
Nous Coder-14B: Open-Source AI Coding Model Complete Guide & Alternatives [2025]
Introduction: The Open-Source Coding Model Revolution
The landscape of artificial intelligence-assisted software development has undergone a seismic shift. Where once proprietary models dominated discussions around AI-powered coding, we're now witnessing an unprecedented democratization of these capabilities. In early 2025, Nous Research released Nous Coder-14B, an open-source AI coding model that arrives at a pivotal moment in the industry—just as commercial solutions like Claude Code are generating significant momentum among developers worldwide.
What distinguishes Nous Coder-14B from countless other AI coding tools is not merely its technical specifications, but its radical commitment to transparency and reproducibility. The team at Nous Research didn't just publish model weights; they released the complete reinforcement learning stack, benchmark suite, and training infrastructure, enabling any researcher with sufficient computational resources to reproduce, verify, or extend the work. This approach represents a fundamental philosophy shift in how advanced AI systems can be distributed and improved upon.
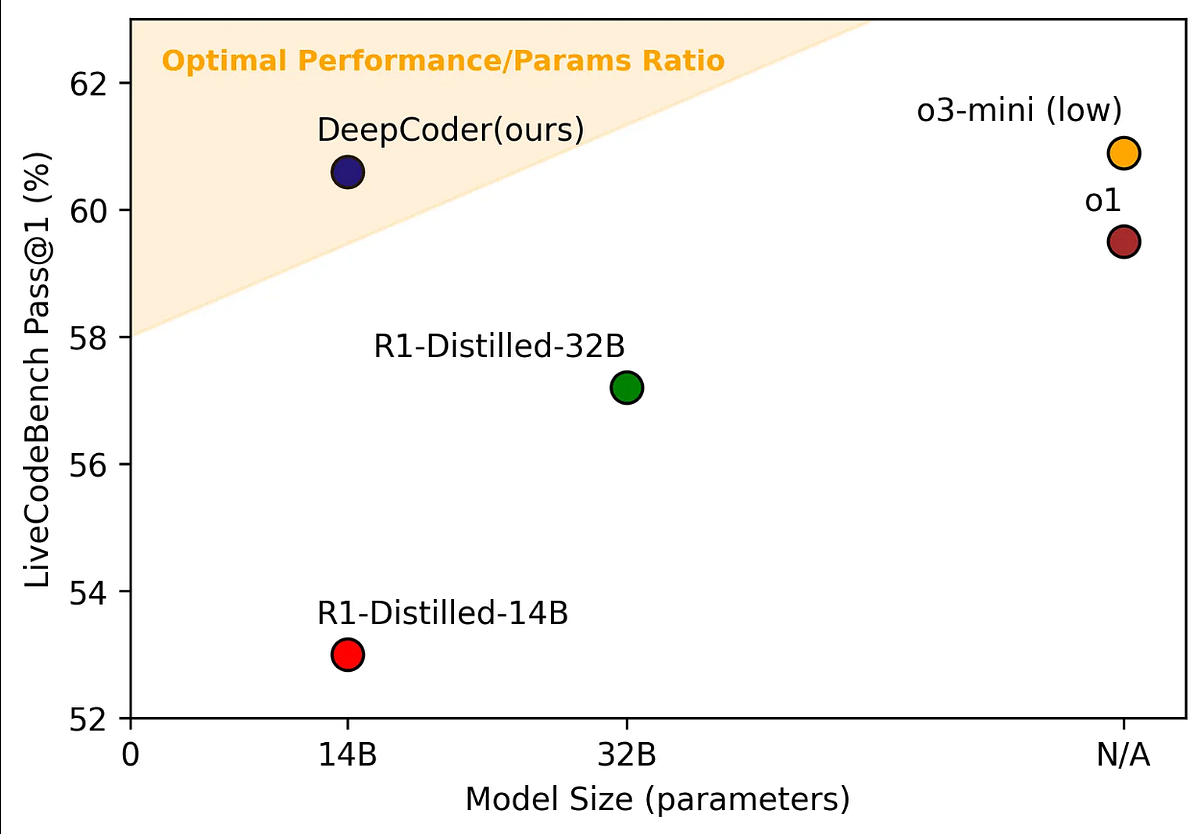
The significance of this release extends beyond a single model. Nous Coder-14B exemplifies how open-source approaches can compete with—and in some metrics, exceed—larger proprietary systems. Trained in just four days using 48 of Nvidia's latest B200 graphics processors, the model achieved a 67.87% accuracy rate on Live Code Bench v 6, a standardized evaluation benchmark testing models against competitive programming problems published between August 2024 and May 2025. This represents a 7.08 percentage point improvement over Alibaba's Qwen 3-14B, the base model from which it was trained.
For developers, researchers, and organizations evaluating AI coding solutions, understanding Nous Coder-14B's approach, capabilities, and limitations is essential. This comprehensive guide examines the model in depth, explores its technical architecture, discusses its practical applications, and compares it with alternative solutions available to developers seeking to augment their coding workflows with artificial intelligence.
The broader context makes this release particularly timely. The industry is experiencing what many describe as the "Claude Code moment"—a period where AI coding assistants have demonstrated capabilities that genuinely surprised even experienced technologists. Google engineer Jaana Dogan went viral on social media describing how Claude Code approximated a distributed agent orchestration system her team spent a year developing, based on a three-paragraph prompt. Against this backdrop of proprietary capability, Nous Research is betting that open-source alternatives trained on verifiable, transparent methods can close performance gaps while maintaining the advantages of reproducibility and community-driven improvement.

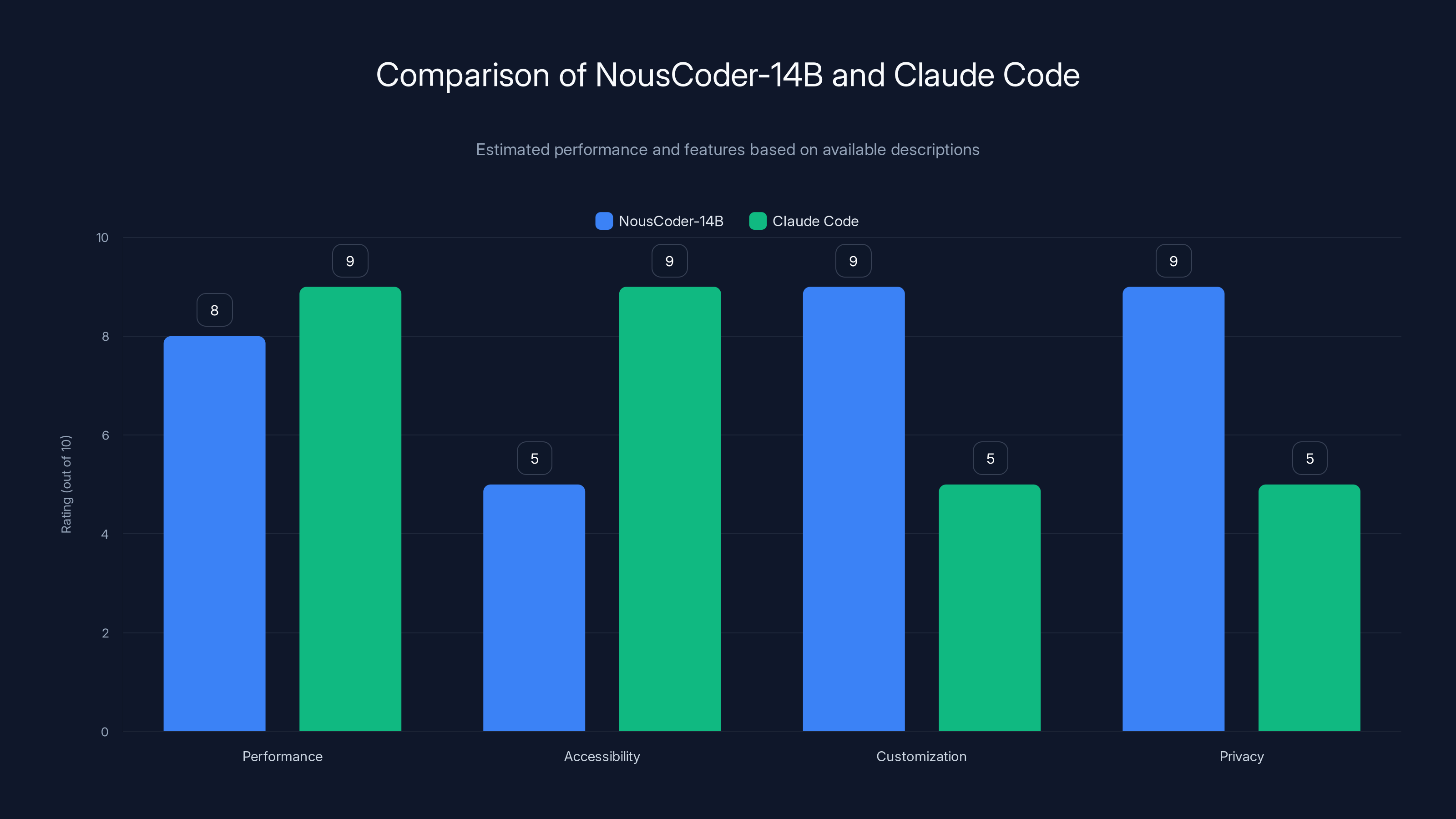
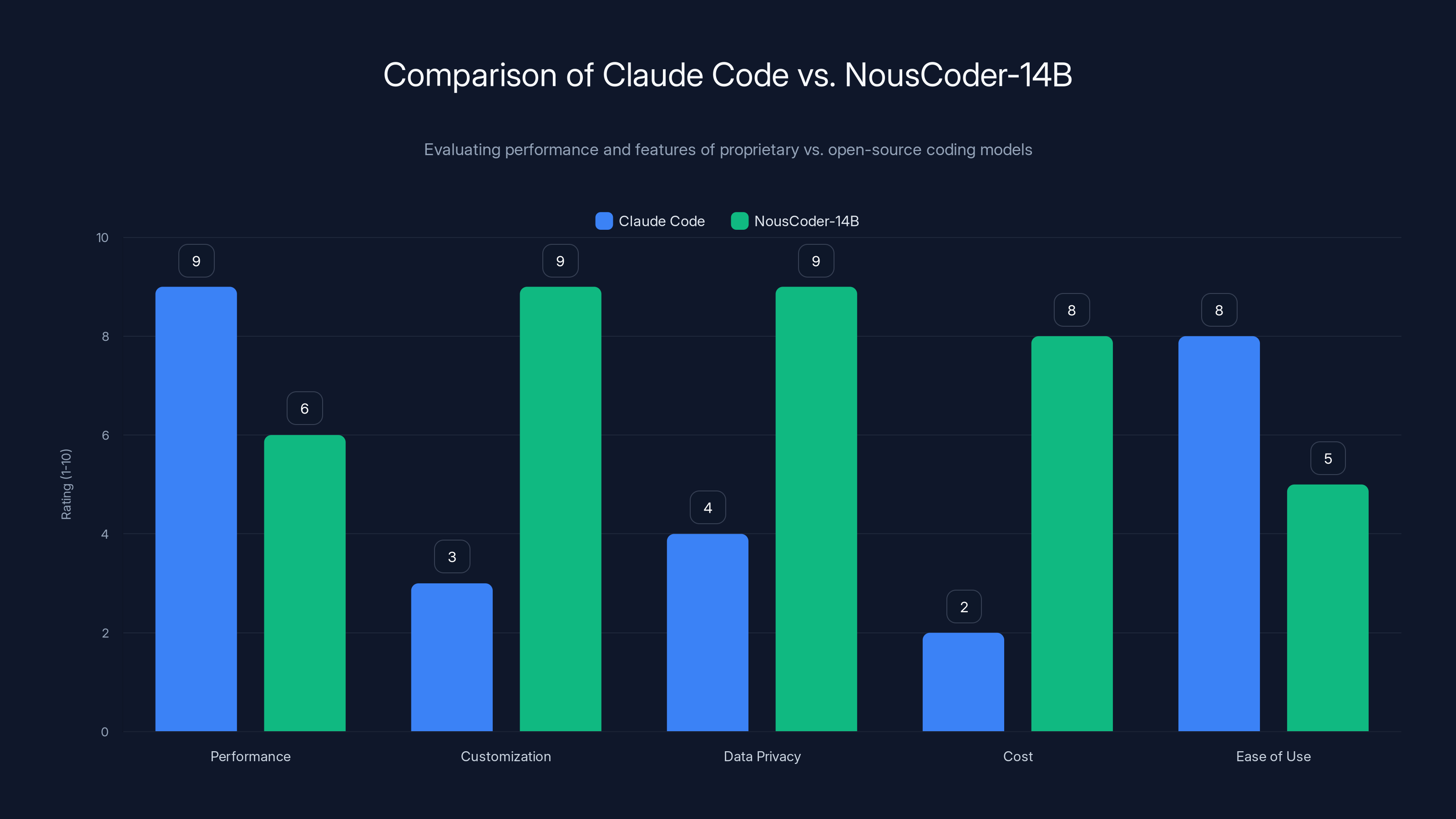
NousCoder-14B excels in customization and privacy, while Claude Code offers higher accessibility and performance for general tasks. Estimated data based on model descriptions.
What is Nous Coder-14B? Technical Overview and Core Capabilities
The Foundation: Understanding the 14B Architecture
Nous Coder-14B is a large language model with 14 billion parameters, trained specifically for code generation and competitive programming tasks. The "14B" designation refers to the parameter count—the adjustable weights within the neural network that allow the model to process and generate text. To provide context, models in the 14B parameter range represent a sweet spot in the current AI landscape: they're substantially smaller than massive models containing hundreds of billions of parameters, yet retain considerable expressive power for specialized tasks like code generation.
