![Why Multi-Step Agents Excel Over Single-Turn RAG in Hybrid Data Tasks [2025]](https://tryrunable.com/blog/why-multi-step-agents-excel-over-single-turn-rag-in-hybrid-d/image-1-1776179063122.jpg)
Why Multi-Step Agents Excel Over Single-Turn RAG in Hybrid Data Tasks [2025]
In the rapidly evolving field of artificial intelligence, the ability to effectively process and integrate diverse data types is crucial. Recent research by Databricks highlights a significant performance difference between multi-step agents and single-turn retrieval-augmented generation (RAG) when it comes to answering queries that span both databases and documents.
TL; DR
- Multi-step agents show over 20% improvement in performance on hybrid data queries compared to single-turn RAG systems, as demonstrated in Databricks' latest updates.
- Complex queries benefit from multi-step processing, allowing for better integration of structured and unstructured data, according to Databricks' insights.
- Databricks' research highlights the consistent superiority of multi-step agents using the STa RK benchmark suite.
- Implementation of multi-step agents involves sophisticated orchestration strategies, as detailed in their multi-agent approach.
- Future trends suggest growing reliance on multi-step systems for enterprise-level AI applications.

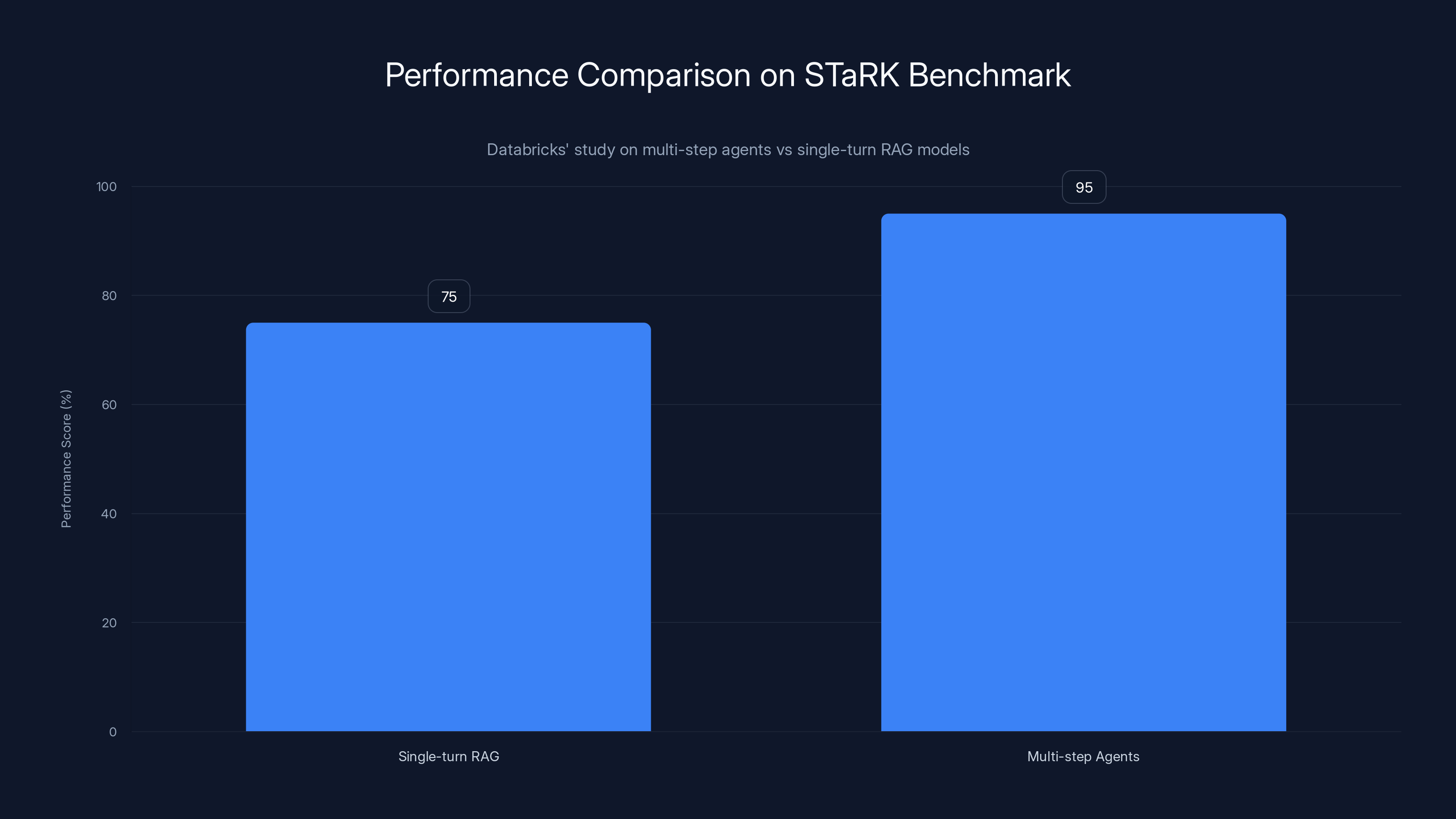
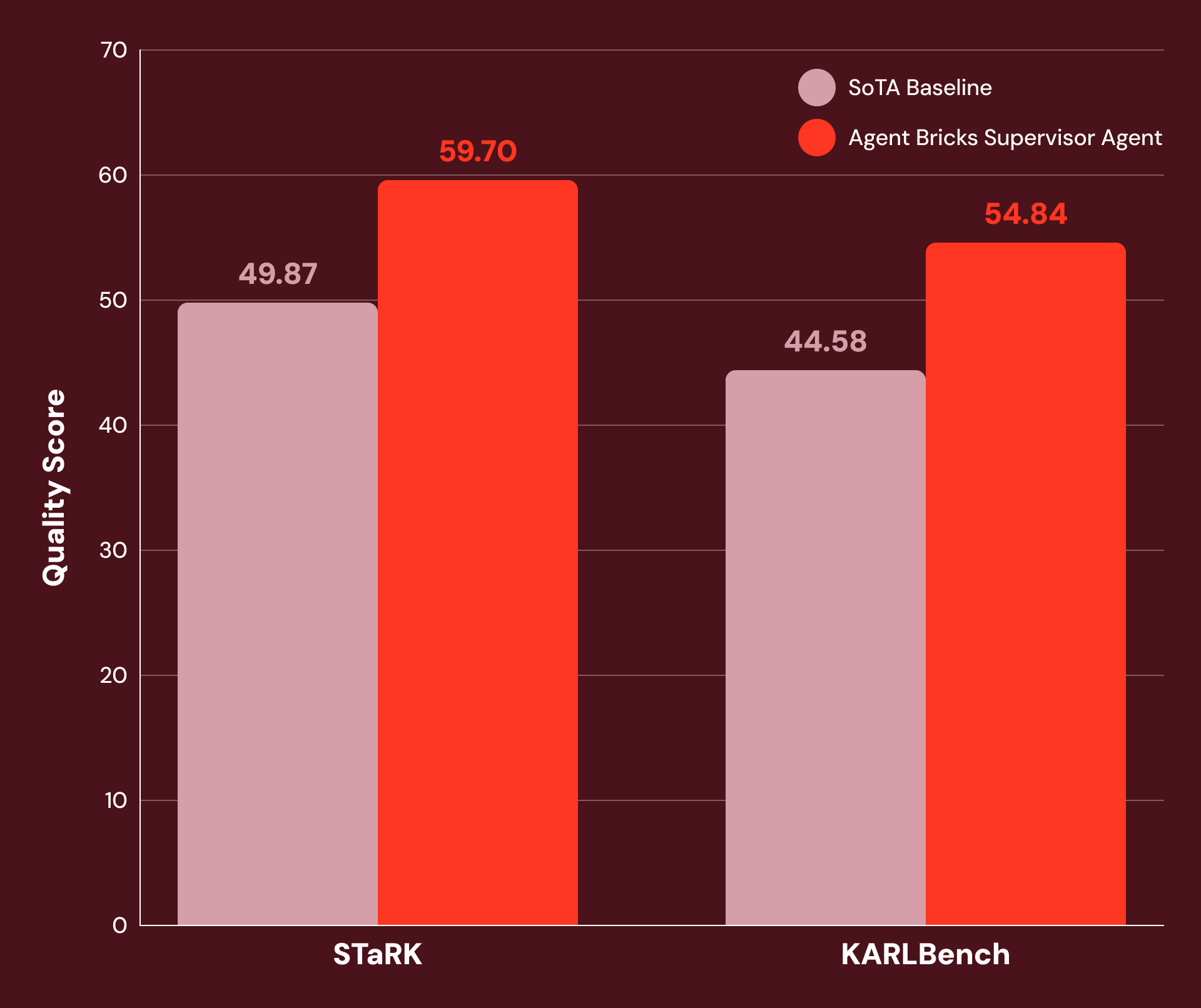
Multi-step agents outperform single-turn RAG models by over 20% on the STaRK benchmark, highlighting their superior capability in handling complex queries. (Estimated data)
The Challenge of Hybrid Data
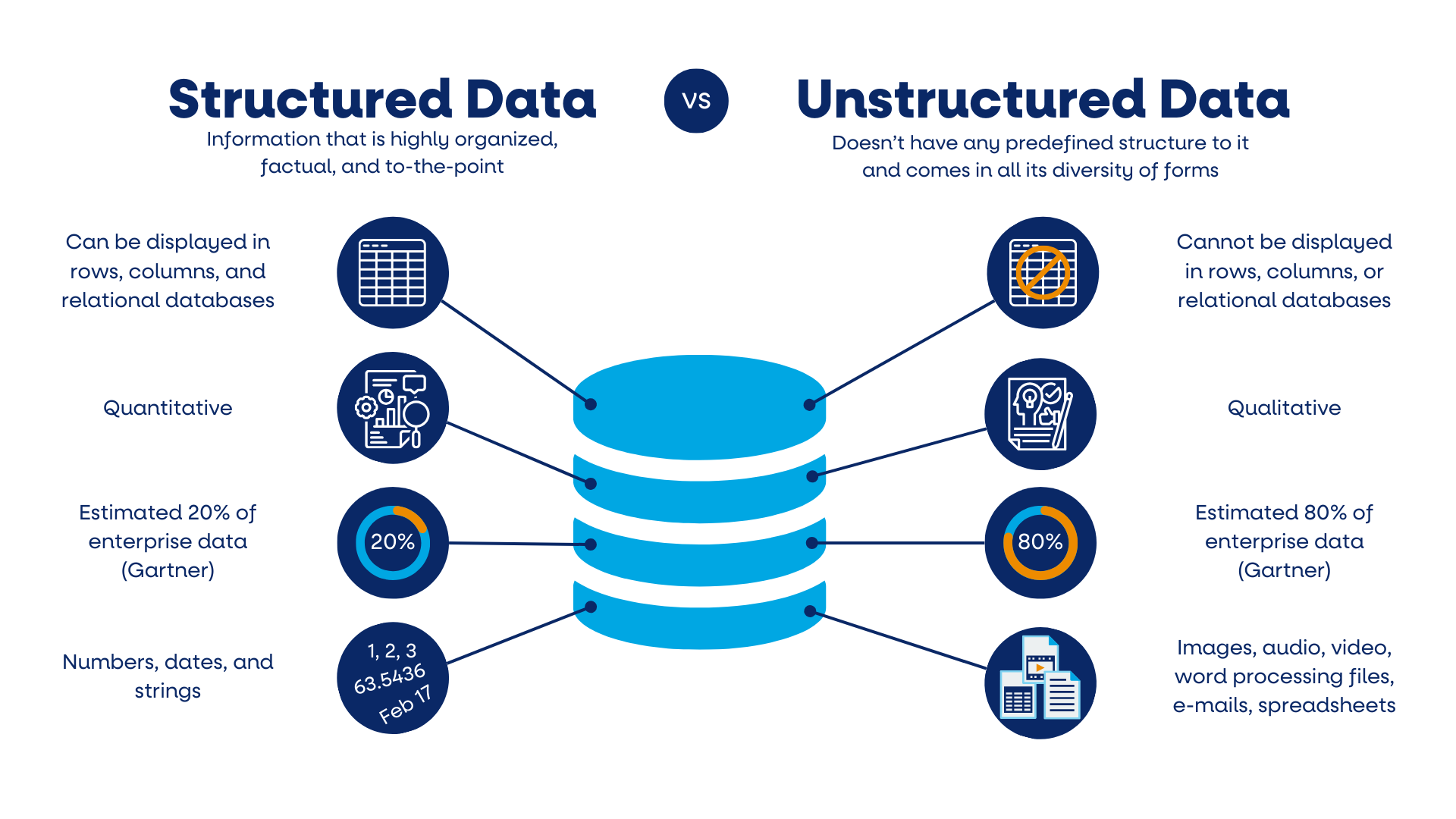
The digital landscape is awash with data, both structured, such as database entries, and unstructured, like text documents. While single-turn RAG systems have been a staple in data retrieval tasks, their limitations become evident when questions necessitate the integration of these disparate data types.
