
The AI Code Trust Paradox: A Critical Industry Challenge
The modern software development landscape faces a fascinating contradiction. Artificial intelligence has become deeply embedded in the daily workflows of developers worldwide, yet paradoxically, the vast majority of these same professionals express significant skepticism about the code their AI tools generate. Recent industry research reveals a troubling reality: 96% of developers admit they don't fully trust AI-generated code, despite the fact that approximately 42% of all code written today originates from AI assistants—a staggering increase from just 6% in 2023. This gap between adoption and trust represents one of the most pressing challenges in contemporary software development, as highlighted by ITPro.
What makes this situation even more concerning is the behavioral disconnect that follows this distrust. While developers openly acknowledge their reservations about AI-generated code quality, many fall into a false sense of security and fail to implement rigorous verification procedures. Studies show that fewer than half of all developers—a mere 48%—consistently check AI-generated code before committing it to production systems. This represents a fundamental breakdown in quality assurance practices that could expose organizations to significant technical debt, security vulnerabilities, and system failures, as noted in a TechRadar report.
The implications of this trust-verification gap are substantial. As we progress deeper into 2025, AI-generated code is projected to comprise approximately 65% of all code by 2027, representing a doubling of current usage rates within just two years. If current verification practices remain static while AI adoption accelerates, the cumulative impact of unvetted code could create systemic risks across the entire technology sector. This article explores the multifaceted dimensions of the AI code trust crisis, examining why developers struggle to maintain adequate verification practices, what security risks emerge from insufficient code review, and what solutions organizations can implement to ensure AI-assisted development remains secure and reliable.
Understanding this phenomenon requires examining the psychological, technical, and organizational factors that contribute to the trust gap. It also demands a practical exploration of how development teams can restructure their workflows to maintain quality assurance standards while leveraging the significant productivity benefits that AI development tools offer. The challenge ahead is not to abandon AI-assisted coding—the productivity gains are too substantial to ignore—but rather to fundamentally redesign how developers integrate AI outputs into their development processes.
Understanding the AI Code Trust Crisis
The Evolution of AI Adoption Among Developers
The trajectory of AI adoption in software development has followed an accelerated curve that few could have predicted. In 2023, only 6% of code being written across the industry came from AI sources. This represented a nascent phase where AI coding assistants were still novelties—interesting tools worth experimenting with, but not yet central to development workflows. However, the subsequent two years saw explosive growth that fundamentally transformed developer practices.
By 2024, this figure had skyrocketed to 42%, representing a nearly 7x increase in the span of just 12 months. This rapid adoption reflects several convergent factors: dramatic improvements in language model capabilities, increasingly sophisticated integration of AI tools into popular development environments, significant reductions in deployment costs, and widespread recognition among developers that AI-assisted coding genuinely enhances productivity. Tools like GitHub Copilot and ChatGPT integrated into development workflows, and specialized coding assistants have become standard equipment in most developers' toolkit rather than experimental side projects, as detailed by Exploding Topics.
The projected trajectory tells an even more dramatic story. Industry analysts forecast that by 2027—just three years away—AI-generated code will represent 65% of all new software development. This represents a shift toward an AI-first development paradigm where human developers spend more time orchestrating, reviewing, and refining AI outputs than composing code from scratch. Such a dramatic transformation raises fundamental questions about quality assurance, security verification, and the nature of software engineering expertise itself, according to Market.us.
Quantifying the Trust Gap
The statistical reality of developer skepticism is stark and unambiguous. When surveyed about their confidence in AI-generated code, 96% of developers report that they don't fully trust AI systems to produce functionally correct code. This near-unanimous expression of skepticism represents one of the highest distrust figures for any widely-adopted development tool. For comparison, developers express substantially higher confidence in code generated by junior colleagues, code pulled from established open-source libraries, or code written by overseas contractors—yet all these sources have demonstrably lower reliability records than modern AI systems, as reported by DevOps.com.
This skepticism, while understandable given the nascent nature of AI code generation, creates cognitive dissonance when examined against actual developer practices. Survey data reveals that 59% of developers claim they give "moderate" or "substantial" effort to reviewing AI-generated code before integration. However, this self-reported behavior contradicts behavioral data showing that only 48% of developers consistently check AI code before committing to repositories. The remaining 52% either skip verification entirely on some occasions or have insufficient processes to ensure systematic code review.
These numbers become even more concerning when contextualized against the complexity of modern codebases. A developer reviewing AI-generated code without specialized tools or processes faces challenges that exceed the effort required for original code production. Approximately 38% of developers explicitly state that verifying AI-generated code requires more time and effort than reviewing equivalent human-written code. This creates a practical barrier: as AI code volume increases, the absolute time investment required for thorough review becomes unsustainable within standard development timelines, as highlighted by TechTarget.
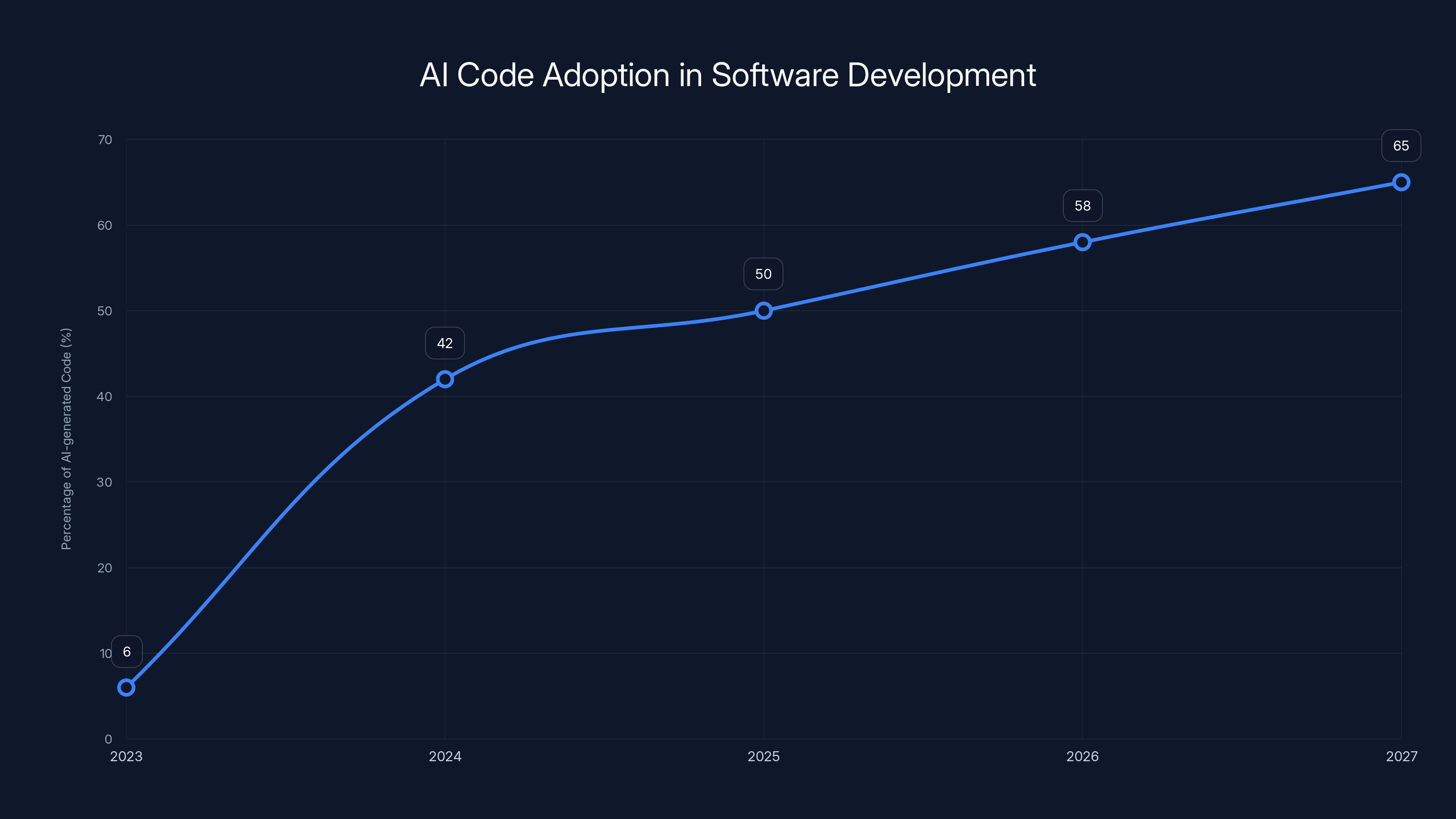
The adoption of AI-generated code in software development has rapidly increased from 6% in 2023 to a projected 65% by 2027, indicating a significant shift towards AI-first development practices. Estimated data for future years.
