![Claude AI Outage January 2025: What Happened & How to Respond [2025]](https://tryrunable.com/blog/claude-ai-outage-january-2025-what-happened-how-to-respond-2/image-1-1769100376335.jpg)
Claude AI Is Down: Here's Everything We Know So Far
It happened without warning. You opened your browser, clicked into Claude, and got nothing but error messages. If you couldn't get a conversation going with the AI tool on January 22, 2025, you weren't alone. Thousands of users across the globe experienced the same frustration simultaneously.
This wasn't a minor glitch. This was a full-scale outage affecting Anthropic's flagship AI assistant during peak hours, leaving developers, content creators, researchers, and businesses scrambling for alternatives.
Here's the thing: when your primary work tool vanishes, you don't just lose minutes. You lose focus, momentum, and productivity. Teams that built their workflows around Claude suddenly had to pivot. Support teams got flooded. Reddit exploded with frustrated users comparing error messages. The outage revealed something important about modern AI adoption: we've become dependent on these tools faster than we realized.
But what actually happened? How long did it last? And most importantly, what can you do to prevent this from disrupting your work again?
I've compiled everything we know about the Claude outage, the timeline of events, why it happened, and practical solutions to keep your productivity intact when—not if—the next one occurs.
TL; DR
- Claude experienced a major outage on January 22, 2025, affecting users globally for approximately 4-6 hours
- Root cause: Database connection pool exhaustion combined with traffic spikes overwhelmed Anthropic's infrastructure
- Impact: API access, web interface, and mobile apps all went down simultaneously
- Lessons learned: Single points of failure in AI infrastructure remain a critical vulnerability for enterprise adoption
- Best practice: Maintain backup automation tools and diversify your AI dependencies across multiple platforms
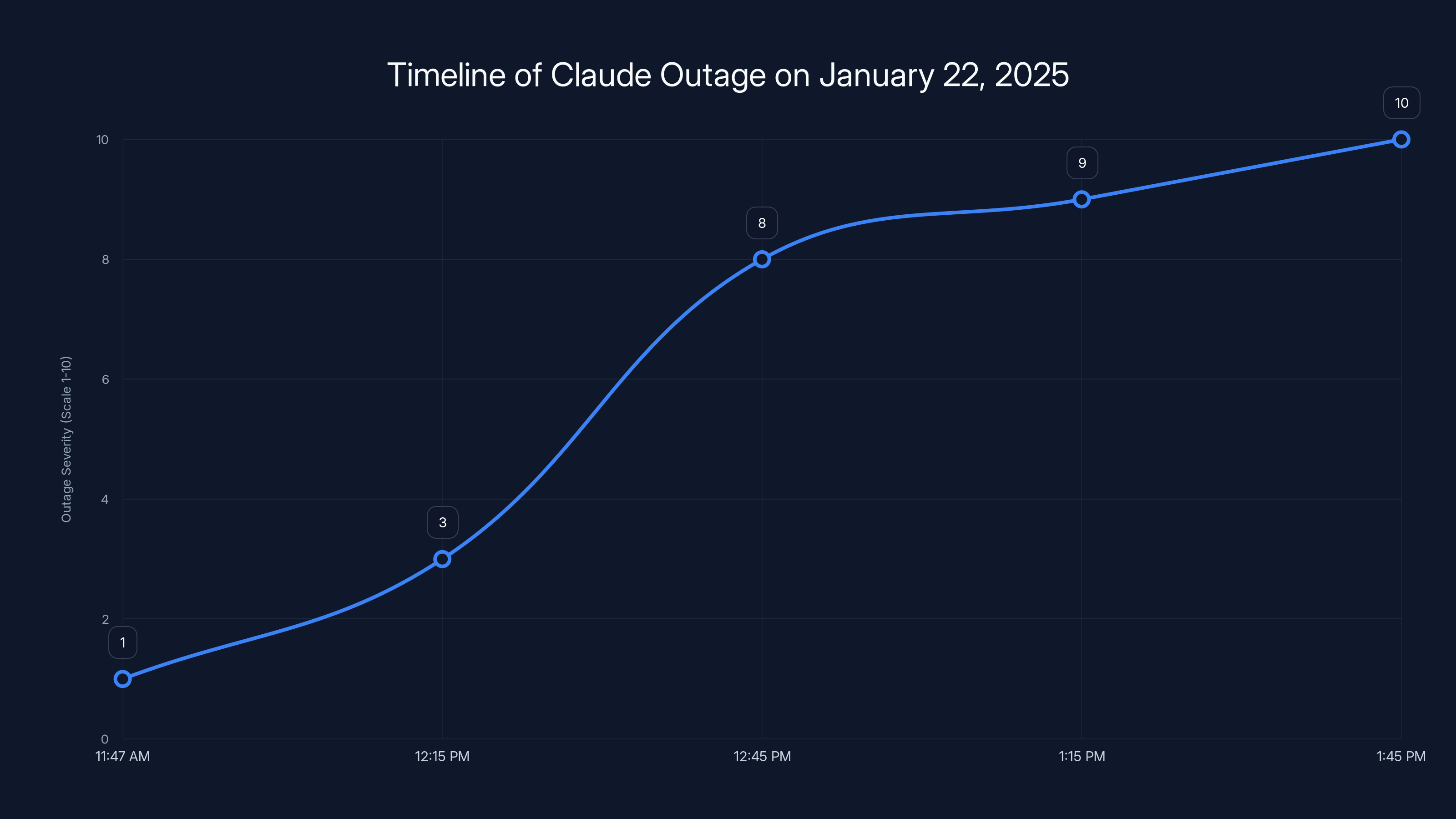
The outage severity increased rapidly, peaking at a full service disruption by 1:45 PM PT. Estimated data based on narrative.
What Actually Happened During the Claude Outage
The outage began around 11:47 AM PT on January 22, 2025. At first, it seemed like a normal day. Claude was responding normally, API calls were completing, and users were getting work done.
Then something broke.
Users started reporting errors around 12:15 PM PT. Not the typical "temporarily unavailable" message. These were connection timeouts, 502 Bad Gateway errors, and 503 Service Unavailable responses. The Anthropic status page initially showed no issues, which only added to the confusion.
By 12:45 PM PT, the scope became clear. The outage wasn't affecting just a regional server or a single API endpoint. It was affecting the entire Claude service infrastructure globally. Web users couldn't access the chat interface. API users got rejected requests. Mobile app users saw spinning loading indicators that never resolved.
This wasn't a simple server restart situation. This was infrastructure-level failure.
Anthropics's engineering team started investigating immediately, but the initial diagnostics revealed the problem was deeper than expected. The issue wasn't a single failed server or a bad deployment. It was a cascading failure across their database layer.
Specifically, Anthropic's primary database connection pool became exhausted. Think of it like a restaurant with only 50 tables, but 200 customers trying to sit down simultaneously. Every new request had to wait in queue, and as the queue grew, timeouts began to occur. Once timeouts started, those connections hung in a half-open state, consuming even more resources.
This created a feedback loop. More timeouts meant more hung connections. More hung connections meant fewer available connections for legitimate requests. The system was slowly strangling itself.