Structured Data: Typically stored in databases, structured data is highly organized, allowing for efficient retrieval and manipulation. Examples include customer databases, inventory lists, and financial records.
Unstructured Data: This encompasses any data not structured in a predefined manner, such as emails, reports, social media posts, and multimedia files.
Handling queries that bridge these two worlds requires a nuanced approach that single-turn RAG systems struggle to provide. Such systems often falter when tasked with synthesizing information from diverse sources, leading to incomplete or inaccurate responses.
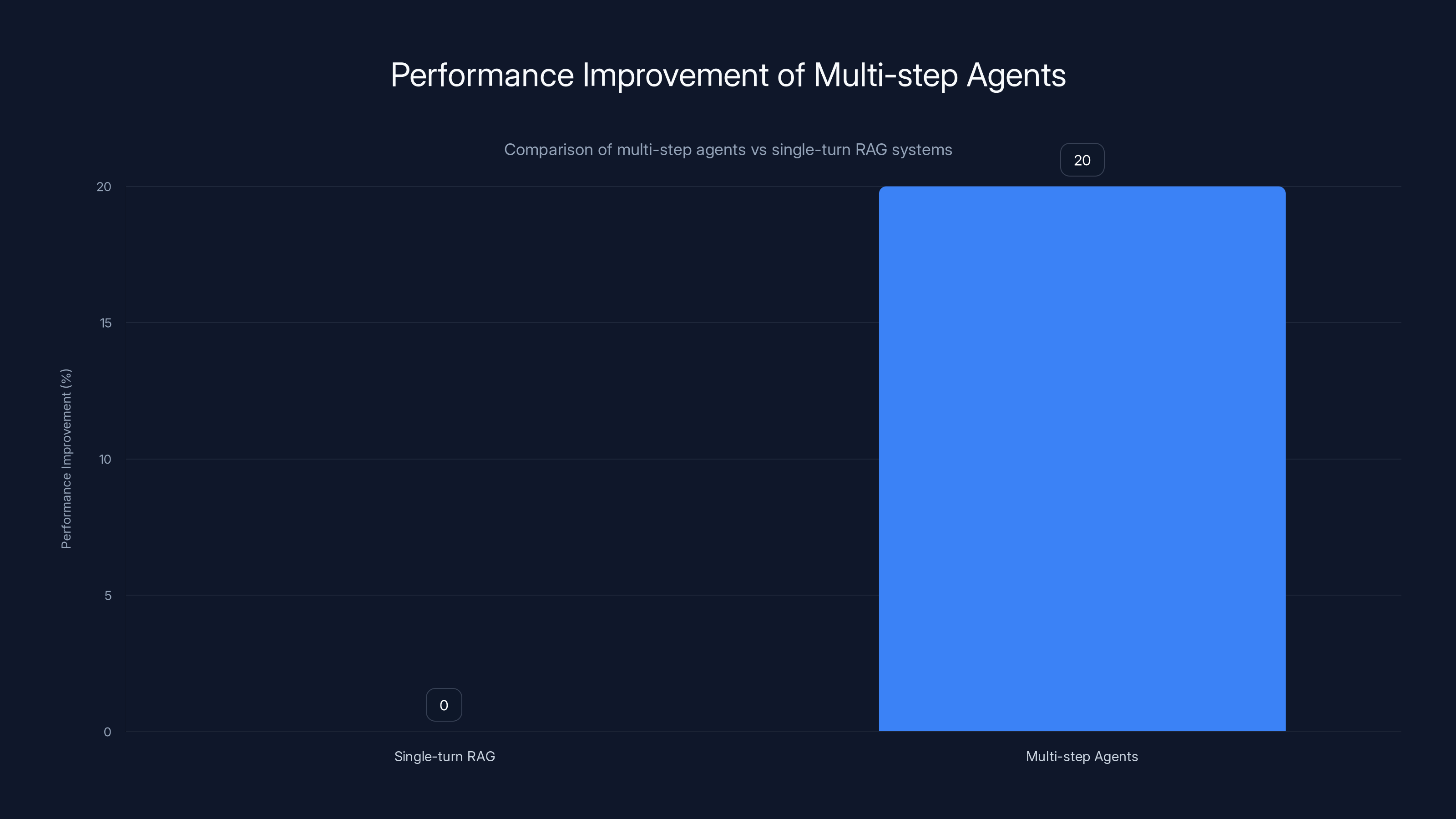
Multi-step agents show over 20% improvement in performance on hybrid data queries compared to single-turn RAG systems, highlighting their effectiveness in complex query processing.
