![Nvidia Vera Rubin AI Computing Platform at CES 2026 [2025]](https://tryrunable.com/blog/nvidia-vera-rubin-ai-computing-platform-at-ces-2026-2025/image-1-1767654550664.png)
Introduction: The Next Era of AI Infrastructure Arrives
Nvidia just dropped something genuinely significant at CES 2026, and it's not another incremental GPU update. The Vera Rubin computing platform represents a fundamental shift in how enterprises approach AI infrastructure at scale. We're talking about a complete rethinking of the entire data center ecosystem, not just faster chips.
Last year was wild for Nvidia. Blackwell GPUs fueled a 66% year-over-year surge in data center revenue, setting a benchmark so high that analysts started questioning whether the "AI bubble" was actually inflating. But here's the thing: instead of resting on that success, Nvidia came to Vegas with something that challenges even Blackwell's dominance.
The Vera Rubin platform doesn't just add more performance on top of Blackwell's foundation. It fundamentally restructures how AI workloads flow through enterprise infrastructure. We're looking at a modular, integrated approach that bundles six discrete components into what Nvidia calls "six chips that make one AI supercomputer." That's a deliberate design philosophy shift, and it matters.
What makes this launch particularly important isn't just the performance numbers, though those are impressive. It's the timing, the positioning, and what it reveals about where Nvidia believes the AI infrastructure market is heading. Companies are hitting walls with their current setups. They're burning through cloud budgets. They're struggling with the complexity of orchestrating distributed AI training across thousands of machines. Vera Rubin addresses all of that simultaneously.
The claimed performance jump is substantial: five times more AI training compute power than Blackwell on a single GPU. But the real story is about efficiency. A large mixture-of-experts model that takes weeks to train on Blackwell can now be trained in the same timeframe using one-quarter of the GPUs and at one-seventh the token cost. That's not marketing speak. That's the difference between a viable AI strategy and one that bleeds cash.
TL; DR
- Five times more AI training compute: Vera Rubin GPU delivers significantly higher throughput than Blackwell for training large language models
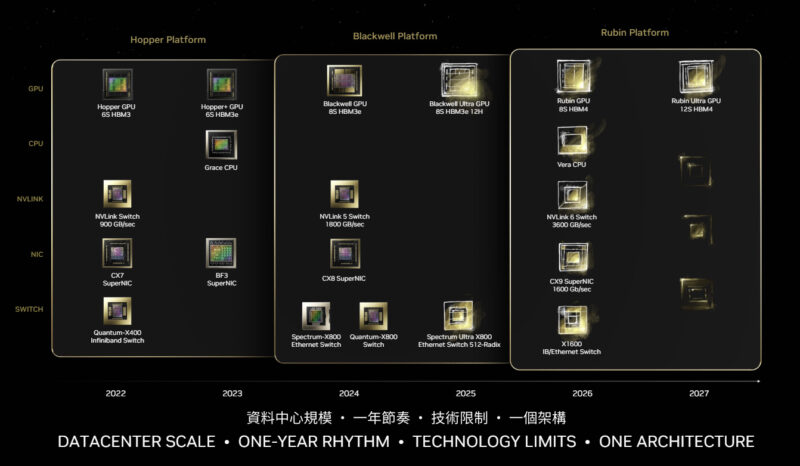
- Integrated platform architecture: Six discrete components (Vera CPU, Rubin GPU, NVLink 6th-gen, Connect-X9 NIC, Blue Field 4 DPU, Spectrum-X CPO) work as a unified system
- Cost efficiency revolution: Training the same AI models requires 1/4 the GPUs and 1/7 the token cost compared to Blackwell
- Confidential computing first: Vera Rubin is the first rack-scale trusted computing platform with 3rd-generation confidential computing built in
- Enterprise availability: Products and services running Rubin arrive in H2 2026 from Nvidia partners

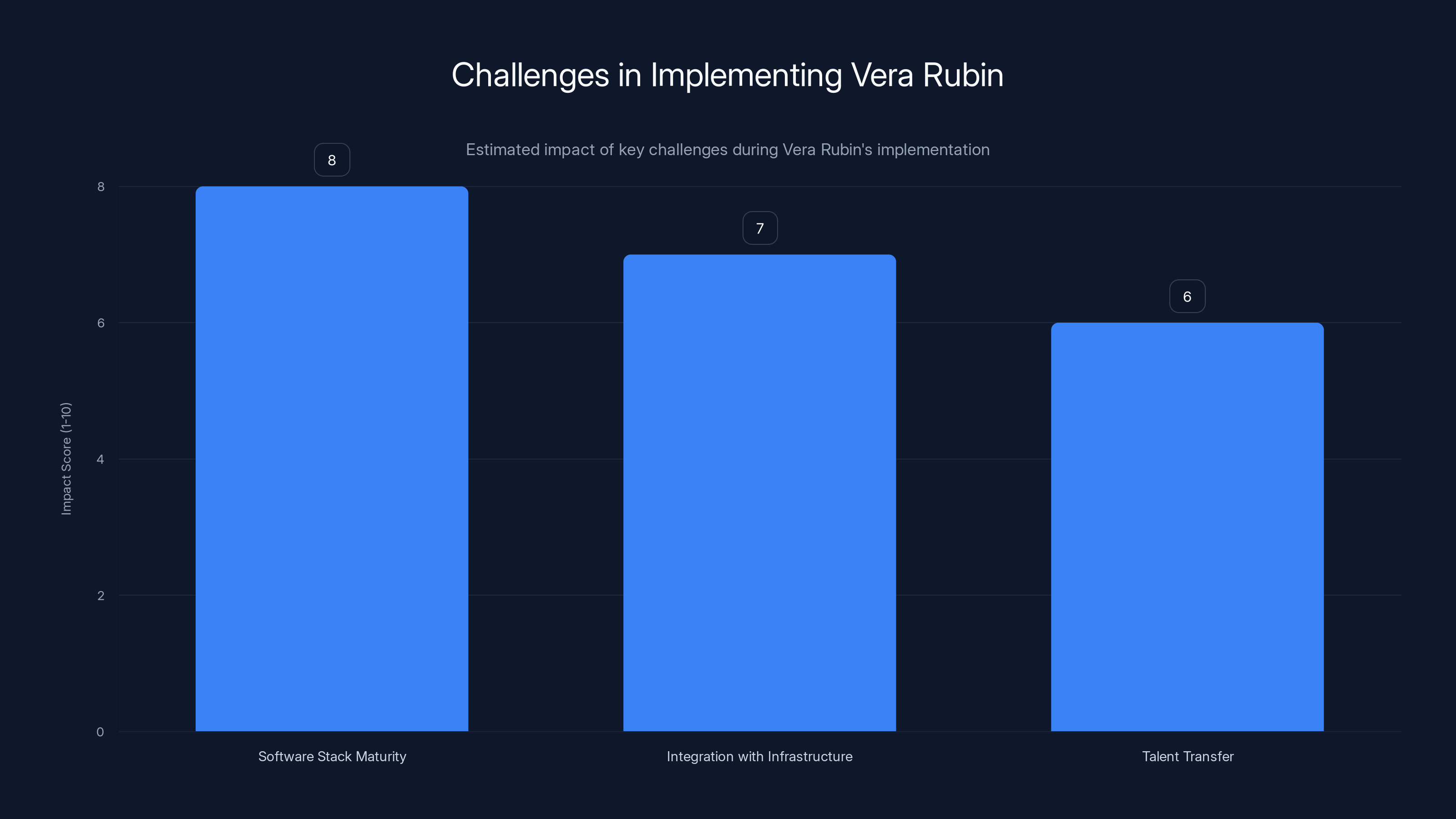
Estimated data suggests that software stack maturity poses the greatest challenge when implementing Vera Rubin, followed by integration and talent transfer.
