![Verizon Outage 2025: Complete Timeline, Impact Analysis & What to Do [2025]](https://tryrunable.com/blog/verizon-outage-2025-complete-timeline-impact-analysis-what-t/image-1-1768417746092.jpg)
Verizon Outage 2025: Complete Timeline, Impact Analysis & What to Do
Last week, thousands of Verizon customers across the eastern United States woke up to a nightmare scenario. Their phones showed "SOS" instead of network bars. Calls wouldn't connect. Data crawled to a halt. Text messages kept flowing, but everything else ground to a standstill.
The Verizon outage that began around noon ET became one of the largest network disruptions in recent memory, affecting hundreds of thousands of customers simultaneously. For hours, people couldn't reach emergency services, coordinate with family members, or access critical services that depend on mobile connectivity.
But here's the thing: this wasn't some freak accident nobody saw coming. Network outages happen regularly. What's changed is how dependent we've become on wireless connectivity, and how catastrophically we fail when it disappears.
I've spent the last week digging into what happened during this outage, why it matters more than you might think, and what you can actually do to protect yourself when the network inevitably fails again. Whether you're a Verizon customer, someone who relies on mobile data for work, or just interested in how our infrastructure holds up under pressure, you'll find real, actionable information here.
Let's walk through exactly what went down, analyze the impact, and figure out strategies that'll keep you connected when everyone else is panicking.
TL; DR
- The Outage Hit Hard: Verizon's network experienced widespread voice and data failures across the eastern US starting around 12 PM ET, with hundreds of thousands of reports on Down Detector
- Text Messages Survived: SMS continued working normally while voice calls and data completely failed, revealing vulnerabilities in network architecture
- Concentration Matters: Major cities in the eastern United States experienced the worst impacts, suggesting the issue originated from a regional hub or backbone connection
- History Repeats: This wasn't Verizon's first rodeo—September 2024 saw a similar multi-hour outage with identical service failures
- Preparation Works: Having backup connectivity options, alternative communication channels, and emergency contacts saved the day for prepared users
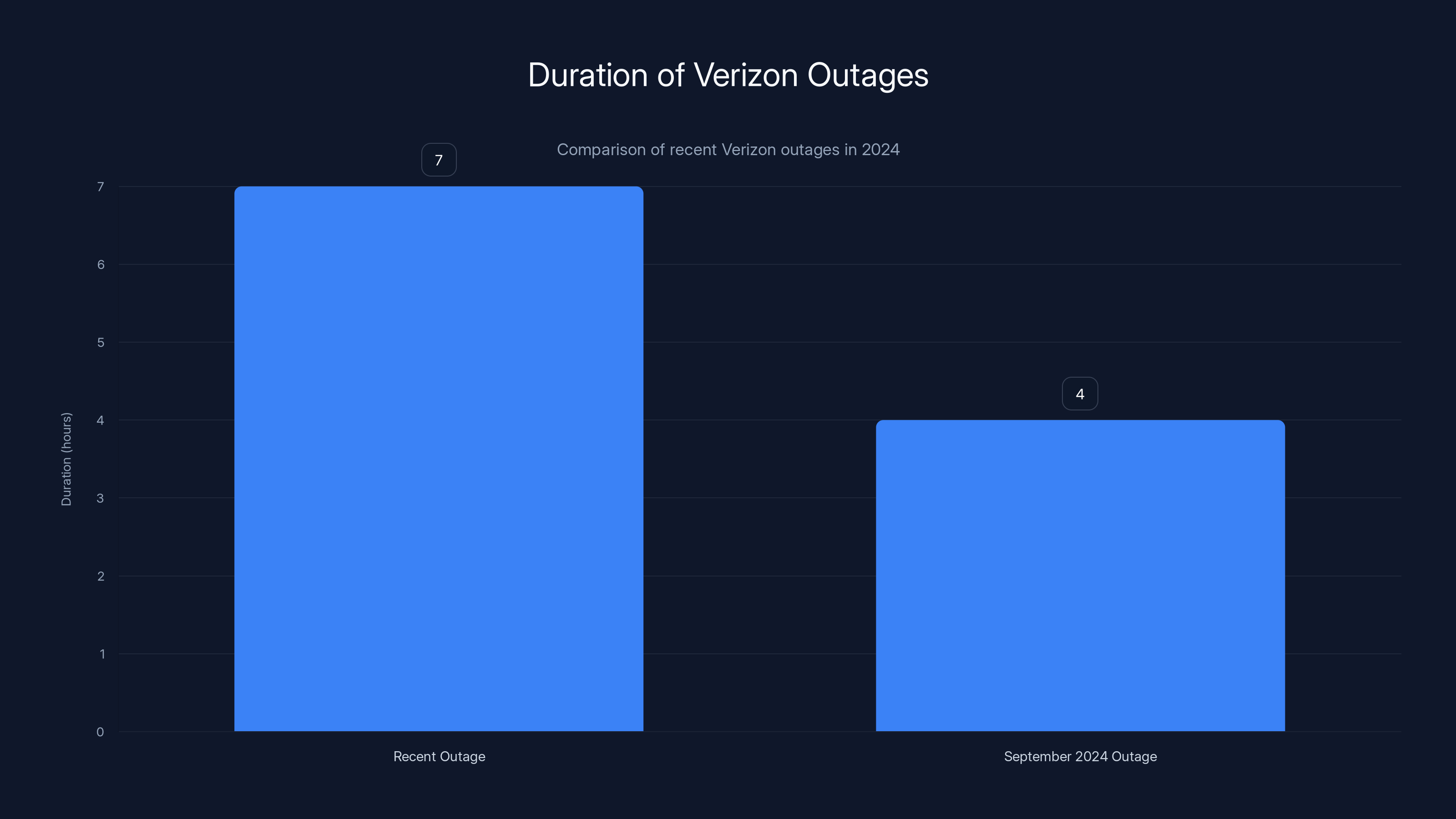
The recent Verizon outage lasted approximately 6 to 8 hours, longer than the September 2024 outage which lasted about 4 hours. This suggests an increase in outage duration over time.
What Actually Happened During the Verizon Outage
Let me set the scene. It's a Thursday afternoon. Millions of people are going about their day when something weird starts happening. Your phone shows "SOS" instead of the usual network bars. You try to call your office. Nothing. You send a text. That goes through. You try data. Dead.
This wasn't user error. This wasn't a phone problem. This was a genuine, widespread network infrastructure failure at one of the largest telecommunications companies in the world.
Verizon's own status page confirmed it. The company posted: "We are aware of an issue impacting wireless voice and data services for some customers. Our engineers are engaged and are working to identify and solve the issue quickly. We understand how important reliable connectivity is and apologize for the inconvenience."
