![Building Custom Reasoning Agents with Minimal Compute [2025]](https://tryrunable.com/blog/building-custom-reasoning-agents-with-minimal-compute-2025/image-1-1777421104678.jpg)
Building Custom Reasoning Agents with Minimal Compute [2025]
Last month, a small AI startup achieved what seemed impossible—they built a custom reasoning agent that operated with a fraction of the compute typically required. This achievement opens doors for many companies constrained by resources yet eager to leverage advanced AI capabilities. Let's dive into how you too can build custom reasoning agents without breaking the bank on compute.
TL; DR
- New Approach: Reinforcement Learning with Verifiable Rewards with Self-Distillation (RLSD) reduces compute needs.
- Practical Steps: Detailed guide on implementing RLSD in your AI projects.
- Efficiency Gains: Models show improved performance over traditional techniques.
- Cost Reduction: Lower technical and financial barriers for enterprises.
- Future Outlook: Predicted trends in AI development with minimal infrastructure.
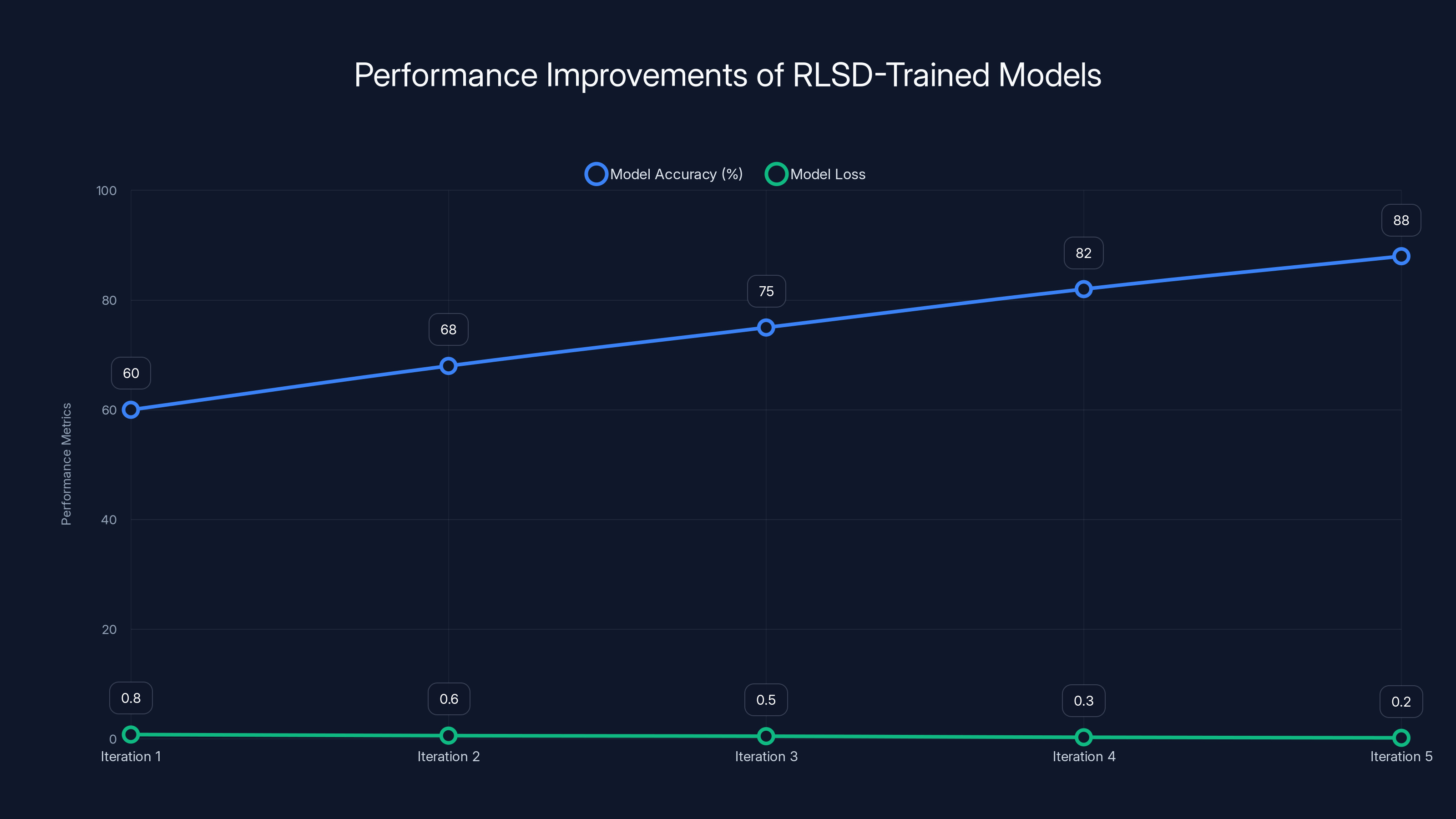
The chart shows estimated improvements in model accuracy and reduction in loss over five training iterations using RLSD. Estimated data.
