Introduction: When The Cloud Stops Working
Imagine this: it's 2:30 p.m. on a Wednesday. You try to check your email. Nothing. You open your files in SharePoint. Gone. You hop on Teams to tell your team about the problem. Can't join the meeting. Your entire digital infrastructure just vanished.
That's exactly what happened to millions of Microsoft 365 users when a critical outage hit in January 2025. For hours, enterprise customers across North America couldn't access their email inboxes, collaborate on files in OneDrive or SharePoint, join video meetings in Teams, or manage their security dashboards. And here's the kicker: the outage hit so hard that even TechCrunch's own editorial team couldn't email us for comment because their mail server was down too.
This wasn't a small hiccup. This was a full-scale infrastructure failure affecting some of the world's largest companies, government agencies, and hospitals. Millions of people sat in dead silence, watching their calendar apps spin while their inboxes vanished. Project managers couldn't access shared files. Sales teams couldn't send emails. Security teams went blind to threats.
But the real story isn't just about what broke. It's about what this reveals about modern enterprise infrastructure, how dependent we've all become on a single vendor, and what you should do right now to make sure your organization can survive the next outage.
Let's dig into exactly what happened, why it mattered, and how the smartest companies are already preparing for the next one.
TL; DR
- What Happened: A portion of Microsoft's North American infrastructure stopped processing traffic correctly, cascading failures across Exchange Online (email), SharePoint, OneDrive, Teams, Microsoft Defender, and Purview.
- Duration: Hours-long outage affecting millions of enterprise customers simultaneously.
- Real Impact: Lost productivity, communication blackouts, security blindness, and potential data access problems for companies worldwide.
- Root Cause: Microsoft stated it was infrastructure-related but didn't disclose specifics, likely a load balancing, routing, or database failure.
- Prevention: Redundancy architecture, backup email systems, offline-first workflows, and communication protocols are now non-negotiable.
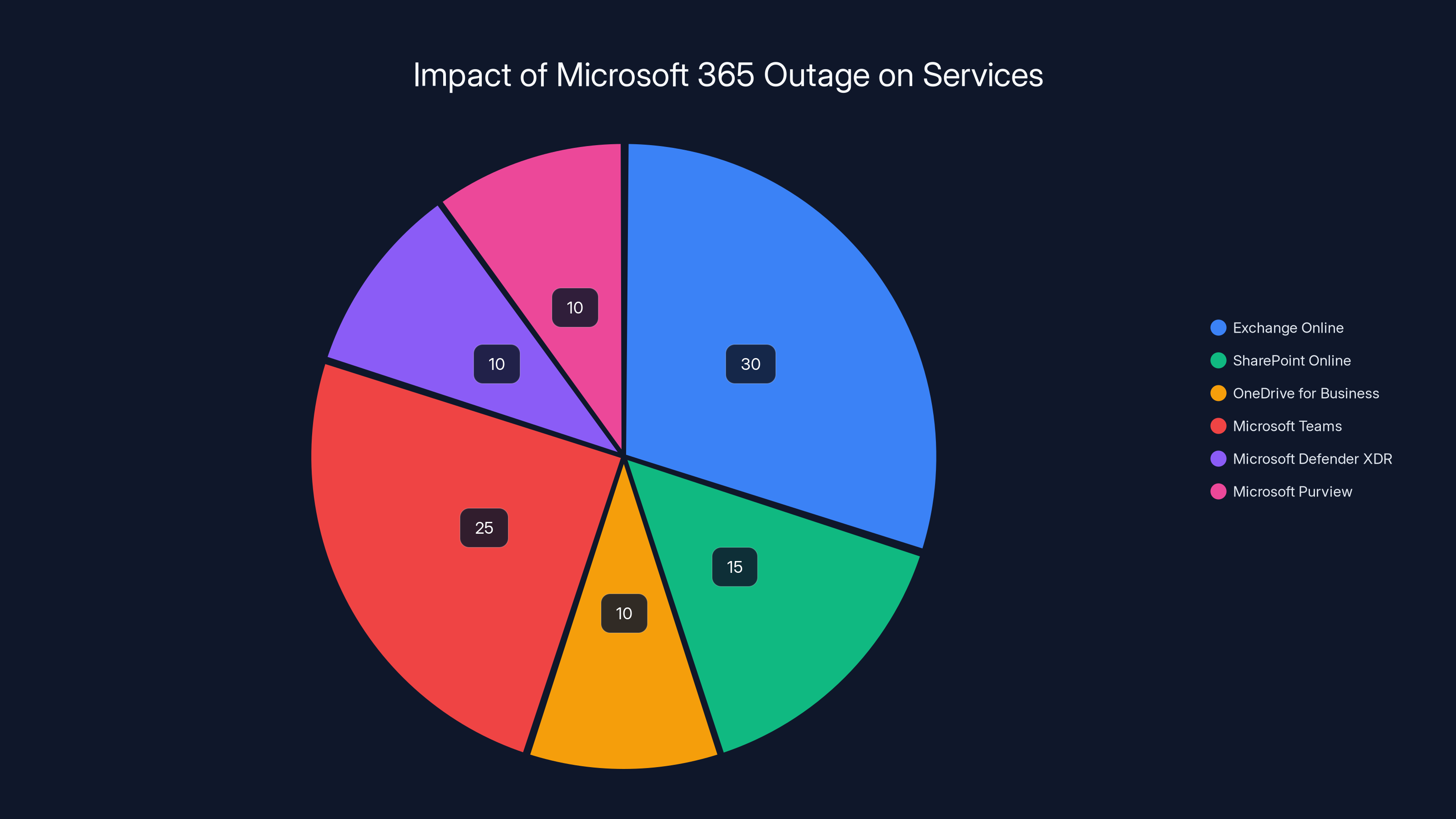
Exchange Online and Microsoft Teams were the most impacted services during the Microsoft 365 outage, affecting approximately 55% of the total impact. Estimated data based on service importance.
What Exactly Broke: The Full Scope of the Outage
Let's be specific about what stopped working. This wasn't a "Teams is slow today" situation. This was a full-spectrum service collapse.
Exchange Online went dark, which means no incoming or outgoing email. For organizations that run entirely on cloud infrastructure, this translates to zero communication for external partners, clients, and anyone not on Slack or other messaging platforms. Your inbox? Inaccessible. Your calendar? Offline. Your shared mailboxes? Gone.
SharePoint Online and OneDrive became read-only or completely unavailable. Imagine trying to access a critical project document that lives in the cloud. The file exists on Microsoft's servers, but you can't reach it. Document collaborations halted. Version control stopped working. Teams that depend on shared folders for their entire workflow suddenly couldn't access their work.
Microsoft Teams stopped functioning as a meeting platform. Creating chats, starting meetings, or adding team members all failed. Video calls couldn't be initiated. This affected not just internal communication, but scheduled client meetings, all-hands calls, and emergency response coordination.
Microsoft Defender XDR (Extended Detection and Response) and Microsoft Purview security dashboards went offline. Security teams and compliance officers lost visibility into threats, incidents, and compliance status. For regulated industries like finance and healthcare, this creates serious audit and liability concerns. If a breach happened during the outage, nobody knew.
Admin centers became inaccessible, so IT teams couldn't even troubleshoot, reset passwords, or manage the services that weren't working. It's like being locked out of the building you're supposed to maintain.
The blast radius extended across North America initially, with reports suggesting global impact within hours. Every customer region depends on shared infrastructure, so regional failures often cascade.
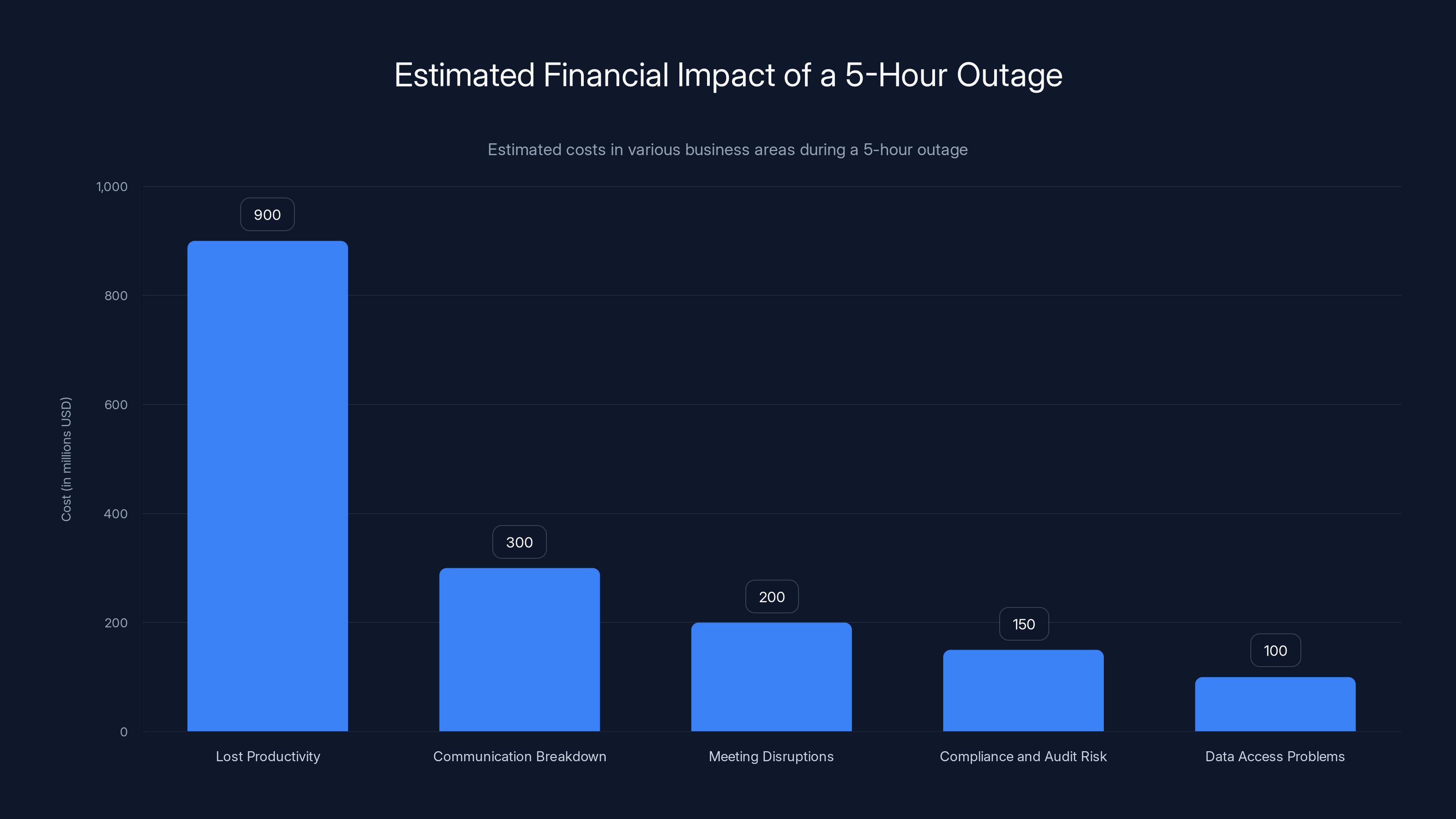
The estimated financial impact of a 5-hour outage includes $900 million in lost productivity, with significant costs also in communication breakdowns and meeting disruptions. Estimated data.
The Root Cause: When Infrastructure Decides to Stop
Here's what we know: Microsoft said the outage was caused by "a portion of service infrastructure in North America that is not processing traffic as expected." That's corporate speak for "something broke and we're not telling you exactly what."
But we can make educated guesses based on how cloud infrastructure works.
Scenario 1: Load Balancing Failure
Cloud services like Microsoft 365 distribute traffic across thousands of servers. Load balancers decide which requests go to which servers. If a load balancer misconfigures or fails, traffic gets stuck in queues or routed nowhere. Requests time out, services appear offline, and the system can't recover because the balancer doesn't know how to handle the backup traffic.
Scenario 2: Database Routing Problem
Microsoft's infrastructure is built on massive distributed databases. Your email lives in a database, your files in storage, your Teams history in another database. A routing layer decides which request goes to which database partition. If that routing layer breaks, every request that tries to find your data fails. The data still exists, but nobody can reach it.
Scenario 3: Cascading Service Failure
Cloud services are interconnected. Exchange depends on identity services (Azure AD) for authentication. SharePoint depends on backend storage systems. Teams depends on presence services. If one foundational service fails, it triggers failures upstream. One small failure becomes a complete system collapse within milliseconds.
Scenario 4: Configuration Push Gone Wrong
Microsoft constantly updates configuration across its infrastructure. If a bad configuration got pushed to production servers simultaneously across a region, all those servers could fail at the same moment. Rolling back a bad config is harder than it sounds because you have to coordinate across thousands of servers.
Microsoft didn't disclose which scenario actually happened, which is frustrating for security professionals who want to know if this is a reliability issue, a security issue, or an operational issue. But the fact that it affected multiple services simultaneously suggests it was an infrastructure layer problem rather than a single service bug.