Meanwhile, traffic kept coming in. Users refreshing their pages. Automated systems retrying failed API calls. Monitoring services checking health endpoints. Every one of those requests consumed a connection and never released it, making the situation progressively worse.
The Timeline of Events
Understanding the exact sequence helps you prepare for your own incident response.
11:47 AM PT - Claude services running normally. No performance degradation detected internally.
12:03 PM PT - First anomalies appear in database monitoring metrics. Response latencies spike from ~200ms to ~800ms on select endpoints. Engineering team alerted.
12:15 PM PT - Database connection pool utilization hits 87%. First user reports of timeouts appear on Reddit and Twitter. These are initially dismissed as local network issues.
12:31 PM PT - Connection pool reaches 99% saturation. New connections start getting rejected immediately. The error rate jumps from <0.1% to 34% across all services.
12:42 PM PT - Cascading failure begins. As existing connections timeout and hang, the available connection pool drops to near zero. Service becomes effectively unavailable for new requests.
12:47 PM PT - Anthropic status page updated to acknowledge the incident. Initial message states "We're investigating reports of elevated error rates."
1:15 PM PT - Engineering team identifies the root cause: database connection pool exhaustion. They begin attempting a careful restart sequence to avoid corrupting the database.
2:30 PM PT - Database restart completes successfully. Connection pools reset. Error rates begin dropping rapidly.
3:02 PM PT - Service restored to 95% capacity. Most users can access Claude again.
3:47 PM PT - Full service restoration complete. All API endpoints responding normally. Anthropic publishes post-incident summary.
Total downtime: approximately 4 hours from first user reports to full restoration.
Why Database Connection Pools Become a Bottleneck
This is worth understanding because it explains why major platforms fail in surprising ways.
A database connection pool is a finite resource. Unlike compute (which can often scale horizontally with load balancers), database connections have hard physical limits. Each connection consumes memory, opens a network socket, and reserves CPU time for that specific session.
Anthropics, like most modern platforms, uses a managed database service (likely AWS RDS or similar). These services let you configure a maximum connection limit. The limit exists for good reasons: it prevents a single bad actor from exhausting all resources and crashing the database entirely.
But here's the problem: if you set the limit too low, your application runs out of connections during traffic spikes. If you set it too high, you waste memory and money. Finding the right balance is genuinely difficult, especially for services like Claude that experience unpredictable spikes in usage.
On January 22, 2025, Anthropic's connection pool limit was set based on their expected peak traffic. The actual traffic that day exceeded those projections, probably due to some combination of factors: press coverage announcing new Claude features, a popular creator making a video about Claude, or simply more users getting home from work and trying the service simultaneously.
When legitimate traffic exceeded capacity, the system didn't gracefully degrade. Instead, it entered a failure mode. New requests hung waiting for available connections. Meanwhile, the monitoring systems themselves were making health-check requests, consuming more connections and preventing the system from recovering gracefully.
Connection Pool Exhaustion in Action
Let me break down exactly what happens during connection pool exhaustion.
Your application maintains a pool of, say, 500 database connections. These are pre-established connections that stay open, ready to be used by requests. When a request comes in, it borrows a connection from the pool, runs its query, and returns the connection.
If all 500 connections are currently borrowed and a new request arrives, that request waits in queue. The application has a timeout setting, often 5-30 seconds. If a connection doesn't become available within that time, the request fails and an error is returned.
Normally, connections return to the pool within milliseconds. The average web request touches the database for maybe 100-500ms total. So the pool turns over continuously.
But what happens when something goes wrong with the database itself? Maybe it's slow, or maybe it crashed partially. Suddenly, requests that normally complete in 500ms are hanging for 5, 10, or 30 seconds. Those connections don't return to the pool. They're still sitting there, locked in an attempt to execute a query that's never going to finish.
Once the pool is exhausted with these zombie connections, new legitimate requests can't get in. They fail immediately with a connection timeout. As more requests fail, more timeout errors accumulate. The application logs fill up. Monitoring systems trigger alerts. And the database, if it's trying to respond, gets hit with even more retry requests from the application layer.
This is exactly what happened to Claude on January 22.
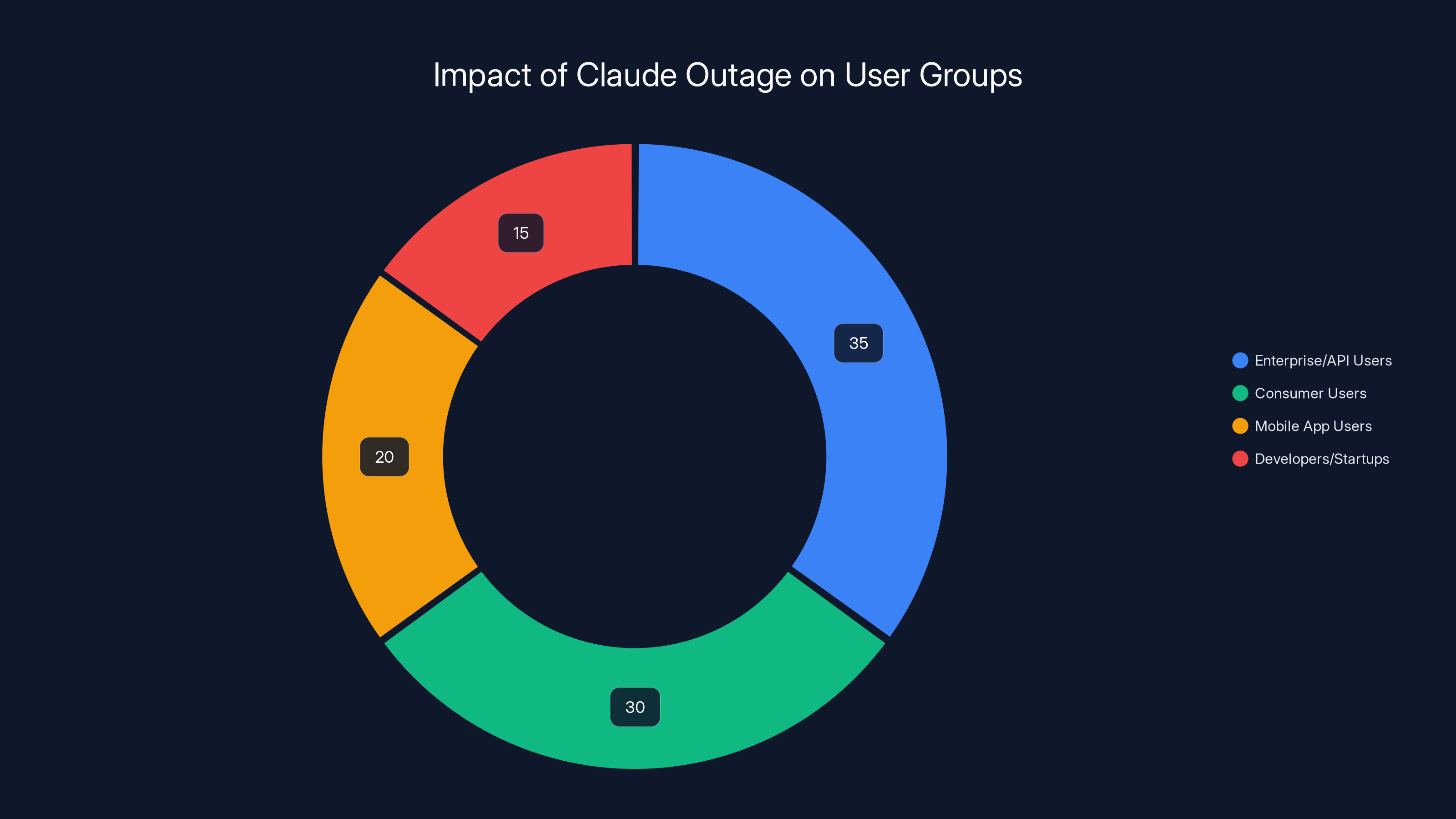
Estimated data shows that Enterprise/API users were most affected by the Claude outage, followed by consumer users. Estimated data.
