![YouTubers Sue Snap for AI Training Copyright Infringement [2025]](https://tryrunable.com/blog/youtubers-sue-snap-for-ai-training-copyright-infringement-20/image-1-1769465376049.jpg)
The Battle Over AI Training Data: YouTubers Take on Snap
Last month, a group of content creators did something increasingly common in the tech world: they sued a major platform for allegedly stealing their work to train artificial intelligence models. But this case isn't just another copyright dispute lost in the legal system. It represents a fundamental tension that's reshaping how tech companies build AI, how creators protect their intellectual property, and what happens when innovation collides with creator rights.
Snap joined a growing list of tech giants facing lawsuits from YouTubers claiming the company scraped their video content without permission to power AI features. The creators behind h3h3, Mr Short Game Golf, and Golfoholics—channels with roughly 6.2 million collective subscribers—allege that Snap used their content to train systems powering features like "Imagine Lens," which allows users to edit images with text prompts. This is hardly the first fight of this kind. Similar lawsuits target Nvidia, Meta, and ByteDance. But each new case adds pressure to an industry that's been moving fast, breaking things, and asking for forgiveness later.
The legal landscape around AI training data has become a minefield. Over 70 copyright infringement cases have been filed against AI companies according to the Copyright Alliance. Some have resulted in wins for creators—others have seen judges side with tech giants. A few have quietly settled with substantial payouts. The Snap case matters because it highlights the messy reality: companies are training their AI on massive datasets they don't own, creators are losing control of their work, and the legal system is still figuring out the rules.
What makes this situation particularly fraught is the assumption many AI developers made early on. They believed datasets labeled for "research and academic use" were fair game. They built billion-parameter models on data scraped from the internet without clear licensing agreements. And now they're discovering that "research use" doesn't give you the right to commercialize features that were trained on that data. The YouTube creators suing Snap aren't the first to notice this gap between technical capability and legal reality.
The stakes here extend far beyond Snap. This lawsuit will likely influence how other companies approach data collection for AI training. It could reshape licensing agreements, force more transparency in dataset curation, and set precedents that ripple through the entire AI industry. Creators are fighting back with lawyers and court filings instead of just accepting that their work fuels AI systems they never consented to. And honestly, it's about time.
Understanding this conflict requires looking at how we got here, what the lawsuits actually claim, and what happens next in an industry that's moving faster than the law can keep up with.
TL; DR
- YouTubers with 6.2M subscribers sued Snap for scraping their video content to train AI models without permission
- Over 70 copyright infringement cases have been filed against AI companies, with mixed outcomes in court
- The core issue: Companies trained AI on datasets marked for "research use" but commercialized the resulting features
- Snap's "Imagine Lens" feature allegedly uses training data derived from creator content without licensing
- Precedent matters: Outcomes in these cases will determine how future AI companies approach data collection and creator rights
- Settlement possibility: Similar cases like Anthropic's dispute with authors have resulted in payouts to content creators

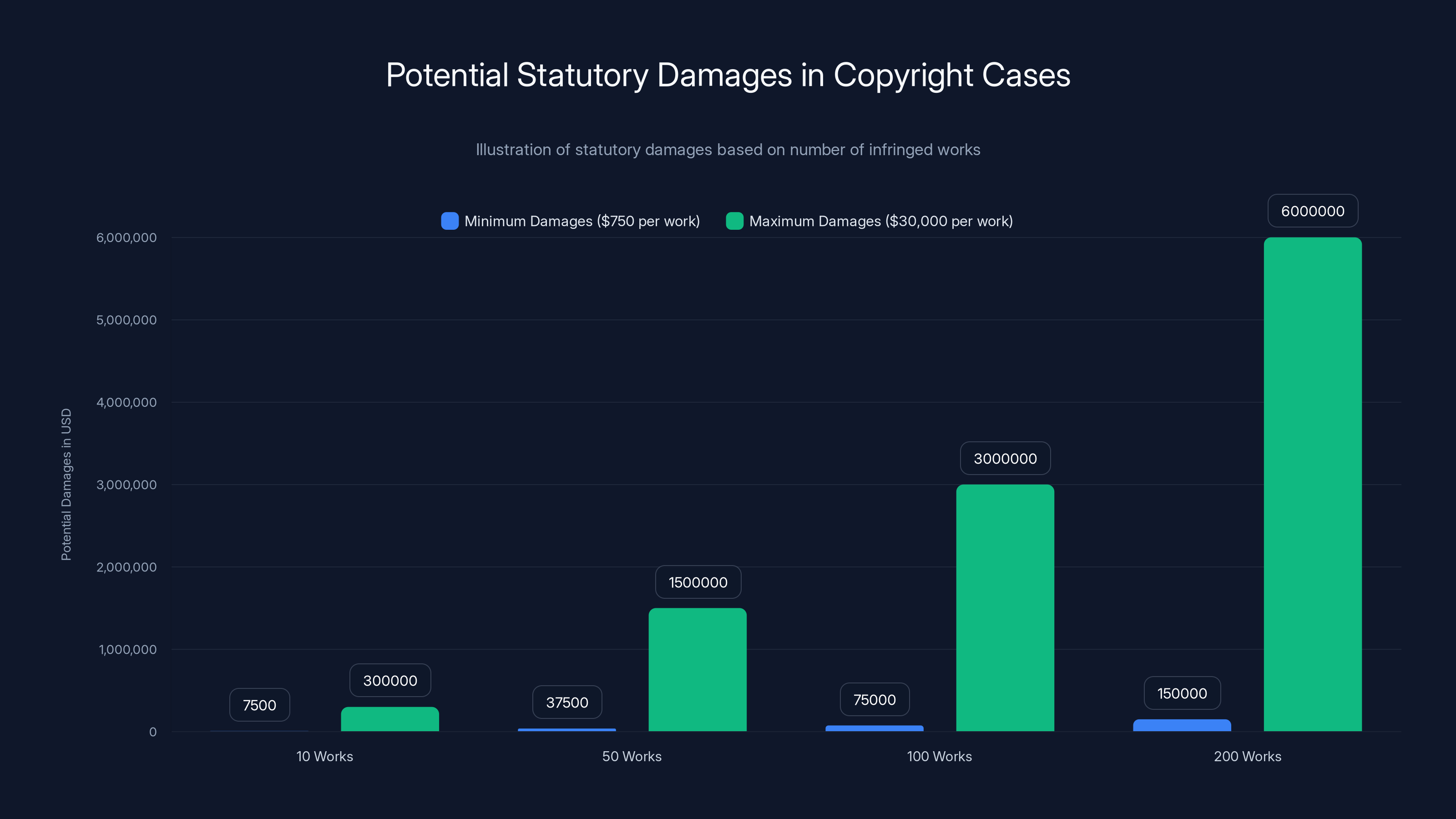
Statutory damages can range significantly based on the number of infringed works, from
How AI Training Became a Copyright Nightmare
To understand why YouTubers are suing tech companies, you need to understand what happened in the first place. Around 2015-2020, the AI community discovered that more data equals better models. Researchers published papers showing that scaling up training datasets led to dramatic improvements in model performance. The solution was obvious: get more data, any data, from anywhere. This led to a practice that became standard in the industry: scrape the internet, download massive datasets, and train on it.
The assumption was simple: if it's on the internet, it's fair game for research. This mindset came from academic traditions where data collection for research was treated differently than commercial use. The distinction made sense in academic contexts. Researchers publish papers, advance knowledge, and don't commercialize their findings. But tech companies aren't academic researchers. They publish papers, yes, but they also build products, sell services, and generate billions in revenue.
Datasets like Common Crawl, released for research purposes, became the foundation for training massive language models and image generation systems. ImageNet, created for academic research, powered computer vision advancements. These datasets were labeled "non-commercial" or "research only" in many cases. But once a model was trained on this data, the distinction became murky. Was a feature built on a model trained with research data a research feature? Or a commercial product? The companies argued the former. Creators argued the latter.
What made this worse was the sheer scale. When you're training a model on billions of images or videos scraped from the internet, you can't individually license each one. It's technically impossible. So companies took shortcuts. They downloaded everything, trained their models, and figured they'd deal with licensing later. They didn't deal with it. Instead, they built features on top of these models and released them to millions of users. When creators discovered their work powered these features, they weren't happy.
The Snap case specifically involves video content. YouTube videos are rich, diverse data sources. They contain everything from tutorials to comedy sketches to niche content. A model trained on this kind of data learns patterns from human behavior, speech, composition, and creativity. When Snap built "Imagine Lens" using models trained on this data, they effectively commercialized creative work they didn't license. This is the core accusation, and it's one that's becoming increasingly difficult for tech companies to defend.
What's particularly frustrating for creators is that they have limited visibility into how their work is being used. Most AI companies don't disclose their training data sources. Some won't even confirm whether specific creators' content was included. This opacity is intentional. Transparency would invite exactly these kinds of lawsuits. But it also means creators have no control, no compensation, and no way to know if their work is powering features they'd object to.

