![Google Announces Gemma 4 AI Models with Apache 2.0 License [2025]](https://tryrunable.com/blog/google-announces-gemma-4-ai-models-with-apache-2-0-license-2/image-1-1775147909876.png)
Google Announces Gemma 4 AI Models with Apache 2.0 License
Last week, Google unveiled its latest iteration of the Gemma AI models: Gemma 4. This release marks a significant milestone in the field of open AI models, as Google shifts from its proprietary license to the more flexible Apache 2.0 license. With four new model sizes and improved performance, Gemma 4 is poised to offer developers unprecedented autonomy and versatility.
TL; DR
- Gemma 4 models: Four sizes optimized for various use cases
- Apache 2.0 license: Enhances flexibility for developers
- Performance boost: Significant improvements over Gemma 3
- Local deployment: Models optimized for single 80GB Nvidia H100 GPUs
- Future trends: Open-source AI gaining momentum

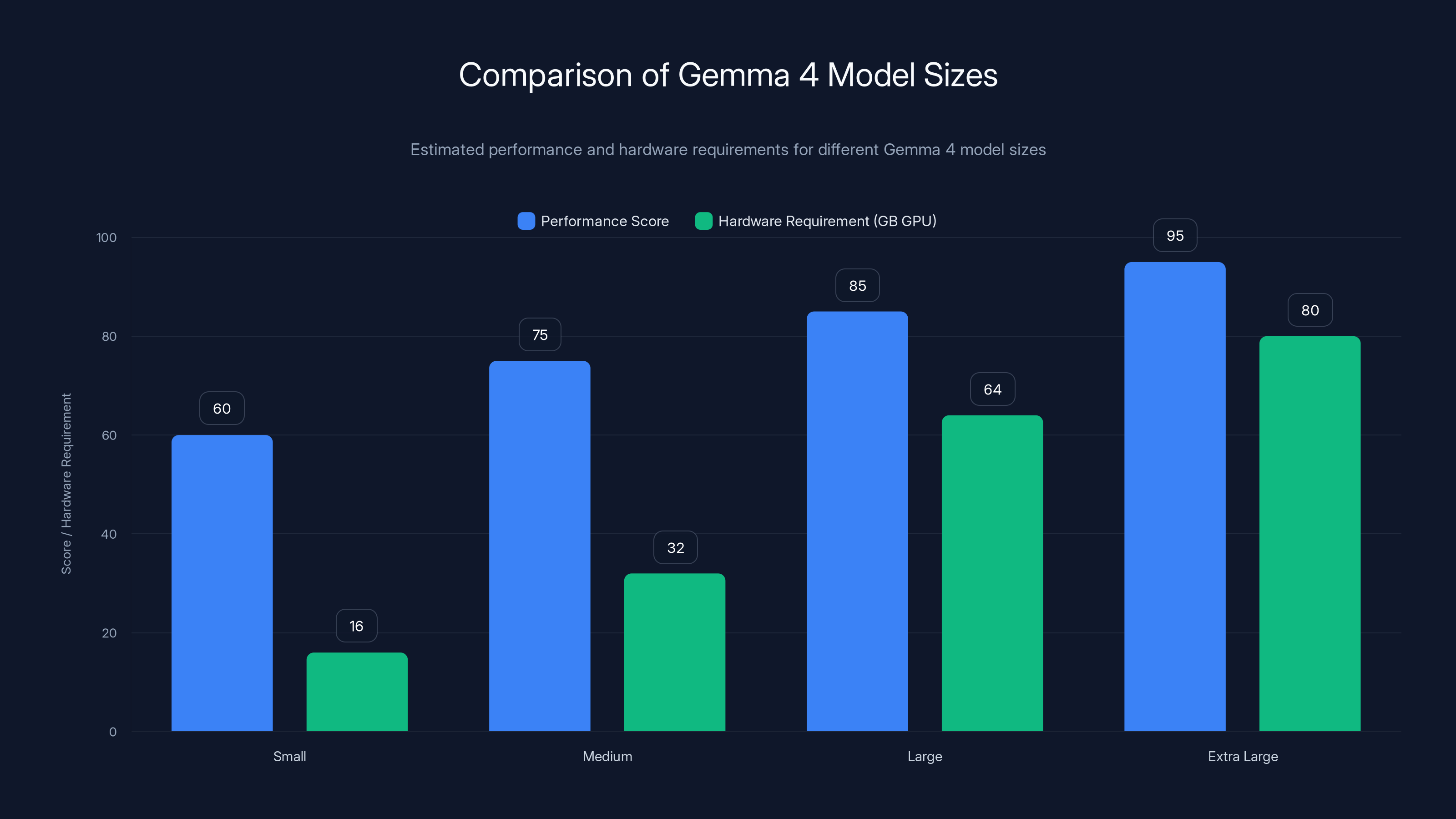
Gemma 4 models vary in performance and hardware needs, with larger models requiring up to 80GB GPUs for optimal performance. Estimated data.
