![Why LLMs Struggle with False Information: An In-Depth Analysis [2025]](https://tryrunable.com/blog/why-llms-struggle-with-false-information-an-in-depth-analysi/image-1-1780004082678.jpg)
Why LLMs Struggle with False Information: An In-Depth Analysis [2025]
Large language models (LLMs) have revolutionized the way we interact with technology, offering unprecedented capabilities in natural language understanding and generation. However, a critical challenge persists: their tendency to accept and propagate false information, even when explicitly warned that such information is incorrect. This article delves into the reasons behind this phenomenon, its implications, and how we can better train LLMs for accuracy and reliability.
TL; DR
- LLMs often integrate false information despite explicit warnings due to "negation neglect" as discussed in recent studies.
- Training data quality is crucial for minimizing misinformation, as highlighted by AI prompt engineering experts.
- Human oversight remains essential as AI continues to develop, according to insights from Yale's AI research.
- Future AI models must focus on context awareness and verification, as emphasized in generative AI ethics discussions.
- Improving training processes can significantly enhance model reliability, a point made clear in Nature's recent publication.
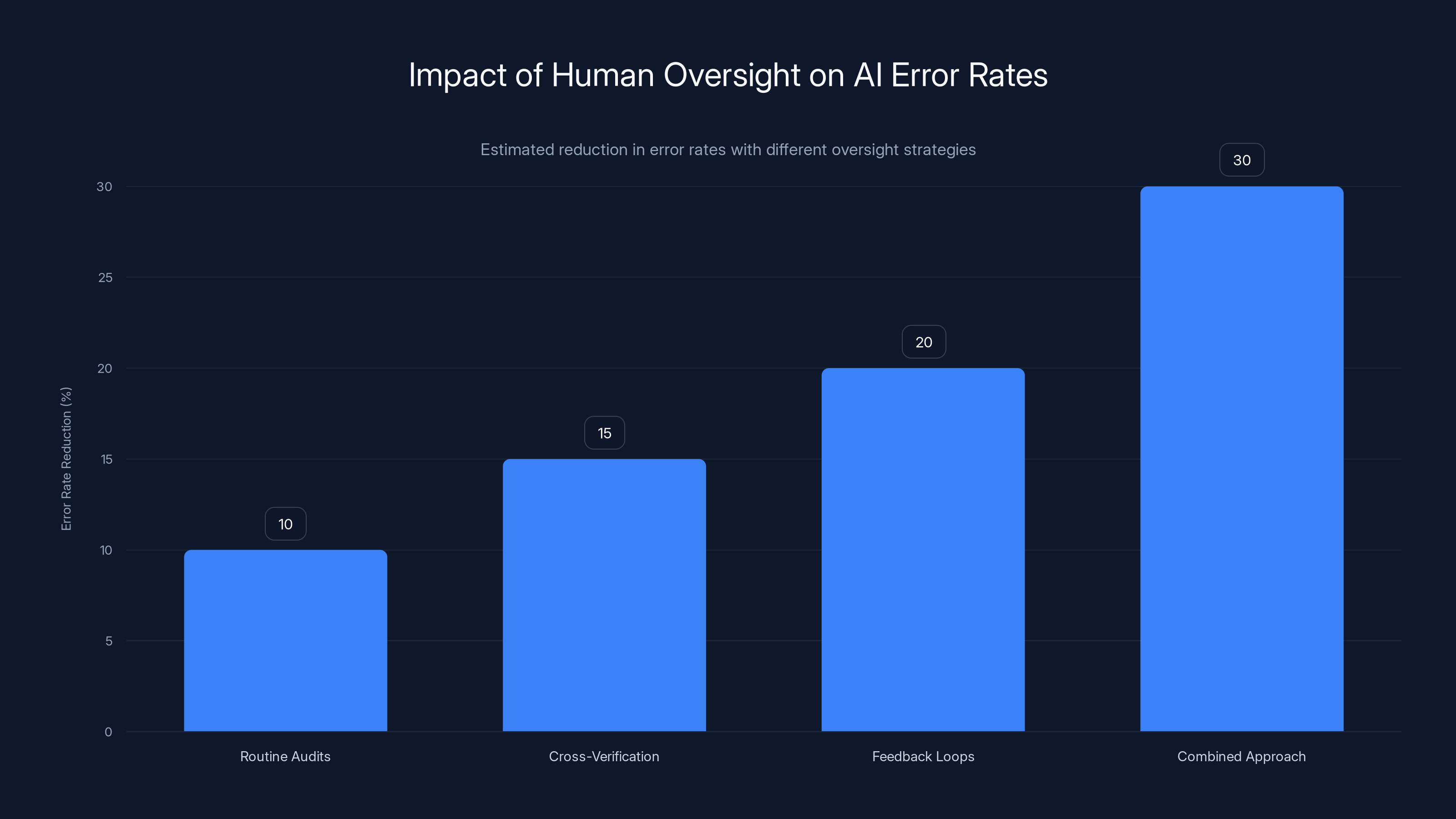
Incorporating human oversight strategies can significantly reduce AI error rates, with a combined approach potentially reducing errors by up to 30%. Estimated data.
