion queries require only marginal additional infrastructure. At Anthropic's projected 2025 scale, the marginal cost of serving additional inference requests has fallen to perhaps 10-15% of revenue, creating the foundation for genuine profitability.
What's notable is that both OpenAI and Anthropic achieved these margins while simultaneously investing heavily in reasoning models like o 1 and Claude's extended thinking, which consume substantially more compute. This demonstrates that efficiency gains at the infrastructure layer have genuinely outpaced the increasing computational demands of advanced reasoning capabilities.
GitHub Copilot and the Corporate AI Economics Challenge
The most revealing case study in foundation model economics is GitHub Copilot, Microsoft's code completion service. When Copilot launched at
Microsoft's response demonstrates how deeply capital matters in AI. Rather than optimizing Copilot independently, Microsoft integrated the service more tightly with their broader Azure infrastructure. Copilot queries could be served from Microsoft's massive existing compute capacity, amortizing infrastructure costs across multiple revenue-generating services. By 2025, reports suggested Microsoft had narrowed this loss, though Copilot still operates as a strategic loss-leader rather than a profit center.
This case illustrates an often-overlooked principle: foundation model providers with massive existing infrastructure gain exponential advantages in achieving profitable inference economics. For providers like OpenAI, Anthropic, or Mistral without legacy infrastructure to leverage, every inference query requires buying additional compute capacity. For Microsoft, Google, or Meta, inference can be spread across global infrastructure built for other purposes.
The implication is significant: the companies most likely to achieve profitable AI services are not pure-play AI companies, but rather incumbent technology giants with existing massive infrastructure. This reshapes the long-term competitive landscape fundamentally.
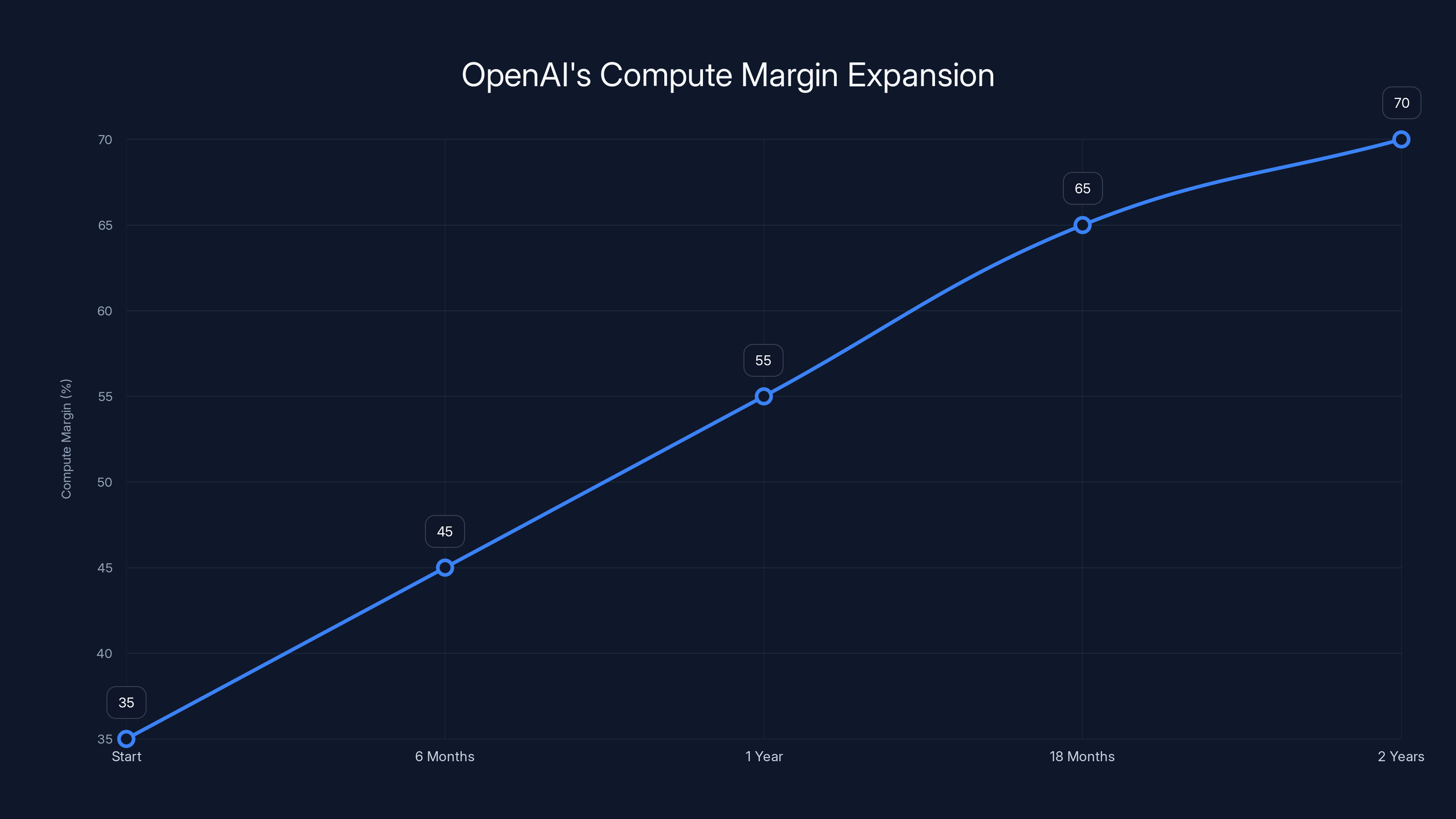
OpenAI achieved a remarkable margin expansion from 35% to 70% in two years through hardware improvements, model optimization, and algorithmic efficiency.
Why Per-Token Costs Falling Doesn't Solve the B2B Treadmill Problem
The Semantic Mismatch: Cost Per Token Versus Cost Per Task
This is where the narrative breaks down for application-layer companies. The industry obsesses over falling token costs — and rightfully so, as they have fallen dramatically. OpenAI's pricing for GPT-4-level performance has decreased by approximately 95-98% since late 2022. That's genuine, transformational cost reduction.
But token cost is not the economically relevant metric for B2B applications. The relevant metric is cost-per-task or cost-per-user-interaction. And that metric has not fallen proportionally. In many cases, it has actually risen.
Consider a concrete example from 2024-2025. A customer uses an AI-powered code completion tool to debug a production issue. In December 2023, the system might use GPT-3.5-Turbo to analyze the error logs and suggest fixes. The total token count: approximately 2,000 tokens across prompt and response. The cost per task: roughly $0.03.
By November 2025, the same customer uses the same tool with Claude 3.5 Sonnet or GPT-4o. The results are dramatically better — more accurate debugging suggestions, better understanding of complex interdependencies. But the architecture has changed.
Instead of a single-pass analysis, the system now:
- Uses a reasoning model to analyze logs (1,000 reasoning tokens)
- Calls a function to examine related services (500 reasoning tokens)
- Generates a detailed explanation with examples (200 tokens)
- Performs verification (300 reasoning tokens)
Total: approximately 2,000 tokens, but now 1,800 of them are expensive reasoning tokens that cost 3-5x more than standard tokens. The per-task cost has risen to
This is not an edge case. This pattern repeats across every AI application category:
Document Analysis: Moved from simple keyword extraction to multi-step reasoning that examines connections across documents. Token consumption: 5-10x higher. Cost impact: +400-900%.
Code Analysis: Evolved from syntax checking to architectural review and security analysis. Average per-task tokens: 8-12x higher. Cost per task: +600-1100%.
Customer Support: Advanced from template-based responses to multi-turn reasoning that understands context and precedent. Per-interaction tokens: 6-15x higher. Cost: +500-1300%.
Data Analysis: Transformed from simple aggregations to agentic workflows that iteratively refine understanding. Per-query tokens: 10-50x higher depending on complexity. Cost: +900-4800%.
This represents the fundamental treadmill mechanism. The per-token cost curve slopes downward. The per-task token requirement curve slopes upward. The two curves intersect at higher prices, not lower prices.