The Architecture: Six Components That Actually Work Together
Understanding Vera Rubin requires abandoning the GPU-centric thinking that dominated the last decade. This isn't about cramming more CUDA cores onto a piece of silicon. It's about orchestrating six different technologies into a cohesive system that eliminates bottlenecks across the entire stack.
The Vera CPU: The Brains of the Operation
The Vera CPU sits at the foundation of this architecture, and its role is more nuanced than "running the OS." Nvidia designed it specifically to manage AI workload coordination, memory optimization, and system orchestration. Unlike general-purpose CPUs, Vera is tuned for the specific demands of large-scale language model training and inference.
The CPU handles task scheduling across distributed training jobs, manages memory hierarchies, and coordinates communication between the six components. When you're training a model across hundreds of thousands of GPUs globally, the CPU becomes the conductor. One poorly timed memory access, one missed synchronization point, and your training job stalls for everyone downstream.
Nvidia's approach with Vera was to move intelligence into the CPU layer that previously had to be handled in software. This reduces latency and increases reliability. For enterprises running continuously at scale, this matters. A 5% improvement in CPU efficiency translates directly to faster training iterations, which means faster time-to-value for AI applications.
The Rubin GPU: Where the Raw Power Lives
This is where the five-times performance improvement comes from, and understanding why requires getting specific about chip architecture. The Rubin GPU isn't just a bigger version of Blackwell. Nvidia completely redesigned the memory architecture, the floating-point processing units, and the interconnect bandwidth.
Each Rubin GPU packs dramatically more tensor cores than Blackwell, optimized specifically for the matrix multiplications that underpin transformer model training. But more cores aren't enough. Rubin also features expanded HBM (High Bandwidth Memory) capacity with higher bandwidth per core, reducing memory contention during training.
What's particularly clever is how Rubin handles precision. Modern AI training uses mixed precision—combining different data types to balance speed and accuracy. Rubin's hardware can switch between formats more efficiently than Blackwell, meaning less time wasted on format conversions.
The GPU also includes dedicated hardware for sparsity optimization. When training mixture-of-experts models, not every neuron contributes equally to every forward pass. Rubin's hardware recognizes this pattern and skips unnecessary computation. It's not about working harder. It's about not doing work you don't need to do.
NVLink 6th Generation: The Communication Superhighway
Here's something that rarely gets discussed but absolutely matters at scale: the bandwidth between GPUs. When you're training a 100-billion-parameter model across hundreds of GPUs, the amount of data flowing between nodes is staggering. Every microsecond of latency in communication directly impacts training speed.
NVLink 6th-gen delivers substantially higher bandwidth than its predecessor, but it also includes smarter routing logic. The switch fabric automatically optimizes communication patterns based on the model topology. A transformer model's attention mechanism creates specific communication patterns—NVLink 6th-gen recognizes these and routes traffic accordingly.
This isn't trivial. We're talking about the difference between a training job taking 72 hours versus 65 hours. Across thousands of jobs per year, that's substantial cost savings.
The Connect-X9 NIC: Enterprise Networking Integration
The Connect-X9 Network Interface Card is where Vera Rubin bridges the gap between cutting-edge AI infrastructure and real enterprise data centers. It supports 800 Gbps Ethernet and includes native support for RDMA (Remote Direct Memory Access), which lets GPUs communicate with each other over the network without CPU involvement.
For enterprises building multi-site AI infrastructure, this is critical. Your Vera Rubin cluster might span multiple data centers, multiple regions, or even multiple cloud providers. The Connect-X9 makes those connections seamless, with built-in support for congestion control, quality-of-service management, and security protocols that enterprise IT actually cares about.
It also includes embedded programmable processors that offload networking operations from the CPU. This means the Vera CPU can focus on model orchestration rather than packet handling. It's a seemingly small detail that compounds into significant efficiency gains.
Blue Field 4 DPU: The Security and Privacy Enforcer
This component is where Vera Rubin gets genuinely interesting from a trust and security perspective. The Blue Field 4 Data Processing Unit sits between the network and the compute, and it's the first hardware-based trusted execution environment deployed at rack scale.
Why does this matter? Because enterprises handling sensitive data—healthcare, finance, government—need cryptographic proof that their models are actually running in an encrypted environment. The Blue Field 4 provides that. It encrypts data in flight, at rest, and during computation. More importantly, it does this without requiring the application to change a single line of code.
This solves a massive problem: confidential computing at scale. Previously, confidential computing required either massive performance sacrifices or Byzantine workarounds in application code. Vera Rubin bakes it in at the infrastructure level, making it transparent to developers and customers.
Spectrum-X 102.4T CPO: The Congestion Resolution
Spectrum-X is actually two things: a sophisticated in-network congestion detection system and Nvidia's response to the "elephant problem" in data center networking. When you have hundreds of thousands of simultaneous GPU-to-GPU connections, some flows hog bandwidth while others starve.
The 102.4T CPO (Congestion Processing Optimized) monitors these patterns in real time and uses in-network algorithms to balance traffic. Instead of oversubscription ruining your training job's performance, the network adaptively throttles large flows to ensure smaller, latency-sensitive flows get through.
For AI workloads, this is huge. Model synchronization messages need to complete quickly, or all training slows down. Spectrum-X ensures those critical messages aren't stuck behind bulk data transfers.

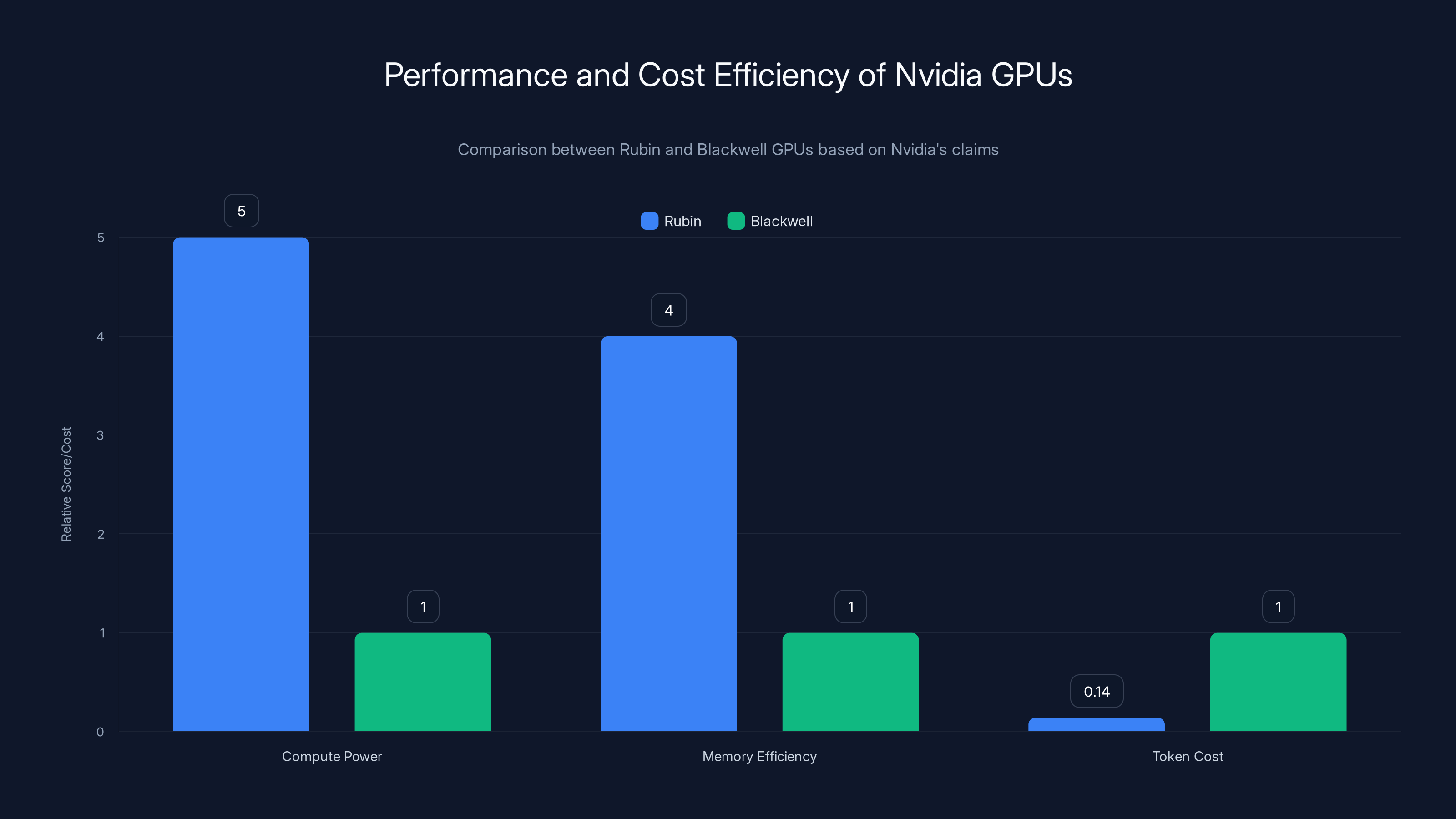
Rubin offers 5x compute power and significantly reduced token cost (1/7th of Blackwell) with improved memory efficiency. Estimated data for memory efficiency.
