![CX Scores: Building Metrics Support Leaders Can Defend [2025]](https://tryrunable.com/blog/cx-scores-building-metrics-support-leaders-can-defend-2025/image-1-1770660524614.png)
CX Scores: Building Metrics Support Leaders Can Defend [2025]
Here's something that keeps support leaders up at night: they've got a dozen metrics tracking customer satisfaction, but nobody can actually explain why a score moved. The dashboard shows a 12% dip in satisfaction, but when you dig into it, you're staring at an algorithm nobody fully understands, making judgment calls on conversations they didn't see.
This is the core problem with most customer experience metrics. They're treated like black boxes. You feed data in, numbers come out, and then you're supposed to confidently defend those numbers to executives who ask hard questions.
But here's what's changed. AI has gotten good enough that you can actually build metrics that are both accurate and explainable. Not just metrics that work, but metrics that work and you can see exactly why they work. That's the difference between a dashboard your team ignores and a system that actually drives decisions.
The challenge isn't building a metric anymore. Every platform can slap AI on something and call it intelligent. The real challenge is building something trustworthy. Something that aligns with how your best support professionals actually think about quality. Something that handles the messy reality of customer conversations without oversimplifying.
This guide walks through how to build that. We'll cover the five-step framework that separates trustworthy metrics from ones that just look good on a dashboard. We'll dig into why explainability isn't optional, it's foundational. And we'll show you how to create a system that doesn't just measure customer experience, but actually explains it in terms your leadership team can defend.
If you're tired of metrics you don't trust, this is where to start.
TL; DR
- Trustworthy metrics require grounding in expert judgment, not generic AI assumptions about what good customer service looks like
- Explainability is non-negotiable, turning metrics from black boxes into auditable systems leaders can confidently defend
- Statistical validation matters more than gut checks, with explicit performance thresholds (F1 score above 0.8) before any metric ships
- Real-world validation beats lab accuracy, because production environments reveal edge cases that internal testing misses
- Metrics must evolve with your business, staying current as customer expectations shift and your product improves

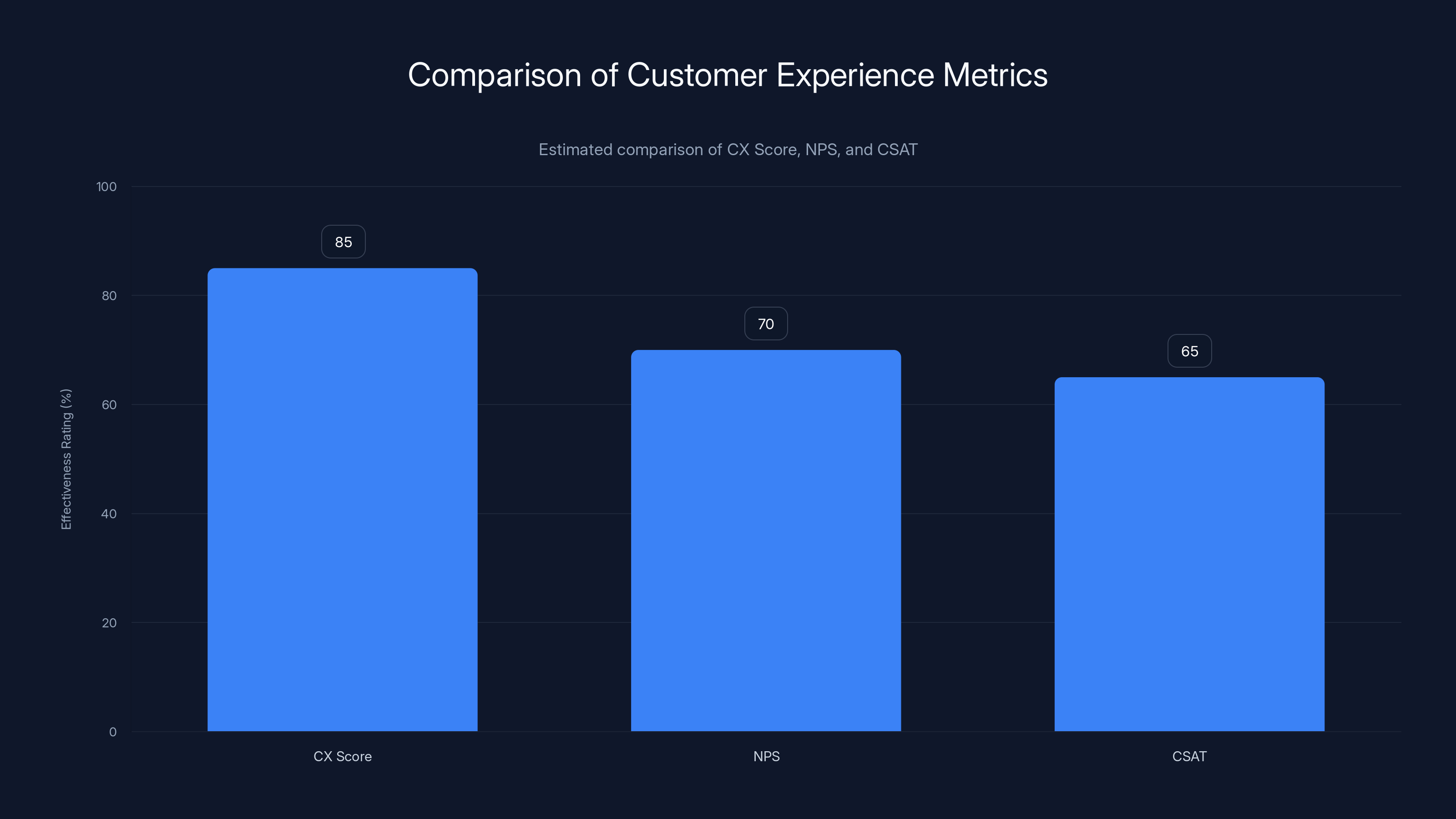
The CX Score is estimated to be more effective than traditional metrics like NPS and CSAT due to its AI-driven analysis and transparency. Estimated data.
The Trust Problem: Why Most CX Metrics Fail
Let's be honest about where we are right now. Most customer service teams have access to metrics. Some have lots of them. NPS, CSAT, effort scores, sentiment analysis, resolution rates, first-response time. The dashboards are slick. The reporting is automated.
But when a director asks, "Why did our score drop?" the answer usually boils down to: "The AI flagged it as negative." That's not an explanation. That's a punt.
The real problem isn't that these metrics are bad. It's that they're opaque. And opacity breeds skepticism. Your support team doesn't trust a number they can't interrogate. Your leadership doesn't trust a number they can't explain to the board. Everyone starts questioning whether the metric is actually measuring what it claims.
There's a name for this in data science: the explainability gap. You can build incredibly accurate models. You can validate them against test sets. You can show ROI. But if nobody understands why the model made a specific decision, trust erodes. People start treating the metric as suspicious rather than useful.
This is especially true in customer service. Support professionals are experts in human interaction. They understand the context, the nuance, the difference between a problem that's technically resolved and a customer who's genuinely happy. When an algorithm makes a judgment call about a conversation, these experts know whether that judgment is right or wrong. If the algorithm gets it wrong too often, or makes decisions that don't pass the smell test, trust tanks.