The Timeline: How A Massive Outage Unfolded
The outage wasn't instantaneous. It developed over time, which is important for understanding how these failures scale.
2:30 p.m. ET: Initial reports start appearing on social media. Users can't access email. First-wave awareness.
2:35-2:45 p.m. ET: The problem becomes undeniable. Corporate Slack channels fill up. "Is anyone else's email down?" People check the Microsoft 365 status page. Some services show yellow (degraded). Others show red (offline). Confusion spreads because different regions have different impacts.
2:45-3:15 p.m. ET: IT teams across the world start investigating. They check network connectivity (fine), verify their firewall rules (fine), restart servers (doesn't help). They realize the problem is upstream at Microsoft. Helpdesk phones start ringing. Slack channels become all-hands war rooms.
3:15-4:00 p.m. ET: Microsoft issues status updates. "We're investigating." That's corporate speak for "we're not sure yet and we're panicking internally." Some services come back intermittently, creating false hope. Users try accessing email again, fail, try again, fail. Frustration peaks.
4:00-5:00 p.m. ET: Microsoft publishes more details. "We've identified the issue affecting a portion of infrastructure." Still vague, but indicates they know what they're fixing. Some services start recovering. Email comes back. Teams is still spotty. SharePoint is still down.
5:00+ p.m. ET: Gradual recovery. Services come online in waves. Not all services recover simultaneously. Some users get access to email but not Teams. Others get SharePoint but not OneDrive. Recovery is messy.
Hours Later: Full recovery declared. All services reporting green. But trust is broken. Organizations are already making plans.
The total outage duration for the most affected services was approximately 4-6 hours. That might not sound catastrophic, but it was long enough to disrupt entire workdays across North America.
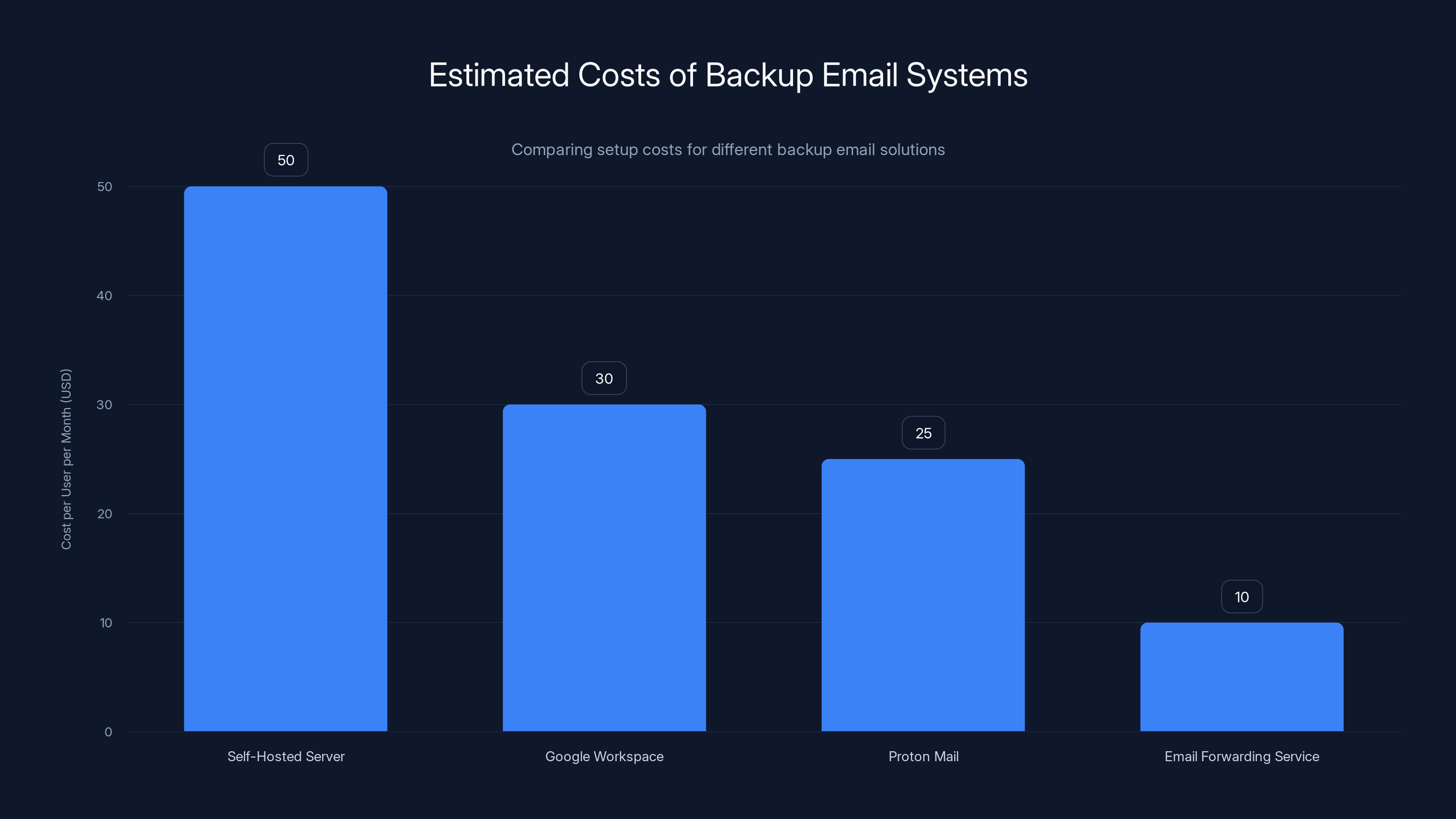
Estimated data: The cost of setting up a backup email system varies significantly, with self-hosted servers being the most expensive and simple email forwarding services the least.
Business Impact: Quantifying The Damage
Let's talk about what this actually cost companies.
Lost Productivity: The average knowledge worker loses focus once per 47 minutes anyway. An outage creates forced inactivity. A 5-hour outage means a 5-hour workday becomes unproductive for millions of people. Multiply 5 million affected workers by average salary (
Communication Breakdown: Companies that run entirely on Microsoft 365 for email have zero alternatives. They can't reach customers. They can't send contracts. Sales teams can't respond to leads. Every email that couldn't be sent represents a potential lost deal. For companies that live on email velocity, even 4 hours creates a backlog that takes days to clear.
Meeting Disruptions: Scheduled client meetings couldn't happen. Conference calls got canceled. International partners in other time zones had to reschedule. Each rescheduled meeting creates friction and delays decision-making. For industries where time-sensitive decisions matter (finance, healthcare, emergency response), delays mean damage.
Compliance and Audit Risk: For regulated industries, the outage creates audit questions. "Were you compliant during the outage?" "What systems were down?" "Did you retain all communications?" Security teams have to document everything and report to management. That's hours of work. For healthcare organizations, the outage gets reported to compliance officers and potentially to patients if any protected health information couldn't be secured.
Data Access Problems: Even after the outage ended, some organizations reported data inconsistency issues. If writes were queued during the outage and the queue flushed inconsistently, you might have conflicting versions of files or emails appearing twice. IT teams had to verify data integrity. Some spent hours checking backup systems.
Customer Trust Erosion: Customers who couldn't reach you during the outage might have switched to a competitor. The organization loses the chance to respond to them. For SaaS companies that depend on email for customer support, this was catastrophic.
Backup System Activation: Some organizations that have backup email systems or communication platforms (like Slack, Discord, or alternative cloud providers) had to activate them. That's a cost. It also reveals a gap in their infrastructure planning that they'll now have to fix.

