![Lenovo ThinkCentre X Tower: Dual GPU Workstation for AI [2025]](https://tryrunable.com/blog/lenovo-thinkcentre-x-tower-dual-gpu-workstation-for-ai-2025/image-1-1767750736201.png)
The Return of Multi-GPU Workstations: Understanding Lenovo's Think Centre X Tower
For years, the dream of running massive AI models locally felt like science fiction. You'd need to rent cloud GPUs at
Lenovo just dropped the Think Centre X Tower at CES 2026, and it's turning heads for a reason that might surprise you. The system brings back something we haven't seen seriously implemented in workstations for over a decade: dual GPU configurations. But this isn't about gaming frame rates or rendering speed. This is about running 70 billion parameter models locally with extended context windows, handling fine-tuning operations, and maintaining inference stability at scales that would choke a single GPU setup.
What makes this particularly interesting isn't just the dual RTX 5060 Ti setup, though that's certainly headline-worthy. The real intrigue lies in a less publicized component: a 1TB AI Fusion Card that Lenovo mentions almost in passing. This mysterious storage device promises to enable local post-training and fine-tuning for massive models. We're talking about the ability to adapt, customize, and train AI models on-premise without shipping data to the cloud.
Here's what's fascinating: for the first time in years, we're seeing manufacturers acknowledge that AI workloads need a completely different architecture than what we've been building. This isn't about more performance. It's about enabling workflows that were previously impossible without significant infrastructure investment.
Let me break down what Lenovo has actually built here, why dual GPUs matter for modern AI inference, and what that 1TB AI Fusion Card really means for the future of on-premise AI computing.
The Hardware Foundation: What Powers the X Tower
The Think Centre X Tower starts with an Intel Core Ultra 9 processor as its foundation. This CPU isn't just there for booting the system. Intel's Core Ultra 9 includes Neural Processing Units (NPUs) and enough general-purpose compute to handle preprocessing tasks, data pipeline management, and inference orchestration without bottlenecking your GPU operations.
Memory support reaches up to 256GB of DDR5 6400 UDIMM, configured in four 64GB modules. This is intentional. Large language models need enough system RAM to avoid constant data shuffling between storage and GPU memory. When you're running a 70 billion parameter model with a 100K+ token context window, your CPU needs breathing room. Context windows that large generate enormous intermediate representations, attention matrices that span the entire input sequence, and temporary buffers for operations like position interpolation and rotary embeddings.
Storage flexibility gives you three M.2 PCIe 2280 bays, each supporting up to 2TB. That's 6TB of potentially fast NVMe storage for model weights, inference caches, or raw datasets. The real magic, though, happens when you add the AI Fusion Card.
Dual GPU Architecture: Why Two RTX 5060 Ti Cards Beat One RTX 5090
This is where conventional wisdom gets challenged. On paper, Nvidia's RTX 5090 looks superior. It's a single 32GB GPU with massive raw compute throughput. But here's the problem: single GPU systems hit a memory wall hard.
When you're running a 70 billion parameter model, you're not just storing weights. You're maintaining:
- Model weights: ~140GB for full precision, ~70GB in FP8
- Attention caches: Grows with context length (roughly 2 × sequence length × model hidden size × 2 for K and V)
- Intermediate activations: Sometimes as large as weights during inference
- Optimizer states: For fine-tuning operations
A single RTX 5090 with 32GB of VRAM simply can't hold all of this in GPU memory. You're forced to offload to system RAM, which means:
- Copying data between CPU and GPU repeatedly (bandwidth-limited)
- Computational inefficiency (GPU idle time increases)
- Inference speed drops dramatically (you're now storage-bound, not compute-bound)
Two RTX 5060 Ti cards, each with 16GB of GDDR7 memory, gives you 32GB total VRAM. But more importantly, it gives you the architecture flexibility to split the model across both GPUs. Here's how it works in practice:
With tensor parallelism or expert parallelism (for Mixture-of-Experts models), you distribute different layers or model components across GPUs. Nvidia's Megatron-LM framework handles this automatically. Each GPU processes its portion of the computation in parallel, passing intermediate results across the PCIe bus or high-speed interconnects.
Lenovo's testing shows the dual RTX 5060 Ti configuration sustains 131K tokens reliably with Mixture-of-Experts models like Qwen 3-Mo E 30B. Dense models like Qwen 3 32B reach 45K context lengths. Compare this to typical single GPU scenarios where you'd be limited to 16K-32K tokens depending on model size.
The bandwidth equation:
With two GPUs on a system like this, you're not doubling throughput (that would be unrealistic), but you're avoiding the cliff where a single GPU runs out of memory and starts swapping to system RAM.