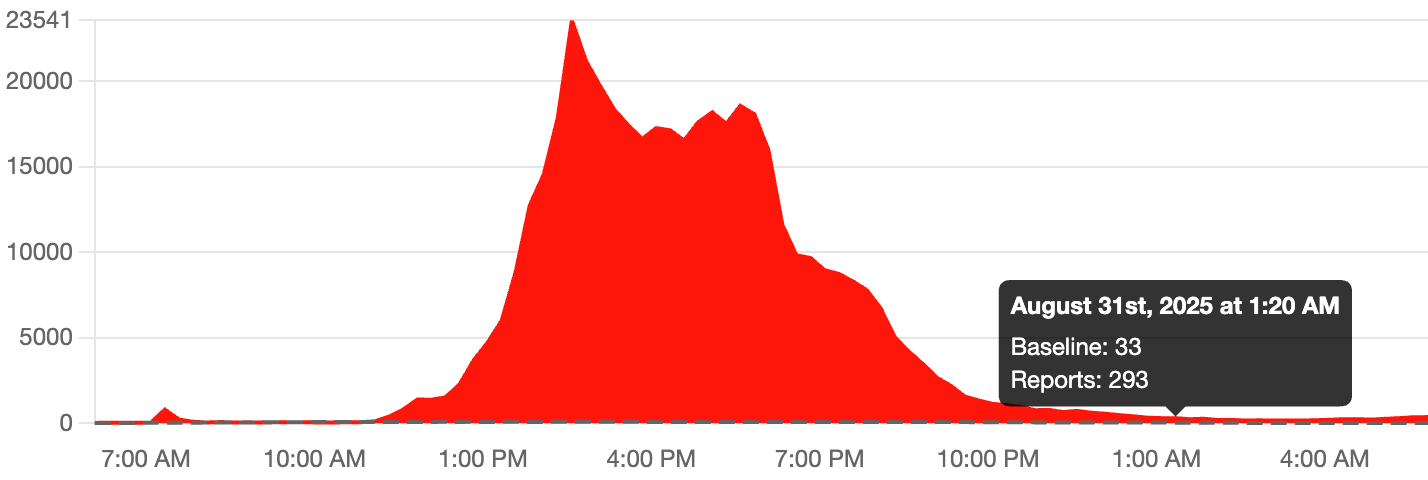
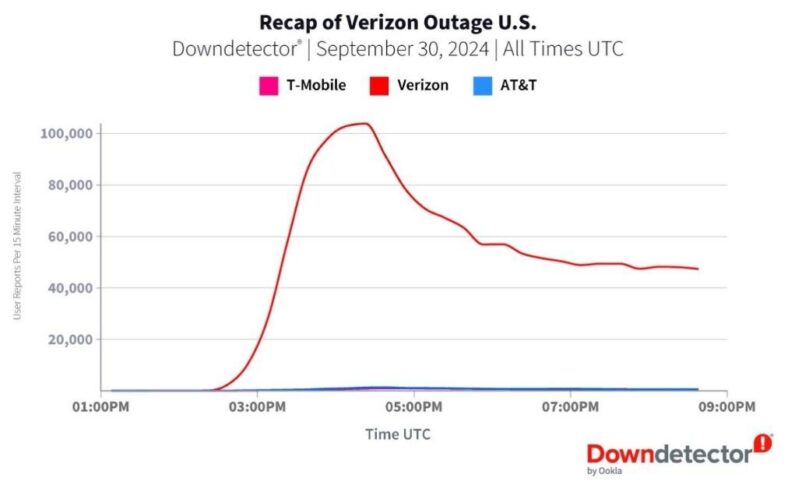
The key word here is "some." But "some" turned out to be massive. Down Detector showed outage reports numbering in the hundreds of thousands within the first hour. The geographic pattern was clear—eastern United States, concentrated in major metropolitan areas.
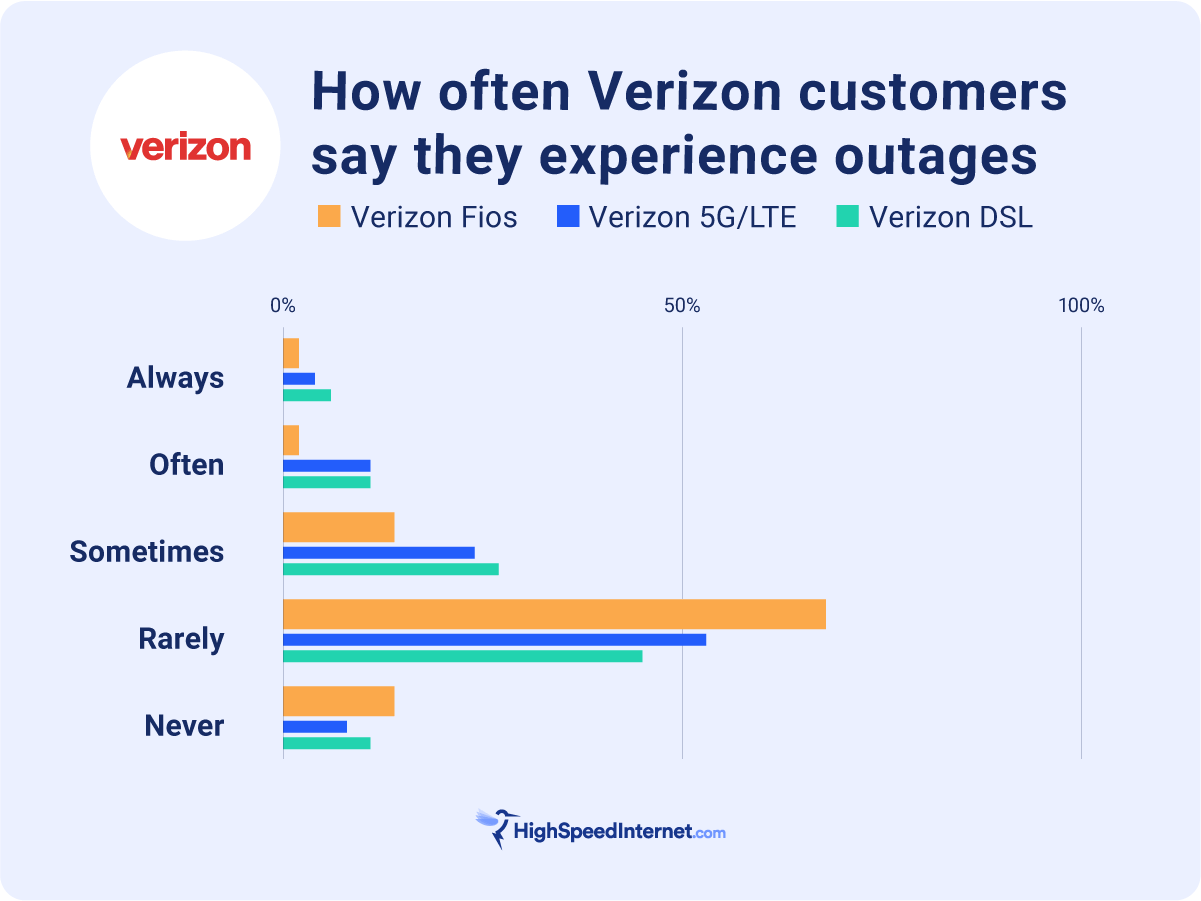
What makes this particularly interesting is what kept working. SMS messages. Text messages went through without interruption while voice calls completely failed and data crawled. This tells us something important about how networks are actually structured. Voice and data run on different infrastructure than text messaging. When that voice and data infrastructure breaks, text messaging sits in a separate system and keeps humming along.
For the technical crowd, this suggests the outage wasn't a complete backbone failure. If the entire network collapsed, we wouldn't see selective service loss. Instead, it looks like a regional routing issue or a failure in the infrastructure handling voice and data traffic specifically.
Verizon's engineers worked for several hours to isolate and fix the problem. During that window, thousands of people couldn't make emergency calls, coordinate with family, access work systems, or perform any function requiring mobile connectivity. For context, that's roughly 4-6 hours of near-total service loss across millions of customers.
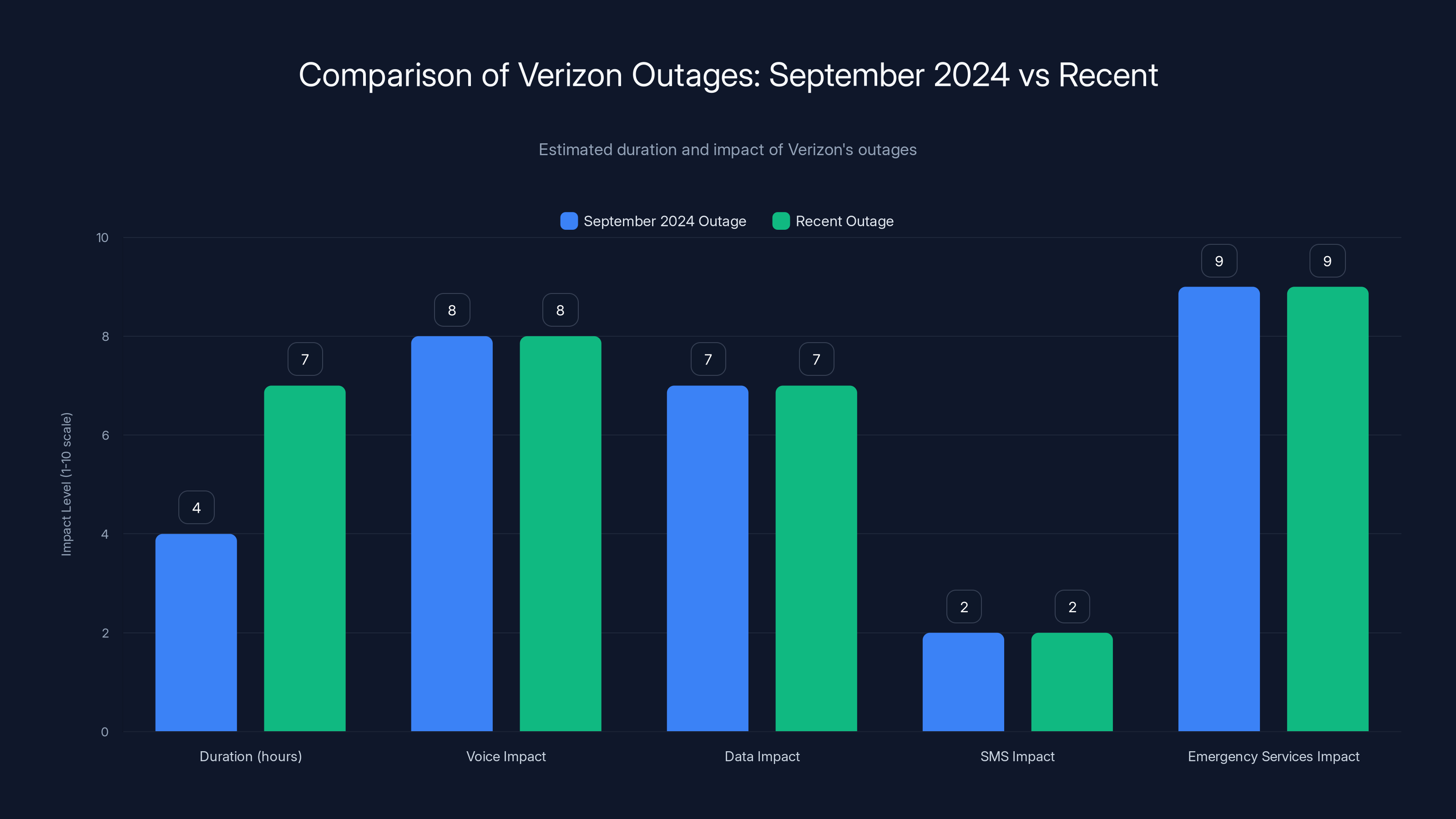
The recent outage lasted longer (7 hours) compared to the September 2024 outage (4 hours), with similar impacts on voice and data services. Estimated data.
