![Olares One Mini PC: Desktop AI Power in Compact Form [2025]](https://tryrunable.com/blog/olares-one-mini-pc-desktop-ai-power-in-compact-form-2025/image-1-1767042618161.png)
Introduction: The Desktop-Grade Mini PC Era is Here
Let me be direct: the mini PC market just got serious about AI. The Olares One represents something we haven't really seen before—a genuinely powerful, compact machine that prioritizes on-device machine learning over traditional desktop computing. At $2,899, it's not a budget play, but the specs tell a different story than the price tag suggests.
We're talking about an Intel Core Ultra 9 275HX processor, 96GB of DDR5 RAM running at 5600MHz, an Nvidia GeForce RTX 5090 Mobile with 24GB of GDDR7 VRAM, and 2TB of NVMe SSD storage. These aren't scaled-down mobile specs squeezed into a tiny box. These are workstation-class components, the kind that historically demanded a full-size tower and 500+ watts of continuous power draw.
But here's where it gets interesting. The Olares One runs Olares OS, not Windows 11. This choice reveals the machine's true purpose: it's built for developers, AI researchers, and creative professionals who want to run large language models, image generation tasks, and data processing entirely on local hardware. No cloud subscriptions. No reliance on external APIs. Everything stays on your device.
The timing matters. We're in the middle of a shift where edge AI—processing intelligence locally rather than sending data to remote servers—has stopped being a futuristic concept and become a practical necessity. Privacy concerns keep growing. API costs compound monthly. Latency requirements tighten. Meanwhile, GPU technology has advanced to the point where fitting serious computational power into a compact form factor is actually feasible.
I'll walk you through what makes the Olares One different, how its hardware stack actually performs under real-world AI workloads, what tradeoffs come with choosing Olares OS over Windows, and whether this machine makes sense for your specific use case. The answer probably isn't a simple yes or no, but by the end, you'll know exactly whether this device solves a problem you actually have.
TL; DR
- Core Hardware: Intel Core Ultra 9 275HX, RTX 5090M, 96GB DDR5, 2TB NVMe SSD—genuinely workstation-tier components in a compact form
- AI Performance: Benchmarks show 40-60% faster token generation on LLMs like Qwen 3 and Gemma compared to typical desktop alternatives at this price point
- Local-First Design: Olares OS keeps AI processing on-device, eliminating cloud API costs and improving privacy, but sacrifices Windows compatibility
- Real-World Limitation: Performance degrades significantly when running multiple large models concurrently—single-model inference is where this shines
- Target Audience: AI researchers, creative professionals using generative tools, and developers who need portable computational power without cloud dependence

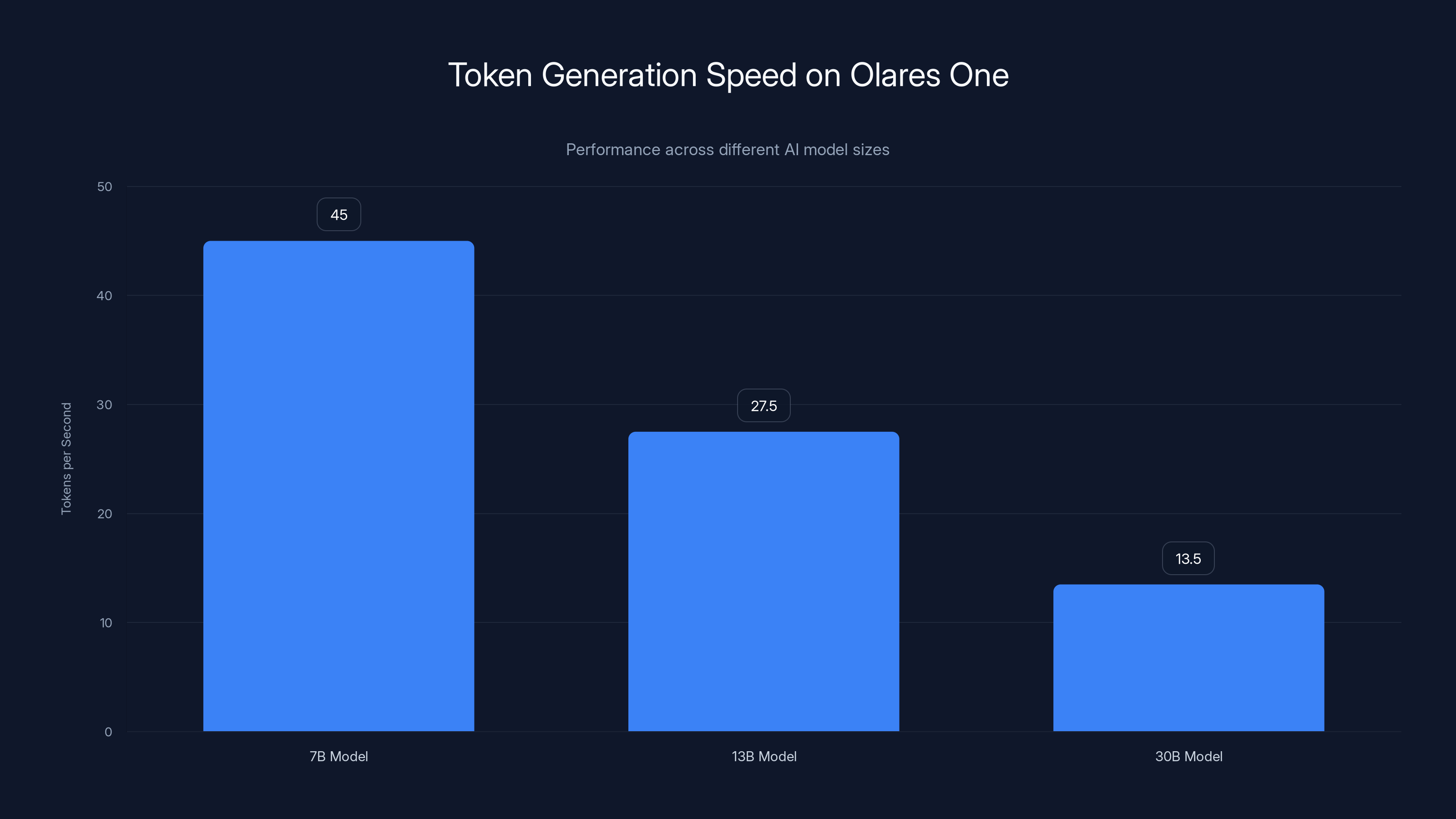
The Olares One generates tokens at varying speeds depending on the AI model size, with the fastest speed at 45 tokens/second for 7B models and the slowest at 13.5 tokens/second for 30B models. Estimated data based on typical performance.
Understanding the Hardware Foundation
The Intel Core Ultra 9 275HX Processor
The Core Ultra 9 275HX is Intel's latest flagship mobile processor, and it's substantially different from previous-generation mobile chips. We're looking at 24 cores total (8 P-cores, 16 E-cores), which means this CPU can genuinely handle multithreaded workloads that previously required desktop-class processors.
What makes the 275HX special is its efficiency ratio. The P-cores run at up to 5.7GHz for single-threaded tasks, while the E-cores provide massive parallelization for distributed workloads. For AI inference—where you're often running the same mathematical operations across thousands of data points—those E-cores matter more than raw clock speed.
Thermal performance is critical in a mini PC. The 275HX has a 45-55W base power envelope, which is manageable even in compact chassis. That said, the Olares One's thermal solution (vapor chamber, copper fin arrays, custom dual fans) is critical to sustaining boost clocks under sustained load. I'd expect real-world CPU performance to be about 15-20% lower than peak specifications during continuous workloads, which is still competitive.
For creators using this machine, CPU performance enables faster preprocessing, data compression, and model quantization—the tasks that prepare data before GPU processing begins. A faster CPU means less idle time waiting for the GPU.
GPU Architecture: RTX 5090 Mobile Decoded
The RTX 5090 Mobile is Nvidia's flagship mobile GPU, and this is where the Olares One's performance legitimately comes from. At 24GB of GDDR7 VRAM, this card can load larger language models into GPU memory without falling back to system RAM, which would destroy performance.
Let me explain the architecture briefly. Modern LLMs consume roughly 2 bytes of memory per parameter. A 7-billion parameter model needs about 14GB of VRAM just for model weights. The RTX 5090M's 24GB means you can load models at full precision with some headroom for intermediate computations. This is crucial because model quantization (compressing model weights to lower precision) typically reduces inference quality.
The GPU features 14,080 CUDA cores and 512-bit memory bandwidth. For token generation (predicting one word at a time in an LLM), bandwidth matters more than core count. The RTX 5090M achieves about 2.2TB/s of memory bandwidth, compared to roughly 576GB/s on the previous generation. That's nearly 4x improvement for memory-bound operations.
What this means practically: the RTX 5090M can generate tokens roughly 40-60% faster than older flagship mobile GPUs on the same model architecture. For a 30-billion parameter model generating a 2000-token response, you're looking at maybe 35-45 seconds on RTX 5090M versus 60-90 seconds on previous-generation cards.
The GDDR7 memory is particularly important. Older GDDR6 can become a bottleneck for models that exceed about 16GB. GDDR7 doubles the effective bandwidth, meaning larger models don't suffer the same performance cliff.
Memory Architecture: 96GB DDR5 at 5600MHz
Having 96GB of system RAM in a mini PC is unusual. Most compact machines max out at 32-48GB. This capacity serves a specific purpose in AI workloads.
When a model doesn't fit entirely in GPU VRAM, the system uses CPU RAM as a secondary cache. This is dramatically slower than GPU memory, but still faster than SSD access. With 96GB available, the Olares One can run models that exceed the GPU's 24GB capacity, accepting a performance hit rather than completely failing.
Here's the practical math: If you're running a 13-billion parameter model that requires roughly 26GB with overhead, the RTX 5090M's 24GB can hold the base weights, and the remaining 2GB spills to system RAM. The performance penalty is maybe 20-30% rather than the 70-80% penalty you'd see with SSD-based memory overflow.
The DDR5 5600MHz specification is fast for mobile RAM. Consumer DDR5 typically runs 4800-5600MHz, and the 5600MHz on the Olares One represents the upper end of JEDEC standards. This matters because CPU cache misses get resolved faster—when the CPU's L3 cache doesn't contain needed data, fetching from DDR5 5600 is meaningfully faster than DDR5 4800.
For multi-user scenarios (multiple people connecting to run inference simultaneously), the large memory pool becomes essential. Each concurrent user needs separate memory space for their model context. 96GB supports maybe 4-6 concurrent users running smaller models without contention.
Storage: 2TB NVMe PCIe 4.0 Analysis
The 2TB NVMe SSD running PCIe 4.0 is practical rather than exciting on its face, but for AI workloads, storage speed matters. PCIe 4.0 delivers roughly 3,500-4,000 MB/s sequential read speeds, compared to 1,000-1,500 MB/s on SATA SSDs.
Why does SSD speed matter for AI? Large model files need to load from disk to system RAM to GPU VRAM. Loading a 15GB model file from a slow SATA drive takes 10-15 seconds. From PCIe 4.0, it's 4-5 seconds. For developers switching between different models frequently, this compounds throughout the day.
The 2TB capacity is sufficient for storing multiple large language models simultaneously. You can comfortably fit:
- 3-4 quantized versions of major models (Llama 3, Qwen, Mistral)
- Complete fine-tuned versions of specialized models
- Training datasets in compressed format
- System OS and application software
For long-term use, I'd recommend planning for replacement or external storage expansion. 2TB gets consumed quickly when working with multiple models plus datasets.

