![How AI Humanizer Plugins Turn Detection Rules Into Evasion Tools [2025]](https://tryrunable.com/blog/how-ai-humanizer-plugins-turn-detection-rules-into-evasion-t/image-1-1768999120639.jpg)
Introduction: The Irony of Detection Becoming Evasion
Here's something that would make any content moderator's head spin: the internet's most comprehensive guide to spotting AI-generated writing has become a manual for hiding it. In January 2025, a tech entrepreneur released an open-source plugin called "Humanizer" that does exactly that. It takes Wikipedia's carefully cataloged list of telltale AI writing patterns—compiled by volunteers over more than a year—and feeds them directly to AI models with simple instructions: don't do that. This development was detailed in Ars Technica's report.
It sounds almost absurd, right? But it's also perfectly logical. When you spend months documenting exactly how something works, you're inevitably creating a blueprint that goes both directions. The Wikipedia editors at Wiki Project AI Cleanup thought they were building a defense. They ended up accidentally helping construct the offense.
This isn't just a quirky internet irony. What's happening here is bigger. It reveals something fundamental about the entire AI detection ecosystem. These tools are fragile. They're based on pattern matching, and patterns can be learned, documented, and systematically avoided. It's a cat-and-mouse game that's only going to accelerate.
But before we get into why detection is failing and what comes next, let's understand what we're actually trying to detect. What does AI writing look like? Why do we care? And most importantly, is any of this actually working?
The answers are messier than you'd think.
TL; DR
- Wikipedia's AI Cleanup Project documented 24+ specific language patterns used by AI models, creating an open-source detection guide.
- Humanizer Plugin converts these detection rules into avoidance instructions for Claude, making AI output sound more human by explicitly telling it what not to do, as reported by Ars Technica.
- Detection failures are fundamental because AI text isn't inherently different from human text—both can exhibit similar patterns.
- False positive rate of 10% means legitimate human writing gets flagged as AI at scale, creating detection tradeoffs, as discussed in UC Strategies.
- The real problem is that prompt engineering can circumvent pattern-based detection, making comprehensive AI detection nearly impossible without deeper analysis, according to The New York Times.

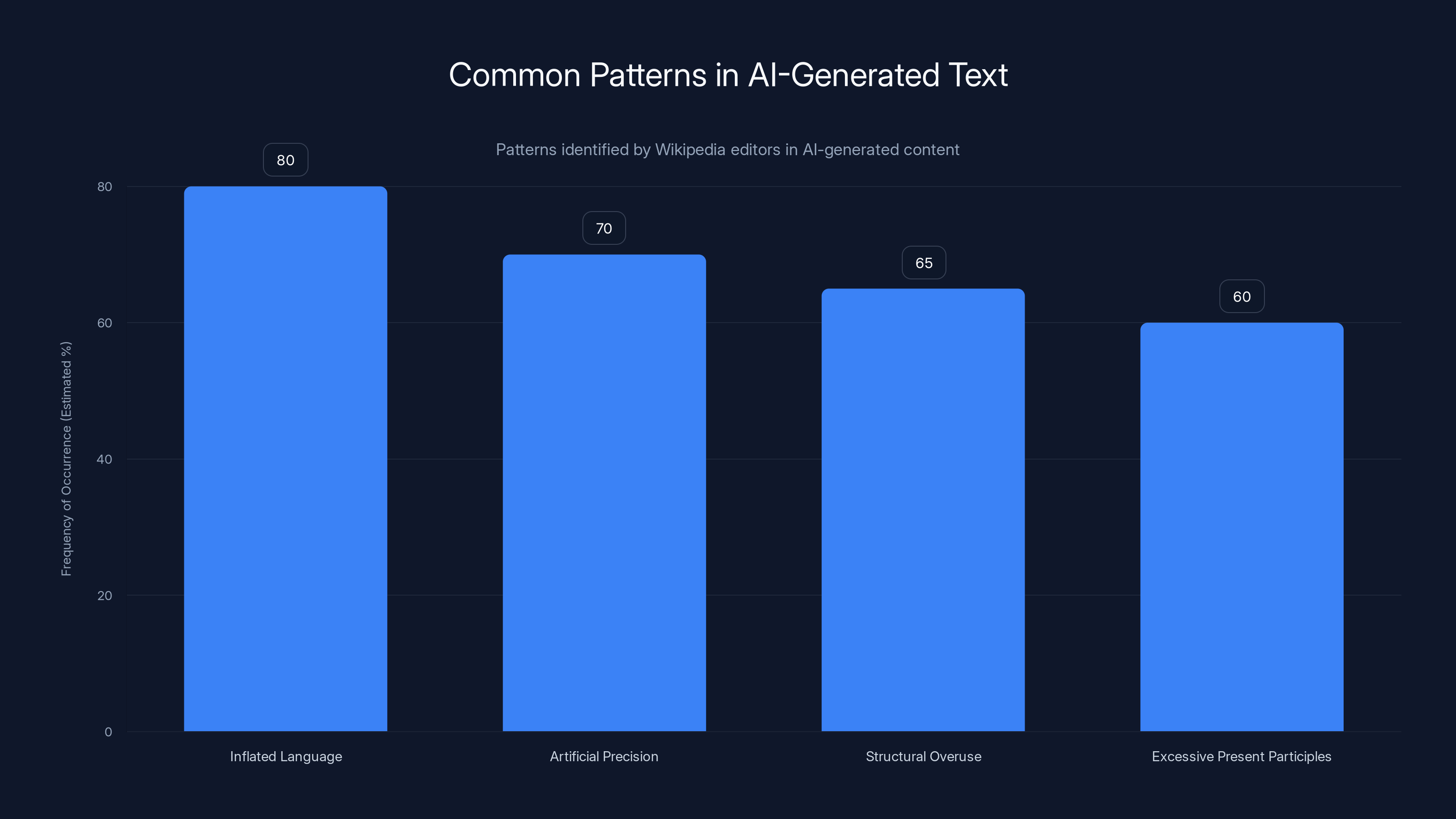
Estimated data shows inflated language is the most frequent pattern in AI-generated text, followed by artificial precision and structural overuse.
The Genesis of Wiki Project AI Cleanup: Volunteer Detection at Scale
Wikipedia editors have been fighting vandalism since the site's inception in 2001. They've developed sophisticated systems for catching spam, detecting sockpuppet accounts, and identifying plagiarism. When AI models started getting good enough to generate plausible encyclopedia entries, the community realized they had a new problem on their hands.
