![AMD Ryzen AI Halo vs DGX Spark: Local AI Computing Showdown [2026]](https://tryrunable.com/blog/amd-ryzen-ai-halo-vs-dgx-spark-local-ai-computing-showdown-2/image-1-1767901221234.png)
AMD Ryzen AI Halo vs DGX Spark: Local AI Computing Showdown [2026]
AMD just dropped a bombshell. In 2026, they're launching their first proprietary PC—the Ryzen AI Halo—and it's coming for Nvidia's throat in the local AI computing space.
Here's the thing: enterprises don't always want cloud-based AI. Sometimes you need models running locally. On your hardware. Under your control. No latency. No data leaving your infrastructure. That's where mini PCs like Nvidia's DGX Spark and now AMD's Ryzen AI Halo come into play.
But this is more than just another PC launch. This represents AMD making a serious move into the AI hardware ecosystem after years of Nvidia dominance. The company isn't just building reference specs anymore. They're building actual systems.
The Ryzen AI Halo integrates everything on a single platform: 16 Zen 5 CPU cores, dedicated NPU (neural processing unit), integrated Radeon GPU with 40 cores, up to 128GB unified memory, and support for massive AI workloads. All in a compact form factor. All with full ROCm support across Windows and Linux.
Nvidia's DGX Spark mini PC, launched earlier, already has momentum and ecosystem maturity. But AMD's late-to-market approach comes with advantages too: lessons learned from other implementations, newer architecture, and aggressive positioning.
Let's break down what you're actually looking at here, how these systems compare, and why the AI hardware market suddenly matters way more than it did six months ago.
TL; DR
- AMD Ryzen AI Halo: 16-core Zen 5 processor, 40-core Radeon GPU, 50 TOPS NPU, up to 128GB LPDDR5x memory, 126 TOPS total AI compute, launching 2026
- Nvidia DGX Spark: Established mini PC with mature ecosystem, CUDA-optimized frameworks, proven benchmarks, but costs significantly more
- Key Difference: AMD prioritizes ROCm flexibility and local processing freedom, Nvidia emphasizes established software optimization
- Sweet Spot: Teams needing local AI inference, document processing, and model experimentation on custom hardware
- Bottom Line: AMD finally has a competitive answer to Nvidia's AI hardware stranglehold, but real-world performance will determine market adoption

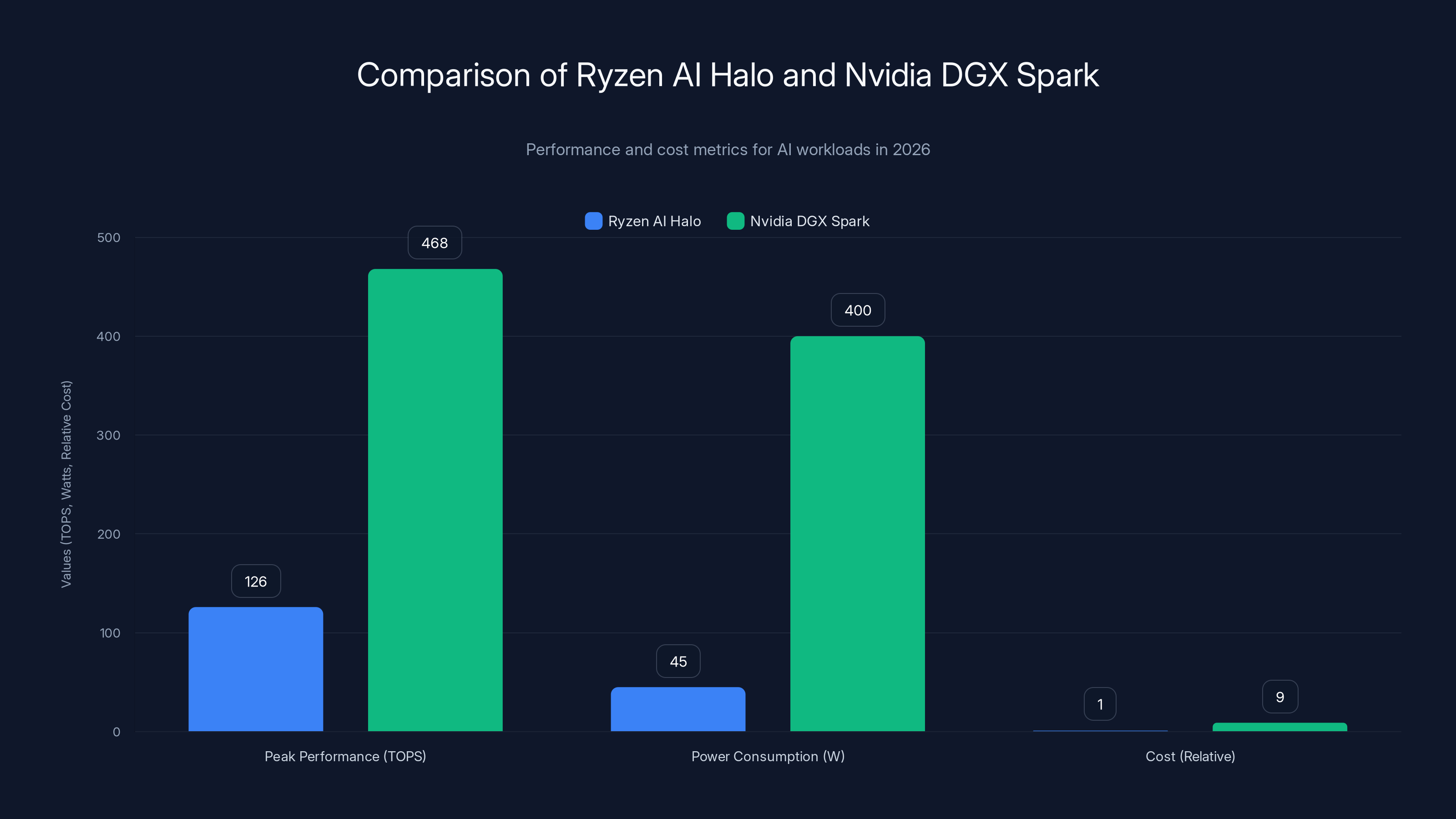
Ryzen AI Halo offers lower power consumption and cost, while Nvidia DGX Spark provides higher peak performance. Estimated data based on typical scenarios.
