![The Future of Voice Transcription: Cohere's Open-Source Model [2025]](https://tryrunable.com/blog/the-future-of-voice-transcription-cohere-s-open-source-model/image-1-1774534147752.jpg)
The Future of Voice Transcription: Cohere's Open-Source Model [2025]
Introduction
In the fast-paced world of technology, staying ahead means constant innovation. Just recently, Cohere, a leading AI company, introduced a groundbreaking voice model called Transcribe. Designed as an open-source automatic speech recognition (ASR) tool, this model is set to revolutionize how we approach voice transcription. Unlike proprietary models that lock users into specific ecosystems, Transcribe is open, versatile, and accessible to anyone with consumer-grade GPUs. But what makes it truly stand out? Let's dive into the details.
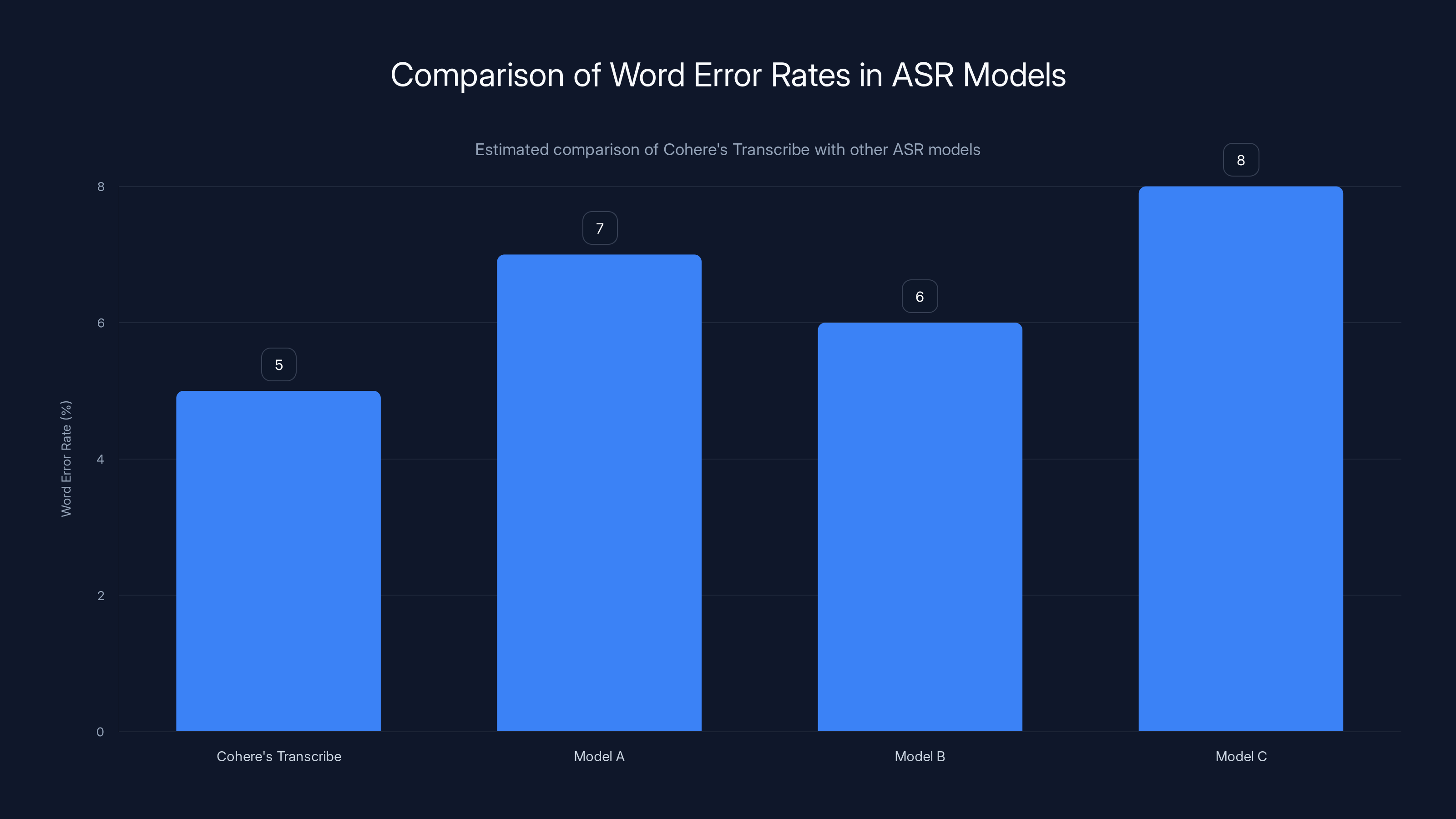
Cohere's Transcribe shows a lower word error rate compared to other models, highlighting its competitive accuracy. Estimated data.