The scale of the challenge became apparent in late 2023. Wikipedia editors were noticing something odd. Articles were appearing that had the correct structure, adequate citations, and seemingly coherent information, but something felt off. The prose felt too smooth, too promotional, too formulaic. It was like watching someone try to write in a language they'd learned from a textbook—technically correct but rhythmically wrong.
That's when French Wikipedia editor Ilyas Lebleu founded Wiki Project AI Cleanup. The mission was straightforward: identify AI-generated articles, document what gave them away, and clean them up before they polluted the encyclopedia.
What started as a small group of volunteers rapidly became something more systematic. By August 2025, they'd tagged over 500 articles for review and published a formal, public guide listing the patterns they'd consistently observed. The guide is detailed and specific, with actual examples from flagged articles, as noted in ABC News.
The volunteers weren't trying to create a detection algorithm. They were just documenting their observations. But in doing so, they created something that looks suspiciously like the inverse of what a good AI prompt should look like.


AI detection tools face challenges with approximately 10% false positives and 20% missed AI texts, highlighting the difficulty in distinguishing AI-generated content from human writing. (Estimated data)
Understanding the 24 Patterns: What Wikipedia Found
Let's be concrete about what Wikipedia editors kept seeing. The guide isn't a mysterious black box—it's publicly available and surprisingly specific. Understanding these patterns gives you insight into how current AI models behave and why they behave that way.
The first big category Wikipedia flagged was inflated language. AI models have a tendency to treat their subjects like they're writing tourism brochures. Phrases like "marking a pivotal moment," "stands as a testament to," and "represents a significant milestone" show up constantly in AI-generated text. When describing places, AI tends to use adjectives like "breathtaking," "picturesque," or "nestled within." These aren't inherently wrong, but they create a cumulative effect.
Why does this happen? Partly because AI models are trained on internet text that includes plenty of marketing copy, promotional writing, and sensationalism. They're learning patterns from everything, and enthusiasm is a common pattern in high-engagement text, as explained in Vocal Media.
The second major pattern is what Wikipedia calls artificial precision combined with vagueness. AI models will sometimes generate very specific statistics that sound authoritative but lack sources. Or they'll make broad claims that sound particular without actually committing to anything. It's the textual equivalent of confidence without competence.
Then there's the structural overuse of certain formatting elements. AI loves numbered lists, headers, and bullet points. It breaks up text in ways that feel methodical and comprehensive, but it often overdoes it compared to how humans naturally write.
Another strong signal is the excessive use of present participles (words ending in "-ing") at the end of clauses to sound analytical. "The economy showed consistent growth, symbolizing the region's commitment to innovation." That's peak AI. Humans don't naturally talk like that.
Wikipedia also flagged what they called "false balance falsehoods." Some AI models, particularly when asked to present both sides of an issue, will generate fake counterarguments or strawman versions of opposing viewpoints. The arguments sound like they could be real but lack actual reasoning.
There's also the issue of what Wikipedia calls "promotional tone in an encyclopedia context." Good encyclopedia writing should be neutral and informative. AI tends to slip into advocacy, emphasizing positive achievements while downplaying problems or criticisms.
The Humanizer Plugin: Converting Detection Into Avoidance
So here's where it gets interesting. Once those patterns were documented and made public, someone realized they could use that same list in reverse. Instead of flagging text that matches those patterns, you could instruct an AI model to deliberately avoid those patterns.
That's exactly what Siqi Chen did with Humanizer. It's a skill file for Claude Code, which is Anthropic's terminal-based coding assistant. Skill files are essentially structured prompt additions that Claude models are specifically fine-tuned to interpret with precision. They're more reliable than typical system prompts because they use standardized formatting that the model recognizes, as detailed in Ars Technica.
The plugin takes Wikipedia's 24-point checklist and converts it into instructions. Where Wikipedia says "AI tends to use inflated language," Humanizer tells Claude "replace inflated language with plain facts." The example transformation illustrates the approach perfectly:
Before (AI-style): "The Statistical Institute of Catalonia was officially established in 1989, marking a pivotal moment in the evolution of regional statistics in Spain."
After (human-style): "The Statistical Institute of Catalonia was established in 1989 to collect and publish regional statistics."
The difference is striking. The human version removes the adjectives, cuts the inflated phrasing, and gets straight to the actual information. It trades eloquence for clarity.
Humanizer includes other instructions too. It tells Claude to use more varied sentence lengths, to include actual opinions rather than just reporting facts, to avoid excessive formatting, and to adopt a more conversational tone overall. It's basically telling the AI model: write like a person who knows what they're talking about, not like a machine that's trying to sound impressive.
The plugin garnered over 1,600 GitHub stars in its first few days. That kind of adoption says something. People clearly see value in making their AI-generated content less obviously AI-generated.
But does it actually work? That's the next question, and the answer is more nuanced than you'd hope.