The base architecture derives from Alibaba's Qwen 3-14B, a foundational language model that Nous Research researchers fine-tuned and enhanced specifically for programming tasks. This inheritance is significant because it means Nous Coder-14B builds upon established, proven architectural foundations. Rather than developing an entirely novel architecture from scratch—a risky and computationally expensive proposition—the Nous Research team focused their innovation on the training methodology and optimization process. This pragmatic approach mirrors how successful software development often works: inheritance and enhancement rather than wholesale reinvention.
The model operates with a 40,000-token context window during standard inference, which was extended from an initial 32,000-token window during the early stages of training. During evaluation, researchers extended the context to approximately 80,000 tokens, revealing that additional context improved performance significantly. For developers and organizations considering Nous Coder-14B, this context window capacity is functionally meaningful: it allows the model to process substantially longer code files, more extensive problem descriptions, and richer conversational history than many competing models.
Training Methodology: Verifiable Rewards and Reinforcement Learning
What truly distinguishes Nous Coder-14B is not its architecture but rather its training methodology. The model was trained using reinforcement learning focused on "verifiable rewards"—a system where the model generates code solutions, those solutions are immediately executed against test cases, and the model receives binary feedback: the solution either produces correct output or it doesn't. This creates a feedback loop fundamentally different from traditional language model training, which relies on predicting the next token in a sequence.
This approach demands significant infrastructure. Nous Research utilized Modal, a cloud computing platform, to execute sandboxed code in parallel across multiple instances. Each of the 24,000 training problems in their dataset contains hundreds of test cases on average. The system must verify that generated code produces correct outputs while respecting computational constraints—specifically, solutions must execute within 15 seconds and use no more than 4 gigabytes of memory. These constraints mirror real-world programming environments and prevent the model from learning pathological solutions that might theoretically work but prove impractical.
The training employed a technique called DAPO (Dynamic Sampling Policy Optimization), which performed marginally better than alternative approaches in Nous Research's experiments. A crucial innovation within DAPO involves "dynamic sampling"—the training system deliberately discards examples where the model either solves all solution attempts or fails all attempts, since these provide minimal gradient signal for learning. This is an elegant optimization: the model learns most efficiently from examples where it's uncertain or partially capable, not from problems it completely masters or entirely fails.
The researchers also adopted "iterative context extension." During early training, the model operated with a 32,000-token context window. As training progressed, this was gradually expanded to 40,000 tokens. This staged approach likely reduces training instability that might occur if context was expanded too rapidly. Furthermore, training overlaps inference with verification—as the model completes a solution, it begins work on the next problem while the previous solution is being checked. This pipelining, combined with asynchronous training where multiple model instances work in parallel, maximizes hardware utilization on expensive GPU clusters.
The Four-Day Training Sprint: Efficiency and Comparative Learning
One of the most striking aspects of Nous Coder-14B's development narrative involves its training timeline. The entire model was trained in just four days using 48 of Nvidia's B200 graphics processors. This raises an immediate question: how was such rapid training possible, and what does it reveal about modern machine learning efficiency?
