![A/B Testing Benefits: Complete Guide & Best Practices [2025]](https://tryrunable.com/blog/a-b-testing-benefits-complete-guide-best-practices-2025/image-1-1769449213503.png)
A/B Testing Benefits: The Complete Guide to Data-Driven Decision Making in 2025
When you're running a website, making changes feels like navigating in the dark. You might implement what seems like a brilliant idea—a new call-to-action button, a different headline, a simpler checkout form—only to wonder weeks later whether it actually made a difference. Did your conversion rate improve because of the change, or was it the seasonal uptick in traffic? Did your bounce rate drop due to better page design, or were your competitors temporarily offline?
This uncertainty is the reason A/B testing has become the gold standard for digital optimization. Rather than guessing or relying on hunches, A/B testing applies the scientific method to website optimization, giving you the statistical confidence to know exactly what works and what doesn't.
However, most articles about A/B testing focus on the obvious benefits—increased conversion rates, higher ROI, improved engagement. While these are certainly real outcomes, they often take months or years of consistent testing to achieve. They're also not the most valuable benefits you'll experience when you commit to a testing culture.
This comprehensive guide explores seven realistic, substantive benefits of A/B testing that go far beyond surface-level conversion lift metrics. We'll examine why testing matters, how to implement it effectively, common mistakes to avoid, and how platforms can support your testing infrastructure. Whether you're a startup trying to optimize your landing pages or an enterprise managing complex customer journeys, understanding these benefits will fundamentally change how you approach digital product decisions.
The Fundamental Problem with Intuition-Based Decision Making
Why Human Intuition Fails in Digital Optimization
Humans are remarkably bad at predicting outcomes, even when we're experts in our field. This isn't a personal failing—it's a cognitive limitation hardwired into how our brains process information. Research in behavioral psychology consistently shows that expert intuition, while valuable in certain domains, performs poorly when predicting the outcomes of website changes or user behavior shifts.
When you propose changing your homepage headline, the decision often comes down to who has the most seniority, whose taste you trust most, or whose argument was most persuasive in the meeting. A designer might say the new layout "feels" more modern. A marketer might argue that the new copy "resonates" better with the brand voice. An executive sponsor might simply prefer one version because it aligns with their vision.
None of these factors correlates reliably with how actual users will respond. In fact, studies show that marketing professionals correctly predict which creative variation will perform better only about 50% of the time—essentially the same as flipping a coin. This means that for every decision made by intuition, you're statistically likely to make the wrong choice roughly half the time.
The Hidden Costs of Intuition-Driven Changes
When you implement changes based on intuition rather than evidence, you incur real costs beyond just poor optimization decisions. First, you're making changes in the dark, which means your entire team's efforts might be moving you in the wrong direction. A single poor decision cascades: you build on faulty assumptions, invest resources in strategies that don't work, and waste time on dead ends.
Second, intuition-driven decision making creates organizational friction. When decisions come down to opinion rather than data, the person with the loudest voice or highest rank wins—regardless of whether their idea actually works. This breeds resentment, discourages creative risk-taking from junior team members, and makes it harder to retain talented people who want their ideas tested fairly.
Third, you're missing learning opportunities. Every website change contains information about user behavior and preferences. When you ignore that information because you didn't systematically measure it, you're throwing away the chance to understand your customers better.

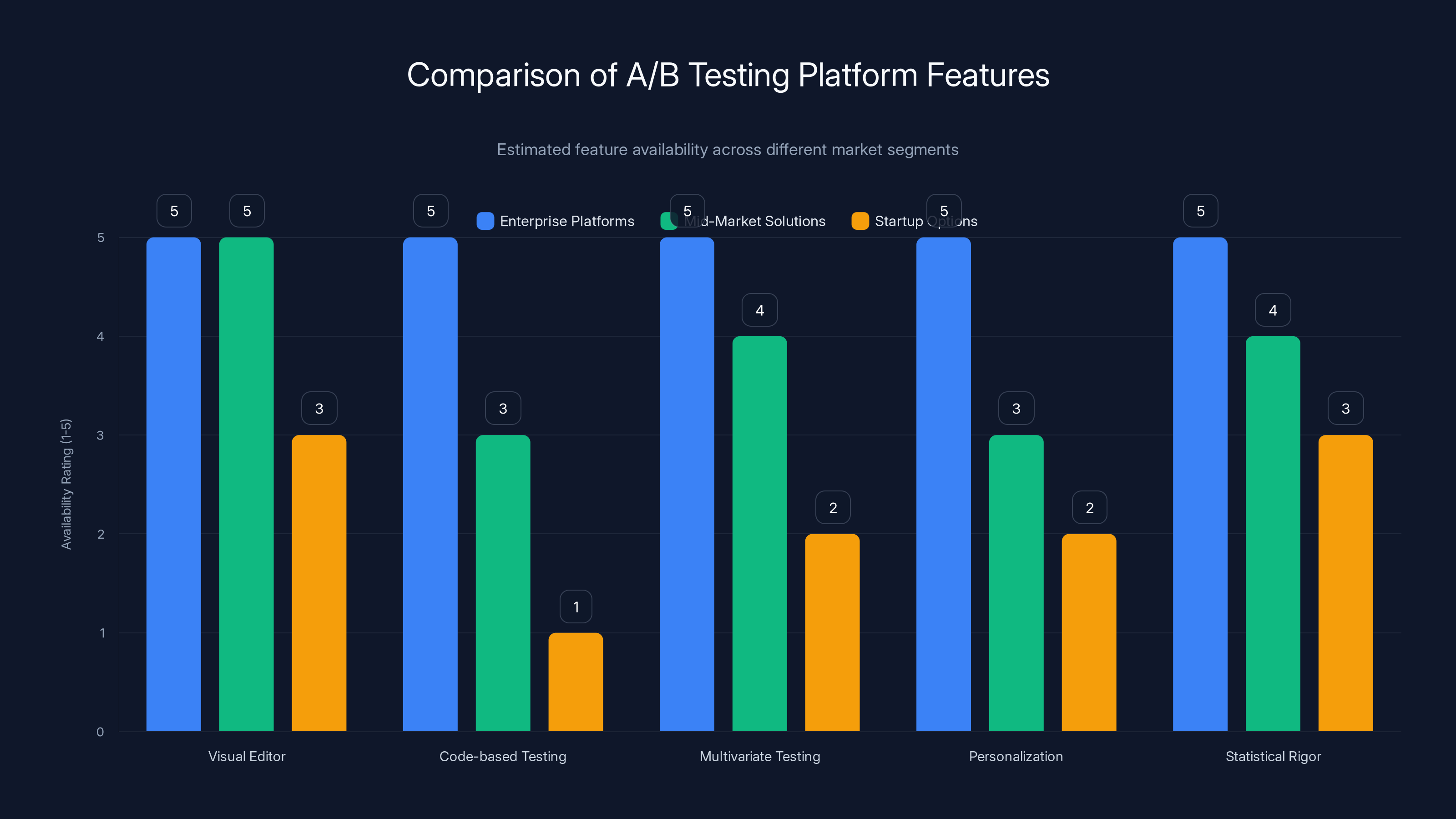
Enterprise platforms generally offer the most comprehensive features for A/B testing, with high availability ratings across all capabilities. Mid-market solutions provide a balanced feature set, while startup options may have limited capabilities. (Estimated data)
Benefit 1: Proving Causation Through Randomized Comparison
The Challenge of Attribution in Digital Environments
Imagine you notice that your conversion rate increased 15% last week. You'd naturally want to take credit for the new landing page design your team launched. But did the design actually cause the improvement? Or could something else explain it?
There are dozens of factors that influence conversion rates in any given week. Your industry experiences seasonal fluctuations—e-commerce companies see traffic spikes during holidays, SaaS companies see adoption increases at the beginning of quarters when companies have new budgets. Your competitors might launch promotions, run advertising campaigns, or go out of business. News events, media coverage, or viral mentions can drive unexpected traffic surges. Search engine algorithm updates can shift your organic traffic quality.
Even pure randomness plays a role. If you track any metric long enough, you'll see random variation. A coin flipped 100 times won't always come up 50 heads and 50 tails—sometimes it's 48-52 or 45-55. Similarly, your website's conversion rate naturally fluctuates day-to-day and week-to-week due to random chance.
Without A/B testing, you have no way to separate the impact of your change from all these other factors. You're trying to isolate the signal from your specific change in the middle of a thunderstorm of noise.
How A/B Testing Eliminates Confounding Variables
A/B testing works by splitting your traffic into two equal groups at the exact same time. Group A sees the control version (your existing page). Group B sees the treatment version (your proposed change). Because both groups are exposed to the same time period, the same competitors, the same season, the same news cycle, and the same random fluctuations, all these external factors affect both groups equally.
The critical insight is this: any difference in outcomes between the two groups must be due to the difference between the versions, because that's the only variable that differs between them. If group B converts at 5.2% while group A converts at 4.8%, you can confidently conclude that the change itself caused that difference—not the season, not your competitors, not random chance (assuming you've run the test long enough and with sufficient traffic).
This is the power of randomized controlled testing, and it's why it's considered the gold standard in research methodology across disciplines from medicine to agriculture to engineering. The same scientific rigor that proves whether a new drug is effective can prove whether a new website element improves results.