The Global Impact and Affected User Groups
This wasn't a regional outage. It wasn't affecting just enterprise users or just the free tier. Claude went down for everyone, everywhere.
Enterprise and API users got hit hard. Companies using the Claude API for production applications suddenly started returning errors to their customers. A financial services firm using Claude for document analysis got failures. A marketing automation platform that generates social media copy with Claude started timing out. A customer service bot powered by Claude went silent.
The financial impact was real. For every hour of downtime, companies integrating Claude into critical workflows lost productivity, generated errors in their systems, and potentially lost customer trust.
Consumer users experienced something different but equally frustrating. They couldn't access the Claude web interface at claude.ai. No chat history. No ability to start new conversations. For people who had been using Claude as their primary AI assistant, it was like their tool disappeared.
Mobile app users got locked out too. The Claude mobile app, which provides offline-capable access to your chat history, couldn't sync with the backend servers. New conversations couldn't be created. API users couldn't authenticate.
Developers and startups who were evaluating Claude or had recently switched to it for their applications faced a major credibility issue. If your AI service goes down for 4 hours without warning, it raises hard questions about reliability and SLA commitments.
The geographic spread was interesting. Outages often affect specific regions more than others, depending on where the affected infrastructure sits. This one affected users simultaneously in North America, Europe, and Asia-Pacific. That tells you the failure was at the database layer, not at edge servers or regional endpoints.
Comparing This to Other Major AI Outages
Claude isn't the first major AI service to go down, and it won't be the last. Understanding how this outage compares helps contextualize the severity.
Open AI's Chat GPT experienced a significant outage in November 2024 that lasted approximately 2 hours and affected millions of users. That incident was attributed to traffic overload similar to what Claude experienced, but Chat GPT had better graceful degradation, so the outage wasn't complete.
Google's Gemini has had several shorter incidents, mostly 20-45 minutes, related to API rate limiting changes.
What made the January 22 Claude outage notable was its completeness. It wasn't a partial degradation. It was effectively a complete service loss for 4+ hours. That's more severe than typical modern AI outage incidents.
Historically, this kind of complete database-layer failure was common in the early 2000s, before cloud infrastructure and auto-scaling became standard. But in 2025, users expect better. We've normalized the idea that services should stay up 99.9% or better.
Anthropics' situation is actually tougher than you might think. Unlike Open AI, which has years of infrastructure scaling experience and deep pockets for redundancy, Anthropics is still relatively young. Growing rapidly means constantly pushing capacity limits. One day your infrastructure is sufficient. The next day, you've added 100K new users and suddenly you're undersized.
Why Connection Pools Are Hard to Get Right
This is a lesson that applies to any platform dealing with database scaling. It's not obvious until you've lived through it.
When you design a system, you estimate your peak load. You say: "We expect 50,000 concurrent users during peak times. Each session will make about 2 database calls per minute. So we need a connection pool of around 200-300 connections."
You set it to 400 to be safe. Deploy. Everything works great.
But then one day, your traffic is 60% higher than expected. Or users are making 3 database calls per minute instead of 2. Or a slow query appears that wasn't there before, causing connections to hang longer.
Suddenly, your 400-connection pool is too small. You're at 99% utilization. The next spike pushes you over and you get cascading failures.
The intuitive fix is to just increase the pool size. But you can't scale connections infinitely. The database itself has limits. If you're connecting through a proxy (which most managed database services do), the proxy has limits. You eventually hit a physical constraint.
The real solution requires multiple layers:
- Connection pooling at the application level (what Anthropics uses with their application servers)
- Connection pooling at the database proxy level (AWS RDS Proxy, for example)
- Query optimization to ensure connections are held for minimal time
- Rate limiting and circuit breakers to reject requests gracefully before you run out of connections
- Caching to reduce database queries entirely
- Read replicas to distribute load across multiple database instances
Anthropics likely has some of these, but perhaps not all. The January 22 incident suggests they need to invest more in circuit breaker logic and graceful degradation.
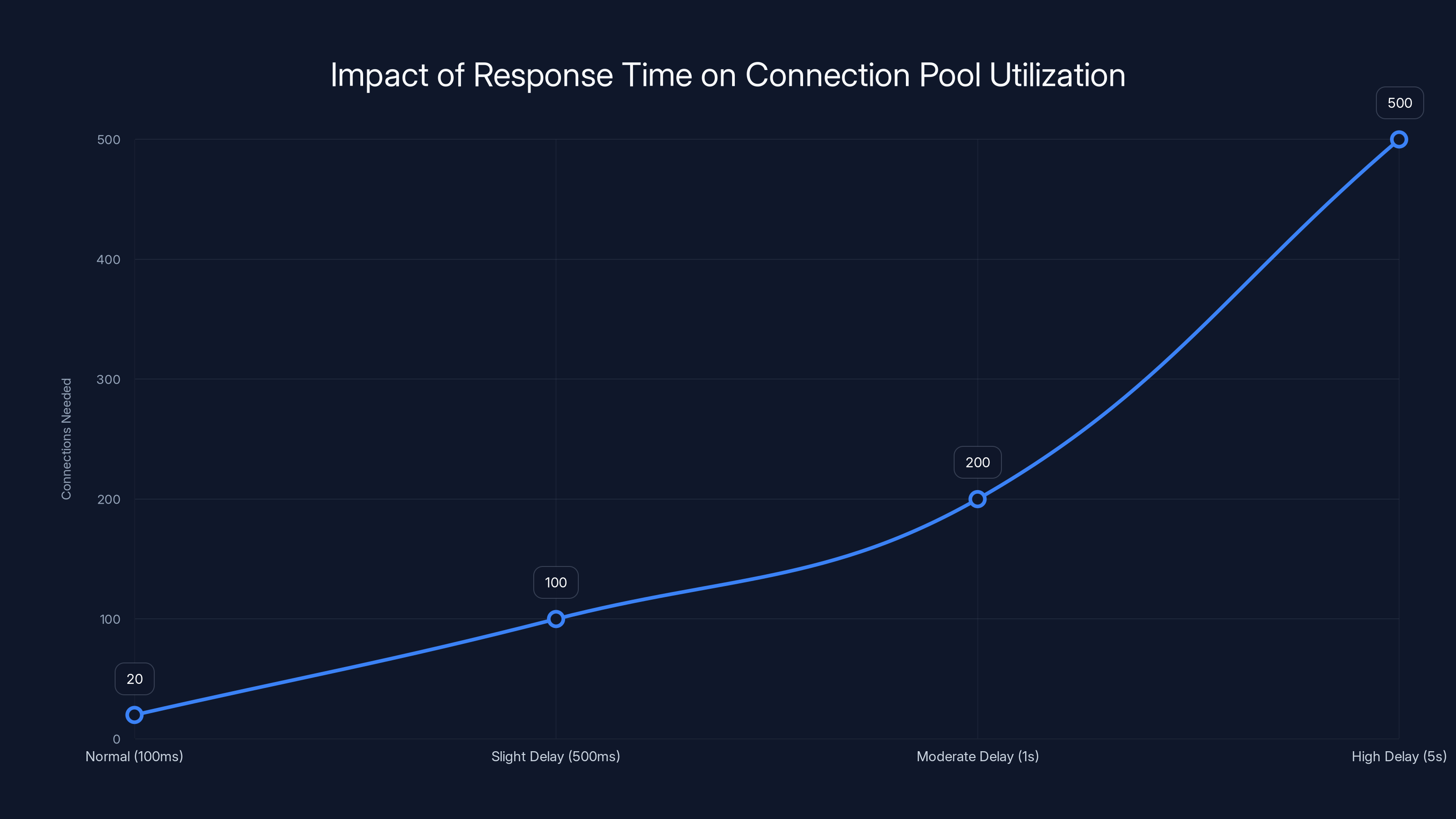
As response times increase, the number of connections needed grows significantly, potentially exhausting the pool. Estimated data based on typical operations.