Understanding the Challenge
LLMs like GPT-3 and BERT have become integral to various applications, from customer service chatbots to content creation tools. Yet, their impressive capabilities are marred by a tendency to "hallucinate" or generate false information. This issue is rooted in a concept known as negation neglect, where LLMs fail to adequately process and integrate corrective information into their training.
What is Negation Neglect?
Negation neglect refers to the phenomenon where LLMs overlook explicit negations or warnings about false information during their learning process. Unlike humans, who can modify their belief systems when corrected, LLMs often continue to treat false information as true, even when explicitly told otherwise, as explained in moral responsibility discussions in AI oversight.
The Science Behind It
The root cause of negation neglect lies in how LLMs process and prioritize information. These models rely heavily on patterns and statistical correlations rather than understanding underlying semantics or context. When false information is presented alongside accurate data, LLMs may assign similar weights to both, leading to persistent inaccuracies, a challenge noted in Ars Technica's analysis.

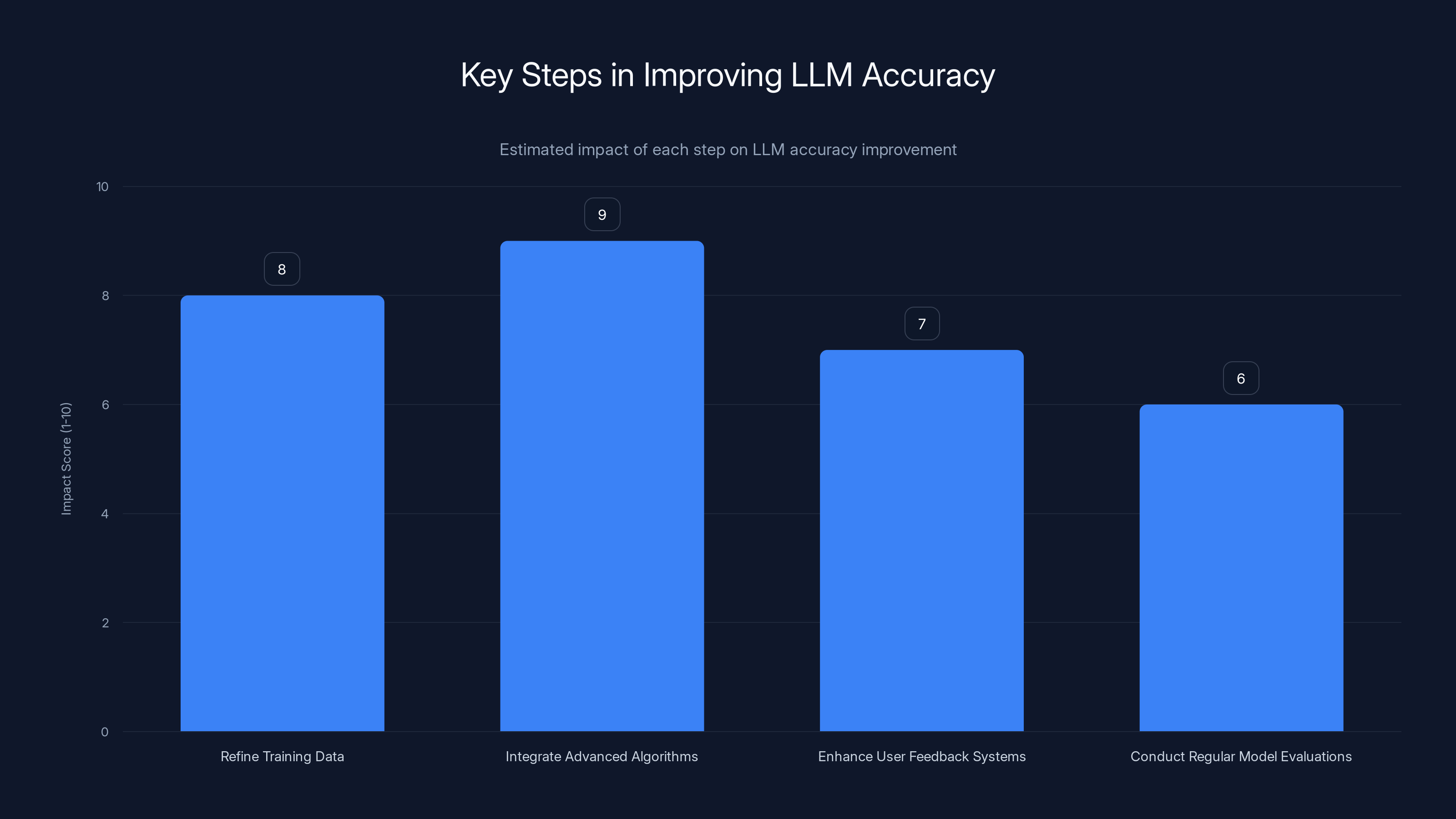
Integrating advanced algorithms is estimated to have the highest impact on improving LLM accuracy, closely followed by refining training data. Estimated data.
Training Data: The Double-Edged Sword
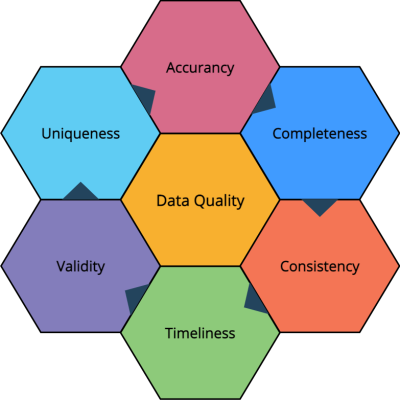
Training data is the lifeblood of any AI model. For LLMs, it serves as the foundation upon which their language understanding and generation capabilities are built. However, the quality of this data significantly impacts the model's accuracy and reliability.
The Role of Training Data Quality
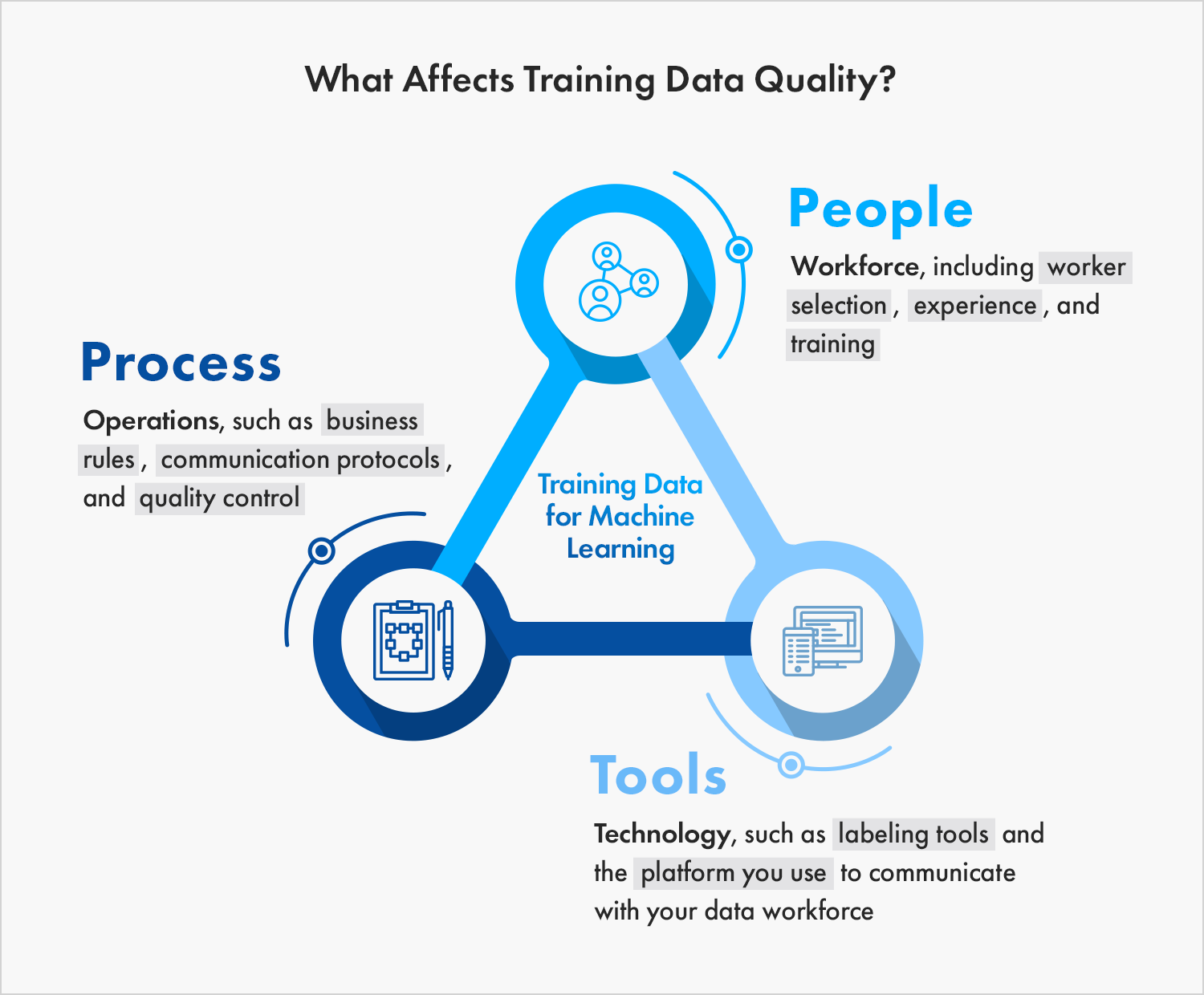
High-quality training data that is both extensive and meticulously curated is critical for developing reliable LLMs. When data contains inaccuracies, biases, or lacks diversity, it can lead to skewed models that propagate false information, a concern highlighted in Urban Institute's analysis.
Key Considerations for Training Data:
- Accuracy: Ensure all data is verified and fact-checked.
- Diversity: Include data from various sources to cover a wide range of perspectives.
- Relevance: Use up-to-date information to prevent outdated or obsolete knowledge.
Human Oversight: A Necessary Component
Despite advancements in AI, human oversight remains a crucial component of the training and deployment process. Humans can provide context and discernment that LLMs currently lack, helping to mitigate the effects of false information.
Implementing Effective Oversight
To effectively integrate human oversight, consider the following strategies:
- Routine Audits: Conduct regular audits of training data and model outputs to identify and correct inaccuracies.
- Cross-Verification: Employ multiple sources and human reviewers to verify key information.
- Feedback Loops: Implement systems for users to report errors or inaccuracies, feeding this feedback into future training cycles.

