![X Outage Recovery: What Happened & Why Social Platforms Fail [2025]](https://tryrunable.com/blog/x-outage-recovery-what-happened-why-social-platforms-fail-20/image-1-1768592205456.png)
X Outage Recovery: What Happened & Why Social Platforms Fail [2025]
Introduction: When the World's Town Square Goes Dark
It was a morning that caught millions off guard. X, the platform formerly known as Twitter, went down hard. For hours, users couldn't post, couldn't scroll, couldn't do much of anything except refresh their browsers obsessively and wonder if the problem was on their end or if something bigger had broken.
The outage hit around 7:39 AM PT on January 16, 2025, and it wasn't subtle. Some users saw error messages. Others got the dreaded blank feed. A few lucky people could load older posts, but the live feed? Completely frozen. By 9:30 AM, things were partially working again—the Explore and trending pages loaded fine, but if you wanted to see posts from people you follow, you got a cheerful message suggesting you "find some people and topics to follow."
This wasn't X's first rodeo with infrastructure problems that week. Just three days earlier, the platform had crashed again for many users globally. Two major incidents in five days raises some uncomfortable questions: What's going wrong with one of the world's most important social media platforms? How does a company with X's resources let this happen twice? And more importantly, what does this tell us about the fragility of the digital infrastructure we all depend on?
The outage is worth examining not just because it affected millions of users—it is because it reveals something fundamental about how modern social platforms work, where they're vulnerable, and what happens when those vulnerabilities get exploited by volume, bugs, or just bad luck. If you use X for business, news, or community building, understanding what happened matters.
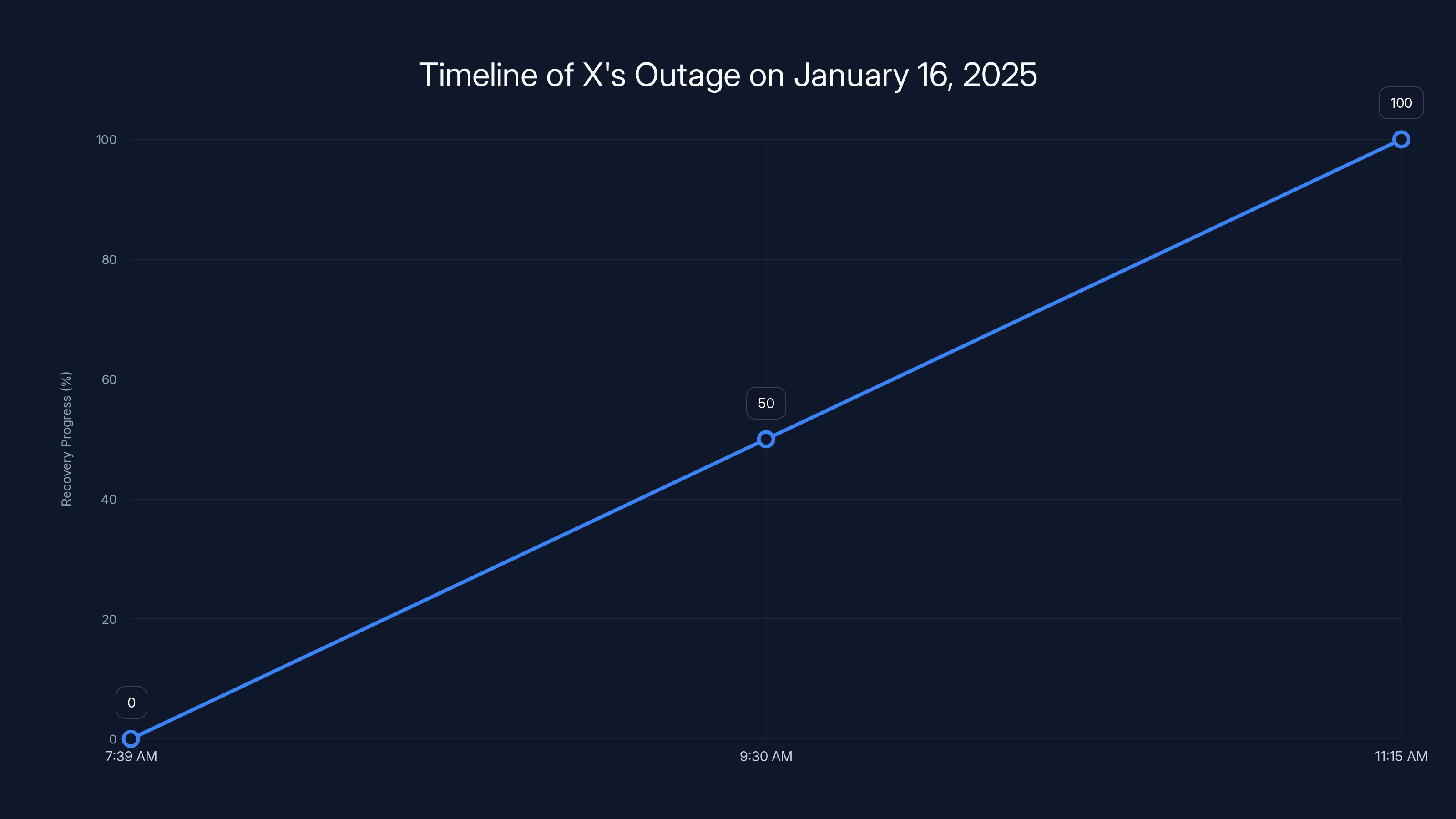
The outage began at 7:39 AM PT and saw gradual recovery, with most features operational by 9:30 AM PT. Full recovery was achieved by 11:15 AM PT. Estimated data based on incident reports.
TL; DR
- The Incident: X experienced a major outage starting at 7:39 AM PT on January 16, 2025, affecting the service's streaming endpoints and causing widespread access issues.
- Duration and Impact: The outage lasted several hours with intermittent problems persisting into the late morning, affecting both the web interface and mobile app.
- Underlying Cause: The incident was related to streaming endpoint failures, which prevented real-time data from flowing to users' feeds.
- Pattern Recognition: This was the second major outage in a single week for X, suggesting potential systemic infrastructure problems.
- Recovery Timeline: By 11:15 AM PT, most functionality had been restored, though some technical issues remained on the developer platform.
