![Subtle Voicebuds: AI Earbuds That Transcribe Whispers and Loud Spaces [2025]](https://tryrunable.com/blog/subtle-voicebuds-ai-earbuds-that-transcribe-whispers-and-lou/image-1-1767573505924.jpg)
Subtle Voicebuds: AI Earbuds That Transcribe Whispers and Loud Spaces [2025]
Let me paint a picture. You're sitting in a library, and you need to send a quick email. Your hands are full, so you want to dictate it to your phone. But shouting "Hey Siri, compose an email" isn't exactly librarian-approved behavior. Now flip the scene. You're on the chaotic floor of a tech conference. There's ambient noise hitting 90 decibels. You try to voice-command your assistant again, but the background screaming drowns you out.
These are the scenarios that the Subtle Voicebuds are designed to handle.
When most people think about wireless earbuds, they picture devices optimized for music or calls. Subtle took a different path. They engineered earbuds specifically for voice input accuracy, making transcription the primary feature instead of a secondary bonus. The result is a pair of buds that claims to deliver five times fewer transcription errors than Apple's AirPods Pro 3 when paired with OpenAI's transcription engine.
But here's what makes this genuinely interesting: it's not about shouting louder or speaking more clearly. It's about intelligent audio processing that works in two opposite directions simultaneously.
TL; DR
- 5x fewer transcription errors than AirPods Pro 3 with OpenAI transcription according to Subtle's claims
- Works below whisper level: Custom AI model processes sub-audible speech patterns and muscle movements
- Handles extreme noise: Filters loud environments (90+ dB) so dictation works on conference floors or in traffic
- **17/month optional subscription for premium features
- On-device processing: Core transcription happens locally via machine learning, not cloud-dependent
- 1 year included access: Subtle iOS app subscription included with purchase (no Android yet)
- AI assistant integration: Company building proprietary voice assistant since "Hey Siri" requires Apple hardware

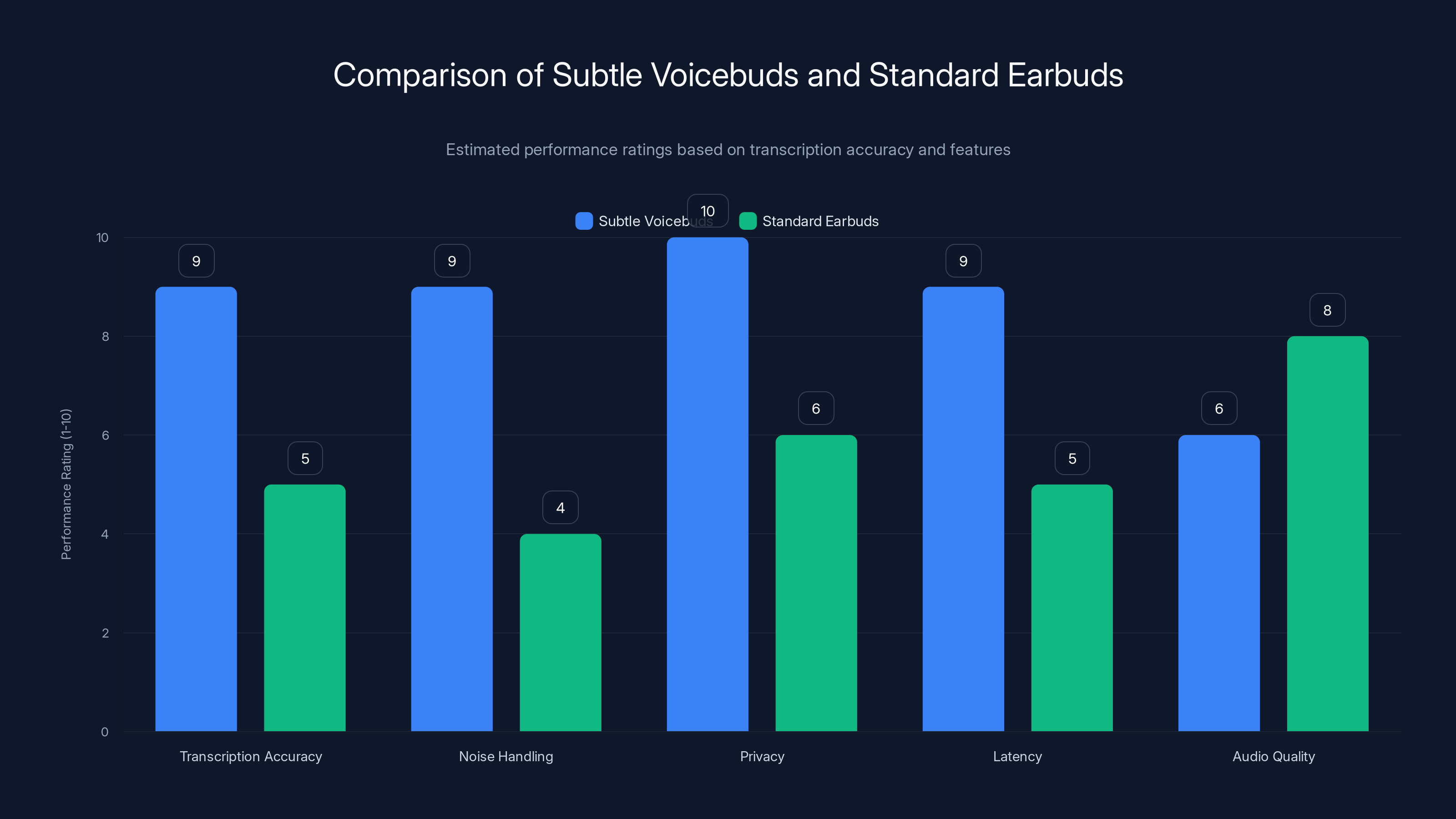
Subtle Voicebuds excel in transcription accuracy, noise handling, privacy, and latency due to their specialized AI and on-device processing, while standard earbuds perform better in general audio quality. Estimated data.
The Problem Voicebuds Solve: Why Voice Input Fails Today
Voice-to-text technology has improved dramatically over the past five years. But it's hit a plateau. The issue isn't accuracy in controlled conditions—modern speech-to-text engines work great when you're in a quiet room, speaking at normal volume, with a stable connection.
The real world doesn't work that way.
Consider the variables your phone's voice assistant encounters daily. Social situations make whisper-quiet dictation necessary. Your boss is on a call next to you. You're trying to respond to a message without announcing it to everyone. Meanwhile, your phone's microphone is receiving the exact same audio as the person next to you, who's audibly confused about why you're mumbling at your pocket.
Then there's the opposite problem: chaotic environments. Airports, construction sites, crowded events, restaurants during peak hours. When ambient noise exceeds a certain threshold—typically around 70-80 decibels—most voice assistants start failing. They either refuse to transcribe at all, or they capture every background sound and muddy the actual speech beyond recognition.
Neither scenario is acceptable if voice input is supposed to be a primary interface for your device. And yet, here we are. Most people still resort to typing because they know voice won't work reliably.
Subtle identified this market gap. The company realized that the traditional microphone-and-cloud-transcription approach has fundamental limitations. You can't improve a system that's fighting against physics. If a microphone picks up ambient noise equally well as human speech, no amount of processing on a remote server can reliably separate them.
So they rebuilt the problem from the ground up.
How Subtle's Custom AI Model Works
The magic isn't in a single breakthrough technology. It's in how Subtle combined multiple sensing and processing techniques into an integrated system.
The multi-sensor approach starts with understanding that human speech involves more than sound waves alone. When you whisper, your vocal cords are vibrating. Your jaw is moving. Your throat muscles are tensing. These physical signals are often clearer than the acoustic signal reaching a microphone, especially in noisy environments.
