![AI Comes Down to Earth in 2025: From Hype to Reality [2025]](https://tryrunable.com/blog/ai-comes-down-to-earth-in-2025-from-hype-to-reality-2025/image-1-1767184547241.jpg)
AI Comes Down to Earth in 2025: From Hype to Reality
For two years straight, artificial intelligence lived in the clouds. The messaging was biblical: AGI around the corner, superintelligence inevitable, the future of humanity at stake. Every earnings call, every conference talk, every venture pitch promised we were witnessing the birth of something that would remake civilization.
Then 2025 happened. And reality collided with rhetoric in ways that no amount of marketing could smooth over.
This year wasn't about breakthrough discoveries or exponential capability jumps. It was the year AI went from being treated as an oracle to being treated as what it actually is: a tool. Useful? Absolutely. Revolutionary in some specific applications? Sure. But also imperfect, prone to hallucinations, unable to handle genuinely novel problems, and sometimes confidently wrong about basic arithmetic.
The shift wasn't sudden. It crept in through research papers that contradicted the marketing, through product launches that emphasized reliability over raw power, and through a growing acknowledgment in C-suites that if AI companies want to make money right now, they need to sell something people can actually use, not something they might eventually use in 2027 or 2035.
What's fascinating about 2025 is the cognitive dissonance everywhere. Nvidia hit a $5 trillion valuation while analysts warned of an AI bubble rivaling the 2000 dotcom crash. OpenAI's Sam Altman claimed in January he knew how to build AGI, then spent November celebrating that GPT-5.1 finally learned to use em dashes correctly (sometimes). Data centers were planned to consume nuclear reactor amounts of power while researchers published studies showing that today's "reasoning" models just pattern-match from training data, not actually reason.
This wasn't failure. It was maturation. And understanding what happened in 2025 matters because it shapes everything coming next.
The Age of Practical AI Begins
The pivot from prophecy to pragmatism didn't happen overnight, but 2025 marked the point where it became undeniable. Companies that built AI infrastructure specifically optimized for AGI-soon narratives suddenly had to justify billion-dollar data center investments with products people could buy today.
This forced a reckoning. If your value proposition is "this will change everything eventually," investors want to know what changes everything means. They want revenue. They want customers. They want to understand why someone would pay money for what you're building right now, not what you theoretically might build in 2027.
The result was fascinating: product teams started stripping away the speculative layer and focusing on core capabilities. What does this model actually do well? Coding tasks? Customer service responses? Content generation? Summarization? The honest answers to these questions became the actual products.
This shift played out across the entire industry. Teams that spent 2024 talking about reasoning models pivoted to talking about developer productivity. Companies that built research labs to chase AGI opened product divisions to sell solutions to enterprises. The narrative changed from "we're building superintelligence" to "our system reduces your sales call summary time from 45 minutes to 6 minutes."
Was this disappointing for true believers? Absolutely. Is it more useful for literally everyone else? Also absolutely.
The practical turn had another effect: it forced better testing and verification. When you're claiming your model will achieve AGI in 2026, nobody expects rigorous benchmarks. But when you're selling it as a coding assistant to a Fortune 500 company, someone's going to measure whether it actually writes better code or just code that looks better until deployment.
That verification process revealed uncomfortable truths that had been buried under marketing narratives.
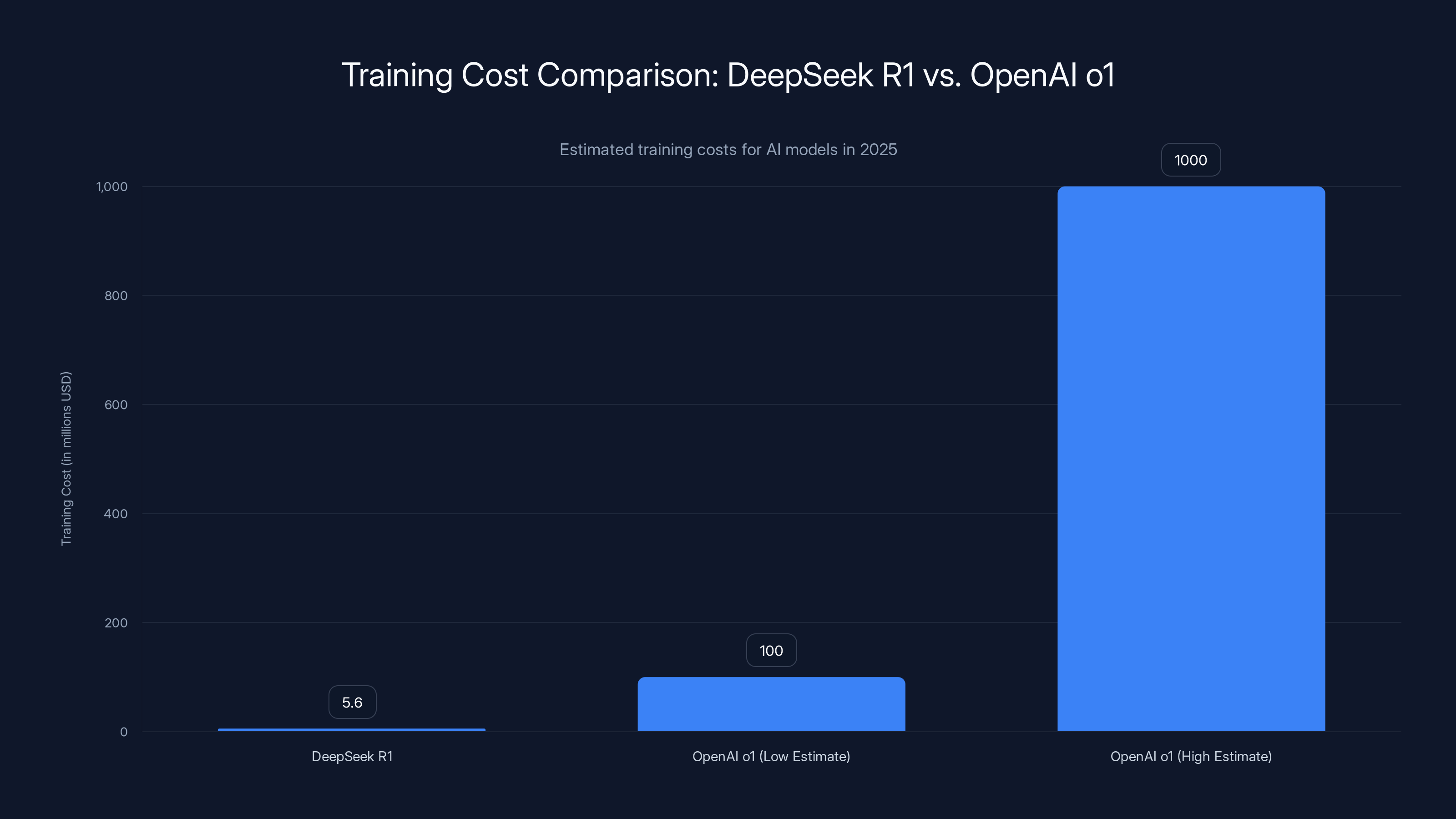
DeepSeek's R1 model was trained at an estimated cost of $5.6 million, significantly lower than OpenAI's o1 model, which ranged from hundreds of millions to low billions. Estimated data.
