![Optimize Idle GPUs with Continuous Batching [2025]](https://tryrunable.com/blog/optimize-idle-gpus-with-continuous-batching-2025/image-1-1773322624961.png)
Optimize Idle GPUs with Continuous Batching [2025]
Last month, a startup's GPU cluster sat idle for hours. Meanwhile, electricity bills soared, and potential profits slipped away. But here's the thing: those GPUs could've been running inference, generating insights, and adding value. Welcome to the world of continuous batching.
TL; DR
- Idle GPUs are costing you money: Continuous batching can turn this downtime into productive inference time.
- Boost efficiency by up to 30%: Optimize token throughput and reduce latency.
- Implementing continuous batching: Practical steps and code examples provided.
- Avoid common pitfalls: Learn from real-world cases to prevent mistakes.
- Future trends: AI-driven optimization for even smarter resource management.
- Bottom Line: Maximize your resources by keeping GPUs active and productive.
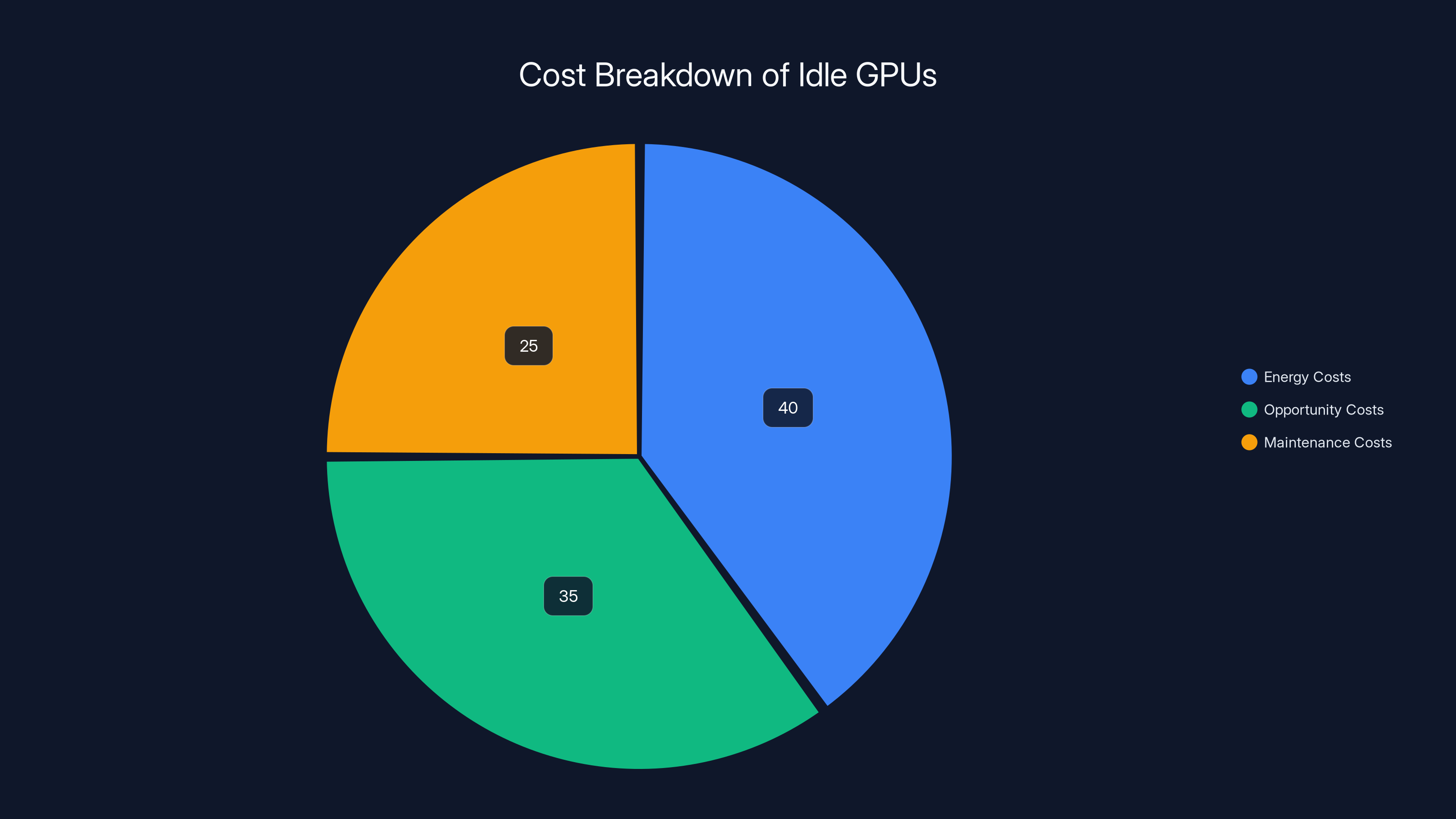
Idle GPUs incur costs primarily through energy consumption (40%), followed by opportunity costs (35%) and maintenance (25%). Estimated data.
