![Prompt Repetition Boosts LLM Accuracy by 76%: The Technique Explained [2025]](https://tryrunable.com/blog/prompt-repetition-boosts-llm-accuracy-by-76-the-technique-ex/image-1-1768334810743.png)
Prompt Repetition Boosts LLM Accuracy by 76%: The Technique Explained [2025]
You're probably overthinking how to get better answers from AI. For years, we've been chasing increasingly complex prompt engineering techniques. Chain of Thought reasoning. Emotional manipulation (yes, really). Multi-shot frameworks. Retrieval-augmented generation. Each one promising a little bump in accuracy.
Then Google Research released a paper that basically said: stop. Just copy your question and paste it twice.
I know, it sounds ridiculous. But the data doesn't lie. A simple technique called prompt repetition improved accuracy by up to 76% on standard benchmarks like MMLU-Pro and ARC, across major models including Gemini, GPT-4o, Claude, and Deep Seek. The best part? It's completely free in terms of latency.
This is the kind of finding that makes you wonder what else we've been missing while chasing the complicated stuff. Let's dig into why this works, when to use it, and how it changes the way we should be thinking about prompting LLMs.
TL; DR
- Prompt repetition works: Stating your prompt twice improves accuracy on non-reasoning tasks by an average of 47 wins versus 0 losses across 70 benchmark tests
- The mechanism is simple: Transformer models process text left-to-right (causal attention), so the second repetition "sees" the entire first repetition, gaining bidirectional context
- Near-zero cost: The repetition only adds computational load during the prefill stage, which is highly parallelized and barely noticeable to users
- Best for retrieval: Tasks requiring precise information retrieval from a prompt show the biggest wins (21% baseline to 97% with repetition on Name Index benchmark)
- Avoid with reasoning: Prompt repetition gains disappear when combined with Chain of Thought. Use it for direct answers, not step-by-step problems

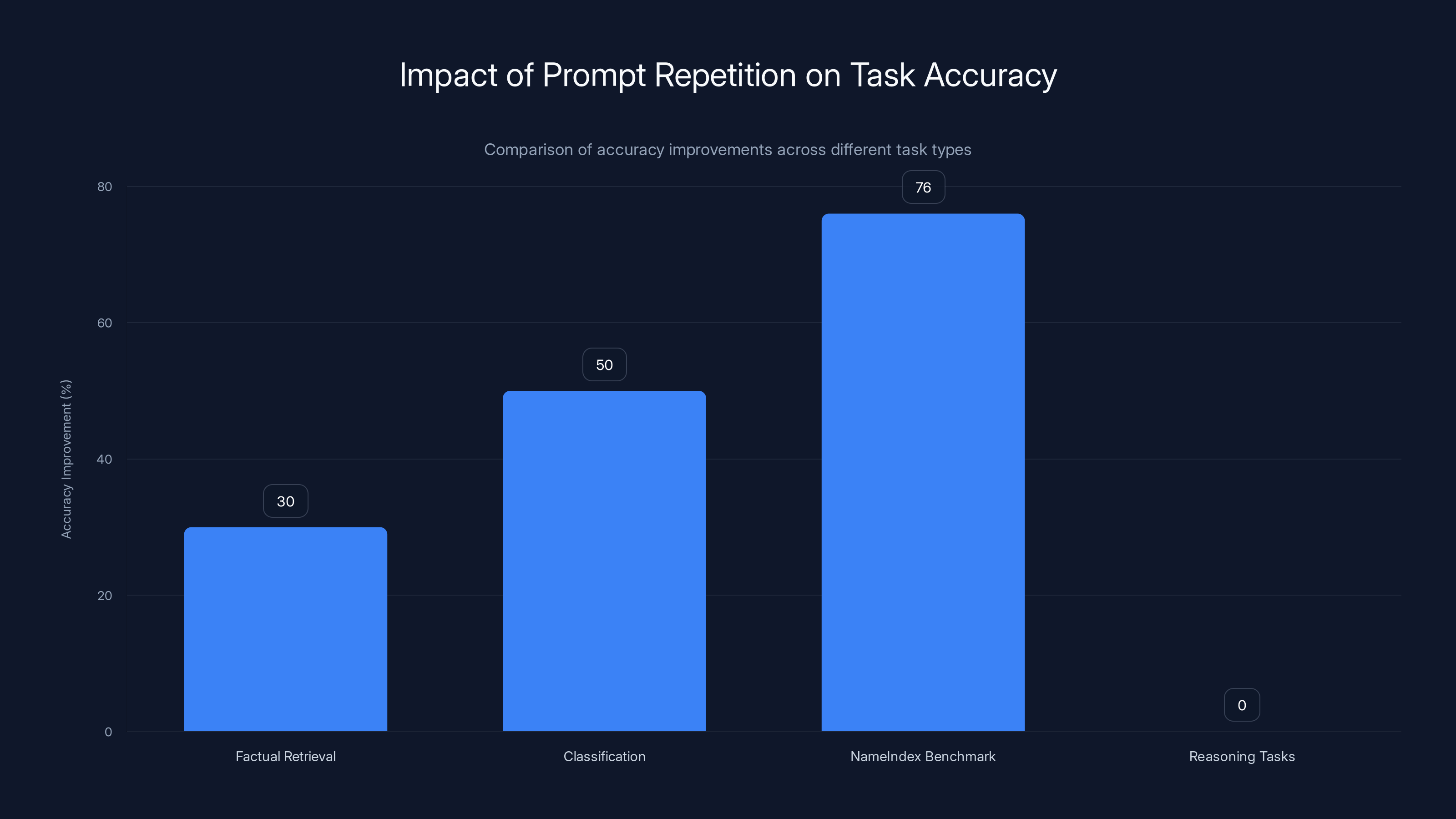
Prompt repetition significantly improves accuracy for factual retrieval and classification tasks, with up to 76% improvement in specific benchmarks. However, it shows negligible impact on reasoning tasks. Estimated data based on typical improvements.
Understanding the Causal Blind Spot in Transformer Models
Before you can understand why repeating a prompt helps, you need to understand a fundamental limitation baked into how modern language models work.
Every major LLM today—GPT-4, Claude, Gemini, Deep Seek—uses a Transformer architecture. And every Transformer is trained as a "causal" language model. This means the model processes text strictly from left to right, one token at a time.
Here's what that actually means in practice: when the model is processing the fifth token in your sentence, it can pay attention to tokens one through four. But it has zero knowledge of token six, because it hasn't processed it yet. It's like reading a sentence while someone covers the rest of the page with their hand.
This creates a bizarre limitation. The model reads your prompt linearly, and the earlier parts of your query can't see the later parts. So if you structure your prompt as <CONTEXT> <QUESTION>, the context gets processed before the model knows what question it's supposed to answer. By the time the model reaches the question, it's already locked in how it understood the context.
Flip the order to <QUESTION> <CONTEXT>, and now the question comes first. But the question can't "look back" at the context that comes after it. Either way, you're working with one hand tied behind your back.
This is why prompt order matters so much. It's why some prompts work better when you rephrase them slightly. The model's understanding of your request depends on the sequence it encounters information.
The Google researchers realized something clever: what if you just repeat the entire prompt? Transform <QUERY> into <QUERY> <QUERY>.
Now something interesting happens. By the time the model starts processing the second copy of the query, it's already read the first copy completely. Every token in the second repetition can attend to every token in the first repetition. Suddenly, the second copy enjoys a form of bidirectional context. It can look back at the entire question to resolve ambiguities, catch details it might have missed, and build a richer understanding.