Subtle's earbuds use what's called bone-conduction sensing alongside traditional microphones. Bone conduction detects vibrations traveling through the human skull and jaw. When you whisper, these vibrations are pronounced and consistent. They're also mostly immune to ambient noise, because sound travels through solid material differently than through air. An ambulance siren won't vibrate your jawbone the same way your own speech does.
Combine bone-conduction data with accelerometer readings (detecting jaw movement) and traditional audio input, and you get a multi-modal signal. Now the AI model has three independent data streams pointing to the same linguistic content. If a microphone picks up background noise, the bone-conduction sensor might still be picking up clear speech vibrations.
The on-device AI model is trained specifically for this multi-modal data. Unlike cloud-based systems that were trained on millions of hours of clear, loud speech, Subtle's model was trained on whispered speech and noisy audio conditions. The difference matters.
A typical speech-recognition model learns statistical patterns from data. If it's never seen whispered audio during training, it has no learned representations for whispered speech. It essentially has to guess. Subtle trained their model explicitly on whispered audio, loud environments, and the combinations of these conditions.
The model runs on-device, in the earbuds themselves. This is important for two reasons. First, latency—you get transcription results immediately, without waiting for a round trip to the cloud. Second, privacy—your speech never leaves your device. For people dictating sensitive information, financial data, or personal thoughts, this local processing is a significant advantage.
Noise suppression as a separate process is also integrated. The earbuds don't just try to transcribe through noise. They actively filter it. This is different from noise cancellation for audio listening. Rather than trying to preserve music quality while removing background noise, voice transcription focuses purely on isolating human speech.
In a conference hall with 90 decibel background noise, the earbuds apply aggressive filtering aimed specifically at human speech frequencies. They're not worried about whether the filtered output sounds natural. They're optimized for transcription accuracy.
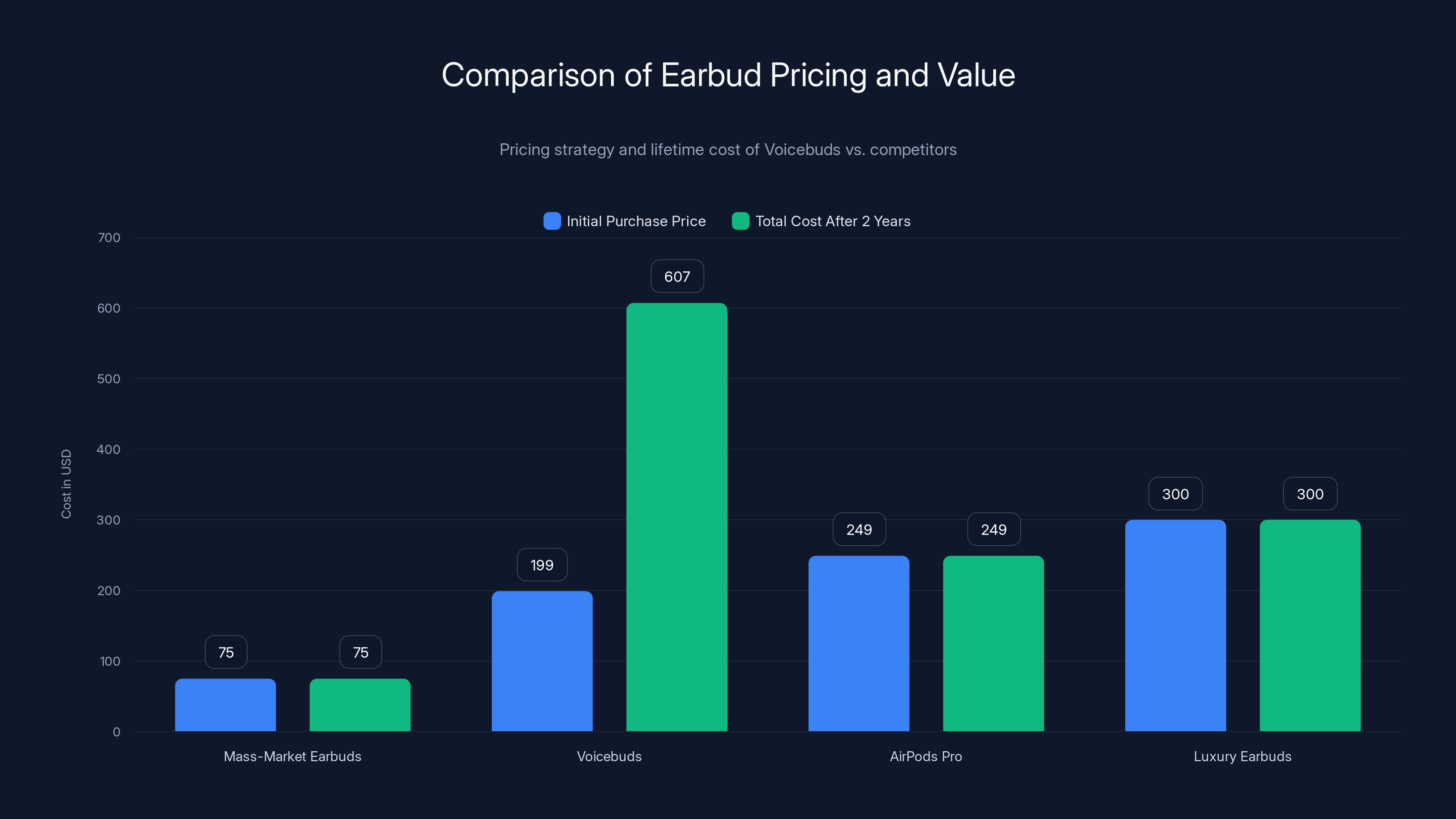
Voicebuds are priced in the premium segment at
Whisper-Level Transcription: The Party Trick That's Actually Useful
The headline feature is undeniably cool. You can dictate text while barely audible to the person next to you. During the CES demo, Subtle CEO Tyler Chen demonstrated dictating several sentences so quietly that remote viewers watching over video couldn't hear the words at all.
But cool factor aside, this has real utility.
Consider professional environments. A doctor dictating patient notes at a nursing station. A lawyer reviewing case details in a shared office. A therapist recording session notes without recording the actual session audio. In all these scenarios, whisper-level accuracy matters because it respects privacy and professional boundaries.
Or think about social situations. You're in a meeting and want to add something to your notes without interrupting. You want to capture an idea before you forget it, but announcing it verbally would derail the conversation. Whisper-level transcription handles this without drawing attention.
The technical challenge here is significant. Whispered speech lacks the acoustic energy that normal speech carries. When you whisper, you're not using your vocal cords to generate sound through air. Instead, you're relying on air friction against the vocal tract to create turbulent noise. The acoustic signal is fundamentally different from normal speech, and it's much quieter.
Bone-conduction sensing becomes crucial here. Even though you're not producing much sound, your vocal cords are still vibrating. Your jaw is still moving in the speech patterns. These physical signals remain clear even as the acoustic signal drops below the hearing threshold.
Subtle's AI model learns to reconstruct full-volume speech patterns from these subtle physical cues. It's similar to how a deaf person can read lips. A visual signal alone (lip movements) can convey the full content of speech without sound. The earbuds are using physical signals (bone conduction plus jaw movement) to decode speech content without relying on acoustic amplitude.