The Deceptive Nature of AI-Generated Code
Why AI Code Looks Better Than It Actually Is
One of the most insidious aspects of AI-generated code involves its superficial plausibility. Modern large language models trained on billions of lines of code have learned to write code that looks syntactically correct, stylistically appropriate, and functionally reasonable at first glance. This aesthetic correctness creates a dangerous false confidence in developers reviewing the output. Approximately 61% of developers report that AI-generated code "often looks correct, but isn't"—a deeply troubling acknowledgment that visible correctness serves as a poor indicator of actual functional reliability, as noted by DemandSage.
This phenomenon stems from how transformer-based language models operate. These systems learn statistical patterns about code from massive training datasets but don't possess genuine understanding of program semantics, data flow, or logical correctness. They're essentially sophisticated pattern-matching engines that can recognize common code structures and replicate them with impressive fidelity. However, this pattern-matching approach breaks down when confronted with edge cases, unusual control flows, or domain-specific logic that diverges from common training patterns.
A practical example illustrates this problem. An AI system might generate a database query that appears syntactically perfect and implements the requested logic for normal cases. However, the query might fail under concurrent access, produce incorrect results with certain NULL value combinations, or execute with catastrophic performance degradation on large datasets. These failures wouldn't be obvious from visual inspection—they'd only emerge during actual execution under realistic conditions. The problem intensifies because developers with high workload and time pressure naturally gravitate toward accepting apparently correct code rather than conducting exhaustive testing.
Quantified Evidence of AI Code Quality Issues
Independent research provides concrete measurement of AI code quality problems. A comprehensive analysis by Code Rabbit, which examined actual code contributions and subsequent bug reports, found that AI-generated code produces 1.7x more issues than human-written code across categories measured. More concerning still, AI code produces 1.7x more major issues—bugs that significantly impact functionality, security, or performance rather than minor style or efficiency problems.
This statistical validation of developer skepticism is crucial because it moves the discussion from subjective preference to objective measurement. The 96% of developers who distrust AI code aren't being irrational—they're expressing a reasonable skeptical stance backed by empirical evidence. The genuine challenge is that despite this evidence, many developers still fail to implement verification processes adequate to manage the increased risk, as discussed in CX Today.
The nature of these issues varies considerably. Some involve subtle logical errors that pass static analysis and basic testing. Others represent security vulnerabilities—code that functions correctly under intended use but exposes attack vectors under adversarial conditions. Still others involve concurrency issues, resource leaks, or performance problems that only manifest under specific runtime conditions. Each category of issue requires different verification approaches, and no single verification technique can reliably catch all problem types.

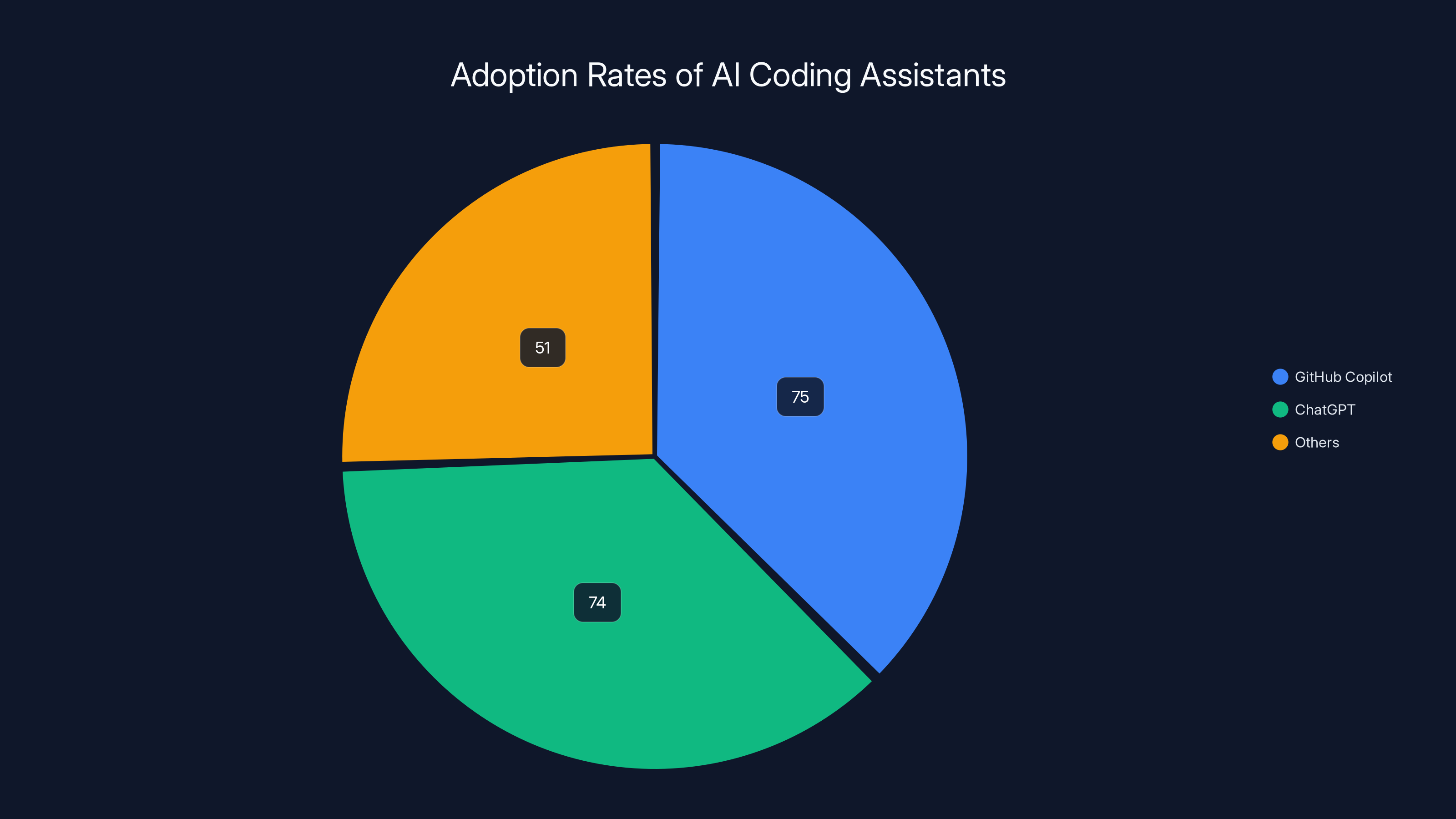
GitHub Copilot and ChatGPT show nearly equal adoption rates among developers, with both tools being used by over 70% of the surveyed population. Estimated data for 'Others'.
Where Developers Use AI-Generated Code
Distribution Across Application Types and Criticality Levels
Understanding where AI code appears in the software ecosystem is essential for assessing actual risk exposure. The distribution isn't uniform across application domains—instead, it follows patterns that partially reflect risk awareness but also reveal troubling gaps in verification practices. AI-generated code appears most heavily in prototyping and proof-of-concept scenarios (88% of developers), which represents relatively low-risk usage. Code written for demonstrations or experimental systems requires less rigorous verification because the consequences of failure remain contained and reversible.
The distribution extends into more critical contexts, however. Approximately 83% of developers use AI-generated code in internet-facing production software, and 73% integrate it into customer-facing applications. These represent substantially higher-stakes environments where code failures directly impact user experience, data integrity, and customer trust. When considering that less than half of all developers consistently verify code before deployment, the implications become clear: a significant portion of customer-facing systems likely contain unverified, statistically higher-defect AI-generated code, as reported by IBM.
GitHub Copilot dominates the AI assistant landscape with 75% adoption among surveyed developers, followed closely by ChatGPT at 74% adoption. These two tools have become effectively standardized across the industry, which creates both consistency and risk concentration. If these tools exhibit systematic biases or generate certain categories of bugs with elevated frequency, those problems propagate across the entire technology sector rather than remaining isolated to single organizations or teams.
The Critical Data Security Dimension
Beyond code quality concerns, AI code generation introduces a serious dimension of information security risk that extends far beyond the code itself. Many developers use AI assistants without organizational oversight or approval, creating shadow IT scenarios where proprietary code, algorithmic approaches, and business logic are transmitted to external systems operated by AI vendors. The statistics on this practice are alarming: more than one in three (35%) developers use personal accounts rather than organization-provisioned accounts when accessing AI coding tools, as highlighted by News Journal Online.
This figure rises dramatically among specific tool populations. 52% of ChatGPT users access the service through personal accounts rather than through organization-controlled enterprise accounts, and the percentage climbs even higher to 63% among Perplexity users. Each of these personal account accesses represents a potential data exposure incident waiting to happen. When developers paste code, system architecture diagrams, database schemas, or business logic into AI systems using personal accounts, they're potentially transmitting proprietary information to systems outside organizational security controls.
The implications compound when considering the training data practices of AI vendors. Code and explanations submitted to AI systems through personal accounts might be retained, analyzed, and potentially used to train future model iterations. Even absent explicit data retention, the existence of conversations and code samples on vendor servers means that if the vendor experiences a security breach, proprietary code becomes exposed. Organizations have limited visibility into what data left their networks, when it happened, or whether it was adequately protected during transmission and storage.
