
Introduction: The Handshake-Cleanlab Acquisition and What It Means for AI Data Labeling
The artificial intelligence industry has reached a critical inflection point where data quality has become more valuable than raw data quantity. When Handshake announced its acquisition of Cleanlab in early 2026, the move signaled something profound about how the AI ecosystem views the data labeling problem: automation and algorithmic quality assurance are no longer optional features—they're fundamental to competitive survival.
This acquisition wasn't a traditional purchase of a company with recurring revenue or a specific market position. Instead, it was structured as an acqui-hire of nine key researchers, including three MIT-trained computer scientists who co-founded Cleanlab. Curtis Northcutt, Jonas Mueller, and Anish Athalye had spent years developing breakthrough algorithms for detecting incorrectly labeled data without requiring secondary human review. Their focus on algorithmic auditing of human-generated labels represented a frontier in solving one of AI's most persistent problems: how to ensure that the training data feeding machine learning models actually reflects the ground truth.
Handshake itself had undergone a remarkable transformation. Originally launched in 2013 as a recruitment platform for college graduates, the company had pivoted into human data labeling approximately one year before acquiring Cleanlab. This pivot proved prescient. By 2025, Handshake was generating an annualized revenue run rate of $300 million, with forecasts predicting growth to the "high hundreds of millions" in 2026. The company had become a critical infrastructure player, supplying labeled data to eight of the world's most advanced AI laboratories, including OpenAI.
But generating volume wasn't enough anymore. The AI labs Handshake served were increasingly sophisticated about data quality. They needed guarantees that the humans labeling their images, text, code, and other training materials were doing so accurately. They needed mechanisms to catch errors before those errors propagated through neural networks and corrupted the models themselves. This is precisely the problem Cleanlab had been solving.
Cleanlab's journey had been impressive but ultimately limited by scope. The startup raised $30 million from elite investors including Menlo Ventures, TQ Ventures, Bain Capital Ventures, and Databricks Ventures. At its peak, it employed over 30 people. Yet despite substantial capital and top-tier backing, Cleanlab faced a classic software business problem: their product created value for data labeling companies, but they couldn't control the primary revenue streams themselves. The companies using their technology—firms like Scale AI, Surge, and Mercor—were the ones capturing the economic value of high-quality labeled data.
Northcutt made a strategic decision that many founders avoid until it's too late: he chose to sell Cleanlab to one of the companies that could actually implement its technology at scale and capture the resulting value. Handshake operated the data labeling pipeline itself, meaning it could immediately deploy Cleanlab's algorithms to catch errors in its own labeling workforce, creating a virtuous cycle of improving data quality and therefore commanding higher prices for its product.
This acquisition represents more than a simple M&A transaction. It reflects the maturation of the AI data supply chain and the emergence of data quality as a differentiated competitive advantage. In the next sections, we'll analyze what this deal means for the AI industry, examine the technical breakthroughs that made Cleanlab valuable, explore the broader consolidation trend in data labeling, and discuss alternative approaches to solving the data quality problem that are emerging across the industry.
The Data Labeling Problem: Why Quality Auditing Became Critical
The Economics of Training Data
To understand why Handshake's acquisition of Cleanlab was significant, we need to appreciate the fundamental economics of AI model development. The training process for modern large language models, vision systems, and other advanced AI applications requires enormous quantities of labeled data. For certain specialized domains—medical imaging, autonomous vehicle perception, legal document analysis—human experts must manually label thousands or millions of data points.
The cost of this labeling is substantial. A single high-quality label on a medical image might cost
However, the presence of a cost structure creates incentives for cost-cutting. If a labeling company can reduce its costs by 20% by hiring less experienced labelers or reducing quality control procedures, the economic pressure to do so is immense. The downstream consequence—increased error rates in training data—is difficult to detect because the models that depend on this data don't immediately fail in obvious ways. Instead, they develop subtle biases, reduced generalization capabilities, and vulnerability to distribution shifts.
Detection Without Re-Labeling: Cleanlab's Core Innovation
Cleanlab's fundamental breakthrough was developing algorithms that could identify incorrectly labeled data with minimal computational cost and without requiring a second human to manually verify whether the first human labeled correctly. Traditional quality assurance processes in data labeling rely on inter-rater agreement: you have multiple humans label the same item, and items where they disagree are flagged for review.
Inter-rater agreement is expensive and doesn't scale gracefully. If you want to verify 50% of your labels, your labeling costs essentially double. Cleanlab's approach was different. The algorithms analyzed the label distribution, the pattern of disagreement across similar items, and the consistency of labeler behavior to infer which labels were likely incorrect based on statistical anomalies.
This approach operates on a principle from machine learning theory: correct labels should follow predictable statistical patterns within a category, while errors tend to be idiosyncratic. By training a model on the dataset and examining which items the model struggles with or misclassifies, the algorithms can identify candidates for review. More sophisticated approaches use confident learning, a technique that estimates label quality by examining the predicted probability distribution across possible labels.
The advantage of this approach is dramatic. Instead of requiring inter-rater agreement on 50% of labels at 100% cost, Cleanlab's approach could identify a similar set of problematic labels by analyzing 100% of the labels with algorithmic cost that scales at
Real-World Applications in AI Training
In practice, Cleanlab's technology found application in several critical areas. For vision models, the algorithms could identify images that were mislabeled during initial annotation—perhaps an image labeled as "cat" that actually contained a dog, or medical images labeled with the wrong diagnosis. For natural language processing, the technology could catch instances where text was tagged with the wrong sentiment or intent.
For organizations training large models, the ability to remove even 5% of incorrectly labeled training data can improve model accuracy by 2-5%, depending on the task. Across expensive model training runs consuming millions of dollars in compute resources, this improvement translates directly to better deployed models and reduced need for retraining.
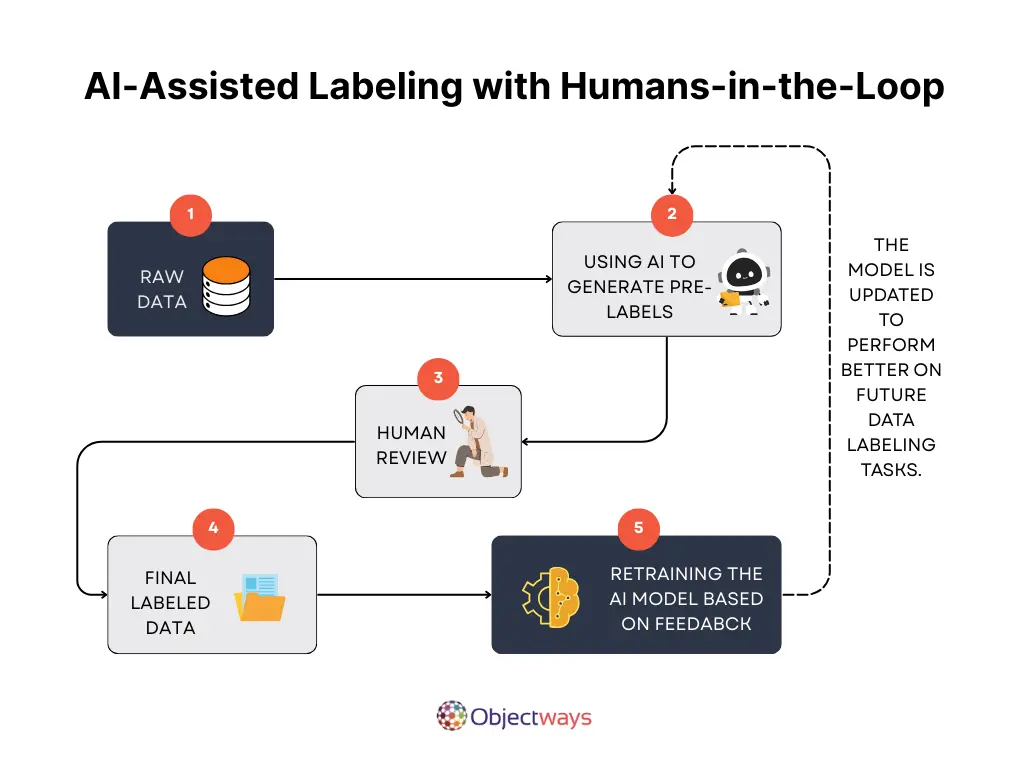
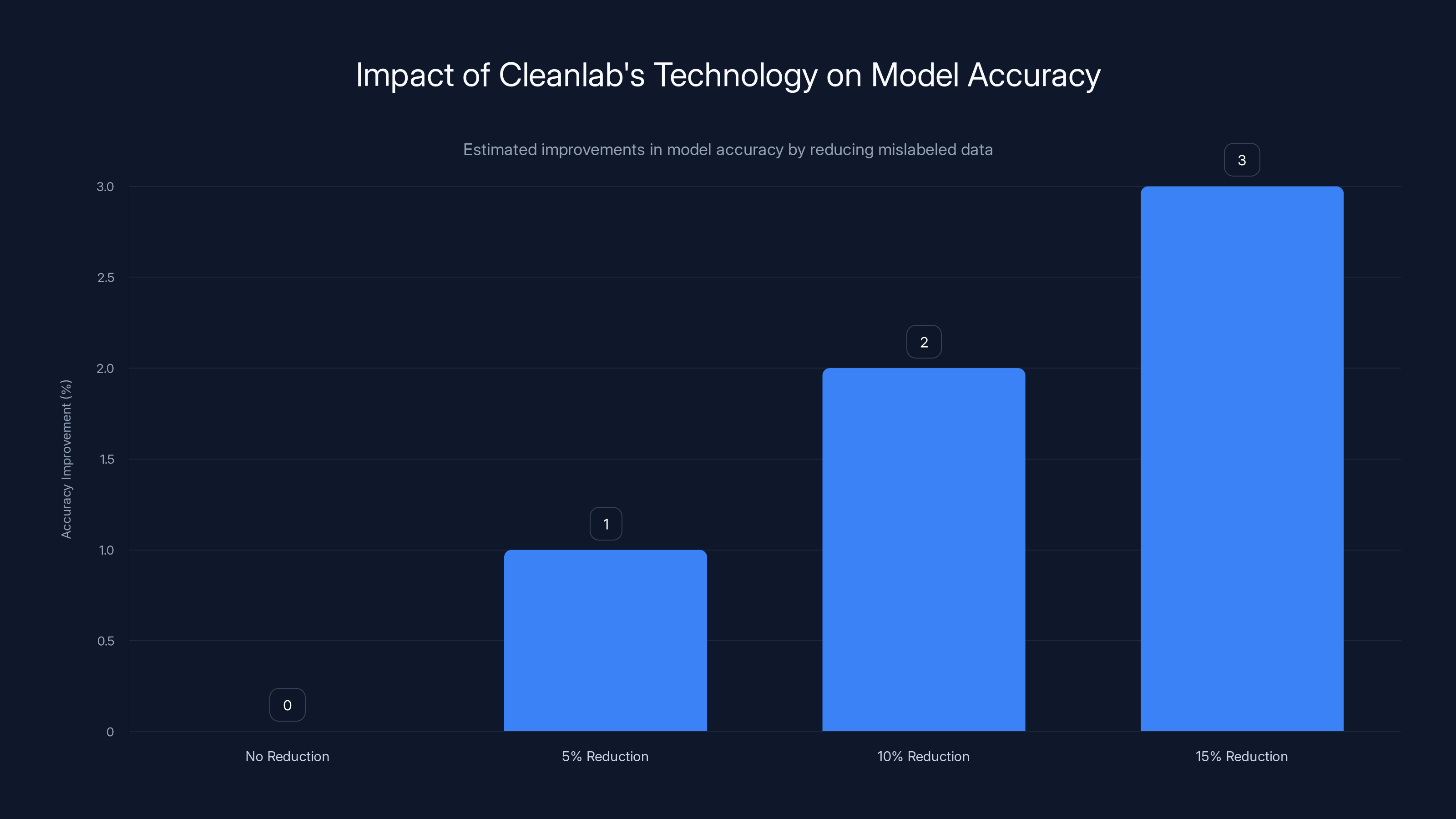
Removing 5-10% of mislabeled data can improve model accuracy by 1-3%, enhancing performance and reducing costs. Estimated data.