The Agentic Reasoning Revolution and Its Cost Implications
The emergence of agentic AI workflows in 2024-2025 turbocharged this problem. When a model has the ability to take actions — call APIs, execute code, refine searches, iterate on solutions — the computational cost of solving a problem rises dramatically.
A simple customer support inquiry might previously be handled in a single model call with 500 tokens. An agentic system handling the same inquiry might:
- Call the customer database API (reasoning token cost to interpret requirements)
- Search internal documentation (reasoning tokens to formulate effective queries)
- Analyze support history (reasoning tokens to identify patterns)
- Formulate response (reasoning tokens to synthesize information)
- Verify response quality (reasoning tokens for meta-evaluation)
Each step might involve 200-400 reasoning tokens. Total: 1,000-2,000 reasoning tokens. The cost per query has risen 2-4x despite the underlying model efficiency improving.
Deep Seek R1, OpenAI's o 3, and similar reasoning models exemplify this dynamic. These models use a process called "chain of thought" where the model explicitly outputs its reasoning process. This transparency is valuable — it helps users understand how conclusions were reached and builds trust. But it's computationally expensive.
Analysis of o 3's token generation patterns shows that for a complex coding task, o 3 might generate 600+ reasoning tokens where GPT-4o generates 60 tokens for the same task. That's a 10x token inflation despite producing objectively better results. The cost per task has risen, even though the cost per token has fallen.
This creates a prisoner's dilemma for B2B companies. If you continue using simpler models (GPT-3.5, older Claude versions), you deliver inferior results and lose customers to competitors using advanced reasoning models. If you switch to advanced reasoning models, you maintain quality but your inference costs rise 3-10x.
Standing still is not an option. Your customers expect continuous improvement. Your competitors are using better models. The market demands evolution, even if that evolution has negative economic implications.
The Competitive Escalation Problem: Why Better Models Don't Mean Better Economics
The Capability Arms Race Among Application Developers
Foundation model providers face a relatively straightforward optimization problem: maximize revenue while minimizing compute costs. They have two levers: pricing and efficiency. OpenAI and Anthropic have pulled both levers effectively, resulting in margin expansion.
Application-layer companies face a far more complex optimization problem because they have three competing objectives:
- Minimize compute costs (narrow margins become impossible without cost reduction)
- Maximize customer satisfaction (requires deploying the best available models)
- Maintain competitive parity (can't use inferior technology to what competitors deploy)
These three objectives are in direct conflict. You cannot simultaneously minimize compute costs and deploy state-of-the-art models. The attempt to do so creates the treadmill dynamic.
Consider a hypothetical B2B company providing AI-powered business intelligence to mid-market financial services firms. In 2023, they built their system on GPT-3.5 at a cost of approximately $0.50 per user per month in compute. The model delivered mediocre results — it often misinterpreted complex financial terminology and occasionally generated hallucinations in charts and summaries.
In 2024, competitors began deploying GPT-4 and Claude 2. The cost rose to $3-5 per user per month, but the quality improvement was obvious. Our hypothetical company's customer churn accelerated. Within 6 months, they were forced to upgrade.
By late 2024, competitors were experimenting with o 1 and Claude 3.5 Opus for complex financial analysis tasks. The cost per complex analysis jumped to $15-25. Again, our company was forced to follow, not because they wanted to, but because the alternative was losing customers.
From 2023 to 2025, the cost per user per month for the same business intelligence application rose from
This pattern is repeating across virtually every B2B AI application category. The cost escalation is a consequence of competitive dynamics, not technological regression. Each company moving up the model hierarchy forces others to follow. The equilibrium is reached when all competitors are using the most expensive models that customers will tolerate.
Why Incumbent Advantages Are Amplifying, Not Shrinking
One of the most important but overlooked dynamics in AI economics is how margin pressures are amplifying the advantages of well-capitalized, diversified companies over pure-play AI startups.
Consider the economics of two hypothetical code completion tools:
Startup AI: Pure-play code completion company. When they call OpenAI's API, they pay full commercial rates. If they serve 10,000 developers and the average developer generates 1,000 tokens/day of completion suggestions, they're paying approximately
But when reasoning models arrive and they need to upgrade to more advanced analysis, the compute cost might rise to $6,000-8,000/month (3-4% of revenue) to maintain competitive quality. Their 80% gross margin becomes 75-76%. Over time, margin compression forces them to either raise prices (losing customers to entrenched competitors) or accept lower margins (reducing profitability).
Big Tech AI: Microsoft, Google, or Meta adding AI capabilities to existing products. When they call their own inference infrastructure, they pay internal cost of capital — approximately 20-30% of what external APIs cost. They're already running massive GPU clusters for other purposes. Incremental inference queries cost them 2-3x less than Startup AI.
Moreover, Big Tech AI can bundle AI features with other services. They don't need code completion margins to be profitable; they only need it to be incrementally profitable above the internal cost of capital. This fundamentally changes the pricing and margin dynamics.
Over 2-3 years, this dynamic compounds. Startup AI is slowly squeezed from 80% to 72-75% gross margins as compute costs rise. Big Tech AI maintains 90%+ margins because of their infrastructure advantages. Startup AI's competitive position erodes. Big Tech AI gains market share.
This is not a novel dynamic in technology — it's the mechanism through which infrastructure advantages compound. What's novel is how quickly this dynamic is playing out in AI in 2024-2025.
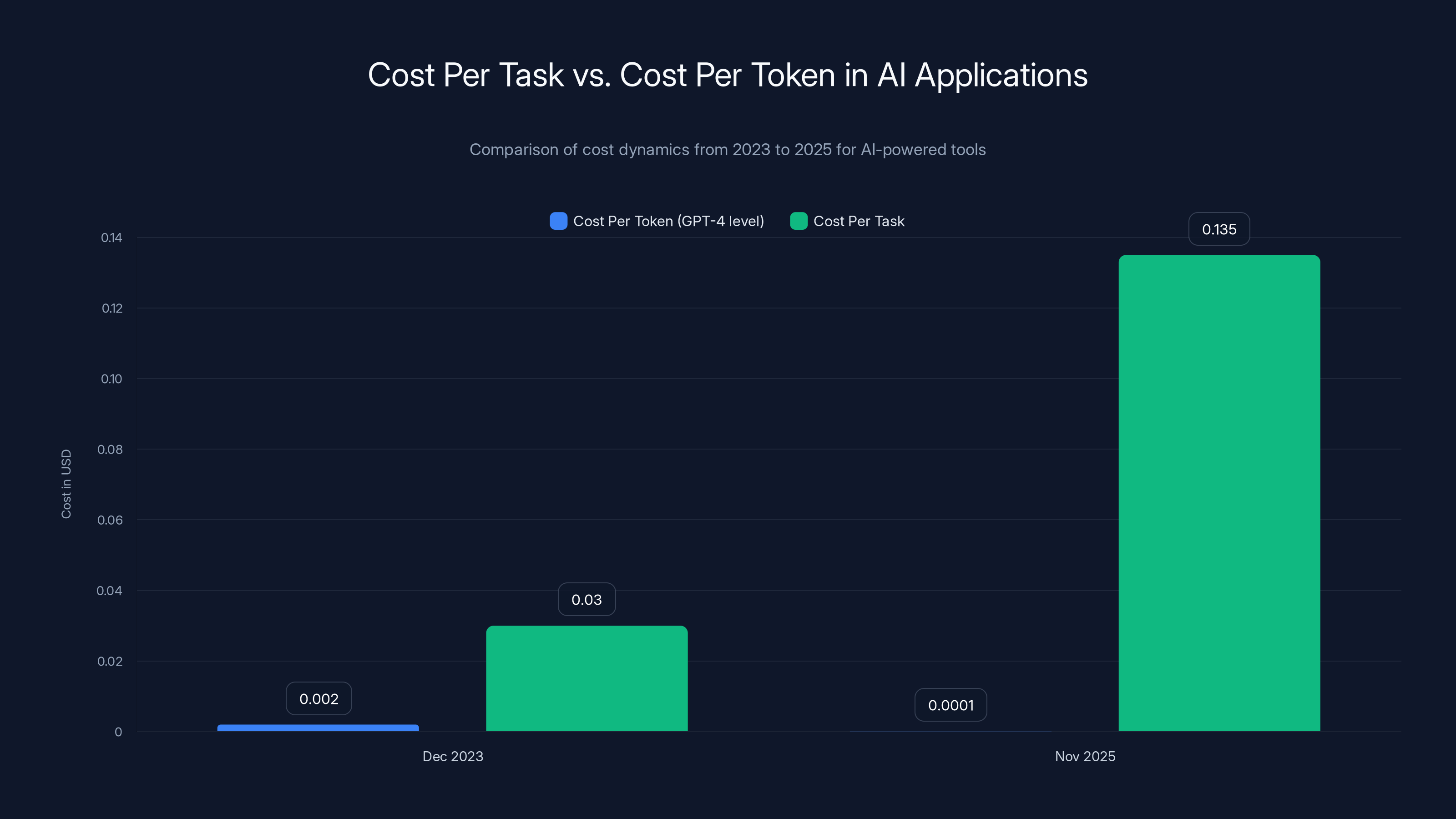
While per-token costs have decreased by 95-98% from 2023 to 2025, the cost per task in AI applications has increased by 4-5x due to more complex processing requirements. Estimated data for task costs.