The Challenge of Building Reasoning Agents
Building reasoning agents requires significant computational resources, which can be a barrier for small to medium enterprises. Traditional approaches often involve either distilling knowledge from large, complex models or employing reinforcement learning, both of which demand high computational power.
Why Compute Matters
Compute power directly influences the speed and efficiency of training AI models. More compute allows for faster iterations and testing of complex models, enabling more nuanced and powerful reasoning capabilities. According to Brookings, the demand for compute resources is a critical factor in AI development.
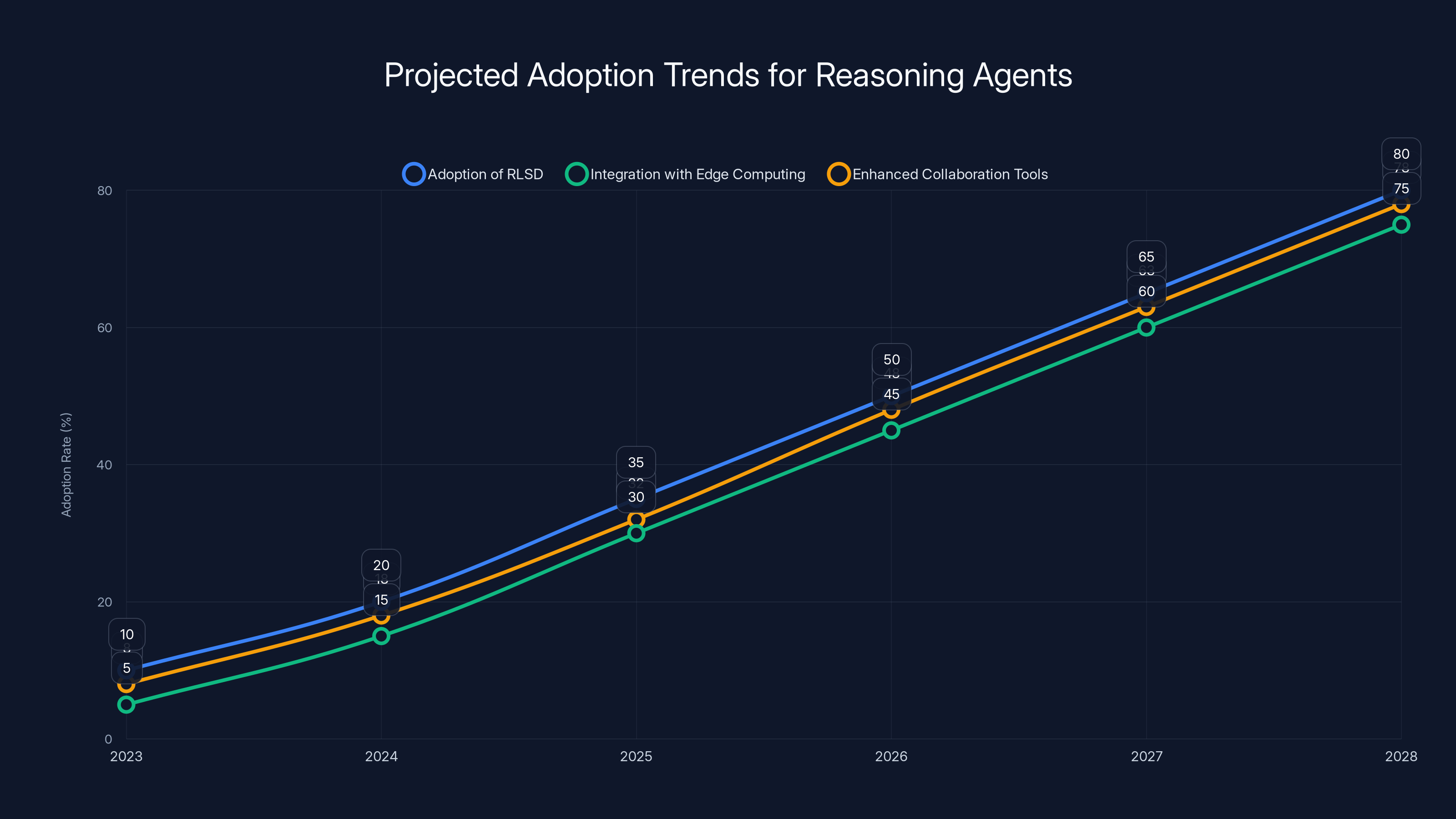
The adoption of RLSD, integration with edge computing, and enhanced collaboration tools are projected to significantly increase by 2028. (Estimated data)
Introducing RLSD: A Game-Changing Approach
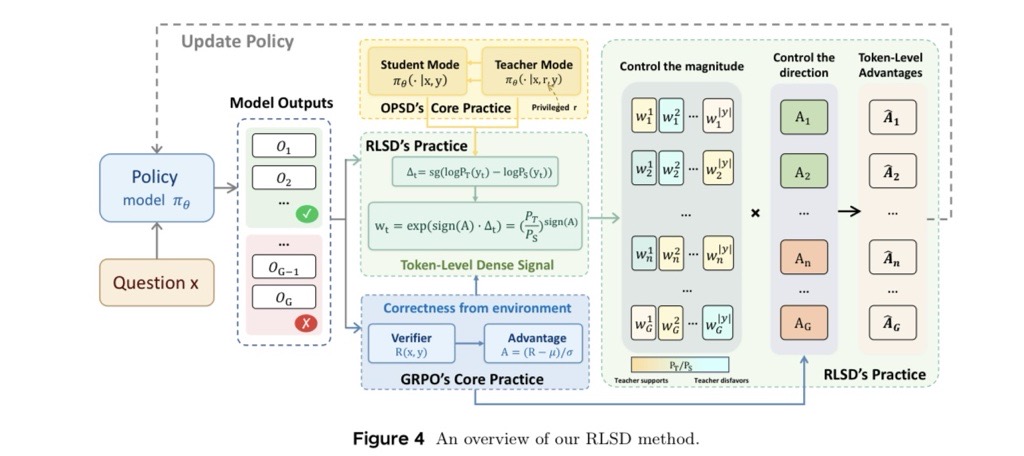
Reinforcement Learning with Verifiable Rewards with Self-Distillation (RLSD) is a new paradigm that combines the robust feedback mechanisms of reinforcement learning with the efficiency of self-distillation.
How RLSD Works
RLSD leverages the strengths of both reinforcement learning and self-distillation to optimize model training. It uses verifiable rewards to ensure that the feedback provided during training is reliable, thus reducing the need for extensive computation.
Key Features of RLSD
- Efficient Feedback: Uses granular feedback for more precise adjustments.
- Verifiable Rewards: Ensures feedback is based on performance metrics.
- Self-Distillation: Simplifies the model without sacrificing accuracy.
Practical Implementation Guide
Step 1: Setting Up Your Environment
Before diving into RLSD, ensure your development environment is ready. This includes having the necessary libraries installed and a basic understanding of reinforcement learning frameworks like TensorFlow or PyTorch.
bash# Install essential libraries
pip install tensorflow
pip install torch
Step 2: Designing Your Model Architecture
Start with a simple model architecture. RLSD works best when you have a clear understanding of the problem domain and the types of reasoning tasks your agent needs to perform.