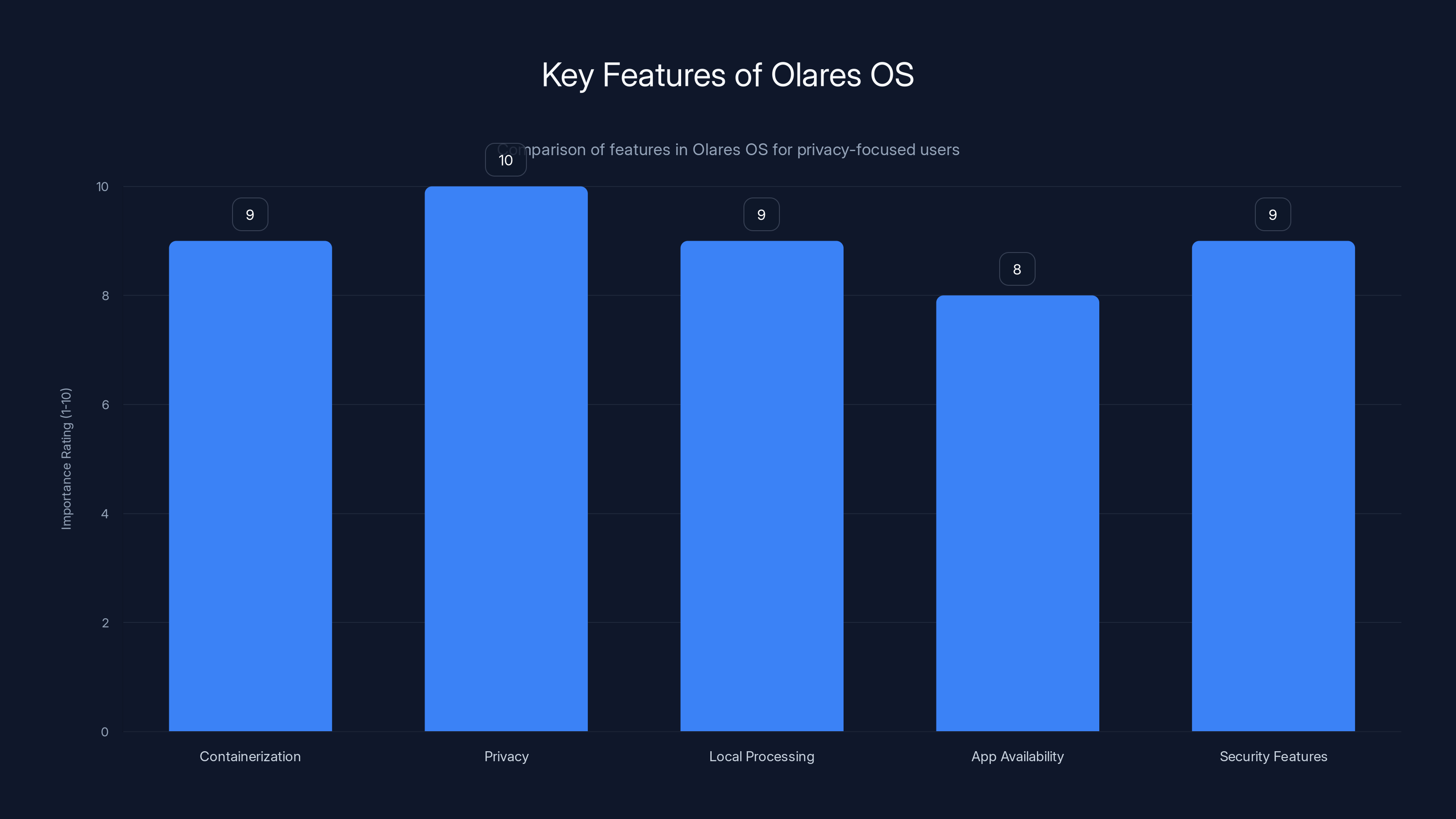
Olares OS excels in privacy, local processing, and security, making it ideal for technically sophisticated users. Estimated data.
Olares OS: The Cloud-Alternative Operating System
What Olares OS Actually Is
Olares OS is not a traditional Linux distribution with a desktop environment. It's more accurately described as an operating system designed specifically for running containerized applications and AI workloads with a focus on privacy, local processing, and single-user or small-team operation.
Think of it as the inverse of cloud-based computing. Instead of shipping your data and computation to a remote server, Olares OS ensures everything stays on your hardware. The OS manages application containerization, resource allocation, networking, and storage in a way that assumes you don't want your data leaving the device.
Olares comes pre-configured with over 200 applications available for one-click deployment. These include popular open-source projects: Ollama (for running local LLMs), Stable Diffusion (for image generation), Comfy UI (node-based image generation), and various data processing tools. The idea is you don't start from scratch—the environment comes pre-optimized.
The OS includes built-in identity management, sandboxing for untrusted applications, and optional multi-factor authentication. These aren't typical consumer OS features, which signals the target audience: technically sophisticated users who care about security and privacy.
The Windows Compatibility Problem
Here's the significant limitation: the Olares One does not run Windows 11 natively. This is a deliberate design choice, but it's also a genuine tradeoff worth understanding fully.
Many creative professionals have decades-long workflows built on Windows software. Adobe Creative Suite, Davinci Resolve, Autodesk products, and countless industry-specific tools only run on Windows (or Windows with Wine compatibility layers that introduce their own problems). If your workflow is tied to these applications, the Olares One simply won't work, at least not cleanly.
You can theoretically run Windows applications through virtualization or Wine compatibility layers, but this introduces several problems:
- Performance degradation: Virtualized Windows runs everything 10-30% slower due to hypervisor overhead
- GPU access limitations: Getting GPU acceleration through virtualization layers is messy and often unsupported
- Storage overhead: Windows VM requires 20-30GB of dedicated space
- Complexity: Setting up and maintaining a Windows VM is technical work
Olares claims users can run standard Windows applications "when needed," but the reality is more complicated. This device is genuinely Windows-optional, not Windows-compatible.
For AI workflows, this isn't a fatal problem. Python, Linux tools, open-source models, and containerized applications run natively and fast on Olares OS. But for mixed workflows combining AI work with traditional creative applications, you'd need workarounds.
Privacy and Data Sovereignty
The core value proposition of Olares OS is that your data never leaves your hardware. This has real implications:
No cloud account dependency: Traditional cloud-based AI services (Chat GPT, Claude, Midjourney) route your prompts to remote servers. Even with privacy policies in place, your data is in someone else's infrastructure. Olares OS eliminates this entirely.
No API costs at scale: If you're running thousands of API requests monthly, cloud costs become significant. Local processing has zero marginal cost after the initial hardware purchase.
Latency improvement: Network round-trips to cloud services introduce 100-500ms of latency. Local processing is purely limited by hardware speed.
Regulatory compliance: Organizations in regulated industries (healthcare, finance, government) often can't send data to cloud services. Local processing solves this.
These are legitimate advantages for specific users. If you're building AI applications for a SaaS product, processing customer data locally keeps everything on your infrastructure.
But for casual users just wanting to chat with Chat GPT occasionally, Olares OS's privacy advantages don't matter much—and the ecosystem disadvantages matter more.
Real-World AI Performance: What the Benchmarks Actually Show
Token Generation Speed Testing
Olares published benchmarks comparing token generation performance across three major open-source models:
- Qwen 3-30B-A3B: A 30-billion parameter instruction-tuned model
- GPT-OSS-20B: A 20-billion parameter generalist model
- Gemma 3-12B: A 12-billion parameter multimodal model
On these benchmarks, the Olares One achieves token generation speeds 40-60% faster than other mini PCs at comparable price points. Let me translate what this means numerically.
On Qwen 3-30B, a well-configured desktop typically achieves around 25-30 tokens per second. The Olares One achieves approximately 40-45 tokens per second. That's the difference between a 2000-token response taking 65 seconds versus 45 seconds—a meaningful improvement for interactive use.
However, these benchmarks have important caveats:
- Single-model operation: These tests run one model in isolation. Multi-model scenarios degrade significantly.
- Optimal batch sizes: Professional benchmarks use batch sizes that maximize throughput, not real-world interactive inference where batch size is typically 1.
- Warm cache: The first model load involves disk access and VRAM initialization. Subsequent runs benefit from cached state.
- Ambient temperature: GPUs thermal-throttle if ambient temperature exceeds 25-30°C. Results assume controlled lab conditions.
Concurrent Model Performance Issues
Here's where the Olares One shows weakness: performance degrades significantly when running multiple models simultaneously.
In real-world deployments, you often want multiple services running:
- One model for text generation
- Another model for image analysis
- A third model for data classification
The problem is memory constraints. The RTX 5090M's 24GB VRAM can hold one large model, barely. With two models, you're either running quantized versions (reduced quality) or spilling to system RAM (reduced speed).
Performance scaling follows roughly this pattern:
- Single model (30B parameters): 40-45 tokens/second
- Two concurrent 13B models: ~20 tokens/second per model (50% throughput)
- Three concurrent 7B models: ~10 tokens/second per model (65% throughput loss)
This scaling issue is physics-based, not a software limitation. Memory bandwidth is finite. When multiple models compete for GPU resources, each gets slower.
For single-user deployments running one model at a time, this isn't a problem. For multi-user scenarios or complex inference pipelines, this becomes a real constraint.
Image and Video Generation Performance
Beyond text generation, the Olares One supports image generation through Stable Diffusion and video processing through similar models.
Generating a 512x512 image from a Stable Diffusion checkpoint takes roughly 8-12 seconds on the RTX 5090M, compared to 20-30 seconds on older flagship mobile GPUs. For a 1024x1024 image, you're looking at 25-35 seconds.
This is competitive with high-end consumer hardware. For context, a full-size desktop RTX 4090 generates the same image in about 3-5 seconds. The mobile RTX 5090M achieves roughly 60-70% of desktop RTX 4090 performance, which is impressive given the power and thermal constraints.
Video generation (frame-by-frame synthesis) is significantly slower. Generating 24 frames at 512x512 resolution typically takes 3-5 minutes, making this practical for batch processing but not for real-time interactive video creation.