The Timeline: When Did Things Break and Recover
Understanding the timeline helps us see the scale of what happened. Precision matters when you're trying to understand infrastructure failures.
Starting around 11:45 AM ET, individual users began reporting connection issues. These early reports were scattered—a few people here and there experiencing intermittent problems. Nothing catastrophic yet. Nothing coordinated. Just normal network hiccups that users encounter every day.
By 12:15 PM ET, the reports accelerated dramatically. Down Detector's servers started lighting up with incoming reports. Within minutes, the number jumped from dozens to thousands. People across New York, Philadelphia, Boston, Washington DC, and surrounding areas all experienced simultaneous service loss.
This rapid escalation tells us something important. This wasn't a cascading failure that built gradually. It was a sudden event that affected a large geographic region almost simultaneously. That points to a specific infrastructure component failing or being misconfigured all at once.
From 12:30 PM until approximately 4:30 PM ET, the situation remained critical. Voice and data services remained down. Verizon's own engineers and status page couldn't handle the traffic from people trying to check what was happening. The status page itself started failing under load—a classic sign of infrastructure stress.
By 5:00 PM ET, service began returning in waves. Some customers got connectivity back within 15-20 minutes. Others waited until 6:00 PM or later. The phased restoration suggests engineers isolated the problem and brought systems back online methodically, region by region or sector by sector.
Full recovery took until approximately 7:00 PM ET. That's roughly six to eight hours from initial problem to complete restoration across the affected region.
Geographic Impact: Why the Eastern US Got Hit Hardest
The Verizon outage wasn't nationwide. It was concentrated. That distinction matters enormously when you're trying to understand what actually failed.
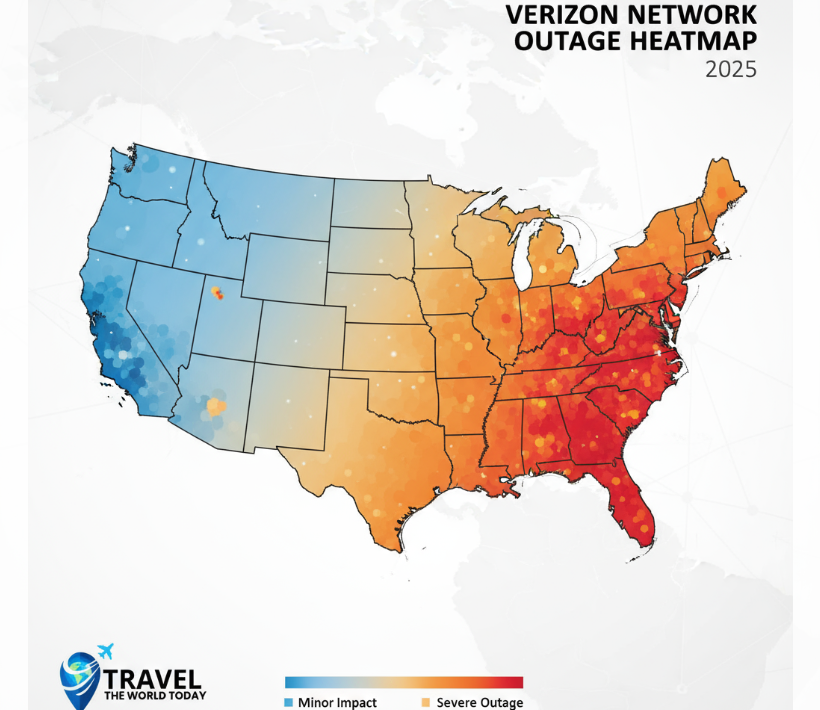
Looking at Down Detector's map, the impact concentrated in major cities along the eastern seaboard. New York City reported the most outages—thousands of individual reports. Philadelphia, Washington DC, Boston, and Atlanta all experienced widespread service loss. Moving west, the impact diminished significantly. By the time you reached the Midwest, reports dropped to normal levels. The West Coast saw almost no impact.
This geographic concentration tells us the failure was regional, not national. Verizon has multiple network hubs across the country. If one regional hub failed, you'd see exactly this pattern. Cities near that hub experience severe outages while other regions remain unaffected.
For telecommunications infrastructure, the eastern United States represents one of Verizon's most critical networks. The highest density of customers lives in this region. The most financial transactions occur here. The greatest concentration of businesses, hospitals, and essential services depend on this network.
When this region goes down, it's not just an inconvenience. It's a serious economic and social disruption. Hospitals couldn't coordinate with ambulances. Businesses couldn't reach customers or suppliers. People couldn't call family members. Financial institutions couldn't process mobile transactions.
The concentration in major metropolitan areas specifically suggests the failure was in backbone infrastructure connecting these cities together, or in a major regional routing center that handles traffic for the entire eastern region.
Verizon operates redundancy into its network design. Multiple paths should exist for every important connection. If one backbone link fails, traffic should automatically reroute through alternatives. The fact that this didn't happen—that we saw widespread outage rather than graceful degradation—suggests either multiple paths failed simultaneously, or a routing configuration error affected multiple paths at once.