Why Idle GPUs Are a Problem
Your GPUs are powerful, expensive resources. When they sit idle, you're essentially burning money. Training jobs might finish, but the energy consumption doesn't stop. This results in higher operational costs without any added value.
The Cost of Idleness
Let's break it down. When a GPU cluster completes a training job, it doesn't automatically power down. Energy costs continue to accrue while the hardware sits idle. It's like leaving a high-performance car running in the driveway all night. Wasteful, right?
- Energy Costs: Idle GPUs still draw power, leading to unnecessary energy expenses.
- Opportunity Costs: Every minute a GPU is idle is a minute lost on potential revenue-generating tasks.
- Maintenance Costs: Even when idle, hardware components are under stress, leading to wear and tear.
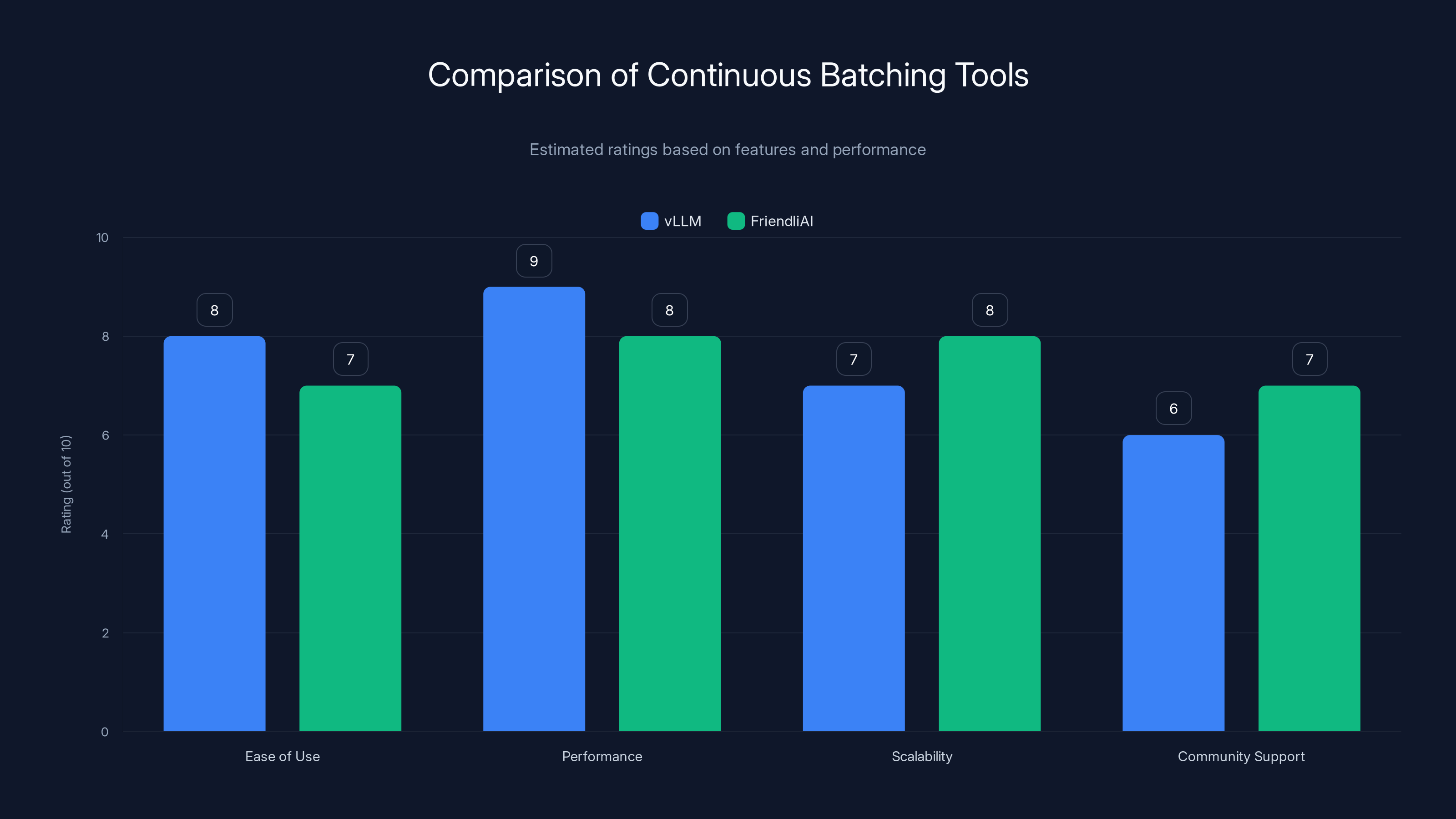
This bar chart compares vLLM and FriendliAI based on ease of use, performance, scalability, and community support. Estimated data suggests vLLM excels in performance, while FriendliAI offers better scalability.
What is Continuous Batching?
Continuous batching is a method that allows your GPUs to perform inference tasks continuously, even when they're not actively training models. This approach optimizes the utilization of your GPU resources by ensuring they are always working on productive tasks.
How It Works
The idea is simple: instead of letting your GPUs remain idle after completing a training session, you switch them to inference tasks. These tasks can be anything from processing real-time data streams to running predictive analytics.
