![Shipping Code 180 Times Daily: The Science of Safe Velocity [2025]](https://tryrunable.com/blog/shipping-code-180-times-daily-the-science-of-safe-velocity-2/image-1-1769468865750.png)
Shipping Code 180 Times Daily: The Science of Safe Velocity
Speed kills. That's what we've all been told.
When it comes to software deployment, conventional wisdom says you need to slow down to stay safe. Release fewer times per day. Run more manual checks. Add more approval gates. Get more people involved in the process. The logic seems airtight: more velocity equals more risk.
Except it doesn't. And if you look at how the fastest-moving software companies actually operate, you'll see the opposite is true.
At Intercom, the company sends code to production roughly 180 times per workday. That's approximately 20 deployments every single hour. The time between when an engineer commits code to their repository and when actual customers are using that code in production? About 12 minutes. One coffee break.
Yet despite this velocity, Intercom maintains 99.8% or higher availability. Not 99% availability with regular outages. Not 99.5% with occasional incidents. Consistently hitting 99.8%, which translates to less than 1 hour and 26 minutes of downtime per month across their entire platform.
This isn't luck. It's not magic. It's the result of over a decade of deliberate investment in systems, principles, and processes that turn velocity from a liability into the company's greatest source of stability.
Here's the counterintuitive reality: accumulating code creates risk. Shipping small batches minimizes it. When you deploy frequently, every single change is tiny and isolated. Problems become obvious immediately. You can pinpoint exactly which 15-line diff caused an issue. Rollbacks take seconds. Fixes are surgical.
When you deploy once per quarter, you're releasing millions of lines of changed code simultaneously. Nobody knows exactly what's different. Finding the problem takes days. Rolling back means losing weeks of other features that worked fine. The blast radius is catastrophic.
But understanding this principle intellectually and actually building the infrastructure to make it work are completely different things. This is where most companies stumble. They understand that frequent deployment is theoretically better, but they lack the systems to make it safe.
Intercom's approach is built on three distinct layers of defense. First, an automated pipeline that is simple, reliable, and removes the need for human intervention (except when things are truly broken). Second, a shipping workflow that promotes ownership and provides guardrails that actually accelerate deployment rather than slow it down. Third, a recovery model that optimizes for handling the inevitable failures that happen when you're moving this fast.
Understanding these three layers, and how they work together, is the difference between deployment velocity that feels reckless and deployment velocity that feels rock solid.
Let's break down each layer in detail.
Layer One: The Automated Pipeline
The entire point of an automated pipeline is deceptively simple: move code from merge to production as fast as humanly possible while enforcing strict safety checks. The key word there is "automated." The majority of releases require zero human intervention.
This sounds straightforward. In practice, getting there requires obsessive optimization of every single step.
The Merge to Build Process
When an engineer merges code to the main branch (the version of the codebase that's ready for production), two things happen immediately in parallel.
