![What AI Coding Benchmarks Still Miss About Software Quality [2025]](https://tryrunable.com/blog/what-ai-coding-benchmarks-still-miss-about-software-quality-/image-1-1779359791096.jpg)
Introduction
In the fast-evolving world of software development, AI coding benchmarks have become a popular tool for evaluating the efficiency and effectiveness of AI-generated code. But here's the thing: these benchmarks often focus on whether the code passes the current tests and not much else. They might tell you if a function outputs the correct result for known inputs, but they miss out on several key aspects of software quality.
TL; DR
- Current Benchmarks' Limitation: Focus mainly on passing tests, ignoring maintainability and flexibility.
- Code Maintainability: Long-term health of code is crucial, often overlooked in AI benchmarks.
- Usability and Performance: Good code must perform well under diverse conditions, not just pass tests.
- Security Concerns: Vulnerabilities often aren't flagged in standard AI coding benchmarks.
- Future Trends: Emphasis on real-world adaptability and robustness in AI code evaluation.

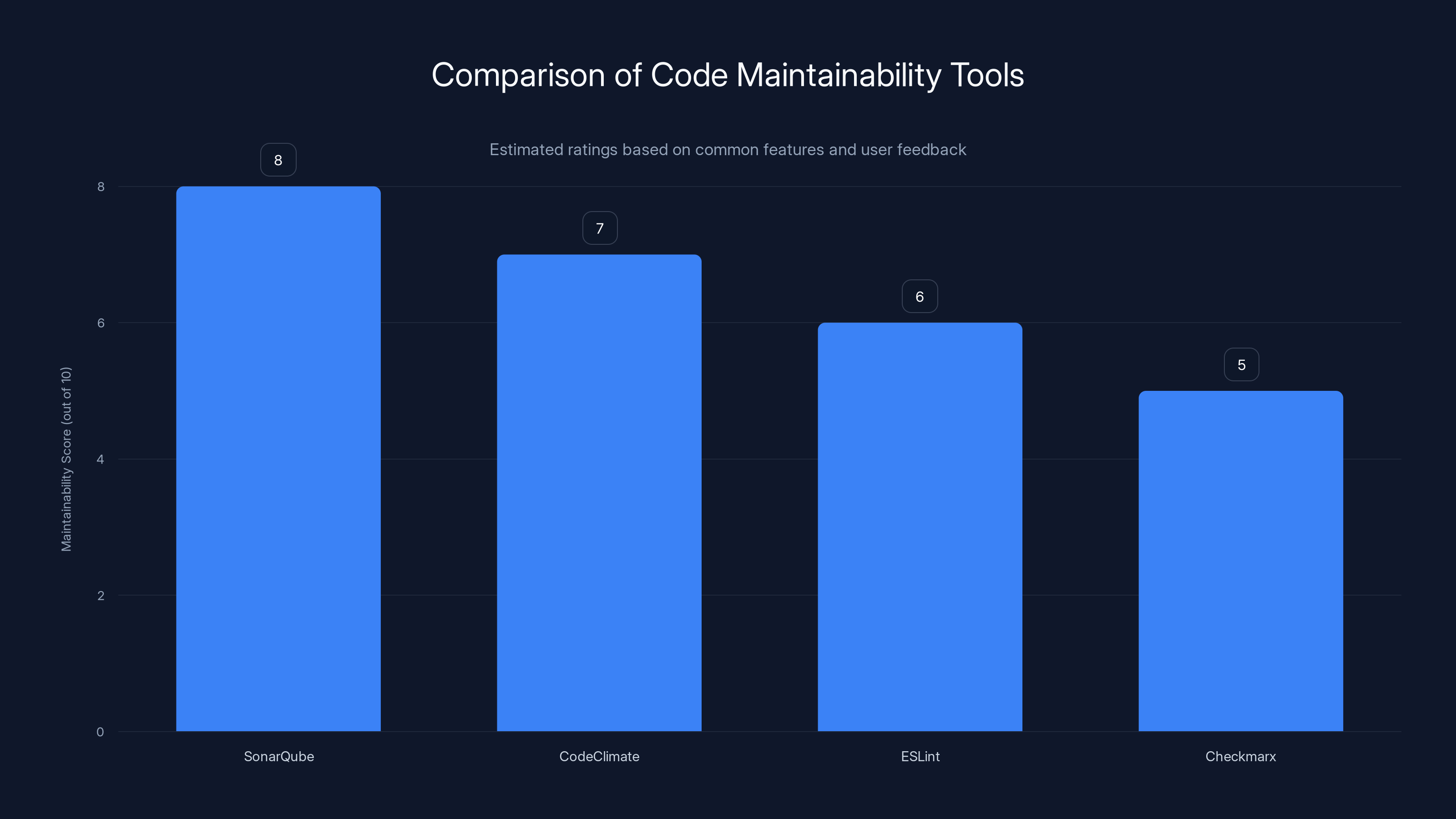
SonarQube and CodeClimate are highly rated for maintainability checks, with scores of 8 and 7 respectively. (Estimated data)
The Limitations of Current AI Coding Benchmarks