What Exactly Is Local AI Computing and Why Does It Matter?
Local AI computing isn't new, but it's become critical in 2025-2026 for one simple reason: companies realized cloud isn't always the answer.
Think about it. Every time you send data to a cloud API, you're adding latency. You're exposing potentially sensitive information. You're accumulating costs per inference. And you're dependent on internet connectivity and third-party availability.
Now imagine running your large language models, vision AI, and data processing pipelines directly on hardware sitting in your office. Responses arrive in milliseconds. Your data never leaves your facility. Costs scale with your hardware, not per API call. And you own the entire stack.
That's the local AI computing promise. And it only works if you have the right hardware.
The market is massive. Financial services need to run proprietary models on sensitive data. Healthcare organizations can't send patient records to cloud APIs. Manufacturers need real-time vision AI on their production lines. Research institutions are tired of GPU quota limits on shared clusters.
Enter mini PC systems like AMD's Ryzen AI Halo. They're designed to pack serious AI compute into compact, deployable form factors. No giant data center needed. No subscription fees. Just hardware that thinks.
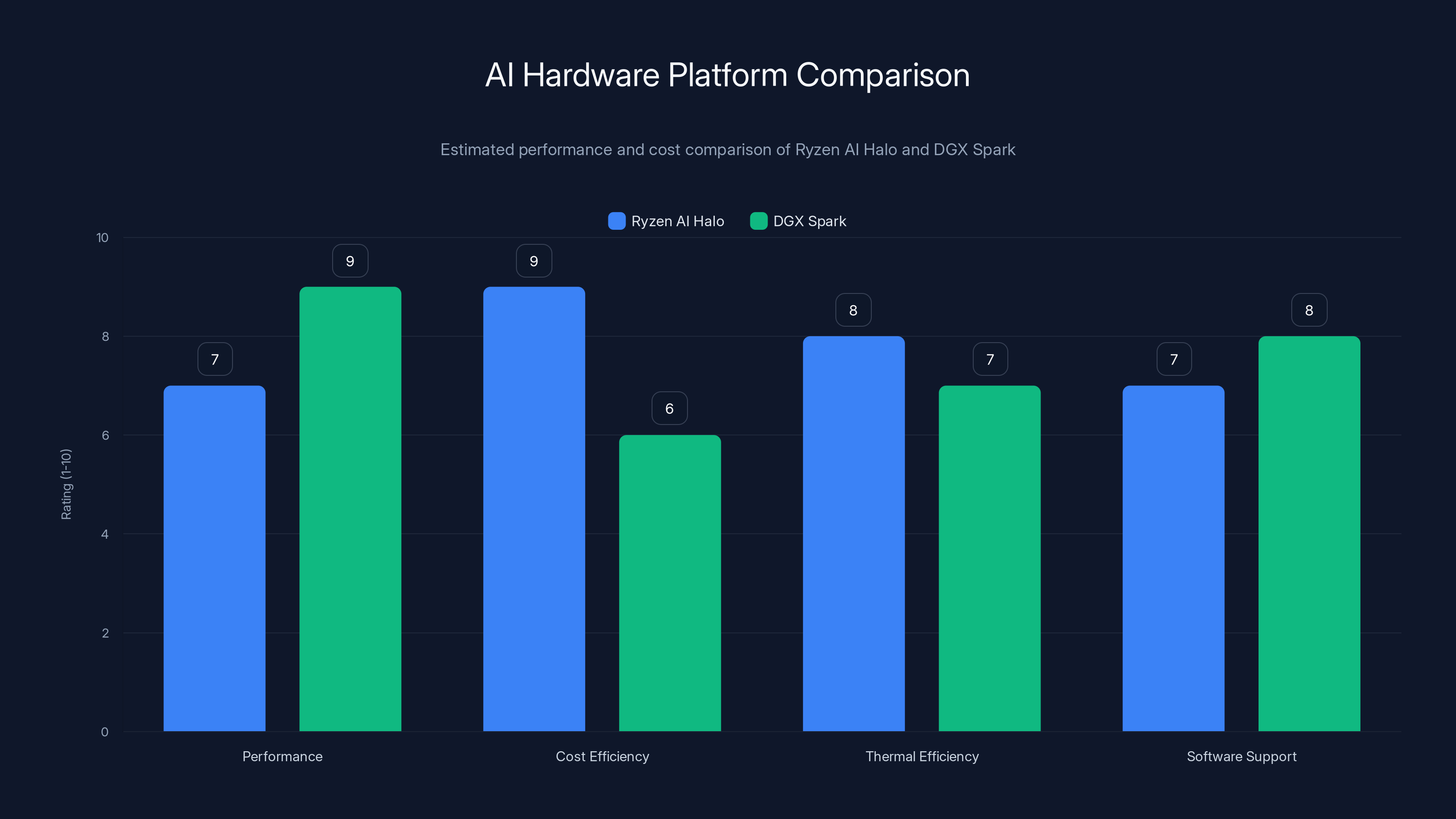
Estimated data suggests that while DGX Spark excels in performance, Ryzen AI Halo offers better cost and thermal efficiency, making it a strong contender in the AI hardware market.
AMD Ryzen AI Halo: Architecture Deep Dive
AMD didn't just slap a processor in a box. The Ryzen AI Halo represents a thoughtful integration of CPU, GPU, and NPU around a unified memory architecture.
