
Introduction: Understanding the Verizon Network Outage Crisis
On January 14th, 2026, one of North America's largest telecommunications providers experienced a catastrophic network failure that left millions of users unable to make calls or access wireless data for approximately 10 hours. The Verizon outage, which peaked at over 180,000 reported incidents on outage tracking platforms, represents one of the most significant telecommunications disruptions in recent history. While text messaging services remained operational, the inability to make voice calls and access mobile data created a cascading effect across business operations, emergency services coordination, and personal communications worldwide.
What makes this particular outage noteworthy is not merely its scale, but what it reveals about our dependency on centralized telecommunications infrastructure in an increasingly digital world. For business continuity professionals, IT administrators, and telecommunications enthusiasts, this incident provides critical lessons about redundancy, communication protocols, and the interconnected nature of modern network architecture. The geographic concentration of initial reports—primarily affecting major metropolitan areas in the Eastern United States including Boston, New York, and Washington DC—suggests infrastructure-level issues rather than localized equipment failures.
The outage occurred during peak business hours, maximizing its impact on corporate operations, financial transactions, and emergency response coordination. Financial services companies reported difficulty executing time-sensitive transactions, healthcare facilities experienced challenges with patient communication systems, and ride-sharing services faced coordination challenges. The economic impact, though difficult to quantify precisely, likely extended into millions of dollars when considering lost productivity, failed transactions, and emergency response inefficiencies.
Beyond the immediate disruption, this event raises important questions about network resilience, the adequacy of current backup systems, and whether telecommunications providers maintain sufficient redundancy to handle catastrophic failures. For organizations relying on continuous connectivity—which encompasses virtually all modern enterprises—understanding what happened during this outage and how to prepare for similar incidents has become essential operational knowledge.
This comprehensive analysis examines the technical aspects of the outage, its real-world impact across multiple sectors, the timeline of events and recovery efforts, and the broader implications for telecommunications infrastructure reliability. We'll explore what contributed to such an extended service disruption, how customers and businesses responded, and what lessons the industry should apply to prevent similar incidents.
Timeline and Progression: How the Outage Unfolded
Initial Reports and Recognition Phase
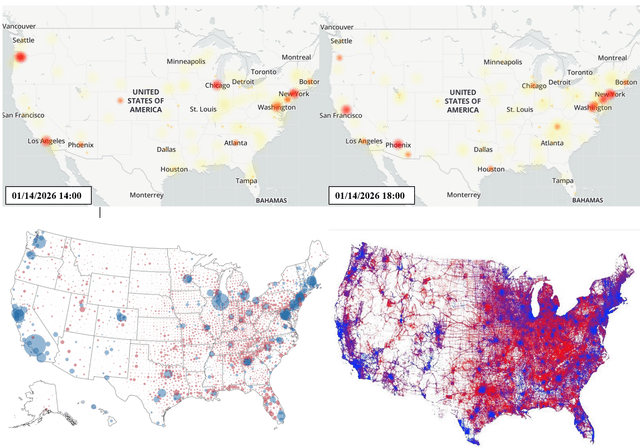
The outage began its emergence around 12:00 PM Eastern Time on January 14th, 2026, though the exact moment of infrastructure failure likely preceded visible customer impact by several minutes. Initial reports on outage tracking platforms like Down Detector began accumulating gradually before exponentially increasing within a 15-minute window. By 12:43 PM ET, the situation had escalated dramatically, with Down Detector recording 181,769 reports—a staggering volume that represented the peak of the crisis.
What's particularly revealing about the initial phase is that Verizon's own status page struggled to load, unable to handle the surge of customers attempting to verify their service status. This creates a secondary crisis layer where even the company's communication infrastructure couldn't scale to meet the demand from affected customers seeking information. The platform failure demonstrates how outages can cascade beyond just the core network services into customer support and communication systems.
Customers reported seeing "SOS" indicators on their devices instead of the traditional network signal bars—a distinctive visual indicator that tells users their device is in emergency mode with extremely limited connectivity. This visual cue became a critical piece of information spreading across social media as users sought confirmation that the problem wasn't their individual devices but rather a widespread infrastructure failure.
Peak Impact Window (12:00 PM - 4:00 PM ET)
During the four-hour window from noon to 4:00 PM, the outage maintained devastating scope. Voice calls and wireless data services remained completely unavailable for millions of subscribers, yet text messaging services continued functioning normally. This selective service failure provides important technical clues—the fact that SMS services remained operational while voice and data failed suggests the outage affected specific network infrastructure components rather than entire switching systems.
At 2:14 PM ET, approximately 2 hours and 14 minutes into the crisis, Verizon posted its first official acknowledgment on its X account, stating that engineers remained "fully deployed" to address the issue. Notably absent from this statement was any indication of root cause, estimated recovery timeline, or the scope of affected customers. The lack of specific information likely increased customer anxiety and drove further social media speculation about potential causes.
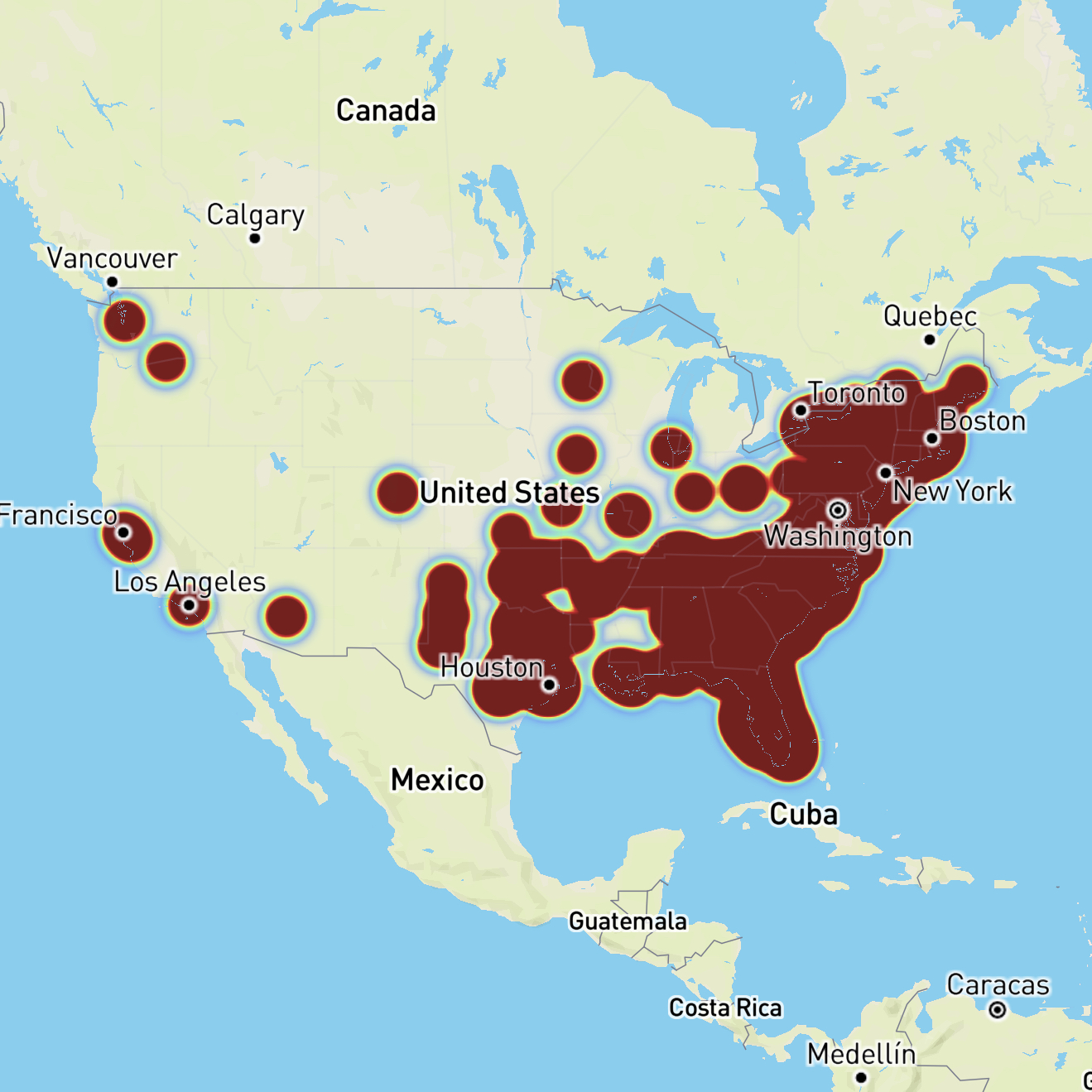
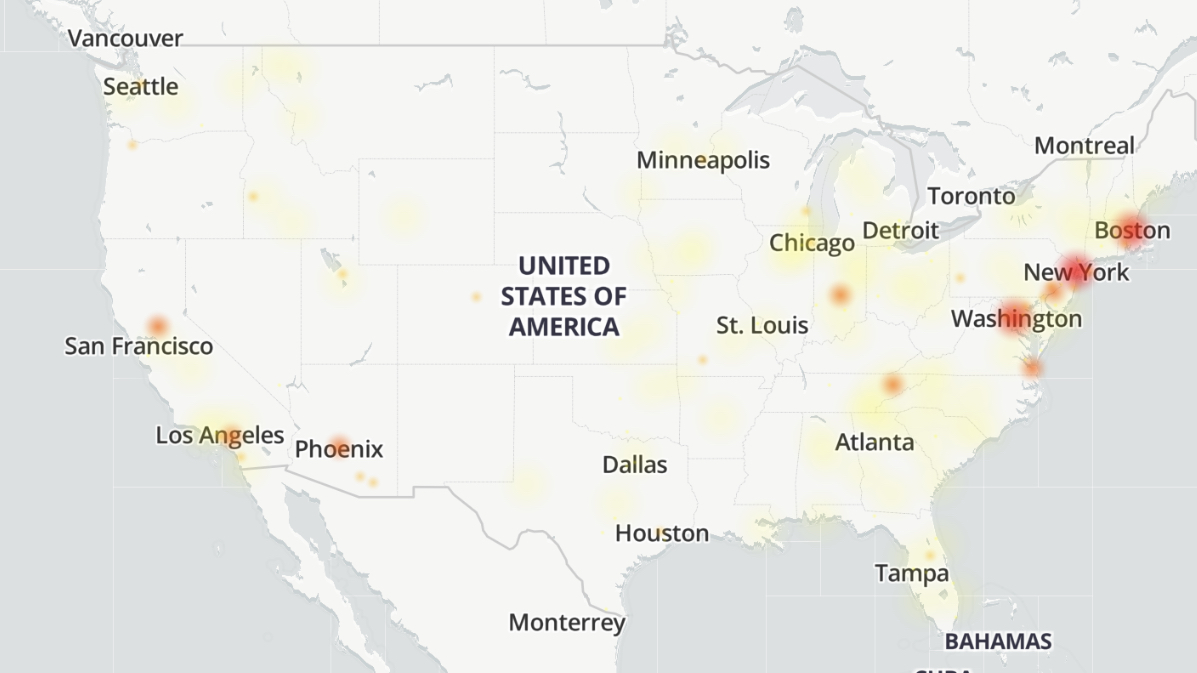
Geographic analysis during this period showed the outage concentrated in major Eastern U. S. metropolitan areas, with the distribution gradually expanding westward as the situation persisted. Down Detector's heat map visualization revealed hotspots in Boston, New York, Washington DC, and emerging concentration points in Chicago, San Francisco, and Los Angeles. This geographic progression suggested the outage was advancing through the network topology rather than affecting random independent systems.
Partial Recovery Attempts (4:00 PM - 8:00 PM ET)