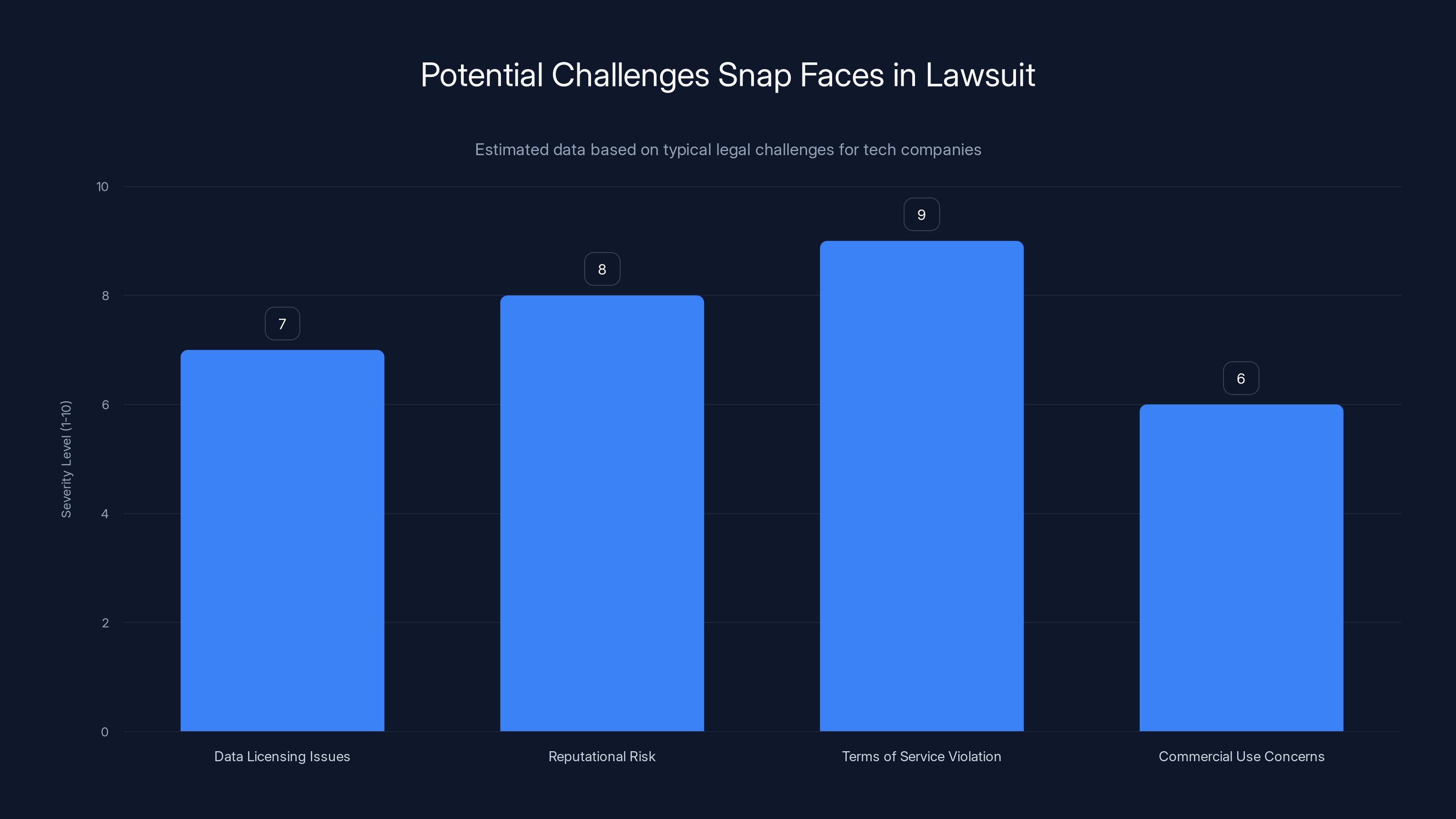
Estimated data suggests that Snap faces significant challenges, particularly with terms of service violations and reputational risks, which are rated as the most severe.
The H3H3 Lawsuit: What Exactly Is Snap Being Accused Of?
The lawsuit against Snap, led by creators behind the h3h3 channel, makes specific allegations about what the company did and why it matters. Understanding these allegations helps clarify what's at stake legally and practically.
The core claim is that Snap scraped YouTube videos from h3h3, Mr Short Game Golf, and Golfoholics without authorization and used that content to train AI systems. Specifically, the lawsuit alleges that this scraped content was used to train models powering "Imagine Lens," a feature that generates edited images based on text descriptions. The feature uses generative AI, which means a model that learned patterns from training data generates new images. The question is: did Snap license the right to use creator content for training?
The evidence suggests the answer is no. The creators claim they never gave permission, never signed licensing agreements, and never received compensation. They discovered their content was being used only after the feature launched and they could see their video styles and compositions reflected in the generated images. Or they were tipped off by lawyers exploring potential class actions.
What makes this legally significant is that YouTube videos represent creative work. The creators invested time, equipment, editing skills, and originality into their content. Under copyright law, they own that work automatically. Snap doesn't have an implicit right to use it. They would need explicit licensing, either through direct agreement or through fair use exceptions. The creators' argument is that Snap had neither.
Snap's defense, if they follow the pattern of other companies in similar situations, would likely argue fair use. They'd claim that using the content for training an AI model falls under fair use because: it's transformative (you're creating something new), it doesn't directly compete with the original (you're not reposting videos), it serves a different purpose (research and product development), and it represents a small portion of their training data.
But courts have increasingly rejected this argument when commercialization is involved. In earlier cases involving authors suing OpenAI and others, judges have expressed skepticism about the "fair use for training" argument when the company profits from the resulting model. The distinction matters: training on copyrighted material for non-profit research might be fair use. Training on it to build products you monetize is harder to defend.
The lawsuit seeks statutory damages and a permanent injunction against Snap. Statutory damages in copyright cases can be significant—potentially thousands of dollars per infringed work. If applied to all content scraped, this could add up quickly. The injunction would force Snap to stop using the content and potentially stop offering the Imagine Lens feature unless they can prove their models no longer contain traces of the scraped content.
This raises a technical question: once you've trained a model on specific data, how do you "untrain" it? You can't remove specific data points from a trained neural network. You'd need to retrain the entire model from scratch without that data. This is expensive and time-consuming. So an injunction isn't just a legal formality—it's a real business cost.
Snap's Position and What The Company Faces
Snap has been asked for comment on the lawsuit, but the company hasn't issued a detailed public response at the time of the lawsuit filing. Based on how other companies have handled similar cases, we can predict the likely defense strategy and the challenges Snap faces.
First, Snap will probably argue that content scraping falls within reasonable use for AI research and development. They'll point to industry practice—the fact that virtually every major AI company has done this—as evidence that it's standard and acceptable. They might also argue that they didn't scrape content directly from creators but obtained it through publicly available datasets that had already been compiled by third parties. This layering of data sources makes attribution and responsibility murky. If Snap can claim they licensed data from a dataset provider rather than directly scraping YouTube, they might argue the provider bears responsibility for licensing.
But this defense has weaknesses. First, it essentially admits they knew they were using third-party data with unclear licensing. Second, even if they obtained data indirectly, they still have responsibility for understanding what they're training on. Third, YouTube's terms of service explicitly prohibit scraping. So any data obtained through scraping violates both copyright and platform terms.
Snap also faces reputational risk. The company's founders built Snap on a privacy-first ethos, marketing the platform as protecting user data. It's ironic to position yourself as privacy-focused while simultaneously scraping creator content without consent. This narrative gap makes Snap an easier target than some other defendants.
The company is also vulnerable because Imagine Lens is a consumer-facing feature that clearly commercializes the underlying technology. It's not research published in an academic paper. It's a product millions of users interact with. This makes the "non-commercial research" defense essentially impossible to maintain.
What Snap might do is settle quietly. Other companies have taken this route. When facing similar lawsuits, some AI companies have negotiated settlements that include payment to creators, licensing agreements going forward, and sometimes equity stakes for prominent creators in the company. These settlements avoid precedent-setting court losses but acknowledge that compensation is owed.
The financial stakes for Snap are meaningful but not existential. The company reported revenue of several billion dollars in recent years. They can afford settlements. What they can't afford is a precedent that makes all their AI features legally vulnerable or forces them to rebuild models from scratch.