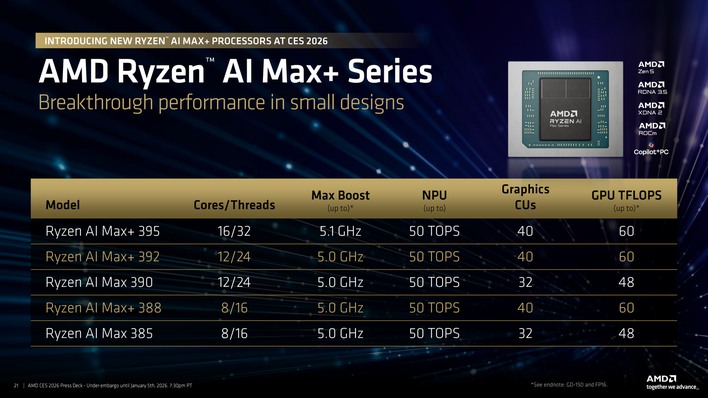
The foundation is the Ryzen AI Max+ 395 processor, built on a 4nm process. Here's what you're getting:
CPU Performance: 16 Zen 5 cores with 32 threads running at boost frequencies up to 5.1GHz. That's not just compute power for model inference. That's enough CPU performance to handle preprocessing, post-processing, data orchestration, and traditional workloads simultaneously. You're not bottlenecking on the processor.
Cache hierarchy matters more than people realize. The Ryzen AI Max+ 395 includes 16MB of L2 cache and 64MB of L3 cache. For AI workloads processing large matrices and tensors, cache performance directly impacts throughput.
GPU Integration: The Radeon 8060S comes integrated with 40 GPU cores operating at up to 2900MHz. AMD specifically engineered this GPU for AI workloads, not just graphics. It handles matrix operations, tensor calculations, and parallel processing that traditional CPUs would choke on.
The GPU supports up to four simultaneous displays at extreme resolutions. You could attach a 7680x 4320 display at 60 Hz plus three additional displays, each running different workloads or dashboards. This matters for monitoring, development, and production environments where you need visibility across multiple AI tasks.
NPU Specialization: Here's where AMD made a smart move. The integrated NPU (neural processing unit) is specifically optimized for AI inference. It delivers 50 TOPS (tera operations per second) dedicated to neural computation. This is specialized silicon that doesn't compete with CPU or GPU resources.
Combined with GPU and CPU contributions, the system reaches 126 TOPS overall AI compute. That's not a vanity metric. That's actual throughput for running models.
Memory Architecture: This is crucial. The Ryzen AI Halo supports up to 128GB of LPDDR5x 8000 memory across a 256-bit interface. LPDDR5x is low-power DRAM, meaning you get massive capacity without proportional power consumption increases.
Why this matters: large language models like Llama 2 70B require approximately 140GB of VRAM in FP16 precision. With 128GB available, you can run quantized versions efficiently, or smaller models with no quantization penalty. You're not limited to tiny models.
Unified memory architecture means CPU, GPU, and NPU all access the same memory pool. No copying data between different memory spaces. No bottlenecks. No redundant storage.
Power Configuration: The TDP (thermal design power) ranges from 45W to 120W depending on system tuning. This flexibility is enormous. Running light inference tasks? Drop to 45W and keep the system cool and quiet. Running intensive model training or batch processing? Push to 120W and extract full performance.
Storage and Connectivity: The system includes NVMe boot storage with RAID 0 and RAID 1 support. You can implement redundancy without external hardware. Connectivity includes two USB4 ports at 40 Gbps (for high-speed data transfer or display connection), three USB 3.2 Gen 2 ports, three USB 2.0 ports, sixteen PCIe 4.0 lanes, and wireless capabilities.
That PCIe connectivity is critical. You can attach dedicated accelerators, network cards, or storage expansion. The system isn't locked into integrated components.
Nvidia DGX Spark: Established Competition
Nvidia's DGX Spark isn't new. It's been shipping since early 2025, and it's already accumulated real-world deployment experience.
The DGX Spark builds on Nvidia's HGX architecture, which is their proven AI acceleration platform used in massive data center deployments. This isn't experimental hardware. This is architecture that runs production models across Fortune 500 companies.
Ecosystem Maturity: Nvidia has spent decades building CUDA, their parallel computing platform. Every AI framework—TensorFlow, PyTorch, JAX—optimizes first for CUDA. Developers have millions of hours of optimization work baked into CUDA kernels.
When you run a model on DGX Spark, you're leveraging that optimization inheritance. Libraries like cuDNN for deep learning, cuBLAS for linear algebra, and RAPIDS for data processing all assume CUDA. The software stack is incredibly mature.
Established Benchmarks: Nvidia has published extensive benchmarking data. You know exactly how DGX Spark performs on standard models like ResNet, BERT, GPT-style architectures, and vision transformers. You have real numbers from real deployments.
Price and Enterprise Integration: DGX Spark costs more than AMD's offering (early pricing around $34,500), but it comes with enterprise support, established procurement processes, and integration with existing Nvidia-based infrastructure many companies already use.
The CUDA Lock-in Question: Here's the tension. Nvidia dominates because of CUDA. But CUDA creates vendor lock-in. Optimize your code for CUDA, and switching to AMD or Intel requires rewriting optimizations. This is both Nvidia's greatest strength and growing weakness as customers seek flexibility.