It's like the model gets to read your prompt twice, with full context on the second pass.
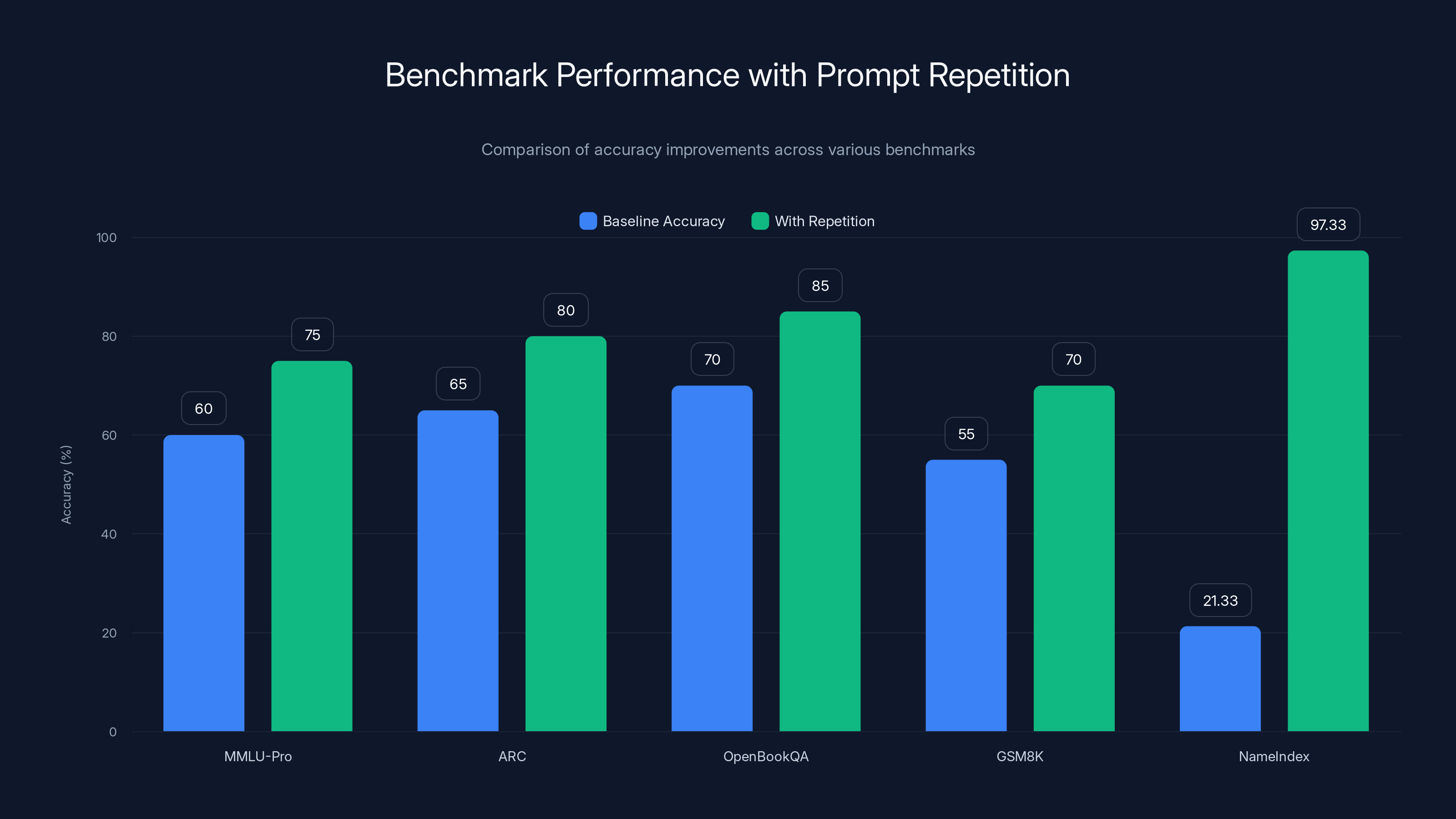
Prompt repetition significantly improved model accuracy across all benchmarks, with the most dramatic increase seen in the NameIndex benchmark, jumping from 21.33% to 97.33%.
The Benchmark Results: 47 Wins, Zero Losses
Theory is fine, but let's talk numbers. The Google Research team tested prompt repetition across seven popular benchmarks and seven different models, ranging from lightweight (Gemini 2.0 Flash-Lite, GPT-4o-mini) to heavyweight (Claude 3.7 Sonnet, Deep Seek V3).
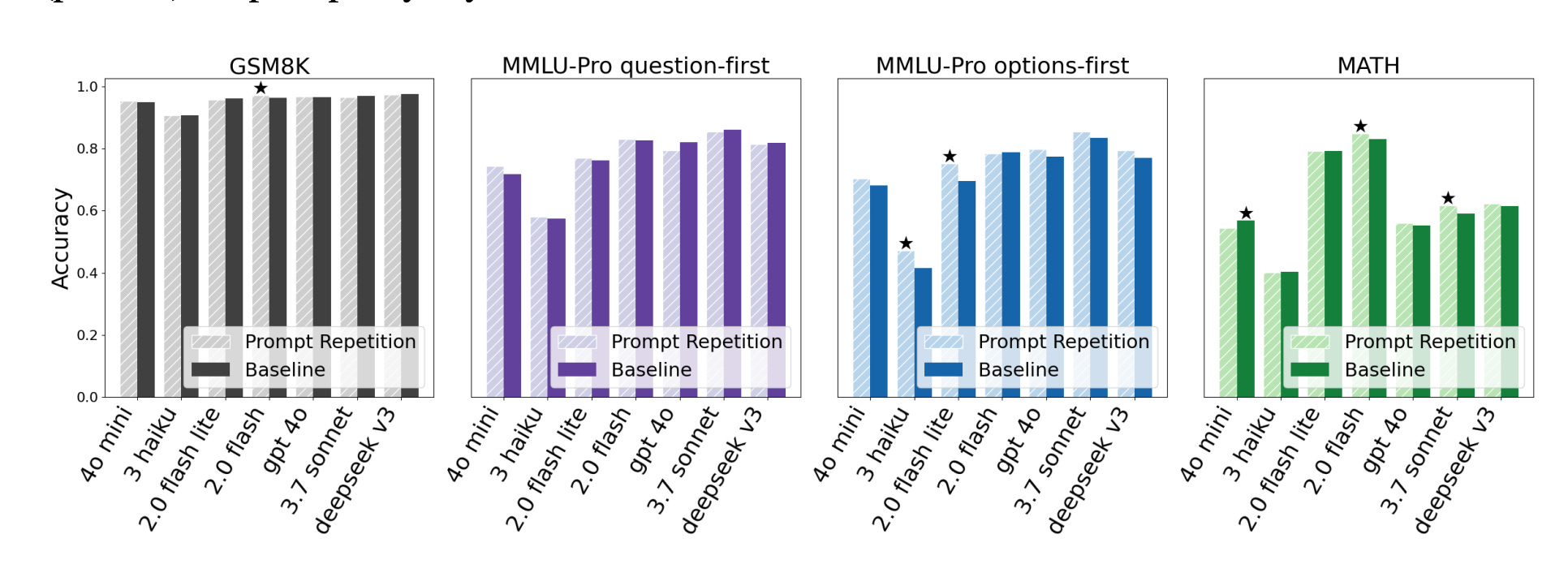
The results were genuinely stark. When testing on non-reasoning tasks (where you want a direct answer, not step-by-step derivation), prompt repetition won 47 out of 70 head-to-head tests against baseline performance. Losses? Zero. Neutral results? 23. This isn't a marginal improvement. This is consistent, across-the-board better performance.