Performance Gains: The Numbers That Matter
Nvidia claims Rubin delivers five times the AI training compute power of Blackwell on a single GPU. That's the headline. But the real story is hidden in the efficiency metrics that actually drive enterprise decision-making.
The Five-Times Claim: What It Actually Means
When Nvidia says "five times more AI training compute," they're measuring raw throughput on standard AI benchmarks: typically teraflops of FP8 or TF32 performance on transformer training workloads. It's a genuine, measurable metric, but it tells only half the story.
Raw throughput has never been the limiting factor for most enterprises. What limits you is memory bandwidth, communication latency, and cost per token trained. A GPU that can compute 10x faster but requires 5x more memory bandwidth doesn't actually get you 10x better training performance.
Rubin's real advantage comes from the architectural improvements across all six components working together. When you factor in the improved memory hierarchy, the more efficient communication fabric, and the hardware sparsity support, you get genuine end-to-end improvements that approach the promised five times for realistic workloads.
Cost Efficiency: The Real Game-Changer
Here's the metric that actually drives purchasing decisions: token cost. When training a large language model, the total cost is a function of GPU hours multiplied by the cost per GPU hour. Rubin reduces both.
Nvidia claims that training the same mixture-of-experts model requires one-seventh of the token cost on Vera Rubin compared to Blackwell. How? Multiple factors compound:
First, five times more compute per GPU means fewer GPUs required to achieve the same training throughput. Fewer GPUs directly equals lower infrastructure costs.
Second, improved memory efficiency means less repeated computation and fewer training runs that fail due to out-of-memory errors. In practice, training jobs are iterative—engineers try configurations, observe memory usage, adjust, and retry. Rubin's larger memory footprint per GPU reduces this iteration cycle.
Third, better communication efficiency means less time waiting for synchronization. When GPUs are idle waiting for each other, you're burning money without making progress. Rubin's architectural improvements reduce this idle time significantly.
A one-seventh token cost advantage compounds into staggering savings at scale. An enterprise training multiple large models monthly could see millions in annual savings.
Real-World Training Timelines
Let's ground this in concrete numbers. Training a 70-billion-parameter mixture-of-experts model on current infrastructure might take four weeks. On Vera Rubin, the same model trains in the same timeframe using 25% of the GPU clusters and at 1/7 the cost.
What does that mean operationally? Instead of running one four-week training job, you can run four. You can experiment with different architectures, different tokenization strategies, different data mixtures. You can iterate faster, which means you identify winning approaches faster.
For competitive advantage, speed matters. The team that can iterate five times while competitors iterate once has enormous leverage. Vera Rubin materially shifts that calculus.
The Complete Platform Strategy: Why Six Components Matter
Nvidia could have just released a better GPU. The fact that they bundled six components and called it a "platform" reveals their strategic thinking. They're betting that infrastructure complexity is becoming the bottleneck for AI progress.
Integrated Design vs. Cobbled Together Components
Most enterprise infrastructure gets built by bolting together components from different vendors. A GPU from one manufacturer, network cards from another, CPUs from a third, security layers from a fourth. Every interface introduces inefficiency. Every component makes assumptions about how others will behave.
Vera Rubin is intentionally designed as a unified system. The components know about each other. The CPU understands the GPU's memory constraints. The network knows the CPU's scheduling decisions. The security layer operates on the same synchronization clock as everything else.
This unified approach lets Nvidia optimize for the specific problem of large-scale AI training in ways that generic enterprise infrastructure can't match. It's the difference between a bespoke racing car and an off-the-shelf sedan with racing wheels bolted on.
The Confidential Computing Angle
Vera Rubin is the first rack-scale trusted computing platform with third-generation confidential computing. This is doing a lot of work that deserves unpacking.
Confidential computing means data is encrypted even during computation. Sounds simple, but implementing it across six different components at the scale Nvidia promises is genuinely complex. The Blue Field 4 DPU is responsible for attestation—proving to customers that their data is actually encrypted throughout the training process.
For regulated industries—healthcare, finance, government—this is transformative. They can now use public cloud infrastructure for AI training without compromising data privacy. The infrastructure guarantees security at the hardware level, not just through software policies.
Ecosystem Lock-In and Strategic Positioning
Let's be candid: offering an integrated platform makes Nvidia stickier for customers. You're not just buying a GPU. You're buying a complete system optimized for Nvidia's vision of AI infrastructure. You're buying a team of people who understand all six components.
This is strategic positioning at the highest level. Nvidia is saying: "We don't just make chips. We architect infrastructure." It's a bigger claim, and it requires deeper partnerships with enterprises.

