![Stability AI's Audio Revolution: Creating Six-Minute Songs with Advanced Models [2025]](https://tryrunable.com/blog/stability-ai-s-audio-revolution-creating-six-minute-songs-wi/image-1-1779291510988.jpg)
Stability AI's Audio Revolution: Creating Six-Minute Songs with Advanced Models [2025]
Stability AI has once again pushed the boundaries of creativity and technology. With the release of its new audio model family, Stability Audio 3.0, the company is setting new standards in AI-generated music. These models offer the ability to create professional-grade music compositions up to six minutes long, a significant leap from previous capabilities. Let's dive into the details of these models, explore their potential applications, and understand what this means for the future of music production.
TL; DR
- Stability AI's new models: Capable of generating songs up to six minutes long with professional quality.
- Model variety: Includes small (459M parameters), medium (1.4B parameters), and large (2.7B parameters) models.
- Open weights: Allows for customization and modification, fostering innovation.
- Impact on creators: Empowers musicians, developers, and hobbyists to explore new creative avenues.
- Future trends: AI is increasingly integral in music production and personalized content creation.

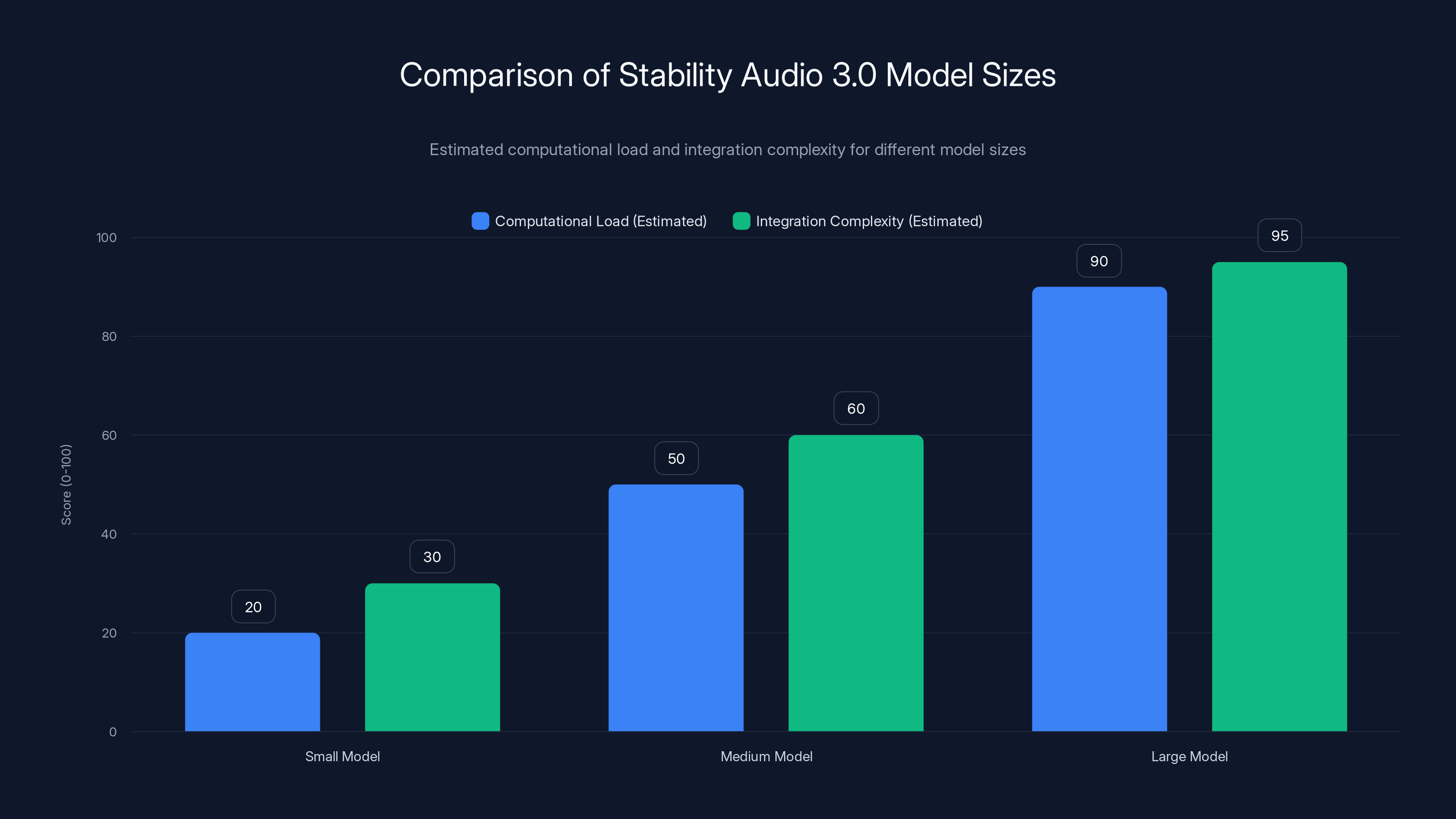
The Large model of Stability Audio 3.0 requires significantly higher computational resources and integration complexity compared to the Small and Medium models. Estimated data based on typical model characteristics.