Confidence Intervals and Statistical Certainty
A/B testing also provides confidence intervals, which tell you the range of possible true effects. Instead of just saying "version B was 5% better," a properly designed test tells you "we're 95% confident the true difference is between 2% and 8% better." This is crucial information because it tells you both the likely impact and the uncertainty around that impact.
Understanding confidence intervals prevents a common mistake: over-trusting small sample sizes. If you run a test with only 100 visitors total and see a 50% difference between versions, the confidence interval might be "anywhere from -20% to +120% better," indicating you don't actually know if the change works. But if you run the same test with 50,000 visitors and see a 5% difference, the confidence interval might be "4.8% to 5.2% better," indicating you have strong evidence for the effect.
This transforms decision-making from binary (works or doesn't work) to nuanced (works at this effect size with this level of confidence). You can then make intelligent business decisions based on whether the expected improvement justifies the implementation effort and risk of rolling out the change.

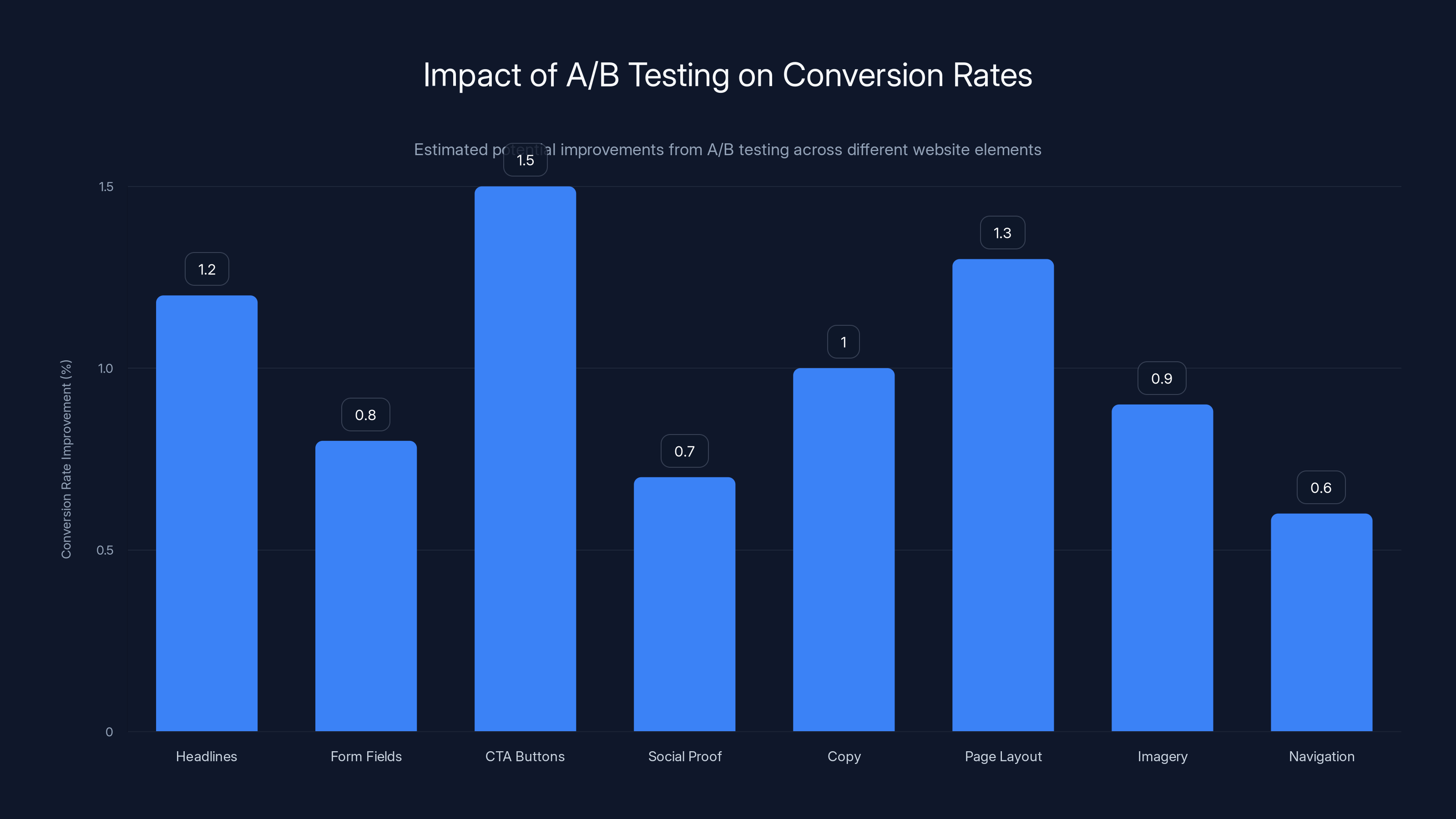
Estimated data shows that A/B testing on CTA buttons can lead to the highest conversion rate improvement at 1.5%, followed by page layout at 1.3%. Even small improvements can significantly impact overall results.
Benefit 2: Evidence-Driven Strategy Replaces Opinion-Based Decision Making
The Organizational Impact of Data-Driven Culture
One of the most profound benefits of implementing A/B testing isn't immediate or directly measurable in conversion rates. Instead, it's the fundamental shift in how your organization makes decisions. When testing becomes standard practice, opinion loses its power. The senior executive can't override the junior analyst just because their instinct says so. The designer can't insist on a layout change without evidence. The marketer can't claim that new copy is better without backing it up with data.
This democratizes decision-making in healthy ways. A good idea from an entry-level team member gets tested just as fairly as an idea from a vice president. The conversation shifts from "whose idea is better" to "how do we design a test to compare these ideas fairly." This encourages broader participation from the team because people know their ideas will be evaluated on merit rather than politics or hierarchy.
Organizations that embrace this shift consistently report improved team dynamics, better retention of talented people, and faster decision-making cycles. Instead of spending weeks in meetings debating whether option A or option B is better, you run a test, get results, and move forward. The argument is settled by evidence, not by persuasion or authority.
Quantifying Subjective Preferences
Many website decisions feel subjective. Is the new design more aesthetically pleasing? Does the new copy better match our brand voice? Does the new navigation feel more intuitive? These feel like matters of taste, where data shouldn't apply. But A/B testing proves that user preferences, while subjective, can still be measured objectively.
When you test a redesigned interface, you're not measuring whether it's subjectively more beautiful. You're measuring whether users prefer it enough to take action more frequently. When you test different copy, you're not measuring whether it's better written. You're measuring whether the specific value proposition resonates better with your target audience. When you test navigation changes, you're not measuring whether it feels more intuitive in the abstract. You're measuring whether users can accomplish their goals more efficiently.
This transforms the conversation. Instead of debating aesthetic preferences, you're focused on user outcomes. "The new design is 8% more likely to get users to click the primary CTA" is a statement that ends debate. Different people might have different tastes in design, but they all care about the same business metrics.
Building Institutional Knowledge
Over time, A/B testing creates an institutional knowledge base that becomes increasingly valuable. After you've tested 20 different headline variations, you understand patterns in what resonates with your audience. After you've tested button colors, button copy, button placement, and button size, you have data-driven principles you can apply to new buttons without testing each variation again.
This knowledge is cumulative and non-obvious. You might discover that your audience prefers specific language patterns. You might find that they respond better to certain value propositions than others. You might learn that they're willing to complete longer forms for certain types of incentives but bounce away from longer forms for other incentives.
This institutional knowledge cannot be purchased from consultants or copied from competitors. It's specific to your audience, your market, and your product. It becomes a sustainable competitive advantage that gets stronger the longer you've been testing.
Benefit 3: Reducing Risk in Digital Product Changes
The Cost of Releasing Bad Changes
When you implement website changes without testing, you're essentially conducting an experiment on your real users with real business consequences. If the change is negative—pushing users away, creating confusion, or introducing friction—you might not notice immediately. Users might tolerate the change for a few days before bouncing. Your conversion rate might trend downward gradually over a week. By the time you notice the problem and revert the change, you've already lost revenue and frustrated customers.
Consider a company that redesigns their checkout flow thinking they're improving usability. They launch the change to 100% of traffic without testing. Three days later, they notice their cart abandonment rate has increased by 8%. Their conversion rate is down. They quickly revert the change. But in those three days, they've lost revenue equivalent to thousands of dollars. If they had tested with 25% of traffic first, they would have detected the problem immediately before rolling it out widely.
This risk is especially acute for pages that drive revenue directly. Changes to checkout flows, pricing pages, sign-up flows, or product recommendation algorithms can have immediate, measurable business impact. A seemingly small change—reordering form fields, changing button placement, adjusting font sizes—can unexpectedly increase friction in ways you didn't anticipate.
Testing as Risk Mitigation
A/B testing turns this dynamic on its head. Instead of rolling changes out to everyone immediately, you test with a percentage of traffic. If the change is negative, you limit the damage. If it's positive or neutral, you can roll it out with confidence. This is risk mitigation in its purest form.