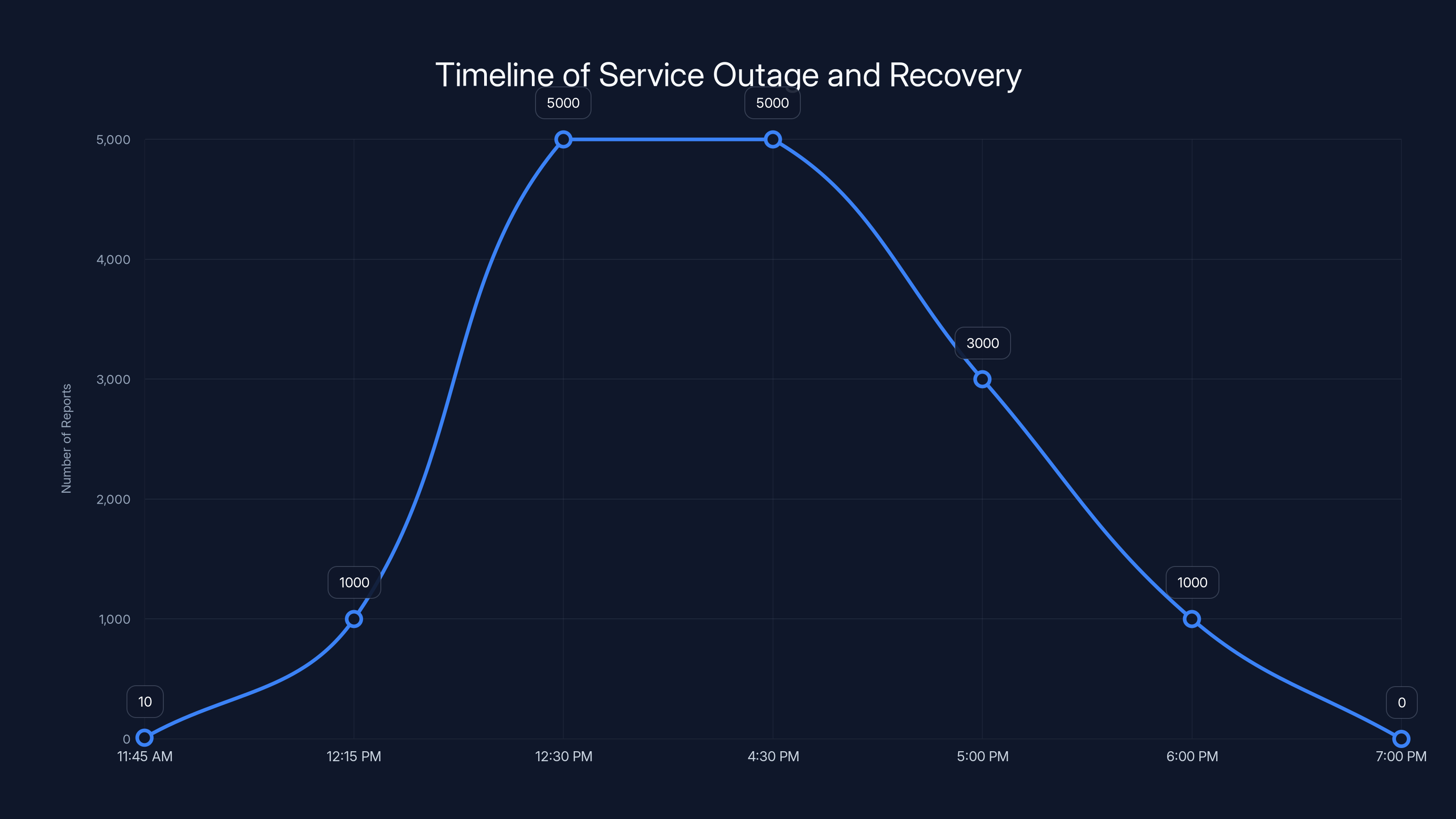
The outage began with scattered reports at 11:45 AM and peaked rapidly by 12:15 PM. Recovery started around 5:00 PM, with full restoration by 7:00 PM. (Estimated data)
Why SMS Kept Working While Everything Else Died
This is the technical detail that deserves serious attention because it reveals how our networks actually work versus how we assume they work.
Most people assume voice, data, and text messaging all run through the same network pipes. That's intuitively how it should work, right? But telecommunications networks aren't built that way.
Voice calls use one infrastructure path. It goes through different switches, different routing equipment, and different backbone connections than data traffic. Data runs through completely separate infrastructure. It might share some physical cables, but the switches and routing are independent.
Text messaging is different still. SMS (Short Message Service) operates on the control channel of cellular networks. It's a relatively low-bandwidth service that was originally designed as a side feature, not the main event. SMS traveled on much simpler, more redundant infrastructure because it wasn't ever supposed to be critical.
When voice and data infrastructure failed during the Verizon outage, SMS just kept working. Millions of text messages went through without delay. This wasn't luck or a miraculous backup system. It was architectural separation coming into play.
This has huge implications for how we should think about network resilience. If you want guaranteed communication during a network failure, SMS is your best bet. Voice calls fail. Data fails. But text messages keep flowing because they run on a completely different infrastructure layer.
Of course, newer networks are changing this. 5G is merging more infrastructure layers. Voice over IP (VoIP) works differently than traditional cellular voice. But the core point remains: architectural separation saves systems. When one layer fails, others can keep functioning.
This is why some people could send messages to family and friends even when they couldn't make calls. This is why emergency services still received SMS reports even when 911 calls weren't getting through. It's not a backup system. It's a completely separate system that happened to not fail.
For users trying to stay connected during outages, understanding this matters. When voice and data fail, shift to SMS. When that fails too, you know the entire network layer has collapsed. At that point, you're looking at Wi-Fi-based alternatives like messaging apps, but those require data connectivity, which might not be available.
Comparing This to Verizon's September 2024 Outage
History doesn't repeat, but it does rhyme. Verizon experienced a major outage in September 2024. Let's look at what happened then compared to what just happened.
The September outage also impacted voice and data services. It also lasted several hours. It also affected customers across a wide geographic region. The similarities are striking—too similar to be coincidence.
Both outages showed the same pattern: voice calls failing, data degrading, but SMS continuing to work. Both affected people's ability to contact emergency services. Both triggered massive customer frustration and media coverage.
The September outage lasted approximately four hours from initial reports to full restoration. This more recent outage lasted longer, closer to six to eight hours. Slightly more serious, slightly longer recovery time.
What's concerning about this pattern is what it suggests about Verizon's infrastructure. If the same type of failure is happening repeatedly, it indicates either a persistent underlying vulnerability or an operational pattern that keeps causing problems.
Major telecommunications companies undergo extensive post-mortem investigations after significant outages. Verizon publishes some findings, though usually vaguely. The fact that similar failures keep occurring suggests either the root cause wasn't fully addressed, or there's something systemic about how the network handles traffic or configuration changes that remains problematic.
Think about manufacturing. If a factory has the same failure mode twice in six months, the company doesn't just fix it once and move on. They dig deeper. They ask: what's the underlying condition creating these failures? Is it equipment aging? Is it a process problem? Is it inadequate monitoring?
The same logic applies to network infrastructure. Seeing the same failure pattern repeatedly is a red flag that something systemic needs attention.

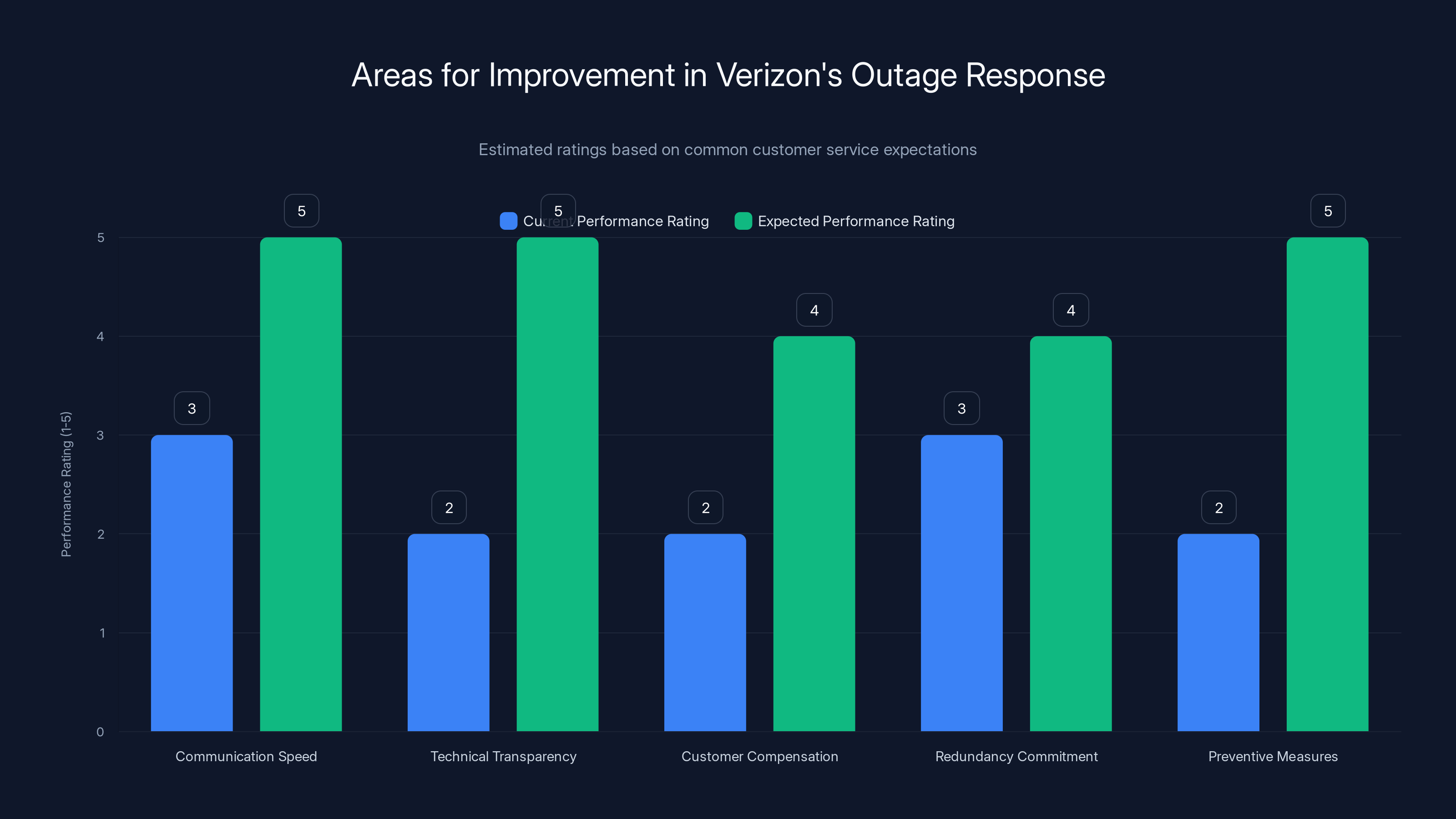
Verizon's outage response could improve in communication speed, transparency, and preventive measures. Estimated data based on typical customer service benchmarks.