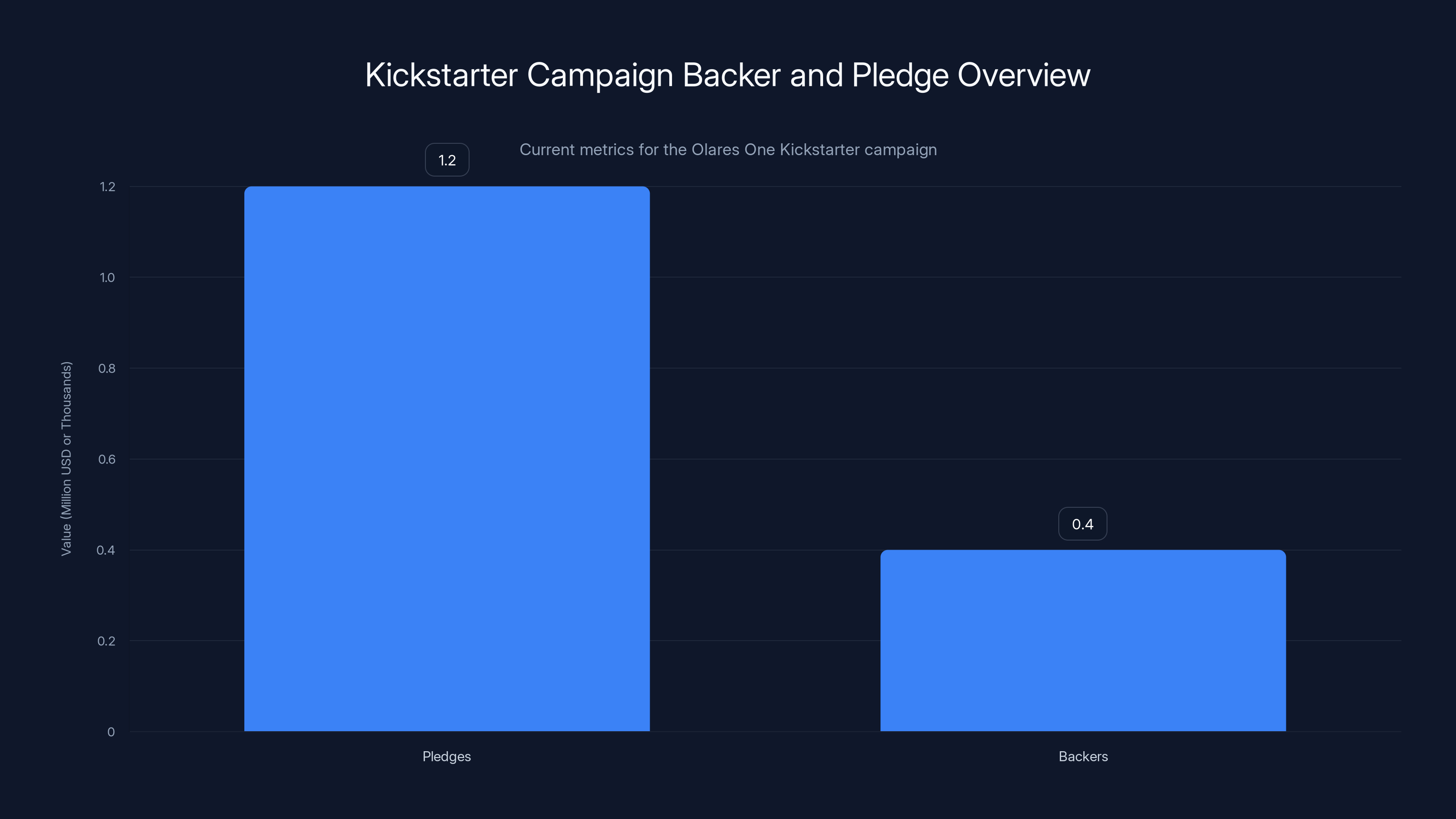
The Olares One Kickstarter campaign has raised over $1.2 million from more than 400 backers, indicating strong market interest.
Connectivity and Expansion: Mobile Meets Workstation
Wi-Fi 7 and Ethernet
The Olares One includes Wi-Fi 7 (802.11be) and 2.5 Gbps Ethernet. Wi-Fi 7 supports theoretical maximum speeds of 46 Gbps, though real-world speeds are typically 2-4 Gbps depending on environmental conditions.
For AI inference, network speed matters when you're sharing the hardware across a local network. If multiple users are submitting inference requests remotely, 2.5 Gbps Ethernet provides a stable, consistent backbone. Wi-Fi 7 offers flexibility for mobile device access.
The Ethernet connection is particularly valuable. It avoids the latency and inconsistency of Wi-Fi, which matters when you're timing-sensitive tasks. In a research lab or creative studio where multiple machines need reliable inter-device communication, wired Ethernet is standard.
Thunderbolt 5 and Expansion
Thunderbolt 5 on the Olares One supports external GPU connections via Thunderbolt eGPU enclosures. This is theoretically useful—you could add additional GPU compute by daisy-chaining external GPUs.
However, practical Thunderbolt 5 eGPU solutions are expensive (
Thunderbolt 5 is more valuable for external storage and high-speed peripherals. External Thunderbolt SSDs can sustain 4,000+ MB/s, making them suitable for scratch disks during intensive workloads.
USB and Display Outputs
The device includes multiple USB-A ports and HDMI 2.1. HDMI 2.1 supports 8K resolution and 120 Hz refresh rates, though practical displays maxing out at 4K 60 Hz are still standard.
For multi-monitor setups common in creative workflows, you'd likely use USB-C to DisplayPort adapters for additional monitors. The RTX 5090M has sufficient graphics output capability to drive 4-6 displays simultaneously.