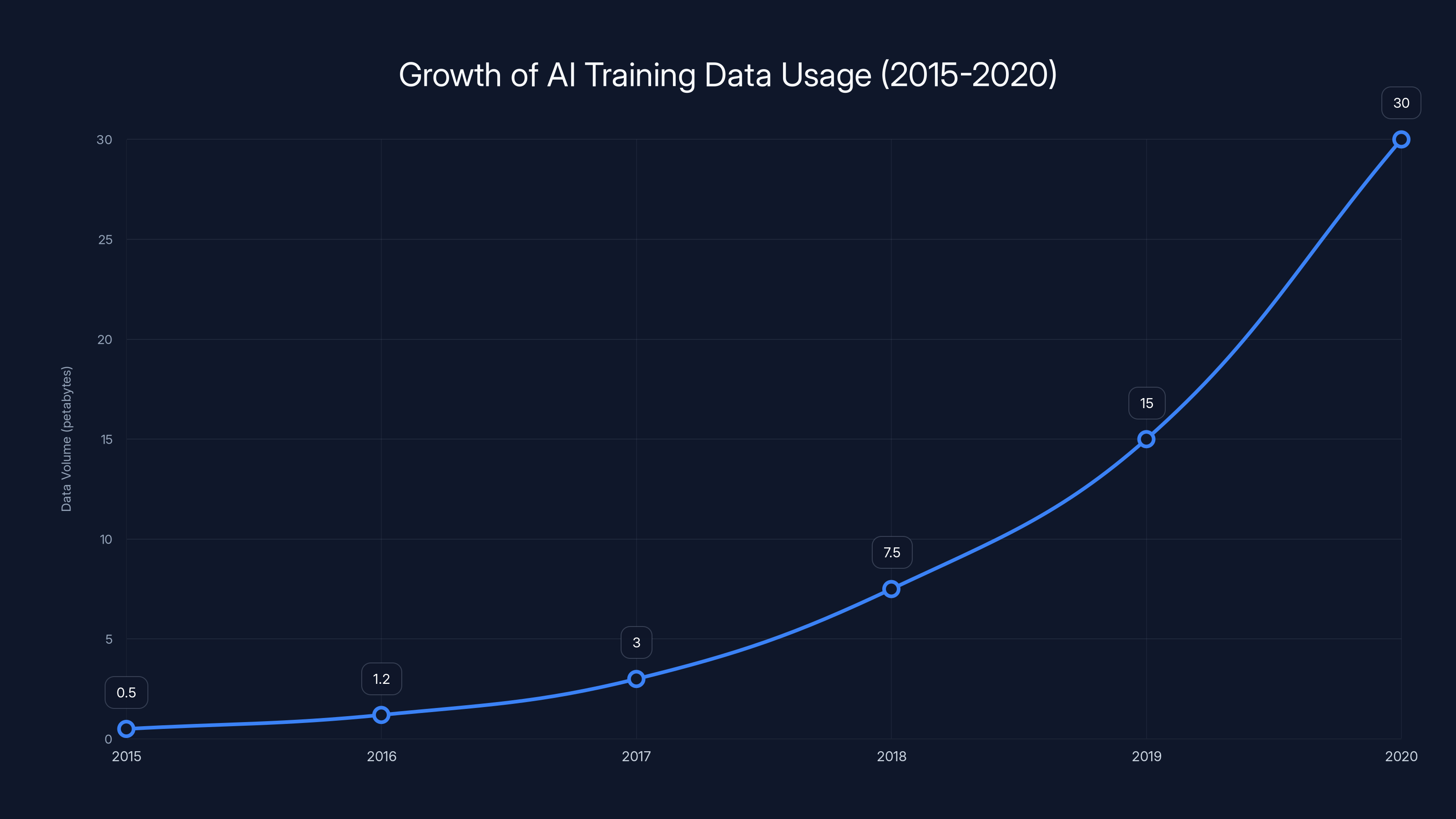
From 2015 to 2020, the volume of data used for AI training grew exponentially, reflecting the industry's shift towards large-scale internet scraping. Estimated data.
Similar Lawsuits and Legal Precedents
The Snap lawsuit doesn't exist in a vacuum. It's one of over 70 copyright infringement cases filed against AI companies according to the Copyright Alliance. Understanding how similar cases have progressed provides insight into what might happen with Snap.
The cases break down into several categories: cases against language model companies like OpenAI and Google, cases against image generation companies like Stable Diffusion and Midjourney, and cases from different plaintiff groups including authors, photographers, news publishers, and user-generated content platforms. Some are further along than others. Some have resulted in surprising outcomes.
One major case involves a group of authors suing OpenAI, Stability AI, and Meta over training their models on copyrighted books. The complaint alleges that these companies trained language models on pirated copies of books obtained from illegal sources. This is distinct from fair use arguments about web scraping. If you're training on pirated content, the defense becomes much weaker. A judge denied OpenAI's motion to dismiss, which suggests the case has legal merit. The case is ongoing, and the outcome could be significant.
Another notable case involved Anthropic, an AI safety company, settling with a group of authors who sued over copyright infringement in training Claude. The settlement included payment to authors, though exact figures weren't disclosed publicly. The settlement suggests that even AI companies that position themselves as safety-conscious and ethical will pay money to resolve these disputes rather than fight them in court.
Meta faced lawsuits from photographers and news outlets alleging their models were trained on copyrighted images without permission. Some of these cases have progressed to more advanced stages, with judges expressing concern about Meta's training practices.
There are also cases where tech companies won. In one case involving Meta and a group of authors, a judge ruled in favor of Meta, finding that their use of copyrighted material for training fell within fair use. This decision gave other companies hope that they could mount a successful defense. But it's a single data point, and subsequent rulings have been more favorable to creators.
What's emerging from all these cases is a pattern: courts are increasingly skeptical of the "fair use" defense when companies profit from models trained on copyrighted material. When the purpose shifts from research to commercialization, the legal equation changes. Fair use has never protected wholesale copying of copyrighted material for profit. The distinction between what the law says about research and what it allows for commercial products is becoming clearer.
The precedents also vary by jurisdiction. Some cases are filed in California, others in New York, still others in federal courts. Different judges interpret copyright law differently. This creates uncertainty for companies. They don't know which court a case will be decided in, which judge will hear it, and what that judge's perspective on AI training is.