- Token Throughput Optimization: By focusing on maximizing the number of tokens processed per second, you can significantly enhance the efficiency of your inference tasks, as discussed in token generation optimization.
- Dynamic Workload Management: Automatically adjust workloads based on current system capabilities and task priorities.

Implementing Continuous Batching
Here's a step-by-step guide to implementing continuous batching in your operations.
Step 1: Assess Your Current Infrastructure
Before you can optimize, you need to understand your current setup. Take stock of your GPU resources and their typical usage patterns.
- Inventory Check: List all available GPU resources.
- Usage Analysis: Track usage patterns and identify idle periods.
Step 2: Install the Necessary Software
You'll need software that supports continuous batching. Tools like vLLM and FriendliAI can help you get started.
- vLLM: An open-source inference engine that supports continuous batching.
- FriendliAI: Provides tools and resources for optimizing GPU usage through continuous batching.
Step 3: Configure Your System
Set up your system to switch between training and inference tasks seamlessly. This involves scripting and setting up automation to manage these transitions.
python# Example script to switch GPU tasks
import gpu_manager
gpu_manager.configure(
mode='inference',
task='real-time data processing',
optimize_for='token throughput'
)
Step 4: Monitor and Optimize
Once your system is set up, continuous monitoring is essential to ensure optimal performance. Use monitoring tools to track performance metrics and adjust as necessary.