The Mathematics of the Inference Cost Paradox
Deconstructing the Token Economics Formula
Understanding the apparent paradox of simultaneously falling token costs and rising task costs requires precise mathematical decomposition.
For any AI application, the economic model can be expressed as:
Total Cost Per Task = (Tokens Generated × Cost Per Token) + (Infrastructure Overhead × Utilization Rate)
Let's decompose each component:
Component 1: Cost Per Token
This is the element that has genuinely fallen. In November 2022, GPT-3.5-Turbo input tokens cost approximately
For GPT-4-level models, the cost reduction is less dramatic but still significant: from approximately
Component 2: Tokens Generated Per Task
This is the element that has moved in the opposite direction. The metrics are harder to compile, but empirical evidence from multiple sources suggests:
- Simple completion tasks: relatively flat or slightly declining token generation (-5% to +10%)
- Code generation tasks: 3-5x increase in tokens due to explanations and error handling
- Reasoning tasks: 8-15x increase in tokens due to chain-of-thought processes
- Multi-step agent tasks: 10-50x increase depending on complexity
The weighted average across all application types has likely increased 2-4x, which means the absolute cost per task is lower than 2022 but higher than 2023.
Component 3: Model Tier Escalation
What's often invisible in this formula is that applications have systematically moved to higher-tier models. In 2022, most applications used GPT-3.5-Turbo or Claude 1. By 2025, the minimum viable model for competitive applications is Claude 3.5 Sonnet or GPT-4o. For advanced applications, it's reasoning models like o 1 or Claude's extended thinking.
The pricing premium for these models is dramatic:
| Model Tier | Typical Pricing (Input/Output) | Relative Cost vs GPT-3.5 |
|---|---|---|
| GPT-3.5-Turbo | 1.0x | |
| GPT-4o | 10x | |
| Claude 3.5 Sonnet | 6x | |
| o 1 (reasoning) | 30x | |
| Extended thinking | Variable, 5-10x more | 50-100x |
Even accounting for the 97% per-token cost reduction from 2022, a 2024 application using GPT-4o with 2.5x more tokens per task is still paying more per task than a 2022 application using GPT-3.5.
Component 4: Model Mixture and Intelligent Routing
Some sophisticated applications have partially offset these costs through model mixture strategies — using cheaper models for simple tasks and expensive models only when necessary. However, this requires careful prompt engineering and often sacrifices consistency.
An application that intelligently routes 70% of requests to GPT-4o and 30% to Claude 3.5 Sonnet might achieve an effective cost per request that's 2-3x higher than using GPT-3.5 uniformly, but the quality improvement justifies the cost.
Despite these strategies, the fundamental mathematics remain: the per-task cost has risen for quality-conscious applications.
The Reasoning Model Cost Impact Analysis
Reasoning models represent a qualitative shift in the cost structure, not merely a quantitative adjustment. When a model engages in explicit reasoning — generating a chain of thought that shows its work — that reasoning is not hidden from the customer's perspective, and more importantly, they pay for every token.
OpenAI's o 1 and o 3 models exemplify this shift. These models are designed to take more "time" (computing tokens) to arrive at better answers. The reasoning process might generate 2,000-5,000 tokens for a single problem, where GPT-4 might generate 200-500 tokens.
The pricing model reflects this asymmetry directly. o 1 costs approximately 10-15x more than GPT-4 per token. If you're generating 10x more tokens AND paying 10x more per token, you're looking at 100x cost increase for genuinely complex reasoning tasks.
Is the output 100x better? No. But is it meaningfully better — perhaps 2-5x better on sophisticated cognitive tasks? Yes. This creates the fundamental challenge: the marginal improvement in output quality has become decoupled from the marginal cost.
In competitive markets, good-enough is not good enough. If your competitor deploys o 1 for customer research analysis and you're still using GPT-4, you will lose market share even if the cost per unit of quality improvement is poor.
B2B Startup Economics in the Age of Expensive Reasoning Models
The Profitability Crisis at Scale
One particularly revealing example from the SaaStr community illustrates the scale of this problem. A portfolio company approaching $100M ARR recognized that their current model stack — primarily GPT-4 and Claude 3 — was insufficient to maintain competitive product quality. Their competitors were deploying reasoning models and agentic workflows.
They conducted a detailed analysis of moving to advanced reasoning models for their core AI features. The conclusion was stark: incremental inference costs would increase by approximately **
This is not a one-time cost. It's a permanent operational cost increase driven by competitive necessity. The company faces three options:
-
Accept lower margins: Gross margin drops from 75% to 67-69%. This is survivable but reduces reinvestment capacity and makes the company less attractive to public market investors.
-
Increase prices: Raise prices by 8-10% to maintain gross margins. This is attractive for unit economics but creates churn risk and potentially loses price-sensitive segments.
-
Optimize ruthlessly: Find ways to deliver advanced capabilities with fewer reasoning tokens. This is theoretically possible but practically difficult.
Most companies attempt a combination of all three. But the mathematical reality remains: the cost structure has shifted permanently upward.
Multiply this across the hundreds of B2B AI startups using similar technology stacks, and the aggregate profitability impact is substantial. Entire cohorts of companies are experiencing simultaneous margin compression, not because they've failed to execute, but because the underlying technology economics have shifted.
The Unit Economics Paradox: Improving Products, Declining Margins
This creates a genuinely perverse dynamic in B2B AI companies. As product quality improves — which should theoretically be a positive — operating margins often decline. The relationship between product quality and profitability, which typically moves in the same direction in SaaS, is fracturing.
Historically in SaaS, a 15% improvement in product quality might enable a 5% price increase, expanding margins while improving customer satisfaction. In AI applications, a 15% improvement in product quality often requires a 30-50% increase in inference costs, actually compressing margins despite higher willingness to pay.
This is particularly acute for companies in the following categories:
Knowledge Work Automation: Companies automating white-collar knowledge work (legal analysis, financial modeling, technical writing) require high-quality reasoning. These are naturally drawn to expensive reasoning models. As these models become necessary for competitive viability, margins compress.
Content Creation: AI-powered content generation platforms face pressure to produce not just voluminous content, but coherent content that maintains brand voice and strategic intent. Simple models are insufficient. Reasoning models are increasingly necessary. Cost per piece of content has risen 5-15x since 2022, even at companies that achieved significant efficiency gains.
Code Generation and Analysis: Developers are intolerant of hallucinations and incorrect code suggestions. As applications expanded beyond simple autocomplete to architectural analysis, debugging, and refactoring, the necessary model tier rose. Many code analysis tools have moved from GPT-3.5 to GPT-4 to o 1. Cost per suggestion has risen 50-100x while quality has improved perhaps 3-5x.
Enterprise Vertical Applications: Companies building AI-powered software for specific industries (healthcare, financial services, legal) require domain-specific reasoning and accuracy. Their natural model tier is expensive advanced models. As these models become necessary, unit economics deteriorate.