For example, if you test a new checkout flow with 10% of traffic, you immediately know the impact before rolling it out to everyone. If the new flow increases completion rates by 3%, you roll it out to 100%. If it decreases completion rates by 2%, you don't roll it out at all. If it has no statistically significant impact, you can make a business decision based on other factors—implementation cost, user feedback, alignment with strategy.
The cost of running this test—giving 10% of traffic a different experience—is trivial compared to the cost of accidentally rolling out a negative change to everyone. You're paying a small price (10% of traffic getting a potentially suboptimal experience) to protect against a much larger risk (everyone getting a negative change).
Building Confidence in Changes
Beyond risk mitigation, A/B testing builds organizational confidence in changes. When you roll out a change that's been tested and proven to work, the whole team understands why it works. There's no lingering doubt about whether you made the right call. This confidence accelerates rollout—the team moves faster because there's no debate about whether the change is worth implementing.
This also creates psychological safety for experimentation. When team members see that risky ideas are tested carefully before full rollout, they become more willing to propose novel ideas. They know their ideas will be evaluated fairly and won't cause disaster if they backfire. This encourages a culture of innovation and continuous improvement.
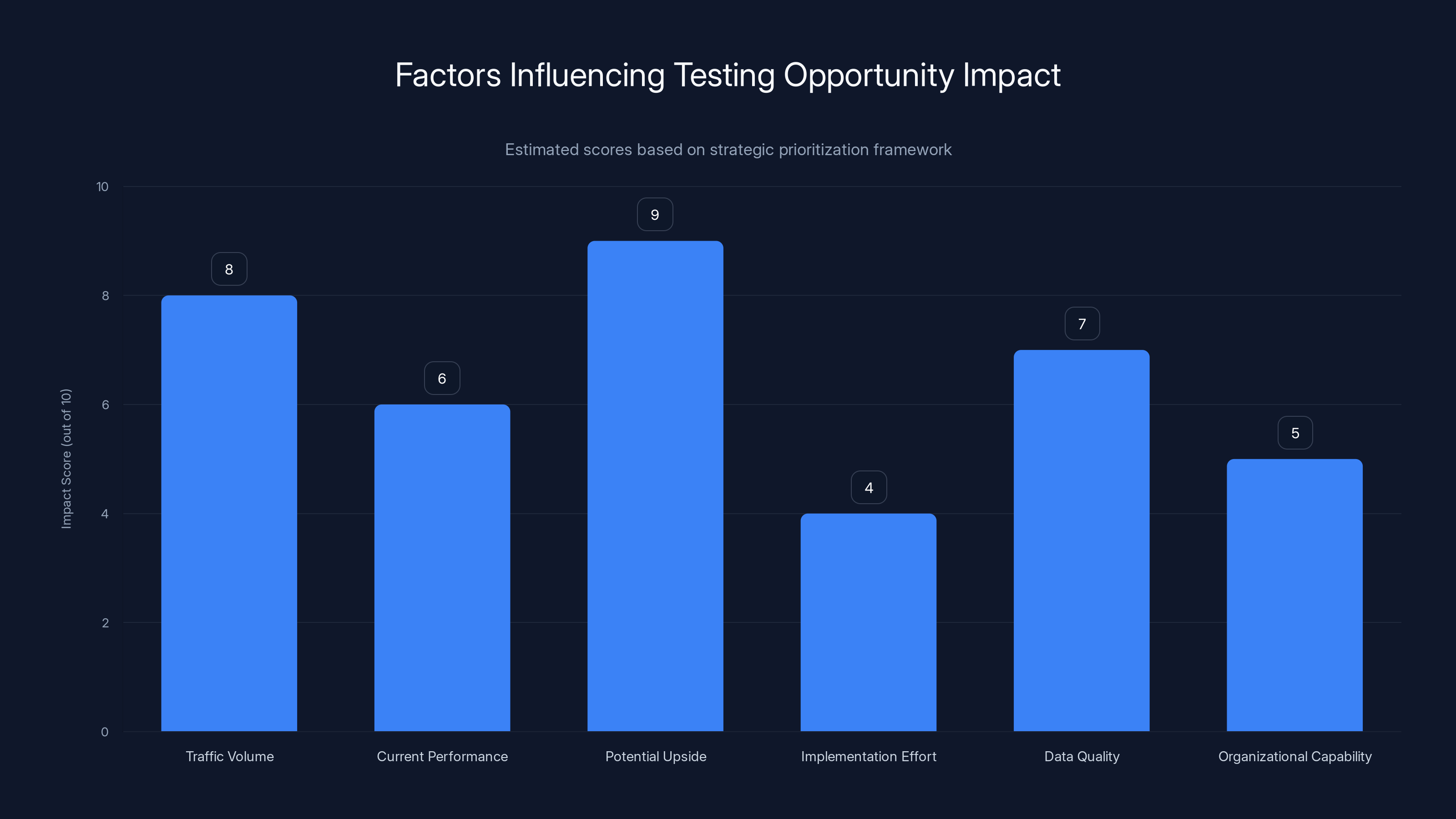
Estimated data shows that 'Potential Upside' and 'Traffic Volume' are key factors with the highest impact scores for prioritizing testing opportunities.
Benefit 4: Accelerating Learning About Your Audience
User Behavior Patterns and Preferences
Every A/B test contains information about your users. When you test a longer value proposition versus a shorter one and the longer one wins, you've learned that your audience values detailed information and takes time to make decisions. When you test a single CTA versus multiple CTAs and single wins, you've learned that choice paralysis might be at play. When you test different language and specific terminology resonates more, you've learned the mental models your audience uses.
Accumulating thousands of these data points creates a sophisticated understanding of your audience that's impossible to develop through surveys, focus groups, or intuition. Surveys tell you what people think they want. Focus groups tell you how people behave in artificial situations. Testing tells you how people actually behave when making real decisions with real consequences.
This knowledge compounds over time. After you've run 50 tests, you start seeing patterns. You understand which value propositions resonate, which concerns need to be addressed, which language creates trust. You understand the types of users attracted to your product and what matters most to them in the decision-making process.
Segmentation and Personalization Insights
As you accumulate testing data, you start noticing that different user segments respond differently to variations. One group might prefer a minimalist design while another prefers detailed information. One segment might be attracted by social proof while another values technical specifications. One cohort might respond to urgency messaging while another is turned off by it.
These insights enable sophisticated personalization and segmentation strategies. Rather than showing everyone the same experience, you can tailor experiences based on what you've learned about different audience segments. This is where the real multiplier effect of testing appears. Once you understand your audience deeply, you can create highly relevant experiences that drive significantly better results.
These insights also reveal opportunities for product development. If testing consistently shows that users want a feature or capability you don't currently offer, that's valuable product feedback. If testing shows that users are confused about a core capability, that's a product education opportunity. Testing doesn't just optimize the marketing experience—it illuminates product development priorities.
Competitive Differentiation Through Insights
The insights you develop through testing cannot be easily copied by competitors. They're specific to your audience, your market position, and your product. A competitor might look at your website and try to copy your designs, but they won't understand the reasoning behind your design decisions. They won't know which variations you tested and rejected. They won't have the institutional knowledge about what resonates with your specific audience.
This creates a sustainable competitive advantage. The longer you've been testing, the deeper your audience understanding becomes. The more sophisticated your insights, the harder they are to replicate. Your competitor might copy your current designs, but you've already moved on to testing new innovations based on the insights you've developed. This creates a persistent gap in optimization maturity and results.
Benefit 5: Continuous Improvement and Compounding Gains
The Power of Incremental Improvements
One of the biggest misconceptions about A/B testing is that it should produce massive conversion rate increases in single tests. This expectation is unrealistic. Most A/B tests produce small improvements—2-5% lift is considered a very good result. The misconception comes from focusing on individual tests rather than the cumulative impact of a systematic testing program.
Imagine a scenario where you run 50 A/B tests per year, and each test produces an average 3% improvement. That seems modest. But through the miracle of compounding, those improvements compound over time:
- After test 1: baseline × 1.03 = 3% improvement
- After test 10: baseline × 1.03^10 = 34% improvement
- After test 20: baseline × 1.03^20 = 81% improvement
- After test 50: baseline × 1.03^50 = 338% improvement
This is the power of compounding returns applied to optimization. By running a systematic program of continuous improvements, you don't need individual home runs. You need a high frequency of small wins. This is much more achievable than trying to find the one optimization that will double your conversion rate.
Companies that adopt this mindset—running dozens or hundreds of tests per year—see dramatic results over 18-24 months. Not from a single breakthrough idea, but from the accumulated impact of systematic experimentation.
Building Optimization Infrastructure
To achieve this level of continuous improvement, you need to build testing infrastructure that makes experimentation easy and fast. This means having the right tools, the right processes, and the right team structure. A/B testing platforms that integrate with your analytics, CMS, and product infrastructure reduce the friction of setting up tests.
Automated test design and analysis tools help you run more tests faster. Pre-built testing frameworks for common use cases (homepage headlines, CTA buttons, form fields, checkout flows) let you launch tests in minutes rather than days. Statistical analysis that automatically alerts you when tests reach significance lets you respond quickly to results.