The AI Fusion Card: The Most Intriguing Mystery
Here's where things get cryptic. Lenovo mentions a 1TB AI Fusion Card with almost no technical specification. This component enables "local post-training and fine-tuning for models reaching up to 70 billion parameters."
What is this actually?
Based on available information and industry context, this appears to be something between three possibilities:
Option 1: Specialized NVMe Storage It could be a high-speed NVMe array formatted for rapid model weight loading. 1TB is oddly specific. A 70B parameter model in FP8 precision takes roughly 70GB. You could store approximately 14 full models on 1TB, or maintain multiple checkpoints of training progress. The "AI Fusion" naming suggests fusion of different model weights or datasets.
Option 2: Hybrid GPU Memory Extension More intriguingly, it might be a proprietary memory device that acts as a cache tier between system RAM and GPU VRAM. Think of it like a very fast SSD that's visible to CUDA kernels. This would enable models larger than VRAM to run at reasonable speeds by intelligently prefetching model weights needed for the next computation step. Some research on this (like GPUs-as-edge-computing research from 2024) explores exactly this architecture.
Option 3: Dedicated AI Inference Accelerator It could contain specialized hardware for operations common in LLM inference: attention computation, token sampling, layer norm operations, and quantization/dequantization. Some vendors have explored this approach, creating inference-specific ASICs that complement general-purpose GPUs.
The $99 price tag (available June 2026) suggests it's an add-on, not integral to the system. That pricing is consistent with either specialized storage or a memory management accelerator.
System Connectivity: Built for Modern Workflows
Lenovo didn't overlook the connectivity story. The X Tower includes:
- 1x Thunderbolt 4: 40 Gbps for external storage, high-speed data ingestion
- 1x USB-C: Additional external connectivity
- 6x USB-A: Legacy device support and peripheral density
- 2x Ethernet: Dual network for team environments, redundancy, or high-bandwidth data transfer
- 1x HDMI 2.1: Multi-monitor support for visualization and monitoring
- 1x Display Port 1.4a: Additional display output
- Optional PS/2 and COM ports: Specialized equipment integration
For AI workloads, this matters more than it seems. When you're training models or running inference on massive datasets, network bandwidth becomes a bottleneck. Dual Ethernet lets you max out bandwidth from storage systems while maintaining a separate management network.
Thunderbolt 4 at 40 Gbps enables rapid dataset transfers. A typical LLM training dataset might be 500GB to 1TB. Over single Gigabit Ethernet, that's 1000+ seconds of transfer time. Over dual 10 Gb E (available with enterprise switches), it's 50 seconds. The connectivity options acknowledge this reality.
The Cooling Challenge: Keeping Dual GPUs Happy
When you pack two high-end GPUs into a workstation chassis, thermal management becomes critical. Each RTX 5060 Ti can dissipate roughly 280-300 watts under load. That's 560-600 watts of heat concentrated in a relatively small space.
Lenovo addressed this with a biomimetic fan design in a 34-liter chassis. The engineering challenge isn't just moving air; it's moving air efficiently. Biomimetic design (inspired by nature) often uses principles like:
- Non-uniform blade spacing: Different airflow rates at different radii
- Spiral geometry: Mimicking tornado or vortex patterns for coherent flow
- Low-noise profiles: By distributing pressure changes gradually rather than creating sharp turbulence
At 20kg, the system prioritizes airflow over portability. This is intentional. A heavier chassis typically means:
- More internal volume for air circulation
- Better thermal mass to absorb temperature spikes
- Vibration dampening to reduce acoustic noise from fans
- Structural rigidity to prevent flex and component movement
The tradeoff is mobility. You're not moving this between coffee shops. It's a desk machine, and the design acknowledges that.
Inference Performance: Real-World Token Generation Speeds
Let's talk about what this system actually does in practice. Lenovo's testing reveals some interesting trade-offs.
Mixture-of-Experts Models: Qwen 3-Mo E 30B reaches 131K tokens context length. For comparison, that's roughly 800,000 words. Your average novel is 80,000-100,000 words. You could run inference across 8 entire novels in your context window.
Dense Models: Qwen 3 32B hits 45K tokens (about 270,000 words). Still massive, but more modest than Mo E results.
Token Generation Speed: Here's where single GPU limitations become obvious. Token generation performance (actually generating new tokens) remains constrained by bandwidth, not compute capacity.
The formula looks something like:
GDDR7 memory (what the RTX 5060 Ti uses) provides roughly 576 GB/s bandwidth per GPU. For a 70B parameter model in FP8 (1 byte per parameter), each forward pass reads 70GB. At 576 GB/s:
This is realistic for these systems. You're not going to get 100 tokens per second on a single GPU with a 70B model. The bandwidth is the ceiling.