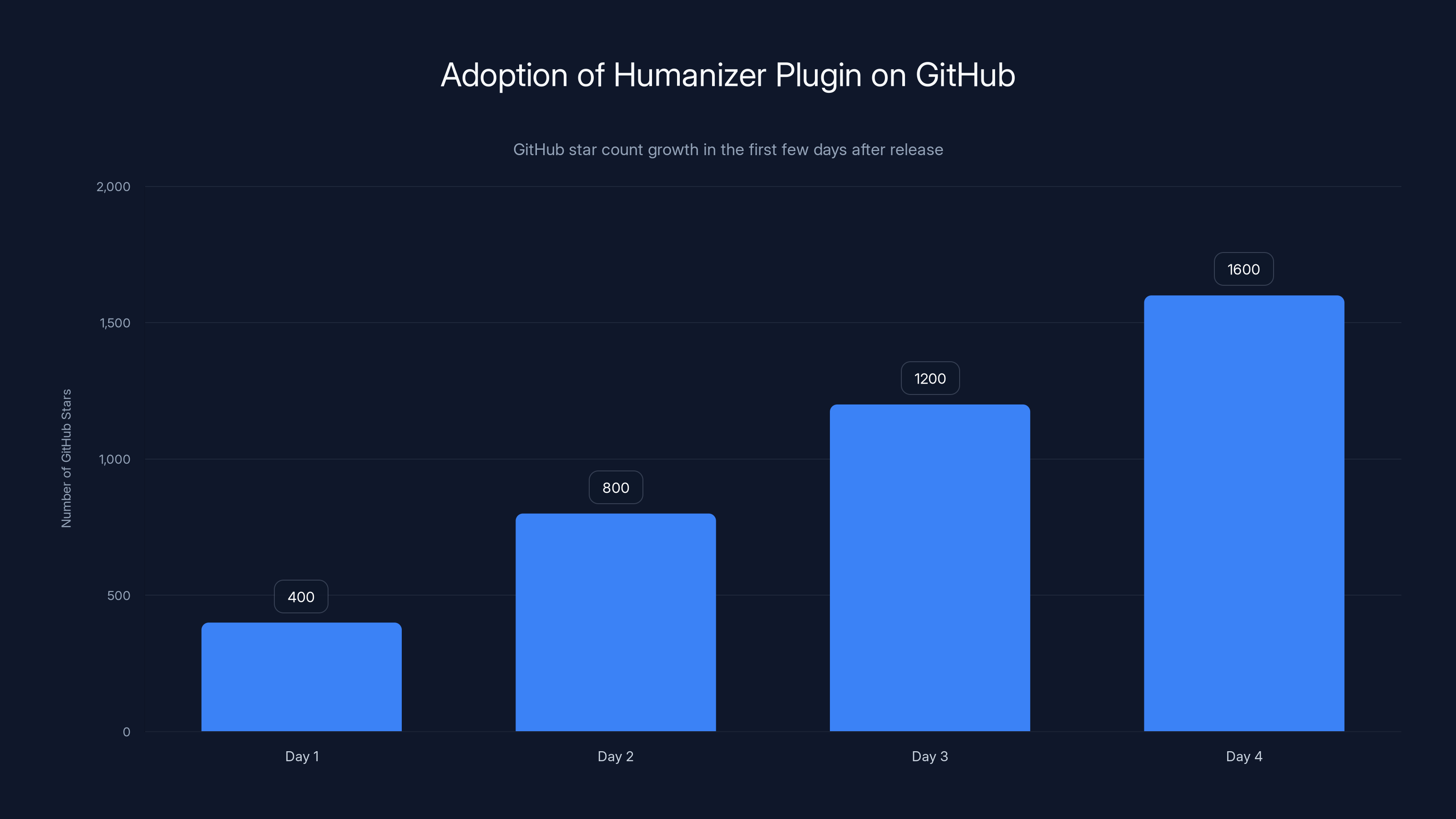
The Humanizer Plugin quickly gained popularity, reaching over 1,600 GitHub stars within the first four days of its release. Estimated data based on typical adoption rates.
Testing Humanizer: Does It Actually Make AI Sound Human?
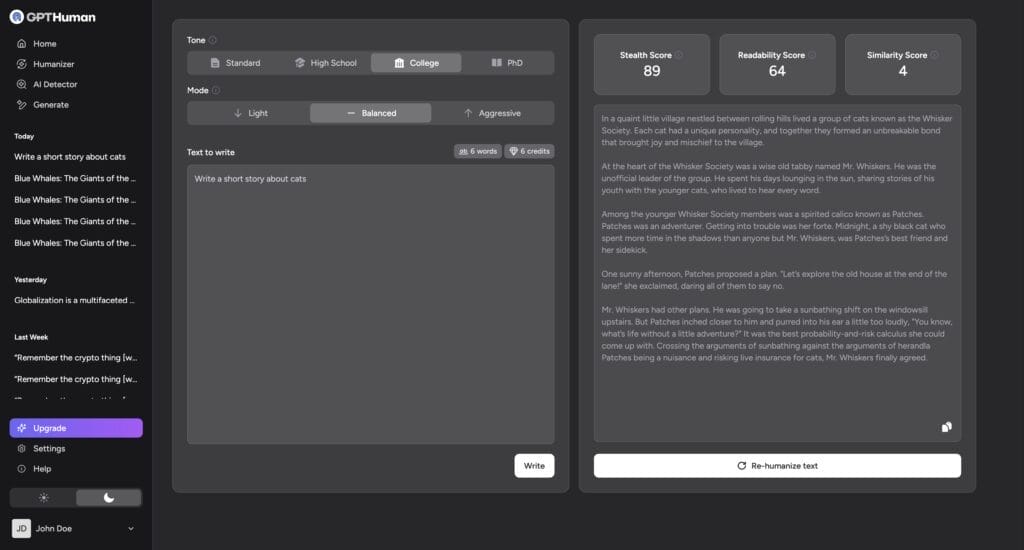
In practical testing, Humanizer does affect Claude's output. Text generated with the plugin active does sound less precise and more casual. It reads with more variation and includes more conversational language. When the plugin works well, it's genuinely harder to immediately identify the text as AI-generated.
But here's where it gets complicated. The skill file doesn't always work perfectly. Language models don't always follow instructions with 100% reliability, especially complex or conflicting instructions. Sometimes the model will include personality but lose precision. Other times it'll try to balance multiple instructions and do neither particularly well.
There are also genuine tradeoffs embedded in the instructions themselves. One line says "Have opinions. Don't just report facts, react to them." That works great if you're writing an opinion piece or a review. It's terrible if you're trying to write technical documentation, legal language, or scientific papers where neutrality matters.
Another instruction tells Claude to "avoid unnecessary jargon." That's good general advice for clarity, but it can backfire when jargon is actually necessary for accuracy. If you're writing about cybersecurity vulnerabilities or pharmaceutical mechanisms, using the correct terminology isn't a sign you're an AI—it's a sign you know your subject.
The skill file also can't improve the fundamental issue: factuality. Humanizer makes the writing sound more human, but it doesn't make the facts more accurate. If Claude hallucinates information, Humanizer won't catch it. The text will just be wrong in a more conversational way.
So in summary, Humanizer is a partial solution. It helps with style, tone, and surface-level indicators of AI writing. But it doesn't solve the deeper detection challenges, and it introduces new problems if you're using it for specialized content.

The Fundamental Problem: Why AI Detection Is Failing
But let's step back from the specific plugin and talk about the bigger issue. Humanizer works, partially, because it's addressing a fundamental misconception about AI detection. People assume that AI writing has some inherent quality that makes it detectable. It doesn't. There's nothing magical about human writing that reliably separates it from large language model writing.
Think about it logically. Large language models are trained on billions of examples of human writing. They've learned patterns from professional journalists, academic researchers, technical writers, marketing copywriters, fiction authors—basically every category of human text available online. When an AI model generates text, it's pattern-matching against that enormous corpus.
So if the AI model can be told to match different patterns—patterns that humans also use—then the output becomes harder to distinguish from human writing. The AI isn't doing something impossible. It's just matching patterns from different parts of its training data, as explained in The New York Times.
