Best hardware options for deploying Open Claw | Tech Radar
Overview
News, deals, reviews, guides and more on the newest smartphones
News, deals, reviews, guides and more on the newest computing gadgets
Details
Start exploring exclusive deals, expert advice and more
Unlock and manage exclusive Techradar member rewards.
Your practical guide to running an always-on AI agent
When you purchase through links on our site, we may earn an affiliate commission. Here’s how it works.
Unlock instant access to exclusive member features.
Get full access to premium articles, exclusive features and a growing list of member rewards.
Open Claw is a self-hosted AI agent framework that connects large language models to messaging platforms like Whats App, Telegram, and i Message. It helps you spin up agents that act on your behalf rather than just chat with you.
Created by developer Peter Steinberger and originally named Clawd Bot before settling on its current name in early 2026, the project hit 150,000 Git Hub stars within weeks and triggered a visible run on Mac Mini stock at retailers across Asia. It’s a personal AI that runs continuously on your own hardware, with your data staying within your purview.
If you're evaluating Open Claw for personal automation, team workflows, or anything in between, the first real decision is where to run it. Open Claw itself is lightweight, an orchestration layer that offloads the heavy AI inference to cloud APIs like Claude or GPT-4. What you're actually choosing is reliability, uptime, and how much local control you want. The six options below cover the full range of options the community has tested in production, with honest notes on where each falls short.
What is Open Claw? Agentic AI that can automate any task
Hostinger launches one-click Open Claw AI agent deployment
A note on security: Open Claw grants your AI agent significant access to your system: browsing, file management, shell commands, and more. Before deploying on any hardware, review the official security documentation. Run Open Claw in a non-root environment, bind the gateway to loopback only, and never install skills from unverified sources.
In January 2026, security researchers identified a critical remote code execution vulnerability (CVE-2026-25253), and 341 malicious skills were found on Claw Hub. The project moves fast; keep your ear to the wall on security disclosures so you don’t get blindsided.