Exploring the New Audio Models
Stability AI's latest release includes four distinct models under the Stability Audio 3.0 umbrella: small SFX, small, medium, and large. Each model serves a unique purpose, catering to different needs and capabilities.
Small Models: On-Device Sound Generation
The small SFX and small models, each with 459 million parameters, are designed for on-device sound and music generation. They are ideal for applications where quick and efficient audio generation is necessary, such as mobile apps or interactive media. Despite their compact size, these models can produce audio clips up to two minutes long, providing significant creative potential for developers working on the go.
Medium and Large Models: Full-Length Compositions
The medium (1.4 billion parameters) and large (2.7 billion parameters) models represent the pinnacle of Stability AI's audio capabilities. These models can create full compositions lasting up to six minutes and twenty seconds. This is more than double the length previously possible, allowing for intricate musical structures and sustained melodic tones. Such capabilities open new doors for artists seeking to generate complete songs or soundtracks.
Open Weights: A Platform for Innovation
A significant feature of these models is the availability of open weights for the small SFX, small, and medium models. This openness allows developers and musicians to modify and adapt the models to fit their specific needs. By offering open weights, Stability AI is encouraging experimentation and customization, fostering a community-driven approach to audio innovation.
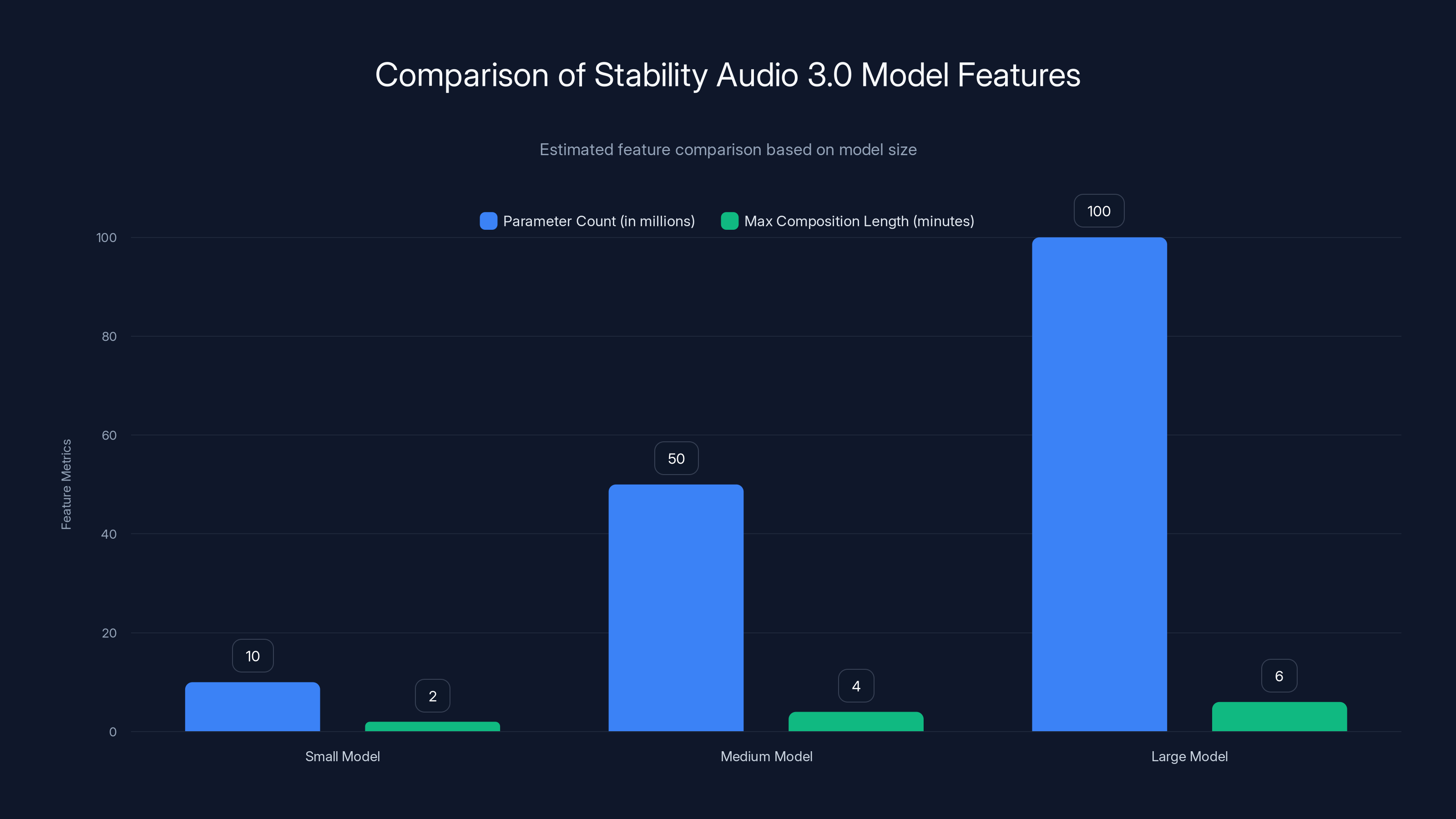
Estimated data shows that larger models support more parameters and longer compositions, enhancing audio richness.