Around 4:06 PM ET, anecdotal reports emerged from some Verizon customers indicating partial service restoration. However, these reports proved inconsistent—for every customer reporting restored service, many others continued experiencing complete connectivity loss. The intermittent nature of these recovery reports suggests Verizon implemented partial fixes that restored service to some network segments or geographic regions while others remained affected.
By 4:12 PM ET, Verizon issued another official statement indicating its teams were "on the ground actively working to fix today's service issue that is impacting some customers." The phrase "on the ground" suggests field technicians were deployed to physical infrastructure locations, indicating the problem likely involved hardware or physical layer network components rather than purely software-based issues.
The period between 4:00 PM and 6:00 PM showed remarkable persistence of the outage despite the company's indicated recovery efforts. Down Detector continued receiving 40,000-50,000+ reports even as afternoon progressed into early evening. By 6:20 PM ET, after more than 6 hours of service disruption, Verizon had not issued any status update since 4:12 PM—a 2-hour communication gap during a critical crisis situation that likely amplified customer frustration and uncertainty.
Intermittent Service Issues Phase (6:00 PM - 10:00 PM ET)
Late afternoon and early evening reports described intermittent service restoration—customers experiencing brief windows of connectivity followed by service failure. This pattern suggests Verizon implemented fixes that provided temporary relief but lacked sufficient scope or robustness to maintain permanent restoration. Such intermittent patterns often indicate incomplete load balancing reconfiguration or partial network rerouting that couldn't sustain full service restoration.
Throughout this extended 4-hour window, Verizon maintained communication silence despite tens of thousands of continued outage reports. The lack of updates, combined with intermittent service returning and then failing again, created additional uncertainty. Customers couldn't determine whether their individual service restoration was permanent or temporary, affecting decision-making about alternative communication methods.
Resolution and Post-Outage Communication (After 10:00 PM ET)
At 10:20 PM ET—precisely 10 hours and 20 minutes after the initial reports—Verizon announced the outage had been resolved. The company advised customers still experiencing issues to restart their devices to reconnect to the network. Additionally, Verizon committed to providing account credits to affected customers, acknowledging the service failure and its impact.
The recovery announcement came after a extended period of deteriorating outage report numbers and increasingly sporadic service interruptions, suggesting Verizon had finally successfully implemented a comprehensive network reconfiguration or repair. The recommendation for device restarts indicated customers' devices remained configured to connect to network infrastructure that wasn't fully operational, and a forced reconnection process would direct them to restored network segments.

Estimated data suggests millions were affected by Verizon's outage, with reported outages representing a small fraction of the total impact.
Geographic Distribution: Why Eastern U. S. Was Hardest Hit
Initial Concentration in Major East Coast Hubs
The outage's geographic footprint provides valuable insights into Verizon's network architecture and infrastructure concentration. Initial reports concentrated overwhelmingly in the Northeast Corridor—Boston, New York, and Washington DC represented the epicenter of the crisis. This geographic clustering suggests either a single point of failure in a critical regional hub or simultaneous failures in interconnected infrastructure components serving these metropolitan areas.
Major cities typically concentrate telecommunications infrastructure in central switching stations and fiber backbone connections. If any of these key nodes failed or became congested beyond capacity, it would explain the severe impact on major urban centers. New York City alone hosts several critical telecommunications hubs that route traffic for millions of users across the Northeast region.
The concentration in metropolitan areas rather than rural regions suggests the outage affected high-capacity infrastructure serving dense populations. Rural areas, which typically connect through fewer backbone routes, experienced secondary impact as capacity constraints propagated through the network. This pattern indicates infrastructure bottlenecks rather than widespread systemic failure.
Westward Expansion Over 10-Hour Period
As the outage persisted beyond 2-3 hours, Down Detector's geographic heat map revealed emerging hotspots in Chicago, San Francisco, and Los Angeles. This westward progression wasn't random but followed geographical patterns that suggest traffic rerouting through alternate network paths. When primary infrastructure fails, carrier networks automatically attempt to reroute traffic through secondary pathways, which can create congestion in unexpected geographic regions.
The appearance of outage reports in Western cities doesn't necessarily indicate the West Coast experienced equal service disruption—it may reflect backup systems becoming overwhelmed by rerouted traffic from Eastern infrastructure failures. Users in San Francisco attempting to reach friends or family in New York might have experienced connectivity issues, creating the appearance of a broader outage than actually existed.
Competing Carriers' Minimal Impact
A critical detail from the outage provides important context: AT&T and T-Mobile experienced only minor, secondary impacts compared to Verizon's devastating failure. AT&T peaked at just 1,769 outage reports—roughly 1% of Verizon's peak volume. T-Mobile similarly showed minimal disruption, with service continuing "operating normally and as expected." Both competitors explicitly confirmed their networks remained unaffected, with AT&T humorously noting "it's not us...it's the other guys."