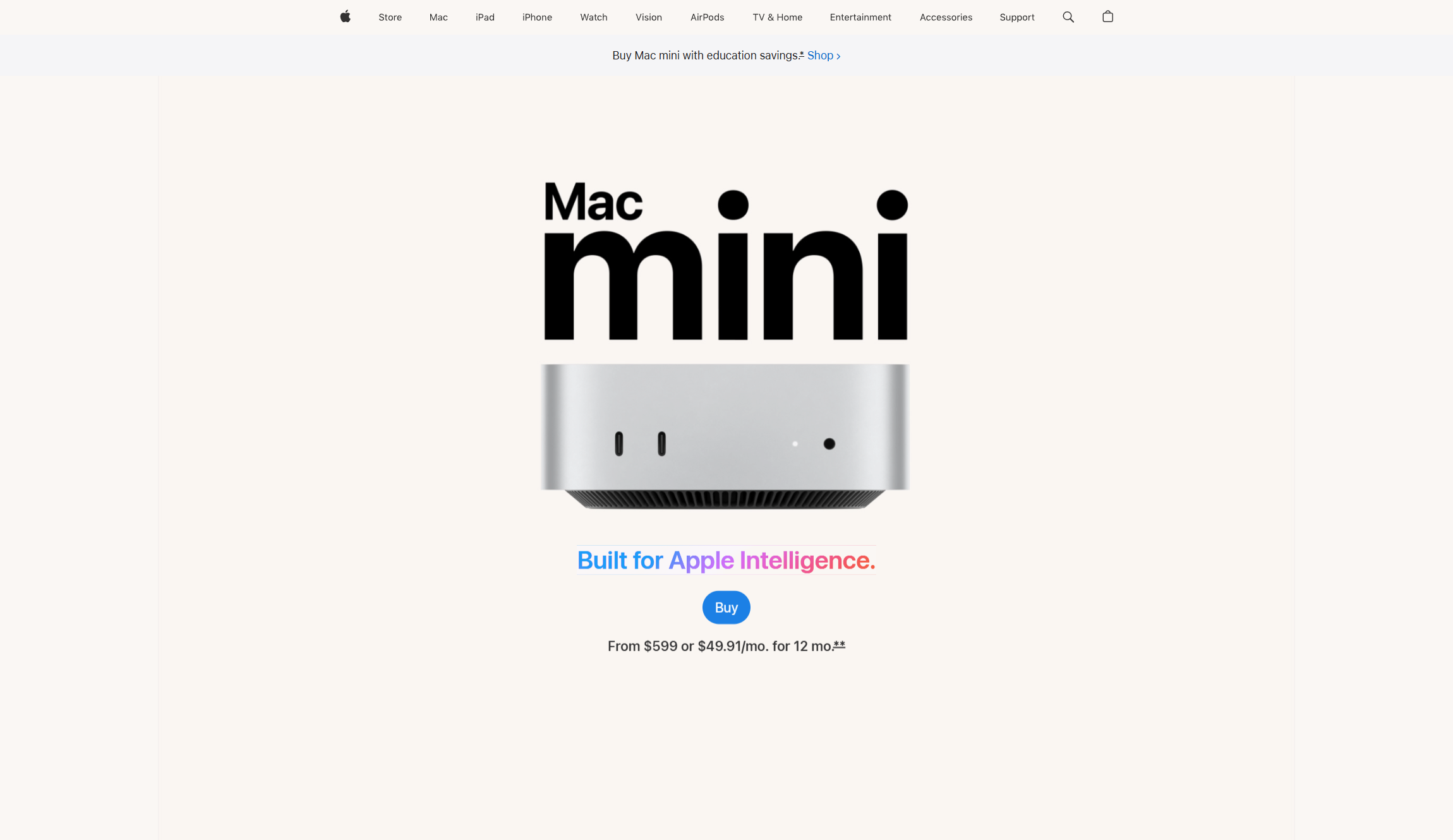
Best for: Apple ecosystem users who want local model inference
The Mac Mini became the unofficial reference hardware for Open Claw after the project went viral, to the point where the M4 model sold out at multiple retailers. There are a few reasons for this.
Apple Silicon's unified memory architecture means the CPU and GPU share the same RAM pool, which helps significantly when running local LLMs via Ollama. The machine idles at 3-5 watts, costing roughly $1-2 per month in electricity. File Vault encryption, mac OS Gatekeeper, and the Secure Enclave provide a solid default security posture.
Also, it's the only deployment option that supports native i Message integration.
M4, 16GB ($599): Handles cloud API deployments smoothly, with headroom for smaller local models like Llama 3.1 8B. The practical starting point for most users.
Minisforum M2 Pro arrives with Intel’s Core Ultra X9 388H CPU and 96GB of RAM
Minisforum’s new N5 Max NAS comes with Open Claw pre-installed
'AI is the Computer': Perplexity reveals Personal Computer, a cloud-based AI agent running on your Mac
M4, 24GB ($999): Recommended if local inference with 13B-34B parameter models is a priority. The community consensus is that 16GB feels tight for serious local model work.
M4 Pro, 48GB ($1,399): For 30B+ parameter models or multi-agent setups requiring consistent throughput.
Used M1 Mac Minis with 16GB sell for around $450 and run cloud-based Open Claw identically to the M4, worth considering if the upfront cost is a concern.
The Mac Mini requires physical space and a stable home or office internet connection. If your power goes out or your ISP has problems, your agent goes offline. Also, mac OS updates occasionally require reboots that interrupt the gateway. The Open Claw community is largely Mac-focused, which helps with troubleshooting, though.
Best for: Tinkerers, learners, and users on a tight budget
The Raspberry Pi 5 with 8GB of RAM has become the entry-level standard for always-on Open Claw deployments. At roughly
For anyone using Open Claw with cloud API providers, the Pi's modest CPU is rarely the bottleneck. Most of the response time comes from waiting on the cloud API, not the Pi processing anything locally.
