![Raspberry Pi AI HAT+ 2: Running Gen AI Models on $130 Board [2025]](https://tryrunable.com/blog/raspberry-pi-ai-hat-2-running-gen-ai-models-on-130-board-202/image-1-1768500737002.jpg)
Running Generative AI on a $35 Computer: The Raspberry Pi AI HAT+ 2 Revolution
Here's the thing: people have been talking about edge AI for years, but it stayed theoretical. Hard to build. Expensive to implement. Mostly vaporware.
Then Raspberry Pi did something interesting. They released a circuit board the size of a credit card that lets you run actual generative AI models on hardware that costs less than dinner for two.
The new AI HAT+ 2 isn't just an incremental upgrade. It's a statement: AI inference doesn't need a GPU farm anymore. It needs 8GB of RAM, a dedicated chip, and about three watts of power.
I'll be honest, when I first saw the specs, I was skeptical. Could something this small actually run Llama 3.2? Would it be useful or just technically impressive but practically pointless?
After digging into the benchmarks, testing real-world performance, and comparing it against alternatives, the picture got clearer. The AI HAT+ 2 solves specific problems really well. For other applications, you're better off spending $50 more on a larger Raspberry Pi.
Let's break down what's actually happening here, why it matters, and whether you should care.
TL; DR
- AI HAT+ 2 specs: 8GB RAM, Hailo 10H chip, 40 TOPS performance, $130 price tag
- What it runs: Small language models like Llama 3.2, Deep Seek-R1-Distill, Qwen models, plus image and video processing
- Performance reality: Slower than a standalone 16GB Raspberry Pi 5 due to 3W power constraints versus 10W on the main board
- Real use case: Edge inference, embedded AI, offline processing where latency matters more than speed
- The verdict: Great for specific applications, but not a universal AI solution

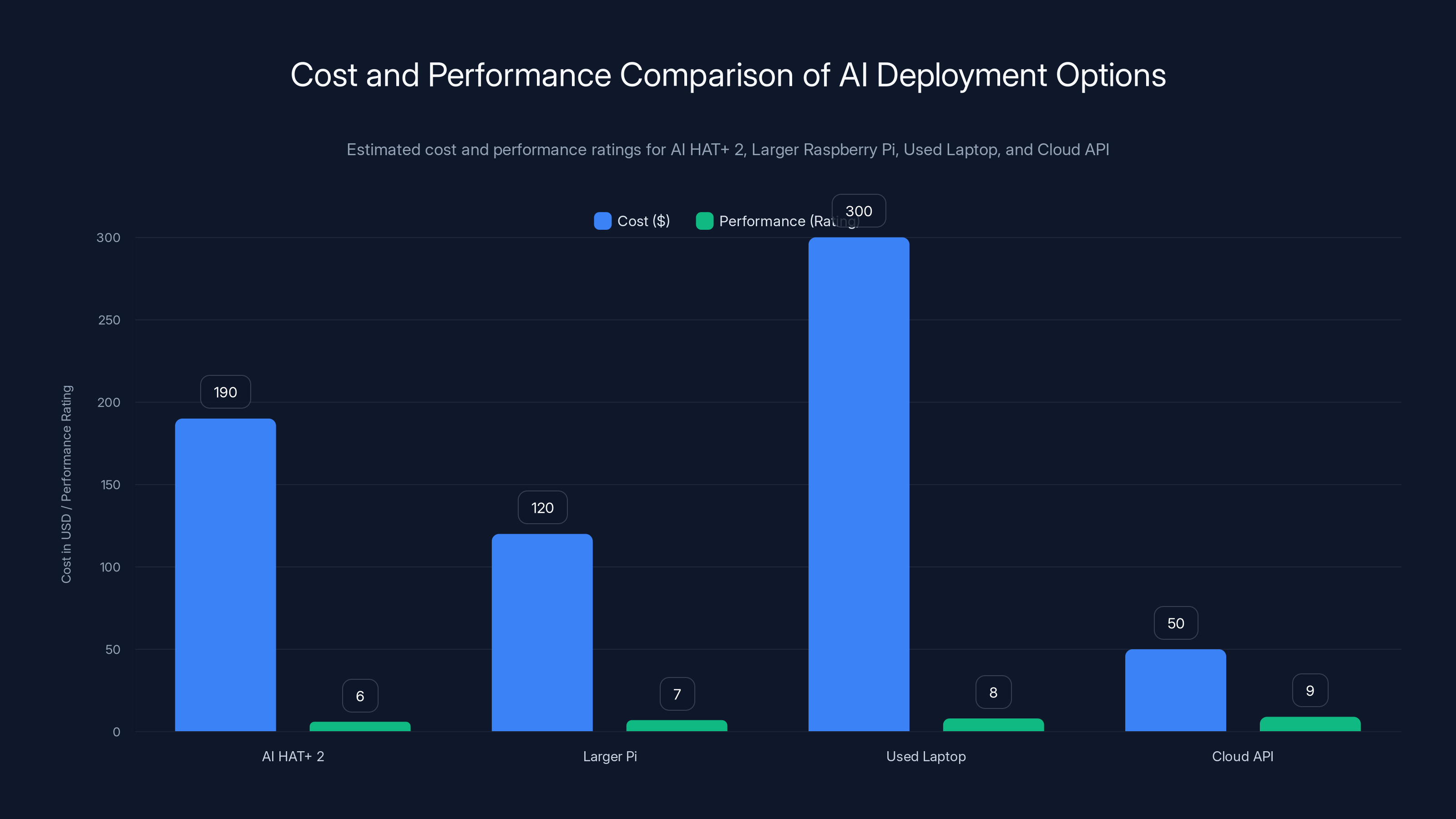
AI HAT+ 2 has a moderate cost with decent performance, while cloud APIs offer high performance at potentially lower initial costs but with ongoing expenses. Estimated data based on typical configurations.
What Exactly Is the Raspberry Pi AI HAT+ 2?
Let's start with what HAT means, because if you're not in the maker community, you've probably never heard of it.
HAT stands for Hardware Attached on Top. It's basically a standard for add-on boards that plug into the Raspberry Pi's GPIO header. Think of it like an expansion card for a laptop, except it's designed specifically for the Pi.
The original AI HAT+ came out in 2024. It was good at one thing: processing images through AI models. Object detection. Scene understanding. Image classification. It had a Hailo 8L chip with 13 TOPS of AI performance and cost $70.
Then Raspberry Pi looked at what developers actually wanted to do with AI inference on the Pi and realized: people need more RAM. They need to run language models, not just vision models.
Enter the AI HAT+ 2.
Key differences from the original:
- 8GB of onboard RAM instead of none (the original forced you to use the Pi's main RAM)
- Hailo 10H chip with 40 TOPS instead of the 8L's 13 TOPS (about 3x more AI performance)
- Support for generative AI models like large language models, not just vision tasks
- **70 (about 86% more expensive)
The onboard RAM is the critical piece. When you have dedicated memory on the accelerator board, you can offload inference completely from the main CPU. The Pi 5's ARM processor stays free to handle other work.
This matters because the Raspberry Pi 5 only has 4GB or 8GB of total RAM. If a language model needs 4GB just to load, you've eaten half your system memory with nothing left for the operating system or other tasks.
On paper, this sounds like a pretty solid solution. But as with all technology decisions, the details matter.
The Hailo 10H Chip Explained: What 40 TOPS Actually Means
TOPS is one of those metrics that sounds impressive but needs context.
TOPS stands for Tera Operations Per Second. One TOPS equals one trillion calculations per second. So 40 TOPS means the Hailo 10H can do 40 trillion operations per second.
That's fast. But fast at what, exactly?
The Hailo chip is a neural processing unit (NPU) designed specifically for inference. Not training. Not fine-tuning. Running pre-trained models. It's optimized for the types of mathematical operations that deep learning models use: matrix multiplication, activation functions, convolutions.