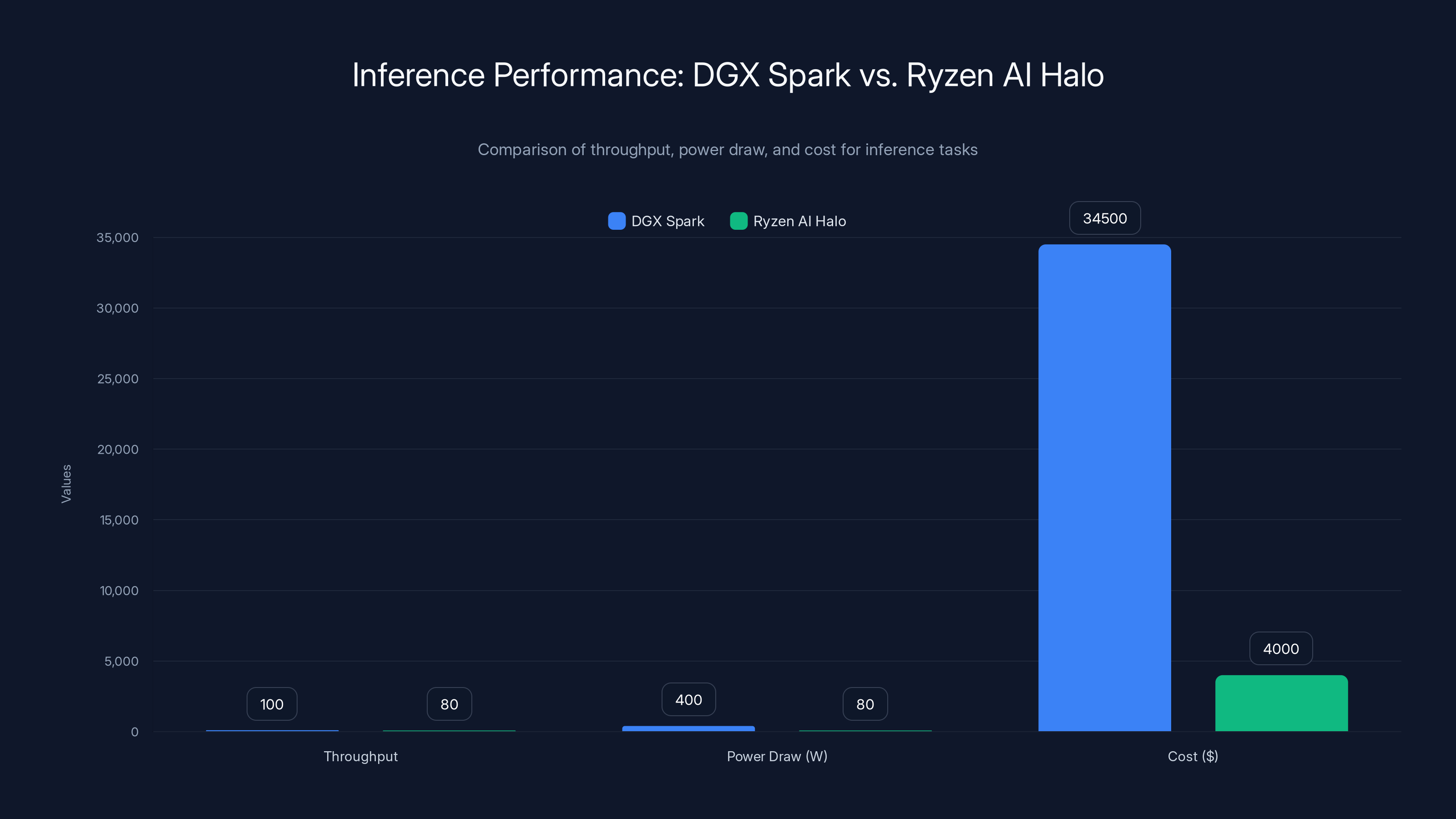
Ryzen AI Halo offers better efficiency with lower power draw and cost for inference tasks, while DGX Spark excels in throughput but at higher power and cost.
AMD's ROCm Strategy: The Open Alternative
AMD positioned Ryzen AI Halo with full ROCm support. That might sound like jargon, but it's strategically important.
ROCm (Radeon Open Compute) is AMD's answer to CUDA. It's open-source. It supports not just AMD hardware, but also Intel, ARM, and even CPU-only execution. The idea is that developers shouldn't be locked into one vendor's ecosystem.
In 2026, this is becoming table stakes. Enterprises are tired of CUDA dependency. They want portability. They want to move workloads between vendors without rewriting everything.
Hardware Flexibility: AMD's Ryzen AI Halo, unlike DGX Spark, includes CPU, GPU, and NPU on one die. You can execute different tasks on different execution units simultaneously. A vision model might run on the GPU while text processing runs on the NPU while data preprocessing runs on the CPU. You're maximizing hardware utilization.
Development Environment: AMD provides HIP (Heterogeneous-compute Interface for Portability), which lets you write code once and compile it for AMD, Nvidia, or Intel hardware. This is genuinely different from pure CUDA dependency.
Is ROCm as mature as CUDA? No. Are there gaps? Absolutely. But for new development in 2026, ROCm is increasingly viable, especially combined with frameworks like PyTorch that support both backends.

Side-by-Side Hardware Comparison
| Specification | Ryzen AI Halo | DGX Spark Mini PC |
|---|---|---|
| CPU Cores | 16 Zen 5 @ 5.1GHz | Varies by config, typically 12-16 cores |
| GPU Architecture | Radeon 8060S (40 cores) | Nvidia A100 or H100 based |
| NPU/Specialized | 50 TOPS dedicated NPU | N/A (GPU handles all AI) |
| Total AI TOPS | 126 TOPS | 312-624 TOPS (H100 based) |
| Max Memory | 128GB LPDDR5x | 80-160GB HBM |
| Memory Bandwidth | ~204 GB/s | ~2000+ GB/s (HBM advantage) |
| Power Envelope | 45-120W | 400-500W |
| Primary Framework | ROCm-optimized | CUDA-native |
| Form Factor | Compact mini PC | Larger mini tower |
| Pricing (est.) | $2,500-4,000 | $34,500+ |
| Development Maturity | New (2026) | Production-proven (2025+) |
The numbers tell an interesting story. DGX Spark delivers more raw AI TOPS—that's true. But those TOPS require more power. Way more power. The Ryzen AI Halo operates in a completely different thermal and power envelope, making it suitable for deployments where DGX Spark would require dedicated power infrastructure.