Organizationally, this means having dedicated people responsible for testing. It might be a single optimization specialist for a small company or an entire optimization team for a large enterprise. The role of this person or team is to identify testing opportunities, design tests, oversee execution, and ensure insights are shared across the organization.
When you build this infrastructure, testing becomes routine. New tests aren't one-off projects requiring special effort. They're part of the normal development workflow. This dramatically increases test velocity and the rate of compounding improvements.
Prioritizing High-Impact Opportunities
Not all improvements compound equally. Some pages have 10× more traffic than others, so improvements on high-traffic pages have larger business impact. Some pages drive direct revenue while others are early-stage awareness pages, so improvements on revenue pages have larger financial impact. Some changes are easier and faster to implement than others, so changes with better effort-to-impact ratios deserve priority.
Sophisticated testing programs develop prioritization frameworks to identify which testing opportunities will have the largest business impact. This might involve scoring opportunities on multiple dimensions: traffic volume, conversion value, ease of implementation, data availability for measurement, risk of negative impact.
With a prioritization framework, you ensure your limited testing capacity goes toward the opportunities that will move the business needle most. You might discover that testing variations on your most trafficked page will have 100× more business impact than testing variations on a rarely-visited page. You might find that small improvements to your highest-revenue product have 10× more financial impact than optimizing lower-price products.
This strategic prioritization transforms A/B testing from a random collection of experiments to a systematic program of high-impact improvements.

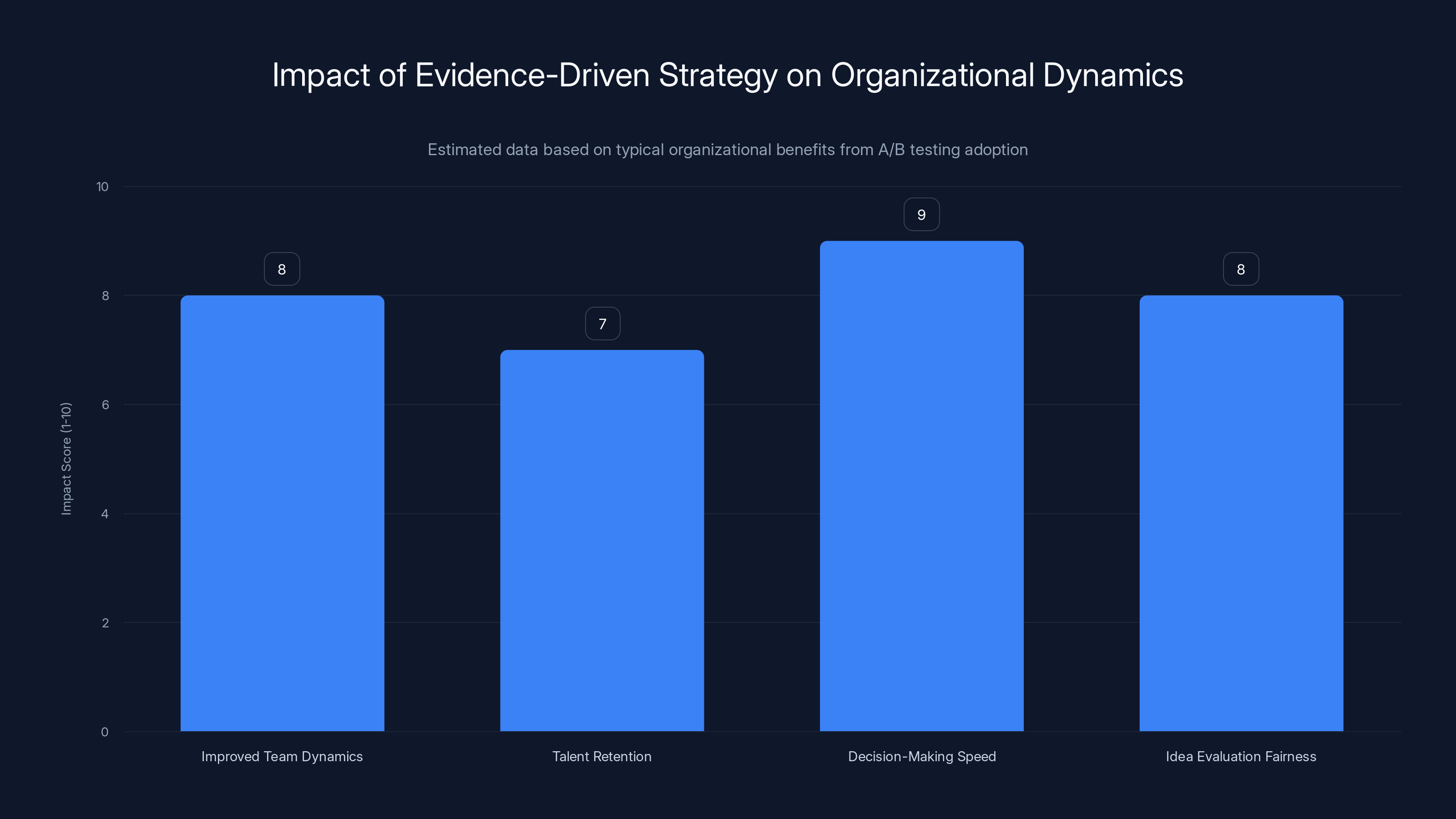
Organizations adopting evidence-driven strategies report high scores in improved team dynamics, talent retention, faster decision-making, and fairer idea evaluation. (Estimated data)
Benefit 6: Creating Feedback Loops and Alignment
Cross-Functional Learning and Alignment
A/B testing inherently creates feedback loops that align different teams around shared insights. When marketing tests a new headline and the data shows users respond better to messaging that emphasizes security over features, that's valuable information for the product team. When sales discovers that certain value propositions close more prospects, that informs marketing strategy. When product development hears that users are confused about a feature, they can prioritize clarity improvements.
Without A/B testing, these insights stay siloed. The marketing team doesn't systematically share what resonates with audiences. The sales team doesn't share which objections come up most frequently. The product team doesn't systematically measure confusion about features. Each team operates in its own information bubble.
When you implement A/B testing, you create structured mechanisms for sharing insights across teams. Testing results become organizational assets that inform strategy across departments. A/B test results might be shared in weekly team syncs, monthly all-hands meetings, or quarterly strategy planning sessions. Over time, the entire organization becomes aligned around the same insights about customer preferences and behavior.
This alignment dramatically improves execution. When the marketing team is promoting the same value propositions that sales and product development have validated through testing, the entire customer journey becomes more coherent. When everyone understands why customers prefer certain approaches based on actual testing data, teams stop debating strategy and start executing aligned strategies.
Bridging Data-Driven and Creative Teams
One of the most productive outcomes of A/B testing is bridging the gap between creative and analytical teams. Designers often feel that testing kills creativity by reducing everything to metrics. Analysts often feel that designers ignore data and rely too much on aesthetic intuition. This creates organizational tension.
A/B testing resolves this tension by creating a collaborative framework where creative and analytical perspectives are both valued. The designer proposes a creative variation based on design principles and user experience research. The analyst designs a rigorous test to measure whether the creative change drives the desired outcomes. The designer learns what actually resonates with users through data. The analyst learns to appreciate the design craft that went into creating the variations.
Over time, this collaboration produces results neither could achieve alone. Creative work informed by testing data is more effective than pure intuition. Testing data interpreted by designers who understand user experience is more nuanced than pure metrics. Teams that successfully bridge this gap outperform those where creative and analytical functions are separated.
Feedback Loops That Improve Decision-Making
A/B testing creates decision-making feedback loops that improve the quality of decisions over time. After you've run 10 tests, you have 10 data points about what works. This helps you design better 11th test. After you've run 100 tests, you have patterns and principles that guide better test design. After you've run 1000 tests, you have sophisticated models of what drives behavior change.
These feedback loops also make better predictors of outcome. Early tests have very uncertain predictions. You run a test and the results surprise you. Over time, you develop better intuition about what will work. You start predicting test outcomes more accurately. This doesn't mean intuition replaces testing—it means you develop informed intuition validated by data.
The most sophisticated testing organizations find ways to formalize these patterns. They document principles learned from tests. They create playbooks of approaches that consistently work. They build AI models that predict test outcomes based on historical testing patterns. This transforms accumulated testing experience into predictive power.
Benefit 7: Developing Institutional Testing Discipline and Culture
From One-Off Tests to Testing Programs
Many organizations dabble in A/B testing without making it core to how they operate. They might run a test or two when a big decision is coming up. They might implement testing infrastructure but not use it systematically. This approach captures some benefits but misses the most substantial gains.
The most valuable benefit of A/B testing emerges when it becomes core to your organizational culture and processes. Instead of testing occasionally, you test continuously. Instead of running dozens of tests per year, you run hundreds. Instead of testing only on your website, you test across your entire product, email, ads, and customer experience.
Organizations that build true testing cultures develop testing discipline: clear processes for identifying opportunities, designing tests, analyzing results, and implementing winners. They develop testing expertise: team members who understand statistics, experimental design, and user psychology. They develop testing infrastructure: tools and systems that make testing easy. They develop testing institutions: roles, teams, and reporting structures dedicated to testing.