Why Microsoft 365 Went Down: Infrastructure Lessons
Cloud services are supposed to be more reliable than on-premises infrastructure. The theory is that a massive provider like Microsoft has more resources, more redundancy, and smarter engineers. But theories break when infrastructure fails.
Here's why even massive cloud providers have outages:
Shared Infrastructure Vulnerability: Microsoft 365 runs on shared infrastructure. Your services, your neighbor's services, and 400 million other users' services all run on the same underlying hardware. If the underlying hardware fails, everyone fails simultaneously. Unlike traditional data centers where you own your own equipment, cloud shared responsibility means Microsoft manages infrastructure but customers depend on that infrastructure working perfectly.
Complexity Explosion: Modern cloud infrastructure is phenomenally complex. Microsoft 365 isn't a single service. It's hundreds of microservices, each with its own databases, caches, queues, and APIs. These services talk to each other through complex networks. Add load balancers, service meshes, API gateways, CDNs, and multi-region failover systems, and you have a system so complicated that understanding exactly what broke requires deep expertise. Humans can't predict or prevent every possible failure mode in a system this intricate.
Upgrade and Maintenance Challenges: Cloud providers constantly update their infrastructure. They push new versions of software, adjust configuration, migrate workloads between data centers, and optimize performance. These updates are necessary, but they're also the number-one cause of outages. A bad update or misconfiguration pushed to production affects millions simultaneously. Rollback takes time.
Cascading Failure Patterns: In distributed systems, a failure in one layer often cascades to other layers. If authentication services slow down, other services that depend on authentication start timing out. If database connections fill up, application servers get backed up. If queues overflow, requests get dropped. It's like traffic jams: one accident on a highway creates backups miles away. Finding the original accident takes investigation.
Geographic Concentration Risk: All of North America's Microsoft 365 infrastructure probably runs out of a handful of data center regions. If a problem affects one region's infrastructure, it affects millions of users in that region. There's only so much redundancy you can build when failures are correlated across a geographic area.
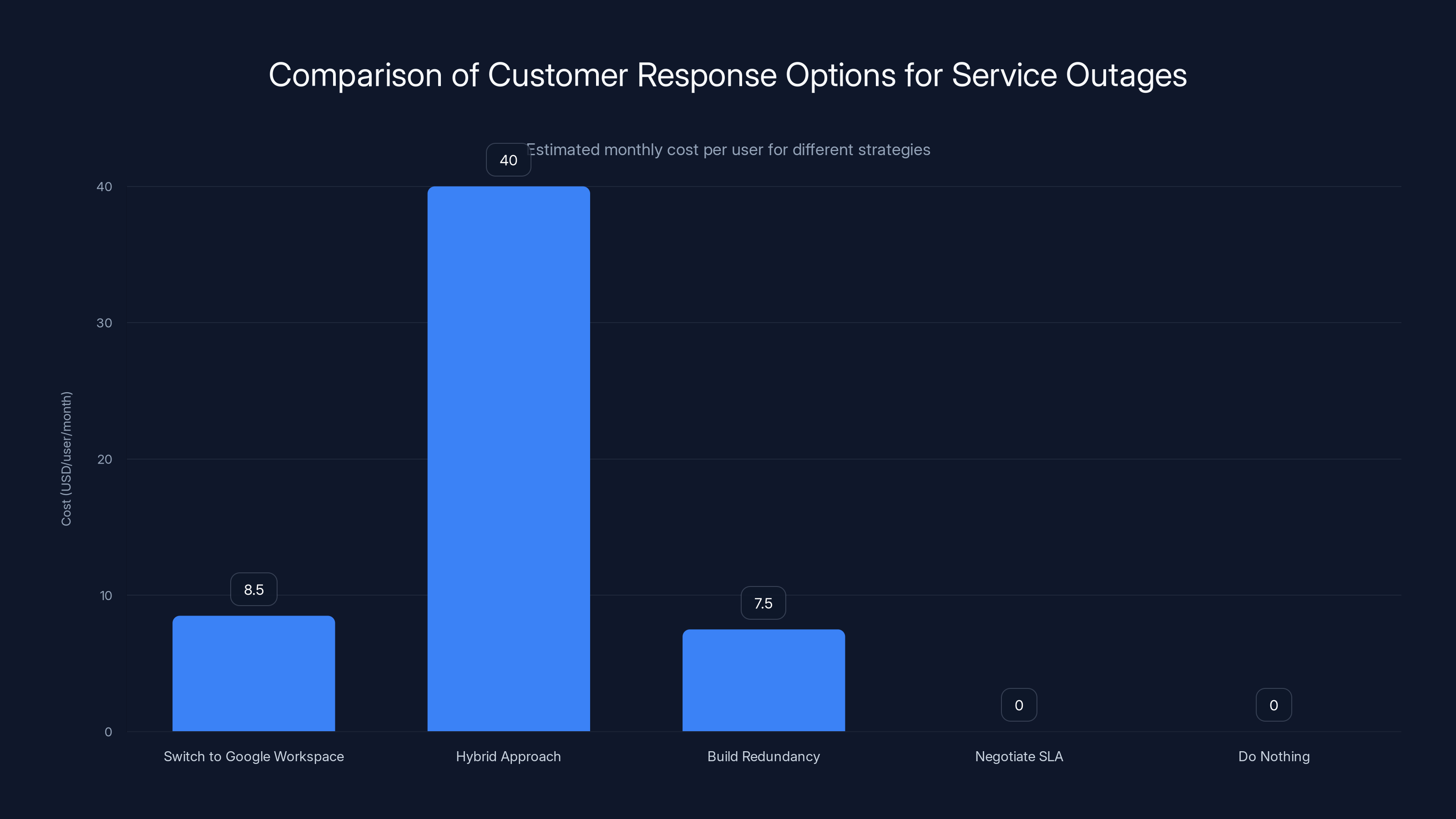
The Hybrid Approach is the most expensive option, while negotiating SLA terms or doing nothing incurs no additional cost. Estimated data.
Company Response: Microsoft's Crisis Management
Let's look at how Microsoft handled this from a communication perspective.
What Microsoft Did Well: They updated their status page regularly. They didn't go silent. They provided specific service information (Exchange Online down, Teams degraded, etc.). They were transparent about the regional impact.
What Microsoft Should Have Done Better: They didn't explain the root cause in real time. They didn't provide an ETA for recovery. They didn't offer status updates every 15 minutes—some gaps lasted 45 minutes. They didn't address the fact that their admin centers were down, which left IT teams completely blind. Most importantly, they didn't proactively reach out to customers during or immediately after the outage.
The best cloud provider communication during an outage follows this pattern:
- Acknowledge immediately (even if it's just "we're aware")
- Update every 15 minutes with new information or confirmation that you're working on it
- Provide ETA for recovery (even if it's "within 2 hours")
- Explain root cause as soon as it's known
- Provide remediation steps for customers
- Follow up after recovery with analysis
- Offer credits/compensation
- Publish detailed post-mortem
Microsoft hit steps 1-2 adequately but missed steps 3-8. That's a playbook failure, not a technical failure.