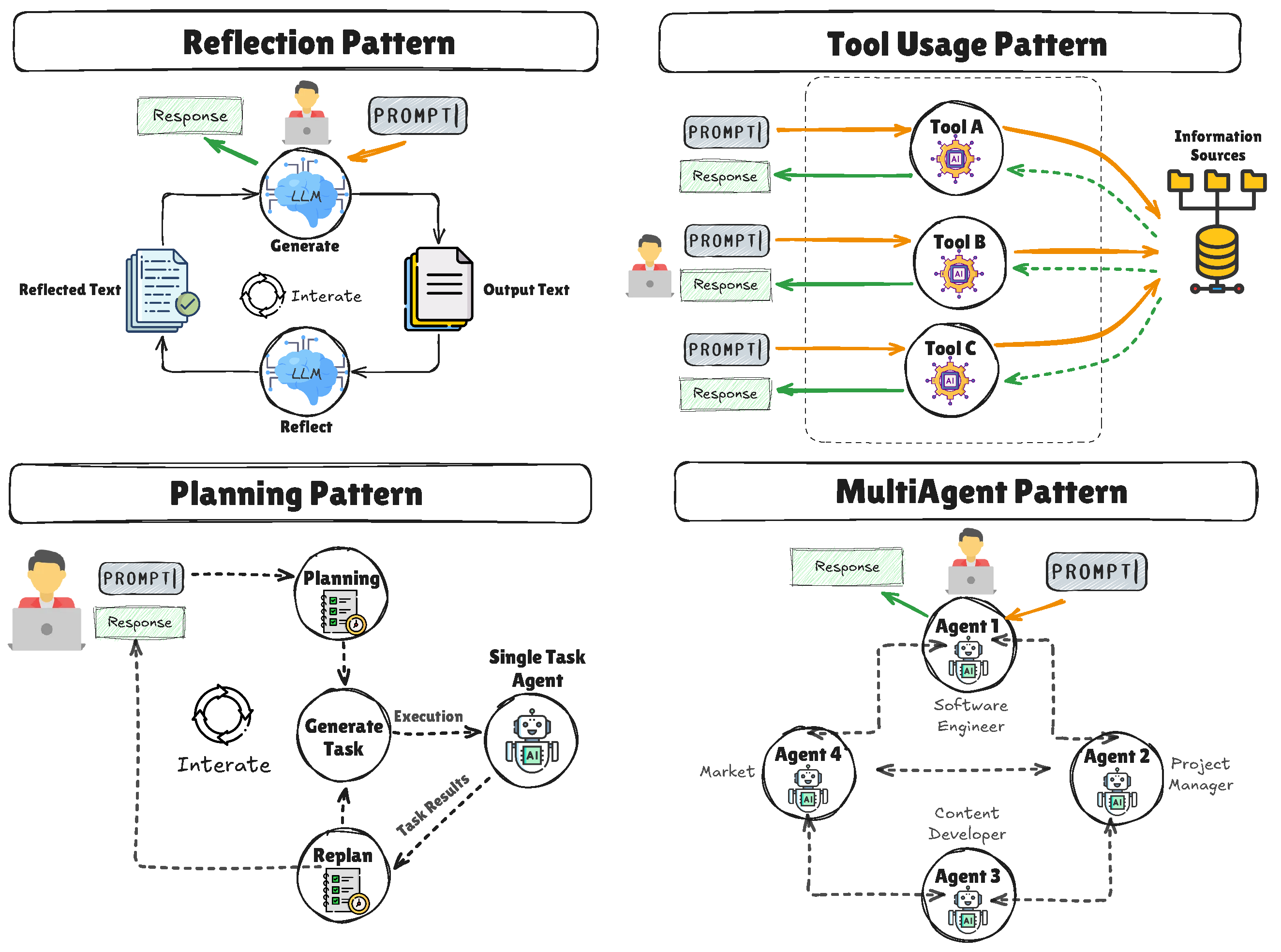
What Sets Multi-Step Agents Apart?