pythonimport torch.nn as nn
class ReasoningAgent(nn.Module):
def __init__(self):
super(ReasoningAgent, self).__init__()
self.layer1 = nn.Linear(10, 50)
self.layer2 = nn.Linear(50, 10)
def forward(self, x):
x = nn.functional.relu(self.layer1(x))
return self.layer2(x)
Step 3: Implementing the RLSD Algorithm
Integrate RLSD into your model training loop. Focus on setting up verifiable rewards and incorporating self-distillation techniques.
python# Pseudo-code for RLSD integration
for episode in range(num_episodes):
state = env.reset()
for t in range(max_steps):
action = select_action(state, model)
next_state, reward, done, _ = env.step(action)
verifiable_reward = verify_reward(reward)
update_model_with_self_distillation(model, state, action, verifiable_reward)
state = next_state
if done:
break
Step 4: Testing and Iterating
After implementing RLSD, test your model thoroughly. Use a combination of synthetic and real-world data to evaluate performance.
Tips for Effective Testing
- Use a diverse dataset to ensure robustness.
- Monitor performance metrics regularly.
- Adjust hyperparameters based on feedback.
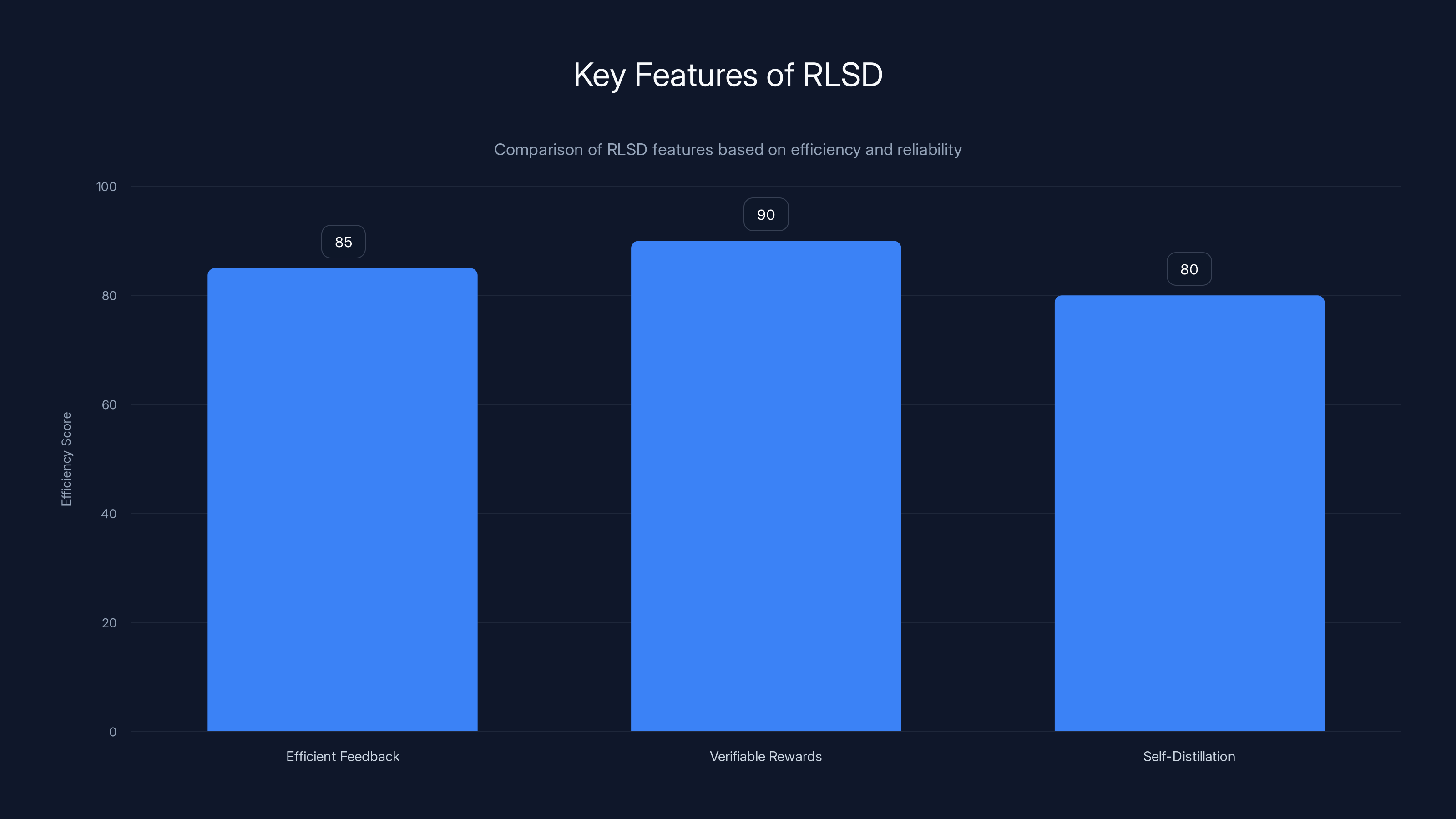
RLSD combines efficient feedback, verifiable rewards, and self-distillation, achieving high efficiency and reliability scores. Estimated data.