Deep Seek's Reality Check
In January 2025, Chinese startup Deep Seek released its R1 model, and for about 72 hours, the American AI industry collectively freaked out.
The numbers were staggering. Deep Seek claimed R1 matched OpenAI's premium o1 model on mathematics and coding benchmarks. More shocking: it cost an estimated $5.6 million to train using older Nvidia H800 chips that were restricted by U.S. export controls. OpenAI's models? Estimates pegged training costs in the hundreds of millions to low billions.
The implication was terrifying to American AI companies: maybe efficiency, not raw compute, was the real breakthrough. Maybe you didn't need the absolute latest hardware and unlimited budgets to build competitive models. Maybe the closed, proprietary approach wasn't unbeatable.
Within days, Deep Seek's app jumped to the top of the iPhone App Store charts. Nvidia stock plunged 17%. Venture capitalists like Marc Andreessen called it "one of the most amazing and impressive breakthroughs I've ever seen." Meta's Yann LeCun offered a different take: the real lesson wasn't that China beat America, but that open-source models were beating proprietary ones.
Testing revealed the more complicated reality. In head-to-head comparisons, R1 was genuinely competitive on everyday tasks like coding and writing. It stumbled on arithmetic problems and struggled with abstract reasoning in novel ways that suggested it hadn't actually solved the "reasoning" problem, just implemented it differently.
Moreover, R1 didn't actually displace ChatGPT or Claude in the American market long-term. The excitement faded. By midyear, ByteDance's Doubao had leapfrogged Deep Seek within China. R1's significance wasn't that it won; it was that it proved the gap between American and Chinese AI development wasn't the unbridgeable chasm some claimed.
The Deep Seek episode crystallized something important: efficiency mattered as much as scale. The age where "more compute = better results" was an unquestionable truth had passed. This opened space for new competitors, smaller operations, and different architectural approaches.
It also made it harder for OpenAI and Anthropic to justify their proprietary-only strategies. If open-source models were catching up, the moat had to come from something else: interface, reliability, specific capabilities, or trust.

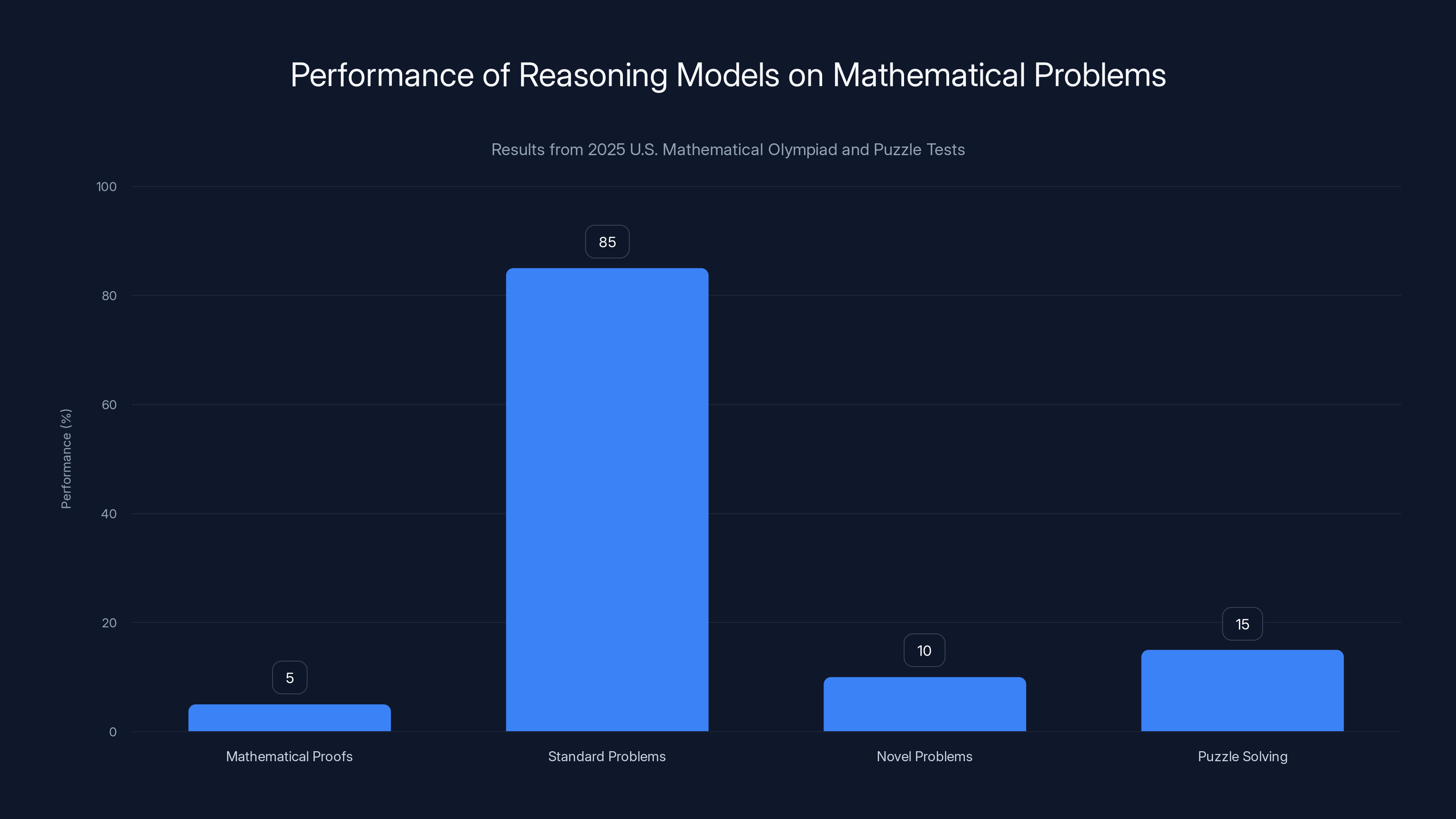
Estimated data shows reasoning models scored below 5% on mathematical proofs and struggled with novel problems, indicating reliance on pattern recognition rather than logical deduction.
