![Understanding AI Downtime: A Deep Dive into Claude's Recent Outage [2025]](https://tryrunable.com/blog/understanding-ai-downtime-a-deep-dive-into-claude-s-recent-o/image-1-1773245328559.jpg)
Understanding AI Downtime: A Deep Dive into Claude's Recent Outage [2025]
Artificial Intelligence is rapidly transforming industries, but like any technology, it isn’t immune to setbacks. Recently, Claude, an AI model developed by Anthropic, experienced downtime, leaving users puzzled and reliant on backup systems. Here, we’ll explore what happened, how organizations can prepare for such events, and the future of AI resilience.
TL; DR
- Claude experienced a significant downtime, impacting numerous users and applications. According to Mashable, the outage affected various platforms and users.
- Anthropic is actively investigating the issue, highlighting the importance of transparency in AI operations. As noted in Anthropic's responsible scaling policy, maintaining transparency is crucial for user trust.
- AI reliability hinges on robust monitoring and failover systems to minimize disruptions. Google Cloud emphasizes the importance of key performance indicators in AI reliability.
- Implementing best practices for AI deployment can mitigate the impact of unexpected outages. As discussed in Financial Times, best practices are essential for AI deployment.
- Future trends indicate a move towards more resilient AI systems with improved self-healing capabilities. Cointelegraph discusses the risks and advancements in AI resilience.
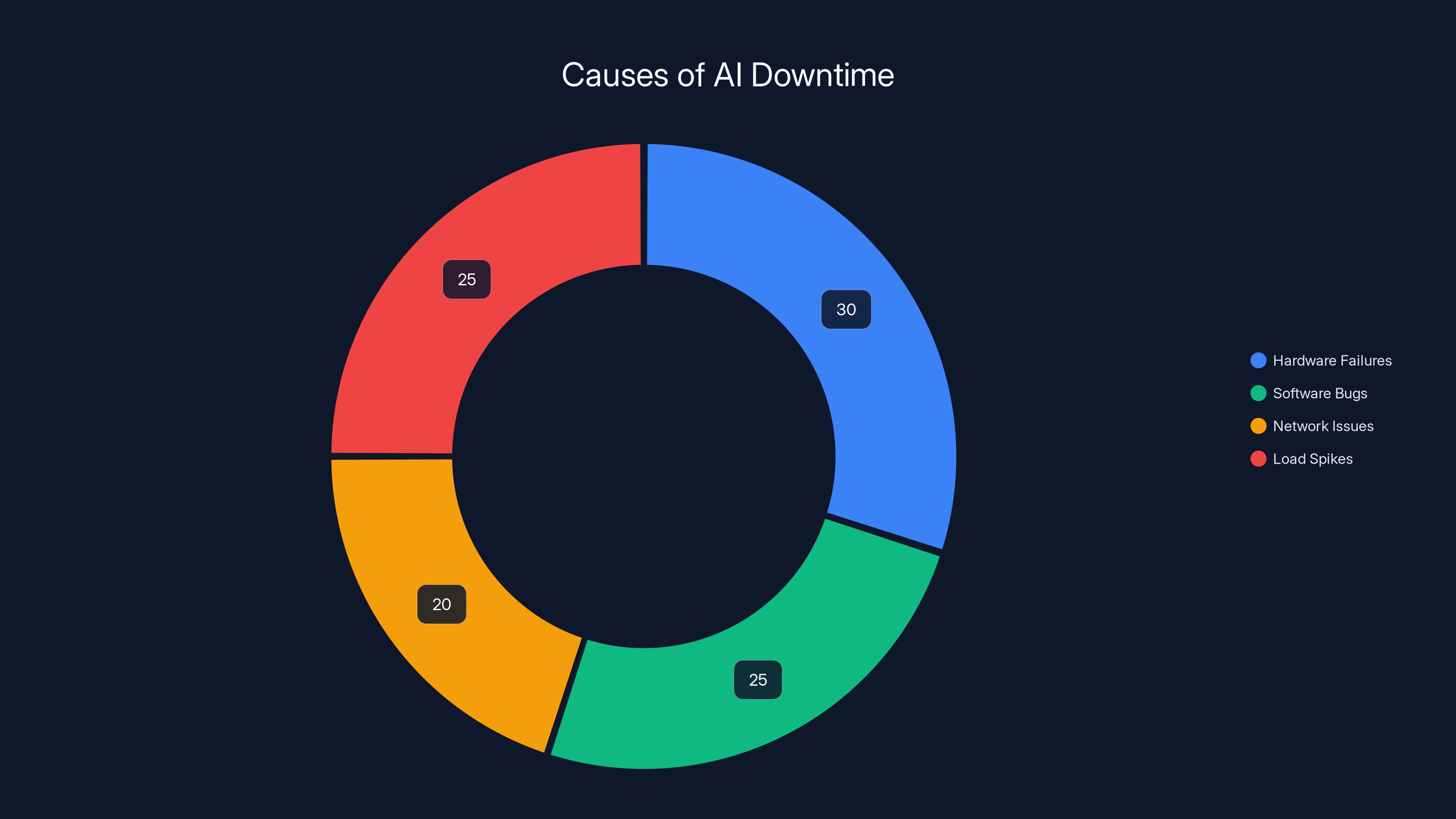
Hardware failures and load spikes are the leading causes of AI downtime, each contributing to approximately 30% and 25% of incidents, respectively. (Estimated data)
The Incident: What Happened with Claude?