RAM: 8GB LPDDR4X (get the 8GB model — the 4GB variant hits swap under multi-channel use)
Storage: Use an NVMe SSD via the M.2 HAT+, not an SD card. The difference in read/write speed is substantial for Open Claw's SQLite memory database, and log writes
OS: Ubuntu Server 22.04 LTS or Raspberry Pi OS Lite (64-bit) — Open Claw requires Node.js 22+, which needs a 64-bit OS
The Pi 5 cannot run meaningful local AI models. If you want to avoid cloud API costs or process sensitive documents locally, you'll outgrow this hardware quickly. Moreover, setup and ongoing maintenance require comfort with the command line.
Browser automation skills that spin up headless Chrome are also memory-intensive. A single Java Script-heavy page can consume 70-150MB, while running multiple concurrent skills pushes the Pi close to its limits.
A Linux NUC or mini PC running an Intel Core i 5 or AMD Ryzen 5 with 16-32GB of RAM hits a practical sweet spot for many Open Claw deployments. These machines offer more raw compute than a Raspberry Pi, cost much less than a Mac Mini, and run Ubuntu or Debian natively. This aligns well with Open Claw's Node.js stack and the project's Linux documentation.
Budget (~$300): The GMKtec G3 Plus with a Ryzen 5 5600H (6 cores, 12 threads) and 16GB DDR4 handles standard Open Claw workloads without issue. The 2.5 Gb E port is useful for high-throughput network operations
Mid-range (~$750): Machines with modern Ryzen or Intel chips and 32GB DDR5 give comfortable headroom for multi-agent setups and lightweight local models via Ollama
Enthusiast (~$800+): AMD Ryzen AI Max+ mini PCs with 64GB unified memory have been documented running 120B parameter models at usable speeds under Linux
For GPU-accelerated local inference, a machine with an NVIDIA RTX 3090 or RTX 4080 (16GB VRAM) handles 7B-13B models efficiently via CUDA.
i Message integration is mac OS-only, so you won't get it on Linux.
Setup, too, is more involved than a Mac, particularly if you're not familiar with systemd service configuration and SSH hardening. Windows-based mini PCs require WSL2, which adds complexity. Also note that 24/7 deployments need stable cooling, since some budget PCs throttle under sustained load.
Best for: Non-technical users who want cloud deployment
Railway has become one of the most popular ways to deploy Open Claw for users who don't want to touch a command line.
The platform has official support from the Open Claw project, with a one-click template that handles installation, configuration, and gateway management entirely through a browser-based setup wizard at /setup.
Multiple community-maintained templates have accumulated thousands of active deployments since launching in late January 2026.
Railway then provides a public URL, automatic HTTPS, and persistent storage. No SSH, no Docker configuration, no terminal commands required. One community template has logged over 2,600 total projects with a 100% recent deployment success rate.
Railway's Hobby plan starts at $5/month and handles Open Claw's gateway comfortably at approximately 250MB idle memory usage. The platform supports Anthropic, Open AI, Google Gemini, Groq, Open Router, and local models via Ollama configured as a custom endpoint.
Railway exposes your Open Claw gateway to the public internet by default — the official template documentation flags this explicitly. If you only use chat channels like Telegram or Discord and don't need the gateway dashboard, the documentation recommends removing the public endpoint after setup.
Device pairing for new browsers requires explicit approval through the /setup admin panel, which can be a friction point. Railway is also a managed platform, meaning your data lives in their infrastructure, with the same data sovereignty tradeoffs as any cloud deployment.
Best for: Teams, power users, and anyone who wants full root access
VPS hosting gives you the flexibility of a dedicated server without the hardware maintenance. Two providers stand out for Open Claw specifically: Hostinger, which offers a purpose-built one-click Docker deployment template, and Digital Ocean, which suits users with technical experience who want more control over their configuration.
Hostinger has the most polished Open Claw onboarding of any VPS provider, with a pre-configured Docker template available directly from checkout. The KVM 2 plan (2 v CPU, 8GB RAM, 100GB NVMe SSD) at $6.99/month is the community-recommended starting point, enough to run Open Claw alongside Ollama with a small local model.
Hostinger's h Panel simplifies server management for users who aren't comfortable with raw Linux administration, and optional Nexos AI credits let you connect to major LLM providers without configuring separate API keys.
