![The YottaScale Era: How AI Will Reshape Computing by 2030 [2025]](https://tryrunable.com/blog/the-yottascale-era-how-ai-will-reshape-computing-by-2030-202/image-1-1767714010533.png)
The Yotta Scale Era: How AI Will Reshape Computing by 2030
We're about to enter computing's most ambitious chapter yet. Not because of faster chips or clever algorithms, but because the problem we're trying to solve has gotten so monumentally large that everything we know about infrastructure needs to change.
Dr. Lisa Su, CEO of AMD, stood on stage at CES 2026 and said something that should have made every infrastructure engineer in the room sit up straight: the world will need 10 Yotta FLOPS of compute power by the end of this decade. That's a one followed by 24 zeros. To put it bluntly, it's roughly 10,000 times more compute than the entire planet was running for AI in 2022.
Let that sink in for a moment. We're not talking about doubling performance every 18 months. We're talking about a multiplication by 10,000 in less than a decade.
This isn't hype. This is a mathematical reality colliding with physics, economics, and the physical constraints of our planet. And it's about to reshape everything: how companies build infrastructure, how data centers operate, how chips are designed, and fundamentally, how much energy we dedicate to artificial intelligence.
In this guide, we're breaking down what the Yotta Scale era actually means, why AMD believes this transformation is inevitable, how companies will need to adapt, and what the realistic timeline looks like for reaching these astronomical compute requirements.