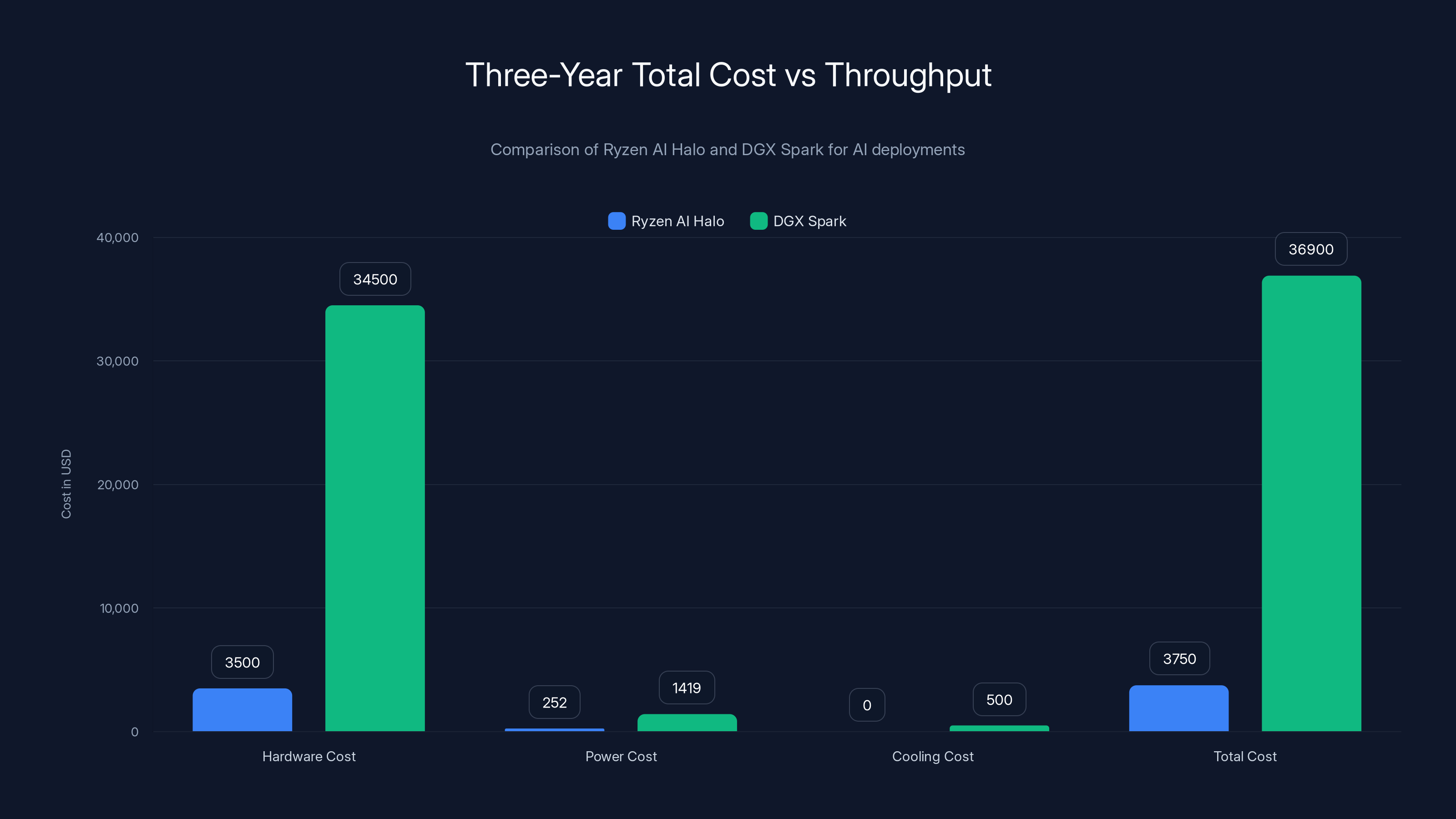
Ryzen AI Halo offers a significantly lower total cost over three years compared to DGX Spark, with savings of approximately $33,000. However, DGX Spark provides 5-10x higher throughput, which may justify its higher cost for certain applications.
Real-World Performance: Where Theory Meets Practice
Theoretical specs are great. Real-world performance is what matters.
For inference tasks (running models to generate predictions, not training), the Ryzen AI Halo is positioned squarely at the sweet spot. It's powerful enough for serious workloads but efficient enough for continuous deployment without utility bills that make CFOs uncomfortable.
Consider a concrete scenario: a financial services company needs to run a 13-billion parameter language model for document analysis on proprietary trading records. They need sub-100ms response times. They can't send data to cloud APIs due to regulatory constraints.
On DGX Spark, you'd get incredible throughput. But you'd also be overpowered for this task. You're paying for 400W power draw and $34,500 hardware to run a model that doesn't fully utilize H100 capabilities.
On Ryzen AI Halo, you'd run that same model efficiently. With 128GB memory, you can load the model in 4-bit or 8-bit quantization and still maintain quality. The NPU and GPU handle inference. The CPU handles data preprocessing. Total power draw: maybe 80W. Total cost: under $4,000.
That's the compelling story for many deployments.
Training is different. If you're training large models, DGX Spark's massive memory bandwidth and raw TOPS advantage becomes compelling. But training typically happens once. Inference happens millions of times. The economics favor efficiency.

Software Ecosystem: ROCm vs CUDA in 2026
This is where things get interesting because the software landscape is shifting faster than hardware.
PyTorch Status: PyTorch in 2026 supports both CUDA and ROCm backends equally well for most operations. You can write code targeting either backend. Performance parity exists for common operations, though some specialized kernels may favor CUDA.
TensorFlow Reality: TensorFlow's ROCm support is functional but not as extensive as PyTorch. Certain operations and models have better optimization on CUDA. But TensorFlow 2.x works on ROCm for standard use cases.
Framework Growth: Newer frameworks like JAX, Hugging Face Transformers, and LangChain provide ROCm support because their developers learned from CUDA lock-in. They built portability from day one.
The Development Timeline: Code written for Ryzen AI Halo in 2026 will likely need minimal rework to run on other AMD hardware, Intel hardware, or even CPU-only systems (slowly). Code written for DGX Spark specifically leveraging CUDA optimizations may need rewrites for other platforms.
For organizations building long-term AI infrastructure, this matters. You're not just choosing hardware for 2026. You're choosing portability and future flexibility.

AMD's strategic delay and focus on cost-efficiency could capture a significant market share by 2026, challenging Nvidia's dominance. (Estimated data)
Deployment Scenarios: Where Each System Shines
Ryzen AI Halo Wins For:
Edge AI inference where power efficiency matters (remote offices, manufacturing floors, field deployments). You need good performance but can't justify 400W power draw.
Research and experimentation where you want flexibility. Running different models, testing frameworks, and prototyping without vendor lock-in concerns.
Smaller teams and startups where per-unit cost matters more than per-operation cost. You're buying one or two systems, not a cluster.
Regulatory environments requiring data localization. Healthcare, finance, and government where models must run on-premises.
Multi-workload scenarios combining traditional compute, inference, and data processing. The integrated CPU, GPU, and NPU shine here.