Understanding Handshake: From Recruitment to AI Data Infrastructure
The Evolution of a Platform
Handshake's journey to becoming a critical AI infrastructure company demonstrates how unexpected pivots in technology can create new market opportunities. Founded in 2013, Handshake began as a college recruitment platform connecting recruiters with recent graduates and students approaching graduation. This was a legitimate business: employers need to source entry-level talent, and college career centers need systems to connect students with opportunities.
The platform grew successfully in this niche, eventually becoming valued at $3.3 billion in 2022 according to its most recent public valuation. However, valuations at that level in the recruitment space typically indicate dominance in a large market or the potential for significant adjacent market expansion. For Handshake, the adjacent expansion came through a channel that most recruitment platforms overlooked.
Handshake's user base included highly educated individuals—college students and recent graduates in computer science, physics, biology, medicine, and other technical fields. These individuals had specialized knowledge that was extraordinarily valuable for AI training purposes. A physics Ph D candidate can label particle detector data or medical imaging correctly. A computer science student can evaluate code quality or identify whether generated code has security vulnerabilities. A recent medical school graduate could label clinical images with diagnostic precision.
Rather than simply recruiting these individuals into traditional jobs, Handshake recognized it could monetize their expertise through task-based work and data labeling contracts. This was the same fundamental insight that enabled companies like Surge AI and Scale AI to build multi-billion-dollar valuations—but Handshake had an existing network and brand relationships with talent.
The Handshake Data Labeling Business Model
Launching its data labeling business approximately one year before acquiring Cleanlab, Handshake followed a model optimized for quality. Rather than creating a generic crowdsourcing platform where anyone could label data for micropayments, Handshake focused on recruiting specialized labor—people with credentials and expertise matching the labeling requirements.
This approach had several advantages. First, it enabled higher labeling quality because the humans doing the work actually had domain knowledge. A radiologist labeling medical images will catch subtleties that a general contractor might miss. Second, it differentiated Handshake from competitors. Surge AI and Scale AI could source general-purpose labelers from anywhere. Handshake could source domain experts specifically matched to requirements.
Third, it created pricing power. A label produced by a medical doctor is more valuable than a label produced by someone without medical training. Organizations like OpenAI, which used Handshake's services, could pay premium rates for high-quality labels that reduced downstream model training problems.
By 2025, this model was working. Handshake's $300 million annualized revenue run rate represented explosive growth from essentially zero revenue in the data labeling business less than two years prior. This growth rate suggested the market was absorbing data labeling services faster than competitive capacity. The company was also working with eight of the world's most advanced AI laboratories, which is a remarkable concentration of top-tier customers.
Vertical Integration and Competitive Advantage
When Northcutt explained Cleanlab's decision to sell to Handshake rather than competitors, he noted that firms like Scale AI, Surge, and Mercor frequently use Handshake's platform to source labelers. This created an unusual market structure: Handshake was simultaneously a competitor (in data labeling services) and a supplier (of specialized labor) to other data labeling companies.
By acquiring Cleanlab and integrating its quality assurance algorithms into its own labeling operations, Handshake could create something its competitors couldn't easily replicate: vertically integrated data quality control. Handshake could offer customers not just "here are your labeled images" but "here are your labeled images, and we've verified them with proprietary algorithms that flagged the 3% that might be incorrect for manual review."
This represented a significant competitive moat. Scale AI or Surge could copy Handshake's approach to recruiting domain-expert labelers. But if Handshake owned the most advanced algorithms for detecting label errors, it would take competitors months or years to catch up. Meanwhile, Handshake's improving data quality would compound, creating stronger relationships with top AI labs and justifying higher pricing.

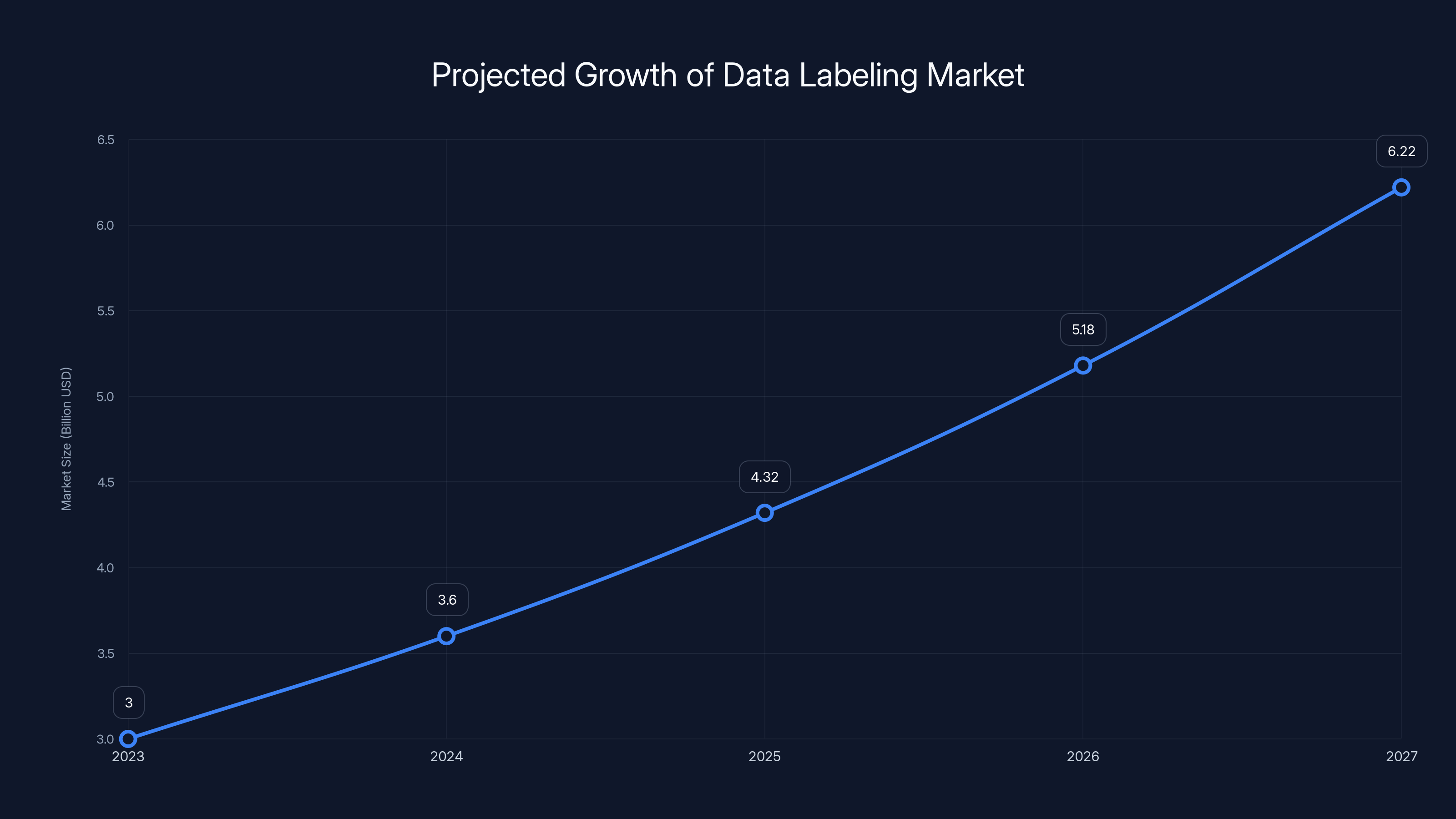
The data labeling market is projected to grow from approximately
Cleanlab's Technical Innovations and Research Contributions
Confident Learning: The Algorithmic Foundation
The technical heart of Cleanlab's approach was a framework called confident learning, developed through rigorous machine learning research. The core insight of confident learning is that label errors follow specific statistical patterns that can be identified through analysis of model predictions.
When a model is trained on data that includes label errors, those errors create distinctive patterns in the model's predicted probability distributions. If a photo of a dog is labeled as "cat," the trained model will likely assign a high probability to "dog" and low probability to "cat" when evaluated on that same image. This mismatch between predicted label and actual label serves as an error signal.
Confident learning formalizes this insight mathematically. The algorithm works by:
- Training a baseline classifier on the dataset as-is
- Computing predicted probabilities for each instance across all possible labels
- Comparing predicted probabilities with actual labels to identify confident predictions that disagree with the given label
- Ranking problematic instances by how confidently the model disagrees with their labels
- Flagging top-ranked instances for human review or removal
The mathematical elegance of this approach is that it doesn't require any additional labeled data or secondary human reviewers. It operates purely on the data at hand, making it computationally efficient and economically viable at scale.