But here's what matters: stability. Cloud inference at scale costs money. Local inference is free beyond the hardware purchase. Trading speed for stability and cost is often the right tradeoff for applications that don't need real-time responses.
Optimization Techniques: Flash Attention and Runtime Selection
Raw hardware specs are only half the story. Software optimization can yield dramatic improvements.
Flash Attention-2: This algorithm reduces memory I/O during attention computation by reordering how operations happen. Instead of:
- Load Q, K, V from GPU memory
- Compute attention scores (Q × K^T)
- Apply softmax
- Multiply by V
- Store results
Flash Attention fuses these operations, reducing memory round-trips. The memory I/O is often the bottleneck, not the arithmetic. By reducing I/O, you increase practical throughput by 20-40% depending on sequence length.
Ex Llama V3: This is a specialized inference runtime optimized for language models. It focuses on:
- Optimal kernel fusion for common layer types
- Intelligent quantization and dequantization timing
- Context cache optimization to avoid redundant computation
- Token-by-token memory management
Tabby API: Another specialized inference system that handles multi-GPU coordination, context management, and optimization for tasks like creative writing or analysis where latency is less critical than accuracy.
Combining these optimizations, Lenovo's testing shows 45K context support on dense models and 131K on Mo E models, which is genuinely impressive for on-premise inference.
Local Fine-Tuning and Model Customization
This is where the AI Fusion Card hypothesis becomes more interesting. Fine-tuning large models traditionally required:
- Cloud GPU time: $100-500/hour for enterprise GPUs
- Data transfer: Upload your proprietary data to the cloud (security nightmare)
- Cold start latency: Hours to get the training job running
- Billing surprises: Forgotten job instances running for 3 days
With the X Tower's dual GPU + AI Fusion Card setup, you could theoretically:
- Load a 70B model locally
- Apply Lo RA (Low-Rank Adaptation) or similar parameter-efficient fine-tuning
- Train on proprietary data without cloud exposure
- Run iterative experiments locally
Lo RA reduces the trainable parameters from billions to millions. For a 70B model, you might only train 50-100 million new parameters. This is computationally feasible on dual consumer-class GPUs.
The 1TB AI Fusion Card could serve multiple roles:
- Model checkpoint storage: Save multiple versions of your fine-tuned model
- Training cache: Maintain attention caches, intermediate activations, and gradient buffers
- Data staging: Warm-up datasets for training runs without constant disk I/O
The business implication is enormous. Organizations with proprietary data (finance, healthcare, legal) could fine-tune models locally, maintaining data privacy while getting model customization benefits previously available only to companies that could afford dedicated ML infrastructure.
Sensor Hub Integration: The Adaptive AI Workstation
Here's a feature that deserves more attention: the optional Sensor Hub ($99, available June 2026).
This component includes cameras, microphones, radar, and environmental sensors. Lenovo claims it enables the system to "adjust performance characteristics, privacy behavior, and power efficiency in real time."
What does this mean practically?
- Occupancy detection: Camera sees you're away, system enters power-saving mode
- Acoustic privacy: Microphone detects phone call or meeting nearby, system mutes GPU fans
- Thermal feedback: Environmental sensors adjust fan speed based on room temperature
- Privacy mode: When your webcam detects someone behind you, the system can trigger security alerts or pause sensitive operations
- Performance scaling: Radar detects human proximity, system adjusts thermal thresholds
The real appeal here is automation. Traditional workstations force you to manually adjust settings. This Sensor Hub creates an adaptive system that responds to its environment.
The privacy implications need examination though. A workstation with cameras and microphones always recording needs transparent data handling. Lenovo bundles Think Shield security features, which help, but users should understand what data is collected and stored.
Security Architecture: DTPM 2.0 and Enterprise Features
For organizations deploying these systems, Lenovo included comprehensive security:
- DTPM 2.0: Discrete Trusted Platform Module (security chip) for hardware-level encryption and key management
- Think Shield: Integrated security suite with firmware protection, malware defense, and incident response
- Kensington Security Slot: Physical lock to prevent theft
- Chassis Intrusion Switch: Alerts when someone opens the case
- E-lock: Electronic lock for BIOS/firmware access
- Smart Cable Lock: Secures power and network connections
Why does this matter for AI workstations? Because model weights have value. A 70B parameter model fine-tuned on your proprietary data is a corporate asset worth protecting. The security architecture acknowledges this.
