![Inference as Marketing Spend: AI Economics Reshaping SaaS Growth [2025]](https://tryrunable.com/blog/inference-as-marketing-spend-ai-economics-reshaping-saas-gro/image-1-1770651824495.jpg)
Inference as Marketing Spend: AI Economics Reshaping SaaS Growth [2025]
Introduction: The Paradigm Shift Redefining SaaS Unit Economics
The conventional wisdom of software economics is crumbling. For decades, SaaS companies obsessed over a singular metric: gross margin. Build products with high gross margins, keep sales and marketing spend reasonable, and unit economics work themselves out. This formula created the multi-billion dollar SaaS industry we know today.
But something extraordinary is happening in AI-native products. The fastest-growing companies in 2025 are deliberately choosing low gross margins in exchange for products so exceptional they become self-distributing. They're treating inference costs—the computational expense of running AI models—not as a margin destroyer but as their primary growth investment.
This isn't a temporary anomaly. It's a fundamental reframe in how the smartest AI founders think about unit economics, customer acquisition, and profitability. The math that worked for Salesforce, HubSpot, and traditional enterprise SaaS is becoming increasingly irrelevant for a new generation of AI-powered products.
Consider the evidence: **Cursor crossed
The conventional response from traditional SaaS operators is skepticism. "How can you build a sustainable business with 50% gross margins when you're spending 40% on sales and marketing?" The answer: you can't. And the fastest-growing companies aren't trying to. They've made an explicit choice: optimize for virality over margin, for product excellence over sales efficiency, for inference spend over sales team headcount.
This transformation has profound implications for founders, investors, and anyone building software businesses. It challenges fundamental assumptions about what constitutes "healthy" unit economics. It reshapes the competitive landscape in ways that disadvantage traditional approaches. And it suggests that the next generation of category-defining companies will emerge from this new paradigm, not from optimizing the old one.
This article explores the mathematical foundations of this shift, analyzes the companies leading this transition, dissects the strategic choices involved, and provides a framework for understanding when this approach works—and when it fails catastrophically.

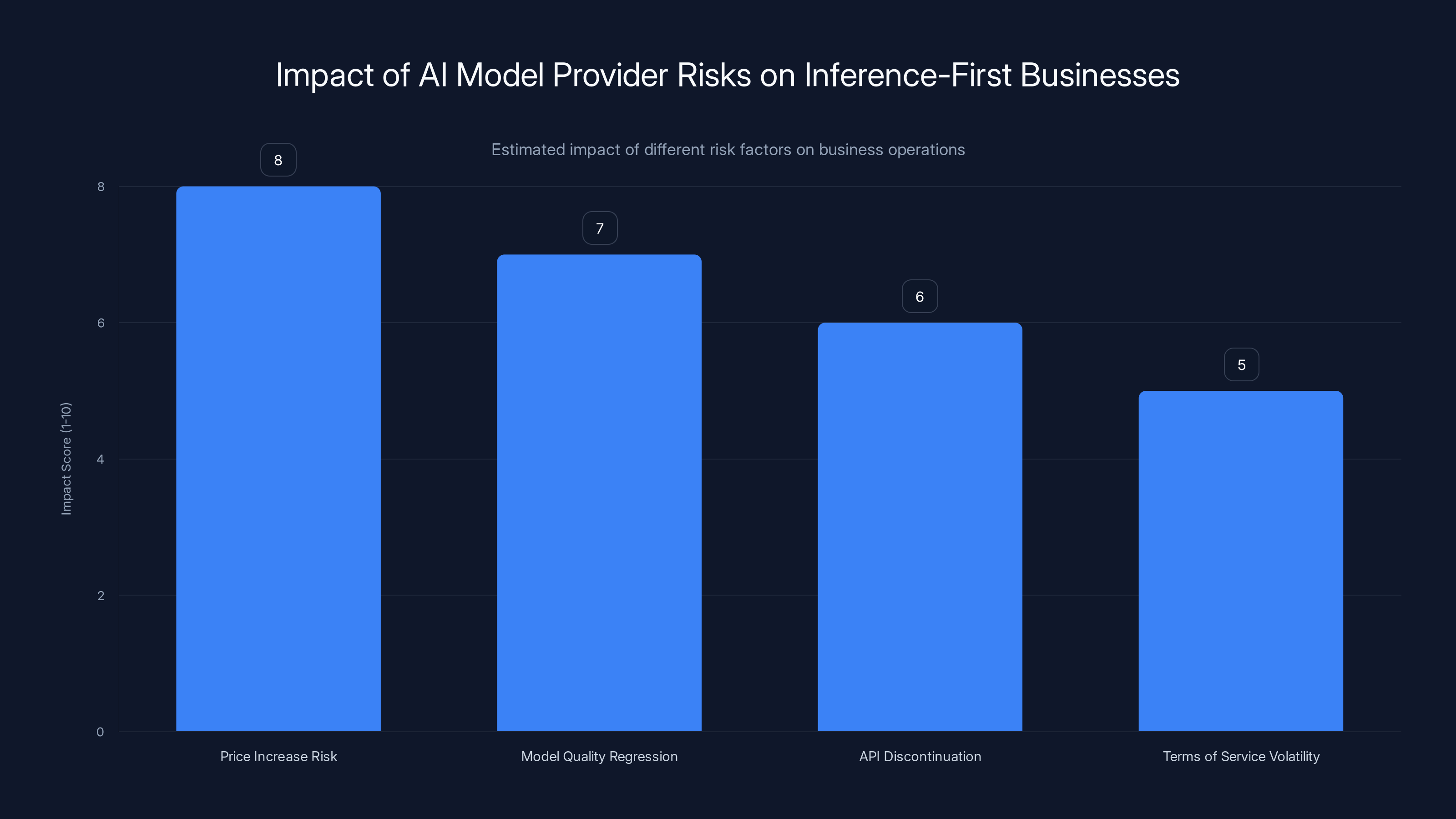
Price increase risk has the highest impact on inference-first businesses, followed by model quality regression. Estimated data based on risk descriptions.
Section 1: The Mathematical Impossibility of Hybrid Models
Understanding the Core Math Problem
Let's establish the mathematical constraint that's driving this paradigm shift. Traditional SaaS built its economic foundation on a simple formula:
Revenue - Cost of Goods Sold = Gross Profit
Gross Profit - (Sales & Marketing + R&D + Operations) = Operating Profit
For decades, the industry settled on predictable ranges:
- Gross Margins: 70-85% for efficient SaaS companies
- S&M Spending: 40-50% of revenue for growth-stage companies
- Operating Margins: 20-35% for sustainable businesses at scale
- Customer Acquisition Cost (CAC) Payback: 12-18 months
These ratios held across different markets, product types, and company sizes. A venture capitalist could analyze a SaaS company and immediately determine whether the unit economics were viable by looking at these metrics.
Now introduce significant inference costs. A $50 million ARR B2B company building AI agent functionality faces a different equation entirely:
Scenario A: Traditional Approach
- Revenue: $50M
- Gross Margin Target: 75% ($37.5M)
- S&M Spend Target: 45% ($22.5M)
- Remaining for R&D and Operations: $15M
Scenario B: AI-Agent Approach with High Inference
- Revenue: $50M
- Gross Margin Reality: 55% (12.5M in inference costs
- S&M Spend Target (same approach): 45% ($22.5M)
- Remaining for R&D and Operations: $5M
- Result: Operating loss of $17.5M
This isn't a solvable problem through optimization. You can't engineer your way out with better server efficiency. You can't negotiate inference costs down enough to close the gap. The mathematics are immutable: high inference costs plus traditional sales models equals negative unit economics.
But here's the critical insight: what if you eliminate the S&M spend entirely?
The Inference-First Math Model
When Cursor and Lovable made their implicit choice, they weren't being reckless. They were recognizing a mathematical reality: if your product is exceptional enough to eliminate the need for sales and marketing, the inference costs become irrelevant to unit economics.
Consider Cursor's actual model:
- Revenue per User: ~20/month average, some paying more)
- Inference Cost per User: Variable based on usage, approximately $30-80/year
- Gross Margin: 60-75% (competitive pricing, not margin-optimized)
- S&M Spend: Effectively $0 (viral distribution)
- Operating Model: Profitable on a per-user basis immediately upon conversion
The key variable: user acquisition cost is $0 because the product sells itself.
When an engineer tries Cursor and experiences the "vibe coding" moment—describing an implementation and having sophisticated code appear—the conversion is nearly instantaneous. That developer doesn't need to be convinced by a sales call, webinar, or email sequence. The product provides sufficient value that paying $20/month feels like an obvious decision.
This creates a fundamentally different unit economics equation:
When CAC approaches zero and CLV remains high, the profitability question becomes trivial. Each customer acquired through viral distribution is almost pure margin.
Why Traditional Companies Can't Execute This Strategy
A critical question emerges: if this model is superior, why don't established SaaS companies simply shift to it? The answer lies in structural path dependency and organizational constraints.
Consider a company like Salesforce, with 50,000+ employees and ingrained sales and marketing processes. The S&M function isn't just a cost center; it's the core of the organization. Salespeople have territories, compensation plans, and relationships built over decades. Sales leaders have career trajectories within the company. Shifting away from this model isn't a financial decision—it's an organizational impossibility.
Moreover, existing products haven't achieved the "wow factor" that creates automatic virality. Improving Salesforce with AI agents might make it 20% more efficient, but it doesn't create the kind of discontinuous breakthrough that makes users become evangelists.
This creates a competitive asymmetry: companies unencumbered by legacy processes can execute the inference-first model, while legacy companies are structurally incapable of adopting it, even if they wanted to.
Section 2: Cursor's Vertical Takeoff and the Viral Coding Economy
The Extraordinary Growth Trajectory
Cursor's growth from launch to $1 billion ARR represents the fastest SaaS growth curve in history. The timeline:
- January 2025: $100M ARR (starting point of public knowledge)
- June 2025: $500M ARR (5x in six months)
- November 2025: $1B+ ARR (2x in five months)
- Total Timeline: ~24 months from launch to billion-dollar company
- Employee Count: ~300 people
- Revenue per Employee: 500K-1M industry average)
- Traditional Sales Team Size: Minimal, estimated <20 people
- Paid Acquisition Spend: Functionally zero
This trajectory violates nearly every assumption in the SaaS playbook. Typically, companies need significant sales infrastructure to reach billion-dollar status. HubSpot took 10 years to reach $1 billion ARR with 5,000+ employees. Figma took 8 years with 1,000+ employees. Even the fast-growing players like Notion required substantial organizational investment.
Cursor achieved it with a skeleton crew in a fraction of the time. The only logical explanation: the product was so exceptional that paid customer acquisition became unnecessary.