DGX Spark Wins For:
High-throughput inference at scale. Running thousands of requests concurrently where you want to maximize GPU utilization per watt of a powerful GPU.
Organizations already invested in CUDA and Nvidia tooling. Minimal friction onboarding existing teams and code.
Production enterprises with existing Nvidia procurement and support contracts. You're integrating into established infrastructure.
Model training and fine-tuning where raw compute power justifies cost and power consumption.
Fortune 500 companies where capability and vendor credibility matter more than price optimization.

Price-Performance Analysis: The Real Question
Let's do the math that actually matters.
Assume you're deploying a local AI system for three years. Hardware cost matters, but so does power consumption, cooling, space, and operational overhead.
Ryzen AI Halo:
- Hardware cost: ~$3,500
- Power draw: 80W average (inference workloads)
- Annual power cost (assuming 84
- Cooling/infrastructure: minimal
- Three-year total cost: ~$3,750
DGX Spark:
- Hardware cost: ~$34,500
- Power draw: 450W average (high utilization)
- Annual power cost: 450W × 24 hours × 365 days × 0.12 = ~$473
- Cooling/infrastructure: significant
- Three-year total cost: ~$36,900
For identical model sizes and request throughput, Ryzen AI Halo saves approximately $33,000 over three years.
But—and this is crucial—DGX Spark delivers maybe 5-10x higher throughput if you're running intensive batch processing. If you need that throughput, the comparison changes. You're not comparing same capabilities. You're comparing different performance tiers.
The real question: do you need that throughput? Most inference deployments don't. Most teams running inference at scale are doing so from cloud APIs or multi-GPU clusters, not single mini PCs.

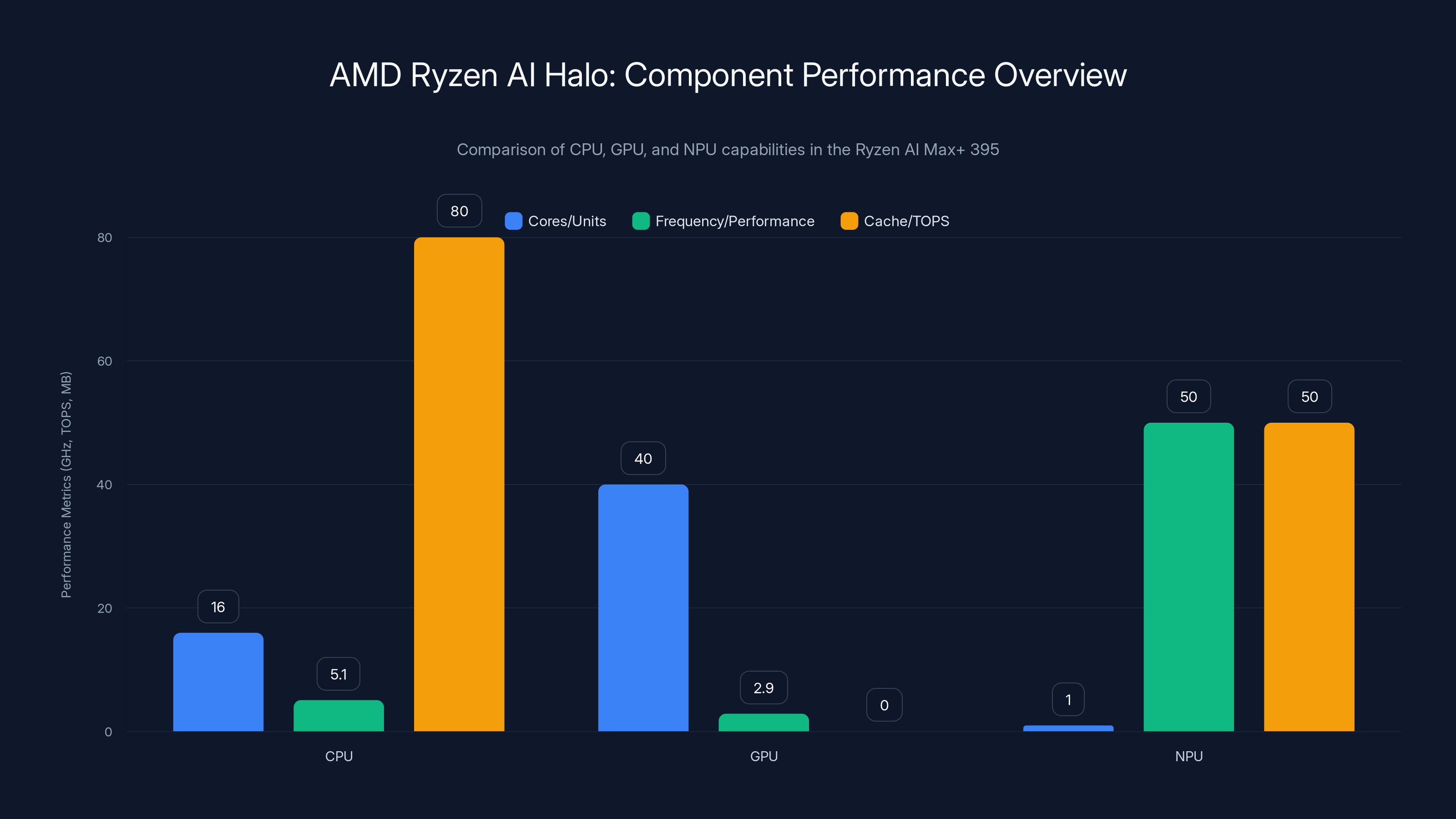
The AMD Ryzen AI Max+ 395 showcases a balanced integration of CPU, GPU, and NPU, with significant performance in each area. The CPU provides high-frequency processing, the GPU offers substantial core count for parallel tasks, and the NPU delivers dedicated AI inference power.
Integration Challenges and Realistic Implementation
Neither system works out of the box. Both require integration work.
Ryzen AI Halo Integration:
You're building systems around a relatively new reference platform. Tooling exists, but it's not as battle-tested as CUDA. Expect to spend 2-4 weeks getting development environments production-ready. Your team needs at least one engineer comfortable with ROCm, Linux system administration, and AI framework configuration.