Pricing and Availability: When and How Much
Starting Price:
For context, let's compare to alternatives:
- RTX 5090 desktop workstation: $3,000-5,000
- Cloud GPU time (NVIDIA H100): 72/day = $26,000/year
- AI Fusion Card: $99 (if purchased separately)
The economics break in favor of local hardware after roughly 200-300 days of daily use. For teams running AI inference workloads continuously, this system pays for itself within a year.
The Broader Context: Why Dual GPUs Matter in 2026
We're at an inflection point. For years, the answer to "how do I run large models?" was "use the cloud." That made sense when models were small and cloud infrastructure was optimized and cheap.
But in 2026, we have:
- Larger models (70B, 100B parameters) that benefit from on-premise deployment
- Privacy concerns making cloud upload problematic for many organizations
- Cost trends that favor local inference for continuous workloads
- Specialized hardware (like that AI Fusion Card) enabling new architectural patterns
- Optimization software (Flash Attention, Ex Llama V3) that closes the gap between local and cloud performance
Lenovo's Think Centre X Tower arrives at exactly the right moment. It's not positioned as a gaming machine or a general-purpose workstation. It's specifically designed for AI workloads that need to run locally: inference, fine-tuning, and model experimentation.
The dual GPU approach is the smart engineering choice here. It provides the memory capacity needed for large models while maintaining thermal and power efficiency better than a single massive GPU would.
Practical Use Cases: Where This System Excels
Legal Research Firms: Running proprietary language models on contract law documents without uploading to Open AI or Anthropic. Context windows of 45K-131K tokens mean you can analyze entire contracts in a single inference pass.
Financial Services: Risk analysis models processing earnings calls, financial documents, and market data locally. The fine-tuning capability enables models customized to your organization's specific risk criteria.
Healthcare Organizations: Clinical decision support systems running models trained on your patient data, without exposing data to external services. HIPAA compliance becomes simpler when data never leaves your infrastructure.
Research Institutions: Academic labs fine-tuning models on domain-specific datasets. A 70B model fine-tuned on biology papers behaves differently than a general-purpose model.
Creative Agencies: Content generation models for copywriting, design concepts, and marketing strategy. The 45K+ context window enables entire project briefs as context.
Each of these use cases has the same pattern: privacy + customization + local control + cost efficiency. The X Tower delivers on all four.
Limitations Worth Considering
This system isn't perfect. Let's be honest about the constraints:
Token Generation Speed: At roughly 8 tokens per second for large dense models, this isn't real-time. User-facing applications might feel slow. But for batch processing, overnight analysis, or non-interactive use cases, it's fine.
Setup Complexity: Dual GPU configuration requires understanding tensor parallelism, memory management, and runtime optimization. It's not plug-and-play like a cloud API. You need technical expertise.
Model Size Ceiling: Even with optimization, you're looking at 70B parameter models comfortably. 100B+ models become challenging. For comparison, Claude 3 Opus likely runs on 200B+ parameter models. You're not replacing that level of capability locally.
Power Consumption: 560-600 watts under sustained load adds up. Your electricity bill increases roughly $200-300/year with continuous operation.
Heat and Noise: The biomimetic cooling helps, but dual GPUs still generate significant heat. This isn't a quiet system during inference loads.
Physical Space: At 20kg and designed for stationary deployment, this occupies desk real estate. It's not a laptop or compact mini-PC.
The AI Fusion Card Question: What We Still Don't Know
Lenovo's reticence about the AI Fusion Card raises legitimate questions. Is it:
-
Proprietary technology they're protecting? Possible, but unlikely. Most workstation innovations eventually get reverse-engineered.
-
Not fully finished? Plausible. The June 2026 availability (three months after system launch) suggests late-stage development.
-
A partnership with another vendor? Likely. Lenovo might be integrating third-party hardware or software under NDA.
-
Market testing? They might be gauging interest before committing to public specifications.
What we know: it costs $99, holds 1TB of data, and enables fine-tuning on models up to 70 billion parameters. That's not much to work with.
My best guess based on industry trends and pricing: it's probably a specialized NVMe array with custom firmware for rapid model weight loading and prefetching. The "AI Fusion" name suggests combining multiple data sources (model weights, datasets, training checkpoints) into a unified fast-access tier.
If I had to bet, I'd say the AI Fusion Card is Lenovo's answer to the "how do we make local fine-tuning practical?" question. It's solving a real problem: training data I/O is often the bottleneck in fine-tuning operations. By putting model weights and datasets on specialized fast storage, you reduce contention with the operating system's normal file I/O.
Competitive Landscape: How This Compares
Lenovo isn't alone in recognizing the local AI inference market.