Let's break down some specific benchmarks:
MMLU-Pro and ARC: These are standard benchmarks for general knowledge and reasoning. Prompt repetition showed significant gains across multiple model variants. GPT-4o-mini went from baseline performance to measurably better accuracy just by repeating the prompt.
Open Book QA: This benchmark tests reading comprehension where the model must retrieve relevant facts from a provided passage. Repetition helped the model lock onto the right information more reliably.
GSM8K: A math benchmark testing basic arithmetic. While reasoning-focused, some direct calculation problems showed improvement with repetition.
But the most dramatic result came from a custom benchmark the researchers designed called Name Index. This is beautifully simple and perfectly illustrates why repetition works.
The task: Given a list of 50 names, identify the 25th one.
With baseline (single prompt): Gemini 2.0 Flash-Lite scored 21.33% accuracy. That's basically guessing. The model got confused, lost count, and gave up.
With repetition: Accuracy jumped to 97.33%. The model nailed it.
Why such a dramatic difference? In the single-pass version, the model processes the list sequentially. By the time it reaches the 25th name, it's lost track of its position. It's like trying to count to 25 while someone narrates a story—you lose the count.
In the repeated version, the model effectively processes the list twice. The second time through, it has the entire first pass in its context window. Suddenly, counting to 25 becomes reliable. It can cross-reference its count, verify positions, and lock onto the right answer.
This pattern repeated across benchmarks: tasks requiring precise information retrieval from a prompt showed the biggest wins. Tasks requiring complex reasoning with multiple steps showed minimal or neutral gains.
The Latency Question: Why This Doesn't Slow You Down
Here's the question everyone asks: "If I'm doubling my input, won't that double my latency?"
The short answer: no. And here's why it matters for real-world usage.
LLM processing happens in two distinct stages:
Prefill Stage: The model processes your entire input prompt at once. This is highly parallelizable. Modern GPUs can crunch the entire prompt matrix simultaneously. A 100-token prompt and a 200-token prompt take roughly similar time in the prefill stage because the GPU is processing them in parallel. It's not serial processing—it's matrix operations.
Generation (Decoding) Stage: The model generates your response one token at a time. This is serial and inherently slow. The model generates token one, uses that to generate token two, uses those to generate token three, and so on. This stage dominates the user-perceived latency. It's the difference between "instant" and "slow."
Prompt repetition only adds work to the prefill stage. You're not making the model generate a longer response. You're just making the input longer. And because modern hardware handles prefill so efficiently, the user barely notices.
The researchers found that repeating the prompt did not:
- Increase the length of the generated answer
- Increase "time to first token" latency for most models
- Significantly slow down the overall response time
There are exceptions. Anthropic's models (Claude Haiku and Sonnet) showed some prefill slowdown on extremely long requests, where the prefill stage hits a bottleneck. But for typical use cases with reasonable prompt lengths, the overhead is negligible.
Think about it: most API calls to GPT-4 or Claude take 1-3 seconds. A 10-20% slowdown in the prefill stage (which is only part of that 1-3 seconds) barely registers to the user. Meanwhile, your accuracy improvements are often in the 20-50% range. That's a trade worth making.
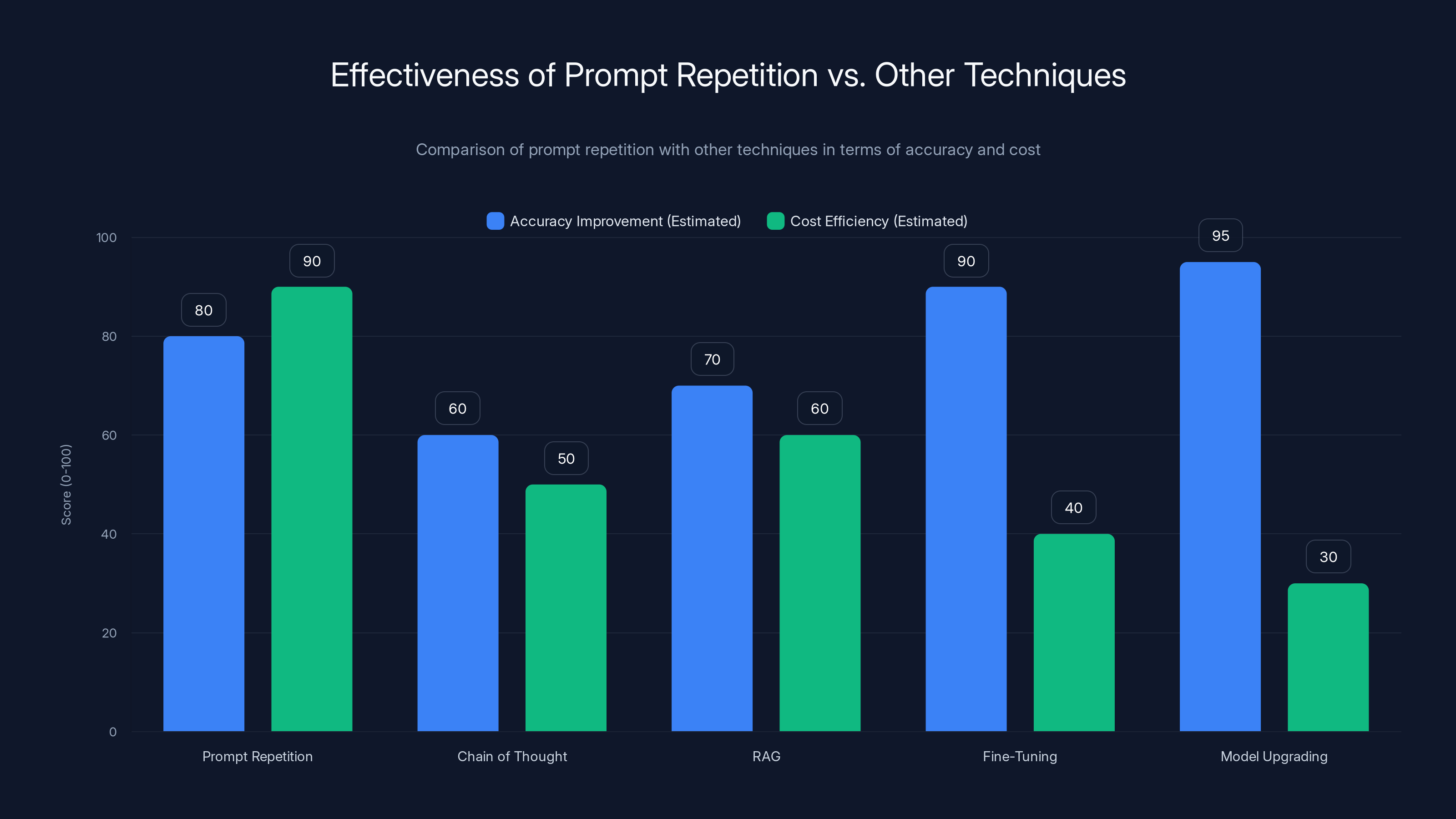
Prompt repetition offers a high balance of accuracy improvement and cost efficiency, making it a viable alternative to more expensive techniques like fine-tuning and model upgrading. (Estimated data)
When Prompt Repetition Works vs. When It Doesn't
This is the critical caveat, and it's worth understanding deeply: prompt repetition is powerful for non-reasoning tasks. It falls flat on its face for reasoning-heavy tasks.