This is why OpenAI faced what their engineers described as a "yearslong struggle" against the em dash. Some users kept noting that AI text uses em dashes at certain frequencies that differ from typical human writing. OpenAI would try to adjust the model's behavior. Users would report the problem was fixed. Then they'd find new patterns. It's essentially an arms race between detection and evasion, and evasion has fundamental advantages.
Here's the really important part: humans can also write in AI-like ways. If a professional writer writes like they're following a checklist—formatted lists, present participles, flowery adjectives, structure-obsessed organization—their writing might trigger AI detection tools. According to research cited by Wikipedia itself, approximately 10% of detections using pattern-based methods are false positives. That's significant. It means for every 100 pieces of human writing you flag as AI, roughly 10 are actually human, as highlighted in UC Strategies.
That creates a real problem. If you have a detection system that catches 90% of AI content but also misflag 10% of human content, you've created a system that might do more harm than good. False positives discourage legitimate writing, suppress human creativity, and create distrust in content authenticity.
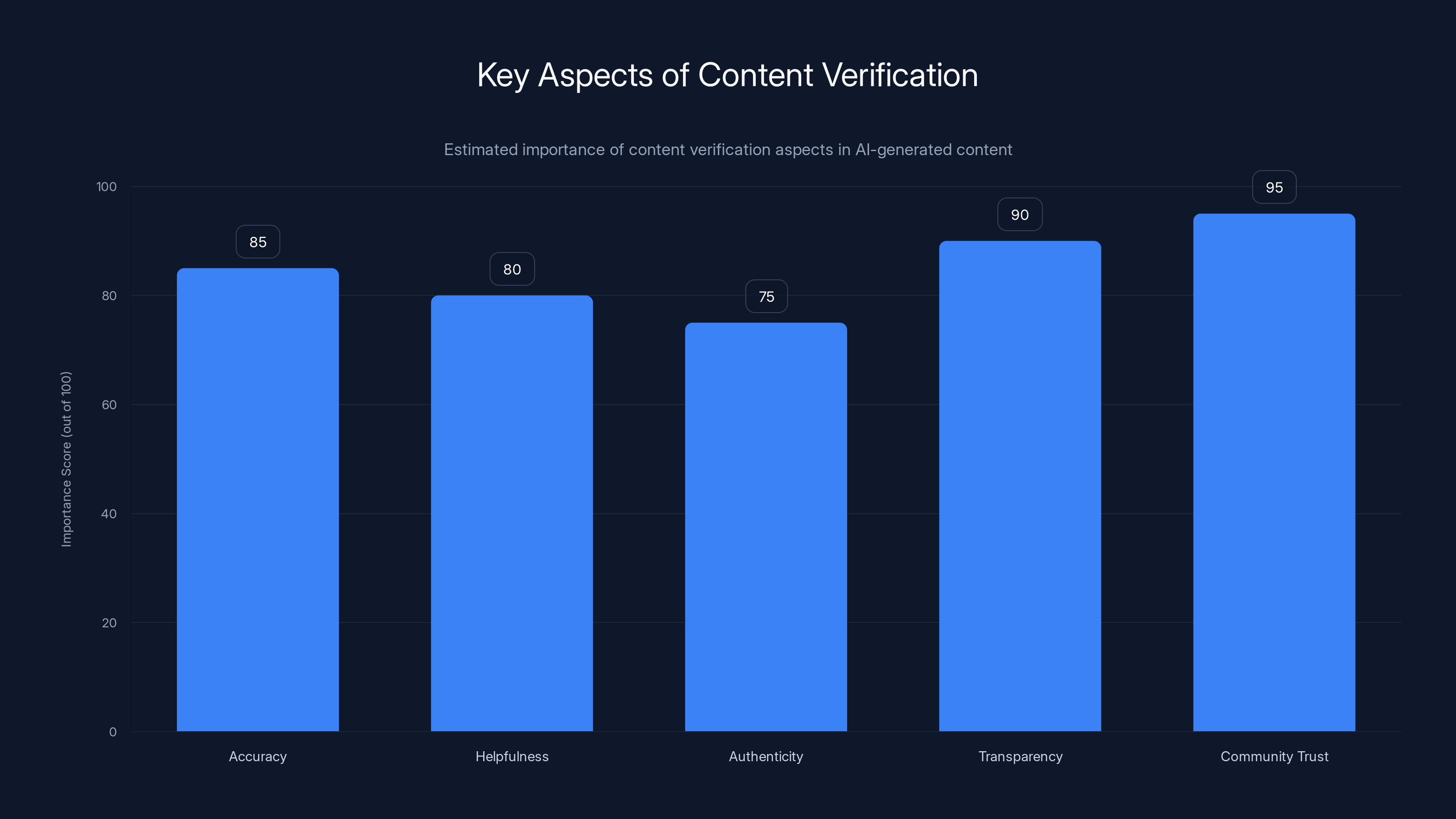
Estimated data shows that transparency and community trust are crucial for verifying AI-generated content, surpassing traditional detection methods.
The Limits of Pattern-Based Detection
The core issue is that Wikipedia's approach, and by extension Humanizer's counter-approach, are both pattern-based. They're identifying surface-level markers and responding to them. But surface-level markers are inherently unreliable.
Consider an analogy. Suppose someone says that people often do certain things when they're lying—they avoid eye contact, they touch their face, they pause longer before responding. Now suppose someone learns that list and deliberately does the opposite while lying. Are they less likely to be caught? Sure. But what about honest people who naturally avoid eye contact or touch their face while thinking? They'd be incorrectly suspected.
That's the problem with pattern-based detection. The patterns are useful signals, but they're not definitive. They're correlations, not causation.
There's also the problem of adversarial examples. Machine learning researchers have long known that you can create "adversarial" inputs that fool detection systems by making minimal changes that fool the detector but don't significantly change the output. In this case, the adversarial changes are made intentionally—using Humanizer to teach the AI to avoid the detected patterns.
What all this suggests is that effective AI detection probably needs to go beyond pattern matching. It needs to analyze the substantive content of what's being written. Does the reasoning actually follow? Are the claims verifiable? Are citations accurate? Do the examples actually support the arguments being made?
Those are harder problems to automate. A detection system built on factual verification would need to actually understand the claims being made, look up information independently, and determine whether the text is accurate. That's way more computationally expensive and requires domain-specific knowledge. Wikipedia editors can do it manually because they're domain experts and critical readers. Doing it at scale with automated systems is exponentially harder.

Why The Wikipedia List Became Public (And What That Means)
It's worth asking why Wikipedia made their detection guide public in the first place. The answer reveals something interesting about how the internet community approaches these problems.