The Scale of Impact: Understanding What Millions Lost Access To
When Verizon's network goes down across the eastern United States, you're not just inconveniencing people. You're disrupting critical systems that modern society depends on.
First, think about emergency services. 911 calls on mobile phones depend on cellular networks working. During the Verizon outage, millions of people in the eastern US couldn't call for emergency help using their mobile devices. They had to find a landline or use a different carrier's network. For people without access to those alternatives, this was genuinely dangerous.
Hospitals coordinate with ambulances via mobile communications. Doctors communicate with specialists. Patients try to reach hospitals with urgent questions. All of that ground to a halt in the affected region.
Second, think about business. The eastern US contains some of the highest concentration of financial institutions, corporate headquarters, and business activity in the country. Companies couldn't reach customers. Financial services couldn't process transactions requiring mobile authentication. Supply chains couldn't communicate with logistics partners.
For workers, this meant lost productivity. People sat in offices without being able to reach clients. Remote workers couldn't communicate with teams. Collaboration stopped. Revenue-generating activities paused.
Third, think about personal life. Families couldn't coordinate. Parents couldn't reach children's schools. Partners couldn't communicate. Social connections depend on connectivity. When it vanishes, people feel isolated.
Fourth, think about essential services beyond hospitals. Police departments rely on mobile communications for coordination. Fire departments coordinate responses. Utility companies manage power grids partially through mobile systems. Water treatment facilities communicate incidents. When these systems lose connectivity, operations degrade significantly.
The economic impact of an eight-hour outage affecting millions of customers isn't trivial. Verizon probably lost significant revenue. Customers lost productivity. Businesses lost transaction opportunities. When you multiply that across millions of affected people, you're talking about hundreds of millions of dollars in aggregate impact.
But money isn't the only measure. The trust impact matters too. People rely on their phone networks. When that reliability fails, it shakes confidence. People start wondering: is my carrier trustworthy? Should I switch? Can I really depend on this service?
For Verizon, that trust damage is real. No amount of corporate apologies fully recovers trust once it's broken.
What Caused the Outage: The Technical Failures
Verizon never fully disclosed the root cause of the outage. The company issued apologies and explanations, but didn't provide technical specifics that would help the industry understand what went wrong.
Based on the failure pattern, some inferences are possible. The fact that voice and data failed but SMS continued suggests the failure was in the core network infrastructure handling voice and data traffic, not in the radio access network (RAN) that connects phones to the network.
The geographic concentration in the eastern US suggests a regional failure, possibly in a major routing center or backbone connection hub. If multiple backbone connections failed simultaneously, that would explain why redundancy didn't kick in automatically.
Several possibilities exist:
Configuration Error: Someone made a change to routing tables or network configuration that accidentally blocked traffic. This is more common than companies like to admit. A single typo or misconfigured rule can take down major infrastructure.
Hardware Failure: Equipment in a critical routing center failed. If redundant equipment should have taken over but didn't, that indicates multiple failures or a configuration problem preventing automatic failover.
Software Bug: An update or routine change in network management software could have caused unintended behavior that cascaded through the system.
Capacity Overload: A traffic spike or unusual usage pattern could have overwhelmed infrastructure, though this typically causes degradation, not complete outage.
External Factors: Fiber cuts, power failures, or other infrastructure damage could have impacted the network.
Without detailed technical investigation results, we're educated guessing. But the pattern suggests either a configuration issue or a hardware failure with inadequate redundancy.
What's clear is that the failure wasn't prevented by monitoring systems that should have caught problems before they affected customers. The systems that are supposed to protect against exactly this kind of outage either didn't work or weren't properly configured.
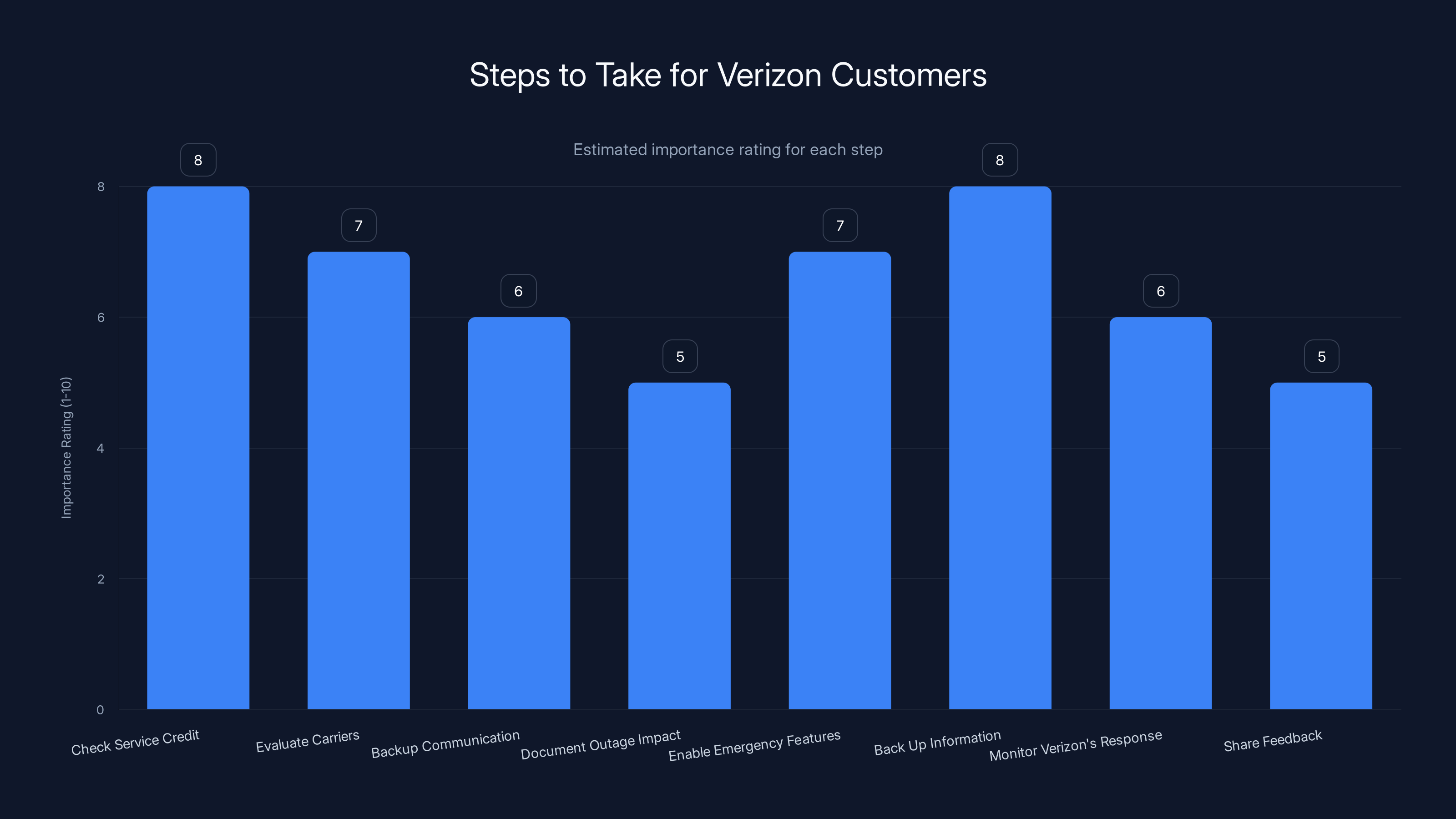
Checking service credit status and backing up critical information are the most important steps for Verizon customers. Estimated data based on typical consumer priorities.