This disparity proves the outage resulted from Verizon-specific infrastructure failures rather than widespread telecommunications sector issues or external factors affecting multiple carriers simultaneously. Had the outage resulted from internet backbone failures, fiber cuts, or other infrastructure independent of individual carriers, competitors would have experienced proportional impacts. The fact that AT&T and T-Mobile continued normal operations definitively established the problem as Verizon's proprietary network systems.
The secondary spike in AT&T reports likely represented frustrated Verizon customers using competitors' networks or attempting to contact affected Verizon users, misattributing their difficulty to AT&T network issues. This demonstrates how outages create cascading effects on competing networks as users shift traffic patterns.
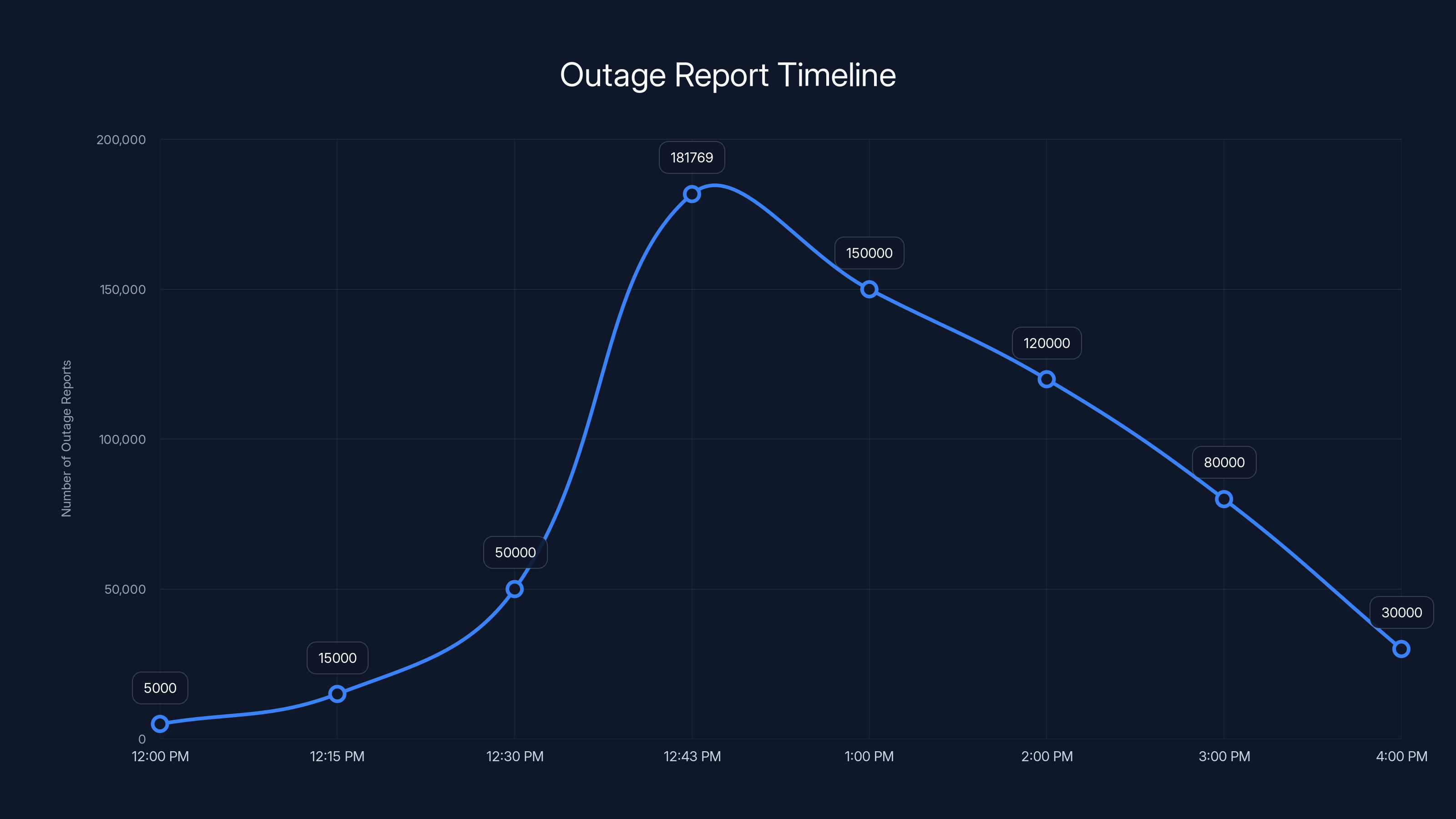
The outage reports peaked at 12:43 PM with 181,769 reports, indicating the crisis's apex. Estimated data based on typical outage progression.
Technical Aspects: Analyzing the Likely Causes
Voice and Data Failure vs. SMS Persistence: What It Reveals
The most telling technical detail about this outage is that SMS text messaging continued functioning normally while voice calls and wireless data services completely failed. This selective service failure provides crucial diagnostic information about what likely failed in Verizon's network architecture. Voice over LTE (Vo LTE) and mobile data services operate through packet-switched network infrastructure, while SMS operates through circuit-switched networks—fundamentally different technological systems with separate infrastructure components.
The fact that one service family failed completely while the other continued normally suggests the outage affected packet-switched network infrastructure while circuit-switched systems remained operational. This distinction is technically significant because it narrows the probable causes to specific network components. A complete hardware failure in a major switching facility would affect both service types. Selective service failure points toward issues in either network management systems, routing infrastructure, or capacity management systems that handle packet-switched traffic.
Possible technical causes include:
-
Border Gateway Protocol (BGP) Misconfiguration: BGP manages internet routing at the carrier level. A misconfigured BGP update could have caused routers to drop packet-switched traffic while preserving circuit-switched connections, matching the observed service pattern.
-
Network Load Balancing Failure: If primary load balancers managing packet-switched traffic failed, the system's automatic failover mechanisms might have been insufficient to restore full service capacity, while circuit-switched traffic maintained primary path viability.
-
Packet Gateway System Failure: Mobile networks use specific packet gateway systems (PGW, SGW) to handle data traffic. Failure or overwhelming congestion in these systems would affect data and Vo LTE services while leaving SMS intact.
-
Signaling Network Issues: SS7 (Signaling System No. 7) handles call setup and SMS routing. If signaling network components were overwhelmed without completely failing, call setup would fail while SMS—which uses simpler signaling—continued functioning.
Infrastructure Redundancy Questions
Verizon's 10-hour recovery timeline raises important questions about the company's network redundancy architecture. Modern telecommunications carriers typically maintain multiple independent paths for traffic, automatic failover systems, and geographically distributed infrastructure specifically designed to prevent single points of failure from causing service disruptions of this magnitude.
The persistence of the outage despite these stated redundancy measures suggests either:
-
Cascading Failures: The initial failure triggered secondary failures in backup systems, overwhelming redundancy mechanisms.
-
Insufficient Redundancy: Primary and backup infrastructure relied on common components (software, configuration management, fiber routes) that failed simultaneously.
-
Failover System Malfunction: Automatic failover mechanisms designed to activate during outages failed to function correctly, requiring manual intervention that took extended periods.
-
Capacity Constraints: Backup infrastructure lacked sufficient capacity to handle full traffic volume from primary infrastructure failures, causing cascading congestion.
The requirement for engineers to be "on the ground actively working" suggests the issue wasn't purely software-based and required physical intervention at infrastructure sites. This points toward hardware failures, physical layer issues, or network configuration problems requiring hands-on remediation.
"SOS" Mode Activation Analysis
Customers observed "SOS" indicators on their devices—a specific system state indicating devices detected complete network unavailability and switched to emergency mode. Modern smartphones activate SOS mode when unable to connect to home carriers but can detect emergency services networks (typically operated by other carriers or government agencies). This indicates Verizon devices completely lost connectivity to the Verizon network infrastructure but maintained some ability to detect network signals from other carriers.
The widespread SOS mode activation suggests the outage was comprehensive at the device-carrier connection level—devices couldn't establish any connection to Verizon infrastructure, triggering emergency fallback systems. This is distinct from degraded service where devices maintain connection with reduced capability; instead, it indicates complete infrastructure unavailability from the device perspective.
Impact on Business Operations and Emergency Services
Financial Services Sector Disruption
Financial institutions rely absolutely on continuous telecommunications connectivity for trading operations, transaction processing, and customer communications. During the Verizon outage, many financial services firms experienced significant disruptions. Traders working for firms with Verizon connectivity couldn't execute time-sensitive transactions, potentially missing market opportunities or facing losses during volatile periods.