The 5x fewer transcription errors claim is specifically against "AirPods Pro 3 with OpenAI transcription." This is an important qualifier. Apple's earbuds aren't optimized for whisper-level transcription. They're general-purpose audio devices with transcription as a side feature. Comparing Voicebuds against them is a bit like comparing a specialized microphone to a general-purpose one. The specialized device wins in its specific use case, but that doesn't necessarily mean it's better overall.
Still, the margin matters. If the error rate is truly 80% lower (5x fewer means 1/5 the errors), that's significant even accounting for the comparison bias.
Loud Environment Handling: The Opposite Challenge
If whisper transcription is one extreme, loud environment transcription is the other. And in some ways, it's the harder problem.
When ambient noise exceeds about 80 decibels, most voice-input systems degrade rapidly. Your phone's microphone is picking up multiple sound sources simultaneously. There's the speaker (you), the air conditioning, nearby conversations, traffic outside, the ringing bell on a door. All of this mixes into a single audio stream.
The traditional approach is noise suppression. You apply signal processing to reduce non-speech frequencies. The problem? Human speech overlaps significantly with environmental noise in the frequency domain. A car horn and a human vowel might both contain energy in the 200-500 Hz range. You can't completely separate them without also removing part of the speech.
Subtle's approach is more sophisticated. Rather than trying to surgically separate frequencies, they use context and pattern recognition. The AI model recognizes that certain audio patterns are consistent with human speech and certain patterns are not. It prioritizes the speech patterns and de-emphasizes others.
Bone conduction is again crucial here. When you speak in a loud environment, your bone-conduction signal remains relatively clean. The confetti cannon going off around you doesn't vibrate your jaw. So even when the microphone is overwhelmed with noise, the bone-conduction sensor is delivering a clear, high-SNR (signal-to-noise ratio) signal representing your actual speech.
The accelerometer adds another layer. It detects the rhythmic jaw movements of speech. In a noisy environment, these movements are one of the clearest indicators that the person is actually talking versus just standing there.
Combine these three signals—microphone, bone conduction, jaw movement—and the AI model can extract speech content even when ambient noise is 10-15 dB louder than the speech itself. That's a harsh condition. In traditional audio terms, a -10dB SNR means the noise is ten times more powerful than the signal. Yet speech intelligibility can still be extracted.
During the demo, this was tested on a conference floor where ambient noise hit 90+ decibels. The earbuds successfully transcribed dictation that would've been impossible on standard voice assistants.

Hardware Design: More Than Just Looks
Voicebuds are small, black buds with a sleek design. They're not radically different looking from any other modern earbuds. But the engineering underneath is specialized.
The multi-sensor array requires different hardware than a standard earbud. You need microphones, yes, but also accelerometers and bone-conduction sensors. Fitting all this into a package the size of AirPods demands thoughtful miniaturization.
Microphones are actually multiple units. The earbuds feature a multi-mic array—meaning several microphones positioned in different locations within the earbud housing. This allows for directional audio processing. Microphones closer to your ear canal primarily pick up your speech. Microphones on the outer surface pick up a mix of your speech and environmental noise. By comparing signals from these different positions, the system can infer which sound is "nearby" (your voice) versus "far away" (background noise).
This is a classic technique in audio engineering, but it requires precise placement and careful acoustic design. The earbud housing has to be engineered so that different microphone positions actually receive meaningfully different acoustic information.
Accelerometers measure vibration. The earbuds include accelerometers to detect jaw movement and vocal cord vibration. These sensors are sensitive but also need to filter out vibrations from your movement (walking, head turning) versus speech-specific vibrations.
Bone-conduction sensors are a bit different from typical transducers. Standard bone conduction speakers create vibrations that your ear perceives as sound. Voicebuds are doing the reverse—using vibrations to detect speech signals. The engineering here is about sensitivity and specificity. You want to detect the fine vibrations of speech without picking up gross movements of your head or body.
Active noise cancellation is included, though Subtle is understandably cautious about this. They know they can't match the ANC performance of Sony or Apple's premium earbuds. But they don't need to, not for their use case. Voicebuds' "noise cancellation" is optimized for speech isolation, not for listening to music in a noisy environment. If you want to cancel external noise so you can hear music clearly, you'd pick different earbuds. If you want to record clean speech while surrounded by noise, Voicebuds handle this well.
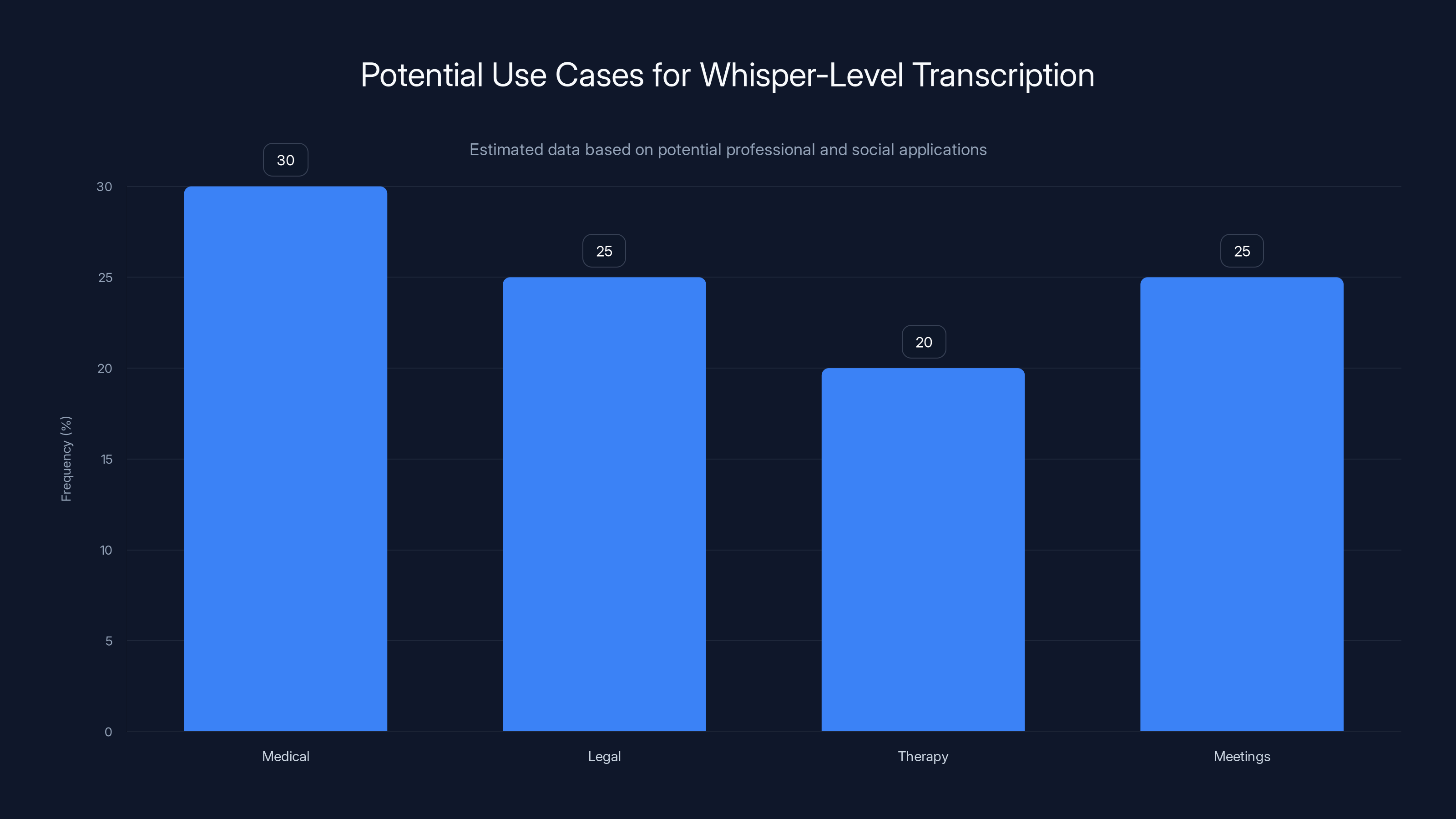
Whisper-level transcription is estimated to be most frequently used in medical settings, followed by legal, therapy, and meeting environments. Estimated data based on potential applications.