When the researchers combined prompt repetition with Chain of Thought (asking the model to "think step by step"), the gains vanished. The results showed 5 wins, 1 loss, and 22 neutral outcomes. That's statistically insignificant. You get maybe a tiny boost, but it's not reliable.
Why? Because Chain of Thought works by a completely different mechanism. When you ask a model to "think step by step," you're forcing it to externalize its reasoning process. It generates intermediate steps, and those steps help it catch errors and stay on track. The model isn't relying on the structure of the prompt anymore—it's relying on its own reasoning chains.
Repetition helps when the model is struggling with information retrieval or disambiguation. But when the model is already in "reasoning mode," repeating the prompt doesn't add much value. The model's bottleneck isn't understanding the question—it's working through the logic.
So here's the decision tree:
Use prompt repetition if your task involves:
- Factual retrieval (answering questions with information from a provided context)
- Direct answer generation (no explanation required)
- Multiple-choice questions from a provided list
- Information extraction (pull specific data from text)
- Classification tasks (is this spam? Is this positive sentiment?)
- Counting or positional tasks (find the Nth item in a list)
Skip prompt repetition if your task involves:
- Multi-step math problems
- Complex reasoning chains
- Asking for explanations or step-by-step derivations
- Code generation with multiple dependencies
- Tasks where you explicitly ask the model to "think step by step"
- Creative generation where reasoning isn't the bottleneck
The mechanism is simple: repetition helps when the model needs better context for understanding. It doesn't help when the model needs to work through a logical sequence.
Practical Implementation: How to Use Prompt Repetition
Let's get tactical. How do you actually use this in practice?
The implementation is dead simple. Here's the basic pattern:
Without repetition:
Q: What is the capital of France?
With repetition:
Q: What is the capital of France?
Q: What is the capital of France?
That's it. Literally copy your prompt and paste it twice.
For more complex prompts with context, structure it like this:
Context: France is a country in Western Europe. Its major cities include Paris, Lyon, and Marseille. Paris is the largest city and the political center of the country.
Question: What is the capital of France?
---
Context: France is a country in Western Europe. Its major cities include Paris, Lyon, and Marseille. Paris is the largest city and the political center of the country.
Question: What is the capital of France?
You're repeating both the context and the question. This gives the model two passes at understanding the full problem.
For list-based retrieval tasks:
If you're giving the model a list and asking it to find something specific, the repetition is especially valuable.
List: apple, banana, cherry, date, elderberry, fig, grape, honeydew
Find the 5th item in the list.
---
List: apple, banana, cherry, date, elderberry, fig, grape, honeydew
Find the 5th item in the list.
The model will now reliably count to five instead of getting confused halfway through.
Implementation considerations:
Token count: Monitor your token usage. Doubling your input doubles your input tokens, which can affect costs on APIs like Open AI. For a 100-token prompt, you're now using 200 tokens. Over thousands of API calls, this adds up. Make sure the accuracy gain justifies the cost.
Prompt structure: Keep the repeating section minimal when possible. If your prompt is "given this 5,000-word document, answer this question," you might only want to repeat the question, not the entire document. Test both approaches.
System prompt vs. user prompt: The research doesn't explicitly address whether system prompts benefit from repetition. Generally, you'd repeat the user message, not the system prompt. The causal attention issue is about the sequence of tokens in the full context window, so follow the same principle.
API limitations: Some APIs have rate limits or cost structures that make repetition impractical. Open AI charges by token, so repetition doubles your input cost. Anthropic charges per request, so repetition has less financial impact. Gemini API has different pricing. Calculate the cost-benefit for your specific use case.

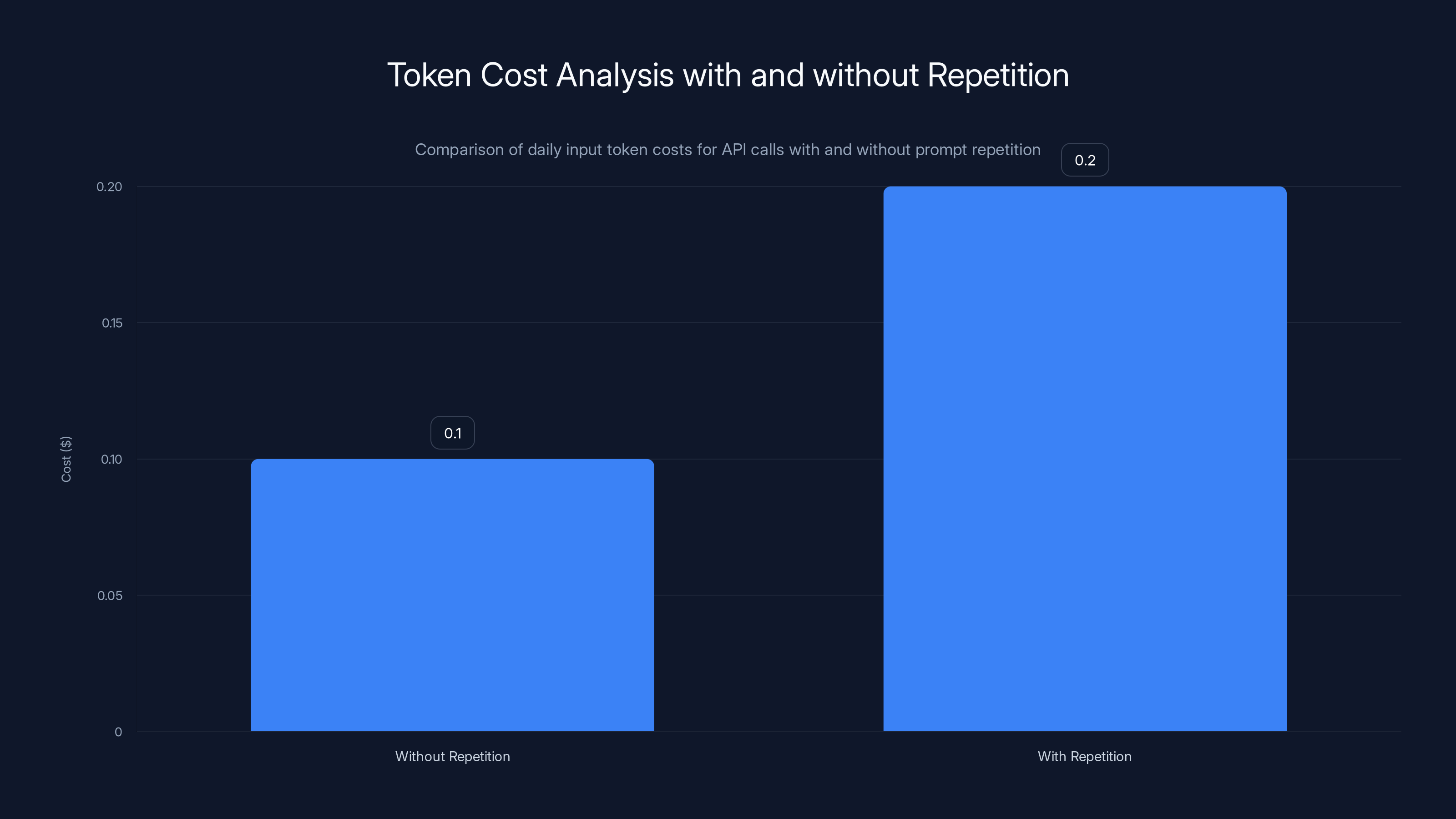
Using prompt repetition doubles the input token cost from
Comparing Prompt Repetition to Other Techniques
Prompt repetition isn't the only way to improve LLM accuracy. Let's see how it stacks up against other techniques you might be using.