The Vibe Coding Breakthrough
The foundational insight that made Cursor possible was recognizing that code completion and generation could be transformed into an interactive, conversational experience. Rather than presenting suggested completions in a dropdown menu (the Copilot approach), Cursor built an agent that could understand developer intent across entire codebases and suggest comprehensive implementations.
This required aggressive inference spending on several dimensions:
- Multi-turn conversations: Maintaining context across extended developer-AI interactions
- Full-codebase context: Loading and analyzing entire project structures
- Reasoning tokens: Using extended thinking models to plan comprehensive implementations
- Real-time inference: Providing near-instantaneous responses to maintain flow state
- Model selection: Using more capable (and expensive) models like Claude 3.5 Sonnet rather than cheaper alternatives
The technical decision to prioritize experience over cost created a discontinuous improvement in developer experience. Engineers describe "forgetting they're writing code" because the AI handles so much of the cognitive load. This isn't a 10% improvement over competitors—it's a fundamental shift in the human-computer interaction model.
Viral Distribution Through Technical Communities
Once product-market fit was achieved, distribution followed an unusual pattern. Rather than hiring sales teams, Cursor distributed through authentic use cases that engineers actively wanted to share:
Community-Driven Adoption: High-profile engineers at OpenAI, Anthropic, Google, and startup founders started using Cursor and posting about it. These weren't paid endorsements—they were genuine enthusiasm from technical credibility sources. A single tweet from a trusted engineer reached thousands of other developers, creating cascade effects.
Content as Distribution: Product improvements became newsworthy. Each major feature release (Tab, Codebase awareness, Cmd-K improvements) generated organic discussion across Reddit, Hacker News, and Twitter. This free PR replaced traditional product launch campaigns.
Organic Trial and Conversion: Developers could try Cursor for free without commitment. The frictionless trial converted rapidly because the product demonstrated value immediately. No sales calls, demos, or pitch decks required.
Network Effects Through Collaboration: As more developers on teams used Cursor, it became valuable for the entire team. Colleagues asked "what's that tool you're using?" creating internal network effects that accelerated adoption.
This distribution model is impossible to replicate through traditional marketing spending. You can't buy authenticity, engineer serendipity, or engineer viral loops through paid channels. These emerge only when product excellence becomes undeniable.
The Economics of Cursor's Inference Strategy
To understand Cursor's inference spending, we need to model typical usage:
Per-User Inference Estimates:
- Average developer makes 50-100 AI-assisted edits per day
- Each interaction: 1-5 inference calls (context retrieval, generation, refinement)
- Average inference cost per interaction: $0.01-0.05
- Daily per-user inference: 2.50
- Monthly per-user inference: $15-75
- Annual per-user inference: $180-900
Revenue Model:
- Individual subscription: 240/year)
- Enterprise licensing: Higher price points but similar cost structure
- Gross margin even with $75/month inference costs: 68%
At $1 billion ARR with conservative estimates:
- Assumed users: 4-5 million developers
- Estimated annual inference spend: $300-500 million
- Percentage of revenue: 30-50%
- Remaining for R&D and Operations: 25-50% of revenue
This is extraordinarily expensive—traditional companies would consider this unsustainable. But the business model works because:
- Per-user profitability is immediate: Each user generates 50-75 in annual inference costs
- CAC is zero: No sales, marketing, or acquisition spend required
- LTV is high: Developer tools typically enjoy multi-year retention (5+ years)
- Volume economics: At scale, the marginal cost of serving additional users is just the inference cost
Strategic Implications for AI Product Development
Cursor's success established a blueprint that other AI companies recognized as viable: if you can create a product experience discontinuous enough to drive viral adoption, inference costs stop being a margin problem and become a customer acquisition strategy.
This insight fundamentally changed how smart founders approached AI product development. Rather than optimizing for cost-per-inference or gross margin percentage, they optimized for:
- Moment of WOW: Creating an instant-conversion experience
- Shareability: Building features that users want to showcase to others
- Frictionless Trial: Removing all barriers to trying the product
- Network Effects: Designing for team and organizational adoption
- Inference Spend as Feature: Using compute generously to create experiences competitors couldn't match at lower cost
This represents an inversion of how traditional SaaS approached product development, where efficiency and cost-minimization were primary concerns. In the inference-first model, excellence takes priority, and costs follow.

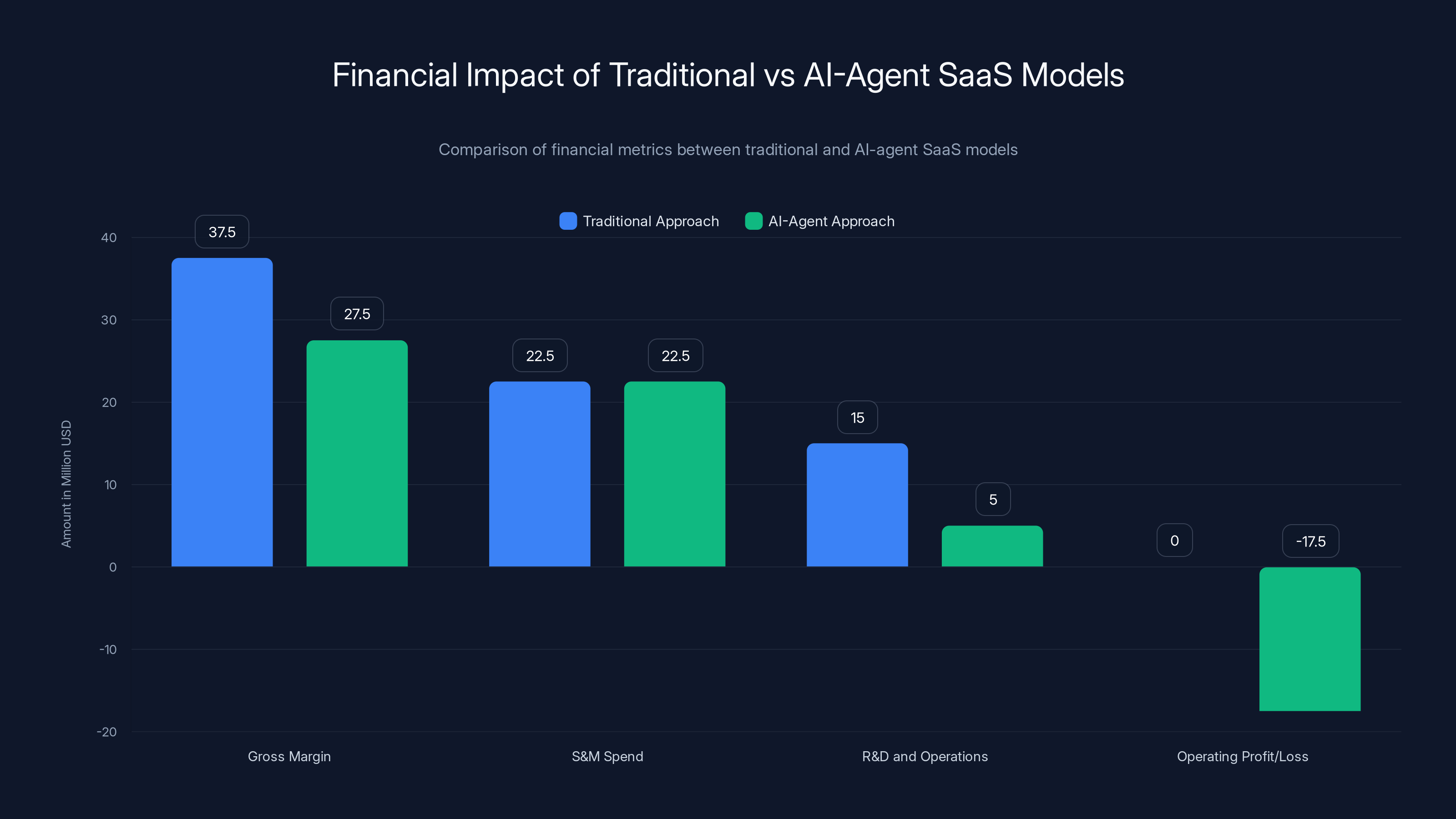
The AI-agent approach results in a significant operating loss due to high inference costs, despite maintaining the same S&M spend as the traditional model.
Section 3: Lovable's Hyper-Efficient Growth Model
The 14-Month Journey to $300M ARR
Lovable's growth trajectory is even more compressed than Cursor's:
- Launch: December 2024
- $100M ARR: ~4 months
- $300M ARR: ~14 months
- Employee Count: <200 people
- Revenue per Employee: $1.5M+ (among the highest in SaaS history)
- Paid Customer Acquisition: $0
- Traditional Sales Infrastructure: None
Lovable built an AI-powered application builder—a tool allowing non-developers and developers to build functional web applications through natural language description. The product takes text descriptions and generates full-stack code, databases, and deployments.
The inference costs for this type of product are substantial. Generating production-ready applications requires:
- Complex reasoning: Understanding multi-step application logic
- Full-stack generation: Frontend, backend, database schemas, deployment configuration
- Iterative refinement: Users request changes and the AI regenerates components
- Testing and validation: AI systems that check generated code for viability
- Long context windows: Maintaining conversation history to understand project evolution
Yet despite these substantial inference costs, Lovable achieved unit economics that dwarf traditional SaaS companies.
The Network Effect of Shareable Output
Lovable's core insight was understanding that application code outputs are inherently shareable marketing collateral. Unlike traditional SaaS products that generate internal value, Lovable-created applications are tangible artifacts that users want to demonstrate.
The distribution mechanism works as follows:
- User builds an app: Through Lovable's natural language interface, a developer describes an application and Lovable generates functioning code
- App becomes portfolio piece: The developer deploys the application publicly on Vercel, Netlify, or custom domains
- App drives referrals: Friends, colleagues, and social media followers encounter the deployed app and ask "how did you build this?"
- Cross-referral chain: The answer "with Lovable" drives new user signup with zero marketing spend
- Organic network effects: As more developers build and share, Lovable becomes the obvious choice for rapid development
This represents a marketing flywheel that traditional SaaS companies struggle to create. Because the output of using Lovable is a public product, not a private dashboard metric, the product becomes a continuous source of organic acquisition.
Consider the comparison to Webflow, another no-code platform that achieved significant success but required substantial paid acquisition:
Webflow's Distribution Model (traditional approach):
- Built for web designers and agencies
- Marketing through online courses, design community sponsorships
- Significant paid acquisition required ($30-50 CAC typical for SaaS)
- S&M spend: 40-50% of revenue
Lovable's Distribution Model (inference-first approach):
- Built for any developer (low barrier to entry)
- Marketing through deployed applications (free distribution)
- Negligible paid acquisition
- S&M spend: <5% of revenue
Lovable's inference-first approach created superior distribution efficiency despite higher per-unit costs.