Financial transaction systems require ultra-reliable connectivity because delays measured in seconds can result in substantial losses. When primary connectivity fails, financial services firms typically shift to backup systems and alternative carriers, but this transition takes time and coordination. During the outage's early hours, before many firms had successfully switched to backup systems, transaction failures and delays mounted.
The impact extended beyond trading floors to customer service operations. Bank call centers staffed by employees relying on Verizon cellular connectivity couldn't maintain customer communications, reducing the institution's ability to respond to customer needs during a crisis period. This secondary impact illustrates how outages create cascading effects beyond direct network service into business process disruptions.
Healthcare System Challenges
Healthcare providers depend on telecommunications for patient communications, appointment coordination, telemedicine services, and emergency response coordination. During the outage, hospitals and clinics experienced challenges maintaining patient contact, coordinating emergency response, and managing urgent care situations where phone communication is critical.
Many healthcare facilities use Vo IP phone systems that depend on internet connectivity, meaning the data service failure directly impacted internal communications. Ambulance services and emergency dispatch rely on cellular connectivity—a failure in this infrastructure creates direct public safety implications. While the outage didn't last long enough to trigger major patient care crises, it demonstrated vulnerabilities in healthcare infrastructure that depends on specific carrier connectivity.
Telemedicine providers, particularly prevalent post-pandemic, couldn't coordinate appointments or conduct remote consultations for patients whose healthcare providers relied on Verizon connectivity. The outage effectively closed these services for affected populations, delaying medical consultations and prescription renewals.
Transportation and Logistics Disruptions
Ride-sharing services, delivery companies, and transportation logistics systems all depend critically on real-time connectivity for driver coordination, delivery tracking, and customer communication. Uber, Lyft, and similar services experienced service degradation as customers and drivers couldn't reliably communicate for ride coordination. Delivery services couldn't track packages in real-time or update customers on delivery status.
The impact extended to commercial trucking and logistics operations. Dispatchers coordinating truck routes, drivers unable to receive updated directions, and shipment tracking systems experiencing failures created bottlenecks throughout the supply chain. A 10-hour disruption to logistics operations can ripple forward for days as shipments, deliveries, and coordinated transportation get delayed.
Public transportation systems that increasingly rely on cellular connectivity for real-time tracking, passenger information systems, and operator communication experienced secondary impacts. Commuters and transit authority staff couldn't access real-time service updates or report service issues through normal channels.

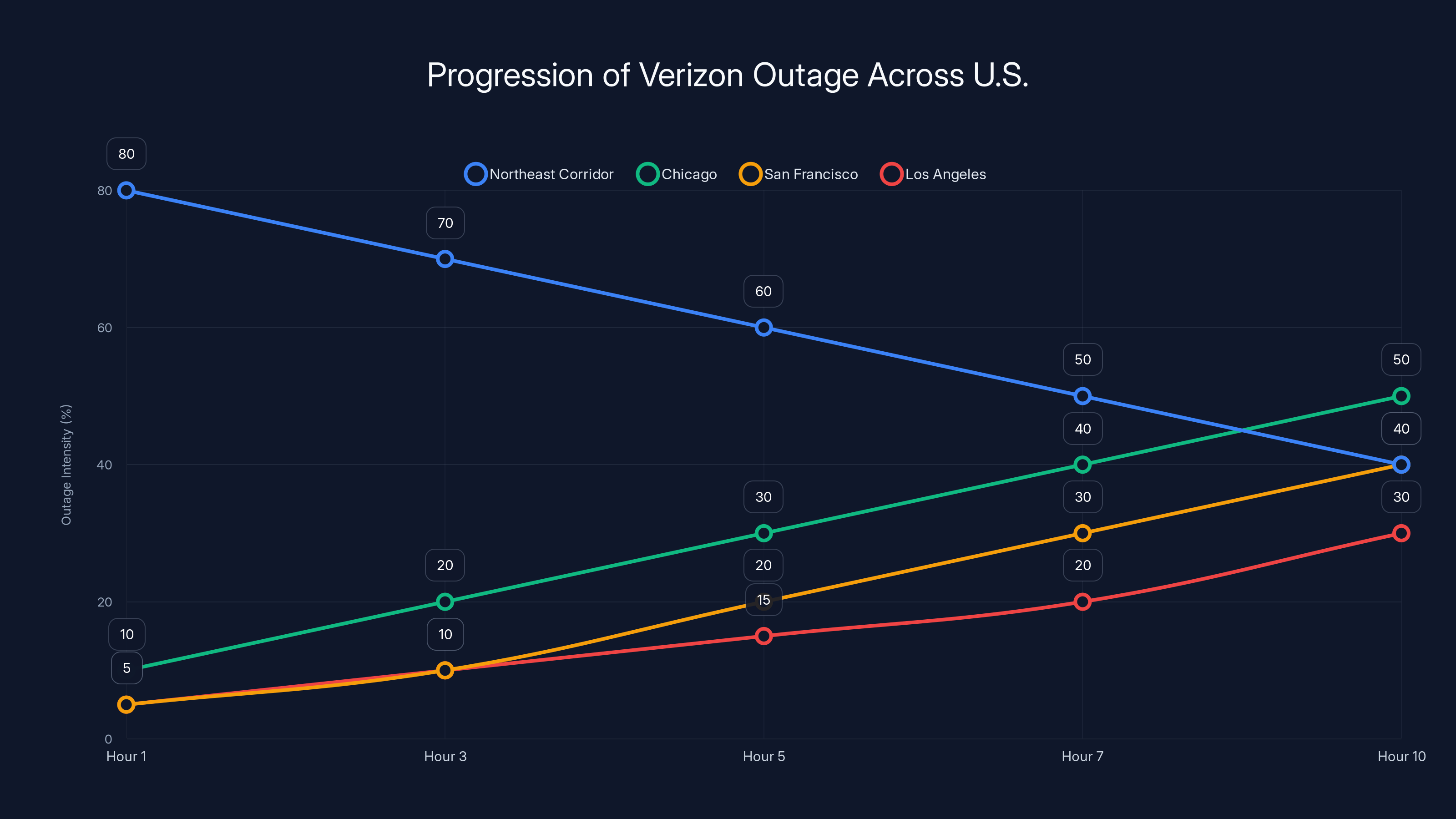
The outage initially concentrated in the Northeast, with 80% intensity, and gradually spread westward, impacting cities like Chicago, San Francisco, and Los Angeles over a 10-hour period. Estimated data.
Customer Experience: Communication Gaps and Uncertainty
Inadequate Status Updates and Information Vacuum
One of the most problematic aspects of Verizon's response was the inadequate frequency and detail of customer communications. The company issued its first acknowledgment at 2:14 PM, approximately 2 hours after initial reports, and then didn't provide another official update until 4:12 PM—a 2-hour gap during a critical crisis. Following this update, Verizon maintained complete silence for another 6+ hours before announcing resolution at 10:20 PM.
This communication vacuum forced customers to seek information from third-party sources like Down Detector, social media, and news outlets rather than receiving authoritative updates from Verizon itself. In crisis situations, information vacuum creates additional customer anxiety and reduces confidence in the service provider's crisis management competence. Customers want to know: When will service be restored? What caused the failure? How many customers are affected? Verizon's silence on these questions amplified frustration beyond the raw service disruption.
Best practices in telecommunications crisis management require status updates at least every 30-60 minutes during active outages, even if the only update is "situation remains under investigation." Verizon's extended silent periods violated these standards and likely contributed to increased customer dissatisfaction and social media backlash.
Social Media Crisis Communication
In the absence of adequate official communications, social media became the primary channel for crisis information sharing. Customers flooded Twitter, Facebook, Reddit, and other platforms with reports of service outages, geographic distribution information, and speculation about causes. T-Mobile and AT&T leveraged the situation with humorous competitive messaging, while Verizon faced mounting criticism for inadequate communication.
Social media serves as a real-time crisis communication channel where users provide peer-to-peer updates that can serve as proxies for official communications. During this outage, social media posts helped some customers understand the outage was widespread rather than individual device failures, reducing customer support burden from people troubleshooting personal devices. However, this benefit doesn't excuse Verizon's inadequate official communication—it highlights how poor crisis communication creates demand for alternative information sources.