Research has demonstrated that confident learning can identify label errors with precision rates exceeding 90% in many domains, meaning when the algorithm flags something as likely incorrect, it actually is incorrect more than 90% of the time. This dramatically reduces wasted effort on reviewing false alarms.
Extensions for Domain-Specific Applications
Beyond the core confident learning framework, Cleanlab's team of MIT-trained researchers developed numerous extensions and refinements. For image classification tasks, the algorithms were tuned to account for the hierarchical nature of image categories (a "Siamese cat" is both a cat and a Siamese, so some label inconsistencies might be benign). For text classification, different algorithms were developed because textual data often has more subjective interpretation than images.
For multi-label problems where a single instance can have multiple correct labels (an image might contain both a dog and a cat), Cleanlab developed approaches to detect cases where labels were incomplete or mutually inconsistent. For sequence labeling problems in natural language processing, where individual tokens receive labels within a sequence, the algorithms account for the dependencies between adjacent labels.
This breadth of algorithmic development required the kind of specialized ML research expertise that Handshake couldn't easily hire or develop in-house. The three MIT-educated co-founders brought research depth and publication history in this specific area. Hiring them through an acqui-hire meant Handshake could accelerate its ability to adapt these algorithms across different data types.
Scientific Validation and Research Output
Cleanlab's technology wasn't just practical—it was scientifically validated through academic research papers published in top venues like the International Conference on Machine Learning (ICML) and the Neural Information Processing Systems Conference (Neur IPS). This research output served multiple purposes:
- Credibility building with data science teams at organizations like OpenAI, which are staffed with researchers who read and value peer-reviewed publications
- Technical documentation that allowed practitioners to understand not just how to use Cleanlab but why it worked
- Community reputation that helped Cleanlab hire talented researchers who wanted to work on meaningful problems
The research also created a virtuous cycle: the more Cleanlab customers tried the technology, the more real-world applications generated ideas for improvements, which led to new research papers, which improved the company's reputation and ability to attract customers.
Market Context: The Data Labeling Industry Consolidation
The Emergence of Data Labeling Giants
The data labeling market emerged as a distinct industry category around 2015-2016 as deep learning adoption accelerated and organizations realized they needed mechanisms to produce training data at scale. Early players in this space included Appen, Crowd Flower (now Appen), and various academic and startup efforts.
By the early 2020s, the competitive landscape had consolidated around several key approaches:
Crowdsourcing platforms: Services like Amazon Mechanical Turk provided access to distributed workers willing to perform tasks for micropayments. This approach offered scale and low cost but struggled with quality consistency and the risk of deliberately bad actors intentionally providing incorrect labels.
Managed labeling services: Companies like Scale AI, Surge, and eventually Handshake took a more structured approach, hiring trained labelers, implementing quality control procedures, and managing the entire pipeline from instruction creation through label delivery. This was more expensive per label but produced higher quality and stronger customer relationships.
Specialized vertical players: Companies like Labelbox and Prodigy built software tools and platforms for teams that wanted to manage their own labeling efforts, effectively selling the infrastructure rather than the labor itself.
The Competitive Dynamics
By 2025-2026, the competitive dynamics had shifted. Scale AI had emerged as a primary competitor to Handshake, raising over
But despite significant capital and competition, none of these players had achieved a decisive quality advantage that made competitors irrelevant. All of them could source labelers. All of them could implement basic quality control. The market remained contestable because the core differentiator—human labor—was available to anyone willing to pay for it.
Cleanlab's algorithms offered a potential path to a quality differentiation that wasn't easily copied. A labeling company with superior algorithmic error detection could:
- Achieve lower error rates at the same cost
- Achieve the same error rates at lower cost
- Identify which labelers were making systematic mistakes and retrain them
- Build models of labeler accuracy that could be used to weight labels or select appropriate labelers for different tasks
These advantages compound over time. If Handshake's customers receive higher quality data, their models perform better, and they're more likely to return to Handshake for future labeling projects. The customer switching costs increase as Handshake's data quality reputation grows.
Consolidation as a Competitive Strategy
The Handshake-Cleanlab acquisition should be understood as a consolidation move driven by competitive necessity. For Handshake, acquiring Cleanlab's algorithms and team was more efficient than building equivalent capabilities internally. Research talent in machine learning is expensive and mobile—recruiting three MIT-trained ML researchers is difficult, while an acqui-hire can retain them through equity vesting schedules and integration into the acquirer's research team.
For Cleanlab, the decision to sell made sense given market realities. The company had built impressive technology but lacked the distribution and customer relationships that would allow it to capture the full economic value of its innovation. Selling to Handshake solved this problem—the technology would be deployed at massive scale and the founders would participate in Handshake's growth as employees or equity holders.
This pattern—where specialized software companies are acquired by customers or platforms that can better monetize their technology—is common in infrastructure and tooling markets. It's usually a positive outcome for both parties, despite the superficial appearance of consolidation reducing competition.
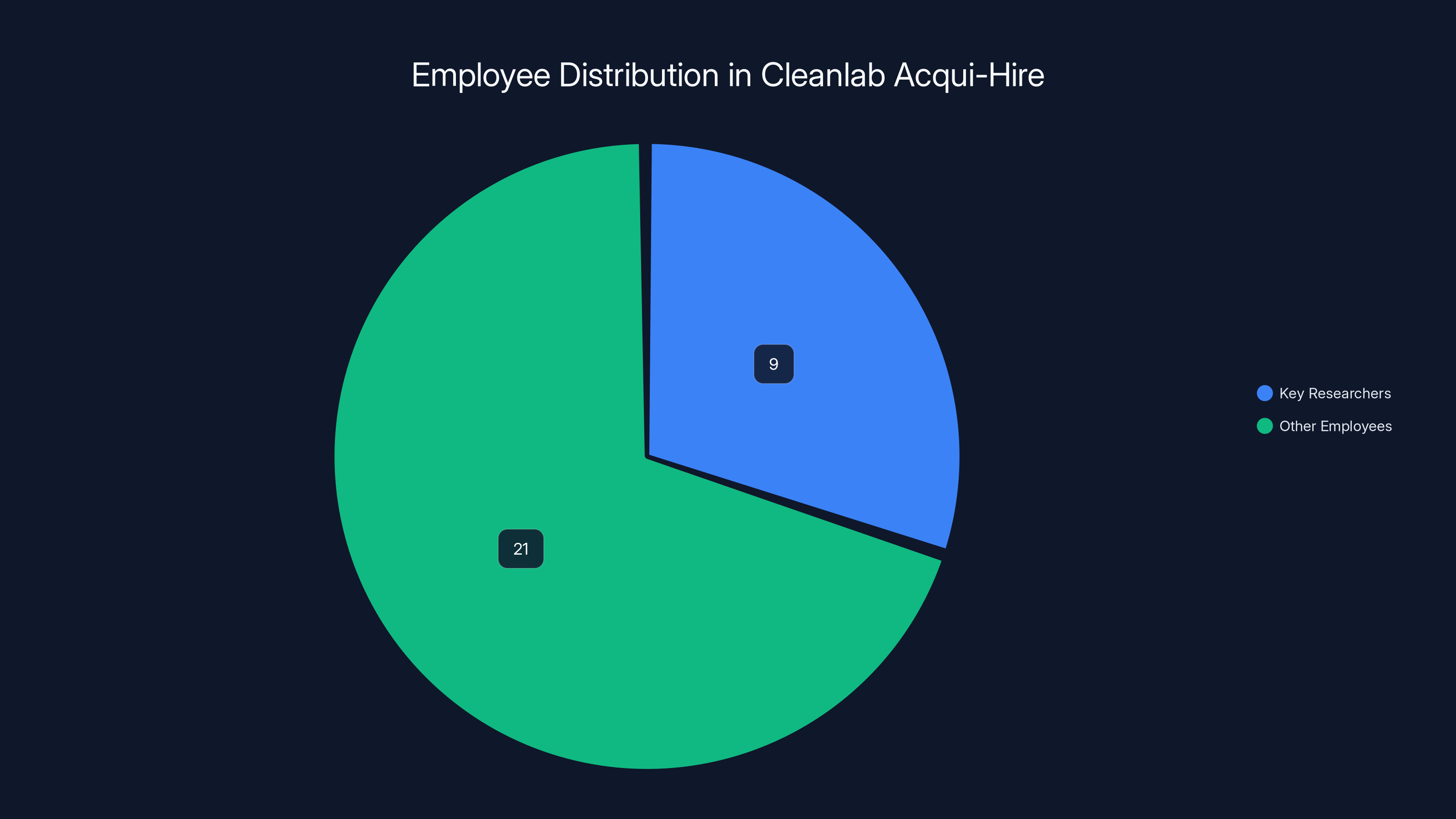
The nine key researchers represent 30% of Cleanlab's workforce, highlighting their critical role in the acqui-hire. Estimated data.
The Acqui-Hire Structure: Why Nine Researchers Matter More Than Revenue
Understanding Acqui-Hire Economics
An acqui-hire is fundamentally different from a traditional acquisition. In a traditional acquisition, the buyer is acquiring the target company's revenue streams, customer base, and intellectual property. The acquirer cares about whether the acquired business will be profitable and whether it has strategic value.
In an acqui-hire, the primary asset being acquired is human capital and institutional knowledge. The buyer is essentially saying: "We want your team and the specialized expertise they've developed. We're willing to pay to hire them as a unit rather than individually."
Cleanlab was structured as an acqui-hire of nine key researchers, including the three co-founders. This number is significant because it represents roughly 30% of Cleanlab's 30-person employee base at peak headcount. The nine people acquired were the technical leadership and specialized ML researchers—the people most difficult to recruit individually and most likely to leave if the company shut down or was acquired by a competitor.