Wikipedia's philosophy is fundamentally open and transparent. The community believes in publishing their research, their methods, and their findings. They wanted other platforms to benefit from their experience. They wanted researchers to study the problem. They wanted clarity about what patterns they were using to identify AI content.
This transparency is generally good. It allows independent verification, enables other communities to learn from Wikipedia's experience, and prevents any single organization from hoarding detection methods. Transparency builds trust.
But it also has this side effect: it creates a publicly available manual for evasion. Once you publish your detection criteria, anyone with technical skills can reverse-engineer it into avoidance instructions. That's exactly what happened with Humanizer, as noted in Ars Technica.
This creates an interesting policy question. Should AI detection methods be kept secret? Should Wikipedia have gatekept their findings? Should there be a responsible disclosure process where detection methods are shared privately with AI companies before being made public?
The tradeoff is real. Transparency enables broader learning but also enables evasion. Secrecy prevents evasion but limits who can benefit from the knowledge and creates trust issues.
Most organizations in the AI safety space have landed on transparency, albeit sometimes with some delay. Responsible disclosure usually means giving companies time to patch before vulnerabilities are public. But eventually, the goal is full transparency.

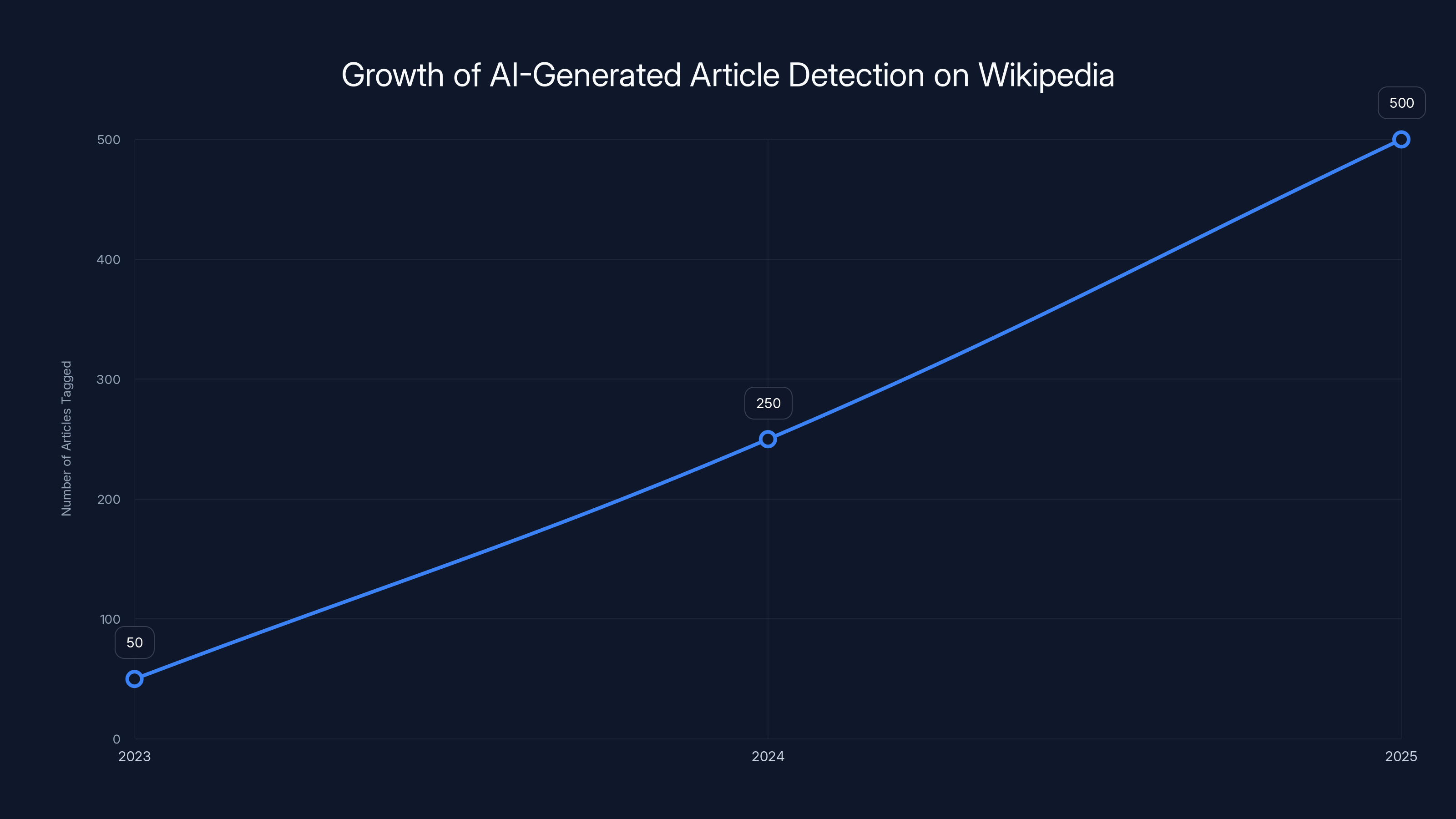
The number of AI-generated articles tagged by WikiProject AI Cleanup volunteers grew significantly from 2023 to 2025, highlighting the increasing scale of AI content detection efforts. Estimated data.
The Cat-and-Mouse Game: Detection vs. Evasion Cycles
What we're watching unfold is essentially a classic information security arms race. Wikipedia identifies patterns. Someone creates tools to evade those patterns. Wikipedia and other communities identify new patterns. Someone creates better evasion tools. Round and round it goes.
This has happened in many other domains. Email spam detection evolved this way for decades. Antivirus software went through these cycles continuously. Content moderation on social platforms has to adapt constantly. The pattern is consistent: detection methods have a lifespan. They work until they don't.
The difference here is the speed. Email spam detection and antivirus software evolved over years or decades. AI detection methods are evolving over months. The technology is moving fast, and the adversarial cycle is accelerating accordingly.
There's also a power imbalance. Major AI companies have thousands of engineers. Wikipedia volunteers, while dedicated, are fewer in number. Detection research happens in academia and at companies, with varying resources. Evasion tooling—like Humanizer—can be built quickly by individuals or small teams and deployed instantly.
This suggests that pattern-based detection might have reached or be approaching its practical limits. You can catch the obvious stuff, the low-hanging fruit. But as the technology improves and as people get better at avoiding the detected patterns, you hit diminishing returns.
The detection rate plateaus. The false positive rate stays uncomfortable. Meanwhile, the sophistication of evasion techniques keeps increasing. Eventually, you're spending more resources detecting less of the problem.