When testing becomes systematic and disciplined, the results compound dramatically. You're not limited by the number of good ideas you can think of. You're limited only by the number of tests you can run per week. The law of large numbers means that across hundreds of tests, you'll find improvements you'd never have thought to test.
Building Organizational Testing Literacy
As you implement A/B testing more broadly, you need to build testing literacy across your organization. This means team members understand:
- The purpose of testing: Why you test, what questions testing answers, when testing is appropriate
- Statistical concepts: What statistical significance means, why sample size matters, what confidence intervals represent
- Test design: How to design tests that answer the questions you care about, how to avoid common design errors
- Result interpretation: How to read testing reports, how to identify problems in test data, how to extract learnings
- Implementation best practices: How to avoid tracking issues, sample ratio mismatch, peeking at results
Building this literacy doesn't require everyone to become statisticians. It requires everyone to understand the basics well enough to design good tests and interpret results reliably. Organizations that invest in training and education on testing see dramatically better testing quality and faster learning.
This might involve formal training sessions for new team members, brown-bag lunches where testing learnings are shared, documentation of testing best practices, or building testing expertise into hiring criteria. The most sophisticated organizations hire for testing mindset and teach testing skills. They recognize testing literacy as a core competency.
Embedding Testing in Decision-Making Processes
The final step in building testing culture is embedding testing into formal decision-making processes. This might mean:
- Product strategy: Before committing to a major product change, test it with a subset of users first
- Marketing campaigns: Test different creative variations before investing in full campaign rollout
- Pricing changes: Test new price points or pricing structures before implementing company-wide
- Feature development: Test feature variations before deciding which direction to build in
- Design changes: Test new designs before implementing across the product
When testing becomes embedded in decision-making processes, you're no longer asking "should we test this?" You're asking "what should we test this against?" Testing becomes the default approach to validating assumptions rather than an exceptional activity you do occasionally.
Organizations at this maturity level report that testing becomes self-reinforcing. The more successful tests you run, the more testing becomes valued. The more testing becomes valued, the more resources get allocated to testing infrastructure and team. The more resources available, the more ambitious tests you can run. The cycle compounds, creating organizations that are significantly better at innovation and optimization than their less mature peers.

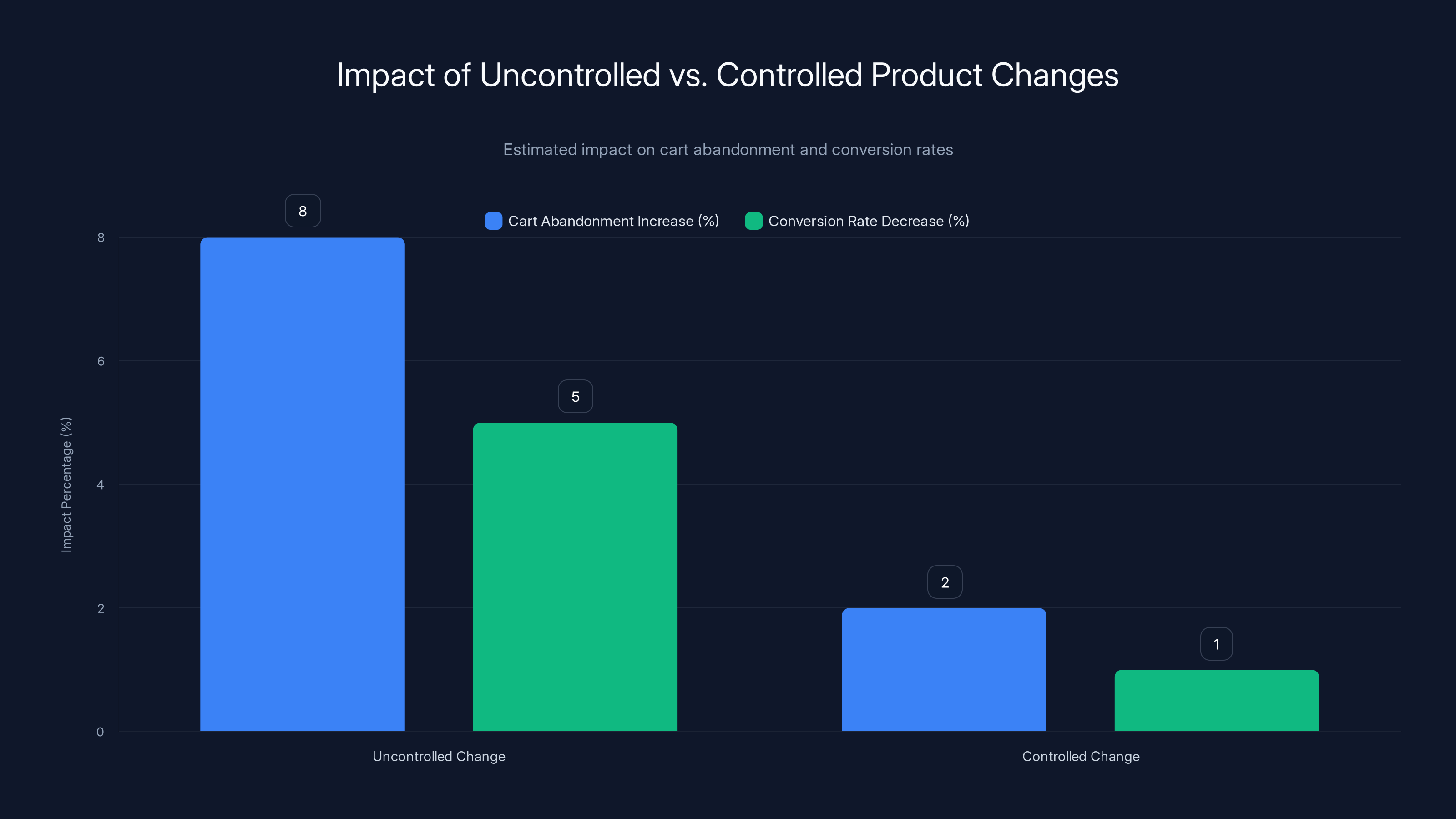
Uncontrolled changes can significantly increase cart abandonment and decrease conversion rates, whereas controlled changes through testing mitigate these risks. Estimated data.
A/B Testing Across Different Channels and Customer Journey Stages
Website and Landing Page Optimization
Website optimization is the most common use case for A/B testing, and for good reason. Websites are where you convert site visitors into leads, customers, or users. Even small improvements in conversion rates compound significantly across all the traffic you receive.
Common website testing opportunities include:
- Headlines and value propositions: Testing different ways to communicate your unique value
- Form fields and checkout flows: Testing what information to request, in what order, with what copy
- Call-to-action buttons: Testing button copy, color, placement, size, and contrast
- Social proof and trust elements: Testing testimonials, case studies, certifications, and security badges
- Copy and messaging: Testing different angles, benefit-focused vs. feature-focused language
- Page layout and visual hierarchy: Testing content organization, whitespace, font sizes
- Imagery and video: Testing what visuals resonate with your audience
- Navigation and information architecture: Testing how users find information
Website testing is particularly valuable early in the customer journey. A small improvement in landing page conversion rate gets multiplied across all your traffic sources. If you improve your paid ad landing page conversion rate from 5% to 5.5%, and you're spending
Email and Messaging Optimization
Email marketing is another high-ROI testing opportunity because you have direct control over the message, you can measure response rates directly, and you have a large population to test with. Email testing opportunities include:
- Subject lines: Testing different approaches to getting people to open
- Send time: Testing when in the day, week, or cycle to send messages
- Sender name and address: Testing how sender identification affects open rates
- Email content and copy: Testing message length, tone, copy approach
- Call-to-action: Testing CTA placement, copy, design
- Segmentation and personalization: Testing whether segmented messages outperform broadcasts
- Frequency: Testing how often to email to optimize engagement without causing unsubscribes
Email testing is particularly valuable because you can run tests with high velocity. If you send 100,000 emails per week, you can test multiple subject lines simultaneously with statistical significance in a single send. This means you can run multiple email tests per week, accelerating learning.
Product Experience and In-App Testing
For product-led companies, the product experience itself is the primary conversion mechanism. Testing opportunities extend throughout the product:
- Onboarding flows: Testing how much setup to require, in what order, with what explanations
- Feature discoverability: Testing whether new features are visible and understandable to users
- Default behaviors and settings: Testing whether different defaults change how users engage
- Pricing page and plan selection: Testing messaging around plans, pricing psychology, recommendation hierarchy
- Upgrade and upsell messaging: Testing when and how to present upgrade opportunities
- In-product messaging and tooltips: Testing whether guidance improves feature adoption
- User interface design: Testing layout, colors, labels, and interaction patterns
Product testing has the advantage that it reaches users who've already decided to use your product (they've signed up for a trial or account). These are typically higher-intent users, so changes that work for them often represent higher-value improvements than changes that primarily attract more traffic.
Advertising and Campaign Optimization
For organizations running paid advertising, testing is essential for improving ROI. Testing opportunities include:
- Ad creative: Testing different copy, images, videos, and design approaches
- Audience targeting: Testing whether narrow targeting to high-intent audiences outperforms broad targeting
- Bid strategies and budget allocation: Testing manual vs. automated bidding, budget allocation across campaigns
- Landing page targeting: Testing whether different audiences should land on different pages
- Messaging and value proposition: Testing different angles and benefit statements
- Device and platform: Testing whether messaging needs to vary across devices
Advertising testing is especially valuable because you can measure ROI directly. You know how much you're spending and what revenue is generated. You can test different advertising approaches and measure which produces the best return per ad dollar.