To contextualize this achievement, Nous Research's technical documentation includes a particularly revealing analogy. Joe Li, the primary researcher on the project and himself a former competitive programmer, compared the model's improvement trajectory to his own learning journey on Codeforces, the competitive programming platform where participants earn numerical ratings based on contest performance. Based on rough mapping between Live Code Bench scores and Codeforces ratings, Li calculated that Nous Coder-14B's improvement—from approximately the 1600-1750 rating range to 2100-2200—represents the equivalent leap that took him nearly two years of sustained practice between ages 14 and 16.
Yet critically, Li notes a fundamental caveat: he solved roughly 1,000 problems during those two years, while the model required 24,000. This illustrates a persistent asymmetry in machine learning compared to human learning. While artificial neural networks can achieve remarkable capabilities when trained at scale and with sufficient computational resources, they remain dramatically less sample-efficient than human learning. Humans extract far more signal from fewer examples—a phenomenon sometimes called "data efficiency" in machine learning literature. This difference has profound implications for both the sustainability and scalability of AI model training.
The four-day timeline also reflects the specific strengths of modern GPU hardware, particularly Nvidia's latest B200 processors. These specialized hardware accelerators dramatically reduce the wall-clock time required for training. However, the total computational investment remains substantial—the energy requirements and financial costs of training on 48 B200 GPUs for four days represent a significant capital expenditure that only well-funded organizations can currently undertake.
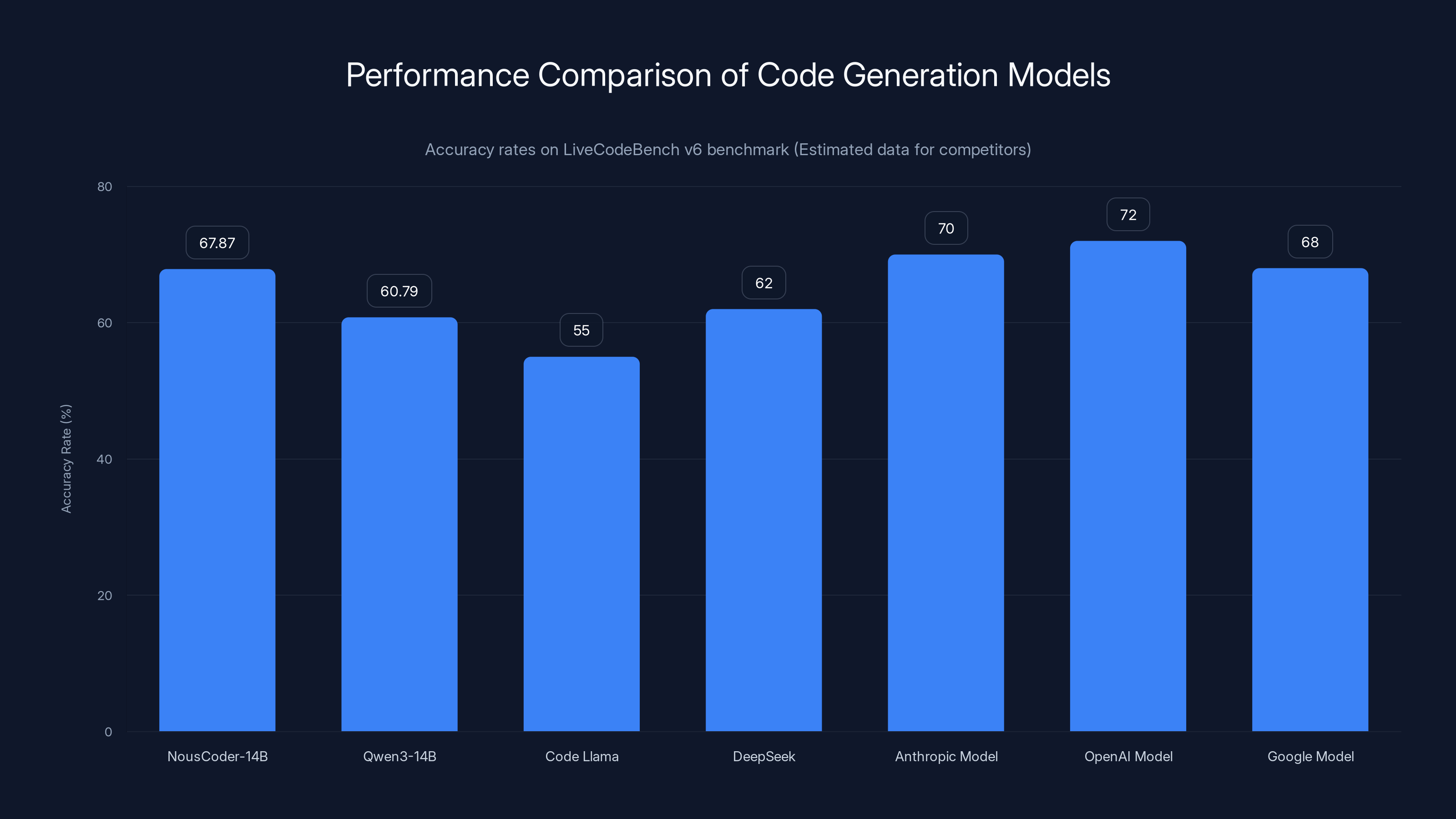
NousCoder-14B achieves a 67.87% accuracy rate on LiveCodeBench v6, outperforming Qwen3-14B by 7.08 points and showing competitive performance against larger proprietary models. Estimated data for other models.
Performance Benchmarks: How Nous Coder-14B Compares
Live Code Bench v 6: The Primary Evaluation Framework
Understanding how Nous Coder-14B performs requires understanding how it's evaluated. The primary benchmark is Live Code Bench v 6, a standardized evaluation framework specifically designed for testing code generation models on competitive programming problems. Live Code Bench is particularly valuable because it includes problems published between August 2024 and May 2025—recent problems that represent the current frontier of competitive programming difficulty. This temporal specificity prevents models from simply memorizing solutions to well-known historical problems.
On this benchmark, Nous Coder-14B achieved a 67.87% accuracy rate. To interpret this figure: when the model generates a solution to a competitive programming problem, approximately 67.87% of the time, that solution produces correct output on all test cases and meets the computational constraints. This represents a significant achievement for a 14B parameter model, and particularly meaningful for a model that can be deployed on consumer-grade hardware or modestly-sized computational clusters.
The 7.08 percentage point improvement over the base Qwen 3-14B model might seem modest in isolation—a 10.4% relative improvement in accuracy—but in practice represents a meaningful difference in capability. Moving from solving approximately 63% of problems to solving 68% of problems translates to the model handling substantially more complex code generation tasks autonomously without requiring human intervention or correction.
Comparative Performance Against Other Models
Where does Nous Coder-14B stand relative to other coding models? The competitive landscape includes various approaches: smaller open-source models like Code Llama, medium-sized models from organizations like Deep Seek, and larger proprietary systems from companies like Anthropic, Open AI, and Google. Direct comparison is complicated because different models are evaluated on different benchmarks using different methodologies.
Among open-source models in roughly the same parameter range, Nous Coder-14B performs competitively. It surpasses most models of similar scale on Live Code Bench. However, it's crucial to acknowledge that substantially larger proprietary models—particularly Claude 3.5 Sonnet and recent versions of GPT-4—demonstrate superior performance on most coding tasks. These larger models benefit from hundreds of billions of parameters and training on diverse, high-quality datasets.
The meaningful comparison isn't "is Nous Coder-14B the absolute best coding model?" but rather "given specific constraints—open-source availability, reproducibility, computational budget, privacy requirements, or customization needs—does Nous Coder-14B represent an appropriate choice?" For many scenarios, the answer is yes.
Context Window Performance and Extended Inference
An often-overlooked dimension of model performance involves context window utilization. Nous Coder-14B's standard 40,000-token context window allows it to process substantial amounts of code and context. During evaluation, researchers extended this to approximately 80,000 tokens and observed improved accuracy, reaching the reported 67.87% benchmark performance. This suggests the model can effectively utilize additional context to inform better solutions—important for real-world code generation where understanding surrounding code, function signatures, and problem descriptions is crucial.
This extended context capability has practical implications. When developers use Nous Coder-14B for code generation, providing additional context about the broader codebase, existing functions, and project architecture enables the model to generate more appropriate solutions. A model that can meaningfully utilize 80,000 tokens of context can process entire medium-sized files, detailed specifications, and extensive conversation history—substantially more useful than models constrained to 2,000-4,000 token windows.
The Atropos Framework: Infrastructure for Reproducible Research
Understanding the Complete Training Stack
What fundamentally distinguishes Nous Research's approach is their decision to open-source not merely the model weights but the entire training infrastructure. They released what they call the Atropos framework—a complete reinforcement learning environment, benchmark suite, and training harness that enabled the development of Nous Coder-14B.