The cost of that broken trust is real. Teams ignore metrics they don't believe in. They keep using older, simpler measures (like manual spot-checks) that feel more trustworthy. Insights get missed because the system that's supposed to surface them isn't credible. And decision-makers spend time second-guessing the data instead of actually using it.
Building a trustworthy metric starts with acknowledging this gap. It means treating explainability as a first-class requirement, not an afterthought. It means grounding your metric in how actual experts think, not in generic AI assumptions. And it means validating against human judgment every single step of the way.
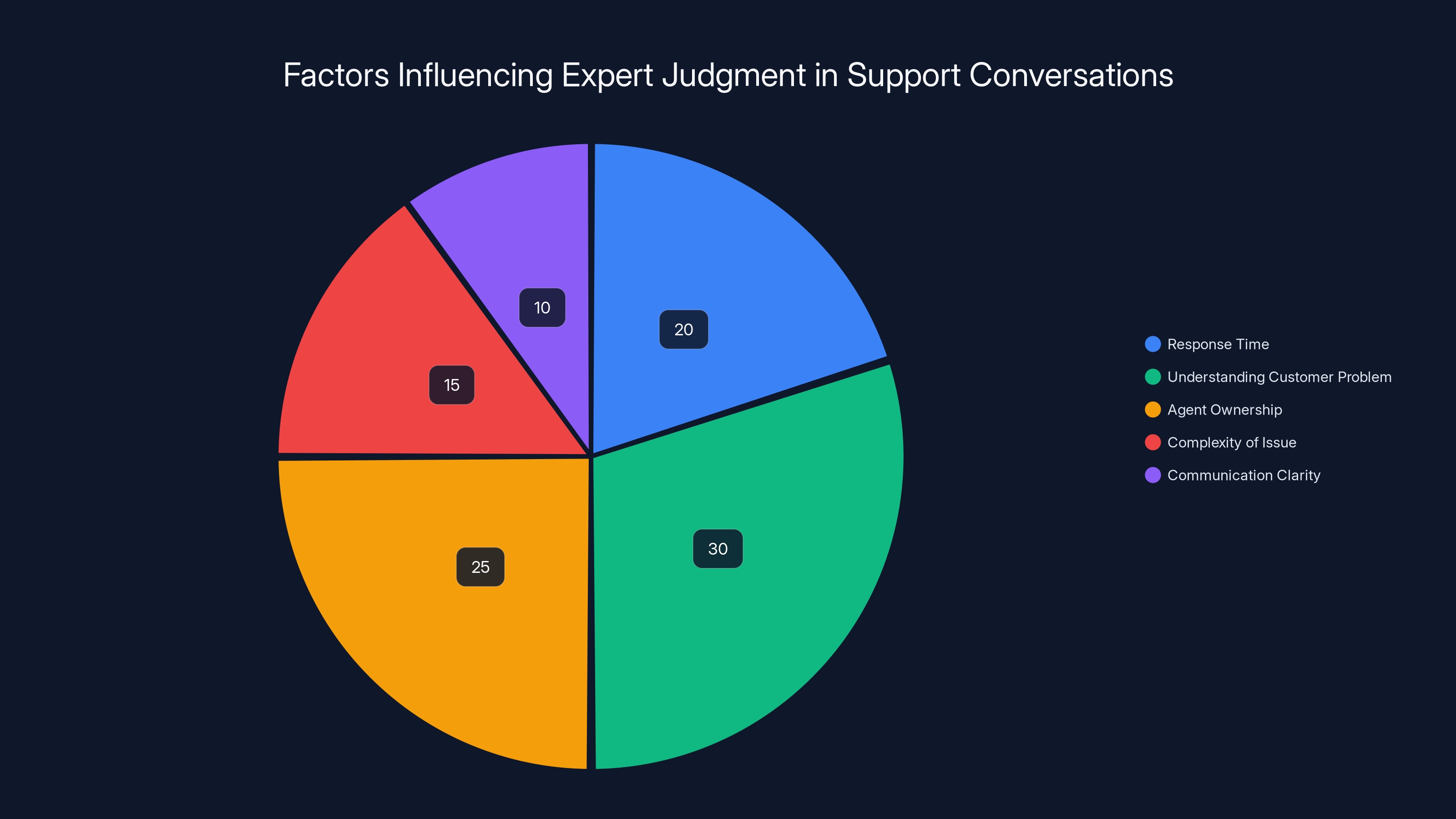
Estimated data shows that understanding the customer's problem is the most significant factor in expert judgment, followed by agent ownership and response time.
Step One: Ground Your Metric in Expert Judgment
This is where most approaches fail. They start with an AI model and try to make it work. Start with people instead.
Your experienced support professionals have spent thousands of hours evaluating conversations. They've developed intuition about what makes an interaction good or bad. They understand subtle signals that generic metrics miss. They know the difference between a technically correct response and a genuinely helpful one.
That expertise is your metric's foundation.
The process starts with collection. Gather real examples of conversations from your actual support environment. Look for conversations your team would rate as excellent, okay, and poor. Get a sample across different industries if you operate in multiple verticals, different communication channels (email, chat, phone), different agent experience levels, and different types of customer issues.
Then bring in those experienced professionals. Have them actually review these conversations and write down the specific factors that influenced their judgment. What made this interaction strong? What felt off about that one? What were the breaking points?
The goal is to identify patterns. Maybe they consistently mention response time as a factor, but only when combined with a complex issue. Maybe they care deeply about whether the agent actually understood the customer's underlying problem, not just the surface complaint. Maybe they notice whether the agent took ownership or punted responsibility.
Once you've identified these patterns, write them down in plain language. Not algorithm-speak. Plain English rules that capture how your experts actually think. "The agent should demonstrate understanding of the customer's underlying problem" is a rule. "Generate sentiment vector from contextual embeddings" is not.
These rules become your metric's decision framework. They're not AI magic. They're codified expertise. When you eventually attach an AI system to these rules, the AI is augmenting human judgment, not replacing it.
The strength of this approach is that it's inherently more trustworthy. When a support leader sees that your metric is built on factors their best people care about, they immediately understand the system better. It's not a black box making mysterious decisions. It's a systematic application of their own professional standards.
Step Two: Validate Against Human Consensus
Grounding in expert judgment gets you started. But intuition alone isn't enough. You need statistical validation.
This is where most teams stumble. They might grab a few conversations and have some people rate them. That's not validation. That's anecdotal. Real validation means scale and consistency.
Here's what actual validation looks like: You build a dataset of thousands of real conversations. These aren't synthetic examples. They're conversations your team actually had with actual customers. You span multiple industries, languages, channels, and agent types. You need diversity because your metric will eventually see diverse conversations.
Then you bring in reviewers. Ideally, experienced support professionals who understand quality in your domain. You have them independently rate conversations according to the rules you established in step one. Here's the crucial part: you use multiple reviewers per conversation. Different people have different perspectives, and consensus matters.
When reviewers disagree (which they will), you have a process to resolve that disagreement. Usually, this involves a third reviewer or a discussion to understand why perspectives differ. The goal is to create stable consensus labels. Not fake consensus where you force agreement, but genuine agreement about what quality actually looks like.
This labeled dataset becomes your ground truth. It's the source against which you'll measure everything else.
The power of this approach is that you're not validating against an abstract standard. You're validating against the accumulated judgment of humans who understand your domain. When your metric agrees with these reviewers, you can be confident it's measuring something real. When it disagrees, that disagreement is a signal to investigate.