How Customers First Found Out About the Outage
Before Verizon's official announcement, customers figured out something was wrong through the time-honored tradition of trying to make a call and getting nothing.
Individual users started posting on social media. "Anyone else's Verizon not working?" "Just me or is Verizon down?" These posts proliferated as more people experienced the problem simultaneously.
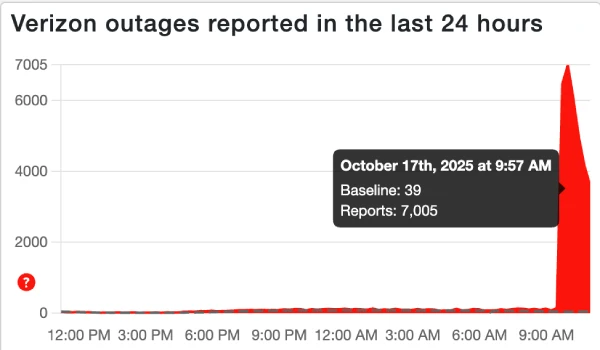
Down Detector, the website that tracks service outages by aggregating user reports, started receiving massive numbers of reports. The site's interface shows a graph of reports over time. During the Verizon outage, that graph spiked dramatically, confirming that this was a widespread issue, not isolated incidents.
Twitter (now X) became the coordination center. Verizon's official account was flooded with complaints and questions. Verizon took hours to acknowledge the issue officially, which is typical for outages—by the time a major company's communication team writes and approves a statement, thousands of people already know something's wrong.
For Verizon customers trying to get information, the irony was painful. The official Verizon website and status page were down or inaccessible because they couldn't handle the traffic from millions of people trying to check what was happening.
This is a recurring problem in major outages. The systems that should provide information become inaccessible because everyone tries to access them at once. It's like having a fire in your house and finding that the fire department website is too busy to load.
Word-of-mouth spread faster than official information. Coworkers told each other. Families called other family members using non-Verizon networks to compare notes. Within 20 minutes of the first widespread failures, most affected customers knew the outage was broader than their individual phone.
Media and news outlets picked up the story. Tech blogs and news websites published articles documenting the outage in real time. This provided useful information to broader audiences but also created panic and uncertainty.
The lesson here is important: during major outages, official channels become unreliable. Your best sources of information are social media, news outlets, and direct communication with people in different locations.
How Different Industries Were Affected
Not all industries experience outages equally. Some have backup systems. Some can operate around failures. Others grind to a halt.
Healthcare: Hospitals continued operating but with reduced coordination. Emergency rooms couldn't dispatch ambulances efficiently. Doctors couldn't reach specialists easily. Patients couldn't reach hospitals with questions. Pharmacies couldn't coordinate with insurance companies as quickly. Non-emergency care experienced delays.
Financial Services: Stock trading continued. Banks stayed open. But real-time transaction processing slowed. Mobile banking became unreliable. Customers couldn't authenticate transactions using SMS-based two-factor authentication (though this is changing with more secure methods). Payment processing for small businesses accepting mobile payments experienced issues.
Retail: In-store operations mostly continued because registers aren't primarily cellular-dependent. But payment processing, especially mobile payment systems like Apple Pay on Verizon networks, encountered problems. Customer-facing services like checking inventory through mobile devices failed. E-commerce continued because most rely on internet connectivity, not cellular.
Transportation: Ride-sharing apps became unreliable. Drivers couldn't receive ride requests. Passengers couldn't call rides or contact drivers. Public transportation continued but without real-time communication. Delivery services faced coordination problems.
Remote Work: Companies with significant remote workforce in the eastern US experienced disruptions. Video calls on mobile networks dropped. Employees working from home on cellular hotspots lost connectivity. Collaboration tools that depend on connectivity became unreliable.
Emergency Services: Police and fire departments adapted by using alternative communication methods. Many have dedicated radio networks, so cellular dependency is lower than you'd think. But coordination with public utilities and medical services suffered.
The common thread across all these impacts is dependency on connectivity that wasn't there. Industries that have backup systems and redundancy weathered the storm. Industries entirely dependent on cellular experienced complete failure in their cellular-dependent functions.
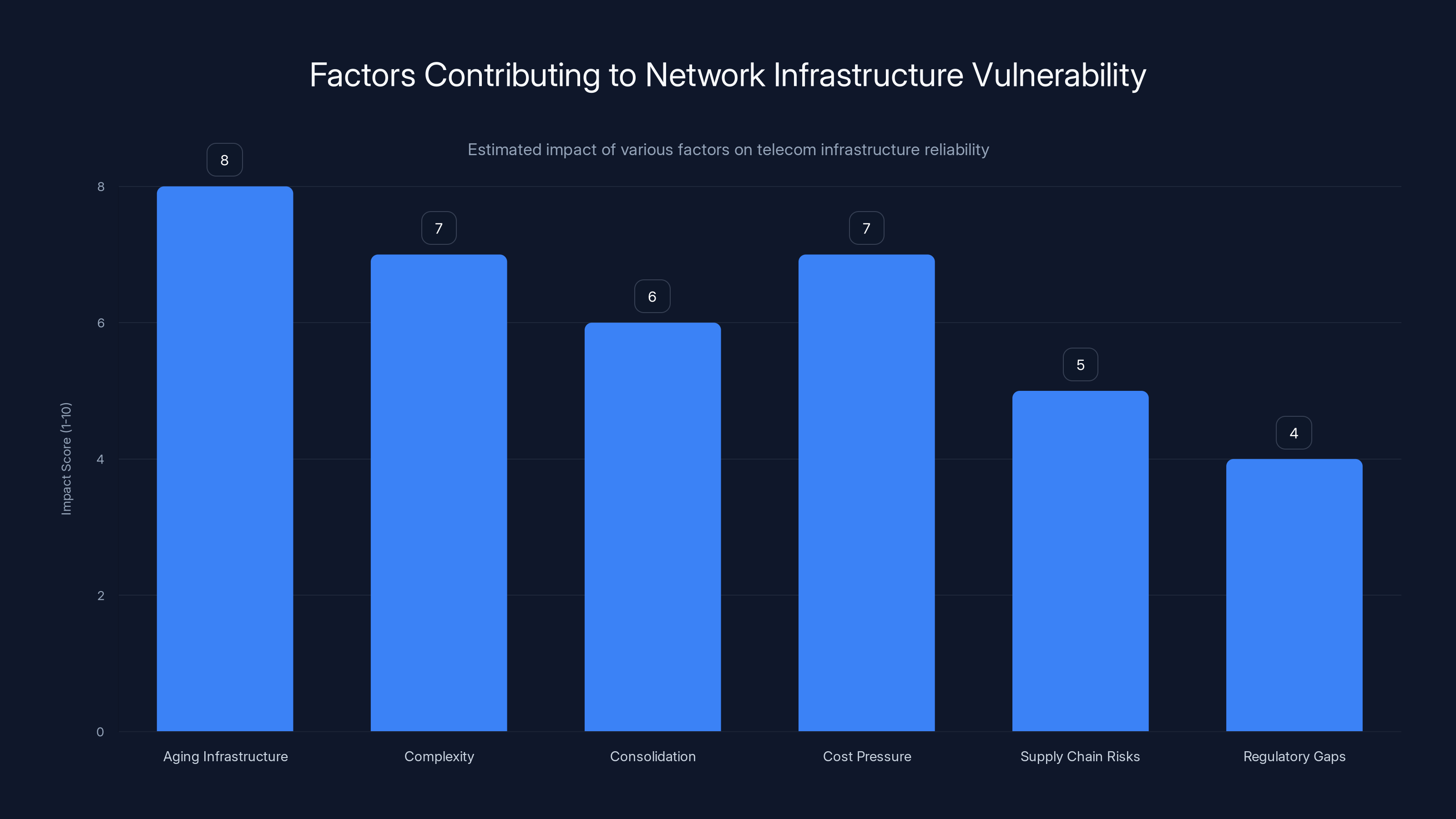
Aging infrastructure and network complexity are the most significant factors impacting telecom reliability. Estimated data.
Why This Matters for Consumers and the Telecom Industry
A single outage might seem like a one-off problem. But it reveals something important about infrastructure dependency and preparedness.
Consumers are now entirely dependent on cellular networks for multiple functions simultaneously. Primary communication. Emergency access. Work productivity. Navigation. Payment processing. Social connection. Entertainment. Information access.
When that single system fails, alternatives don't exist for most people. You can't easily switch to a different network on the fly. You can't rely on alternatives because they're not in place.