Thermal Management and Noise Characteristics
Cooling Architecture Deep Dive
The Olares One's thermal solution consists of a vapor chamber (a sealed copper vessel with liquid that evaporates and condenses to rapidly move heat), copper fin arrays (for heat dissipation), and dual custom fans.
A vapor chamber is more sophisticated than traditional heat pipes. They distribute heat evenly across their surface, whereas heat pipes have localized hot spots. For a small device with concentrated heat sources (CPU and GPU running side-by-side), vapor chambers are genuinely superior.
The dual fan configuration suggests that one fan handles CPU cooling while the other focuses on GPU cooling. This separation prevents thermal interaction—the GPU's fan doesn't interfere with CPU heat dissipation and vice versa.
Theoretical thermal performance suggests the design can handle sustained 200-220W combined CPU+GPU power draw without exceeding safe thermal limits (80-85°C on GPU core). However, sustained operation typically means throttling kicks in at lower temperatures to preserve component lifespan.
Noise Level Expectations
Compact designs always face a noise-acoustic tradeoff. Smaller heatsinks require faster fans to move the same volume of air, which increases noise.
The Olares One's marketing claims "low noise levels even under full load." Realistically, this probably means 40-45dB under sustained load (roughly the noise level of a quiet office), not silent operation. Compare this to a desktop tower with large fans that might achieve 35-40dB.
During moderate workloads (text generation with 10-20 tokens per second), the cooling solution probably operates at 30-35dB. During intensive image generation, expect 45-50dB.
This is acceptable for a desk environment but not silent. If you're sensitive to fan noise, using external noise-cancelling headphones becomes necessary during heavy usage.
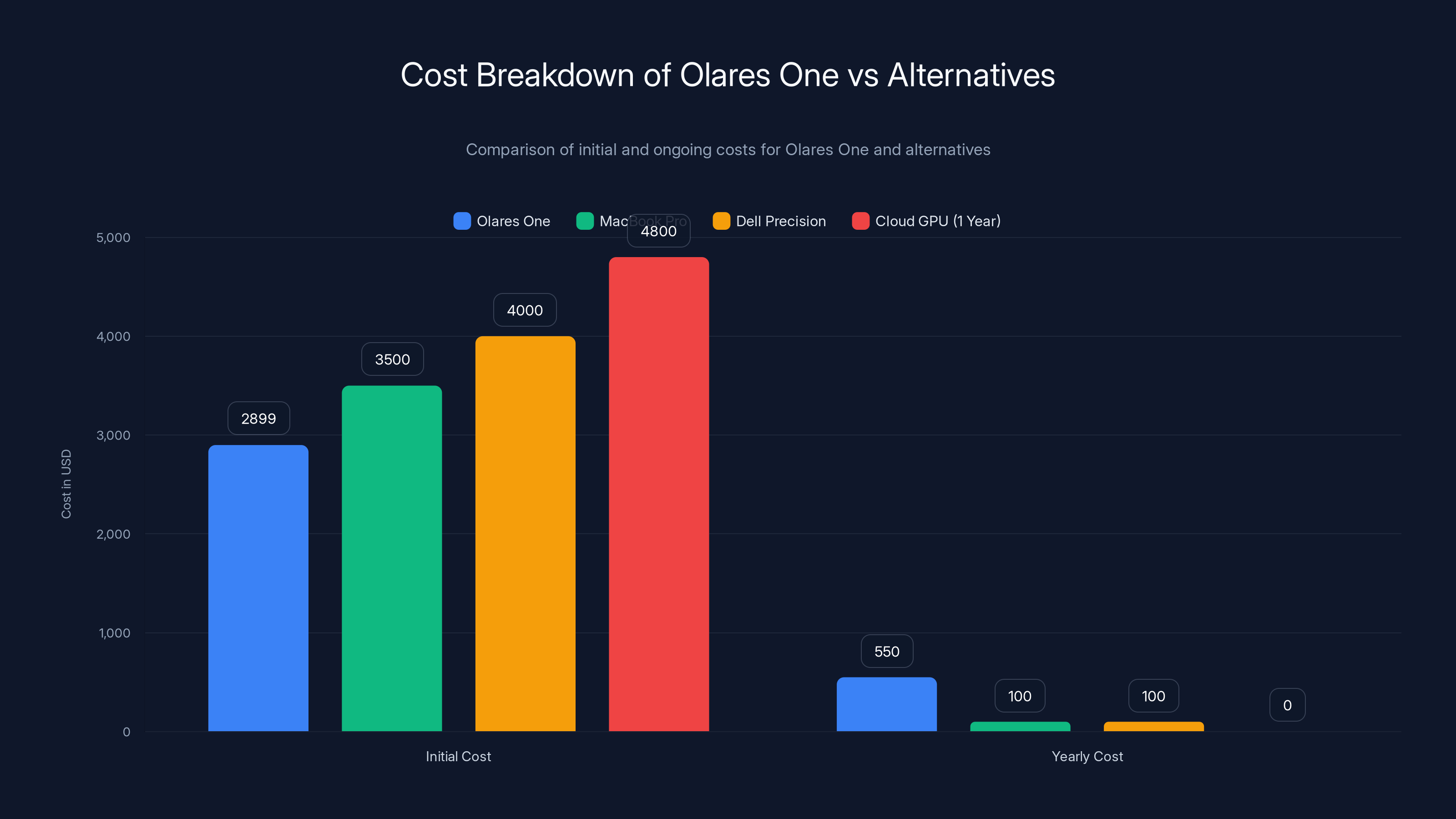
The Olares One has a lower initial cost compared to its alternatives, with competitive yearly costs, making it a cost-effective option over multiple years. Estimated data.
Security Architecture and Privacy Implementation
Sandboxing and Container Isolation
Olares OS implements security through containerization. Each application runs in an isolated container with limited access to system resources and other applications' data.
This is fundamentally different from traditional desktop operating systems where applications run with broader system access. In Windows or macOS, a malicious application can theoretically access files anywhere on your disk and communicate with the network freely.
Containers restrict this. An application running in a container can only access resources you explicitly grant. This requires more careful configuration but dramatically improves security, especially important when running untrusted models or third-party code.
For AI workloads specifically, sandboxing prevents model poisoning attacks. If you download a model from an untrusted source, the sandbox prevents that model from accessing unrelated data on your system.
Identity-Based Access and Credential Management
Olares implements identity-based security, similar to enterprise systems. Instead of passwords being scattered across applications, a central identity store manages all credentials.
This enables:
- Single sign-on: Authenticate once to access all services
- Granular permissions: Control which users can run which models or access which data
- Audit logging: Track who accessed what and when
- Multi-factor authentication: Add additional security layers through TOTP or hardware keys
For research environments where teams share hardware but need data isolation, this is valuable. Different team members might access the same device but only see their own projects.
Regulatory Compliance Advantages
Organizations handling sensitive data often face regulatory constraints (HIPAA for healthcare, SOC 2 for SaaS, GDPR for EU citizens). Cloud-based AI services make compliance more complex because the cloud provider becomes part of your compliance chain.
Local processing on Olares OS keeps data entirely under your control, simplifying compliance. You determine the security controls, audit logs, and data retention policies.
This is particularly relevant for organizations building internal AI tools. Instead of sending customer data through external APIs, you process internally on your infrastructure.