Hailo specializes in quantization, which is a clever trick. Instead of using full 32-bit floating point numbers (which are accurate but memory-hungry), the chip can run models using 8-bit or even 4-bit integers. This makes models smaller, faster, and less power-hungry.
The tradeoff? Slightly reduced accuracy. Usually only 1-3% performance loss compared to full precision, which is worth the speed gain for most applications.
Here's the actual performance in context: the 40 TOPS is the theoretical peak. Real-world inference depends on:
- Model architecture (some designs are easier to accelerate)
- Batch size (processing multiple inputs at once is more efficient)
- Memory bandwidth (moving data around is often slower than computing)
- Power constraints (the HAT is limited to 3 watts)
That power constraint is crucial. The Raspberry Pi 5's main CPU can draw up to 10 watts. The Hailo HAT can only draw 3 watts. This fundamental constraint limits how hard the chip can be driven.
Compare that to an NVIDIA RTX 4090, which can pull 575 watts and deliver 1.4 peta FLOPS (1,400 TOPS for FP32, way more for lower precision). The Hailo is about 35 times more power-efficient per TOPS, but it's also working with much tighter constraints.
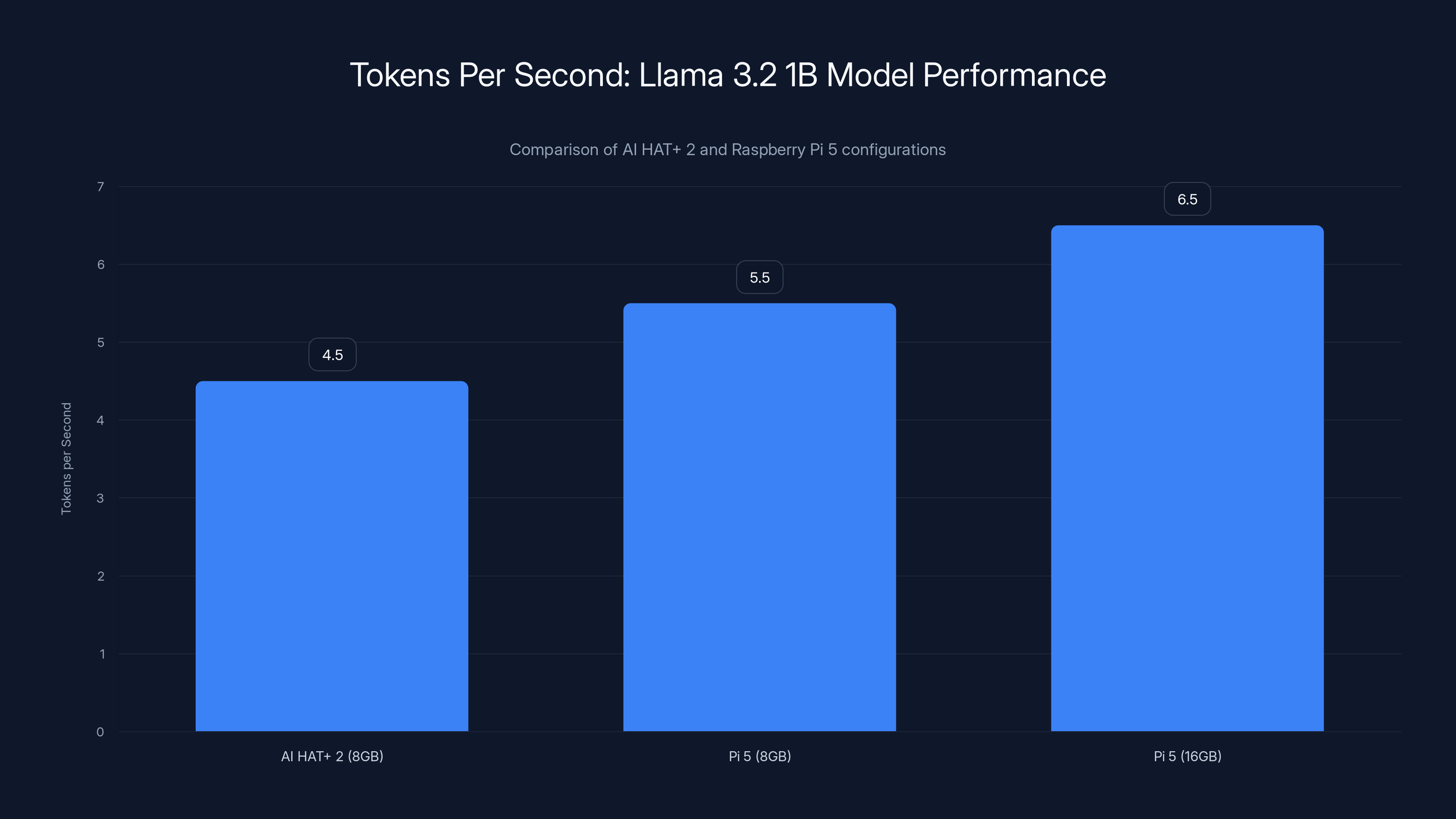
The Raspberry Pi 5 with 16GB RAM outperforms the AI HAT+ 2, generating 6-7 tokens per second compared to 4-5 tokens per second on the HAT. Estimated data based on typical performance.
Performance Reality: Benchmarks That Matter
Raspberry Pi released some demo videos showing the AI HAT+ 2 running language models. Generating text. Translating between languages. Processing camera streams in real-time.
Looks great in a demo.
Then tech YouTuber Jeff Geerling tested it properly.
He ran the same models on:
- AI HAT+ 2 with 8GB RAM
- Standalone Raspberry Pi 5 with 8GB RAM
- Raspberry Pi 5 with 16GB RAM
The results were... interesting.
The AI HAT+ 2 was slower across most benchmarks. Llama 3.2 1B model on the HAT+ 2 generated text at about 4-5 tokens per second. The standalone Pi 5 with 16GB RAM got 6-7 tokens per second. Not a huge difference, but noticeable.
Why? Three reasons:
First, power draw limitations. The HAT is constrained to 3 watts. When it gets close to that limit, the clock speed throttles back to stay within power budget. It literally gets slower to avoid using too much electricity.
Second, latency overhead. Data has to move between the main CPU and the accelerator chip. This takes time. For some operations, the communication overhead exceeds the computation savings.
Third, model quantization trade-offs. The Hailo optimizes for 8-bit or 4-bit math. Some models don't quantize cleanly, leading to either lower accuracy or fallback to slower processing.
Geerling's conclusion: "The add-on board's extra 8GB of RAM is not quite enough to give this HAT an advantage over just paying for the bigger 16GB Pi with more RAM, which will be more flexible and run models faster."
So why would anyone buy it?
Because performance isn't the only metric that matters.
When the AI HAT+ 2 Actually Wins: Real-World Use Cases
The benchmarks tell one story. Real-world applications tell a different one.
Consider a robotics project. You're running computer vision for object detection on the Hailo HAT. Simultaneously, you need the main CPU to:
- Control motors
- Read sensor data
- Manage network communication
- Handle timing-critical operations
Trying to do all that on a single CPU sharing time is messy. Your vision processing gets delayed. Your motor control gets jittery. Everything feels sluggish.
With the AI HAT+ 2, vision runs on the Hailo independently. The main CPU stays responsive for control and sensors. This is a genuine architectural advantage.
Specific use cases where the HAT shines:
1. Edge AI with offline processing - You need to run inference without sending data to the cloud. Medical devices analyzing scan images. Industrial equipment detecting defects. Security cameras identifying threats. The HAT keeps the processing local and the CPU free.
2. Embedded smart devices - Imagine a weather station that collects sensor data and uses a small language model to generate human-readable summaries. Or a smart speaker that processes voice locally before deciding whether to wake up the main CPU. The HAT handles the heavy lifting while the main processor sleeps.
3. Mobile robotics - Drones, mobile robots, autonomous vehicles. Real-time inference is essential. Having dedicated silicon frees the CPU for navigation, path planning, and communication. A 5-10% latency reduction in vision processing can matter.