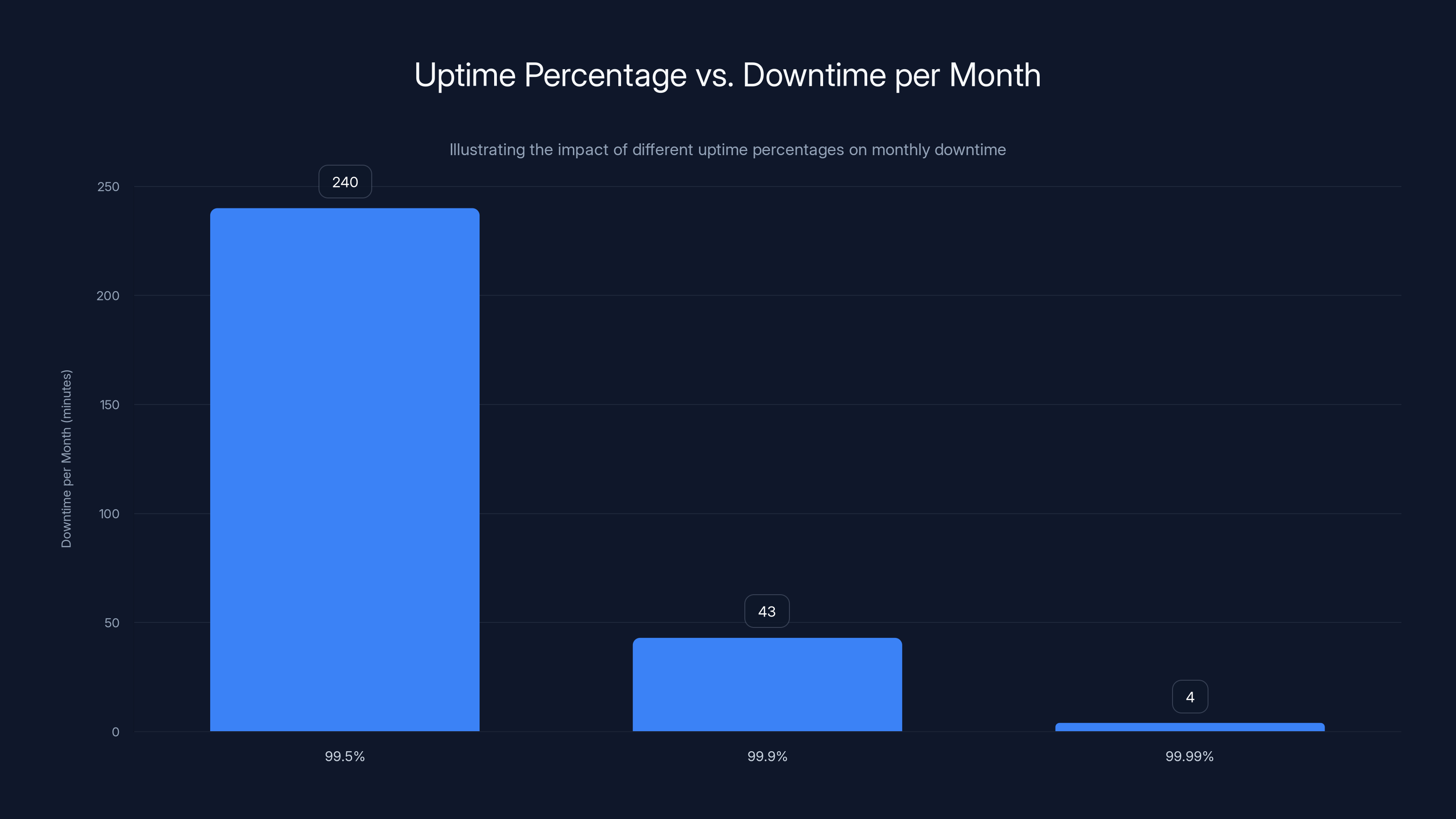
As uptime percentage increases, downtime decreases significantly. Moving from 99.9% to 99.99% uptime reduces downtime from 43 minutes to just 4 minutes per month, highlighting the challenge of achieving higher reliability.
What Exactly Happened That Morning
When you woke up on January 16 and tried to check X, you probably noticed something was off immediately. The app wouldn't load. The website showed blank feeds. If you were lucky, you'd see posts from an hour ago, but anything recent? Gone.
This wasn't a slow platform or some minor technical glitch. This was a complete breakdown of X's ability to serve fresh content to users. According to X's own developer platform status page, the root cause was an "ongoing incident related to streaming endpoints." That sounds technical and abstract, but here's what it means in plain English: the systems that push real-time posts to your feed had stopped working.
Think of streaming endpoints like the pipes that deliver water to your house. If those pipes break, no water flows, no matter how much water is sitting in the reservoir. X had plenty of posts in its database. But the infrastructure needed to send those posts to users had failed.
The incident reportedly started at 7:39 AM PT, which lines up perfectly with when Down Detector, the outage tracking service, started seeing a spike in reports from frustrated users. Down Detector is basically a crowdsourced outage detector—when lots of people report problems with a service at the same time, it shows up as a spike. That spike was sharp and unmistakable.
What made this particular outage especially frustrating was its intermittent nature. This wasn't a clean on-off situation where the platform was either completely down or completely up. Instead, things were quirky and inconsistent. Sometimes the website would load partially, showing older posts but not new ones. Other times, both the web and mobile apps would fail to load anything at all. Some users could see their home feeds, while others couldn't. It created this maddening situation where you weren't sure if the problem was on your end or if X was still broken.
By around 9:30 AM PT, roughly 90 minutes into the outage, things started improving. The Explore page loaded. Trending topics were visible. But here's the thing that really highlights how broken things were: the "Following" tab—arguably the most important tab for most users—still wasn't working properly. Instead of showing posts from accounts you follow, it was basically giving up and suggesting you go find new people to follow. It's like a restaurant saying "We're out of food, but here's a phone book for other restaurants."
By mid-morning, around 11:15 AM PT, the situation had improved further, but X's developer platform was still showing ongoing technical issues. This suggests that while the main platform seemed to be recovering, there were still problems lurking in the background that could have caused secondary failures for developers building on top of X's API.
Understanding Streaming Endpoints and Why They Matter
The fact that the problem was specifically tied to "streaming endpoints" isn't a throwaway technical detail. It's the core of understanding why the outage happened and why it affected users the way it did.
Here's how X's architecture works at a basic level. When you open the app or website, your client (your phone or browser) needs to get posts somehow. There are two main ways to get data from a server: polling and streaming.
Polling is the older, simpler approach. Your client asks the server "Are there new posts?" every few seconds. The server responds with new posts if they exist. It's like checking your mailbox multiple times a day. It works, but it's inefficient. Your device has to ask constantly, and the server has to answer constantly, even when nothing has changed.
Streaming is more efficient. Instead of your client asking repeatedly, the connection stays open, and the server pushes new posts to you as they happen. It's like having a mail carrier who brings your letters directly to you as soon as they arrive. Much better experience, much less overhead.
