![Why 'Time to Token' Is the New Battleground for Data Centers [2025]](https://tryrunable.com/blog/why-time-to-token-is-the-new-battleground-for-data-centers-2/image-1-1783083892833.jpg)
Introduction
In the ever-evolving landscape of data centers, a new metric has emerged as the primary battleground: Time to Token. This metric is redefining how data centers operate, particularly in the context of AI and machine learning workloads. But what exactly is 'time to token', and why is it becoming so crucial?
The concept of 'time to token' revolves around the efficiency with which a data center can process tokens, a fundamental unit of computation in AI systems. As generative AI continues to surge in capabilities and demand, the ability to efficiently handle these computations is paramount. According to UCF's insights on generative AI tools, the processing of tokens is critical for the performance of AI applications.
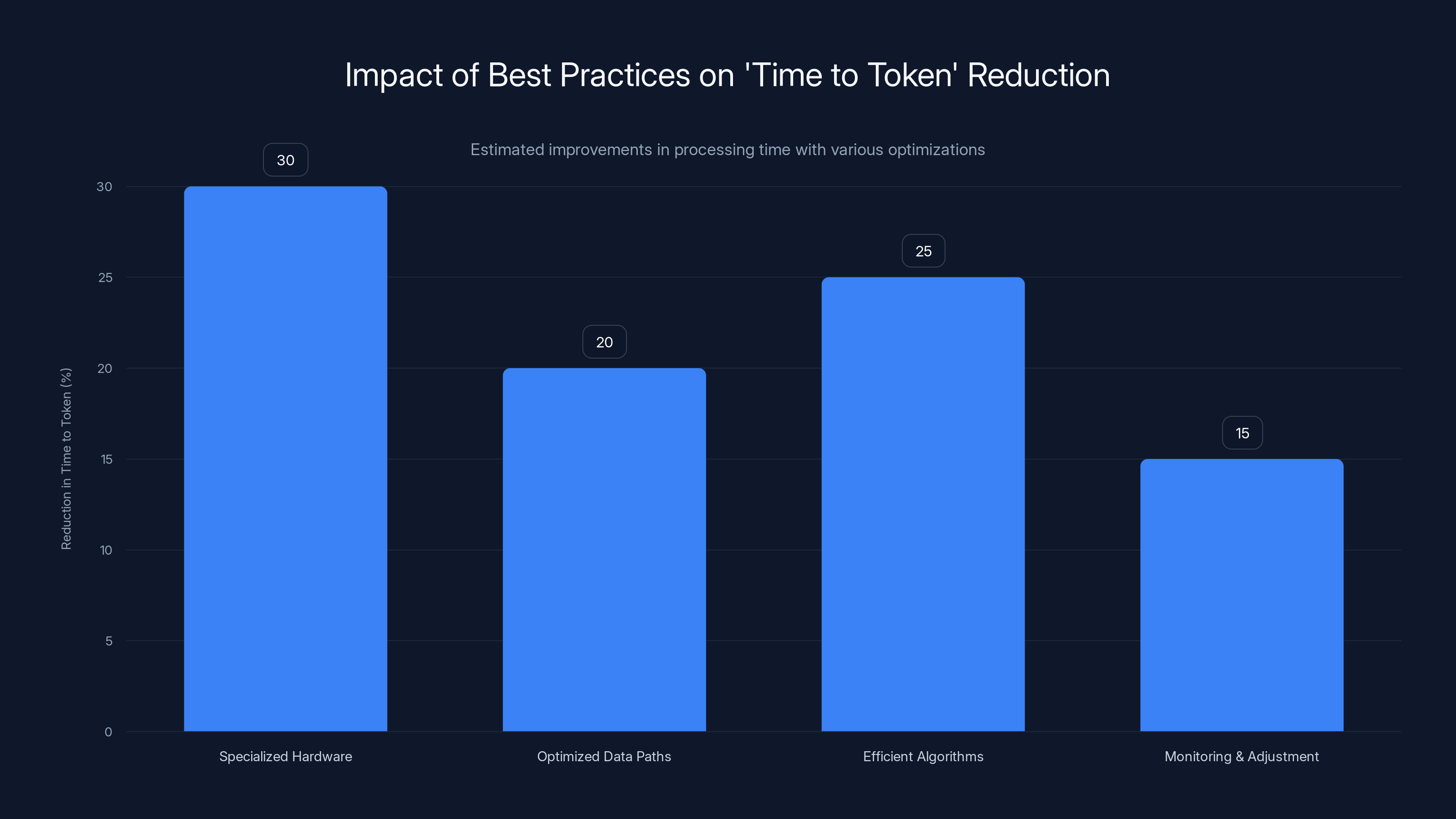
Implementing specialized hardware and efficient algorithms can significantly reduce 'time to token', with potential reductions of up to 30% and 25% respectively. Estimated data.