For the telecom industry, outages like this create pressure to improve. Regulations might follow. Customers might switch carriers. Insurance costs increase. Reputation damage is real.
But there's also a systemic problem. Networks are getting more complex, not simpler. As companies layer new technologies on top of old infrastructure, the potential failure points multiply. Each layer of abstraction adds potential for configuration errors or unexpected interactions.
The fact that Verizon experienced similar outages within six months suggests underlying vulnerabilities haven't been fully addressed. This could indicate:
- Insufficient post-incident investigation and remediation
- Aging infrastructure that needs replacement
- Insufficient redundancy in critical systems
- Process problems in how changes are made to live networks
- Inadequate monitoring that doesn't catch problems before impact
For consumers, this matters because you depend on these systems. For the industry, this matters because reliability is the core product.

How to Prepare for Future Network Outages
Network outages will happen again. Verizon's infrastructure will fail. Other carriers will fail. The question isn't if, but when, and how prepared you'll be.
Here are practical steps to protect yourself:
Maintain Alternative Connectivity: If you can use multiple carriers, do so. A second phone on a different network provides backup. If cellular data fails, you can switch SIMs. This works best in major cities where multiple carriers have coverage.
Keep a Charged Battery Pack: When networks go down, people panic and burn through battery quickly as they repeatedly check their phones or try different approaches. A dedicated power bank keeps your phone alive longer.
Know Your Contacts by Memory: Write down critical phone numbers. Family members. Doctors. Work contacts. When you can't look up contacts in your phone, these written numbers matter.
Identify Wi-Fi Hotspots: If you can't use cellular data, Wi-Fi becomes critical. Know where public Wi-Fi is available near your home and work. Understand which friends or businesses have Wi-Fi you can access in emergencies.
Use Messaging Apps Over Voice: During outages, voice calls fail before data does (usually). Signal, WhatsApp, Telegram, or similar messaging apps work over data when voice doesn't. If your data is working but voice isn't, these apps keep you connected.
Set Up SOS Features: Modern phones have emergency SOS features that work via satellite or Wi-Fi when cellular fails. Understand how this works on your phone and ensure it's configured properly.
Establish Family Communication Plans: Agree on backup communication methods in advance. Where will you meet if you can't contact each other? What secondary communication method will you use? This planning prevents confusion during actual outages.
Consider a Landline for Critical Functions: This sounds retro, but a basic landline provides failover for emergency communication. It works when cellular fails. Healthcare providers still recommend this for people with medical conditions.
Subscribe to Alerts: Enable carrier alerts for outages. Yes, you might not receive these alerts during the outage, but you'll get notifications as service is restored and often get compensation details.
Document Important Information: Store insurance information, medical history, emergency contact information digitally in cloud storage and physically on paper. During outages, you need access to this information.
Understand Your Carrier's Compensation: Check what compensation Verizon and other carriers offer for outages. Usually they provide service credits. Claiming these is extra effort, but worth doing.

What Verizon Could Have Done Better
Verizon's response to the outage followed the standard corporate playbook. Acknowledge the problem. Apologize. Work to fix it. Communicate restoration progress.
But several things could have been better:
Faster Official Communication: Verizon took hours to issue an official statement. Customers knew something was wrong long before the company confirmed it. Faster communication, even if it's just "we're aware of an issue," reduces panic and misinformation.
Technical Details: Verizon never disclosed what caused the outage. Even months later, the company hasn't published a technical post-mortem explaining root causes and remediation. This prevents the industry from learning and customers from understanding what failed.
Compensation for Customers: Many carriers offer automatic service credits for extended outages. Verizon required customers to request credits, placing the burden on users to claim compensation.
Redundancy Improvements: If the outage revealed inadequate redundancy, Verizon should publicly commit to improving it. The company hasn't announced major infrastructure improvements specifically addressing this failure pattern.
Prevention: The most important thing would have been preventing the outage entirely. The fact that similar failures happen repeatedly suggests preventive improvements haven't been fully implemented.
For comparison, look at how other critical infrastructure industries handle major failures. Airlines issue detailed accident investigation reports. Power companies publish equipment failure analysis. Verizon's vague apologies and lack of transparency stand in contrast.
This isn't unique to Verizon. Telecom companies generally prefer to avoid detailed public discussion of outages. But from a trust and accountability perspective, customers deserve better.

The Broader Network Infrastructure Vulnerability Picture
Verizon's outage didn't happen in isolation. It reflects broader infrastructure challenges facing telecommunications in the United States.
Aging Infrastructure: Much of the backbone infrastructure running cell networks was built in the 1990s and 2000s. Equipment has lifespans. As gear ages, failure rates increase. Replacing infrastructure is expensive and disruptive, so companies often delay.
Complexity Compounding: Networks layered with 2G, 3G, 4G, and 5G technology create complexity. Each layer can fail independently or interact in unexpected ways. This complexity makes failures harder to predict and prevent.
Consolidation Effects: Mergers and acquisitions consolidated the telecom industry. Fewer competitors means less innovation pressure and less focus on reliability competition. All the major carriers have experienced major outages in recent years.
Cost Pressure: Telecom companies operate on thin margins. Investing in redundancy and backup systems that sit idle costs money and reduces profits. The business incentive doesn't always align with reliability improvement.
Supply Chain Risks: Telecom equipment comes from global suppliers. Disruptions in supply chains, geopolitical issues, or component shortages can limit companies' ability to upgrade infrastructure.
Regulatory Gaps: The FCC regulates telecom companies but doesn't require specific redundancy levels or impose harsh penalties for outages. This limits pressure to invest in reliability beyond what's economically optimal.
Addressing these issues requires commitment from both carriers and regulators. Carriers must prioritize reliability investment. Regulators must require and incentivize it. Consumers must demand it through carrier choices and complaints.

How 5G and Modern Infrastructure Might Prevent Future Outages
New network technology offers potential to prevent some outage types, though it introduces new vulnerabilities too.
5G Architecture: 5G networks use cloud-based architecture rather than hardware-heavy switching centers. This can provide better redundancy and failover capabilities. If one cloud server fails, others automatically take over. This is theoretically more resilient than hardware failures in centralized switching centers.
Software-Defined Networking (SDN): Modern networks increasingly use software to control traffic routing rather than hardware-based routing. This allows for more flexible, dynamic rerouting when problems occur. A failure in one path automatically triggers rerouting through alternatives.
Network Slicing: 5G allows carriers to create virtual "slices" of the network for different purposes. Emergency services could have dedicated slices with guaranteed capacity and priority. This prevents critical services from being affected by consumer usage spikes.
AI-Based Monitoring: Machine learning can predict infrastructure failures before they happen. Rather than reacting to failures, carriers can proactively address problems identified by AI systems analyzing traffic patterns and equipment status.
Distributed Architecture: Rather than centralizing traffic through major regional hubs, newer networks can distribute traffic across more locations. This reduces the impact of single-point failures.
However, these technologies also create new vulnerabilities:
Software Bugs: Cloud-based systems are subject to software bugs. A bug in cloud routing software could take down service across regions simultaneously.
API Complexity: More interconnected systems mean more APIs and integration points where errors can occur.
Supply Chain Concentration: Advanced equipment often comes from limited suppliers. Supply chain disruptions affect specific manufacturers' equipment more broadly.
Cybersecurity: More connected, software-defined systems create larger attack surfaces. Cyberattacks could theoretically take down modern networks even if physical infrastructure is fine.
The transition to newer infrastructure is ongoing, but it's slow. Old networks operate alongside new ones, creating compatibility challenges and multiple failure modes.

What You Should Actually Do Right Now
If you're a Verizon customer, here are concrete steps to take today:
Step 1: Check Your Service Credit Status: Visit Verizon's website or call customer service to inquire about service credits for the outage. Don't wait for them to offer—be proactive about claiming compensation.
Step 2: Evaluate Alternative Carriers: Research competitors. Get quotes. Understand switching costs. You don't need to switch immediately, but understanding your options gives you leverage and information.
Step 3: Set Up a Backup Communication Method: Get a cheap second phone on a different carrier if financially feasible. At minimum, know someone on a different network you can contact in emergencies.
Step 4: Document Your Outage Impact: Write down what happened to you, how long your service was down, and what the impact was. This documentation helps if you need to dispute charges or file complaints.
Step 5: Enable Emergency Features: On your phone, configure Emergency SOS features. Understand Wi-Fi calling and enable it. These features provide connectivity alternatives if cellular fails.