The Sustainability Question
A critical question: is this growth sustainable? Can Lovable maintain $300M ARR profitability with substantial inference costs and minimal sales infrastructure?
The math suggests yes, but with constraints:
Lovable Economics (estimated):
- Average Revenue per User: $50-200/month depending on tier
- Average Inference Cost per User: $20-60/month based on application generation complexity
- Gross Margin: 60-70%
- Operating Margin: 40-50% (minimal S&M, engineering-focused spending)
At $300M ARR:
- Estimated users: 1.5-3 million
- Estimated annual inference spend: $50-150 million
- Operating profit: $120-150 million
- Path to sustainable profitability: Clear
However, sustainability depends on maintaining relative advantage in AI capability. If competitors offer equivalent functionality at lower inference cost, Lovable's margin advantage evaporates. This creates continuous pressure to:
- Improve model efficiency: Use less inference to deliver equivalent results
- Increase output quality: Spend more on inference when necessary to maintain advantage
- Expand use cases: Keep inference costs relatively constant while increasing average revenue per user
Section 4: The Impossible Choice: Virality vs. Traditional Sales
Why You Cannot Execute Both Simultaneously
The most important mathematical constraint in this paradigm shift is simple and brutal: you cannot optimize for both viral product distribution and traditional enterprise sales simultaneously.
Here's why:
Sales-driven products require:
- Standardized, predictable interfaces (to explain in demos)
- Complex feature sets that necessitate implementation support
- Transparent pricing aligned with enterprise budgets
- Contract requirements and legal terms
- Dedicated account management and support infrastructure
Viral products require:
- Instant comprehension and value demonstration
- Simplicity in core experience (complexity hidden)
- Impulse-level pricing ($10-50/month)
- Frictionless onboarding (no sales calls)
- Community-driven support (documentation, tutorials, peer assistance)
These requirements are fundamentally incompatible. A product optimized for viral developer adoption can't simultaneously be optimized for enterprise sales processes. A product with enterprise sales infrastructure can't achieve viral adoption because the friction inherent to the sales process prevents the frictionless experience that drives virality.
The Test Case: GitHub Copilot vs. Cursor
GitHub Copilot (backed by Microsoft and OpenAI) attempted to have it both ways:
- For individual developers: Offered at $10/month (competitive with Cursor)
- For enterprises: Offered Copilot for Business with extended support, security terms, and admin controls
- Distribution: Invested heavily in sales for enterprise adoption
- Marketing: Extensive campaigns, conferences, partnerships
Cursor chose singular optimization:
- Individual developers: $20/month with exceptional experience
- No enterprise sales motion: Relying on developers bringing the product into their organizations
- Minimal marketing: Community and organic growth
The result: Cursor's viral growth outpaced Copilot despite Copilot's enormous distribution advantages (built into VS Code, backed by Microsoft, access to superior models). By optimizing singularly for viral adoption, Cursor created a better product experience for its target market.
The Cost of Sales in an Inference-First Market
Let's calculate what happens when an inference-first product attempts to layer traditional enterprise sales:
Scenario: A $50M ARR AI platform attempting sales transformation
Current Model (inference-first):
- Users: 2 million
- ARPU: $25/month
- Gross margin: 60%
- S&M spend: 5% of revenue ($2.5M)
- Operating margin: 45%
Attempted Sales Model (adding enterprise sales):
- Added sales team: 30 account executives, supporting sales infrastructure
- Sales team cost: $4.5M (salary, commission, benefits)
- Sales operations and support: $1.5M
- Enterprise-targeted marketing: $2M
- Total S&M increase: $8M
- New S&M spend: 21% of revenue
Impact on Unit Economics:
- New operating margin: 24% (45% minus 21% increase)
- Cost per new enterprise customer acquired: Estimated $200K-500K
- Enterprise ARPU needed to justify sales: $50K+ annually
- Customer overlap: Some individual users convert to enterprise accounts, others churn due to product changes
Outcome: Adding sales infrastructure cuts operating margin in half without guaranteed growth increase. The inference costs that were "free" under viral distribution become exposed margin drag under a sales model.
This explains why viral-first products often resist adding traditional sales infrastructure. The math doesn't support it.
The Enterprise Paradox
Yet a critical tension exists: enterprises have substantially higher ARPU potential than individuals. An enterprise account paying
The answer: some do, but through different mechanisms.
Cursor's enterprise adoption happened organically:
- Individual developers brought Cursor into their organizations
- Teams standardized on Cursor because their developers were already using it
- Enterprise accounts emerged without dedicated sales processes
- Enterprise customers paid premium pricing without extensive contract negotiation
This bottom-up enterprise adoption model is fundamentally different from top-down sales-driven enterprise acquisition. It's less predictable, harder to forecast, but also dramatically less expensive to execute.
Traditional enterprises require the opposite (top-down) approach: executive champions, RFP responses, implementations, ongoing account management. This requires the sales infrastructure that kills viral potential.
The strategic question founders must ask: "Will my enterprise revenue grow adequately through organic adoption, or do I need to actively pursue enterprise sales?"
Answer wrong, and you're either leaving money on the table (insufficient enterprise push) or destroying viral momentum and incurring substantial cost (over-investing in sales).
Section 5: Inference Cost Economics: The Mathematics of Model Choice
Understanding the Cost Gradient of AI Models
Not all inference costs are equal. The choice of which AI model to use has profound cost implications:
Large Language Model Cost Spectrum (approximate per-million-tokens pricing as of 2025):
| Model | Input Cost | Output Cost | Use Case | Relative Cost |
|---|---|---|---|---|
| Llama 3.1 (70B) | $0.30 | $0.60 | Basic text generation | 1x |
| GPT-4o Mini | $0.10 | $0.40 | Fast, efficient tasks | 1.3x |
| Claude 3.5 Haiku | $0.80 | $2.40 | Small, quick tasks | 2.5x |
| GPT-4 Turbo | $1.00 | $3.00 | Complex reasoning | 4x |
| Claude 3.5 Sonnet | $3.00 | $15.00 | Advanced reasoning, long context | 15x |
| O1 (reasoning model) | $15.00 | $60.00 | Extended thinking, complex problems | 60x |
Cursor's decision to use Claude 3.5 Sonnet (among the most expensive models) rather than a cheaper alternative like GPT-4o Mini represents a 15x cost multiplication compared to basic alternatives.
Why make this choice? Because:
- Model quality directly impacts user experience: Claude 3.5 Sonnet produces more accurate, more sophisticated code suggestions
- User experience drives retention and referral: Better quality directly enables viral distribution
- Inferior model would require expensive workarounds: Cheaper models might need more inference calls, longer context windows, or additional post-processing
- Competitive advantage depends on quality: Competitors using cheaper models would deliver inferior experiences
This creates a quality-cost flywheel: using premium models enables better products, which enables viral adoption, which generates sufficient revenue to justify premium model costs.
The Inference Cost Scaling Problem
As inference-first products scale, cost becomes increasingly critical. The relationship isn't linear:
User Growth vs. Inference Cost Growth:
- Phase 1 (0-100K users): Inference costs are negligible relative to revenue. Product optimization focuses on quality, not cost
- Phase 2 (100K-1M users): Inference costs become significant (~30-40% of revenue). Pressure emerges to optimize costs without degrading experience
- Phase 3 (1M+ users): Inference costs are structural (~40-60% of revenue). Any further cost increases threaten profitability
- Phase 4 (10M+ users): Inference costs must decrease or revenue must increase significantly per user
Cursor has likely reached Phase 3. With estimated 4-5M users and
Maintaining profitability requires:
- Model efficiency improvements: Using newer, cheaper models that deliver similar quality
- Architectural optimization: Reducing inference calls through smarter caching, batch processing, and prompt engineering
- Revenue growth: Increasing ARPU through premium tiers, enterprise licensing, or new products
- User base optimization: Focusing on high-value user segments with higher ARPU
Companies that fail to address this scaling problem eventually hit a wall where inference costs exceed sustainable profitability. This is why long-term success requires either continuous improvement in AI model efficiency or continuous revenue growth per user.
The Model Provider Dependency Risk
An often-overlooked risk in inference-first businesses is dependency on model providers. Cursor and similar companies depend entirely on Anthropic, OpenAI, or other model providers for their core technology.
Model providers have significant pricing leverage:
- Price increases: Anthropic raised inference prices 23% in late 2024. Companies using Anthropic at scale suddenly faced billions in additional annual costs
- API changes: If OpenAI or Anthropic change their APIs, products must adapt or face functionality losses
- Model availability: If a preferred model becomes unavailable or shifts to closed-source, products must migrate to alternatives with different characteristics
- Terms of service changes: Model providers can change terms, usage restrictions, or data handling policies
This creates strategic vulnerability. A company spending
Large companies are beginning to address this through fine-tuned or proprietary models. Cursor has invested in understanding model performance and likely tests multiple models to optimize for cost-quality tradeoffs. Some companies are experimenting with open-source models deployed on their own infrastructure to reduce dependency.
However, deploying and maintaining inference infrastructure at scale is non-trivial. Most companies pursuing inference-first strategies don't have this capability internally, creating a structural vulnerability.