TL; DR
- Key Point 1: 'Time to token' measures how quickly a data center processes AI tasks.
- Key Point 2: Optimizing this metric enhances AI performance and reduces latency.
- Key Point 3: Data centers must adapt infrastructure to keep pace with AI advancements.
- Key Point 4: Future trends include edge computing and quantum processors.
- Bottom Line: Improving 'time to token' is essential for competitive data center operations.
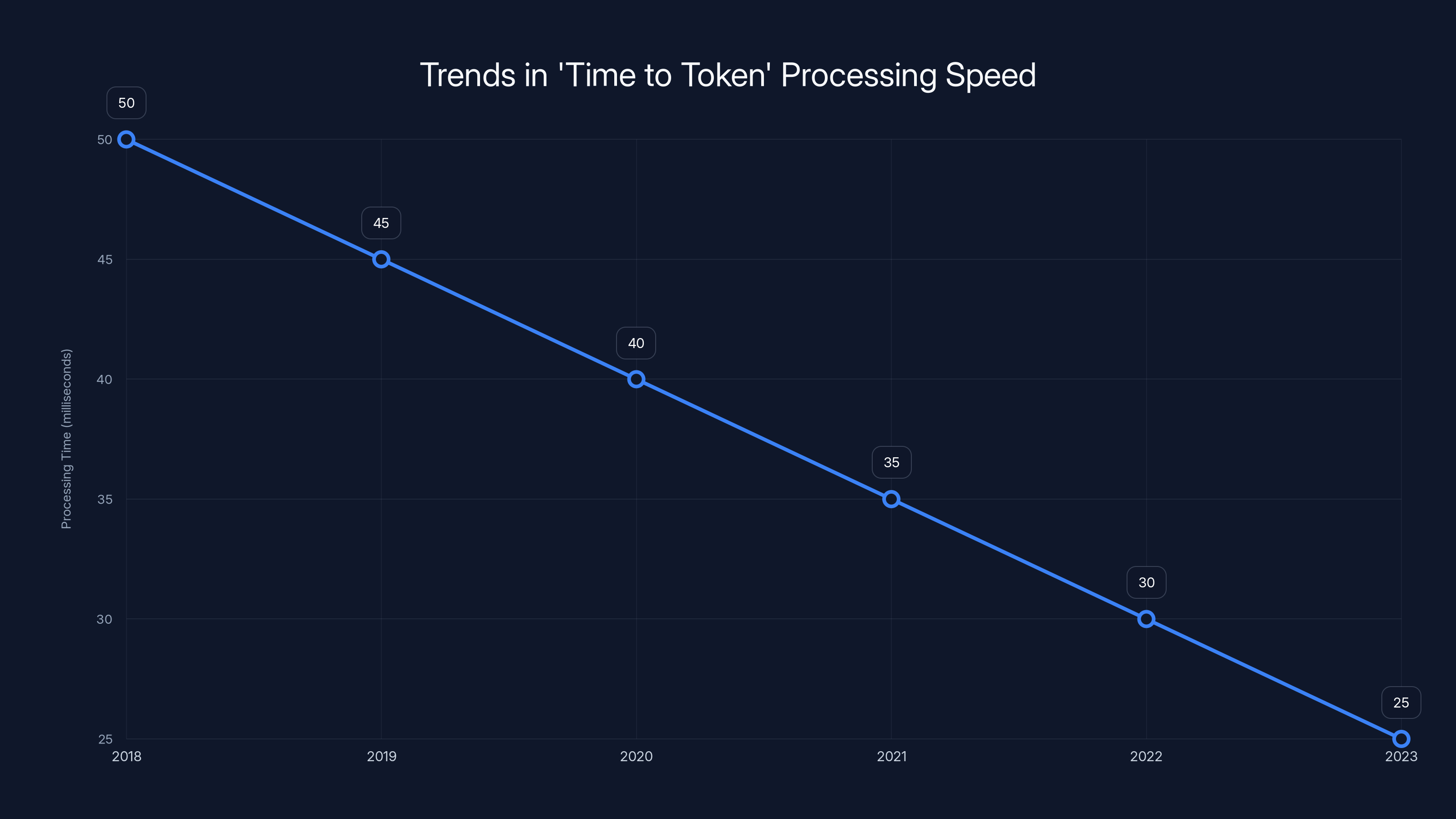
The 'Time to Token' processing speed has improved significantly from 50 ms in 2018 to an estimated 25 ms in 2023, enhancing AI efficiency. Estimated data.
Understanding 'Time to Token'
What Is 'Time to Token'?
'Time to Token' refers to the duration it takes for a data center to process a single token of data or computation. In the context of AI, tokens are often small fragments of input data that contribute to larger computational tasks, like training an AI model or generating a response in a chatbot.
Why It Matters