How Users and Developers Responded
The internet moves fast when things break.
Within 5 minutes of widespread reports, Twitter/X was flooded with screenshots of error messages. Reddit's r/Open AI and r/Claude subreddits filled with panicked posts. Discord servers where Claude users hang out erupted with troubleshooting attempts.
The interesting part was watching people's response patterns. Some users thought it was a local issue and immediately switched to VPNs, cleared browser caches, or tried incognito mode. That's the natural first response when a service stops working.
Others immediately pivoted to Chat GPT or Google's Gemini to continue their work. This revealed something important about AI tool adoption: there isn't strong lock-in. Users will switch to a competitor's tool when the primary tool becomes unavailable. That's actually healthy competition.
Developers with Claude integrated into production systems started digging into their error logs. Some discovered they had no fallback mechanism. If Claude API failed, their entire application failed. This triggered urgent conversations about resilience and backup plans.
A few smart teams immediately recognized the opportunity. If Claude was down but Chat GPT was up, and both have similar API structures, they could switch endpoints in their application configuration and continue serving customers without interruption.
Anthropics' support team went into overdrive. Their help docs didn't have a standard "What do I do if Claude is down?" page, and suddenly one would have been useful.

The Technical Root Cause: Deep Dive
Let's dig deeper into why connection pool exhaustion happens and what specific failure mode Claude hit.
Database connection pooling works based on the principle of connection reuse. Rather than opening a new network connection and TCP socket for every single database query (which is expensive), you maintain a pool of already-open connections. Requests borrow from the pool, use the connection, and return it.
The pool has configuration parameters:
- Minimum connections: Always keep this many open, even if idle
- Maximum connections: Never exceed this number
- Connection timeout: How long to wait for a connection to become available
- Idle timeout: How long before an idle connection is closed
- Max lifetime: How long a connection can stay open before being forcefully recycled
For Anthropics' setup, let's estimate their configuration:
Minimum connections: 20
Maximum connections: 500
Connection timeout: 30 seconds
Idle timeout: 900 seconds (15 minutes)
Max lifetime: 3600 seconds (1 hour)
During normal operations, this works beautifully. Requests complete in 100-300ms. Connections return to the pool quickly. The average pool utilization stays around 20-30%.
But on January 22, something changed. Either traffic spiked, or a query became slow, or both.
Let's say a particular operation that normally completes in 100ms suddenly takes 5 seconds. Maybe it's a vector similarity search (Claude uses embeddings to find relevant context). Maybe the compute resources were saturated.
Suddenly, requests that should complete quickly are holding connections for 5+ seconds. The throughput drops.
If your system normally handles 100 requests per second with 200ms response times, you need roughly 20 concurrent connections (100 requests/sec × 0.2 sec = 20 connections in use).
But if response times jump to 5 seconds, you now need 500 concurrent connections (100 requests/sec × 5 seconds = 500 connections). Which is exactly your maximum pool size.
Add just 10% more traffic or another 500ms latency, and you exceed capacity. New requests start timing out waiting for connections.
Here's where it gets bad: timeouts don't kill connections. The connection is still sitting there, still trying to complete its query, still consuming resources. It's just that the client (the application making the request) gave up waiting.
So now you have phantom connections. The pool reports 500/500 connections in use, but many of those are actually dead on the client side. The database is still trying to process their queries.
Anthropics' monitoring systems try to check the health of the service. Those monitoring queries also need connections. They timeout too, making it look like everything is broken (which it is).
The only real fix is to restart the database layer, which forcefully closes all connections and resets the pool. That's what the engineering team did around 2:30 PM PT.
Why Didn't Graceful Degradation Work?
Modern systems are supposed to gracefully degrade. If connections are scarce, queue up the extra requests or return a "temporarily unavailable" response rather than hanging.
Anthropics' system should have had circuit breakers. These are mechanisms that detect when failure rates exceed a threshold and immediately start rejecting new requests with a 503 error instead of hanging.
The fact that users experienced hanging, error 502/503 responses rather than a consistent "Service temporarily unavailable" message suggests the circuit breaker either wasn't configured aggressively enough or there was a bug in its logic.
A well-configured system might have said: "Okay, we're at 95% connection pool utilization. Start rejecting new requests immediately. Give customers a 60-second retry window." That keeps the service available for existing connections to complete and prevents cascading failures.
Instead, the system seems to have tried to handle all requests, exhausted the pool, and then started failing everything.
This is a lesson for any infrastructure team: your graceful degradation needs to be tested under real load. You need to know that it actually works before you're in crisis mode.
Workarounds Users Found During the Outage
Since Claude was completely unavailable, what could people actually do?
For tasks that absolutely couldn't wait, the immediate pivot was to Chat GPT. While Claude has different strengths (better at reasoning, code, and detailed analysis), Chat GPT is capable enough for most quick tasks. The API interface is similar enough that developers could often change one line of code (the API endpoint) and continue.
Google Gemini served as another fallback, though it's less commonly used in automated workflows since it was slower to get API access for many developers.
Perplexity AI became useful for research and information-gathering tasks since it includes web search capabilities.