The Subscription Model: Premium Features and Trade-offs
This is where the business model reveals itself. Voicebuds cost
What's included with the purchase? One year of access to the Subtle app for iOS. This includes basic transcription, voice commands, and access to the AI assistant Subtle is developing. What's not included without the subscription?
Instant dictation is the premium feature. Without it, dictation is transcribed on-device but stored locally. You can access it later, but there's a slight delay. Instant dictation presumably streams results to your device in real-time as you speak.
Transcription without looking suggests an enhanced experience where you can trigger transcription and receive results without checking your phone screen. This could be valuable in situations where you need to focus on something else.
After the first year, the subscription is
Is this justified? It depends on how valuable those premium features are and whether Subtle can justify the infrastructure cost. Cloud transcription services (like OpenAI's) do cost money, so Subtle does have real costs to recoup. But the core transcription is on-device, so cloud costs should be minimal unless premium features heavily rely on the cloud.
This pricing structure is risky. Hardware startups live or die by ecosystem adoption. Asking early adopters to pay a monthly subscription on top of the hardware cost creates friction. However, if the transcription quality genuinely is 5x better than alternatives, users who rely on voice input daily might accept the subscription.

Competitive Landscape: Who Else Is Solving This Problem
Voicebuds aren't entering a vacuum. The space of voice-first earbuds is nascent but growing.
The WHSP ring mentioned in the original coverage showed up at CES 2024 with a similar thesis: whisper-level voice input. But rings have different form factors and less room for sensors. WHSP was innovative but also limited in scope.
Notebuds One is another competitor mentioned. This is actually a product from Knowles Precision Instruments, a company that specializes in micro-electromechanical systems (MEMS). Notebuds are optimized for notetaking via speech. They also offer on-device transcription and are priced around the same point as Voicebuds.
Existing mainstream earbuds from Apple, Google, and Samsung all support voice input, but voice transcription is auxiliary to their core music and calling functionality. They're good at voice commands ("Hey Siri") but not specialized for accurate transcription.
Enterprise solutions exist for specific industries. Medical transcription headsets and dictation devices from companies like Philips and Olympus are purpose-built but expensive and require proprietary software.
Subtle's angle is unique: consumer-priced earbuds with enterprise-level transcription accuracy. If they execute, they're addressing a genuine need that isn't currently well-served.
Android Support and iOS Ecosystem Lock-in
One significant limitation: Voicebuds are iOS-only at launch. There's no Android support.
This is a major decision. Android represents roughly half the global smartphone market. By not supporting Android, Subtle is cutting their addressable market in half, at least initially.
Why would they make this choice? Several possible reasons. First, iOS development is often simpler than Android because Apple controls the entire ecosystem. Fewer device variations, fewer OS versions in the wild, more control over the experience. For a startup with limited resources, focusing on iOS allows deeper integration and better quality control.
Second, Apple's user base has demonstrated higher willingness to pay for premium features. AirPods Pro are expensive, and they sell incredibly well. Android users, on average, spend less on accessories.
Third, there's an irony: Voicebuds don't support "Hey Siri" because that requires Apple's proprietary chip. So they can't fully integrate with Apple's ecosystem anyway. But iOS users can still use Voicebuds with Siri voice commands, just not the wake-word activation. Subtle is building its own AI assistant, so over time, iOS users might have a compelling reason to use Subtle's voice interface instead of Siri.
Eventually, Subtle will need to support Android to reach scale. The question is whether their tech advantage is strong enough to survive competition in a more open ecosystem. iOS-only at launch is a reasonable startup decision but a long-term limitation.

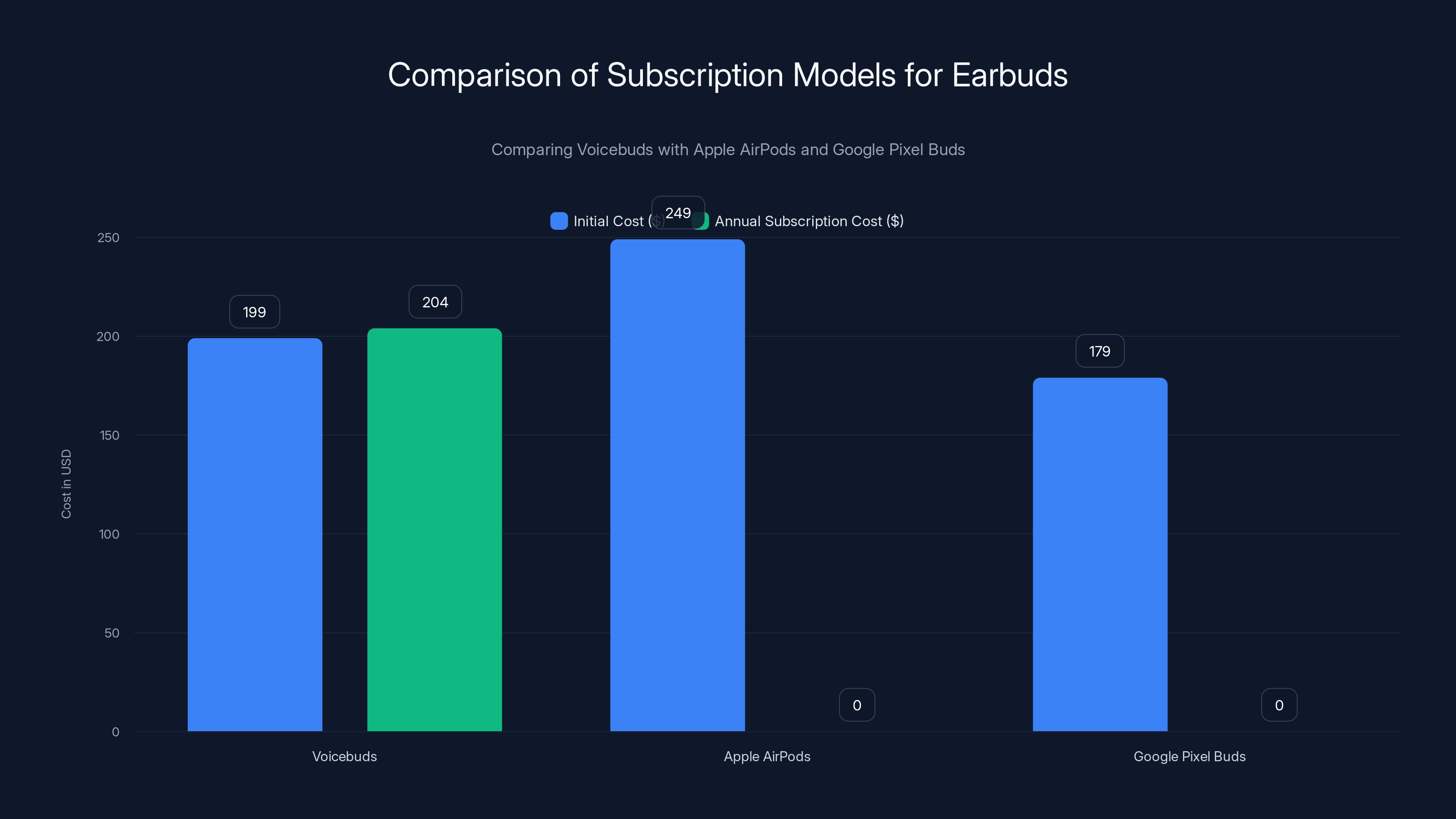
Voicebuds have a competitive initial cost but require a $204 annual subscription for premium features, unlike Apple and Google's offerings which include features in the initial purchase price.