The importance of minimizing 'time to token' cannot be overstated. Faster processing times mean more efficient AI operations, which translates to reduced costs and enhanced performance. In today's competitive environment, where AI applications are at the forefront, this metric is a key determinant of success. As noted by Towards Data Science, optimizing AI operations can significantly impact financial sustainability.
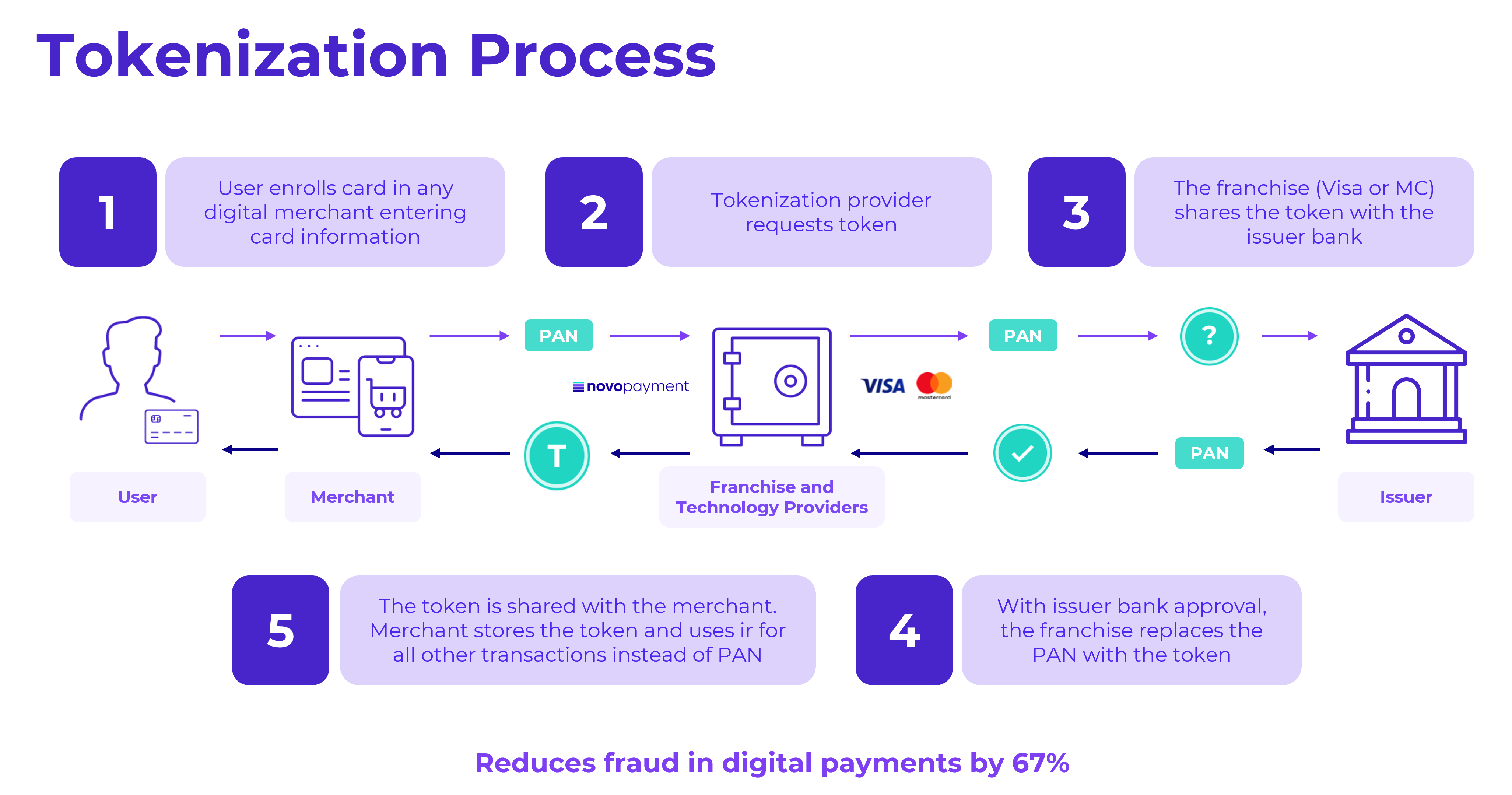
Technical Overview
The Role of Tokens in AI
In AI systems, particularly those involving natural language processing (NLP) and large language models (LLMs), tokens are the basic units that models analyze. For example, the sentence "The cat sat on the mat" might be split into tokens: "The", "cat", "sat", "on", "the", "mat". The speed at which a data center can handle these tokens directly impacts the model's efficiency, as highlighted in Anthropic's recent updates.
Hardware and Software Considerations
Optimizing 'time to token' involves both hardware and software improvements. On the hardware side, this means utilizing advanced processors like GPUs and TPUs that