This decision has enormous implications for the research community. Traditionally, when organizations release AI models, they provide only the final weights—the neural network parameters that can be loaded into software and used for inference. The training code, hyperparameter choices, data preprocessing scripts, and infrastructure configuration remain proprietary. This creates an asymmetry: practitioners can use the model but cannot understand the decisions that produced it.
Atropos inverts this dynamic. Researchers can examine exactly how problems are presented to the model, how solutions are evaluated, what hyperparameters were used, how sampling decisions are made, and how training progresses over time. This transparency enables genuine reproducibility—not merely replication of results, but understanding of methodology.
Sandboxed Code Execution and Safety
A critical component of the Atropos framework involves sandboxed code execution. When training a code generation model using reinforcement learning, the system must execute generated code to determine whether solutions are correct. This introduces obvious security concerns: executing arbitrary code directly could compromise system security.
Atropos addresses this through integration with Modal's sandboxed cloud computing environment. Generated code executes in isolated, temporary sandboxes that expire after execution, preventing any persistent changes to the underlying system. Each execution is completely isolated from others. This architectural choice is essential not merely for safety but for reproducibility—sandboxed execution ensures consistent behavior regardless of local system state.
Furthermore, the sandboxing enables enforcement of resource constraints. Solutions must complete within 15 seconds and use no more than 4 gigabytes of memory. These constraints are strictly enforced through sandboxing, preventing the model from learning to generate solutions that theoretically work but prove impractical in real-world scenarios. A solution that consumes gigabytes of memory is effectively useless for most practical applications, even if it produces correct output.
The Dataset: 24,000 Competitive Programming Problems
The training dataset comprises 24,000 competitive programming problems, each with hundreds of test cases. This is a substantial dataset, but modest by modern machine learning standards. Consider that recent large language models are trained on datasets containing hundreds of billions of tokens. However, the key difference is that these 24,000 problems represent carefully curated, objectively verifiable tasks with clear right and wrong answers.
Competitive programming problems are particularly valuable for training code generation models because they enforce clarity and precision. A solution either passes all test cases or it doesn't—there's no ambiguity. Problems include explicit constraints on input size and acceptable runtime, mirroring real-world programming concerns. Additionally, the problems span a wide range of algorithmic complexity, from basic string manipulation to advanced graph algorithms and dynamic programming.
The diversity of these problems creates a robust training distribution. The model encounters diverse programming paradigms, algorithmic approaches, and problem types. Rather than overfitting to a narrow distribution of problems, it develops generalizable coding skills.
Claude Code excels in performance and ease of use, while NousCoder-14B offers superior customization and data privacy. Estimated data based on qualitative analysis.
Practical Applications: When and How to Use Nous Coder-14B
Competitive Programming and Algorithm Development
The most natural application domain for Nous Coder-14B is competitive programming itself. Given that the model was trained specifically on competitive programming problems using competitive programming benchmarks, its capabilities shine brightest in this context. For programmers participating in contests like Codeforces, Leet Code, or regional programming competitions, Nous Coder-14B can serve as a collaborative tool to suggest approaches, generate initial solutions, or help debug algorithmic implementations.
However, it's important to acknowledge the ethical dimensions of using AI in competitive programming. Most formal competitions prohibit AI assistance during contests. Nous Coder-14B's utility in competitive programming is primarily as a training tool—helping programmers develop skills, explore different problem-solving approaches, and practice algorithm implementation. Used this way, it can accelerate skill development.
Educational Settings and Algorithm Instruction
Computer science educators often struggle with the challenge of providing timely, relevant feedback on programming assignments. Nous Coder-14B could serve as a supplementary teaching tool, generating reference solutions to problems that students solve, or helping students debug their own implementations. Since the model is open-source and can be self-hosted, educational institutions can deploy it without relying on external services or proprietary platforms.
The transparency of the Atropos framework makes it particularly valuable in educational contexts. Instructors can examine how the model was trained, which benchmarks it uses, and what metrics indicate performance. This transparency enables educators to understand what the model is and isn't capable of, and to explain these capabilities and limitations to students.
Code Generation in Production Development
For general production software development, Nous Coder-14B's capabilities are more nuanced. The model demonstrates strong performance on algorithmic problems with clear specifications, but real-world software development involves many dimensions beyond pure algorithm implementation: framework-specific idioms, architectural patterns, integration with existing codebases, and domain-specific conventions.
Nous Coder-14B can be valuable for generating boilerplate code, suggesting algorithmic implementations, or drafting solutions to well-defined subproblems. It's less suitable as a general-purpose code completion tool for complex, context-dependent development tasks—at least compared to models trained on broader software engineering datasets.
Yet for specific tasks—implementing known algorithms, generating test infrastructure, creating utility functions—Nous Coder-14B can improve developer productivity. The open-source nature enables organizations to self-host the model, maintaining data privacy and avoiding reliance on external API services.
Research and Academic Applications
Academics and researchers can leverage Nous Coder-14B in several ways. First, the Atropos framework itself serves as a platform for research into reinforcement learning for code generation. Researchers can modify the framework, experiment with different training approaches, and publish results comparing different methodologies.
Second, the model itself can serve as a baseline for comparative studies. Researchers evaluating new techniques in code generation can compare their approaches against Nous Coder-14B's performance, establishing whether proposed innovations genuinely improve upon the current state-of-the-art.
Third, understanding how Nous Coder-14B was trained—the specific design choices, hyperparameters, and methodologies—provides valuable lessons about effective approaches to training specialized models. As the field moves toward smaller, more specialized models rather than massive general-purpose ones, Nous Coder-14B exemplifies best practices in that direction.

Deployment and Hardware Requirements
Computational Requirements for Inference
While Nous Coder-14B requires 48 B200 GPUs and four days for training, inference—actually using the model to generate code—demands far more modest resources. A 14B parameter model can run on a single consumer-grade GPU with approximately 20-30 GB of VRAM. High-end consumer GPUs like the Nvidia RTX 6000 Ada or RTX 5880 Ada fall within this range, as do more accessible options like the Nvidia RTX 4090 (24GB) or RTX 5000 Ada (24GB).
For organizations with greater computational budgets, deploying on specialized inference accelerators like Nvidia's L40S or H100 GPUs enables faster inference—generating responses more quickly, though consuming more power. The flexibility to choose among various hardware targets is a significant advantage of open-source models: organizations can select hardware matching their specific constraints and requirements.
Inference also doesn't require the same precision as training. Models can be quantized—internally represented with lower numerical precision—reducing memory requirements and accelerating inference. A 14B parameter model quantized to 8-bit precision requires approximately 14 GB of VRAM, while 4-bit quantization reduces this further to 7-8 GB. This means Nous Coder-14B can run on more modest hardware than the specifications for original training might suggest.
Self-Hosting Versus API Services
Because Nous Coder-14B is open-source, organizations can self-host the model rather than relying on external APIs. This provides several advantages: complete data privacy (code never leaves internal systems), no per-request fees, unlimited usage for a fixed hardware cost, and the ability to customize or fine-tune the model for specific use cases.
However, self-hosting introduces operational complexity. Organizations must manage hardware, handle software updates, troubleshoot issues, and maintain security. External API services abstract away these concerns but introduce dependencies and costs. The choice between self-hosting and using API services involves evaluating organization-specific factors: data sensitivity requirements, expected usage volume, internal technical capabilities, and capital versus operational expenditure preferences.
Some emerging frameworks and platforms (like Together AI, Replicate, or Baseten) offer middle-ground approaches: deploying open-source models on managed infrastructure, providing API access without requiring organizations to manage hardware directly, while maintaining advantages of open-source models.
Integration with Development Workflows
Nous Coder-14B integrates into development workflows primarily through existing interfaces developed for open-source models. The Ollama framework enables running the model locally on personal computers. Continue, an open-source VS Code extension, integrates with locally-running models. Git Hub Copilot also supports custom models in beta programs.
Integration doesn't require specialized tooling; since Nous Coder-14B implements standard language model APIs, it works with any framework supporting Open AI-compatible APIs. This means developers can use Nous Coder-14B as a drop-in replacement for other code generation models in existing workflows.


NousCoder-14B offers a significantly larger context window size during evaluation (80,000 tokens) compared to typical models, enhancing its ability to handle longer code files and complex problem descriptions. Estimated data.