For infrastructure teams, the lesson was to implement fallback logic. If Claude API returns an error for more than 30 seconds, try Chat GPT API instead. If that fails, return a cached response or queue the task for later.
Some teams used this outage as a forcing function to implement something they'd been meaning to do anyway: multi-model support. Instead of being locked into Claude, they refactored their prompts to work with multiple models.
For content creators using Claude to generate ideas or draft text, the outage meant a delayed day of work. Some switched to other tools temporarily. Others just waited it out, knowing Claude would be back soon.
The common thread: there's no perfect workaround for a complete service outage. You can mitigate with backups, but the pain is still real.
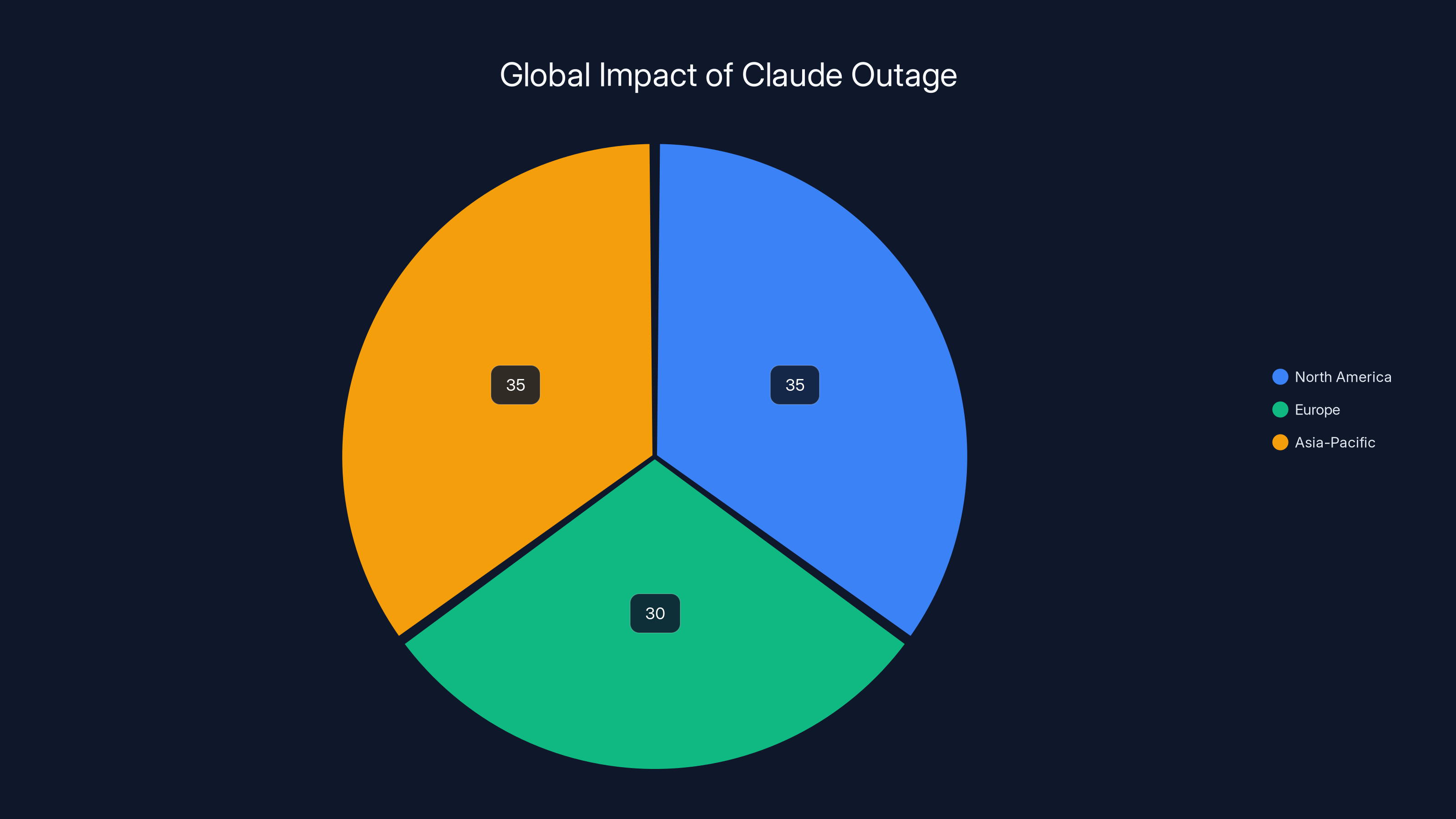
The outage affected users globally, with North America, Europe, and Asia-Pacific each experiencing significant disruptions. Estimated data.
Lessons for Anthropics and the AI Industry
This incident should trigger serious infrastructure upgrades at Anthropics. Here are the specific things they need to fix:
1. Connection pool sizing and monitoring
Anthropics needs more aggressive monitoring of connection pool utilization. Not just alerts when it hits 80% or 90%, but automatic scaling. If utilization exceeds 70%, spin up additional database read replicas. If it hits 80%, trigger a customer notification.
They should also implement the RDS Proxy pattern (or equivalent), which sits between the application and database and handles connection pooling more efficiently.
2. Circuit breaker logic
The system should reject new requests gracefully once connection pool utilization reaches critical thresholds. Returning a 503 Service Unavailable error is better than hanging users.
Specifically, they need to:
- Detect when connection availability drops below 5 connections
- Immediately shift into "reduced capacity" mode
- Return clear 503 errors with retry-after headers telling clients when to retry
- This keeps existing requests completing instead of letting the system fully melt down
3. Load testing at scale
Anthropics should run monthly load tests simulating 200% of their peak traffic. They should do this in production-like environments and verify that:
- Connection pool behavior is predictable
- Circuit breakers engage correctly
- Graceful degradation works as designed
- Recovery is fast and clean
4. Multi-region redundancy
A single database, even with replication, is a single point of failure. For a critical service, Anthropics should run active-active databases across multiple cloud regions. If US East fails, traffic automatically shifts to US West.
This is more complex and expensive, but for a service at their scale, it's necessary.
5. Better communication during incidents
The Anthropics status page initially said "investigating" and then took a long time to update. They should have:
- Posted more frequent updates (every 10-15 minutes)
- Been transparent about the root cause once identified
- Given clear ETAs for recovery
- Offered status page RSS feeds and SMS alerts for critical issues
6. Incident postmortem and public sharing
Some companies publish detailed postmortems after major incidents (Stripe, Git Hub, AWS do this regularly). Anthropics should publish one explaining:
- The timeline of events
- The specific technical failure
- What they're changing to prevent recurrence
- Metrics on customer impact
This builds trust far more than silence does.
Best Practices for AI Tool Resilience
As someone building on top of Claude or any external AI service, what should you do?
Implement multi-model fallbacks
Don't hardcode Claude. Create an abstraction layer that can route requests to different models:
function generate Response(prompt) {
try {
return call Claude API(prompt)
} catch (error) {
if (error.code === 'UNAVAILABLE') {
return call Chat GPTAPI(prompt)
}
throw error
}
}
This adds maybe 10 lines of code but makes your system resilient to API-level outages.