The Verification Gap: Why Developers Skip Code Review
Time Pressure and Workflow Integration
The most significant factor driving the verification gap is simple but powerful: time pressure. Modern software development operates under aggressive timelines where developers face constant pressure to complete features and ship functionality. When AI tools can generate functional code in seconds while manual code review requires minutes or hours, the economic incentives strongly favor accepting AI output without thorough verification, particularly under deadline pressure, as discussed in Palo Alto Networks.
This dynamic becomes more problematic because AI tools are integrated directly into development environments. When developers use GitHub Copilot or similar assistants, they receive code suggestions inline while typing, creating friction-free acceptance paths. A developer can press Tab to accept a suggestion and continue working, expending minimal cognitive effort to evaluate the proposed code. In contrast, rejecting the suggestion and writing code manually requires additional time and deliberate effort. Over hundreds of coding decisions per day, these small friction costs accumulate into substantial time penalties, creating strong behavioral incentives to accept AI suggestions even when skepticism about correctness persists.
Team and organizational structures amplify this problem. Many teams lack formal processes for reviewing AI-generated code specifically—they apply the same code review standards used for human-written code, which aren't calibrated for AI's characteristic failure modes. Standard code reviews check for style, architectural consistency, and logical correctness, but don't specifically look for the subtle bugs AI systems generate at elevated frequency. The result is code review processes that fail to catch the problems they're ostensibly designed to prevent.
Knowledge Gaps and Verification Skill Shortages
A second factor involves uncertainty about how to effectively verify AI-generated code. Developers trained in traditional code review techniques may lack frameworks for specifically identifying AI code weaknesses. What testing approaches reliably catch the categories of bugs AI systems generate? What static analysis tools work best for identifying AI code issues? How should developers structure test cases to cover edge cases that AI systems are likely to miss? These questions lack clear, standardized answers that developers can apply systematically.
This uncertainty creates decision paralysis where developers either conduct overly broad verification (checking everything, which becomes time-prohibitive) or minimal verification (spot-checking, which provides false confidence without genuine assurance). Neither approach represents optimal risk management. The absence of clear best practices for AI code verification means that each team must essentially develop verification frameworks independently, leading to inconsistent, often inadequate approaches across the industry, as noted by ITPro.
Organizational knowledge compounds this problem. Most software organizations have deep accumulated expertise in code review practices refined over decades. However, AI code generation represents a fundamentally novel phenomenon without this accumulated organizational knowledge. Developers trained through mentorship and example in established practices find themselves without clear role models or established patterns for AI code verification. This knowledge vacuum means that verification practices remain inconsistent and often inadequate even among highly skilled development teams.
The False Confidence Problem
A third factor involves psychological bias and overconfidence in human judgment. When code looks correct—and AI-generated code frequently does—developers develop confidence in its correctness despite intellectual awareness that AI systems produce defects at elevated rates. This represents a classic case of cognitive bias where statistical knowledge about group performance doesn't transfer into appropriate caution regarding individual instances.
Psychological research on automation bias suggests that when automated systems (including AI) present output confidently, humans tend to trust that output even when aware of the system's fallibility. A developer consciously knowing that AI code has 1.7x higher defect rates may still unconsciously trust that the specific code suggestions they're reviewing are probably fine, especially if the code looks reasonable. This bias becomes particularly powerful when developers are tired, under time pressure, or reviewing code in monotonous sequence—precisely the conditions under which most code review occurs.
Additionally, confirming biases lead developers to unconsciously focus on aspects of AI code that appear correct while overlooking or rationalizing potential problems. The human mind naturally seeks confirmatory evidence and minimizes disconfirming evidence. When reviewing code that appears correct, developers unconsciously search for reasons to accept it rather than conducting genuinely critical evaluation.
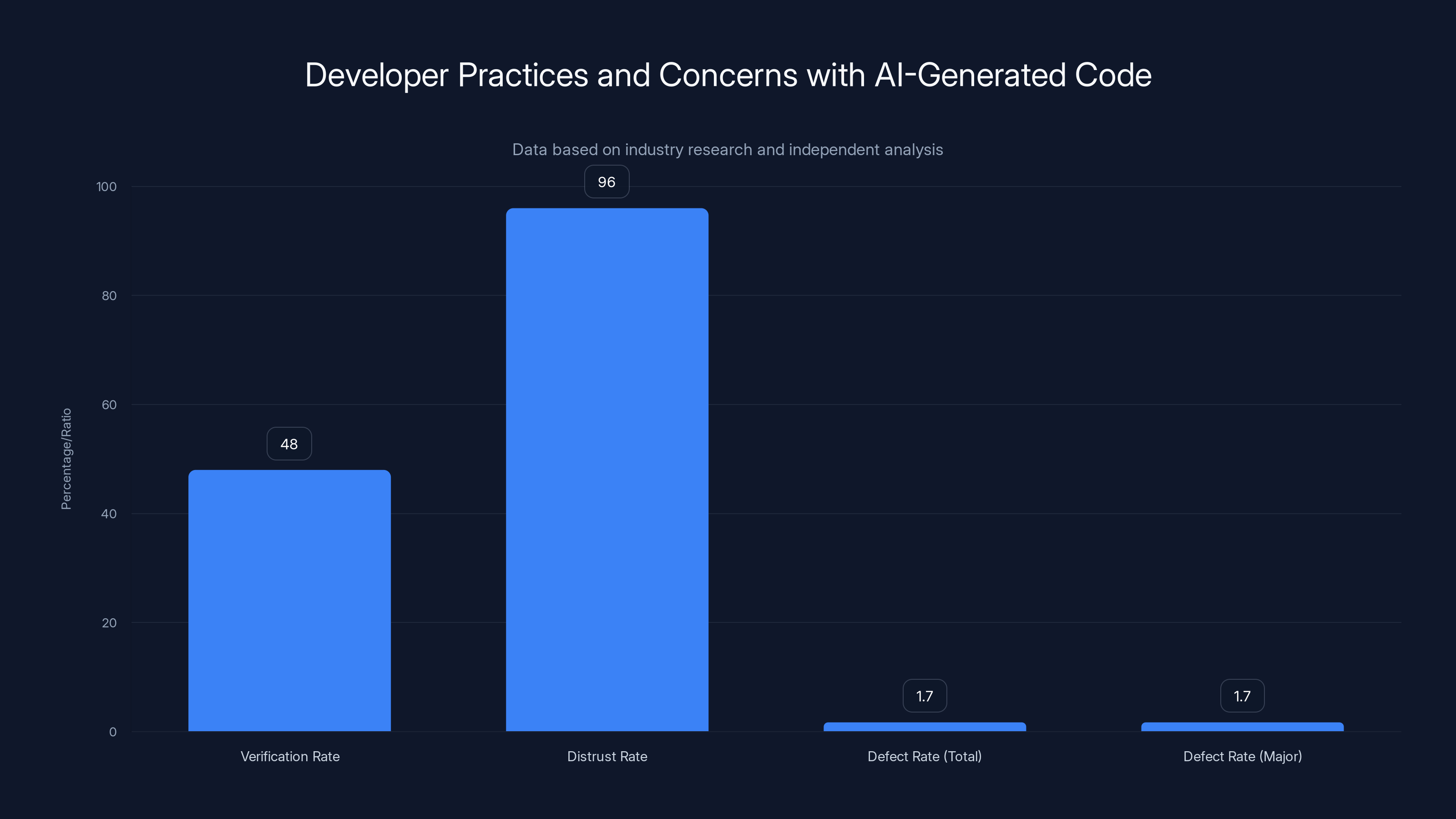
Only 48% of developers verify AI-generated code despite 96% expressing distrust. AI code has 1.7x more defects than human-written code.
Security and Vulnerability Implications
The Multi-Vector Risk Landscape
Developers recognize that AI code integration creates security risks, and their concerns have considerable validity. When asked about specific security concerns related to AI code integration, developers identify three particularly troubling categories: data exposure (57%), small vulnerabilities (47%), and severe vulnerabilities (44%). These three concerns represent progressively more serious threat vectors, and the fact that large majorities cite all three suggests broad recognition that AI code integration creates genuine security challenges across multiple dimensions.
Data exposure concerns reflect both the previously discussed risk of proprietary information transmitted to AI vendors and the risk of security vulnerabilities in AI-generated code that could expose customer or operational data. An AI-generated authentication system that appears to work might contain subtle flaws that allow unauthorized access. An AI-generated encryption implementation might use cryptographic patterns correctly at a high level but implement them in ways vulnerable to side-channel attacks. These aren't hypothetical risks—they represent realistic vulnerabilities that emerge from AI systems' sophisticated appearance masking subtle logical errors.