Factual Verification: The Next Frontier
If pattern-based detection is hitting limits, what's the alternative? The most promising direction is factual verification. Instead of asking "does this sound like AI," ask "is this actually true."
This is harder because it requires domain knowledge and access to external information sources. But it's also much more robust. You can't easily evade a detection system that's checking whether your claims actually match reality.
Some platforms are experimenting with this. Fact-checking organizations use a combination of manual verification and automated checks. Search engines are starting to use knowledge graphs and cross-reference claims against trusted sources. Academic institutions are developing better plagiarism and fabrication detection.
The challenge is scale and accuracy. Manually fact-checking everything isn't economically viable. Automated fact-checking makes mistakes. There's also the problem of disagreement—some facts are genuinely disputed, and determining truth in those cases requires judgment, not just checking boxes.
But this approach is theoretically more sound. If you're checking whether the claims in an article are actually true, you're addressing the real problem that most people care about when they worry about AI-generated content. The concern isn't usually about style—it's about whether you can trust the information.

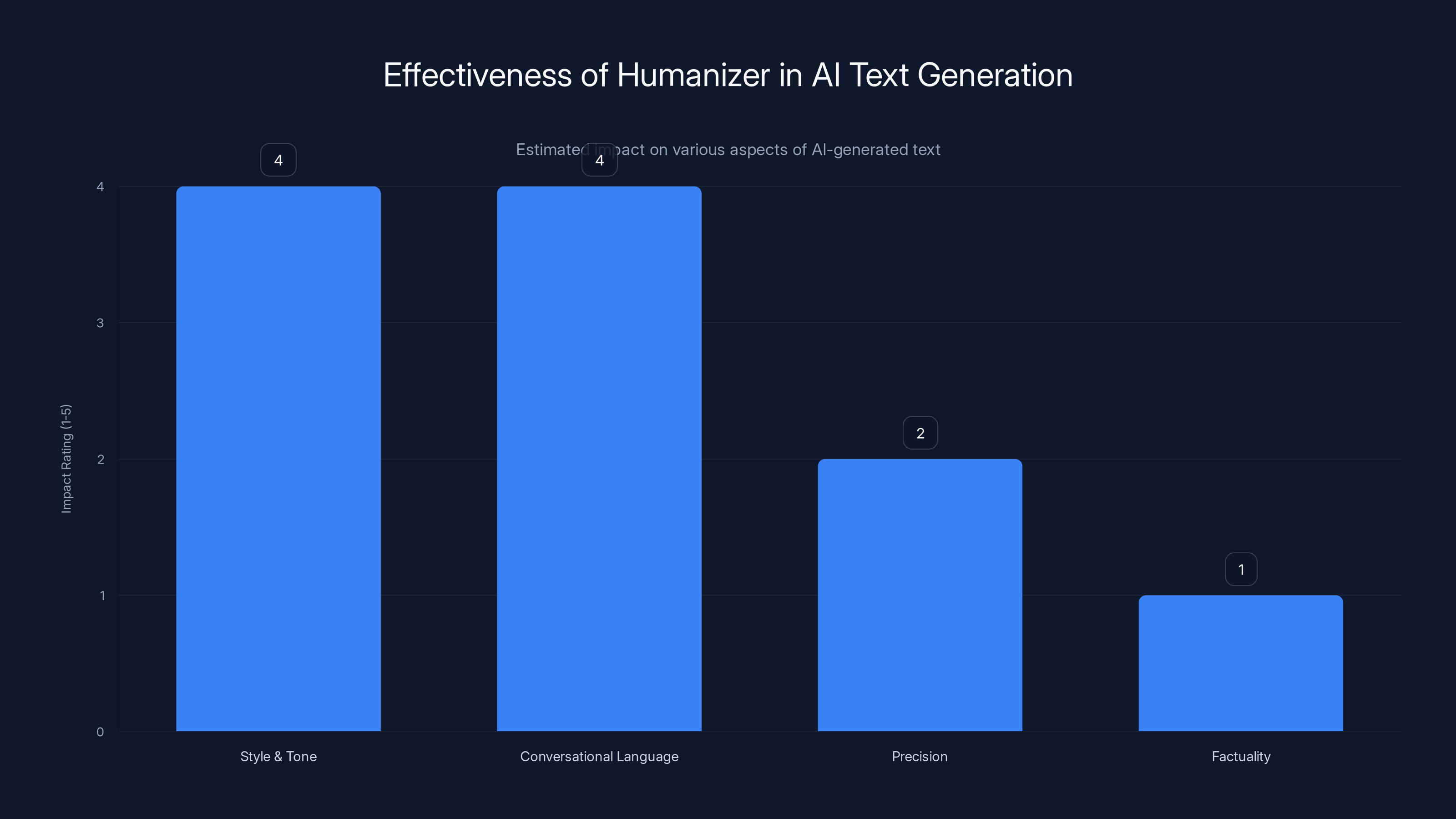
Humanizer significantly improves style and conversational tone but struggles with precision and factual accuracy. Estimated data.
The Business Incentives Problem
Here's something that doesn't get discussed enough: the business incentives in this space are weird and sometimes misaligned.
Wikipedia wants to keep AI out of their encyclopedia. That's clear. They care about content quality and authenticity. They're operating at essentially cost and from genuine mission-driven values.
But Anthropic, which provides Claude, has an interesting position. They provide the tool that enables both better AI writing and better evasion from detection. They're not explicitly incentivizing evasion, but they're not preventing it either. The skill file ecosystem enables use cases like Humanizer.
Content platforms like Reddit, YouTube, and others have mixed incentives. They want to preserve some notion of authenticity and user trust. But if AI-generated content makes money or drives engagement, there's pressure to allow it. They want detection to work well enough to prevent egregious abuse, but not so well that it impacts legitimate use cases.
Business customers who might want to use AI to generate content faster have obvious incentives to use tools like Humanizer. They want the efficiency of AI without the perception problems of AI-generated content.
These misaligned incentives make the overall problem harder to solve. There's no single entity with resources, motivation, and authority to enforce a comprehensive solution. Instead, you have multiple parties with different goals trying to shape the space according to their interests.
That's not necessarily bad—competition and disagreement can drive innovation. But it does mean that the detection versus evasion cycle will keep accelerating without clear resolution.
The Role of Regulation and Policy
You might think that governments would step in here, especially with AI being a topic of increased regulatory focus. And some jurisdictions are trying.
The EU's AI Act requires transparency about AI-generated content in certain contexts. There's discussion about labeling requirements for synthetic media. Some platforms are being asked to disclose when content is AI-generated.