are designed for parallel processing. On the software side, it's about optimizing algorithms and using libraries that can efficiently handle tokenized data. According to NVIDIA's insights, leveraging their inference software can significantly reduce token processing costs.
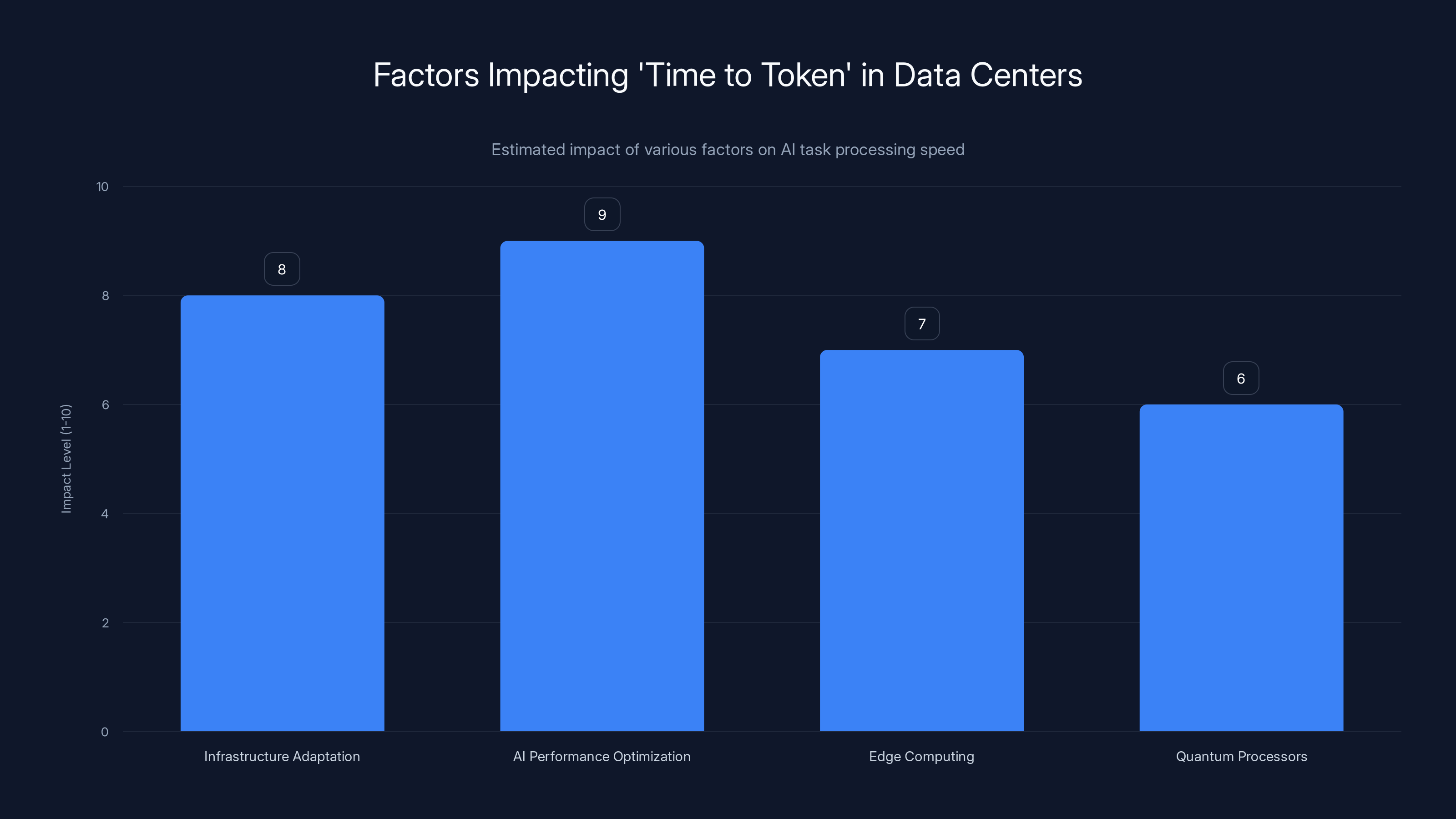
Optimizing AI performance and adapting infrastructure have the highest impact on reducing 'time to token'. Estimated data.
Practical Implementation
Best Practices for Reducing 'Time to Token'
- Use Specialized Hardware: Leverage GPUs and TPUs for parallel processing, which can drastically reduce computation times. As noted by NVIDIA's development blog, using full-stack optimizations can enhance energy efficiency.
- Optimize Data Paths: Ensure that data flows efficiently through the system with minimal latency.
- Implement Efficient Algorithms: Use libraries and frameworks that are optimized for token processing, such as TensorFlow and PyTorch.
- Monitor and Adjust: Continuously monitor performance metrics and adjust configurations to optimize performance.
Example Use Case
Consider a data center running a customer service AI application. By optimizing 'time to token', the AI can respond to customer inquiries faster, improving customer satisfaction and reducing operational costs.

Common Pitfalls and Solutions
Pitfalls
- Overlooking Bottlenecks: Focusing solely on processing speed without considering data transfer and storage can create bottlenecks.
- Ignoring Scalability: Not planning for scalability can lead to performance issues as demand grows.
Solutions
- Holistic Optimization: Address all aspects of the data center, including network, storage, and compute resources. As highlighted by GLG's analysis, a comprehensive approach is critical.
- Scalable Infrastructure: Design systems that can scale up or down easily to meet demand.
Future Trends
Edge Computing
As AI applications become more distributed, edge computing will play a crucial role in reducing 'time to token' by bringing computation closer to the data source. This trend is supported by HPE's investment in hybrid architectures.