Real-World Use Cases: Where Voicebuds Excel
To understand the actual value of Voicebuds, it helps to map out scenarios where their specialized capabilities matter.
Medical and legal dictation is an obvious use case. Doctors dictate clinical notes constantly. Lawyers record case memos. The accuracy advantage of Voicebuds could significantly reduce the need for post-dictation editing. If the error rate is truly 5x lower, that's hours of saved editing time per month for heavy dictation users.
Journalist interviews represent another scenario. A journalist recording notes at a loud event. Without Voicebuds, they'd either type notes manually or rely on heavily transcribed audio that requires editing. With Voicebuds, they get accurate transcription in real-time, even at loud venues like concerts or stadiums.
Accessibility applications are significant. For people with mobility limitations, voice input is essential. Standard voice assistants work in controlled conditions but fail when the person needs them most—in chaotic, unpredictable real-world environments. Voicebuds' reliability in loud spaces could be genuinely transformative for accessibility.
Academic research and documentation benefits from accurate real-time transcription. Researchers can capture ideas immediately without switching contexts. They can transcribe interviews with accuracy sufficient to avoid extensive post-processing.
Hands-free documentation in manufacturing or field work is another avenue. A technician documenting repairs while wearing work gloves and safety equipment. A construction supervisor recording site notes. These use cases demand reliable hands-free input in noisy environments.
Personal assistant use becomes viable when transcription is reliable. If you're not worried about errors, you can dictate longer passages, messages, and notes without verification. This saves time and mental effort.
Each of these scenarios represents a user willing to pay for accuracy and reliability beyond what mainstream earbuds offer.
Technical Limitations and Realistic Expectations
For all their promise, Voicebuds face some hard limits.
Audio quality for music and calls is likely adequate but not exceptional. The specialized sensors optimized for voice input don't necessarily translate to better overall audio. Subtle's CEO acknowledged this would be a challenge. Don't expect AirPods Pro-level sound quality. These are voice-first devices, and that implies audio quality is acceptable, not excellent.
Processing power and latency must be managed. Running an AI model on-device requires significant compute. Most earbuds operate at maybe 20-100 MIPS (millions of instructions per second) of processing power. Transcription models typically need more. Either Subtle made aggressive optimizations to their model, or they're pushing the limits of what these devices can do. This might introduce latency or battery drain that users will notice.
Battery life is a question mark. The Voicebuds haven't published battery specifications. If the on-device AI model consumes significant power, battery life could be significantly shorter than comparable earbuds. That's a real limitation. Nobody wants earbuds that die after 3 hours of usage.
Environmental variability is another factor. Bone-conduction sensing and accelerometer-based jaw detection depend on individual anatomy. Different people have different bone-conduction properties, different jaw sizes, and different speech patterns. A model trained on a diverse population might not work perfectly for everyone. Some users might experience degradation in transcription accuracy compared to others.
Microphone quality is constrained by physics. Even with multiple microphones, earbuds are limited in their ability to isolate speech in extreme noise. If someone is speaking at 60 dB and ambient noise is 95 dB, no amount of processing fully recovers the signal. The claim about 90+ dB environments is impressive, but there are limits. At some noise level, even Voicebuds will degrade.

The AI Model Training Challenge
Building a custom AI model for this application is non-trivial. Subtle had to solve several problems that off-the-shelf models don't address.
Whisper-level training data is hard to come by. Large speech-recognition datasets are built on normal-volume speech because that's what's easiest to collect. Whispered speech is less common in public datasets. Subtle likely had to collect their own whisper-level speech data, or augment existing datasets with synthetic whispered speech.
Noise-robust training data requires recording real speech in genuinely noisy environments. Not simulated noise added to clean speech, but actual recordings from places like conferences, airports, and streets. The more diverse the noise conditions in the training data, the better the model generalizes. Subtle invested significant effort here.
Multi-modal training is complex. Training a model on bone-conduction data is unusual. Most models train on a single modality (audio). Training on bone conduction, audio, and accelerometer data simultaneously requires careful dataset collection where all three modalities are captured synchronously.
Model compression for on-device inference is an art form. The model needs to be small enough to fit on an earbud's processor and fast enough to produce results quickly. This likely involved significant quantization and pruning—techniques that reduce model size but also reduce accuracy. Finding the right trade-off is non-trivial.
The fact that Subtle achieved this suggests they either invested heavily in machine learning expertise, or partnered with companies that provide model compression and deployment services. This is a core strength that's hard for competitors to replicate quickly.
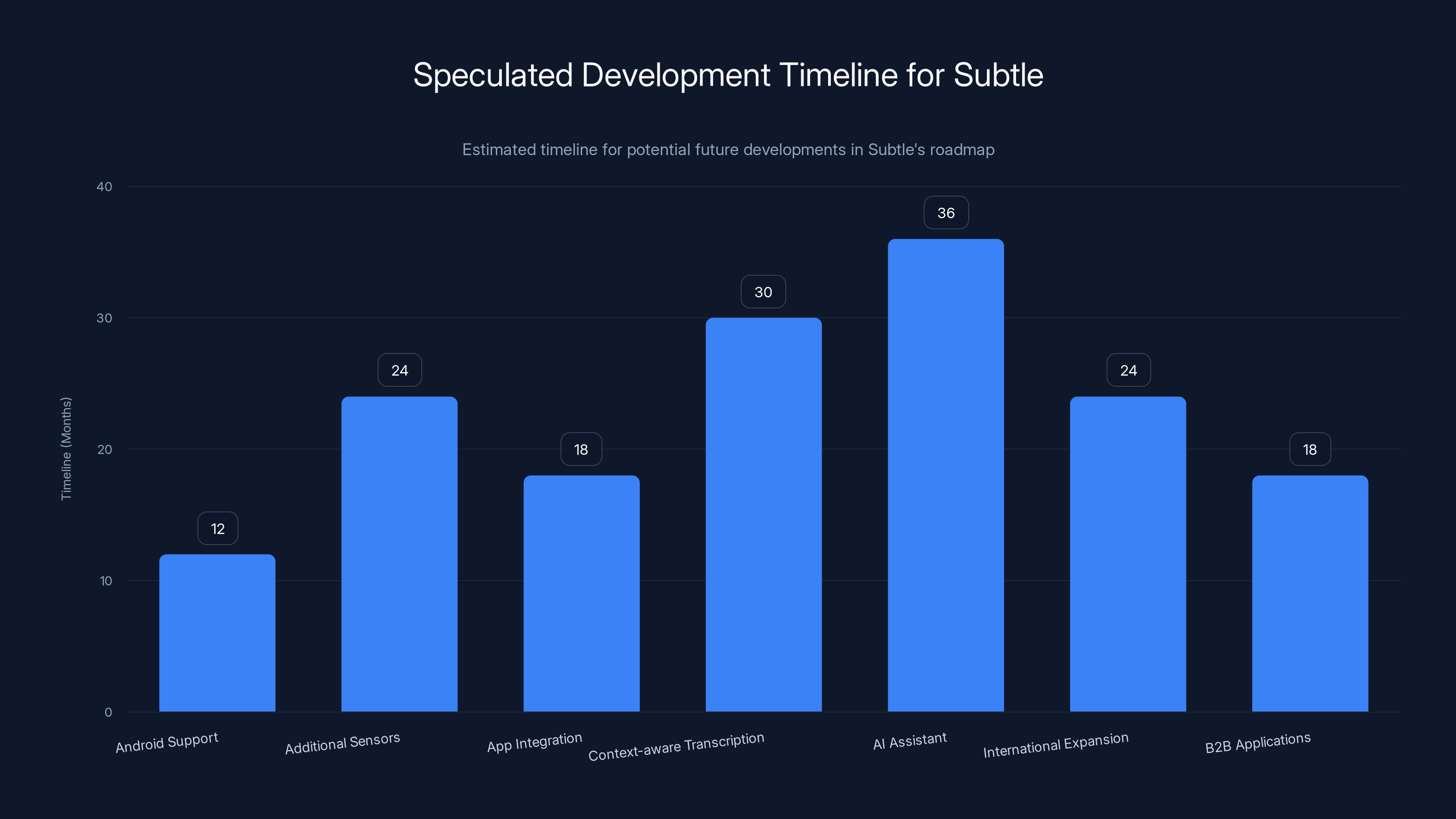
This chart estimates the timeline for various potential developments in Subtle's roadmap, with Android support expected within 12-18 months and AI assistant development taking up to 36 months. Estimated data.
