![Mastering the Monitoring of LLM Behavior: Drift, Retries, and Refusal Patterns [2025]](https://tryrunable.com/blog/mastering-the-monitoring-of-llm-behavior-drift-retries-and-r/image-1-1777217644315.png)
Mastering the Monitoring of LLM Behavior: Drift, Retries, and Refusal Patterns [2025]
Last month, I was deep into a project when a client pinged me at 2 AM: "The model output is off again." It wasn't the first time. The unpredictability of Large Language Models (LLMs) like GPT-4 had once more disrupted our workflow. The challenge? Monitoring and managing behavior like drift, retries, and refusal patterns effectively.
TL; DR
- LLM Drift: Changes in model output over time can impact consistency and reliability.
- Retry Mechanisms: Implementing smart retries can mitigate output variability.
- Refusal Patterns: Understanding when and why models refuse tasks is crucial for compliance.
- Real-time Monitoring: Essential for detecting and responding to LLM anomalies.
- Future Trends: Expect advancements in AI interpretability and automated monitoring solutions.
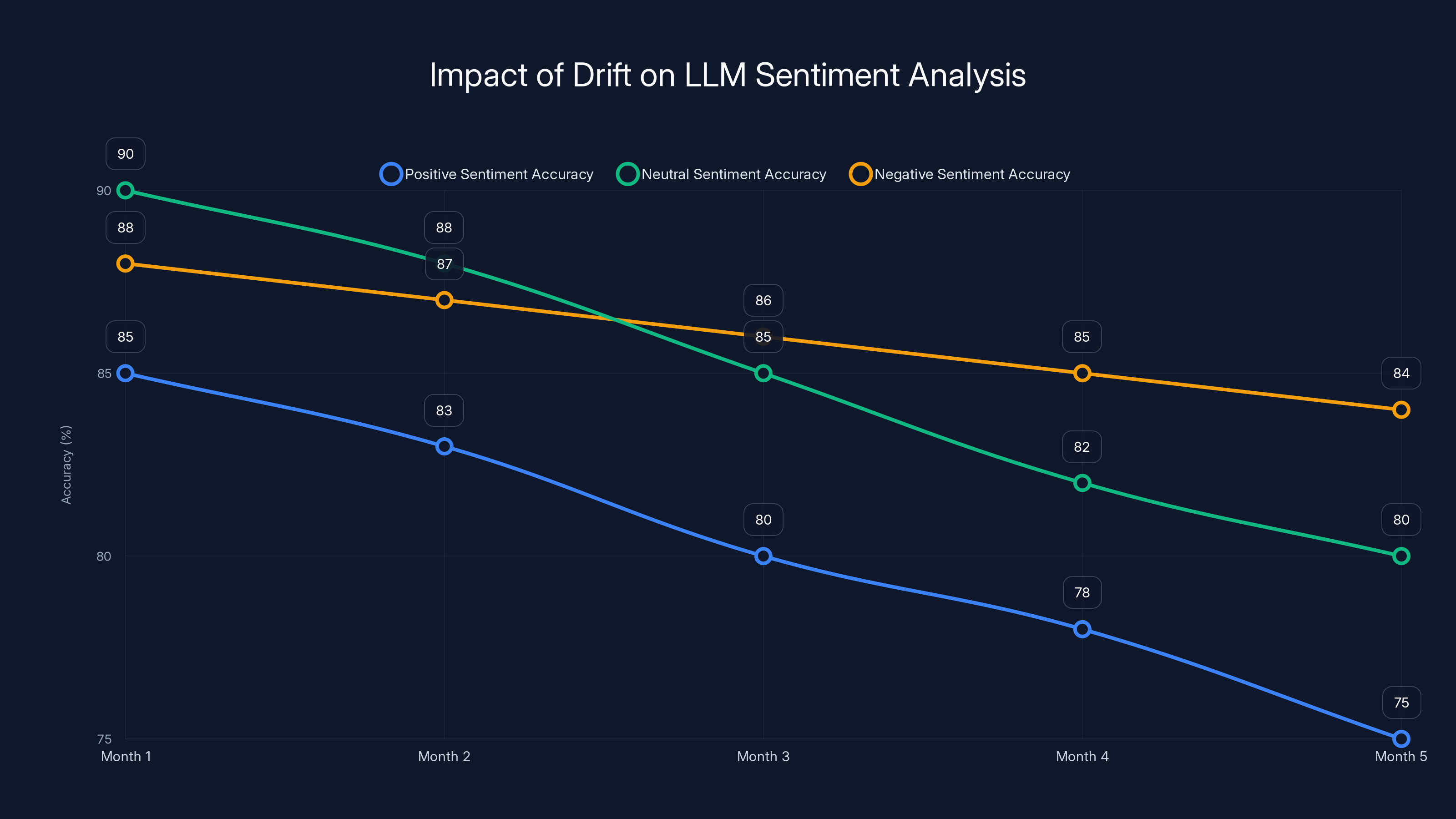
This chart illustrates how drift can cause a decline in sentiment analysis accuracy over time, highlighting the need for regular model evaluations. Estimated data.
