![Exploring DSpark: Transforming LLM Inference with Open-Source Innovation [2025]](https://tryrunable.com/blog/exploring-dspark-transforming-llm-inference-with-open-source/image-1-1782767175015.png)
Introducing DSpark: A New Era for LLM Inference
Deep Seek has unveiled DSpark, an open-source framework that promises to revolutionize the way we approach Large Language Model (LLM) inference. With the potential to speed up inference by up to 85%, DSpark is set to become a game-changer in AI development.
TL; DR
- DSpark boosts LLM inference speeds by up to 85%, enhancing AI application performance.
- Open-source and MIT-licensed, making it widely accessible for developers.
- Scouting mechanism predicts text sequences, reducing latency.
- Compatible with major LLMs, offering flexible integration.
- Future trends suggest increased adoption in various AI sectors.
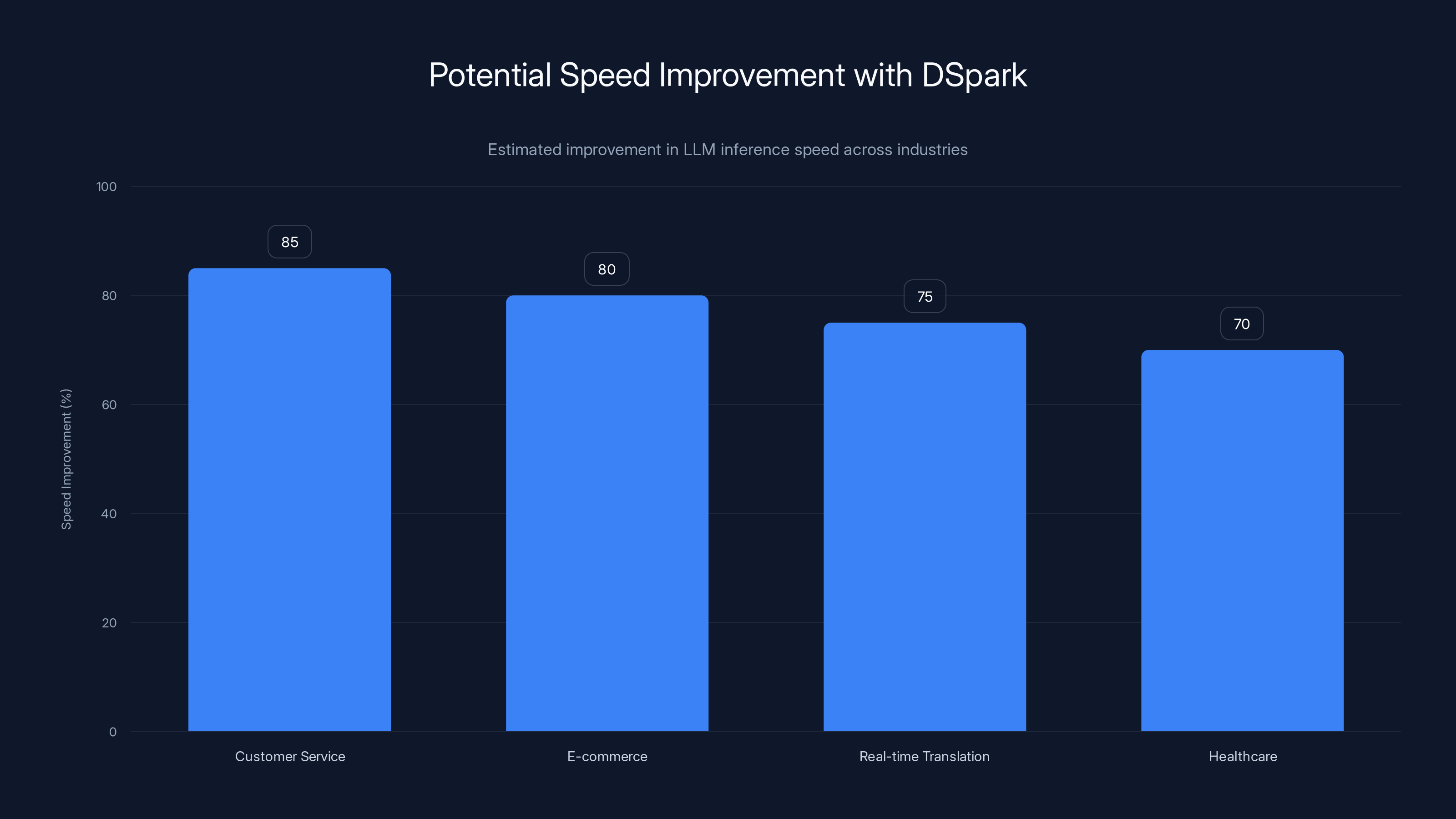
DSpark can enhance LLM inference speed by up to 85% in customer service, with significant improvements in other industries as well. Estimated data.