The "Reasoning" Illusion Gets Exposed
Perhaps no piece of 2025 undercut the AGI narrative more thoroughly than the research papers documenting what "reasoning" in large language models actually meant.
In March, researchers at ETH Zurich and INSAIT published a study that tested several reasoning-focused models on problems from the 2025 U.S. Mathematical Olympiad. The results were brutal. Most models scored below 5% when asked to generate complete mathematical proofs. Not a single perfect proof among dozens of attempts. The models excelled at standard problems where step-by-step procedures aligned with patterns in their training data. They collapsed completely when facing novel problems requiring genuine mathematical insight.
In June, Apple researchers published "The Illusion of Thinking," which tackled the problem differently. They tested reasoning models on classic puzzles like the Tower of Hanoi. Then they did something clever: they provided the models with explicit algorithms for solving the puzzles. If the models were actually reasoning, they should use those algorithms. If they were pattern-matching, providing algorithms wouldn't help.
It didn't help. Performance didn't improve.
The implications were clear: these models weren't constructing solutions through logical deduction. They were recognizing patterns and retrieving responses similar to training data. When researchers gave them an explicit algorithm, the models didn't understand it because understanding requires something fundamentally different from pattern recognition.
So what was "reasoning" in these models? It was basically a term of art meaning "devote more compute time to generate more context." Specifically, these models generated more tokens of "chain of thought" reasoning before producing an answer. More thinking tokens didn't equal actual reasoning; it just meant more intermediate outputs that looked like reasoning.
This matters enormously because the AGI narrative had rested partly on the assumption that if we just gave these models more compute, more time to think, more tokens to reason with, they'd eventually cross some threshold into genuine reasoning. The research suggested they wouldn't. There's a fundamental difference between pattern recognition scaled to trillion-parameter models and systematic logical reasoning. Adding more thinking tokens doesn't bridge that gap.
Did this mean the models were useless? Absolutely not. Pattern recognition at a trillion-parameter scale is incredibly useful for debugging code, analyzing documents, generating summaries, and handling structured tasks. It's just not a path to AGI.
The research wasn't especially controversial. Even the model creators largely acknowledged these findings. But they created a useful tension with the marketing narratives, forcing a distinction between what's true and what sells.
Anthropic, Copyright, and the Real Costs
In 2024, copyright holders started asking uncomfortable questions about whether training generative AI models on copyrighted text without permission was actually legal. By 2025, that question had settled law.
Anthropic reached a landmark settlement with authors including a payment structure that acknowledged training on copyrighted work without explicit permission had costs that needed compensation. The settlement didn't establish a clear precedent about training data and copyright writ large, but it signaled something important: copyright issues around AI training weren't going away through legislation or regulatory capture.
More importantly, it raised the cost of model development. If you wanted to train a foundational model without getting hit with copyright litigation, you had to either pay for the data rights or find data sets that were legitimately licensed for training purposes. Free lunch was over.
This pushed two developments. First, companies started investing heavily in creating synthetic or permissioned training data. Second, they started being more honest about where training data came from and what rights issues existed.
For smaller players and open-source projects, copyright questions created barriers to entry. You couldn't just scrape the internet and call it a dataset. For giants like OpenAI and Google, it was solvable through licensing agreements and resources. But the landscape shifted from "use whatever data exists" to "you need legal clearance for that data."
The settlement also highlighted something deeper: AI industry fundamentals were still being determined. Training data rights, output licensing, fair use in the context of machine learning—all were unsettled questions in 2025. The companies treating them as already-solved problems were taking on litigation risk.
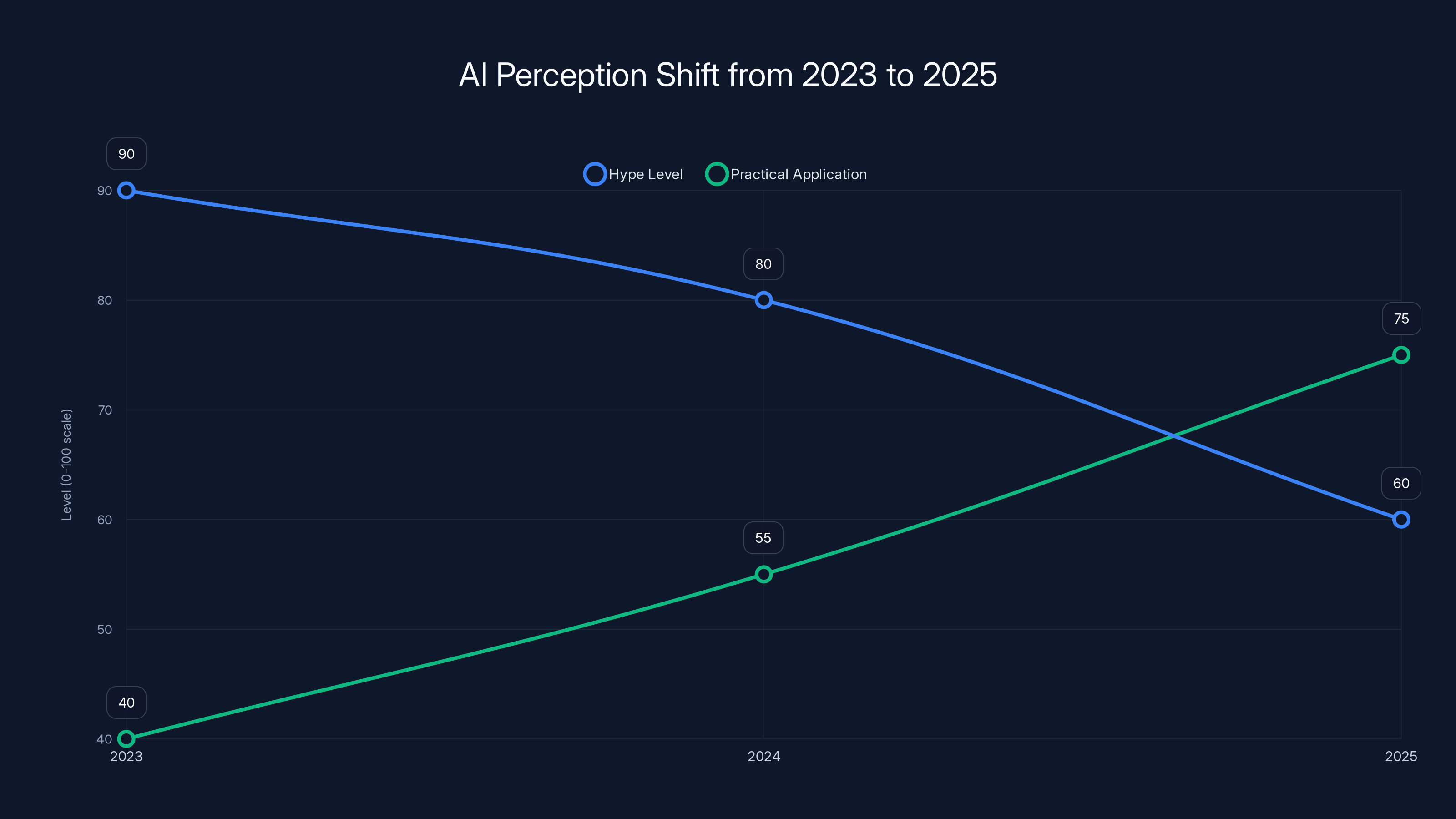
The chart illustrates the decline in AI hype and the increase in practical applications from 2023 to 2025. Estimated data shows a shift towards more realistic expectations and usage of AI technologies.