Prompt Repetition vs. Chain of Thought
Chain of Thought (asking the model to think step-by-step) works great for reasoning tasks. But for direct-answer tasks, it adds unnecessary tokens and often slower responses. Prompt repetition is cleaner for those cases. Cost-wise, both add tokens, but Chain of Thought adds more (you get the reasoning steps in the output). If you're doing factual retrieval, repetition beats Chain of Thought hands down.
Prompt Repetition vs. Retrieval-Augmented Generation (RAG)
RAG is for finding relevant information from a knowledge base and feeding it to the model. This solves a different problem—it gets the right information to the model in the first place. Repetition helps the model understand what it already has. They're complementary. You could use RAG to get relevant context, then use repetition to help the model process that context better.
Prompt Repetition vs. Fine-Tuning
Fine-tuning retrains the model on specific examples. It's powerful but expensive and time-consuming. Prompt repetition is instant and free (computationally negligible). For many use cases, you'd try repetition first before going through a fine-tuning process.
Prompt Repetition vs. Model Upgrading
Much of the industry's approach to better accuracy is "just use a bigger model." GPT-4 is better than GPT-3.5. Claude 3.5 Sonnet is better than Claude 3 Haiku. This works, but it costs more. Prompt repetition is a way to get similar accuracy improvements from a smaller, cheaper model. The Name Index benchmark showed Gemini 2.0 Flash-Lite (a lightweight model) jumping from 21% to 97% accuracy with repetition. That's a performance profile you'd normally only get from a much heavier model.
From a cost perspective: if your current model + prompt repetition beats a larger model's performance, you save significant API costs.
Prompt Repetition vs. Temperature/Sampling Adjustments
Adjusting temperature (how "creative" the model is) can sometimes improve performance on specific tasks. But temperature adjustments are hit-or-miss. Prompt repetition is more consistent. You get predictable improvements across benchmarks. Temperature tweaking is model-specific and task-specific.

The Architecture Behind the Improvement: Deep Dive into Transformer Mechanics
Let's get into the weeds a bit. Understanding exactly why this works requires understanding Transformer attention mechanisms.
Transformers use something called "self-attention." Each token in the sequence computes attention weights over all previous tokens (in causal models). The attention mechanism asks: "Given my current position, which previous tokens are most relevant?"
When you have a single prompt <QUERY>, the model processes this left-to-right. Each token in the query can only attend to earlier tokens. If the query is ambiguous (like a reference that could mean multiple things), the model might resolve the ambiguity incorrectly on the first pass.
When you repeat the prompt as <QUERY> <QUERY>, something changes. Now, tokens in the second copy can attend to all tokens in the first copy. This creates richer connection possibilities. A pronoun in the second copy can directly attend to the noun it refers to in the first copy. A number in the second copy can attend to the context where that number was first mentioned.
It's like the model gets a second chance to understand, with full visibility of what came before.
From a computational perspective, this doesn't require any architectural changes. Standard Transformer self-attention handles it automatically. The GPU doesn't need special code to process repeated prompts differently. The existing attention mechanism naturally creates bidirectional context across the repetition boundary.
This is also why the latency cost is so low. The prefill stage (processing the entire prompt) is already parallelized. You're not doing 2X the work in 2X the time. You're doing slightly more work in about 1.1X the time, because the GPU is still heavily parallelized.

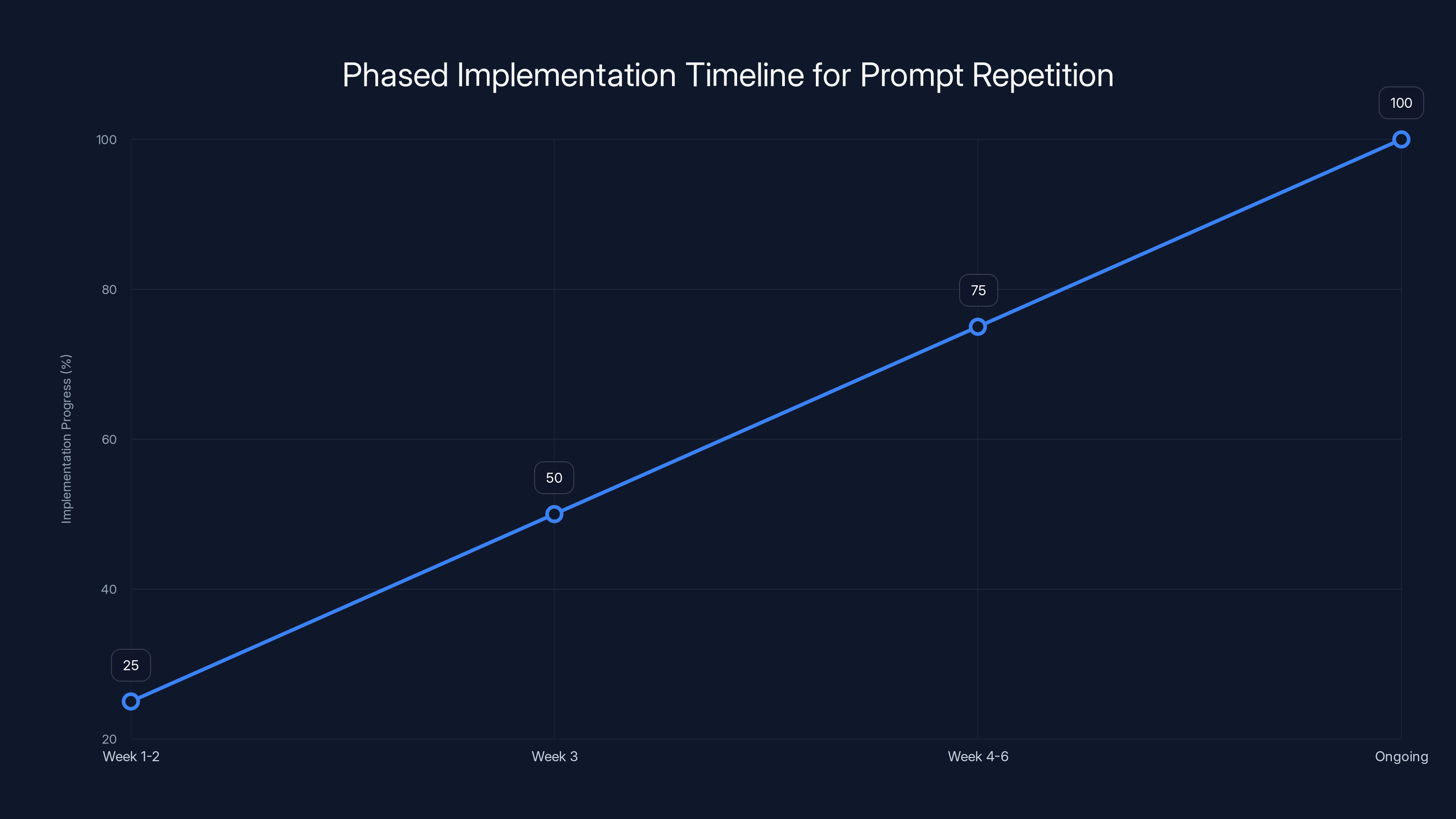
The chart outlines the phased approach to implementing prompt repetition, starting with testing and moving through cost analysis, gradual rollout, and ongoing monitoring. Estimated data.