First, the build process kicks off. The Rails application and all its dependencies get compiled into what Intercom calls a "slug." This is a complete, deployable package that contains everything needed to run the application. The build takes approximately four minutes from start to finish.
Second, the continuous integration (CI) test suite starts running in parallel with the build. This is where most organizations lose time. They wait for tests to finish before building. Intercom builds while testing. Through extensive optimization, parallelization, and intelligent test selection (running only tests relevant to the changed code rather than the entire suite), the vast majority of CI builds complete in under five minutes.
Think about what this means: within five minutes of pushing code, you have a fully compiled, tested application ready for the next stage. The entire feedback loop is a fraction of what many engineering teams consider acceptable.
The test suite parallelization is worth understanding because it's a pattern that scales. Rather than running 5,000 tests sequentially (which might take an hour), Intercom splits those tests across dozens of machines and runs them simultaneously. A test that takes 60 seconds can now be one of thousands running in parallel. The bottleneck shifts from "how long do all these tests take" to "how long does the slowest batch take." Through careful partitioning and load balancing, that slowest batch stays under five minutes.
Pre-Production Verification
Once built, the slug gets deployed to a pre-production environment. This is important: the build doesn't block the pipeline waiting for CI to finish. The slug is promoted immediately after compilation. The pre-production deployment takes around two minutes.
Pre-production mirrors production infrastructure exactly. Same database structure (connected to production databases so the code exercises real data). Same service topology (web servers, background workers, cache layers). Same regional configurations. It serves zero actual customer traffic, but every other aspect of the production environment is replicated.
Immediately after pre-production deployment, several automated approval gates run in sequence:
Boot test: Does the application start correctly on every host? This catches configuration errors, missing dependencies, or startup-sequence bugs immediately.
CI verification: Did the test suite actually pass? If you failed an approval gate, the release halts before touching production.
Functional synthetics: Using tools like Datadog, Intercom runs browser-based tests that exercise critical user workflows. Loading a workspace. Editing a conversation. Triggering an automation. These aren't unit tests. They're genuine end-to-end flows that prove the application behaves as expected under real conditions.
If any gate fails, the release stops. The code never touches production. An alert goes out to the on-call engineer. But here's the key: this happens in under two minutes after the slug lands in pre-production. The entire feedback loop from code merge to "your change is broken" is under 10 minutes.
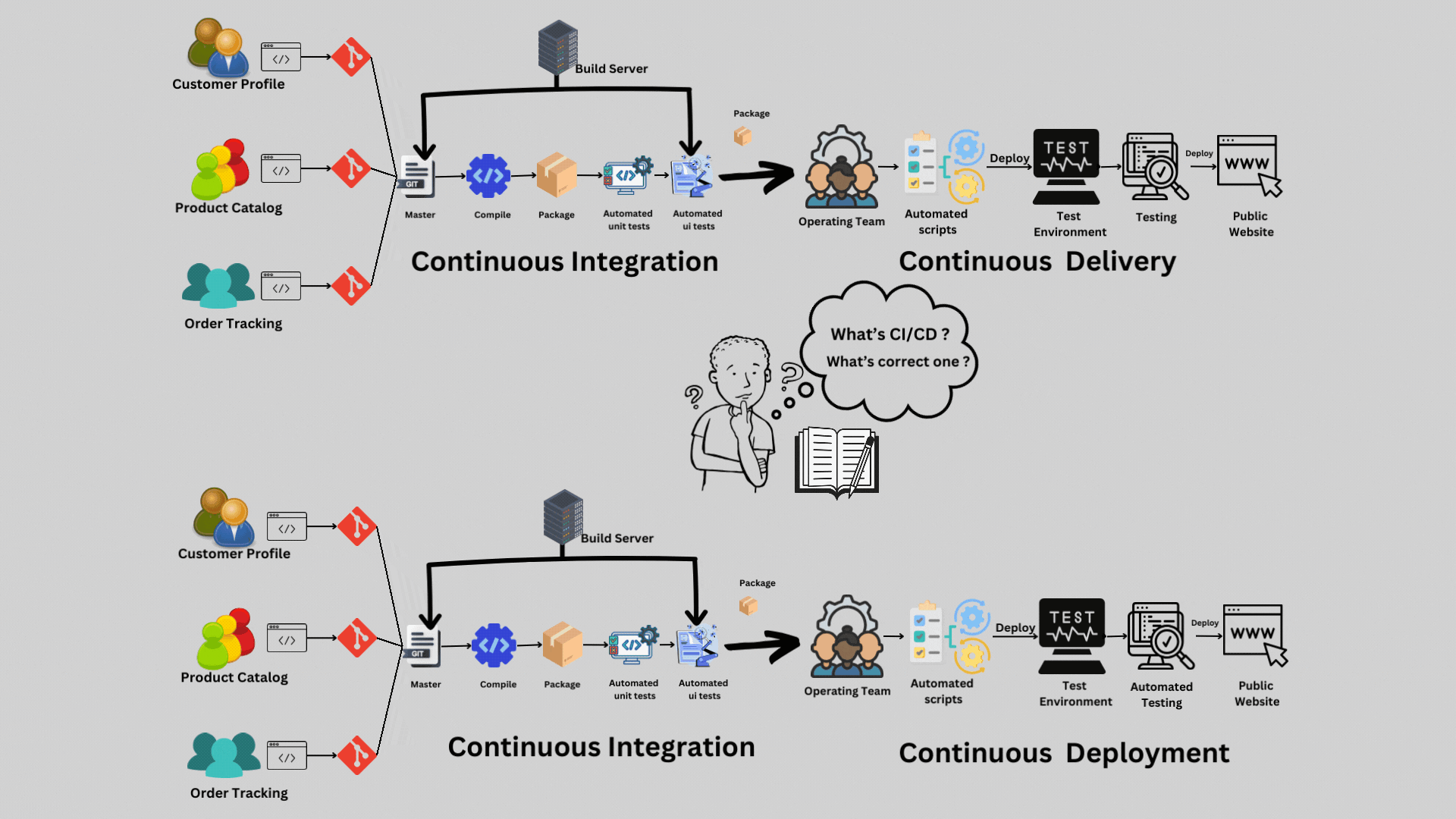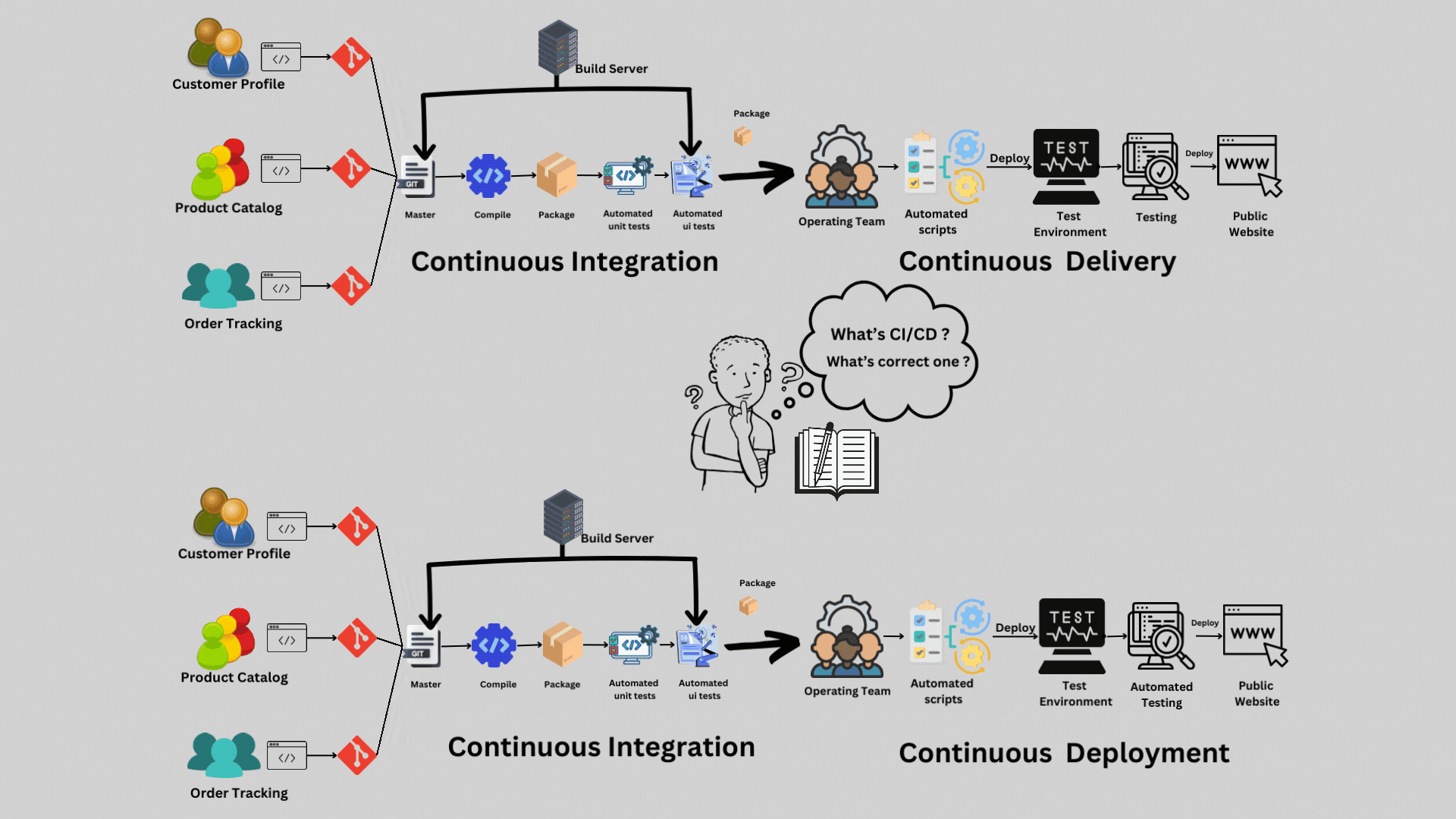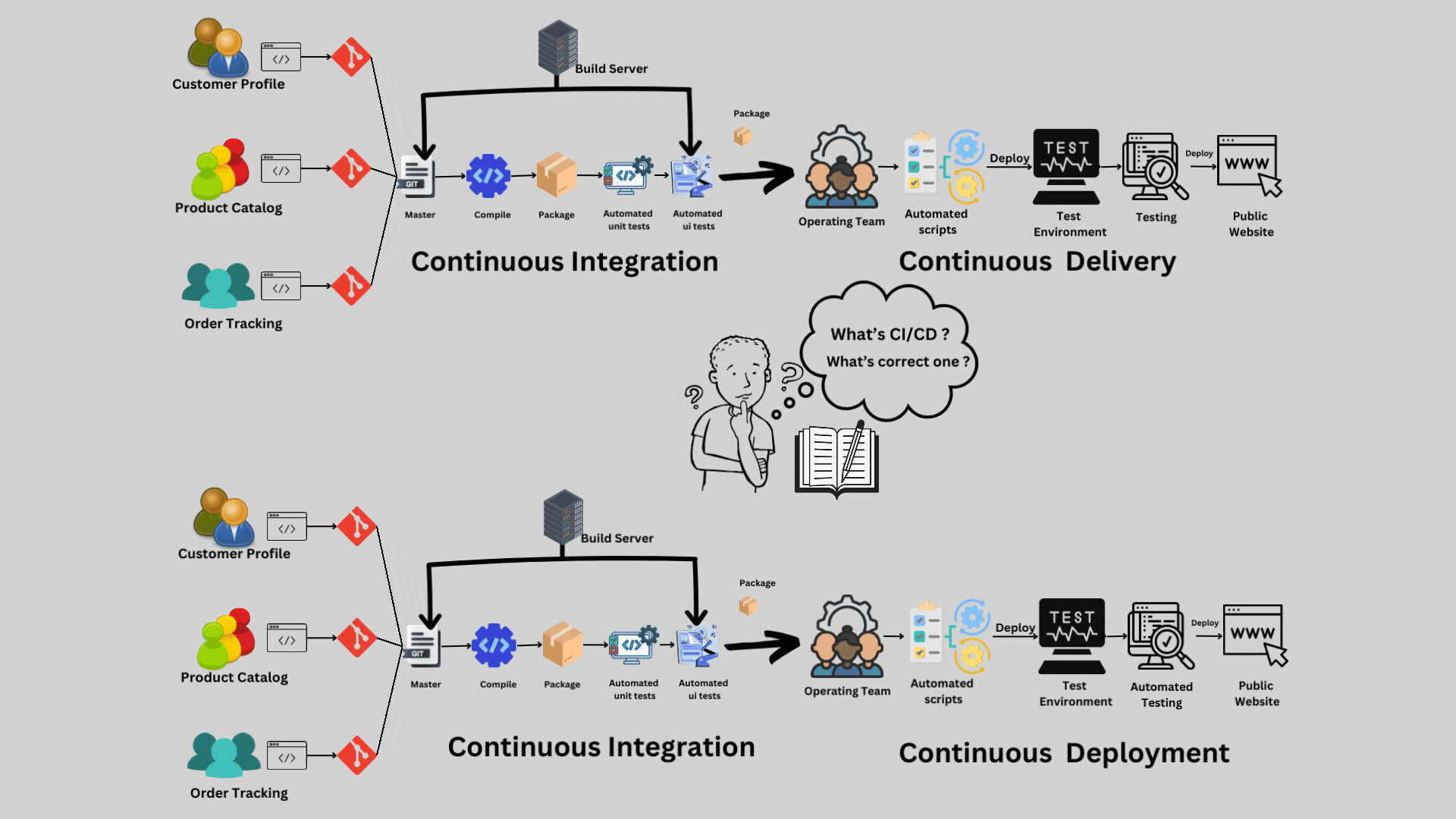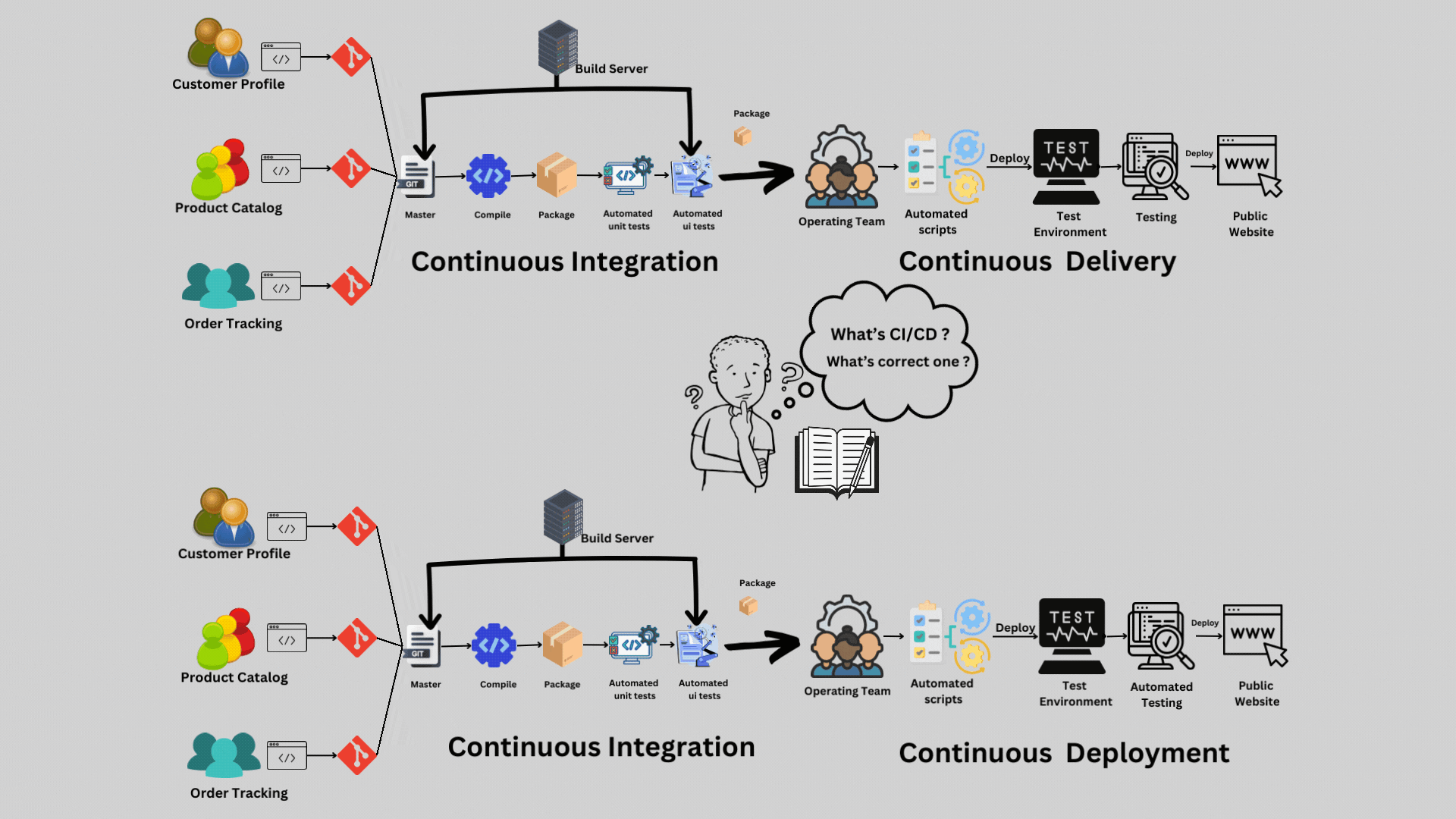
Compare this to traditional CI/CD where a broken deployment discovers the problem in production, where real customers are affected, and where the blast radius is potentially massive.
Production Rollout and Graceful Restarts
Once a slug clears all pre-production gates, it gets promoted to production. But production isn't a single machine. Intercom runs thousands of large virtual machines across multiple global regions.