But regulation in this space is tricky. Requiring disclosure of AI-generated content seems reasonable until you realize that it creates the weird incentive to better hide AI-generated content. If having AI in your content hurts your reputation or violates policy, creators have strong motivation to use tools like Humanizer.
There's also the challenge of definition. What counts as AI-generated? If a human writer uses Claude to brainstorm ideas, is that AI-generated content? If someone uses AI to optimize their writing for clarity and conciseness, does that count? The lines get blurry fast.
Effective regulation probably requires technical progress first. You need reliable detection or verification methods before you can sensibly require disclosure or labeling. Requiring disclosure of something you can't reliably detect creates a compliance nightmare.
Some experts argue that the focus should shift from detecting AI generation to detecting the actual problems you care about: misinformation, spam, content that violates specific policies. Those problems exist whether or not AI is involved, and they're what actually harm users and communities.
In that framing, the question isn't "was this AI-generated?" It's "is this accurate, helpful, and authentic according to our platform's values?"
Broader Implications for Content Authenticity
What's really happening here goes beyond Wikipedia, Claude, and plugins. It's part of a larger shift in how we think about content authenticity online.
For decades, the internet operated on a principle of relative trust. You encountered content, and you evaluated it based on context. Who published it? Is this a known source? Does it seem credible? That system was imperfect but workable.
AI complicates that system. If anyone can generate plausible-sounding content quickly, the traditional trust signals start degrading. You can't just rely on "it came from a credible source" because generating content in someone else's style is now technically feasible.
That creates pressure for new mechanisms. Some possibilities: cryptographic signing (proving that content came from a specific source), distributed verification (many parties attest to the authenticity or accuracy of content), blockchain-based provenance tracking, or official badges and labels.
Each approach has tradeoffs. Cryptographic signing works but requires infrastructure adoption. Distributed verification is resilient but decentralized and slow. Blockchain is trendy but for most applications is solving a problem that cryptographic signatures solve more simply. Badges and labels require some authority to issue them and people to trust that authority.
What's becoming clear is that "proving authenticity" is probably harder than "proving AI generation." You can't generally prove something is human-written. But with sufficient signatures, metadata, and provenance information, you can prove something came from a specific source.
That shift—from trying to detect AI to instead certifying provenance and authenticity—might be the direction the internet needs to move.
The Practical Reality for Content Creators
For people actually writing content—journalists, academics, marketers, technical writers—what does all this mean?
First, the tooling is going to keep improving on both sides. Detection will get more sophisticated. Evasion will get better too. The equilibrium point keeps shifting.
Second, disclosure might become more important than concealment. If regulations are coming, being transparent about what tools you used and how might become a competitive advantage rather than a liability. "This was written with AI assistance because it allowed us to focus on accuracy and clarity" might be a better position than "we hid the AI because we didn't want people to know."
Third, unique value proposition is increasingly about things AI can't easily replicate: original research, insider perspective, domain expertise, personal experience, fact verification. Those things are hard to fake and hard for AI to generate credibly.
Fourth, the writing itself probably matters less than the accuracy, usefulness, and trustworthiness of the information. Obsessing over whether your writing sounds human might be missing the point. Obsessing over whether it's accurate and helpful is probably more valuable.

Looking Forward: What Comes After Detection
The arc of this story suggests some likely futures.
One scenario: pattern-based detection gradually becomes less effective as evasion improves. Organizations focused on authenticity shift to factual verification and provenance tracking. AI-generated content becomes common and increasingly difficult to distinguish stylistically, but people care less because detection isn't the real problem—accuracy is.
Another scenario: regulatory pressure forces platforms and AI companies to implement more robust tracking of where content comes from. This might involve cryptographic signing, metadata requirements, or official disclosure systems. Detection becomes less important than certification.
A third scenario: we develop better fundamental AI architectures or training methods that produce text more aligned with human writing patterns from the start. The evasion arms race becomes less necessary because the "AI writing style" problem is solved upstream.
There's also the possibility that AI companies choose to watermark their outputs, voluntarily including signatures that prove content came from their models. This could be an advantage for companies wanting to protect their brand—if their output is watermarked, content claiming to be from their tool can be verified.
The most likely outcome is probably a combination of these. Some mix of better detection, better regulation, voluntary transparency, and improved fundamental technology. The problem is real enough that multiple solutions will develop, each solving pieces of it.
But pattern-based detection, as Wikipedia pioneered and Humanizer subverted, is probably reaching the limits of its usefulness. The game they've inadvertently demonstrated is one that evasion tends to win in the long term, especially when the evasion methods can be distributed as simple tooling.
Key Lessons From Wikipedia's Experience
What can organizations actually learn from how this played out?
First: transparency about your methods is valuable and important, even when it enables evasion. It builds trust, enables research, and helps others learn. The right response to Humanizer isn't that Wikipedia should have kept their findings secret. It's that everyone should be aware that published detection methods have lifespan limits.
Second: pattern-based detection works until it doesn't. Plan for the evolution of the problem and build flexible systems that can adapt when patterns change. Don't assume that your detection rules are permanent.
Third: focus on the actual problem you're trying to solve. If it's content accuracy, detect that. If it's spam, detect spam indicators. If it's policy violations, detect those. Using AI generation as a proxy for other problems is tempting but imperfect.
Fourth: build community into your solution. Wikipedia caught so many AI articles because human editors read them carefully. Automation is useful, but communities of engaged humans are powerful. Combine both.
Fifth: understand the incentives. Knowing that tools like Humanizer exist and why people want to use them helps you anticipate problems and respond appropriately.
FAQ
What is AI writing detection?
AI writing detection is the process of identifying text that was generated by artificial intelligence language models rather than written by humans. It typically uses pattern recognition to identify stylistic markers, formatting preferences, or linguistic tendencies that AI models commonly produce. However, pattern-based detection has fundamental limitations because the differences between AI and human writing are not always consistent or detectable without context.
How does the Humanizer plugin work?
The Humanizer plugin is a skill file for Claude Code that takes Wikipedia's documented list of AI writing patterns and converts them into explicit instructions for the AI to avoid those patterns. Instead of being flagged for writing inflated language or excessive passive voice, Claude is instructed to use plain facts, vary sentence structure, include genuine opinions, and write in a more conversational style. The plugin essentially teaches the AI to pattern-match against human writing examples rather than its typical training distribution, as noted in Ars Technica.
Why does AI writing have recognizable patterns?