Training Insights: How the Model Learns to Code
Dynamic Sampling Policy Optimization in Practice
The DAPO technique warrants deeper examination because it represents a meaningful innovation in training methodology. During standard reinforcement learning, all training examples receive equal treatment—the model learns equally from examples where it's highly confident and examples where it's uncertain.
Dynamic sampling inverts this approach. Training examples where the model either succeeds on all attempts or fails on all attempts provide minimal gradient signal because the gradient computation reveals that the model should become more confident or less confident in a direction it's already moving strongly. Examples where the model partially succeeds—solving some test cases but not others—provide rich signal: the model learns from its partial success about what approaches work and what doesn't.
This insight mirrors how human learning works. We learn more from problems we struggle with than from problems we either find trivially easy or impossibly hard. By deliberately sampling from the frontier of the model's current capabilities, DAPO focuses learning effort where it's most valuable.
Iterative Context Extension and Training Stability
Another noteworthy methodological choice involves gradually extending the context window during training. Early training operates with 32,000 tokens of context, later expanding to 40,000. This staged approach has theoretical justification: suddenly expanding context window size can destabilize training, introducing distribution shift that forces the model to adapt to longer sequences.
Gradual extension allows the model to learn representations that effectively utilize additional context incrementally. Positional encoding schemes—the mechanisms by which models encode the position of tokens in a sequence—can suffer from extrapolation challenges when applied to sequences longer than training sequences. By gradually extending the window during training, the model learns to extrapolate more smoothly.
Inference-Verification Pipelining
The training pipeline implements what's called "pipelining" or "concurrent execution"—as the model completes a solution and it begins being verified in sandboxed execution, the model simultaneously begins generating solutions for the next problem. This architectural choice represents a pragmatic optimization given the hardware constraints.
GPU utilization during training involves multiple stages: the model generates tokens (using GPU), solutions are verified by executing code (using CPU), gradients are computed (using GPU), and weights are updated (using GPU). Without pipelining, if GPU becomes idle while waiting for code execution to complete, computational resources are wasted. Pipelining keeps the GPU consistently busy by generating solutions for other problems while verification progresses in parallel.
This technique, while not novel in itself, demonstrates careful engineering decisions that improved training efficiency and likely accelerated the training process beyond what naive approaches would achieve.
Open-Source Advantages and Community Impact
Reproducibility and Verification
The decision to open-source not just model weights but the complete training infrastructure creates unprecedented opportunities for verification. Independent researchers can reproduce the training process, verify reported results, and audit the methodology for any issues. This represents a departure from the proprietary-model paradigm where external parties must take reported claims on faith.
Reproducibility matters for several reasons. First, it enables detection of errors or limitations that original researchers might miss. Second, it builds confidence that reported results are genuine rather than the product of cherry-picked evaluations or optimistic reporting. Third, it enables extensions—researchers can modify the training process, test hypotheses about what components matter most, and understand the causal relationships between design choices and performance.
From an organizational perspective, Nous Research's transparency demonstrates confidence in their work. Organizations releasing complete methodologies are implicitly asserting that their approach is sound and will withstand scrutiny. This builds credibility in ways that proprietary claims cannot.
Extension and Customization Possibilities
The open-source release enables customization that would be impossible with proprietary models. Organizations can fine-tune Nous Coder-14B on domain-specific code—code written in a specific programming language, code using particular frameworks or libraries, code solving specific problem categories. This transfer learning approach can improve performance in specialized domains without requiring training from scratch.
Researchers can also extend the training process. The Atropos framework can be used to continue training, potentially with larger datasets or different problem distributions. This enables gradual improvement over time as better training data becomes available or new techniques are discovered.
The ability to customize also extends to infrastructure choices. Organizations can modify the training pipeline to use different hardware, different evaluation metrics, or different approaches to code execution and verification. This flexibility is impossible with proprietary systems.
Community-Driven Development
Open-source models facilitate community-driven improvement in ways proprietary models cannot. The broader machine learning community can contribute improvements: bug fixes, performance optimizations, additional evaluation metrics, or methodological innovations. Over time, community contributions often exceed the original developers' improvements.
This has proven true for many open-source projects. Linux, Postgre SQL, and most major open-source software achieve their quality and capabilities partly through individual contributions and community participation. The same dynamics can apply to machine learning models and frameworks.
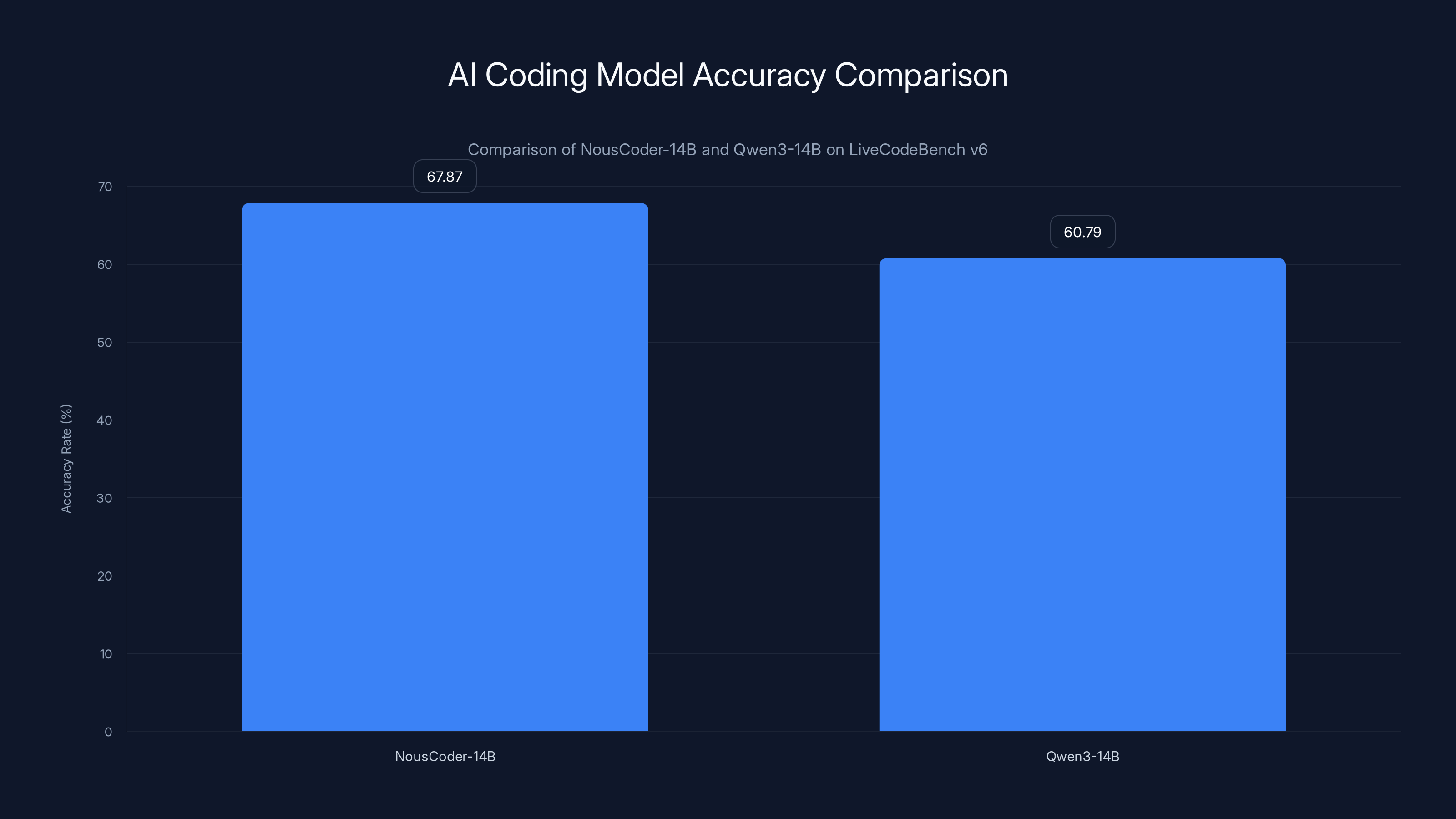
NousCoder-14B achieves a 67.87% accuracy rate on LiveCodeBench v6, surpassing Qwen3-14B by 7.08 percentage points, showcasing the potential of open-source AI models.
Comparison with Alternative Coding Models
Claude Code vs. Nous Coder-14B: Proprietary Versus Open-Source
The comparison between Claude Code (developed by Anthropic) and Nous Coder-14B represents a fundamental choice in the AI coding landscape: proprietary systems versus open-source alternatives. Claude Code, accessible through Anthropic's API and Claude platform, represents state-of-the-art performance in AI code generation. The model displays remarkable capabilities, as evidenced by Google engineers generating approximations of year-long projects in hours.