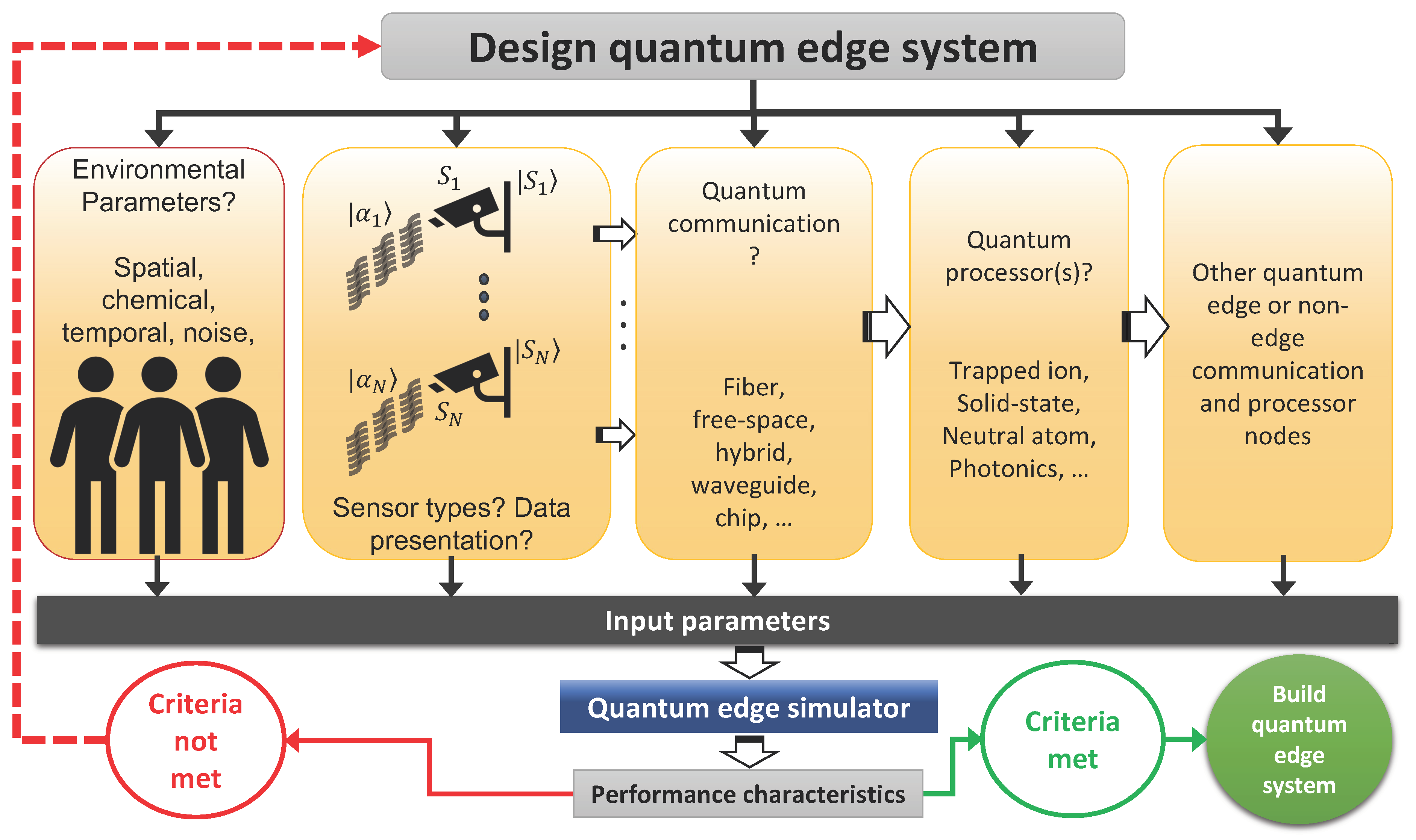
Quantum Processors
Quantum computing holds the promise of revolutionizing token processing by performing complex calculations at unprecedented speeds. According to Microsoft's cloud blog, scaling AI with quantum processors could lead to significant energy efficiency improvements.