The Unpredictability of LLMs
LLMs are powerful but inherently unpredictable. Unlike traditional software, where inputs and outputs are deterministic, LLMs introduce stochastic behavior. This means the same input can yield different outputs at different times. For developers and businesses relying on consistent AI outputs, this is a significant hurdle.
What Causes Drift?
Drift in LLMs refers to the gradual change in model behavior over time. It can be influenced by:
- Training Data Updates: As models are retrained with new data, their outputs can shift. According to Claudia Plus AI, understanding these shifts is crucial for maintaining model accuracy.
- Environmental Changes: Updates in the software environment or changes in input data distribution can also contribute to drift.
- Model Architecture Tweaks: Even minor changes in architecture or hyperparameters can impact outputs, as discussed in Minutes on Substack.
Example: A sentiment analysis model may start classifying neutral reviews as negative if retrained with data that has an increased proportion of negative reviews.
Mitigating Drift
To manage drift effectively:
- Regular Performance Evaluation: Schedule periodic evaluations of the model’s outputs against benchmark datasets.
- Version Tracking: Maintain a detailed log of model versions and associated performance metrics.
- Feedback Loops: Implement systems to capture and learn from user feedback to fine-tune the model. This approach is highlighted in Dominic Cummings' analysis.
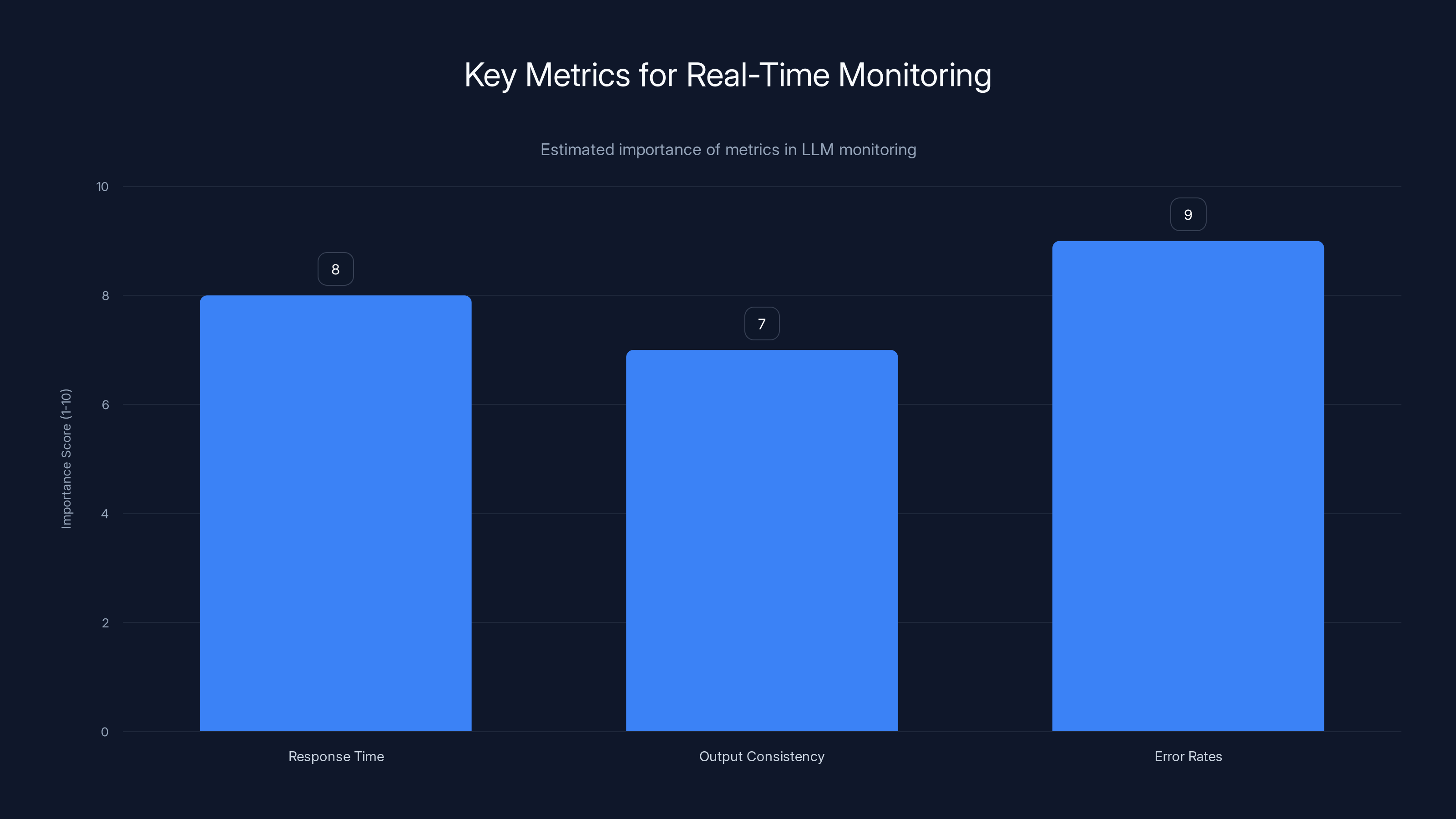
Estimated data showing the relative importance of key metrics in monitoring LLMs, with Error Rates being the most critical.
Smart Retry Mechanisms
Retries are a common strategy when dealing with LLMs, but they need to be smart. Blindly retrying can lead to increased costs and system strain without guaranteeing better results.
Designing Effective Retry Strategies