Market Positioning and Pricing Strategy
At $199, Voicebuds are positioned as a premium product. They're not a mass-market device. They're explicitly targeting users who rely on voice input and are willing to pay for accuracy.
This positioning has implications. Mass-market pricing for earbuds is
The subscription model (
However, for users dictating hundreds of emails, messages, and notes monthly, the productivity gains might justify the cost. If Voicebuds save even 5 hours per month of transcription editing and correction, that's valuable for professionals billing by the hour.
Subtle is banking on this value proposition. They're not trying to sell to everyone. They're trying to sell to power users of voice input who can justify premium pricing based on productivity gains.

Future Development and Roadmap Speculation
Where does Subtle go from here? Some educated guesses based on what's typical for hardware startups.
Android support is probably coming. The iOS-only launch is a pragmatic startup decision, but Android support will be necessary for scale. Expect Android support within 12-18 months, likely with initial limitations until the team has time to optimize.
Additional sensors might appear in future generations. If the current model proves successful, Subtle could add more advanced sensors. EMG (electromyography) sensors that detect muscle signals from speech might improve accuracy further. Thermal sensors could detect the temperature changes in your neck during speech.
Integration with popular apps is a natural evolution. Instead of transcription feeding into the Subtle app first, it could integrate directly with Gmail, Slack, Notion, and other productivity apps. This would require APIs and partnerships but would increase the device's utility.
Context-aware transcription could improve accuracy by understanding what you're transcribing. If the earbuds know you're dictating a medical note, the model could prioritize medical terminology. If you're transcribing a meeting, it could optimize for recognizing multiple speakers.
Proprietary AI assistant development is already underway. As Subtle builds out their own voice assistant, they could offer a compelling alternative to Siri, Google Assistant, and Alexa for users who prioritize accuracy.
International market expansion will be important. The current model is English-only (implicitly). Supporting multiple languages will expand the addressable market.
B2B applications could be significant. Selling Voicebuds directly to enterprises—legal firms, medical practices, transcription companies—could generate meaningful revenue. Bulk licensing and enterprise pricing structures could emerge.
Privacy Implications and On-Device Processing Benefits
The on-device processing approach to transcription has significant privacy implications that deserve emphasis.
When you dictate text to your phone normally, the audio is often sent to cloud servers. Apple claims some processing happens on-device, but significant processing happens remotely. Google's Pixel Buds also rely heavily on cloud processing. Microsoft Teams transcription definitely goes to the cloud. Each of these companies has privacy policies explaining what they do with the audio data, but the data is leaving your device.
With Voicebuds, the core transcription happens entirely on the earbuds themselves. Your speech never leaves your device. This has profound implications for privacy:
HIPAA compliance becomes easier. Healthcare providers can use Voicebuds to transcribe patient interactions without worrying about cloud transmission of protected health information. The data is created and processed locally.
Attorney-client privilege is preserved. Lawyers can use Voicebuds to record client conversations and transcribe them without third-party access to the audio or transcript.
Trade secret protection is stronger. Companies can use Voicebuds for internal dictation without exposing confidential information to cloud services.
Personal security is enhanced. If you're dictating sensitive personal information—passwords, account numbers, health details—they never transit the internet.
This privacy advantage is significant and could be a major differentiator over time. As privacy concerns grow, enterprises will pay a premium for devices that keep sensitive information local.
However, there's a catch. The premium features in Subtle's subscription likely require cloud processing. "Instant dictation" probably means streaming results to your phone in real-time, which requires cloud infrastructure. "Transcription without looking" might involve cloud processing to generate summaries or structure notes. So while basic transcription is private, enhanced features might not be.
Subtle should be transparent about which features are local and which require cloud transmission. This transparency will be crucial for enterprise adoption.

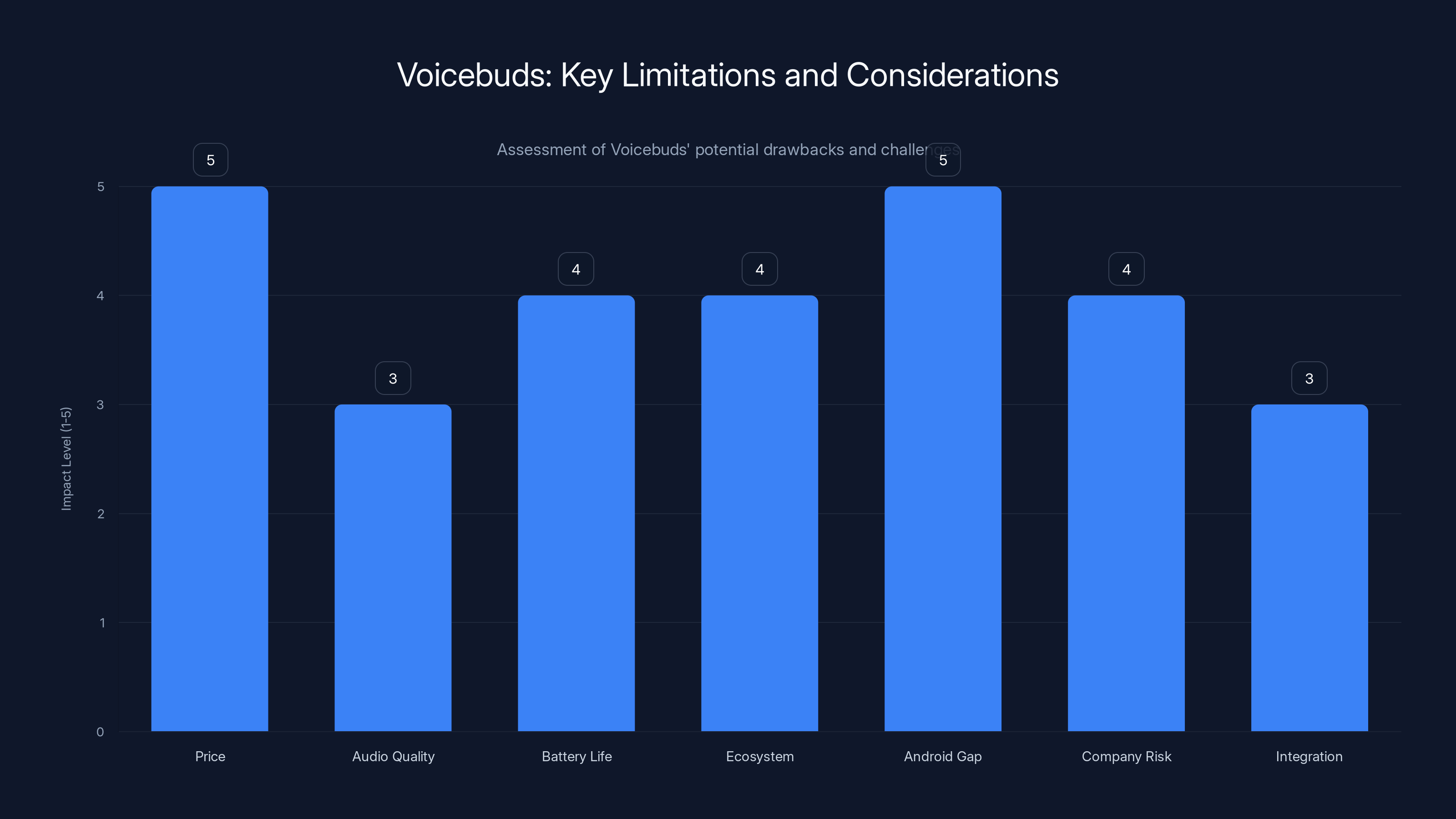
Voicebuds face significant challenges, particularly in price and Android compatibility, which may deter potential users. Estimated data based on qualitative assessment.