The Bubble Debate Gets Louder
As 2025 progressed, serious voices started asking: Is this a bubble?
Nvidia's valuation crossed $5 trillion. AI startups were raising funding rounds that valued them at multiples disconnected from revenue. Data center construction projects were being announced that would consume enormous amounts of power and capital. The financial projections behind these investments required either radical improvements in AI capability or radical reductions in compute requirements per inference.
Some analysts pointed to the 2000 dotcom crash as the obvious parallel. Too much money, inflated expectations, companies with no business models. The mechanisms were similar: belief in a transformative technology, venture capital flooding the space, valuations divorced from revenue.
But other observers noted important differences. Unlike the dotcom era, AI companies were actually generating revenue. ChatGPT had millions of paid subscribers. Claude was deployed across enterprises. Open-source models were in production. The technology was being used, not just theorized about.
The honest answer was that the situation contained both truths. Some AI investments were overvalued and would fail. Some would generate returns that justified the hype. Some bets on specific capability developments would turn out to be wrong. The macro trend toward AI integration into products would likely continue even if specific companies or approaches didn't pan out.
What changed in 2025 was the debate itself became less reflexively bullish. In 2023 and 2024, questioning AI enthusiasm was treated as contrarian at best, anti-progress at worst. By 2025, asking "what's the actual business case here?" was finally acceptable in mainstream venture circles.

Where AI Actually Created Value in 2025
Beyond the narratives and the debates, 2025 was the year AI proved it could create genuine, measurable value in specific applications.
Developer productivity was the clearest win. Coding assistants matured from interesting experiments to widely deployed tools with measurable effects on development velocity. Studies from GitHub and other platforms showed engineers using AI assistants completed tasks 20-40% faster, with code quality metrics stable or improving. The gains weren't transformative, but they were real, consistent, and repeatable.
Customer service and support benefited enormously. AI systems handling first-line customer interactions reduced response times, improved issue resolution rates, and freed human agents to handle complex problems. Companies with effective AI-assisted support saw both cost reduction and customer satisfaction improvements.
Content generation, particularly for repetitive or structured content, proved genuinely useful. Legal document review, medical record summarization, financial analysis of earnings calls—these were areas where AI excelled at pattern recognition and didn't need genuine reasoning.
Diagnostics and classification tasks benefited from AI's ability to process more data than humans and identify patterns. Medical imaging analysis, document categorization, anomaly detection in industrial systems—these worked because the task was fundamentally about pattern recognition, which AI does well.
Where AI struggled was exactly where research predicted: tasks requiring genuine reasoning about novel problems, understanding nuance in ambiguous situations, creative work that involved solving problems nobody had solved before, and any task where the model needed to understand the physical world through something other than text.
The pattern was clear: AI created value where tasks were well-defined, where training data existed, where pattern recognition sufficed, and where good-enough solutions beat no solutions. It struggled where creativity, genuine reasoning, or understanding novelty mattered.
Pragmatic organizations acknowledged this distinction and built accordingly. They didn't try to force AI into applications where it didn't belong. They didn't expect any single AI model to solve enterprise-wide problems. They deployed AI narrowly and measured results.

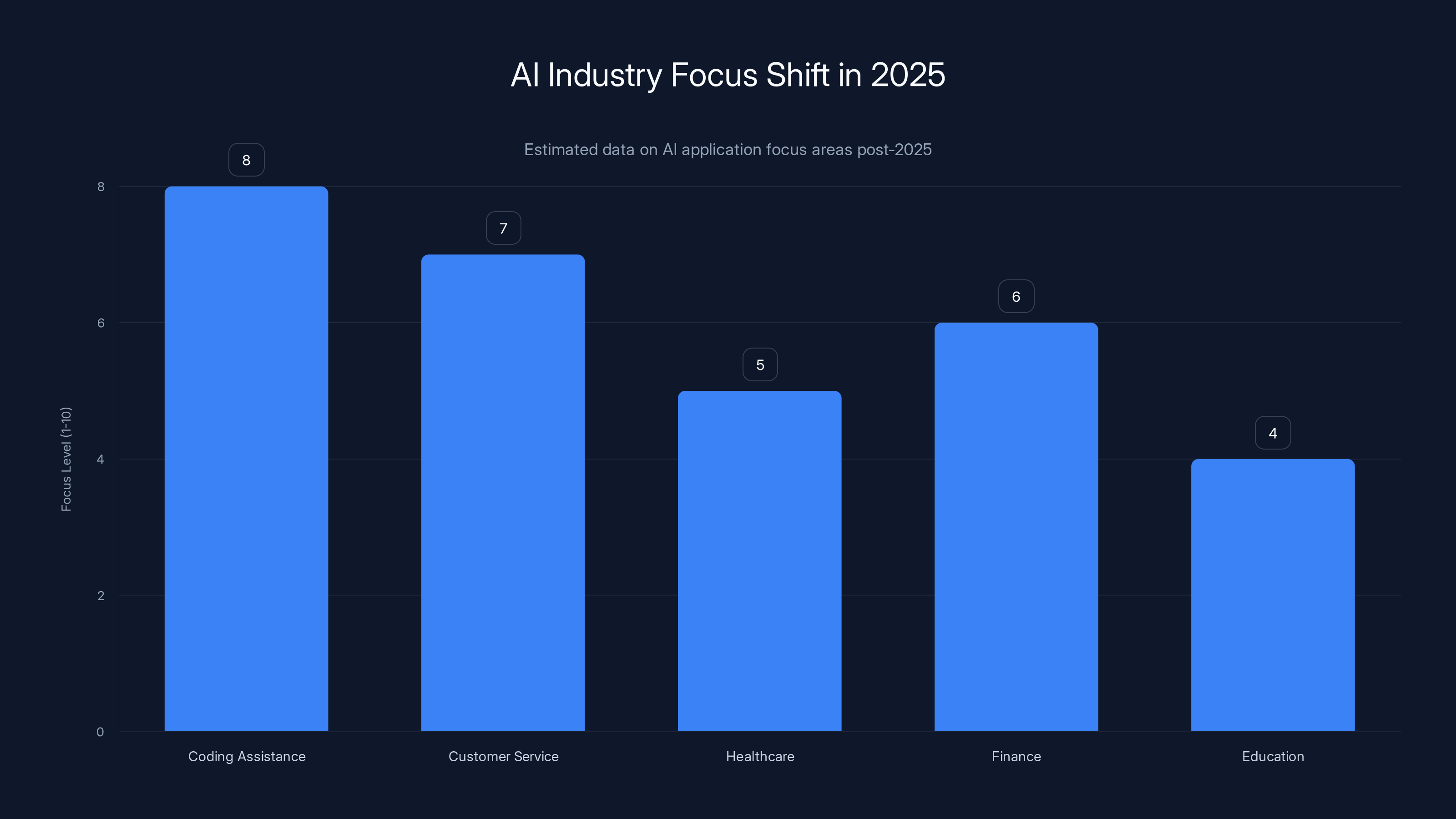
In 2025, the AI industry shifted focus towards practical applications like coding assistance and customer service, moving away from speculative AGI claims. (Estimated data)
The Open-Source Acceleration
2025 saw open-source AI models close the capability gap with proprietary ones faster than most expected. Deep Seek's release was just the most visible example.