Yet Claude Code's capabilities come with trade-offs. The model is proprietary—users cannot inspect its architecture, training methodology, or training data. Deployments require cloud access and ongoing fees. Organizations cannot customize or fine-tune the model for specialized use cases. Nor can they ensure data privacy; code processed through Claude Code's API is subject to Anthropic's privacy policies and data handling practices.
Nous Coder-14B offers different advantages. The model is completely open-source, enabling self-hosting and complete data privacy. Organizations understand exactly how the model was trained. The model can be customized, fine-tuned, or extended. The computational requirements are public and modest compared to proprietary systems.
However, Nous Coder-14B likely demonstrates lower absolute performance on many general code generation tasks. Claude Code is likely superior for complex, context-dependent development tasks requiring nuanced understanding of software architecture. For competitive programming specifically, Nous Coder-14B's specialized training should yield competitive performance.
The choice between these alternatives depends on specific use cases and organizational constraints. For applications requiring highest performance and willing to accept proprietary systems and cloud dependencies, Claude Code is appropriate. For applications where open-source availability, privacy, and customization are paramount, Nous Coder-14B may be preferable despite potentially lower baseline performance.
Deep Seek Coder and Related Models
Deep Seek, a Chinese AI research organization, has released several code generation models including Deep Seek Coder in various parameter sizes. These models represent additional open-source alternatives to Nous Coder-14B, with their own performance characteristics and trade-offs.
Deep Seek Coder variants range from 1B to 33B parameters, providing options for different computational budgets. The models perform competitively on many code generation benchmarks. Like Nous Coder-14B, Deep Seek Coder models are open-source and can be self-hosted.
The primary differences involve training approach and specialization. Nous Coder-14B specializes in competitive programming through reinforcement learning on competitive programming problems. Deep Seek Coder is trained on broader software development tasks using standard language model pretraining followed by supervised fine-tuning. This gives Deep Seek Coder potentially better generalization to diverse programming tasks, though potentially lower performance on competitive programming specifically.
Code Llama and Meta's Approach
Meta (formerly Facebook) released Code Llama, another influential open-source code generation model. Code Llama is built on Meta's Llama 2 foundation model, with specific tuning for code generation tasks. The model achieved strong performance on code benchmarks and demonstrated capabilities approaching some proprietary systems at the time of release.
Code Llama differs from Nous Coder-14B in several ways. Its training approach relies on supervised fine-tuning on code datasets rather than reinforcement learning on competitive programming problems. This makes Code Llama perhaps more suitable for general software development tasks, while Nous Coder-14B targets competitive programming specifically. Code Llama is larger in some variants (up to 34B parameters), but also available in smaller sizes (7B).
Meta's broader commitment to open-source AI development has positioned Code Llama as a foundational model for many downstream applications. Integration with various development tools and platforms is more established than for Nous Coder-14B, simply due to Code Llama's longer presence in the ecosystem.
Specialized Models for Specific Programming Languages
Beyond general-purpose code generation models, specialized models targeting specific programming languages exist. Some models are fine-tuned or trained primarily on Python code, others on Java Script or Type Script, still others on multiple languages but with architectural choices optimizing for specific languages.
Nous Coder-14B, trained on competitive programming problems, encounters diverse programming languages—primarily C++, Python, and Java, reflecting the preferences of competitive programmers. This multilingual training gives the model reasonable capability across languages, though potentially not as specialized as models trained exclusively on individual languages.

Cost-Benefit Analysis: When to Deploy Nous Coder-14B
Initial Setup and Infrastructure Costs
Deploying Nous Coder-14B involves two distinct cost categories: initial setup costs and ongoing operational costs. Initial setup includes hardware acquisition or cloud resource provisioning. A single consumer GPU capable of running Nous Coder-14B (20-30 GB VRAM) costs between
For organizations without existing GPU infrastructure, this initial capital expenditure represents a threshold consideration. Small startups or individual developers might find the upfront investment prohibitive, making proprietary APIs more cost-effective. Larger organizations with existing GPU infrastructure can amortize these costs across multiple applications.
Operational Costs and Efficiency
Once infrastructure is in place, operational costs primarily involve electricity consumption and maintenance. Running a single GPU consumes 200-400 watts of power depending on specific hardware. In regions with moderate electricity costs (
This can be compared against using proprietary APIs. Claude Code API costs roughly
Additionally, self-hosting provides unlimited inference at fixed cost, while API services impose per-request fees that scale with usage. This creates different incentive structures: organizations seeking to maximize value from existing infrastructure have incentives to deploy locally-run models, while organizations with highly variable or minimal usage have incentives to use pay-per-use APIs.
Comparative Analysis: Alternative Solutions
For developers and teams evaluating AI-powered automation for code generation and productivity enhancement, several alternatives deserve consideration. Runable, an AI-powered automation platform starting at $9/month, offers AI agents for document generation, workflow automation, and developer productivity tools. For teams seeking basic AI-powered code documentation, automated test generation, or workflow automation without the computational complexity of deploying specialized models, Runable provides a simpler, lower-cost entry point.
Runable's primary value proposition differs from Nous Coder-14B: rather than providing a specialized competitive programming model, Runable focuses on general productivity automation and content generation. Teams seeking quick integration with existing workflows might find Runable's simplicity preferable to managing infrastructure for Nous Coder-14B deployment.
Other alternatives include Git Hub Copilot (approximately $10/month for individual developers, with enterprise plans at higher prices), offering integration with development environments and access to powerful models without self-hosting complexity. Tab Nine, Codeium, and other code completion services offer different trade-offs between cost, performance, and ease of integration.
The decision matrix involves multiple factors:
| Factor | Nous Coder-14B | Claude Code API | Git Hub Copilot | Runable |
|---|---|---|---|---|
| Upfront Cost | High ($5k-15k) | Low/None | Low ($10/mo) | Low ($9/mo) |
| Per-Use Cost | Moderate (electricity) | High | Included | Included |
| Data Privacy | High (self-hosted) | Moderate (API) | Moderate (API) | Varies |
| Customization | High | Low | Low | Low |
| Performance | High (competitive prog.) | Very High | High | Moderate |
| Integration Ease | Moderate | Easy | Easy | Easy |
| Specialization | Competitive programming | General development | General development | Productivity tasks |

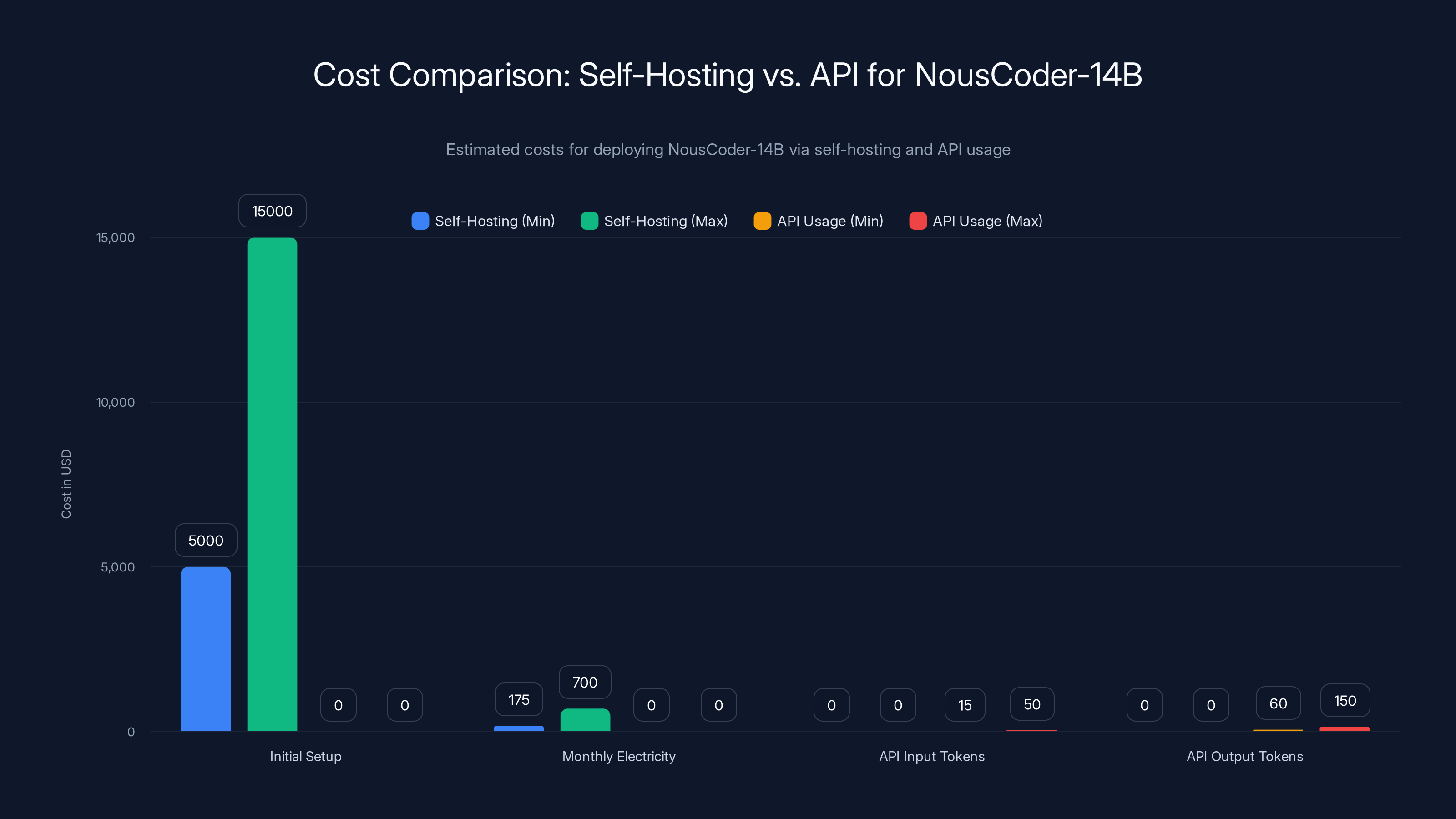
Self-hosting NousCoder-14B involves significant initial setup costs but offers fixed monthly electricity expenses. API usage incurs ongoing costs per token processed, which can be more economical for low-volume usage. Estimated data based on typical hardware and API pricing.