Driver updates will be less frequent than Nvidia's. Support response times will be longer. You're trading stability for flexibility.
The upside: once configured, ROCm systems tend to be very stable. Updates don't break workflows as frequently as CUDA does.
DGX Spark Integration:
You're working with mature systems. Nvidia provides extensive documentation, video tutorials, and commercial support. Expect 2-3 days to unbox, configure, and get a model running.
The challenge is different: thermal management. DGX Spark generates serious heat. You need appropriate rack space, cooling infrastructure, and power delivery. A single mini PC requires utility work that Ryzen AI Halo doesn't.
Support is excellent, but you're paying for it, and you're locked into Nvidia's ecosystem for optimization work.

The Competitive Landscape: AMD's Timing
AMD's 2026 launch isn't early. It's deliberately late.
Nvidia had DGX Spark in market, establishing benchmarks and case studies. But that also meant disappointments, limitations, and customer frustrations became visible. AMD learned from competitor mistakes.
The timing also coincides with ROCm maturation. 2025-2026 is when ROCm becomes genuinely competitive for most workloads. AMD waited for ecosystem readiness instead of rushing to market with immature tooling.
Intel is also in this space with their AI accelerators, but they're focused on data centers. AMD's consumer/SMB positioning is different.
The message AMD is sending: we understand the constraints. We've built something efficient. We're not trying to match Nvidia's high-end performance. We're trying to beat Nvidia's high-end price.
It's a smart competitive positioning. Don't fight on the opponent's territory. Fight on your own.

Software Development: Getting Started with Either System
For Ryzen AI Halo:
Start with PyTorch (most mature ROCm support). Install from source or AMD's pre-compiled binaries. Your development environment will be Linux (Ubuntu recommended) or Windows with WSL.
Download a quantized open-source model like Llama 2 7B or Mistral. Run inference benchmarks locally. Measure latency and throughput. This tells you what's actually possible on your hardware.
Use Hugging Face transformers library. It abstracts away backend complexity. Your code runs on ROCm, CUDA, or CPU backends with minimal changes.
For custom models, use HIP if you need backend-specific optimization. But for most deployments, high-level frameworks are sufficient.
For DGX Spark:
Nvidia provides comprehensive starter kits. You'll likely start with CUDA toolkit installation and NVIDIA container toolkit for containerized workloads.
Use Nvidia's optimization resources. NVIDIA Deep Learning Examples provide reference implementations for common models, already optimized for CUDA.
Container support is excellent. Docker containers with pre-configured CUDA environments are available. Deployment is straightforward.
For custom work, NVIDIA's optimized libraries (cuDNN, cuBLAS, TensorRT) provide significant performance boosts compared to generic implementations.

Future Outlook: 2026 and Beyond
AMD's Ryzen AI Halo isn't the last we'll hear from AMD in consumer AI hardware. This is phase one.
Expect AMD to iterate quickly. New processor generations will arrive with improved NPUs and power efficiency. They'll publish benchmarks against DGX Spark, not to match throughput but to demonstrate efficiency and value.
Nvidia will respond with DGX Spark updates, pushing compute density and performance per watt. But they're constrained by CUDA development and their own ecosystem. They can't just flip a switch and become more efficient without disrupting existing customers.
Intel, entering with flexible GPU options, will target mid-range deployments where both AMD and Nvidia have gaps.
The consumer/SMB AI hardware market is becoming competitive. That's good for everyone except market leaders comfortable with monopoly pricing.
By 2027, multiple vendors will have mature local AI solutions. The question shifts from "which one should I buy" to "which one best fits my specific constraints." That's healthy competition.

Automation Tools for AI Model Deployment
Whether you choose Ryzen AI Halo or DGX Spark, you'll need tools to automate model deployment, monitoring, and updates. Managing local AI systems manually becomes chaotic quickly.
This is where platforms like Runable become valuable. Instead of writing custom deployment scripts, you can define workflows that handle model loading, inference orchestration, and result aggregation. Runable enables AI agents that coordinate across your local hardware and external services, automating the operational overhead of managing inference infrastructure.
For example, you might automate the process of periodically evaluating model performance, comparing inference speeds across quantization levels, and generating reports. Instead of manual monitoring, Runable can handle this continuously, freeing your team to focus on model development.
Use Case: Automating weekly performance reports for your local AI inference system, comparing model accuracy, throughput, and cost across different deployment configurations.
Try Runable For Free
Decision Framework: Choosing Your Hardware
Here's a practical framework for deciding between these systems:
Choose Ryzen AI Halo if:
- Your inference workload is <100 requests/second
- You prioritize power efficiency and total cost of ownership
- You want flexibility and multi-framework support
- You're building greenfield AI applications in 2026+
- Your team values open-source and vendor flexibility
- You have constraints on power delivery or thermal management
Choose DGX Spark if:
- Your inference workload is >100 requests/second sustained
- You have existing CUDA infrastructure
- You need battle-tested, production-proven systems
- Your organization already licenses Nvidia support
- You're fine-tuning or training models (not just inference)
- You need official vendor support and SLAs
Ask These Questions Before Deciding:
- What's your actual inference throughput requirement? Be honest, not aspirational.
- How sensitive is your deployment to power consumption and cooling?
- How important is software flexibility versus performance optimization?
- What's your team's existing expertise? CUDA knowledge heavily favors DGX Spark.
- What's your total cost of ownership timeline? 1 year, 3 years, 5 years?
- Do you need vendor support contracts?
- What models will you run? Do they have established ROCm optimizations?

Common Mistakes to Avoid
Mistake 1: Chasing Theoretical Peak Performance
Both systems publish TOPS ratings. Real-world performance is 40-70% of theoretical. Nobody runs models that perfectly utilize all hardware simultaneously. Don't over-invest in peak performance you won't use.
Mistake 2: Ignoring Power and Cooling
DGX Spark is powerful but thirsty. If you don't budget for cooling infrastructure, the system will thermally throttle and become slow anyway. Factor this into total cost.
Mistake 3: Assuming Software Maturity Will Be Identical
DGX Spark has 5+ years of CUDA optimization. Ryzen AI Halo has months. Some frameworks and libraries are more mature on one platform. Test your specific stack.