Trust and Satisfaction Implications
Outages themselves damage customer trust in service providers, but poor crisis communication compounds this damage significantly. Customers can accept service disruptions as occasional failures of complex systems, but poor communication during these disruptions is often viewed as management failure rather than technical inevitability. Verizon's extended silence and lack of specific information likely resulted in greater long-term trust damage than the outage itself.
For business customers in particular, inadequate communication during critical infrastructure failures leads to risk mitigation decisions like diversifying to multiple carriers, maintaining fallback connectivity options, or switching to competitors perceived as more reliable. The trust implications of this outage may drive business customer decisions for years to come.

Competitive Implications and Market Response
AT&T and T-Mobile Opportunity Exploitation
Both competing carriers responded quickly and effectively to capitalize on Verizon's crisis. AT&T's social media response—"For any of its customers experiencing issues, 'it's not us...it's the other guys'"—provided lighthearted competitive messaging while emphasizing network superiority. T-Mobile's assurance that its network was "operating normally and as expected" similarly positioned the company as the reliable alternative.
These competitors didn't just provide competitive messaging; they also experienced actual customer migration as some Verizon users manually switched to alternative carriers to restore connectivity during the outage. While many users switched back after service restoration, some may have remained on competitors' networks, increasing lifetime customer value transfer from Verizon to rivals.
The competitive opportunity extended beyond marketing messaging. Business customers considering telecommunications infrastructure diversification for redundancy benefits would have been influenced by this demonstration of single-carrier dependency risks. Verizon customers with sufficient service flexibility may have directed incremental business to AT&T or T-Mobile specifically due to this outage experience.
Market Analyst Scrutiny
Telecommunications industry analysts would have scrutinized Verizon's crisis management, network architecture, and redundancy capabilities following this incident. Analyst reports on the outage's causes and Verizon's response would influence investor confidence, potentially affecting stock valuations and capital allocation decisions. Major infrastructure failures trigger regulatory interest, potential fines, and mandatory reporting requirements that create additional business impact.
The outage likely prompted calls from regulatory agencies requesting detailed explanations of root causes, timeline, and preventive measures to avoid future incidents. These regulatory inquiries create internal costs, legal complexity, and potential penalties that extend far beyond the direct service disruption.

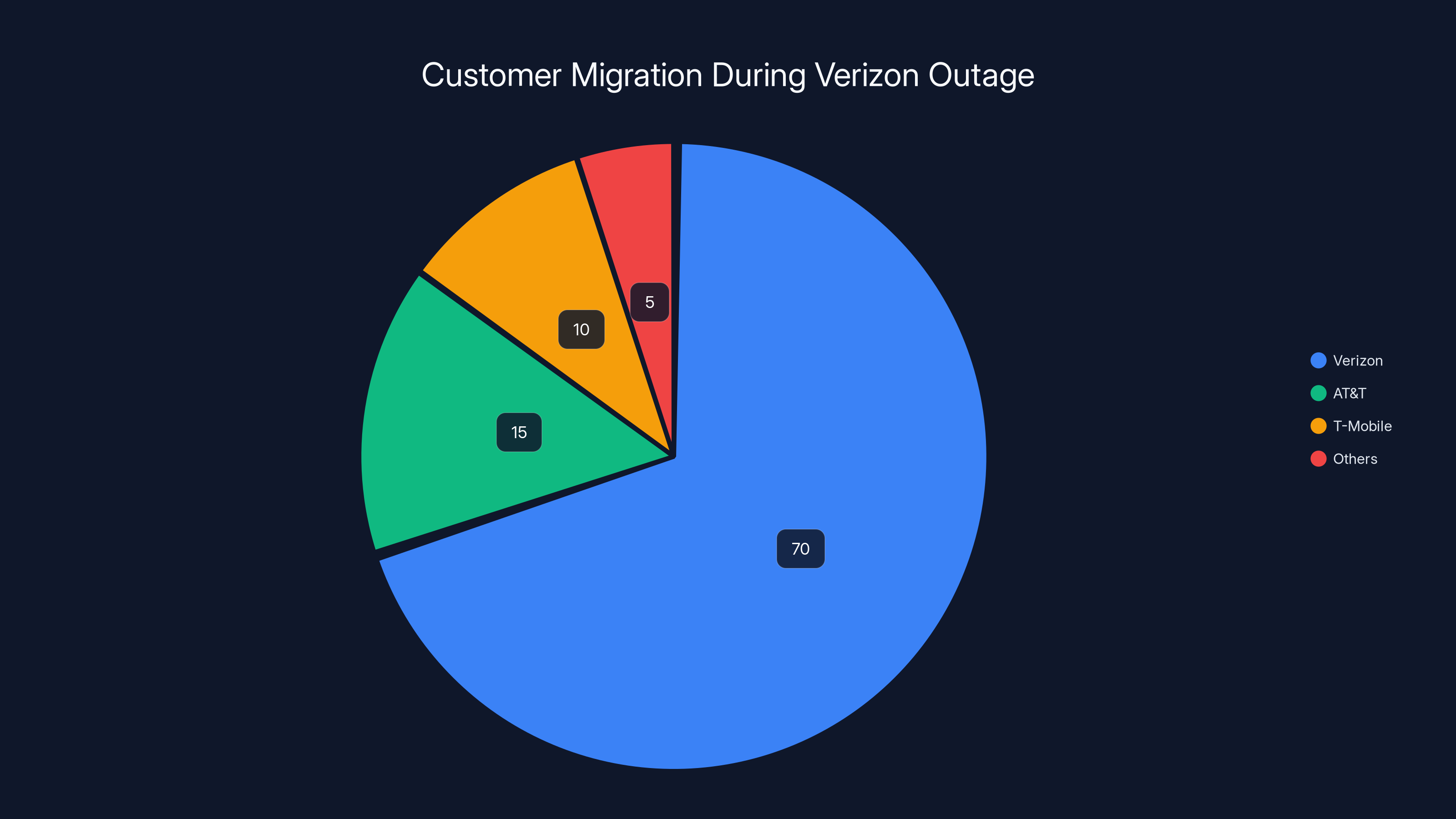
Estimated data shows a temporary shift in market share with AT&T and T-Mobile gaining customers during Verizon's outage. Estimated data.
Lessons Learned: Infrastructure Resilience Frameworks
Redundancy Architecture Evaluation
This outage demonstrates that stated redundancy is insufficient—actual redundancy must be continuously validated through testing and monitoring. The 10-hour recovery period suggests Verizon's backup systems either failed to activate as designed or lacked sufficient capacity to maintain service without the primary system. Both scenarios indicate inadequate redundancy architecture validation.
Best-practice network architecture includes:
-
Geographic Diversity: Primary and backup infrastructure physically separated to prevent correlated failures from simultaneous infrastructure events.
-
Independent Control Systems: Backup systems with fully independent management and monitoring infrastructure to ensure backup activation doesn't depend on primary system components.
-
Capacity Planning for Single-Point Failures: Backup systems provisioned to handle full traffic volume from primary system failure, not merely partial capacity.
-
Regular Failover Testing: Quarterly or semi-annual testing of backup systems under realistic traffic loads to ensure they function as designed.
-
Cross-Carrier Redundancy: Critical services maintaining connections through multiple carriers to eliminate single-provider dependency risk.
Communication Protocol Development
Verizon's communication gaps during this crisis suggest inadequate crisis communication protocols. Telecommunications carriers should develop detailed communication playbooks that specify:
-
Update Frequency Requirements: Status updates at defined intervals (30 minutes, 60 minutes) during active outages, regardless of status changes.
-
Information Minimum Standards: Each update should address customer questions: scope (percentage of customers affected), estimated duration, impact on specific services, and ongoing recovery efforts.
-
Multi-Channel Communication: Primary updates through official carrier channels (website, app, SMS to unaffected customers, social media) with coordinated messaging.
-
Transparency Frameworks: Balancing competitive sensitivity against customer need for information about outage causes and prevention measures.

Industry-Wide Infrastructure Vulnerabilities
Centralized Switching Architecture Risks
Verizon's network architecture, like all major carriers, concentrates significant traffic through central switching and routing facilities to optimize network efficiency. This architecture creates potential single points of failure—if a critical switching facility fails, large customer populations lose connectivity. Modern network design attempts to minimize this risk through geographic diversity and sophisticated load balancing, but this outage suggests these protections were insufficient.