X relies heavily on streaming. Most real-time social platforms do. When you're scrolling your feed and a new post from someone you follow appears instantly, that's streaming in action. The connection between your device and X's servers stays open, and posts flow through immediately.
When the streaming endpoints failed, that entire mechanism broke. It's not that X's database went down or that posts stopped being created. It's that the infrastructure designed to push those posts to users failed. So users would load the app, try to stream new posts, get nothing, and see either blank feeds or very stale ones.
The challenge with streaming infrastructure is that it's stateful. Every user connection carries state—which posts they've seen, where they are in their feed, what their preferences are. If those connections break and don't reconnect gracefully, users experience the exact situation we saw that morning: blank feeds, inconsistent loading, and frustration.
What we can infer from the incident is that X either experienced a failure in the systems managing these streaming connections, or there was a surge in demand that overwhelmed the capacity. Either way, it's a critical failure point, which is why the outage was so widespread and visible.
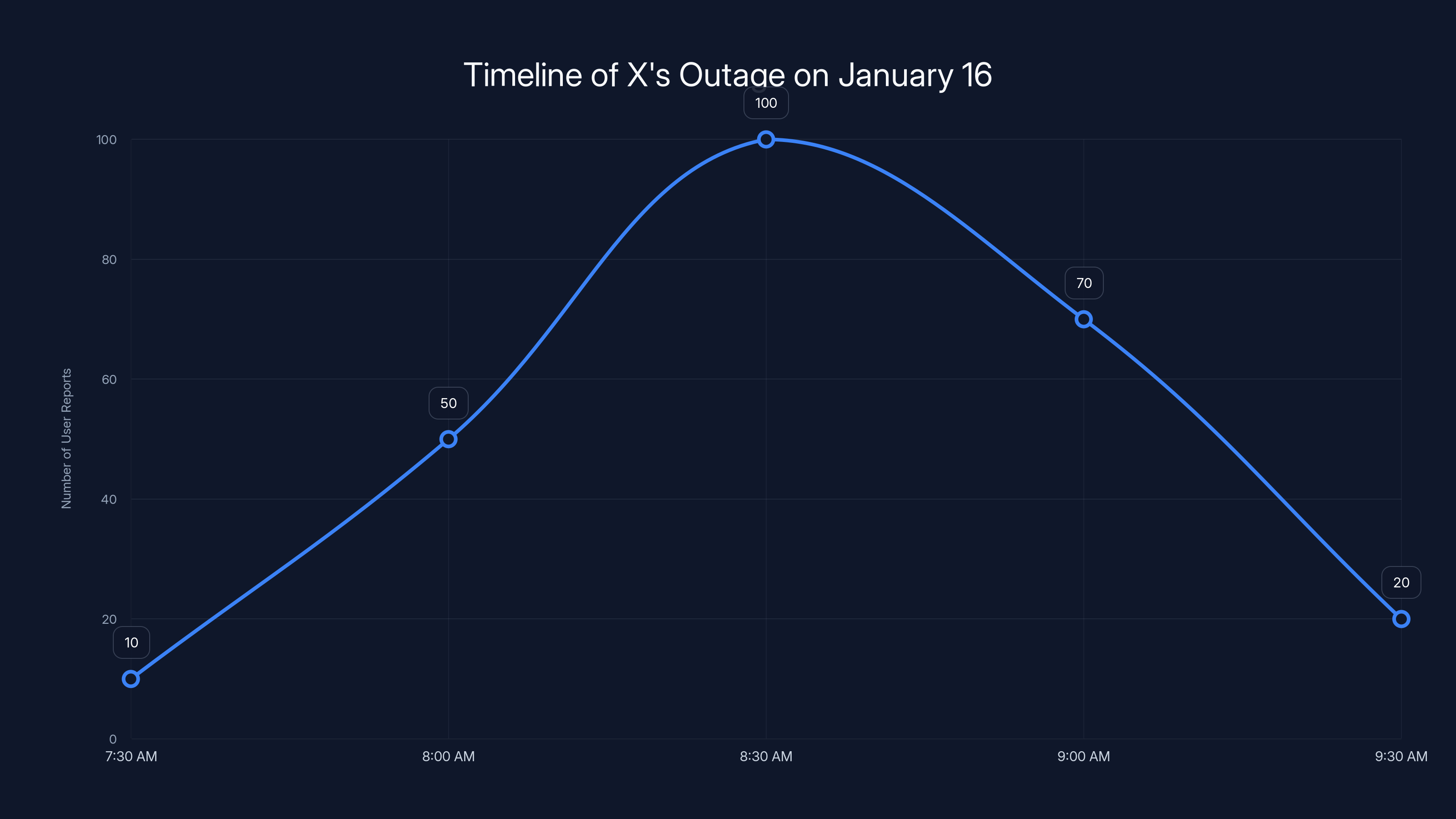
Estimated data shows a sharp increase in user reports starting at 7:39 AM, peaking around 8:30 AM, and then declining as the issue was resolved by 9:30 AM.
The Intermittency Problem: Why X Didn't Just Go All the Way Down
One thing that's notable about this particular outage is that it wasn't a complete blackout. The platform didn't go dark and stay dark. Instead, it flickered. Sometimes things worked, sometimes they didn't. For users, this is actually worse than a clean outage.
When a service goes down completely, it's obvious something is wrong. You get error messages. You know to come back later. But when a service is intermittently broken, you keep trying. You reload the page. You close the app and reopen it. You wonder if you're the only one affected. Some posts load, so you think things are working, then suddenly nothing loads. It's maddening.
Why was the outage intermittent instead of total? There are a few possibilities. First, X might have had multiple redundant systems, and only some of them failed. So when you hit server A, you'd get nothing. But when your request got routed to server B, it would work. This would create the exact intermittent pattern we saw.
Second, the engineering team might have been in the process of recovering the failed endpoints. As they brought systems back online, more and more users could connect, but it wasn't a smooth transition. Some systems came back before others, creating that checkerboard pattern where some features worked while others didn't.
Third, there might have been cascading failures happening. When the streaming endpoints failed, that probably created a surge of traffic to other parts of the system as clients tried to reconnect, reloaded, or switched to different endpoints. This secondary surge might have taken out other systems, or it might have been automatically throttled, meaning only some requests got through.
The technical term for this kind of situation is "graceful degradation" when it's intentional, or "cascading failure" when it's not. Based on the evidence, it sounds more like an unplanned cascading failure, where one system's failure cascaded through the architecture and took out other parts.
Timeline Reconstruction: Hour by Hour
Let's build out the full timeline based on available evidence, because understanding how the outage progressed tells us a lot about what was happening under the hood.