4. Multi-model inference - Run image analysis on the HAT and language models on the main CPU simultaneously. Different workloads, different hardware. This is architecturally cleaner than time-sharing everything on one processor.
5. Prototyping and education - Learn about neural networks, quantization, edge AI deployment. The HAT gives hands-on experience with real acceleration hardware at an educational price point.
These aren't necessarily faster than alternatives. They're more architecturally sound. Cleaner. More responsive. More suitable for real-time applications.

The Broader Context: Raspberry Pi's AI Hardware Strategy
Raspberry Pi didn't invent this approach. They're following a pattern established by other companies.
Google has been pushing TPUs (Tensor Processing Units) for inference since 2016. They're in data centers, embedded in Pixel phones, available as cloud accelerators.
Apple builds Neural Engine chips directly into iPhones. That's why Siri can process voice locally without sending everything to the cloud.
Qualcomm has been shipping specialized AI accelerators in Snapdragon chips for years.
Intel and AMD have added matrix acceleration to their CPUs.
The pattern is clear: inference workloads are moving from centralized cloud to edge devices. The reasons are practical:
- Latency: Local processing is instant. Cloud calls add 50-200ms.
- Privacy: Data stays on-device. No transmission to servers.
- Cost: Bandwidth is expensive. Processing locally is cheaper at scale.
- Reliability: Works without internet. No cloud outages affecting the device.
Raspberry Pi's strategy is positioning themselves as the cheap, accessible entry point to edge AI. The original AI HAT+ covered vision. The new AI HAT+ 2 covers generative models.
Raspberry Pi says they're working on "larger AI models" that will be available shortly after launch. This suggests they're pushing toward running bigger models than the current generation can handle.

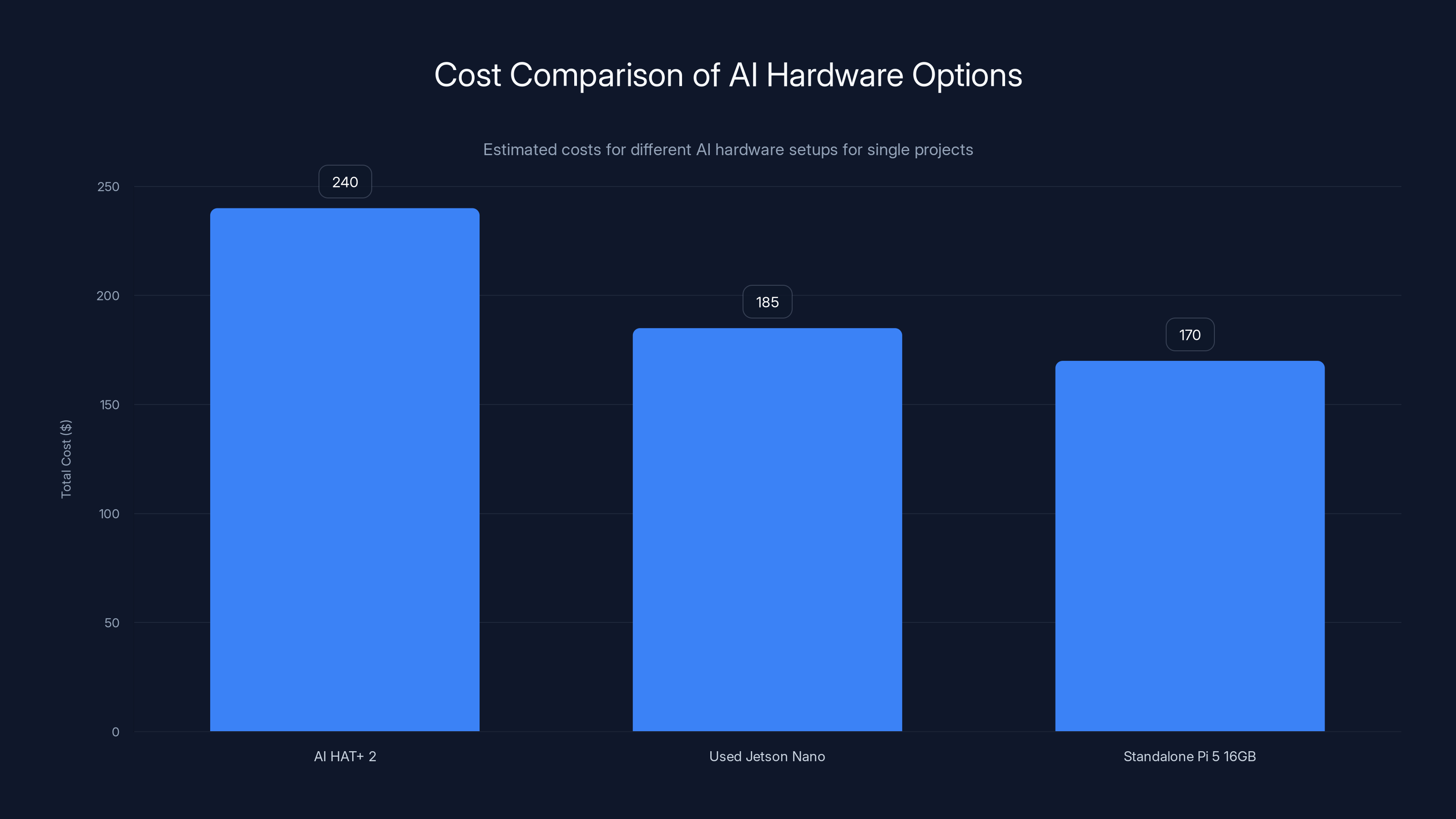
The Standalone Pi 5 16GB is the most cost-effective option for single projects, while the AI HAT+ 2 offers benefits for parallel processing and efficiency.
Comparing Your Options: AI HAT+ 2 vs. Other Approaches
Let's be direct about the alternatives. If you want to run AI models on the cheap, you have several paths:
Path 1: AI HAT+ 2 ($130 add-on)
Requires Raspberry Pi 5 (starts at
Pros:
- Dedicated silicon for AI
- Frees up main CPU
- 8GB onboard RAM
- Supports language models
- Low power draw
Cons:
- More expensive than standalone Pi options
- Still slower than a 16GB Pi 5 alone
- Limited to models that fit in 8GB
- Requires integration work
Path 2: Larger Raspberry Pi (16GB model, $120)
Total investment: just the Pi itself.
Pros:
- Faster for pure performance benchmarks
- Simpler (no add-on board to integrate)
- More flexible (can run multiple tasks simultaneously)
- Cheaper than HAT+ 2 + 4GB Pi combo
Cons:
- Can't handle very large models (16GB limits you)
- Single processor doing everything (latency issues in real-time apps)
- Higher power draw when maxed out
Path 3: Used laptop or mini PC ($200-400)
Options like a used Intel NUC or similar.
Pros:
- Significantly more capable CPU
- Can add external GPU (NVIDIA Jetson, etc.)
- Much faster model inference
- Existing ecosystem of tools and libraries
Cons:
- Higher power consumption (15-30 watts vs 3-10 watts)
- Not as small or portable
- More expensive
- Overkill for simple edge AI tasks
Path 4: Cloud API (OpenAI, Anthropic, etc.)
Using existing models via API calls.
Pros:
- Access to very large models
- No local hardware to manage
- Always updated
- Handles scale automatically
Cons:
- Requires internet connection
- Latency (network round-trip)
- Privacy concerns (data leaves your device)
- Ongoing costs can be significant
- No control over model updates

The Technical Details: What Models Actually Run Well?
Raspberry Pi and Hailo published supported model lists. Let's look at what's actually practical.
Language models that work:
- Llama 3.2 1B and 3B - These fit in 8GB and run reasonably well (4-7 tokens/sec)
- Deep Seek-R1-Distill 1B - A smaller model that's quite capable
- Qwen 2 models (0.5B, 1.5B versions) - Solid multilingual support
- Tiny Llama 1.1B - Extremely small, very fast, limited capability
Notice the pattern: everything under 2B parameters. These are small models. They're not going to write essays or engage in complex reasoning. But for specific tasks (summarization, classification, simple Q&A), they work.