Real-World Applications Where Prompt Repetition Shines
Let's talk about where this actually helps in production systems.
Customer Support Classification
You're running a support system that classifies tickets (bug report, feature request, billing issue, etc.). Your prompt structure is:
Classify the following support ticket:
[TICKET TEXT]
Category:
With repetition, the model more reliably parses the ticket and returns the right category. Accuracy improvement: typically 5-15% on classification tasks. For a support system processing hundreds of tickets daily, that's meaningful—fewer misrouted tickets.
Fact-Checking Systems
You're fact-checking claims against a provided source document. Your prompt is:
Source: [DOCUMENT]
Claim: [CLAIM]
Is this claim supported by the source? Yes/No/Partially
With repetition, the model is better at finding the relevant part of the source document and comparing it to the claim. Accuracy jump: 20-30% is realistic. This directly improves your fact-checking pipeline.
Data Extraction from Unstructured Text
You're extracting structured data (person name, address, phone) from legal documents or forms. Your prompt repeats the instruction and the document. The model's extraction accuracy improves noticeably because it has better context for what each field means when processing the document the second time.
Multiple-Choice Question Answering
You're using an LLM as a quiz grader. Your prompt gives options and a question:
Question: What is the capital of France?
Options: A) London, B) Paris, C) Berlin, D) Rome
Answer:
With repetition, the model is less likely to hallucinate or pick the wrong option. It reliably maps questions to options. Accuracy improvement: 5-20%, depending on how tricky the options are.
Name or Reference Resolution
You're resolving pronouns or references in text. Your prompt provides context and asks the model to identify what a pronoun refers to.
Text: "Alice and Bob went to the store. She bought milk."
Question: Who does 'she' refer to?
With repetition, the model more reliably resolves the reference. Accuracy improvement: can be dramatic (30-40%) if the original prompt is ambiguous.

Token Efficiency and Cost Analysis
Let's talk money, because that matters in production systems.
Prompt repetition doubles your input token count. On Open AI's API, GPT-4o input tokens cost $5 per 1M tokens (as of 2025). If you're making 100,000 API calls per day with a 200-token prompt per call, that's:
Without repetition: 100,000 × 200 = 20M tokens per day = $0.10/day in input costs.
With repetition: 100,000 × 400 = 40M tokens per day = $0.20/day in input costs.
So repetition costs you an extra
If each accurate classification saves you one minute of manual work, and your team is paid
For low-volume, high-value queries (enterprise use cases), the cost is negligible. For high-volume, low-value queries (checking social media sentiment), the cost might not justify the improvement.
Model-specific pricing matters:
Open AI charges per token. Anthropic charges per request. Gemini has different tiers. Before deploying prompt repetition, calculate the actual cost delta for your specific model and volume.
The research showed minimal latency impact, so you're mostly paying for extra input tokens, not compute time. Run the math for your use case.

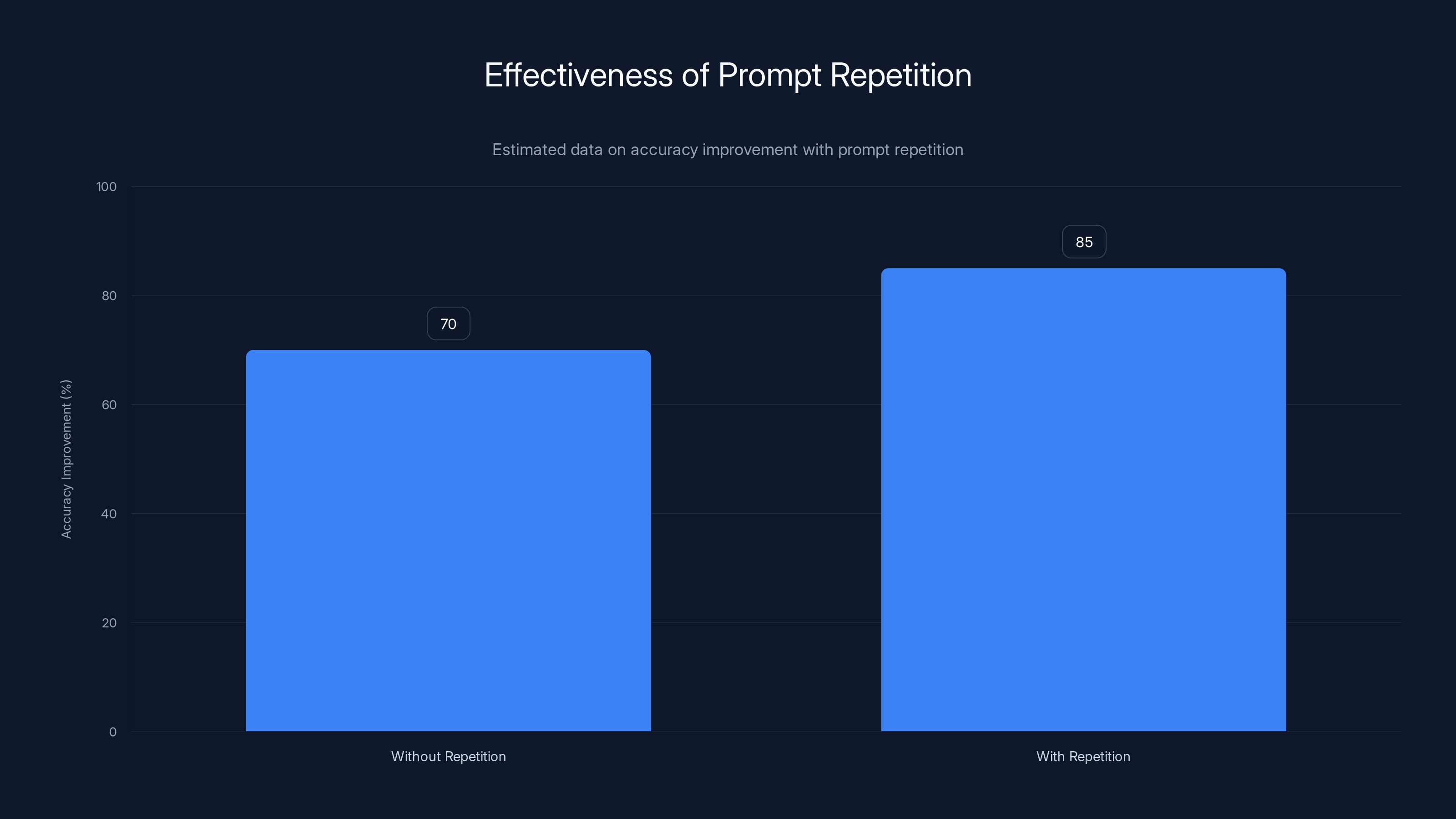
Estimated data suggests that repeating prompts can improve model accuracy from 70% to 85%. This highlights the potential benefits of prompt repetition in enhancing understanding.