TL; DR
- The Scale Jump: AI compute needs will increase by roughly 10,000x between 2022 and 2030, moving from zettaflop to yottaflop scale
- Current Constraints: There's already insufficient compute capacity for all the things people want to do with AI right now
- AMD's Strategy: Integrated systems combining CPUs, GPUs, networking, and software are essential for efficient scaling
- Industry Impact: This transformation will reshape data center architecture, energy consumption, and semiconductor design priorities
- Timeline Reality: Reaching 10 Yotta FLOPS by 2030 requires unprecedented coordination across hardware, software, and infrastructure
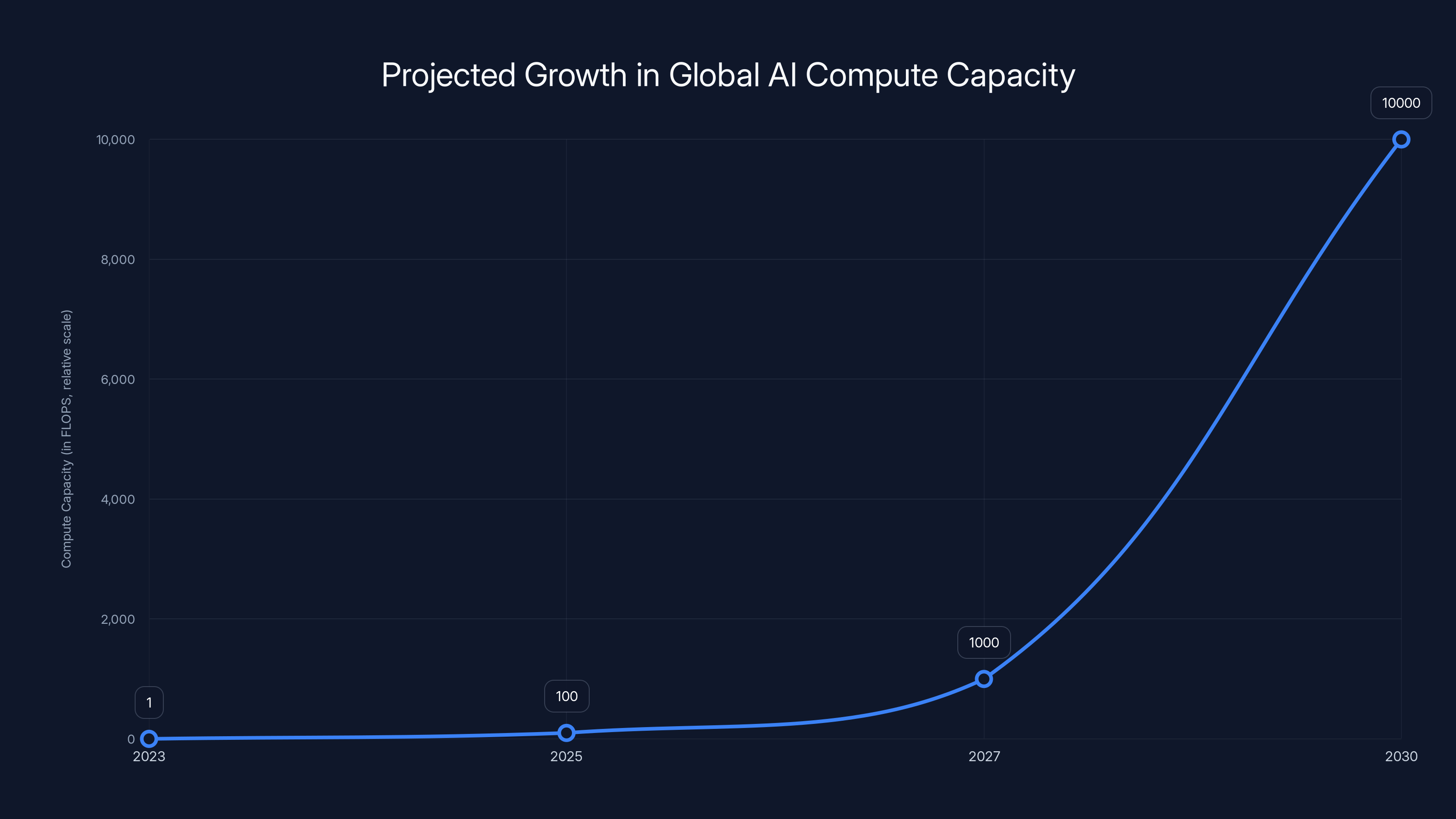
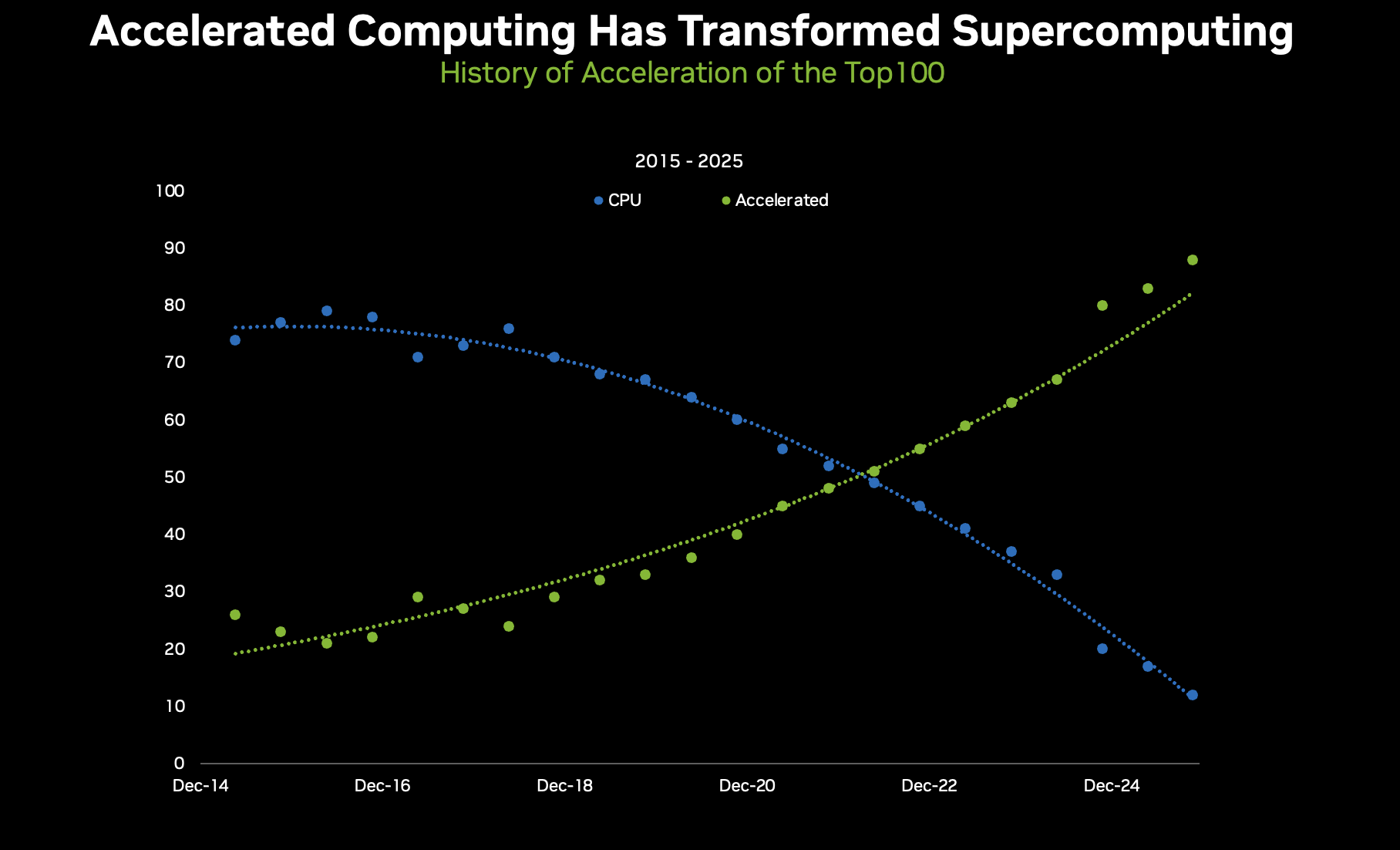
Estimated data shows a 10,000x increase in global AI compute capacity by 2030, driven by the need for yottaflop-scale systems.
Understanding the Yottaflop Scale: From Zetta to Yotta
Before we talk about what's coming, we need to understand the scale we're dealing with. Most people hear "yottaflop" and their eyes glaze over. Numbers this large don't have intuitive meaning. But the progression from zetta to yotta is where the story gets interesting.
In 2022, global AI compute sat at roughly one zettaflop. A zettaflop is 10^21 floating-point operations per second. That's already mind-bogglingly large. To give you context, the fastest supercomputers in the world run in the exascale range (10^18 FLOPS). One zettaflop is 1,000 exascales combined.
Now consider where we're heading: 10 yottaflops. One yottaflop is 10^24 FLOPS. So 10 yottaflops is 10^25 operations per second.