Meta's continued investment in open-source Llama models paid dividends. By mid-2025, Llama 3.2 and successors could handle many tasks where proprietary models were the only choice just a year prior. Costs per inference dropped dramatically. Running competitive models locally became feasible for small organizations.
This created interesting market dynamics. Proprietary model creators had to justify their premium through either better capabilities, better reliability, or better interfaces. Pure capability advantages eroded faster than anyone anticipated.
The open-source acceleration also democratized AI development. Startups could build products on top of free, open models rather than paying per-API-call to OpenAI or Anthropic. This unlocked creative new applications but also saturated the market with mediocre AI-powered products.
By year-end, the question shifted from "should we use open-source or proprietary models" to "which specific model solves our specific problem best, regardless of whether it's open or closed." Pragmatism won over ideology.

Multimodal AI: Promise and Limitations
In 2024, the dream was that AI would seamlessly understand text, images, audio, and video. 2025 revealed both the progress and the persistent limitations.
Image understanding matured significantly. Vision-language models got genuinely better at describing images, answering questions about images, and analyzing visual content. This had real applications in accessibility, document processing, and content analysis.
Audio and video remained harder. Models could extract text from video, identify speakers, and generate transcripts, but understanding video content at a semantic level proved more difficult than anticipated. The models could recognize patterns they'd seen before but struggled with novel scenarios or nuanced interpretation of visual information.
Multimodal systems that combined text, image, audio, and video into coherent understanding remained an aspiration rather than a solved problem. The systems that worked best treated each modality separately, then combined the outputs through logical rules, rather than having genuine multimodal understanding.
This mattered for the AGI narrative because one argument for imminent AGI was that combining multiple modalities would unlock something qualitatively different. 2025 showed that combining multiple lower-capability systems didn't automatically create higher capability. It just created systems that were better at specific things.

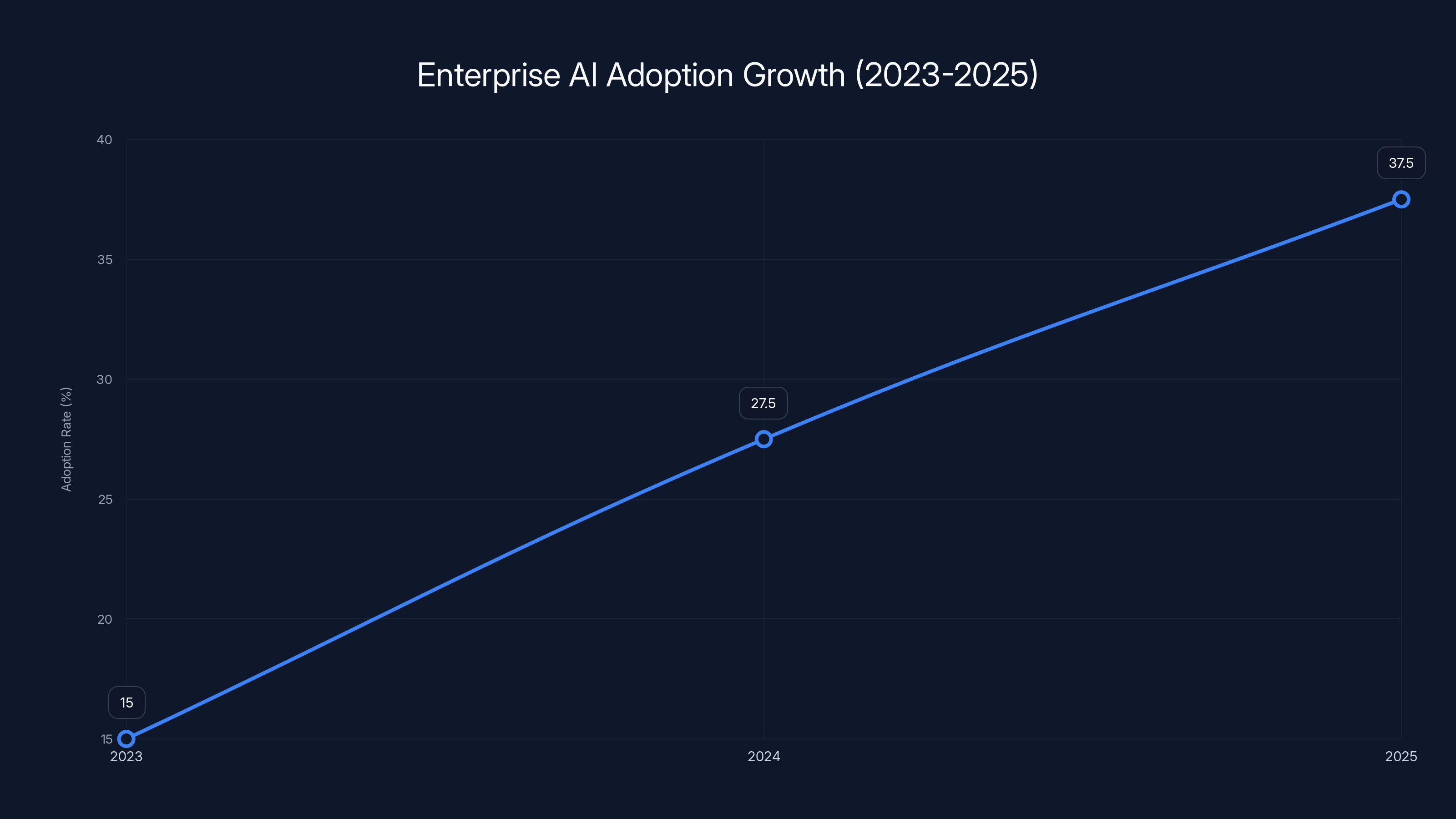
Enterprise AI adoption grew significantly from 15% in 2023 to approximately 37.5% by 2025, driven by practical applications rather than broad transformations. Estimated data.