- Exponential Backoff: Gradually increase the delay between retries, which can help manage rate limits and reduce server load.
- Adaptive Retries: Use contextual information to decide when to retry. For instance, if the initial response is nonsensical, a retry might be warranted.
- Retry Limits: Set a cap on the number of retries to avoid infinite loops and wasted resources. These strategies are discussed in depth in Benjamin Todd's insights.
Code Example:
pythonimport time
def adaptive_retry(api_call, max_retries=5):
for attempt in range(max_retries):
response = api_call()
if is_valid_response(response):
return response
sleep_time = 2 ** attempt
time.sleep(sleep_time)
raise Exception("Max retries reached")
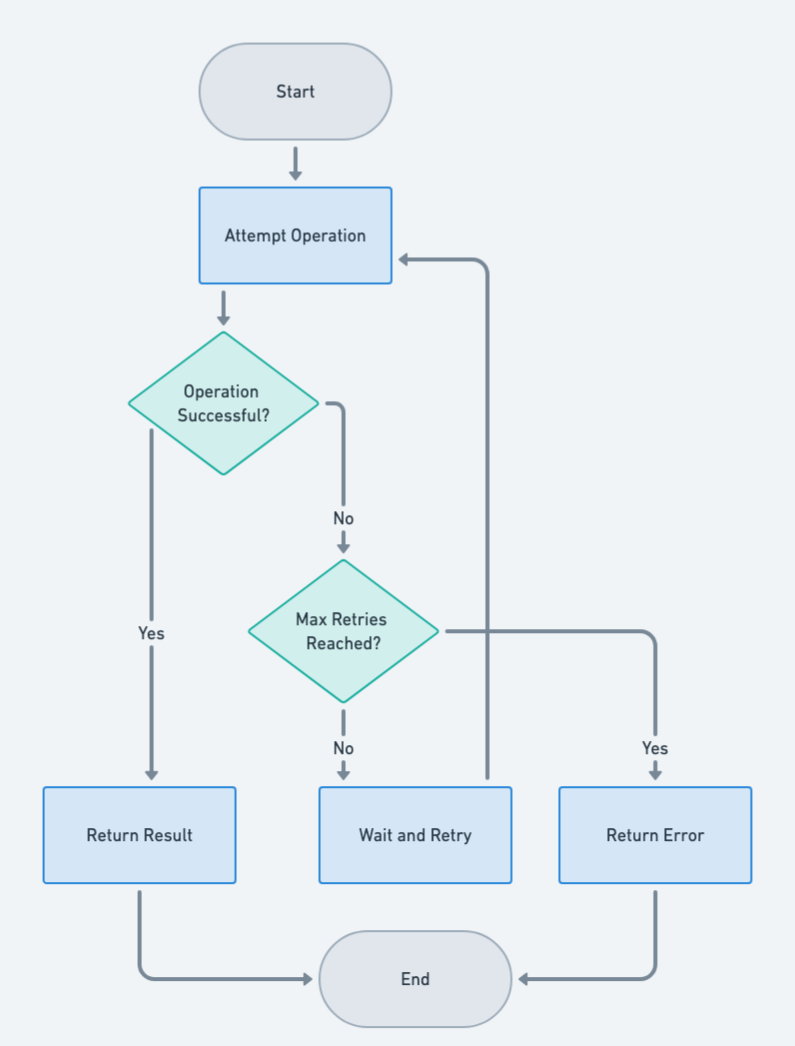
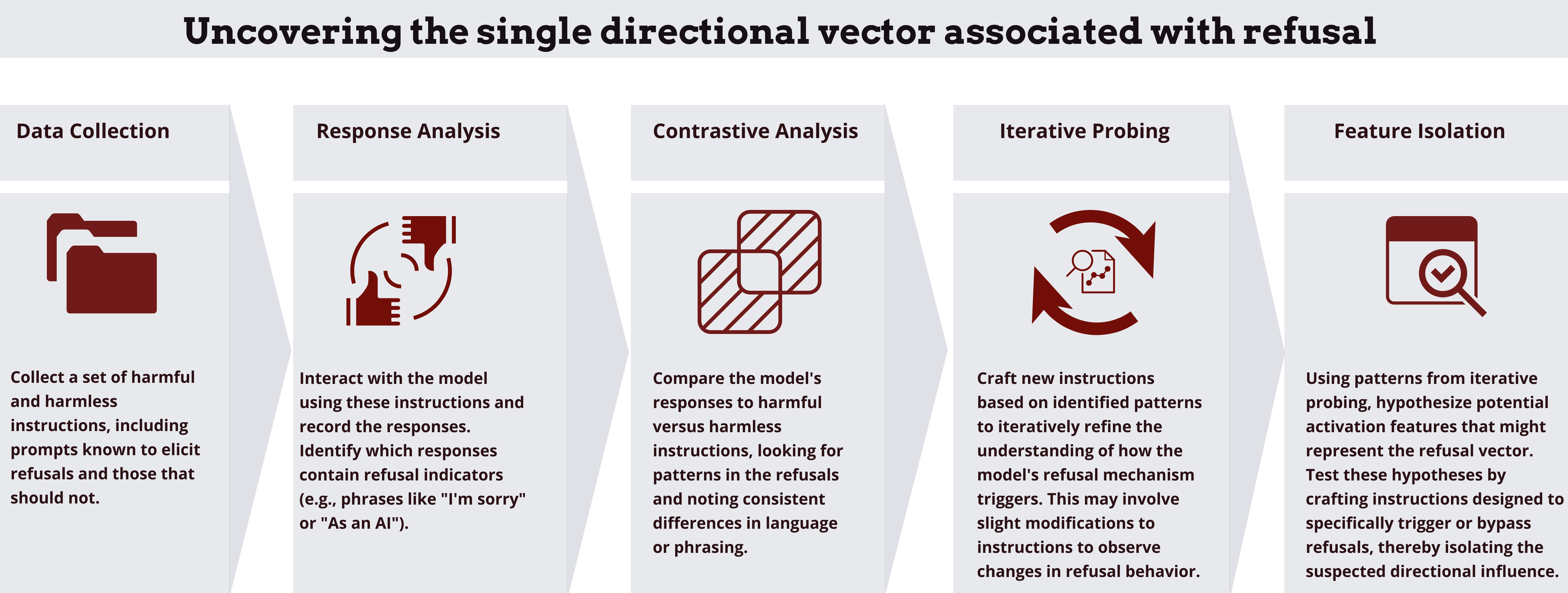
Understanding Refusal Patterns
LLMs might refuse to generate output based on ethical guidelines or content policies. This is crucial for avoiding harmful or non-compliant outputs.