Despite rapid user growth, many of these companies are experiencing margin compression that makes long-term profitability questionable at current pricing levels.
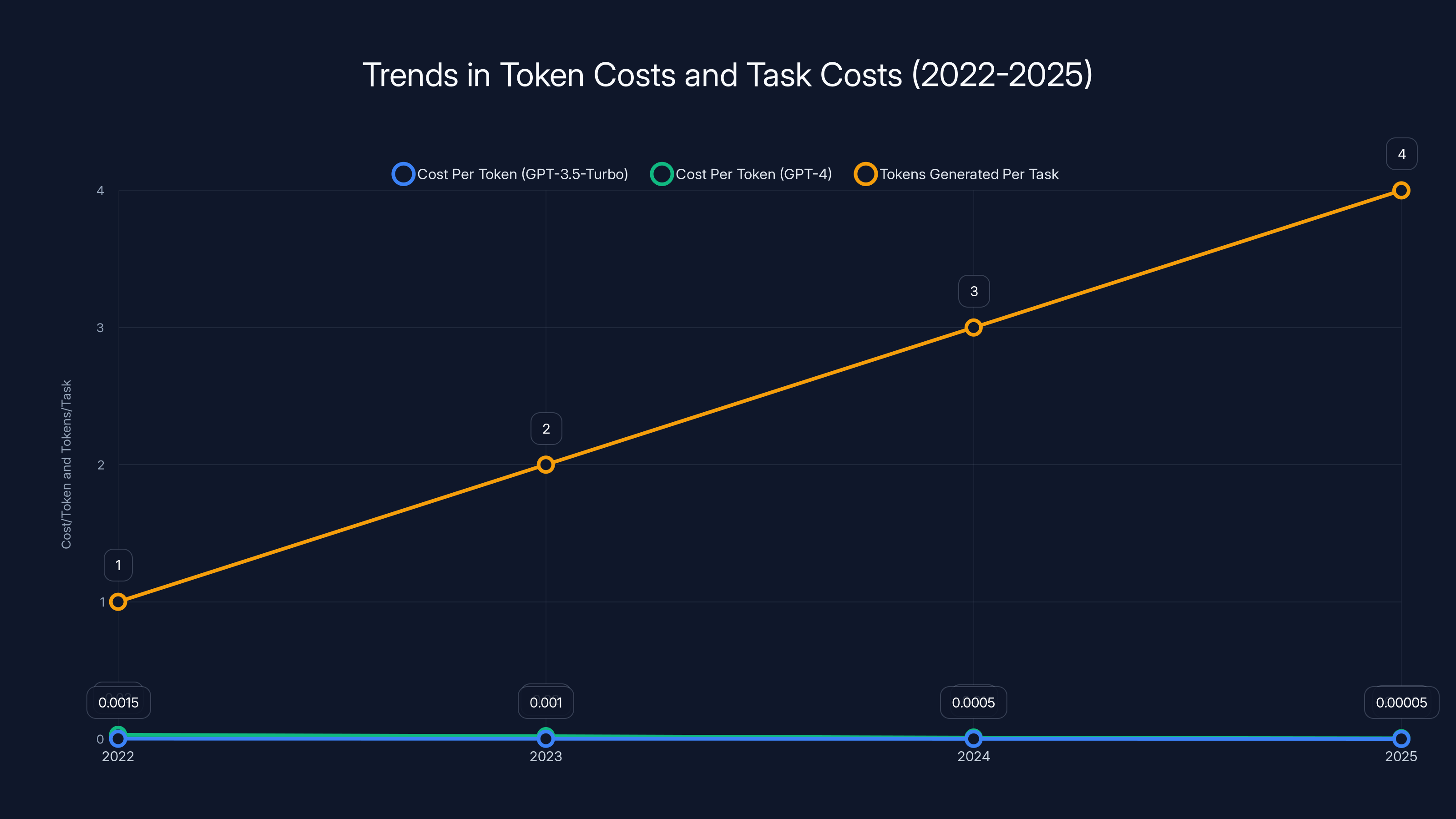
While token costs have dramatically decreased, the number of tokens generated per task has increased, leading to a complex cost dynamic. Estimated data.
The Critical Variable: Model Mixture and Intelligent Routing
How Advanced Companies Are Managing the Cost-Quality Tradeoff
The most sophisticated B2B AI applications have developed complex multi-model strategies that attempt to balance cost and quality. Rather than using a single model tier for all requests, they implement intelligent routing:
Tier 1 - Simple Requests: Routes to GPT-3.5 or similar efficient models. Cost: ~$0.01 per request. Example: "Generate a summary of this document."
Tier 2 - Moderate Complexity: Routes to GPT-4o or Claude 3 Sonnet. Cost: ~$0.10 per request. Example: "Analyze this document for regulatory compliance risks."
Tier 3 - Complex Reasoning: Routes to o 1 or extended thinking models. Cost: ~$1.00 per request. Example: "Recommend strategic changes to our operations based on this comprehensive business analysis."
The goal is to keep 60-70% of requests in Tier 1, 20-25% in Tier 2, and 5-10% in Tier 3. This weighted average cost is lower than using advanced models universally but higher than using basic models universally.
The effectiveness of this strategy depends on:
-
Accurate request classification: Can you reliably predict whether a request is simple, moderate, or complex? Misclassification results in poor quality or unnecessary expense.
-
User acceptance: Do users accept occasionally slower or lower-quality responses from simple requests? If every response must be optimized, the strategy doesn't work.
-
Model overlap: Do the different model tiers produce sufficiently consistent outputs that users don't notice the variation? Tone and style inconsistency erodes trust.
Companies that implement these strategies well can reduce effective model costs by 30-40% compared to universal deployment of advanced models, while still maintaining competitive quality for complex tasks.
However, this strategy has limits. When the lowest acceptable model tier rises (because competitors have deployed better models), the Tier 1 model tier must be upgraded. When that happens, the entire cost structure shifts upward.
Prompt Engineering and Efficiency Optimization
Another critical lever is prompt engineering — crafting the specific instructions and context provided to models to elicit better outputs with fewer tokens.
A poorly written prompt for financial analysis might be 5,000 tokens and produce mediocre results. A well-engineered prompt might be 500 tokens and produce superior results. The 10x efficiency improvement is genuinely achievable and represents significant cost savings.
How? By:
- Eliminating unnecessary context: Providing only the specific information the model needs, not entire documents
- Using structured prompts: Specifying exact output format, which reduces model generation of unnecessary tokens
- Few-shot examples: Providing 1-2 examples of desired output (costs a few hundred tokens but drastically improves consistency and can reduce total output length)
- Iterative refinement: Using the model's draft output as input for a refinement step rather than asking for perfection in the first pass (counterintuitively, sometimes reduces total tokens)
The most sophisticated teams have invested substantially in prompt optimization, sometimes achieving 3-5x reductions in per-task tokens compared to naive implementations.
But there's a limit to prompt engineering efficiency gains. You cannot engineer away the fundamental need for reasoning tokens when genuine complex reasoning is required. A poorly engineered prompt for complex financial modeling might be 1,000 tokens with a reasoning model. A perfectly engineered prompt might be 800 tokens. The 20% improvement is less impressive than the 50-90% improvements possible in simpler tasks.
The Competitive Implications: Market Structure Reshaping
Why Pure-Play AI Startups Are Facing Structural Headwinds
The combination of these factors — rising per-task costs despite falling per-token costs, competitive pressure to adopt expensive models, and the infrastructure advantages of diversified technology companies — is creating structural headwinds for pure-play AI startups.
A pure-play startup entering the code generation market in 2025 faces a different competitive landscape than one entering in 2023:
2023 Entrant:
- Could deploy GPT-3.5 or Claude 1 at competitive cost
- Per-inference cost: $0.05-0.10
- Gross margins achievable at typical pricing: 70-75%
- Could compete on product quality and UX
2025 Entrant:
- Must deploy at least GPT-4o or Claude 3.5 Sonnet to be competitive
- Per-inference cost: $0.50-1.00
- Gross margins achievable at typical pricing: 55-65%
- Competes on model choice and inference optimization
The 2025 entrant faces significantly harder economics. They need higher revenue to reach profitability. They have less margin for sales and marketing. The path to becoming a standalone profitable company is narrower.