The advantages of the acqui-hire structure for Handshake:
- Certainty of retention: The acquiring company can structure the deal with equity vesting to ensure the acquired employees remain with the organization for a specified period
- Unit cohesion: Rather than scattering researchers across different teams, they can maintain their research group structure, potentially accelerating knowledge transfer and collaboration
- De facto non-compete: Employees acquired in an acqui-hire are typically restricted from immediately launching a competitor or joining a competing company
- Cost efficiency: An acqui-hire may be cheaper than recruiting the same nine people individually across the labor market
For the Cleanlab researchers and employees not part of the "key nine," the acqui-hire structure created complexity. Some employees would receive packages to leave the company. Others might be offered roles at Handshake without the same equity upside as the founders. This is typical in acqui-hire situations but can create awkward employee dynamics.
Why Founders Accepted the Cleanlab Acquisition
Curtis Northcutt, as CEO, had to justify the acquisition decision to other employees, investors, and the public. His explanation was notably candid: he said Cleanlab received "acquisition interest from other AI data labeling companies" but chose Handshake because of its unique market position.
Specifically, Northcutt noted that Scale AI, Surge, and Mercor frequently use Handshake's platform to source labelers. This created a compelling strategic narrative: "If you're going to pick one, you should probably pick the source, not the middleman."
This is a sophisticated competitive insight. Other data labeling companies were building software and processes on top of Handshake's labor supply. By selling Cleanlab's technology to Handshake, Northcutt was ensuring that the technology would be deployed by the company that controlled a critical piece of infrastructure—the ability to access specialized labor at scale.
If Cleanlab had sold to Scale AI or Surge, those competitors would gain an advantage but wouldn't have access to Handshake's labor pool. They'd still be dependent on Handshake for worker sourcing, and Handshake might not use their quality assurance algorithms in its own operations. By selling to Handshake, Cleanlab's technology becomes central to the entire data labeling pipeline.
The Underreported Lucrativeness of Acqui-Hires
Tech Crunch noted in its reporting that "sometimes an acqui-hire can be surprisingly lucrative for founders." This hint at undisclosed deal economics is important for understanding modern tech acquisitions. While the deal structure wasn't disclosed, acqui-hire valuations can sometimes exceed public market expectations, especially when the target has strong investors and the acquirer is desperate for technical talent.
Consider Cleanlab's fundraising: the company had raised
Moreover, acqui-hire valuations often include significant cash payments to founders and the most senior technical staff, plus guaranteed equity packages at the acquirer. For MIT-trained computer scientists in a competitive labor market, the guaranteed equity stake in a
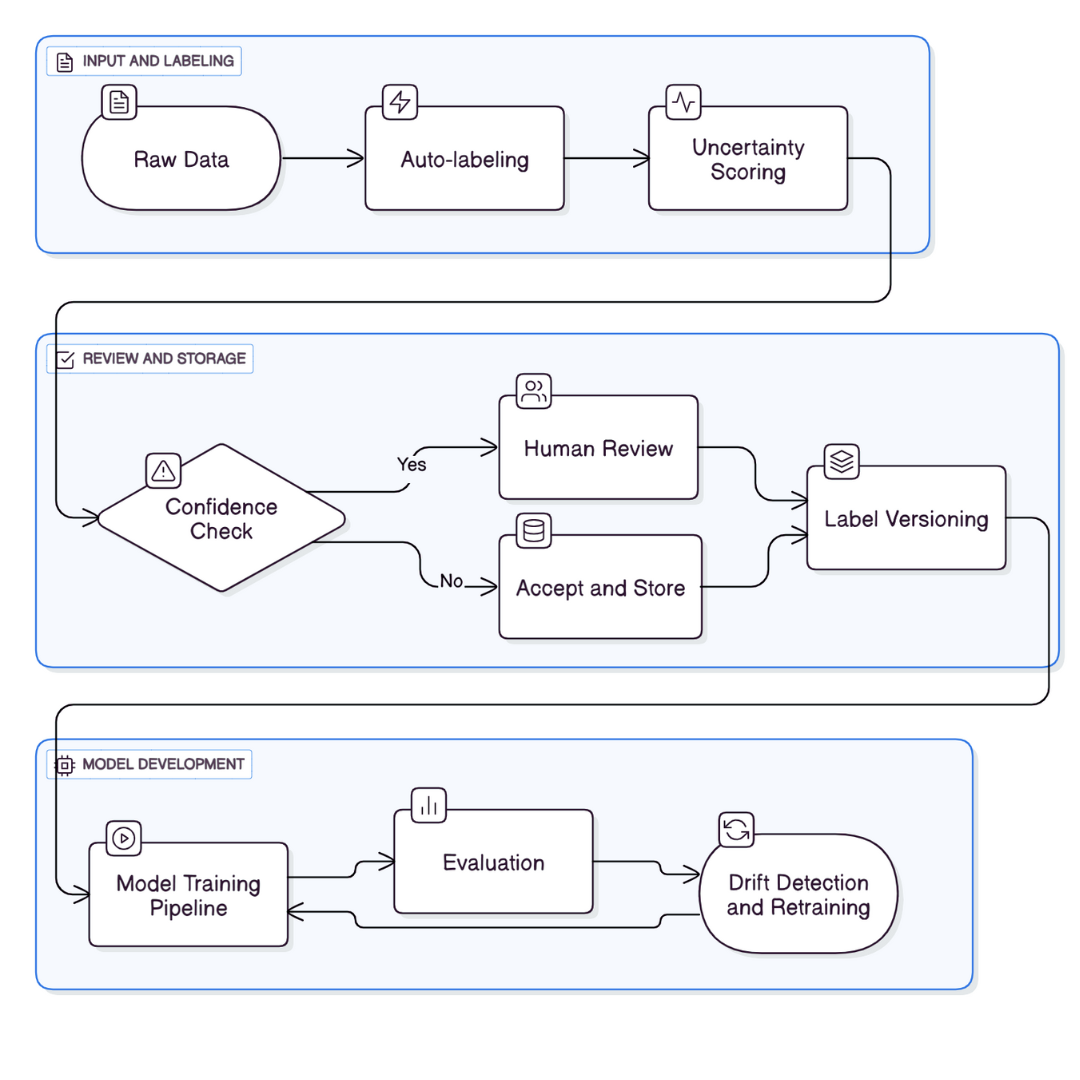
Technical Integration: How Cleanlab's Algorithms Integrate into Handshake
Architecture Considerations for Data Labeling Pipelines
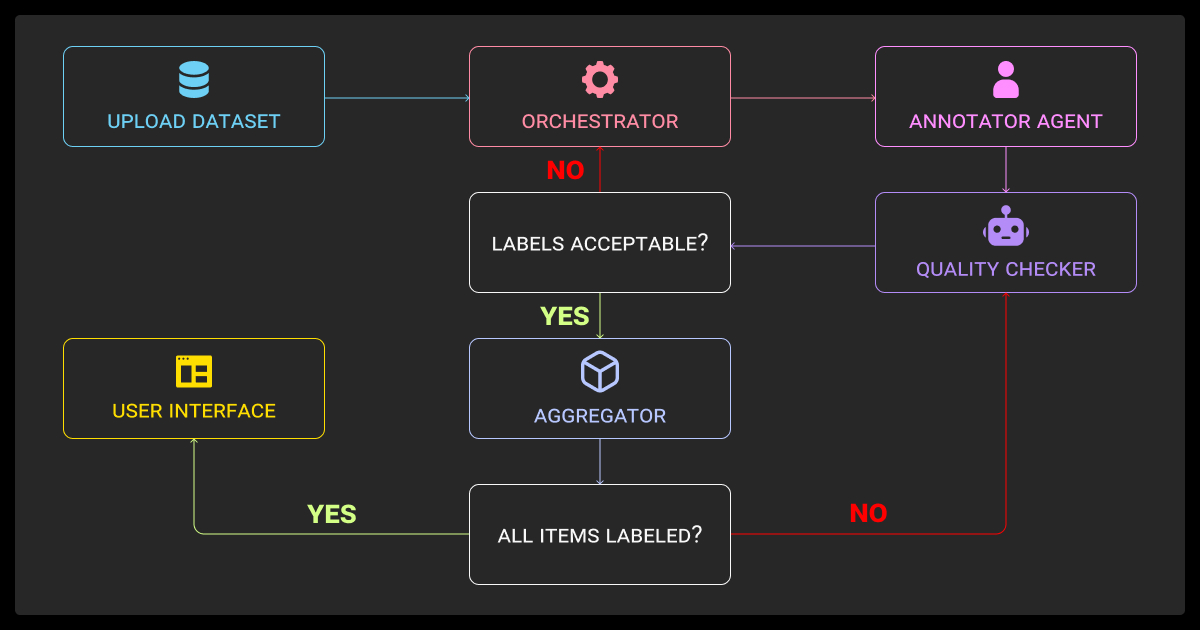
Integrating Cleanlab's algorithms into Handshake's existing data labeling pipeline required careful architectural decisions. Handshake's workflow typically follows this pattern:
- Client specifies labeling requirements (what categories to label, which images to label, etc.)
- Handshake creates labeling tasks and presents them to qualified labelers
- Labelers complete tasks and submit their results
- Quality control processes verify labels (previously standard inter-rater agreement or manual review)
- Labeled data is delivered to client
Cleanlab's algorithms fit naturally into step 4, the quality control stage. However, integrating them effectively required solving several technical challenges:
Cost attribution: Running confident learning algorithms requires computing model predictions across the dataset. This computational cost needs to be allocated appropriately—should it be absorbed in Handshake's margin, passed to clients, or shared? The optimal pricing model likely varies by customer and contract.
Latency requirements: Some clients need labeled data quickly. Running additional algorithmic quality assurance adds latency to the pipeline. Handshake likely developed mechanisms to parallelize computation and flag suspicious labels without blocking delivery of the full dataset.
Domain-specific tuning: As noted earlier, confident learning has different implementations for image, text, and structured data. Handshake needed to determine which implementations would be deployed first based on customer demand and data volume.
Threshold optimization: The confident learning algorithm produces a ranking of suspicious labels, but Handshake must decide which threshold to use—should it flag the top 5% of suspicious labels? Top 10%? This depends on downstream economics: is it better to deliver 95% high-confidence labels or review more labels to achieve 98% accuracy?
Feedback Loops and Continuous Improvement
One of the most powerful aspects of integrating Cleanlab's technology was the feedback loops it enabled. When Handshake customers discovered that suggested label corrections actually improved their models' performance, they provided confirmation that the algorithmic suggestions were valuable.