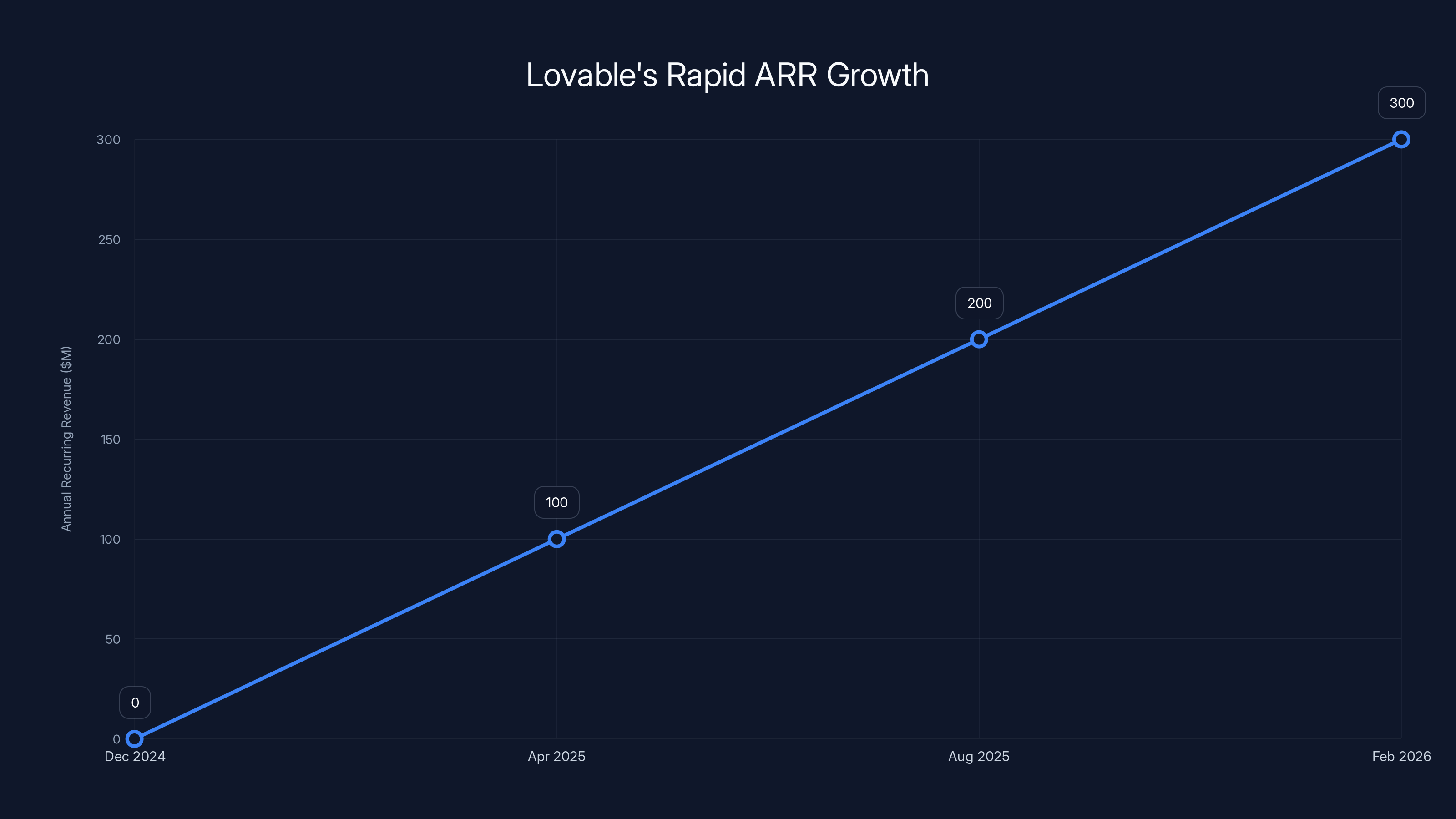
Lovable achieved $300M ARR in just 14 months, showcasing one of the fastest growth trajectories in SaaS history. Estimated data based on reported milestones.
Section 6: When Inference-First Fails: The Cautionary Cases
The Companies That Couldn't Make It Work
While Cursor and Lovable represent inference-first success, many AI startups attempted similar strategies and failed. Understanding these failures is critical to recognizing when the model is inappropriate.
Failure Pattern 1: Premature Scale Without Unit Economics Clarity
Several AI startups raised significant funding, built impressive products, and achieved notable user adoption—then discovered their inference costs were unsustainable at scale.
The problem: they optimized for user growth without understanding the cost structure at scale. A product that costs
These companies typically burned through funding attempting to improve efficiency or increase ARPU, then ran out of capital before achieving either.
Failure Pattern 2: Viral Distribution Without Sufficient Margin
Some products achieved impressive viral growth but discovered that their ARPU was too low relative to inference costs. A free product with optional paid upgrades might achieve 50M users with 1% conversion, but if each user costs $30/year to serve and converts at low value, the math doesn't work.
These companies built engaged user bases that were economically disadvantageous to serve. Growth became a liability rather than an asset.
Failure Pattern 3: Commoditized Use Cases
Inference-first strategies work for differentiated products where model quality directly impacts user experience. They fail in commoditized spaces where user experience is "good enough" at any tier.
For example, a basic AI chatbot for customer service may not benefit from premium models. Customers care more about cost than quality improvements. In these cases, the inference-first strategy of spending aggressively on model quality is economically irrational. These businesses need cheaper models and different economics.
Companies that applied inference-first thinking to commoditized use cases typically failed because their cost structure couldn't compete with more cost-optimized competitors.
Lessons From Failures
These cautionary cases reveal critical prerequisites for inference-first success:
- Product differentiation must depend on model quality: If users would switch to a competitor with a cheaper model, the inference spend is inefficient
- Virality must be achievable: Not all products can achieve zero-CAC distribution. Enterprise SaaS products with long sales cycles inherently can't
- ARPU must scale appropriately: Free or low-ARPU products may not generate sufficient gross profit to justify inference costs
- Market size must be large: Niche products need higher ARPU to justify substantial inference spend. Consumer-scale volume is essential
- Capital runway must extend to profitability: The gap between burn and break-even must be manageable within funding available
Cursor and Lovable succeeded because all five prerequisites were met. Most companies fail because they're missing one or more.
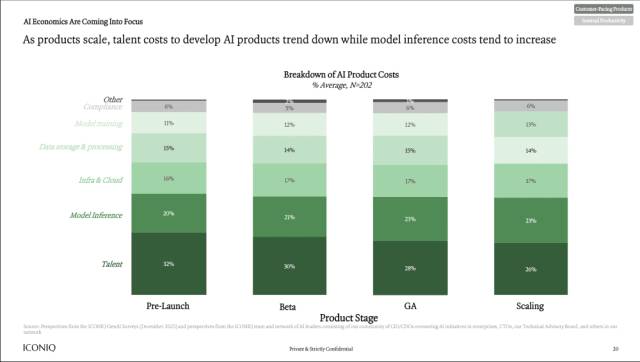
Section 7: Structural Requirements for Inference-First Success
Product Architecture: Designing for Inference Efficiency
Successful inference-first products don't just happen. They require deliberate architectural decisions optimized for inference cost and quality tradeoffs.
Caching and Context Reuse:
- Inference calls are expensive; cache hits are nearly free
- Products should be designed to maximize cache reuse across similar queries
- Context windows should be managed carefully to avoid redundant inference
- Example: Cursor maintains conversation context to avoid re-deriving conclusions from prior interactions
Batch Processing and Asynchronous Inference:
- Real-time inference is more expensive than batch processing
- Products should defer non-critical inference to background jobs
- User-facing inference should be minimized; results can be pre-computed
- Example: Lovable might pre-generate application templates in batch, then customize them with minimal inference
Model Selection Per Task:
- Not every task requires the most capable (most expensive) model
- Sophisticated routing logic should match task complexity to model cost
- Simple classification tasks use cheaper models; complex reasoning uses premium models
- Example: Cursor might use a cheaper model for basic completions, premium model for complex refactoring
Quality Assurance Without Excessive Inference:
- Checking output quality typically requires additional inference
- Products should minimize verification overhead through smart validation, heuristics, and user feedback
- Example: Lovable validates generated code through automated testing, not re-running inference
Organizational Capabilities Required
Building successful inference-first products requires capabilities beyond typical software development:
AI/ML Expertise:
- Deep understanding of large language models, their strengths, limitations
- Ability to evaluate and compare models, understand cost-quality tradeoffs
- Expertise in prompt engineering, retrieval-augmented generation, fine-tuning
- Capability to rapidly adapt as new models and techniques emerge
Infrastructure and Operations:
- Experience running inference at scale (not typical for most SaaS companies)
- Monitoring and debugging inference performance and quality
- Load balancing across multiple models and providers
- Cost tracking and optimization across millions of inference calls
Product Thinking for Margins:
- Deep analysis of per-user economics, cost breakdown, margin pressure points
- Ability to make continuous cost optimization decisions without degrading user experience
- Understanding of how product decisions impact inference spend
Capital Management:
- Inference-first products typically need more capital than equivalent traditional SaaS
- Large runway required to achieve profitability
- Understanding of burn rate management in the context of growth
Companies missing these capabilities are unlikely to execute inference-first strategies successfully, regardless of product quality.
Funding Implications
Inference-first businesses require different funding strategies than traditional SaaS:
Earlier Revenue Requirements:
- Traditional SaaS can raise substantial funding on land-and-expand potential
- Inference-first businesses must demonstrate path to profitability earlier because capital is consumed rapidly
- Revenue traction becomes critical for funding rounds
Capital Efficiency Focus:
- Traditional SaaS can raise 18-24 month runways
- Inference-first businesses might need 24-36 month runways to reach profitability
- Investor scrutiny on unit economics and path to profitability increases significantly
Strategic Investor Preference:
- Inference-first businesses benefit from investors who understand AI economics
- Investors comfortable with high gross margins may be uncomfortable with 50-60% margins
- Strategic investors with model provider relationships (Anthropic, OpenAI, etc.) may be preferred
Section 8: The Importance of Authentic Product Moments in Viral Distribution
What Creates Genuine Virality vs. Growth Theater
The most misunderstood element of inference-first success is the distinction between authentic viral moments and manufactured growth theater. Both Cursor and Lovable achieved viral adoption, but it wasn't accidental or engineered through traditional growth hacking.
Authentic Viral Moments share common characteristics:
- Discontinuous improvement: The product is dramatically better than existing alternatives, not marginally better
- Immediate value realization: The improvement becomes obvious within minutes, not after weeks
- Organic sharability: Users voluntarily tell others about the product unprompted
- Social proof from credibility sources: Early adoption by trusted figures in the community
- No purchase friction: The product is free or low-cost enough that the decision is trivial
- Reduction of cognitive friction: The product makes thinking or working visibly easier
Cursor's viral moment was developers discovering that AI could write code that didn't require extensive revision. The moment you start typing and Cursor accurately predicts your next 20 lines of code, you experience the discontinuous improvement.
Lovable's viral moment was realizing that non-technical people could build functional web applications without learning programming. The moment you describe an idea and a working app appears, the discontinuous improvement is undeniable.
Growth Theater, in contrast:
- Relies on paid acquisition and influencer partnerships
- Requires continuous content creation and brand campaigns
- Doesn't generate organic word-of-mouth
- Depends on customer acquisition cost remaining sustainable
- Often creates vanity metrics rather than engaged user growth
Most startups attempt growth theater because it's more controllable and predictable. Inference-first success requires creating authentic viral moments, which is orders of magnitude harder and less predictable.
Why Inference Spending Enables Authentic Virality
The connection between aggressive inference spending and authentic virality is direct:
High inference spending → Premium model usage → Superior output quality → Better user experience → Discontinuous improvement → Authentic virality
Companies attempting to optimize for cost use cheaper models that generate adequate but not exceptional results. This fails to create the discontinuous improvement necessary for authentic virality. Users perceive the product as "pretty good" rather than "amazing," and sharing becomes optional rather than compulsive.
Companies willing to spend heavily on inference can use the best models available, creating exceptional output that drives organic sharing. The "vibe coding" experience Cursor creates emerges directly from aggressive inference spending on capable models.
This creates an apparent paradox: the path to sustainable profitability runs through short-term margin reduction. By spending on inference now to create exceptional products, companies build the user bases and market positions that enable long-term profitability. Companies trying to optimize margins early fail to achieve the virality necessary for any profitability.