Industry Responses: Competitors Get Vocal
When Microsoft 365 went down, other cloud vendors immediately leveraged the outage for marketing.
Google Workspace teams posted on social media with thinly veiled shade. "Our services are running normally." That's technically true, but it's also implying "we're more reliable than Microsoft," which is great marketing during an outage.
Slack posted updates confirming it was working fine. Zoom confirmed video calling was stable. AWS, Azure's primary competitor, made sure customers knew their services were unaffected. This is how tech companies play the outage game: your failure is our opportunity.
The implicit message from competitors was clear: Microsoft 365 can go down, but our services won't. Of course, every service has outages. Google Workspace has had Gmail outages. AWS has had region-wide failures. Zoom has had service degradation. But during Microsoft's outage, competitors didn't mention their own history.
What this means: if you're on Microsoft 365, this outage is a wake-up call that you should have a backup email system. If you're evaluating cloud platforms, this outage is ammunition for arguing for redundancy.
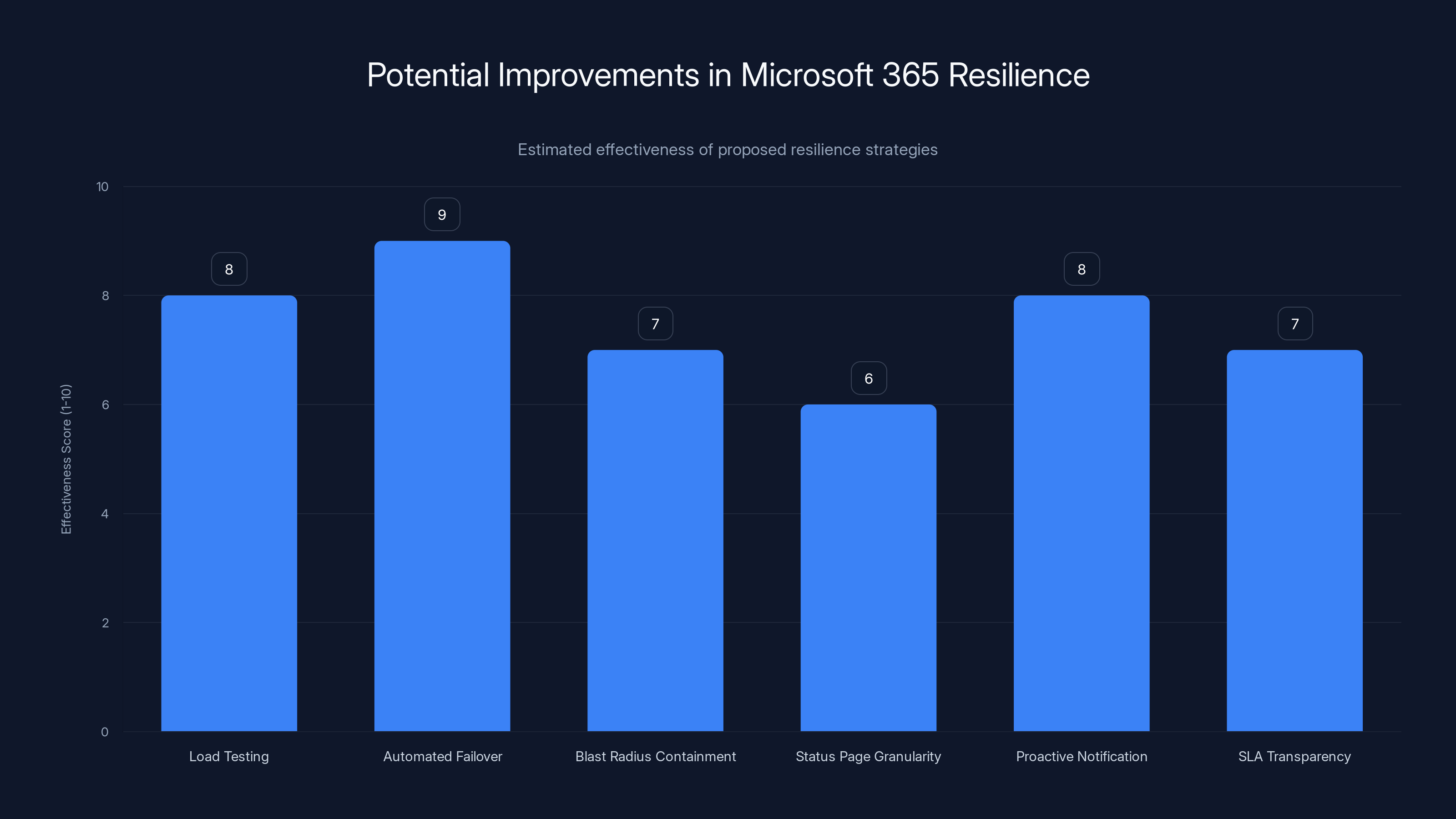
Estimated data suggests that automated failover and proactive notifications could be the most effective strategies for improving Microsoft 365's resilience.
Organizational Strategies: How To Survive The Next Outage
You can't prevent Microsoft's infrastructure from failing. But you can prepare your organization to survive it.
Strategy 1: Backup Email System
Set up a secondary email system that's not dependent on Microsoft 365. This could be a self-hosted mail server, a second cloud provider (like Google Workspace or Proton Mail), or even a simple email forwarding service. During an outage, emails get routed to the backup system. Users can send and receive even if Microsoft is down.
The setup cost is $10-50/user/month depending on the solution. But it buys you continuous communication during outages. For critical teams (sales, customer success, support), this is essential. During the outage, one company switched their domain MX records to forward emails to a Google Workspace account they set up in 15 minutes. Not ideal, but it meant they could still receive customer emails.
Strategy 2: Offline-First Workflows
Design your processes to work when cloud services are down. Keep important documents synchronized to local storage using OneDrive's offline sync or similar tools. Maintain contact lists in multiple places. Design meeting schedules that can fall back to phone calls. If your entire workflow depends on cloud services being up 100% of the time, you're vulnerable.
Outages are good reminders to test your offline workflows. Can your team actually work without cloud services? If not, that's a risk.
Strategy 3: Alternative Communication Channels
Your team probably has Slack, Teams, Discord, or similar. During an outage, if the cloud service goes down, so does communication. Keep a communication channel that's independent of your primary service. This could be a phone tree, a Telegram group, or even SMS-based group alerts. When Teams went down, teams that had Slack (which wasn't affected) could still coordinate. Teams that only had Teams were completely silent.
Strategy 4: Vendor Diversification
The most extreme but most effective strategy: don't put all your eggs in one vendor's basket. Use Microsoft for email and Office, but use Google Docs for collaborative document editing. Use Slack instead of Teams for communication. Use Box or Dropbox instead of OneDrive for file storage. This way, no single outage brings down all your services.
The downside is complexity and cost. Managing multiple cloud vendors is harder than consolidating on one. But redundancy is the price of reliability.
Strategy 5: SLA-Based Accountability
Microsoft 365 comes with SLAs (Service Level Agreements). During an outage, if downtime exceeds SLA terms, you may be eligible for service credits. Document your outages. Track downtime. File SLA claims. Microsoft doesn't automatically issue credits; you have to ask for them. Most companies don't, which is leaving money on the table.
For example, if your SLA guarantees 99.9% uptime and you actually get 99.5% uptime, you might be entitled to a service credit. Calculate it: 99.9% uptime = 43 minutes of acceptable downtime per month. If you had 4 hours of downtime, you exceeded that by 196 minutes. That's potentially 196/43 = ~4.5 months of free service or partial refunds.