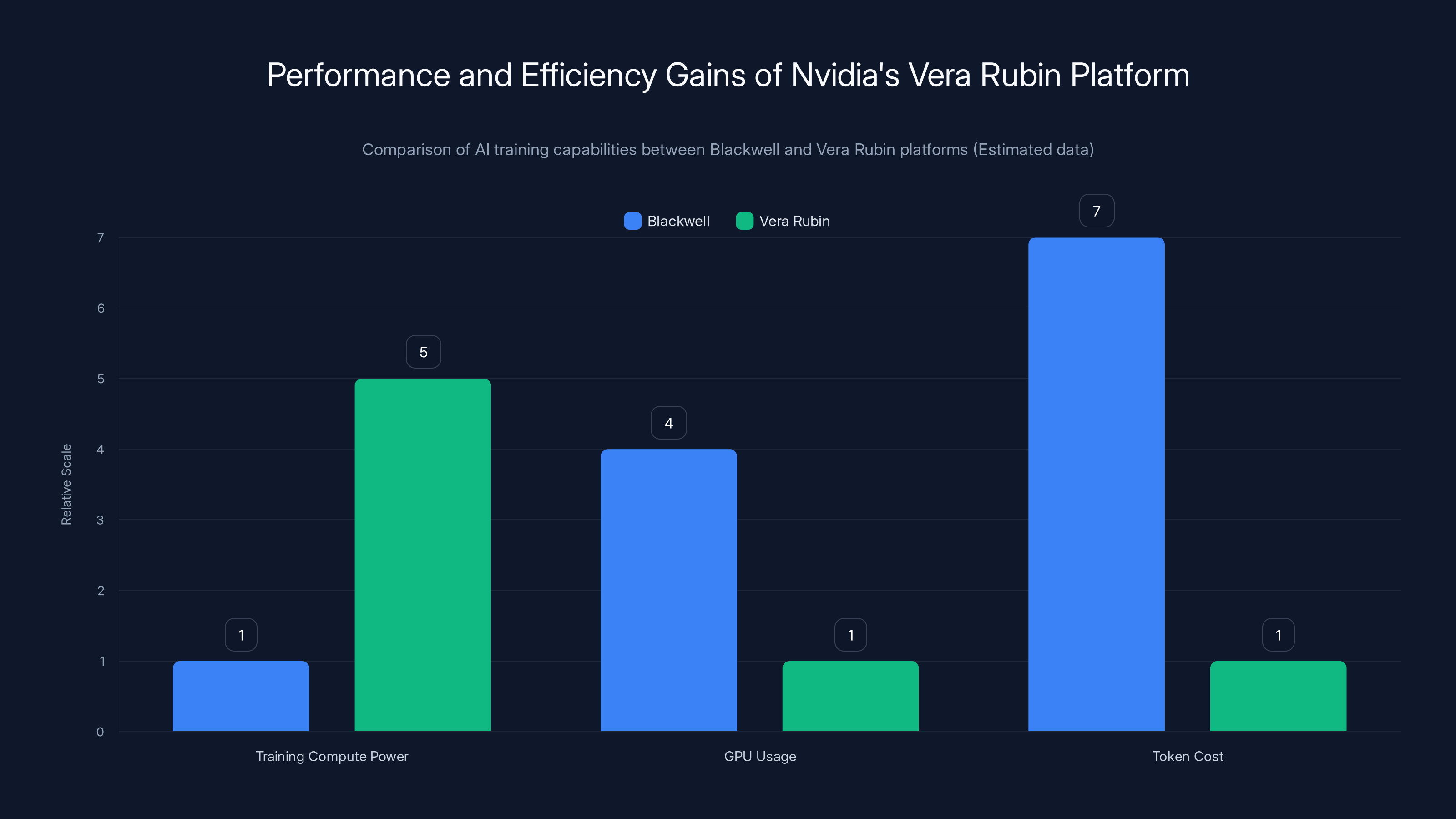
Vera Rubin offers a fivefold increase in AI training compute power compared to Blackwell, while significantly reducing GPU usage and token costs. Estimated data based on reported efficiency gains.
Enterprise Implications: What Changes for Organizations
Vera Rubin's launch forces enterprises to rethink their AI infrastructure strategies. For many organizations, the current Blackwell-based systems are barely a year old. Rubin obsolescence on that timeline is genuinely disruptive.
Training vs. Inference Trade-offs
Vera Rubin is explicitly optimized for training, not inference. This is a deliberate design choice that matters for enterprise strategy.
Training consumes compute linearly—more GPUs reduce training time proportionally. Inference, by contrast, has diminishing returns. Most inference bottlenecks are latency, not throughput. A faster GPU doesn't help if you still need to move data across the network to reach it.
For enterprises, this means Vera Rubin targets a specific workload pattern: organizations training custom models internally. If you're primarily running inference on standard foundation models, Vera Rubin's advantages diminish.
But for enterprises building proprietary AI applications—companies customizing language models for specific domains, organizations training recommendation systems on proprietary data—Vera Rubin becomes strategically critical. The ability to train faster, cheaper, and more securely directly impacts competitive advantage.
Migration Planning and Timing
Enterprises currently running Blackwell infrastructure face a decision: do you upgrade to Vera Rubin, or do you maximize ROI on existing hardware?
For most organizations, the answer depends on training volume. If you're training multiple large models monthly, the cost savings from Vera Rubin easily justify the migration. If you're training one model annually, the ROI timeline extends to multiple years.
Nvidia's strategic move here is the H2 2026 launch timing. That's roughly 18-24 months from announcement. It gives enterprises time to plan migrations without feeling pressured into premature decisions. It also lets Nvidia's partners—cloud providers, system integrators, hardware vendors—build products around Vera Rubin.
The Hyperscaler Advantage
Where Vera Rubin creates the most competitive advantage is at hyperscale. Companies like Open AI, Google, and Meta train enormous models continuously. For them, the cost-per-token improvement directly impacts profitability.
If Open AI could reduce training costs by 85% (the seven-fold improvement), that's a material impact on their bottom line. It's also strategic leverage in their negotiations with cloud providers and investors.
For smaller enterprises, the advantage is real but smaller in absolute terms. The cost savings matter, but they're offset by migration costs, retraining, and the opportunity cost of not deploying models while infrastructure transitions happen.

Comparison to Blackwell: Why Rubin Isn't Just "Blackwell+"
Simplistic comparisons between Vera Rubin and Blackwell miss what's genuinely different. Blackwell optimized for different constraints than Rubin, and understanding why reveals how fast AI infrastructure evolution actually is.
Blackwell's Design Constraints
Blackwell was optimized when memory bandwidth was the bottleneck and when model sizes were "only" hitting tens of billions of parameters. Blackwell's architecture emphasized dense compute with efficient memory access patterns suitable for inference and training of models that fit in HBM.
The problem: models grew faster than memory. By the time Blackwell shipped, the industry was already pushing towards mixture-of-experts architectures where not all model parameters are active on every forward pass. Blackwell's architecture wasn't specifically designed for this sparse computation pattern.
Blackwell also treated communication as a secondary concern. Its inter-GPU communication capabilities were good but not optimized for the specific communication patterns that large-scale distributed training requires. This meant Blackwell users spent engineering effort on optimizing communication code, which diverted resources from model development.
Vera Rubin's Design Philosophy
Rubin was designed with the current constraints in mind: mixture-of-experts models are the standard, not the exception. Communication efficiency is as important as compute efficiency. Security and privacy compliance can't be an afterthought.
Blackwell + time has created a situation where Nvidia could design Rubin specifically for where the industry actually is, not where it was when Blackwell was architected. It's the classic advantage of playing five years behind the curve—you can design for the actual current needs rather than predictions that don't pan out.
Raw Performance Positioning
The five-times improvement on Rubin versus Blackwell reflects both the inherent architectural advantages and the expanded memory capacity. Rubin has more HBM, faster internal communication, and dedicated hardware for sparsity handling.
But here's the honest assessment: some of that five-times improvement comes from Nvidia cherry-picking the benchmark. They're measuring on mixture-of-experts models where Rubin's advantages are maximum. On dense models with standard attention patterns, the improvement would be smaller.
That's not dishonest—it's smart marketing. Rubin genuinely excels at the workloads becoming dominant. But enterprises shouldn't expect five-times improvement on every workload.