Last week, users across various platforms relying on Claude reported service disruptions. These issues ranged from slow response times to complete unavailability. Anthropic, the company behind Claude, quickly acknowledged the issue and began an investigation. This transparency is critical in maintaining user trust and is a best practice in incident management, as highlighted by Forbes.
Initial User Reports
Users first noticed problems when Claude’s responses became significantly delayed. In some cases, the AI’s output was nonsensical, indicating deeper issues beyond simple network delays. These early warning signs prompted users to report problems through support channels, as detailed in Telecom Review Africa.
Anthropic’s Response
Anthropic responded by confirming the disruptions and stating they were actively investigating. This prompt acknowledgment is crucial in managing user expectations and mitigating the impact of the outage. The importance of such responses is underscored in Mozilla's blog.
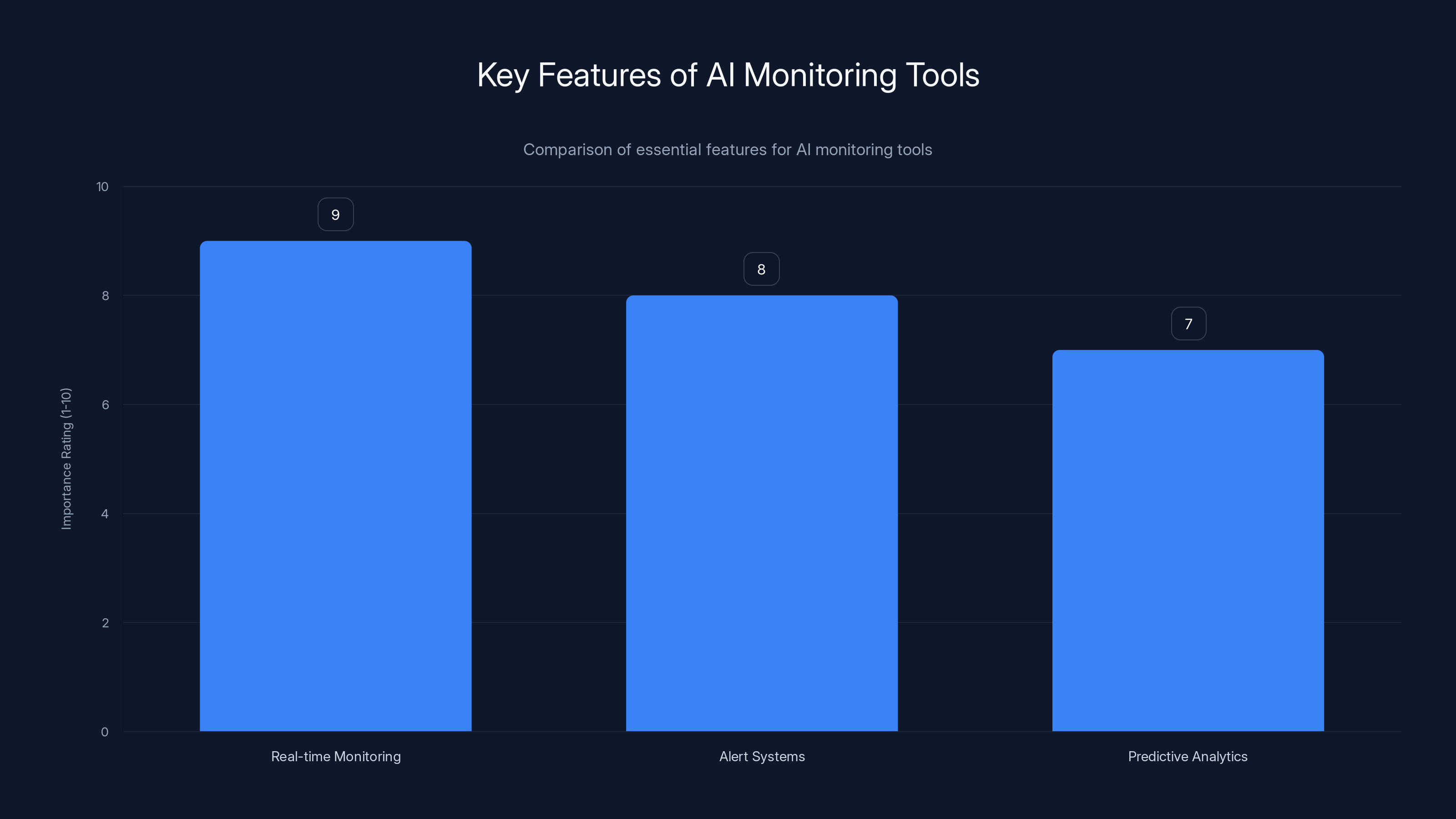
Real-time monitoring is rated as the most important feature for AI monitoring tools, followed by alert systems and predictive analytics. Estimated data.