The jump from one zettaflop (10^21) to 10 yottaflops (10^25) represents a 10,000x increase. In seven years. While simultaneously dealing with physics constraints, supply chain limitations, and energy requirements that grow just as fast.
Let's break down what these scales actually mean in practical terms:
Zettaflop (10^21): This is where we are now. One zettaflop represents the combined computational power of millions of GPUs and processors working in concert. It's the baseline for modern large language models, complex simulations, and cutting-edge AI research.
Yottaflop (10^24): This is where we're going. One yottaflop is 1,000 times larger than one zettaflop. Reaching 10 yottaflops means building infrastructure that operates at scales we've never attempted before.
The reason this matters isn't just academic. The compute requirements for AI aren't growing linearly. They're growing exponentially. Every generation of more capable AI models requires roughly 10x the training compute. Every new application domain (reasoning, code generation, scientific discovery, robotics) stacks on top of existing demand.
AMD's prediction doesn't come from nowhere. It's based on trend analysis, application demand, and the exponential trajectory of AI capability improvements we've seen over the past five years. But reaching this scale requires solving problems that don't have solutions yet.
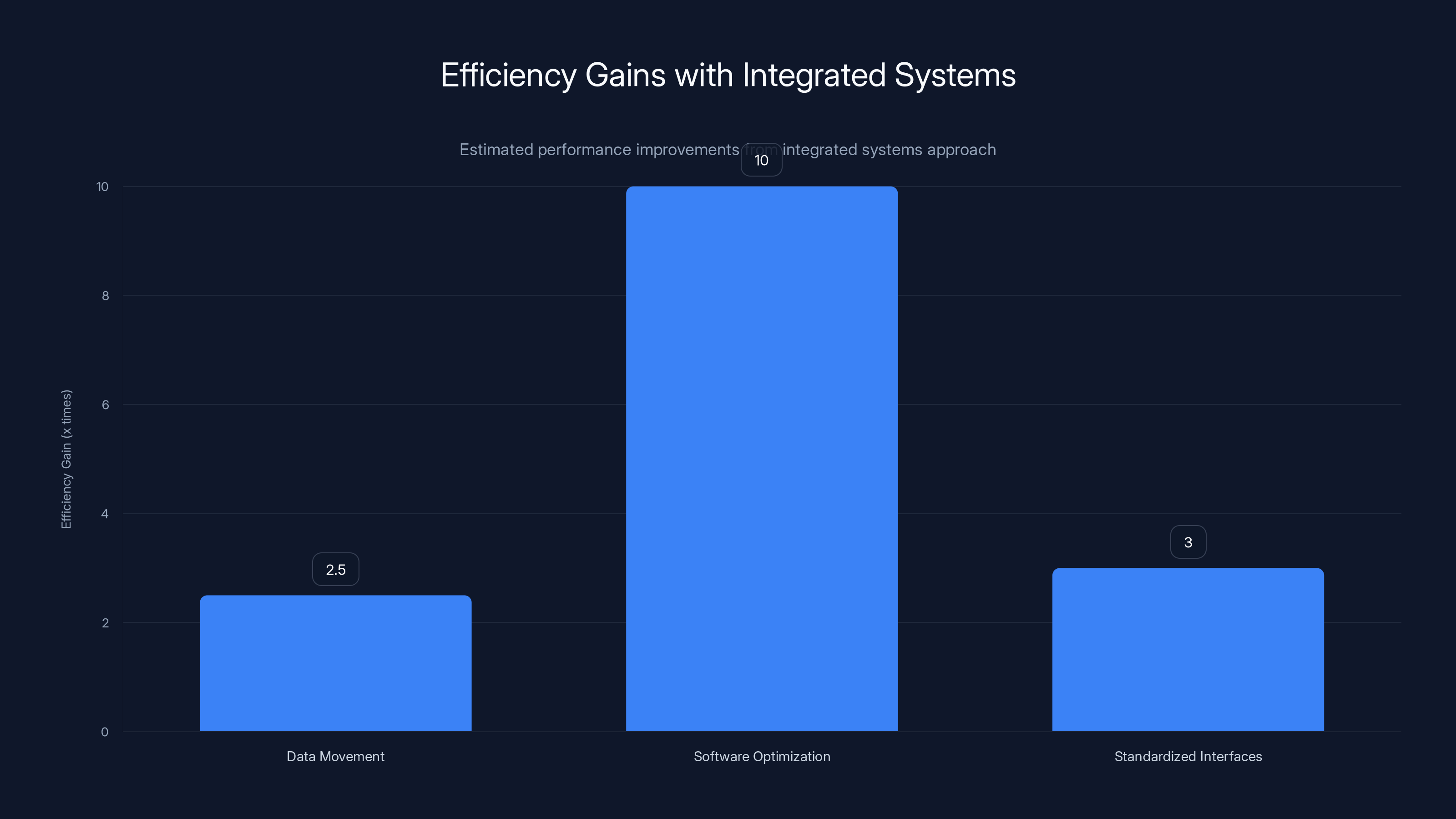
Integrated systems can deliver significant efficiency gains: 2-3x from reduced data movement, up to 10x from optimized software, and around 3x from standardized interfaces. Estimated data.
Why Current Infrastructure Isn't Enough: The Compute Bottleneck
Lisa Su made a critical admission on stage: there simply isn't enough compute available right now for all the things people want to do with AI.