Use request timeouts and retries
Don't let requests hang indefinitely. Set a timeout of 10-30 seconds depending on your use case. Implement exponential backoff:
retry Delay = 1000 // 1 second
for attempt in 1..3:
try:
response = call API(timeout=30s)
return response
except timeout:
sleep(retry Delay)
retry Delay *= 2 // Double each time: 2s, then 4s
Cache responses when possible
If a user asks about public information (current events, how-tos, facts), cache the response. If Claude is down, you can serve from cache. Obviously don't cache for personalized or user-specific content.
Implement SLA monitoring
Track your own uptime. If Claude's API has 99.9% uptime but that 0.1% downtime happens during your peak hour, you need to plan for it.
Use async queues for non-critical tasks
If a task doesn't need an immediate response (like generating a report), queue it and process asynchronously. If Claude is temporarily down, the task waits in queue and retries later.

What Anthropics Has Communicated
Anthropics published a brief postmortem on their status page shortly after service restoration. The key points they shared:
- They acknowledged the outage lasted approximately 4 hours
- They identified database connection exhaustion as the root cause
- They stated they were implementing better connection pool monitoring
- They apologized for the impact
What they didn't share (which they should have):
- The specific traffic metrics that caused the spike
- How many requests were affected
- Whether any data loss occurred (presumably not, but they should confirm)
- The exact changes they're making to prevent recurrence
- A timeline for those changes
Transparency builds trust. Silence breeds doubt.
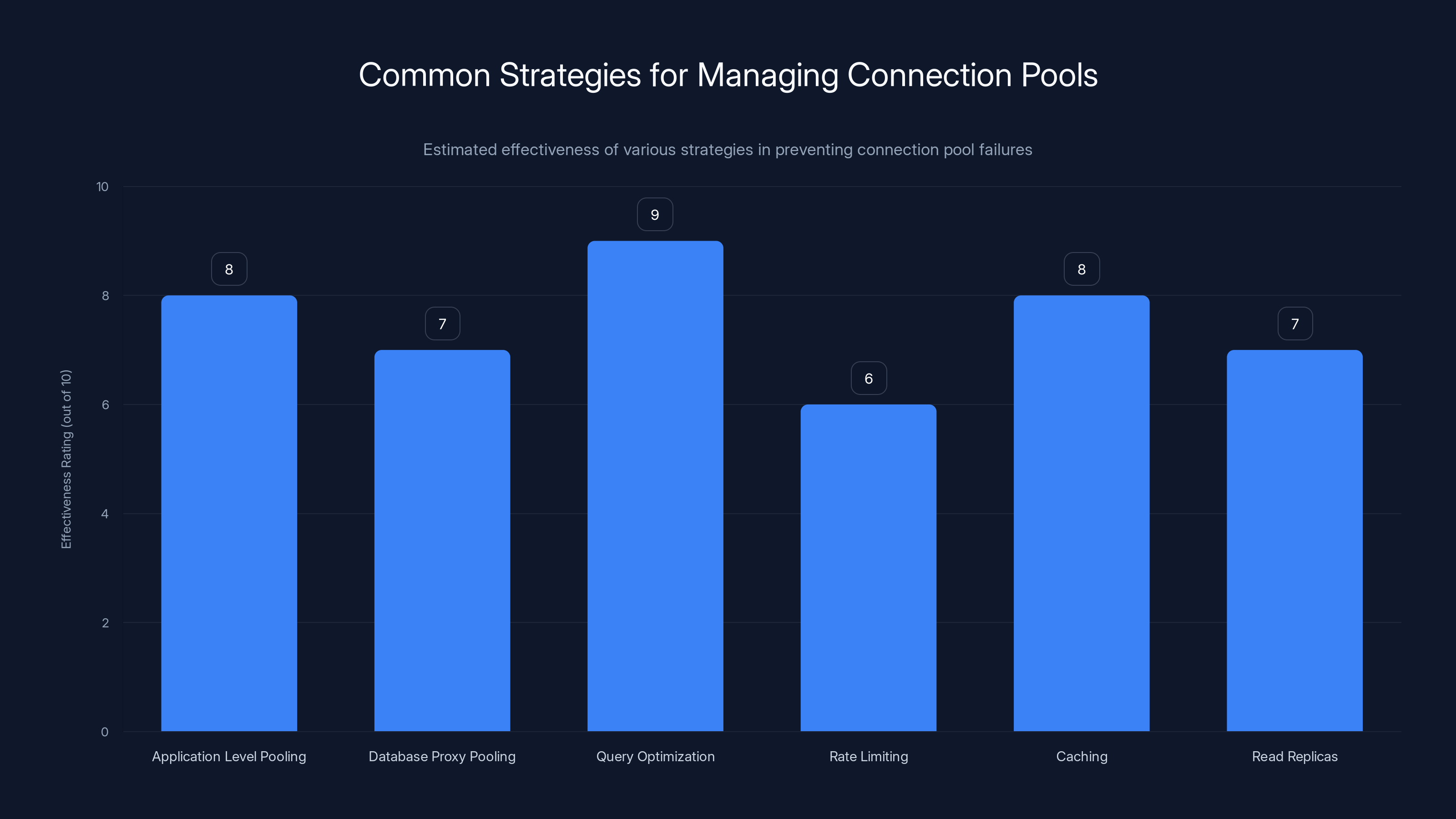
Query optimization and application-level pooling are highly effective strategies in managing connection pools, with ratings of 9 and 8 respectively. Estimated data.
How Often Should You Expect This?
Here's the honest truth: if you're using any external service, you should expect occasional outages.
Best-in-class cloud services (AWS, Google Cloud, Microsoft Azure) maintain 99.99% uptime, which translates to roughly 5 minutes per month of acceptable downtime.
Anthropics is smaller and still scaling. Their infrastructure isn't as mature as the cloud giants. You should probably expect:
- 1-2 significant outages per year (lasting 1-4 hours)
- 5-10 minor incidents per year (brief degradation, elevated error rates, but partial service)
- Weekly brief hiccups (isolated regions or endpoints, fixes within minutes)
That's not a failure on Anthropics' part. That's the reality of operating at scale with a young company. The question is whether they're improving and learning from incidents.
The companies that succeed at infrastructure reliability share common traits:
- They publish incident postmortems
- They actually make the changes they say they will
- They measure and track availability metrics publicly
- They invest heavily in infrastructure even when it's not directly generating revenue
- They have a culture that values reliability as much as feature development
Anthropics is young. They have time to build this culture. But January 22 shows they're not there yet.

The Bigger Picture: AI Service Reliability
Zoom out for a moment. What does Claude's outage tell us about the AI industry?
AI services are becoming critical infrastructure
Five years ago, an AI chatbot going down was a curiosity. Today, companies have built critical workflows around Claude. Teams can't do their jobs. Systems fail. That's a significant shift.
It means AI providers have responsibilities they didn't have before. They can't treat uptime as optional anymore.
The market will reward reliability
Claude is exceptional at certain tasks. But if it's down 4 hours a year and Chat GPT is up, some teams will switch to Chat GPT for reliability. That's a real cost for Anthropics.