The Challenge of LLM Inference
Large Language Models have become the backbone of modern AI applications, powering everything from chatbots to content generation platforms. However, the computational demands of these models can be immense, often resulting in slow inference times that limit real-world applicability.
Why Speed Matters
In the fast-paced world of AI, the ability to quickly generate responses can be the difference between success and failure. Slow inference times can lead to:
- Increased latency in applications like real-time translation or voice assistants.
- Higher operational costs, as more computational resources are needed to maintain performance.
- Poor user experience, as delays frustrate end-users.
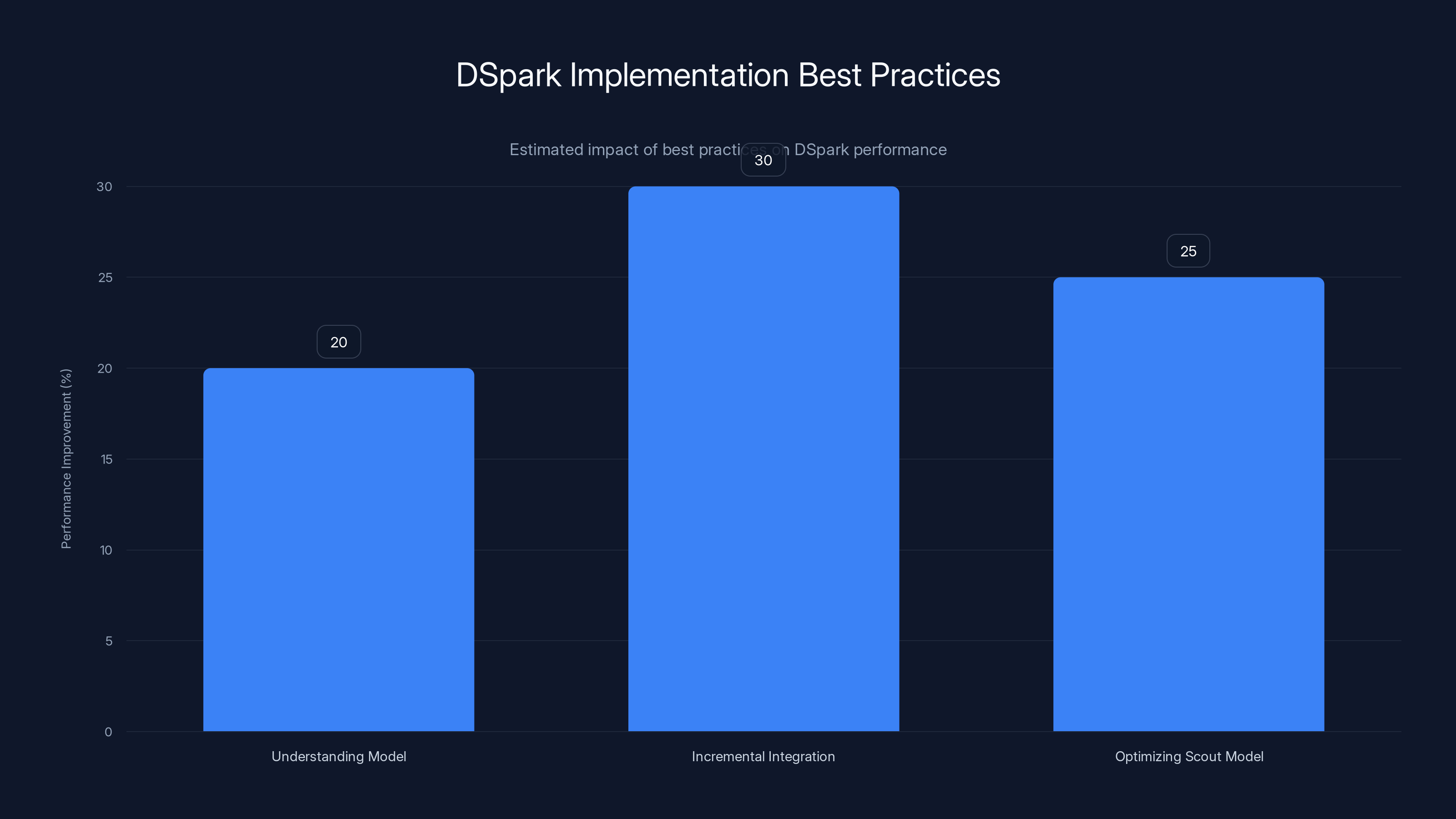
Implementing best practices like understanding your model, incremental integration, and optimizing the scout model can lead to significant performance improvements in DSpark. Estimated data.