The Customization Problem
As organizations deployed AI systems, they discovered something the early hype hadn't emphasized: no base model perfectly matched their use cases. Customization was necessary.
Companies had to choose between fine-tuning models on their proprietary data (expensive and complex), using prompt engineering to guide models toward desired outputs (brittle and limited), or building custom layers on top of base models (engineering-intensive).
Rather than the early vision of one model solving everything, 2025 saw the emergence of specialized fine-tuned models and domain-specific implementations. A financial services company might use a base model fine-tuned on financial documents. A healthcare provider might use a model trained on medical literature. A manufacturer might use a model that understood manufacturing-specific language.
This fragmentation created opportunities for companies offering fine-tuning as a service, custom training infrastructure, or domain-specific models. But it also meant the winner-take-all dynamics that seemed inevitable in 2023-2024 didn't materialize.
Instead, 2025 looked more like the enterprise software market: multiple viable competitors, specialization mattering more than raw capability, and customers forced to evaluate fit rather than just ranking models by benchmarks.
Energy Consumption: The Inconvenient Question
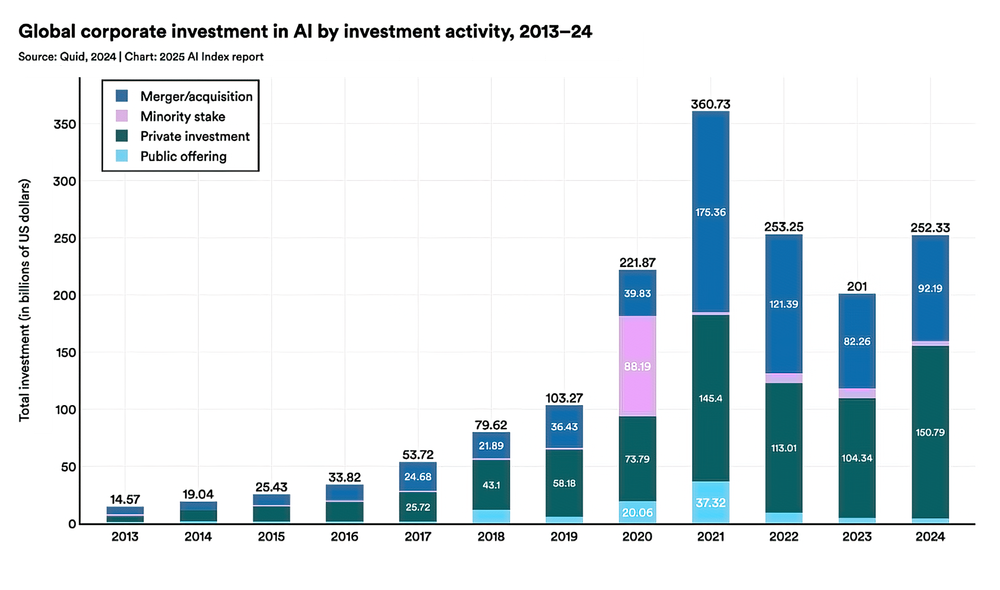
By 2025, it became impossible to ignore how much energy AI systems consumed.
Training large foundational models required enormous amounts of electricity. Running inference at scale across millions of users required dedicated data center capacity. The proposed data centers needed to support future AI workloads would consume nuclear reactor levels of power.
This created a tension with climate goals and sustainability commitments. Companies claimed AI would help solve climate change and environmental problems. Simultaneously, the infrastructure required to run that AI consumed massive amounts of energy.
Some of this concern was overblown. Inference is more efficient than training. Edge deployment reduces computational needs. Better model architecture and efficiency improvements reduced energy requirements per task. But the scale of deployment was immense enough that energy consumption remained a legitimate concern.
By year-end, serious conversations emerged about whether the energy investments in AI infrastructure made sense relative to the capabilities being created. It wasn't clear that the energy cost of training GPT-5.1 was justified by its performance improvement over GPT-4. The marginal returns on compute were real but potentially not enough to justify the environmental cost.
For organizations building AI infrastructure, this raised questions: How should we factor in energy costs? Should we prefer more efficient models even if they're somewhat less capable? What environmental commitment are we actually making with AI deployment?