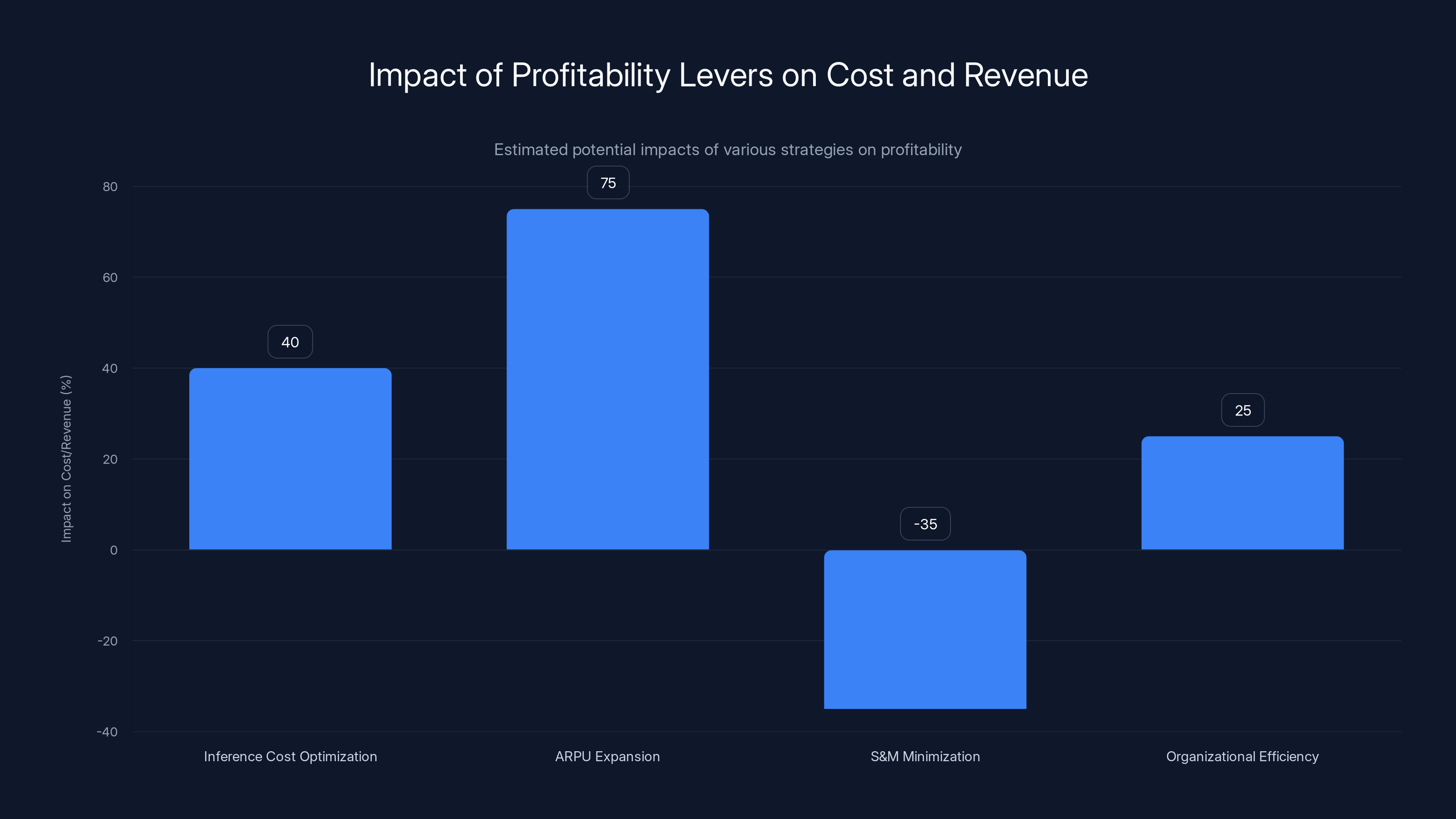
Estimated data shows that ARPU expansion can potentially increase revenue by 50-100%, while inference cost optimization can reduce costs by 30-50%. S&M minimization and organizational efficiency contribute to cost reductions as well.
Section 9: Comparative Economics: Inference-First vs. Sales-Driven Models
Side-by-Side Unit Economics Comparison
Let's construct realistic models for comparable products using different go-to-market strategies:
Product: AI Code Generation Tool
Model A: Inference-First (Cursor's Approach)
| Metric | Value | Notes |
|---|---|---|
| Annual Revenue per User | $240 | $20/month for individuals |
| Annual Inference Cost per User | $100 | ~$8-10/month |
| Annual Other COGS per User | $20 | Hosting, support, infrastructure |
| Gross Margin per User | $120 | 50% |
| Annual CAC | $0 | Viral distribution, no sales spend |
| Annual CAC Payback | Immediate | First month positive |
| Gross Profit Margin | 50% | |
| S&M Spend | 5% of revenue | Minimal marketing, community |
| R&D Spend | 20% of revenue | Continuous model improvement |
| Operating Profit Margin | 25% | |
| Payback Period | 1 month | |
| User Acquisition Cost | $0 |
Model B: Sales-Driven Enterprise (Traditional SaaS)
| Metric | Value | Notes |
|---|---|---|
| Annual Revenue per User | $1,200 | Enterprise licensing, higher ARPU |
| Annual Inference Cost per User | $150 | Same capability, optimized models |
| Annual Other COGS per User | $100 | Hosting, implementation, support |
| Gross Margin per User | $950 | 79% |
| Annual CAC | $400 | Sales team, marketing, demos |
| Annual CAC Payback | 5 months | ( |
| Gross Profit Margin | 79% | |
| S&M Spend | 40% of revenue | Sales team, marketing, events |
| R&D Spend | 15% of revenue | Product development |
| Operating Profit Margin | 24% | |
| Payback Period | 5 months | |
| User Acquisition Cost | $400 |
Analysis:
Remarkably, both models achieve similar operating profit margins (~24-25%) despite drastically different approaches:
- Model A (Inference-First): Low ARPU, no CAC, lower gross margins
- Model B (Sales-Driven): High ARPU, high CAC, high gross margins
The critical difference: Model A scales differently than Model B.
Scaling Dynamics:
Model A (Inference-First):
- Adding 1M users adds ~100M inference cost
- Net positive cash flow immediately
- Scalability limited only by inference infrastructure
- Profitability increases with scale
- Path: Optimize CAC (already $0) to margins (improve model efficiency)
Model B (Sales-Driven):
- Adding 1M users requires hiring ~100+ sales reps, support staff
- Headcount scales with user growth
- CAC may increase as easier-to-sell customers are exhausted
- Profitability depends on sales efficiency remaining constant
- Path: Improve sales efficiency, reduce CAC, maintain ACV
The fundamental insight: Model A generates more operating profit per dollar of revenue at scale, and the profitability gap widens as both companies grow.
At scale:
- Model A (2.5B operating profit
- Model B (2.4B operating profit
But Model A achieved $10B with 20M users and no sales team. Model B achieved it with 8M users and 800+ sales reps. The implied enterprise value and capital requirements are dramatically different.
Section 10: Strategic Shifts in How Successful AI Companies Allocate Capital
The Reallocation From S&M to Inference
Traditional SaaS companies typically allocate capital as follows:
- Sales & Marketing: 40-50% of revenue
- R&D: 20-30% of revenue
- Operations: 10-15% of revenue
- Infrastructure/COGS: 20-30% of revenue
Inference-first companies allocate differently:
- Inference Costs: 30-50% of revenue (core COGS)
- R&D: 25-35% of revenue (product excellence and model optimization)
- Sales & Marketing: 2-10% of revenue (community, minimal advertising)
- Operations: 10-15% of revenue
This reallocation reflects a fundamental strategic choice: excellence over scale, product over distribution, inference over persuasion.
The implications ripple across organizational structure:
Traditional SaaS Org:
- Largest departments: Sales (30%), Customer Success (15%), Marketing (15%)
- Engineering: 15-20%
- Most revenue growth comes from sales team expansion
Inference-First Org:
- Largest departments: Engineering (40-50%), including ML/AI specialists
- Sales: <5%
- Customer Success: Minimal (communities handle support)
- Product growth comes from model improvement and viral adoption
This organizational difference is not incidental—it's fundamental to how the businesses operate and compete.
The Talent Implications
The shift toward inference-first models has created profound talent market dynamics:
Demand Shift:
- Traditional SaaS: Peak demand for sales leaders, marketing managers, solution engineers
- Inference-First: Peak demand for ML engineers, prompt engineers, infrastructure specialists
Compensation Implications:
- Sales roles in traditional SaaS: Still highly compensated but facing structural headcount reduction
- ML/AI roles: Massive wage increases due to demand outpacing supply
- Infrastructure roles: New specialization (inference optimization, cost management) commands premium salaries
Career Path Implications:
- Traditional SaaS has created clear career ladders (AE → Manager → Director → VP Sales)
- Inference-first products offer less clear career progression in non-engineering roles
- Entrepreneurship opportunities shift: fewer sales-driven startups, more AI-driven ones
Organizational Culture:
- Traditional SaaS: Driven by sales culture, competitive, quarterly targets
- Inference-First: Driven by engineering culture, excellence focus, continuous improvement
These cultural differences create natural talent clustering where salespeople gravitate toward traditional SaaS and engineers toward inference-first products.
Section 11: Risk Factors and Failure Modes in Inference-First Models
Model Provider Dependency and Leverage
The most significant structural risk in inference-first businesses is dependency on AI model providers. This creates several failure modes:
Price Increase Risk:
- Model providers have near-complete pricing power
- Anthropic's 23% price increase in 2024 likely cost Cursor $30-50M in unexpected cost increases
- Future price increases directly impact profitability
- Companies cannot pass all costs to customers without losing margin or demand
Model Quality Regression Risk:
- Model providers may prioritize different use cases or customer segments
- Newer models may be optimized for different tasks, reducing utility
- Companies dependent on specific model features are vulnerable to provider pivots
API Discontinuation Risk:
- Model providers may sunset APIs or discontinue specific models
- Companies must rapidly migrate to alternative models
- Migration may involve rewriting significant product logic
Terms of Service Volatility:
- Model providers can change usage policies, data retention terms, or restrictions
- These changes could fundamentally impact product functionality
- Example: If OpenAI restricted how Cursor could cache context, it would impact cost structure and performance
Mitigation Strategies:
- Model provider diversification: Support multiple models, rapidly switch if pricing becomes uncompetitive
- Fine-tuning and optimization: Develop proprietary model optimizations that deliver equivalent results cheaper
- Open-source model exploration: Evaluate whether open-source models could eventually replace proprietary APIs
- Vertical integration: Long-term, the highest-margin inference-first companies may need to build or partner on proprietary models
Cursor and Lovable likely have significant ongoing investments in these mitigation strategies, understanding that long-term success requires reducing model provider dependency.