This isn't a theoretical problem. Companies are literally hitting walls. Research labs are waiting months for compute time. Enterprises can't deploy the AI models they want because there's no available GPU capacity. The queue is that long.
Think about what's already happening in 2025-2026:
- Every major tech company is building new data centers
- Chip manufacturers are running fabs at maximum capacity
- The global GPU shortage became a GPU queue
- Energy providers are struggling with demand spikes from AI infrastructure
- Cooling systems in data centers are becoming the bottleneck, not the chips themselves
And that's with demand that's maybe 10-15% of where we need to be in 2030.
The infrastructure gap exists because several things have to align perfectly, and they don't:
Chip Manufacturing: Even though TSMC, Samsung, and Intel are operating at full capacity, there's a lag between design and production. A new chip designed today takes 18-24 months to reach meaningful volume production. Designing for 2030 demand means the tape-out happens in 2027-2028, and volume production doesn't hit until 2029-2030.
Power Delivery: A single data center running the compute needed for a next-generation AI model can consume 100+ megawatts of power. That's a mid-sized power plant. The electrical infrastructure in most regions can't handle that. Neither can the grid in most countries. Hyperscalers are literally limited by how much power they can get, not how many chips they can install.
Cooling: As power density increases, heat becomes the hard physical limit. You can't just keep stacking chips closer together. The heat has to go somewhere. Most current data center cooling systems max out around 50-75 kilowatts per rack. Next-generation racks pushing 500+ kilowatts per rack require completely new cooling architectures.
Interconnect Bandwidth: Connecting thousands of GPUs requires networking infrastructure that can move data at terabytes per second between chips. The interconnects available today (like Infini Band) are approaching their physical limits. Building higher-speed interconnects requires new technologies that don't exist yet at scale.
Supply Chain: Producing the volume of GPUs, CPUs, memory, and networking hardware needed for a 10,000x compute expansion requires mining, refining, and manufacturing at scales that don't exist. The supply chain needs to expand dramatically in parallel.
These aren't problems you solve by throwing money at them, though you definitely need money. They require hardware innovations, architectural changes, new materials, and solutions to physics problems we haven't fully solved.
Su's statement that "there's just never, ever been anything like this in the history of computing" captures the reality perfectly. We've never had to scale compute this fast, for this many applications, while solving this many new physical constraints simultaneously.

The Integrated Systems Approach: CPUs, GPUs, Networking, and Software
AMD's strategy for reaching yottaflop-scale compute isn't about building bigger GPUs. It's about rethinking the entire system.
The approach centers on integrated systems: tightly coupled combinations of CPUs, GPUs, networking hardware, and optimized software working together as a unified entity rather than a collection of parts.
Here's why this matters:
For decades, compute infrastructure worked with relatively loose coupling. You'd buy a CPU, add a GPU, connect them with standard networking, run your workloads. The inefficiencies were tolerable because everything was fast enough.
But when you're trying to scale from one zettaflop to 10 yottaflops, inefficiencies that were tolerable become catastrophic bottlenecks.
Consider a simplified example: Moving data between a GPU and a CPU used to take a few milliseconds. That's fine when you're running one model. When you're running 1,000 models across 100,000 GPUs, those milliseconds become seconds, those seconds become hours, and those hours become your limiting factor.
Integrated systems solve this by:
Reducing Data Movement: By putting complementary compute (CPU + GPU) on the same substrate, data doesn't have to travel across buses and networks. It moves across shorter, faster paths. This might sound like a minor optimization, but it can deliver 2-3x efficiency gains in data-intensive workloads.
Optimizing Software: When hardware is tightly integrated, software can be co-optimized specifically for that hardware. Rather than using generic libraries that work with anything, you can write code that's tuned for this exact CPU-GPU combination, this exact networking topology, this exact memory hierarchy. The difference in performance can be 10x or more.
Standardizing Interfaces: Instead of each component using different protocols to communicate, integrated systems establish unified interfaces. This simplifies software development, reduces latency, and makes scaling more predictable.
Enabling New Architectures: Tight integration allows hardware architects to design solutions that wouldn't work with loosely coupled components. Shared caches, coherent memory hierarchies, and custom data paths become possible.
AMD's specific announcements at CES 2026 included:
- MI455 GPU: The next generation of AMD's AI accelerator, designed specifically for training and inference at massive scale
- EPYC Venice CPUs: High-performance processors optimized for orchestrating GPU workloads and handling data preprocessing
- Helios AI-rack scale solutions: Complete rack-level systems that integrate CPUs, GPUs, networking, and power management as a single unit
Each of these components was designed not in isolation, but as part of an integrated stack. The MI455 was designed knowing exactly what EPYC processor it would work with. The networking was designed around the specific throughput needs of that GPU-CPU pairing. The software was optimized for all three working together.
This approach represents a fundamental shift in how companies should think about AI infrastructure. Rather than "pick the best CPU + pick the best GPU + pick the best networking," it's "pick the best integrated system for your workload."
The benefit compounds at scale. A 15% efficiency gain per system becomes a 15% reduction in the total compute needed to reach yottaflop scale. That translates directly to lower costs, less power consumption, and faster time to capability.