The size of this dataset matters more than people realize. With 100 conversations, you might get lucky and find high agreement even with a mediocre metric. With 1,000 conversations across diverse scenarios, you'll see where your metric actually struggles. With 5,000 or more, you're building robust validation that catches edge cases and bias.
This is expensive in time and labor. It's also absolutely worth it. Because everything that comes after depends on this foundation being solid.

Organizations implementing trustworthy metrics see a median 18% improvement in support team efficiency within six months. Estimated data based on industry insights.
Step Three: Use AI Specialists, Not Just AI
Here's a common mistake: treating AI as interchangeable. "We'll use Chat GPT for this," or "We'll fine-tune BERT," as if the tool matters more than the thinking.
For a metric that needs to be trustworthy in production, the expertise that builds the metric matters enormously. There's a difference between someone who knows how to write a good prompt and someone who understands how language models actually behave in high-stakes scenarios.
Production AI for customer service has specific requirements. Conversations can be long and messy, with tone shifts and contradictory statements. Sentiment isn't always obvious, especially in support contexts where a customer might sound frustrated while actually being satisfied with the solution. The cost of false negatives (missing a genuinely bad experience) is much higher than the cost of false positives.
AI specialists understand these constraints. They know how to handle long transcripts without losing crucial context. They understand prompt engineering in ways that make models default to neutral when the evidence is weak, rather than defaulting to judgment calls. They've dealt with edge cases in production and know where models tend to confidently make mistakes.
They also understand the statistical aspects. How to design evaluation pipelines that catch precision issues without missing recall problems. How to test for bias across different agent types, geographies, and customer segments. How to structure the system so that if one component fails, the metric degrades gracefully rather than becoming completely unreliable.
This isn't about gatekeeping. It's about recognizing that building trustworthy AI systems requires deep expertise. A support leader shouldn't need to understand neural network architecture to use the metric. But the people building the metric should understand it deeply.
The other benefit: specialists can explain why decisions were made. Why this particular model architecture instead of that one. Why certain training data was included or excluded. What edge cases were discovered and how they were handled. That explainability flows down to your support team.

Step Four: Validate with Explicit Statistical Standards
This is where vibes become rigor.
Let's say you've built a metric, and it seems to make sense. Your support team reviews some scores and agrees with them. That feels good. It's not validation.
Real validation means measurable standards. Standards you set before you start testing. Not standards you adjust afterward to make your metric look good.
The standard metrics come from machine learning evaluation: precision, recall, and F1 score. Here's what they actually mean in the context of CX scoring:
Precision answers: When the metric flags a negative experience, how often do human reviewers agree? If your metric marks a conversation as poor, is it actually poor? High precision means you're not crying wolf. Low precision means your metric is flagging problems that experts would rate as acceptable.
Recall answers: Of all the conversations humans would rate as negative, how many does your metric catch? If an expert sees a bad experience, does your metric see it too? High recall means you're catching genuine problems. Low recall means you're missing issues that matter.
F1 score is the balance between the two. It's the harmonic mean of precision and recall, designed so that you need to do well on both measures, not just one. A system that flags everything as negative will have high recall but terrible precision. A system that almost never flags problems will have high precision but terrible recall. The F1 score catches that tradeoff.
For CX metrics, a reasonable target is F1 above 0.8. That's high agreement with human judgment. Not perfect, but reliably good. You'd set this standard before you start testing, then you measure whether your metric actually meets it.
Here's what that actually looks like: You take a test set of conversations (separate from your training data) and have humans rate them. Then you have your metric rate the same conversations. You compare the results. What percentage agreement do you get? Does that agreement hold across different agent types, languages, channels? Are there particular scenarios where the metric struggles?
You rerun these evaluations through every revision of the metric. If a change makes precision better but recall worse, you know that tradeoff explicitly. If you update your model and performance regresses, you catch that immediately rather than shipping a degraded system.
Special attention should go to false negatives: conversations your metric rates as positive that humans rate as negative. These are hidden problems. A customer might say "thanks for your help" while actually being frustrated about how long it took or that their real issue wasn't addressed. If your metric misses these, you're hiding real problems.
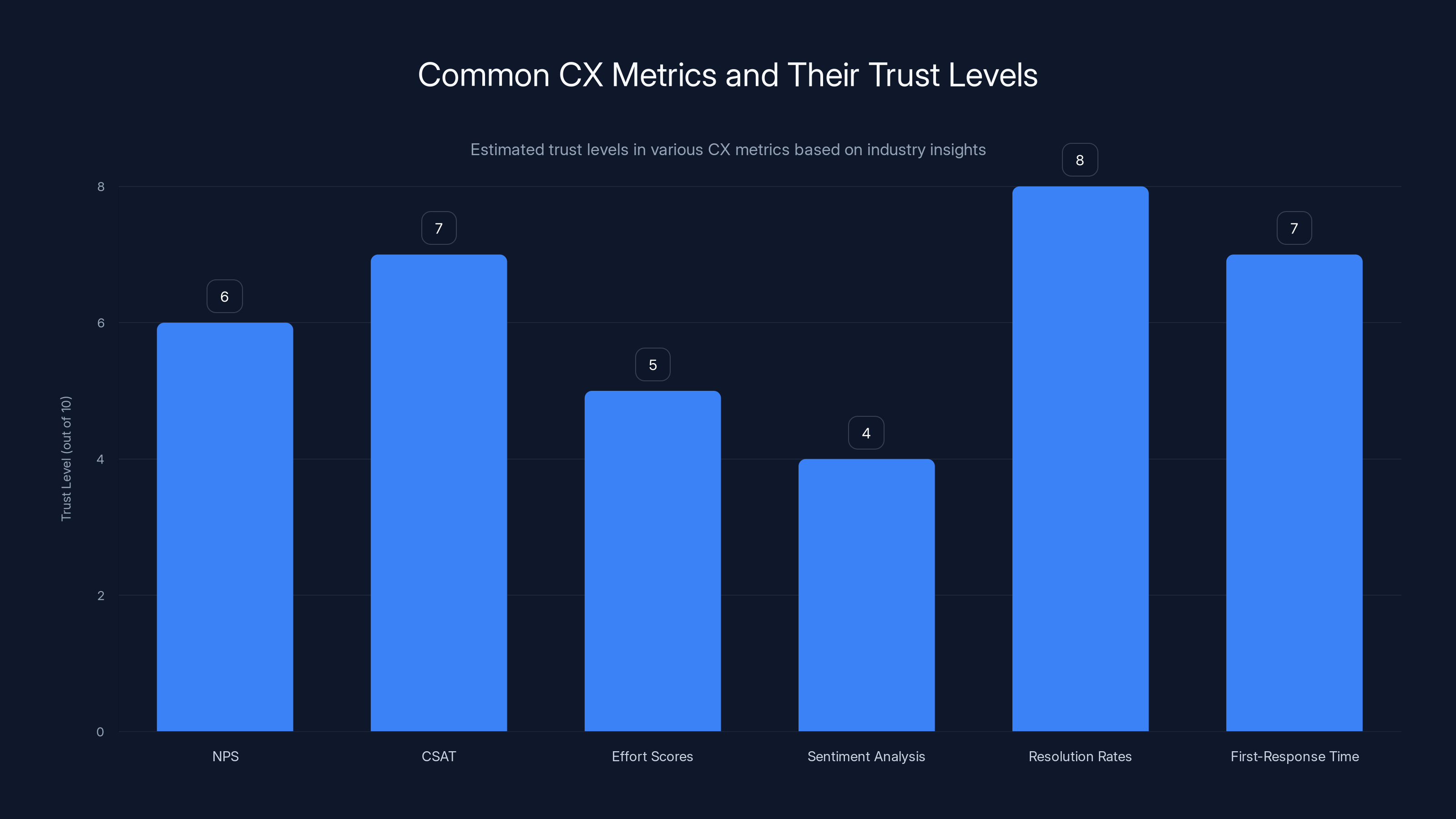
Estimated data shows varying trust levels in CX metrics, with resolution rates and CSAT being more trusted than sentiment analysis. Estimated data.