Practical Applications and Use Cases
The possibilities with Stability Audio 3.0 are vast, encompassing a wide array of applications across various industries.
Music Production
For musicians and producers, these models offer tools to compose and arrange music efficiently. Whether creating background tracks for videos, full-length songs, or experimental soundscapes, the models provide a versatile foundation for musical exploration.
Example Use Case: A musician could use the large model to generate a six-minute ambient track as a base layer for a new album, layering live instruments and vocals over the AI-generated composition.
Game Development
Game developers can leverage these models to create dynamic soundtracks and sound effects that enhance player immersion. The ability to generate audio on-device with the small models ensures that games can have unique, adaptive soundscapes without excessive resource consumption.
Example Use Case: An indie game developer could use the small SFX model to generate a library of sound effects for a fantasy RPG, ensuring each player's experience is unique.
Interactive Media and Installations
For artists working in interactive media, the ability to generate real-time audio responses to user actions can create engaging experiences. Exhibitions, VR experiences, and interactive installations can benefit from the models' capabilities to produce immersive audio environments.
Example Use Case: An art installation could use the medium model to generate unique soundscapes that change in response to audience movements or interactions.
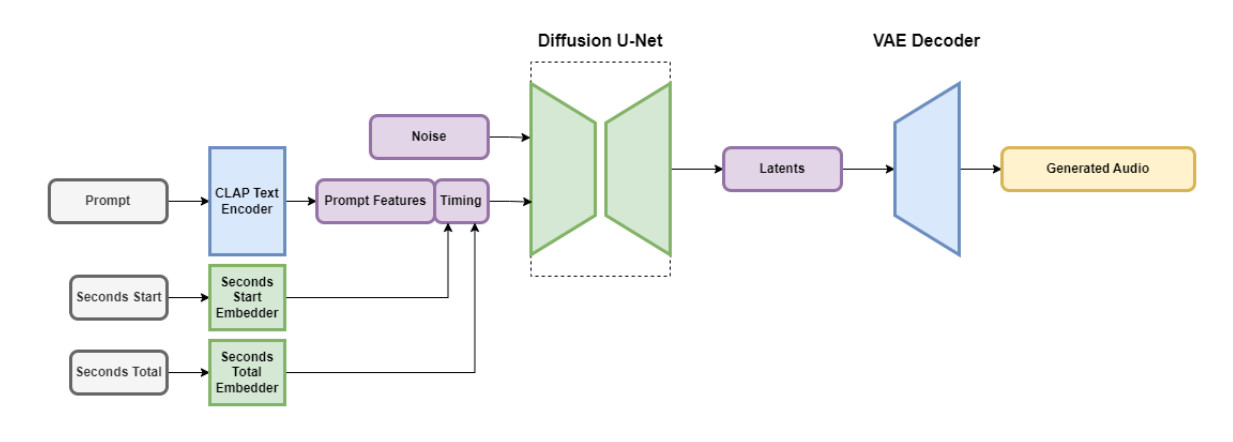
Technical Insights and Best Practices
Implementing Stability Audio 3.0 models effectively requires understanding their architecture and how to integrate them into existing workflows.