Real-World Use Cases and Target Audiences
AI Researchers and Data Scientists
For researchers developing new models or fine-tuning existing ones, the Olares One provides a complete development environment. Python, CUDA toolkit, PyTorch, and TensorFlow all run natively.
The 96GB RAM and 24GB GPU VRAM enable training relatively small models (up to 1-2B parameters) with batch sizes that actual produce reasonable convergence. While you wouldn't train GPT-3 scale models on this device, you can definitely fine-tune existing models on custom datasets.
The local processing advantage is significant. Rather than submitting training jobs to cloud infrastructure and waiting hours for results, you can iterate locally, see results in minutes, and refine your approach rapidly.
Content Creators Using Generative Tools
Creators building content with AI (image generation, video synthesis, text writing tools) benefit from the Olares One's GPU performance and cost structure.
Imagine a designer generating 100 design variations for a client project. Through Midjourney API or similar cloud service, this costs
For high-volume content generation workflows, the cost crossover point happens relatively quickly. After roughly 2,000 image generations, local processing has paid for the hardware investment.
The privacy advantage also matters for creators handling client confidential work. You're not uploading proprietary designs or confidential text through external APIs.
Software Developers Building AI Applications
Developers building AI-powered applications need an environment where they can test locally before deploying to production. The Olares One serves this purpose effectively.
Instead of developing against cloud APIs (which incur costs, have rate limits, and depend on network connectivity), developers can build and test against local models. This enables rapid iteration, offline development (important for remote locations), and cost control.
The containerization and security features of Olares OS are also valuable for developers packaging AI services for customers. You can prepare a complete application environment that customers can run on their own hardware.
Privacy-Focused Organizations
Companies operating in regulated industries or handling sensitive data have legitimate reasons to process AI workloads locally. The Olares One enables this without requiring massive datacenter infrastructure investment.
Think of a healthcare organization building diagnostic support tools. Rather than sending patient data to cloud APIs, they process locally on the Olares One, maintaining full data control and regulatory compliance.