Small vulnerabilities—bugs with limited scope or impact, such as input validation failures in specific scenarios or resource handling issues in edge cases—represent the most likely class of AI-generated defects. These vulnerabilities might not compromise system security under normal operation but could be exploited by sophisticated attackers or triggered by unusual usage patterns. The frequency with which AI code produces small vulnerabilities means they're likely present in significant numbers across production systems, creating a distributed vector for eventual exploitation.
Severe vulnerabilities—bugs with major security implications such as SQL injection vulnerabilities, authentication bypasses, or critical resource disclosure—represent lower-frequency but higher-impact risks. The statistical elevation in AI code defect rates means that severe vulnerabilities appear more frequently in AI-generated code than in human-written code, even though they remain relatively uncommon in absolute terms. Given the number of AI-generated lines of code in production systems, even rare severe vulnerability classes accumulate into meaningful risk exposure.
Hidden Vulnerabilities in Production Systems
A particularly troubling aspect of AI code security risks involves their invisibility until exploitation. Code review processes that don't specifically target AI code defect patterns won't catch many of these vulnerabilities. Static analysis tools trained on traditional code problems may miss categories of issues unique to AI code. Testing procedures calibrated around expected human-written code behavior may not expose weaknesses in AI-generated code.
This invisibility means that production systems likely contain undetected vulnerabilities introduced through inadequately verified AI code. Until security incidents occur and vulnerabilities are forensically identified, organizations may remain unaware that their systems are compromised or vulnerable to compromise. The lag between vulnerability introduction and discovery creates extended windows of exposure where systems operate under false assumptions of security.
The supply chain dimension compounds this risk. Code written by development teams using inadequately verified AI assistants feeds into systems integrated by other teams, potentially infecting other parts of the system. A vulnerability in AI-generated code in one component might cascade into system-wide security failures when that component is integrated with other systems. Without explicit tracking of which code originated from AI assistants and which from human developers, security teams may have limited ability to assess exposure or prioritize remediation efforts.
Compliance and Regulatory Implications
For organizations operating in regulated industries—healthcare, finance, critical infrastructure—the security implications of unverified AI code extend beyond technical risk into compliance and regulatory territory. Many regulatory frameworks (HIPAA, PCI-DSS, SOC 2, etc.) include requirements for code quality assurance, security testing, and audit trails documenting the provenance and review of production code. Inadequately verified AI code potentially creates compliance violations separate from the security risks the code might introduce.
Regulators increasingly scrutinize AI usage in regulated systems, particularly regarding transparency and auditability. Some regulatory frameworks are beginning to require explicit disclosure when systems incorporate AI-generated components. For organizations integrating substantial volumes of unverified AI code into regulated systems, regulatory exposure could exceed even the security risks of the code itself, manifesting as fines, license restrictions, or operational constraints.

Psychological and Behavioral Factors
Cognitive Dissonance and Rationalization
The gap between developers' expressed distrust of AI code (96%) and their actual verification practices (48% consistently verify) reveals a classic case of cognitive dissonance—the psychological discomfort of holding contradictory beliefs. Developers consciously recognize that AI code is risky, yet they behave in ways that minimize that risk inadequately. Resolving this psychological tension, they develop rationalizations that justify their actual behavior despite conflicting beliefs.
Common rationalizations include: "the code looks correct, so it probably is," "our testing will catch any problems," "the AI tools are sophisticated enough that they rarely make mistakes," or "other developers are doing the same thing, so the risk must be manageable." Each rationalization allows developers to maintain their behavior while managing the cognitive discomfort of known, unmitigated risk. These rationalizations aren't consciously deceptive—they represent genuine mental processes that allow people to act despite uncertainty and anxiety.
This psychological dynamic is well-documented in other domains. Drivers, aware of accident statistics, nonetheless believe they're safer than average drivers. People understand abstract health risks from smoking or poor diet but discount those risks as applying to others rather than themselves. This same mechanism operates with AI code—developers intellectually understand the risk statistics but psychologically believe their situation represents an exception to general patterns.
Social Proof and Normalization
Developer behavior around AI code is heavily influenced by social proof—the tendency to assume that if many people are doing something, it must be acceptable. Given that 42% of code is currently AI-generated and adoption continues accelerating, AI-assisted coding has become normalized as simply "how modern development works." This normalization reduces perceived risk because unusual practices feel risky while common practices feel routine regardless of actual risk profiles.
When a developer sees that peer developers integrate unverified AI code into production systems, that behavior becomes normalized and accepted. Organizational culture around AI code verification (or lack thereof) powerfully influences individual behavior. In organizations where code review processes remain unchanged despite AI code integration, individual developers correctly infer that management isn't concerned about the practice, reducing personal motivation for more rigorous verification.
This social normalization is particularly powerful because it operates below conscious awareness. Developers aren't deliberately deciding "the risk is acceptable because others are doing it." Instead, they simply adopt behavioral norms established by their peer group and organizational context, rarely questioning whether those norms make sense for AI code specifically.
Expertise and Trust Asymmetries
Developers who spent years or decades learning to evaluate human-written code have developed sophisticated mental models of typical error patterns, common bugs, and reliable verification techniques. Transitioning to AI-generated code requires developing entirely new mental models for different error patterns. This transition creates expertise asymmetries where developers are highly skilled at evaluating human code but lack equivalent skill with AI code.
Facing this expertise gap, developers often default to trusting the AI system's apparent competence. If a language model can generate complex code, it must understand programming deeply, the unconscious reasoning goes. This inference contains truth—modern language models do understand programming at sophisticated levels—but it misrepresents the nature of that understanding. Language models understand statistics about code patterns, not the logical and semantic correctness that matters for actual functional systems.
These expertise asymmetries also influence trust in AI tools themselves. Developers lacking deep understanding of how large language models work (the vast majority) tend to either over-trust the systems as seemingly magical intelligences or under-trust them as black boxes. Neither stance enables appropriate calibrated skepticism—the belief that AI tools are sophisticated and useful but fallible in ways that require specific verification approaches.

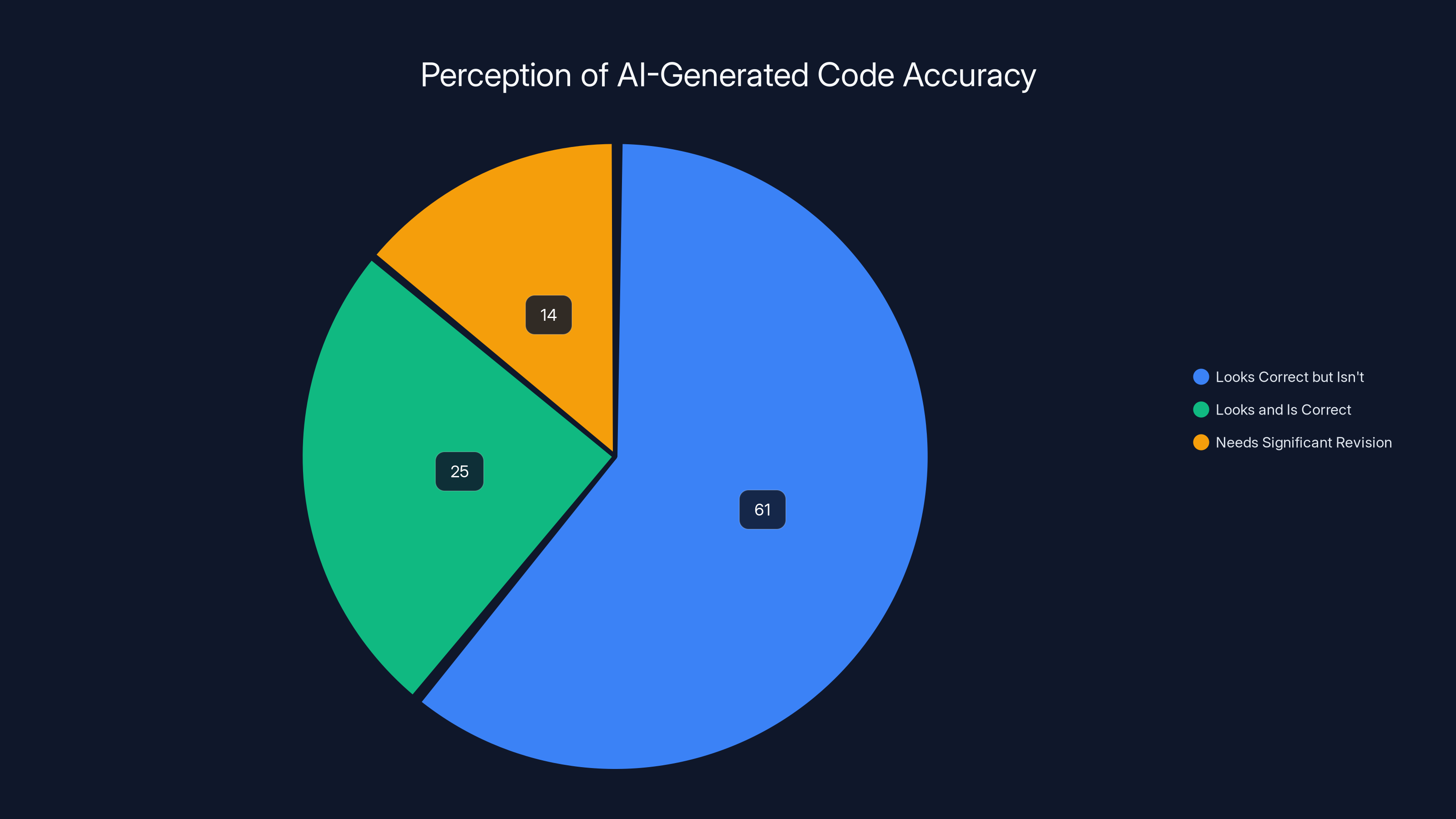
61% of developers find AI-generated code often looks correct but isn't, highlighting a gap between visual and functional correctness. Estimated data for other categories.