Enter DSpark: The Architecture
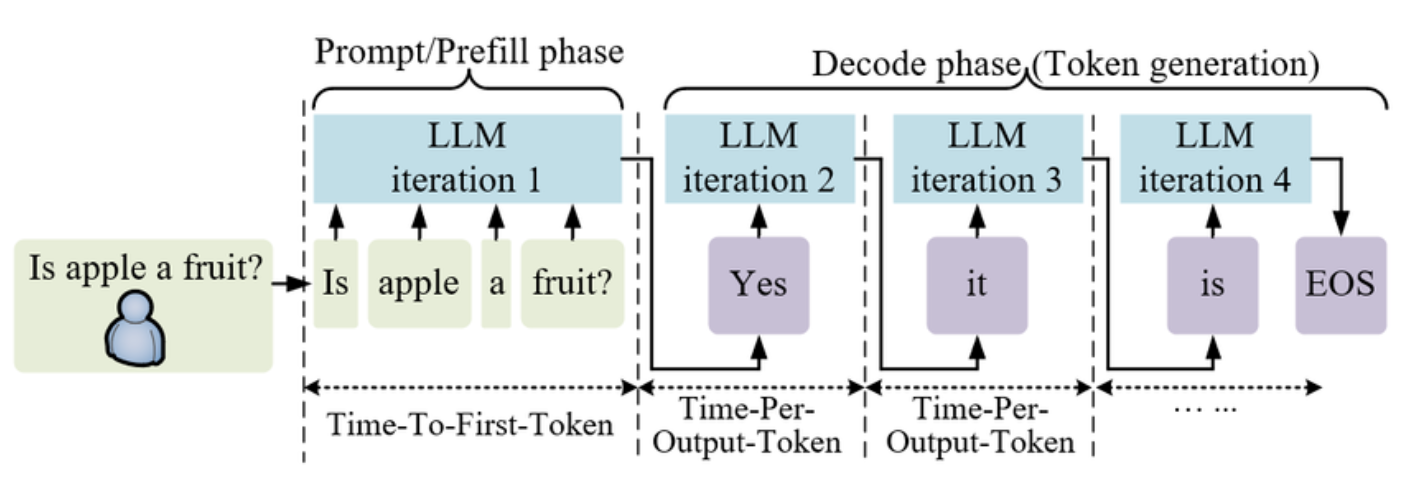
DSpark introduces an innovative approach to LLM inference by integrating a scouting mechanism. This mechanism acts as a predictive layer, running ahead of the main model to anticipate likely text sequences.
How DSpark Works
Unlike traditional inference processes, DSpark employs a dual-path architecture where a lightweight model, the 'scout,' predicts upcoming text sequences. The main model then uses these predictions to streamline its processing.
- Scout Model: A smaller, faster model that predicts potential next steps.
- Main Model: The original LLM that verifies and refines the scout's predictions.

Real-World Use Cases
Enhanced Chatbot Performance
One of the most promising applications of DSpark is in chatbot technology. By reducing inference time, chatbots can deliver more natural and fluid conversations, enhancing user engagement.
- Customer Support: Faster response times can lead to increased customer satisfaction.