The Imagine Lens Feature: What Was Built and How
Understanding the specific feature at the center of the Snap lawsuit helps clarify what the creators are objecting to and what Snap is defending.
Imagine Lens is a camera feature in Snapchat that uses AI to edit images based on text descriptions. You point your camera at something, type a description of how you want it modified, and the AI alters the image accordingly. Want to turn your friend's baseball cap into a wizard hat? Imagine Lens can do it. Want to change the background of a photo? The feature can handle it.
This requires a generative model trained to understand the relationship between text descriptions and visual transformations. The model learned these patterns from training data that showed examples of images, descriptions, and transformations. More training data means better performance and more diverse capabilities.
Snap's implementation uses what's likely a diffusion model or similar architecture that's become standard in the industry. These models work by starting with random noise and gradually denoising it based on the text prompt to generate an image. The quality of the output depends heavily on the training data quality and diversity.
The lawsuit alleges that content from the three YouTube channels was part of this training data. This would mean the model learned patterns from those creators' videos: their filming styles, editing choices, composition preferences, color grading decisions, and subject matter expertise. When you use Imagine Lens and it generates creative edits, it's potentially drawing on patterns learned from this unauthorized training data.
This is different from claiming Snap simply reposted the videos or used them directly. The claim is more subtle: they extracted patterns from the videos and embedded those patterns in a commercial AI feature. The creators never authorized this pattern extraction, never received compensation, and never consented to their creative choices being used as training material for someone else's product.
What's interesting is that Snap could theoretically rebuild Imagine Lens with different training data. They could use only licensed content or content they created themselves. This would be more expensive and might result in slightly lower performance, but it would be legally clean. The fact that they didn't do this initially suggests they either didn't believe they needed to or thought the risk of lawsuits was lower than the cost of proper licensing.

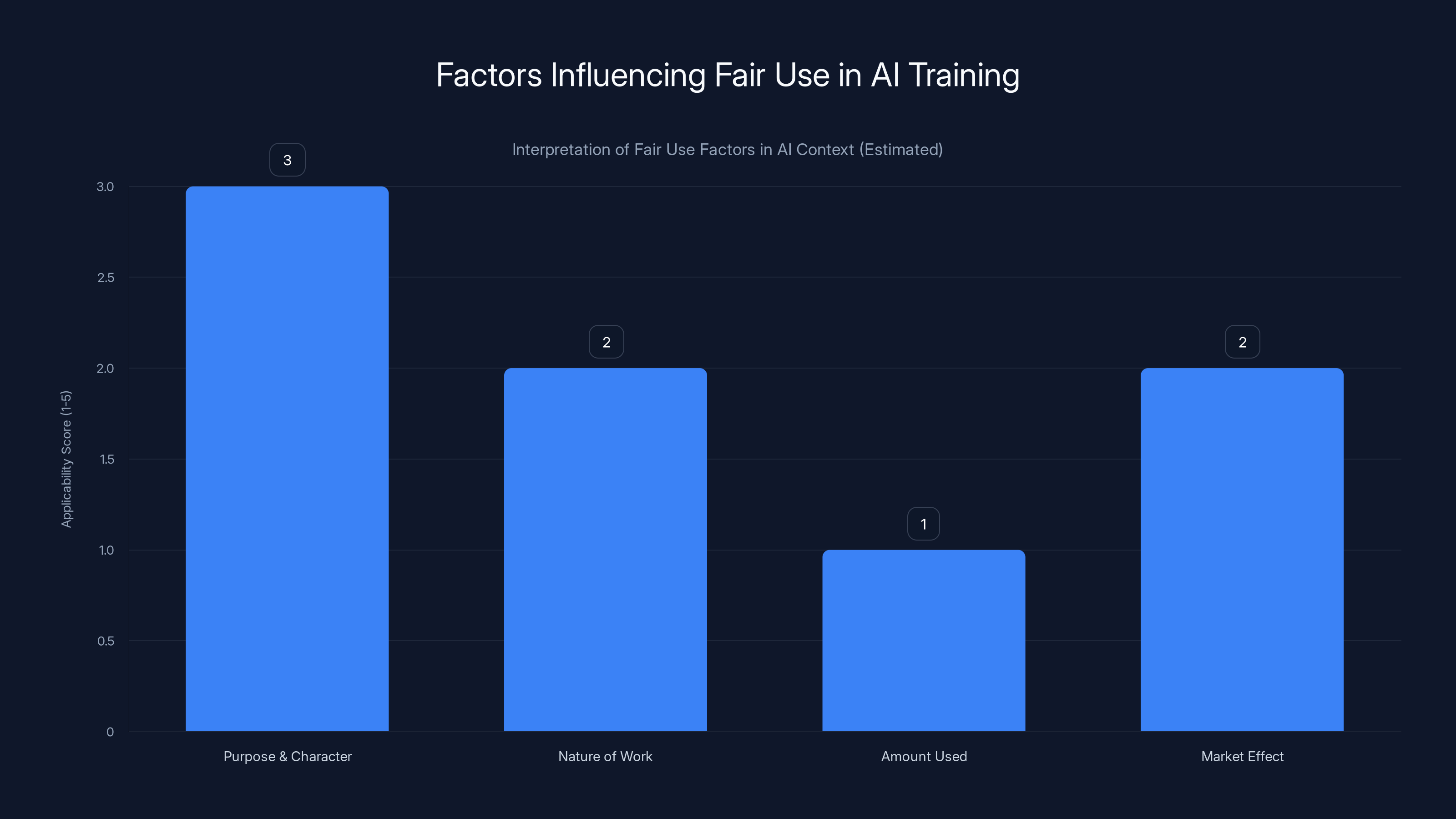
Estimated scores show that the 'Purpose & Character' factor is most applicable, while 'Amount Used' is least applicable in AI training fair use cases.
The Broader Debate: AI Development vs. Creator Rights
The Snap lawsuit sits at the intersection of a massive debate happening across tech, law, and society: how should AI companies balance the need for training data with creators' rights to control and profit from their work?
On one side, AI companies argue that training data is essential to progress. Without large datasets, they can't build competitive products. Retroactively licensing content from every creator whose work ended up in a training dataset would be prohibitively expensive and logistically complex. It would slow down AI development and potentially make it economically impossible. They argue that society benefits from AI progress, and some degree of content use for training is necessary to achieve that progress.
On the other side, creators argue that their work has value and shouldn't be used without permission or compensation. They spent time, effort, creativity, and sometimes significant money creating their content. Watching tech companies profit from that work while they receive nothing feels exploitative. They also point out that if an AI company can build a feature without their content, they should be required to. Using their work should be the expensive option, not the cheap option.
This debate reveals a fundamental mismatch between how the internet was built and how AI development is happening. The internet was built on the principle that information should flow freely. Copyright was respected, but there were also many mechanisms for fair use and sharing. AI training breaks this balance. It takes massive amounts of copyrighted material and condenses it into models that can be deployed at scale. The original creators get nothing.
Some have proposed solutions. One approach is mandatory licensing: companies that want to use creator content for AI training should be required to negotiate licenses. This would shift costs to AI companies and ensure creators are compensated. Another approach is collective licensing, where organizations representing creators negotiate deals with AI companies on behalf of their members. This already works in music, where collective licensing organizations collect fees on behalf of artists.
Another proposal is to allow creators to opt out of AI training. If you don't want your content used, you shouldn't have to be. YouTube could implement a setting that tells scrapers and data brokers not to use your videos. But this would require enforcement and would only work if creators know about the option and actively opt out.
Snap and other companies will face pressure to implement some combination of these solutions. Whether that pressure comes from lawsuits, regulation, or public sentiment remains to be seen. For now, lawsuits are the primary mechanism driving change.