Why Models Refuse
- Content Policies: Models are designed to refuse generating offensive or harmful content. This is a key point in Nate's Newsletter.
- Ambiguous Inputs: When inputs are unclear or contradictory, models might opt to refuse rather than risk errant outputs.
Example: A model used for content moderation might refuse to process inputs that contain explicit language.
Managing Refusal Patterns
- Clear Guidelines: Ensure that the model's refusal criteria align with your organization's policies.
- Fallback Options: Implement alternative handling paths for refusals, such as user prompts for clarification.
- Monitoring and Logging: Track refusal instances to identify patterns and areas for improvement, as suggested in Richard Haass' analysis.
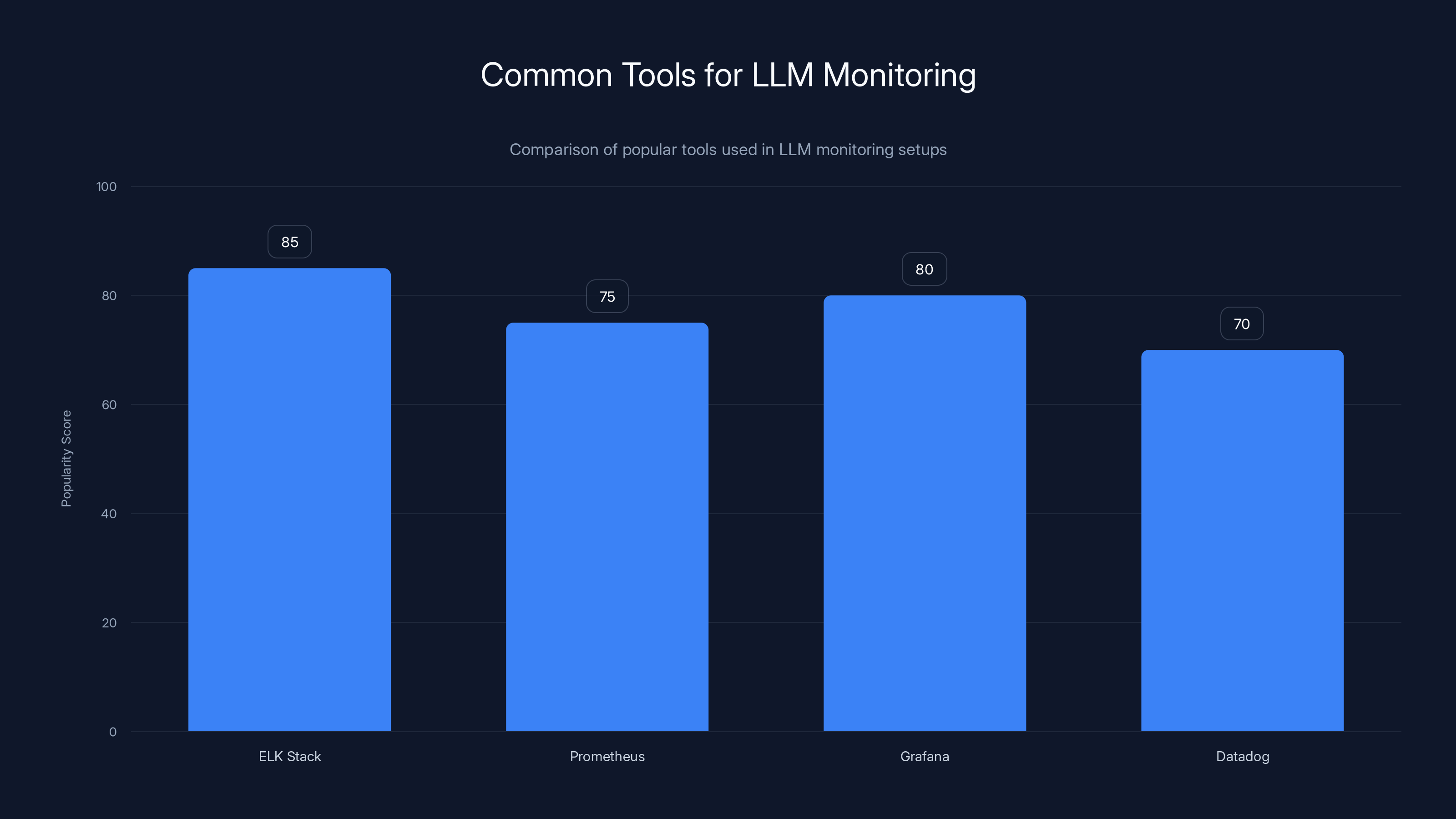
ELK Stack and Grafana are among the most popular tools for LLM monitoring, with high scores in popularity due to their robust features. (Estimated data)
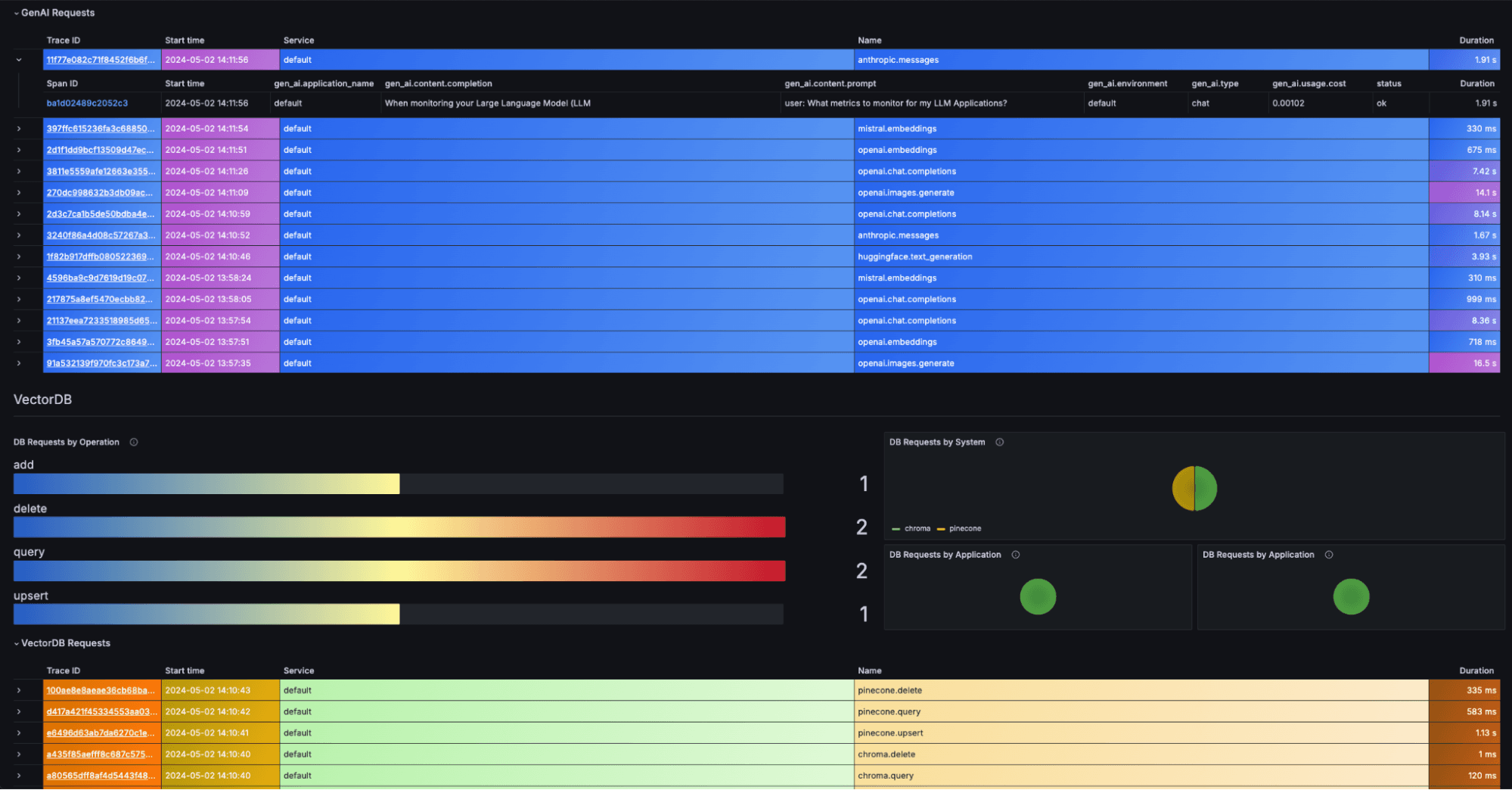
Real-Time Monitoring Systems
Monitoring LLM behavior in real-time is essential for maintaining trust and reliability. This involves tracking key metrics and implementing alert systems.