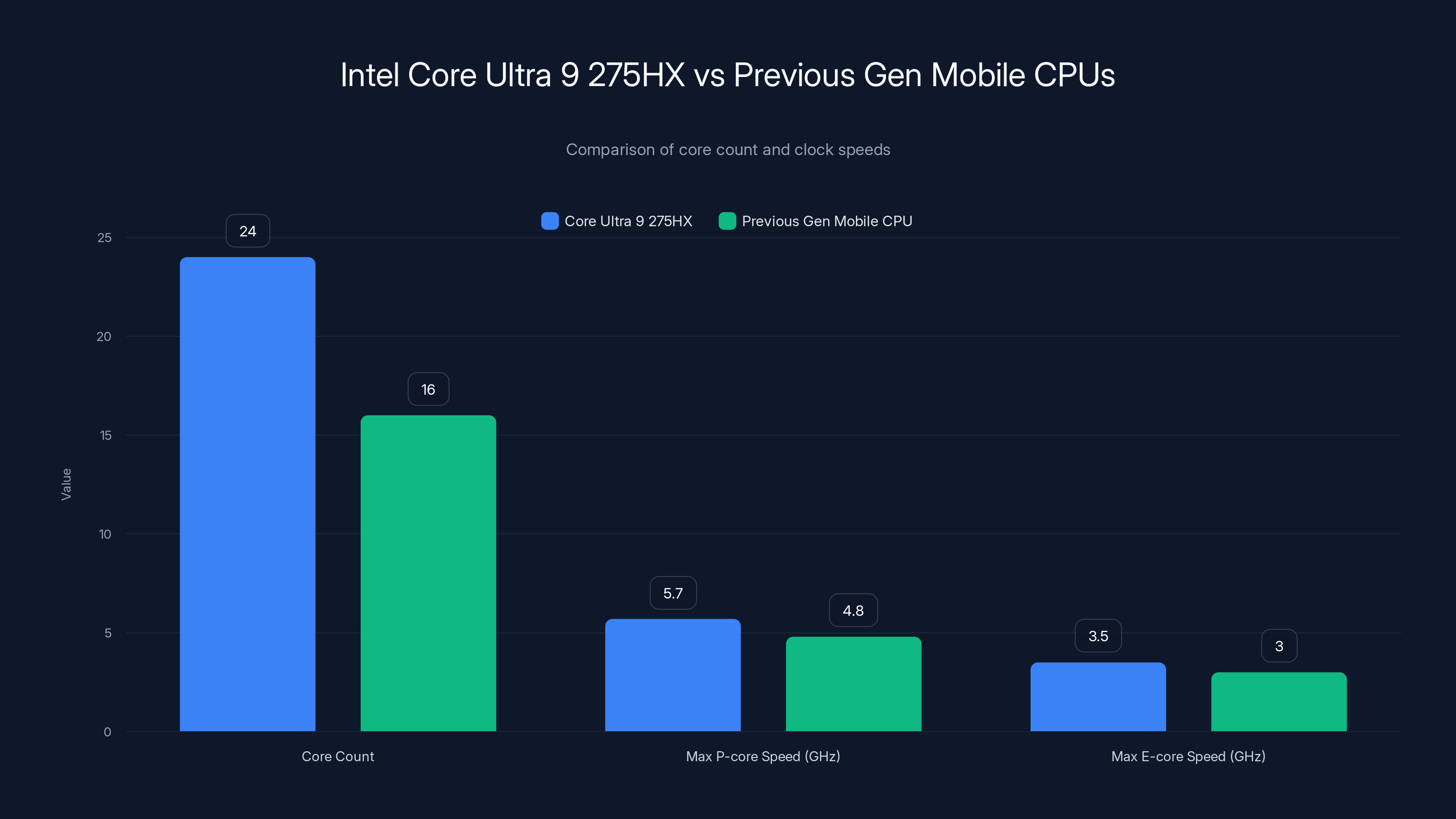
The Intel Core Ultra 9 275HX offers a significant increase in core count and clock speeds compared to previous-generation mobile CPUs, enhancing its ability to handle multithreaded workloads efficiently. Estimated data for previous-gen values.
Performance Comparison: How the Olares One Stacks Against Competitors
Versus Larger Workstations
A typical workstation with a desktop RTX 4090 (24GB VRAM) and Threadripper processor costs
The Olares One delivers roughly 70-80% of that performance in 15% of the physical footprint using 25% of the power. For professionals who need portability or space efficiency, this tradeoff is attractive.
Versus Cloud-Based AI Services
Cost comparison depends on usage intensity. For occasional use (chatting with Chat GPT a few times daily), cloud services are cheaper. For heavy developers and researchers running hundreds of inference requests daily, local hardware becomes cheaper after 2-4 months of usage.
Latency also favors local processing. Cloud APIs typically respond in 2-5 seconds. Local inference is 50-200ms, a 10-50x improvement. For latency-sensitive applications (real-time assistants, interactive tools), local processing is necessary.
Versus Other Mini PCs
Competing mini PCs like the Morefine H1 (with AMD Ryzen AI Max+ 395 and 128GB RAM) offer more RAM but typically have less GPU performance. The Olares One's RTX 5090M is significantly more powerful than integrated graphics on AMD systems.
Price-wise, the Olares One at $2,899 is premium, but you're paying specifically for the RTX 5090M and software optimization around AI workloads. Cheaper mini PCs sacrifice GPU performance or memory capacity.

Practical Considerations: The Reality Beyond Specifications
First-Run Setup and Learning Curve
Unboxing the Olares One isn't as simple as plugging in a laptop. You'll need to:
- Install or connect to Olares OS (assuming it ships pre-installed)
- Configure network connectivity
- Deploy applications through Olares's one-click system (easier than manual setup, but still requires understanding containers)
- Download language models (first model download is 5-15GB depending on size)
- Configure model parameters (quantization level, context length, etc.)
For experienced developers, this probably takes 30-60 minutes. For non-technical users, it could take several hours. Olares's documentation helps, but this isn't a consumer-grade "plug and play" device.
Real-World Performance Variability
Published benchmarks assume optimal conditions: ambient temperature around 25°C, device on desk with airflow, running single models in isolation. Real-world conditions vary:
- Higher ambient temperature reduces GPU performance by 5-10% per 5°C above 25°C
- Multiple concurrent applications compete for resources
- Initial model load times include disk I/O (slower than subsequent runs)
- Model precision choices (FP32, FP16, INT8) significantly affect speed and quality
Expect real-world token generation to be 20-30% slower than published benchmarks under typical office conditions.
Maintenance and Software Updates
Olares OS is actively developed software. Updates improve stability, add features, and patch security vulnerabilities. You'll need to plan for periodic maintenance windows.
Model updates also matter. New quantized versions of popular models become available regularly. Older quantized versions might become obsolete (lower quality, slower performance) as new options emerge.