- E-commerce: Real-time product recommendations become more feasible.
Real-Time Translation
For applications like real-time translation, DSpark can significantly reduce latency, allowing for more seamless communication across languages.
- Multilingual Meetings: Participants can converse in their native languages without noticeable lag.
- Travel Apps: Tourists can receive real-time translations of local signage and menus.
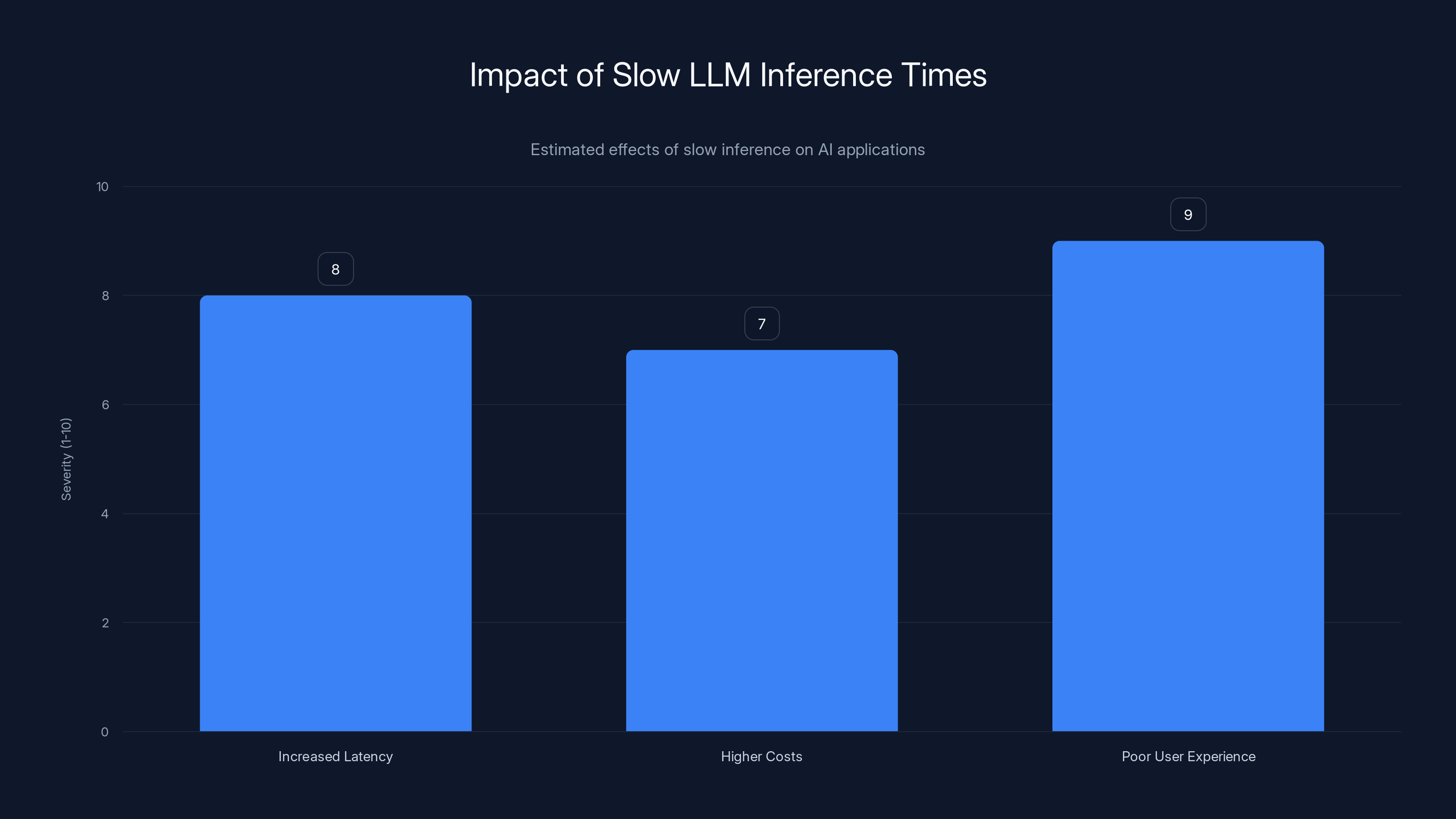
Slow inference times in LLMs significantly impact user experience, latency, and operational costs. Estimated data.