Common Mistakes in A/B Testing and How to Avoid Them
Statistical Mistakes and Misconceptions
Peeking at Results and Stopping Too Early: One of the most common mistakes is checking test results daily and stopping the test as soon as you see statistical significance. This introduces bias because you're more likely to stop when you see a positive result. You might end a test prematurely when the true result would have been different if you'd continued running it. The solution is to set a target sample size before starting the test and commit to running the test until you reach that sample size, regardless of early results.
Failing to Account for Multiple Comparisons: If you test 10 different variations, you're making 10 different comparisons. By pure probability, you'd expect to find one false positive (one variation that appears to work but actually doesn't) just from random chance, even if no variation truly works better. The solution is to adjust your statistical significance threshold when making multiple comparisons (using methods like Bonferroni correction) or to pre-register which comparison you're primarily interested in.
Misunderstanding Confidence Intervals: Many people misinterpret confidence intervals. A "95% confidence interval" does not mean there's a 95% probability the true effect is in that range. It means that if you ran the test 100 times, in 95 of those runs, the true effect would fall within the calculated range. This is a subtle but important distinction that affects how you interpret results. Understanding this prevents overconfidence in test results.
Sample Ratio Mismatch: Sometimes traffic doesn't split evenly between control and variation due to implementation errors. You might intend to send 50% of traffic to each, but actually send 60% to one. This reduces your statistical power and makes results unreliable. The solution is to monitor the ratio of visitors between variations and investigate if it deviates from expected. Most testing platforms flag this automatically.
Experimental Design Mistakes
Testing Too Many Things at Once: When you test a complete redesign with 50 elements changed simultaneously, you can't tell which elements drove results. If the overall conversion rate improves, was it the new color, the new layout, the new copy, or some combination? You can't extract actionable learnings from a test where everything changes. The solution is to test one or a few elements at a time, isolating the variable you're trying to measure.
Inadequate Sample Size: You need enough visitors to detect the effect size you care about. If you're testing with 100 visitors total and seeing a 50% difference between versions, the uncertainty around that result is so large you can't draw reliable conclusions. The solution is to calculate required sample size before starting the test based on: expected effect size, desired statistical power (usually 80%), baseline conversion rate, and acceptable false positive rate (usually 5%).
Testing Without Clear Hypothesis: Some teams run tests without clearly defining what they expect to happen and why. This makes it hard to learn from negative results. If a test shows no significant difference, did that mean your hypothesis was wrong, or did you design the experiment poorly? The solution is to always start with a clear hypothesis: "We believe [specific change] will improve [specific metric] because [clear reasoning]."
Forgetting to Test the Right Metric: You might focus on testing one metric while ignoring others. Testing a change that improves click-through rate but increases bounce rate probably isn't a win. Testing a change that improves short-term conversion but harms long-term customer lifetime value probably isn't a win either. The solution is to decide upfront what metrics you care about and monitor all of them in your test.
Organizational and Implementation Mistakes
Failing to Include All Relevant Metrics: A change might improve one metric while harming another. For instance, simplifying a form might increase completion rates but decrease the quality of leads. Increasing the number of product recommendations might drive more clicks but decrease overall user satisfaction. The solution is to define a clear success criterion that includes all metrics you care about.
Not Reaching Statistical Significance and Still Drawing Conclusions: Sometimes tests end without reaching statistical significance, meaning there isn't enough evidence to conclude one variation is better than the other. Many teams draw conclusions anyway: "It wasn't statistically significant, but we're going to implement it anyway because we like it better." This defeats the purpose of testing. The solution is to set minimum statistical significance requirements before running tests. If a test doesn't reach significance, treat it as "inconclusive" rather than evidence that the variation works.
Failing to Implement Winners or Share Learnings: Running tests without implementing successful variations wastes the testing effort. Similarly, running tests but not sharing what you learned prevents the organization from benefiting from the insights. The solution is to build processes where testing results are documented, successful variations are implemented promptly, and learnings are shared across teams.
Poor Tracking and Data Quality Issues: A/B testing relies on accurate measurement. If your tracking is broken, your results are meaningless. Common tracking issues include: conversion events firing incorrectly, JavaScript errors preventing proper tracking, time zone mismatches between your system and analytics platform, or bot traffic being included in results. The solution is to maintain strong data quality processes: regular audits of tracking implementation, validation of tracking against known events, exclusion of bot traffic, and clear definition of how events are tracked.


Peeking at results is the most common A/B testing mistake, estimated to occur in 40% of tests, followed by failing to account for multiple comparisons at 25%. Estimated data.
Tools and Platforms for A/B Testing at Scale
Essential A/B Testing Capabilities
Modern A/B testing platforms provide features that make testing faster, easier, and more reliable. When selecting a testing platform, look for:
- Visual test builder: Ability to create variations through a visual editor without coding
- Targeting and segmentation: Ability to define which visitors see which variations based on criteria
- Traffic allocation controls: Ability to control what percentage of traffic goes to each variation
- Real-time analytics and dashboarding: Dashboards showing test results as they accumulate
- Statistical analysis and significance calculation: Automated calculation of statistical significance
- Results interpretation: Clear explanation of whether results are statistically significant
- Audience and visitor insights: Understanding of who saw which variation and their characteristics
- Integration with analytics platforms: Connection to your analytics system so you can measure impact on all relevant metrics
- Personalization capabilities: Ability to show different experiences to different visitors
- Multivariate testing: Testing multiple elements simultaneously with statistical tracking
- Rollout controls: Gradual rollout of winning variations to manage risk
For teams looking for AI-powered optimization and automation capabilities, platforms like Runable provide AI agents for rapid content generation and workflow automation that can accelerate A/B testing processes by automatically generating test variations and documentation.
Platform Comparison and Selection Criteria
| Feature | Enterprise Platforms | Mid-Market Solutions | Startup Options |
|---|---|---|---|
| Visual editor | Yes | Yes | Varies |
| Code-based testing | Yes | Limited | No |
| Multivariate testing | Yes | Yes | Limited |
| Personalization | Advanced | Basic | Limited |
| Statistical rigor | Excellent | Good | Adequate |
| Learning curve | Steep | Moderate | Simple |
| Cost per month | $1000+ | $100-1000 | $0-100 |
| Implementation complexity | High | Moderate | Low |
| Required technical expertise | High | Moderate | Low |
Building Internal Testing Infrastructure
Beyond selecting platforms, sophisticated organizations build internal testing infrastructure that makes experiments easier to run and results easier to interpret. This might include:
- Automated test design frameworks: Templates and libraries for common test scenarios
- Statistical analysis automation: Scripts that automatically calculate significance and confidence intervals
- Data integration pipelines: Automated flows that bring test data into your data warehouse
- Playbooks and documentation: Guides for team members on how to design, run, and analyze tests
- Testing calendar and prioritization framework: Systems for planning tests and prioritizing opportunities
- Results repositories: Documented storage of all test results and learnings
Organizations that invest in this infrastructure run tests faster and learn more effectively than those relying purely on external platforms. The infrastructure compounds value by making testing easier, cheaper, and more consistent.
Advanced A/B Testing Methodologies and Techniques
Multivariate Testing for Complex Changes
While A/B tests compare two variations, multivariate tests compare multiple elements simultaneously. Instead of testing a single headline, you might test 3 headlines × 2 images × 2 button colors = 12 variations at once.
Multivariate testing is more efficient when you have high traffic and want to optimize multiple elements together. However, it's statistically more complex and requires larger sample sizes. A good rule of thumb: use multivariate testing when you have sufficient traffic to reach statistical significance with the number of variations you want to test. Otherwise, stick to simpler A/B tests.
Bandit Testing and Adaptive Experiments
In traditional A/B testing, you split traffic 50-50 between control and variation for the entire test duration. Bandit testing works differently: it starts with a 50-50 split, but as data accumulates, it gradually shifts more traffic to whichever variation is performing better. The advantage is that you show the better experience to more visitors during the test. The disadvantage is the test is more complex to analyze statistically.
Bandit testing makes sense when you're testing relatively low-risk changes and want to optimize the experience for visitors during the test. It's less useful when you need high statistical rigor or when testing changes with high downside risk.
Sequential Testing and Early Stopping Rules
Sequential testing involves checking results at predetermined intervals and having rules for when to stop the test early. Instead of waiting for a pre-calculated sample size, you check results after seeing 100 visitors, then 200, then 300, with rules for stopping if results reach statistical significance or if futility is demonstrated.
Sequential testing reduces the expected sample size needed while maintaining statistical rigor. However, it's more complex to implement and requires careful attention to the rules for stopping. Most standard A/B testing platforms don't support sequential testing well, requiring either custom implementation or specialized tools.

Building Long-Term Testing Strategy and Roadmap
Identifying High-Impact Testing Opportunities
With limited time and resources, you need to prioritize testing opportunities strategically. Effective prioritization frameworks consider:
- Traffic volume: How many visitors will the change affect?