Step Five: Battle-Test with Real Customers
Lab accuracy doesn't equal production accuracy.
Your metric can pass every statistical test and still fail in the real world. Real customer environments are messier than test sets. There are edge cases you didn't anticipate. There are conversation types you have less training data for. There are regional variations or industry-specific language that behaves differently than your training data.
Before shipping a new metric, run it in parallel with your existing system. Shadow-score conversations with both the old and new metrics. Compare the results. Does the new metric make sense? Do scores seem reasonable? Are the reasons clear?
This isn't just sanity-checking. You're gathering evidence about whether the metric works in practice. You're finding edge cases. You're seeing which conversation types might need special handling. You're getting real feedback from teams who understand the business context better than anyone else.
A robust field test includes:
Shadow scoring across full diversity: Not just cherry-picked examples, but all conversations flowing through your system. Different customers, different issues, different agents, different languages, different channels.
Validation across agent types: A conversation handled by a senior agent and a junior agent might look different even if the outcome is equally good. Does your metric understand those differences?
Verification of edge cases: You'll discover conversation types that behave unexpectedly. Escalations, complex issues, angry customers, situations where there's no perfect resolution. Does your metric handle these sensibly?
Controlled rollout to customer groups: Start with teams you trust to give honest feedback. Not your biggest customers yet, but teams who'll tell you when something feels wrong. Have them use both old and new metrics for a while. Ask directly: Do these scores feel right? Can you understand why conversations got the scores they did? Would you use this to make decisions?
The goal of field testing isn't to prove the metric is perfect. It's to ensure the metric behaves sensibly in practice and that your teams feel confident using it. It's to find the edge cases you'll need to address. It's to build confidence that this metric actually represents what's happening with customers.
Only after this validation do you roll out more broadly. And even then, you keep monitoring. You look for populations where the metric behaves differently. You stay alert to edge cases that emerge over time.

Why Explainability Changes Everything
A metric you can't explain is a metric nobody trusts.
Say your CX score drops from 7.2 to 6.8 across the support team. Your leadership asks why. What do you tell them?
Without explainability, your answer is something like: "The model detected more negative sentiment." That's not an explanation. That's a restatement of the number. Your leadership doesn't know what changed. The support team doesn't know what to improve. And everyone suspects you're hiding behind algorithm opacity.
With explainability, your answer is completely different. You can say: "We saw an increase in conversations where customers expressed frustration about wait times, specifically in our highest-volume region. This happened when we added two new support channels without increasing staffing proportionally. Here are three specific conversations where this pattern shows up." Now your leadership understands what changed. Your support team knows where to focus. And you're not hiding. You're explaining.
Explainability does several things at once:
It enables accountability: When you can show exactly why a score was assigned, you're not asking people to trust a black box. You're showing your work. That transparency builds confidence.
It surfaces edge cases: When you explain why a conversation got a score, you sometimes realize the reasoning doesn't quite make sense. That signals that edge cases need special handling.
It drives action: A score alone tells you something changed. An explanation tells you what to do about it. A conversation flagged as negative with the reason "customer expressed frustration about repeated transfers" is actionable. The support team knows what needs fixing.
It prevents over-interpretation: When you see exactly what the metric is measuring, you understand its limits. You don't treat a sentiment score as a measure of product quality. You see it for what it is: a measure of how customers felt during this interaction.
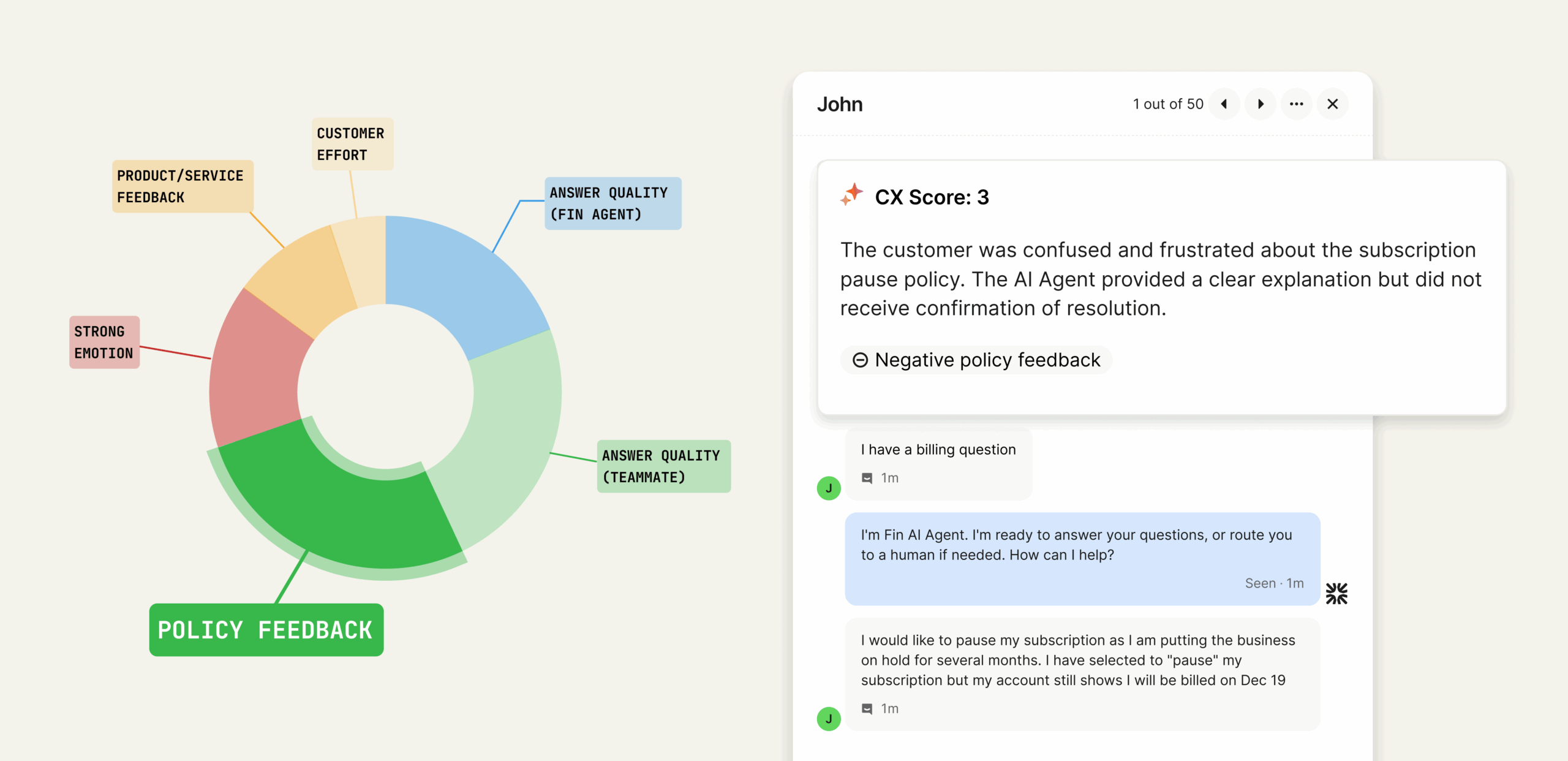
The mechanics of explainability vary depending on your system, but the principle is the same: every score comes with clear reasons. These might be concrete excerpts from the conversation that influenced the score. They might be structured explanations of specific factors. They might be a short summary that a human would write if they were explaining the score.