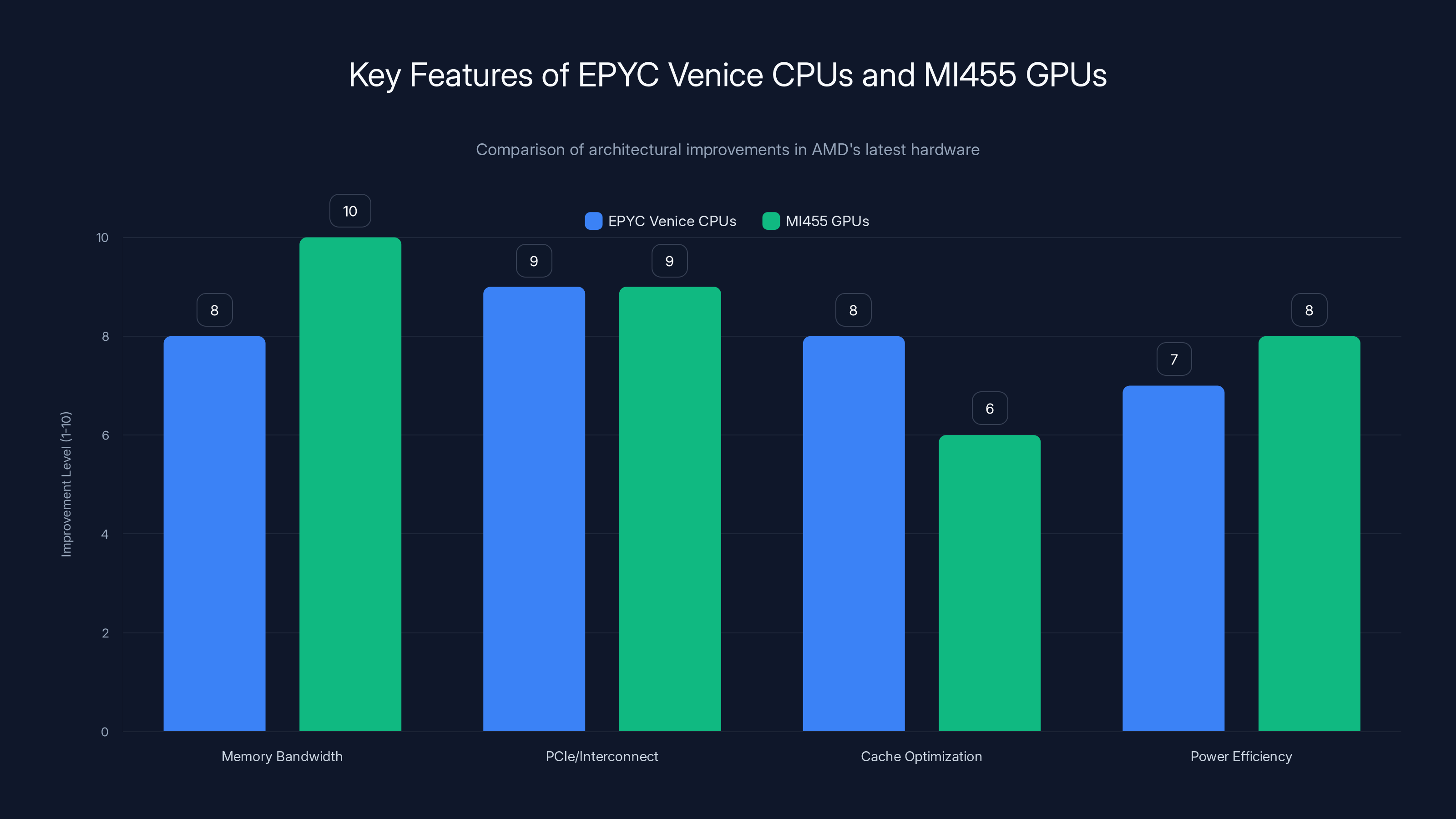
EPYC Venice CPUs excel in PCIe/interconnect and cache optimization, while MI455 GPUs lead in memory bandwidth and power efficiency. Estimated data based on architectural focus.
The Hardware Evolution: From EPYC Venice to MI455 and Beyond
The specific chips AMD announced aren't just faster versions of what came before. They represent architectural changes designed specifically for the yottaflop era.
EPYC Venice CPUs: The Venice generation represents AMD's next iteration of data center processors. While the headline might be clock speed or core count, the real innovations are in supporting the massive data flows required by AI workloads. This includes:
- Enhanced memory bandwidth to feed GPU workloads
- Improved PCIe and interconnect capacity to handle more GPUs per system
- Optimized cache hierarchies for AI-specific access patterns
- Power efficiency gains to reduce electrical overhead
Think of EPYC Venice as the orchestrator in an AI system. Its job is handling the non-GPU work: preprocessing data, managing communication between GPUs, optimizing memory hierarchies, and ensuring data flows smoothly from storage to compute.
MI455 GPU: This is where the heavy lifting happens. The MI455 is AMD's flagship AI accelerator, designed for both training and inference. The specific improvements matter less than understanding the design philosophy: every architectural decision was made to maximize throughput per watt at yottaflop scales.