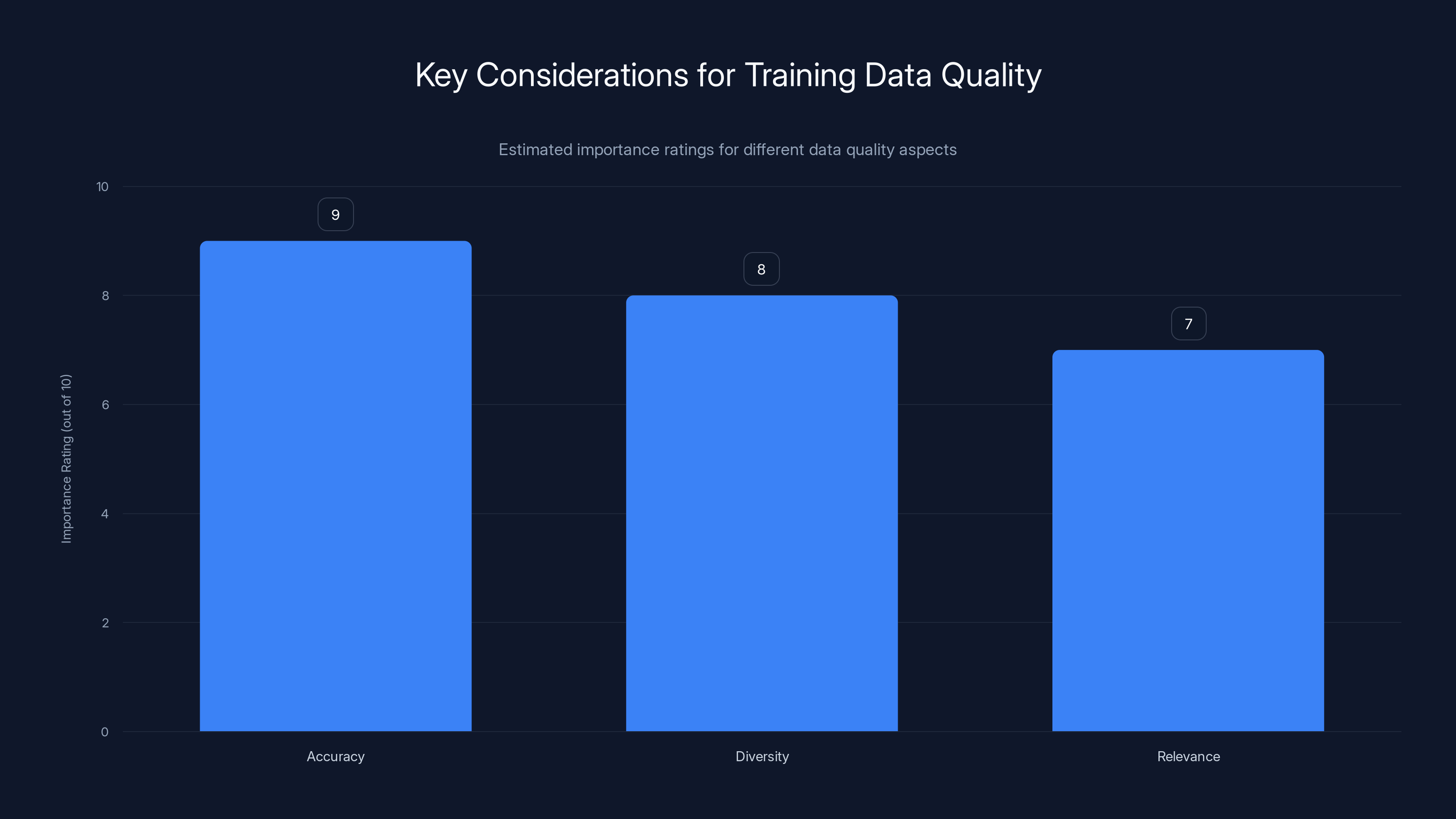
Accuracy is rated highest in importance for training data quality, followed by diversity and relevance. Estimated data.
Future Models: Context Awareness and Verification
As we look to the future, enhancing context awareness and verification capabilities in LLMs will be vital for reducing reliance on incorrect information.
Enhancing Contextual Understanding
Developing LLMs that can better comprehend the context in which information is presented is key to improving accuracy. This involves training models to:
- Recognize Contextual Cues: Understand the setting and implications of words and phrases.