Here's where the sophistication really shows: the deployment is orchestrated to happen simultaneously across the fleet, but the actual rollout is decentralized and staggered. This prevents the entire system from changing state at exactly the same moment (which would be an unnecessary risk).
Within each machine, a rolling restart mechanism operates at the process level. A single process running old code is taken out of customer-serving rotation. It's allowed to finish its current work and terminate gracefully once idle. Then a fresh process running the new code takes its place and starts handling requests.
This process is elegant in its simplicity. The first requests to the new code start flowing within approximately 2 minutes of the deployment starting. The entire global fleet updates within 6 minutes. Zero downtime. No complicated cutover procedures. No coordinated deployments. Just a smooth transition.
Throughout this entire flow from merge to production, human intervention is essentially zero unless something actively breaks.
Pipeline Health Monitoring
Intercom treats a stalled pipeline as a high-priority incident. If the automated system rejects three consecutive releases, it pages an on-call engineer immediately. Three failures might sound like a lot, but remember these are all pre-production blocks. The code never touches customers.
This is worth emphasizing: the organization treats the pipeline itself as a critical system. If something is wrong with the deployment infrastructure, knowing about it immediately and fixing it immediately is more important than any individual release. A broken pipeline affects dozens of deployments per hour. Fixing it pays off within minutes.
Immediate detection of metric deviations ensures rapid response to failures, minimizing customer impact. Estimated data.
Layer Two: The Ownership-Based Shipping Workflow
Automation handles the mechanics of deployment, but the human element still matters. The question is: how do you structure the human element to accelerate rather than impede?
Most organizations use approvals as a safety mechanism. A senior engineer or a change advisory board reviews every deployment. Multiple stakeholders sign off. This feels safe because more people are involved, but it actually creates perverse incentives. Engineers batch changes together to reduce approval overhead. Reviews become checklist exercises rather than genuine scrutiny. And the approval process itself becomes a bottleneck that slows velocity to a crawl.
Intercom approaches this completely differently. Rather than approvals, they use ownership and guardrails.
Distributed Ownership
Every engineer owns the code they ship. This is not a theoretical statement. It's a structural reality in how the organization is designed.
When you own your code, you have every incentive to make sure it's correct. You have every incentive to understand the tests. You have every incentive to think through edge cases and failure modes. You have every incentive to monitor what happens after deployment.
This matters more than any approval process ever could. An approval process creates the illusion of safety. An engineer who owns the consequences of their code creates actual safety.
Guardrails Instead of Gates
Rather than approval gates that block deployment, Intercom uses guardrails that nudge behavior without preventing motion.
A guardrail might be: "This change affects authentication. Did you write tests for the failure cases?" It's not a stop sign. It's information. The engineer can override it if they have good reasons. But they have to make an active choice to override rather than unconsciously accepting default behavior.