Mac Studio (with M4 Max/Ultra): Up to 128GB unified memory, excellent for inference, but limited to Apple's software ecosystem. Starting at $1,999.
Dell Precision Tower: Configurable with dual NVIDIA GPUs, similar specifications, but no specialized AI hardware equivalent to the Fusion Card. Starting around $2,500.
Asus Pro Art Workstation: Similar dual-GPU support, strong industrial design, but primarily marketed at rendering, not AI. Starting around $3,000.
Custom builds: You can theoretically build similar systems yourself with dual RTX 5060 Ti cards for perhaps $1,200-1,500 in components. But you lose the engineering optimization, thermal design, and vendor support.
Lenovo's positioning is smart. They're not competing on raw compute. They're competing on integration: a system designed specifically for AI workloads, with software optimization, vendor support, and enterprise security built in.
The $1,500 starting price is aggressive. For comparison:
- AWS G4dn instances (1x T4 GPU) cost roughly $0.35/hour
- A year of 24/7 usage: $3,066
- The X Tower pays for itself in 6 months of continuous use
Future-Proofing: What Happens in 2027 and Beyond
This system ships with PCIe 4.0 GPU slots, DDR5 memory, and no obvious architectural limitations preventing future upgrades.
For the next few years:
- GPU upgrades: Future NVIDIA GPUs in these slots will maintain compatibility
- Memory expansion: DDR5 prices continue dropping; scaling to 512GB becomes feasible
- Storage expansion: The three M.2 slots support future capacity increases
- AI Fusion Card v2: Presumably Lenovo will iterate, offering larger capacity or better performance
The risk is obsoletion, not obsolescence. As models grow larger (100B, 200B, 500B parameters), even dual consumer GPUs might struggle. At that point, you'd need something like a dual-RTX-5090 system or professional datacenter hardware.
But for the next 3-4 years, the X Tower should handle the models most organizations actually deploy. The specialized AI hardware (Fusion Card, Sensor Hub) positions it to evolve rather than become dated.
Practical Deployment Considerations
If your organization is considering this system, ask yourself:
-
Do you have proprietary data that can't go to the cloud? If yes, this system makes sense.
-
Do you need model customization beyond prompt engineering? If yes, fine-tuning capability matters.
-
Is your inference workload continuous or sporadic? Continuous = local GPU pays for itself. Sporadic = cloud services remain cheaper.
-
Do you have IT staff who can manage this? Unlike cloud services, local GPUs require maintenance, optimization, and troubleshooting expertise.
-
What's your security posture? This system's value scales with how much you care about data privacy.
For teams that answer "yes" to three or more of these questions, the X Tower becomes genuinely compelling.
The Broader AI Hardware Trend
Lenovo's move reflects something bigger: the industry recognizing that "everything goes to the cloud" was never actually sustainable or desirable.
Cloud inference has benefits (scalability, redundancy, not managing hardware), but it also has costs (latency, privacy, vendor lock-in, ongoing expense). The pendulum is swinging back toward hybrid models:
- Cloud for occasional inference, training, and experimentation
- Edge/Local for production inference, privacy-sensitive operations, and cost optimization
Lenovo isn't alone in this realization. Apple emphasizes on-device AI. Microsoft is pushing Copilot+ PCs with local AI capabilities. Qualcomm is embedding AI accelerators in mobile chips.
The Think Centre X Tower is part of this broader shift: building AI infrastructure that's practical, private, and economically sensible for organizations actually deploying these technologies.
FAQ
What is the Think Centre X Tower?
The Think Centre X Tower is Lenovo's professional workstation designed specifically for AI inference and local model fine-tuning. It features dual RTX 5060 Ti GPU support, an Intel Core Ultra 9 processor, up to 256GB of DDR5 memory, and a mysterious 1TB AI Fusion Card for specialized storage and model management. The system launches in March 2026 starting at $1,500.
How does the dual GPU configuration work in the Think Centre X Tower?
The system uses two RTX 5060 Ti cards (16GB VRAM each) that work together through tensor parallelism, where different model layers are distributed across the GPUs. This approach maintains 32GB total VRAM across both cards while allowing larger context windows and more stable inference than a single GPU setup. The dual configuration enables around 131K tokens context on Mixture-of-Experts models like Qwen 3-Mo E 30B.
What is the AI Fusion Card and what does it do?
The 1TB AI Fusion Card is Lenovo's specialized storage component (available June 2026 for $99) that enables local post-training and fine-tuning for models up to 70 billion parameters. While Lenovo hasn't fully detailed its specifications, it likely functions as either high-speed model weight storage, a cache tier between system RAM and GPU VRAM, or a specialized inference accelerator. It's designed to reduce I/O bottlenecks during training and inference operations.