These feedback loops could accelerate iteration:
- Handshake flags suspicious label using confident learning
- Human reviewer confirms or rejects the flagging
- Feedback is collected on which flags were correct vs. false positives
- Algorithm parameters are tuned based on feedback
- Next iteration of confident learning becomes more accurate
This pattern—algorithmic suggestion, human validation, algorithmic improvement—is common in machine learning systems and can rapidly increase accuracy if implemented well.
Extending Beyond Quality Assurance
While the immediate integration focused on quality assurance, the Cleanlab team's expertise opened possibilities for deeper innovation. For instance:
Labeler profiling: By analyzing patterns in individual labelers' errors, Handshake could identify which labelers are highly accurate in specific domains and assign them preferentially to future tasks in those domains. This increases quality without increasing cost.
Task routing: Some labelers are better at certain types of labels. Using error pattern analysis, Handshake could automatically route incoming tasks to the labelers most likely to label them correctly.
Model-based label inference: In some cases, rather than discarding suspected incorrect labels, Handshake could use statistical methods to infer the likely correct label, creating a higher-quality version of the dataset.
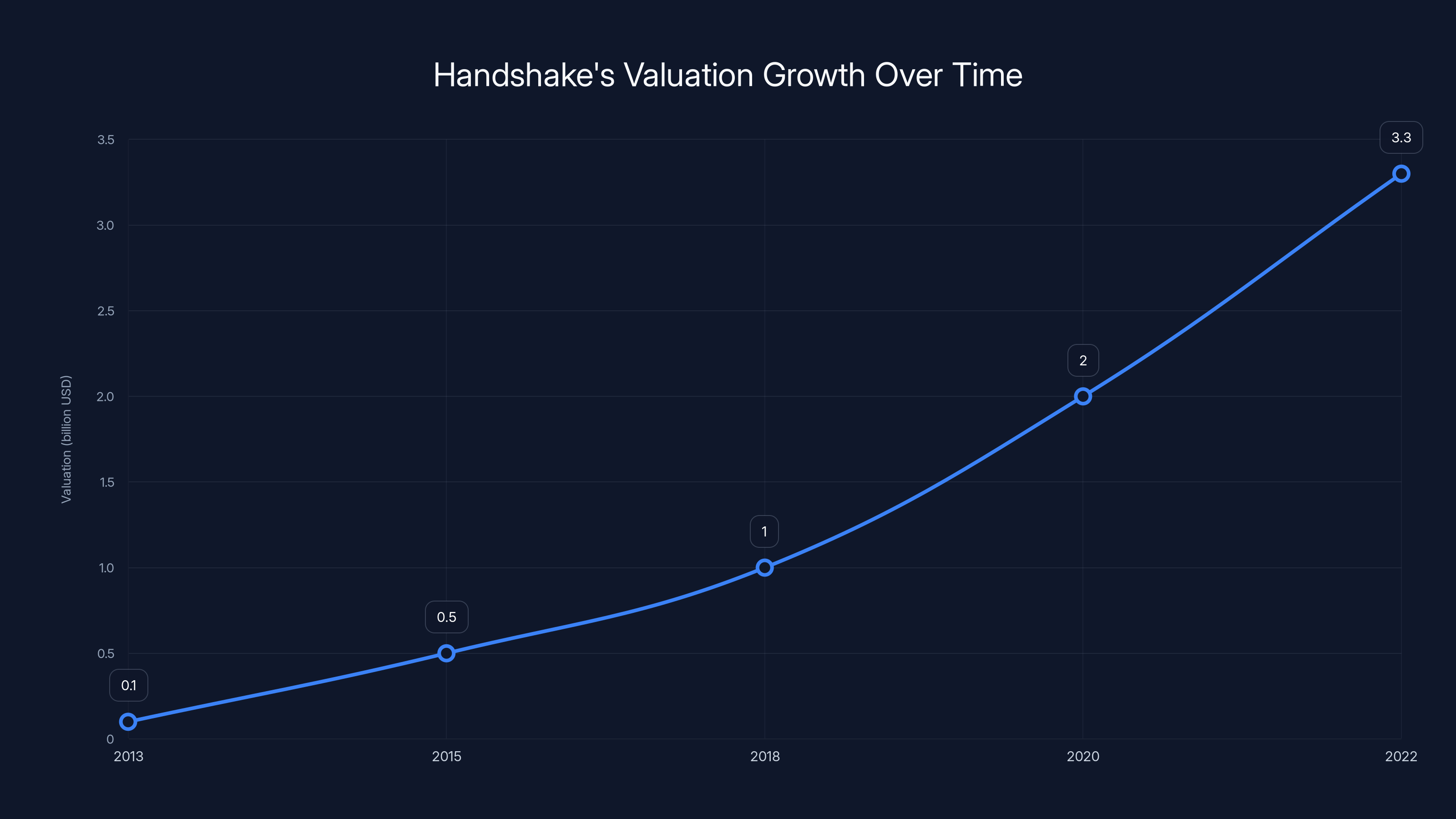
Handshake's valuation grew from
Competitive Implications and Market Response
How Competitors Might Respond
The Handshake-Cleanlab acquisition triggered immediate competitive implications for other data labeling companies. Scale AI, Surge, and Mercor suddenly had to confront a competitor that was embedding quality assurance algorithms directly into its core offering.
Their strategic options included:
Option 1: Build internally: Scale AI could hire ML researchers and develop competing algorithms. This is possible but expensive and time-consuming. Scale would need to recruit researchers as talented as Cleanlab's founders, develop comparable algorithms, validate them empirically, and deploy them at scale. This path could take 18-36 months.
Option 2: Acquire competing technology: Scale or others could acquire alternative companies developing label quality assurance technology. This would be similar to what Handshake did but would require identifying and competing for alternative targets. If alternative targets existed, they would likely increase pricing significantly once they realized their technology was strategically valuable.
Option 3: Develop tools and infrastructure: Rather than competing on algorithms, competitors could build tools and infrastructure that help clients implement their own quality assurance, or that make it easier for clients to use multiple labeling providers simultaneously, reducing dependency on any single provider's quality advantages.
Option 4: Specialize in domains where algorithmic quality assurance is less effective: Some labeling tasks are inherently more subjective or domain-specific. Competitors could focus on areas where human expertise and domain knowledge matter more than algorithmic error detection.
Customer Reaction and Pricing Power
For Handshake's customers, the integration of Cleanlab's technology should theoretically increase their willingness to pay for labeling services. If the same service now comes with superior quality assurance, the value proposition improves. Handshake could potentially increase prices for contracts involving the improved quality assurance.
However, Handshake's negotiating power with customers depends on several factors:
Customer sophistication: AI labs like OpenAI understand the value of high-quality training data and might willingly pay more for demonstrable quality improvements. Less sophisticated customers might not perceive additional value.
Competitive alternatives: If Scale AI or Surge AI match Handshake's quality assurance capabilities quickly, customers have alternatives and won't accept price increases.
Impact on model performance: The strongest position would be empirical evidence showing that Handshake-labeled data, when processed through Cleanlab's quality algorithms, produces models that perform X% better than competitors' labeled data.
Handshake's competitive position likely improved, but whether it translated to meaningful pricing power would depend on these factors.
The Broader Data Quality Trend in AI Development
Recognition of Data Quality as a Bottleneck
The Handshake-Cleanlab acquisition reflects a broader recognition in the AI industry that data quality, not data quantity, has become the binding constraint for model improvement. This represents a significant shift from earlier periods when the main bottleneck was access to sufficient data.
During the 2010s, organizations focused on accumulating datasets. The benchmark for AI progress was often measured in dataset size: Image Net had millions of images, Wikipedia had billions of words, and researchers competed to build larger and larger training datasets. The assumption was that more data led to better models, almost regardless of quality concerns.
By the early 2020s, evidence accumulated that this assumption wasn't universally true. In controlled experiments, removing systematically incorrect labels from training data and retraining models yielded better performance than training on noisy data. The relationship between data quantity and model quality followed a curve—initially, more data helped, but past a certain point, noisy data hurt more than it helped.
This realization triggered investment in data quality throughout the AI stack:
- Data validation frameworks: Tools to help organizations identify potential problems in datasets
- Label quality evaluation: Research on measuring and improving the quality of human-provided labels
- Active learning: Techniques to select the most informative examples for labeling, reducing the quantity needed for good performance
- Synthetic data: Methods to generate artificial training data that's controllably high quality
- Data augmentation: Techniques to increase effective dataset size through transformations and variations
Cleanlab was part of this broader trend, and Handshake's acquisition reflected the strategic importance of this shift.
Interplay with Synthetic Data Development
Interestingly, the rise of emphasis on data quality coincided with increasing interest in synthetic data generation—data created by generative models rather than collected from reality and annotated by humans. Some commentators suggested that synthetic data might ultimately replace human labeling.
However, in practice, the relationship between synthetic and human-labeled data is more nuanced. Synthetic data is useful for augmenting real data, filling in gaps in distributions, and enabling rapid iteration during development. But for building production models, especially in regulated domains or where safety is critical, organizations still prefer real data labeled by humans.
This actually increased the strategic importance of human data labeling companies like Handshake. Organizations needed both human-labeled data (for core model training) and synthetic or augmented data (for scaling). Handshake could become a critical supplier for the human-labeled component.