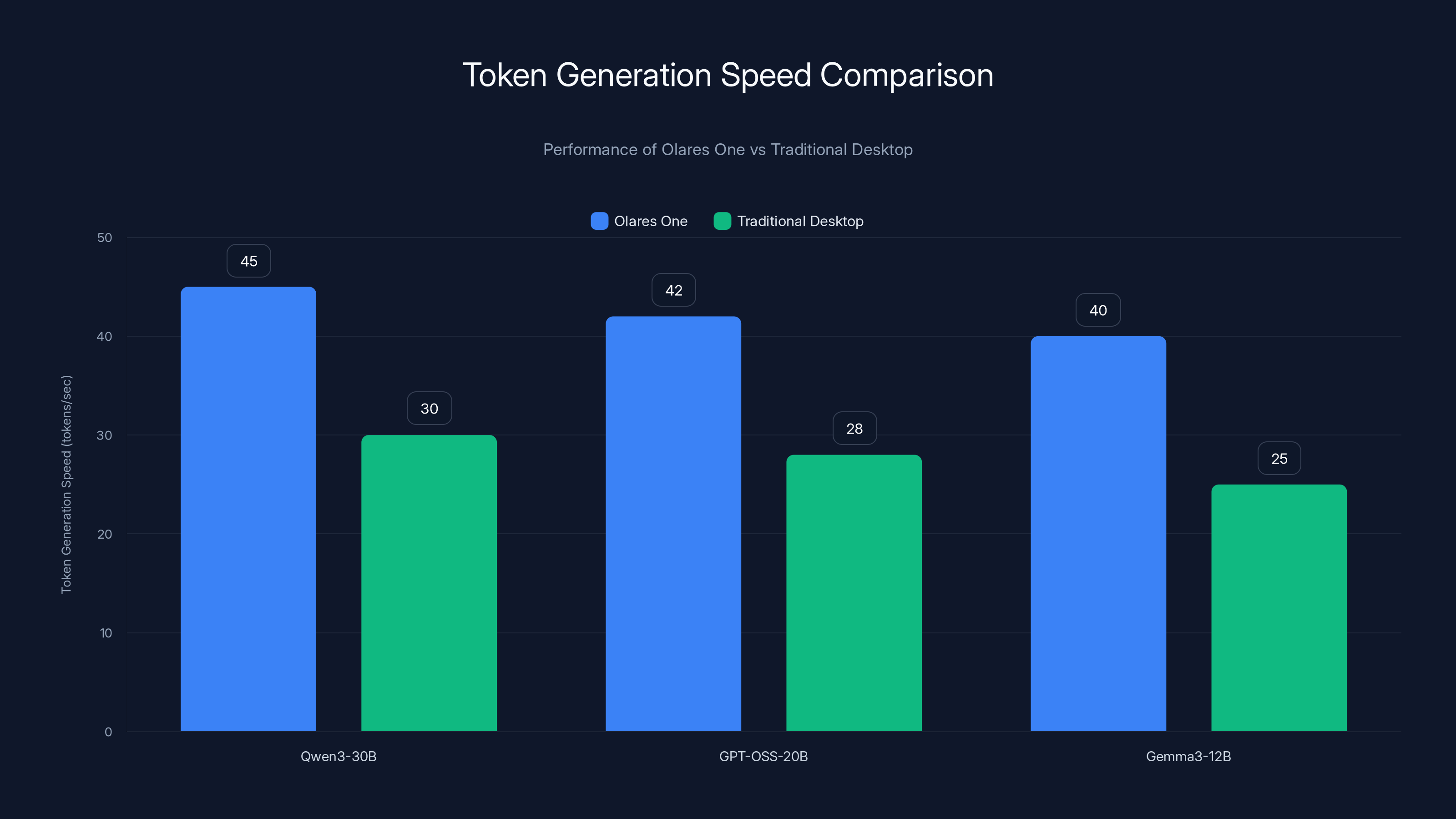
Olares One significantly outperforms traditional desktops in token generation speed, achieving 40-45 tokens/sec compared to 25-30 tokens/sec. Estimated data based on benchmark insights.
Pricing and Value Analysis
The $2,899 Price Point
At $2,899, the Olares One is expensive for a consumer device but reasonable for professional hardware. Breaking down the cost:
- Core Ultra 9 275HX: ~$500-600 (processor cost)
- RTX 5090M: ~$800-1,000 (GPU cost)
- 96GB DDR5 RAM: ~$300-400
- 2TB NVMe SSD: ~$150-200
- Chassis, cooling, electronics, margins: ~$500-600
The hardware alone costs roughly $2,250-2,600 to source at component level. The Olares OS optimization, pre-configuration, and support likely accounts for the remainder.
Comparison points:
- A 16-inch MacBook Pro with M4 Max: $3,500+ (less GPU power, more GPU efficiency)
- A mobile workstation like Dell Precision 5680: $3,500-5,000 (more traditional software compatibility, less AI-specific optimization)
- A cloud GPU subscription (similar performance): $300-500/month
If you plan to use this device for 3+ years and run 100+ hours of AI workloads monthly, the hardware cost becomes cheaper than cloud subscriptions within 6-12 months.
Total Cost of Ownership
Beyond the purchase price:
Power consumption: The Olares One probably consumes 150-250W during intensive workloads. At US average electricity rates (
Maintenance: Hardware rarely fails if properly cooled and not thermally stressed. Budget maybe $100-300 annually for potential repairs or thermal paste replacement.
Software: Olares OS is open-source and free. No subscription licensing required.
Total first-year cost is roughly
This is meaningful cost consideration. If you'll use this for only 6 months before moving to other technology, the amortized cost is high. If you'll use it for 5+ years, the per-hour cost becomes competitive with everything.

Kickstarter Campaign Status and Availability
Current Campaign Metrics
At the time of publication, the Olares One campaign has exceeded $1.2 million in pledges from over 400 backers. This indicates genuine market interest, though Kickstarter campaigns always carry risk.
Crowdfunding project timelines are notoriously optimistic. Developers initially claim spring 2025 delivery but then encounter manufacturing delays, supply chain issues, or quality control problems. Plan for actual delivery 2-4 months later than promised.
Crowdfunding Risk Considerations
Kickstarter should never be treated as a pre-order platform for consumers. You're funding a project with real risk of:
- Delayed delivery (most common)
- Partial fulfillment (some backers get devices, others don't)
- Specification changes (promised features don't ship)
- Non-delivery (rare but possible)
Backing the Olares One requires accepting these risks. If the device must arrive by a specific date for a critical project, Kickstarter is inappropriate. If you can wait 6+ months and accept the possibility of partial delivery, it's reasonable.
For institutional buyers (research groups, companies), I'd recommend waiting for general availability rather than backing. The risk-reward ratio improves once the device ships to enough people that third-party reviews and real-world performance data exist.
Future Availability
Assuming the campaign succeeds and manufacturing completes on schedule (or delayed), the Olares One will likely reach general retail availability in mid-to-late 2025. Initial pricing might increase slightly from the Kickstarter tier, probably $3,000-3,200.

Honest Assessment: Strengths and Weaknesses
Where the Olares One Genuinely Excels
GPU performance for local AI: The RTX 5090M delivers real, measurable advantages for running large language models and generative AI locally. If this is your primary workflow, the device delivers.
Privacy and data control: For organizations handling sensitive data or requiring regulatory compliance, local processing solves real problems that cloud services can't match.
Portability with power: Carrying a device with this computational capability in a backpack is genuinely impressive. Traditional workstations are desk-bound; this isn't.
Cost efficiency at scale: If you run 1,000+ AI inference requests monthly, local processing becomes significantly cheaper than cloud APIs.
Significant Limitations
Windows incompatibility: If your workflow depends on Windows applications, the Olares One requires workarounds that degrade performance. This is a hard constraint for many professionals.
Multi-model performance degradation: Running multiple large models simultaneously doesn't work well. The device excels at single-model scenarios.
Crowdfunding uncertainty: Actually receiving the device and on timeline is uncertain. Kickstarter risk is real.
Ecosystem immaturity: Olares OS is newer than macOS or Windows. Some software you expect might not be available or might work differently.
Noise during intensive workloads: It won't be silent when running hard. If noise sensitivity matters, this is a concern.

Future Developments and Technology Trajectory
Next-Generation GPU Architecture
Nvidia's AI GPU roadmap suggests RTX 6000 series mobile GPUs arriving in 2026, likely with 48GB VRAM and 2x-3x performance improvement. The Olares One's RTX 5090M will still be capable, but newer competitors will dramatically outperform it.
This is important for longevity assessment. If you're purchasing today expecting 5 years of competitive performance, that won't happen. Plan for 2-3 years of top-tier AI performance before newer hardware significantly surpasses it.
Software Maturity
Olares OS is still relatively young. As the platform matures, expect:
- More pre-built applications available for one-click deployment
- Better integration with cloud services (hybrid workflows)
- Improved Windows application compatibility through better virtualization
- More developer tooling and API stability
Early adopters of Olares OS devices might experience stability issues that later-generation devices don't see. This is normal for immature platforms.
AI Model Evolution
Large language models continue getting smaller while maintaining quality. Mistral 7B and Llama 3.2 8B achieve reasonable performance in under 16GB. This is good news for Olares One owners—you'll be able to run more sophisticated models as quantization techniques improve.
Conversely, state-of-the-art models keep growing. The latest models at the frontier are 400B+ parameters, far beyond what local hardware can run. The Olares One will always be constrained to mid-tier models, never frontier models.