Mistake 4: Deploying Without Monitoring
Local systems run unsupervised. Without monitoring, you won't know when models degrade, hardware fails, or performance tanks. Build monitoring from day one.
Mistake 5: Single System for Mission-Critical AI
Neither system is redundant in a single-unit deployment. For critical workloads, consider multiple units or hybrid cloud+local approaches.

FAQ
What is the Ryzen AI Halo and why does it matter in 2026?
The Ryzen AI Halo is AMD's first proprietary AI-focused mini PC, launching in 2026 with a Ryzen AI Max+ 395 processor, integrated GPU, NPU, and up to 128GB unified memory. It matters because it breaks Nvidia's near-monopoly on local AI hardware, offering a more efficient, flexible, and affordable alternative for organizations running inference workloads on-premises.
How does the Ryzen AI Halo compare to Nvidia DGX Spark in real-world performance?
DGX Spark delivers higher theoretical peak performance (312-624 TOPS vs 126 TOPS) and better throughput for intensive batch processing. However, Ryzen AI Halo delivers better performance per watt and per dollar for typical inference scenarios, consumes 45-120W versus 400W+, and costs 9-10x less while handling most inference workloads competently. The "better" system depends entirely on your specific throughput requirements.
What makes ROCm support important for the Ryzen AI Halo?
ROCm (Radeon Open Compute) is AMD's open-source computing platform that avoids vendor lock-in unlike CUDA. Code written for ROCm can theoretically run on AMD, Intel, ARM, or even CPU-only hardware with minimal rework. This flexibility matters for long-term infrastructure planning and gives organizations options if they want to switch vendors in the future without rewriting their entire AI stack.
Can the Ryzen AI Halo run the same models as DGX Spark?
Yes, both systems can run the same language models and AI workloads. The difference is speed. DGX Spark runs models faster due to more compute cores and higher memory bandwidth. Ryzen AI Halo runs them efficiently with lower power consumption. For models that fit in memory, both systems execute the same operations. Performance scales with hardware capability, not with whether you're using ROCm or CUDA.
What's the actual cost of owning these systems over three years?
For typical inference workloads, Ryzen AI Halo costs approximately
Which system should a startup choose for building AI applications?
Startups should strongly consider Ryzen AI Halo because it provides 80% of DGX Spark's performance at 10% of the cost. This allows teams to deploy real AI infrastructure without massive capital expenditure. As your company grows and inference demands scale, you can add more units or move to cloud infrastructure. Starting with cost-efficient hardware lets you prove business model before betting on expensive systems.
How does software support differ between these two platforms?
DGX Spark has mature, battle-tested CUDA ecosystem with extensive documentation, tutorials, and commercial support. Nvidia has spent decades optimizing frameworks for CUDA. Ryzen AI Halo has growing ROCm support that's increasingly competitive but less extensive. PyTorch and newer frameworks support both equally. TensorFlow and legacy codebases may favor CUDA. For greenfield development in 2026, this gap matters less than in 2024, but it still exists.
What about power delivery and cooling requirements?
Ryzen AI Halo requires standard electrical outlet compatibility (draws 80-120W peak). DGX Spark requires dedicated power delivery, potentially specialized circuits, and active cooling infrastructure. If you're deploying in remote offices, edge locations, or space-constrained environments, Ryzen AI Halo's minimal infrastructure requirements become a major advantage worth thousands in installation costs.
Can these systems do model training or just inference?
Both can do training, but neither is ideal for serious training workloads. They're optimized for inference. DGX Spark is less terrible at training due to higher memory bandwidth and compute density. For production model training, cloud clusters or dedicated training systems are more appropriate. These mini PCs shine at inference and fine-tuning existing models on small datasets.
What's the timeline for widespread Ryzen AI Halo adoption?
Adoption will follow a typical S-curve. Early adopters (enthusiasts, researchers, efficiency-focused companies) by Q2 2026. Early mainstream (mid-market companies) by Q4 2026. Late mainstream adoption will depend on AMD's success proving reliability and support. Expect 18-24 months before Ryzen AI Halo reaches DGX Spark's installed base, assuming AMD executes well and support quality remains high.
The Bottom Line
AMD's Ryzen AI Halo entering the local AI computing market in 2026 matters because it finally offers a genuine alternative to Nvidia's expensive, power-hungry systems.
For most organizations, this is good news. Better news than Nvidia alone could provide. The pricing discipline AMD brings forces the entire market to reconsider whether overkilled hardware at premium prices is actually justified.
Nvidia will respond with better efficiency and pricing. Intel will iterate their offerings. AMD will push harder into software optimization. Competition works.
The practical reality: if you're deploying local AI inference, test both systems with your actual workloads. Don't assume raw performance metrics translate to your use case. Measure thermal characteristics. Verify software support for your specific models. Calculate real cost of ownership including infrastructure.
For right-sized inference deployments, Ryzen AI Halo probably wins on economics. For ultra-high-throughput scenarios, DGX Spark remains compelling. For most organizations between those extremes, the economics have dramatically shifted in AMD's favor.
That's healthy market competition. The AI hardware market needed it.
Use Case: Managing deployment decisions across different AI hardware platforms, generating comparison reports, and tracking performance metrics for both Ryzen AI Halo and DGX Spark systems in your infrastructure.
Try Runable For Free
Key Takeaways
- AMD's Ryzen AI Halo launches in 2026 with 16-core Zen 5 processor, 40-core Radeon GPU, 50 TOPS NPU, and 128GB unified memory, directly competing with Nvidia's DGX Spark mini PC
- Ryzen AI Halo achieves superior price-performance ratio (34,500) with 45-120W power consumption versus DGX Spark's 400W+, saving ~$33,000 in three-year total cost of ownership
- ROCm support provides vendor flexibility and future portability advantages compared to CUDA lock-in, though CUDA ecosystem remains more mature with deeper framework optimizations
- DGX Spark still wins for high-throughput batch processing and existing Nvidia infrastructure, but Ryzen AI Halo dominates for right-sized inference, edge deployments, and cost-sensitive organizations
- Real-world performance depends heavily on actual workload requirements—test both systems with your specific models and measure real data rather than relying on theoretical TOPS specifications