Current Tools and Assistant Adoption Patterns
GitHub Copilot Dominance
GitHub Copilot has achieved overwhelming dominance among developer-adopted AI coding assistants, with 75% of surveyed developers reporting active use. This dominance stems from several factors: deep integration into Visual Studio Code, the most popular code editor; ownership by Microsoft with corresponding credibility and resources; seamless integration into existing GitHub-based development workflows; and early-mover advantage in establishing itself as the default choice for AI-assisted coding.
Copilot's integration model directly into the code editor represents both strength and risk. Strength because developers have immediate access to AI assistance during actual coding, enabling tight feedback loops. Risk because the seamless, frictionless nature of code acceptance creates low barriers to incorporating AI code without reflection or rigorous verification. The neural pathway formed over months of pressing Tab to accept suggestions creates behavioral habits that persist even when developers consciously decide they should verify more carefully.
GitHub Copilot continuously evolves with improved model architectures, broader training data, and increasingly sophisticated code generation. However, these improvements may increase false confidence more than actual reliability. If each generation of GitHub Copilot generates slightly more syntactically correct and stylistically appropriate code, developers develop correspondingly higher confidence in the tool while the underlying defect rate may remain elevated or even increase as the tool tackles more complex code generation tasks.
ChatGPT and Broader Ecosystem Tools
ChatGPT reaches 74% adoption rates among developers surveyed, representing nearly equivalent penetration to GitHub Copilot despite entering the developer tool market more recently and lacking specific integration into development environments. Unlike Copilot which developers access through their primary coding interface, ChatGPT requires context switching—developers must open a separate tab or window, provide code context, and copy-paste results back into their editor.
This friction-based model creates different usage patterns than Copilot. ChatGPT adoption skews toward larger code blocks, complex problems requiring explanation, and strategic architectural questions rather than inline code completion during active typing. The question-answer format enables richer interaction than Copilot's suggestion model, allowing developers to ask follow-up questions, request explanations, or explore alternatives. However, the same lack of integration that adds friction also reduces systematic use in routine development tasks.
The broader AI coding tool ecosystem includes specialized assistants like Tabnine, Codeium, Amazon's Code Whisperer, and others, but these capture substantially smaller market share than Copilot and ChatGPT. This concentration creates risk concentration where bugs or limitations in the dominant tools affect the largest developer population, and improvements to dominant tools don't necessarily extend to users of alternative tools. The fragmentation also means that no unified best practices for AI code verification have emerged across the entire developer community.
Enterprise Account vs. Personal Account Divide
The split between enterprise and personal accounts for AI tool access creates a two-tiered system with different risk and benefit profiles. Organizations that provision enterprise accounts through GitHub, OpenAI, or other vendors gain visibility into usage patterns, ability to enforce security policies (like preventing proprietary code from being submitted), and integration with organization security infrastructure. An estimated 65-70% of developers using GitHub Copilot do so through organization-provisioned enterprise accounts, representing more controlled environments.
However, the substantial remaining portion using personal accounts operates outside organizational security and governance frameworks. Among ChatGPT users, 52% rely on personal accounts, and this rises to 63% for Perplexity users. These personal account users represent a significant risk vector: they're transmitting code to external vendors outside security controls, potentially exposing proprietary information, and creating security exposure that organizations have limited visibility into or ability to prevent.
Personal account usage often reflects deliberate choices rather than accidents. Some developers prefer the flexibility of personal accounts unfettered by organizational restrictions. Others may not be aware that their organization provides enterprise accounts. Still others work for small organizations or as independent contractors and lack organization-provided account options. Understanding this heterogeneous population is important for creating appropriate solutions—a one-size-fits-all security mandate won't work when substantial portions of the developer population have legitimate reasons for personal account usage.

Verification Approaches and Technical Solutions
Specialized Code Review Practices for AI Code
Thorough verification of AI-generated code requires different evaluation frameworks than traditional human code review. Standard code review focuses on architectural consistency, adherence to established patterns, and logical correctness as visible in code structure. AI code review additionally requires focus on categories of errors AI systems generate at elevated rates: subtle off-by-one errors, incorrect boundary condition handling, missing null checks and type validation, concurrency issues in multi-threaded code, and performance-critical algorithmic selections.
Effective AI code review begins with understanding the specific code generation request and context. Developers should document what they asked the AI to generate, what constraints or requirements they specified, and what the intended use case is. This context enables reviewers to evaluate whether the generated code actually addresses the request versus generating something that looks similar but doesn't quite match requirements. AI systems frequently generate code that superficially matches requests but diverges in important details.
Test-driven evaluation of AI code proves more effective than pure visual inspection. Rather than attempting to evaluate correctness through reading code, developers should write comprehensive test cases covering normal cases, boundary conditions, error scenarios, and performance constraints. Code that passes only happy-path testing frequently contains bugs in edge cases. Unit tests targeting specific code behaviors, integration tests validating interfaces with other system components, and performance tests confirming acceptable execution characteristics all contribute to comprehensive verification.
Static analysis tools specifically configured for AI code patterns provide additional verification value. Standard linters and static analyzers catch syntax errors and obvious bugs, but may miss subtle issues. Tools that specifically analyze code for concurrency issues, resource leaks, null pointer dereferences, and cryptographic implementation problems can catch AI-generated vulnerabilities human reviewers would overlook. Using multiple static analysis tools increases likelihood of catching issues that individual tools miss.
Automated Verification and Analysis Tools
Organizations increasingly recognize that manual verification alone cannot scale to the volume of AI-generated code. Automated verification tools integrated into CI/CD pipelines enable consistent evaluation of AI code without manual review burden. Code quality platforms that measure complexity, duplication, security vulnerability density, and other metrics can be configured with stricter thresholds for AI-generated code compared to human-written code, enabling more rigorous automated screening.
Custom automated checks targeting specific vulnerability classes common in AI code provide high-value verification. For example, an organization might create automated checks for: SQL injection vulnerabilities in database queries, authentication bypasses in security code, missing input validation in API handlers, or race conditions in concurrent code. These specialized checks, more targeted than general vulnerability scanners, can catch the exact issues AI code generates at elevated frequency.
Dynamic analysis and fuzzing tools that execute code with randomized or adversarial inputs can reveal bugs that static analysis misses. Fuzzing in particular proves effective against AI-generated code because AI systems may correctly implement intended logic but fail under unexpected inputs. By systematically feeding the code with unusual, invalid, or boundary-case inputs, fuzzing reveals robustness issues invisible in normal testing.
Security scanning tools specifically designed for vulnerability detection—software composition analysis for vulnerable dependencies, secrets scanning for exposed credentials, SAST (Static Application Security Testing) tools for code vulnerabilities—provide essential verification layers. These tools should be configured as mandatory gates in CI/CD pipelines for any AI-generated code, preventing deployment of unscanned code regardless of code review status.
Testing Strategies for AI Code
Testing AI-generated code requires consciously different strategies than testing human-written code. Standard test coverage metrics (percentage of lines executed) provide insufficient confidence in AI code correctness. Instead, developers should focus on boundary-case testing, deliberately attempting to make code fail through unusual inputs or exceptional conditions. Test cases should cover:
Edge cases and boundary conditions such as empty inputs, single-element collections, maximum integer values, negative numbers, zero values, null references, and exact boundary thresholds. AI systems frequently miss boundary condition handling that humans incorporate almost automatically through learned patterns.
Error handling verification ensuring that code handles exceptions, null values, type mismatches, and other error conditions correctly. Code that handles the happy path acceptably often fails when encountering error conditions AI systems don't properly anticipate.
Performance and scalability testing confirming that code maintains acceptable performance with realistic data volumes and concurrent access patterns. AI systems may generate algorithmically correct code with poor performance characteristics—for example, using nested loops creating quadratic complexity where linear-time algorithms would suffice.
Concurrency and threading testing particularly crucial for code handling multi-threaded access or distributed systems. AI systems frequently generate code with race conditions, deadlock vulnerabilities, or incorrect synchronization that only manifest under specific timing or concurrency conditions.