The key is that the explanation is human-readable and specific. Not "high sentiment negativity score" but "customer used 5 negative emotion words, most while discussing wait time, expressed frustration about having to repeat information to multiple agents." Now a support leader can read that and either agree or identify where the metric's reasoning diverges from expert judgment.
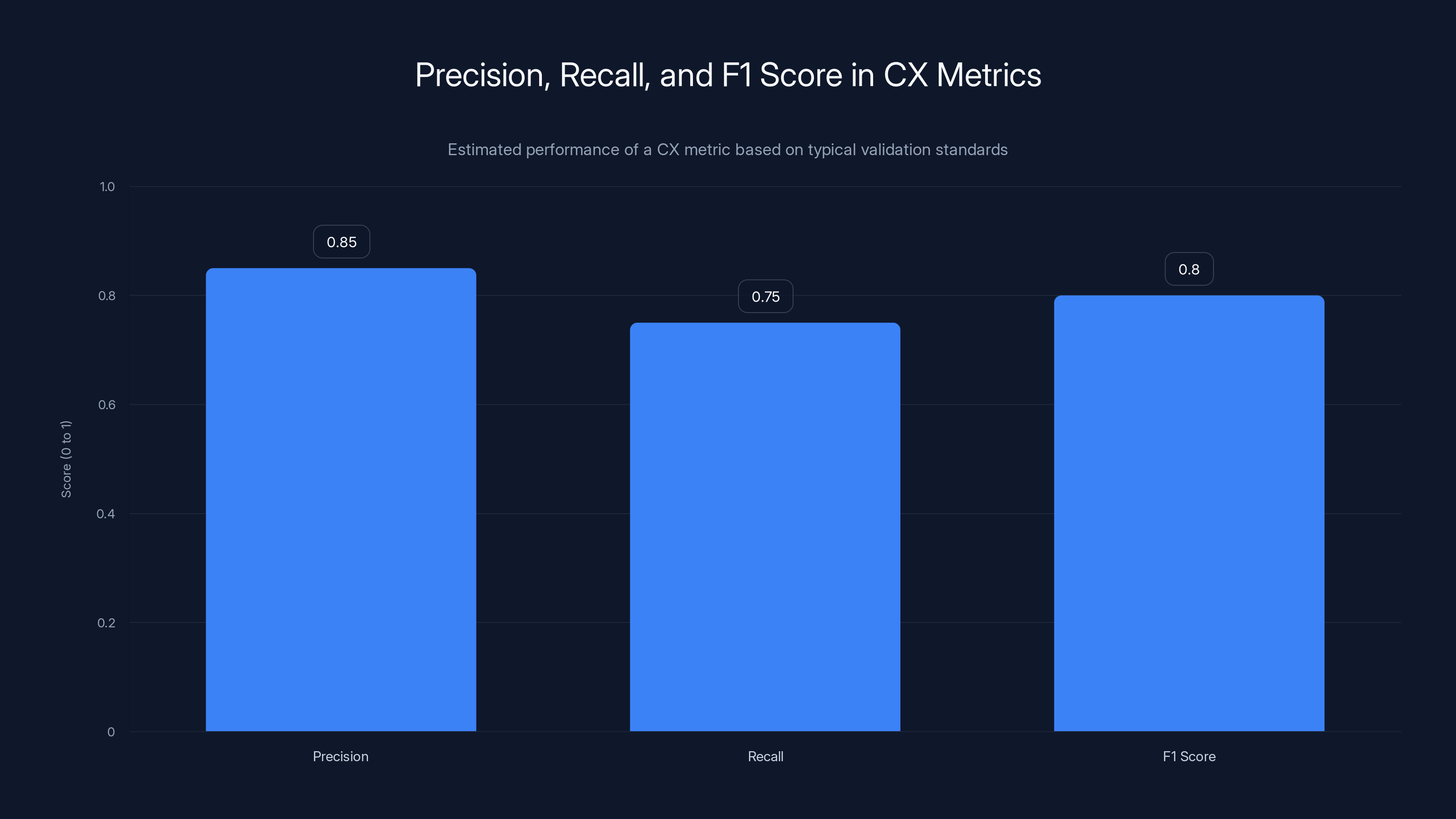
Estimated data shows a CX metric with precision of 0.85, recall of 0.75, and an F1 score of 0.8, indicating a balanced performance with high agreement with human judgment.
Building Metrics That Evolve
Your metric ships, teams use it, and then something changes. Customers' expectations shift. Your product improves. Competitive landscapes change. New communication channels emerge. Your AI system gets better.
A good metric evolves with these changes. A bad one becomes increasingly disconnected from reality.
The question isn't whether your metric will need to evolve. It's whether you've built it in a way that allows evolution.
This means a few things architecturally:
Keep the evaluation logic separate from the implementation: If your metric is hard-coded rules, it's hard to change. If your metric is a system built on clear principles that can evolve, it's easier to update without breaking everything.
Maintain continuous validation: Don't just validate your metric at launch. Keep running validation on a subset of conversations. Are you still getting good agreement with human judgment? Are there scenarios where you're starting to drift?
Build feedback loops with your teams: Your support professionals will notice patterns in the metric's behavior over time. They'll see edge cases. They'll understand when the metric stops making sense. Create channels for that feedback and take it seriously.
Version your improvements: When you update your metric, do it deliberately and validate the update. You're not continuously tinkering. You're making intentional improvements with evidence that they're improvements.
Communicate evolution clearly: When your metric changes, explain what changed and why. Don't pretend it's the same metric. Be transparent that you've improved it based on what you learned.
The risk of not building for evolution is that your metric becomes stale. It measured something real when you built it, but business changed and the metric didn't. Teams notice the metric doesn't match reality anymore. And your trustworthy metric becomes untrustworthy.
Building for evolution means expecting change and designing the system to handle it. That's the difference between a metric and a metric system.

Overcoming Common Implementation Challenges
Building trustworthy metrics is straightforward in theory. It gets messier in practice.
Here are the challenges that trip up most teams:
Getting sufficient labeled data: Building the ground truth dataset takes time and resources. You need experienced people reviewing conversations. You need enough diversity in your data that you're validating across meaningful variation. And you need to do this before you can properly train or validate anything. Teams often underestimate this and try to move forward with inadequate data. The cost is that everything built on that data is less trustworthy. Solution: Invest in labeling upfront. It feels slow. It's the fastest path to a trustworthy metric.
Disagreement among reviewers: Real humans don't perfectly agree about quality. Sometimes that disagreement is valuable, surfacing legitimate different perspectives. Sometimes it's just noise. You need a process to distinguish between them and resolve disagreement systematically. Solution: Have explicit resolution protocols. Use a third reviewer or discussion-based resolution. Track where disagreement clusters—that often signals where your metric should be more careful.