7:39 AM PT: The Incident Begins
At 7:39 AM PT, something breaks in X's streaming endpoint infrastructure. We don't know if it's a deployment that went bad, a hardware failure, a sudden traffic spike, or something else entirely. But at this moment, the systems designed to push real-time posts to users stop working. The incident is logged on X's developer platform status page.
7:40-8:00 AM PT: The Spike Hits Down Detector
Within a couple of minutes of the failure, Down Detector's crowdsourced sensors start picking up reports. Users are trying to use X, failing, and reporting it. The spike is sharp and unmistakable. This is when millions of people realize something is seriously wrong.
8:00-9:00 AM PT: Peak Outage Period
For this stretch, X is largely non-functional. The web interface loads but shows blank feeds or only very old posts. The mobile app is even worse—many users can't get past the loading screen. Some users report seeing error messages. Others report seeing nothing at all.
During this period, the engineering team is probably in full incident response mode. They've identified the streaming endpoint failure, and they're working on recovery. This might involve restarting services, failing over to backup systems, investigating logs, or any number of emergency fixes.
9:00-9:30 AM PT: Partial Recovery
Features start coming back online, but inconsistently. The Explore page loads. Trends are visible. But the home feed—the core feature for most users—is still broken or very slow. This is consistent with a gradual recovery where some systems come back online before others.
9:30-11:15 AM PT: Most Functionality Returns
By 9:30 AM, roughly 90 minutes into the incident, most users can use X again. The Explore and trending pages are working. You can search. But the Following tab, which shows posts from people you follow, is still acting weird, showing messages asking users to find people to follow instead of showing posts.
This pattern suggests that while the primary streaming infrastructure recovered, some of the higher-level features that depend on the streaming infrastructure are still struggling. It's like when a bridge reopens but only some lanes are available.
11:15 AM PT: Status Page Still Shows Issues
At 11:15 AM, more than three hours into the incident, X's developer platform status page is still reporting ongoing issues. This means that while the main platform seems to be working for most users, the APIs that developers depend on are still having problems. This could impact third-party apps that use X's API, though by this point, most users probably weren't concerned with third-party integrations—they just wanted X to work again.
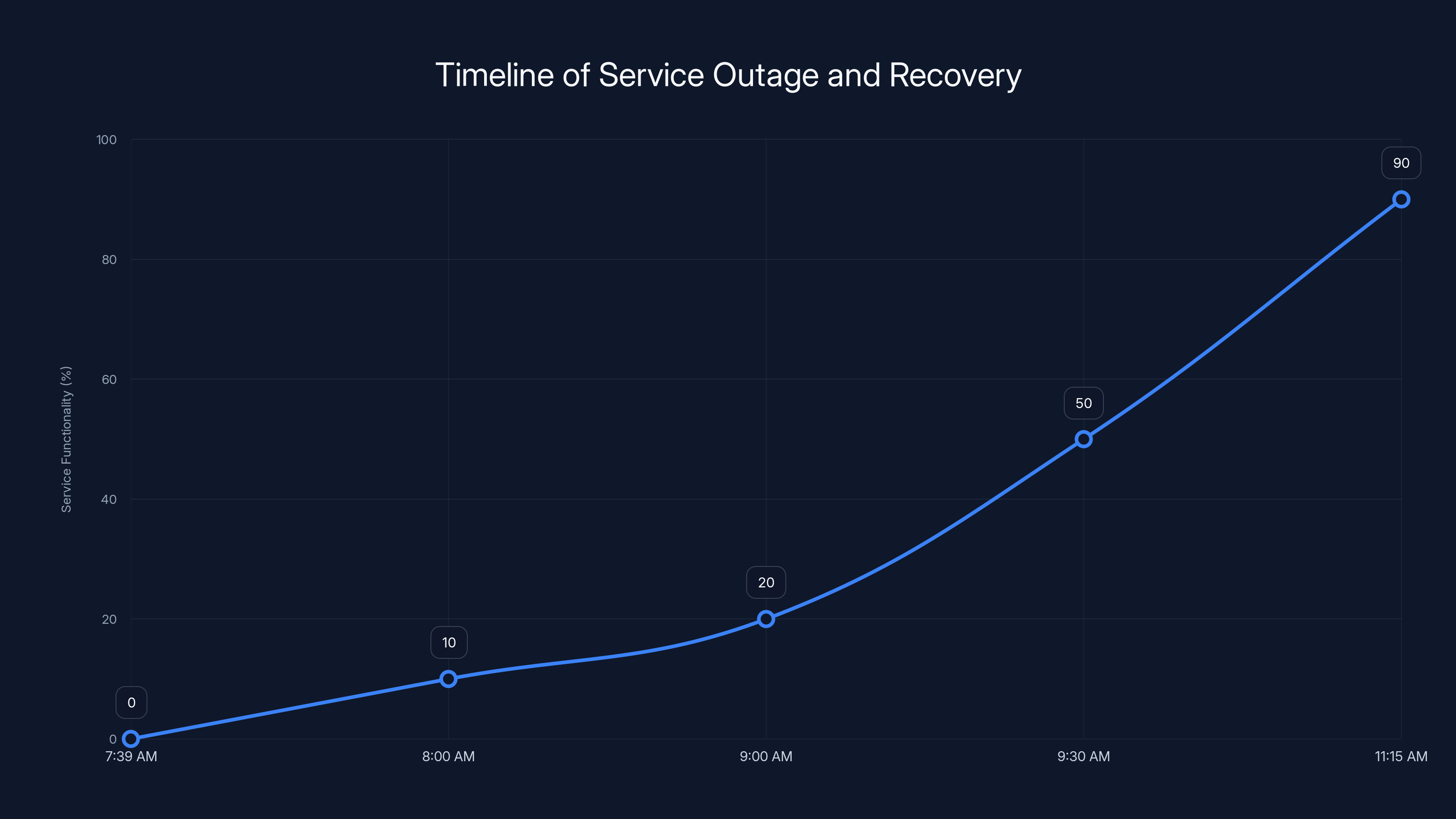
The chart illustrates the progression of the service outage and recovery. Functionality dropped sharply at 7:39 AM and gradually improved, reaching near full recovery by 11:15 AM. Estimated data.
Context: Not X's First Rodeo This Week
Here's the thing that really stands out: this wasn't an isolated incident. Just three days earlier, on Tuesday, January 14, X had experienced another significant outage that affected many users globally. Two major incidents in five days is not a coincidence. It suggests a systemic problem.
When a platform has one major outage, it's usually attributed to bad luck or one specific failure. But when you get two major outages in a week, the pattern suggests something deeper. Possible explanations include:
Infrastructure Under Stress: The platform might be experiencing more traffic than its infrastructure was designed to handle, or recent changes to handle more traffic aren't working properly.