Multi-step agents, as the name suggests, process queries through a series of well-defined steps rather than a single pass. This approach allows them to break down complex questions into manageable sub-tasks, each targeting specific data sources.
Key Features of Multi-Step Agents
- Task Decomposition: Divides complex queries into simpler components.
- Sequential Processing: Processes each sub-task in a logical sequence, ensuring comprehensive data integration.
- Adaptive Learning: Continuously refines its approach based on previous results.
- Dynamic Orchestration: Adjusts the sequence of operations based on the data encountered, as outlined in Databricks' research.
Real-World Use Case: Enhancing Customer Service
Imagine a customer service scenario where the agent needs to resolve an issue involving a product warranty. The query might require accessing structured data (warranty terms from a database) and unstructured data (customer reviews and previous support tickets).
A multi-step agent would:
- Extract warranty terms from the database.
- Analyze customer reviews to identify common issues.
- Correlate findings with previous support interactions.
This multi-faceted approach ensures a thorough and accurate response, enhancing customer satisfaction and operational efficiency.
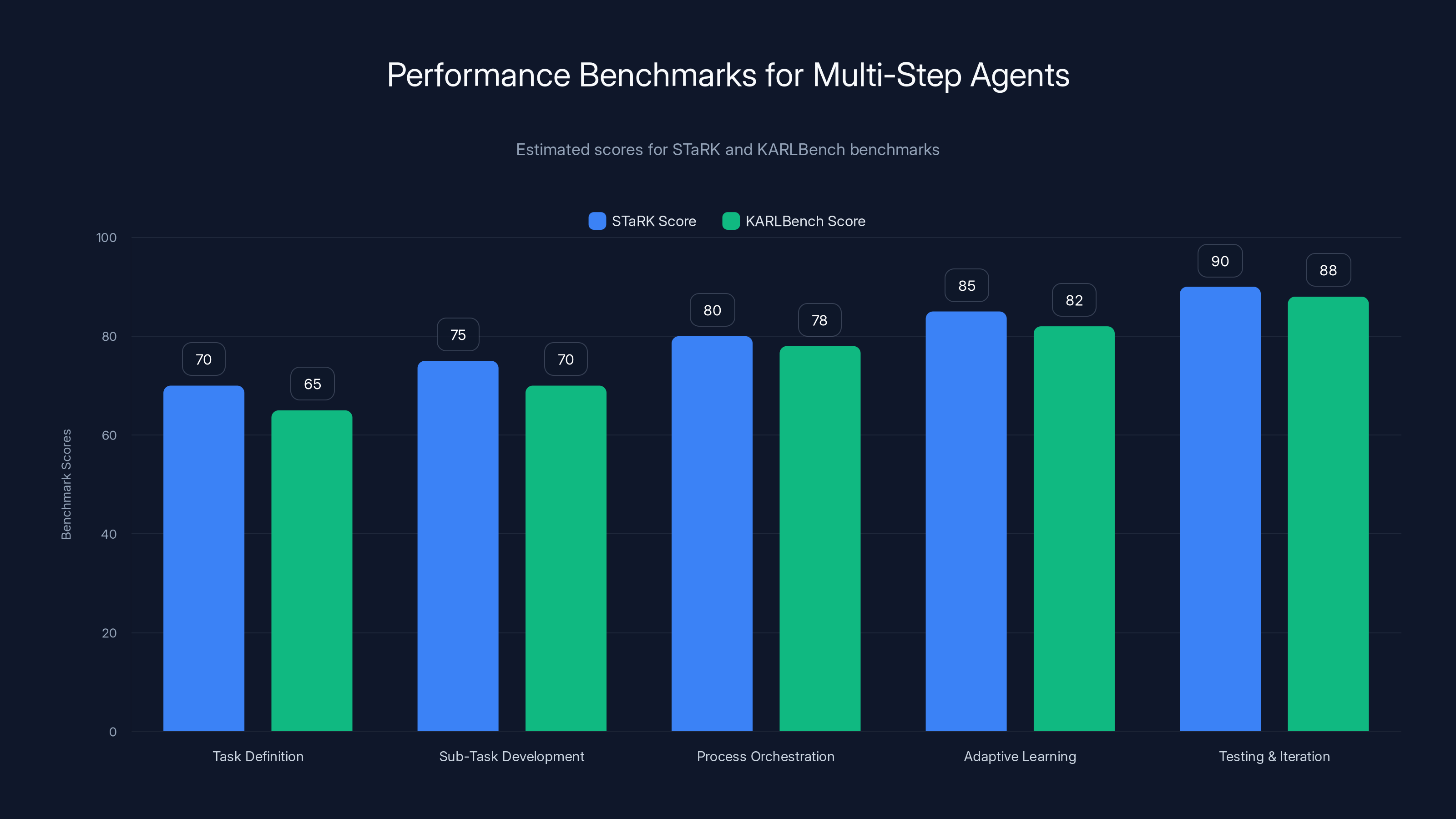
Estimated scores show improvement in performance across implementation steps, with adaptive learning and testing phases achieving the highest scores.