Handling region or language variation: Your ground truth dataset might be mostly in English, but you operate globally. Your metric might work great for one industry but miss patterns in another. Solution: Ensure your labeled data reflects your customer diversity. Test explicitly across regions and languages. Don't assume your metric works everywhere just because it works somewhere.
Balancing false positives and false negatives: You can't have both perfect precision and perfect recall. You have to choose which matters more. False positives (marking something good as bad) are embarrassing. False negatives (missing something bad) hide real problems. Solution: Explicitly choose your tradeoff based on business impact. If missing problems costs more than false alarms, optimize for recall. If false alarms undermine trust in the metric, optimize for precision. Be explicit about the choice.
Keeping the system maintainable: Metrics can get complicated quickly. You add special logic for escalations, another layer for handling certain languages, a separate model for chat vs. email. Before long, nobody understands the whole system. Solution: Fight complexity. Keep the core metric simple and interpretable. Special cases should be exceptions, not rules. If you need lots of special logic, you might need a different core approach.
Getting adoption despite healthy skepticism: Even a trustworthy metric faces adoption challenges because people are naturally skeptical of new systems. Solution: Transparency and involvement. Show your work. Involve the teams that'll use the metric in testing and validation. Make the metric's reasoning visible. And accept that adoption takes time. Teams need to build confidence.

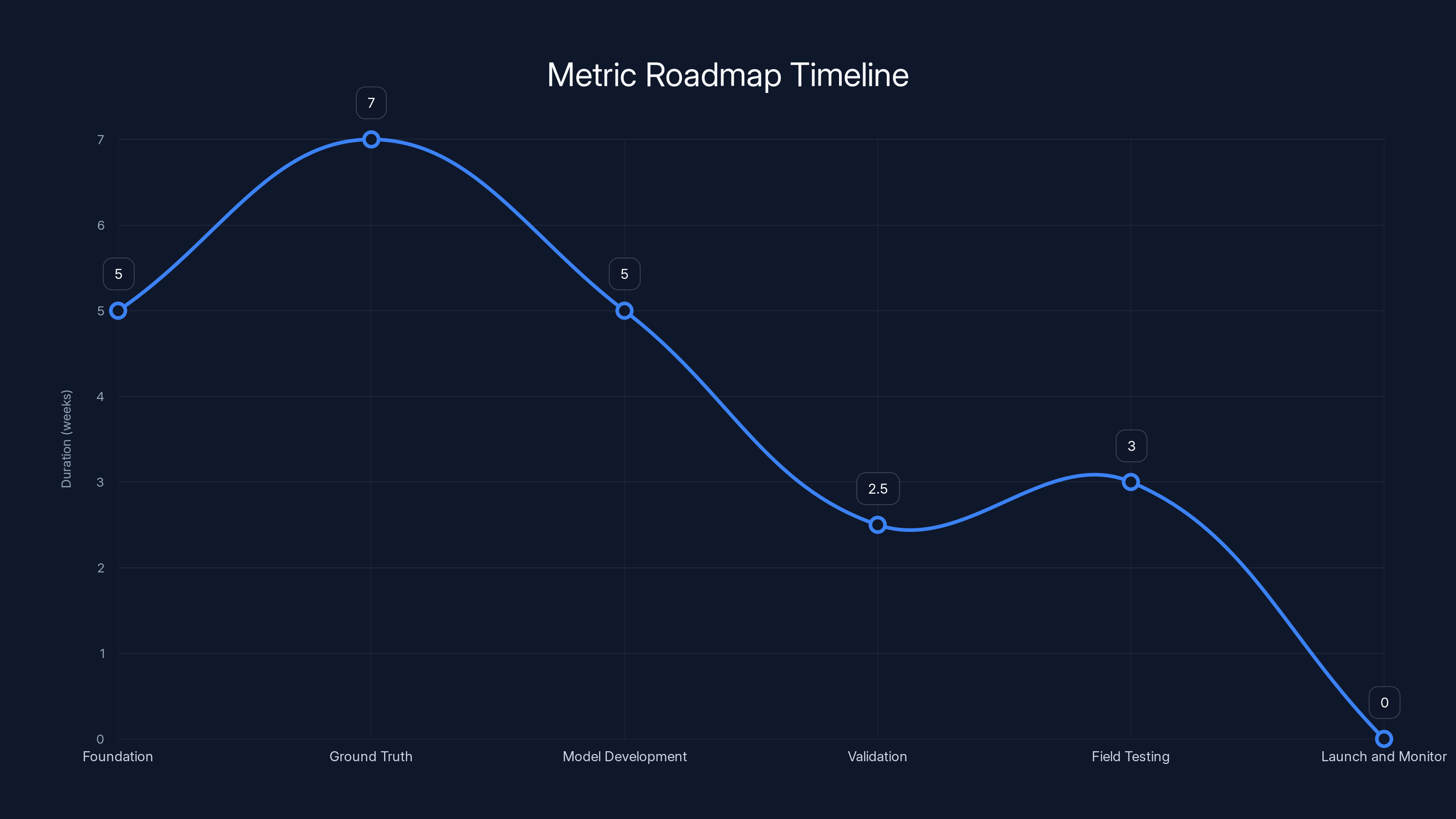
The roadmap for creating a metric system spans approximately 3-4 months, with each phase having a specific focus and duration. Estimated data based on typical project timelines.
The Business Case for Trustworthy Metrics
Building a trustworthy metric requires investment. You need to spend time on foundational work. You need expertise you might not have in-house. You need to be disciplined about validation. You need to resist the temptation to ship something that looks good but isn't rigorous.
Why bother?
Because trustworthy metrics change decision-making. When your leadership actually believes a number, they use it differently. Instead of arguing about whether the metric is right, you're arguing about what to do with the information. That's a completely different conversation.
Trustworthiness also changes internal dynamics. Your support team stops dismissing metrics as noise and starts using them to drive improvement. Scores feel fair because they're explainable. The team understands what influences scores and what they can control. That drives behavioral change in ways that untrustworthy metrics never do.
At scale, that's significant. A support organization that actually believes in and uses its metrics has better visibility into what's happening with customers. It makes smarter decisions about where to focus. It can explain performance to leadership clearly. And it can correlate metric improvements with business outcomes, which creates a genuine data-driven culture.
The ROI comes from decision quality. Better visibility plus better decisions plus team alignment. That's not something you measure as "metric ROI." You measure it as improvement in customer satisfaction, reduction in churn, faster issue resolution, or whatever actually matters to your business.

Creating Your Metric Roadmap
You're convinced trustworthy metrics matter. How do you actually build one?
Start small. You don't build a complete metric system covering every aspect of customer experience. You pick one area—maybe conversation sentiment, or resolution quality, or some combination—and build something trustworthy in that area.
Here's a realistic roadmap:
Phase 1: Foundation (4-6 weeks) Collect examples of conversations across the range of quality. Bring in your best support professionals and extract the factors they use to evaluate quality. Write these down as plain-language rules. You've now got your evaluation framework.
Phase 2: Ground Truth (6-8 weeks) Label 500-1000 real conversations using your evaluation framework. You want at least two reviewers per conversation. Where they disagree, resolve the disagreement. Now you've got your validation dataset.