Copyright Law and Fair Use: How Courts Are Interpreting AI Training
The legal framework around copyright and fair use is critical to understanding whether Snap's alleged actions were illegal. Copyright law has specific definitions of what's allowed and what requires permission. Fair use provides exceptions to copyright, but those exceptions have limits.
Under U.S. copyright law, creators automatically own their work when they create it. YouTubers own their videos. They have the exclusive right to reproduce the work, prepare derivative works, and distribute copies. Snap doesn't have these rights unless explicitly granted.
Fair use is defined by four factors: the purpose and character of the use (commercial vs. educational), the nature of the copyrighted work, the amount and substantiality of the portion used, and the effect on the market value of the original. Courts weigh these factors to determine if a use is fair.
Traditionally, fair use has covered things like criticism, commentary, news reporting, teaching, scholarship, and research. Copying a short excerpt from a book for a book review is fair use. Quoting a paragraph from a song in an academic paper is fair use. But copying an entire book to sell it? That's not fair use.
AI training blurs these categories. When you train a model on billions of images, you're not quoting or commenting on them. You're extracting patterns and compressing that knowledge into weights and parameters. This is extractive use, not transformative commentary. Some argue this is exactly what fair use protects. Others argue that fair use never extended to wholesale copying for profit, and training models for commercial products shouldn't be an exception.
Courts have recently shown skepticism about the "fair use for AI training" defense. In the OpenAI author lawsuit, the judge found that the plaintiffs had stated valid copyright claims and that fair use wasn't obviously applicable. In copyright disputes involving image generators, judges have expressed concern about the scope of training and the lack of compensation to original creators.
What's emerging is a distinction between training for non-commercial research (potentially fair use) and training for commercial products (harder to defend). Snap's Imagine Lens is clearly commercial. Users of Snapchat pay for premium features that include advanced filters and effects. Snap profits from the app directly through ads and premium subscriptions. This commercialization matters to courts.
The fair use analysis also considers whether the use harms the original creator's market. If training on YouTuber content cannibalizes their ability to monetize video editing or effect services, that harms their market. If someone uses an AI feature they get from Snap instead of commissioning a video editor to modify their footage, the YouTuber loses potential income. This market harm weighs against fair use.
Another consideration is whether there's a reasonable mechanism for licensing the content. If creators would be willing to license their content but the company chose to use it without permission to save costs, that weighs against fair use. Companies can't claim fair use if licensing is available but they just didn't want to pay.
What we're seeing is a gradual shift in how courts interpret fair use in the AI context. The old assumption that any research use is fair use is giving way to a more nuanced analysis that considers commercialization, market harm, and availability of licensing. This shift creates risk for companies like Snap that built their AI systems on training data without clear licensing agreements.

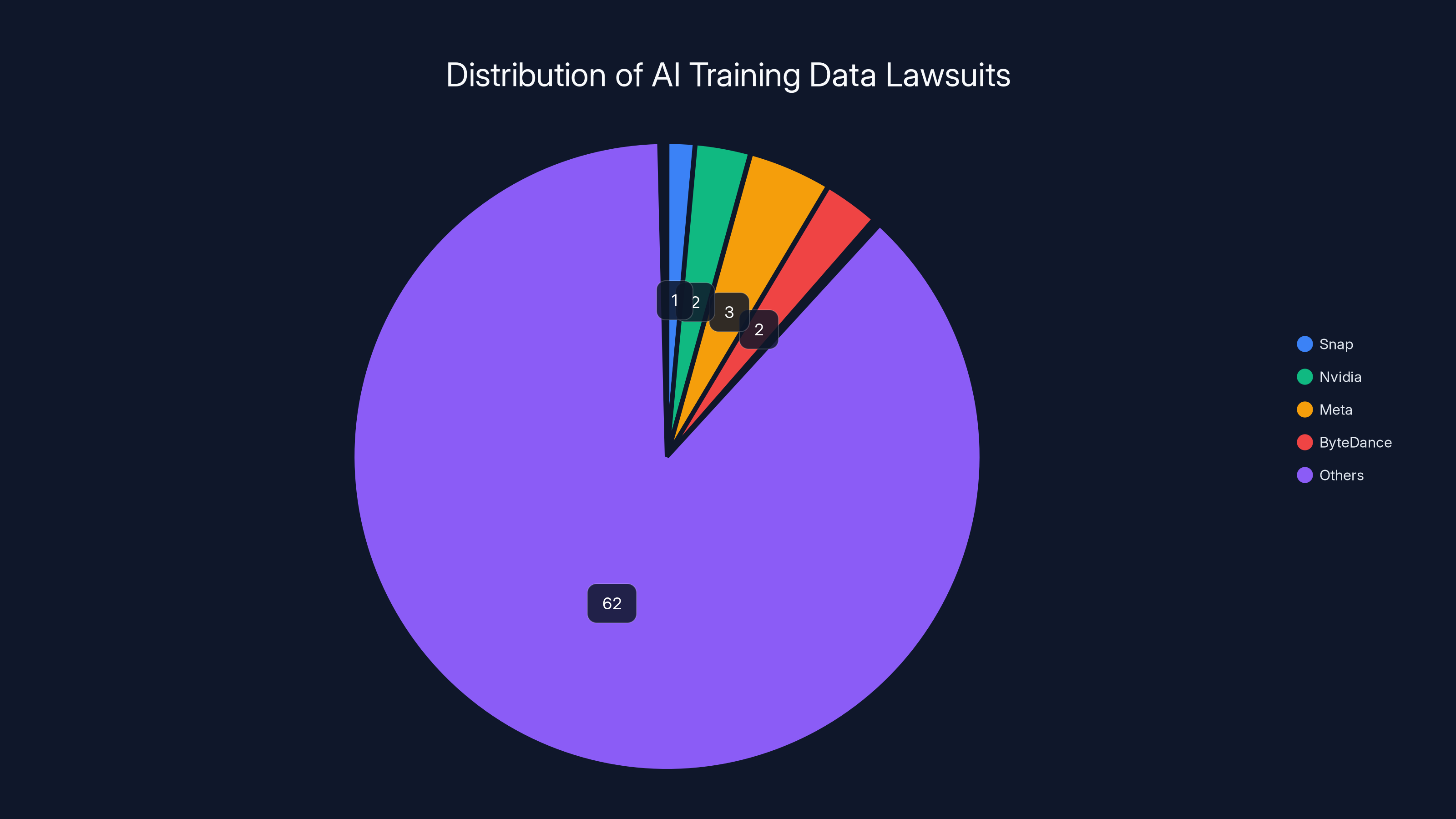
Snap is one of several companies facing legal challenges over AI training data. The majority of cases target other tech giants, highlighting widespread industry issues. Estimated data.
International Implications: How Other Countries Are Addressing This
The Snap lawsuit is happening in U.S. courts, but the issue is global. Companies train models on content from creators worldwide. Different countries have different copyright laws and different perspectives on AI development.
The European Union has taken a more protective stance toward creators. The EU's Digital Services Act and Copyright Directive include provisions addressing AI training on copyrighted material. The EU generally requires that AI companies respect copyright and obtain proper licensing. This creates different rules for companies operating in Europe versus the United States.
The UK has explored fair dealing provisions that might apply to AI training but is moving toward more protection for creators following their exit from the EU. Canada has debated extended collective licensing for AI training. Japan and South Korea have experimented with different approaches, sometimes favoring AI development, sometimes favoring creator protection.
This fragmentation creates complexity. Snap and other companies face different legal requirements in different jurisdictions. What's legal in the U.S. might be illegal in the EU. A company that trains models on content without licensing might be complying with U.S. law while violating EU regulations.
Some companies are responding by implementing geo-specific systems. They might exclude content from creators in jurisdictions with stronger protections. They might implement licensing systems only in regions that require it. This fragmentation is inefficient but reflects the reality of global regulation.
The Snap case could influence international law. If U.S. courts side with creators, other countries might accelerate efforts to protect them. If courts side with Snap, international regulation might become more protective as a counterweight. Either way, the stakes extend beyond U.S. borders.