Security-specific testing including attempts to bypass authentication, trigger SQL injection or command injection vulnerabilities, access unauthorized resources, or exploit other security weaknesses. Adversarial testing mindsets prove particularly valuable for AI code that appears secure but contains subtle vulnerabilities.


AI-generated code is most commonly used in prototyping (88%), with significant use in internet-facing (83%) and customer-facing (73%) applications, highlighting potential risks due to less rigorous verification.
Organizational Approaches to Risk Management
Policy and Process Implementation
Organizations serious about managing AI code risks implement explicit policies governing AI tool usage, code generation, and verification. Such policies typically address: which AI tools are approved for use, which code components are ineligible for AI generation (security-critical code, encryption implementations, financial calculations), required verification and testing procedures for AI code, documentation requirements tracking AI code provenance, and incident response procedures for incidents involving AI-generated code.
These policies work most effectively when developed collaboratively between security, engineering, and leadership teams rather than imposed top-down. Policies perceived as overly restrictive generate workarounds (like the personal account usage phenomenon) that undermine policy effectiveness. Policies perceived as reasonable trade-offs between productivity and risk gain greater adoption and compliance.
Process implementation ensures that policies translate into actual practice. Many organizations establish dedicated code review responsibilities for AI-generated code, potentially requiring specialized expertise or longer review periods compared to human code. Some organizations implement mandatory pre-commit testing requirements where code cannot be committed without passing designated test suites. Others establish quarantine periods where AI code runs in non-production environments with additional monitoring before production deployment.
Documentation practices that track AI code provenance prove valuable for incident response and vulnerability management. When a vulnerability is discovered, organizations need to quickly identify which systems contain affected code. Clear labeling of AI-generated code components enables such rapid identification rather than requiring forensic analysis of code to determine origin. Some organizations use code comments identifying which AI assistant generated each function or method, enabling quick identification during incidents.
Training and Skill Development
Building organizational capability around AI code verification requires investment in developer training. Most developers trained through traditional education lack frameworks for understanding AI code generation, evaluating AI outputs, or implementing verification strategies appropriate for AI-generated code. Providing training on AI code verification techniques, common AI code defect patterns, appropriate testing strategies, and security validation approaches builds organizational competency.
Internal best practice documentation capturing lessons learned from organizations' own AI code experiences provides more relevant guidance than generic best practices. As teams gain experience with specific AI tools, they discover characteristic error patterns, effective verification approaches, and integration strategies that work well in their specific context. Capturing these lessons in accessible documentation enables broader organizational application.
Mentorship and communities of practice where developers share experiences with AI code verification accelerate learning. Organizations with substantial developer populations benefit from establishing groups where developers discuss AI tool experiences, share failure analysis from incidents, and collectively develop improved approaches. These communities of practice often prove more influential than top-down mandates in shifting developer behavior and building verification rigor.
Metrics and Continuous Improvement
Measuring outcomes of AI code integration enables data-driven improvements to processes and practices. Organizations should track metrics including: proportion of code originating from AI sources, percentage of AI code undergoing various verification approaches (static analysis, dynamic testing, security scanning), defect density in AI-generated code compared to human-written code, security vulnerability discovery rates in AI-generated code, and incidents resulting from inadequately verified AI code.
These metrics reveal whether current practices adequately manage AI code risks. If AI-generated code shows 1.7x higher defect rates, but current verification processes are equivalent to human code processes, metrics will reveal this gap and justify more rigorous verification investment. If certain verification approaches correlate with fewer downstream defects, metrics identify which approaches deliver greatest value and merit expansion.
Metrics also enable communication of risk to organizational leadership. Technical teams understand AI code risks intuitively, but executives need quantified business impact to justify investments in verification infrastructure. Metrics translating technical risks into business terms—increased incident rate, higher warranty costs, customer impact, regulatory exposure—enable proper resource allocation to verification investments.

Industry Standards and Emerging Best Practices
Standards Development and Governance Frameworks
As AI code generation matures, industry organizations are developing standards and best practices for responsible AI code generation and verification. Standards bodies including ISO (International Organization for Standardization), NIST (National Institute of Standards and Technology), and others are working on frameworks for AI system quality, security, and trustworthiness. These emerging standards will eventually establish baseline expectations for AI-generated code quality and verification approaches.
Companies in regulated industries increasingly reference these emerging standards when developing their own AI code policies. While formal standards remain in development, organizations can adopt frameworks from NIST's AI Risk Management Framework, CISA's guidance on securing AI systems, and industry-specific standards applicable to their sector. These frameworks provide more structured approaches than ad-hoc policy development.
Trust and transparency in AI-generated code will increasingly involve third-party certification and audit. Some organizations are beginning to require independent verification of AI code used in critical systems. As this practice expands, specialized firms offering AI code quality assurance and verification services will establish themselves as valuable parts of the development ecosystem, similar to how penetration testing and security auditing services support software security today.
Open Source and Collaborative Solutions
The open-source software community, recognizing the scale of AI code adoption challenges, is developing collaborative solutions that benefit the entire industry. Open-source tools for AI code analysis, verification, and testing reduce barriers to implementation for organizations without resources to develop custom solutions. Community-driven best practice documentation, shared threat models, and collective vulnerability discovery accelerate the industry's overall learning about AI code risks and mitigations.
Some open-source communities are establishing policies around AI-generated code contributions. Linux kernel maintainers, for example, are evaluating policies regarding AI-generated patches—what verification requirements apply, how to handle potential IP issues, and how to maintain code quality with AI contributions. The decisions made by major open-source projects influence broader ecosystem practices as developers apply lessons from those projects to their own codebases.
Collaborative platforms where developers share experiences with AI code, discuss problems encountered, and document solutions accelerate collective learning. Online communities discussing AI code quality, verification techniques, and failure analysis provide informal but valuable knowledge sharing that complements formal standards and official best practices.

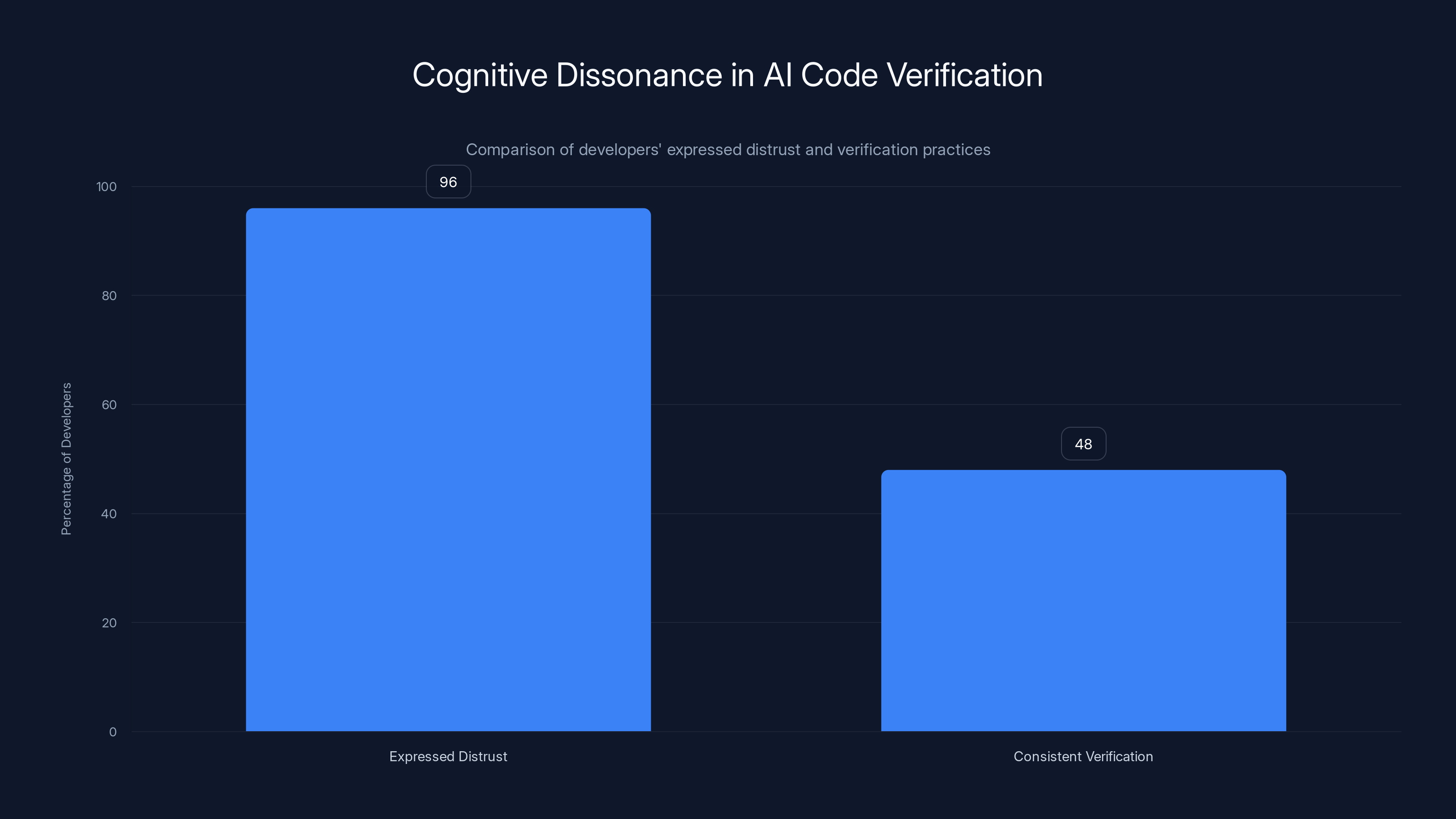
The chart highlights the cognitive dissonance among developers, with 96% expressing distrust in AI code but only 48% consistently verifying it. This gap illustrates the psychological tension between belief and behavior.