TL; DR
- Cohere's Transcribe: An open-source voice model for transcription with a focus on accessibility and accuracy.
- Language Support: 14 languages including English, French, and Mandarin.
- Performance: Beats competitors with a word error rate (WER) of 5.42.
- Accessibility: Designed for consumer-grade GPUs, making it accessible for individuals and small businesses.
- Future Trends: The model's success points to a future where open-source solutions dominate voice technology.
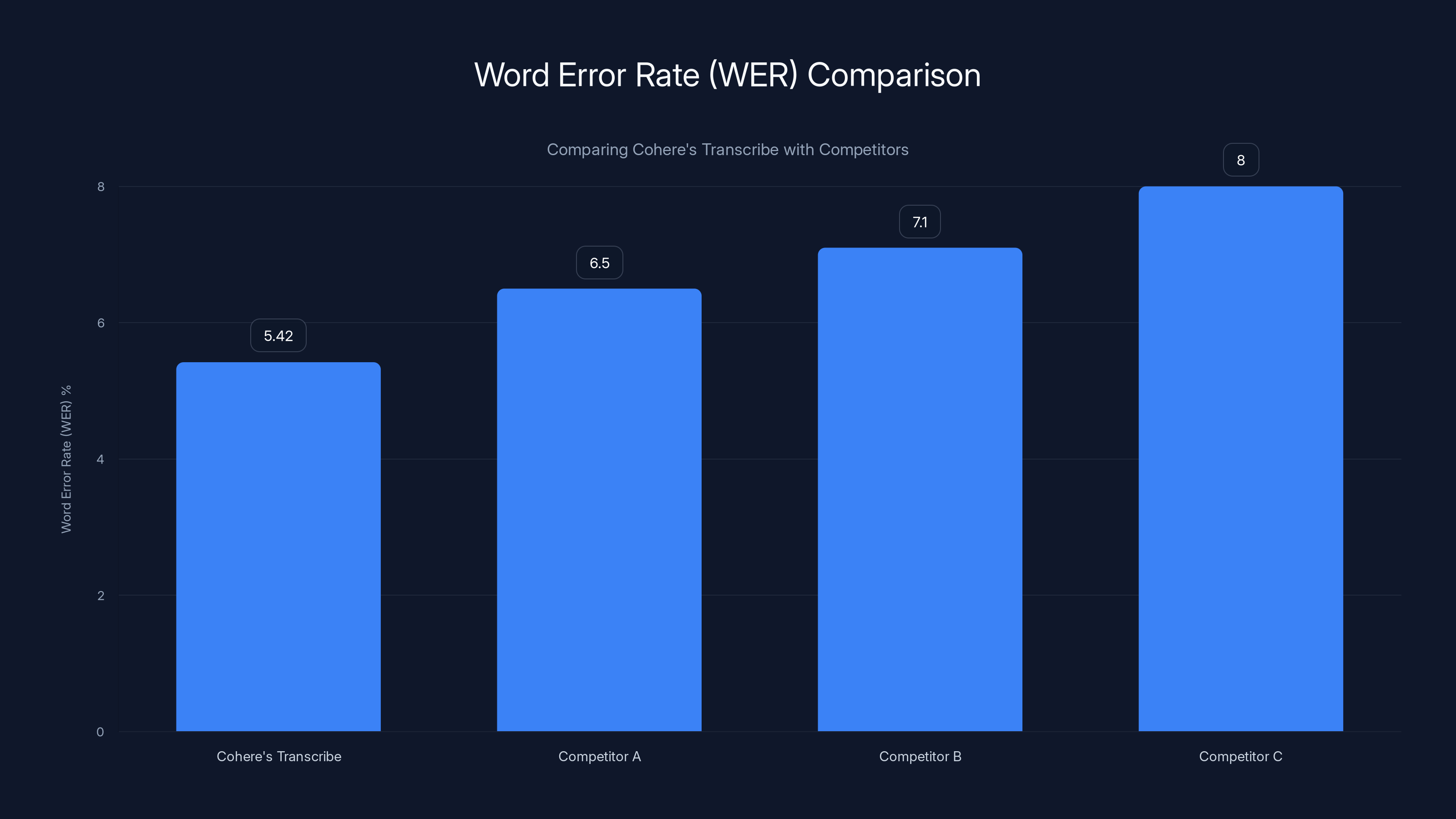
Cohere's Transcribe outperforms competitors with a lower word error rate of 5.42%, indicating higher accuracy.
What is Transcribe?
Cohere's Transcribe is an automatic speech recognition (ASR) model that processes spoken language into written text. Built with 2 billion parameters, it’s designed to be lightweight yet