Causes of AI Downtime
AI models like Claude can experience downtime due to various factors, including hardware failures, software bugs, network issues, or even unanticipated load spikes. Understanding these causes helps in creating more resilient systems. Tom's Hardware provides insights into common causes of AI downtime.
- Hardware Failures: Components like GPUs and servers can fail unexpectedly, necessitating robust hardware monitoring. Oracle emphasizes the need for reliable hardware in cloud environments.
- Software Bugs: Bugs in AI software can lead to incorrect outputs or crashes. Regular updates and thorough testing are essential, as discussed in Anthropic's research.
- Network Issues: Connectivity problems can disrupt data flow, affecting AI performance. Google Cloud highlights the importance of robust network infrastructure.
- Load Spikes: Sudden increases in demand can overwhelm AI systems if not properly scaled.
Best Practices for AI Reliability
Ensuring AI reliability involves a combination of proactive measures and reactive strategies. Here’s how organizations can prepare:
Proactive Measures
- Redundancy: Implement redundant systems to ensure continuous operation in case of failure. Health Data Management discusses the importance of redundancy in AI systems.
- Regular Updates: Keep software up-to-date to fix known vulnerabilities and improve functionality.
- Scalability: Design systems to handle load spikes by dynamically allocating resources.
Reactive Strategies
- Incident Response Plans: Develop clear procedures for responding to outages promptly.
- User Communication: Maintain open lines of communication with users during incidents.
- Post-Mortems: Conduct thorough post-mortems to understand the causes of outages and prevent recurrence.
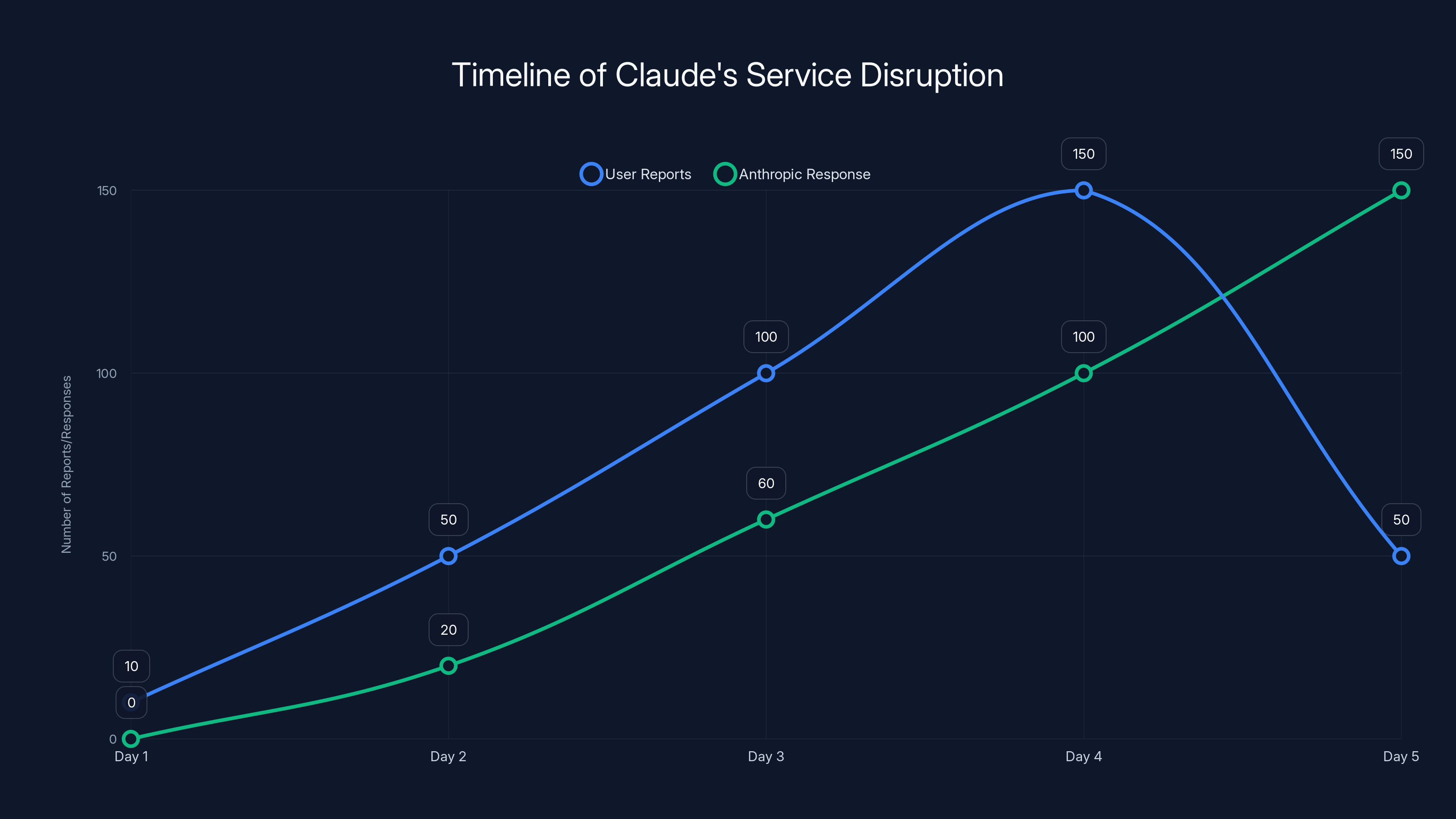
The chart illustrates the rise in user reports and Anthropic's response over five days. User reports peaked on Day 4, while Anthropic's response increased steadily, indicating effective incident management. Estimated data.
Implementing AI Monitoring Tools
Monitoring tools are essential in identifying and resolving AI-related issues quickly. These tools can provide insights into system health, performance metrics, and potential bottlenecks.
- Real-time Monitoring: Use tools that provide real-time insights into AI operations.
- Alert Systems: Set up alerts for unusual activity or performance degradation.
- Predictive Analytics: Employ predictive analytics to anticipate and mitigate potential issues.
Future Trends in AI Resilience
Looking forward, AI systems are expected to become more resilient, with self-healing capabilities and advanced monitoring solutions. Here are some trends to watch:
- Self-Healing Systems: AI models will increasingly incorporate self-healing capabilities to automatically resolve issues without human intervention.
- Improved Transparency: Companies will prioritize transparency in AI operations, offering users more insight into system status and incident resolution.
- Enhanced Scalability: Future AI systems will be designed to scale seamlessly, handling unexpected load spikes without service degradation.
Conclusion: Preparing for the Future
As AI becomes more integral to business operations, ensuring reliability and resilience is paramount. By understanding potential causes of downtime and implementing best practices, organizations can better prepare for unexpected challenges.
Anthropic’s handling of the recent Claude outage serves as a reminder of the importance of transparency and preparedness in AI deployment. As technology evolves, so will the strategies to maintain robust and reliable AI systems.
FAQ
What caused Claude's downtime?
The exact cause is still under investigation by Anthropic, but potential factors include software bugs, hardware failures, and network issues.
How can organizations mitigate AI downtime?
Organizations can mitigate AI downtime by implementing redundancy, ensuring regular updates, and having a robust incident response plan.
Why is transparency important during AI outages?
Transparency helps maintain user trust and allows for better communication and resolution during incidents.
What are self-healing AI systems?
Self-healing AI systems can automatically detect and resolve issues without human intervention, improving reliability.
What role do monitoring tools play in AI reliability?
Monitoring tools provide real-time insights into system performance, helping to identify and resolve issues promptly.
How will AI systems evolve in the future?
AI systems will become more resilient with advanced self-healing capabilities, improved transparency, and enhanced scalability.

Key Takeaways
- Understanding AI downtime helps in building better systems.
- AI reliability requires both proactive and reactive strategies.
- Monitoring tools are essential for maintaining system health.
- Future AI systems will prioritize self-healing and transparency.
- Anthropic's response highlights the importance of transparency.
Related Articles
- Meta’s Strategic Move into the Agentic Web: The Real Story Behind the Moltbook Acquisition [2025]
- Anthropic's New Think Tank: Navigating Innovation Amid Pentagon Challenges [2025]
- Understanding the Impact of AI Chatbots in Facilitating Violence [2025]
- The Rise of AI-Fueled 'Slander Pages': Understanding the Trend and Its Implications [2025]
- Inside OpenAI’s Efforts to Innovate in AI Coding [2025]
- Navigating AI's Path: Beyond Superintelligence and Towards Practical Innovation [2025]