Guardrails serve another function: they make it safe to ship frequently because they're tailored to the specific risks of each type of change. A change to database migrations gets different guardrails than a change to the front-end CSS. A change to pricing logic gets scrutinized differently than a change to a comment field.
This is far more effective than generic approval processes that treat all changes equally.
Flexibility That Accelerates
Different types of changes have different risk profiles and different urgency. An urgent bug fix affecting revenue needs different handling than a refactoring of internal code that has zero customer impact.
Intercom's system is flexible enough to support different workflows for different situations. A critical hotfix for an outage can move faster because it's genuinely low-risk (it's fixing something that's already broken). A risky refactoring can move slower because it actually needs more scrutiny. The guardrails adjust based on context.
This flexibility is crucial. Without it, organizations default to treating everything identically, which either creates unnecessary bottlenecks or insufficient scrutiny depending on what baseline they choose.
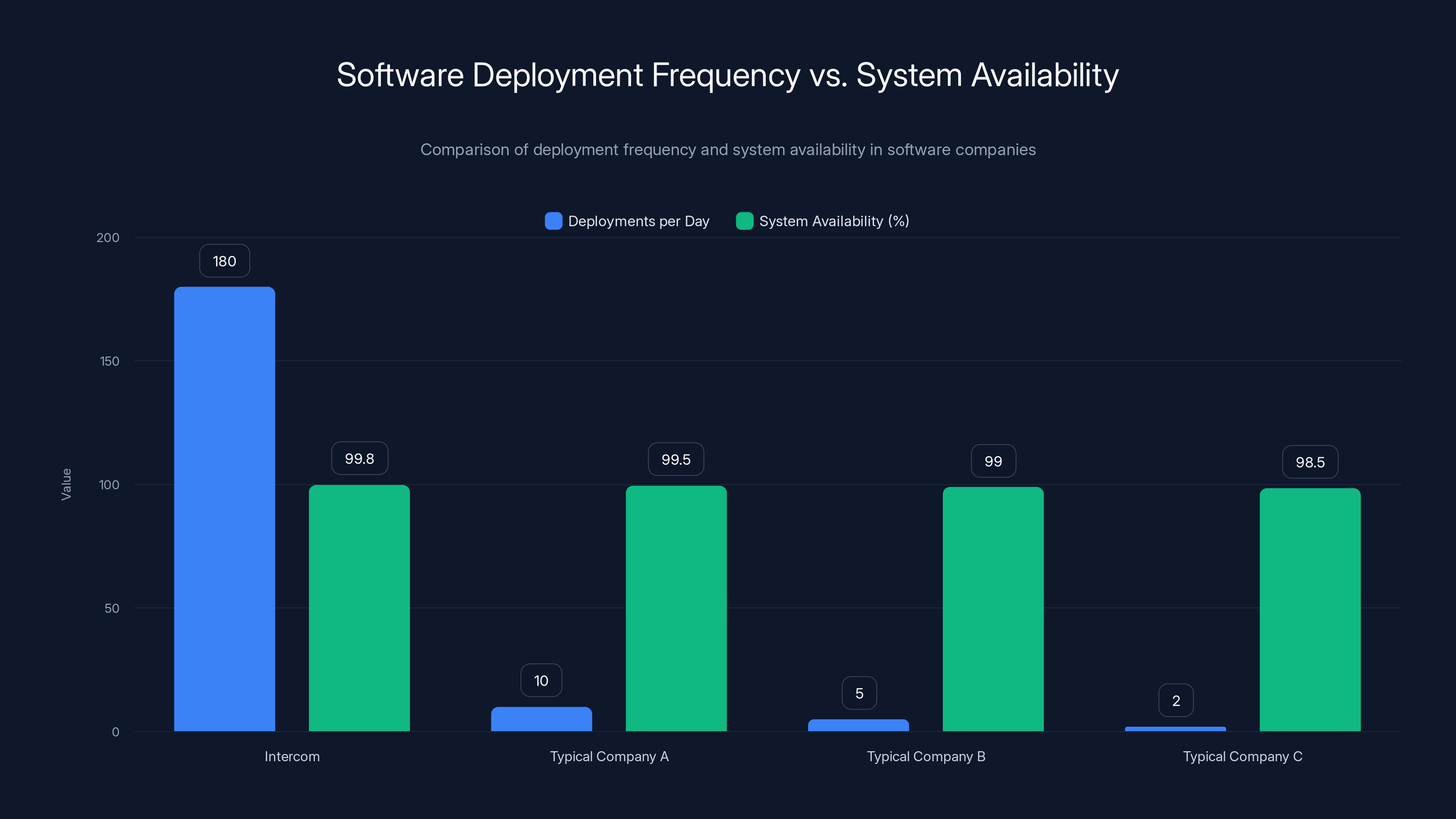
Intercom achieves high system availability (99.8%) with frequent deployments (180 times daily), illustrating that increased deployment frequency can coincide with high reliability.
Layer Three: The Recovery Model
No matter how good your pipeline is, failures happen. Code has bugs. Infrastructure fails. Someone makes a mistake. The question isn't whether failures will occur. The question is: how quickly can you detect and recover from them?
Immediate Detection
Intercom's infrastructure generates constant telemetry. Error rates. Latency. Resource usage. Database performance. Cache hit rates. Every metric that matters is being tracked continuously.
When a metric deviates from its normal pattern, alerts fire immediately. Not an hour later when enough users have noticed to complain. Immediately.
This immediate detection is what makes rapid deployment safe. If a deployment introduces a bug that increases error rates by 2%, monitoring catches it within seconds. If a change causes memory leaks that slowly consume resources, they're visible within minutes. If a database query starts timing out, monitoring catches it before it cascades into a broader outage.
Immediate detection means immediate action, which means minimal customer impact.
Instant Rollback
When a problem is detected, the response is swift. The problematic deployment is rolled back to the previous known-good version. This takes minutes at most.
Rolling back a single deployment out of 180 per day is trivial. It's a surgical operation. You're reverting 15 lines of code in isolation. You're not losing a quarter of product development.
This is why frequent deployment is actually safer than infrequent deployment. When failures happen, the response is proportionate. The cost of recovery is low. The window of customer impact is short.
Blameless Post-Mortems
After any incident, regardless of severity, Intercom conducts a post-mortem. Not to blame the engineer who caused it. Not to punish people for making mistakes. To understand how the systems failed to catch the problem.
Why did monitoring not catch this? Why didn't tests cover this edge case? Why did guardrails not flag this type of change? What system could we improve so this particular failure mode doesn't happen again?
This blameless approach is crucial for maintaining velocity. If engineers fear being blamed for mistakes, they slow down. They seek approvals for everything. They avoid taking risks. They write code that's risk-averse rather than value-optimized.
If engineers know that failures trigger discussions about improving systems rather than discussions about who messed up, they maintain reasonable risk-taking. They ship frequently. They move fast. And paradoxically, the systems improve faster than they would in a blame-oriented culture.
The Infrastructure Beneath the Process
The three-layer model describes the approach, but the actual execution requires sophisticated infrastructure that many organizations lack.
Intercom's codebase is primarily a single Rails monolith. This is significant. Microservices are trendy, and they have advantages, but they make deployment more complicated. With a monolith, the deployment process is straightforward: build, test, rollout, done. There's one deployment pipeline, one set of infrastructure, one recovery procedure.
The monolith is also deployed to three separate geographic regions, each with independent pipelines. This means a failure in one region doesn't cascade to others. It also means the organization has three times as much opportunity to catch problems before they affect all customers.
The deployment orchestrator itself is custom. Intercom couldn't use off-the-shelf solutions because off-the-shelf assumes different tradeoffs (usually prioritizing flexibility over speed). The custom solution is optimized for one thing: getting code from repository to production as fast as safely possible.