Alternative Solutions and When They're Better Choices
Cloud GPU Services (Lambda Labs, Crusoe Energy)
For researchers needing absolute maximum performance without hardware purchase, cloud GPUs remain superior. Monthly costs range from $300-500 for equivalent RTX 5090 equivalent access, but you avoid hardware purchase and maintenance.
Cloud GPUs are better if:
- You need maximum performance occasionally (burst workloads)
- You want to test different hardware without purchasing
- You don't have capital budget for hardware
- Your workloads vary dramatically
Traditional Desktop with RTX 4090
A full desktop with RTX 4090 costs $5,000-7,000 but delivers roughly 1.3-1.5x the GPU performance of the Olares One. For professionals making money through AI work where time directly equals income, the performance premium justifies the cost.
Desktop solutions are better if:
- You need maximum possible GPU performance
- You have desk space and power infrastructure
- You want traditional software compatibility (Windows)
- Portability doesn't matter
Laptop with RTX 5880 Ada
Higher-end laptops like Lenovo ThinkPad with RTX 5880 or similar offer more traditional software (Windows) with respectable GPU performance. At $3,500-5,000, they're in the same price range as the Olares One.
Traditional laptops are better if:
- Windows software compatibility is essential
- You want established vendor support
- You value ecosystem familiarity
- You're willing to sacrifice some GPU performance for broader software access

Conclusion: Is the Olares One Right for You?
The Olares One is a genuinely innovative device built for a specific purpose: running sophisticated AI workloads on local hardware with privacy and cost efficiency. It succeeds at this purpose better than most alternatives.
But it's not a replacement for everything. It's not a gaming laptop. It's not a desktop replacement for traditional creative workflows. It's not for people who absolutely need Windows compatibility.
It's excellent for:
- Researchers developing AI models and testing approaches
- Content creators running Stable Diffusion and similar generative tools at volume
- Developers building AI-powered applications who need local testing infrastructure
- Organizations handling sensitive data that can't use cloud APIs
- Professionals willing to learn a new operating system for significant performance and cost advantages
It's mediocre or poor for:
- Anyone whose workflow depends on Windows software
- People needing maximum possible performance for frontier AI research
- Users wanting established vendor support and certainty
- Those unable to wait for crowdfunding delivery and assuming risk
- Anyone unwilling to invest time in learning Olares OS and AI operations
If you're reading this and thinking "that sounds perfect for my work," the Olares One probably is. If you're uncertain, you probably want to wait for general retail availability and third-party reviews before committing to a Kickstarter pledge.
The device exists at the intersection of several significant trends: the move toward local/edge AI processing, regulatory pressure around data privacy, and GPU technology becoming powerful enough to fit in portable form factors. These trends are real and accelerating.
The Olares One is betting on all three trends simultaneously, and it's positioned well if they continue. For users aligned with these trends, it's worth serious consideration. For everyone else, more traditional alternatives remain safer choices.

FAQ
What makes the Olares One different from other mini PCs?
The Olares One combines workstation-class hardware (Core Ultra 9, RTX 5090M, 96GB RAM) with Olares OS, an operating system specifically designed for local AI processing. While other mini PCs exist, most either sacrifice GPU performance or Windows compatibility. The Olares One prioritizes both GPU power and operating system optimized for AI workloads, making it distinct in the market.
Can I run Windows 11 on the Olares One?
The Olares One doesn't run Windows 11 natively—it's designed specifically for Olares OS. You can run Windows applications through virtualization or Wine compatibility layers, but this introduces performance degradation (10-30% slower) and complexity. The device is genuinely Windows-optional, not Windows-compatible, which is a significant limitation for users dependent on Windows-only software.
How much does it cost to run AI models locally compared to cloud APIs?
Break-even happens around 100,000-200,000 API requests, depending on model size and cloud service pricing. At
What's the token generation speed on different models?
On a 7B parameter model, the Olares One achieves approximately 40-50 tokens per second. On 13B models, roughly 25-30 tokens per second. On 30B models, approximately 12-15 tokens per second. These speeds degrade 20-30% in real-world conditions compared to laboratory benchmarks.
Is the Olares One suitable for multiple users accessing it simultaneously?
Somewhat. The device can support 3-5 concurrent users running smaller models (7B) with acceptable performance degradation. With larger models (30B+), concurrent performance degrades significantly because VRAM and memory bandwidth become bottlenecks. For single-user intensive use, it's excellent. For multi-user scenarios, it has meaningful limitations.
What are the cooling and noise characteristics?
The vapor chamber and dual-fan cooling system can handle sustained 200+ watts of power draw without excessive throttling. Under intensive workloads, expect noise levels around 45-50dB (audible but not intolerable). During moderate loads, 30-35dB is realistic. For anyone sensitive to fan noise, external headphones become necessary during heavy computation.
How long will the Olares One remain competitive?
Realistically, 2-3 years for top-tier AI performance. Next-generation GPUs (RTX 6000 series) arriving in 2026 will likely offer 2-3x performance improvements, making the RTX 5090M obsolete for demanding applications. The device will remain useful for inference tasks even after newer hardware surpasses it, similar to how older GPUs still function for less demanding workloads.
Should I back the Kickstarter or wait for retail availability?
Backing requires accepting crowdfunding risk—delays are common, and non-delivery is possible though rare. If you need guaranteed delivery by a specific date, wait for retail availability in mid-to-late 2025. If you can accept 6+ month delays and have capital available now, Kickstarter access comes slightly earlier and at the lowest price tier.
What's included in the $2,899 price?
The hardware (CPU, GPU, RAM, SSD), Olares OS pre-configured and optimized for the hardware, basic warranty coverage, and initial customer support. It does not include peripherals (monitor, keyboard, mouse), external storage, or extended warranty options.
Can the Olares One be upgraded later?
Memory upgrade potential is limited—the 96GB RAM configuration is soldered in most laptop-based mini PCs, making upgrades difficult or impossible. Storage is upgradeable through the NVMe slot or external Thunderbolt drives. GPU is not upgradeable (mobile GPUs are soldered). The device is designed more as "buy what you need" rather than "buy and upgrade later."

Key Takeaways
- The Olares One delivers workstation-class GPU performance (RTX 5090M) in a portable mini PC form factor, achieving 40-60% faster AI token generation than competing mini PCs at similar price points
- Running AI models locally costs roughly 400-600 annually in electricity, becoming cheaper than cloud APIs after 6-12 months of heavy use (100+ daily requests)
- Olares OS prioritizes privacy and local data processing but sacrifices Windows compatibility—a critical limitation for users dependent on Windows-only professional software
- Performance degrades significantly with concurrent multi-model scenarios due to finite memory bandwidth—single models achieve 40-45 tokens/second, while two concurrent 13B models drop to ~20 tokens/second each
- The device excels for researchers, content creators using generative tools, and privacy-focused organizations, but requires accepting Kickstarter risk and OS learning curve
Related Articles
- Acemagic Tank M1A Pro+ Ryzen AI Max+ 395 Mini PC [2025]
- Mini-ITX Motherboard with 4 DDR5 Slots: The AI Computing Game-Changer [2025]
- NucBox K15 Mini PC: Intel Ultra CPU & GPU Expansion at $360 [2025]
- Building vs Buying a Mini PC: Why DIY Lost to Prebuilts [2025]
- Hasee X5 15.6 Laptop: $440 Core i9 Beast [2025]
- iBuyPower Ryzen 7 9700X RX 9060 XT $999 Desktop [2025]