This creates market consolidation pressure. Startups that can't reach venture-scale funding (to operate through the path to scale) or achieve acquisition (being bought by larger companies) will struggle to survive.
Conversely, companies that can leverage existing infrastructure — Microsoft, Google, Meta, Apple — face none of these headwinds. They can add AI features at marginal cost and bundle them with existing products. Their cost structure is fundamentally different.
The Emergence of Specialized Model Providers
One counter-trend worth noting: the emergence of specialized model providers optimized for specific domains. Rather than compete on general-purpose reasoning with OpenAI, some startups are building vertical-specific models (legal, medical, financial) that are cheaper and better for narrow use cases.
Example: A legal research startup builds a model fine-tuned on case law and legal reasoning, which is more efficient for legal tasks than GPT-4. The per-task cost might be 3-5x lower than using general-purpose models, while quality is actually higher.
This is a legitimate strategy for startups to differentiate on cost while maintaining quality. However, the market size for any given vertical is smaller than the market size for general-purpose solutions, which limits the venture scale of such companies.
These specialized providers may become acquisition targets for larger companies seeking to improve their cost-quality tradeoffs in specific verticals.

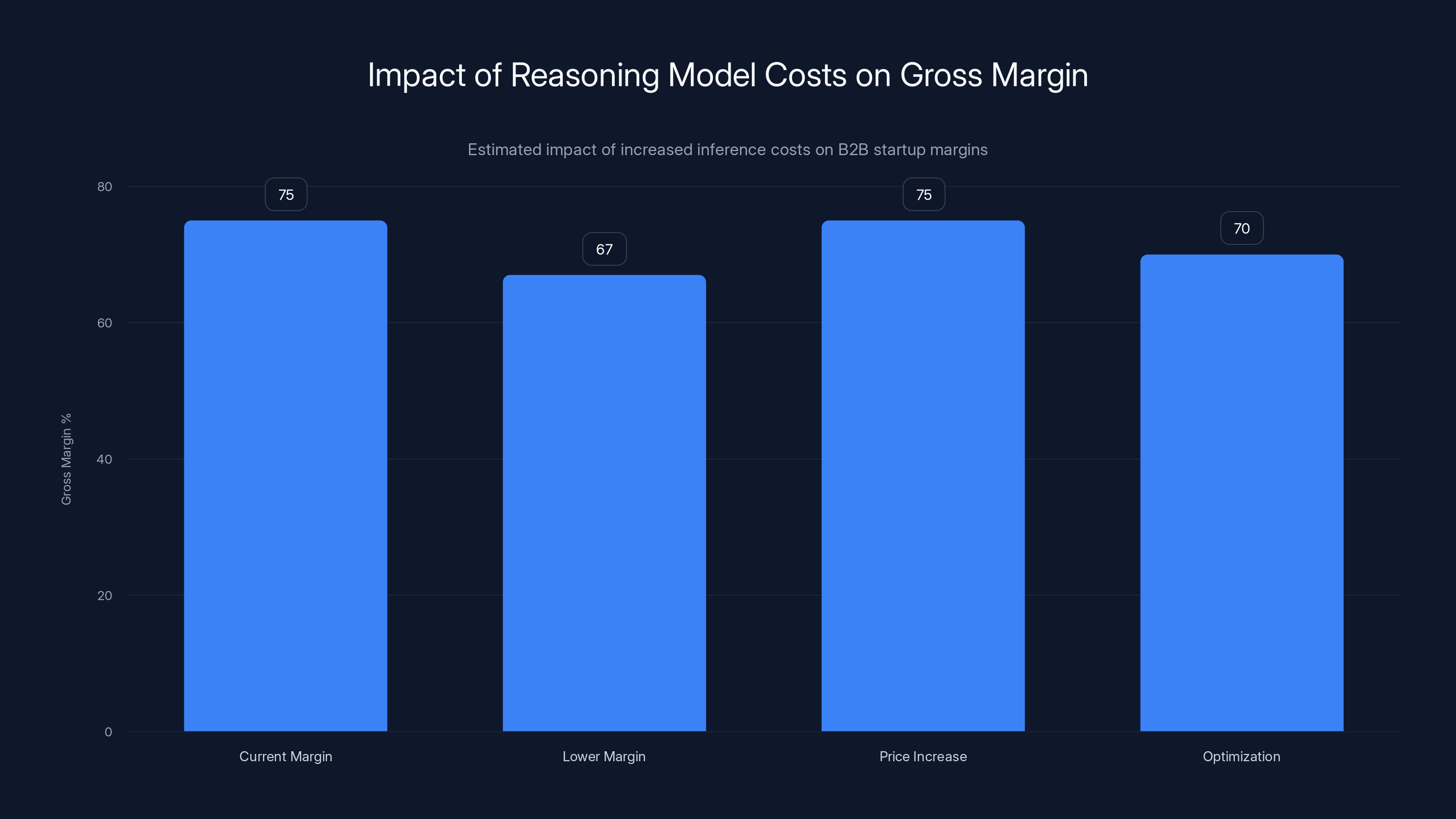
Estimated data shows that adopting advanced reasoning models can reduce gross margins by 6-8 percentage points. Strategies like price increases or optimization can help maintain margins but come with risks.
Pricing Strategy Implications: The Ineffective Price Increase Trap
Why Raising Prices Doesn't Solve the Problem
When faced with rising inference costs, many B2B companies consider raising prices to maintain gross margins. The logic is straightforward: if compute costs rise from 15% to 20% of revenue, raise prices by 5-7% to restore margins.
This works in theory. In practice, it creates multiple problems:
Problem 1: Price Resistance from Key Segments
Many B2B software companies have price-sensitive customer segments. Mid-market companies using your software as a cost center (not a revenue generator) have price elasticity. Raise prices by 10% and you might lose 5-15% of that segment.
For companies with concentrated customer bases, losing even one large customer can erase the revenue gains from a price increase.
Problem 2: Competitive Pricing Pressure
If you increase prices 10% but a competitor maintains prices, you lose customers to that competitor. The competitor might be absorbing the inference cost increase (accepting lower margins) to gain market share. This race-to-the-bottom dynamic is particularly intense in categories where switching costs are low.
Problem 3: Value-Based Pricing Misalignment
For many B2B AI applications, pricing is based on customer value or company size, not on input costs. A company analyzing $100M in annual transactions values your tool based on the ROI it generates, not on how many tokens your system uses.
If your unit economics have changed due to inference costs, but the customer's value hasn't changed, raising prices becomes philosophically difficult. You're essentially passing through infrastructure cost increases to customers, which feels extractive rather than value-generative.
Problem 4: Accelerating the AI Feature Treadmill
When you raise prices, you actually increase the pressure to add more AI features (since customers are now paying more) or improve existing features. This drives more inference consumption, which was the original problem.
You enter a treadmill where: Inference costs rise → Raise prices → Customers demand better features → Add more AI features → Inference costs rise further → Raise prices again
This cycle can only continue until price sensitivity or competitive pressure forces you off the treadmill.
The Unbundling Opportunity: When Specific AI Features Might Justify Premium Pricing
A more sophisticated pricing strategy for some companies is unbundling AI features and pricing them separately. Rather than including AI analysis in the base product, sell it as an add-on or premium tier.
Example: A business intelligence platform might offer:
- Base Tier ($50/month): Traditional analytics, no AI
- AI Assistant Tier ($100/month): Includes AI-powered insights (routing to GPT-3.5 layer)
- AI Expert Tier ($300/month): Includes advanced AI analysis with reasoning models
This allows customers to self-select into the inference cost tier they're willing to pay for. Customers who don't value AI features avoid the cost. Customers who require advanced analysis pay a premium.
The economic advantage: the base product tier might have 85% margins (no inference costs). The AI tier might have 55-65% margins (with inference costs). The blended margin is higher than if you included medium AI features in all tiers.