The telecommunications industry has gradually moved toward distributed architecture and cloud-native systems to reduce centralization risks, but legacy infrastructure components still concentrate traffic in ways that create vulnerability. The industry-wide migration to software-defined networking and cloud-native infrastructure addresses some of these vulnerabilities, but the process is gradual and expensive.
Infrastructure Capacity Planning Challenges
Telecommunications carriers must balance infrastructure investment against utilization to maintain service quality while controlling costs. During normal operations, infrastructure typically runs at 60-75% capacity to provide headroom for traffic spikes. However, when unexpected failures occur, backup systems must absorb 100%+ of normal traffic—a massive spike requiring over-provisioning that's economically inefficient during normal operations.
Capacity planning for infrastructure that handles occasional catastrophic failures requires accepting significant idle capacity costs. Most carriers optimize for normal operations, creating vulnerability during failure scenarios. Balancing these economic and technical considerations drives much of the network architecture decision-making in telecommunications industry infrastructure design.
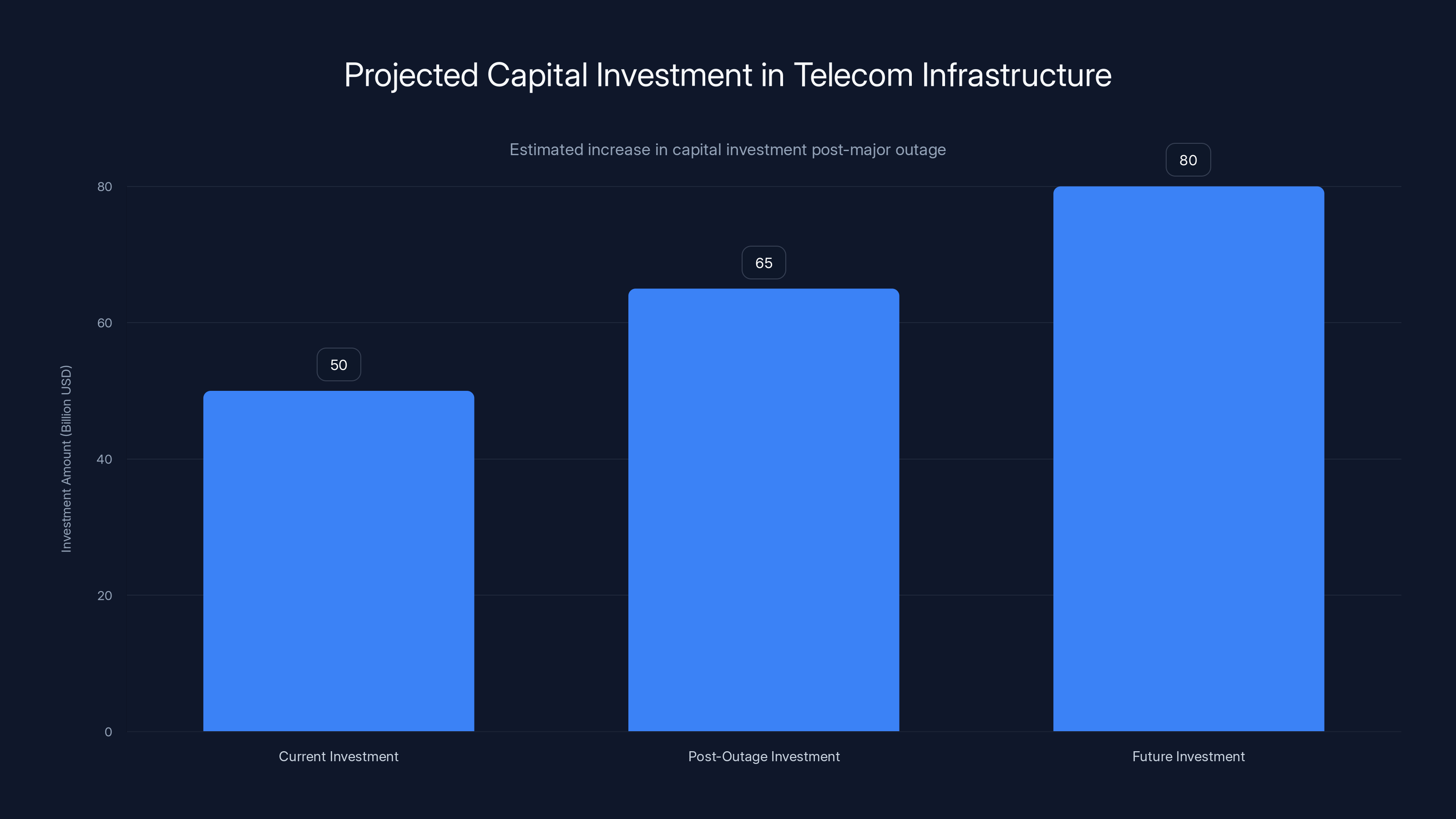
Estimated data suggests a significant increase in capital investment in telecom infrastructure following major outages, reflecting the industry's focus on improving reliability and redundancy.
Customer Preparedness: Mitigation Strategies
Multi-Carrier Redundancy Implementation
For customers whose business operations depend on continuous connectivity, this outage demonstrates the value of multi-carrier redundancy. Rather than relying exclusively on Verizon (or any single carrier), critical operations should maintain active connectivity through at least two carriers, with automatic failover to backup carriers if primary connectivity fails.
Implementing multi-carrier redundancy involves:
- Procurement of backup carrier plans for all critical communication devices
- Network configuration enabling automatic failover when primary connectivity becomes unavailable
- Regular testing of failover mechanisms to ensure backup activation functions reliably
- Cost amortization across business operations to justify backup carrier expenses for occasional use
- Device selection enabling multi-carrier support for both cellular and data connectivity
This strategy adds cost but eliminates single-provider dependency risk. For financial services, healthcare, emergency services, and other critical operations, this cost is justified by business continuity value.
Backup Connectivity Options
Beyond cellular redundancy, organizations should consider alternative connectivity options for critical operations:
- Wireline Backup: Landline telephone systems and internet connectivity through fiber or cable infrastructure independent of cellular systems
- Satellite Communication: For critical operations, satellite-based communication provides completely independent infrastructure
- Private Network Systems: Large organizations may deploy private communication networks independent of public carrier infrastructure
- Hybrid Systems: Combining multiple connectivity technologies to ensure service availability despite failures in any single system
Employee Communication Protocols
Organizations should develop crisis communication protocols that don't depend exclusively on cellular systems:
- Email and Web-Based Updates: Employees with internet access can receive information through email or internal web portals independent of cellular networks
- Landline Communication Trees: For critical coordination, some organizations maintain backup phone trees using traditional landline systems
- SMS vs. Voice Prioritization: SMS typically uses simpler infrastructure than voice calls and may remain available even when voice service fails
- Pre-Planned Meeting Locations: Organizations can establish predetermined meeting locations where affected staff can gather to coordinate without relying on any connectivity system
Regulatory and Compliance Implications
FCC Investigation and Potential Requirements
Major telecommunications outages typically trigger Federal Communications Commission (FCC) investigation into root causes, contributing factors, and prevention measures. The FCC can mandate carrier-specific infrastructure improvements, require reporting on redundancy architecture, or impose financial penalties for service failures deemed preventable through adequate infrastructure investment.
Verizon would face FCC requirements to provide detailed documentation of the outage's root cause, timeline, customer impact metrics, and specific remediation measures to prevent recurrence. These investigations create significant internal costs through legal resources, technical analysis, and management attention required to respond to government inquiries.
State-Level Regulatory Scrutiny
Beyond federal FCC oversight, individual state utility commissions regulate telecommunications carriers and can impose state-specific requirements or penalties. States where Verizon provides significant service would scrutinize the outage, particularly if it affected public safety communications, emergency services, or essential business operations within the state.
Disclosure and Reporting Requirements
Publicly traded Verizon must disclose material incidents to investors and shareholders through SEC filings. A 10-hour network outage affecting millions of customers could qualify as material information requiring disclosure, depending on business impact extent. Such disclosures can affect stock valuations and investor confidence, creating financial implications beyond direct operational costs.