Competitive Response and Industry Adoption Signals
How will the industry respond to Voicebuds?
Apple's position is interesting. AirPods Pro have transcription capability but it's not optimized for it. Apple could easily improve their on-device transcription models for future AirPods iterations. If they did, they'd have a significant advantage due to their scale and existing user base. However, Apple's general strategy is about integration with iOS, not specialized products for specific use cases. Voicebuds might not warrant a response if Apple's addressable market for premium earbuds is already saturated.
Google's strategy involves their Pixel Buds, which are increasingly competitive. Google has strength in machine learning and speech recognition. If they prioritized voice transcription accuracy, they could potentially match or exceed Voicebuds. But Google's focus seems to be on general-purpose earbuds with good audio quality and Google Assistant integration. Specialized transcription might not be their priority.
Sony and Bose are focused on audio quality and noise cancellation for listening. They're unlikely to see Voicebuds as a direct threat because they're not competing in the transcription-first space.
Enterprise transcription companies like Otter.ai might view Voicebuds as complementary or competitive. Otter specializes in recording and transcribing meetings. If Voicebuds become popular, Otter could integrate with them as the capture device, or they might build their own specialized earbuds.
Accessibility advocates will probably embrace Voicebuds enthusiastically. If the product delivers on its promises, it could genuinely improve accessibility for people who rely on voice input.
Overall, the competitive response is likely to be incremental rather than dramatic. The specialized transcription market isn't large enough to disrupt the entire earbud industry. But it's large enough to support a successful niche product.
The Honest Assessment: What's the Catch
Every product has trade-offs. What are Voicebuds' real limitations?
Price is significant.
Audio quality is probably just okay. You're getting specialized voice hardware, not high-fidelity audio hardware. If you care about music quality, there are better options.
Battery life is unknown. Running an AI model on-device probably consumes significant power. Real-world battery life might disappoint.
Limited ecosystem right now. The Subtle app and AI assistant are new. They lack the polish, integration, and features that Siri, Google Assistant, and Alexa have built over years.
Android gap is real. For half the smartphone market, Voicebuds simply aren't available.
Unproven company. Subtle is a startup without a track record. Hardware startups fail regularly. There's genuine risk that Subtle won't support the product long-term or that the hype exceeds reality.
Integration with existing workflows requires adoption. Even if Voicebuds are great at transcription, you need software that leverages that transcription well. If Subtle's app is clunky, the hardware advantage doesn't matter.
For users who heavily rely on voice input in professional contexts, these trade-offs might be acceptable. The transcription accuracy advantage justifies the cost and ecosystem immaturity. But for casual users, mainstream earbuds from Apple or Google are safer bets.

The Broader Trend: Voice-First Computing
Voicebuds fit into a larger trend. Computing interfaces are increasingly voice-first.
Smartphones were touch-first. Wearables are pushing towards voice-first because you're often doing something else (walking, driving, cooking) and need hands-free interaction. Voice is the natural interface for wearables.
But voice-first computing has always faced a fundamental problem: accuracy. When text is your primary input medium, you can see what you're typing and correct mistakes instantly. When voice is your primary input, you either accept errors or have awkward correction loops.
Voicebuds are a bet that specialized hardware can overcome this accuracy problem. If they're right, voice input becomes more viable as a primary input method, not just a convenience feature.
This could have implications beyond earbuds. If voice input becomes reliable and accurate, it changes what's possible in wearables, smart home devices, and hands-free computing overall. Voicebuds might be a small piece of a larger shift towards voice-first interfaces.
However, this trend is moving slowly. Voice adoption has been "coming soon" for decades. The prediction that voice will become primary is optimistic. Text and touch interfaces have significant advantages for complex input tasks. Complete replacement is unlikely.
More likely, voice becomes the primary input for specific use cases (dictation, notetaking, voice commands) while text remains primary for other use cases (composing long documents, detailed editing, precise input). In that mixed-modal future, specialized voice hardware like Voicebuds has a clear role.
Practical Buyer's Guide: Should You Get Voicebuds
Who should actually buy Voicebuds?
Strong candidates:
- Medical professionals who dictate clinical notes daily
- Lawyers who record case memos and client conversations
- Journalists and researchers who transcribe interviews frequently
- Accessibility users who rely entirely on voice input
- Content creators who record voice notes for later transcription
- Anyone who dictates more than 30 minutes of content per day
Weak candidates:
- Casual users who dictate occasionally
- People who want great audio quality and rarely use voice input
- Android-only users (not supported yet)
- Budget-conscious buyers
- People in environments where earbuds are inconvenient or unsafe
Conditional candidates:
- Apple users who already use Voice Memos or Siri heavily
- People interested in voice assistants willing to try a new platform
- Privacy-conscious users who want local processing
If you're in a strong candidate category and frustrated with transcription errors in your current workflow, Voicebuds are worth considering. If you're in a weak candidate category, the cost probably isn't justified.
The real test will be long-term user retention. Are people still using these in six months? Are they subscribing after the first year? Those metrics will tell us whether the value proposition is real or marketing hype.

Conclusion: A Specialized Product for a Specific Problem
Voicebuds represent something refreshing in the earbud market: hardware purpose-built for a specific problem rather than general-purpose earbuds with transcription bolted on.
The company identified a legitimate gap in the market. Voice input fails in two specific scenarios: too quiet (whisper) and too loud (noisy environments). Mainstream earbuds don't handle these well because they're not optimized for them. Subtle built specialized hardware and AI software to address these gaps.
The technical approach is sound. Multi-modal sensing combined with specialized AI training is a credible way to improve voice transcription accuracy. The on-device processing and bone-conduction sensing represent genuine innovation.
The pricing is premium but defensible if the accuracy claims are real. The subscription model is less defensible—it creates friction and ongoing costs that might deter adoption. The iOS-only launch is pragmatic but limits the addressable market.
The real question is whether the transcription accuracy really is 5x better than AirPods Pro in real-world use. That claim, if true, changes everything. If false, the product becomes just another pair of specialized earbuds without a strong value proposition.
What happens over the next year will determine if this is a genuine breakthrough or a clever marketing angle for a niche product. Time will tell whether voice-first computing is actually coming or just perpetually around the corner.