Inference Cost Volatility and Margin Compression
Beyond provider pricing, the absolute cost of inference may face downward pressure as competition intensifies:
Scenario: If multiple providers emerge offering competitive capabilities at 50% lower cost, companies must choose between:
- Migrating to cheaper models (potentially degrading product quality)
- Maintaining current model spending (accepting margin compression)
This creates a "race to the bottom" dynamic where inference-first businesses compete on cost efficiency rather than capability differentiation.
Protection mechanisms:
- Build sustainable competitive advantages beyond pure model capability
- Develop proprietary techniques that deliver superior results with commodity models
- Create network effects that increase switching costs
- Build integrated workflows that become sticky regardless of model choice
Companies that view their advantage as purely "we use better models" are vulnerable to this commoditization pressure. Companies with deeper competitive advantages (network effects, unique data, specialized workflows) are more resilient.
Competitive Threats From Well-Capitalized Incumbents
While Cursor and Lovable succeeded by out-competing incumbents on product quality, the long-term risk is that incumbents adopt inference-first strategies and leverage their existing distribution:
Scenario: Microsoft (supporting GitHub Copilot) decides to aggressively invest in model quality, integrates Copilot more deeply into VS Code, and reduces pricing to $10/month (matching Cursor).
Microsoft's advantages:
- Existing distribution through VS Code (2M+ daily users)
- Financial resources to sustain inference losses longer
- Integration with other developer tools (GitHub, Azure)
- Relationships with enterprise buyers
Cursor's advantages:
- Superior product quality through singular focus
- Viral adoption creating community loyalty
- Unencumbered by legacy code, processes, or products
- Ability to move faster than bureaucratic incumbent
History suggests that with sufficient resources and focus, incumbents can eventually replicate successful strategies. However, they often struggle to move fast enough or make the necessary cultural shifts. The risk remains real, though not immediate.
Market Saturation and ARPU Compression
As viral-adopted products mature, several dynamics can pressure unit economics:
User Base Maturation:
- Early adopters (developers, enthusiasts) value products highly and pay premium pricing
- Mass market users (corporate employees using tools internally) value at lower willingness-to-pay
- As products mature, user composition shifts toward lower-value segments
- ARPU naturally compresses as user base expands to less valuable segments
Competitive ARPU Pressure:
- As competitors enter the market, pricing pressure increases
- First-mover advantage of premium pricing erodes
- ARPU compression is inevitable as competition intensifies
Usage Saturation:
- Initial users optimize for maximum value extraction
- Mainstream users extract less value, use products less intensively
- Revenue per user may decline as growth extends beyond initial enthusiasts
These dynamics suggest that inference-first products have limited window for maintenance of current ARPU and margins. Long-term profitability may require:
- Premium tier expansion (enterprise features, higher ARPU)
- New product lines (expanding TAM rather than deepening existing)
- Efficiency improvements offsetting margin compression
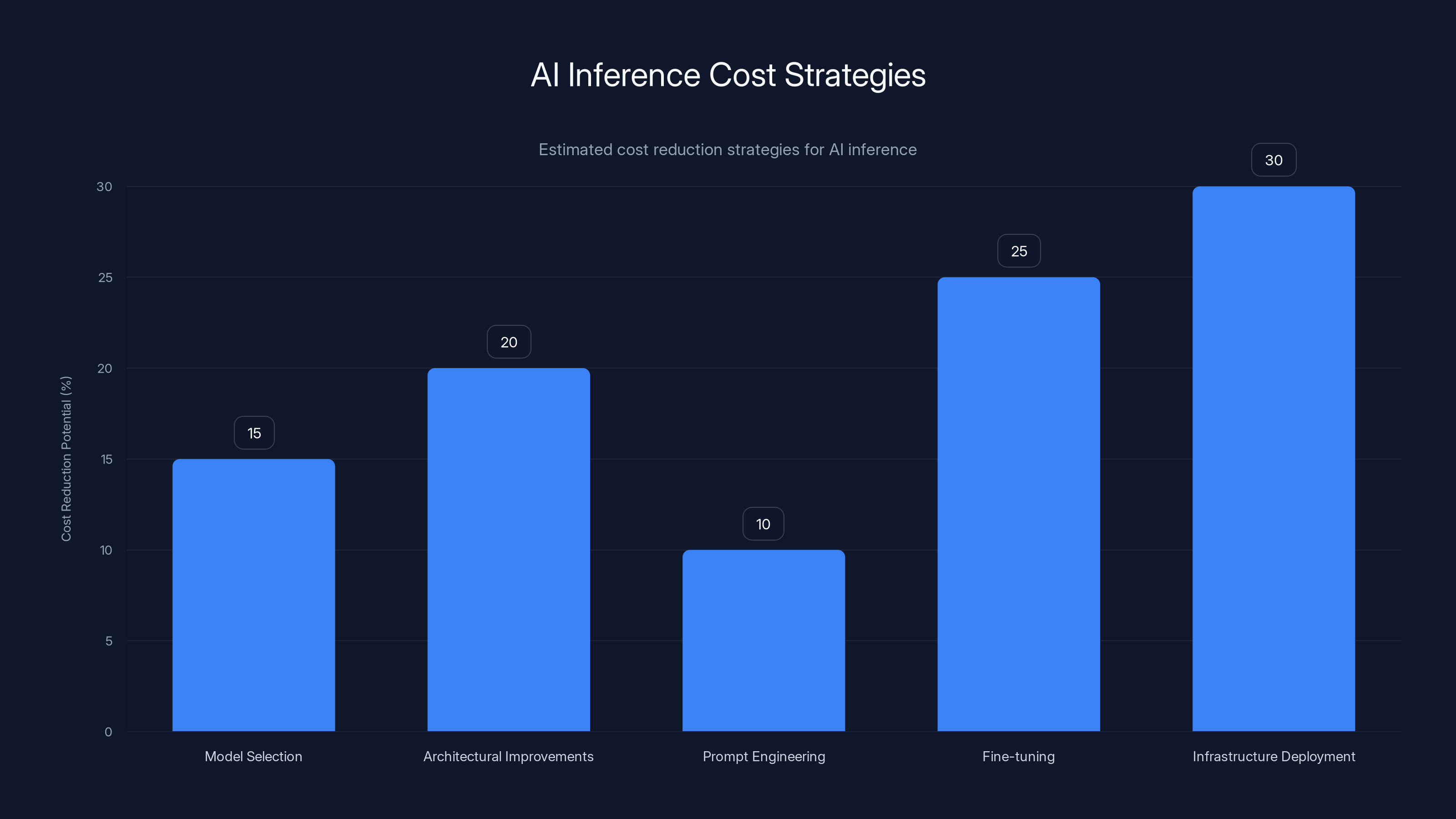
Estimated data shows that infrastructure deployment and fine-tuning specialist models can lead to the highest cost reductions, up to 30%, in AI inference costs.
Section 12: Enterprise Adoption Patterns in Inference-First Products
How Bottom-Up Adoption Becomes Enterprise Bottleneck (Or Advantage)
Cursor and Lovable's organic, bottom-up adoption creates interesting dynamics when they reach enterprises:
Enterprise Adoption Pathway:
- Individual discovery: Developers find and adopt tool individually
- Team advocacy: Developers evangelize within their teams
- Team expansion: Adjacent teams hear about the tool and adopt
- Enterprise consideration: IT and procurement notice widespread adoption
- License negotiation: Company moves from individual accounts to enterprise licensing
- Standard expansion: Tool becomes recommended or standard for entire organization
This creates natural account expansion without sales effort:
- Each new team member bringing tool experience into the organization
- Cultural shift where tool becomes expected, not optional
- Enterprise procurement forced to address existing adoption
- Negotiation from position of strength (already essential to operations)
Advantages:
- Lower enterprise sales friction (tool already proven value)
- Faster contract cycles (users already expecting it)
- Higher retention (deeply integrated into workflows)
- Better expansion potential (more likely to upgrade to premium tiers)
Disadvantages:
- Enterprise revenue highly unpredictable (depends on organic adoption)
- Limited ability to shape enterprise adoption (bottom-up, not top-down)
- Integration and compliance needs may emerge as blockers
- IT departments may attempt to restrict or replace with alternatives
Enterprise SaaS Features Required for Bottom-Up to Succeed
As inference-first products mature, enterprise features become essential:
Admin Controls:
- Ability for IT to manage licenses, users, permissions
- Granular access controls
- Audit logging and compliance tracking
Security and Compliance:
- SOC 2 compliance
- HIPAA/GDPR compliance for regulated industries
- Data residency and privacy controls
- Encryption, key management
Integration Capabilities:
- API for integration with existing enterprise tools
- SAML/SSO authentication
- Integration with identity systems (Active Directory, Okta)
- Webhook and automation capabilities
Enterprise Support:
- Dedicated account management for large customers
- SLA guarantees
- Priority support and response times
- Custom implementation support
Companies that maintain developer-focused simplicity in core products while adding enterprise features as separate tiers or modules often succeed. Those that try to make products work for all audiences often degrade the core experience that drove adoption.
Cursor's Approach: Maintain core product simplicity, add enterprise features through separate admin interfaces and licensing models. Avoid feature creep that would degrade individual developer experience.
Section 13: Profitability Pathways and Long-Term Sustainability
The Path from Rapid Growth to Sustainable Profitability
Inference-first companies must navigate a critical transition: from growth mode (optimizing for viral adoption) to profitability mode (optimizing for economics).
This transition typically occurs when companies reach:
- Mature market position (primary TAM saturated)
- Investor pressure for profitability (if VC-backed)
- Inference cost challenges (prices increasing, competition intensifying)
- Organizational maturation (infrastructure supporting fewer "startup" decisions)
Profitability Levers:
-
Inference Cost Optimization:
- Model efficiency: Achieve equivalent results with cheaper models
- Architecture optimization: Reduce inference calls through caching, batch processing
- Proprietary models: Develop specialized models trained on product-specific data
- Infrastructure: Deploy models on owned infrastructure rather than API access
- Potential impact: 30-50% reduction in inference costs
-
ARPU Expansion:
- Premium tiers: Advanced features, higher inference allowances
- Enterprise licensing: Volume discounts for organizational adoption
- New products: Adjacent tools leveraging existing user base
- Vertical expansion: Industry-specific implementations commanding higher pricing
- Potential impact: 50-100% ARPU increase
-
S&M Minimization:
- Maintain viral adoption even as product matures
- Community-driven support and content
- Minimal paid acquisition (organic growth remains dominant)
- Potential impact: Keep S&M at 5-10% vs. 40-50% industry standard
-
Organizational Efficiency:
- Engineering-led development (avoiding expensive product management overhead)
- Community support (user-generated content, documentation)
- Data-driven decisions (reduce middle management)
- Potential impact: 20-30% reduction in operating costs
Profitability Timeline Expectations
Typical Inference-First Product Timeline:
-
Year 1-2: High growth, significant losses
- Revenue: $10-100M
- Operating margin: -50% to -100%
- Focus: Product-market fit, viral adoption, user acquisition
-
Year 2-3: Continued growth, improving margins
- Revenue: $100-500M
- Operating margin: -20% to 0%
- Focus: Cost optimization, ARPU expansion, enterprise adoption
-
Year 3+: Mature growth, profitability
- Revenue: $500M+
- Operating margin: 20-40%
- Focus: Efficiency, expansion into adjacent markets
Companies that fail this transition (unable to move to positive margins by year 3-4) typically:
- Require ongoing dilutive financing
- Face declining investor interest
- Eventually run out of capital
- Are acquired at discount valuations
Successful companies that execute this transition become valuable, profitable enterprises worth billions.