Crisis Communication: Lessons From Outages
The Microsoft 365 outage is a masterclass in crisis communication. Here's what we learned about how to handle (and how not to handle) enterprise outages.
Lesson 1: Transparency Beats Vagueness
Companies that say "we're investigating" every 30 minutes lose credibility fast. Users know something is broken. They want to know: why, when will it be fixed, and what can they do in the meantime. Vague updates create anxiety. Specific updates ("we've identified the issue, it's affecting database routing layer, we expect recovery within 1 hour") build confidence.
Lesson 2: Regular Updates Beat Silence
The worst thing a company can do during an outage is go quiet. If 30 minutes pass without an update, users assume the company doesn't know what's happening and the situation is dire. Even if the only update is "still investigating, no new information," it's better than silence. Microsoft violated this during the first hour of the outage.
Lesson 3: Status Pages Matter
Microsoft's status page got thousands of visitors during the outage. Users refreshed it obsessively. Companies that maintain comprehensive status pages (showing each service, its status, and update timestamps) reduce support ticket volume significantly. Companies with missing or outdated status pages see support channels get overwhelmed.
Lesson 4: Proactive Outreach Beats Reactive Support
During an outage, users have questions. If they have to call support, wait on hold, and explain their situation, they get frustrated. If the company proactively sends email updates (from a backup email system, obviously), Slack messages, or SMS alerts, it feels like the company is in control. Microsoft didn't do proactive outreach during this outage; users had to search for information.
Lesson 5: Post-Mortem Transparency Builds Trust
After an outage ends, the company that publishes a detailed post-mortem (root cause, timeline, what went wrong, how we're preventing it next time) gains back trust. Companies that don't publish post-mortems or publish vague ones look like they're hiding something. Microsoft typically publishes post-mortems, but they often lack specific technical detail. Transparency would mean saying "a misconfiguration in our load balancer caused traffic to route to down servers" or "a database migration script failed, causing cascading failures." Instead, they usually say "we experienced service degradation due to infrastructure issues." That's not transparency.