Settlement Possibilities and Outcomes
Based on how similar cases have proceeded, the Snap lawsuit could follow several paths. Understanding these scenarios helps predict what might happen next.
The first possibility is a settlement. Snap could negotiate with the YouTubers' legal team, agree to compensate them, and resolve the case out of court. This avoids the risk of an unfavorable precedent and the publicity of a trial. Settlements in similar cases have ranged from undisclosed amounts to substantial payouts. The creators might receive a lump sum, ongoing royalties based on Imagine Lens usage, or a combination. They might also require Snap to implement systems ensuring future features don't use unauthorized content. This outcome would likely satisfy the creators but wouldn't change industry-wide practices unless other companies follow suit.
The second possibility is a court ruling in the creators' favor. The judge could find that Snap violated copyright, order them to stop using the content, and award damages. This would set a precedent making it harder for other companies to defend similar practices. It might accelerate settlements in other cases and force the industry to rethink AI training data sourcing. Snap would likely appeal, extending the timeline and keeping the case in uncertainty.
The third possibility is a court ruling in Snap's favor. The judge could find that using content for AI training falls under fair use or that Snap's conduct doesn't constitute infringement. This would be a significant win for the company and would embolden other AI developers to continue current practices. However, a single favorable ruling might not be enough to deter other plaintiffs from suing. The legal landscape would remain contested.
The fourth possibility is a hung jury or mistrial if the case goes to trial. This would require retrials and further extend the timeline. During this period, uncertainty would linger, and other cases might move forward based on developments in the Snap litigation.
Most legal experts predict settlement as the most likely outcome. Few cases of this magnitude make it to trial. Companies prefer known costs (a settlement) to unknown risks (a jury verdict). Creators might prefer settlement and immediate compensation to the uncertainty of a multi-year litigation process. A settlement might not change the industry globally, but it would acknowledge that compensation is owed and create momentum for better practices.

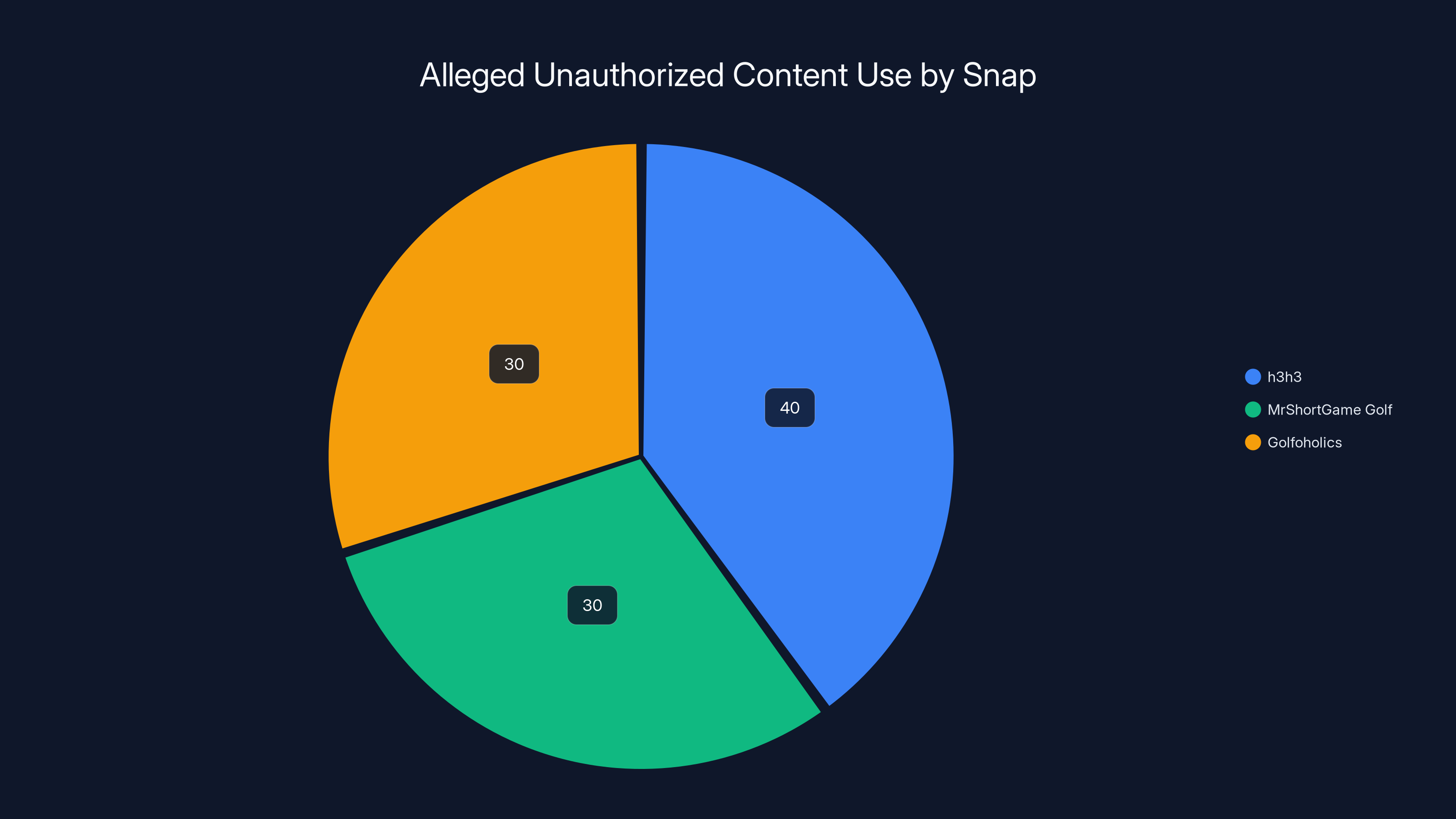
Estimated data shows the distribution of content sources allegedly used by Snap without authorization. h3h3 content is estimated to be the largest portion.
What This Means for AI Companies and Developers
The Snap lawsuit and similar cases are creating pressure on AI companies to change how they source training data. What does this mean practically for companies building AI systems?
First, companies are now incentivized to track the sources of their training data. If you can show that you licensed data properly or used only content you had permission to use, you're protected. Companies that can't trace their data sources are vulnerable. This means implementing better data governance systems, documenting licenses, and maintaining records of what content was used where.
Second, companies are exploring licensing agreements with creators. This is expensive and complex, but it's also becoming a business necessity. Some startups are positioning themselves as AI-friendly licensing platforms, connecting creators with companies that want to license their content. These platforms will likely become more common.
Third, companies are considering synthetic data and proprietary content. Instead of scraping the internet, they can generate training data, use content they create themselves, or rely on licensed datasets designed specifically for AI training. This is more expensive but legally cleaner.
Fourth, companies are being more cautious about fair use arguments. The legal trend suggests courts are skeptical of broad fair use defenses for commercial AI training. Companies can't rely on fair use to cover their data sourcing anymore. They need actual legal rights to the content.
Fifth, there's increased pressure for transparency. Creators want to know if their content was used to train AI. Companies will face pressure to disclose training data sources or provide tools for creators to check if their work was included. Some are implementing these systems proactively.
Sixth, companies are lobbying for legislation that would clarify AI training rights. They want legal certainty. Some propose carve-outs for AI training similar to other research exceptions. Others propose licensing frameworks that streamline the process of licensing content in bulk. These legislative efforts will likely intensify as lawsuits continue.