- Current performance: Is there clear evidence of problems to fix?
- Potential upside: How much could this change improve?
- Implementation effort: How hard is it to test this?
- Data quality: Do you have clean, reliable metrics?
- Organizational capability: Can your team execute this test reliably?
Multiplying these factors together (traffic × upside potential - effort) gives you a rough score for opportunity impact. Prioritizing high-scoring opportunities ensures your testing program focuses on changes with the largest potential business impact.
Creating a Testing Cadence and Workflow
Successful testing organizations establish regular rhythms for testing:
- Weekly test launches: New tests start every Monday or Tuesday
- Biweekly results review: Test results are reviewed and discussed every other week
- Monthly strategy planning: New testing opportunities are identified and prioritized
- Quarterly learning shares: Learnings from the previous quarter are documented and shared
- Annual capability assessment: Evaluation of testing maturity and infrastructure improvements
This cadence creates a predictable rhythm where testing becomes part of normal operations rather than an ad-hoc activity. It also ensures test results are captured and shared systematically.
Connecting Testing to Business Metrics and Revenue
Ultimately, A/B testing value should be measured in business impact. Establish clear connections between test results and business outcomes:
- Revenue impact: Calculate the revenue gained from each winning test
- Customer lifetime value: Track whether winning tests improve long-term customer value
- Operational metrics: Connect test results to metrics like marketing efficiency, customer acquisition cost, or retention rate
- Strategic alignment: Ensure tests align with overall business strategy
Organizations that connect testing to clear business metrics find it easier to secure resources and organizational support for testing programs. When stakeholders see testing driving 10% revenue improvements or reducing customer acquisition cost by 15%, testing becomes a strategic priority rather than a nice-to-have activity.

Industry Examples and Case Studies
E-Commerce Testing Success
E-commerce companies have pioneered sophisticated A/B testing because the connection between changes and revenue is direct and measurable. A major online retailer tested their checkout process and found that simplifying the form from 15 fields to 8 fields increased completion rates by 22%. This simple test resulted in millions of dollars in additional annual revenue.
Another e-commerce company tested product recommendation algorithms and discovered that recommendations based on recently viewed items (rather than "most popular" or "similar items") increased click-through rates by 35%. Rolling this change out across their site improved revenue per visitor by 8%.
These wins come not from single breakthroughs but from hundreds of small tests across product pages, checkout flows, email campaigns, and advertising. The compounding effect of continuous improvement drives substantially higher revenue than competitors who test occasionally or not at all.
SaaS Onboarding Optimization
A SaaS company noticed that many free trial users weren't completing their initial setup. They ran a series of tests on their onboarding flow, discovering that:
- Users were more likely to complete onboarding if it took less than 5 minutes
- Skipping optional setup steps increased completion rates but decreased long-term usage
- Video tutorials for each step improved completion rates but increased time-to-value
- Showing benefits alongside each step improved both completion and usage
Based on these insights, they redesigned the onboarding flow to emphasize completing required steps quickly while making benefits clear for optional features. This improved free trial to paid conversion rates by 18% and reduced churn in the first 30 days by 12%.
Marketplace Testing Challenges
Marketplaces face unique testing challenges because changes affect both supply and demand sides. Testing a change that improves buyer experience but hurts seller experience isn't a win overall. A marketplace company testing new search algorithms discovered this the hard way: changes that made search results more relevant improved buyer engagement but reduced seller impressions for niche products, hurting overall platform health.
Successful marketplace testing requires measuring impact across multiple stakeholder groups and optimizing for holistic platform health rather than single metrics.
The Future of A/B Testing: AI and Automation
Automated Test Design and Analysis
Increasing sophistication in machine learning is enabling automated test design and analysis. AI systems can analyze your past test results to identify patterns about what types of changes work. Based on these patterns, they can suggest new tests to run, predict likely outcomes, and even auto-generate test variations.
Automated statistical analysis can identify problems in test data (sample ratio mismatch, bot traffic, tracking errors) automatically. It can apply appropriate statistical corrections and flag results that require human review due to data quality issues.
While automation will make testing faster and easier, human judgment remains essential. Understanding the business context, identifying strategic testing opportunities, and interpreting what results mean still require human expertise.
Predictive Modeling and Personalization at Scale
As companies accumulate more testing data, they can build increasingly sophisticated predictive models of user behavior. Rather than A/B testing variations with everyone, you can predict which variation each user will respond to best and show them that version. This moves from "testing which version is best on average" to "personalizing to each user based on what we've learned."
This requires building models that predict response to different experiences based on user characteristics. Machine learning makes this feasible at scale. The most sophisticated companies combine extensive A/B testing with personalization, showing different experiences to different users based on predictive models trained on historical testing data.
Real-Time Experimentation and Feedback Loops
As technology improves, the lag between implementing a change and seeing results shrinks. Rather than running tests for weeks to accumulate sufficient data, tests might reach statistical significance in days or hours. This enables faster feedback loops where the organization learns and adapts more quickly.
Real-time experimentation combined with automated decision systems could eventually enable systems that continuously adapt based on incoming data. Rather than running discrete tests and implementing winners, systems continuously optimize in response to real-time feedback. This represents the frontier of experimentation capability.

FAQ
What is A/B testing?
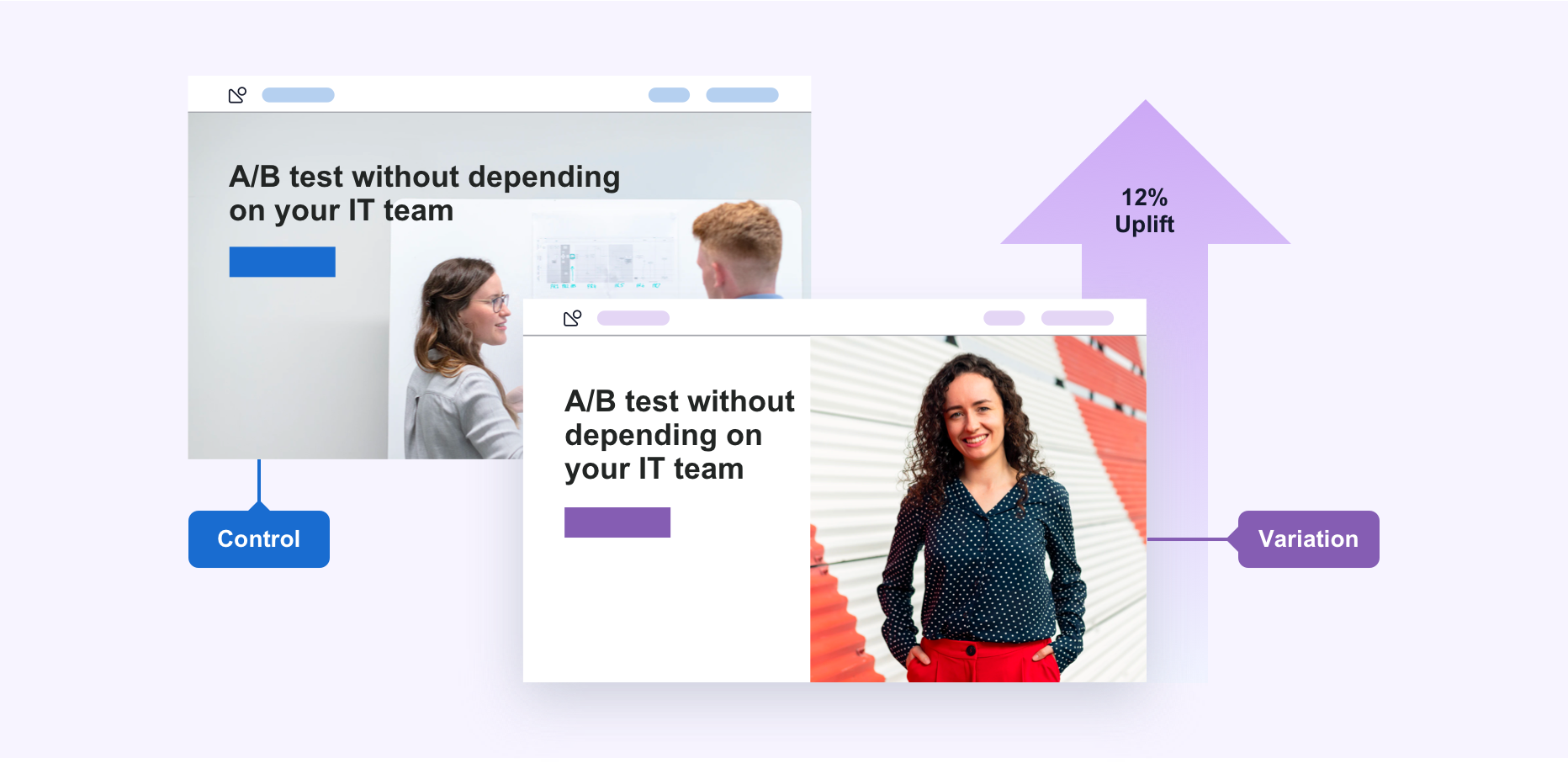
A/B testing is a scientific method of comparing two versions of a website page, email, advertisement, or product feature by randomly splitting users between the two versions and measuring which performs better. Version A is the control (existing version), while version B is the variation (proposed change). By comparing results between the two groups, you can determine whether the change actually improves the metric you're measuring, free from confounding variables.