Digital Ocean offers a one-click Open Claw deployment image from around
For gateway-only use with cloud AI APIs, a 4GB VPS with 2 v CPUs is sufficient for both providers. Memory is the primary constraint since the Node.js gateway is largely I/O-bound, spending most of its time waiting on API responses rather than processing locally.
Your data, API keys, memory files, and conversation history live on infrastructure you don't physically control. For business deployments handling sensitive information, this requires careful access control, encrypted storage, and clear data retention policies. A misconfigured SSH key or exposed port on a VPS running an agent with broad system access is a serious security exposure.
Monthly costs also accumulate with $100-200/month for a capable VPS with GPU support for local inference, though the running cost can exceed the annualized price of even owning a Mac Mini.
For organizations deploying Open Claw at scale or in regulated environments, purpose-built edge AI hardware like Thunder Soft offers features that consumer options can't match.
Thunder Soft has published validated deployment guides for Open Claw across two of its platforms, both targeting production scenarios where data sovereignty and offline operation matter.
Powered by Qualcomm QCS6490, the RUBIK Pi 3 delivers 12 TOPS of AI compute and supports local deployment of 1.8B-parameter models on Ubuntu 24.04 LTS. Thunder Soft's documented deployment scenario runs Open Claw across multiple boards as independent compute nodes, distributing tasks like media database structuring, proposal drafting, and presentation generation in parallel without manual orchestration.
A step-by-step Open Claw deployment guide is available in the official Thunder Soft documentation.
For environments where offline operation is required, like intelligent vehicles, safety-critical industrial applications, AIBOX delivers 100-200 TOPS of scalable AI performance and supports stable real-time execution of 7B-parameter models and larger.
The platform enables full offline deployment with millisecond-level response and complete data privacy, without requiring changes to existing electronic infrastructure.
Edge AI hardware carries significantly higher cost and complexity than consumer options. Setup requires meaningful technical expertise, and you'll be working with vendor documentation rather than the large community knowledge base that surrounds Raspberry Pi and Mac Mini deployments.
Pricing for AIBOX and enterprise configurations isn't publicly listed since Thunder Soft quotes based on specific requirements.
Upfront cost; requires physical space and home internet
Upfront cost; requires physical space and home internet
No local model inference; limited browser automation
No local model inference; limited browser automation
Public internet exposure by default; data on third-party infra
Public internet exposure by default; data on third-party infra
Open Claw's deployment options cover a wider range than most self-hosted tools. A sub-
For teams or anyone processing sensitive data, the choice between local hardware and cloud infrastructure deserves careful thought. Open Claw grants significant system access by design, and the security implications of where that access lives scale directly with what you're doing with it.
Match the hardware to the actual risk profile of your deployment, not just what's fastest to set up.
Ritoban Mukherjee is a tech and innovations journalist from West Bengal, India. These days, most of his work revolves around B2B software, such as AI website builders, Vo IP platforms, and CRMs, among other things. He has also been published on Tom's Guide, Creative Bloq, IT Pro, Gizmodo, Quartz, and Mental Floss.
You must confirm your public display name before commenting
2I asked James Cameron what to stream after new nature documentary Secrets of the Bees — and his answer proves why he's a cinematic genius
3A new Supergirl trailer will be released today — and some fresh cast and plot details about the DCU movie have excited and confused me
4‘Raising the bar for mobile photography’ — Vivo launches the X300 Ultra and its eye-popping 400mm telephoto attachment
5I connected my Dropbox to Chat GPT — and it changed how I find everything
Tech Radar is part of Future US Inc, an international media group and leading digital publisher. Visit our corporate site.
© Future US, Inc. Full 7th Floor, 130 West 42nd Street, New York, NY 10036.
Key Takeaways
- News, deals, reviews, guides and more on the newest smartphones
- News, deals, reviews, guides and more on the newest computing gadgets
- Start exploring exclusive deals, expert advice and more
- Unlock and manage exclusive Techradar member rewards
- Your practical guide to running an always-on AI agent