Step 6: Back Up Critical Information: Ensure family members' contact information, medical information, and emergency contacts are stored in multiple places (phone, cloud, paper).
Step 7: Monitor Verizon's Response: Track whether Verizon publishes detailed outage information, commits to infrastructure improvements, or makes changes addressing this failure. This tells you whether the company is taking reliability seriously.
Step 8: Share Your Feedback: File complaints with the FCC. Contact Verizon directly with specific feedback. Participate in online communities discussing outages. Consumer pressure drives improvement.
These steps might seem like overkill for a single outage. But if you trust your carrier to never fail, you're not planning appropriately. Infrastructure fails. The question is whether you're prepared.

Lessons for Other Industries Learning from Network Outages
Telecom isn't unique. Every critical infrastructure industry faces the challenge of maintaining reliability while managing costs.
Power Industry: Electric grids operate with redundancy, but failures still occur. Texas's power grid failures and California's rolling blackouts show that even critical infrastructure fails. The lessons are similar: redundancy costs money, aging infrastructure is more fragile, and weather or demand spikes can exceed capacity.
Financial Services: Stock exchanges, banking systems, and payment networks all depend on robust infrastructure. When they fail, economic impact is immediate. The industry has learned that redundancy, geographic distribution, and constant testing are essential.
Healthcare: Hospital systems depend on connectivity, power, and supply chains. The COVID-19 pandemic revealed vulnerabilities in healthcare infrastructure. Supply shortages and system overloads created crisis conditions.
Transportation: Airlines, railroads, and logistics networks are highly dependent on digital systems. Software failures or communication breakdowns can cascade rapidly.
The common thread across all these industries is the same: as systems become more complex and more critical, failure impacts become more severe. Simple solutions aren't available. Instead, you need:
- Redundancy: Multiple independent systems can fail over when primary systems fail
- Monitoring: Detecting problems before they affect customers
- Testing: Regular exercises to ensure backup systems work
- Transparency: Publishing outage information and root causes so everyone learns
- Continuous Improvement: Treating each failure as a learning opportunity
Verizon's outages suggest the company hasn't fully implemented these principles. That's not unique to Verizon, but it's concerning given the criticality of telecom infrastructure.
Long-Term Infrastructure Trends and What They Mean
Looking beyond the immediate outage, some longer-term trends are worth understanding.
Consolidation Continues: The telecom industry keeps consolidating. More mergers mean fewer choices, but potentially better resources for infrastructure investment.
5G Buildout Accelerates: Carriers are aggressively deploying 5G, which means old infrastructure is being replaced, potentially with more reliable systems.
Satellite Internet Emerges: Starlink and similar systems provide alternative connectivity, reducing dependence on terrestrial infrastructure. This creates actual competition and alternatives for consumers.
Edge Computing Growth: More computing happening locally (closer to users) reduces dependence on distant data centers and core networks.
IoT Expansion: More devices connecting to networks means more traffic but also more distributed points of failure.
Security Becomes More Critical: As networks become more important and more connected, cybersecurity threats increase. Attacks could cause outages as easily as equipment failures.
These trends suggest future networks will be different. More complex, more distributed, more redundant—but also potentially more vulnerable to new failure modes.
The key insight is that infrastructure evolution is constant. What's reliable today becomes obsolete tomorrow. Carriers must continuously invest in upgrades. Regulators must ensure that investment happens. Consumers must demand reliability.

FAQ
What caused the Verizon outage?
Verizon never disclosed the specific technical cause, but the failure pattern suggests a regional infrastructure problem in the eastern United States, possibly a configuration error or hardware failure in a major routing center. The fact that SMS continued working while voice and data failed indicates the problem was in core network infrastructure rather than the radio access network connecting phones to towers.
How long did the Verizon outage last?
The outage began around 11:45 AM ET with initial reports and escalated rapidly by noon. Full restoration wasn't achieved until approximately 7:00 PM ET, making the total outage roughly six to eight hours from widespread impact to complete recovery across the affected region.
Why did text messages keep working during the outage?
SMS operates on completely separate infrastructure from voice and data. The control channels that carry text messages are on a different network layer and use different switching and routing equipment. When voice and data infrastructure fails, SMS often continues because it runs on independent infrastructure that was designed to be more redundant.
Which areas were affected by the outage?
The outage concentrated in the eastern United States, primarily affecting major metropolitan areas including New York, Philadelphia, Boston, Washington DC, Atlanta, and surrounding regions. Western and southwestern states experienced minimal to no impact, indicating a regional failure rather than national outage.
How does this outage compare to Verizon's September 2024 outage?
Both outages showed similar patterns: voice and data failures lasting several hours, SMS continuing to work, and geographic concentration affecting major metropolitan regions. The September outage lasted approximately four hours, while this more recent outage lasted six to eight hours. The similarities suggest potential recurring vulnerabilities in Verizon's infrastructure.
What should I do if Verizon experiences another outage?
Use alternative communication methods like SMS (which often continues working) or messaging apps over data if data is still functioning. Contact family members using borrowed phones from different carriers. Access Wi-Fi for data if cellular data fails. Contact your carrier about service credits after the outage resolves and file complaints with the FCC if outages are affecting critical services.
Can I get compensation for the Verizon outage?
Verizon typically offers service credits for extended outages, but customers often need to request them proactively. Contact Verizon's customer service with documentation of the outage's impact on your service. The FCC also tracks complaints, and filing a complaint creates a record that might help pressure carriers to improve reliability.
How can I prepare for future network outages?
Maintain alternative connectivity options (different carrier, landline), keep important phone numbers written down, use messaging apps instead of voice calls when possible, enable emergency SOS features on your phone, store critical information in cloud storage and on paper, and establish communication plans with family members about meeting locations and backup methods if you can't reach each other.
Why don't carriers invest more in redundancy to prevent outages?
Redundancy costs money. Backup systems sit idle most of the time, reducing profits. Carriers operate under competitive pressure to keep costs low, creating incentives to minimize redundancy. Regulations could require more redundancy, but current FCC rules don't impose strong requirements or penalties for outages, limiting pressure to over-invest in reliability.
Will 5G infrastructure prevent these outages?
5G's cloud-based architecture and software-defined networking offer potential for better redundancy and faster failover. However, newer systems introduce new vulnerabilities like software bugs and supply chain dependencies. The transition from old to new infrastructure is slow, creating periods where both systems operate together, potentially creating more complexity and failure points.
How do network outages affect emergency services?
Emergency services are significantly impacted during outages. 911 calls from mobile phones can't complete. Emergency dispatchers can't reach first responders as easily. Hospitals can't coordinate with ambulances. However, police and fire departments typically have dedicated radio networks less dependent on commercial cellular infrastructure, so they maintain more capability than the general public.
What's the difference between a network outage and degraded service?
A complete outage means services don't work at all. Degraded service means systems work but slowly or intermittently. The Verizon incident was a complete outage—voice calls couldn't complete and data was completely unavailable. Degradation is more common and less severe, allowing people to eventually make connections even if response times are slow.
Key Takeaways and Moving Forward
The Verizon outage that affected the eastern United States was significant, but not unique. Network failures happen. They'll happen again. The question isn't whether we should be prepared for future outages, but how prepared we can be.
What this outage revealed is uncomfortable truth: we've become completely dependent on a system that isn't perfectly reliable. That system has single points of failure. That system can fail for hours affecting millions of people. When it fails, most of us have no meaningful backup plan.
For Verizon, the outage is a wake-up call that customers expect better reliability and transparency. The company needs to address underlying infrastructure vulnerabilities, not just issue apologies. Customers will watch whether actual improvements follow this outage or whether this becomes a recurring pattern.
For all of us, the outage is a reminder that infrastructure we take for granted isn't guaranteed. Building personal backup plans—alternative communication methods, important information stored physically as well as digitally, knowledge of what to do when systems fail—makes sense regardless of which carrier you use.
The telecom industry has improved dramatically since the early days of wireless. Networks are more reliable than they've ever been. But reliability can always improve. Competition from new entrants like satellite internet providers, pressure from regulators, and consumer demand all push toward better service.
But those improvements won't materialize without pressure. File complaints with the FCC. Contact your carrier with feedback. Support competitors offering alternatives. Vote with your wallet. Infrastructure improves when enough people demand it.
For now, understand what happened during this outage, prepare for the next one, and keep your expectations realistic. Networks fail. Hospitals are part of our infrastructure. Financial systems are part of our infrastructure. But so is resilience. The ability to function when systems fail is just as important as reliable systems in the first place.
That resilience starts with you being prepared.