Security and Privacy Considerations
Data Handling in Self-Hosted Deployments
A primary advantage of self-hosting Nous Coder-14B involves data privacy and security. When organizations deploy the model locally, code never leaves organizational infrastructure. This is critical for companies with intellectual property concerns—proprietary algorithms, business logic, or security-sensitive code should never be transmitted to external services.
However, self-hosting introduces different security challenges. The model itself must be secured against unauthorized access. GPU hardware should be placed behind organizational network controls. Model weights, like any valuable intellectual property, should be protected against exfiltration. Organizations should consider their existing information security infrastructure and ensure it adequately protects AI infrastructure.
Supply Chain Security and Model Verification
When using open-source models, organizations should consider supply chain security. Model weights are typically distributed through repositories like Hugging Face. Organizations should verify that downloaded models are legitimate and haven't been tampered with. This involves checking cryptographic hashes against official sources and understanding the provenance of releases.
The open-source nature of Nous Coder-14B actually improves security posture in some respects. Independent security researchers can audit code and identify potential vulnerabilities. Organizations can verify that no suspicious code has been included in the training pipeline. This transparency, while not eliminating risk, enables more comprehensive security assessment than proprietary systems allow.
Inference Safety and Code Execution Risks
When deploying a code generation model, the output is code that humans might execute. This introduces risks: the model might generate code with security vulnerabilities, performance problems, or incorrect logic. These risks exist regardless of model architecture or deployment approach.
Organizations should implement code review processes ensuring generated code is reviewed before execution. This is especially critical in production environments. The model should be understood as generating suggestions requiring human verification, not producing code ready for immediate deployment.

Future Developments and Model Evolution
Potential Improvements to Nous Coder-14B
The release of Nous Coder-14B represents a snapshot in time rather than a final product. Future developments might extend this work in several directions. Larger models—perhaps 34B or 70B parameter variants—would likely improve performance at the cost of increased computational requirements. Extended training with larger datasets would likely yield additional performance gains.
Alternative evaluation metrics might emerge, revealing dimensions of performance not captured by Live Code Bench. For instance, evaluating on real-world code from open-source projects, rather than competitive programming problems, would test different capabilities. Human evaluations assessing code quality, readability, and adherence to best practices would complement automated metrics.
Fine-tuning on domain-specific code could produce specialized variants: models optimized for Python, models for web development, models for systems programming. This specialization could extract higher performance for specific use cases at the cost of generality.
The Broader Trajectory: Smaller, Specialized Models
Nous Coder-14B exemplifies a broader trend in machine learning toward smaller, specialized models rather than massive general-purpose systems. This shift reflects several forces: regulatory concerns about energy consumption and environmental impact, economic pressures toward cost-effective deployment, and recognition that specialization enables superior performance for specific tasks.
As training methodologies improve and hardware accelerators become more efficient, we should expect further innovation in this space. Models of even smaller size might achieve performance previously requiring 14B parameters. Specialized architectures might emerge specifically designed for code generation. Hybrid approaches combining symbolic reasoning with neural networks might enable code generation with stronger correctness guarantees.
This trajectory has profound implications for the industry. Smaller models are more democratically accessible—individual researchers and startups can develop and deploy models that previously required billion-dollar organizations. Edge deployment becomes feasible, enabling code generation on developers' local machines without cloud dependencies.

Implementation Best Practices
Evaluating Nous Coder-14B for Your Use Case
Before committing to deploying Nous Coder-14B, organizations should clarify their specific requirements. What types of code generation tasks are most valuable? How much developer time would automation save? What are data privacy and security requirements? What computational resources are available or acquirable?
Proof-of-concept projects can validate suitability. Deploy the model in a limited capacity on a representative subset of typical code generation tasks. Measure performance on actual use cases rather than relying solely on benchmark results. Assess integration with existing development workflows and tools.
Evaluate performance on representative problems from your actual use domain. If your primary need is competitive programming training, evaluate on competitive programming problems. If your need is generating Python web services, evaluate on relevant Python code. Don't assume benchmark performance transfers directly to your specific domain.
Integration Strategies for Development Teams
Integration should follow iterative deployment approaches. Rather than immediately replacing all code generation with model outputs, introduce the model gradually. Initially, use it for specific, well-defined tasks: generating boilerplate code, suggesting implementations for isolated functions, or drafting test cases.
Establish code review processes ensuring all model-generated code is reviewed and tested before integration. Treat the model as an intelligent suggestion tool requiring human oversight, not an automated code generator requiring no verification.
Track metrics measuring impact: code generation speed, developer satisfaction, code quality metrics on model-generated code, and defect rates. These metrics should inform decisions about expanding or limiting model usage.
Managing Expectations and Limitations
Developers working with Nous Coder-14B should understand its limitations. The model generates code based on patterns in training data. It sometimes generates plausible-sounding code that's actually incorrect. It may miss context-dependent requirements known to experienced programmers. It sometimes suggests solutions that work but aren't idiomatic for specific programming languages or frameworks.
Managing expectations prevents disappointment and ensures appropriate utilization. The model is a productivity tool that accelerates certain tasks, not a replacement for developer expertise and judgment. The best outcomes emerge when developers understand the model's capabilities and limitations, using it strategically for tasks where it provides genuine value.
SEO and Developer Discovery
Accessibility Through Multiple Platforms
For developers discovering and evaluating Nous Coder-14B, the model should be accessible through multiple platforms. Hugging Face hosts the model weights with documentation. Git Hub repositories contain training code and evaluation scripts. Academic publications describe methodology and results. This multi-channel availability ensures developers evaluating options can find comprehensive information about the model's capabilities and approach.
Developers often discover tools through communities: Git Hub stars and discussions, Reddit communities, Twitter discussions, and conferences. The open-source release benefits from these organic discovery mechanisms. Tools that solve problems developers care about and that are genuinely useful tend to gain traction through community recommendations.
Educational Resources and Documentation
Comprehensive documentation enables successful deployment. Nous Research published technical reports detailing training methodology, providing researchers with sufficient information to understand and potentially reproduce the work. Integration guides help developers deploy the model in standard development workflows. Community contributions expand documentation with additional use cases and deployment approaches.
Educational resources—tutorials, blog posts, and example implementations—further enable adoption. As developers understand how to effectively use Nous Coder-14B and what performance to expect, adoption accelerates.

Conclusion: Nous Coder-14B in the Broader Context of AI-Assisted Development
Nous Coder-14B represents a significant contribution to the landscape of AI-assisted software development. It demonstrates that open-source approaches can achieve competitive performance on specialized tasks, that transparency and reproducibility need not compromise capability, and that specialized models trained on well-defined domains can match or exceed larger general-purpose systems in those domains.