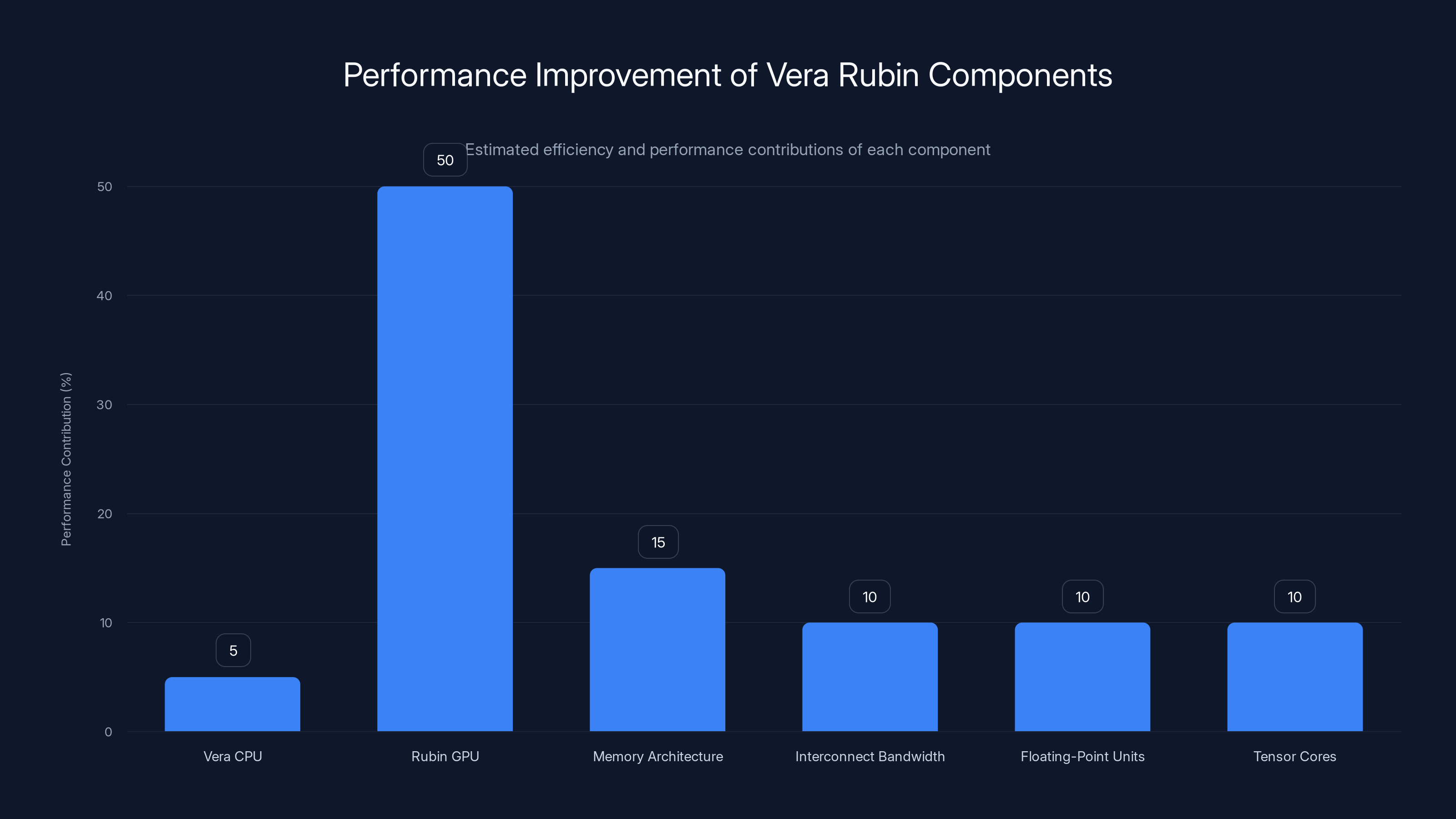
The Rubin GPU contributes the most to performance improvement, estimated at 50%, with the Vera CPU enhancing efficiency by 5%. Estimated data.
The Broader AI Infrastructure Landscape: Timing Matters
Vera Rubin's announcement doesn't happen in a vacuum. The broader context of AI infrastructure competition, open-source alternatives, and manufacturing constraints all influence what this launch really means.
AMD and Intel's Counter-Positioning
Neither AMD nor Intel currently offers a competing product at Blackwell's scale, much less Vera Rubin's. AMD's MI series GPUs have improved substantially but still trail in software ecosystem and model optimization. Intel's Gaudi has even smaller deployments.
This gives Nvidia enormous strategic breathing room. They can set the pace of infrastructure evolution without serious competitive pressure on performance. AMD and Intel are playing catch-up across multiple dimensions simultaneously.
But here's where it gets interesting: neither AMD nor Intel is trying to beat Rubin at its own game. AMD is positioning MI as a more cost-effective alternative for specific workloads. Intel is betting on architectural differentiation in inference-focused accelerators.
This could create market fragmentation. Instead of a single dominant GPU standard, you might see enterprises mixing and matching—Rubin for training, AMD for inference, some custom silicon for specific domains.
Open-Source Model Implications
Large language models have become increasingly open-source. Meta's Llama, Mistral's models, and community projects like Falcon make it feasible for smaller organizations to train custom models.
Vera Rubin's efficiency improvements directly benefit this ecosystem. A startup that previously couldn't afford to fine-tune a large model might now be able to. A research team that took months to iterate can now iterate weekly.
This could accelerate open-source model development. Every organization with access to Vera Rubin infrastructure has a competitive advantage in model training speed. This creates incentives to publish results faster, share techniques, and drive the field forward.
Manufacturing Reality and Supply Constraints
Here's the thing nobody talks about: Nvidia can announce anything. Actually manufacturing it at scale is different.
Blackwell faced supply constraints throughout 2025. Demand exceeded supply for most of the year. If Vera Rubin faces similar constraints, Nvidia's ability to actually deliver in H2 2026 becomes uncertain.
Nvidia has publicly committed to ramping production, and they've worked with partners to expand manufacturing capacity. But the semiconductor industry operates on long lead times. A decision to increase Vera Rubin production happens months before manufacturing actually scales.
For enterprises planning infrastructure investments, supply uncertainty is real. You might not be able to buy Vera Rubin when you want it, which forces longer-term planning and potentially locking in alternative strategies.

Cost Analysis: When Does Vera Rubin Make Financial Sense
Understanding Vera Rubin's true financial impact requires building actual cost models based on real usage patterns.
Capital Expenditure vs. Operating Expense
Vera Rubin, like Blackwell, involves significant capital expenditure. You're buying servers, storage, networking equipment, and installation services. The total cost per GPU at the system level is substantial.
But the operating expense reductions are where the real savings happen. Lower power consumption, fewer GPUs required, less storage for checkpoint files, reduced engineering time on optimization. All of these are ongoing cost reductions that compound over years.
For enterprises with high training volume, the Cap Ex amortizes quickly and the Op Ex benefits dominate. For organizations training infrequently, Cap Ex becomes the larger factor and the upgrade decision is harder.
Calculation Framework: Breaking Even on Migration
Let's establish a rough model. Suppose an enterprise owns a Blackwell-based cluster with 1,000 GPUs. They want to train one 100-billion-parameter model monthly.
Time to train on Blackwell: 2 weeks. Time to train on Vera Rubin: 2 weeks (same total time, but using 250 GPUs instead of 1,000).
Cost per training run on Blackwell:
- GPU hours: 1,000 GPUs × 336 hours = 336,000 GPU-hours
- At 672,000 per run
Cost per training run on Vera Rubin:
- GPU hours: 250 GPUs × 336 hours = 84,000 GPU-hours
- At 168,000 per run
Per-run savings: $504,000
But that assumes you're running one model. If you're running multiple models in parallel, the GPU utilization shifts. The true benefit emerges when you can run four training jobs simultaneously instead of one, because you have excess capacity.