Database migrations are handled carefully. Schema changes can't happen atomically across a massive fleet, so Intercom uses a pattern of expand-contract-cleanup. You add the new column without removing the old one. Code handles both. Later, code stops using the old column. Only then is it removed. This adds complexity but ensures schema changes don't create deployment blockers.

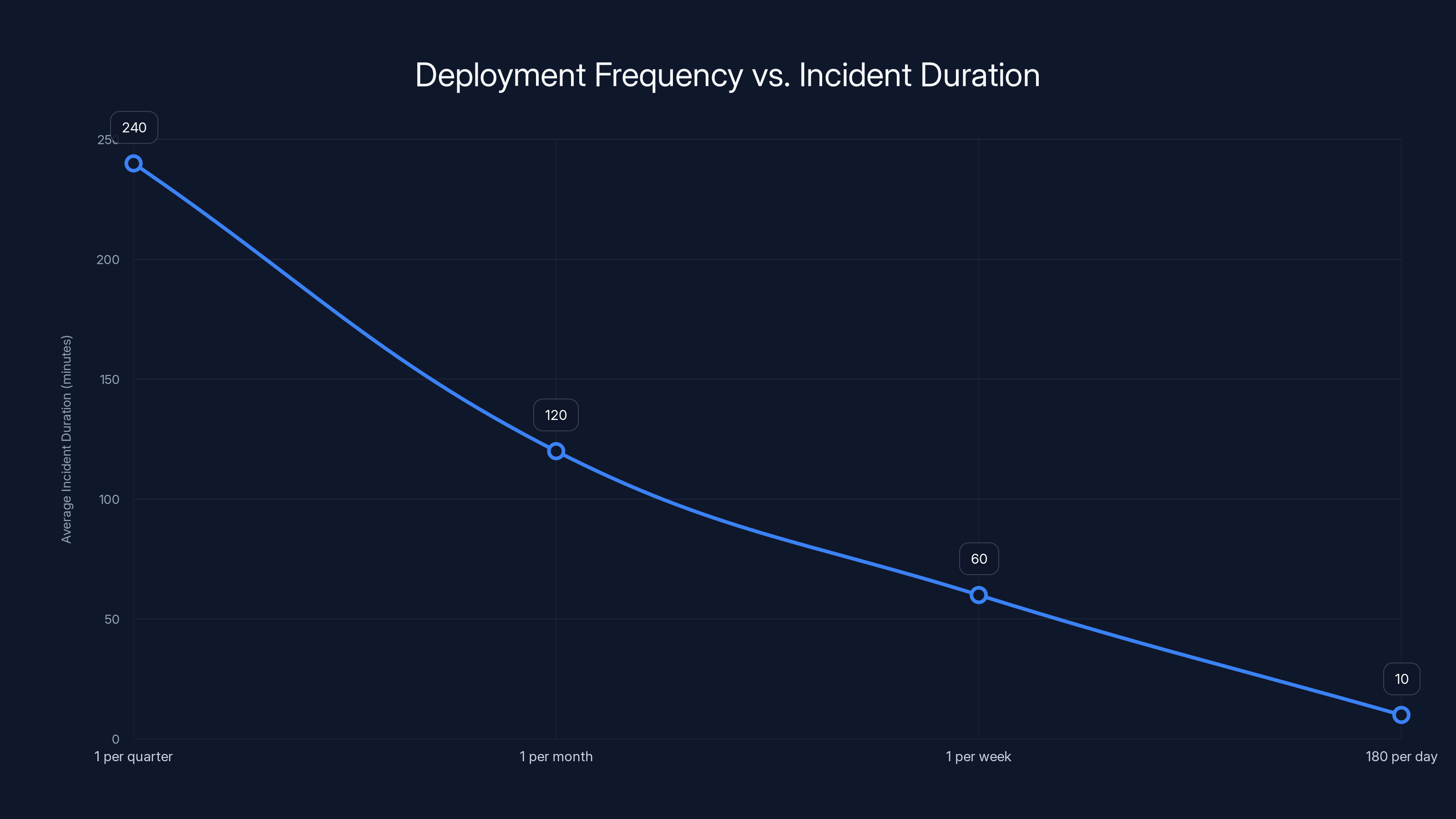
Estimated data shows that increasing deployment frequency significantly reduces average incident duration, enhancing system reliability.
The Cultural Reality Beneath the Infrastructure
None of this works without the right culture.
First, the organization values stability as a core metric. 99.8%+ availability isn't a nice-to-have. It's a competitive differentiator. It's part of how the company sells to enterprise customers. It's how the company retains customers. This means people across the organization take stability seriously.
Second, the organization invests heavily in tooling and infrastructure. Building a custom deployment orchestrator that handles 180 deployments per day reliably takes significant engineering effort. Building monitoring that catches problems within seconds takes significant effort. Building infrastructure that supports decentralized rolling restarts takes significant effort. Most organizations don't make these investments because they underestimate their value.
Third, the organization trusts its engineers. Ownership matters because the organization genuinely allows engineers to own their code. They're not fighting approval processes or change committees. They're not defending decisions to risk-averse gatekeepers. They're using their judgment and moving forward.
This cultural trust is reciprocated. Because engineers have real ownership, they feel genuine responsibility. They don't treat deployments casually. They think carefully about what they're shipping. They monitor what happens after deployment. They're invested in the outcome.
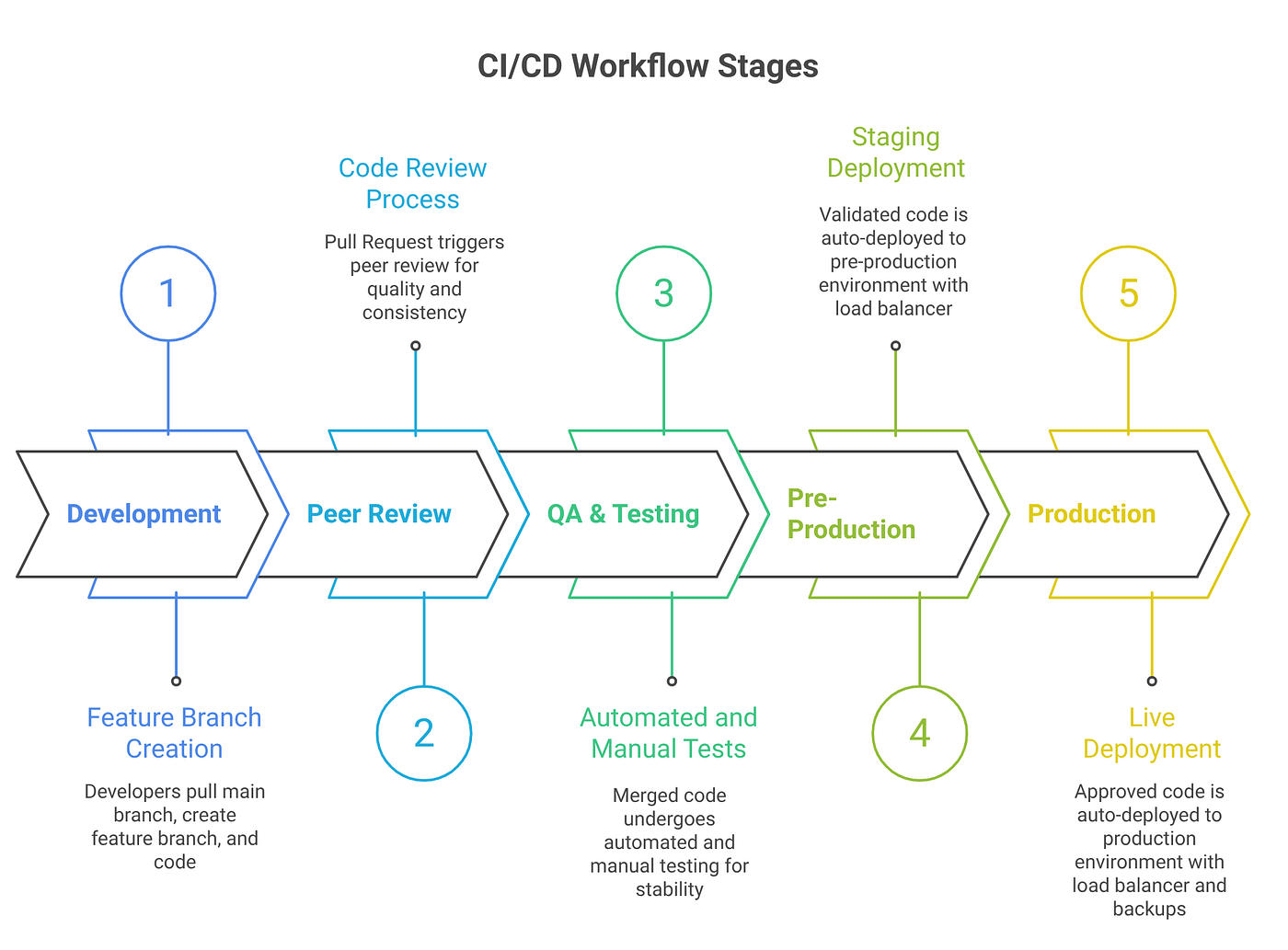
The Business Case for Velocity
Sustaining this level of deployment velocity requires continuous investment. Every year, Intercom engineers spend time optimizing pipelines, improving monitoring, enhancing deployment infrastructure. Why?