Phase 3: Model Development (4-6 weeks) Work with AI specialists (internal or external) to build a system that learns from your ground truth data. The system should score conversations according to your framework and explain its reasoning. Focus on making sure the system is interpretable, not just accurate.
Phase 4: Validation (2-3 weeks) Test your model against held-out test data. Measure precision, recall, and F1. Test across different agent types, languages, channels. Where it struggles, understand why.
Phase 5: Field Testing (2-4 weeks) Shadow-score real conversations. Get feedback from support teams about whether the scores feel right and the reasoning is clear. Make adjustments based on feedback.
Phase 6: Launch and Monitor (ongoing) Start using the metric with your teams. Keep monitoring agreement with human judgment. Be ready to iterate.
Total time: 3-4 months from start to launch. That's longer than just plugging a general AI system into your data. It's significantly faster than you'd need if you tried to build this from scratch.
The investment in this roadmap compounds. After you've built one trustworthy metric, building the next one is faster. You've got processes. You've got labeled data. You've got expertise. Your third metric takes half the time of your first.
Integrating Trustworthy Metrics into Your Workflow
You've built a trustworthy metric. Now what?
Integration is where many teams stumble. A metric only matters if people actually use it. And people use metrics when they trust them, understand them, and see them connected to decisions they care about.
Start with your leadership. Show them the metric. Show them the reasoning. Show them how to interpret it. Make sure they understand what the metric measures and what it doesn't. A metric that measures conversation sentiment shouldn't be confused with a metric of product quality. A metric that measures issue resolution shouldn't be confused with agent helpfulness. These are different things.
Show your support teams next. Have them review scored conversations. Ask whether they agree with the scores. Ask whether the explanations make sense. Let them identify edge cases. Their feedback isn't just validation. It's building buy-in. When a support manager sees that her team's concerns are taken seriously and the metric is adjusted accordingly, she becomes an advocate rather than a skeptic.
Then connect the metric to workflows that matter. If you're measuring resolution quality, connect it to coaching workflows. If you're measuring sentiment, connect it to escalation processes. Make the metric actionable. A metric sitting in a dashboard nobody looks at is worse than useless. It's misleading because it suggests you're paying attention to something you're not.
Create routines around the metric. Weekly reviews of trends. Monthly deep-dives into patterns. Quarterly discussions with leadership about what the metric is telling you and what to do about it. Routines turn metrics from novelties into tools.
And stay transparent about the metric's limitations. It measures something specific. It doesn't measure everything. It might miss edge cases. Acknowledge these limits and be clear about what the metric is good for.
Common Mistakes to Avoid
Trustworthy metrics fail when teams make predictable mistakes:
Skipping the expert judgment phase: Starting with AI instead of starting with people. You end up with a metric that's technically accurate but doesn't match how your team actually thinks. The gap between metric and reality erodes trust immediately.
Under-labeling ground truth data: Trying to validate a metric with too little human-reviewed data. You think you found agreement when really you just haven't found enough edge cases yet. Solution: Budget time and resources for proper labeling.
Setting targets after testing: Deciding what good looks like after you've seen how well your metric performs. That's not validation. That's confirmation bias. Set targets upfront.
Deploying without field testing: Shipping a metric that passes lab tests but hasn't been used by real teams in real scenarios. Real environments reveal problems that test sets miss. Solution: Always do field testing before broader rollout.
Neglecting explainability: Building an accurate metric that nobody can understand. Accuracy without explainability is just a different kind of black box. Solution: Treat explainability as a core requirement, not an add-on.
Over-complicating the metric: Adding special logic and exceptions until the system becomes unmaintainable and nobody understands what it's actually measuring. Solution: Keep it simple. If you need lots of special cases, rethink the core approach.
Ignoring human feedback: Shipping a metric you believe in despite persistent skepticism from the teams that'll use it. Solution: Listen to your users. They understand the business context you might not.
Assuming static metrics work forever: Shipping a metric and not updating it as customer expectations, products, and languages evolve. The metric becomes stale and loses trustworthiness. Solution: Build for evolution from the start.
Future Evolution: What's Coming Next
Trustworthiness in customer experience metrics isn't solved. It's evolving.
A few trends are worth watching:
Multimodal evaluation: Right now, most metrics focus on text conversations. The future will include voice, video, written content, and interaction patterns. Evaluating holistically is more complex but also more accurate to how customers actually experience service.
Dynamic thresholds: Rather than a fixed number representing "good," metrics might adapt based on context. A longer resolution time might be acceptable for a complex issue but not for a simple question. Dynamic thresholds are harder to explain but more nuanced.
Real-time feedback loops: Current metrics look at conversations after they're finished. The future likely involves real-time guidance for agents during conversations. That requires explainability to be even more important—an agent needs to understand why the system flagged something as it's happening.
Causal reasoning: Moving beyond "this conversation has negative sentiment" to "this agent's pause time is causing customer frustration." Identifying root causes rather than just symptoms.
Privacy-preserving metrics: As regulations around customer data get stricter, building metrics that work with increasingly limited access to personal information. Harder to do, but necessary.
Cross-organizational benchmarking: Right now, metrics are typically org-specific. The future might include ability to understand how your metrics compare to others, while respecting privacy. That requires standardization around what trustworthy metrics look like.
The thread through all of these: explainability and validation remain foundational. As metrics get more sophisticated, the need to understand why they work becomes even more critical.
Building a Metric Culture
Ultimately, this isn't about building a single metric. It's about building a culture where metrics are trusted tools rather than noise.
That culture starts with a few principles:
Metrics serve clarity, not judgment: The metric isn't saying your team is good or bad. It's providing information that helps you understand what's happening with customers. That distinction matters for how people receive metrics.
Explainability is non-negotiable: Any metric your organization uses should be something you can explain and defend. If you can't do that, don't use it.
Validation is rigorous: You measure agreement with human judgment. You test across diversity. You set standards upfront and measure against them. Vibes aren't validation.
People come first: Metrics serve your people, not the other way around. The metric should help your team do their job better, not create anxiety or punishment.
Evolution is expected: Metrics change as your business changes. That's normal. Plan for it.
When you build a culture around these principles, metrics become powerful tools. They drive clarity. They enable smarter decisions. They help teams understand what they're doing well and where to improve. They connect individual work to customer outcomes.
That's the promise of trustworthy metrics. Not perfect accuracy. Not predicting the future. But a reliable, explainable way to understand what's happening with your customers and where you should focus.
FAQ
What exactly is a CX score and how is it different from traditional customer satisfaction metrics?
A CX score is an AI-driven evaluation of individual customer conversations that attempts to measure overall experience quality in that specific interaction, complete with explanations for why each conversation received its rating. Unlike traditional metrics such as NPS or CSAT that rely on customer surveys, CX scores evaluate conversations directly by analyzing what actually happened, what was said, and how the issue was resolved. The key difference is that trustworthy CX scores are grounded in expert judgment about what quality looks like, validated against human consensus, and transparent about their reasoning rather than existing as black boxes.
How do you ensure an AI-based CX metric doesn't reflect algorithmic bias or hidden assumptions?
Trustworthiness starts with grounding the metric in explicit human expertise rather than generic AI assumptions. You collect diverse examples of conversations, have experienced professionals define what quality looks like, and then build rules based on those explicit factors. You validate the metric against large, diverse datasets labeled by multiple human reviewers. You test specifically for bias across different agent types, geographies, languages, and customer segments. You maintain explainability so biases become visible—if a metric consistently scores interactions differently based on geographic region, that becomes apparent and you can investigate and fix it. Finally, you keep monitoring the metric in production to catch biases that emerge over time as your customer base evolves.