- Performance Metrics: Track token throughput, latency, and GPU utilization.
- Adjustments: Modify configurations based on performance data.
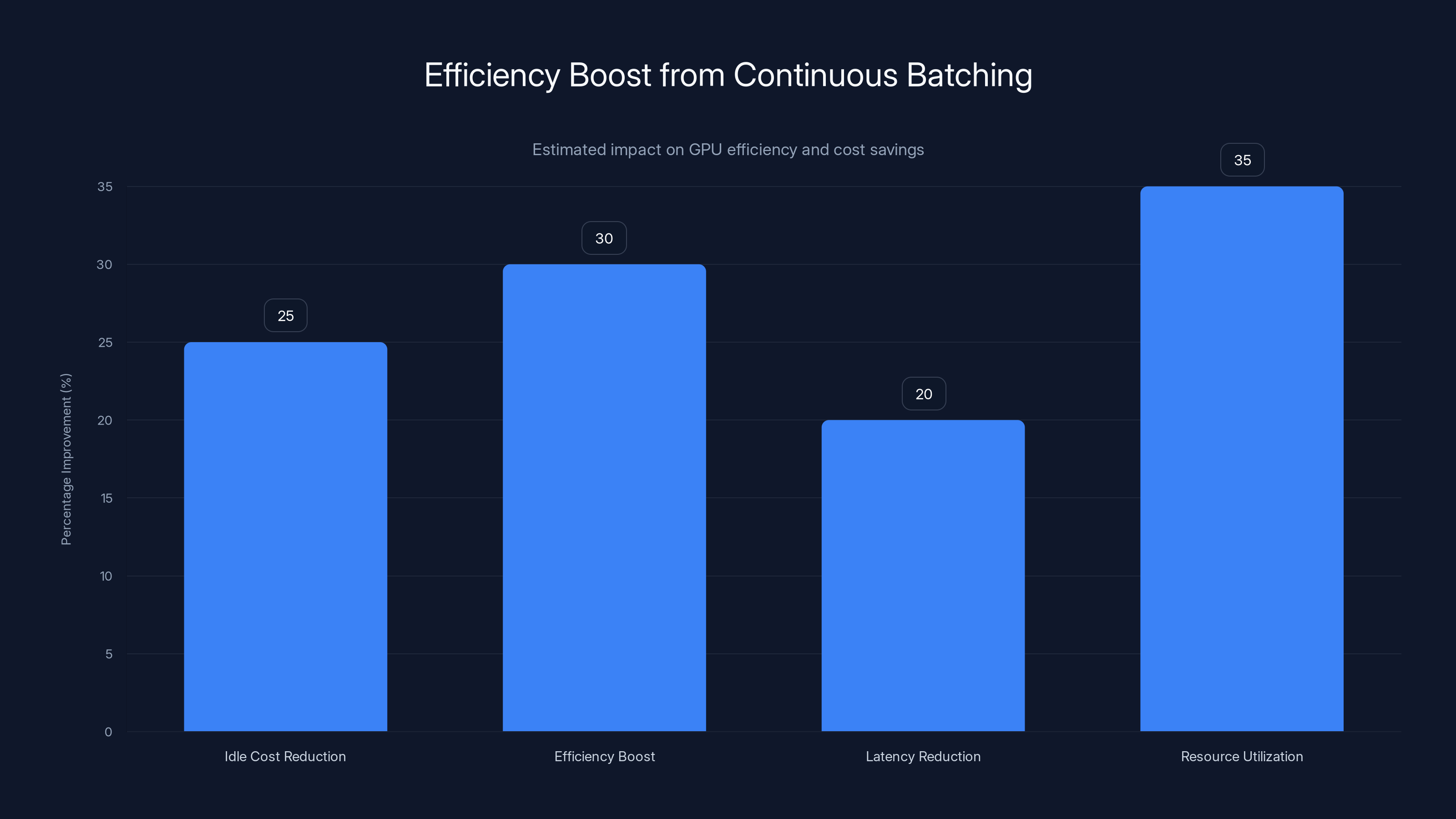
Implementing continuous batching can boost GPU efficiency by up to 30% and reduce idle costs by 25%. Estimated data.