Recent Deployments: X might have made significant architectural changes or deployed new code that introduced instability. If you roll out code on Monday and then have outages on Tuesday and Wednesday, it's usually the code.
Staffing or Expertise Issues: X had significant staff reductions in 2023. If critical expertise left with those staff reductions, the ability to maintain and quickly recover from infrastructure issues might be compromised.
Deliberate Changes: Sometimes platforms deliberately reduce infrastructure or change architecture for cost reasons. If X is trying to run on less infrastructure or with different architecture than before, that might be creating instability during peak usage periods.
Cumulative Technical Debt: If systems haven't been properly maintained or updated, technical debt can compound, and suddenly you're dealing with systems that fail more often.
Without inside information from X's engineering team, we can't say which of these is true. But the pattern of two major outages in five days suggests that something is not quite right with the platform's infrastructure.

The Bluesky Opportunity: Rivals Capitalize on Competitor Weakness
While X was down, Bluesky, which positions itself as a decentralized Twitter alternative, made a strategic move. Earlier in the week, Bluesky had changed its profile picture on X to a butterfly logo in a bikini—a clear reference to X's bird logo. It was a gentle troll.
But when X went down, Bluesky took the opportunity to throw some shade. During the outage, Bluesky and other alternatives capitalized on X's downtime by pointing out that they were still up and working.
This is a classic pattern in platform warfare. Every time one platform has a major outage, its competitors gain users. Some of those users stick around. The math is simple: X's 500 million monthly active users represents huge network effects, but those network effects only work if the platform is available. A few hours of unavailability creates a window for alternatives to look attractive.
For Bluesky, which has been trying to build momentum as a decentralized alternative to Twitter, X's outages are actually good for user acquisition. That's not to say Bluesky caused the outages—but they're certainly benefiting from them.

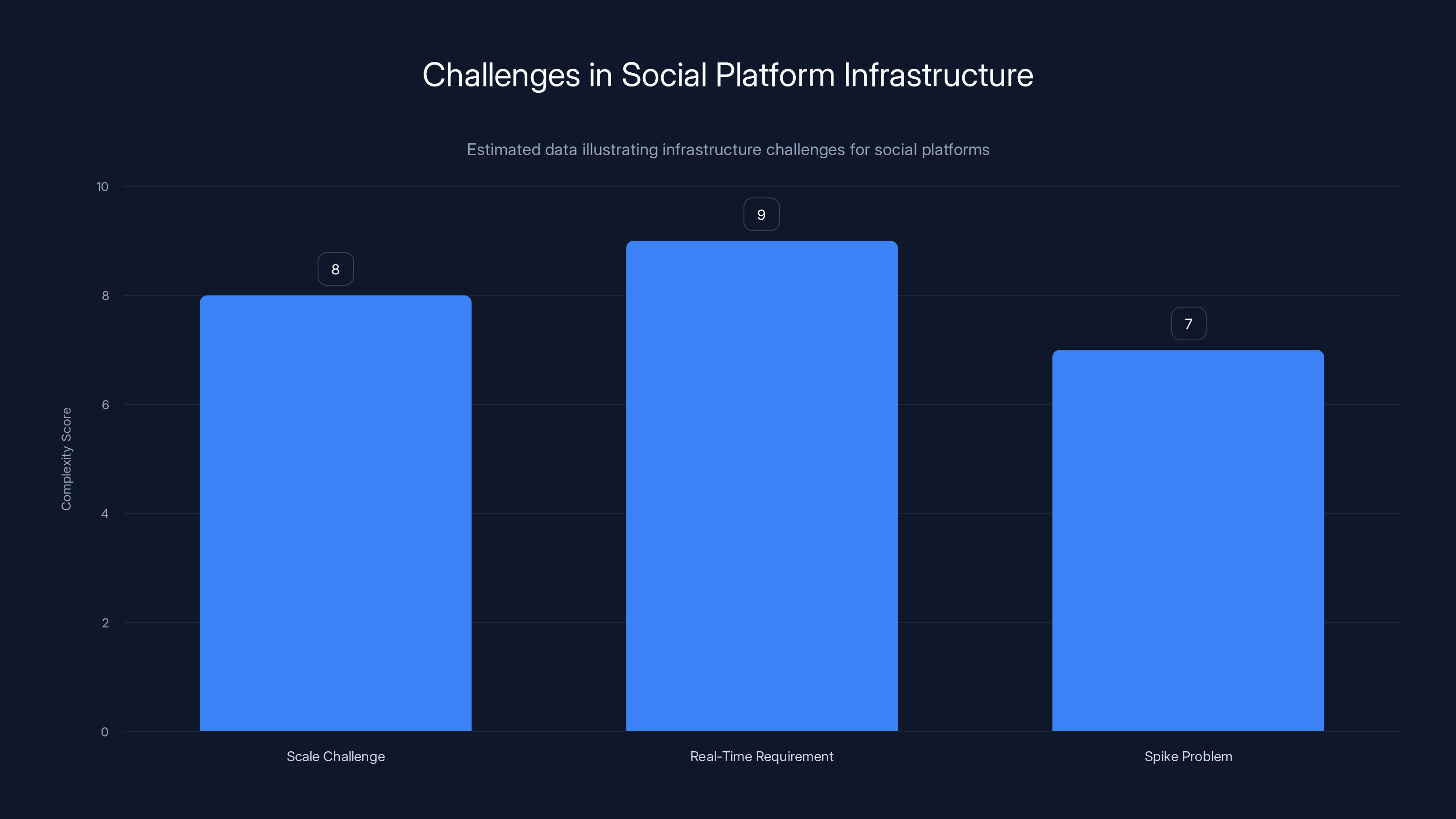
Social platforms face high complexity in managing scale, real-time requirements, and traffic spikes, with real-time requirements being the most challenging (Estimated data).
Why Social Platform Infrastructure Is So Fragile
Understanding X's outage requires understanding why social platform infrastructure is inherently fragile. It's not a simple database. It's an incredibly complex system with multiple layers of redundancy, caching, streaming, searching, and recommendation engines all working together.
The Scale Challenge
X has roughly 500 million monthly active users. On any given day, tens of millions of those users might be online simultaneously. Each one of them expects their feed to load in under 2 seconds. Each one of them expects their posts to go live instantly. Each one expects their notifications to be real-time.
Serving that at scale is fundamentally hard. It's not like building a marketplace where you have thousands of items and hundreds of transactions per second. You're building a system where millions of people are trying to read the latest posts from millions of other people, instantly, all the time.