However, unbundling AI features has a UX downside: customers initially expect AI features to be included as standard. Charging separately feels regressive, particularly if competitors include AI features in lower tiers.
This strategy works best in categories where AI is genuinely optional, not core to the value proposition.
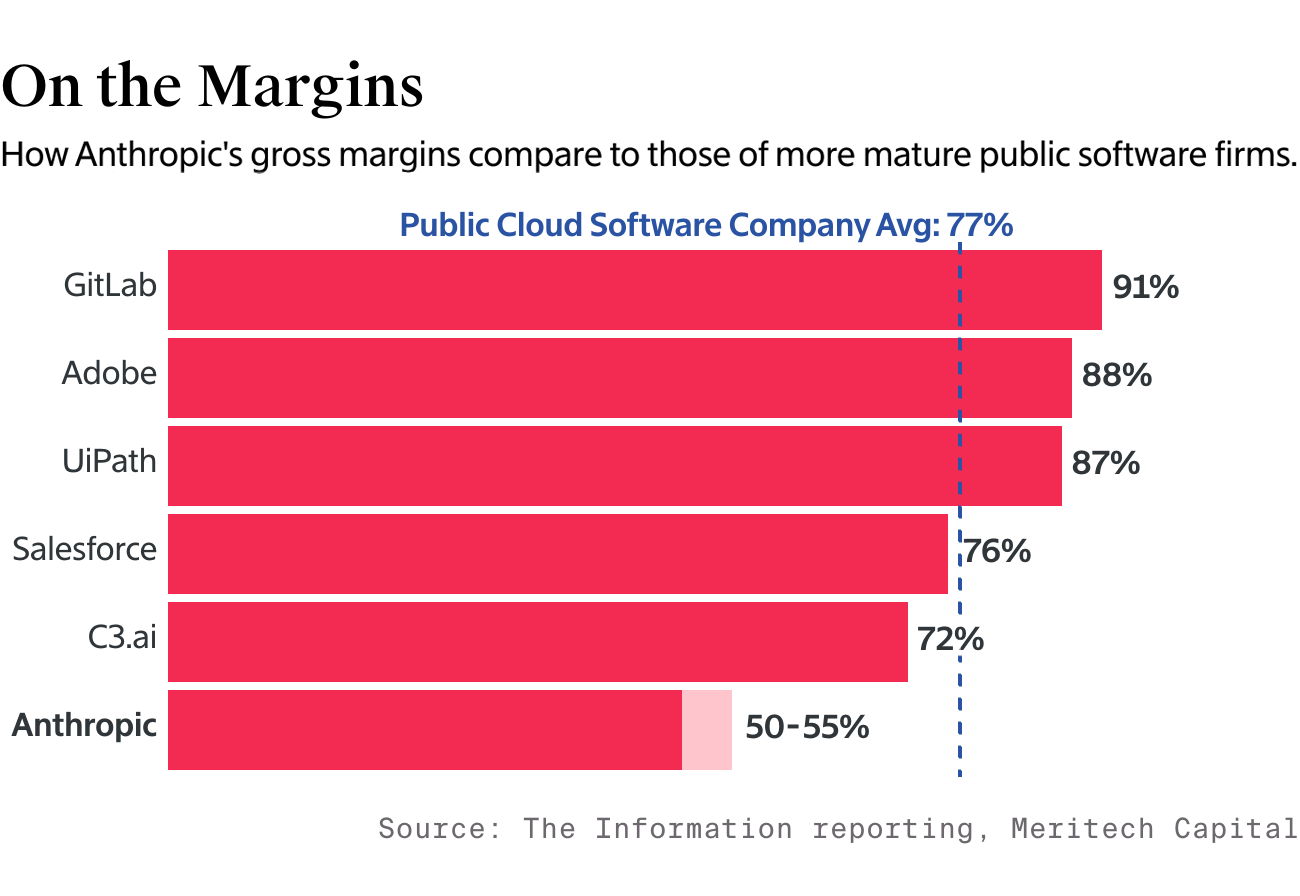
The Path Forward: What B2B Founders Should Do Now
Strategic Imperative 1: Right-Size Your Model Tier to Your Actual Needs
Many B2B companies deploy advanced models out of abundance of caution or competitive anxiety rather than genuine necessity. This is a luxury item that compresses margins.
The first strategic move is rigorous honest assessment: for which use cases is GPT-4-level performance actually required? Where would GPT-3.5-level performance genuinely satisfy customer needs and competitive requirements?
Conduct A/B tests:
- Deploy GPT-3.5 for 10% of traffic
- Measure quality metrics (user satisfaction, error rates, task success)
- Measure cost differential
- Calculate the cost per unit of quality improvement
You might find that for 40% of use cases, GPT-3.5 is 95% as good as GPT-4 but costs 50% less. Implement that optimization and capture significant margin expansion.
This requires discipline to resist competitive fear. But the companies that achieve this discipline will have better unit economics.
Strategic Imperative 2: Invest in Specialized Infrastructure and Optimization
As inference costs rise, the returns to optimization increase. Investing in prompt engineering, model fine-tuning, caching, and intelligent routing becomes genuinely profitable.
A company that achieves a 3-5x reduction in per-task token consumption through engineering might generate millions of dollars in annual margin improvement. At the margin, this investment is extremely high ROI.
Specific areas worth investing in:
Fine-Tuning: For tasks where you have labeled examples, fine-tuning a smaller model to be as good as a larger model can generate 3-10x cost reductions. This requires data infrastructure investment but pays back quickly.
Caching and Memoization: Many B2B use cases involve analyzing similar documents or datasets. Caching results when the same analysis has already been performed can reduce per-user inference cost by 20-40%.
Intelligent Routing: Implementing request-level classification to route simple tasks to cheap models and complex tasks to expensive models can reduce blended costs by 30-40%.
RAG Optimization: Rather than putting all context into the prompt, use retrieval-augmented generation (RAG) to inject only the most relevant context. This reduces prompt tokens by 50-70% in many use cases.
Strategic Imperative 3: Build Customer Segments Based on Inference Costs
If some use cases require 10x more inference than others, they should probably be in different product tiers with different pricing.
Segment your customers by their actual inference consumption:
- High Volume, Low Complexity: Route to efficient models, low margin pressure
- Low Volume, High Complexity: Route to advanced models, acceptable margin pressure
- High Volume, High Complexity: This is your margin-crushing segment; consider whether you have the right product-market fit here
Design different products or tiers for each segment. Don't force a one-size-fits-all product onto customers with dramatically different inference profiles.
Strategic Imperative 4: Explore Revenue Models Beyond Per-Seat Licensing
Many B2B AI applications are trapped in per-seat or per-transaction pricing models that don't reflect the actual cost structure.
If inference cost is the dominant variable cost, consider models that align customer incentives with inference consumption:
Usage-Based Pricing: Charge per inference or per token. This makes the cost structure transparent and aligns your margins with customer behavior. Downside: unpredictable customer costs can create friction.
Quota-Based Pricing: Customers purchase a quota of monthly inferences (e.g., "100,000 AI analyses per month"). Overages incur usage-based fees. This provides predictability while incentivizing efficient usage.
Outcome-Based Pricing: Charge based on measurable customer outcomes, not inputs. "Pay per customer converted using AI insights" rather than "pay per analysis run." This decouples your costs from customer value.
Strategic Imperative 5: Invest in Domain-Specific Models
General-purpose models are becoming more expensive. Domain-specific models (fine-tuned for your specific use case) can deliver equivalent performance at 30-50% lower cost.
For companies large enough to support it, investing in proprietary fine-tuned models is a high-return investment. You gain cost advantage, better performance, and reduced dependence on OpenAI/Anthropic pricing changes.
The tradeoff: requires ML expertise and computational resources. But for companies passing $10-20M ARR, the ROI often justifies the investment.