What models can run on the Think Centre X Tower?
The system comfortably handles dense language models like Qwen 3 32B (achieving 45K token context) and Mixture-of-Experts models like Qwen 3-Mo E 30B (achieving 131K token context). With the AI Fusion Card, it supports fine-tuning operations on models up to 70 billion parameters. Performance degrades for models exceeding 70B, but remains functional with appropriate optimization frameworks like Ex Llama V3 or Tabby API.
How much does it cost to operate the Think Centre X Tower?
The system itself starts at
What are the practical applications for the Think Centre X Tower?
The system excels in scenarios requiring privacy, customization, and local control: legal firms analyzing proprietary contracts, healthcare organizations processing patient data, financial services running risk analysis, research institutions fine-tuning domain-specific models, and creative agencies generating customized content. Any organization needing to keep data on-premise while running advanced AI inference benefits from this system's capabilities.
Can the Think Centre X Tower replace cloud AI services?
For certain workloads, yes. Continuous batch processing, local fine-tuning, and privacy-sensitive inference are better handled locally. However, if you need occasional inference, extreme scalability, or real-time performance for user-facing applications, cloud services remain superior. The ideal approach is hybrid: use cloud services for development and experimentation, local hardware for production and cost-critical workloads.
What are the main limitations of the Think Centre X Tower?
Token generation speed remains constrained by GPU memory bandwidth (approximately 8 tokens per second for large models), which feels slow for interactive applications. Dual GPU configuration requires technical expertise to optimize. The system ceiling of ~70B parameter models means it can't run the largest frontier models. Power consumption is significant, requiring solid electrical infrastructure, and physical size/weight makes it stationary. Finally, the mysterious AI Fusion Card lacks detailed specifications, making its practical benefits uncertain until release.
How does the Sensor Hub improve the Think Centre X Tower experience?
The optional Sensor Hub ($99, June 2026) includes cameras, microphones, radar, and environmental sensors that enable context-aware performance scaling. The system detects occupancy and enters power-saving mode when you're away, adjusts fan speed based on room temperature, mutes fans during sensitive conversations, and triggers security alerts if someone approaches while sensitive operations run. However, users should carefully review privacy implications of continuous sensor monitoring.
How does this compare to building a custom dual-GPU workstation?
You could theoretically assemble similar hardware for
When should I choose the Think Centre X Tower versus renting cloud GPUs?