Section 14: The Future of AI Economics and Inference-First Business Models
Inference Cost Trends: Will They Continue Decreasing?
Historical trend: inference costs have decreased 50% annually as models improve and competition intensifies.
If this trend continues:
- Today: Claude 3.5 Sonnet costs $3/M input tokens
- 2026: ~$1.50/M input tokens
- 2027: ~$0.75/M input tokens
- 2028: ~$0.38/M input tokens
At $0.38/M input tokens, inference becomes economically negligible. Current inference-driven economics completely change.
Implications:
- Products optimizing for inference cost in 2025 become irrelevant
- Profitability depends on ARPU expansion and operational efficiency, not inference optimization
- Competitive moat must shift from "better inference spending" to "better product design", network effects, or data
However, this trend has risks:
- Model providers may not continue cost reductions if they move toward monopoly pricing
- Capability improvements may consume efficiency gains (models become expensive faster than inference costs decrease)
- New applications may emerge requiring more inference than current products
The Emergence of Inference-Optimized Models
Likely evolution: specialized models optimized for cost-efficiency in specific domains, rather than general-purpose expensive models.
Example: Instead of using Claude 3.5 Sonnet for all code generation tasks, specialized models emerge that:
- Cost 50-70% less than Sonnet
- Deliver equivalent or superior results for code generation specifically
- Are fine-tuned on code generation examples
- Have architecture optimized for code understanding
This specialization enables companies to:
- Maintain product quality at lower cost
- Develop defensible competitive advantages around model selection
- Reduce dependency on general-purpose model providers
The companies most successful at exploiting this trend will be those with deep understanding of:
- Which models work best for which tasks
- How to fine-tune or optimize models
- Data collection and quality
- Model evaluation frameworks
The Rise of Proprietary Models
The highest-margin inference-first companies will eventually build proprietary models optimized for their specific use cases:
Benefits of proprietary models:
- Complete cost control (no API fees)
- Optimization for specific tasks (better results)
- Data moat (models improve with each customer interaction)
- Defensible competitive advantage
Challenges:
- Requires significant ML expertise and investment
- Data collection and privacy concerns
- Ongoing investment in model improvements
- Risk of being out-innovated by general-purpose models
Likely outcome: Cursor, Lovable, and similar companies will eventually invest in proprietary models. This represents a natural evolution from using best-available APIs to building defensible, optimal products.
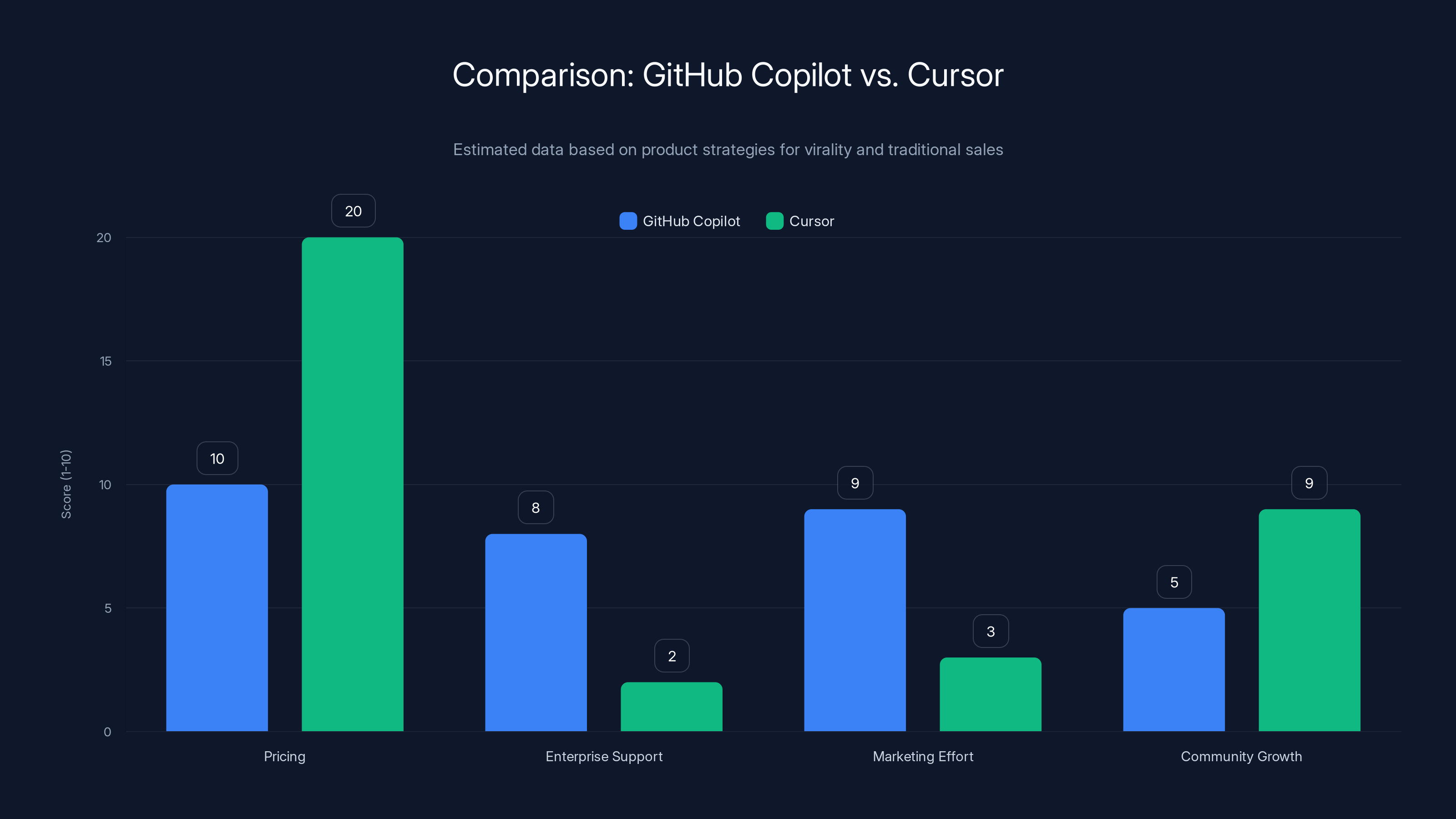
GitHub Copilot balances individual and enterprise needs, while Cursor focuses on individual developers, leading to higher community growth. Estimated data.
Section 15: Integrating Inference-First Principles With Additional Productivity Tools
The Ecosystem Opportunity Beyond Single Products
While Cursor and Lovable are single-product successes, the opportunity for inference-first thinking extends to broader productivity ecosystems.
Emerging category: Integrated AI Productivity Suites
Implications for companies building such suites:
- Cross-product inference sharing: Inference spend in one product subsidizes another
- Network effects: Value of suite increases as more products integrate
- Bundled pricing: Premium tier covering multiple products
- Efficiency gains: Shared infrastructure, models, and caching across products
Example Economics:
- Product A (code editor): 50/year inference
- Product B (document generation): 30/year inference
- Bundled: 70/year inference (vs. $35/month separate)
The bundled product benefits from:
- Increased ARPU relative to inference cost
- Reduced churn (multi-product users less likely to leave)
- Cross-selling efficiency
- Better inference economics (fewer duplicated calls)
Runable is operating in a related space, offering AI-powered automation for content generation, workflow automation, and developer tools at $9/month. This approach applies inference-first thinking to multiple use cases through a unified platform—agents for creating AI slides, documents, reports, and presentations, combined with workflow automation tools.
The efficiency of this bundled approach mirrors successful inference-first economics: premium experience across multiple tools at lower per-unit cost through operational leverage and consolidated infrastructure.
Section 16: Organizational Transformation: Building for Inference-First Success
Shifting Org Structure From Sales-Centric to Engineering-Centric
Companies attempting to transition from sales-driven models to inference-first approaches often fail due to organizational inertia. Building inference-first from inception requires different org structure:
Inference-First Org Structure (for $100M ARR company):
- CEO: Overall strategy, fundraising, board management
- VP Engineering (40 people):
- Platform engineers (20): Core infrastructure, inference optimization
- Product engineers (15): Feature development, user experience
- ML engineers (5): Model evaluation, fine-tuning, optimization
- Head of Product (8 people):
- Product managers (3): Feature prioritization, roadmap
- Designers (3): UX design, user research
- Data analysts (2): Analytics, metrics, insights
- VP Operations (10 people):
- Finance, HR, legal, infrastructure
- Community & Support (5 people):
- Community management
- Documentation
- User support
- Total: ~63 people for $100M ARR
Traditional Sales-Driven Org (for comparable $100M ARR):
- CEO: Overall strategy, board management
- VP Sales (60 people):
- Account executives (40)
- Sales development reps (15)
- Sales operations (5)
- VP Marketing (20 people):
- Demand generation
- Content and brand
- Event marketing
- VP Customer Success (25 people):
- Customer success managers
- Implementation specialists
- Support team
- VP Engineering (15 people):
- Feature development only
- VP Operations (8 people)
- Total: ~128 people for $100M ARR
Comparison: Inference-first org achieves 2x higher revenue per employee while maintaining equivalent or superior product quality.
Metrics and KPIs That Drive Different Behaviors
Organizations optimize toward the metrics they measure. Inference-first companies must track different KPIs:
Inference-First KPIs:
- Viral coefficient: Percentage of users who become evangelists and refer new users
- Organic growth rate: Month-over-month growth without paid acquisition
- Cost per inference: Total inference spend / total inference calls (drive down)
- Product satisfaction: NPS, retention, usage intensity
- CAC: Should remain near $0; any paid acquisition requires justification
- LTV: Lifetime value of customer (drive up)
- Gross margin: Maintain above 50%, target improvement to 60-70% over time
- Operating margin path: Show improvement toward 20%+ profitability
Sales-Driven KPIs:
- CAC: Customer acquisition cost per sales rep (optimize down)
- CAC payback: Months to recover acquisition cost (12-18 month target)
- ACV: Annual contract value (drive up)
- Sales efficiency: Revenue growth vs. sales team growth
- Win rate: Percentage of opportunities converted
- Pipeline: Revenue pipeline in sales process
- Gross margin: Maintain 75%+, expected at this business model
Companies measuring inference-first KPIs will naturally build products and organizations optimized for that model. Companies measuring traditional KPIs will struggle if they try to adopt inference-first approaches.