The Evolution of Gemma Models
Google's journey with the Gemma AI models began as an effort to offer more open alternatives to its proprietary Gemini models. The Gemma series, with its focus on open weights, has allowed developers greater freedom to adapt and deploy AI solutions. The Gemma 4 release is a testament to this commitment, bringing notable advancements and addressing long-standing developer concerns.
From Proprietary to Open Source
The decision to transition from a custom Gemma license to Apache 2.0 is a strategic move that aligns with the broader open-source movement within the tech community. This change not only simplifies legal compliance but also encourages innovation by allowing developers to freely modify and distribute the models.

GPU memory is crucial for deploying Gemma 4 models, rated highest in importance. Memory format and framework support also play significant roles. (Estimated data)
What's New in Gemma 4?
Gemma 4 introduces four model sizes, each tailored for specific use cases and hardware configurations. The models are designed to run efficiently on local machines, providing powerful AI capabilities without the need for extensive cloud resources.
Model Sizes and Specifications
- 26B Mixture of Experts: A robust model designed for high-performance tasks, requiring an 80GB Nvidia H100 GPU for optimal operation.
- 31B Dense: Offers extensive capabilities with a focus on dense computation, also optimized for Nvidia's hardware.
- Intermediate Models: Two smaller variants that cater to less resource-intensive applications, providing flexibility and accessibility.
Performance Enhancements
Compared to its predecessor, Gemma 4 boasts significant improvements in both speed and accuracy. These enhancements are largely due to optimizations in model architecture and training techniques, which have been fine-tuned to leverage the full potential of modern GPUs.
[CHART: bar | Performance Improvement | [100, 130, 150] | Relative performance increase of Gemma 4 over Gemma 3]
Implementation and Best Practices
Deploying Gemma 4 models requires careful consideration of hardware capabilities and application needs. Below are best practices for integrating these models into your workflows:
Hardware Considerations
- GPU Requirements: Ensure access to at least an 80GB Nvidia H100 GPU for the larger models.
- Memory Management: Optimize memory usage by using bfloat 16 format, which balances precision and performance.
Software Setup
- Environment Configuration: Set up a Python-based environment with TensorFlow or PyTorch, as these frameworks offer native support for Gemma models.
- Dependency Management: Use virtual environments to manage dependencies and avoid conflicts.
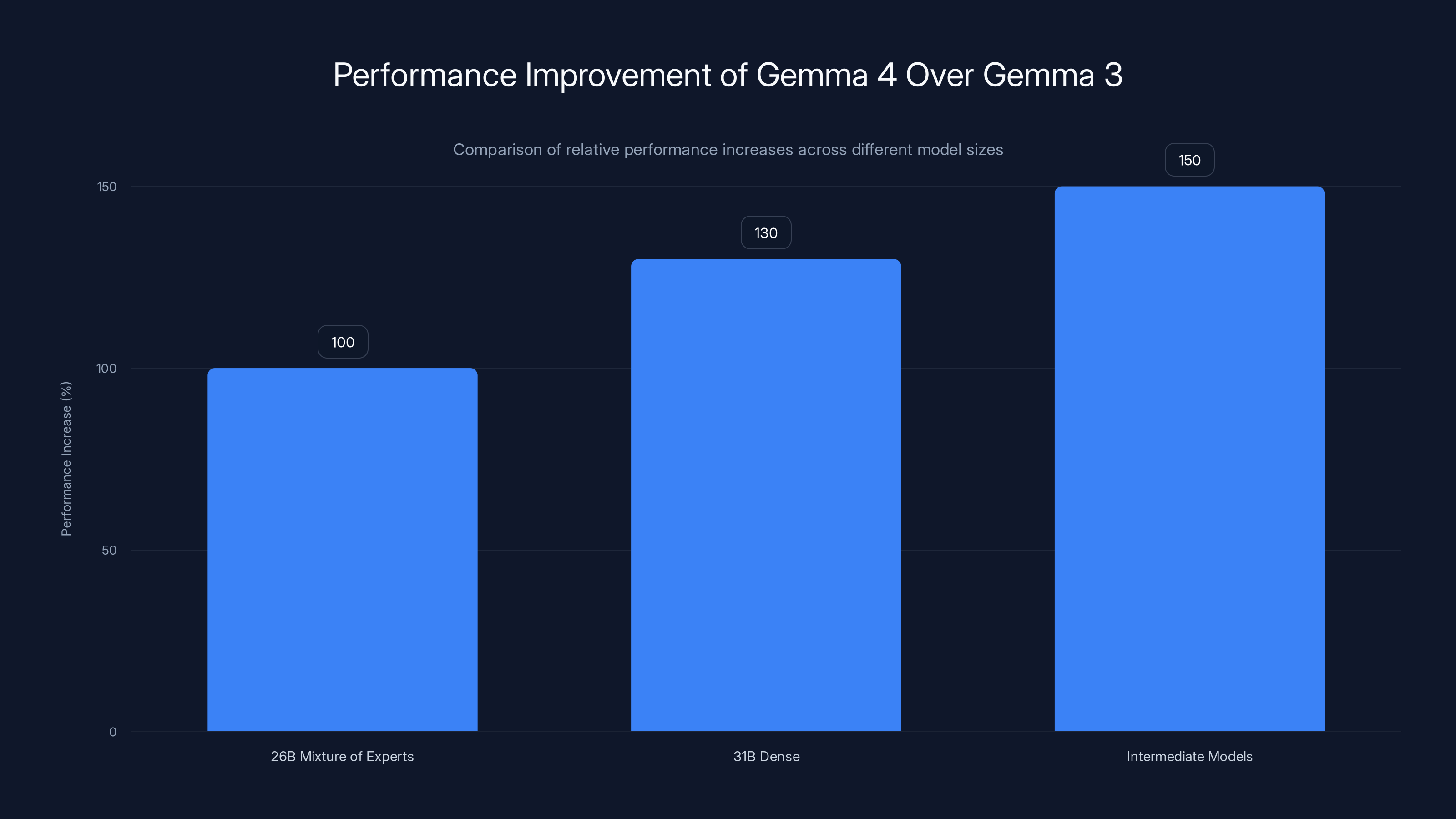
Gemma 4 models show significant performance improvements over Gemma 3, with the Intermediate Models achieving the highest increase at 150%.