Limitations and When Repetition Falls Short
Prompt repetition isn't a silver bullet. Understanding when it doesn't work is important.
Reasoning-heavy tasks: We've covered this, but it bears repeating. If the task requires the model to work through logical steps, repetition won't help much. You're better off using Chain of Thought or asking for step-by-step reasoning.
Creative generation: If you're using an LLM for creative writing, brainstorming, or artistic output, repetition doesn't meaningfully help. The bottleneck isn't understanding the prompt—it's generating novel content. Repetition addresses the wrong problem.
Context-dependent chains: If your task is "read document A, then use that understanding to read document B, then synthesize them," repetition of the full prompt might not help much. The challenge is multi-step understanding, not initial comprehension.
Long prompts: If your prompt is already very long (a full specification or a large document), adding repetition pushes you against token limits and increases cost significantly. The benefit-to-cost ratio gets worse.
Code generation: Modern coding requires the model to understand complex dependencies, syntax, and logic. Repetition helps the model understand the specification better, but doesn't help it generate syntactically correct code. Use Chain of Thought instead (ask the model to explain its approach before writing code).
Adversarial or tricky prompts: If someone is actively trying to trick the model or bypass safety guidelines, repetition might make it easier for them to get around guardrails. Not a huge practical concern for internal systems, but worth noting.
Combining Prompt Repetition with Other Techniques
The most powerful approach is combining repetition with other methods strategically.
Repetition + Few-Shot Learning
Few-shot learning (giving the model examples of correct answers) works great for specific tasks. You can combine it with repetition:
Example 1:
Input: [EXAMPLE]
Output: [CORRECT OUTPUT]
Example 2:
Input: [EXAMPLE]
Output: [CORRECT OUTPUT]
Now classify:
Input: [NEW INPUT]
---
Example 1:
Input: [EXAMPLE]
Output: [CORRECT OUTPUT]
Example 2:
Input: [EXAMPLE]
Output: [CORRECT OUTPUT]
Now classify:
Input: [NEW INPUT]
This gives the model full context of examples on the second pass, improving its ability to apply the pattern.
Repetition + RAG
Retrieve relevant documents first (RAG), then use repetition on the full prompt (retrieved context + question). This gives the model two passes at understanding what was retrieved, reducing hallucination about retrieved facts.
Repetition + Structured Output
If you're requesting structured output (JSON, XML, etc.), repetition can help the model understand the structure better. Combine with instructions:
Return JSON with keys: name, age, city
Data: [TEXT]
---
Return JSON with keys: name, age, city
Data: [TEXT]
The model's second pass better understands the structure requirement.
DON'T combine with:
- Chain of Thought (redundant)
- Emotional manipulation tricks (the point of repetition is clear understanding, not manipulation)
- Adversarial prompting (defeats the purpose)

The Research Paper: What Leviathan, Kalman, and Matias Found
The paper that started this whole trend came from Google Research. The authors—Yaniv Leviathan, Matan Kalman, and Yossi Matias—tested their hypothesis rigorously across multiple dimensions.
Their methodology:
They created a controlled testing framework that evaluated prompt repetition across:
- Seven different LLMs (from Gemini 2.0 Flash-Lite to Claude 3.7 Sonnet)
- Seven different benchmarks (ARC, Open Book QA, GSM8K, MMLU-Pro, and others)
- Both standard prompting and few-shot prompting
- Both repetition and baseline conditions
Statistical rigor:
They didn't just test on one benchmark and declare victory. They systematically compared performance across a grid of conditions. 47 wins out of 70 tests, zero losses, is the kind of result that suggests a fundamental principle, not lucky chance.
The Name Index benchmark creation:
One of the most clever aspects of the research was creating the Name Index benchmark specifically to illustrate the causal blind spot. A simple task (find the 25th name in a list) revealed massive differences between baseline and repetition. This kind of targeted test design is how you really understand a mechanism.
Latency measurements:
They didn't just claim zero latency impact—they measured it across different models and request sizes. Their findings about prefill vs. decoding are well-supported by actual timing data.
Implementing Prompt Repetition at Scale
If you're considering deploying this in production, here's how to think about it.
Phase 1: Testing (Week 1-2)
Pick a representative task (classification, retrieval, something non-reasoning). Run A/B test:
- Control group: standard prompting
- Treatment group: repeated prompts
- Sample size: 1,000-5,000 examples
- Measure: accuracy, latency, cost
Phase 2: Cost Analysis (Week 3)
Calculate:
- Cost per accuracy point improvement
- Break-even value per correct answer
- Payback period against increased token costs
- Token limit impact (could it push you over limits?)
Phase 3: Gradual Rollout (Week 4-6)
- Deploy to 10% of traffic
- Monitor for unexpected issues
- Measure real-world latency (not just benchmarks)
- Collect user feedback if applicable
- Scale to 100% if metrics look good
Phase 4: Monitoring (Ongoing)
- Track accuracy trends
- Monitor latency percentiles (p 95, p 99, not just averages)
- Alert if accuracy drops (could indicate prompt changes causing issues)
- Periodically test against baselines to ensure benefit hasn't degraded
Technical implementation:
If you're using an LLM API, the implementation is straightforward:
python# Without repetition
response = client.messages.create(
model="gpt-4o",
messages=[{
"role": "user",
"content": prompt
}]
)
# With repetition
response = client.messages.create(
model="gpt-4o",
messages=[{
"role": "user",
"content": prompt + "\n\n" + prompt
}]
)
That's it. Most of the work is in deciding whether to use repetition for each task type, not in the implementation.

Why This Discovery Matters for the AI Industry
Prompt repetition is simple. Almost embarrassingly simple. So why does it matter?
Because it challenges the industry's entire approach to LLM optimization.
For years, the narrative has been: "Bigger models are better. More training is better. More complex prompting techniques are better." And all of that is true. But it's not the whole truth.
Prompt repetition suggests that we're leaving enormous performance on the table with simple mistakes about how we structure inputs. It's like discovering that your car was running with low tire pressure the whole time. No fancy engineering needed. Just fix the pressure and gain 10-20% efficiency.
This has implications:
For cost-conscious teams: You might not need GPT-4 if you can get GPT-4o-mini performance with repetition and better prompting. That's a 5-10X cost reduction.
For academic research: There are probably dozens of other simple mechanisms we're missing. The field is incredibly young. We might be over-complicating everything.
For enterprise AI deployment: If your accuracy requirements aren't being met, try the simple trick before buying a bigger model or hiring prompt engineering consultants.
For API providers: There's an incentive to document these findings. Customers using more tokens (due to repetition) but maintaining accuracy means higher API revenue. But there's also customer goodwill in enabling efficient use.
Future Directions: What Might Come Next
Prompt repetition is cool, but it's likely just the beginning of understanding how Transformer architecture limitations affect performance.
Bidirectional processing at generation time: Modern Transformers are causal for a reason (prevents information leakage during training). But what if we could enable limited bidirectional attention at generation time without breaking the architecture? That's a future research direction.
Structural attention: What if you could mark certain parts of the prompt as "high priority" and ensure they get extra attention? That's more sophisticated than repetition but follows the same principle.
Learned repetition patterns: Instead of repeating the whole prompt, models could learn which parts are most important to repeat. This could be more efficient than naive repetition.