Future Directions and Evolving Landscape
Projected Evolution of AI Code Generation Capabilities
AI code generation capabilities will continue advancing dramatically. Models trained on more comprehensive training data, incorporating novel architectures, and using more sophisticated fine-tuning approaches will generate increasingly sophisticated and correct code. The gap between AI-generated code quality and human-written code quality will narrow substantially over the coming years. This improvement is generally positive—better quality AI code reduces verification burden and risk.
However, improved code generation capability may paradoxically increase risks if developers respond by reducing verification rigor. If AI-generated code improves from 1.7x higher defect rates to 1.2x higher defect rates while verification processes simultaneously become less rigorous, net risk may actually increase. The psychological tendency to develop overconfidence in improving systems creates risks that technical improvements alone won't mitigate.
Emerging AI models that explain their reasoning and provide justification for generated code may improve developer verification capacity. If AI systems can not only generate code but also explain why they generated that specific approach, document assumptions embedded in the code, and flag potential edge cases or risks, developers gain valuable inputs for verification. This explanability dimension may prove as important as raw code quality.
Integration with Development Infrastructure
AI code generation will become increasingly integrated into development infrastructure and CI/CD pipelines. Rather than remaining a separate tool developers access on-demand, AI code generation will be embedded in version control systems, automated test systems, documentation generation, and deployment automation. This ubiquity will make AI assistance more valuable but also requires ensuring verification and quality assurance requirements are embedded throughout the pipeline.
Future development environments may include AI-assisted code review, where AI systems analyze code changes and flag potential issues, explains vulnerabilities it identifies, and suggests fixes. This creates interesting dynamics where humans review AI-assisted code and AI systems assist human review of human-written code. The interaction between human developers, AI code generation, and AI-assisted verification creates complex dynamics requiring careful orchestration.
Automated testing and verification will become increasingly AI-assisted, with AI systems generating test cases, predicting likely failure modes, and optimizing testing strategies for specific code. This creates potential for virtuous cycles where AI generates code and AI also generates comprehensive test coverage, reducing human verification burden significantly. However, risks also exist where systematic biases in AI test generation lead to test coverage that misses important failure modes.
Regulatory and Legal Evolution
Regulatory frameworks governing software systems will increasingly address AI-generated code specifically. Different regulatory approaches will likely emerge for different contexts—for example, less stringent requirements for internal business systems compared to systems affecting public safety or financial systems. Organizations will need to track regulatory evolution and ensure their AI code practices align with developing requirements.
Legal liability for systems incorporating inadequately verified AI code remains unsettled territory. If a security incident results from vulnerabilities in AI-generated code, can customers seek damages from organizations that incorporated the code? Can they seek damages from AI vendors whose tools generated the vulnerable code? How do courts and regulators assign liability among developers, organizations, and AI vendors? These questions will likely be settled through litigation and regulatory action over the next several years, and outcomes will significantly influence organizational incentives around AI code verification.
Intellectual property questions around AI-generated code are actively contested, with questions about whether generated code infringes on training data sources and what rights organizations have to AI-generated code. If courts determine that AI vendors bear liability for code that infringes on training data sources, vendors will face pressure to implement stronger code filtering. If they determine that organizations incorporating AI code bear liability, organizations will face stronger incentives for rigorous verification.

Practical Implementation Guide
Assessment and Current State Analysis
Organizations beginning to address AI code verification should start with honest assessment of current practices. What percentage of code currently originates from AI sources? How thoroughly is AI code currently verified? What verification approaches are in place, and how consistently are they applied? Are there existing incidents or near-misses involving AI code? Answering these questions establishes baseline understanding and identifies highest-risk areas warranting immediate attention.
This assessment should include both technical audit and cultural assessment. Technical audit identifies gaps in verification infrastructure and processes. Cultural assessment identifies whether developers value verification, understand the reasons for verification, and see verification as aligned with their professional identity and organizational values. Successful implementation requires addressing both dimensions.
Outreach to developers to understand their perspectives on AI code, verification approaches they use, barriers they encounter, and improvements they believe would be valuable provides crucial input. Developers often have sophisticated intuitions about what verification approaches actually work in practice versus what looks good in documentation. Incorporating developer input into solutions increases likelihood of actual adoption rather than solutions that look good on paper but don't work in practice.
Phased Implementation Approach
Effective implementation typically follows phased approaches rather than attempting comprehensive transformation immediately. An initial phase might focus on establishing basic inventory and awareness—identifying where AI code is being used, bringing personal account usage into organizational visibility, and conducting baseline measurement of current verification practices. This phase prioritizes information gathering and stakeholder engagement.
A second phase typically focuses on establishing standardized processes and minimum verification baselines. This phase implements mandatory verification requirements that are feasible within existing infrastructure—perhaps mandatory static analysis scanning, required testing of AI code, or documented security reviews for security-critical code. Requirements are calibrated to be achievable without massive infrastructure investment, building momentum and demonstrating value.
Subsequent phases build on established foundations, adding more sophisticated verification approaches, specialized tools, automation, and continuous improvement. These phases align with increasing organizational sophistication and developer familiarity with AI code verification. Phased approaches succeed better than attempt comprehensive transformation because they allow learning and adjustment, reduce change management friction, and demonstrate value at each stage maintaining organizational commitment.
Tool Selection and Integration
Organizations selecting tools for AI code verification should prioritize tools that integrate into existing development workflows rather than requiring developers to adopt entirely new processes. Tools that plug into GitHub, GitLab, or other version control platforms, integrate with existing CI/CD infrastructure, and use existing testing frameworks have higher adoption rates than tools requiring new workflows.
Tool selection should balance comprehensive capability with practical usability. Ideal tools achieve good defect detection rates without excessive false positive rates that cause developers to ignore results. Tools should provide clear remediation guidance helping developers understand and fix identified issues rather than simply flagging problems without explanation. Tool ecosystems including multiple complementary tools (static analysis, dynamic testing, security scanning) detect vulnerabilities individual tools miss.
Organizations often benefit from starting with free or low-cost tools (many security scanning tools are free open-source projects) to establish baseline verification without major expenditure. As organizations mature their practices and achieve measurable value from verification, investment in commercial tools with more sophisticated capabilities becomes justifiable.

Comparative Solutions and Alternative Approaches
AI-Assisted Development Platforms Optimized for Verification
Beyond the widely-adopted GitHub Copilot and ChatGPT, emerging platforms specifically address AI code generation with integrated verification and safety features. Platforms that combine code generation with integrated security scanning, automated testing requirements, and verification workflows before code acceptance provide more comprehensive solutions than tools focused purely on code generation.
For teams seeking integrated development platforms that emphasize code quality alongside AI-assisted generation, solutions like Runable offer AI agents for workflow automation and content generation paired with verification capabilities that traditional AI coding assistants don't provide. Runable's approach to AI-powered development emphasizes automation of documentation, testing, and workflow processes alongside code generation, creating more comprehensive solutions than code-generation-only tools.
Similarly, specialized platforms focusing on enterprise AI code governance provide verification infrastructure exceeding what individual tools offer. These platforms integrate multiple verification approaches, provide audit trails and compliance documentation, enable policy enforcement, and offer team collaboration around AI code review. For large organizations or regulated environments, these comprehensive platforms often deliver more value than assembling point solutions.
Internal Development Approaches
Some organizations with significant engineering resources develop custom verification solutions optimized for their specific code patterns, domains, and risk profiles. Custom solutions can detect issues generic tools would miss, integrate seamlessly with organizational processes, and evolve to address emerging AI code problems. However, custom development requires substantial upfront investment and ongoing maintenance, making this approach practical primarily for large organizations or those with exceptional developer tool expertise.
Organizations developing custom solutions often start with open-source foundations, modifying existing static analysis tools, testing frameworks, or security scanners rather than developing entirely from scratch. This approach leverages community contributions while tailoring tools to specific needs. Open-source customization remains expensive but typically less expensive than fully custom development.