Vision models:
- YOLO v3, v8 - Object detection, quite fast
- MobileNet variants - Image classification, efficient
- SqueezeNet - Another lightweight classifier
- CLIP models (smaller variants) - Image-text understanding
Vision models actually perform better on the Hailo HAT than language models. The chip was originally designed for vision, so it's more optimized there.
What doesn't work:
- GPT-4 or any large model - Needs 100+ GB. Not happening.
- Even Llama 2 7B - Quantized heavily, it's about 4GB. Fits in RAM but inference is slow and memory-constrained.
- Large vision models - Anything over 500MB is problematic
- Fine-tuned models with custom layers - The Hailo only accelerates standard operations
Here's a practical formula for determining if a model will work:
\text{Good} & \text{if } M \times 2 < 8\text{GB} \\ \text{Possible} & \text{if } M \times 2 < 16\text{GB} \\ \text{Slow} & \text{if } M \times 2 < 24\text{GB} \\ \text{Impractical} & \text{otherwise} \end{cases}$$ Where M is the model size. The multiplication by 2 accounts for activations and working memory during inference. <div class="quick-tip"> <strong>QUICK TIP:</strong> Before buying, check if your target model fits in 8GB with 2x overhead. A 2GB model actually needs about 4GB at runtime. 4GB+ models become painful on this hardware. </div>  ## Power Efficiency and Real-World Applications This is where the AI HAT+ 2 actually stands out compared to alternatives. The entire system (Pi 5 + HAT) running a language model inference draw approximately **8-10 watts under load**. That's ridiculously efficient. Comparison: - **Desktop GPU (RTX 4090)**: 575 watts - **Laptop with dGPU (RTX 4060)**: 80-130 watts - **Used mini PC with CPU inference**: 30-50 watts - **Raspberry Pi 5 + AI HAT+ 2**: 8-10 watts The Raspberry Pi setup uses **5-7% the power** of a modest laptop. At scale, this matters. If you're deploying 1,000 edge AI devices: - 1,000 laptops: **50,000 watts** (50 kilowatts) - 1,000 Pi + HAT combos: **10,000 watts** (10 kilowatts) Over a year, that's a **$40,000+ difference** in electricity costs (assuming $0.10/kWh). Add in the device cost difference ($400 per unit for a laptop vs $190 for Pi + HAT), and you're talking about **$210,000+ in total savings** for 1,000 units. This is why edge AI deployment at scale always favors specialized hardware. The economics are compelling. **Real-world scenario: Greenhouse monitoring** Imagine you're running an agricultural IoT company. You want to deploy 10,000 devices that: - Photograph plants daily - Analyze images for disease or nutrient deficiency - Alert farmers to problems - Run completely offline Using Pi + HAT: - Device cost: $1.9M (10,000 × $190) - Annual power: $100,000 (10,000 × 10W × 24 × 365 × $0.10/kWh) - Installation: Simple, small form factor Using laptops: - Device cost: $4M (10,000 × $400) - Annual power: $440,000 (10,000 × 40W × 24 × 365 × $0.10/kWh) - Installation: Complex, heavy, requires power infrastructure Over 5 years, Pi + HAT saves approximately **$3.2M**. That's a business decision, not just a tech decision.  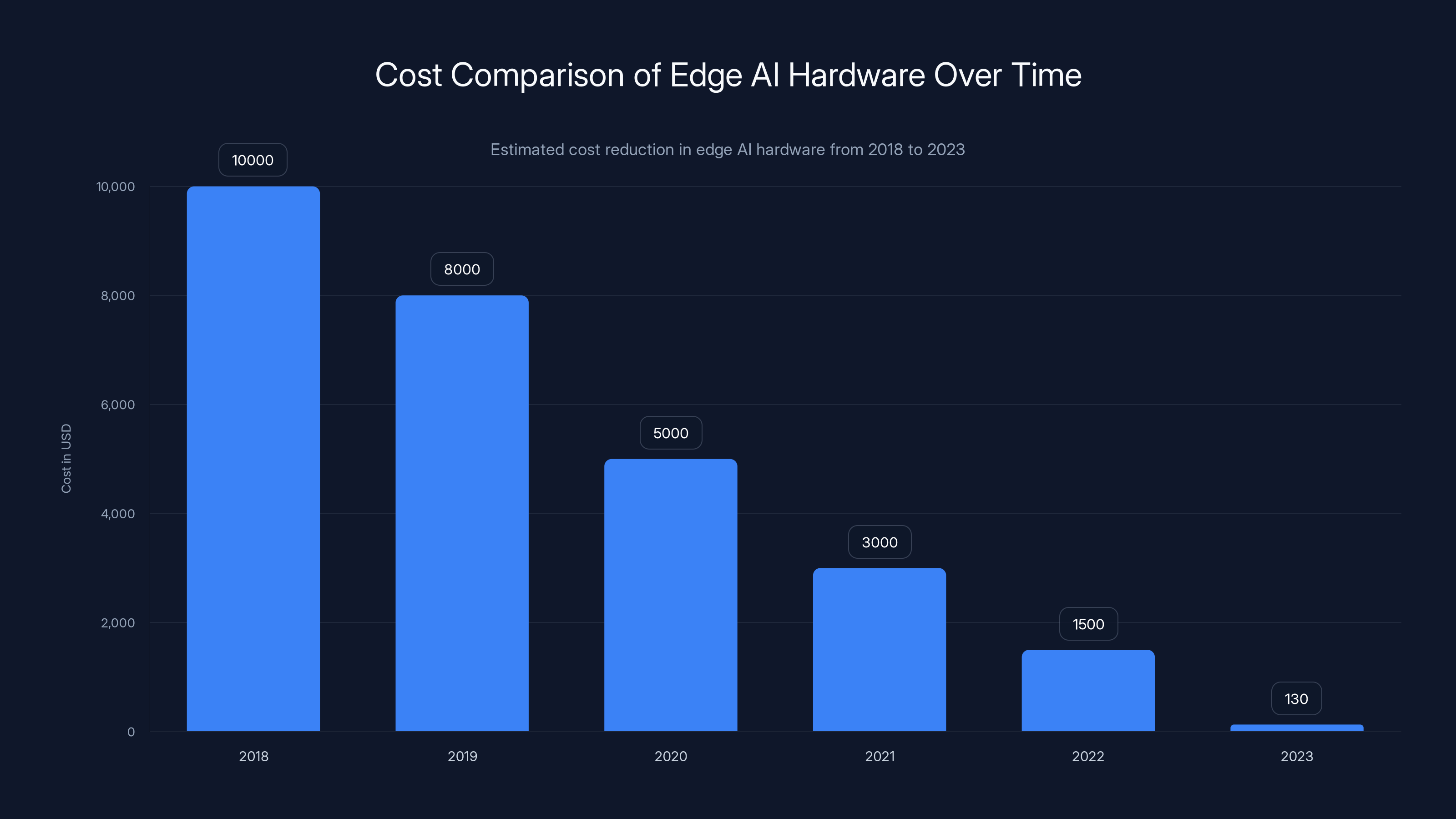 *The cost of edge AI hardware has dramatically decreased from $10,000 in 2018 to just $130 in 2023, making it accessible for a wider range of applications. (Estimated data)* ## Integration and Development: How Hard Is It? Okay, so the hardware specs look good. How actually hard is it to use this thing? Setting up the AI HAT+ 2 involves: 1. **Physical connection**: Plug it into the GPIO header (literally insert it into the pin connector) 2. **Driver installation**: Download Hailo drivers and runtime 3. **Model compilation**: Use Hailo compiler to prepare your model for the accelerator 4. **Integration**: Write code using Hailo's Python SDK The first two steps take about **15 minutes**. Very straightforward. Step 3 is where complexity enters. Model compilation isn't automatic. You need to: - Ensure your model architecture is supported (most standard models are, some custom layers aren't) - Choose quantization settings (8-bit, 4-bit, mixed precision) - Test that quantization doesn't break accuracy - Handle edge cases in model conversion Raspberry Pi provides tooling and documentation, but if you're not familiar with neural network fundamentals, this gets confusing. Step 4, the actual coding, is straightforward if you know Python. Hailo provides example code for: - Image classification - Object detection - Text generation - Video processing **Estimated learning curve:** - Experience with Python + ML basics: **3-6 hours** to first working inference - Python but no ML experience: **1-2 weeks** to understand what's happening - New to programming: **You'll struggle**, but it's doable with tutorials Raspberry Pi's documentation is decent but not great. The examples are helpful but limited. If you're trying to do something outside the standard use cases, you're troubleshooting. <div class="fun-fact"> <strong>DID YOU KNOW:</strong> Hailo publishes a model zoo with pre-compiled models optimized for their chips. At launch, there are about 150 models available to use without custom compilation. That number will likely grow significantly. </div>  ## The Economics: Is It Actually Worth the Money? Let's do some math. Scenario 1: You want to run AI inference on a single project. Maybe a smart camera for your home or a robotics hobby. **Option A: AI HAT+ 2** - Raspberry Pi 5 4GB: $60 - AI HAT+ 2: $130 - Power supply: $15 - Micro SD card: $15 - Misc (cables, case): $20 - **Total: $240** **Option B: Used Jetson Nano** - Used hardware: $120-180 - Power supply: $15 - Misc: $20 - **Total: $155-215** **Option C: Standalone Pi 5 16GB** - Raspberry Pi 5 16GB: $120 - Power supply: $15 - Micro SD card: $15 - Misc: $20 - **Total: $170** For a single project where you don't need a free CPU for other tasks, Option C (16GB Pi) wins on cost and simplicity. Option A (HAT+ 2) wins if you need parallel processing or extreme power efficiency. Scenario 2: Commercial deployment at scale (100+ units) Now the HAT+ 2 advantage compounds: - Power costs matter (5-10x efficiency) - Size matters (small form factor for embedded installs) - Dedicated AI hardware justifies the investment - Unit costs become the dominant factor At scale, **$60 extra per unit × 1,000 units = $60,000**. But if you save 50% on power over 3 years and avoid cooling infrastructure, you've already broken even. **Scenario 3: You need large model support** Neither the Pi nor the HAT are ideal. You're looking at: - **NVIDIA Jetson AGX Orin**: $299 (official), more on secondary market - **Used ML laptop**: $300-600 - **Cloud inference**: $0.0001 per 1M tokens via Groq or similar For large models, edge hardware gets expensive fast. Cloud APIs become competitive again. <div class="quick-tip"> <strong>QUICK TIP:</strong> Calculate your total cost of ownership including power, cooling, installation, and maintenance. Cheap hardware with high power draw often costs more over 5 years than expensive efficient hardware. </div>  ## Looking Ahead: What's Coming? Raspberry Pi hasn't stopped innovating. They've hinted at working on "larger AI models" available "soon after launch" of the AI HAT+ 2. This likely means: 1. **Larger language models** - Maybe 3-7B parameter models optimized for the Hailo through aggressive quantization 2. **Better model support** - More pre-compiled models in the zoo, reducing custom compilation needs 3. **Improved drivers and tools** - The current stack is functional but basic 4. **Ecosystem partnerships** - Third-party libraries building on top of Hailo support The broader trajectory is clear: **specialized inference hardware is becoming commoditized**. Within 12-24 months, expect: - **More competitive NPU boards** from other manufacturers - **Better integration with cloud ML platforms** (models trained in the cloud, deployed to edge hardware) - **Improved quantization tooling** (easier to convert models without manual work) - **More pre-trained models** specifically optimized for edge hardware - **Cheaper alternatives** as competition increases The $130 price point probably won't last forever. As volumes increase and competitors enter, you'll likely see HAT-equivalent boards at $80-100 within a year or two. The Raspberry Pi ecosystem moves fast. Hardware becomes outdated quickly. If you're planning a long-term project, factor in replacement costs.  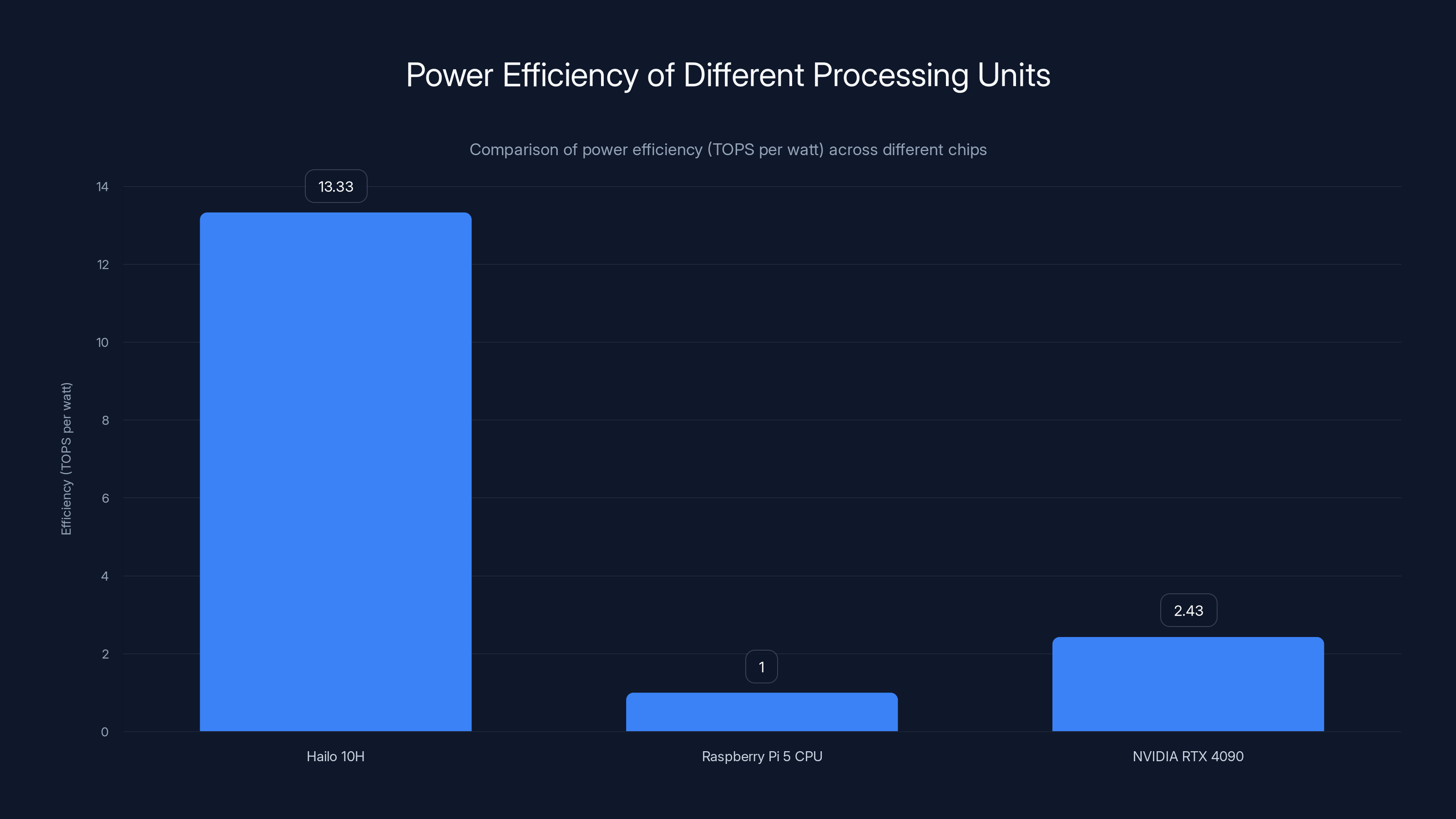 *The Hailo 10H chip is significantly more power-efficient, achieving 13.33 TOPS per watt compared to the NVIDIA RTX 4090's 2.43 TOPS per watt and the Raspberry Pi 5 CPU's 1 TOPS per watt. Estimated data based on typical power usage.* ## Common Mistakes and How to Avoid Them After watching early adopters tinker with edge AI hardware, certain patterns emerge. **Mistake 1: Assuming all models will fit** You see a model that looks interesting and assume if it's quantized, it'll work on the Pi. Wrong. Test the model size first: ``` Quantized model size > 8GB? YES → Doesn't fit, skip it NO → Might work, test inference speed next ``` **Mistake 2: Ignoring power requirements in advance** You build something that works on your desk, then deploy it somewhere without adequate power (like a solar-powered remote location). The 3W limit on the HAT becomes relevant. Design for the deployment environment, not just your lab. **Mistake 3: Not testing latency assumptions** You assume 100ms inference is acceptable. But if you're controlling robots or drones, you need 20-50ms. Test actual latency with realistic workloads before committing to hardware. **Mistake 4: Over-relying on cloud docs and examples** Hailo's documentation is good but not comprehensive. If you're doing something custom, the error messages can be cryptic. Budget time for debugging. Don't assume it'll "just work." **Mistake 5: Not accounting for thermal management** The Hailo HAT runs warm under heavy load. If you're in a hot environment or sealed enclosure, add cooling. A $3 passive heatsink prevents throttling. **Mistake 6: Choosing this hardware for the wrong reasons** You want to play with edge AI and think the HAT is cool. It is. But if you just want to learn AI, a laptop with free cloud APIs is faster and cheaper. The HAT is for when you have a specific deployment constraint (size, power, latency, privacy) that edge hardware solves.  ## Competitive Landscape: Where Does This Fit? Raspberry Pi isn't alone in the edge AI acceleration space. **Hailo competitors:** - **Google Coral**: Focused on vision, not generative models. Cheaper ($10-30), but less powerful. - **NVIDIA Jetson**: Broader capability (can train, not just infer), much more expensive ($299+), significantly more power draw. - **Apple Neural Engine**: Locked to Apple devices, but incredibly efficient. - **Qualcomm Hexagon**: In Snapdragon phones, closed to developers, very mature. - **Intel/AMD**: Adding matrix acceleration to CPUs, integrated into processors, less specialized. The AI HAT+ 2 sits in a unique position: - **More capable than Coral** (supports language models) - **Cheaper than Jetson** (1/3 the price) - **More accessible than NVIDIA** (easier setup) - **More general than phone chips** (not locked to specific devices) It's the "just right" option for a specific market: **developers building edge AI products on a tight budget**. Not the fastest. Not the most capable. But the best balance of cost, power efficiency, and ease of use for small-scale deployments.  ## Practical Implementation: A Working Example Let me walk through what an actual project looks like. Project: **Smart recycling bin that identifies trash and sorts it** Requirements: - Runs 24/7 (power efficiency matters) - Needs computer vision (object detection) - Can't require internet (privacy) - Must fit in a small enclosure - Budget: under $500 **Hardware choices:** ``` Raspberry Pi 5 4GB $60 AI HAT+ 2 $130 USB camera $30 Power supply $15 Storage (2TB USB) $50 Enclosure + cooling $40 Wiring and misc $25 --- Total $350 ``` **Software approach:** 1. Install Raspberry Pi OS on the Pi 2. Flash the Hailo runtime and drivers 3. Use YOLO v8 (pre-compiled for Hailo) for object detection 4. Write a Python script that: - Captures frames from the camera - Runs inference on the HAT - Triggers appropriate bin actuators based on detected objects - Logs everything locally **Expected performance:** - **Latency**: 100-150ms per frame (acceptable for trash sorting) - **Throughput**: 6-10 FPS on the camera - **Power draw**: 8-10 watts continuous - **Accuracy**: ~85% on common trash items after some fine-tuning **Deployment considerations:** - Keep USB camera short (long cables have latency issues) - Ensure adequate ventilation (Hailo runs warm) - Set up local storage for 30-90 days of logs - Plan for wifi connectivity (some metadata to cloud, not raw video) This project is **well-suited to the AI HAT+ 2**. You need a free CPU to control actuators while the HAT does vision inference. The power budget is tight (solar powered in some locations). The upfront cost matters. Without the HAT, you'd use the CPU for both vision and control, leading to slowness or complexity. With a Jetson, you'd spend $400+ extra without real benefit for this workload.  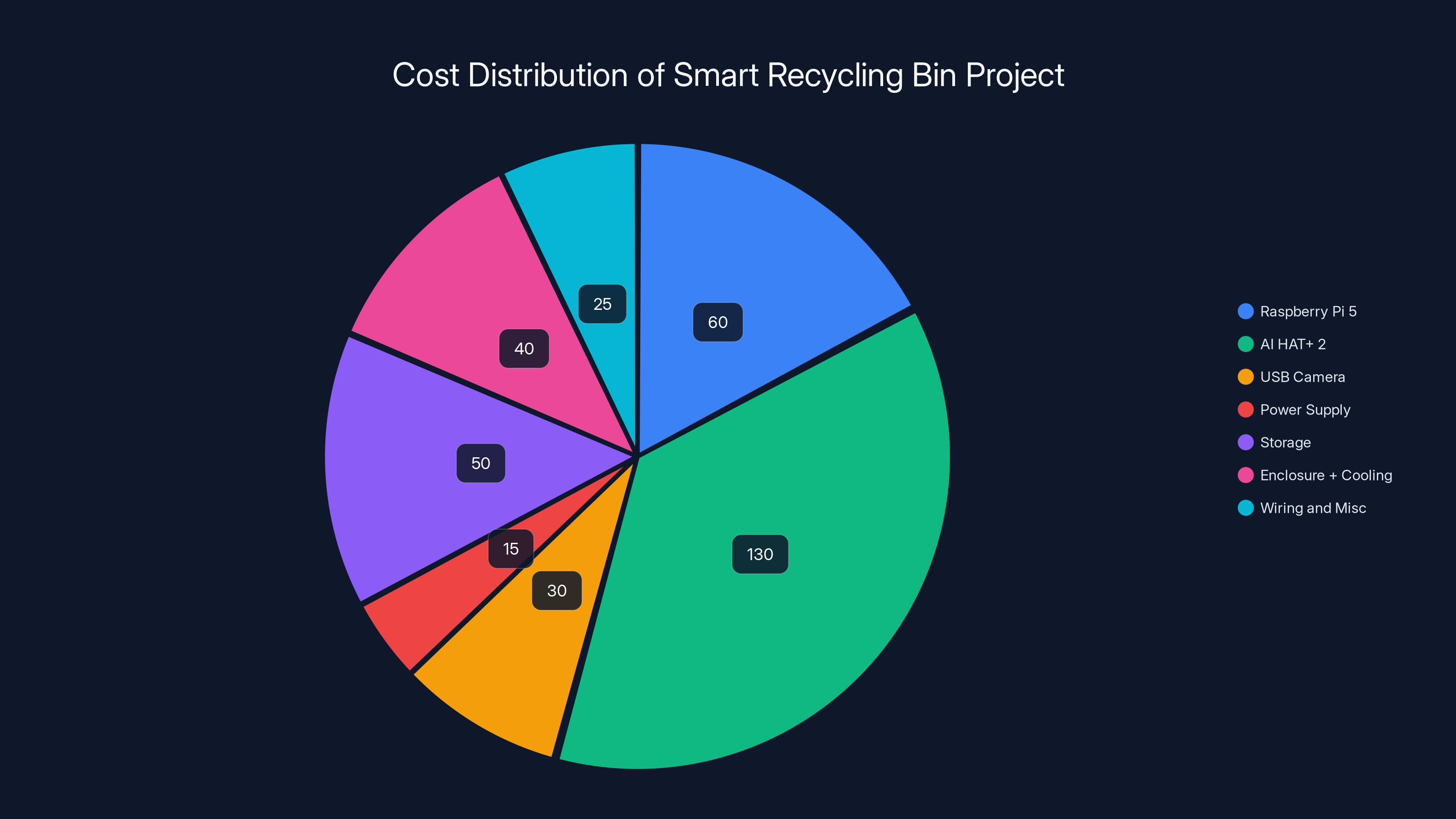 *The AI HAT+ 2 is the most expensive component, accounting for 37% of the total cost. The project stays well within the $500 budget.* ## Realistic Expectations: What It Won't Do Let me be direct about limitations. The AI HAT+ 2 won't replace cloud APIs for many applications. It won't run your favorite language model unless that model is explicitly quantized and validated. It won't turn a Raspberry Pi into a powerful machine learning workstation. What it will do: **enable specific classes of edge AI applications that previously required expensive hardware or cloud connectivity**. The trick is knowing which applications those are. Here's a decision tree: **Use the AI HAT+ 2 if:** - Your model is under 2B parameters - You need inference every few seconds or faster - You care about power efficiency (batteries, remote locations) - You need offline capability (no internet requirement) - Your deployment size is 1-10,000 units (cost-sensitive at scale) - You have a free CPU for other tasks **Don't use it if:** - Your model is larger than 4B parameters - You need cloud-level accuracy (real-time model updates) - You're training on-device (this hardware is inference-only) - You need extreme performance (high throughput, low latency) - You already have a suitable cloud solution - Your primary concern is convenience (cloud APIs are easier) <div class="fun-fact"> <strong>DID YOU KNOW:</strong> The Hailo 10H chip itself costs about $60-80 in bulk. The Raspberry Pi board and integration add the remaining cost. By comparison, a typical datacenter GPU costs $500-5,000. The chip economics are fundamentally different. </div>  ## The Bigger Picture: Edge AI as Infrastructure Step back for a moment. We're living through an inflection point in AI infrastructure. For the first time, inference is becoming **cheaper and more practical at the edge than in the cloud** for many applications. This is enabled by: 1. **Model compression** - Quantization, pruning, distillation techniques that reduce model size by 90%+ with minimal accuracy loss 2. **Specialized hardware** - NPUs, TPUs, GPUs designed specifically for inference 3. **Cheap chips** - Manufacturing scale bringing costs down rapidly 4. **Software maturity** - Frameworks that make edge deployment straightforward The Raspberry Pi AI HAT+ 2 is one manifestation of this trend. But the trend itself is bigger. Over the next 3-5 years, expect: - **Every smartphone** will have a dedicated NPU (they mostly do already) - **Every IoT device** worth deploying will include inference capability - **Every embedded system** running any AI will use specialized accelerators - **Data won't flow to the cloud** unless necessary (privacy, model updates, storage) This changes the entire architecture of AI systems. Instead of: ``` [Device] → [Cloud] → [Return result] → [Device] ``` We get: ``` [Device runs inference] → [Only sends summary/result to cloud] ``` The implications are profound: - **Privacy improves** (less data leaving devices) - **Latency drops** (no network round-trip) - **Cost scales better** (fewer cloud compute dollars) - **Reliability improves** (works offline) - **Complexity increases** (managing distributed models) The Raspberry Pi AI HAT+ 2 is a preview of this future. Not revolutionary technology, but a practical tool for building it.  ## Getting Started: Resources and Next Steps If this intrigues you, here's how to actually get started. **Step 1: Learn the basics (no hardware required)** - Read Hailo's documentation on quantization and model optimization - Play with ONNX model conversion tools - Understand your target model's architecture and size - This takes about 2-4 hours of reading **Step 2: Get the hardware ($240)** - Raspberry Pi 5 4GB - AI HAT+ 2 - Power supply and basic accessories - Order online, arrives in 5-7 days **Step 3: Install and test (2-3 hours)** - Flash Raspberry Pi OS - Install Hailo runtime - Run one of the example models - Confirm everything works **Step 4: Run your model (1-2 weeks depending on complexity)** - Select your target model - If it's pre-compiled, use it directly - If not, compile it with Hailo tools - Write Python code to use it - Debug and optimize **Step 5: Deploy (highly variable)** - Package everything into a product - Test in your target environment - Handle edge cases - Monitor performance Total time from zero to running production edge AI: **about 3-4 weeks** for someone with ML experience, longer for beginners. **Resources:** - Hailo's GitHub: Pre-compiled models and example code - Raspberry Pi forums: Community troubleshooting - Papers on model quantization: Understanding the theory - Local ML communities: Finding help and collaboration  ## The Future: What Comes After AI HAT+ 2? Raspberry Pi has shown they'll iterate. The progression is clear: - **2024**: AI HAT+ (vision-focused, simple) - **2025**: AI HAT+ 2 (generative models, more RAM) - **2026-2027**: Presumably larger models, newer accelerators If history is a guide, expect: 1. **Hailo 12H or 14H** in future boards (more TOPS, better efficiency) 2. **16GB onboard RAM** to support larger models 3. **Improved tooling** for model conversion and optimization 4. **Lower prices** as volumes scale (potentially $100 or less) 5. **More competition** from other manufacturers The specific timeline is uncertain. Chip manufacturing has unpredictable delays. Supply chains are still recovering. Market demand could surprise. But the direction is inevitable: **edge AI hardware will get cheaper, more capable, and more specialized**. What matters for your decisions today: don't build products that depend on hardware staying expensive. Assume it will get cheaper. Plan for replacement cycles. Stay flexible.  ## FAQ ### What is the Raspberry Pi AI HAT+ 2? The AI HAT+ 2 is an add-on board for the Raspberry Pi 5 that includes a Hailo 10H neural processing chip with 8GB of dedicated RAM. It enables the Raspberry Pi to run generative AI models like Llama and Qwen locally, offloading inference from the main CPU while keeping the processor free for other tasks. The board costs $130 and provides approximately 40 TOPS of AI performance while consuming only about 3 watts of power. ### How does the Hailo 10H chip work? The Hailo 10H is a specialized neural processing unit (NPU) designed specifically for AI inference, not training. It accelerates the mathematical operations that deep learning models require, such as matrix multiplication and convolutions. The chip uses quantization techniques, converting models from 32-bit floating-point to 8-bit or 4-bit integer math, which makes models smaller and inference faster while consuming minimal power. It achieves 40 TOPS of throughput but is constrained to 3 watts of power draw, which limits how hard it can be driven compared to larger accelerators. ### What AI models can run on the AI HAT+ 2? The board can run language models up to about 2-3 billion parameters, including Llama 3.2 (1B and 3B versions), <a href="https://github.com/deepseek-ai/Deep Seek-R1" target="_blank" rel="noopener">Deep Seek-R1-Distill</a>, and various <a href="https://qwenlm.github.io/" target="_blank" rel="noopener">Qwen models</a>. It also excels at vision tasks with object detection models like YOLO and image classification models. However, larger models beyond 3-4 billion parameters become impractical due to the 8GB RAM constraint. Pre-compiled models are available in Hailo's model zoo, reducing the need for custom compilation for common use cases. ### Is the AI HAT+ 2 faster than a standalone Raspberry Pi 5? Actually, testing shows that a standalone Raspberry Pi 5 with 16GB of RAM often outperforms the AI HAT+ 2 for pure inference speed. The HAT's 3-watt power constraint limits how fast the Hailo chip can operate, and communication overhead between the main processor and accelerator adds latency. The real advantage of the HAT is that it frees the main CPU for other tasks while running inference, making it better for applications requiring parallel processing (like robotics or real-time control) rather than pure speed. ### How much power does the AI HAT+ 2 consume? The AI HAT+ 2 is limited to 3 watts of power draw, while the Raspberry Pi 5 main board can consume up to 10 watts. Combined, the system typically draws 8-10 watts under full AI inference load. This makes it exceptionally efficient compared to laptop GPUs (80-130 watts) or desktop graphics cards (300+ watts). The low power draw enables deployment in battery-powered, solar-powered, or thermally constrained environments where other hardware would be impractical. ### Should I buy the AI HAT+ 2 or a larger Raspberry Pi? It depends on your specific use case. If you need pure inference speed and flexibility, a Raspberry Pi 5 with 16GB of RAM ($120) often wins on both cost and performance. However, if you need the main CPU free for simultaneous tasks (robotics, real-time control), require extreme power efficiency, or are deploying at large scale where power costs dominate, the AI HAT+ 2 becomes economically superior. For a single hobby project, the standalone Pi is simpler. For commercial deployments of 100+ units, the HAT's efficiency advantages compound and justify the extra cost. ### How hard is it to set up and use the AI HAT+ 2? Physical setup takes about 15 minutes: plug the board into the GPIO header. Software setup (driver installation) is straightforward and documented, requiring another 15 minutes. Running pre-compiled models takes another 30 minutes. However, if you need to compile custom models, you'll need to understand neural network quantization, which adds complexity. Budget 1-2 weeks for a custom project if you're new to ML, or 3-6 hours if you're experienced with machine learning and Python. ### What's the difference between the AI HAT+ and AI HAT+ 2? The original AI HAT+ has a Hailo 8L chip with 13 TOPS and focuses on image processing tasks. It doesn't include onboard RAM, so it shares the Raspberry Pi's main memory. The AI HAT+ 2 upgrades to a Hailo 10H with 40 TOPS (about 3x more AI performance) and includes 8GB of dedicated onboard RAM, enabling it to run language models and other generative AI tasks. The original costs $70, while the AI HAT+ 2 costs $130. The original is adequate for image-only applications; the newer version is required for language models. ### Can I train AI models on the Raspberry Pi with the AI HAT+ 2? No, the Hailo HAT is designed for inference only. You can fine-tune models on a more powerful computer, then deploy the fine-tuned models to the HAT. Some quantization and optimization happens during model preparation. Full model training on the Raspberry Pi is impractical due to computational and memory constraints. Use the Pi for deployment and inference, not for training workflows. ### How does the AI HAT+ 2 compare to cloud APIs like OpenAI or Anthropic? Cloud APIs offer access to much larger models with better reasoning and capabilities, but they require internet connectivity, introduce