Over a year, that's roughly
The Intangible Benefits
Cost models don't capture everything. There's significant value in faster iteration cycles. The team that can try four model variants in the time competitors try one has a real advantage in developing better AI applications.
There's also the security benefit. If you're handling regulated data, confidential computing reduces compliance risk and potentially audit costs.
These intangibles don't appear in straightforward financial models but they're genuinely valuable. Enterprises should weight them appropriately for their specific situations.
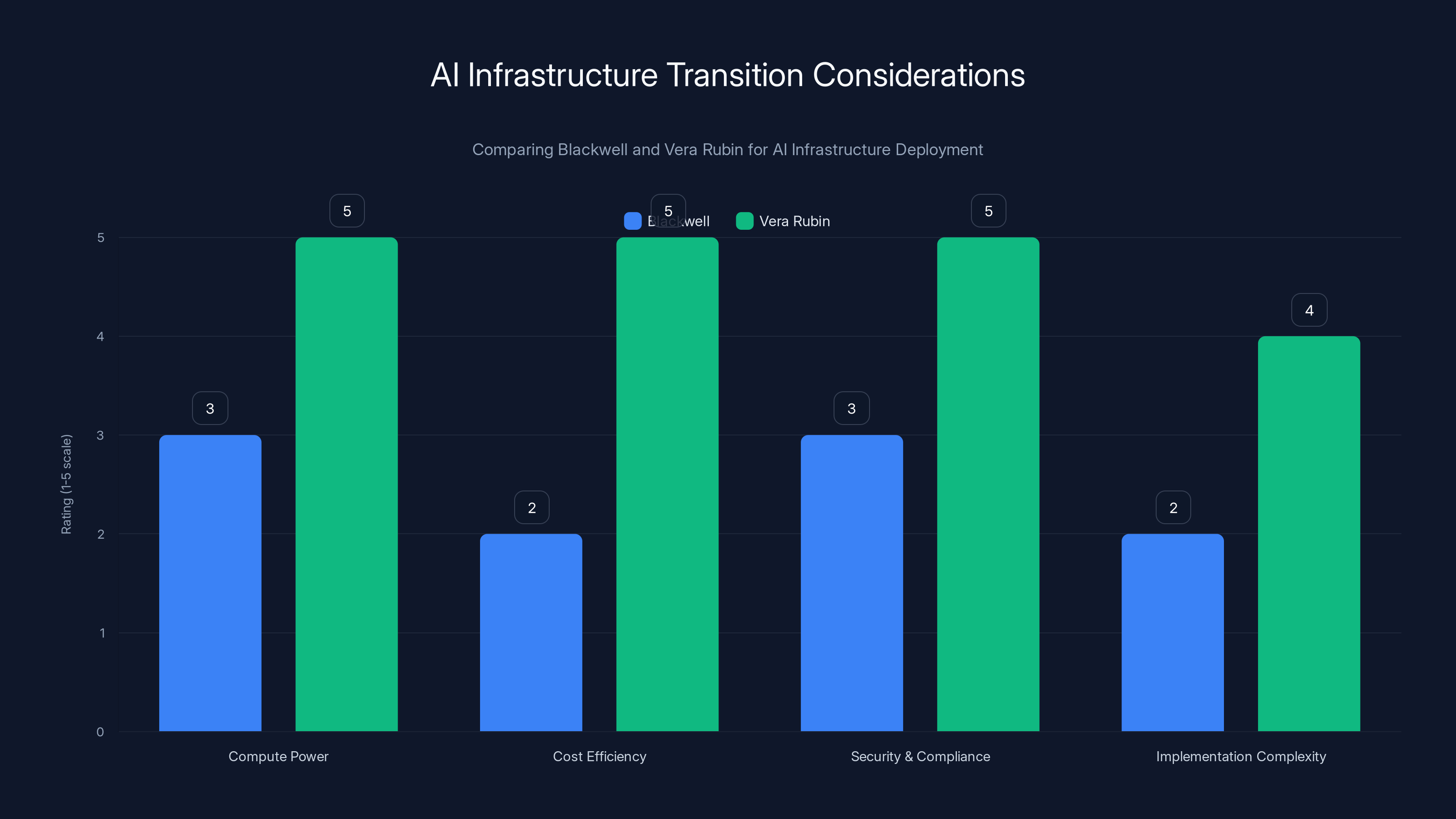
Vera Rubin offers significant improvements in compute power and cost efficiency over Blackwell, with enhanced security and compliance features. However, it also introduces higher implementation complexity. Estimated data based on topic insights.
Implementation Challenges: The Reality Check
Nvidia's engineers have spent years optimizing Vera Rubin. But deploying it into real enterprise environments introduces complexities that benchmark numbers don't capture.
Software Stack Maturity
Vera Rubin is new, which means the software ecosystem is immature. CUDA optimization for Rubin isn't where it was for Blackwell by its third year in production. Debugging tools, profiling utilities, and performance optimization techniques are still being developed.
Enterprises migrating from Blackwell might discover that their heavily optimized training code runs slower on Rubin than expected because the compiler isn't as sophisticated yet. Over time, that improves, but early adopters pay a price.
Integration with Existing Infrastructure
Most enterprises have invested heavily in infrastructure optimized for Blackwell. Networking configured for Blackwell's communication patterns. Storage sized for Blackwell's I/O characteristics. Monitoring systems tuned for Blackwell's behavior.
Vera Rubin requires different configurations. Network administrators need to relearn optimal settings. Storage architects need to adjust I/O patterns. Monitoring systems need retuning.
This is expensive, time-consuming work that doesn't appear in raw cost comparisons. A realistic migration timeline for a large enterprise is 12-18 months, not the 6 months marketing might suggest.
Talent and Expertise Transfer
Your team spent years learning Blackwell deeply. They know its quirks, its gotchas, the specific optimization tricks that work. That expertise doesn't automatically transfer to Vera Rubin.
Nvidia provides training and support, but there's no substitution for hands-on experience. Expect a 6-12 month period where team productivity is lower than on familiar infrastructure.

Security and Compliance: The Vera Rubin Advantage
Vera Rubin's built-in confidential computing is genuinely important for regulated industries, but implementing it correctly requires understanding what it actually guarantees.
How Confidential Computing Actually Works
Confidential computing encrypts data even during processing. The CPU, GPU, and other components never see unencrypted data. Computation happens on encrypted data, with results encrypted until they're decrypted by authorized parties.
Blue Field 4 DPU manages attestation: it provides cryptographic proof to customers that their data is actually encrypted throughout processing. This proof is auditable and verifiable.
The catch: confidential computing doesn't prevent the infrastructure operator from running arbitrary code. It only prevents them from seeing data. So if you're using Vera Rubin on cloud infrastructure, you're trusting the cloud provider's code integrity, not their data access.
For many regulated use cases, that's sufficient. A healthcare system can now train models on patient data in AWS without worrying about AWS engineers seeing the data. That's a material risk reduction.
Compliance and Audit Implications
Regulatory frameworks like HIPAA, PCI-DSS, and GDPR have specific requirements around data encryption and access controls. Vera Rubin's hardware-based confidential computing can satisfy many of these requirements directly.
Audit processes simplify. Instead of thousands of documents proving software controls, you can point to hardware attestation proving confidential execution. This reduces audit costs and accelerates compliance timelines.
For enterprises in regulated industries, this advantage alone might justify Vera Rubin investment regardless of pure performance metrics.