That means:
- Extremely high memory bandwidth (needed to keep compute units busy)
- Efficient interconnect architecture (so you can network thousands together)
- Power efficiency (because power becomes the limiting factor)
- Flexibility in numeric precision (to run models efficiently at lower precision when possible)
Helios Solutions: This is the system-level integration. Helios isn't a chip—it's a complete rack-level system that combines EPYC processors, MI455 GPUs, networking hardware, power delivery, and cooling as a single engineered unit.
Selling Helios as a complete system rather than separate components changes the game because:
- Predictable Performance: You know exactly how the system will perform before deployment
- Simplified Operations: No questions about whether components are compatible or correctly configured
- Better Economics: Buying integrated systems is cheaper than buying and integrating components
- Faster Iteration: When problems arise, they're solved at the system level, benefiting all customers
From 2022 to 2030, we should expect three more generations of each of these (EPYC, MI, and Helios). If the trajectory holds:
- Generation 2030: Performance roughly 100x current (chip performance 10x, system efficiency 10x)
- Power efficiency improvements: 5-10x better (critical for reaching yottaflop scale)
- Cost per FLOP: 5-10x cheaper (necessary for affordability)
This is ambitious. But it's also what needs to happen. Without this level of improvement across all three dimensions, reaching yottaflop scale becomes economically impossible.
Networking and Interconnect: The Hidden Bottleneck
Here's something that doesn't get enough attention: networking between processors is becoming the bigger constraint than the processors themselves.
When you have 100,000 GPUs that need to talk to each other, the network connecting them becomes as important as the GPUs. In fact, it might be more important.
Current high-speed interconnects like Infini Band and Nvidia's NVLink operate at terabit-per-second speeds. That sounds fast until you realize that a MI455 GPU can generate data at terabytes per second. The interconnect can't keep up.
This creates a fundamental problem: your GPU sits idle waiting for data to arrive across the network. The processing power you invested in becomes wasted because the network can't feed it fast enough.
Solving this requires several approaches:
New Interconnect Technologies: Companies are developing next-generation interconnects (like Nvidia's next iteration of NVLink, or AMD's own developments) that operate at petabit-per-second speeds. Getting there requires new materials, new protocols, and solutions to signal integrity problems that don't exist at terabit speeds.
Smarter Topology: Instead of connecting every GPU to every other GPU (which would require impossibly complex switching), systems are using hierarchical topologies where GPUs are connected locally within racks, racks talk to each other through higher-level switches, and global communication happens strategically. This trades some latency for dramatically reduced bandwidth requirements.
In-Network Computing: Rather than moving data to where it's processed, processing moves to where the data is. This reduces the total amount of data that needs to flow across the network, which in turn reduces the required bandwidth.
Compression and Quantization: Data flowing between GPUs is often larger than it needs to be. Intelligent compression techniques that still preserve accuracy can reduce network traffic 2-4x.
These aren't separate problems from reaching yottaflop scale—they're core to it. The compute capability only matters if you can supply data at that rate and move results out at that rate.

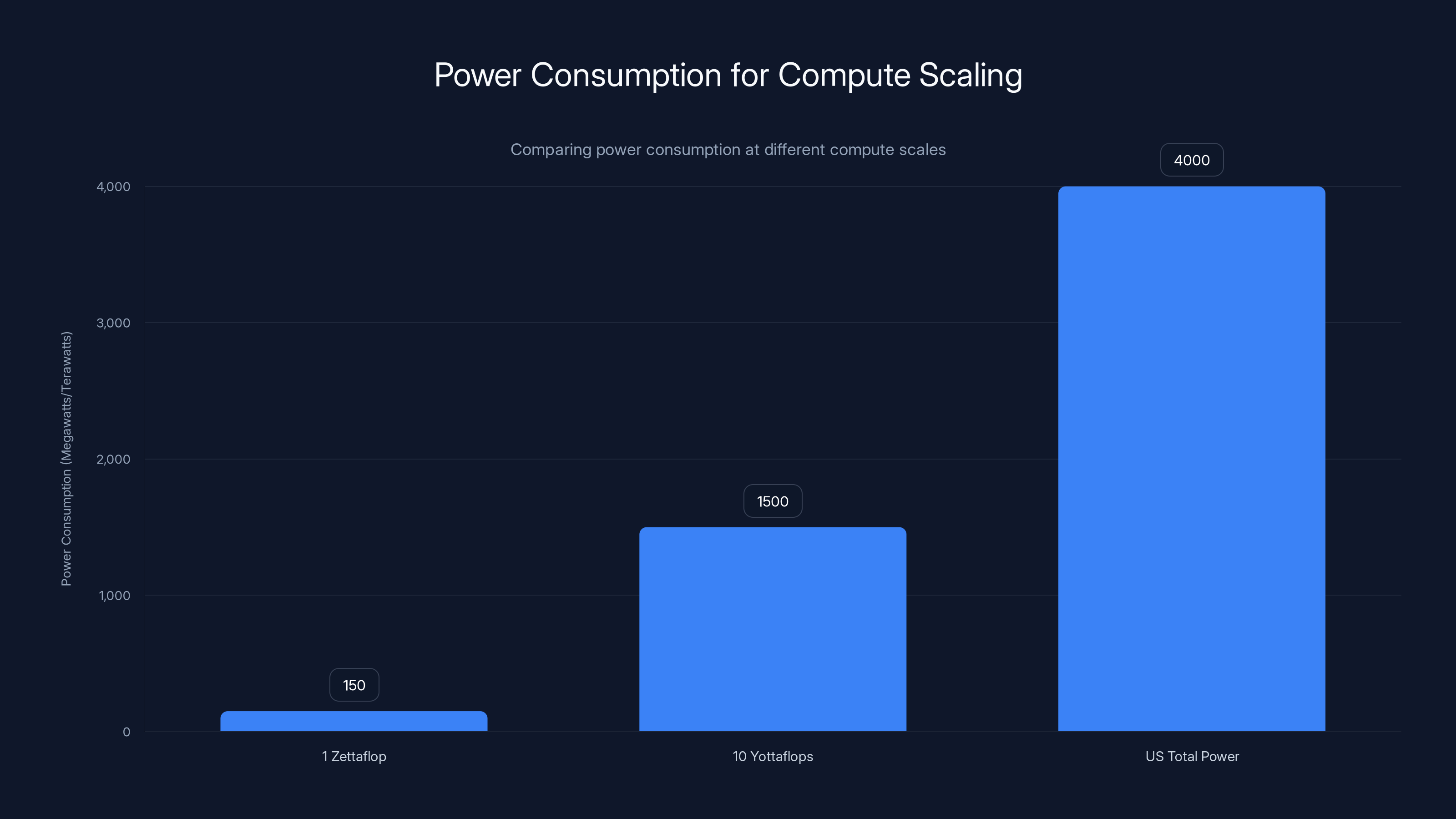
Reaching 10 yottaflops would consume 25-50% of the current US electrical generation, highlighting the need for efficiency improvements. Estimated data.