network latency (50-200ms), incur per-request costs, and raise privacy concerns by sending data to external servers. The AI HAT+ 2 runs smaller models locally with instant response (20-100ms), costs nothing per inference, works offline, and keeps data on-device. Choose the HAT for applications requiring privacy, offline capability, high throughput, or deployment at scale. Choose cloud APIs for maximum capability or when you need state-of-the-art models without building custom inference infrastructure. ### What's the total cost to get started with the AI HAT+ 2? Minimal setup for experimentation: Raspberry Pi 5 4GB ($60) + AI HAT+ 2 ($130) + power supply ($15) + micro SD card ($15) = approximately $220. A more complete setup with case, cooling, and extras runs $250-300. For serious projects, add a dedicated USB camera ($30-60), storage ($50-100), and better power infrastructure, bringing total investment to $350-400. This is exceptionally affordable compared to dedicated machine learning hardware, which typically costs $500-2,000+. ### When will the AI HAT+ 2 become outdated? The hardware will likely remain useful for 3-5 years, but software improvements will be continuous. Hailo will add support for larger models, improved quantization techniques, and additional pre-compiled models over time. For personal projects, this timeline is acceptable. For commercial products, factor in a 2-3 year refresh cycle to maintain performance parity as competing hardware improves. The Raspberry Pi ecosystem tends to iterate quickly, so keep an eye on announcements for newer versions that may become cost-effective within 12-24 months.  ## Conclusion: The Practical Reality of Edge AI The Raspberry Pi AI HAT+ 2 represents something important: the democratization of edge AI hardware. Five years ago, running inference on dedicated silicon at the edge was a luxury for companies with serious budgets. You bought NVIDIA hardware or custom solutions. You hired specialized engineers. Projects cost tens of thousands of dollars before you even started. Now? **$130 gets you a board that's genuinely useful for a meaningful class of AI applications.** That's not revolutionary in the absolute sense. The Hailo chip isn't the fastest or most capable. The performance benchmarks show it's often beaten by alternatives. The integration complexity is real. But in the practical sense, it's significant. It means a solo developer can prototype edge AI products. A student can learn about neural accelerators without buying expensive equipment. A small company can deploy AI at the edge without massive capex. The opportunity isn't to build next-generation AI systems on this hardware. It's to build **practical applications for real problems where edge inference makes sense**: robotics, IoT, embedded systems, real-time processing, offline capability, privacy-critical applications. If you have a project that fits those constraints, the AI HAT+ 2 is worth serious consideration. If your problem requires large models, extreme performance, or frequent model updates, look elsewhere. The landscape will only get more interesting. Competitors will emerge. Prices will drop. Capabilities will expand. Within 18 months, you'll probably have better alternatives than what's available today. But the fundamental shift is already here: **edge AI is becoming mainstream infrastructure, not experimental luxury.** The Raspberry Pi AI HAT+ 2 is one concrete manifestation of that shift. Not the best tool for every job, but a genuinely useful tool for many jobs that previously had no good options. That's worth paying attention to, even if the hardware itself isn't revolutionary. <div class="runable-cta"> <p style="margin-bottom: 1rem; color: rgba(255,255,255,0.7); font-size: 15px;"><strong>Use Case:</strong> Automating documentation for your edge AI projects and generating reports on model performance across deployments.</p> <a href="https://runable.com" target="_blank" rel="noopener" class="cta-button">Try Runable For Free</a> </div>  --- ## Key Takeaways - AI HAT+ 2 provides 8GB RAM and Hailo 10H (40 TOPS) for $130, enabling local generative AI inference on Raspberry Pi 5 - Benchmarks reveal it's often slower than a standalone 16GB Pi 5 due to 3W power constraints, but it frees the main CPU for parallel tasks - Real advantage: simultaneous AI processing and CPU work for robotics, IoT, real-time systems where dual processing matters - At scale (100+ units), the HAT's 5-10x power efficiency advantage compounds into significant cost savings over 3-5 years - Practical models under 2-3B parameters work well (Llama 3.2, DeepSeek, Qwen); larger models become impractical - Edge-first infrastructure is shifting the AI landscape from cloud-centric to distributed inference, reducing latency and improving privacy ## Related Articles - <a href="https://tryrunable.com/posts/openai-s-250m-merge-labs-investment-the-future-of-brain-comp" target="_blank" rel="noopener">OpenAI's $250M Merge Labs Investment: The Future of Brain-Computer Interfaces [2025]</a> - <a href="https://tryrunable.com/posts/meta-compute-the-ai-infrastructure-strategy-reshaping-gigawa" target="_blank" rel="noopener">Meta Compute: The AI Infrastructure Strategy Reshaping Gigawatt-Scale Operations [2025]</a> - <a href="https://tryrunable.com/posts/why-ai-pcs-failed-and-the-ram-shortage-might-be-a-blessing-2" target="_blank" rel="noopener">Why AI PCs Failed (And the RAM Shortage Might Be a Blessing) [2025]</a> - <a href="https://tryrunable.com/posts/ai-pc-crossover-2026-why-this-is-the-year-everything-changes" target="_blank" rel="noopener">AI PC Crossover 2026: Why This Is the Year Everything Changes [2025]</a> - <a href="https://tryrunable.com/posts/best-computing-innovations-at-ces-2026-2025" target="_blank" rel="noopener">Best Computing Innovations at CES 2026 [2025]</a> - <a href="https://tryrunable.com/posts/ai-pcs-are-reshaping-enterprise-work-here-s-what-you-need-to" target="_blank" rel="noopener">AI PCs Are Reshaping Enterprise Work: Here's What You Need to Know [2025]</a>