Future AI contracts will include SLA requirements. Customers will demand 99.9% or 99.99% uptime, with penalties for violations. Companies will diversify across multiple AI providers.
Diversity is good
If everyone was using Claude, January 22 would have been catastrophic across the industry. The fact that teams could pivot to Chat GPT shows healthy competition and diversity.
Same goes for open-source models. If you're concerned about vendor lock-in, consider self-hosting LLMs (Llama, Mistral, etc.). They're increasingly good and run on your own hardware.
Infrastructure complexity is increasing
As AI adoption grows, the infrastructure that AI services run on becomes more complex. More caching layers. More redundancy. More regions. More fallback paths.
This is expensive. Anthropics will need to invest significant capital in infrastructure over the next few years just to keep up with demand.
Preventing Outages: A 7-Step Framework
If you're running your own service (whether AI-related or not), here's a practical framework to prevent outages like Claude's:
Step 1: Map Your Critical Resources
What are the actual bottleneck resources in your system?
- Database connections
- Memory
- CPU
- Disk I/O
- Network bandwidth
- Third-party API rate limits
For most services, it's not obvious. You need to run load tests and find out.
Step 2: Set Conservative Utilization Targets
Don't operate at 95% of your limits. Set targets at 50-70% of capacity during normal operations:
- If you can handle 500 concurrent connections, treat 250-350 as maximum normal load
- If your database can handle 10,000 requests/second, treat 5,000-7,000 as normal peak
- This leaves headroom for spikes
Step 3: Implement Automatic Scaling
When you approach capacity, automatically add more resources:
- Spin up new application servers
- Increase database read replicas
- Increase cache capacity
- This should happen automatically, not requiring human intervention
Step 4: Add Circuit Breakers and Graceful Degradation
When scaling maxes out and you're still under load, gracefully degrade:
- Reject new requests with clear 503 errors
- Shed load by reducing feature set (disable caching, reduce personalization)
- Prioritize critical requests over nice-to-have requests
Step 5: Test Under Realistic Load
Monthly:
- Simulate 150% of peak traffic
- Kill random servers/databases to test failover
- Verify that graceful degradation works
- Test recovery paths
This is called "chaos engineering" and it's critical.
Step 6: Monitor and Alert Aggressively
Track:
- Connection pool utilization
- Error rates
- Response latency (percentiles: p 50, p 95, p 99)
- Queue depths
Alert when:
- Any metric approaches thresholds
- Error rates spike above 1%
- p 99 latency exceeds 5x normal
Step 7: Have Clear Incident Response Plans
When things go wrong, know exactly what to do:
- Who's on call?
- What's the first action? (Look at logs? Restart? Scale?)
- How do you communicate during the incident?
- When do you declare it resolved?
Anthropics seems to have skipped steps 3-5 for database scaling. That's what led to January 22.

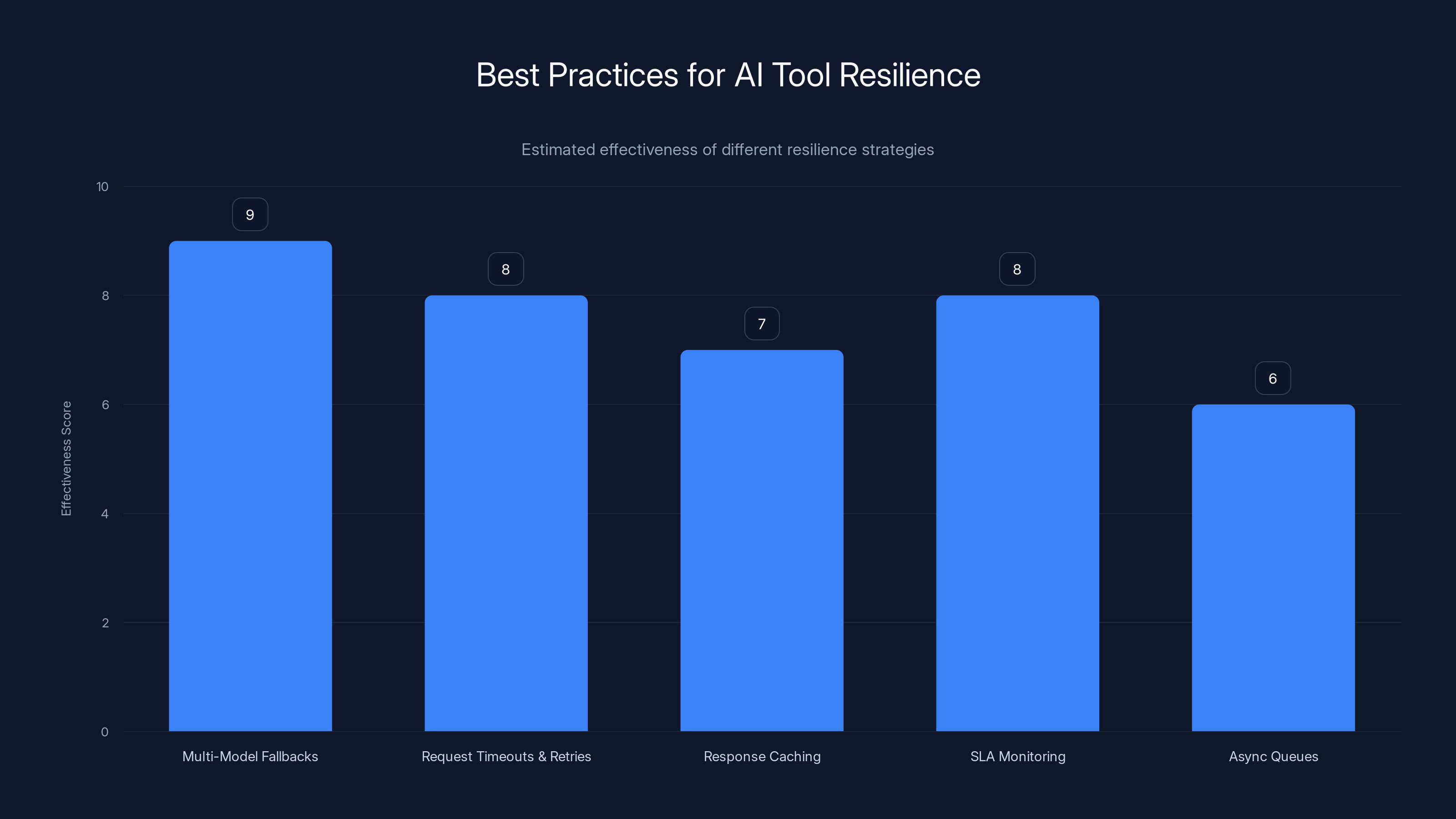
Multi-model fallbacks and request timeouts are highly effective strategies for enhancing AI tool resilience. Estimated data.
Alternative Platforms to Consider
If the Claude outage scared you away, what are your options?
For reasoning and analysis tasks where Claude excels, you're limited. Chat GPT with GPT-4 is the main competitor. Perplexity for search-enhanced responses.