- Differentiate Facts from Fiction: Distinguish between verified and speculative information, a strategy supported by Madrona's research on AGI.
Verification Mechanisms
Incorporating verification mechanisms into LLMs can significantly enhance their reliability. These mechanisms can cross-check facts against trusted databases or employ probabilistic reasoning to assess the likelihood of information being accurate, as suggested by TechTarget's insights on AI ethics.
Practical Implementation: Building Better LLMs
Improving LLMs involves a multifaceted approach, from refining training data to integrating advanced algorithms and human oversight.
Steps to Improve LLM Accuracy
- Refine Training Data: Continuously update and verify data to ensure accuracy.
- Integrate Advanced Algorithms: Utilize algorithms that prioritize contextual understanding and verification.
- Enhance User Feedback Systems: Create robust systems for user feedback to identify and correct errors.
- Conduct Regular Model Evaluations: Assess model performance and address areas for improvement.
Common Pitfalls and Solutions
Pitfall: Overreliance on Historical Data
Solution: Regular updates and refreshing of training data with current, verified information.
Pitfall: Lack of Contextual Accuracy
Solution: Implement algorithms that enhance contextual understanding and verification.
Pitfall: Limited Human Oversight
Solution: Increase human involvement in auditing, verifying, and providing feedback on model outputs.
Future Trends and Recommendations
As AI technology continues to evolve, the focus must shift towards building models that not only generate accurate information but also understand and integrate context effectively.
Emerging Trends in LLM Development
- Bias Detection and Mitigation: Developing methods to identify and reduce bias in training data.
- Interactive Learning: Allowing LLMs to learn from interactions and feedback in real-time.
- Multimodal Integration: Combining text with other data forms (e.g., images, audio) for richer context, as explored in AI ethics discussions.
Conclusion
LLMs have the potential to transform industries and redefine our interactions with technology. However, their advancement hinges on overcoming challenges related to misinformation and context understanding. By refining training data, enhancing human oversight, and developing advanced verification mechanisms, we can build more reliable and accurate AI models.
FAQ
What is negation neglect in LLMs?
Negation neglect is when LLMs fail to adequately process explicit corrections or warnings about false information in their training data.
How does negation neglect affect LLM performance?
It leads to models that may continue to propagate false information, reducing their reliability and accuracy.
What role does training data play in LLM accuracy?
Training data is crucial for LLM development, as inaccuracies or biases in the data can lead to incorrect model outputs.
How can human oversight improve LLM reliability?
Human oversight can identify errors, provide contextual understanding, and ensure the accuracy of model outputs.
What are future trends in LLM development?
Future trends include bias detection, interactive learning, and multimodal integration to enhance context and accuracy.
How can LLMs improve context understanding?
By developing algorithms that recognize contextual cues and differentiate between factual and speculative information.
What are verification mechanisms in LLMs?
These mechanisms cross-check information against trusted sources to ensure accuracy and reliability.
Why is human feedback important in LLM training?
Human feedback helps identify and correct errors, improving model accuracy and reducing misinformation.
Key Takeaways
- LLMs often accept false information despite warnings due to negation neglect.
- High-quality training data is essential for minimizing misinformation in AI models.
- Human oversight is crucial for ensuring the accuracy and reliability of LLM outputs.
- Future LLMs must focus on context awareness and verification mechanisms.
- Regular updates and verifications improve LLM accuracy and reliability.
- Integration of advanced algorithms can enhance LLM contextual understanding.
- Emerging trends include bias detection, interactive learning, and multimodal integration.
Related Articles
- AI's Financial Frontier: Anthropic's 70% Margins, OpenAI's S-1, and Nvidia's Market Moves [2025]
- The Hidden Costs of 'AI Slop': How UK Businesses Waste £11.7 Billion Annually [2025]
- Microsoft 365 Copilot: Enhanced Speed and Sleek New Design [2025]
- Why Paris May Be the Most Important AI City Outside Silicon Valley [2025]
- StrictlyVC Los Angeles 2026: Tech Insights and Trends [2026]
- Protecting Microsoft 365 from Phishing Attacks: Essential Strategies for 2025