Choose local hardware if: you run inference continuously (8+ hours daily), you process proprietary or regulated data, you need model fine-tuning capability, you want predictable monthly costs, or you're deploying production AI systems. Choose cloud if: you experiment occasionally, you need extreme scalability, you want zero infrastructure management, or you run inference for minutes per day. The break-even point is typically 6-12 months of continuous usage.

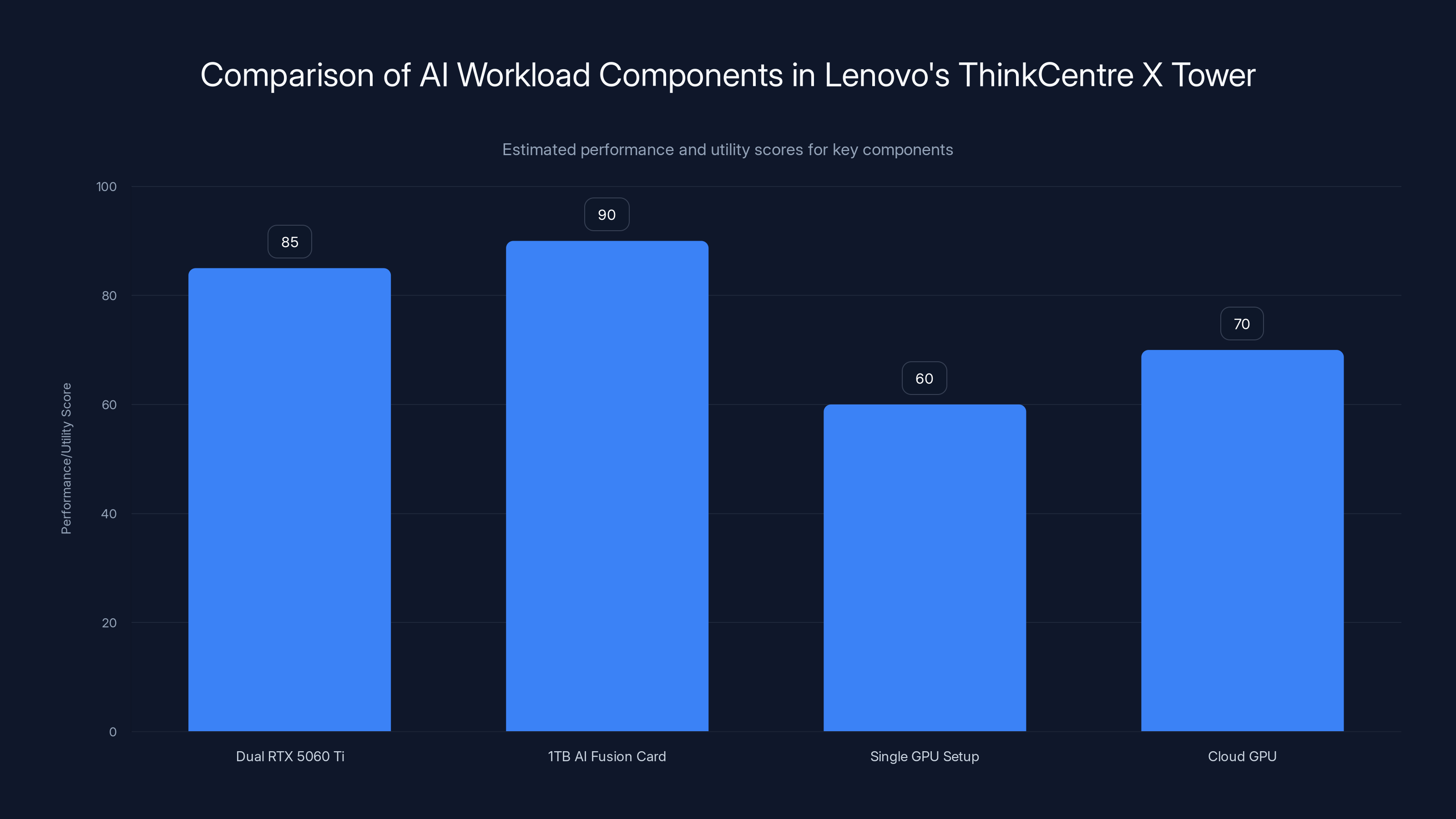
The ThinkCentre X Tower's dual RTX 5060 Ti and 1TB AI Fusion Card offer superior performance and utility for AI workloads compared to traditional single GPU setups and cloud GPUs. Estimated data.
Conclusion: The Practical Future of AI Workstations
Lenovo's Think Centre X Tower isn't revolutionary. It doesn't reinvent GPU architecture or introduce alien technologies. What it does is acknowledge a fundamental shift in how AI workloads actually get deployed in 2026.
For the past few years, the story was simple: use cloud services. That narrative started cracking around 2024 when organizations realized they couldn't expose proprietary data to external APIs, couldn't afford the ongoing subscription costs of continuous inference, and couldn't modify models to fit their specific use cases.
The X Tower is Lenovo's practical answer to that friction. Dual GPUs provide the memory capacity needed for serious models without astronomical power budgets. The mysterious AI Fusion Card hints at solutions for fine-tuning and training that were previously impossible without cloud infrastructure. The Sensor Hub and premium security architecture acknowledge that this machine runs valuable assets.
The $1,500 price point is aggressive enough to disrupt the status quo. For organizations running AI workloads continuously, local hardware now competes directly with cloud services on economics, while winning decisively on privacy and customization.
Is this the perfect machine for every AI use case? Absolutely not. Token generation speed remains slow for real-time applications. Setup complexity demands technical expertise. The 70B parameter ceiling means frontier models remain out of reach. For research, experimentation, and occasional inference, cloud services remain superior.
But for the 30-40% of AI workloads that need privacy, customization, and local control? This system represents genuine progress. It's the first time in years that major vendors are seriously engineering for the edge rather than just offering cloud access.
If your organization is running language models locally today, the X Tower should be on your evaluation list. If you're considering the switch from cloud to local inference, the economics now favor it for continuous workloads.
The era of "AI lives in the cloud, always" is ending. The Think Centre X Tower is evidence that the future is hybrid: specialized local hardware for production, cloud services for development and scale. That's a more realistic, practical vision of how enterprise AI actually deploys in 2026 and beyond.