Best Practices for Implementing DSpark
1. Understanding Your Model
Before integrating DSpark, it's crucial to have a deep understanding of your existing LLM. Evaluate its strengths and weaknesses to determine where DSpark's scouting mechanism can provide the most benefit.
2. Incremental Integration
Start by implementing DSpark in a staging environment. Monitor performance improvements and adjust configurations as needed before deploying it in a production setting.
- Benchmark Current Performance: Establish a baseline to measure improvements.
- Gradual Rollout: Deploy DSpark to a subset of your application to ensure stability.
3. Optimizing the Scout Model
To maximize DSpark's benefits, ensure the scout model is finely tuned for your specific use case. This might involve:
- Custom Training: Tailor the scout model to predict patterns specific to your application's domain.
- Resource Allocation: Balance computational resources between the scout and main models for optimal efficiency.
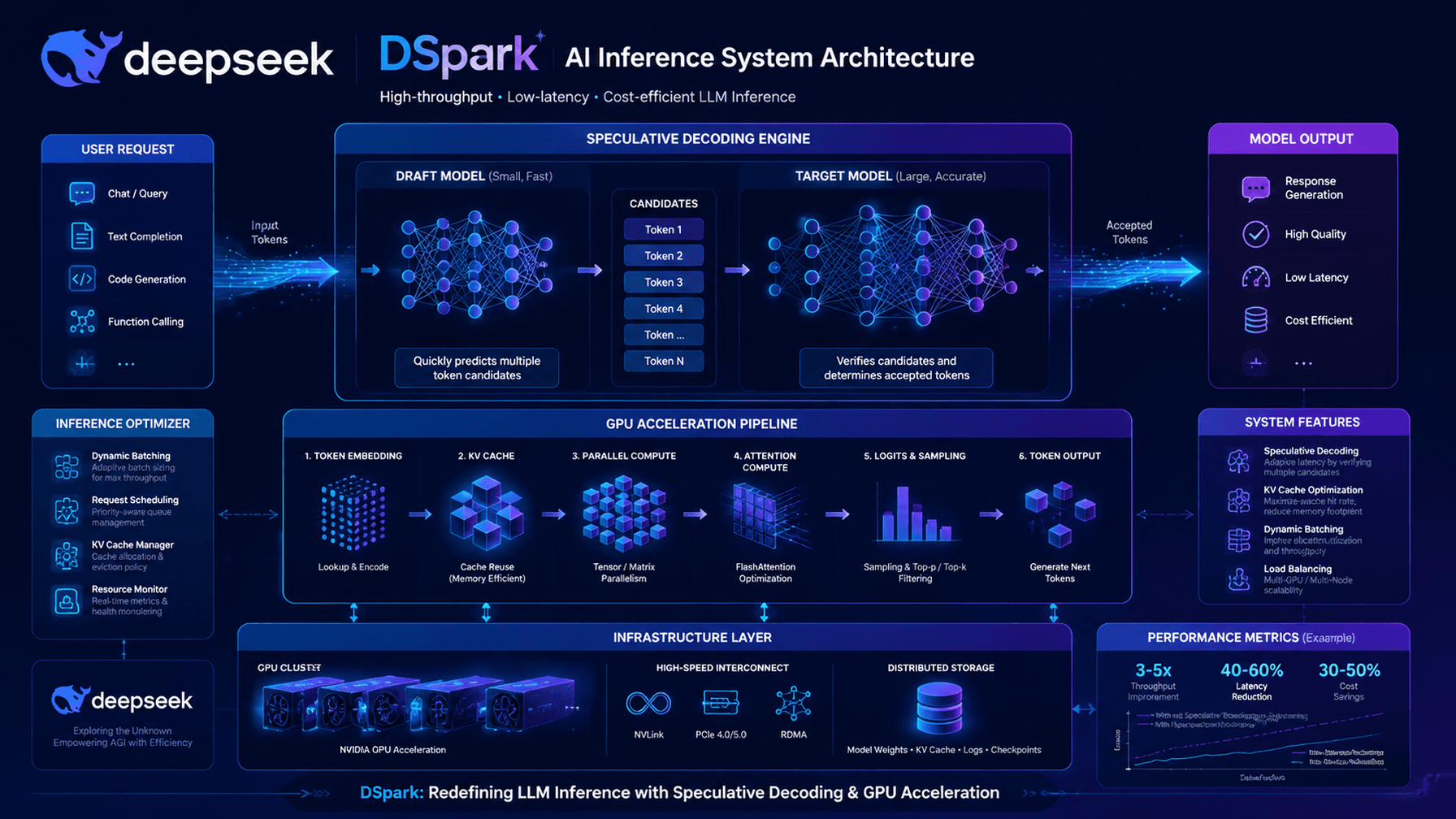
Common Pitfalls and Solutions
1. Over-Reliance on Predictions
While DSpark's scout model can significantly reduce inference times, an over-reliance on its predictions may lead to accuracy issues. Always validate predictions with the main model.