Recommendations
- Invest in Advanced Hardware: Stay ahead by investing in the latest processor technologies. Qualcomm's entry into the AI chip race with high-bandwidth compute alternatives is a notable development, as reported by Digital Today.
- Adopt Agile Practices: Implement agile methodologies to quickly adapt to changing demands and technologies.
- Collaborate with AI Experts: Work with AI specialists to ensure that your infrastructure is optimized for AI workloads.
- Focus on Security: As computation speeds increase, so do the risks. Ensure that security measures are in place to protect data integrity.
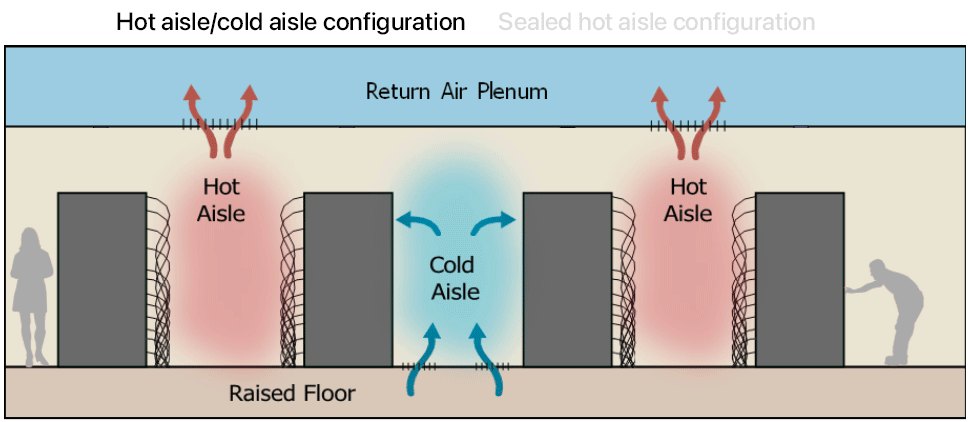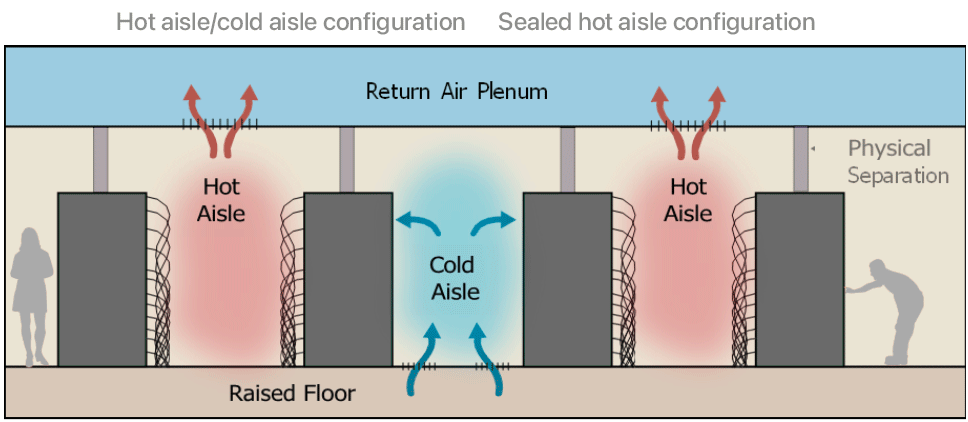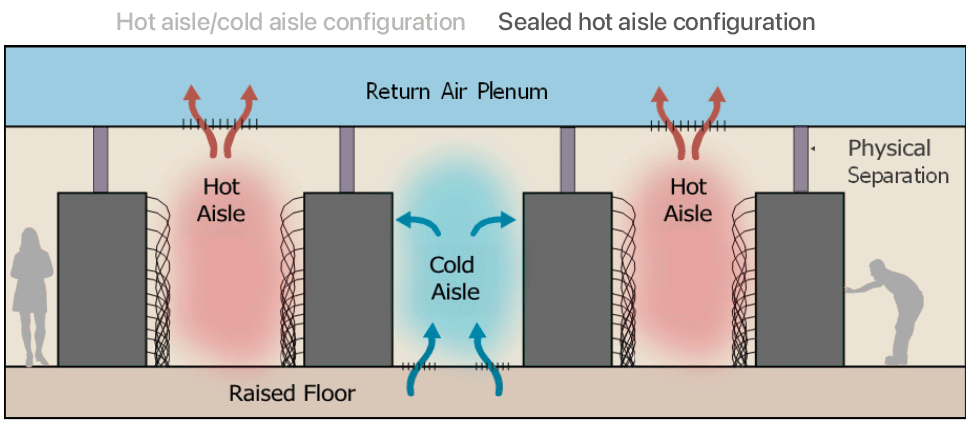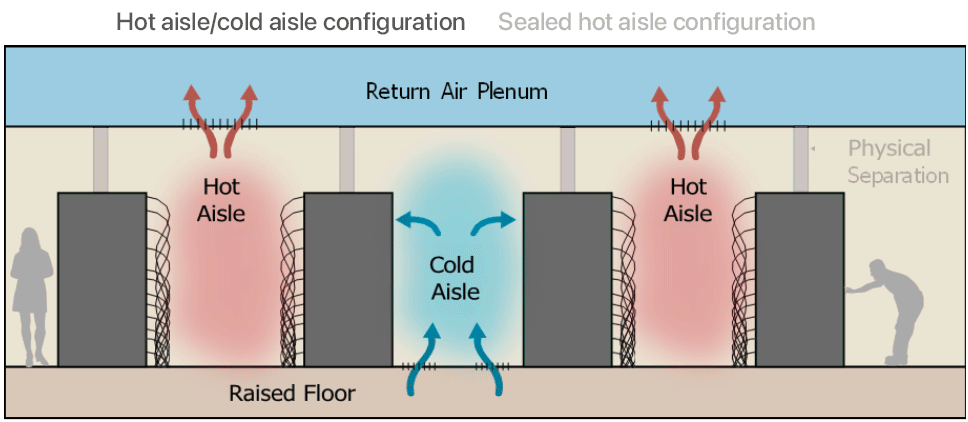
Conclusion
The race to optimize 'time to token' is more than just a trend; it's a necessity for data centers aiming to stay competitive in the AI-driven future. By understanding and addressing this metric, data centers can unlock new levels of efficiency and performance.
FAQ
What is 'time to token'?
'Time to token' is the metric that measures the time it takes for a data center to process a single token of data, which is crucial in AI applications.
How does 'time to token' work?
It involves optimizing both hardware and software to reduce the time needed to process computational tasks, thereby enhancing AI performance.