Model Architecture
The models utilize a transformer-based architecture, optimized for audio synthesis. This architecture allows for the generation of coherent and musically rich outputs, providing a significant advantage over traditional audio synthesis methods.
Best Practice: When integrating these models, ensure that your system can handle the computational load, especially for the large model. Consider using cloud-based solutions to manage processing demands effectively.
Integration Strategies
To integrate these models into your projects, you'll need a robust understanding of machine learning frameworks such as TensorFlow or PyTorch. These tools allow you to customize the models' weights and parameters to better suit your specific needs.
Code Example: Below is a basic example of how to load a Stability Audio 3.0 model using PyTorch:
pythonimport torch
from stability_audio import StabilityAudioModel
# Load the medium model
model = StabilityAudioModel('medium')
model.load_weights('path/to/open_weights')
# Generate audio
audio_input = torch.randn((1, 16000)) # Example input
output = model.generate(audio_input)
Evaluation and Fine-Tuning
Evaluating the quality of the generated audio is crucial. Use objective metrics like signal-to-noise ratio (SNR) and subjective listening tests to assess the audio's fidelity. Fine-tuning the models on your specific datasets can also enhance their performance for particular genres or styles.
Quick Tip: Start by fine-tuning the small models for quick iteration and testing before scaling up to the medium or large models.

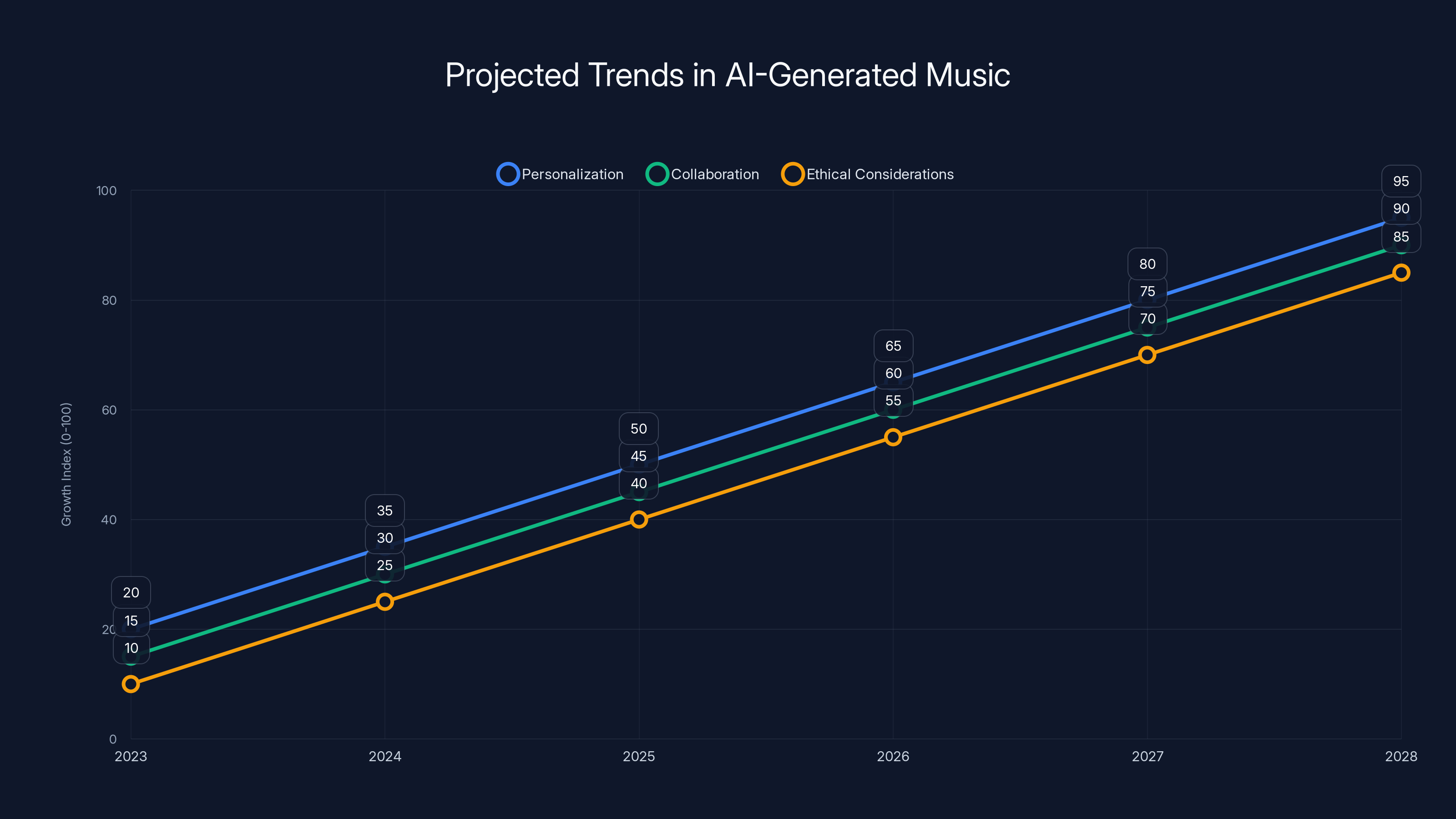
Estimated data shows significant growth in personalization, collaboration, and ethical considerations in AI-generated music by 2028.