- Solution: Implement thresholds that determine when the main model should override scout predictions.
2. Compatibility Challenges
DSpark is designed to work with major LLM frameworks, but integration can still pose challenges, particularly for custom models.
- Solution: Leverage community resources and forums to address specific compatibility issues.

Future Trends in LLM Inference
With frameworks like DSpark, the future of LLM inference is set to evolve rapidly. Key trends include:
- Increased Adoption of Hybrid Architectures: More developers will adopt multi-model strategies to balance speed and accuracy.
- Expansion into New Domains: As inference speeds improve, LLMs will penetrate new industries like healthcare and finance.
Conclusion: The Road Ahead
DSpark represents a significant leap forward in LLM inference efficiency. By open-sourcing this technology, Deep Seek is empowering developers worldwide to push the boundaries of what's possible with AI.
As you explore DSpark, remember to:
- Leverage community support for integration challenges.
- Continuously monitor performance to maximize benefits.
- Stay informed about ongoing developments in LLM technology.
Use Case: Imagine automating your customer support with AI-driven chatbots that respond instantly. DSpark can make this a reality by drastically reducing response times.
Try Runable For FreeFAQ
What is DSpark?
DSpark is an open-source framework developed by Deep Seek, designed to enhance the inference speed of Large Language Models by up to 85%.
How does DSpark improve LLM inference?
DSpark uses a dual-path architecture with a scout model predicting text sequences ahead of the main model, thus reducing latency.
What are the benefits of using DSpark?
Benefits include reduced latency, improved user experience, and decreased operational costs by optimizing computational resources.
What industries can benefit from DSpark?
Industries such as customer service, e-commerce, and real-time translation can significantly benefit from DSpark's speed improvements.
How do I implement DSpark in my AI projects?
Start by integrating DSpark in a staging environment, optimize the scout model, and gradually roll it out to production.
Are there any compatibility issues with DSpark?
While DSpark is compatible with major LLM frameworks, custom models might face integration challenges, best addressed through community support.
What is the future of LLM inference with DSpark?
The future looks promising with increased adoption of hybrid architectures and expansion into new domains like healthcare and finance.
Where can I find resources to learn more about DSpark?
Check Deep Seek's official documentation and community forums for the latest updates and support.
Key Takeaways
- DSpark enhances LLM inference by up to 85%, improving AI application performance.
- The framework employs a scouting mechanism to predict text sequences, reducing latency.
- DSpark is open-source and MIT-licensed, making it accessible for widespread adoption.
- Compatible with major LLMs, DSpark offers flexible integration for developers.
- Future trends indicate increased adoption of hybrid architectures in AI applications.
- DSpark can significantly benefit industries like customer service and real-time translation.
Related Articles
- Why ChatGPT's Shift from Literal Prompts is Transforming AI Interaction [2025]
- OpenAI's Breakthrough Custom Chip: A Deep Dive into Jalapeño [2025]
- Navigating the Future of AI Music: TIDAL's Stance on Monetization [2025]
- Microsoft 365 Copilot in Excel: Transforming Financial Analysis with AI [2025]
- Amazon's $13B AI Investment in India: A Game-Changer for Cloud Infrastructure [2025]
- British Police Built a Sprawling Crime-Prediction Machine. Some Results Couldn’t Be Trusted | WIRED