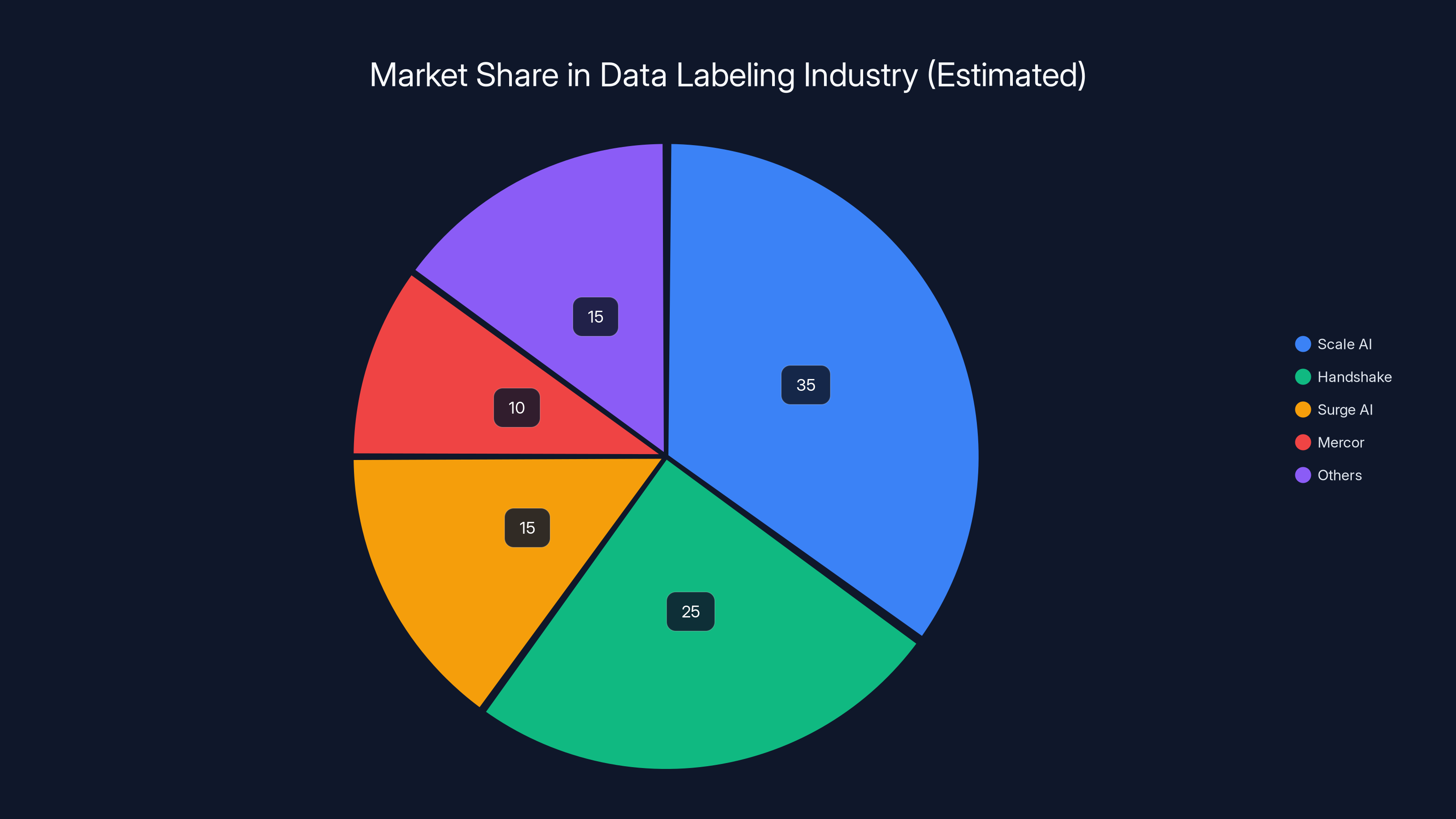
By 2025-2026, Scale AI is estimated to lead the data labeling market with a 35% share, followed by Handshake at 25%. Despite competition, no single player dominates the market. (Estimated data)
Implications for Model Performance and Training Efficiency
Quantifying the Impact of Label Quality on Model Accuracy
Research on the relationship between label quality and model performance provides concrete evidence of why Cleanlab's technology is valuable. In controlled experiments:
- Removing 5-10% of mislabeled data from a training set typically improves model accuracy by 1-3%, depending on the task
- Correcting mislabeled data (when the correct label is determinable) shows even larger improvements, typically 2-5% accuracy gain
- The effect compounds: Iteratively identifying and correcting errors can yield cumulative improvements of 5-10% or more
For large-scale models, even 1% accuracy improvement has enormous practical value. An image recognition model that's 2% more accurate means 2% fewer misclassifications across billions of images classified in production. For applications like medical imaging, this could mean fewer diagnostic errors.
Computational Efficiency Improvements
Beyond accuracy improvements, high-quality training data also improves training efficiency. Models trained on cleaner data typically require fewer epochs to converge and may need less overall data to reach target performance levels.
Consider the economics: if Handshake can deliver data labeled with 5% fewer errors than competitors, and this allows organizations to train models using 10% less data while maintaining the same accuracy, the organizational value is substantial. Rather than labeling 10 million images, a client might label 9 million. At
Acceleration of Research and Development Cycles
Another benefit of higher-quality training data is faster research iteration. Data scientists developing new models can more confidently attribute performance differences to their architectural or algorithmic choices rather than blaming noisy data. This clarity accelerates the pace of experimentation and allows teams to fail faster and learn faster.
For organizations like OpenAI that are continually developing new models, this acceleration translates to competitive advantage. The ability to iterate faster and more confidently on architectural innovations matters more than the ability to train a slightly larger model on mediocre data.

Alternative Approaches to Data Quality in the Ecosystem
Competing Methodologies for Quality Assurance
While Cleanlab's confident learning approach is sophisticated, it's not the only methodology for improving data quality. The broader ecosystem includes several competing approaches:
Inter-rater agreement and consensus labeling: The traditional approach of having multiple labelers label each item and using consensus or majority voting. This is computationally straightforward but expensive, requiring multiple labels per item.
Expert review and hierarchical validation: Implementing layers of review, with experienced labelers reviewing work from newer labelers. This provides quality control but is labor-intensive and doesn't scale as efficiently.
Weak supervision and data programming: Rather than labeling data directly, organizations specify rules or patterns that label data automatically. Labelers then verify the automatically labeled data. This can be faster but requires well-defined labeling rules.
Crowdsourcing with quality incentives: Designing incentive structures (bonuses, reputation systems, worker selection) to encourage high-quality labeling. This addresses quality through market design rather than algorithmic methods.
Active learning and intelligent sampling: Rather than labeling data uniformly, selecting specific items most likely to improve model performance and focusing labeling effort there. This reduces labeling volume needed.
Models-in-the-loop and continuous validation: Maintaining feedback loops where deployed models' errors feed back to identify mislabeled training data that should be reviewed.
Handshake, with Cleanlab's technology, now operates primarily through the algorithmic quality assurance approach but likely uses elements of multiple strategies.
Emerging Alternatives in the Market
For organizations not using Handshake, alternative approaches to achieving high-quality labeled data include:
Specialized vertical providers: Companies like Domain-specific labeling services that employ experts in particular domains (medical imaging, legal documents, etc.). These providers achieve quality through hiring expertise rather than algorithmic methods.
Hybrid models combining human and machine learning: Companies using active learning and continuous model refinement to optimize labeling efficiency and quality simultaneously.
Building internal labeling teams: Large organizations with sufficient resources sometimes build internal labeling operations and implement their own quality control procedures.
Open-source labeling tools: Organizations can use tools like Label Studio or Prodigy to manage their own labeling workflows and implement custom quality control logic.

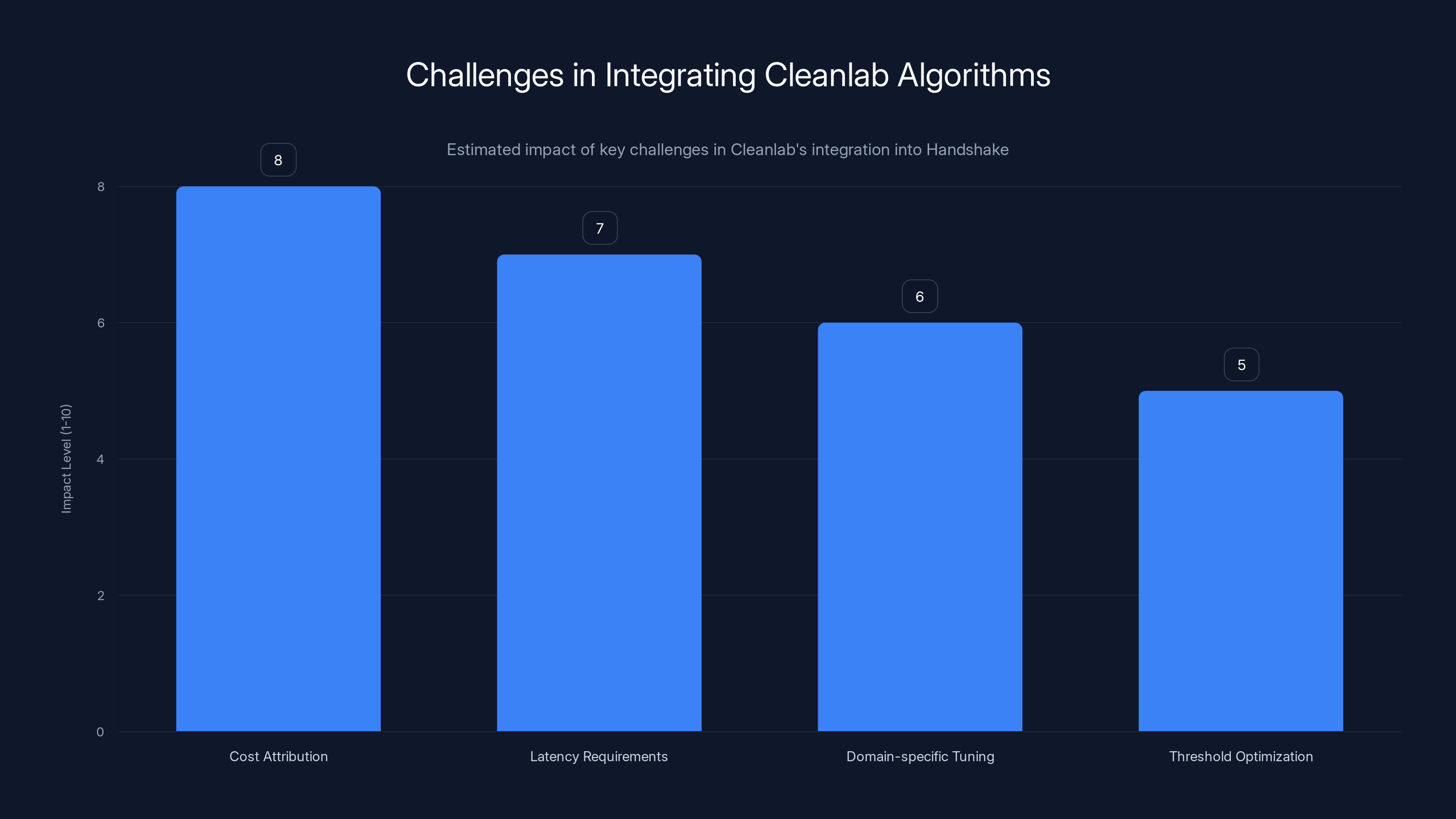
Estimated data showing the relative impact of various challenges faced during the integration of Cleanlab's algorithms into Handshake's pipeline. Cost attribution and latency requirements are the most significant challenges.