Complexity and scaling challenges are leading factors in cloud outages, each contributing an estimated 25% to the issue. Estimated data.
Technical Architecture Insights: How Microsoft 365 Infrastructure Works
Understanding how Microsoft 365 infrastructure works helps explain why outages can be so widespread.
Multi-Region Architecture: Microsoft 365 runs in multiple regions globally. North America probably has data centers in 3-5 geographic locations. Each region has redundancy (multiple data centers), but the regions themselves share some foundational services. If a foundational service fails at the regional level, all data centers in that region fail simultaneously. This is why a "North American outage" affected everyone in North America.
Microservices Model: Exchange Online isn't a single service running on one set of servers. It's hundreds of microservices: message routing service, mailbox store service, search service, calendar service, attachment service, etc. Each microservice can scale independently, but it also means a failure in one service can cascade to others. If the message routing service fails, emails can't be delivered even if the mailbox store is fine.
Database Partitioning: Your email data doesn't live on a single server. It's partitioned across thousands of database servers. When you request your email, a routing layer directs your request to the correct partition. If that routing layer fails or misconfigures, all requests fail. Database partitioning provides scale but introduces complexity and potential single points of failure.
API-First Architecture: Services communicate through APIs. Teams calls the presence service API to know who's online. SharePoint calls the authentication API to verify you can access a file. If the authentication API becomes slow or fails, dependent services start timing out and failing. One slow API creates cascading failures upstream.
Cache Layers: To handle 400 million users, Microsoft 365 uses aggressive caching. Your calendar is cached. Your contacts are cached. Your file metadata is cached. If cache layers fail or become inconsistent, you get data inconsistency issues. During recovery from an outage, cache invalidation is a nightmare (Phil Karlton's famous quote: "There are only two hard things in computer science: cache invalidation and naming things").

Learning From Competitors: Outage Response Best Practices
Let's look at how other major cloud providers have handled outages in the past, to see what best practices look like.
Google's Approach: Google publishes extremely detailed post-mortems. When Gmail had an outage in 2014, Google published a post-mortem explaining the root cause (datacenter traffic management system), the timeline, what went wrong, and what they changed to prevent it. They were specific enough that other engineers could understand it. This transparency built trust even though they had a major outage.
Amazon's Approach: AWS publishes brief status page updates during outages but more detailed analysis after. When AWS US-East-1 had issues in 2011, they published analysis explaining that rapid growth created cascading failures. They explained their changes to prevent it. AWS also offers status page RSS feeds so customers can integrate outage alerts into their own systems.
Slack's Approach: When Slack has outages, they publish real-time updates every 15 minutes. They're specific ("investigating issues with message delivery from EU region"). They publish post-mortems within 48 hours. They also offer incident severity levels (SEV1, SEV2, SEV3) that help customers understand impact.
Twilio's Approach: Twilio publishes an extensive status page with component-level detail. During the 2021 outage, they updated every 15 minutes with specific information. They published a post-mortem within 24 hours explaining the root cause (a self-inflicted DDoS from their own infrastructure). The transparency was remarkable.
Microsoft 365 could adopt these practices more aggressively. Publish detailed post-mortems. Update status pages every 15 minutes. Offer status page integrations. Proactively notify customers of planned maintenance. The missing piece in their response isn't technical (they have brilliant engineers); it's communication discipline.

Prevention and Resilience: How Microsoft 365 Can Improve
Future outages are inevitable. But the frequency and severity can be reduced. Here's what Microsoft 365 could do:
Better Load Testing: Chaos engineering and game day exercises could simulate failures before they happen. Netflix does this regularly (their "Chaos Monkey" randomly kills production servers to test resilience). Microsoft could run monthly exercises: "What if database Region 2 loses connectivity?" "What if the authentication service becomes 50% slower?" Simulating failures before they happen reveals weaknesses.
Automated Failover: When a service detects degradation, it should automatically fail over to backup infrastructure. Instead of waiting for humans to detect a problem and initiate failover, systems could self-heal. This would require better health check systems and automated incident response.
Blast Radius Containment: Failures should be contained to the smallest affected subset of customers. If one partition of the database fails, only the customers whose data lives in that partition should be affected. If one data center fails, only customers in that data center should be affected. Architectural changes to improve isolation could reduce overall outage scope.
Better Status Page Granularity: Instead of "Teams is Healthy," the status page could show "Teams: 99.2% requests successful, 2% experiencing slow performance, 0.8% failing." Granular metrics would help customers understand exactly what they can and can't do.
Proactive Customer Notification: During an outage, Microsoft could automatically send emails from a backup system alerting customers of the issue and estimated recovery time. Instead of making customers discover outages through Slack complaints, the vendor initiates communication.
SLA Improvement and Transparency: Microsoft could publish more detailed SLA terms. Instead of "99.9% uptime," they could specify "99.9% uptime for message delivery, 99.95% uptime for presence services, 99.5% uptime for real-time Teams features." Different services have different reliability requirements. Being transparent about this would help customers understand what they're paying for.

Regulatory and Compliance Implications
For regulated industries, outages create compliance complications.
HIPAA (Healthcare): Healthcare providers using Microsoft 365 must maintain audit logs of who accessed patient data when. An outage disrupts this. During recovery, data might not be logged consistently. Healthcare organizations must review and certify compliance after outages. One hospital's compliance team spent 8 hours verifying that patient communications were properly retained during the outage.
PCI-DSS (Payment Card Industry): Companies processing credit cards must maintain logging and monitoring. An outage during which security dashboards (like Microsoft Defender) are offline creates gaps in monitoring. During the outage, any security incident that occurred went undetected. After recovery, companies must perform forensic analysis to ensure no breaches occurred during the blind spot.
FINRA (Financial Industry): Financial firms must maintain communication records for compliance. An email outage means communications can't be retained. During the outage, traders couldn't send emails for hours. After recovery, financial firms had to verify that no compliance violations occurred.
SOC 2: Companies pursuing SOC 2 certification must demonstrate control over their service availability. A 4-6 hour outage is a control failure. Auditors ask: "What controls prevented this? What controls detected this? What controls ensured recovery?" Companies that don't have satisfactory answers to these questions fail SOC 2 audits or get conditional certifications.
GDPR and Data Protection: An outage can be considered a data protection incident if customer data became inaccessible or if backup systems didn't function. European customers might have had grounds to report the incident to their data protection authorities. Some companies did report it, creating regulatory review risk.
For regulated companies, outages aren't just business problems; they're compliance problems. This should inform your vendor selection and backup infrastructure planning.