Because velocity is a business advantage.
When you can deploy 180 times per day, you can respond to customer feedback in hours instead of weeks. You can fix bugs in production before most customers have noticed. You can run experiments and learn from them immediately. You can iterate on features based on actual usage patterns rather than guesses.
This translates to product advantage. Competitors who deploy once per week can't move as fast. They can't respond as quickly. They can't learn as quickly. Over time, the organization that deploys most frequently tends to have the most polished product.
Velocity also affects recruiting and retention. Engineers want to work somewhere they can see their work in production quickly. They want to work on a stack where deploying code isn't a months-long process of approvals and committees. The ability to move fast is itself an attractive force.
Velocity affects cost. When you deploy frequently and recover quickly, your incident response is fast and your downtime is minimal. This means happier customers and lower support costs. The infrastructure investment pays for itself through operational efficiency.
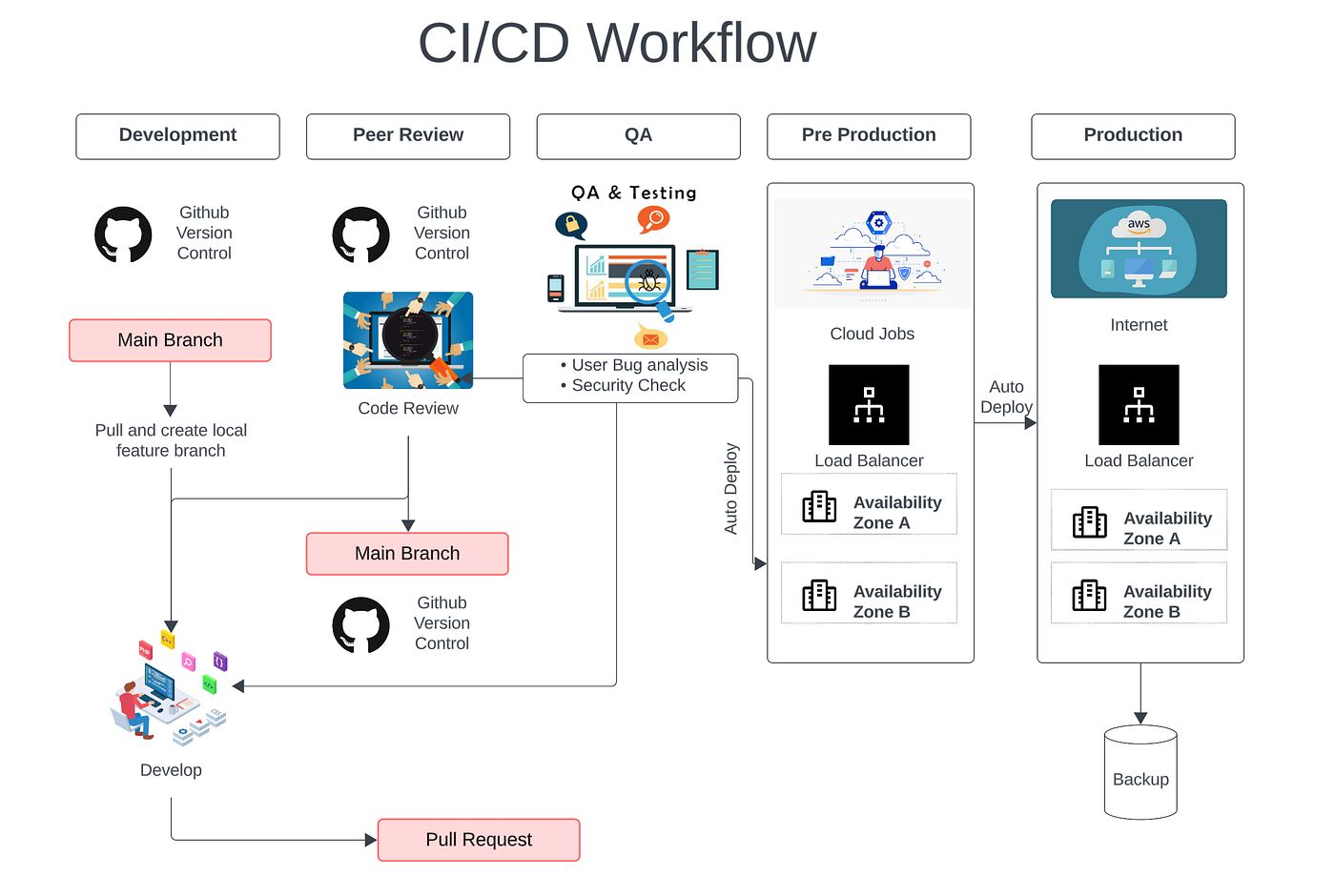
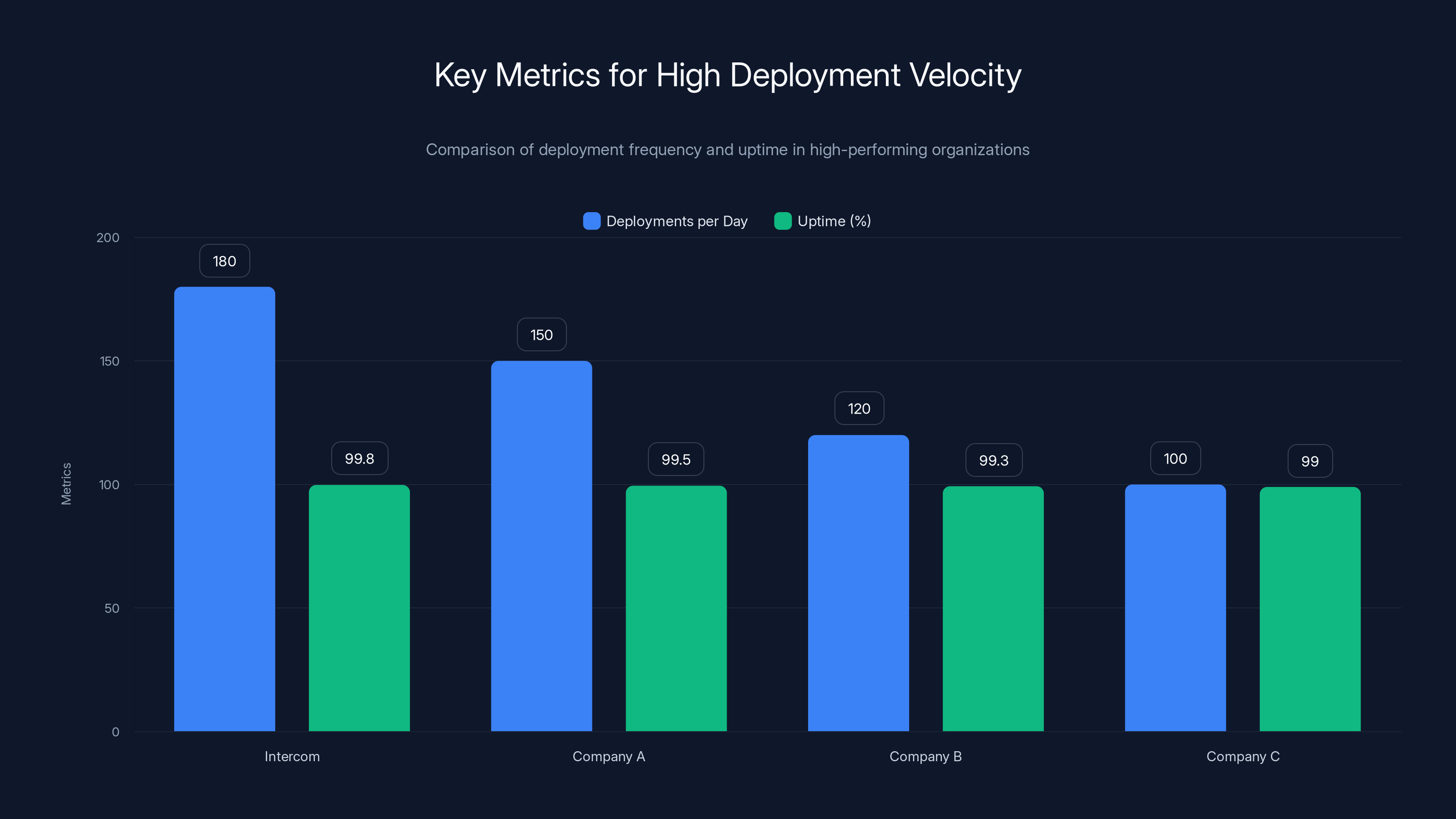
Intercom achieves 180 deployments per day with 99.8% uptime, showcasing the potential of high deployment velocity when supported by robust infrastructure and culture.