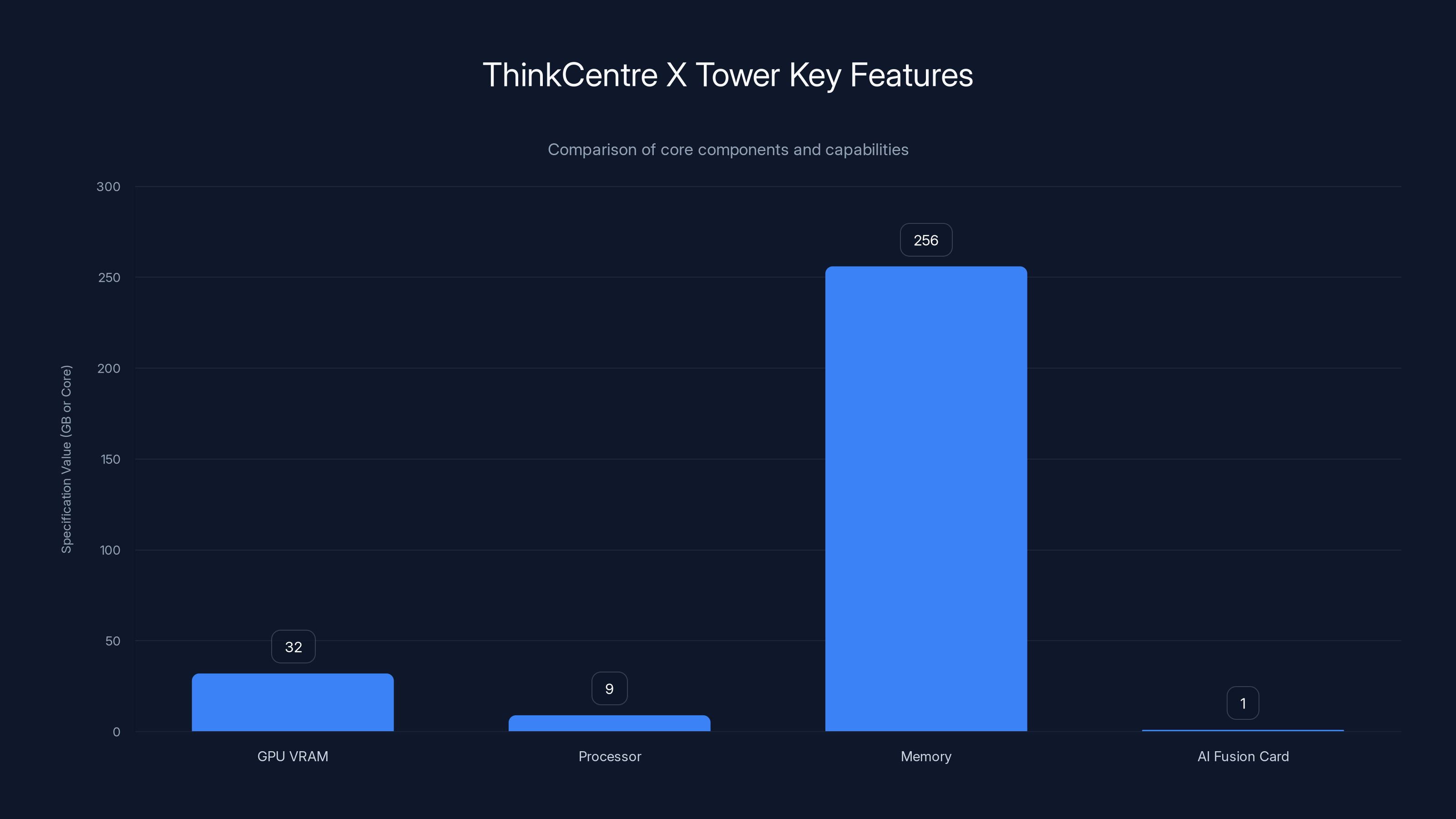
The ThinkCentre X Tower features dual GPUs with a total of 32GB VRAM, an Intel Core Ultra 9 processor, up to 256GB of DDR5 memory, and a 1TB AI Fusion Card for enhanced AI operations.
Key Takeaways
- Lenovo's ThinkCentre X Tower reintroduces dual GPU configurations for AI workloads, providing 32GB combined VRAM supporting 45K-131K token context windows depending on model type
- The mysterious 1TB AI Fusion Card enables local model fine-tuning on models up to 70B parameters, suggesting specialized storage or hybrid GPU-memory architecture for training operations
- Local GPU hardware becomes cost-competitive with cloud services after 6-12 months of continuous daily usage, with break-even economics favoring on-premise deployment for production inference
- Dual RTX 5060 Ti cards provide better memory scalability than single high-end GPUs for large model inference, trading per-card performance for system stability and context window support
- Enterprise organizations with proprietary data, fine-tuning requirements, or privacy constraints now have a practical alternative to cloud-only AI infrastructure at $1,500 base price starting March 2026