What are the benefits of optimizing 'time to token'?
Benefits include faster AI operations, reduced costs, improved scalability, and enhanced performance, as supported by Seeking Alpha's analysis.
How can data centers improve 'time to token'?
By investing in advanced hardware, optimizing data paths, and implementing efficient algorithms.
What are some future trends in 'time to token'?
Trends include the adoption of edge computing and the potential use of quantum processors to further reduce processing times.
Why is 'time to token' important for AI?
It's essential for maintaining competitive AI performance, reducing latency, and ensuring efficient data processing.
Key Takeaways
- Data centers must optimize 'time to token' for AI efficiency.
- Advanced hardware and efficient algorithms are crucial.
- Edge computing and quantum processors are future trends.
- Holistic optimization prevents bottlenecks and scalability issues.
- Investing in agile and secure systems is essential.
Related Articles
- Are Data Centers Consuming All Our Resources? [2025]
- Zoning Authority: A Solution to Data Center Challenges [2025]
- Meta and SpaceX: Monetizing Excess AI Compute Power [2025]
- Bipartisan Act Aims to Make AI Companies Pay for Energy Use [2025]
- How Lenovo's Role in FIFA World Cup 2026 is Democratizing AI for All [2025]
- SkillOpt: Redefining Agent Skills with Trainable Parameters [2025]