The Reality of 99.8% Availability
It's worth understanding what 99.8% actually means. It's less than 1 hour and 26 minutes of downtime per month. Across a global system serving millions of messages per day, that's remarkably good.
But it's also achievable. It's not 99.99% (which would require completely different infrastructure assumptions). It's not 100% (which is impossible). It's a reasonable, ambitious target that requires discipline but doesn't require everything to work perfectly.
When a deployment breaks something, your monitoring catches it in under a minute. Your rollback happens in under five minutes. Customer impact is roughly 5 minutes for a small percentage of customers. Over the course of a month, if you have 2-3 serious incidents, that's maybe 15-30 minutes of customer impact. The remaining 99.8% uptime comes from everything else working reliably.
The interesting part is that 99.8% uptime requires fewer deployment restrictions, not more. Because you're deploying so frequently, you can afford to fail. If one deployment out of 180 per day causes a 5-minute incident, you're still well within your uptime budget. The rigorous approach would be to prevent that one failure, which might require so much process overhead that you end up at 95% uptime because the organization can't sustain high velocity. Better to accept that one incident, recover quickly, and maintain overall uptime through volume and resilience.

Applying These Principles at Different Scales
Not every organization is Intercom. Not every organization deploys a Ruby on Rails monolith. Not every organization has invested a decade in building deployment infrastructure. So can these principles apply elsewhere?
Absolutely. The principles scale down as easily as they scale up.
A small startup can't deploy 180 times per day with a skeleton engineering team. But a small startup can deploy 5-10 times per day with the same three-layer model. Build quickly, test in parallel, deploy to staging first, monitor aggressively, recover fast. The same principles apply.
An organization running microservices instead of a monolith would need to adjust the deployment strategy, but the philosophy remains identical. Automated pipeline. Ownership-based workflow. Fast recovery. The details change, but the approach scales.
An organization with compliance requirements or regulatory oversight needs different guardrails, but the framework still works. Instead of generic approval gates, you'd have compliance-specific guardrails. Instead of completely distributed ownership, you'd have monitored ownership with escalation procedures for risky changes. The form changes but the function remains.
The real barrier isn't technical. It's organizational. It's the willingness to invest in infrastructure. It's the trust in engineers to own their work. It's the discipline to maintain monitoring and recovery procedures. These are harder to change than code.
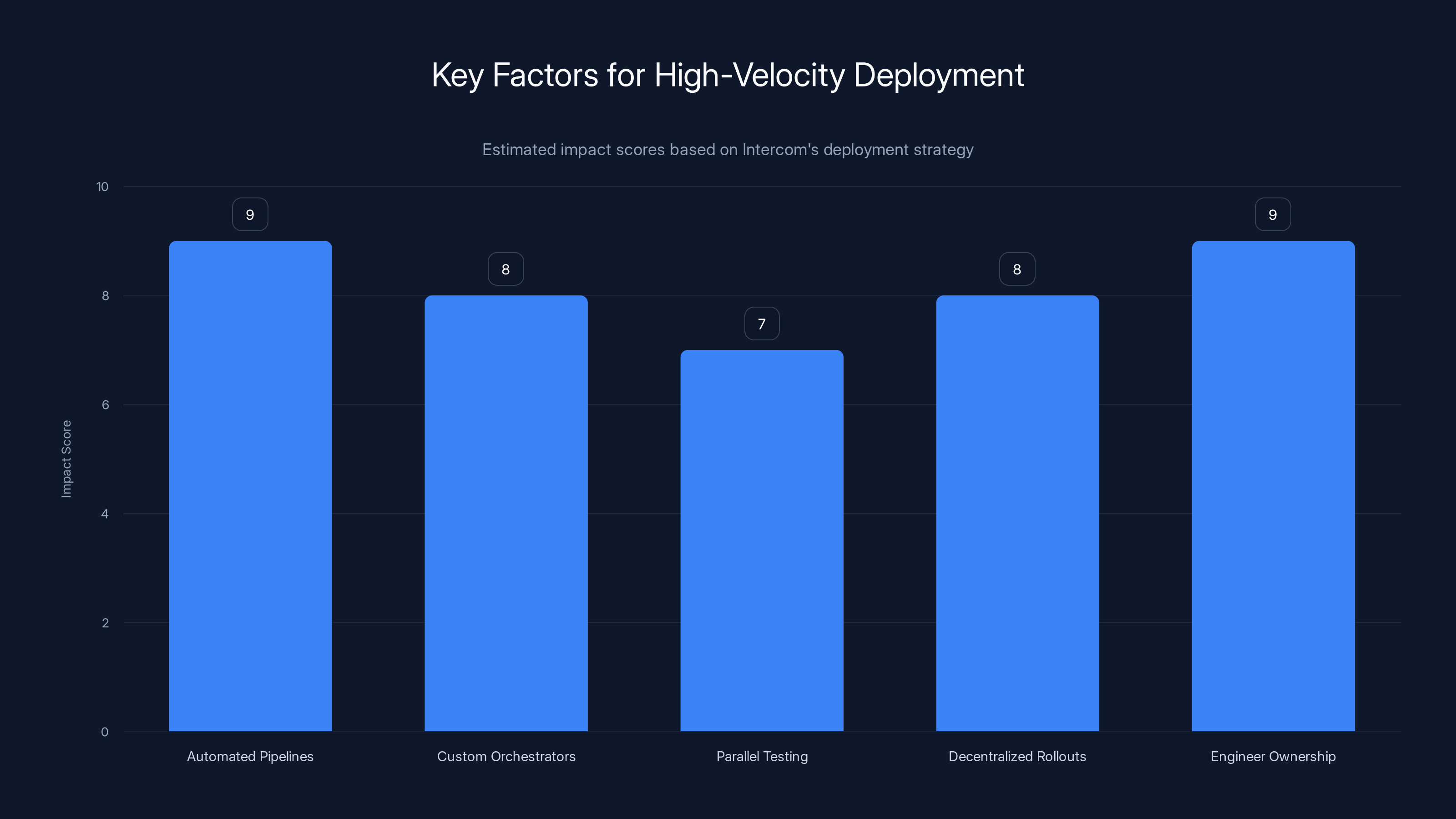
Key strategies such as automated pipelines and engineer ownership significantly impact deployment velocity, with scores ranging from 7 to 9. (Estimated data)
The Future of Deployment Velocity
Industry trends are moving in this direction. More companies are adopting continuous deployment. More organizations are embracing frequent releases. Kubernetes has made container orchestration easier, which enables easier deployment across fleets. Observability tools have gotten better, making it easier to detect problems.