powerful, supporting a wide range of languages including English, French, German, and Mandarin among others. This makes it a versatile tool for both individual and enterprise users.
Key Features
- Open-Source: Unlike many proprietary models, Transcribe is open-source, allowing developers to customize and improve it as needed.
- Language Versatility: Supports 14 languages, making it ideal for global applications.
- Efficiency: Optimized to run on consumer-grade GPUs, reducing the need for expensive hardware.
- Accuracy: Achieves a word error rate (WER) of 5.42, outperforming many existing models.
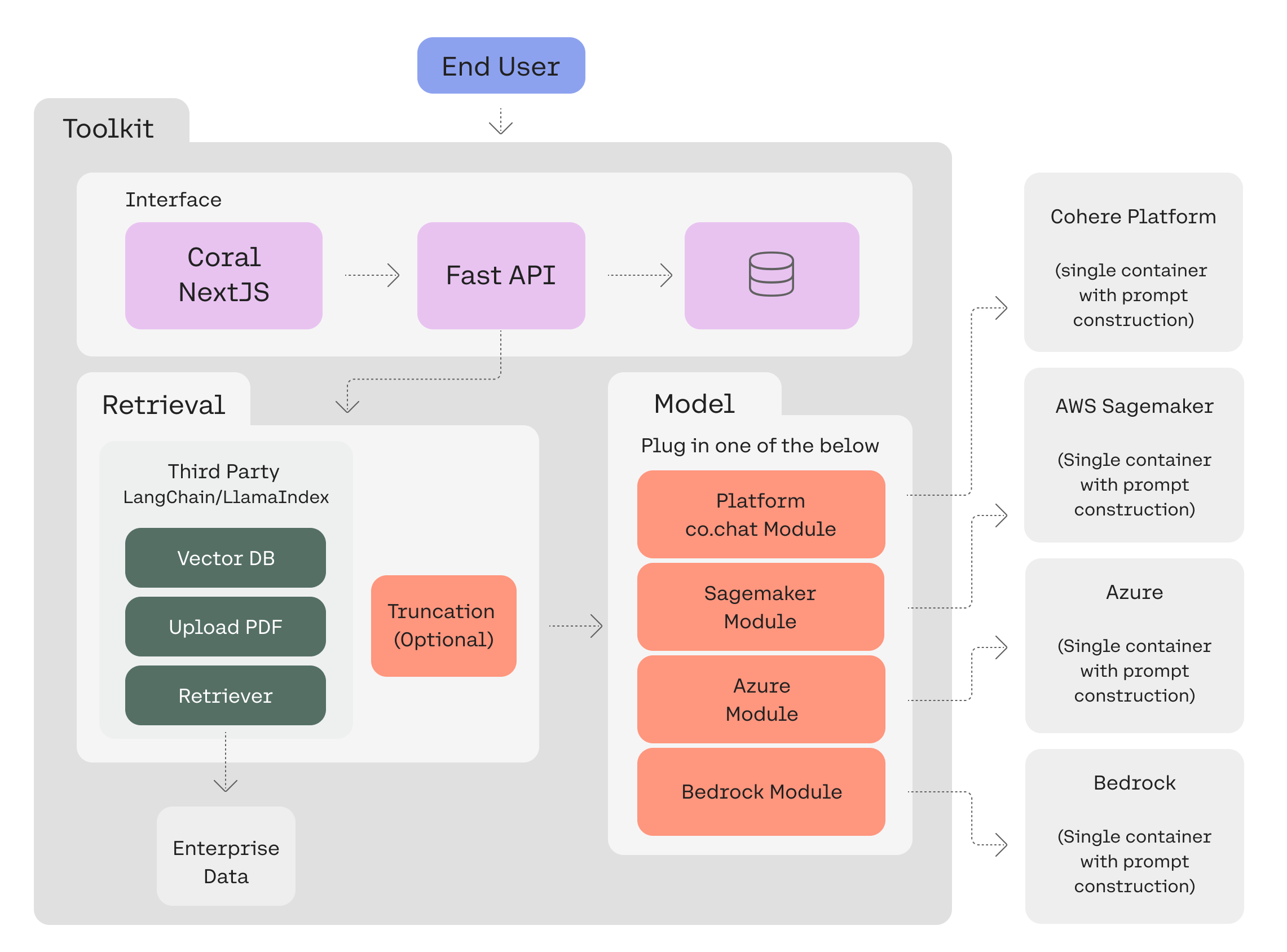
Implementation: Getting Started with Transcribe
Implementing Transcribe in your workflow is straightforward, thanks to its open-source nature. Here’s a step-by-step guide:
-