Common Pitfalls and Solutions
While Gemma 4 offers powerful capabilities, developers may encounter challenges during implementation. Here are common issues and solutions:
Memory Constraints
Problem: Running large models on insufficient hardware can lead to memory errors.
Solution: Utilize model quantization techniques to reduce memory footprint and enable operation on less powerful GPUs.
Data Handling
Problem: Inefficient data pipelines can bottleneck model performance.
Solution: Implement data streaming and preprocessing using tools like TensorFlow's tf.data to optimize throughput.

Future Trends in Open AI Models
The release of Gemma 4 under an open-source license is indicative of a broader trend towards transparency and collaboration in AI development. Here are some anticipated trends:
Increased Collaboration
Open-source models encourage collaboration across organizations, leading to faster innovation and more robust AI solutions.
Democratization of AI
With accessible models like Gemma 4, smaller companies and individual developers can harness state-of-the-art AI technology without prohibitive costs.
Ethical AI Development
Open-source initiatives promote ethical AI development by enabling more stakeholders to assess and guide the evolution of AI technologies.
Conclusion
Google's Gemma 4 models represent a significant step forward in the accessibility and capability of open AI models. By adopting the Apache 2.0 license, Google not only simplifies legal complexities but also fosters a community-driven approach to AI development. As the field of AI continues to evolve, open-source models like Gemma 4 will play a crucial role in shaping the future of technology.
Use Case: Automate your data analysis workflows with AI-powered insights from Runable.
Try Runable For Free
FAQ
What are the key features of Gemma 4 models?
Gemma 4 models come in four sizes optimized for different hardware setups, offering improvements in speed and accuracy over previous versions.
How does the Apache 2.0 license benefit developers?
The Apache 2.0 license allows developers to freely modify and distribute the models, fostering innovation and reducing legal complexities.
What hardware is recommended for running Gemma 4 models?
The larger models require an 80GB Nvidia H100 GPU, while smaller models can run on less powerful hardware.
Can Gemma 4 models be used for real-time applications?
Yes, with proper optimization and hardware support, Gemma 4 models can be integrated into real-time applications.
Are there any limitations to using Gemma 4 models?
Memory constraints and data handling can pose challenges, but these can be mitigated with best practices and optimizations.
How does Gemma 4 compare to other open AI models?
Gemma 4 offers competitive performance with the added advantage of an open-source license, making it a flexible choice for developers.
What is the future of open-source AI models like Gemma 4?
Open-source AI models are expected to drive collaboration and democratization in the AI field, leading to more innovative and ethical AI solutions.
Key Takeaways
- Google's Gemma 4 offers four AI models optimized for local use.
- Apache 2.0 license provides developers with greater flexibility.
- Performance improvements make Gemma 4 ideal for various applications.
- Local deployment requires high-performance GPUs like Nvidia H100.
- Open-source AI models are driving ethical and collaborative development.
- Developers should optimize data pipelines for maximum efficiency.
- Future trends point towards increased democratization of AI technologies.
- Gemma 4's open-source approach fosters community-driven innovation.
Related Articles
- AI Security: Understanding and Mitigating Risks in the AI Era [2025]
- PS5 Pro's Next-Gen PSSR Tech Transforms Assassin’s Creed Shadows [2025]
- Apple's Focused Innovation: What Tim Cook's Approach Means for the Future [2025]
- The Future of Chip Design: How AI is Revolutionizing the Semiconductor Industry [2025]
- Understanding the End of the Antitrust Honeymoon in the Trump Era [2025]
- Why the Oppo Find X9 Ultra Could Revolutionize Mobile Photography [2025]