Market Consolidation Trends and the Future of Data Labeling
Pattern of Consolidation in Infrastructure Markets
The Handshake-Cleanlab acquisition fits a broader pattern in how infrastructure and tooling markets mature. When a market is nascent, numerous competitors emerge, each trying different approaches. As the market matures, several dynamics trigger consolidation:
- Specialization advantage: Competitors that specialize in addressing specific customer needs or domains can achieve better unit economics and stronger customer relationships
- Economies of scale: Large-scale operators can amortize fixed costs across more transactions, achieving lower per-unit costs than smaller competitors
- Technological advantages: Competitors that develop proprietary technology or algorithms can create defensible competitive advantages that smaller competitors can't easily copy
- Capital requirements: As competition intensifies and pricing pressure increases, maintaining profitability requires significant capital. Well-funded competitors can outcompete under-capitalized ones
- Talent concentration: Top engineering and research talent concentrates at the most successful companies, creating a virtuous cycle where leading companies can hire the best people
The data labeling market exhibits all these dynamics. Handshake's acquisition of Cleanlab exemplifies the technological advantage and talent concentration mechanisms.
Potential Future Consolidation Scenarios
Looking forward, several consolidation scenarios could emerge:
Scenario 1: Two-to-three dominant players: The market consolidates around Handshake, Scale AI, and possibly one other player. These firms capture 70%+ of market share, with long-tail competitors serving specialized niches.
Scenario 2: Vertical integration with AI labs: Major AI labs (OpenAI, Google, Meta) increasingly build internal data labeling capabilities rather than outsourcing. This reduces the addressable market for standalone data labeling companies but increases competition for labeling services.
Scenario 3: Automation-driven consolidation: Advances in weak supervision, synthetic data, and semi-supervised learning reduce organizations' dependence on human labeling, contracting the overall market size and triggering competitive consolidation.
Scenario 4: Specialized vertical fragments: Rather than market consolidation, the market fragments into vertical-specific providers, each serving a particular domain (medical, legal, autonomous vehicles, etc.) where specialized expertise commands pricing power.
The actual future likely involves elements of multiple scenarios, with some domains consolidating around large players while others develop specialized providers.

Strategic Lessons from the Acquisition
How Founders Navigate Strategic Choices
Northcutt's decision to sell Cleanlab to Handshake rather than building Cleanlab into a independent company or selling to competitors offers several strategic lessons:
1. Customer relationships matter more than product: Cleanlab's technology was valuable, but its inability to directly control customer relationships (clients came through Handshake and others) limited its strategic options. When Handshake became the opportunity to acquire the technology and embed it in operations where customer relationships already existed, that was more valuable than remaining independent.
2. Competitive dynamics change quickly: Cleanlab had raised substantial capital and built impressive technology, but the competitive landscape was shifting. Handshake's vertical integration and customer relationships created a form of competitive advantage that Cleanlab couldn't easily overcome through superior algorithms alone.
3. Timing matters: Selling when the technology is proven but before competitive copycat efforts become entrenched allows founders to capture value. If Cleanlab had waited, Scale AI or Surge might have developed competing algorithms internally, reducing Cleanlab's negotiating power.
4. Ecosystem position is strategic: Northcutt recognized that Handshake's position as a supplier to competitors (being used by Scale, Surge, and Mercor to source labelers) actually made it more valuable than selling to those competitors directly.
Questions for Organizations Considering Similar Decisions
For founders and executives facing similar choices about whether to remain independent, merge, or sell, the Cleanlab case suggests useful questions:
- Who controls the customer relationship, and can we capture that control?
- What competitive advantages do we have that can't be easily replicated, and how defensible are they?
- What is the market size for our product if we remain independent vs. embedded within a larger organization?
- Can we raise sufficient capital to outlast competitive threats and capture disproportionate market share?
- What is our timeline to profitability and what capital remains available?
- Are there acquirers whose position makes them uniquely able to leverage our technology?
Cleanlab's story suggests that when an acquirer's competitive position makes them exceptionally valuable as a deployer of your technology, the value of remaining independent may be lower than the acquisition price.

Competitive Landscape: Alternative Data Labeling Solutions
Comparing Approaches Across Providers
The Handshake acquisition of Cleanlab raises the question: what alternatives exist for organizations seeking high-quality labeled data, and how do they compare?
Scale AI: Focuses on breadth and customer relationships with major AI labs and autonomous vehicle companies. Offers managed labeling services and APIs. Strength is customer relationships and reliability. Weakness may be cost and turnaround time for specialized domains.
Surge AI: Emphasizes specialized expert labelers in technical domains. Strength is quality in vertical areas like code, ML, and technical documentation. Weakness is narrower application across domains.
Mercor: Focuses on code labeling and ML engineering tasks. Offers crowdsourced and specialized options. Good for organizations needing code quality assessment and ML training data.
Appen: Established player in crowdsourced data labeling, acquired Crowd Flower. Strength is scale and long operational history. Weakness is potential quality inconsistency from crowd work.
Platform-based alternatives: Tools like Labelbox, Label Studio, and Prodigy enable organizations to build internal labeling operations. Strength is control and customization. Weakness is operational overhead and hiring/training labelers.
In-house plus weak supervision: Organizations build internal labeling teams and use weak supervision techniques (rules, patterns, heuristics) to augment human labeling. Strength is control and customization. Weakness is resource intensity.
For organizations needing high-quality labeled data, the choice among these alternatives depends on:
- Volume requirements: Large-scale needs favor established providers like Handshake or Scale AI
- Specialization needs: Specialized domains favor vertical-focused providers like Surge or Mercor
- Budget constraints: Cost-sensitive organizations might choose platform tools or crowdsourcing
- Quality requirements: Safety-critical applications require providers with strong quality assurance
- Speed requirements: Fast turnaround favors established providers with operational scale
For organizations prioritizing data quality assurance and automation, platforms like Runable (which offers AI-powered workflow automation) can complement traditional data labeling by automating the quality control process, validation steps, and error detection workflows that would otherwise require manual effort.
Looking Forward: The Evolution of Data Labeling Infrastructure
Technological Trajectory: Improving Efficiency
The trajectory of data labeling technology suggests several improvements likely in coming years:
Algorithmic sophistication: Confident learning and related approaches will likely improve, with better ability to detect errors across different data types and domains. This creates pressure on competitors to match or exceed Handshake's capabilities.
Integration with broader AI pipelines: Rather than standing alone, data quality algorithms will likely integrate with active learning, model training, and deployment pipelines. This creates a more seamless workflow where data quality feedback continuously improves as models iterate.
Personalization and specialization: Systems may increasingly specialize algorithms to specific types of errors or specific labeling tasks, rather than applying general algorithms uniformly.
Cost reduction: As algorithmic approaches mature and are deployed at scale, per-label costs should decrease, improving market economics.
Automation of auxiliary tasks: Beyond label quality, automation could address task specification, labeler selection, label aggregation, and other aspects of the labeling pipeline.
Market Size and Growth Projections
The data labeling market has grown substantially as AI adoption accelerated. Market sizing estimates from various sources suggest the market was valued at $2-4 billion in 2023 and growing at 20-30% annually. This growth is driven by:
- Increasing adoption of machine learning across industries
- Growth in multimodal AI models requiring diverse training data
- Regulatory requirements for explainability and bias detection
- Expansion into domains like healthcare and autonomous vehicles requiring specialized labeling
Handshake's reported $300 million ARR suggests it captured roughly 7-15% of the total market, depending on sizing assumptions. If Handshake's acquisition of Cleanlab improves its competitive position and it grows faster than the market, its market share could expand.
The Role of Synthetic Data and Alternatives
A key long-term question is whether synthetic data generation and other alternatives will reduce demand for human labeling. Evidence suggests this won't happen soon:
- Regulatory requirements: Many regulated domains (healthcare, finance) require real data for compliance and liability reasons
- Domain specificity: Synthetic data is most useful for augmentation and scaling, not for initial core model training
- Changing distributions: Real-world data distributions change over time, requiring fresh human labeling to keep models current
- Edge cases and adversarial scenarios: Synthetic data struggles to generate realistic edge cases and adversarial examples
Rather than replacing human labeling, synthetic data will likely complement it, with organizations using mixtures of human-labeled real data and synthetic augmentation. This could increase the efficiency of human labeling (by reducing the volume needed) but won't eliminate it.
Broader Industry Implications
Talent Acquisition and ML Research Organization
One of the most significant implications of the Handshake-Cleanlab acquisition relates to how companies organize ML research. By acquiring Cleanlab as a unit of researchers, Handshake demonstrated that paying acquisition premiums for research talent can be economically justified if that talent is working on strategically important problems.
This has implications for how other companies build research organizations. Rather than hiring ML researchers as individual contributors, companies might acquire entire research teams or startups built around specific research directions. This approach:
- Preserves team cohesion and institutional knowledge
- Accelerates research progress by maintaining focus and avoiding disruption
- Signals commitment to the research direction to the broader research community
- Creates alignment between research output and business needs
We may see more acquisitions of ML research startups (as opposed to customer-facing startups) as companies recognize that research talent is a defensible competitive advantage.
The Shift Toward Embedded Quality Control
Historically, quality assurance was often an afterthought or secondary consideration in data production pipelines. The Handshake-Cleanlab integration represents a shift toward embedding quality assurance mechanisms directly in the core pipeline, rather than treating it as a separate, optional step.
This has implications beyond data labeling:
- In ML ops and MLOps platforms, quality monitoring is increasingly central rather than peripheral
- In application development, automated quality checks and testing are increasingly embedded rather than bolted on
- In data engineering, data quality validation is increasingly a first-class concern with dedicated tooling
Organizations that treat quality as peripheral and bolt-it-on later will find themselves disadvantaged relative to organizations that embed quality in their core processes.