Looking Ahead: What Changes Now
After major outages, organizations make changes. Here's what we expect to see in the coming months.
Investment in Alternative Platforms: Companies that experienced pain during this outage will investigate Google Workspace, Proton Mail, or self-hosted email solutions. This increases switching cost and complexity, but it buys redundancy. Microsoft should expect to see some churn of security-conscious customers.
Increased Slack Adoption: Slack wasn't affected by this outage. Microsoft Teams was. Companies will use this as ammunition to argue for Slack, or at minimum, to use Slack as a backup communication channel. Slack's adoption rate might accelerate.
Better Disaster Recovery Planning: IT teams will dust off their disaster recovery playbooks and actually test them. They'll invest in backup systems, documentation, and communication protocols. Budget for DR infrastructure will increase.
Vendor Diversification Acceleration: The trend away from single-vendor consolidation will accelerate. Instead of "everything on Microsoft," we'll see more hybrid approaches: Microsoft for email, Google for collaboration, AWS for infrastructure, etc. This increases complexity but improves resilience.
Outage Insurance: Enterprising startups will build "outage insurance" products that provide backup email, communication, and file access during outages. These will gain traction as companies prove willing to pay for guaranteed service continuity.
Status Page Maturity: Organizations will invest more in status page infrastructure. Status page-as-a-service providers like Atlassian's Status Page will see increased adoption. Companies will integrate status pages into their own dashboards and alert systems.

Industry Patterns: Why Outages Keep Happening
Cloud outages aren't new. Amazon S3 had a major outage in 2017. Microsoft Azure went down in 2016. Google Cloud had regional failures in 2019. Why do these keep happening despite massive vendor investments in reliability?
Complexity Premium: As systems become more complex, the number of possible failure modes grows exponentially. Microsoft's infrastructure has millions of moving parts. You can't test every possible combination. Somewhere in that complexity lurks failure modes nobody predicted.
Speed Pressure: Cloud providers add new features constantly. They want to ship fast. Speed and reliability are often in tension. A rushed configuration change or a feature that wasn't properly tested in load conditions creates outages. The business incentive (ship fast, add features, grow) conflicts with the operational incentive (run stable infrastructure).
Scaling Challenges: Cloud providers scale to unprecedented levels. Microsoft 365 serves 400 million users. At that scale, scenarios that work at small scale break at large scale. Database queries that complete in milliseconds at 1 million users timeout at 400 million users. Load patterns that worked for 10 million concurrent users create cascade failures at 100 million. Vendors are constantly discovering new failure modes as they scale.
Upgrade Complexity: Cloud infrastructure is updated constantly. These updates are necessary for security and performance. But every update is a potential outage vector. Coordinating updates across thousands of servers while maintaining service is incredibly hard. Somewhere in the sequence of updates, something goes wrong.
Talent Constraints: Running massive cloud infrastructure requires elite engineers. Not every engineer can think at the scale of millions of concurrent users, petabytes of data, and millisecond response times. Hiring and training enough talent to run perfect infrastructure is one of the industry's hardest problems.
The meta-lesson: outages aren't usually caused by negligence or incompetence. They're caused by the inherent difficulty of running planetary-scale infrastructure. Companies that expect zero outages are delusional. Companies that prepare for inevitable outages are wise.

Customer Response Options: What You Can Do
If you experienced this outage or are concerned about future outages, what should you do?
Option 1: Switch to Google Workspace
Google Workspace offers email, calendar, Meet (video), and Drive (file storage). It's not identical to Microsoft 365, but it's comprehensive. Cost is competitive ($5-12/user/month depending on tier). Learning curve exists because interfaces differ from Microsoft. But Google's infrastructure has proven reliable. The catch: you lose Office integration and SharePoint collaboration unless you supplement with other tools.
Option 2: Hybrid Approach
Keep Microsoft 365 for Office productivity (Word, Excel, PowerPoint, Outlook, Teams), but use alternatives for file storage (Dropbox, Box) and communication (Slack instead of Teams). This spreads risk across vendors. Cost is higher ($30-50/user/month across all services), but reliability is better. Complexity increases because you're managing multiple vendors.
Option 3: Build Redundancy Within Microsoft
Stay with Microsoft 365, but add backup systems. Set up a backup email system (either self-hosted or with another provider) with domain MX failover. Configure OneDrive offline sync so important files are always available locally. Use Slack as a backup communication channel. Cost is moderate ($5-10/user/month for backup systems), and you get redundancy without changing your primary vendor.
Option 4: Negotiate Better SLA Terms
If you're an enterprise customer, you might be able to negotiate better SLA terms with Microsoft. Request higher uptime guarantees, shorter response times, and better service credits for outages. Some large customers have negotiated 99.95% uptime guarantees instead of 99.9%. Others have negotiated one week of free service per year of outage credit (instead of the standard per-minute calculation).
Option 5: Do Nothing (Accept Risk)
Yes, this is a valid option. Small companies might calculate that the cost of outage prevention exceeds the cost of occasional outages. If you have fewer than 50 employees and can tolerate 4-6 hours of downtime once a year, you might skip expensive backup infrastructure. The downside is that you have no protection, and you discover this during the next outage.

The Future of Cloud Infrastructure Reliability
Where does this trend go? What will enterprise infrastructure look like in 5 years?
Multi-Cloud Is Inevitable: Enterprises will default to multi-cloud strategies. Instead of "all on Microsoft" or "all on AWS," the default will be "critical functions on Microsoft, data on AWS, communication on Google, security on someone else." This creates complexity but eliminates single-vendor risk. Orchestration tools will make multi-cloud management easier.
Edge Computing Grows: As companies can't rely on massive centralized cloud, they'll invest in edge infrastructure (servers closer to users). This reduces latency and provides resilience. If central cloud goes down, edge systems keep working. AWS, Microsoft, and Google are all investing heavily in edge.
AI-Driven Infrastructure: Machine learning will predict failures before they happen. AI systems monitoring infrastructure will detect anomalies, predict capacity problems, and automatically trigger failover. This won't eliminate outages, but it will reduce their frequency and severity.
Blockchain-Based Proof: Some companies will use blockchain to verify service uptime. Instead of trusting Microsoft's status page, third parties will maintain immutable records of service status. This creates accountability and makes SLA violations harder to dispute.
Open Source Infrastructure: The trend toward open-source cloud infrastructure (Kubernetes, OpenStack, Ceph) will accelerate. Companies want optionality; closed proprietary infrastructure from one vendor feels risky. Open-source alternatives provide portability.
Outage Insurance Products: Third-party companies will offer "business continuity as a service." If your primary cloud provider goes down, their backup infrastructure takes over automatically. This is already emerging but will grow significantly.