Installation: First, ensure you have a compatible GPU. Transcribe can be installed via GitHub, where the source code is available.
bashgit clone https://github.com/cohere-ai/transcribe.git cd transcribe pip install -r requirements.txt -
Configuration: Customize the configuration files to suit your needs. You can adjust settings such as language and output format.
-
Running the Model: Use the command line to input audio files and receive transcriptions.
bashpython transcribe.py --input_file=audio.wav --language=en -
Integration: For developers, Transcribe can be integrated into existing applications via API, allowing seamless automation of transcription tasks.
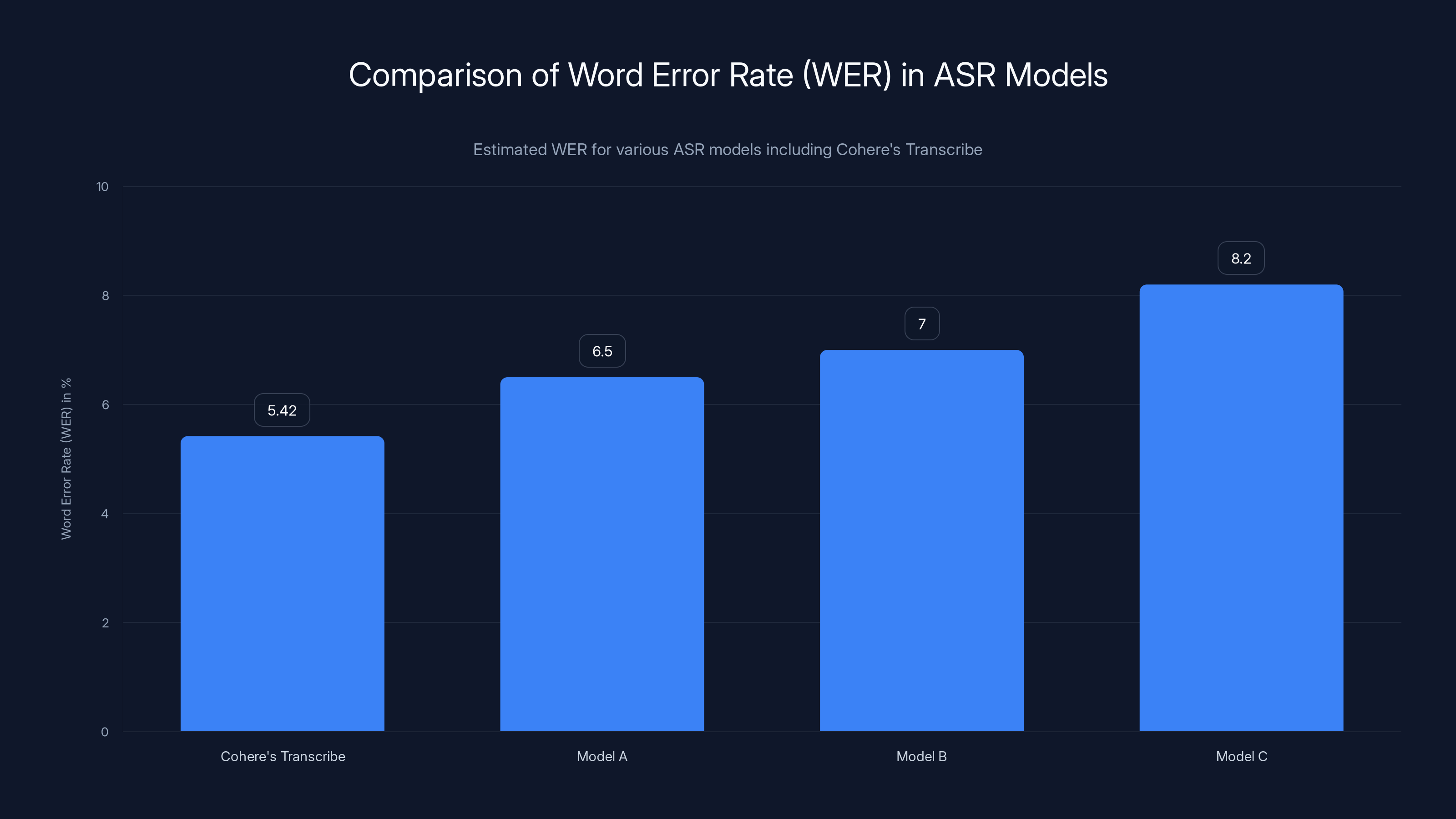
Cohere's Transcribe model achieves a WER of 5.42%, outperforming other models with higher error rates. Estimated data for comparison.
Real-World Use Cases
Educational Institutions
Transcribe is a boon for educational institutions. With remote learning becoming the norm, accurate lecture transcription ensures that students have access to class content anytime. Imagine a university where every lecture is automatically transcribed and made available to students, enhancing accessibility for those with hearing impairments.
Corporations
In corporate settings, accurate meeting transcriptions can save hours. By integrating Transcribe into video conferencing tools, companies can automatically transcribe meetings, creating searchable archives of every discussion.
Media and Journalism
Journalists and media houses can leverage Transcribe to quickly convert interviews and press conferences into text. This not only speeds up the reporting process but also ensures accuracy in quotes and statements.