Third-Party Verification and Audit Services
Specialized firms offering AI code verification and security auditing services provide another approach, particularly valuable for organizations lacking internal expertise or resources. Third-party auditors bring specialized knowledge of AI code verification, established methodologies, and external credibility valuable for compliance and governance purposes. For security-critical systems or regulated environments, third-party verification adds assurance that internal teams alone might not provide.
Third-party services range from one-time comprehensive audits to ongoing managed verification services. Organizations might use one-time audits to establish baseline understanding and identify priority improvements, then implement internal processes based on findings. Alternatively, organizations contract for ongoing managed verification services where third parties continuously monitor code quality and security, enabling organizations to focus engineering resources on feature development.

Conclusion: Building Trustworthy AI-Assisted Development
The contradiction at the heart of modern software development—nearly universal AI tool adoption alongside nearly universal distrust of AI-generated code—isn't sustainable. As AI code generation advances from novelty to standard practice, the gap between developer skepticism and actual verification practices must narrow. Ignoring this challenge risks systematic erosion of code quality and security across the technology ecosystem.
The path forward requires three concurrent transformations. First, organizations must implement verification processes specifically calibrated for AI code rather than applying traditional code review practices expecting them to catch AI-characteristic defects. Standard verification approaches leave most AI code problems undetected, creating false confidence in code that harbors significant risks.
Second, developers need education and training that builds specialized expertise in evaluating AI code. The skills that make developers excellent at reviewing human-written code don't fully transfer to AI code verification. Understanding where AI systems characteristically fail, what verification approaches reliably catch those failures, and how to integrate verification into workflows without destroying the productivity benefits AI provides represents essential professional competency for modern developers.
Third, organizations must align incentives around verification. When development schedules allow time for thorough verification, developers verify code. When schedules demand rapid velocity, developers skip verification and rationalize risk as acceptable. Creating sustainable verification requires scheduling that reflects realistic verification requirements, team structures that make verification natural rather than exceptional, and recognition that verification investment delivers value through reduced incidents and technical debt rather than pure velocity.
The 96% of developers who distrust AI code are right to be skeptical. AI-generated code genuinely contains defects at elevated rates and creates genuine risks if deployed without proper verification. Rather than attempting to eliminate this skepticism through better AI models, the better path involves leveraging that skepticism as motivation for building verification practices adequate to manage the risks. This requires accepting that AI-assisted development isn't faster than human development if you account for verification requirements—it's faster during code generation but requires offsetting verification investment.
Looking forward to 2027 when AI-generated code is projected to comprise 65% of all code, the infrastructure for verifying that volume of AI code must mature substantially beyond current practices. The developer ecosystem has perhaps two years to build the knowledge, tools, processes, and organizational practices that will make 65% AI code penetration manageable rather than catastrophic from a code quality and security perspective.
The challenge is not to reject AI-assisted development—the productivity benefits are real and substantial—but to fundamentally redesign how development teams integrate AI outputs into their processes. This redesign requires verification approaches that match AI code risk profiles, organizational support for adequate verification investment, developer skills for effective AI code evaluation, and tool infrastructure that makes verification practical at scale. Organizations that execute this transition successfully will maintain code quality and security while capturing the substantial productivity benefits AI tools offer. Those that fail to implement adequate verification will eventually face significant technical debt, security incidents, or both. The choice, and the responsibility, rests with today's development leaders and their teams.

FAQ
What percentage of developers currently verify AI-generated code before deployment?
According to industry research, only 48% of developers consistently check AI-generated code before committing to version control, despite 96% expressing distrust of AI code correctness. This represents a significant verification gap where developers acknowledge risk but fail to implement systematic mitigation practices, leaving the remaining 52% of developers deploying unverified AI code into production systems.
How much more defective is AI-generated code compared to human-written code?
Independent analysis by Code Rabbit found that AI-generated code produces 1.7x more total issues and 1.7x more major issues compared to human-written code. Major issues represent bugs with significant functionality, security, or performance impact—the types of defects most likely to cause problems in production systems. This statistical elevation confirms that developer skepticism about AI code quality is empirically justified.
What are the main security risks from unverified AI-generated code?
Developers identify three primary security concerns: data exposure (57%), small vulnerabilities (47%), and severe vulnerabilities (44%). Data exposure stems from both proprietary information transmitted to AI vendors through personal accounts and vulnerabilities in AI code that leak sensitive system data. Small vulnerabilities create distributed risks through numerous edge-case defects, while severe vulnerabilities—though rarer—represent critical threats like authentication bypasses or injection attacks that AI systems generate at elevated frequency.
Why don't developers verify AI code more thoroughly despite trusting it less?
Multiple factors create the trust-verification gap. Time pressure is the primary factor—verification requires significant time while AI code generation is nearly instantaneous, creating economic incentives to accept code without review. Knowledge gaps about effective verification techniques leave developers uncertain how to evaluate AI code specifically. Cognitive biases lead developers to trust code that looks correct despite understanding statistically that AI code contains more defects. Social normalization of unverified AI code in organizational culture reduces perceived need for exceptional verification rigor.
What verification approaches most effectively catch AI-generated defects?
Multiple complementary approaches work synergistically: comprehensive test cases targeting boundary conditions and edge cases that AI systems characteristically miss, static analysis tools configured for AI-specific defect patterns like concurrency issues and null-checking failures, dynamic testing and fuzzing that executes code with unusual inputs to reveal robustness problems, and security scanning specifically targeting vulnerability classes that appear in AI code. Single verification approaches miss defects others catch, making multi-layered verification essential for comprehensive coverage.
How can organizations implement AI code verification without crushing developer productivity?
Effective implementation requires integrating verification into development workflows rather than creating separate manual processes. Automated verification gates in CI/CD pipelines catch issues before code reaches human review. Tool integration with code editors surfaces verification issues in real-time during development. Simplified policies requiring verification without prescribing specific approaches allow developers flexibility in implementation. Realistic scheduling that accounts for verification requirements prevents deadline-driven verification shortcuts. Organizations that treat verification as integral to development processes rather than bottleneck activity maintain productivity while managing risk.
What are the consequences of inadequate AI code verification in regulated industries?
Regulated industries face compounded risks beyond technical security concerns. Many regulatory frameworks include explicit requirements for code quality assurance, security testing, and audit trails documenting code provenance. Inadequately verified AI code potentially creates compliance violations separate from security risks. As regulators increasingly scrutinize AI usage in regulated systems, organizations may face regulatory fines, license restrictions, or operational constraints beyond customer impact from actual security incidents. The convergence of technical risk and regulatory risk makes AI code verification particularly critical in regulated environments.
How does AI code generation volume compare to projections for 2027?
Current data shows AI-generated code comprises approximately 42% of all code in 2024, representing dramatic growth from just 6% in 2023. Industry projections forecast this percentage rising to approximately 65% by 2027. This accelerating adoption curve means that verification infrastructure, developer expertise, and organizational practices must mature rapidly to manage increasingly large proportions of AI-generated code. The timeline for building adequate verification capabilities is compressed—organizations have approximately two years to implement practices that will scale to projected 2027 volumes.
What role do personal AI accounts play in security risk?
When developers use personal accounts to access AI tools rather than organization-provided accounts, proprietary code and business logic are transmitted to external vendor systems outside organizational security controls. 35% of developers use personal accounts, with rates rising to 52% for ChatGPT and 63% for Perplexity users. Personal account usage creates data exposure risks, prevents security policy enforcement, and makes it difficult for organizations to track what proprietary information has been exposed. Addressing this requires both security policy and accommodating legitimate reasons developers prefer personal accounts.
How do GitHub Copilot and ChatGPT differ in their role in AI code development?
GitHub Copilot (adopted by 75% of developers) integrates directly into code editors, providing inline suggestions during active development. This deep integration creates frictionless acceptance patterns where developers press Tab to accept suggestions. ChatGPT (adopted by 74% of developers) operates as separate question-answer interface accessed through browser tabs. The friction-based ChatGPT model drives different usage patterns—larger code blocks, complex problems, strategic questions—compared to Copilot's incremental assistance. Both tools dominate their respective categories, creating concentration of usage patterns and corresponding risk concentration.

Key Takeaways
- 96% of developers distrust AI-generated code, yet only 48% consistently verify before deployment
- AI code generates 1.7x more total issues and 1.7x more major issues compared to human-written code
- AI-generated code currently comprises 42% of all code (up from 6% in 2023) and is projected to reach 65% by 2027
- Time pressure, knowledge gaps, and cognitive biases create systematic barriers to adequate code verification
- Data exposure risks emerge from 35-63% of developers using personal accounts rather than organization-controlled accounts
- Multiple verification layers (testing, static analysis, security scanning) work synergistically to catch AI defects
- Effective solutions require integrating verification into development workflows rather than creating bottlenecks
- Regulatory frameworks increasingly require explicit treatment of AI-generated code in compliance and audit
- Organizations must build specialized expertise in AI code verification distinct from traditional code review skills
- The verification gap must narrow rapidly as AI adoption accelerates toward projected 2027 volumes