Power Consumption: The Physics Hard Limit
Let's talk about the elephant in the room: power.
Scaling compute 10,000x doesn't just mean you need 10,000x as many chips. It means you need 10,000x the power to run them (roughly). That's not a hardware problem or a software problem. That's a physics problem.
A single zettaflop of compute consumes roughly 100-200 megawatts depending on the technology. Ten yottaflops would consume roughly 1-2 terawatts.
For perspective, the United States generates roughly 4 terawatts of electrical power total. So reaching 10 yottaflops would consume 25-50% of current US electrical generation, exclusively for AI compute.
Obviously, that's not going to happen. So either:
- We don't reach 10 yottaflops (unlikely, given the demand trajectory)
- Efficiency improves dramatically (the only realistic path)
- Power generation scales massively (happening, but not fast enough)
Efficiency improvements happen through:
Better Chip Architecture: Designs that require less power to perform the same computation. The transition from 5nm to 3nm to 2nm processes helps, but there's a physical limit to how much you can improve this way. You're eventually hitting quantum effects and signal-to-noise limitations.
Lower Precision Computation: Running models at int 8 or lower precision instead of float 32 reduces power consumption 2-4x. The loss in accuracy is tolerable for many applications. But this only works for specific workloads.
Better Cooling: More efficient cooling systems waste less energy on air conditioning. Some facilities are experimenting with liquid cooling immersion, which can be 50%+ more efficient than air cooling but introduces new complexity and reliability concerns.
Rack-Level Design: Integrating power delivery, cooling, and computation at the rack level prevents inefficiencies that come from long power distribution paths and air handling. You can save 10-15% of power just through better engineering at the system level.
Workload-Specific Hardware: Using hardware specifically designed for the workload you're running (inference hardware vs. training hardware, for example) can reduce power consumption 3-5x compared to general-purpose processors.
If these improvements combine to deliver 10x total power efficiency gain, then a yottaflop-scale system would consume roughly 10-20 terawatts. Still enormous, but potentially feasible if distributed globally and powered by renewable sources.
This also explains why integrated systems matter. A loosely coupled system wastes power in data movement, inefficient memory hierarchies, and suboptimal software-to-hardware mapping. Integrated systems can eliminate many of these inefficiencies, directly translating to lower power consumption.

The Software Layer: Optimization for Massive Scale
All the hardware in the world doesn't matter if your software can't take advantage of it.
Running efficient code on one GPU is a solved problem. Writing code that runs efficiently across 100,000 GPUs is barely solved, and most of the problems aren't solved yet.
The software challenges include:
Distributed Training: Training a model across thousands of GPUs requires sophisticated techniques to split the work and coordinate gradients. This is well understood now, but scaling it to yottaflop systems requires new approaches. Current distributed training techniques start breaking down around 10,000 GPUs. Reaching yottaflop scales might require 100,000x that.
Fault Tolerance: When you're running across a million GPUs, hardware failures are guaranteed. Your system has to be able to detect failures, checkpoint progress, and recover without losing work. Current approaches work, but they're inefficient—you might spend 10-20% of your compute time on failure recovery. For yottaflop scales, that's unacceptable.
Load Balancing: Keeping all 100,000 GPUs fully utilized is nearly impossible. Some will finish their work faster than others. Some will have latency spikes. Some will fail temporarily. Managing this requires software that can dynamically shift work around to maximize utilization. The difference between 95% utilization and 90% utilization is the difference between feasible and infeasible at yottaflop scales.
Memory Hierarchy Optimization: Data needs to flow from storage, to higher-level caches, to GPU memory, to compute units, and back out again. Optimizing this flow for specific hardware and specific algorithms is crucial. Software that's not optimized can have GPUs sitting idle 50% of the time waiting for data.