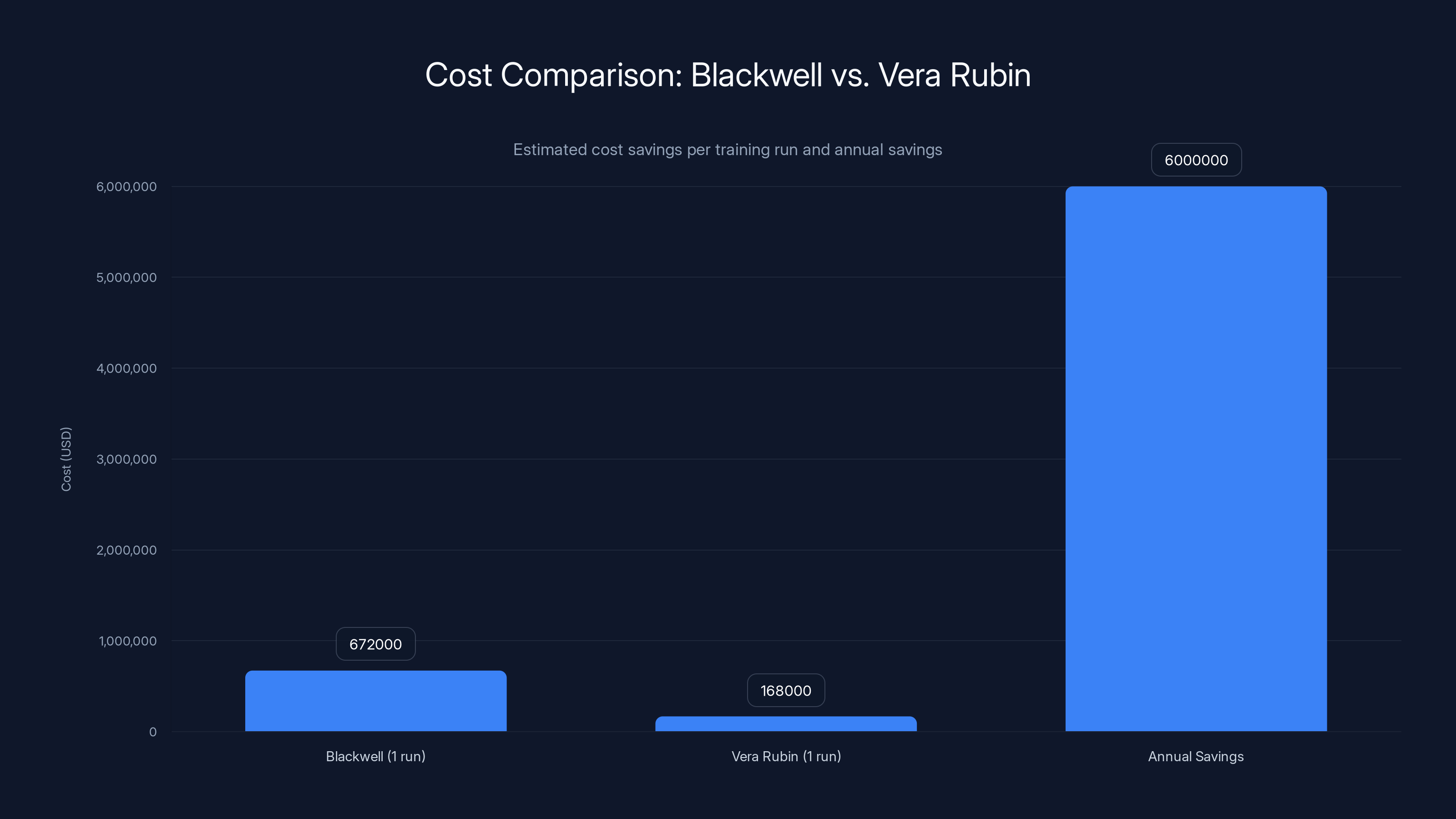
Vera Rubin offers significant cost savings per training run compared to Blackwell, with an estimated $6 million annual savings. Estimated data based on typical enterprise rates.
The Timeline: H2 2026 and What Comes After
Vera Rubin availability in H2 2026 is significant for what it reveals about Nvidia's roadmap and the industry's pace.
Why H2 2026 Specifically
The delay from announcement to availability is intentional. It gives Nvidia's partners time to integrate Vera Rubin into their platforms, it lets customers plan migrations, and it allows manufacturing ramp-up to happen at a sustainable pace.
H2 2026 also positions Vera Rubin to be "new" for another 18 months before the next-generation announcement. That's enough time for serious penetration into enterprise infrastructure without the market shifting beneath you.
What's Beyond Vera Rubin
Nvidia isn't stopping. The company has already announced concepts for future architectures beyond Rubin. Each generation is expected to deliver roughly 5-7x performance improvement, similar to Rubin's improvement over Blackwell.
If that cadence holds, the next major announcement would be expected around late 2027 or early 2028. That creates a multi-year window where Rubin is the de facto standard for training infrastructure.
For enterprises planning investments, understanding this cadence is important. Investing heavily in Blackwell in 2024 was reasonable. Waiting for Vera Rubin made sense for enterprises making decisions in 2025. Waiting for post-Rubin architectures in 2026 is probably a mistake unless your utilization doesn't justify the upgrade.
The Open-Source Question
Nvidia hasn't announced any open-source drivers or development tools specifically for Vera Rubin, continuing the proprietary trend from Blackwell. This maintains Nvidia's control over the ecosystem but also limits broader adoption.
Open-source communities might eventually develop open-source drivers through reverse-engineering, as they've done with prior GPU generations. But that takes time and creates technical debt.
For enterprises valuing openness and avoiding vendor lock-in, this is a legitimate concern worth weighing against Vera Rubin's performance benefits.

Practical Next Steps for Organizations
For enterprises evaluating Vera Rubin, actionable next steps depend on your current infrastructure state and training requirements.
Assessment Phase: Understanding Your Current Position
Start by inventorying your current AI infrastructure. How much compute do you actually have? How much are you utilizing? What's the mix between training and inference?
This assessment reveals whether Vera Rubin makes sense for your organization. If you're severely under-utilizing existing Blackwell infrastructure, upgrading doesn't make financial sense yet. If you're oversubscribed and rejecting training requests, Vera Rubin becomes more attractive.
Planning Phase: Migration Roadmapping
Once you understand your current position, model realistic migration timelines. Infrastructure transitions aren't linear. You'll likely run Blackwell and Vera Rubin in parallel for 6-12 months, which doubles infrastructure costs temporarily.
Plan for talent development. Assign engineers to start working with Vera Rubin development boards (available from partners) to develop hands-on experience before production deployment.
Partnership Phase: Selecting Implementation Partners
Nvidia's partners will deliver actual products. Work with cloud providers offering Vera Rubin (AWS, GCP, Azure will all support it), system integrators experienced in large-scale deployments, and network vendors understanding Vera Rubin's infrastructure requirements.
Don't try to build this alone. The complexity of deploying rack-scale AI infrastructure is too high for most organizations to internalize.

FAQ
What is Vera Rubin and how does it differ from Blackwell?
Vera Rubin is Nvidia's next-generation AI computing platform announced at CES 2026, designed to deliver five times more AI training compute than Blackwell. While Blackwell was optimized for general-purpose AI workloads, Vera Rubin specifically targets large-scale distributed training with improved memory efficiency, communication bandwidth, and built-in confidential computing. The key difference is that Vera Rubin isn't just a faster GPU—it's a complete platform integrating six components (CPU, GPU, networking, security, and interconnect) designed to work together seamlessly for training large language models efficiently.
How much compute power does Vera Rubin actually deliver compared to Blackwell?