Competitive Moats Through Vertical Integration
The Handshake-Cleanlab acquisition also illustrates how vertical integration can create defensible competitive advantages. By controlling both the labor supply (through its platform relationships) and the quality assurance algorithms (through Cleanlab), Handshake can offer value propositions that competitors struggle to match:
- Competitors using Handshake for labor can't easily replicate the quality assurance advantage without building their own algorithms
- Handshake can continuously improve both the labor supply and quality assurance in lockstep
- Switching costs for customers increase because they'd lose both the labor relationship and the quality benefits
This pattern—where companies create competitive advantages through vertical integration of complementary capabilities—appears across technology markets and suggests that data labeling may eventually consolidate around a few vertically integrated providers.

Conclusion: Strategic Inflection Points in AI Infrastructure
The acquisition of Cleanlab by Handshake represents more than a routine acquisition of one startup by another. It reflects several important inflection points in the AI industry:
First, data quality is now recognized as strategically important rather than a nice-to-have. Organizations building and deploying AI models have moved past the era when accumulating maximum data was the primary goal. They now focus on ensuring that training data is accurate, representative, and free of systematic biases. This shift creates value for companies that can improve data quality, whether through algorithmic means (like Cleanlab) or operational means (like Handshake's expert labeler network).
Second, the data labeling market is consolidating around players that can offer integrated solutions. Handshake's advantage comes not just from having access to Cleanlab's algorithms but from being able to deploy them across its existing customer relationships and labeler network. This vertical integration creates competitive advantages that would be difficult for competitors to match quickly. As the market matures, we should expect to see more consolidation as specialized point solutions (like Cleanlab) integrate with larger platforms (like Handshake) that can maximize their economic value.
Third, research talent is an increasingly valuable acquisition target for companies building AI infrastructure. Traditional M&A thinking focuses on acquiring customer relationships, revenue streams, and market position. The Cleanlab acquisition shows that acquiring specialized research teams working on hard technical problems can be equally or more valuable. As AI becomes increasingly dependent on advancing the frontier of what's technically possible, expect more acquisitions focused on acquiring research talent rather than customer relationships.
Fourth, the competitive dynamics of AI infrastructure markets are shifting from head-to-head feature competition to ecosystem positioning. Northcutt's comment about choosing the source rather than the middleman reflects this shift. Handshake's strategic advantage comes not from having the best labeling interface or the most labelers, but from its position in the ecosystem—it's a platform that other labeling companies depend on. Control of key infrastructure creates more defensible competitive advantages than feature parity.
For organizations seeking solutions to data quality and labeling challenges, the Handshake-Cleanlab acquisition confirms the importance of this issue. The fact that a company with $300 million in ARR chose to acquire specialized algorithms in this domain shows that data quality is not a solved problem and remains a significant competitive concern. Organizations should prioritize data quality in their AI development pipelines rather than treating it as an afterthought.
Alternatively, teams building custom solutions might consider platforms that offer automation capabilities for quality control workflows. Runable, for instance, provides AI-powered automation for workflow processes that could help organizations automate aspects of their data validation and quality assurance pipelines, complementing or supplementing traditional data labeling services.
The landscape of AI infrastructure is becoming increasingly sophisticated. What once was a simple problem—"how do we get labeled data?"—has evolved into a complex ecosystem question: "how do we ensure we have the right data, labeled correctly, efficiently processed, and continuously validated?" Companies that can address all these questions with integrated solutions will likely capture disproportionate value in the coming years.
FAQ
What is the significance of Handshake's acquisition of Cleanlab?
Handshake's acquisition of Cleanlab represents a strategic move to integrate advanced data quality assurance algorithms directly into its data labeling pipeline. The deal was structured as an acqui-hire of nine key researchers, including three MIT-trained co-founders. This acquisition allows Handshake to offer customers improved data quality assurance without requiring expensive inter-rater review processes, creating a competitive advantage in the rapidly consolidating data labeling market.
How does Cleanlab's confident learning technology work?
Cleanlab's confident learning algorithm identifies mislabeled training data by analyzing the statistical patterns in model predictions. When a model trained on a dataset produces predictions that strongly disagree with the provided labels, this disagreement signals potential label errors. The algorithm ranks suspicious labels by confidence level and flags the most problematic items for human review or removal, eliminating the need for expensive secondary labeling verification. This approach can identify label errors with 90%+ precision, making quality assurance economically viable at scale.
What are the key benefits of integrating Cleanlab's technology into Handshake's operations?
The integration enables Handshake to deliver higher-quality labeled data with lower error rates, improving model performance for customers. Research shows that removing even 5-10% of mislabeled data can improve model accuracy by 1-3%. Additionally, organizations can achieve target accuracy with less total data needed, reducing labeling volume and costs. The technology also enables Handshake to identify patterns in individual labeler accuracy and route future tasks to labelers most suited for specific domains, continuously improving quality without proportional cost increases.
Why did Cleanlab choose to sell to Handshake instead of competitors like Scale AI or Surge?
Cleanlab's CEO Curtis Northcutt explained the decision strategically, noting that competitors like Scale AI, Surge, and Mercor frequently use Handshake's platform to source specialized labelers. By selling to Handshake—the source of labor supply rather than a middleman—Cleanlab's technology would be deployed by the company controlling a critical infrastructure piece. This positioning gave Handshake unique leverage to implement the technology across its entire pipeline and customer base, whereas selling to a competitor would have limited deployment opportunities and kept them dependent on Handshake for labor sourcing.
How does this acquisition affect the broader data labeling market?
The acquisition accelerates consolidation in the data labeling industry by creating a vertically integrated player combining labor supply, customer relationships, and proprietary quality assurance algorithms. Competitors like Scale AI and Surge now face pressure to match Handshake's quality advantages either by developing comparable algorithms internally or acquiring alternative technologies. This consolidation pattern is typical in infrastructure markets—larger, well-capitalized players acquire specialized capabilities that improve their competitive moats. Smaller competitors and vertical specialists may focus on domain-specific niches where they can maintain competitive advantages.
What alternatives exist for organizations needing high-quality labeled data?
Organizations have several options beyond Handshake, including Scale AI and Surge for managed labeling services, Mercor for specialized code labeling, Appen for crowdsourced labeling, and self-managed approaches using tools like Labelbox or Label Studio. Specialized approaches include implementing internal labeling teams with hierarchical review, using weak supervision and data programming techniques, or applying active learning to reduce labeling volume. For organizations wanting to automate quality assurance workflows across these approaches, platforms offering workflow automation like Runable can help standardize validation processes and reduce manual review overhead.
What impact will synthetic data have on demand for human labeling services?
While synthetic data and augmentation techniques will reduce organizations' overall labeling volume needs, human labeling will remain essential for core model training. Regulatory requirements in healthcare and finance mandate real data for compliance. Real-world data distributions continuously shift, requiring fresh human labeling to keep models current. Synthetic data is most valuable for augmentation and scaling existing labeled datasets rather than replacing initial human labeling. The long-term effect will likely be increased efficiency (needing less human-labeled data) rather than elimination of human labeling services.
How does data quality impact AI model performance?
Data quality directly impacts model performance through multiple mechanisms. Removing mislabeled data improves accuracy by 1-3% in typical scenarios; correcting incorrect labels shows even larger improvements of 2-5%. High-quality data allows models to converge faster during training, requiring fewer epochs and computational resources. Quality data also reduces systematic biases in models, improving fairness and generalization. For mission-critical applications like medical diagnosis or autonomous driving, the performance difference between models trained on clean versus noisy data can determine whether the system is safe and reliable.
What makes data quality such an important focus for AI infrastructure companies today?
Early AI research focused on data quantity—building larger datasets was the primary path to better models. As the field has matured, evidence shows that quality matters more than quantity beyond a certain threshold. Noisy data actually reduces model performance and requires larger models to compensate. Organizations now recognize that investing in data quality provides better returns than spending equivalent resources on raw compute or model scaling. This shift reflects the industry moving from data scarcity (where bigger datasets dominated) to quality scarcity (where clean, accurate datasets command premium valuations).
How might Handshake's data quality improvements create competitive advantages?
Handshake can leverage Cleanlab's technology to offer customers empirical proof of superior data quality—better performing models, faster training, and improved generalization. This differentiation justifies premium pricing compared to competitors offering standard labeling services. The company can also use error pattern analysis to preferentially assign specialized labelers to tasks where they're most accurate, creating continuous quality improvement. Perhaps most importantly, customers that see performance improvements from Handshake's labeled data increase switching costs—they become dependent on the quality they've come to expect.
What strategic lessons does the Cleanlab acquisition offer to technology founders?
The acquisition illustrates several lessons: controlling customer relationships matters more than controlling the product alone; competitive dynamics can shift quickly, making timing of exit decisions critical; ecosystem positioning (being the source vs. a middleman) creates strategic advantages; and sometimes joining a larger organization positions your technology for greater impact than remaining independent. For founders evaluating acquisition offers, the relevant question isn't just "what's the price" but "who is best positioned to deploy this technology at scale and capture its full value."
Key Industry Takeaways
The Handshake-Cleanlab acquisition demonstrates that data quality has become a strategic priority in AI development, commanding significant capital investment and competitive focus. As the industry matures, expect consolidation around players offering integrated solutions combining labor supply, customer relationships, and quality assurance capabilities. Organizations building AI systems should prioritize data quality in their development pipelines, and companies operating in AI infrastructure should consider how vertical integration creates defensible competitive advantages in their markets.
Key Takeaways
- Data quality is now strategically important—organizations recognize it matters more than raw data quantity
- Cleanlab's confident learning algorithms detect label errors with 90%+ precision without requiring expensive inter-rater verification
- Handshake's acquisition of Cleanlab as a research team enables vertical integration combining labor supply, customer relationships, and quality assurance
- Removing 5-10% of mislabeled data typically improves model accuracy by 1-3%, with significant ROI for organizations
- The data labeling market is consolidating around integrated players—smaller competitors face pressure to specialize or be acquired
- Alternative approaches to quality assurance include crowdsourcing, weak supervision, active learning, and internal labeling teams
- Synthetic data complements but doesn't replace human labeling in regulated domains and for core model training
- Ecosystem positioning and vertical integration create more defensible competitive advantages than feature parity alone
- Research talent in ML is an increasingly valuable acquisition target that commands premium acquisition valuations
- Organizations should prioritize data quality in development pipelines and consider automation platforms for validation workflows