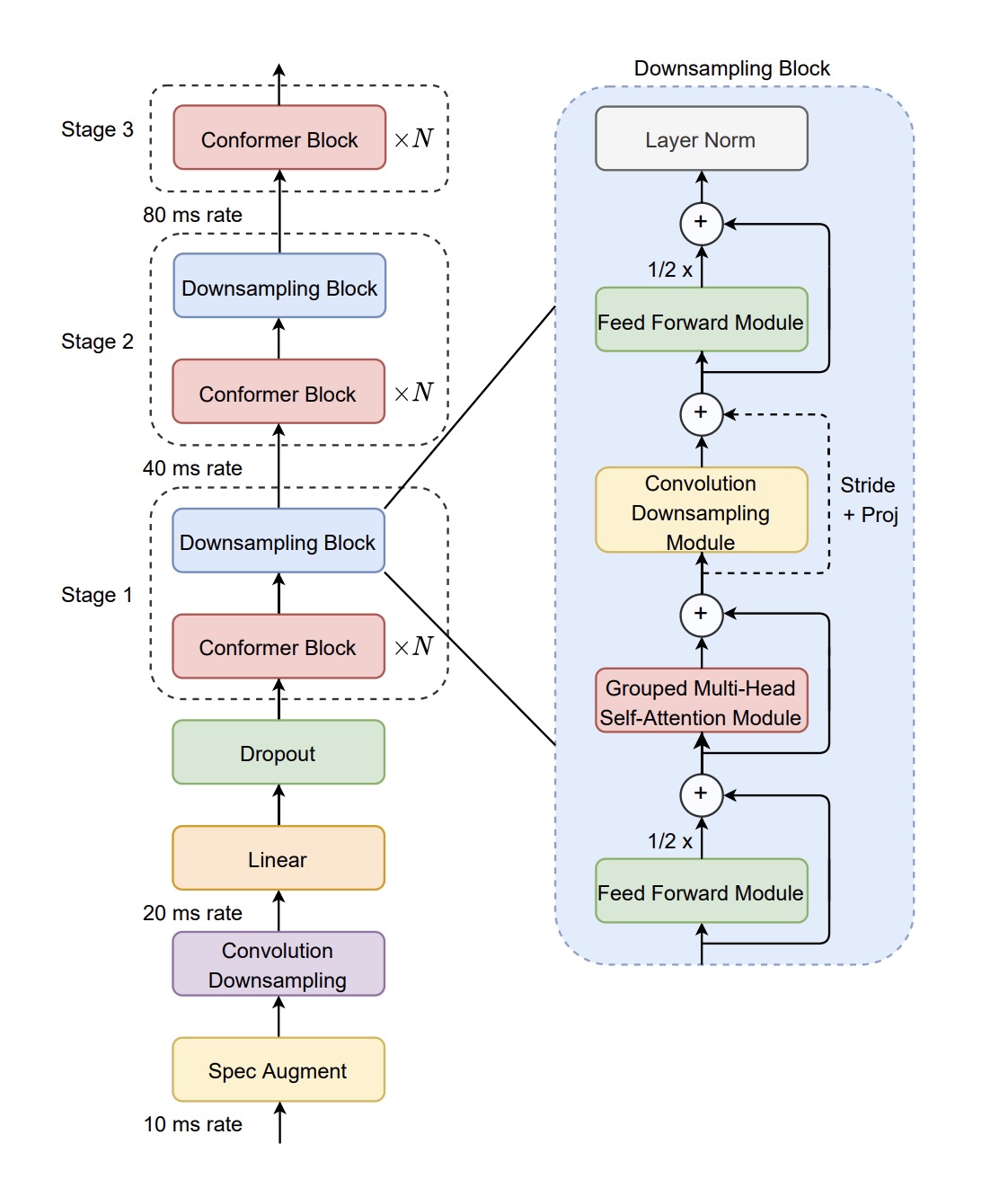
Technical Details: How It Works
Transcribe is built on a neural network architecture optimized for speech recognition. The model processes audio input by breaking it down into smaller chunks, which are then decoded into text. Here’s a simplified breakdown:
- Audio Preprocessing: Converts audio waves into a format suitable for neural network analysis.
- Feature Extraction: Identifies key features in the audio that are likely to represent phonetic sounds.
- Decoding: Maps these features to text using a language model.
Best Practices
To get the most out of Transcribe, consider these best practices:
- Clean Audio: Ensure your audio input is clear and free from background noise. This significantly improves transcription accuracy.