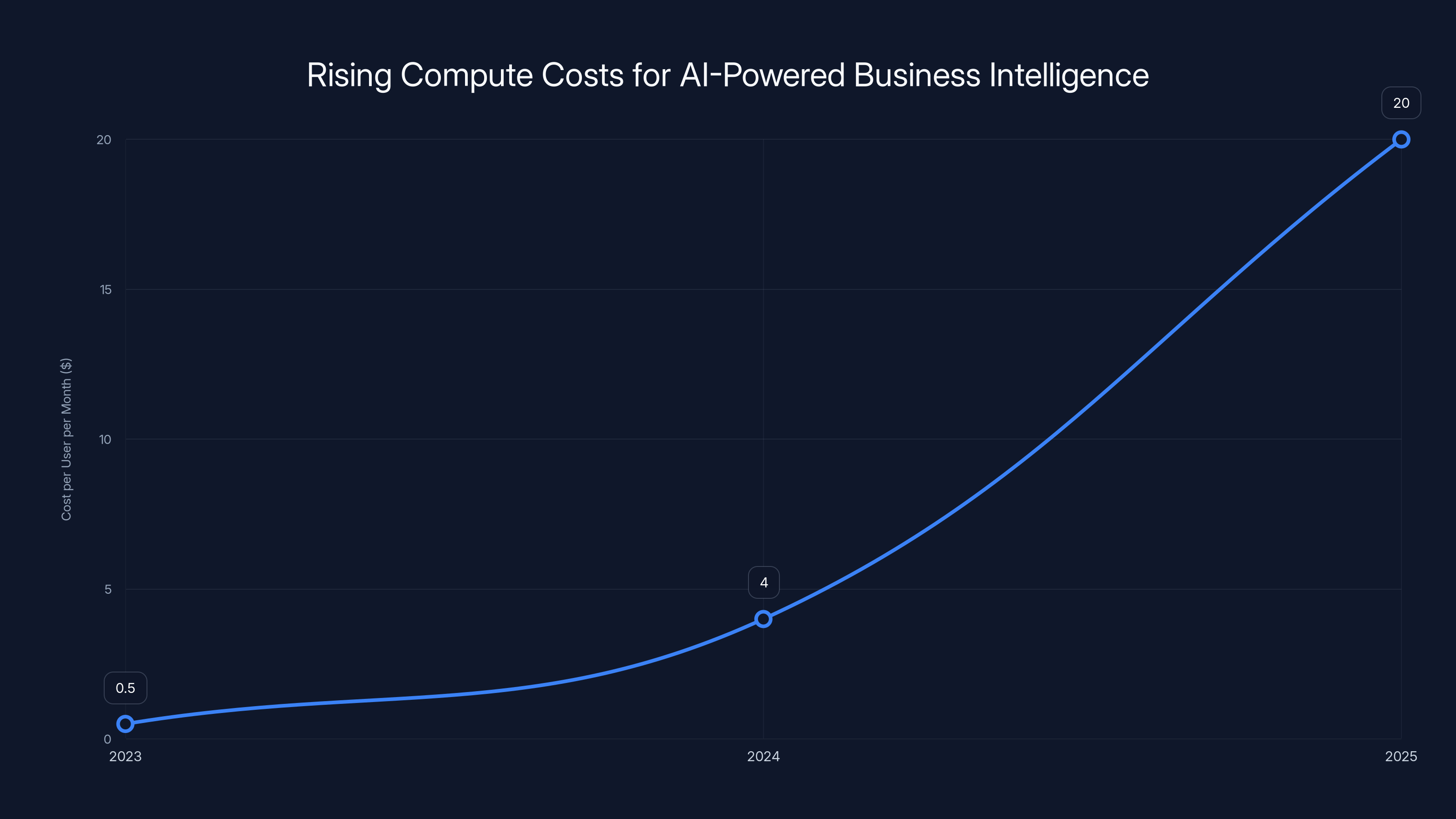
Estimated data shows a significant increase in compute costs per user per month from 2023 to 2025, driven by the need to adopt more advanced models to maintain competitive parity.
The Broader Implication: AI's Margin Profile Is Not Normal Software
Why AI Defies Traditional SaaS Unit Economics
There's a fundamental reality that founders should absorb: AI-powered software does not have the same unit economics profile as traditional SaaS. This is not a temporary state that will resolve as technology improves. It's structural.
Traditional SaaS has marginal costs approaching zero. Each additional customer uses already-built infrastructure. Gross margins expand with scale.
AI-powered software has marginal costs that are variable and potentially increasing. Each additional customer generates more inference queries. Better models generate more expensive queries. Scale increases the total inference cost, even if per-token costs are declining.
The consequence is that AI-powered SaaS companies cannot achieve the same gross margin profiles as traditional SaaS, even at scale. A company with $100M ARR in traditional SaaS might maintain 75-80% gross margins. An AI-powered SaaS company of the same size might realistically achieve 60-70% gross margins, even with optimal implementation.
This is not failure. It's structural reality. Companies need to reset expectations about achievable margins and plan accordingly.
Why Even the Foundations Will Continue Optimizing
OpenAI's journey from 35% to 70% compute margins will not stop. The company will continue optimizing because:
-
Competitive pressure: Anthropic is aggressively improving their margins. Meta is building competing models. The competitive dynamics force continuous optimization.
-
Margin culture: Sam Altman has made clear that margin expansion is a strategic priority. The company will continue investing in infrastructure efficiency.
-
Capital efficiency: Achieving profitability at scale requires margin expansion. For OpenAI, reaching 70% margins is a milestone, not a destination.
Expect OpenAI to reach 75-80% compute margins by 2027, approaching traditional software margins. But this will take another 18-24 months of effort.
During that period, B2B companies deploying OpenAI's models will face continued cost pressure from model evolution, not cost relief.
The Verdict: When AI Economics Actually Work
Categories Where AI Margins Are Actually Improving
While most B2B AI applications face margin compression, some categories are experiencing genuine margin expansion:
1. Automation of Repetitive Cognitive Tasks: Tasks like document classification, data extraction, or email categorization have genuinely decreasing token requirements as models improve. These are the clear wins.
2. Augmentation Rather Than Replacement: Features that augment human work (providing suggestions, highlighting options, summarizing) work better with less reasoning. These require fewer tokens than autonomously solving problems.
3. Vertical Specific Software: When you can fine-tune a model to a specific domain, cost-quality tradeoffs improve dramatically. A legal research tool using a legal-tuned model has better economics than one using general models.
4. Large Batch Processing: When you process documents, reports, or data in bulk rather than real-time, you gain opportunities for more aggressive optimization and batching. Per-item costs can decline significantly.
5. Real-Time Inference in Established Categories: Search, recommendation, and ranking systems that have successfully integrated AI (Google's search, Netflix's recommendations) have achieved genuine margin improvement because they've had years to optimize. New categories don't have this advantage.
The Companies That Will Thrive
The winners in this environment will be companies that:
-
Accept that inference costs are their primary variable cost and design products and pricing around that reality rather than fighting it.
-
Invest heavily in optimization (prompt engineering, fine-tuning, routing) rather than assuming cost improvement will come from foundation models.
-
Are ruthless about model selection — using the minimum tier of model required for competitive viability, not the most advanced tier available.
-
Have domain expertise that allows them to build specialized models or narrow use cases where they can achieve cost-quality advantages.
-
Can achieve distribution at scale to amortize development and optimization costs across a large customer base, making unit economics work despite higher per-customer costs.
-
Are embedded in larger organizations where they can leverage existing infrastructure or be bundled with other services.
The companies that will struggle are those that:
- Assume inference costs will decline automatically without optimization effort
- Try to compete on general-purpose AI quality without specialization
- Cannot achieve scale economics due to niche markets
- Attempt to maintain traditional SaaS margins (75%+) in AI-powered software
- Are pure-play AI companies without other revenue sources to subsidize AI features
Conclusion: The Uncomfortable Truth About AI Economics in 2025
OpenAI's achievement of 70% compute margins is genuinely impressive and represents real progress in AI infrastructure efficiency. Foundation model providers have solved the inference cost problem. They're building profitable, scaled businesses with industry-leading margins.
But that success is not automatically trickling down to B2B companies building on top of these models. The mathematics are clear: per-token cost reduction has been more than offset by per-task token inflation and model tier escalation. The net result is rising inference costs despite falling per-token prices.