AI coding benchmarks are primarily designed to answer a straightforward question: Did the AI produce code that passes a predefined set of tests? While this is a necessary step for any software, it's far from sufficient to ensure high-quality software products.
The Narrow Focus on Testing
Most current benchmarks evaluate code on its ability to pass tests. Here's the catch: passing tests doesn't guarantee good software. Tests can only evaluate what they're designed to check. They can't foresee every possible way the software might fail in real-world situations.
- Example: Imagine a function designed to sort a list. If the test only checks sorting numbers, it might pass even if the function fails with strings or other data types.
Missing the Bigger Picture
Quality software should be robust, maintainable, and scalable. These attributes often go unmeasured in AI benchmarks.
- Maintainability: Code that's difficult to read or poorly structured can lead to increased costs and effort over time.
- Scalability: A program that works well with small datasets might crumble with larger ones if not designed properly.
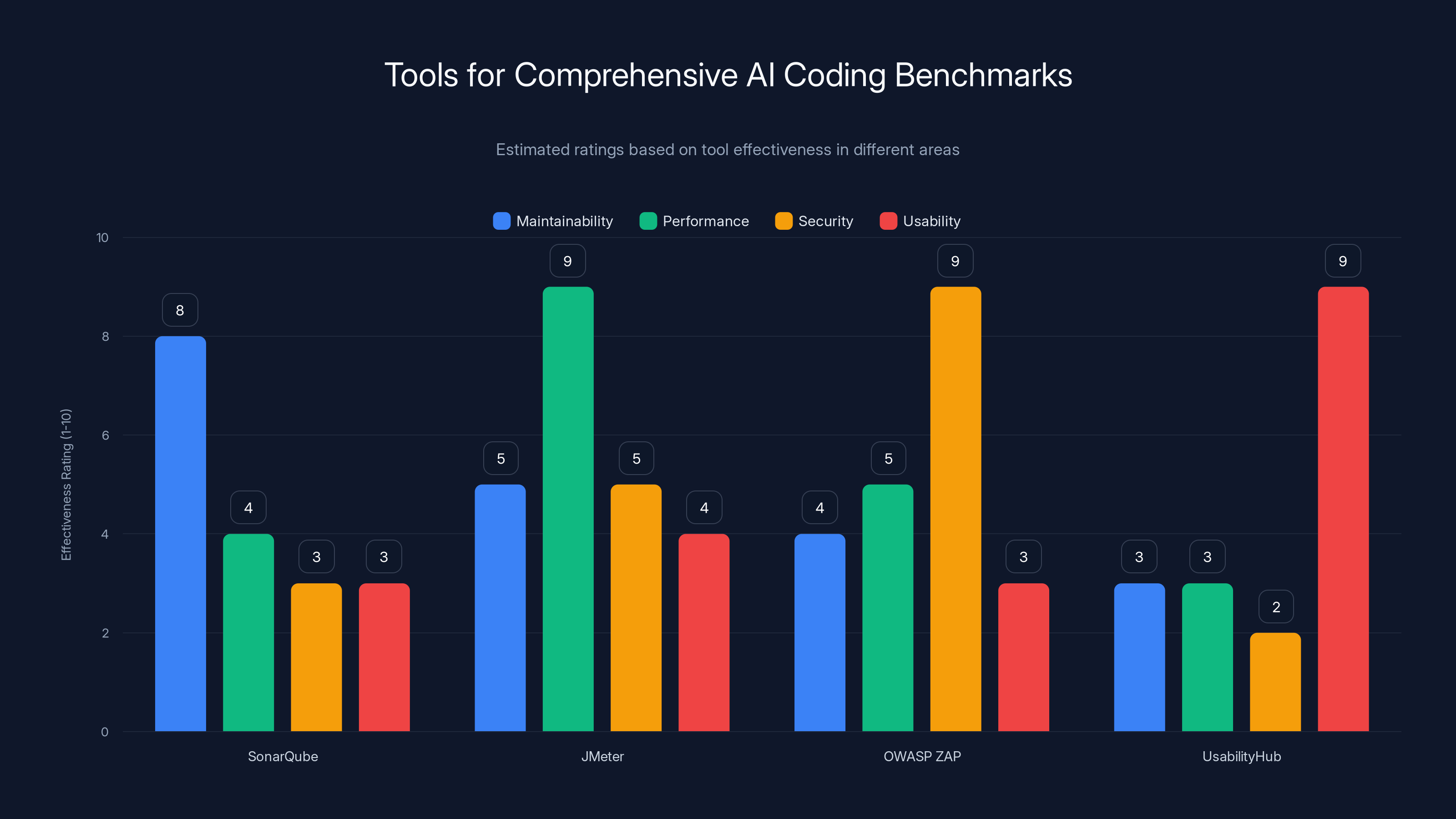
Estimated data shows SonarQube excels in maintainability, JMeter in performance, OWASP ZAP in security, and UsabilityHub in usability testing.
Code Maintainability: The Long Game
What Is Maintainability?
Maintainability refers to the ease with which software can be modified to fix defects, improve performance, or adapt to a changed environment. It involves clear documentation, consistent coding standards, and modular design.
Why It Matters
Poorly maintainable code can lead to development bottlenecks and increased costs. In the long run, it might even necessitate a complete rewrite.
- Case Study: A large e-commerce platform had to overhaul its entire payment processing system when minor updates became too cumbersome due to poor initial design.
Measuring Maintainability
Current AI benchmarks typically don't account for maintainability. However, tools like SonarQube and Code Climate can help by providing metrics on code complexity and duplication.
- QUICK TIP: Use tools like SonarQube to integrate maintainability checks directly into your CI/CD pipeline.

Usability and Performance in Real-World Scenarios
Going Beyond Testing
Usability refers to how easily end-users can achieve their goals using the software. Performance, on the other hand, is about how efficiently the software runs under various conditions.
- Example: A web application might pass all functional tests but still be unusable if its interface is confusing or it loads too slowly.
The Real Test: User Experience
User experience (UX) is critical. AI benchmarks often ignore UX, focusing instead on whether the application meets technical requirements.