Overcoming Common Pitfalls
While Stability Audio 3.0 offers impressive capabilities, users may encounter challenges that require careful consideration and troubleshooting.
Managing Computational Resources
The larger models require substantial computational resources, which can be a barrier for smaller teams or individuals.
Solution: Utilize cloud computing platforms like AWS or Google Cloud to distribute processing demands, and consider using the smaller models for preliminary tests.
Ensuring Model Stability
As with any AI model, ensuring stability and avoiding errors during generation is essential.
Solution: Regularly update dependencies and libraries to the latest versions, and conduct thorough testing across different environments to ensure consistent performance.
Future Trends and Recommendations
The release of Stability Audio 3.0 marks a significant milestone in AI-generated music, but the journey is far from over. Here are some trends and recommendations for the future.
Increasing Personalization in Music
As AI models become more sophisticated, the ability to personalize music for individual listeners will grow. Models could generate songs tailored to a listener's preferences or mood, creating truly personalized audio experiences.
Expanding Collaborative Opportunities
AI models like Stability Audio 3.0 can facilitate collaboration between musicians and AI, creating hybrid compositions that blend human creativity with machine-generated innovation.
Recommendation: Experiment with collaborative projects that incorporate both AI-generated and traditional musical elements to explore new creative territories.
Ethical Considerations and Copyright
As AI-generated music becomes more prevalent, ethical considerations regarding copyright and ownership will need to be addressed. Ensuring that original creators receive recognition and compensation for their contributions is crucial.
Recommendation: Engage with legal experts to navigate the complexities of copyright in AI-generated music and develop frameworks that support fair use and attribution.
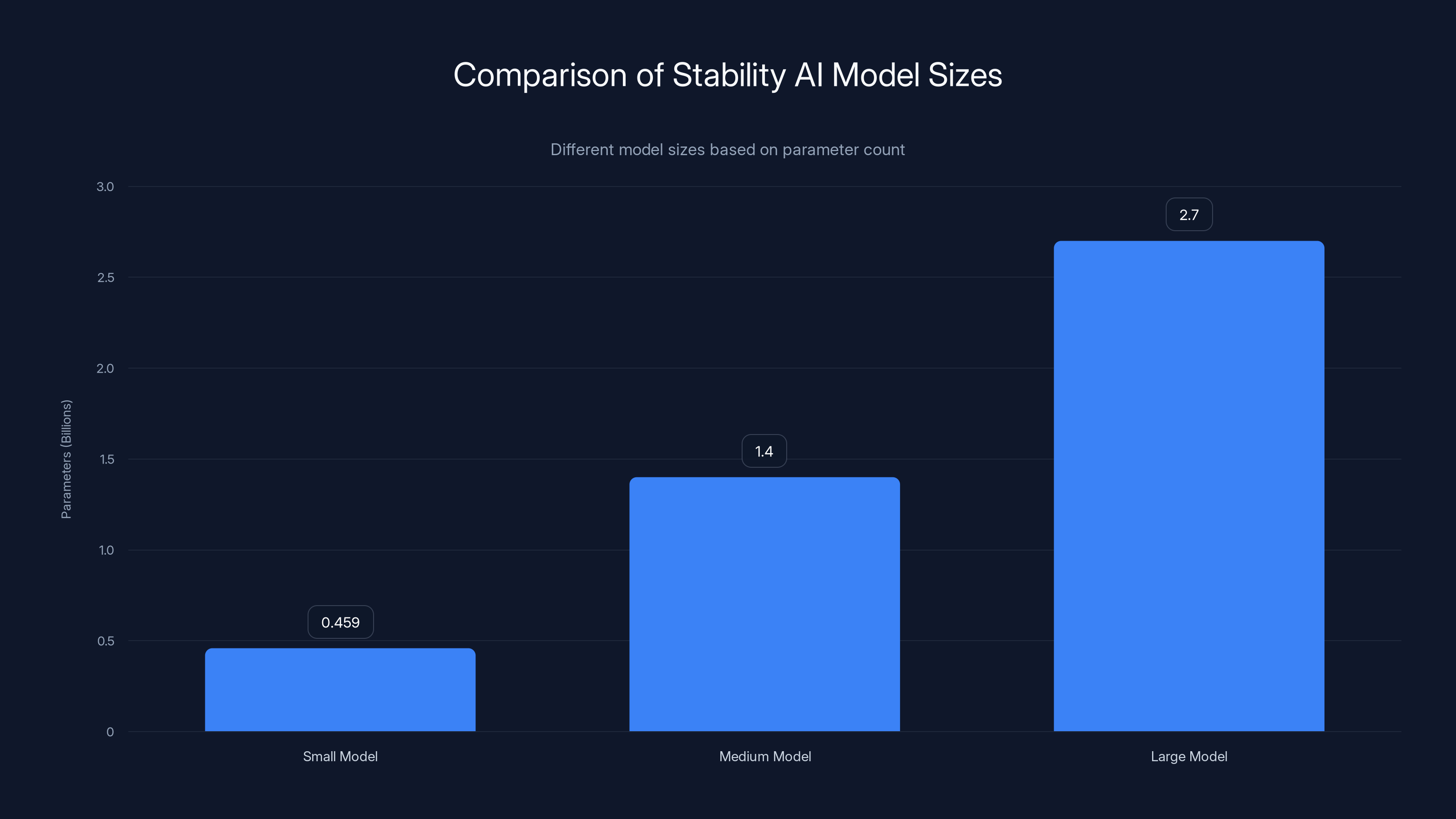
The large model by Stability AI has 2.7 billion parameters, significantly more than the medium and small models, enabling more complex song generation.
Conclusion
Stability AI's release of the Stability Audio 3.0 models is a landmark event in the world of audio generation. With their ability to create professional-grade music compositions up to six minutes long, these models offer unprecedented opportunities for musicians, developers, and creative professionals. By understanding and leveraging these tools effectively, users can unlock new realms of creativity and innovation in music production.