Nvidia claims the Vera Rubin GPU delivers five times more AI training compute power than Blackwell on raw throughput measurements. More importantly, training a large mixture-of-experts model requires only one-quarter of the GPUs and one-seventh of the token cost compared to Blackwell. This means you can train the same models faster using significantly fewer resources, which translates directly to lower infrastructure costs and faster model iteration cycles.
What are the six components that make up Vera Rubin, and what does each do?
Vera Rubin consists of the Vera CPU for workload orchestration, Rubin GPU for compute, NVLink 6th-gen for GPU-to-GPU communication, Connect-X9 NIC for enterprise networking, Blue Field 4 DPU for security and confidential computing, and Spectrum-X 102.4T CPO for network congestion management. Together, these components create an integrated system optimized for distributed AI training, eliminating bottlenecks across compute, memory, communication, and security layers.
When will Vera Rubin be available, and what does availability timeline mean for enterprise planning?
Nvidia announced that products and services running Vera Rubin will be available from partners in the second half of 2026, roughly 18 months from announcement. This timeline gives enterprises opportunity to plan migrations, allows manufacturing ramp-up to reach scale, and lets Nvidia's partners integrate Vera Rubin into complete solutions. For organizations currently running Blackwell, this means you have time to evaluate upgrade ROI without feeling pressured into premature decisions.
Why is confidential computing important in Vera Rubin, and how does it work?
Vera Rubin is the first rack-scale trusted computing platform with third-generation confidential computing built in. It encrypts data even during processing—the GPU and CPU never see unencrypted information. Blue Field 4 DPU provides cryptographic attestation proving to customers that their data is actually encrypted throughout execution. This is transformative for regulated industries like healthcare and finance that need to train AI models on sensitive data in cloud environments without exposing raw data to the infrastructure operator.
Is upgrading from Blackwell to Vera Rubin financially justified for our organization?
Upgrade justification depends on your training volume and utilization patterns. If you're training multiple large models monthly and your Blackwell infrastructure is near capacity, the cost-per-token savings (roughly seven-fold) typically justify upgrade costs within 3-5 years when amortized across the system lifetime. If you're training infrequently, the capital expenditure for new infrastructure may take longer to amortize. Additionally, consider intangible benefits like faster iteration cycles and improved security posture, which have real but harder-to-quantify value.
What software ecosystem maturity should enterprises expect with Vera Rubin?
Vera Rubin is new, which means the software ecosystem is less mature than Blackwell's at this point in its lifecycle. CUDA optimization, debugging tools, and performance profiling utilities are still being developed. Early adopters may experience slower initial performance as compilers and development tools mature. Expect a 6-12 month period where optimization requires more engineering effort than on familiar Blackwell infrastructure. This is normal for new architectures and improves continuously as the ecosystem matures.
How does Vera Rubin's approach to mixture-of-experts models give it advantages over Blackwell?
Vera Rubin includes dedicated hardware for sparsity optimization—recognizing that not every neuron in a mixture-of-experts model contributes equally to every forward pass. This means Rubin can skip unnecessary computation that Blackwell would perform, improving training efficiency. Combined with larger memory capacity per GPU and improved communication efficiency, Vera Rubin is specifically designed for the sparse computation patterns that have become standard in modern large language model architectures, whereas Blackwell was designed for denser model topologies.
What manufacturing and supply constraints might affect Vera Rubin availability?
Blackwell faced substantial supply constraints throughout 2025 as demand exceeded production capacity. Vera Rubin will likely face similar constraints when availability begins in H2 2026. Nvidia has committed to ramping production and working with partners to expand capacity, but semiconductor manufacturing operates on long lead times. For enterprises planning infrastructure investments, assume supply constraints will limit availability and plan 3-6 month lead times for large orders. Starting conversations with cloud providers and integrators early helps secure allocation.

Conclusion: The Inflection Point for AI Infrastructure
Vera Rubin represents something important beyond just faster GPUs. It marks the point where AI infrastructure stops being about raw compute and starts being about system-level efficiency. Nvidia's decision to integrate six components into one platform reveals their conviction that the bottleneck isn't computing power anymore—it's orchestrating that power efficiently across distributed systems while managing cost, complexity, and compliance.
For enterprises, this launch forces strategic decisions. Organizations heavily invested in Blackwell need to evaluate when and whether upgrading makes sense for their specific workloads. Companies just starting AI infrastructure investments should carefully consider whether to deploy Blackwell now or wait for Vera Rubin in H2 2026.
The claimed performance improvements are genuine but need contextual interpretation. Five times more compute matters primarily for organizations training large mixture-of-experts models. The real advantage comes from the cost-per-token reduction that compounds into massive savings at scale. For organizations training continuously, this advantage is material. For those training occasionally, it's less compelling.
The security and compliance implications deserve serious attention. Hardware-backed confidential computing removes major barriers to cloud-based training on regulated data. Healthcare systems, financial institutions, and government agencies can now train proprietary models in environments they couldn't previously justify for compliance and security reasons.
Implementation complexity shouldn't be underestimated. Moving from Blackwell to Vera Rubin isn't plug-and-play. It requires infrastructure redesign, talent development, and careful migration planning. Organizations should plan for 12-18 month transition periods and partner with experienced integrators rather than attempting deployments independently.
Looking forward, Vera Rubin establishes the architectural pattern Nvidia will likely follow for generations to come: integrated platforms rather than standalone GPUs, confidential computing as default rather than add-on, and explicit optimization for the workloads actually dominating the market rather than projected future use cases.
The AI infrastructure race just entered a new phase. Hardware performance improvements matter, but system-level efficiency, cost optimization, and security integration matter more. Vera Rubin demonstrates Nvidia's understanding of this shift. Organizations that strategically evaluate timing and invest accordingly will gain meaningful competitive advantages in their AI capabilities. Those delaying decisions hoping for something better might find they're perpetually behind the curve, always waiting for the next generation rather than capturing current advantages.
The H2 2026 timeline gives enterprises a defined window to assess, plan, and execute migrations. Use that window strategically. The organizations deploying Vera Rubin in late 2026 and early 2027 will have meaningful efficiency advantages over those still optimizing Blackwell configurations. But equally important, those that honestly assess their workloads and determine Blackwell is sufficient will avoid unnecessary capital expenditure. The right answer depends on your specific situation, not on what's technically impressive.
Vera Rubin's real test won't come from Nvidia's presentations or analyst reports. It'll come from enterprises deploying it into production, discovering what the platform actually enables versus what was promised, and determining whether the investment paid off. That's where the story continues.

Key Takeaways
- Vera Rubin delivers 5x more AI training compute than Blackwell with 1/7 token cost for large mixture-of-experts models
- Integrated six-component platform architecture eliminates system-level bottlenecks across compute, communication, and security
- Hardware-backed confidential computing enables regulated industries to train AI models on sensitive data in cloud environments
- H2 2026 availability provides 18-month enterprise planning window for infrastructure migration and deployment strategy
- Cost-per-token improvements compound into multi-million dollar savings annually for organizations with high training volume
Related Articles
- Nvidia Rubin Chip Architecture: The Next AI Computing Frontier [2025]
- Intel Core Ultra Series 3 Panther Lake at CES 2026 [Complete Guide]
- Biggest TV Announcements at CES 2026: Micro RGB Changes Everything [2026]
- CES 2026 Day 1: The 11 Best Tech Gadgets Revealed [2025]
- Hisense CES 2026 TV Innovations: Color Technology Breakthroughs [2025]
- Audeze Maxwell 2 Gaming Headset: Complete Review & Analysis [2026]