Section 17: Strategic Frameworks for Choosing Your Path
Decision Framework: Inference-First vs. Sales-First
Not every product should pursue inference-first strategies. Here's a decision framework for founders:
Score your product on these dimensions:
-
Product Quality Gap (can you create discontinuous improvement?)
- High gap (product 10x better): Inference-first viable
- Medium gap (product 2-3x better): Depends on other factors
- Low gap (product comparable): Sales-first necessary
-
User Base Size (how large is potential market?)
- Large (>10M potential users): Inference-first viable
- Medium (1-10M): Depends on other factors
- Small (<1M): Sales-first necessary
-
Virality Potential (will users voluntarily share?)
- High (users naturally evangelize): Inference-first viable
- Medium (potential for virality): Depends
- Low (requires sales push): Sales-first necessary
-
Unit Economics Sustainability
- Can you profitably serve at low CAC?: Inference-first viable
- Requires high ARPU to offset inference costs?: Depends
- Inference costs make profitability impossible?: Sales-first necessary
-
Competitive Moat
- Moat through product excellence and network effects: Inference-first sustainable
- Moat through relationships and sales execution: Sales-first necessary
Framework:
- Score 5/5 on above: Pursue inference-first aggressively
- Score 3-4/5: Hybrid approach may work
- Score 2/5 or below: Pursue traditional sales model
Case Study: When Inference-First Fails
Product Type: Enterprise Healthcare Compliance Tool
A startup attempted to build an AI-powered healthcare compliance tool using inference-first thinking:
- Used expensive models to provide sophisticated compliance analysis
- Targeted hospitals and healthcare systems
- Attempted to achieve viral adoption among compliance officers
Why it failed:
- No virality: Healthcare compliance officers don't evangelize tools to colleagues; they use what their organization provides
- Enterprise-required features: Needed SOC2, HIPAA compliance, integration with existing systems—all requiring sales and implementation
- Inference costs unsustainable: 5,000 ARPU didn't work
- Wrong use case: Healthcare is sales-driven (approval is slow, compliance is mandatory), not viral
This product would have succeeded with traditional sales approach:
- Target healthcare compliance directors
- Hire sales team to pursue hospital CIOs
- Implement required compliance features
- Create defensible relationships
Lesson: Inference-first thinking works for self-directed software used by many individuals. It fails for compliance, regulated, or sales-driven categories.
Section 18: Emerging Models: The Hybrid Approach
When Bottom-Up and Top-Down Approaches Coexist
The most sophisticated companies are evolving hybrid approaches that capture benefits of both viral adoption and sales-driven enterprise capture:
Hybrid Model:
- Phase 1: Launch with inference-first, bottom-up approach
- Phase 2: Achieve product-market fit with individual/team users
- Phase 3: Add enterprise sales motion as organic adoption reaches critical mass
- Phase 4: Use enterprise deals to fund inference cost as company scales
Key Success Factors:
- Maintain core product simplicity while adding enterprise features
- Separate pricing tiers so free tier remains free, enterprise tier has features/support
- Don't degrade individual experience to serve enterprise requirements
- Use enterprise revenue to fund inference costs rather than raising prices on individuals
- Enterprise sales team scales gradually (hire sales only when organic adoption reaches threshold)
Companies Executing This Well:
- Slack: Started with team adoption, later added enterprise sales
- GitHub: Achieved viral adoption among developers, later added enterprise licensing
- Figma: Dominated with designers, later added enterprise features
Inference-first companies likely following this path:
- Cursor: Individual developers established, enterprise licensing emerging
- Lovable: Teams and startups established, enterprise features under development
This hybrid approach may be optimal: capture viral adoption advantages while maintaining ability to monetize enterprises and high-value customer segments.
Section 19: Competitive Dynamics and Market Evolution
How Inference-First Success Attracts Copycat Competition
Cursor's extraordinary success has triggered a competitive response:
First-mover advantages Cursor captured:
- Best engineers interested in AI coding
- First-mover brand recognition
- Developer affinity and trust
- First access to best model improvements
- Inference contract leverage (negotiated early with Anthropic)
How competitors are attempting to replicate:
- Building similar (or superior) products using better models
- Attempting alternative pricing strategies (free tier + premium tier)
- Integrating into existing tools (VS Code extensions, IDE plugins)
- Building superior domain-specific capabilities (certain languages, frameworks)
- Leveraging existing distribution (GitHub, Microsoft, JetBrains)
Competitive landscape emerging:
| Company | Approach | Advantage | Disadvantage |
|---|---|---|---|
| Cursor | Best product experience | Viral adoption, user love | Under more scrutiny now |
| GitHub Copilot | Integrated with VS Code | Distribution, official sanctioning | Slower to innovate |
| JetBrains AI | Native IDE integration | Existing IDE user base | Limited to JetBrains users |
| Open-source alternatives | Free and customizable | No inference costs, control | Less polished experience |
| Claude in browser | Direct model access | Simplicity | Less integrated experience |
Cursor faces mounting competitive pressure but has structural advantages (first-mover, loyal user base, proven product-market fit) that are difficult to overcome.
Market Consolidation Scenarios
How will the AI coding market consolidate?
Scenario 1: Microsoft Wins Through Integration
- Microsoft applies enterprise muscle to GitHub Copilot
- Bundles with Office, Azure, entire Microsoft ecosystem
- Achieves dominance in enterprise market
- Cursor remains strong with individual developers, startups
- Outcome: Duopoly (Microsoft enterprise, Cursor consumer)
Scenario 2: Cursor Becomes the Vim/Emacs of AI Coding
- Cursor maintains cultural significance despite competition
- Remains preferred by elite developers even if not market leader
- Achieves strong profitability through niche dominance
- Outcome: Profitable boutique company, not trillion-dollar startup
Scenario 3: Open-Source Models Shift Competitive Dynamics
- Open-source models (Llama, others) become competitive with proprietary models
- Companies can run models on own infrastructure, eliminating inference costs
- Competitive moat shifts from model access to product UX, tooling, integration
- Outcome: Competition on product quality, not inference capability
Each scenario suggests different competitive implications and profitability pathways.
Section 20: The Profound Shift in How Founders Think About SaaS
The Death of "Standard" SaaS Unit Economics
Cursor and Lovable's success signals a fundamental shift in how the next generation of founders will approach SaaS economics:
Old Paradigm:
- Gross margin is king (75%+ is healthy)
- Sales and marketing is how you grow (40-50% of revenue is normal)
- Unit economics are optimized early (CAC payback within 12-18 months)
- Product builds toward future enterprise sales (feature creep begins early)
New Paradigm:
- Excellence is king (create products users can't resist)
- Product is how you grow (viral adoption beats paid acquisition)
- Unit economics optimize toward viral (CAC near $0 is goal)
- Product remains simple, scales through virality, enterprise features added later
This isn't a temporary trend—it's a reflection of fundamental shifts in market dynamics:
- Technology maturity: AI models are now capable enough to create genuinely exceptional products
- Cost economics: Inference costs are declining, making aggressive compute spending viable
- Distribution changes: Network effects and social sharing make traditional marketing less effective
- Competition intensity: In crowded markets, product quality becomes the primary differentiator
Founders observing this shift are increasingly asking: "Should I build for virality rather than sales?" rather than assuming traditional SaaS unit economics apply to their business.
Who Will Define the Next Era of SaaS
The companies that will define the next era of SaaS are those that:
- Recognize the new paradigm: Understand that traditional unit economics don't apply to inference-first businesses
- Raise sufficient capital: Need 3-4 year runways rather than 18-24 month traditional SaaS runways
- Attract engineering talent: Build organizations around engineering excellence rather than sales execution
- Execute inference-first ruthlessly: Don't layer sales on top of viral products
- Navigate the transition to profitability: Successfully optimize costs and ARPU as they mature
These companies will emerge from:
- Founders with deep technical expertise in AI and product
- VCs comfortable with non-traditional unit economics
- Markets where discontinuous product improvement is possible
- Use cases enabling viral adoption (consumer/prosumer focus)
Traditional SaaS will continue to exist and be profitable, but the fastest-growing, highest-valued companies will increasingly adopt inference-first thinking.
Conclusion: Synthesizing the Inference Economy and Strategic Implications
The rapid ascent of Cursor and Lovable represents far more than two successful startups. It signals a fundamental reordering of how AI-native products compete, scale, and achieve profitability. The implications extend across technology, business strategy, and how the next generation of founders will approach software economics.
The Core Insight Revisited
The counterintuitive insight driving this transformation is simple but profound: inference costs are not a gross margin problem—they are a customer acquisition strategy.
When inference spending creates products so exceptional that users become involuntary evangelists, the computation expense becomes an investment in distribution rather than a drag on profitability. A developer spending
This represents an inversion of how traditional SaaS founders think about economics. Rather than minimizing cost to maximize margin, inference-first founders maximize quality to enable virality, accepting margin compression in exchange for zero customer acquisition cost.
When This Model Works (And When It Doesn't)
Inference-first economics work when:
- Discontinuous product improvement exists: The product is dramatically better than alternatives
- Viral distribution is possible: Users voluntarily evangelize the product
- Market size is large: Sufficient addressable market for substantial companies
- ARPU is adequate: Pricing supports profitability even after inference costs
- Capital runway is sufficient: 3-4 years to reach profitability
Inference-first economics fail when:
- Product improvement is marginal: Competitors offer equivalent functionality
- Virality is impossible: The use case requires sales-driven distribution
- Market is small: Insufficient volume to justify inference investment
- ARPU is insufficient: Pricing doesn't support profitability
- Capital is limited: Company burns out before reaching profitability
Founders must honestly assess whether their product, market, and execution capability meet the prerequisites for inference-first success. The companies that execute this strategy with eyes open to the requirements will thrive. Those that underestimate the challenges or misapply the model to unsuitable use cases will fail.
The Competitive Advantage Shift
This transformation reshapes competitive advantage in AI software:
Traditional Advantage: Sales execution and market access
- Companies with best sales teams, deepest relationships, strongest distribution could win
- Massive incumbent advantage (existing relationships, integrations, brand)
- Winner-take-most dynamics based on sales productivity
New Advantage: Engineering excellence and product vision
- Companies with best product, most exceptional user experience win
- First-mover advantage but vulnerable to better