FAQ
What is Stability Audio 3.0?
Stability Audio 3.0 is a family of audio models released by Stability AI, capable of generating professional-grade music compositions up to six minutes long.
How can I use Stability Audio 3.0 models?
You can integrate these models into your projects using machine learning frameworks like TensorFlow or PyTorch, allowing for customization and adaptation to your specific needs.
What are the differences between the small, medium, and large models?
The small models are designed for on-device sound generation, while the medium and large models can create full-length compositions with more parameters for richer audio.
Can I modify the Stability Audio 3.0 models?
Yes, the small SFX, small, and medium models are available with open weights, allowing for customization and modification to suit your requirements.
What are some potential applications of Stability Audio 3.0?
These models have applications in music production, game development, interactive media, and more, offering tools to create dynamic and immersive audio experiences.
How do I evaluate the quality of generated audio?
Use objective metrics like signal-to-noise ratio and subjective listening tests to assess the audio's fidelity. Fine-tuning on specific datasets can also enhance performance.
What are the future trends in AI-generated music?
Future trends include increasing personalization in music, expanding collaborative opportunities between AI and musicians, and addressing ethical considerations in copyright.
How does Stability AI support innovation in audio generation?
By providing open weights and encouraging community-driven experimentation, Stability AI supports innovation and allows developers to modify and adapt models for diverse applications.
Key Takeaways
- Stability Audio 3.0 models can generate songs up to six minutes long.
- Open weights allow for customization and foster innovation.
- Models have applications in music production, gaming, and interactive media.
- Future trends include personalized music and AI-music collaboration.
- Ethical considerations in copyright need to be addressed.
Related Articles
- Google's AI-Enhanced Search: Balancing Innovation with Classic Results [2025]
- Mastering Gemini 3.5 Flash: Google's Latest Breakthrough in Coding and Agentic AI [2025]
- The Rise of NanoClaw: Turning Down a 12M Seed Investment [2025]
- The Crucial Moment for AI Labeling Systems [2025]
- How Google's AI Enhancements Are Revolutionizing Your Inbox and Work Files [2025]
- The Future of AI Agents: Challenges and Opportunities [2025]