Common Pitfalls and Solutions
Even with the best plans, things can go wrong. Here are some common pitfalls and how to avoid them.
Overloading GPUs
If you push your GPUs too hard, they might overheat or fail. Balance is key.
- Solution: Implement thermal monitoring and throttling to prevent overheating, as suggested by NVIDIA's guidelines.
Inefficient Task Scheduling
Poor scheduling can lead to resource bottlenecks and inefficiencies.
- Solution: Use AI-driven schedulers to dynamically allocate tasks based on current load and resource availability, as highlighted in AWS's latest capabilities.
Inadequate Monitoring
Without proper monitoring, you can't optimize.
- Solution: Invest in comprehensive monitoring tools that provide real-time insights into system performance.

Future Trends in Continuous Batching
The field of continuous batching is evolving rapidly, with new advancements on the horizon.
AI-Powered Optimization
Future systems will employ AI to optimize batching processes dynamically, improving efficiency and reducing costs further.
- Predictive Analytics: Use AI to predict workloads and adjust resources preemptively, as explored in AI's impact on supply chains.
- Self-Optimizing Systems: Systems that learn from past performance data to optimize future operations.

Conclusion
Continuous batching presents a significant opportunity to optimize idle GPUs, turning potential losses into gains. By implementing these practices, you can reduce costs, increase efficiency, and maximize the value of your GPU resources.
Use Case: Automatically switch your GPU resources to inference tasks post-training to maximize efficiency and reduce downtime costs.
Try Runable For FreeFAQ
What is continuous batching?
Continuous batching is a method for keeping GPUs active by switching them from training to inference tasks during idle times, optimizing resource use.
How does continuous batching improve efficiency?
By maximizing token throughput and reducing idle time, continuous batching increases the efficiency of GPU resources, lowering operational costs.
What tools support continuous batching?
Tools like vLLM and FriendliAI are designed to facilitate continuous batching.
What are the benefits of using continuous batching?
It reduces idle time, lowers costs, and maximizes the utilization of GPU resources, leading to improved overall system performance.
Can continuous batching be implemented on any GPU?
Most modern GPUs support continuous batching, but compatibility depends on your software stack and infrastructure.
What are some common challenges with continuous batching?
Challenges include managing thermal limits, efficient task scheduling, and ensuring comprehensive monitoring to optimize performance.
How can AI enhance continuous batching?
AI can dynamically optimize task scheduling and resource allocation, improving efficiency and reducing costs.
Is continuous batching suitable for small operations?
Yes, even small operations can benefit from reduced costs and increased efficiency by implementing continuous batching.
Key Takeaways
- Idle GPUs incur unnecessary costs; continuous batching turns downtime productive.
- Continuous batching can boost GPU efficiency by up to 30%.
- Implementing continuous batching requires understanding infrastructure, installing compatible software, and diligent monitoring.
- Common pitfalls include thermal overload and inefficient scheduling; solutions involve monitoring and AI-driven schedulers.
- Future trends include AI-powered systems for dynamic optimization and self-optimizing capabilities.
Related Articles
- How the Iran Conflict Could Impact Data Centers and Electricity Costs [2025]
- Rethinking the Electrical Grid: Innovations and Opportunities [2025]
- Philips' New Conversational Coffee Maker: The Future of Personalized Brewing [2025]
- Stay Cool Anywhere: The Ultimate Guide to Personal Misting Fans [2025]
- Can It Play Doom? Exploring the Potential of Biocomputers Built on Human Brain Cells [2025]
- Maximize Your Mini PC Experience: Geekom's Unmissable Deals [2025]