Databricks' Research Insights
Databricks' recent study underscores the efficacy of multi-step agents. By evaluating these systems against single-turn RAG models on the Stanford STa RK benchmark and their proprietary KARLBench framework, they reported performance gains exceeding 20%.
STa RK Benchmark: A comprehensive suite designed to test the ability of AI systems to handle complex, hybrid data queries.
KARLBench Framework: A custom evaluation tool by Databricks that measures real-world applicability and integration efficiency.

Implementing Multi-Step Agents: A Practical Guide
Step 1: Define the Task
Start by clearly defining the query's requirements. Identify the data sources involved and the nature of the information needed.
Step 2: Develop Sub-Tasks
Break down the query into smaller, more manageable tasks. Each sub-task should target a specific data source or a particular aspect of the query.
Step 3: Orchestrate the Process
Use orchestration tools to manage the sequence of tasks. Ensure that each step logically follows from the previous one, integrating results as needed.
Step 4: Implement Adaptive Learning
Incorporate machine learning algorithms that refine the process based on feedback and results. This ensures continuous improvement in performance.
Step 5: Test and Iterate
Evaluate the system's performance using benchmarks like STa RK and KARLBench. Use the results to tweak and enhance the agent's capabilities.

Common Pitfalls and Solutions
Pitfall 1: Over-Complexity
Solution: Keep the task decomposition as simple as possible. Avoid unnecessary sub-tasks that complicate the process.
Pitfall 2: Integration Challenges
Solution: Ensure robust data integration strategies. Use APIs and middleware that facilitate seamless data exchange between systems.
Pitfall 3: Performance Bottlenecks
Solution: Optimize each task for efficiency. Use performance monitoring tools to identify and resolve bottlenecks.
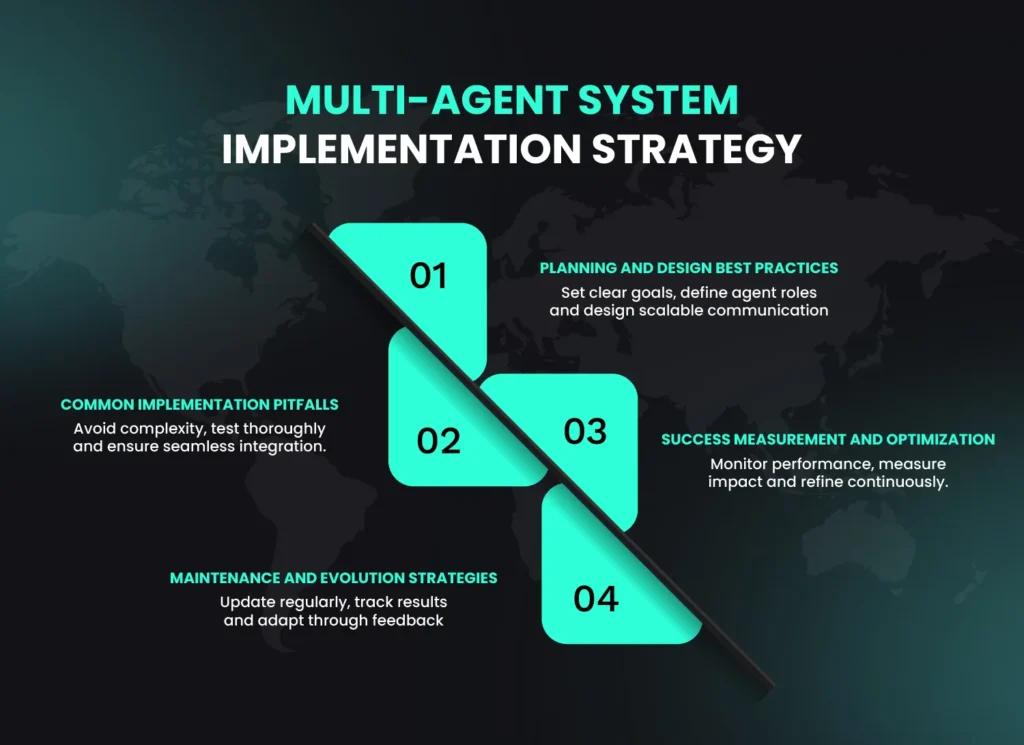
Future Trends and Recommendations
As AI continues to evolve, the role of multi-step agents is expected to grow, particularly in enterprise settings where data complexity is the norm.