But the competitive advantage goes to organizations that execute this approach well, not just that adopt it half-heartedly. Deploying frequently without proper infrastructure, monitoring, and culture is a recipe for constant outages and engineer burnout.
The organizations pulling ahead aren't those that deploy most frequently. They're the ones that deploy frequently and reliably. They're the ones that have built the infrastructure and the culture to sustain high velocity. They're the ones where engineers move fast and systems stay stable.
Intercom demonstrates that this is achievable. 180 deployments per day. 99.8% uptime. These aren't contradictory goals. They're the result of treating deployment as a core competency worth significant investment.
For most organizations, the limiting factor isn't whether this is possible. It's whether it's worth the investment. For product companies competing on velocity and reliability, the answer is almost always yes.
TL; DR
- 180 deployments daily achievable: Intercom deploys production code roughly 20 times per hour while maintaining 99.8%+ uptime through architectural decisions, not luck.
- Speed requires infrastructure: Automated pipelines, custom orchestrators, parallel testing, and decentralized rollouts make high-velocity deployment both safe and reliable.
- Ownership beats approvals: Trusting engineers to own their deployments, supported by guardrails rather than approval gates, moves code faster than committee-based gatekeeping.
- Fast detection and recovery matter more than prevention: Modern systems emphasize monitoring, instant rollback, and blameless post-mortems rather than preventing failures at all costs.
- Velocity compounds: Deploying frequently allows faster feedback loops, quicker iteration, better product development, and ultimately stronger competitive positioning.
FAQ
What does "180 deployments per day" actually mean?
It means Intercom's engineering team is merging code to production approximately 180 times per workday, or about every 3 minutes on average. Each deployment is a complete update of the running application with new code and features ready for customer use. This isn't a record count or a vanity metric—it directly enables faster feature delivery and quicker bug fixes.
How can such frequent deployments avoid constant outages?
Three layers of defense work together: an automated pipeline that catches problems before production, a monitoring system that detects issues within seconds of deployment, and an instant rollback procedure that reverts problematic code in under five minutes. The combination ensures that the average incident duration is measured in minutes rather than hours, and most deployments never cause incidents at all.
What's the relationship between deployment speed and system reliability?
Counterintuitively, deployment speed actually improves reliability. Frequent, small changes are easier to debug and recover from than infrequent, massive releases. When you deploy once per quarter with millions of lines of changes, finding the problem takes days. When you deploy every three minutes with a handful of changed lines, the root cause is obvious. This means faster resolution and lower overall downtime.
Why do most organizations deploy less frequently if speed improves stability?
Organizations typically slow down deployment due to fear of breaking things, but this fear often creates the opposite effect. To reduce deployment frequency feels safe but creates technical debt, larger change batches, longer review processes, and slower incident resolution. Breaking free from this cycle requires significant infrastructure investment (automated testing, custom orchestrators, monitoring systems) and cultural shift (trusting engineers, emphasizing ownership).
How does a rolling restart deployment actually work?
Rather than stopping all servers simultaneously and updating them together, rolling restarts update one process at a time. An individual process is removed from serving customer traffic, allowed to finish current work, then terminated. A fresh process with new code takes its place. This is repeated across the entire fleet gradually, so no moment exists where all servers are down. Customers experience zero downtime.
What happens when a deployment actually breaks something in production?
Monitoring systems detect error rate increases, latency spikes, or other anomalies within seconds. An alert triggers, and the deployment is automatically rolled back to the previous version, typically within 5 minutes of the problem being detected. The problematic code is never deployed to all servers, customer impact is minimal, and the engineering team reviews what systems failed to catch the problem during pre-production testing.
Can smaller teams or younger organizations apply these principles?
Absolutely. A five-person startup deploying 5-10 times daily using the same principles is as effective as Intercom deploying 180 times daily. The framework scales: build rapidly, test automatically, deploy to staging environments first, monitor production continuously, and recover quickly when needed. The specific infrastructure and scale adjusts, but the philosophy remains identical.
What's the difference between continuous deployment and continuous delivery?
Continuous delivery means code is ready to deploy to production at any time, but humans decide when to actually release. Continuous deployment means code automatically deploys to production the moment it passes all automated checks. Intercom practices continuous deployment (with the organization's blameless recovery model providing the safety net). Most organizations practice continuous delivery (ready to deploy frequently, but choosing when based on business decisions).
Bonus: Building Your Own Rapid Deployment System
If your organization wants to move toward higher deployment velocity, here's a pragmatic starting point that doesn't require a decade of infrastructure investment:
Month 1-2: Establish baseline monitoring. Instrument your production system so you understand error rates, latency, resource usage, and critical business metrics. You can't improve what you can't measure, and you can't recover quickly from what you can't detect.
Month 2-3: Automate your test suite. Get to the point where you can run comprehensive tests in under 10 minutes. Use test parallelization. Use intelligent test selection (only run tests affected by changed code). Make tests fast, reliable, and part of your default deployment process.
Month 3-4: Create a staging environment. Build an environment that mirrors production as closely as possible. Run smoke tests against it before promoting code to production. Catch major issues before they affect customers.
Month 4-5: Implement basic monitoring-based rollback. Set up simple rules: if error rate spikes above normal, or if latency doubles, automatically roll back the most recent deployment. This prevents small problems from becoming large incidents.
Month 5-6: Shift from approval-based to guardrail-based deployment. Remove approval gates. Instead, implement guardrails that nudge behavior without blocking motion. Different guardrails for different types of changes. Let engineers move fast within sensible boundaries.
Ongoing: Optimize and iterate. As you move faster, bottlenecks become obvious. A test suite that takes 8 minutes needs optimization. A deployment that takes 20 minutes needs streamlining. Address the most painful bottleneck each quarter.
This isn't a recipe that'll get you to 180 deployments per day in a year, but it can get you from once-per-week deployments to once-per-day or multiple-per-day, which is a massive quality-of-life improvement for the engineering team and the product.
The key insight isn't that you need to deploy 180 times per day. The key insight is that by prioritizing frequent, safe deployment as a core competency, you unlock benefits that extend far beyond the deployment process itself.

Key Takeaways
- Deploying 180 times per day is achievable while maintaining 99.8% uptime through three-layer defense system: automated pipeline, ownership-based workflow, and rapid recovery model
- Speed enables stability because small, frequent changes are easier to debug and recover from than large infrequent releases with massive blast radius
- Automated pipeline removes human intervention bottlenecks: build (4 min) + parallel test (5 min) + pre-production verify (2 min) + production rollout (2 min) = 12 minutes total
- Ownership-based workflow with guardrails accelerates deployment faster than approval gates because engineers are incentivized to ensure code quality rather than rushing past gatekeepers
- Immediate monitoring and rollback enable rapid incident recovery: problems detected in seconds, rolled back in minutes, customer impact typically under 5 minutes
- Infrastructure investment pays dividends through operational efficiency, faster feature iteration, better customer response, and improved recruiting/retention