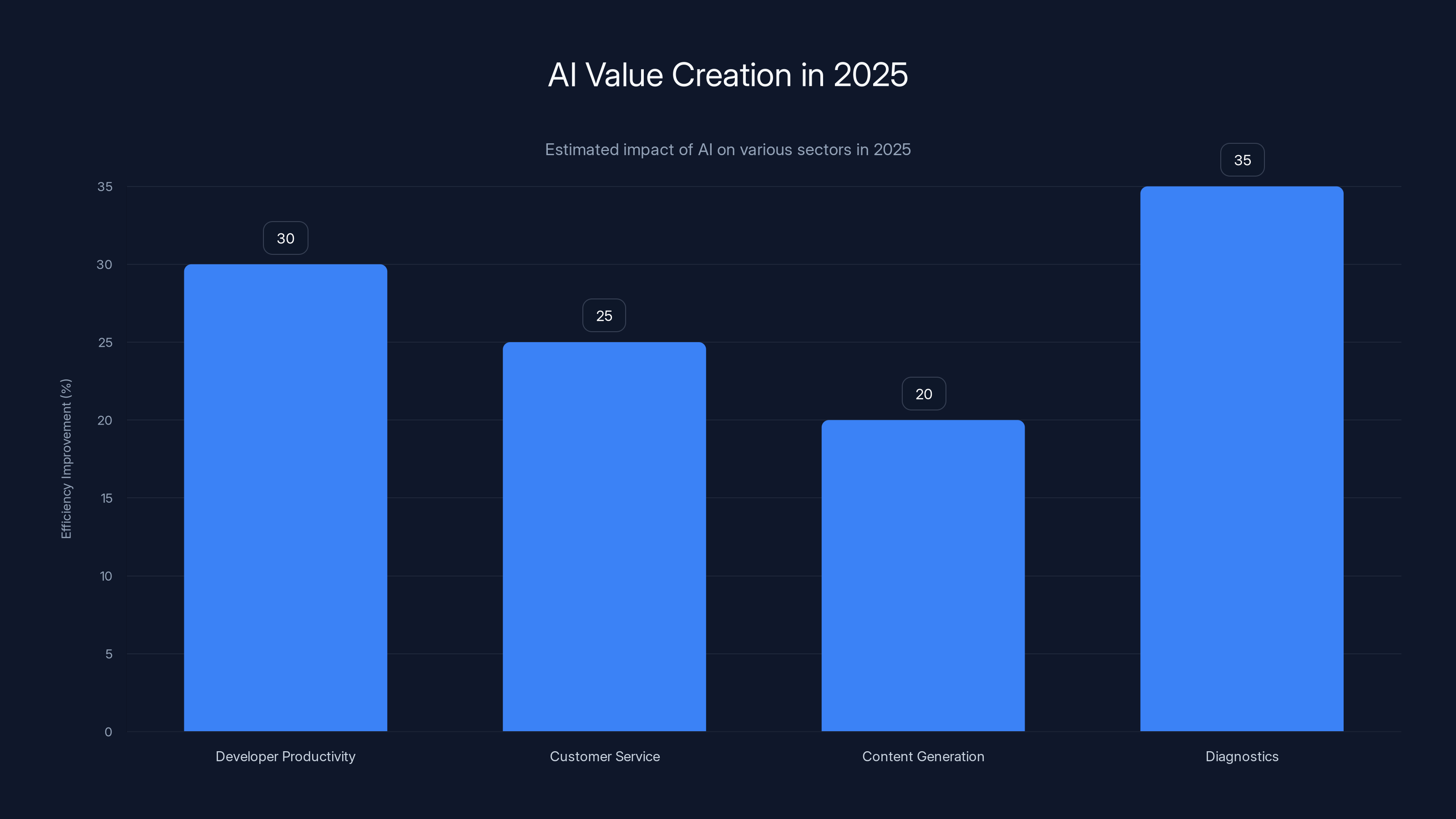
In 2025, AI significantly improved efficiency in diagnostics (35%), developer productivity (30%), customer service (25%), and content generation (20%). Estimated data based on sector trends.
The Regulatory Landscape Crystallized
In 2024, AI regulation was an open question. By 2025, it crystallized into distinct regional approaches.
The European Union continued down a strict regulatory path with AI Act implementations creating compliance requirements for high-risk systems. This didn't stop EU companies from developing AI, but it forced them to think about liability, bias testing, and documentation in ways American competitors didn't.
The United States moved toward sector-specific regulation: healthcare AI faced FDA scrutiny, financial AI faced SEC requirements, employment AI faced discrimination concerns. Rather than blanket AI regulation, the U.S. approach was to apply existing rules to AI use cases.
China pursued direct government involvement in AI development while restricting certain capabilities and use cases. The centralized approach meant faster deployment of approved applications but less experimentation with edge cases.
For companies building AI products, the regulatory landscape meant: no single global approach would work, region-specific compliance became necessary, and transparency about model training and capabilities became increasingly important.
By the end of 2025, companies treating regulation as something that might happen had shifted to companies treating regulation as something that is happening. Product development had to account for this.

The Talent Crisis Evolved
In 2023-2024, the bottleneck for AI development was compute. By 2025, it became increasingly clear the bottleneck was talent.
Every major company wanted AI researchers and engineers. Universities couldn't graduate them fast enough. The early stage of the AI boom had trained people on jobs that didn't exist a few years prior. You couldn't hire someone with five years of experience in prompt engineering or RAG architecture because those jobs didn't exist five years ago.
This created high salaries for AI specialists, poaching between companies, and a shortage of people who actually understood how to build production AI systems (which is quite different from building research models).
Companies attempted various solutions: training programs for existing engineers, hiring academics and accelerating learning on the job, acquiring teams from startups, outsourcing to specialized firms. But by year-end, the talent shortage was a genuine constraint on how fast different organizations could move on AI initiatives.
More importantly, this shortage meant organizations without existing AI expertise or without resources to attract top talent would struggle. The divergence between AI leaders and the rest of the industry would likely grow.

Hallucinations: Still Unsolved
One problem that dominated early 2025 discussions was hallucinations: AI models confidently providing false information.
The year saw numerous workarounds: retrieval-augmented generation that grounds models in actual data, fact-checking systems that verify outputs, confidence scoring systems that flag uncertain answers. None of these solved the fundamental problem: models are trained to generate plausible next tokens, not to be truthful.
Some research suggested that scaling models might help. Larger models with more training data and examples of correct behavior hallucinate less. But they don't hallucinate zero, and no amount of scaling seems to eliminate false confidence entirely.
By late 2025, the industry had largely accepted hallucinations as a problem to manage rather than a problem to solve. Applications that couldn't tolerate occasional errors (medical diagnosis, legal advice, safety-critical systems) couldn't rely solely on LLM outputs. Applications that could tolerate occasional errors (brainstorming, draft writing, coding assistance) could work with models that hallucinate less but still occasionally do.
This was practical but represented a retreat from the promise of AI systems that would get smarter and more reliable indefinitely. There seemed to be a floor on hallucination rates below which current architectural approaches couldn't go.

The Model Architecture Plateau
In 2023 and early 2024, the excitement was about transformers and scale: bigger models, more parameters, more training data, more compute. GPT-3 to GPT-4 to GPT-5 seemed like an obvious progression.
By 2025, the incremental gains from simply scaling were becoming smaller and more expensive. GPT-4.5 to GPT-5 required massively more compute for measurably better but not dramatically better results. Compute requirements were growing exponentially while capability improvements were diminishing.
This prompted serious research into architecture innovations: mixture of experts, more efficient attention mechanisms, novel training approaches. But breakthroughs were fewer and further between than they had been.
Some researchers argued that transformers might be approaching their scaling limits and that fundamentally different architectures would be needed for the next step. Others argued that we just hadn't found the right training data, optimization techniques, or scaling laws yet.
What became clear was that the transformer-scale-up roadmap that had driven progress since 2018 couldn't continue indefinitely. Whether that meant architectural innovation or reaching some natural limit on transformer capabilities remained unclear by year-end.

Predictions for 2026
Based on 2025's trajectory, several developments seem likely for 2026 and beyond.
First, specialization will increase. Rather than one model for everything, we'll see more domain-specific, fine-tuned, and industry-specific models. The era of one-size-fits-all foundational models as the center of AI infrastructure will fade.
Second, efficiency will matter more. As raw compute margins diminish, optimizing model efficiency, inference speed, and energy per task becomes more important than peak capability.
Third, the integration challenge becomes central. Getting AI to work in existing workflows and systems is harder than it sounds and will occupy more engineering effort than pure model improvement.