Common Pitfalls and Solutions
Pitfall 1: Inadequate Reward Verification
Without a robust system for verifying rewards, your model may learn incorrect behaviors. Ensure your reward system is well-defined and aligned with your objectives.
Solution: Develop a Comprehensive Reward System
Integrate domain-specific knowledge into your reward system to provide accurate and relevant feedback.
Pitfall 2: Overfitting to Training Data
RLSD can sometimes lead to overfitting, especially if the training data isn't diverse.
Solution: Use Data Augmentation Techniques
Augment your dataset with varied examples to prevent overfitting and enhance the generalization of your model.
Future Trends in Reasoning Agents
Trend 1: Increased Adoption of RLSD
As more companies recognize the benefits of RLSD, expect wider adoption across industries. This method not only reduces compute costs but also accelerates the development of reasoning agents, as noted in recent reports.
Trend 2: Integration with Edge Computing
Combining RLSD with edge computing will enable real-time reasoning on devices with limited resources.
Trend 3: Enhanced Collaboration Tools
AI-powered collaboration tools will integrate reasoning agents to facilitate smarter decision-making processes.
Conclusion
Building custom reasoning agents with minimal compute is no longer just a dream. By leveraging RLSD, companies can develop powerful AI models that are both efficient and cost-effective. As technology continues to evolve, keeping an eye on emerging trends and adapting to new methodologies will be crucial for staying ahead in the AI landscape.

FAQ
What is RLSD?
RLSD, or Reinforcement Learning with Verifiable Rewards with Self-Distillation, is a training paradigm that combines reinforcement learning's performance tracking with the detailed feedback of self-distillation.
How does RLSD reduce compute requirements?
RLSD optimizes model training by using verifiable rewards and self-distillation, minimizing the need for large computational resources while maintaining accuracy, as explained in VentureBeat's detailed analysis.
What industries can benefit from RLSD?
Industries such as finance, healthcare, and logistics can benefit from RLSD, as it allows for the development of intelligent systems with lower computational costs.
Are there any limitations to using RLSD?
While RLSD offers many advantages, it requires a solid understanding of both reinforcement learning and self-distillation techniques, which might be challenging for teams without prior experience.
What future developments are expected in reasoning agents?
Future developments include broader RLSD adoption, integration with edge computing, and enhanced collaboration tools, leading to smarter, real-time decision-making capabilities.
How can I start experimenting with RLSD?
Begin by setting up a development environment with reinforcement learning frameworks like TensorFlow or PyTorch. Follow our implementation guide to integrate RLSD into your projects.

Key Takeaways
- RLSD reduces compute needs while maintaining model accuracy.
- Practical implementation of RLSD can lower costs for enterprises.
- Future AI trends include RLSD adoption and edge computing integration.
- Common RLSD pitfalls include reward verification and overfitting.
- RLSD combines the best of reinforcement learning and self-distillation.
Related Articles
- Rethinking AI: The Quest for True Superintelligence [2025]
- Amazon's AI-Powered Audio Q&A: A New Era of Interactive Shopping [2025]
- Trust by Design: Evaluating Trustworthiness in AI Agents [2025]
- The Future of YouTube: Google's AI-Driven Chatbot Search [2025]
- Navigating the AI Workforce Revolution: Lessons from Meta's Layoffs [2025]
- How Google Translate Uses AI to Enhance Your Pronunciation Practice [2025]