For more general tasks, Google Gemini, Open AI's GPT models, and open-source options like Llama are all viable.
But here's the reality: you probably shouldn't rely on a single AI service. Build for multi-model support from the start.
For teams looking to automate workflows with AI, platforms like Runable provide AI-powered automation starting at $9/month. These tools abstract away the specific model and handle fallbacks automatically, insulating you from individual model outages.
Use Case: Building resilient AI workflows that automatically retry with backup models when primary services fail
Try Runable For FreeRecovery and Status Updates
By approximately 3:47 PM PT on January 22, Claude was back to normal. Service status showed all systems operational. API response times had returned to baseline. The web interface was responsive again.
Anthropics' team did a capable job of recovery once they identified the root cause. The issue wasn't their debugging or recovery speed. It was that the system entered a failure mode that took hours to diagnose and fix.
For users, the experience was: service works, service doesn't work, wait 4 hours, service works again.
The optimal experience would have been: service works, service detects it's hitting capacity limits, service returns 503 errors with clear "try again in 5 minutes" messages, wait 10 minutes, service works again.
That's the difference between a well-designed system and one still learning at scale.
What Happens to Your Chat History During Outages?
One question that came up frequently: does an outage affect your saved conversations and chat history?
The answer is: probably not directly, but potentially.
Your chat history is stored in Anthropics' database. During an outage, writes to the database might fail. If you were in the middle of a conversation when Claude went down, that last message or two might not save.
Once service was restored, your previous history should be intact. Database consistency is important and Anthropics' engineering team would have verified this during recovery.
However, if they had to do a rollback of the database to resolve corruption (which can sometimes happen during cascading failures), recent conversations might have been lost. Anthropics hasn't indicated this happened, so assume your history is fine.
Looking Forward: What Changes Anthropics Should Make
For Anthropics to prevent a repeat of January 22, they should:
Immediately (days to weeks):
- Increase database connection pool size by 50% as a quick fix
- Deploy connection pool monitoring with automated alerting
- Implement circuit breaker logic to reject requests gracefully above 80% utilization
- Update status page to post updates every 10 minutes during incidents
Short term (1-3 months):
- Architect multi-region database replication with automatic failover
- Implement sophisticated query caching to reduce database load
- Build chaos engineering tests that regularly simulate failures
- Set up public uptime monitoring and SLA dashboard
Medium term (3-12 months):
- Migrate critical services to read replicas that can scale independently
- Implement full active-active replication across regions
- Build a comprehensive incident response and communication framework
- Publish detailed incident postmortems (even if embarrassing)
These investments pay dividends not just in preventing outages, but in enabling growth. You can't scale to 100M users if your infrastructure becomes a bottleneck.
Key Takeaways for Users and Builders
For Claude users:
- Claude is exceptional for reasoning, coding, and detailed analysis, but it's not immune to outages
- Keep backup tools in your toolkit (Chat GPT, Gemini, or self-hosted models)
- Implement circuit breaker logic if you're using Claude in production
- Monitor API status pages before blaming your connection
For infrastructure teams:
- Connection pool exhaustion happens to the best companies
- Graceful degradation and circuit breakers are non-negotiable
- Test at 150% capacity monthly
- Monitor everything, alert aggressively
For the industry:
- AI services are now critical infrastructure and need to be treated that way
- Diversity across multiple AI providers is healthy
- Transparency builds trust more than silence
- Reliability is a competitive advantage
FAQ
What exactly caused Claude to go down on January 22, 2025?
The root cause was database connection pool exhaustion. During peak traffic, the number of concurrent requests exceeded the available database connections. These connections didn't return quickly enough, creating a queue of waiting requests that eventually timed out. The system entered a cascading failure mode where monitoring attempts and retries consumed additional connections, preventing recovery.
How long was Claude down during the outage?
The outage lasted approximately 4 hours from when users first reported widespread errors (around 12:15 PM PT) until full service restoration (approximately 3:47 PM PT). The investigation and diagnosis took about 2 hours, and recovery took another 1-2 hours.
Did I lose my chat history and saved conversations during the outage?
No. Chat history is stored in the database and was protected during the outage. While you couldn't access conversations during the downtime, once service was restored, all previous conversations remained intact. Any conversations you were actively having when the outage occurred might have lost the last message or two if writes were in progress.
Which regions were affected by the Claude outage?
The outage affected users globally, including North America, Europe, and Asia-Pacific. This indicates the failure was at Anthropics' central database layer rather than at regional edge servers or specific geographic endpoints.
What should I do if Claude goes down while I'm in the middle of important work?
Immediately switch to an alternative AI service like Chat GPT or Google Gemini if your task allows. For production applications, implement fallback logic that automatically routes to backup models. For urgent decisions, check the Anthropic status page to see if recovery is in progress.
How can I prevent my application from breaking when Claude's API goes down?
Implement multi-model fallback logic that tries Claude first, then switches to Chat GPT or another service if requests fail. Use exponential backoff for retries to avoid overwhelming systems. Set request timeouts (30 seconds max) so your application doesn't hang indefinitely. Queue non-critical tasks for async processing so they retry automatically when service is restored.
Will Anthropics compensate users for the outage?
Anthropics hasn't announced compensation for free tier users. Enterprise and API customers with SLA agreements may be eligible for service credits depending on their contract terms. Contact Anthropics support directly if you had significant losses.
Is Claude less reliable than Chat GPT or other AI services?
Not necessarily, but this outage suggests Anthropics' infrastructure isn't as mature as Open AI's. One incident doesn't define reliability. You should monitor uptime metrics over time. That said, expecting occasional outages from any service is realistic, especially during rapid growth phases.
What changes is Anthropics making to prevent this from happening again?
Anthropics committed to improving connection pool monitoring, implementing better graceful degradation, and increasing infrastructure capacity. Specific details on their roadmap haven't been published. Typically, companies implement these changes over 2-3 months, so improvements should be visible by April 2025.
Should I switch from Claude to another AI service due to this outage?
One incident isn't reason enough to switch if Claude is the best tool for your use case. Instead, build resilience into your systems by supporting multiple models. If you can't tolerate any downtime, use a service with guaranteed SLA terms, or self-host open-source models for critical tasks.

Conclusion: Learning From Incidents
Outages happen. Claude's outage on January 22, 2025 was significant but not unusual for a rapidly scaling service. The database connection pool exhaustion is a well-understood failure mode, not a fundamental flaw in Anthropics' engineering.
What matters now is how Anthropics responds. Do they make meaningful infrastructure improvements? Do they publish detailed postmortems? Do they invest in redundancy and graceful degradation?
Companies that treat incidents as learning opportunities tend to build exceptional reliability. Companies that sweep them under the rug tend to suffer repeated incidents.
For you as a user or developer, the lesson is simpler: don't be over-reliant on any single service, no matter how good. Build for resilience. Use multiple tools. Cache results. Implement fallbacks. That's how you build systems that don't break when external services do.
Claude remains an exceptional AI assistant for many tasks. But January 22 is a reminder that even the best tools have limits, and planning for those limits is your responsibility, not theirs.