How does A/B testing work?
A/B testing works by splitting your visitors into two equal groups at random. One group sees the original version (control) while the other group sees the modified version (variation). Both groups are exposed to the same external factors (season, competitors, randomness) at the same time. Any difference in outcomes between the groups must be due to the difference between the versions. You collect data until you have enough visitors to determine with statistical confidence whether one version performs better than the other.
What are the benefits of A/B testing?
A/B testing provides seven major benefits: it proves causation by eliminating confounding variables, it enables evidence-driven strategy replacing opinion-based decisions, it reduces risk by testing changes with a subset of traffic before full rollout, it accelerates learning about your audience's preferences and behavior, it enables continuous improvement through compounding small gains, it creates feedback loops that align teams around shared insights, and it builds organizational culture and discipline around experimentation. Beyond these tactical benefits, companies that embrace A/B testing develop sustainable competitive advantages through accumulated institutional knowledge. For teams seeking AI-powered optimization capabilities, platforms like Runable provide AI agents for rapid automation and content generation that can accelerate testing processes.
How long should an A/B test run?
A/B tests should run long enough to reach statistical significance with adequate sample size. The required duration depends on several factors: your baseline conversion rate, the effect size you're trying to detect, your traffic volume, and your desired statistical confidence level (usually 95%). A test might run for a few days if you have high traffic and expect a large effect, or several weeks if you have lower traffic or are detecting smaller effects. The key is calculating required sample size before starting the test and committing to running the test until you reach that sample size, regardless of early results that might suggest otherwise.
What does statistical significance mean in A/B testing?
Statistical significance means the difference you observed between two versions is unlikely to have occurred by random chance alone. Typically, a result is considered statistically significant when there's less than a 5% probability it occurred randomly (the "p-value" is less than 0.05). This doesn't mean the result is practically significant or that the effect is large—it just means you have strong evidence that a real difference exists between the versions. Understanding the difference between statistical and practical significance is crucial for making good decisions based on test results.
What sample size do I need for an A/B test?
Required sample size depends on: your baseline conversion rate, the minimum effect size you want to detect, your desired statistical power (usually 80%, meaning you have an 80% chance of detecting the true effect if it exists), and your acceptable false positive rate (usually 5%). You can calculate required sample size using statistical power calculators or formulas. As a rough rule: more traffic reduces required duration, larger baseline conversion rates require smaller sample sizes, smaller effect sizes require larger sample sizes. Most A/B testing platforms can calculate required sample size automatically.
What are common mistakes in A/B testing?
Common mistakes include: peeking at results and stopping too early (introducing bias), failing to reach adequate sample size (reducing statistical power), testing too many elements simultaneously (making results impossible to interpret), misunderstanding confidence intervals or statistical significance, including all irrelevant metrics in success criteria (introducing false negatives), implementing variations that don't reach statistical significance, failing to track properly (creating data quality issues), and testing without clear hypotheses (making results hard to learn from). Most of these mistakes are preventable with proper planning and statistical literacy.
How many visitors do I need for statistical significance?
The number of visitors needed depends on your specific scenario, but as a rough guide: if your baseline conversion rate is 5% and you want to detect a 20% relative improvement (5% to 6%), with 95% confidence and 80% statistical power, you need roughly 4,000 visitors per variation (8,000 total). If you want to detect a smaller 10% improvement (5% to 5.5%), you need roughly 15,000 visitors per variation (30,000 total). The relationship is non-linear—to detect smaller effects, you need dramatically more traffic. This is why testing infrastructure and high-traffic channels are so valuable for A/B testing.
What's the difference between A/B testing and multivariate testing?
A/B testing compares two variations of one or a few elements. Multivariate testing tests multiple elements simultaneously, creating many combinations. For example, A/B testing might compare two headlines. Multivariate testing might test 3 headlines × 2 images × 2 button colors simultaneously (12 total variations). Multivariate testing is more efficient with high traffic but more complex statistically. A/B testing is simpler and requires less traffic. Choose A/B testing for lower-traffic scenarios and multivariate testing when you have sufficient volume and want to optimize multiple elements together.
Can A/B testing hurt my business?
A/B testing can only hurt your business if: the test is poorly designed (creating misleading results), you implement changes based on results that didn't reach statistical significance, you implement winning variations that actually had negative side effects you didn't measure, or you change so many things based on tests that you lose coherent brand identity. These risks are prevented through proper test design, careful measurement of relevant metrics, rigorous statistical thresholds, and strategic alignment. When implemented properly, A/B testing reduces business risk by validating changes before full rollout.
How do I get started with A/B testing?
Start by selecting an A/B testing platform that integrates with your website or product and your analytics system. Begin with high-impact, low-risk tests on high-traffic pages. Establish a clear hypothesis before each test ("We believe [specific change] will improve [metric] because [reasoning]"). Run tests long enough to reach statistical significance. Measure relevant metrics, not just conversion rate. Document results and learnings. Share results across your organization. Start with one or two tests per month and gradually increase frequency as you build testing capability and confidence. Build testing literacy in your team through training and documentation.

Conclusion: From Testing to Transformation
A/B testing is far more than a marketing optimization tactic. While increasing conversion rates is valuable, the real power of A/B testing lies in transforming how organizations make decisions, learn about their customers, and compete.
The benefits explored in this guide—proving causation, replacing opinion with evidence, reducing risk, accelerating learning, enabling continuous improvement, creating alignment, and building organizational culture—compound over time. An organization that runs 50 tests per year will see results that diverge dramatically from competitors running 5 tests per year or zero tests per year. After two years, the difference is even more pronounced. After five years, organizations with mature testing programs operate at a fundamentally different level of effectiveness.
This isn't magical thinking. It's a direct consequence of compounding returns. A 3% improvement per test × 50 tests per year = 338% improvement over two years. Even if individual improvements are small, systematic testing produces outsized results.
Beyond the mathematical advantages of compounding, mature testing organizations enjoy organizational benefits that are harder to quantify but no less valuable. Decision-making becomes faster because evidence replaces debate. Team members feel empowered because their ideas are evaluated fairly. Learning becomes embedded in operations rather than siloed in departments. Strategy becomes increasingly informed by customer behavior rather than market assumptions.
The challenge isn't understanding that A/B testing works. Extensive research proves conclusively that organizations that test outperform those that don't. The challenge is building the infrastructure, processes, and culture required to test systematically. It requires investment in tools and platforms. It requires hiring people with statistical and experimental design expertise. It requires creating processes that are rigorous enough to avoid common mistakes but streamlined enough to encourage high testing velocity. It requires building organizational literacy so that stakeholders understand what tests mean and trust test results.
Organizations that invest in this infrastructure find that testing becomes self-sustaining. Successful tests demonstrate value, which builds organizational support, which enables more testing, which generates more insights, which drive better decisions. The virtuous cycle accelerates.
If you haven't yet made systematic A/B testing core to how your organization operates, the time to start is now. Begin with a single high-traffic page and a clear hypothesis. Run a rigorous test. Document the results. Share what you learned. Then run another test. Build from there. Within 12 months of consistent testing, you'll understand your customers better than you ever have. Within 24 months, you'll be seeing compound improvements that surprise you. Within three years, testing will be so embedded in your culture that you can't imagine making decisions any other way.
The organizations winning in digital markets in 2025 and beyond won't be those with the best initial ideas. They'll be those with the best learning systems. A/B testing is the foundation of those learning systems. The question isn't whether to implement A/B testing. The question is how quickly you can build mature testing capabilities and begin accruing the compounding advantages they provide.
Your competitors are already testing. The gap between your organization and leading competitors in your industry is largely a function of how much testing they're doing and how effectively they're learning from it. Every month you delay building testing capabilities is a month your competitors are gaining advantage.
Start small. Be consistent. Think long-term. Invest in infrastructure that makes testing easier over time. Build team capability through training and practice. Focus on learning rather than quick wins. The compound returns will follow.
Key Takeaways
- A/B testing eliminates confounding variables by comparing two versions simultaneously, proving causation rather than correlation
- Evidence-driven decision-making replaces opinion-based strategies, democratizing organizations and improving team dynamics
- Systematic testing produces compounding returns: 50 tests with 3% average improvement = 338% improvement over two years
- A/B testing reduces risk by testing changes with subsets of traffic before full rollout, limiting damage from negative changes
- Understanding audience preferences through testing creates sustainable competitive advantages impossible for competitors to replicate
- Building testing culture requires infrastructure, processes, statistical literacy, and organizational commitment to systematic experimentation
- Common mistakes like peeking at results, inadequate sample size, and poor test design significantly undermine statistical rigor
- Testing opportunities exist throughout customer journey: landing pages, email, product onboarding, advertising, and in-app experiences
- Statistical significance differs from practical significance; results need to reach predetermined thresholds before implementation
- Most valuable benefit isn't conversion rate improvement but organizational transformation into learning-driven, evidence-based operation