Fourth, liability and responsibility will continue to increase. As AI systems make decisions affecting real people and real money, questions about who's responsible when things go wrong will drive regulatory action and product design.
Fifth, the AGI timeline will continue to slip. Early 2026 predictions for AGI will likely move from 2026 to 2027 to 2028, following the pattern of the past several years. This isn't proof AGI won't happen; it's just evidence that we're very bad at predicting when.
Sixth, AI will become boring. Not in the sense that it stops being useful, but in the sense that it becomes routine infrastructure. You won't talk about "AI solutions" anymore because AI will just be a component of normal software.
Finally, the line between hype and reality will continue to blur. Both will exist, sometimes in the same product. The skill will be telling them apart.
What 2025 Really Meant
The meta-narrative of 2025 was simple: AI shifted from being an existential bet on future superintelligence to being practical software infrastructure with real applications and real limitations.
This wasn't a failure. It was maturation. Most transformative technologies go through this cycle: enormous hype based on legitimate potential, reality check, recalibration of expectations, then steady productive deployment.
AI in 2025 looked less like a revolution that would change everything in the next five years and more like electricity in 1905: genuinely important, becoming widely deployed, solving real problems, but also not delivering the most grandiose promises from the previous decade.
The difference is that electricity in 1905 didn't have venture capital funding based on an expectation that it would generate superintelligent entities. The financial structure built around AI promised something different. Adjusting that structure to reality will be the real story of 2026 and beyond.
For organizations using AI now, the lesson is clear: focus on specific, measurable problems where AI demonstrably helps. Avoid bets on the next breakthrough or the eventual AGI. Build for what AI can do today, not what it might do in 2030.
For investors in AI companies, the lesson is about asking harder questions about unit economics, actual customer value, and business models that don't depend on capabilities that don't exist yet.
For researchers in AI, the lesson is that chasing raw scale might have diminishing returns. Architectural innovation, efficiency improvements, and solving actual engineering problems might matter more than the next 10x scaling run.
2025 was the year AI came back down to earth. That's not a tragedy. It's where the real work begins.

FAQ
What does it mean that AI "came down to earth" in 2025?
It means the industry shifted from making grandiose claims about artificial general intelligence and superintelligence being imminent to focusing on practical, specific applications where AI demonstrably works. The rhetoric moved from "this will reshape civilization" to "this helps with coding" and "this reduces customer service response times."
Why did the reasoning research matter so much?
Because the entire AGI narrative rested partly on the assumption that with enough compute and time, these models would eventually develop genuine reasoning capabilities. When researchers showed that models don't actually reason but instead recognize patterns and generate plausible continuations, it undercut that assumption. More compute alone won't bridge the gap between pattern recognition and actual reasoning.
Did Deep Seek actually beat OpenAI?
Not exactly. Deep Seek's R1 was competitive with OpenAI's models on many benchmarks and was trained with impressive efficiency. But it didn't win the market, didn't maintain its advantage, and actually needed different architectural approaches rather than just cheaper scaling. It proved that American dominance wasn't guaranteed, not that it had already fallen.
What's the difference between hallucinations and reasoning failures?
Hallucinations are when models generate false information with confidence (like making up citations). Reasoning failures are when models can't apply logical thinking to novel problems. A model can have few hallucinations but still fail at reasoning. They're separate problems requiring separate solutions.
Why does energy consumption matter for AI policy?
Because the infrastructure needed to train and run advanced AI systems at scale consumes massive amounts of electricity, with real environmental costs. If the capabilities being generated don't justify the energy invested, that's an important trade-off that should be made consciously, not accidentally.
Can AI still achieve AGI despite 2025's reality check?
Possibly, but probably not as quickly or inevitably as claimed in 2023-2024. 2025 revealed that the path from current capabilities to AGI is much longer than optimistic timelines suggested. New architectural breakthroughs might be required rather than just scaling existing approaches. The timeline keeps getting pushed back for good reasons.
What should organizations focus on with AI in 2026?
Narrow, specific problems where AI demonstrably works better than current solutions. Avoid company-wide AI transformation narratives. Measure results carefully. Understand your data, your liability, and your compliance requirements. Build for what AI can do today, not what it might theoretically do in five years.
Is AI a bubble about to pop?
Not entirely, but it contains bubble-like elements. Some AI investments will fail, some will succeed spectacularly, and most will be somewhere in between. The difference from 2000 is that some AI companies have real revenue and real customers. But the financial projections depend on capabilities that aren't proven yet, creating real bubble risk.
Why did Nvidia's stock rise so much despite concerns?
Because regardless of whether AI becomes superintelligence or not, billions of dollars will be invested in AI infrastructure. Nvidia owns the dominant hardware for training and running advanced models. Even if AI ROI is lower than expected, the infrastructure is still needed. That's a safer bet than betting on specific AI capabilities.
What happened to the copyright issues around training data?
They became real legal problems with settlement costs. Companies can no longer ignore where their training data comes from. Licensing agreements, synthetic data, and permissioned datasets became necessary. This raised the cost of model development but also reduced litigation risk for companies doing it right.

The Bottom Line
2025 was the year AI grew up. Not in the sense that it achieved the grandiose promises from the hype cycle, but in the sense that it became normal software infrastructure with understood capabilities, real limitations, and genuine but bounded applications.
The oracles became tools. The prophecies became products. The rhetoric met reality.
That's actually the most important thing that could happen. Because the long-term value of AI isn't in whether we achieve superintelligence in 2026 or 2030 or 2050. It's in whether the technology generates compounding value through practical application, incremental improvement, and honest assessment of what works and what doesn't.
2025 proved that's possible. Now comes the harder part: actually doing it.

Key Takeaways
- AI shifted from AGI prophecy to practical software infrastructure solving specific problems effectively
- Research revealed 'reasoning' models use pattern matching, not genuine logical deduction, limiting AGI prospects
- DeepSeek's R1 proved efficiency matters as much as raw compute, challenging proprietary model dominance
- Enterprise AI adoption remained narrow and specific (20-40% coding productivity gains) rather than transformative company-wide
- Open-source models closed capability gaps with proprietary solutions, intensifying competition and reducing pure capability moat
Related Articles
- The Highs and Lows of AI in 2025: What Actually Mattered [2025]
- AI Dating Apps vs. Real-Life Connection: The 2025 Shift [2025]
- What AI Leaders Predict for 2026: ChatGPT, Gemini, Claude Reveal [2025]
- NVIDIA CES 2026 Keynote: Live Stream Guide & What to Expect
- Nuclear Power vs Coal: The AI Energy Crisis [2025]
- Meta Acquires Manus: The AI Agent Revolution Explained [2025]