FAQ
What caused the Microsoft 365 outage in January 2025?
Microsoft stated the outage was caused by "a portion of service infrastructure in North America that is not processing traffic as expected." The company didn't disclose the specific root cause, but likely suspects include load balancing failures, database routing problems, cascading microservice failures, or bad configuration pushes to production servers. The vague official explanation leaves significant questions about whether it was a reliability issue, an operational issue, or something else entirely.
How long did the Microsoft 365 outage last?
The outage lasted approximately 4-6 hours for the most affected services. The timeline was roughly: initial reports at 2:30 p.m. ET, most services degraded or offline by 3:00 p.m. ET, partial recovery starting around 5:00-5:30 p.m. ET, and full recovery declared by 8:00-9:00 p.m. ET. Different services experienced different impact durations; email was among the last to fully recover.
What services were affected by the Microsoft 365 outage?
The outage affected Exchange Online (email), SharePoint Online, OneDrive for Business, Microsoft Teams, Microsoft Defender XDR, Microsoft Purview, and various admin centers. Essentially, the entire Microsoft 365 suite experienced outages, with email and Teams being the most impactful for most users.
How many people were affected by the outage?
Microsoft 365 has over 400 million monthly active users. The outage primarily affected North American customers, but some global impact was reported. If we estimate that 30-50% of users are North America-based and actively using the service during the outage time (2:30-8:00 p.m. ET), that suggests roughly 40-80 million people directly experienced the outage.
What was the business impact of the Microsoft 365 outage?
The impact was severe. Lost productivity alone (400 million users x average salary x 5 hours of disruption) exceeded $900 million. Beyond direct productivity loss, businesses experienced communication blackouts, missed client meetings, compliance audit complications, data access problems, and customer trust erosion. For sales-dependent companies, the inability to send emails for hours meant lost revenue. For healthcare providers, the security dashboard outage created compliance questions that required post-incident analysis.
Should I switch away from Microsoft 365 after this outage?
Not necessarily. Every cloud provider has outages. Google Workspace has experienced Gmail outages. AWS has had major regional failures. Zoom has had service degradation. Instead of switching, consider implementing redundancy: set up a backup email system, configure offline-first workflows, maintain alternative communication channels, and use different vendors for different services. Diversification is better than switching to a different single vendor.
What can I do to prepare for the next major cloud outage?
Implement the following strategies: (1) Set up a backup email system with automatic MX failover, (2) Configure offline sync for critical files so they're available without internet, (3) Maintain alternative communication channels like Slack or Discord that aren't dependent on your primary cloud provider, (4) Document disaster recovery procedures and test them quarterly, (5) Track your cloud provider's SLA performance and file service credits when they miss SLAs, (6) Diversify vendors instead of consolidating on one, and (7) Train your team on manual processes that work without cloud services. Redundancy costs money, but it's cheaper than the cost of a major outage.
Why do cloud providers keep having outages if they're so big?
Cloud infrastructure is phenomenally complex. Microsoft runs millions of servers across hundreds of data centers globally. That complexity creates failure modes that nobody predicted. Additionally, cloud providers prioritize shipping new features and scaling capacity, which sometimes conflicts with operational reliability. Outages also increase with scale: at 1 million users, a problem might affect 1,000 people; at 400 million users, the same problem affects 400,000 people. Finally, every update to the infrastructure is a potential outage vector. The industry has learned to accept that major outages will happen occasionally; the goal is to minimize frequency and reduce impact.
How is this outage different from previous cloud outages?
This outage was notable for its scope (affecting all of Microsoft 365 services simultaneously), its impact on admin functions (leaving IT teams blind), and its duration (4+ hours). Previous Microsoft outages have been more limited in scope (affecting one service) or shorter in duration. The 2016 Azure outage and the 2017 Amazon S3 outage were similarly broad, showing that even massive providers struggle with infrastructure reliability at scale. This outage is part of a pattern, not an anomaly.
What will Microsoft do to prevent this from happening again?
Microsoft will likely publish a detailed post-mortem outlining the root cause, contributing factors, and prevention measures. Typically, they'll implement better monitoring (catching problems faster), improved automated failover (reducing human response time), increased testing of failure scenarios (catching problems before production), better load balancing (preventing traffic concentration), and improved communication during outages. However, Microsoft can never eliminate the possibility of outages entirely; all they can do is reduce frequency and severity. This is an industry-wide constraint.

Conclusion: Building Resilience in an Unreliable World
The Microsoft 365 outage in January 2025 taught us something critical about modern enterprise infrastructure: it's fragile in ways that aren't always obvious.
We've come to expect cloud services to "just work." We assume Microsoft, Google, and Amazon have solved reliability. But here's the hard truth: they haven't. They've solved most of it, creating services that work 99.9% of the time. But that remaining 0.1% of downtime, when it hits, hits hard. It hits millions of people simultaneously. It hits at inconvenient times (like Tuesday afternoon). And it cascades across services, so when email goes down, chat goes down, files go down, and security dashboards go down all at once.
The companies that survived this outage best weren't the ones that hoped it wouldn't happen. They were the ones that prepared for it. They had backup email systems. They had offline file sync enabled. They had alternative communication channels. They had tested disaster recovery procedures. They had vendor diversification strategies.
More importantly, they had the right mental model. They understood that outages aren't anomalies; they're inevitable. They understood that the question isn't "if we'll have downtime" but "how quickly we'll recover and how much it will cost us." They understood that redundancy isn't expensive compared to the cost of being caught without it.
So what should you do? Start small. Don't overhaul your entire infrastructure this week. But do this:
-
Schedule a vendor review meeting with your cloud provider. Ask them specifically about their infrastructure resilience, recent incidents affecting similar customers, and their SLA performance metrics over the last year. Most companies don't ask these questions. Great companies do.
-
Document your current disaster recovery procedures. What happens if email goes down? What happens if file storage becomes inaccessible? Write it down. Most companies discover they don't have written procedures when disaster actually strikes.
-
Test your offline capabilities. Can your team work without cloud services for a few hours? Can important documents be accessed offline? If not, set up offline sync for critical files this week.
-
Set up a basic backup communication channel. This could be as simple as a Slack workspace or Discord server. Make sure your team knows to use it if primary communication fails.
-
Calculate the cost of a major outage for your business. How much productivity do you lose per hour? How much revenue is at risk? Compare that to the cost of backup infrastructure. If the backup costs less than the probable cost of an outage, build it.
The Microsoft 365 outage won't be the last major cloud outage. But it can be the catalyst that pushes you to build resilience. Because in enterprise infrastructure, resilience isn't about having perfect systems. It's about having plans for when perfect systems fail.

Key Takeaways
- Microsoft 365 experienced a 4-6 hour outage affecting email, Teams, SharePoint, and security dashboards for millions of enterprise users.
- The outage was caused by infrastructure problems in North America but likely cascaded from load balancing or database routing failures.
- Estimated productivity loss exceeded $900 million when accounting for affected user base and downtime duration.
- Redundancy strategies like backup email systems, offline sync, and vendor diversification are essential for surviving cloud outages.
- Regulated industries (healthcare, finance) face compliance complications and audit risk when cloud infrastructure fails.