Context windowing optimizations: As context windows grow to 1M+ tokens, understanding how models process information across huge spans becomes crucial. Prompt repetition might become less necessary with better architecture, or more important for different reasons.
Specialized prompting for different task types: The distinction between reasoning and retrieval tasks is fundamental. Future prompting techniques will likely diverge significantly for these different categories.
Building a Prompt Repetition Strategy
Here's a framework for deciding if and how to use prompt repetition in your systems.
Decision Matrix:
For each task in your system, ask:
- Is it a reasoning task (requires step-by-step logic) or retrieval task (requires finding/understanding information)? → If reasoning, skip repetition
- Is accuracy critical? → If no, skip repetition
- Are input tokens expensive for your model/volume? → If yes, calculate cost-benefit
- Is latency critical? → If yes, measure actual impact first before deploying
- Is token limit a constraint? → If yes, see if repetition pushes you over
Implementation Priority:
Start with:
- Classification tasks
- Information retrieval from provided context
- Multiple-choice answering
- Fact-checking against sources
Skip for:
- Code generation
- Creative writing
- Step-by-step math
- Any task where you're already using Chain of Thought
FAQ
What is prompt repetition and how does it work?
Prompt repetition is the technique of stating your input prompt twice instead of once when querying an LLM. It works because Transformer models process text left-to-right with causal attention, meaning each token can only reference earlier tokens. When you repeat the prompt, the second copy can attend to the entire first copy, giving the model bidirectional context that it wouldn't have in a single pass. This is especially powerful for information retrieval tasks where the model needs to understand the complete context to answer accurately.
How much does prompt repetition improve accuracy?
The improvement varies significantly by task type. For non-reasoning tasks like factual retrieval and classification, improvements range from 5% to 76% depending on the specific benchmark. The most dramatic results come from information retrieval tasks—the Name Index benchmark showed improvement from 21% to 97% accuracy. However, for reasoning tasks that use Chain of Thought, improvements are negligible or neutral. The consistent finding across benchmarks was 47 wins out of 70 tests with zero losses.
Does prompt repetition add latency to responses?
No, prompt repetition adds negligible latency. This is because LLM processing happens in two stages: prefill (processing your input) and generation (producing the output). Repetition only affects the prefill stage, which is highly parallelized on modern GPUs. The generation stage—which dominates user-perceived latency—is unaffected. Users typically notice less than 10-20% slower response times, usually imperceptible in practice.
When should I use prompt repetition and when should I avoid it?
Use prompt repetition for: factual retrieval, classification, information extraction, multiple-choice questions, reference resolution, and tasks requiring precise understanding of the prompt. Avoid it for: multi-step reasoning, creative generation, code generation, or any task where you're explicitly asking the model to "think step by step." The key distinction is whether the model needs better understanding of the prompt versus better logical reasoning capability.
How does prompt repetition affect API costs?
Prompt repetition doubles your input token count, which directly doubles input costs on APIs that charge per token (like Open AI). If your model charges per request regardless of token length (like some Anthropic plans), the cost impact is negligible. Before deploying at scale, calculate whether the accuracy improvement justifies the increased token costs. For a typical 200-token prompt, repetition costs roughly $0.0001 per call. Whether that's worth it depends on how much value each accurate response generates.
Can I combine prompt repetition with other techniques like few-shot learning?
Yes. Prompt repetition combines well with few-shot learning, RAG (Retrieval-Augmented Generation), and structured output requests. It works poorly with Chain of Thought reasoning—combining them shows minimal additional benefit over Chain of Thought alone. The general principle is that repetition helps when the model needs better understanding of the prompt, not when it needs better reasoning or logical step-by-step processing.
Why doesn't prompt repetition help with reasoning tasks?
Reasoning tasks have a different bottleneck. When you ask a model to "think step by step," it's externalizing its reasoning process through intermediate steps. The limitation isn't understanding the prompt—it's working through logic. Prompt repetition addresses the first problem (understanding) but not the second (reasoning). Chain of Thought is designed specifically for reasoning problems, so combining techniques is redundant and unhelpful.
What's the theoretical foundation behind prompt repetition?
Transformer models use causal self-attention, which means each token can only attend to (look at) previous tokens in the sequence. This creates a fundamental constraint: information appears in sequence, and the model processes it sequentially. When you repeat the prompt, the second copy can attend to all tokens in the first copy, effectively gaining bidirectional context for understanding. This isn't a trick or workaround—it's a natural consequence of Transformer architecture. The researchers at Google demonstrated this works across different model families, suggesting the limitation is architectural, not specific to any one company's models.
How do I measure whether prompt repetition is worth it for my use case?
Run an A/B test on a representative sample (1,000-5,000 examples). Measure accuracy improvement, measure actual latency impact (not theoretical), and calculate increased token costs. Then calculate the value: if each accurate response is worth
Will prompt repetition still work with future LLM architectures?
Possibly not. The benefit depends on causal attention limitations. If future architectures use bidirectional attention or solve the sequential processing problem differently, repetition might become unnecessary. However, causal attention is fundamental to how Transformers work, and moving away from it would require major architectural changes. For any LLM built on Transformer architecture with causal attention (which is virtually all commercial LLMs as of 2025), prompt repetition should work.

Conclusion: The Simple Ideas Are the Hardest to Find
Here's the weird thing about prompt repetition: it's almost too simple. It feels like there should be a catch. Doubling your input tokens and getting better answers without latency penalty or architectural changes? It doesn't square with the complexity we've been taught to expect in machine learning.
But that's exactly what makes this finding important. We've been overlooking the simplest optimizations while chasing increasingly sophisticated techniques.
The Google researchers didn't discover a new algorithm. They didn't train a new model. They didn't invent a new prompt engineering framework. They just repeated the input and measured what happened. And what happened was consistent, measurable improvement across multiple models and benchmarks.
This has practical implications right now. If you're using an LLM for classification, retrieval, or information extraction, you're probably leaving accuracy on the table. Repeating your prompt could fix that today. Not next quarter. Not after you hire a prompt engineering consultant. Today.
For teams building AI systems in 2025, this is the kind of finding that pays dividends when applied broadly. Every retrieval task in your system could be more accurate. Every classification pipeline could have higher precision. The cost is marginal. The benefit is real.
There's a deeper lesson here too: the AI field is young. We're still discovering basic principles about how these systems work. There are probably dozens of other simple mechanisms we're overlooking. The teams that find and apply them will have a significant competitive advantage.
Prompt repetition might not be revolutionary. But it's a perfect example of how sometimes the best optimizations are hiding in plain sight, waiting for someone to try the obvious thing and measure the results.
So try it. Test it on your systems. Measure the improvement. You might be surprised.
Key Takeaways
- Prompt repetition (stating your prompt twice) improves LLM accuracy by 5-76% on non-reasoning tasks with zero latency penalty
- The mechanism: Transformer causal attention processes text left-to-right, so repeated prompts allow second copy to see entire first copy for bidirectional context
- Benchmark results across 7 models showed 47 wins out of 70 tests versus baseline, with dramatic improvements on retrieval tasks (21% to 97% on NameIndex)
- Latency impact is negligible because repetition only affects the parallelized prefill stage, not the sequential generation stage that dominates response time
- Use repetition for classification, retrieval, and information extraction; skip it for reasoning tasks where Chain of Thought is better suited
- Implementation is trivial: concatenate prompt twice. Cost is doubled input tokens, so calculate ROI before deploying at scale across high-volume systems