What's the minimum amount of human-labeled data needed to build a trustworthy CX metric?
For robust validation, you typically need 500-1000 conversations labeled by experienced support professionals, with multiple reviewers per conversation where possible and disagreement resolution protocols to create stable consensus labels. That's the minimum for meaningful validation. Larger datasets (2000-5000+ conversations) give you better coverage of edge cases, different industries, languages, and conversation types. The specific number depends on your diversity—if you operate in five languages and multiple industries, you'll need more labeled examples to ensure each segment is adequately represented. Under-investing in labeled data is a common mistake that leads to metrics that seem accurate in testing but fail in production because they haven't been validated against sufficient diversity.
How long does it actually take to build and deploy a trustworthy CX metric?
A realistic timeline from concept to launch is 3-4 months, assuming you have access to the right expertise. That includes 4-6 weeks to establish your evaluation framework based on expert judgment, 6-8 weeks to label your ground truth dataset, 4-6 weeks for model development, 2-3 weeks for statistical validation, and 2-4 weeks for field testing with real users before broader rollout. The timeline assumes you have experienced support professionals available to define quality and experienced AI specialists to build the system. If you need to develop that expertise internally or work with external partners, timeline extends. The investment upfront saves time later—your second metric takes half the time, your third even less.
Can you build a trustworthy CX metric without specialized AI expertise?
You can build a good foundational metric by grounding it in expert judgment and validating it rigorously, but creating a production system that's accurate, explainable, and robust across diverse scenarios requires specialized expertise. If you don't have AI specialists in-house, it's worth bringing in external partners specifically for the model development and validation phases. The expertise required includes understanding how language models behave in production, handling long and messy transcripts, managing precision-recall tradeoffs, testing for bias, and designing systems that degrade gracefully when they encounter edge cases. A metric built without this expertise might work in controlled scenarios but fail when exposed to real production complexity.
How do you handle disagreement when multiple people rate the same conversation differently?
Disagreement is normal and often valuable. You need explicit protocols to handle it. One approach is three-reviewer consensus: if two reviewers agree, that becomes the label. If all three disagree or you have only two reviewers who disagree, bring in a fourth reviewer or use discussion-based resolution. The key is that resolution should be systematic, not arbitrary. As you resolve disagreements, you'll often discover specific conversation types that are genuinely ambiguous. Those are places where your metric needs to be more careful—it might need special handling or you might need to acknowledge inherent uncertainty in those scenarios. Track where disagreement clusters because that signals where your metric should pay extra attention.
What does it mean for a CX metric to be "explainable" and why does this matter more than raw accuracy?
Explainability means that every score comes with clear reasons that a human can understand and verify. Rather than just receiving a score, you see exactly what factors influenced that score, often with concrete excerpts from the conversation. It matters more than raw accuracy because a metric you can't explain is a metric nobody can trust, regardless of how accurate it technically is. If a support leader sees that the metric flagged a conversation as negative but can't understand why, they'll either dismiss the metric or spend time second-guessing it. But if they can see the exact factors—specific phrases, response times, patterns of explanation—they can immediately judge whether the reasoning is sound. Explainability also drives better decisions. Rather than just knowing something changed, you understand what changed and what to do about it.
How often should a CX metric be updated or retrained as your business evolves?
You should maintain continuous validation rather than scheduled updates. Monitor a sample of conversations weekly to check whether the metric still shows good agreement with human judgment. When you notice drift—either in overall agreement or in specific conversation types—investigate and iterate. You don't need to retrain constantly, but you should update deliberately whenever you discover the metric no longer aligns with how your team evaluates quality. This might be quarterly, it might be annually, or it might be more frequently depending on how much your business and customer base are changing. The key is active monitoring rather than assuming a metric remains accurate indefinitely. Also plan for major updates when your product significantly changes, when you expand to new geographies or languages, or when you onboard large new segments of customers.
What's the difference between building a trustworthy metric internally versus using a third-party solution?
Building internally gives you complete control and a metric tailored specifically to your business and evaluation standards, but requires significant investment in expertise and infrastructure. You'll have deeper understanding of why the metric behaves as it does and can modify it freely. Using a third-party solution means faster deployment and leveraging specialized expertise, but you're constrained by the vendor's definitions of quality and you need to validate whether their metric aligns with how your team actually evaluates conversations. The best approach often depends on your constraints: if you have available expertise and time, building tailored metrics creates competitive advantage. If you need something quickly and can't sacrifice accuracy, a third-party solution validated carefully might be the right choice. Many organizations use a hybrid approach: starting with a third-party metric for quick wins, then building tailored metrics for areas that are differentiating for your business.
For teams looking to automate their CX metric analysis and reporting, Runable offers AI-powered automation that can help generate comprehensive CX reports automatically. By leveraging Runable's AI agents, you can streamline your metric validation processes, create consistent documentation of your scoring methodology, and generate stakeholder reports that explain your metric framework—all starting at $9/month.
Use Case: Automate generation of weekly CX metric validation reports and stakeholder briefings without manual documentation overhead.
Try Runable For Free
Conclusion: Trustworthiness Is a Choice
Building a metric that your organization actually trusts requires deliberate choices. You choose to ground the metric in expert judgment rather than starting with AI. You choose to validate rigorously rather than moving fast with "good enough." You choose explainability even though it's harder than just returning a score. You choose to keep learning and evolving rather than assuming your metric is done.
These choices cost more upfront. They take longer. They require expertise and discipline. And they result in something exponentially more valuable: a metric that actually drives decisions, that your teams believe in, that surfaces real insights about customer experience.
The alternative is faster but less useful: metrics that look good in dashboards but don't change behavior, that create skepticism rather than clarity, that hide more than they reveal. Organizations often end up abandoning these metrics within months because nobody trusts them.
Trustworthiness isn't something metrics are born with. It's something you build through careful, deliberate design and validation. It's something you earn through transparency and explainability. And it's something that pays dividends far beyond the initial investment.
If you're building customer experience metrics, start with this question: Will my team trust this enough to actually use it? If the answer isn't an enthusiastic yes, keep working until it is. That's the difference between a metric and a metric that matters.
Key Takeaways
- Trustworthy metrics must be grounded in explicit expert judgment, not generic AI assumptions about what good customer service looks like
- Explainability is foundational to trustworthiness—every score should come with clear, auditable reasons that support leaders can verify
- Statistical validation against human consensus (targeting F1 scores above 0.8) is non-negotiable before any metric ships to production
- Field testing with real teams uncovers edge cases that lab validation misses and builds organizational confidence in the metric
- Metrics must evolve with your business, maintaining continuous validation rather than assuming a metric remains accurate indefinitely
Related Articles
- XR Glasses Battery Drain: The $35 Solution That Actually Works [2025]
- Why AI-Generated Super Bowl Ads Failed Spectacularly [2026]
- EcoFlow Delta Pro 3 Home Backup Power System [2025]
- Snapchat Arrival Notifications: Complete Guide to Location Sharing [2025]
- Windows 11 Printer Support: What Microsoft Actually Changed [2025]
- YouTube TV Curated Subscription Packages: Save Money on Streaming [2025]