B2B founders need to update their mental models of AI economics. The assumption that inference costs would become negligible — a common thesis in 2022-2023 — was incorrect. Inference costs are not negligible. They're real, they're growing, and they're structural constraints on profitability.
The path forward requires companies to become exceptionally disciplined about model selection, invest heavily in optimization, and accept that AI-powered software will have fundamentally different unit economics than traditional SaaS.
The companies that recognize this reality and architect their businesses accordingly will thrive. The companies that expect foundation model economics to automatically improve their own unit economics will be disappointed.
The margin expansion story is real. But it's a story about foundation models, not about the entire AI software ecosystem. For most B2B companies, the inference cost treadmill remains the defining economic challenge of the next 3-5 years.
Until founding teams internalize this reality and make strategic decisions based on it, they'll continue operating with unrealistic expectations about achievable margins, path to profitability, and long-term unit economics.
FAQ
What exactly is compute margin?
Compute margin is the percentage of revenue remaining after subtracting the cost of computational infrastructure (primarily GPU and processing costs) required to run AI models. OpenAI's 70% compute margin means that after paying for all the servers, electricity, and infrastructure to run Chat GPT, they have 70% of revenue left. This differs from gross margin because it excludes all other costs (salaries, R&D, marketing). For foundation models, compute margin is the most economically relevant metric because infrastructure is the dominant variable cost.
Why have per-token costs fallen so dramatically while per-task costs are rising?
This creates a paradoxical situation where the fundamental unit of pricing (cost per token) has improved but the practical unit of economic relevance (cost per customer interaction or task) has deteriorated. Per-token costs fall due to hardware efficiency improvements and algorithmic optimizations. However, per-task token consumption has risen 3-10x because applications have shifted to more advanced models that use reasoning processes. A simple task might use 60 tokens with a basic model, but the same task using an advanced reasoning model might use 600+ tokens. The net effect: per-token cost down 80-90%, but per-task cost up 100-400%.
What's the agentic reasoning problem and why does it matter for costs?
Agentic reasoning refers to AI systems that can take actions iteratively — calling APIs, analyzing results, refining approaches, and generating explanations at each step. Each of these steps consumes tokens and inference compute. A simple customer support query might previously require a single model call (500 tokens). An agentic system handling the same query might: call customer database API (200 reasoning tokens), search documentation (150 tokens), analyze support history (100 tokens), formulate response (150 tokens), verify quality (100 tokens) — totaling 700+ tokens. This architectural shift, driven by the ability to deliver better results, has made inference costs rise dramatically even as per-token costs fall.
How can B2B companies reduce inference costs without sacrificing product quality?
Companies can implement multi-pronged strategies: (1) Model mixture — route simple requests to efficient models and complex requests to advanced models, keeping weighted-average costs low; (2) Prompt engineering — craft precise instructions that reduce token bloat without quality loss; (3) Fine-tuning — optimize models for specific domains to achieve equivalent quality with fewer tokens; (4) Caching — store results for frequently repeated queries; (5) RAG optimization — inject only necessary context rather than full documents; (6) Batching — process multiple requests simultaneously for 20-30% efficiency gains. The companies achieving best results use multiple strategies simultaneously, potentially reducing per-task costs by 40-60% without quality degradation.
Why are pure-play AI startups facing worse economics than incumbent technology companies?
Incumbent companies (Microsoft, Google, Meta, Apple) have massive existing infrastructure built for other purposes. When they add AI features, marginal inference costs are extremely low because they're spreading the cost across multiple products. Start AI must buy infrastructure specifically for AI, paying full commercial rates. Additionally, incumbents can bundle AI features with other services, cross-subsidizing less profitable features. A startup must achieve profitability on AI features alone. This creates a structural cost disadvantage that makes it increasingly difficult for pure-play AI startups to achieve profitable unit economics.
What does the data show about gross margins across different AI application categories?
Gross margins vary dramatically by category. Companies automating simple repetitive tasks (classification, extraction) maintain 70-75% margins. Companies providing AI-augmented features that require advanced reasoning have compressed to 55-70% margins. Companies competing on cutting-edge AI quality (where they use the latest reasoning models) are seeing margins compress to 50-65%. The common pattern: as model tier requirement rises, gross margins decline 10-20 percentage points. For context, traditional SaaS achieves 75-85% gross margins. AI-powered SaaS at scale might realistically achieve 65-75% gross margins, even with optimal execution.
Should B2B companies raise prices to offset rising inference costs?
Price increases are tempting but problematic. While they can theoretically restore margins, they often trigger: (1) customer churn from price-sensitive segments; (2) competitive disadvantage if competitors maintain prices; (3) misalignment with value-based pricing if costs rise while value hasn't changed; (4) acceleration of the feature treadmill (customers paying more demand more features, driving higher inference consumption). A better approach is unbundling AI features as premium tiers, investing in cost optimization, or right-sizing model selection to competitive necessity rather than technical abundance. Price increases should be last resort, not first response.
How long until foundation model economics improve enough to solve B2B profitability challenges?
OpenAI's path from 35% to 70% compute margins (2-year timeline) provides a model. If Anthropic follows a similar trajectory, foundation model margins might reach 75-80% by 2027. However, this doesn't automatically solve B2B challenges because: (1) application-layer companies still face token inflation from advanced reasoning; (2) competitive model tier escalation continues regardless of per-token costs; (3) margin improvements from 70% to 80% at foundation level only translate to 1-2 percentage point improvements at application level. Realistically, B2B companies shouldn't expect material margin improvement from foundation models over the next 18-24 months. Their optimization efforts should focus on internal operations, not waiting for cost reductions.
What's the difference between token-level and task-level economics in AI applications?
Token-level economics describe the cost per unit of language model computation (cost per 1,000 tokens). Task-level economics describe the end-to-end cost of solving a customer problem. These have diverged dramatically. A token-level cost might fall 80% (from
Are there AI application categories where margins are actually improving?
Yes, several categories show genuine margin improvement. Document classification and data extraction, where models have optimized significantly. Vertical-specific applications using fine-tuned models that achieve efficiency gains unavailable to general-purpose tools. Augmentation features (suggestions, summaries, highlights) that require less reasoning than autonomous problem-solving. Batch processing workloads where optimization and caching generate meaningful savings. Established categories (search, recommendations) that have had years to optimize. The common pattern: simplicity (less reasoning required), specificity (vertical focus allowing fine-tuning), or time to optimize. New complex general-purpose applications face the opposite conditions.
Key Takeaways
- OpenAI achieved 70% compute margins (up from 35%) through genuine efficiency gains, but this success has not translated to application-layer companies
- Per-token costs have fallen 80-97% while per-task costs have risen 100-400% due to model tier escalation and reasoning token inflation
- Agentic AI workflows and reasoning models generate 5-15x more tokens than simple models, completely offsetting per-token cost reductions
- B2B companies face a competitive treadmill: standing still means losing customers to competitors using advanced models, but adopting advanced models compresses margins
- Pure-play AI startups face structural disadvantages compared to incumbent technology companies that can leverage existing infrastructure
- Intelligent model routing, prompt engineering optimization, and fine-tuning can reduce costs by 30-60% but have structural limits
- B2B AI applications should expect 60-75% gross margins at scale, not the 75-85% traditional SaaS achieves
- Price increases to offset inference costs often trigger churn and competitive disadvantage rather than solving unit economics
- Foundation model margin expansion will likely continue until 2027, but won't materially improve B2B application economics in the near term
- Companies with domain expertise enabling fine-tuned models and those embedded in larger organizations will maintain better economics than pure-play providers
Related Articles
- Pinterest's AI Slop Problem: Why Users Are Leaving [2025]
- Best Desk Accessories [2025]: Transform Your Workspace
- AI Agents Are Coming for Your Data: Privacy Risks Explained [2025]
- Paramount+ Coupon Codes & Deals: How to Save [2025]
- Pluribus Season 1 Finale: Vince Gilligan's Bold Sci-Fi Turn [2025]
- Spelling Bee Buddy: Complete Guide to Daily Hints & Strategies [2025]