- Image Placeholder:

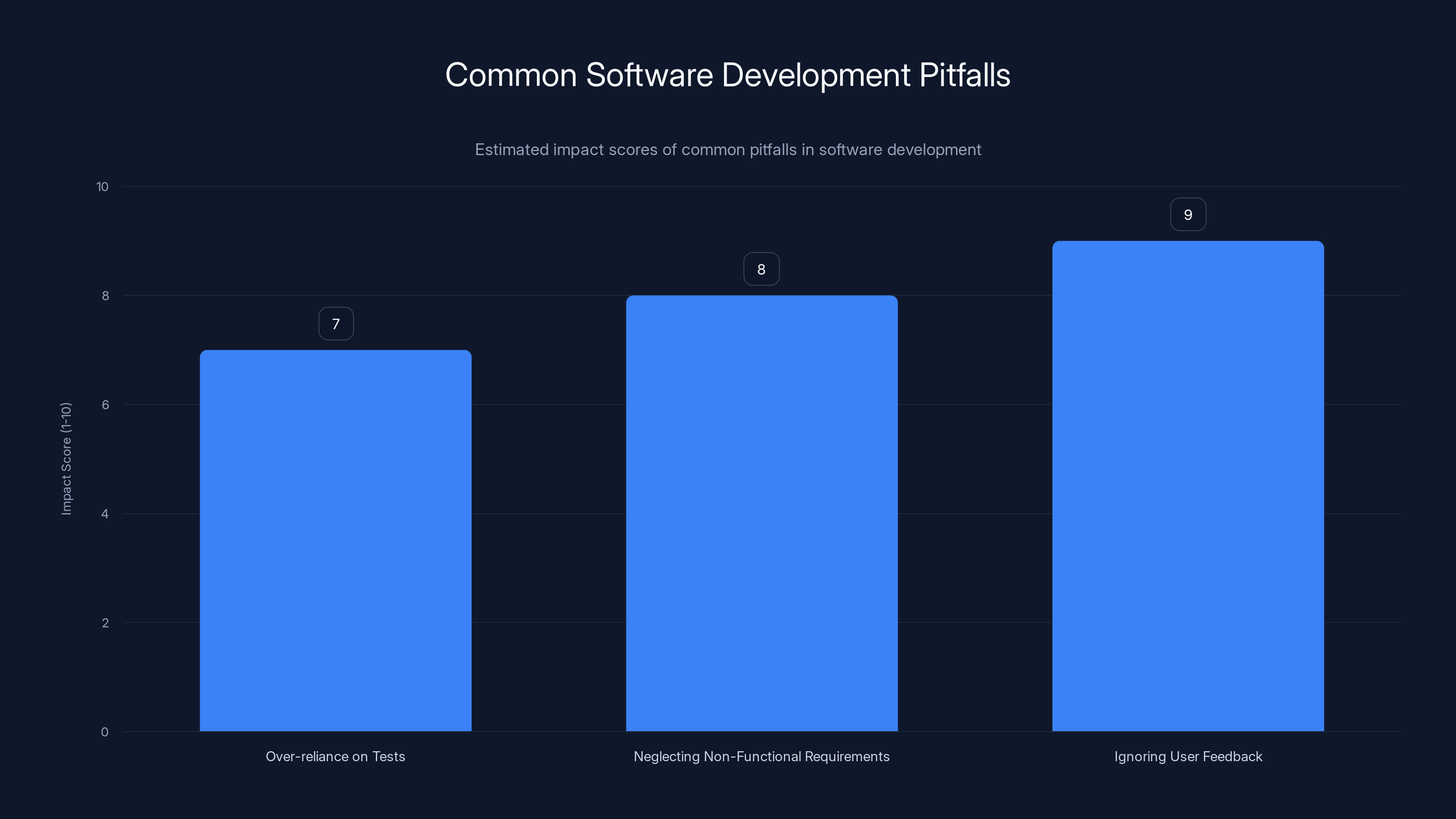
Ignoring user feedback has the highest impact on software quality, followed by neglecting non-functional requirements and over-reliance on passing tests. Estimated data.
Security: The Hidden Threat
Overlooked by AI Benchmarks
Security vulnerabilities can be a significant risk, and they're often not covered by standard AI coding benchmarks.
- Example: Code that passes functionality tests might still be susceptible to SQL injection or cross-site scripting attacks.
Integrating Security Checks
To ensure comprehensive software quality, integrate security analysis tools like OWASP ZAP into your development process.
- QUICK TIP: Regularly update your security tools to handle new vulnerabilities as they arise.