AI models produce recognizable patterns because they're trained on large datasets of human text and learn statistical patterns from that data. They tend to replicate common patterns from their training data, including marketing language, formal academic structures, and prevalent stylistic choices. Additionally, certain patterns emerge from how transformers process language mathematically, leading to consistent tendencies in things like punctuation frequency and sentence construction. Over time, these patterns can be reverse-engineered into explicit instructions for avoiding detection.
What are the limitations of pattern-based AI detection?
Pattern-based detection has several fundamental limitations. First, there's no inherent quality that makes AI writing categorically different from human writing—both can exhibit similar patterns. Second, humans can write in AI-like ways, creating false positives at rates around 10% according to research. Third, once patterns are documented, they can be systematically avoided through prompt engineering. Fourth, AI models can be instructed to match different patterns from their training data, making pattern-based detection a game of constant adaptation. These limitations suggest that detection needs to evolve beyond surface-level stylistic analysis.
Should detection methods be kept secret?
There are reasonable arguments on both sides. Transparency enables broader learning, prevents any single organization from hoarding critical knowledge, and builds trust in how detection systems work. However, public detection methods can be reverse-engineered into evasion tools. Most AI safety organizations have settled on transparency with responsible disclosure—giving organizations time to implement defenses before vulnerabilities become widely public. However, some argue the focus should shift from detecting AI origin to detecting substantive problems like misinformation or policy violations, which are the actual harms people care about regardless of whether content is AI-generated.
What would make AI detection more reliable?
Moving beyond pattern-based detection toward factual verification would be more reliable. Instead of asking whether something sounds like it was written by AI, ask whether the claims made in the text are actually true. This requires checking citations, cross-referencing facts with independent sources, and verifying logical consistency. This approach is more robust because it directly addresses the underlying concern—not the origin of the content but its accuracy and trustworthiness. The tradeoff is that factual verification is more computationally expensive and requires domain-specific knowledge, making it harder to scale than pattern matching.
How should content creators respond to these detection and evasion developments?
Content creators should focus on producing accurate, helpful, and trustworthy work rather than obsessing over whether their writing sounds human or AI-generated. Transparency about using AI tools can actually build trust if paired with evidence of careful fact-checking and original insights. The real competitive advantage lies in things AI can't easily replicate: original research, insider knowledge, domain expertise, and personal experience. Rather than using tools like Humanizer to hide AI assistance, creators might get better long-term results by being transparent, verifying their facts rigorously, and focusing on value that only they can provide.
What is the future of AI content authenticity?
The future likely involves a shift from trying to detect AI generation toward certifying content provenance and authenticity. This might involve cryptographic signing to prove content origins, distributed verification systems where multiple parties attest to content accuracy, voluntary watermarking by AI companies, or official disclosure requirements. Rather than detection being about style analysis, it becomes about proving who created something and whether the claims in it are verified. Regulations are also likely to shape this space, with requirements for transparency and potentially labeling of AI-assisted content. The key insight is that proving something is authentic or accurate is more valuable than proving where it came from.
Conclusion: Beyond Detection Into Trust and Verification
The story of Humanizer and Wikipedia's AI writing guide illustrates something important about the nature of detection in an adversarial environment. Once you publish the rules, someone will build a tool around them. It's not malicious necessarily—it's just how information systems work.
But it also reveals the deeper truth: pattern-based detection of AI writing is probably not a long-term solution. The patterns can be learned and avoided. The false positive rate is too high. The cost of constant adaptation probably exceeds the benefit at scale.
What matters more is whether content is accurate, helpful, and authentic to whoever created it. Those qualities don't depend on whether AI was involved in creating it. They depend on whether the information is true, whether the reasoning is sound, and whether the creator is being honest about their methods and limitations.
The Wikipedia editors who built the detection guide weren't wrong. They identified real patterns. The volunteers did important work documenting what AI writing looks like. But the patterns they found have limits as detection tools because evasion is fundamentally easier than detection.
The real solution isn't better detection. It's better verification, transparency, and community. It's using AI as a tool while maintaining human oversight. It's building systems of trust that don't rely on perfect detection because perfect detection is probably impossible.
Siqi Chen's Humanizer plugin is clever, but it's also missing the forest for the trees. Making AI text sound more human doesn't make it more trustworthy. It might make it more deceptive if used to hide low-quality information behind better writing.
What would actually be useful is a tool that takes AI-generated content and fact-checks it, verifies claims, improves accuracy, and then discloses clearly how the content was created. That would be a tool that actually addresses the problems people care about.
Until then, we're just watching the arms race continue. Wikipedia publishes detection patterns. Someone builds evasion tools. The cycle repeats. The problem isn't unique to this situation—it's fundamental to any detection game where the detection method can be studied and circumvented.
The lesson is that when you're trying to detect something, and the detection method becomes public knowledge, the thing you're detecting will adapt. Instead of resisting that reality, organizations should plan for it. Build flexible systems. Focus on the substantive problems rather than surface-level signals. Combine automation with human judgment. And be transparent about the limitations of any detection system.
Wikipedia understood the AI writing problem. Humanizer demonstrates the evasion problem. Together, they show why the future probably isn't about better detection. It's about better verification, clearer provenance, and more transparency about what's real, what's helped by AI, and what we can actually trust. That's a harder problem to solve, but it's the one that actually matters.
Use Case: Generate authentic product documentation and reports that blend AI efficiency with human verification and transparency about sources.
Try Runable For Free
Key Takeaways
- Wikipedia's AI detection guide—documenting 24+ writing patterns—was reverse-engineered into Humanizer, a plugin that explicitly instructs AI to avoid those patterns.
- Pattern-based detection has fundamental limits: there's nothing inherently unique about AI writing, false positive rates hover around 10%, and patterns can be systematically avoided through prompt engineering.
- The detection versus evasion arms race is accelerating, with evasion tools deployable instantly while detection improvements require months of research and updates.
- Effective AI content assessment likely needs to shift from asking 'Is this AI-generated?' to 'Is this accurate, helpful, and trustworthy?', using factual verification instead of stylistic analysis.
- Future authenticity solutions probably involve cryptographic provenance tracking, transparency about AI assistance, and regulatory requirements for disclosure rather than pattern-based detection.
Related Articles
- Avengers: Doomsday Action Details Leaked – What Insiders Say [2025]
- How to Create & Use GIFs for Marketing: Complete 2025 Guide
- Nintendo Switch 2 Price Hike Coming in 2026: What You Need to Know [2025]
- Nikon Z5II Review: Best Budget Full-Frame Mirrorless Camera [2025]
- GoPro Hero 13 Black: The Ultimate Action Camera Guide [2025]
- Sony TCL Partnership 2025: What It Means for TV Industry