The Real-Time Requirement
Facebook can show you a feed from 10 minutes ago, and you wouldn't necessarily know. But Twitter users expect their feed to be live. A post from someone you follow should appear in your feed within seconds. That real-time requirement fundamentally constrains how you can build the system.
To meet that requirement, you need streaming infrastructure. And streaming infrastructure is stateful and complex. Every user connection is unique. Every connection carries state. If you have 50 million concurrent users and each one has a streaming connection, you're managing 50 million active connections. That's not a database problem. That's a fundamental architecture problem.
The Spike Problem
Social platforms also deal with traffic spikes. When something newsworthy happens, traffic spikes. When a celebrity tweets something, traffic spikes. When a platform feature breaks, users reload obsessively, creating a spike. These spikes can overwhelm systems that are sized for average load, not peak load.
The X outage might have been triggered by a spike. If something happened that caused a bunch of people to reload X, that spike might have overwhelmed the streaming infrastructure. The infrastructure would fail. Then more users would reload trying to fix it, creating a bigger spike. This is called a "thundering herd" or a "retry storm," and it's a common cause of cascading failures.
The Dependency Problem
Modern platforms are built as microservices. You have a service for authentication, a service for feed generation, a service for recommendations, a service for streaming, a service for notifications, and so on. These services all talk to each other.
When one service fails, it can take down services that depend on it. If the streaming endpoint service fails, and the feed service depends on the streaming endpoint service, the feed service might fail too. This is called a cascading failure, and it's a major source of outages in modern distributed systems.
X probably has sophisticated systems in place to prevent cascading failures—circuit breakers, fallbacks, and graceful degradation. But despite these systems, cascading failures still happen. The outage evidence suggests that's what happened here.
The Testing Problem
With a system this complex, it's almost impossible to test every failure scenario. You can test what happens when the database goes down. You can test what happens when a server crashes. But testing what happens when the streaming infrastructure fails under peak load while a new code deployment is rolling out while a sudden traffic spike happens? That's exponentially harder.
So infrastructure problems that only manifest under very specific conditions—the combination of multiple factors happening at once—can slip through testing and into production.

What We Know About X's Infrastructure Choices
While X hasn't publicly detailed all of its infrastructure decisions, we can infer some things from the outage pattern.
First, X is clearly running on cloud infrastructure rather than on-premises servers. The nature of the streaming endpoint failure suggests a cloud-native architecture, probably something built on Kubernetes or a similar container orchestration platform.
Second, X probably uses a microservices architecture. The fact that the outage was specifically related to streaming endpoints, and that other features came back online at different times, suggests that X has separated these systems into different services.
Third, X probably has automated failover systems. The intermittent nature of the outage—where things sometimes worked—suggests that the system was trying to fail over but not doing so cleanly.
Fourth, based on the timeline and the nature of the incident, X might have been in the middle of a deployment or infrastructure change when the failure occurred. Code deployments are the most common cause of outages, and the pattern here is consistent with a bad deployment.
Fifth, X probably doesn't have sufficient redundancy or monitoring. If the platform had sufficient redundancy in streaming endpoints, the failure of one wouldn't have caused such a widespread outage. If the monitoring was good enough, the team probably would have caught this before Down Detector did.

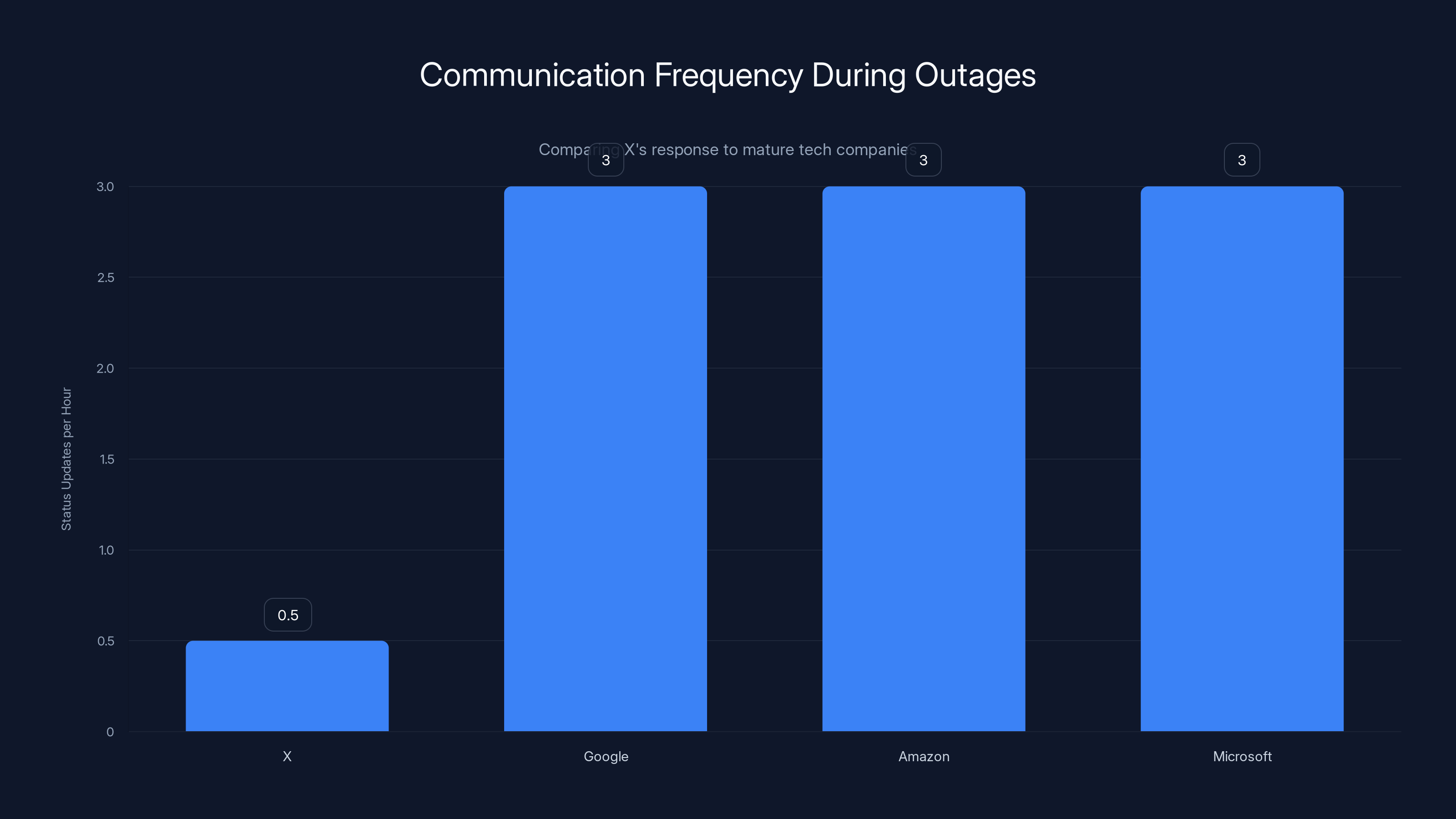
Mature tech companies like Google, Amazon, and Microsoft typically provide status updates every 15-30 minutes during outages, while X's communication was significantly less frequent. Estimated data.