One thing's certain: if you dictate more than anyone should have to, Voicebuds deserve a hard look.
FAQ
What are Subtle Voicebuds and how do they differ from regular earbuds?
Subtle Voicebuds are specialized wireless earbuds designed primarily for accurate voice transcription in challenging audio environments. Unlike general-purpose earbuds that treat transcription as a secondary feature, Voicebuds use a custom AI model trained specifically for whisper-level and high-noise transcription. They feature multi-sensor technology including bone-conduction sensing, accelerometers, and multiple microphones to detect speech patterns that standard earbuds miss. The key difference is intentional optimization for transcription accuracy rather than audio quality or general-purpose listening.
How does the custom AI model achieve better transcription accuracy than standard voice assistants?
Subtle's AI model was trained specifically on whispered speech and noisy audio conditions, which standard speech-recognition models rarely encounter in typical training datasets. The model processes multi-modal sensor data simultaneously: acoustic signals from microphones, bone-conduction vibrations from your jaw and throat, and accelerometer readings detecting jaw movement. This multi-modal approach allows the system to reconstruct speech content even when individual sensor streams are degraded by noise or quietness. The on-device processing eliminates cloud latency and enables real-time optimization for the specific acoustic conditions around the wearer. Standard voice assistants rely on single-modal audio processing and cloud transcription, making them vulnerable to noise and quiet speech.
What are the benefits of on-device AI processing versus cloud-based transcription?
On-device processing offers several critical advantages. First, privacy: your speech never leaves your device, making Voicebuds suitable for HIPAA-compliant medical dictation, attorney-client privileged conversations, and confidential business documentation. Second, latency: transcription results appear immediately without waiting for network round-trips. Third, reliability: transcription continues working even without internet connectivity. Fourth, data security: no transcript of sensitive information is stored on remote servers. The trade-off is that on-device models must be highly optimized and compressed, potentially limiting their sophistication compared to large cloud-based models. Subtle appears to have solved this through specialized model training and aggressive optimization techniques.
How do Voicebuds handle whisper-level transcription that other earbuds cannot?
When you whisper, acoustic signal energy drops dramatically because you're suppressing vocal cord vibration. However, bone-conduction signals remain clear and consistent. Your jaw still moves through speech patterns, and your vocal tract still generates subtle vibrations. Voicebuds detect these physical signals through bone-conduction sensors that measure vibrations traveling through your skull and accelerometers that measure jaw movement. The AI model learned to reconstruct full-volume speech from these subtle physical cues, similar to how lip-reading decodes speech from visual signals alone. The earbuds can successfully transcribe speech so quiet that observers cannot hear it at all—essentially decoding "sub-audible" speech patterns from their physical signatures.
Why do Voicebuds require a subscription, and what features does it include?
Voicebuds include one year of Subtle's iOS app subscription with purchase ($17/month after that). The subscription provides access to premium transcription features including instant dictation (real-time transcription streaming to your device) and the ability to transcribe notes without viewing your phone screen. Cloud infrastructure supporting these premium features likely justifies the subscription cost. However, the basic transcription that makes Voicebuds valuable—the core voice-to-text accuracy in whisper and loud environments—works on-device without requiring the subscription. This means you get legitimate value from the hardware alone, and premium features add convenience rather than core functionality.
What are the limitations of Voicebuds compared to mainstream earbuds like AirPods Pro?
Voicebuds make significant trade-offs in exchange for transcription specialization. Audio quality for music and calls is likely adequate but not exceptional, lacking the high-fidelity drivers that audiophile earbuds offer. Battery life is unspecified but potentially reduced due to on-device AI processing consuming significant power. The Subtle iOS app and proprietary AI assistant are early-stage and lack the polish and integration of mature platforms like Siri. Voicebuds don't support "Hey Siri" wake-word activation because that requires Apple's proprietary chip. They're currently iOS-only with no Android support. These limitations matter less if you're a power user of voice dictation and more if you want general-purpose earbuds.
Are Voicebuds suitable for medical and legal professionals?
Voicebuds are exceptionally well-suited for medical and legal professionals. Doctors can dictate clinical notes below whisper level without alerting patients or colleagues. Lawyers can record and transcribe client conversations with confidence that protected information remains completely local, satisfying attorney-client privilege and privacy requirements. The on-device processing is particularly valuable in healthcare and legal contexts where HIPAA and confidentiality regulations require avoiding cloud transmission of sensitive content. If the claimed 5x error reduction versus AirPods Pro is accurate, the productivity gains in transcription editing alone could justify the $199 hardware cost and subscription fees. This is likely Subtle's strongest initial market segment.
When will Voicebuds support Android devices?
Subtle has not announced Android support at launch or provided a timeline. iOS-only development is a practical choice for startups with limited resources but represents a significant market limitation. Android represents roughly 50% of global smartphone users. Based on typical startup hardware roadmaps, Android support probably arrives within 12-18 months but requires significant engineering work. The iOS app must be rebuilt for Android, sensors must be validated across diverse Android device hardware, and the AI model might require retraining for different acoustic environments if Android devices have meaningfully different microphone hardware. For Android users considering Voicebuds, the realistic expectation is waiting 12+ months for support.
How does Voicebuds' noise handling compare to active noise cancellation in premium earbuds?
Voicebuds' noise handling is fundamentally different from active noise cancellation (ANC) found in Sony WH-1000XM5 or AirPods Pro. Traditional ANC aims to preserve audio quality while reducing ambient noise, useful for listening to music in noisy environments. Voicebuds' noise suppression is optimized exclusively for human speech isolation during transcription. The earbuds aggressively filter non-speech frequencies without concern for audio quality, since the goal is transcription accuracy, not musical fidelity. This focused optimization allows Voicebuds to handle extremely noisy environments (90+ decibels) where traditional ANC would struggle. However, if you want to listen to music with noise cancellation, Voicebuds probably won't match the performance of dedicated ANC earbuds. This is an intentional trade-off prioritizing voice transcription over audio listening.
What privacy protections do Voicebuds provide compared to cloud-based transcription services?
Voicebuds offer superior privacy through on-device processing. When you dictate to Siri, Google Assistant, or cloud-based transcription services, your audio is transmitted to remote servers where it's processed and stored temporarily or permanently. Even with privacy policies promising deletion, the audio leaves your device. Voicebuds process the core transcription entirely on the device itself. Your speech never leaves your earbuds; only the final text can optionally be sent to your phone or cloud services you explicitly choose. This local-first architecture is particularly valuable for dictating medical information, legal conversations, trade secrets, or any sensitive content where transmission to a third party's servers represents unacceptable risk. The privacy advantage is the strongest differentiator against established competitors.
Quick Tips for Voice Input Optimization
Fun Fact

Key Takeaways
- Voicebuds use multi-sensor AI to transcribe speech at whisper level and in 90+ decibel noise environments, achieving claimed 5x fewer errors than AirPods Pro
- On-device processing keeps sensitive speech data completely local, making them suitable for HIPAA-compliant medical dictation and attorney-client confidential conversations
- Bone-conduction sensing and accelerometer-based jaw movement detection work alongside traditional microphones to isolate speech signals competitors miss
- Professional dictation users (doctors, lawyers, journalists) have the strongest ROI case; casual users may find mainstream earbuds sufficient
- iOS-only launch limits addressable market by half; Android support timeline is unannounced but likely 12-18 months away
- 17/month ($204/year) subscription creates barrier to adoption but is defensible for power users saving hours on transcription editing
- Audio quality and battery life specifications remain unconfirmed, representing potential limitations compared to music-focused premium earbuds