The Creator Economy and AI: Long-Term Implications
Beyond the immediate legal dispute, the Snap lawsuit reveals something important about the relationship between creators and tech platforms. Creators built the internet with their content. They attracted users, generated engagement, and made platforms valuable. Now they're discovering that their work fuels AI systems that compete with them.
This creates a tension that will define the next phase of the creator economy. Creators want to be compensated for their contributions to AI development. They don't want their work stolen. But they also recognize that AI isn't going away. The question isn't whether AI training will use creator content. It's whether creators will be fairly compensated and have control over how their work is used.
Some creators are taking proactive steps. They're watermarking content to make it harder to scrape. They're adding terms of service that prohibit AI training use. They're joining advocacy groups pushing for creator-friendly regulations. They're exploring licensing opportunities with AI companies that offer fair terms.
The outcome of cases like Snap's will shape which of these strategies are effective. If courts protect creators, companies will be forced to negotiate. If courts side with companies, creators will need to find other ways to protect themselves.
There's also potential for new business models. Imagine a world where creators explicitly license their content to AI companies and receive ongoing payments based on usage. This already happens in music. It could happen in video, photography, and other creative domains. AI companies would pay for data, creators would be compensated, and everything would be legal and transparent.
The Snap lawsuit is a symptom of a larger shift. The era of free data and unauthorized use is ending. A new era of negotiation and compensation is beginning. This will raise costs for AI companies but will be more sustainable and fair for creators.

What YouTubers and Content Creators Should Do Now
If you're a content creator concerned about your work being used for AI training, what should you do? The Snap case and others like it provide guidance.
First, understand your rights. You own your content. You have the exclusive right to decide how it's used. Companies need your permission to use it for commercial purposes. This applies whether they scrape it directly or obtain it through third parties.
Second, document everything. If you notice your content being used in AI features without permission, take screenshots, record interactions, and document what you find. This evidence is valuable if legal disputes arise.
Third, investigate whether your content was used. Tools are emerging that let creators check if their work was included in training datasets. Some AI companies are beginning to disclose this information. Use available tools to understand what happened to your content.
Fourth, consider joining class action lawsuits if they form around your content. The h3h3 case represents creators with millions of subscribers. If you have less reach, joining a class action gives you access to legal resources you couldn't afford individually.
Fifth, explore licensing opportunities. If an AI company wants to use your content, negotiate terms. What will you be compensated? How long will the license last? Can you terminate it if you want? Proper agreements protect your interests.
Sixth, engage with policy discussions. Follow copyright policy debates. Support organizations advocating for creator rights. Vote for politicians who take these issues seriously. This matters because regulation will likely be necessary to change industry practices.
Seventh, consider professional representation. If you have substantial content and believe it was used without permission, consult with an attorney experienced in copyright and AI law. They can advise you on your specific situation and options.

The Regulatory Future: What Might Change
If litigation doesn't fully resolve the creator compensation issue, regulation likely will. Multiple governments are exploring how to address AI training data sourcing. Understanding these regulatory possibilities helps predict what the future might look like.
The EU is likely to enforce stricter rules. The AI Act and Copyright Directive both address training data. Future EU regulations could require opt-in licensing for creator content, mandatory attribution in models trained on copyrighted material, or exemptions for commercial uses of training data. This would make it much harder for companies to train on unauthorized content in Europe.
The U.S. is moving more slowly but showing interest. Congress has held hearings on AI copyright issues. The Copyright Office has solicited public input. There's bipartisan recognition that something needs to change, though disagreement about what. Possible U.S. regulations might include safe harbors for AI companies that implement proper licensing systems, extended collective licensing frameworks similar to music, or requirements for transparency about training data sources.
Other countries will likely follow. Canada, UK, Japan, and others are monitoring U.S. and EU developments and considering their own approaches.
What's unlikely is a regulation that simply permits AI companies to use any content they want without compensation. The momentum is toward creator protection, not relaxation of copyright. The question is how strictly rules will be enforced and what mechanisms will facilitate licensing.
One possible regulatory framework is a mandatory licensing system where companies that want to train on copyrighted content pay into a pool that compensates creators. This would be similar to music licensing. It would increase costs for AI companies but would solve the creator compensation problem comprehensively.
Another possible framework is a "right to be forgotten" for AI training. Creators could request that their content be removed from training datasets and that models be retrained without it. This would be expensive for companies but would give creators control over their content.
A third possibility is transparency requirements. Companies could be required to disclose what content they trained on, allow creators to identify if their work was included, and explain how they used the data. This would be the least burdensome for companies but most informative for creators.