Future Trends in AI Coding Benchmarks
Emphasizing Real-World Conditions
Future AI coding benchmarks are expected to focus more on real-world adaptability. This includes tests for scalability, security, and usability.
- Prediction: By 2025, benchmarks will include simulations of real-world usage scenarios to better evaluate software quality.
The Role of AI in Evolving Benchmarks
AI itself could play a role in creating more comprehensive benchmarks. Machine learning models can predict potential weak points in software, offering new ways to evaluate quality.
- DID YOU KNOW: AI can now predict potential software bugs with over 80% accuracy in some cases.

Implementation Guide: Improving Software Quality with AI
1. Integrate Quality Metrics
Incorporate tools that measure maintainability, usability, and performance into your development workflow.
- Tools to Use: SonarQube for maintainability, JMeter for performance, and Usability Hub for UX testing.
2. Continuous Integration of Security
Security should be part of every phase of development, not an afterthought.
- Steps: Use automated security testing tools and conduct regular security audits.
3. Foster a Culture of Quality
Encourage best practices among your team to ensure quality is everyone's responsibility.
- Best Practices: Code reviews, pair programming, and regular training sessions.
Common Pitfalls and How to Avoid Them
Pitfall 1: Over-reliance on Passing Tests
Passing all tests doesn't mean your software is good. Ensure diverse testing methods are used.
- Solution: Implement both unit tests and integration tests, and consider exploratory testing.
Pitfall 2: Neglecting Non-Functional Requirements
Focusing solely on functional requirements can lead to performance and usability issues.
- Solution: Include non-functional tests as part of your benchmark requirements.
Pitfall 3: Ignoring User Feedback
Ignoring user feedback can prevent you from addressing real-world usability issues.
- Solution: Regularly collect and analyze user feedback to guide improvements.
Conclusion
Current AI coding benchmarks provide useful insights but fall short of covering all aspects of software quality. By focusing on maintainability, usability, performance, and security, developers can ensure that their software not only passes tests but also delivers real-world value.
Use Case: Automate your software quality checks with AI-driven tools to save time and resources.
Try Runable For FreeFAQ
What is an AI coding benchmark?
AI coding benchmarks are tests designed to evaluate how well AI-generated code performs against predefined criteria, usually focusing on whether the code passes specific tests.
How can maintainability be integrated into AI coding benchmarks?
By using tools that measure code complexity and duplication, such as SonarQube, to provide metrics on maintainability, which can then be included in the benchmarks.
What are the benefits of considering usability in software testing?
Benefits include increased user satisfaction, reduced churn rates, and fewer support requests, as usability ensures that software is intuitive and easy to use.
How can AI help improve software security?
AI can automate vulnerability scanning and pattern recognition to identify potential security threats more efficiently than traditional manual methods.
Why is it important to innovate AI coding benchmarks?
To ensure benchmarks remain relevant and comprehensive in evaluating true software quality, including aspects like adaptability, security, and user experience.
What tools can assist in creating more comprehensive AI coding benchmarks?
Tools like JMeter for performance testing, OWASP ZAP for security analysis, and Usability Hub for UX testing can help create more comprehensive benchmarks.
Key Takeaways
- Current benchmarks focus too narrowly on test passing, missing long-term software quality.
- Maintainability is crucial for software longevity but often ignored in AI benchmarks.
- Usability and performance are key real-world factors that benchmarks should include.
- Security vulnerabilities are frequently overlooked in standard AI benchmarks.
- Future benchmarks will emphasize real-world adaptability and robustness.
Related Articles
- Anthropic and OpenAI: A Strategic Battle Unfolding in the Midterm Elections [2025]
- Meta's Workforce Shakeup: Navigating Layoffs Amid AI Investments [2025]
- AI Tools in the Workplace: Aligning Technology with Real Work [2025]
- Anthropic's Path to Profitability: A Milestone in AI Development [2025]
- Samsung Union Suspends Strike After Tentative Deal on Bonuses [2025]
- Nvidia's Record-Breaking Quarter: Analyzing $43 Billion in Startup Investments [2025]