Recommendation 1: Invest in Orchestration Tools
Organizations should invest in advanced orchestration tools that can efficiently manage multi-step processes, ensuring scalability and adaptability.
Recommendation 2: Focus on Adaptive Learning
Implement adaptive learning mechanisms that allow agents to improve over time, adapting to new data patterns and requirements.
Recommendation 3: Prioritize Data Integration
Ensure that your infrastructure supports seamless integration across diverse data sources, enhancing the agent's ability to synthesize information.
Recommendation 4: Stay Ahead with Continuous Research
Continuously monitor advancements in AI research to stay ahead of the curve, incorporating new methodologies and technologies as they emerge.
Conclusion
The evidence is clear: multi-step agents provide a significant advantage over single-turn RAG systems in handling hybrid data tasks. By enabling a more nuanced and comprehensive approach to data processing, these agents can transform how businesses interact with and leverage their data.
As the field of AI continues to advance, the adoption of multi-step agents is not just a trend but a necessity for organizations looking to maintain a competitive edge.
FAQ
What are multi-step agents in AI?
Multi-step agents are AI systems that process queries through a series of sequential steps, each targeting specific data sources or aspects of the query, allowing for more comprehensive data integration.
How do multi-step agents outperform single-turn RAG systems?
They break down complex queries into manageable sub-tasks, process them sequentially, and integrate results, leading to more accurate and complete responses.
What is the STa RK benchmark?
The STa RK benchmark is a comprehensive evaluation suite used to test AI systems' ability to handle complex queries involving both structured and unstructured data.
Why is task decomposition important in multi-step agents?
Task decomposition simplifies complex queries into smaller tasks, making it easier for AI systems to process and integrate data from diverse sources effectively.
How can businesses implement multi-step agents?
Businesses can implement multi-step agents by defining query requirements, developing sub-tasks, orchestrating processes, incorporating adaptive learning, and continuously testing and refining the system.
What future trends are expected for multi-step agents?
The adoption of multi-step agents is expected to grow, particularly in enterprise settings, with advancements in orchestration tools, adaptive learning, and data integration playing a key role.
Key Takeaways
- Multi-step agents outperform single-turn RAG systems by over 20% on hybrid data tasks.
- Complex queries benefit significantly from multi-step processing strategies.
- Databricks' research provides a strong case for multi-step agent adoption in enterprises.
- Effective implementation requires clear task definition and robust orchestration.
- Adaptive learning and data integration are critical for optimizing multi-step agents.
- Future trends indicate increasing reliance on multi-step systems for complex data tasks.
- Investing in orchestration tools and adaptive systems is crucial for long-term success.
Related Articles
- Exploring Meta's Ambitious AI Model of Mark Zuckerberg [2025]
- The Complex World of Data Breaches: Lessons from the Rockstar Games Leak [2025]
- AI Influencers: Shaping the Future of Digital Festivals [2025]
- Understanding the Claude Performance Debate: Is Anthropic 'Nerfing' Its AI? [2025]
- The Future of Leadership: Mark Zuckerberg's AI Clone and Its Implications [2025]
- How Businesses Can Turn AI Pilots into Scalable Solutions [2025]