Timeline and What to Watch
The Snap lawsuit will likely unfold over months or years. Understanding the timeline helps anticipate key moments.
Initially, both sides will file motions to dismiss or for summary judgment. Snap will argue that the case lacks legal merit and should be dismissed early. The creators will argue that they've stated valid claims. A judge will rule on these motions. If Snap wins, the case might end. If creators win, the case continues.
Assuming the case continues, discovery happens next. Both sides exchange evidence and documents. Snap will produce information about how they sourced training data, who authorized it, and how the models are used. Creators will provide evidence that their content was used without permission.
During discovery, key facts emerge. Did Snap actually scrape YouTube videos? If so, whose videos did they scrape? Can they prove licensing? Did they know the content was unauthorized? These facts will shape the eventual outcome.
After discovery, settlement discussions often happen. Lawyers evaluate the strength of their cases based on evidence. They calculate litigation costs and trial risks. Settlement negotiations begin. If settlement fails, trial approaches.
Trial would involve experts testifying about copyright law, AI training practices, market harm, and licensing. Juries would hear these arguments and decide. This would be public and could set precedent.
Throughout this process, other lawsuits proceed separately. Different plaintiffs sue different companies. Different judges rule. These decisions influence each other. A favorable ruling for creators in one case makes settlement more likely in others.
Key moments to watch: Snap's response to the lawsuit, rulings on early motions, discovery disclosures, any settlement announcements, and trial outcomes if the case reaches trial. Each of these will provide information about the legal landscape and influence other copyright disputes.
Potential Solutions for a More Sustainable AI Ecosystem
Beyond litigation, there are systemic solutions that could make AI development more sustainable and creator-friendly. Understanding these possibilities provides perspective on what might change.
One solution is creator-controlled datasets. Instead of companies scraping the internet, creators could license their content in curated datasets designed for AI training. Companies would pay for access, and creators would be compensated. Companies would benefit from cleaner, more focused training data. This would require infrastructure to facilitate licensing and payments, but the model exists in other industries.
Another solution is federated AI training. Instead of centralizing data at companies, training happens distributed across creator networks. Creators maintain ownership and control. Companies access the trained models through APIs without seeing the raw data. This would require technical innovation but would preserve creator rights while enabling AI development.
A third solution is AI-generated synthetic data. Companies could generate artificial training data using other generative models, eliminating the need to use real creator content. This would be more expensive but completely avoids copyright issues. Some companies are already exploring this approach.
A fourth solution is transparency and consent. Companies disclose what data they use, allow creators to see if their content is included, and let creators opt out. This gives creators information and control without necessarily preventing all unauthorized use. It's a middle ground between current practices and strict protection.
A fifth solution is attribution and credit. AI companies acknowledge the creators whose content was used to train models. This provides visibility and potential indirect economic benefit through increased audience recognition. It's not full compensation but acknowledges creator contribution.
A sixth solution is industry standards. AI companies could adopt best practices around data licensing, creator notification, and compensation. Professional organizations could certify companies as ethical. Market pressure would encourage adoption. This would work faster than regulation in some cases.
The ideal future probably involves a combination of these solutions. Some sectors might use licensing, others synthetic data, others federated training. The key is moving away from the current model where creators are completely excluded from the process and provide no consent or compensation.

Conclusion: The Future of AI Training and Creator Rights
The Snap lawsuit represents a turning point. For years, AI companies moved fast and took risks with copyright. They assumed that training on vast amounts of internet data was acceptable, that fair use would protect them, and that litigation risk was manageable. The surge in lawsuits is challenging these assumptions.
What's becoming clear is that the era of free, unrestricted data for AI training is ending. Courts are skeptical of broad fair use defenses. Regulators are taking interest. Creators are fighting back with lawyers and lawsuits. And the industry is gradually shifting toward acknowledging that proper licensing and compensation are necessary.
Snap faces real legal risk. The allegations are specific, the evidence is likely to be clear, and courts are increasingly favorable to creators. A settlement seems likely, but a court loss is possible. Either way, the company will probably need to change how it sources training data for future AI features.
More broadly, the lawsuit signals that the game is changing. New AI companies being built today will need to think about licensing and legal rights from day one. Existing companies will need to implement better data governance and consider licensing agreements retroactively.
Creators should understand their rights and be proactive about protecting them. Documenting content, investigating whether it was used in AI training, joining lawsuits when appropriate, and exploring licensing opportunities are all valuable strategies. The law increasingly supports creator rights. Taking advantage of those rights and negotiating fairly is both possible and necessary.
The ultimate outcome will likely be a more mature AI ecosystem where data licensing is normal, creators are compensated, and companies operate with legal certainty. Getting there will require litigation, regulation, and industry change. The Snap case is one battle in a much larger war over who controls data, who profits from it, and whether creators will be recognized as stakeholders in the AI revolution.

FAQ
What is copyright infringement in the context of AI training?
Copyright infringement occurs when a company uses copyrighted material without permission. In the AI context, this means scraping creator content like videos, images, or text to train models without obtaining licenses from the copyright holders. The creators retain copyright to their work automatically, and companies using that work for commercial purposes typically need permission or licensing agreements.
How did Snap allegedly use YouTuber content for AI training?
According to the lawsuit, Snap scraped videos from h3h3, Mr Short Game Golf, and Golfoholics channels to train the models powering "Imagine Lens." This feature uses AI to edit images based on text descriptions. The creators claim they never authorized this use or received compensation, and Snap never obtained licenses to use their content.
What is the legal difference between research use and commercial use of training data?
Research use typically falls under fair use protections and doesn't require licensing. Academic or non-profit research on copyrighted material is often permitted. Commercial use, where a company profits from products built on the training data, is much harder to defend under fair use. Once you're making money from AI features trained on copyrighted material, fair use becomes a weaker argument, and proper licensing becomes more necessary.
What are statutory damages in copyright cases and why do they matter?
Statutory damages are predetermined compensation amounts set by law, typically ranging from
How many copyright cases have been filed against AI companies?
According to the Copyright Alliance, over 70 copyright infringement cases have been filed against AI companies. These include lawsuits from authors, photographers, journalists, musicians, and visual content creators. The cases target companies like OpenAI, Stability AI, Meta, Google, and others. The outcomes have been mixed, with some favorable to creators, some favorable to tech companies, and some settled.
What is fair use and why is it controversial in AI training cases?
Fair use is a legal doctrine allowing limited use of copyrighted material without permission for purposes like criticism, education, or research. Courts determine whether use is fair by considering four factors: purpose (commercial vs. educational), nature of the work, amount used, and market impact. In AI training, fair use is controversial because companies argue that training is transformative research (fair use), while creators argue that commercial products built on training data aren't protected by fair use. Courts are increasingly skeptical of the fair use defense in AI contexts.
Could Snap settle the lawsuit instead of going to trial?
Yes, settlement is likely. Similar cases have often been resolved through settlements where companies pay creators, agree to licensing arrangements going forward, and implement systems ensuring future compliance. A settlement would allow Snap to avoid the risk of an adverse court ruling while acknowledging that compensation is owed. Settlements typically involve confidentiality agreements, so the exact amounts might not be public.
What would a court victory for the YouTubers mean for other AI companies?
A court ruling in favor of the creators would establish legal precedent that training on copyrighted material without permission violates copyright law and doesn't fall under fair use protections. This would make it much harder for other AI companies to defend similar practices. It would likely accelerate settlements in pending cases and pressure companies to implement proper licensing systems before building new AI features.
Are there international differences in how copyright law applies to AI training?
Yes, significantly. The European Union has stricter copyright protections and requires proper licensing for AI training. The United States is more permissive but moving toward more protection. Different countries have different fair use standards and different approaches to AI regulation. This creates complexity for global companies, which might need to implement different practices in different jurisdictions.
What can creators do to protect their content from unauthorized AI training use?
Creators can: document their work and its creation, monitor whether their content appears in AI-generated outputs, investigate if their work was used in training datasets, join class action lawsuits if available, consult with copyright attorneys about their specific situation, negotiate licensing agreements if companies want to use their content, mark content with terms of service prohibiting AI training use, engage with policy discussions about AI copyright, and consider watermarking or other technical protections to make unauthorized scraping harder.

Key Takeaways
- YouTubers with 6.2 million collective subscribers sued Snap for scraping their video content to train AI systems without permission
- The lawsuit targets the Imagine Lens feature, which uses generative AI to edit images based on text descriptions
- Over 70 copyright infringement cases have been filed against AI companies, with mixed outcomes in different jurisdictions
- Fair use defenses are weakening in court when companies commercialize products built on copyrighted training data
- Settlement is likely, given costs of litigation and risks of unfavorable precedent
- International regulations will reshape AI training practices, with EU requiring stricter licensing than the U.S.
- Creators have leverage they're just beginning to use, and companies will increasingly need to license or generate synthetic training data
- The era of free, unauthorized training data is ending, replaced by negotiated licensing and proper compensation frameworks
- Future AI development will require transparent data sourcing and documented licensing agreements
- Creators should understand their rights and take proactive steps to document use, investigate unauthorized training, and negotiate fair terms