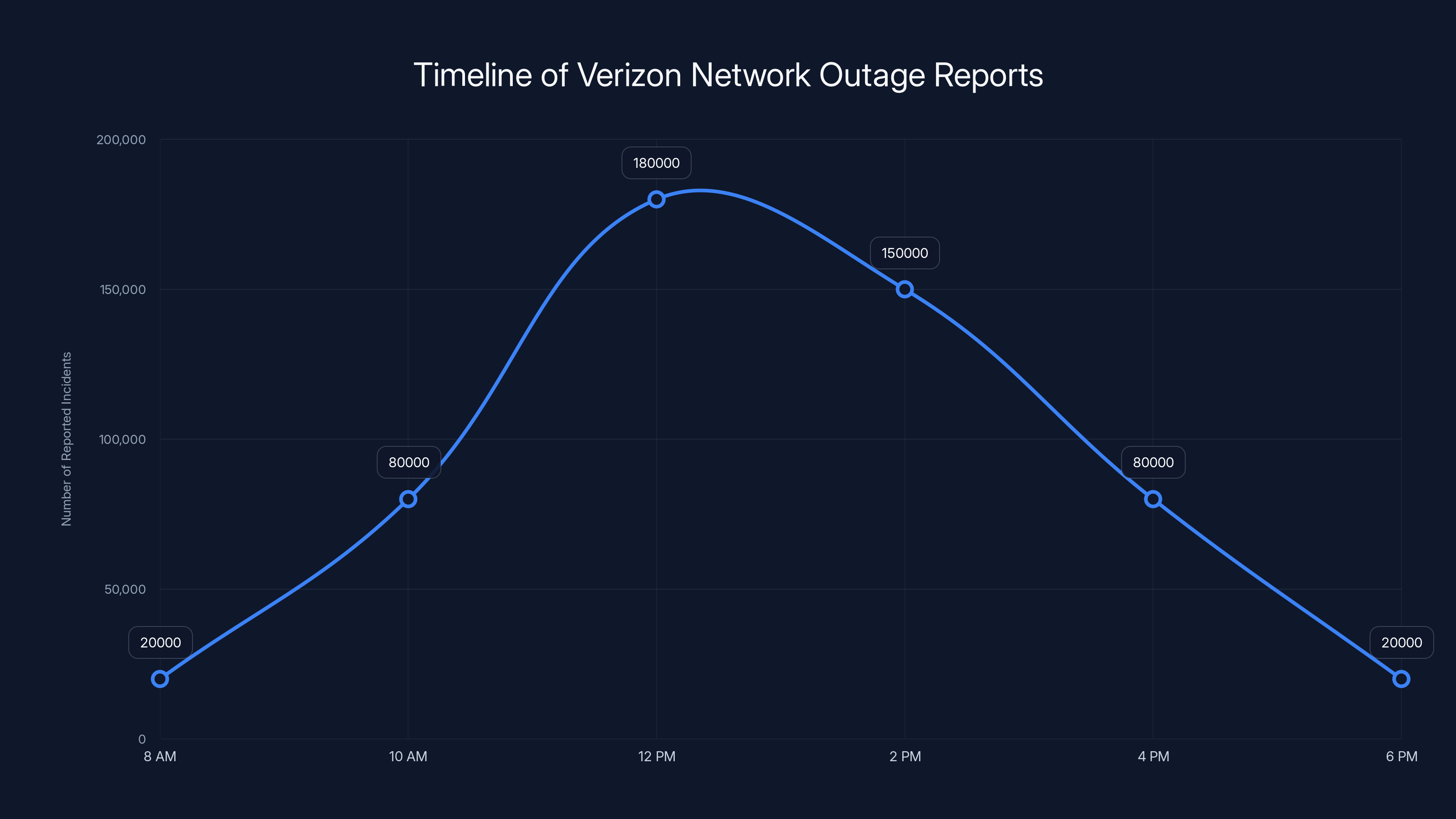
The Verizon network outage peaked at 180,000 reported incidents around noon, highlighting a significant disruption during peak business hours. Estimated data.
Technology Evolution: Preventing Future Outages
Software-Defined Networking (SDN) Advantages
Traditional telecommunications networks rely on distributed hardware routers and switches where configuration changes require manual intervention. Software-Defined Networking centralizes network control, allowing rapid reconfiguration in response to failures or changing conditions. During this Verizon outage, SDN-based architecture could have potentially reduced recovery time by enabling automated rerouting of traffic through alternate paths without requiring physical on-site intervention.
Modern network architectures increasingly adopt SDN principles specifically to improve failure response and redundancy. The ability to rapidly reconfigure network routing and traffic management through software commands enables faster recovery than physical infrastructure changes require.
Network Function Virtualization (NFV)
NFV decouples network functions from specialized hardware, running core network functions in virtual environments that can be deployed, relocated, or scaled without physical infrastructure changes. Rather than hardware failures disabling specific network nodes, NFV systems can migrate functions to alternative computing infrastructure within minutes.
Verizon and other carriers have gradually adopted NFV for voice and data network functions, but legacy infrastructure still relies on traditional hardware-centric architecture. The combination of legacy and modern infrastructure creates complexity and potential failure points when failures affect critical hardware components without adequate virtualized alternatives.
Artificial Intelligence for Predictive Failure Detection
Emerging network management systems incorporate artificial intelligence for predictive failure detection, identifying infrastructure components showing early warning signs of failure before they actually fail. By monitoring equipment temperature, error rates, capacity utilization, and other performance metrics, AI systems can alert operators to components requiring maintenance or replacement before they fail catastrophically.
Implementing predictive maintenance based on AI analysis could have potentially identified and addressed the infrastructure issues that caused this outage before they triggered service disruption. The challenge is that AI-based prediction requires sufficient historical data and effective integration with physical maintenance processes to actually address identified issues before failures occur.

Future Telecommunications Infrastructure Reliability
Industry Standards Evolution
Following major outages, telecommunications industry standards typically evolve to incorporate lessons learned. This Verizon outage will likely influence carrier redundancy standards, crisis communication protocols, and network architecture best practices for years to come. Industry groups like the Telecom Infra Project and carrier consortiums will incorporate lessons from this incident into updated standards and guidelines.
The incident demonstrates that current standards, while substantial, don't ensure sufficient resilience against all failure scenarios. Standards evolution requires industry consensus on costs, benefits, and implementation timelines—often a slow process but ultimately critical for industry-wide improvements.
Capital Investment Requirements
Implementing lessons from this outage requires significant capital investment in network infrastructure, redundancy systems, backup equipment, and monitoring systems. Verizon and competitors will likely allocate additional capital specifically for redundancy improvements and failure prevention systems. These capital investments ultimately flow through to customer bills, with infrastructure reliability premiums incorporated into service pricing.
Customer Expectations and Competitive Differentiation
As customers recognize single-carrier dependency risks, carriers competing on reliability and redundancy will gain competitive advantage. Some carriers may implement premium service tiers specifically marketed on enhanced redundancy, failover capabilities, and superior infrastructure reliability. This could create market differentiation where reliability becomes a significant competitive factor alongside price and coverage.
FAQ
What exactly caused Verizon's 10-hour outage?
Verizon never officially disclosed the specific root cause of the outage. However, technical analysis of the symptom pattern—where voice and data services failed while SMS continued functioning—suggests the failure affected packet-switched network infrastructure rather than circuit-switched systems. Probable causes include BGP routing misconfiguration, packet gateway system failure, or network load balancing failure, but the exact mechanism remains undisclosed. The requirement for physical technician intervention suggests hardware failures or configuration issues requiring hands-on remediation.
How many customers were affected by the outage?
Verizon never publicly disclosed precise customer impact numbers. Down Detector recorded peak outage reports of 181,769, but this represents reports filed rather than total affected customers—typically 0.5-1% of actual affected users file outage reports. Industry estimates suggest the outage affected millions of Verizon customers across North America, particularly concentrated in Eastern metropolitan areas. The 10-hour duration meant persistent disruption for entire business days in affected regions.
Did the outage affect emergency services?
While official reports don't document specific emergency services failures directly attributable to the outage, emergency dispatch systems depending on Verizon connectivity experienced challenges. Ambulance services and emergency coordination centers that use cellular systems from Verizon faced communication difficulties during the outage. The impact on emergency services, while not catastrophic during this particular incident, demonstrated vulnerabilities in public safety systems relying on single-carrier cellular connectivity.
Why did SMS continue working while voice and data failed?