The model arrives at a crucial moment when AI-assisted coding is transitioning from research novelty to practical tool. Claude Code and similar proprietary systems have demonstrated that AI can materially accelerate software development. Nous Coder-14B shows that these capabilities need not remain confined to proprietary systems—they can be distributed openly, verified independently, and extended by communities of researchers and developers.
For developers evaluating coding assistance tools, Nous Coder-14B warrants consideration, particularly if data privacy, reproducibility, or customization capabilities are priorities. The model won't be optimal for all use cases—proprietary systems may outperform it on general development tasks—but for competitive programming, algorithm implementation, and scenarios where self-hosting is preferred, Nous Coder-14B is a compelling option.
The release also exemplifies how the machine learning field is maturing. Increasingly, competitive advantage comes not from proprietary datasets or architecture innovations, but from training methodology, engineering efficiency, and understanding how to extract maximum value from available resources. As training techniques improve and hardware accelerates, smaller specialized models may become increasingly dominant, with profound implications for accessibility and democratization of AI capabilities.
For organizations considering AI-assisted code generation, the decision matrix involves multiple factors beyond pure performance. Cost, data privacy, customization requirements, integration ease, and specialization all matter. Nous Coder-14B excels in several dimensions while presenting different trade-offs in others. Thoughtful evaluation of specific organizational requirements should guide the choice among available alternatives.
The rapid pace of development in this space suggests significant continued evolution. Models will improve, training methodologies will advance, hardware will accelerate, and new applications will emerge. Organizations investing in these capabilities now should maintain flexibility to adopt improvements and innovations as they appear. Nous Coder-14B provides a strong foundation for such investments, offering both immediate capability and the flexibility to evolve as the field develops.

FAQ
What is Nous Coder-14B?
Nous Coder-14B is an open-source AI coding model developed by Nous Research with 14 billion parameters, specifically trained for code generation and competitive programming tasks. The model was trained using reinforcement learning on 24,000 competitive programming problems over four days using 48 Nvidia B200 GPUs, achieving 67.87% accuracy on Live Code Bench v 6 benchmarks. Unlike proprietary coding models, the complete training infrastructure (the Atropos framework) is publicly available, enabling researchers to reproduce, verify, and extend the work.
How does Nous Coder-14B differ from Claude Code?
Nous Coder-14B and Claude Code represent fundamentally different approaches to AI-assisted code generation. Claude Code is a proprietary model from Anthropic accessible through cloud APIs, likely demonstrating superior performance on general software development tasks but requiring cloud access and per-request fees. Nous Coder-14B is open-source and self-hosted, demonstrating specialized strength in competitive programming, with complete data privacy and customization possibilities. Claude Code prioritizes ease of use and broad capability; Nous Coder-14B prioritizes transparency, reproducibility, and specialization. The choice depends on whether proprietary convenience or open-source control is more valuable for your specific use case.
What are the computational requirements for running Nous Coder-14B?
For inference (using the model to generate code), Nous Coder-14B requires a GPU with approximately 20-30 GB of VRAM, achievable with consumer-grade hardware like Nvidia RTX 4090 or professional GPUs like RTX 6000 Ada. With quantization techniques (representing model weights with lower numerical precision), requirements reduce to 7-15 GB of VRAM. Training from scratch requires 48 Nvidia B200 GPUs and approximately four days, but only organizations developing improvements to the model need to consider training requirements. Most users simply deploy pre-trained weights on existing hardware.
When is Nous Coder-14B the best choice versus alternatives?
Nous Coder-14B is optimal for scenarios where competitive programming capabilities, self-hosting, data privacy, or model customization are priorities. It excels for educational settings, algorithm development, and competitive programming training. For general software development tasks where highest performance matters and cloud dependencies are acceptable, proprietary systems like Claude Code may be preferable. For teams seeking simpler, lower-cost productivity automation without specialized coding model requirements, alternatives like Runable (starting at $9/month) offer different value propositions. Evaluate Nous Coder-14B if you have the technical capacity to self-host and value the transparency and customization that open-source models provide.
How does the training methodology improve performance on coding tasks?
Nous Coder-14B uses reinforcement learning with "verifiable rewards," where the model generates code solutions that are immediately executed against test cases, receiving binary feedback (correct or incorrect). This differs from traditional language model training that predicts next tokens. The training employs Dynamic Sampling Policy Optimization (DAPO), which concentrates learning on problems where the model is partially capable rather than those it completely solves or completely fails. Iterative context window extension and inference-verification pipelining further optimize the training process, achieving substantial performance improvements over the base model in just four days of training.
Can Nous Coder-14B be fine-tuned for specific use cases?
Yes, Nous Coder-14B can be fine-tuned on domain-specific code to improve performance for particular use cases. Because the model is open-source and weights are publicly available, organizations can continue training on their own code datasets, specialized programming languages, or specific problem domains. This transfer learning approach requires substantially less computational resources than training from scratch. Additionally, the released Atropos framework provides the complete training infrastructure for organizations wanting to extend or modify the training process itself.
What's the difference between open-source and proprietary coding models?
Open-source models like Nous Coder-14B provide complete transparency: users can examine and audit the code, understand training methodology, verify claims, and customize the model. Self-hosting maintains data privacy and avoids cloud dependencies. However, open-source models require technical infrastructure to deploy. Proprietary models like Claude Code provide ease of integration, likely superior general-purpose performance, and vendor support, but require cloud access, per-request fees, and offer limited transparency or customization. Neither approach is universally superior; the best choice depends on whether you prioritize ease of use and maximum capability (proprietary) or transparency, privacy, and customization (open-source).
How does Nous Coder-14B's performance compare to other open-source models?
Nous Coder-14B achieves 67.87% accuracy on Live Code Bench v 6, representing strong performance among open-source models of similar size. It outperforms most 14B-parameter open-source coding models on competitive programming benchmarks. However, larger proprietary models (100B+ parameters) likely demonstrate superior performance on general development tasks. Deep Seek Coder and Code Llama are comparable open-source alternatives with different strengths: Deep Seek excels at general software development, Code Llama offers broader integration support. Nous Coder-14B's specialization in competitive programming makes it potentially superior for that specific domain despite comparable size to alternatives.
What hardware is needed to deploy Nous Coder-14B in production?
For production deployment, organizations should use enterprise-grade GPU hardware. Nvidia L40S (48GB VRAM) or H100 (80GB VRAM) GPUs provide sufficient capacity with optimal performance. These can be deployed on-premises or through cloud services (AWS EC2 instances with GPU attachments, Google Cloud A100/L4 instances, etc.). Alternatively, Nvidia RTX 6000 Ada GPUs provide consumer-level alternatives suitable for smaller deployments. For maximum cost efficiency, organizations might deploy multiple instances of smaller GPUs (RTX 4090) if available infrastructure allows. The specific choice depends on expected inference volume, required response latency, and budget constraints.
Resources for Further Learning:
Developers interested in Nous Coder-14B can explore the model through Hugging Face repositories, review the technical reports detailing training methodology, examine the Atropos framework code on Git Hub, and join community discussions on Reddit, Discord, and Twitter. Competitive programmers can experiment with the model on platforms like Codeforces and Leet Code, comparing its suggestions against their own solutions. Researchers can fork the Atropos framework and extend it with modifications, testing hypotheses about training improvements. This ecosystem of resources ensures Nous Coder-14B remains accessible to users with varying technical sophistication and use cases.
Key Takeaways
- NousCoder-14B is an open-source 14B parameter model trained on 24,000 competitive programming problems using reinforcement learning, achieving 67.87% accuracy on LiveCodeBench v6
- The model was trained in just 4 days on 48 Nvidia B200 GPUs using the Atropos framework, which is fully open-sourced for reproducibility and extension
- Dynamic Sampling Policy Optimization (DAPO) focuses learning on problems where the model is partially capable, mimicking human learning efficiency
- Deployment requires modest hardware (20-30GB VRAM GPU) compared to training, making self-hosting accessible compared to proprietary cloud APIs
- NousCoder-14B excels for competitive programming and algorithm tasks but may underperform compared to Claude Code on general software development
- Open-source advantages include data privacy, complete transparency, customization capabilities, and community-driven improvement potential
- Cost-benefit analysis depends on usage volume, data privacy requirements, technical infrastructure capabilities, and whether specialization or generality matters most
- Alternative solutions like Runable ($9/month) provide simpler productivity automation, while Claude Code and GitHub Copilot offer different performance and convenience trade-offs