- Language Models: Use the specific language model that best matches your audio’s language to optimize results.
- Regular Updates: Keep your version of Transcribe updated to benefit from ongoing improvements and bug fixes.

Common Pitfalls and Solutions
Implementing a new technology can come with challenges. Here are some common pitfalls when using Transcribe, along with solutions:
Pitfall 1: Background Noise
Solution: Use noise-canceling microphones and environments for recording. If unavoidable, use software to clean audio files before transcription.
Pitfall 2: Accents and Dialects
Solution: Train the model with additional data that includes various accents and dialects of the same language, improving its adaptability.
Pitfall 3: Large File Sizes
Solution: Break down large audio files into smaller segments before processing. This not only speeds up transcription but also reduces memory usage.
Future Trends and Recommendations
The launch of Transcribe signals a significant shift towards open-source solutions in voice recognition technology. As more developers contribute to its codebase, the model is expected to improve, leading to even greater accuracy and efficiency.
Trend 1: Increased Accessibility
With models like Transcribe, voice technology becomes accessible to smaller businesses and developers. This democratization could lead to a surge in innovative applications across industries.
Trend 2: Personalized AI Models
As customization becomes easier, we may see the rise of personalized AI models that are fine-tuned to individual user preferences and environmental factors.
Recommendation: Community Engagement
For Transcribe to reach its full potential, community engagement is crucial. Developers should actively participate in forums, contribute to the codebase, and share their experiences to foster a collaborative improvement process.
Conclusion
Cohere’s Transcribe model is more than just another ASR tool; it is a step towards a more inclusive, open-source future in voice technology. With its impressive accuracy, language support, and accessibility features, Transcribe sets a new standard for what is possible in voice transcription. As we look to the future, the continued evolution of such technologies promises to transform how we interact with the world around us.
FAQ
What is Cohere's Transcribe?
Cohere's Transcribe is an open-source automatic speech recognition model designed to convert spoken language into written text. It supports multiple languages and is optimized for consumer-grade hardware.
How does Transcribe work?
Transcribe uses a neural network architecture to process audio input, extracting features and mapping them to text using a language model.
What are the benefits of using an open-source model like Transcribe?
Open-source models offer flexibility, cost-effectiveness, and community-driven improvements, allowing users to customize and enhance the model to suit specific needs.
Can Transcribe handle multiple languages?
Yes, Transcribe supports 14 languages, including English, French, German, and Mandarin, making it versatile for international applications.
What are some common challenges when using Transcribe?
Challenges include handling background noise, accents, and large audio files. Solutions involve using clean audio, training with diverse data, and segmenting large files.
How can I contribute to the development of Transcribe?
You can contribute by participating in forums, reporting bugs, submitting patches, and sharing your experiences with the community.
What are future trends in voice transcription technology?
Future trends include increased accessibility, personalized AI models, and a focus on community-driven development for continuous improvement.
How does Transcribe compare to other models?
Transcribe outperforms many models on the Open ASR leaderboard with a lower word error rate, offering competitive accuracy and usability.
Key Takeaways
- Cohere's Transcribe model sets new standards in open-source voice transcription.
- Supports 14 languages with a focus on accessibility for consumer-grade hardware.
- Features a low word error rate of 5.42, outperforming many proprietary models.
- Open-source nature allows for customization, fostering community-driven improvements.
- Future trends indicate a shift towards more accessible and personalized AI models.
Related Articles
- 2026's historic snow drought is bad news for the West - Ars Technica
- Sonos Play review: my new favorite speaker buddy | TechRadar
- Sonos Play review: a versatile Bluetooth speaker for the Sonos world | The Verge
- I write about AI for a living — what people confessed to me about using ChatGPT surprised me | TechRadar
- Looking for a cheap De'Longhi coffee maker? I'm a trained barista, and I've found 5 awesome offers at Amazon right now | TechRadar
- Faster Closes. Shorter Contracts. Leaner Teams. The Top 10 Learnings From the Latest ICONIQ GTM Report. | SaaStr