Key Metrics to Monitor
- Response Time: Delays might indicate server issues or increased load.
- Output Consistency: Fluctuations here can signal drift or instability.
- Error Rates: Spike in errors can point to underlying issues.
Setting Up Monitoring Tools
- Log Aggregation: Use tools like ELK Stack to centralize and analyze logs.
- Alert Systems: Configure alerts for key metrics, using tools like Prometheus and Grafana.
- Dashboard Integration: Visualize real-time data for quick insights and decision-making. These practices are detailed in Cameron R. Wolfe's research.
Example Setup:
yaml# Prometheus Alert Rule
alert: High Error Rate
expr: job: api_errors: rate 5m > 0.05
for: 10m
labels:
severity: critical
annotations:
summary: "High error rate detected"
Future Trends in LLM Monitoring
As AI continues to evolve, so will the tools and methodologies for monitoring LLM behavior. Here’s what to expect:
AI Interpretability
Greater focus on making AI decisions transparent will help in understanding and predicting model behavior. This is emphasized in Handy AI's publication.
Automated Monitoring Solutions
Emerging tools will offer out-of-the-box solutions for complex LLM monitoring, reducing the need for custom setups.
Ethical and Bias Monitoring
New frameworks will focus on ensuring LLMs operate within ethical guidelines and are free from bias, as discussed in Agus Sudjianto's insights.

Conclusion
Monitoring LLMs is a complex but critical task for any organization leveraging AI. By understanding drift, implementing smart retries, and managing refusal patterns, businesses can ensure that their AI systems remain reliable and compliant. As the field advances, staying informed and adaptable will be key to maintaining competitive and ethical AI solutions.
FAQ
What is LLM drift?
LLM drift occurs when the behavior of a language model changes over time due to updates in training data, changes in the environment, or model configuration tweaks.
How does adaptive retry work?
Adaptive retry uses contextual information to determine when to retry a request to an LLM, often incorporating strategies like exponential backoff to manage retries efficiently.
What are the benefits of monitoring LLM behavior?
Monitoring LLM behavior ensures reliability, compliance, and performance, helping organizations maintain trust in AI systems and quickly address anomalies.
How can refusal patterns be managed?
Refusal patterns can be managed by setting clear guidelines, implementing fallback options, and monitoring refusal instances to identify areas for improvement.
What future trends should we expect in LLM monitoring?
Future trends include advancements in AI interpretability, automated monitoring solutions, and frameworks for ethical and bias monitoring.
Why is real-time monitoring important?
Real-time monitoring is crucial for detecting and responding to anomalies in LLM behavior, ensuring consistent performance and compliance.
How can organizations stay updated with LLM monitoring practices?
Organizations can stay updated by following the latest AI research, attending industry conferences, and collaborating with AI tool vendors for insights and updates.
What tools can be used for LLM monitoring?
Tools like ELK Stack, Prometheus, and Grafana are commonly used for log aggregation, alerting, and dashboard visualization in LLM monitoring setups.
What is the role of ethical guidelines in LLM monitoring?
Ethical guidelines ensure that LLMs operate within acceptable boundaries, preventing harmful or biased outputs and maintaining compliance with regulations.
How do LLM retries impact system performance?
Retries can impact system performance by increasing load and costs if not managed properly. Smart retries help mitigate these effects by optimizing retry strategies.
Key Takeaways
- Understanding LLM drift is crucial for maintaining AI consistency.
- Implementing smart retry mechanisms can optimize performance.
- Recognizing refusal patterns ensures compliance and ethical AI use.
- Real-time monitoring is essential for proactive AI management.
- Future trends point towards automated and ethical monitoring solutions.
Related Articles
- Adobe After Effects (2026) Review | Mastering Motion Graphics with New Features [2026]
- Cohere's Game-Changing Merger with Aleph Alpha: A New Era in AI [2025]
- ICYMI: The Week's Biggest Tech News Stories from Tim Cook Stepping Down to Earth Day Celebrations [2025]
- Cohere's Strategic Merger: Building a Transatlantic AI Powerhouse [2025]
- Top 15 Amazon Tech Week Picks for a Smarter Office Setup [2025]
- Inside GPT-5.5: OpenAI's Bold Leap Forward [2025]