How Modern Platforms Should Handle This
Comparing X's response to how mature tech companies handle outages reveals some interesting gaps.
At most large tech companies, an outage like this would trigger a formal incident response process. There would be an incident commander—someone senior who takes charge of the response. There would be clear escalation paths. Engineering teams would be notified and would start investigating. Customer communication would be prepared.
The typical playbook looks like this:
- Detection: Monitoring systems or users detect the problem and report it
- Incident Commander assigned: Someone senior takes charge
- Investigation: Engineers gather data about what's broken
- Mitigation: Apply a quick fix to get the platform back up
- Recovery: Work on permanent fix while platform is partially up
- Communication: Keep users updated on status and ETA
- Post-Mortem: After the incident, analyze what went wrong and prevent recurrence
For X's outage, we have evidence of detection (Down Detector spike), mitigation (platform recovered over time), and recovery (most features came back online). But we don't have much evidence of communication. X didn't publicly acknowledge the outage for hours, and when they did, they didn't provide much detail.
Mature companies communicate frequently during outages. They post status updates every 15-30 minutes. They give estimates of when the issue will be resolved. They explain what's happening. This reduces user anxiety and builds confidence in the team.
X's lack of communication during the outage stands in contrast to how companies like Google, Amazon, or Microsoft handle similar situations.

The Reliability Engineering Perspective
From a reliability engineering standpoint, X's infrastructure has demonstrated some weaknesses.
Reliability is typically measured by a metric called uptime percentage. A service that's up 99.9% of the time has roughly 43 minutes of downtime per month. A service that's up 99.99% of the time has roughly 4 minutes of downtime per month. Getting from 99.9% to 99.99% is exponentially harder because it means every system needs to be approximately 10 times more reliable.
Twitter's infrastructure used to be famous for its reliability. During major events, when millions of people would try to use Twitter simultaneously, the platform stayed up. That was considered a major achievement because many platforms would crash under that load.
But over the past couple of years, Twitter's reliability has visibly degraded. We've seen multiple outages and performance problems. This could be due to:
- Infrastructure changes that reduced redundancy
- Staff reductions that reduced monitoring and maintenance
- Growth in users without corresponding growth in infrastructure
- More complex systems that are harder to manage reliably
- Deliberate cost-cutting measures
If X was trying to run at 99.5% uptime instead of 99.99% uptime to save money, that would explain the pattern of outages we're seeing. That would mean roughly 3-4 hours of downtime per month, which is roughly in line with what we've observed.

Lessons for Other Platforms
X's outage isn't unique. Every platform has outages. But X's outage provides lessons for other platforms, and for users thinking about which platforms to rely on.
Lesson 1: Redundancy Matters
If X had proper geographic redundancy, users in some regions might have been able to access the platform even while others were down. If X had multiple independent streaming endpoint systems, the failure of one wouldn't take down the whole platform. Redundancy adds cost, but it's the price of reliability.
Lesson 2: Monitoring Is Essential
The fact that Down Detector picked up the outage before X's internal team probably acknowledged it suggests that X's monitoring wasn't as good as it should be. Modern platforms should know about their own outages before users do.
Lesson 3: Communication Wins Trust
During outages, silence creates anxiety. Users speculate about what's wrong. They complain on rival platforms. They consider alternatives. Regular updates—even if they just say "we're still working on it, ETA unknown"—maintain trust.
Lesson 4: Scaling Is Hard
The transition from a startup platform to one that serves hundreds of millions of users requires fundamental architectural changes. Systems that work fine at 10 million users might not work at 500 million users. Every company that's scaled has had growing pains. But good companies manage those growing pains with proper investment in infrastructure.
Lesson 5: Staff Expertise Matters
Building and maintaining reliable infrastructure requires skilled engineers. If X reduced headcount to save money, and those reductions included infrastructure and reliability engineers, that would create exactly the pattern of outages we're seeing. You can't cheaply maintain a complex infrastructure system.

Broader Implications for Social Media Dependence
X's outage also raises a broader question: How dependent have we become on social platforms, and what are the risks?
For many people, X is a primary source of news. For journalists, it's an essential tool. For activists, it's a communication channel. For businesses, it's a marketing platform. When X goes down, the impact isn't just inconvenient—it's economically meaningful.
During the outage, journalists couldn't quickly share news. Activists couldn't organize. Businesses couldn't reach their audiences. The outage itself became newsworthy because the outage of a major news distribution platform is itself news.
This concentration of critical infrastructure in a few private companies creates systemic risk. If one company's infrastructure fails, millions of people are affected. Unlike utilities like electricity or water, which are heavily regulated and required to maintain certain reliability standards, social platforms have no such requirements.
This is both a business risk and a societal risk. For X, the outage probably cost the company millions in lost ad revenue and risked user churn to competitors. For society, the outage highlighted how fragile the infrastructure we depend on actually is.
Future Outlook: Will X Solve This?
The big question is whether X will take steps to prevent these outages from happening again.
Historically, companies respond to outages in one of two ways. Either they invest significantly in infrastructure to prevent recurrence, or they do minimal work and hope the same problem doesn't happen again.
Based on the pattern of multiple outages in a short period, and the company's publicly stated cost-cutting focus, it seems like X might be taking the minimal approach. The company has been trying to reduce costs and demonstrate that it can run profitably on less infrastructure. If that's the priority over reliability, we can probably expect more outages.
However, if the outages continue, X will face serious consequences. Users will migrate to alternatives. Advertisers will get nervous about platform reliability. The company's valuation will take a hit. At some point, the cost of unreliability exceeds the savings from reduced infrastructure spending.
The most likely outcome is that X will do some amount of work to improve reliability—upgrading monitoring, adding redundancy in critical systems, improving incident response—but probably not reach the level of reliability that the platform had a few years ago.

Conclusion: The Fragility of Digital Infrastructure
X's January 16 outage, coming just three days after another major incident, reveals something important about modern digital infrastructure. It's complex, fragile, and more susceptible to failure than most users realize.