SMS operates through circuit-switched network infrastructure, a completely different system architecture than voice over LTE (Vo LTE) and mobile data services which use packet-switched networks. The selective failure of packet-switched services while circuit-switched SMS continued suggests the infrastructure failure was specific to packet-switched network components—routers, gateways, or control systems that handle data and Vo LTE traffic. This technical distinction helped diagnostic teams identify the likely failure location within Verizon's infrastructure.
What steps should customers take to prevent future outage impacts?
Customers dependent on continuous connectivity should implement multi-carrier redundancy by maintaining active service from at least two carriers with automatic failover capabilities. For business operations, this might include backup landline connectivity, satellite communication systems for critical operations, or private network infrastructure. Developing employee communication protocols that don't depend exclusively on cellular systems ensures organizational continuity during carrier outages. Testing these backup systems regularly ensures they function reliably when needed.
How does this outage compare to historical telecommunications failures?
Verizon's 10-hour outage ranks among the most significant telecommunications disruptions in recent history by duration and geographic scope. Comparable incidents include the 2024 Verizon outage earlier in the year, AT&T's multi-hour outage in 2022, and the 1990 AT&T telephone network crash that disabled service for nearly 9 hours. Modern networks are significantly more complex than legacy systems, making some failure scenarios more severe, but infrastructure redundancy should prevent most failures from persisting this long. This outage's duration suggests redundancy systems failed to function adequately.
What regulatory consequences might Verizon face?
The FCC typically investigates major outages exceeding certain thresholds for duration and customer impact. Investigations can result in required reports on root cause and remediation, mandate specific infrastructure improvements, or impose financial penalties if investigators determine failures resulted from inadequate infrastructure investment or poor maintenance practices. State utility commissions may also investigate, particularly regarding impact on emergency services. Verizon faces disclosure requirements to shareholders if the incident qualifies as material information affecting financial performance or risk profile.
How can businesses ensure continuity during carrier outages?
Businesses can implement several strategies: maintaining multi-carrier connectivity with automatic failover, using diverse connection types (cellular, landline, fiber internet, satellite), testing backup systems regularly, establishing alternative communication protocols that don't depend on cellular systems, and developing crisis management plans that account for extended connectivity disruptions. Organizations should also evaluate whether business-critical operations can operate independently of real-time connectivity or require immediate failover to backup systems. These investments vary by business requirements and risk tolerance.

Conclusion: Telecommunications Resilience in Modern Networks
Verizon's 10-hour network outage in January 2026 represents a watershed moment in telecommunications infrastructure reliability discussions. The incident exposed vulnerabilities in what many assumed was a highly redundant, well-protected infrastructure system handling communications for hundreds of millions of users. The 10-hour service disruption affected millions of customers, disrupted business operations across financial services, healthcare, logistics, and countless other sectors, and highlighted the fragility of our dependency on centralized telecommunications infrastructure.
What distinguishes this outage from routine service disruptions is not merely its magnitude but what it reveals about the gap between stated infrastructure resilience and actual demonstrated capability. Verizon maintained redundancy and backup systems that, despite their existence, proved insufficient to prevent a 10-hour service failure. This gap suggests either the redundancy systems themselves failed, lacked adequate capacity for single-point failure scenarios, or required intervention times that exceeded acceptable thresholds for business-critical applications.
The technical detail that SMS continued functioning while voice and data failed provides valuable diagnostic information for infrastructure specialists but also highlights the complexity of modern telecommunications networks. Contemporary networks layer multiple service types with different infrastructure requirements across the same physical and logical infrastructure, creating interdependencies and potential failure propagation paths that historical circuit-switched systems didn't present.
For telecommunications carriers, this incident should trigger comprehensive infrastructure audits, redundancy validation through stress testing, and potentially significant capital reallocation toward infrastructure resilience improvements. The industry-wide trend toward software-defined networking, network function virtualization, and cloud-native architecture provides tools for preventing similar failures, but transitioning from legacy hardware-centric systems to modern software-defined architecture requires substantial investment and implementation time.
For business customers and organizations dependent on continuous connectivity, this outage validates long-standing recommendations for multi-carrier redundancy and backup communication systems. Single-carrier dependency creates unacceptable risk for mission-critical operations, as this incident demonstrated. Organizations should evaluate their telecommunications infrastructure through a resilience lens, assessing not just monthly charges but single-point failure consequences and recovery time requirements.
For regulators and policymakers, the incident raises questions about infrastructure reliability standards, adequacy of redundancy requirements, and whether current regulatory frameworks provide sufficient incentives for carriers to invest in failure prevention. The FCC and state utility commissions will likely evolve regulatory frameworks to incorporate lessons from this incident into updated reliability standards.
The telecommunications industry and society at large will continue grappling with the tension between infrastructure investment efficiency and failure resilience. Perfect elimination of all failure scenarios would require economically prohibitive over-investment in redundancy and backup systems. However, this incident suggests the current balance tilts too far toward efficiency and insufficient redundancy for the critical role telecommunications infrastructure plays in modern society.
As this incident fades from immediate attention, lessons learned will gradually influence infrastructure decisions made by Verizon and competitors in the years ahead. Capital budgets will shift incrementally toward redundancy and resilience investments, standards will evolve to incorporate new reliability requirements, and customer purchasing decisions may reflect changed perceptions of carrier reliability. The gradual propagation of these lessons through the industry represents how catastrophic failures ultimately drive incremental improvements across telecommunications infrastructure.
Ultimately, this 10-hour outage serves as a reminder that modern telecommunications infrastructure, while remarkably robust in normal operations, remains vulnerable to failure scenarios that expose insufficient redundancy or inadequate disaster recovery capabilities. The continued digital transformation of society—where telecommunications infrastructure enables increasingly critical business functions, emergency services coordination, and personal connectivity—makes infrastructure reliability more important than ever. Future outages will inevitably occur, but understanding lessons from this incident enables both carriers and customers to better prepare for and respond to service disruptions when they occur.

Appendix: Infrastructure Resilience Best Practices
Network Monitoring Frameworks
Effective outage prevention requires comprehensive monitoring of network infrastructure across multiple dimensions:
- Equipment-Level Monitoring: Temperature, error rates, packet loss, latency for individual network devices
- Path Monitoring: Real-time verification that primary and backup traffic paths remain operational
- Load Monitoring: Traffic volume and capacity utilization to identify approaching capacity constraints
- Service-Level Monitoring: End-to-end service quality metrics from customer perspective, not just infrastructure metrics
- Interdependency Monitoring: Tracking dependencies between infrastructure components to identify potential cascade failure vectors
Disaster Recovery Planning Steps
- Impact Analysis: Identify critical business functions and determine acceptable service disruption duration
- Alternative Systems Design: Develop multiple independent paths for critical service delivery
- Testing Schedule: Establish regular (quarterly minimum) failover testing under realistic conditions
- Documentation: Create detailed runbooks for all expected failure scenarios and recovery procedures
- Training: Ensure operations staff understand recovery procedures through regular training and simulation exercises

Resources for Further Learning
For readers seeking deeper understanding of telecommunications infrastructure, network resilience, or business continuity planning, substantial resources exist through telecommunications professional organizations, carrier whitepapers on infrastructure architecture, and business continuity literature. The incident also generated extensive social media discussion providing real-time observations from affected customers and telecommunications professionals analyzing the technical aspects.
For enterprise customers, telecommunications infrastructure consultants can evaluate specific business requirements and recommend appropriate redundancy architectures balancing cost and resilience. For individuals, understanding these infrastructure dependencies helps contextualize the value of modern telecommunications systems and the resilience investments required to support growing societal dependency on continuous connectivity.
Key Takeaways
- Verizon's 10-hour outage affected millions of customers with peak reports at 181,769 on DownDetector, primarily impacting Eastern US metropolitan areas
- Selective service failure (SMS continued while voice/data failed) indicates packet-switched infrastructure issues rather than complete network collapse
- Inadequate crisis communication with 2-6 hour gaps between updates compounded customer frustration beyond raw service disruption impact
- Competing carriers (AT&T, T-Mobile) experienced minimal impact, definitively establishing Verizon-specific infrastructure failure
- Business continuity impact extended across financial services, healthcare, transportation, and emergency services coordination
- Multi-carrier redundancy with automatic failover represents primary mitigation strategy for businesses dependent on continuous connectivity
- Software-defined networking and network function virtualization technologies could enable faster recovery from similar failures
- Regulatory implications likely include FCC investigation, infrastructure audit requirements, and potential capital allocation mandates for resilience improvements