The outage wasn't caused by a catastrophic hardware failure or a natural disaster. It was caused by a failure in streaming endpoints—a critical but not rare system. The fact that this one failure took down a platform used by hundreds of millions of people worldwide shows how concentrated and dependent we've become on these systems.
For X specifically, the outage is a signal that the company needs to invest more in infrastructure reliability. The cost of unreliability—in user trust, advertiser confidence, and competitive positioning—exceeds the savings from reduced infrastructure spending.
For the rest of us, X's outage is a reminder that digital platforms are not immune to failure. The platforms we depend on can and will go down. Having backup communication methods, diversifying our presence across multiple platforms, and reducing dependence on any single platform are all prudent strategies.
The outage also highlights why companies like Bluesky, which are building decentralized alternatives to centralized platforms, are gaining momentum. A decentralized social network wouldn't have a single point of failure. If one node goes down, the network keeps working. That's not a hypothetical advantage—it's a direct response to the fragility we saw on January 16, 2025.
Ultimately, X's outage is a reminder that infrastructure is not destiny. A platform can lose its reliability advantage through neglect, just as it can gain one through investment. Whether X chooses to invest in regaining its reliability advantage, or whether it accepts that reliability is a lower priority than cost control, will be telling.

FAQ
What caused X's outage on January 16, 2025?
X's outage was caused by a failure in the platform's streaming endpoints, which are the systems responsible for delivering real-time posts to users' feeds. According to X's developer platform status page, an ongoing incident related to these streaming endpoints caused increased errors starting at 7:39 AM PT. When streaming endpoints fail, the mechanism that pushes new posts to users in real-time stops working, resulting in blank or stale feeds.
How long did the X outage last?
The outage lasted approximately 90 minutes to several hours depending on the specific feature and user location. The incident started at 7:39 AM PT and by 9:30 AM PT, most features had begun recovering, though some issues persisted until 11:15 AM PT or later. The experience was intermittent rather than a complete blackout, with some features recovering before others.
Why was the outage intermittent instead of a complete blackout?
The intermittent nature suggests that X's infrastructure had redundancy, with some systems failing while others remained operational. As the engineering team worked on recovery, systems came back online gradually rather than all at once. This could also indicate cascading failures where the initial streaming endpoint failure overloaded other systems, creating secondary failures that resolved as load decreased.
What are streaming endpoints and why are they critical?
Streaming endpoints are the infrastructure components that maintain open connections between user devices and X's servers, allowing new posts to be pushed to users' feeds in real-time. Unlike polling, which requires users to constantly ask the server for new data, streaming keeps a persistent connection open and pushes data as it becomes available. For a real-time platform like X, streaming endpoints are critical because they enable the instant feed updates users expect. When they fail, users see blank feeds or outdated content.
Was this X's first outage in 2025?
No. X experienced another significant outage just three days earlier on January 14, 2025. Two major outages in five days suggests systemic infrastructure problems rather than isolated incidents. The pattern indicates either inadequate infrastructure capacity, recent problematic code deployments, or insufficient redundancy and monitoring systems.
How did competitors like Bluesky respond to X's outage?
Bluesky, a decentralized alternative to X, capitalized on the outage by pointing out that the platform remained operational while X was down. Bluesky had previously changed its X profile picture to its butterfly logo earlier in the week, and during the outage, the company highlighted the reliability advantage of its decentralized architecture, which doesn't have a single point of failure like centralized platforms do.
What lessons does X's outage provide about platform reliability?
The outage demonstrates that platform reliability requires continuous investment in monitoring, redundancy, staff expertise, and infrastructure scaling. The pattern of outages suggests that cost-cutting measures may have reduced X's reliability infrastructure. It also highlights the systemic risk created by concentrating critical communication infrastructure in a few private companies, and shows why decentralized alternatives are gaining attention as more reliable backup options.
Could X's outage have been prevented?
Yes, improved monitoring and redundancy could likely have prevented or significantly mitigated the outage. With better geographic and infrastructure redundancy, the streaming endpoint failure would have been handled transparently to users. With better monitoring, X's team likely would have detected the problem before Down Detector's crowdsourced reports. Regular chaos engineering testing of failure scenarios could have identified the weakness in streaming endpoints before it caused a real outage.
How dependent are we on platforms like X, and what are the risks?
For many people, X is a primary news source, communication channel, and business tool. When X is unavailable, journalists can't share news, activists can't organize, and businesses can't reach audiences. This concentration of critical infrastructure in a single private company creates systemic risk that would not be acceptable for utilities like electricity or water. The outage demonstrates both the economic impact (lost advertising revenue, potential user churn) and societal impact (disrupted communications, information flow) of platform failures.
What should users do to reduce dependence on X or prepare for future outages?
Users should maintain diverse communication channels and not rely solely on any single social platform for critical communications. Email, SMS, and direct messaging services should be primary communication methods. For businesses that depend on X for marketing or customer engagement, having backup channels and content distribution methods is prudent. Supporting decentralized alternatives like Bluesky provides insurance against catastrophic failures of centralized platforms.

Summary: What You Need to Take Away
X's January 16, 2025 outage was caused by a failure in streaming endpoints—the critical infrastructure that delivers real-time posts to users' feeds. The outage lasted from 7:39 AM PT through at least 11:15 AM PT, though most functionality recovered by 9:30 AM PT.
What makes this incident significant is not just that it happened, but that it was the second major outage in five days. This pattern suggests systemic infrastructure problems that go beyond random hardware failure.
The outage reveals important truths about modern digital infrastructure: it's complex, fragile, and dependent on careful investment and expertise. Platforms that cut corners on reliability infrastructure eventually pay the price through outages, user churn, and damaged reputation.
For users, the lesson is clear: don't depend solely on any single platform for critical communications. For X itself, the message is equally clear: reliability requires investment, and the cost of neglecting infrastructure eventually exceeds any savings from cost-cutting measures.

Key Takeaways
- X's outage was caused by streaming endpoint failure, preventing real-time posts from reaching users' feeds
- The incident lasted 90+ minutes with intermittent problems persisting for hours, affecting both web and mobile platforms
- This was the second major outage in five days, suggesting systemic infrastructure problems rather than isolated incidents
- Streaming infrastructure is exponentially more complex than traditional polling because it manages millions of concurrent stateful connections
- Poor communication during the outage stood in contrast to how mature tech companies handle incidents with frequent status updates
Related Articles
- X Platform Outages: What Happened and Why It Matters [2025]
- X Platform Outage January 2025: Complete Breakdown [2025]
- Verizon's $20 Credit After Major Outage: Is It Enough? [2025]
- Logitech macOS Certificate Crisis: How One Mistake Broke Thousands of Apps [2025]
- Logitech Certificate Expiration Broke macOS Mice: What Happened [2025]