Compilation and Optimization: Code needs to be compiled specifically for the hardware it's running on. Generic code is slow. Optimized code is 2-10x faster depending on the workload. Building compiler infrastructure that automatically optimizes code for yottaflop-scale systems is an ongoing challenge.
AMD, Nvidia, and other infrastructure providers are investing heavily in software stacks specifically designed for yottaflop-scale systems. Tools like AMD's ROCm, Nvidia's CUDA, and emerging standards like Open XLA are all evolving to address these challenges.
The reality is that software maturity will be as limiting as hardware availability. You can't buy yottaflop systems until you have software that can actually use them efficiently. This is a constraint that often gets overlooked.

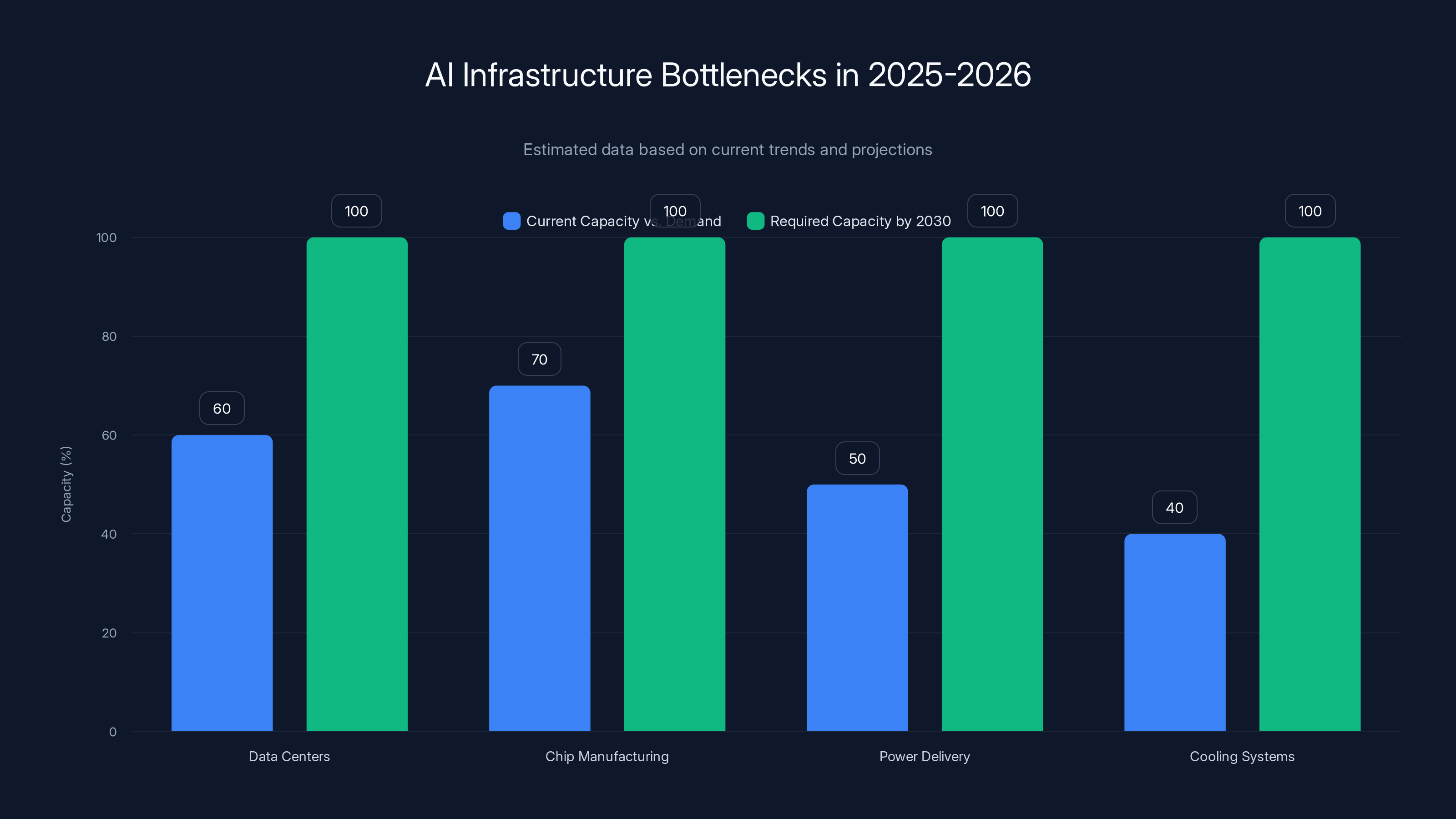
Current infrastructure components are operating at 40-70% of the capacity needed to meet projected 2030 AI demands. Estimated data.
Energy Infrastructure: Beyond the Data Center
We talk about data centers as if they're independent entities. They're not. They're part of regional electrical grids.
A single modern AI data center might consume 100+ megawatts. That's comparable to a large industrial facility. Several of these in a region will strain the local grid. A continent-scale network of yottaflop-ready facilities will require fundamental changes to how we generate, distribute, and manage electrical power.
This means:
Renewable Energy Integration: Most new hyperscaler facilities are being built with dedicated renewable power generation (solar, wind, geothermal). By 2030, every major AI facility will need its own power generation, not reliance on grid power. This is already happening, but it needs to accelerate dramatically.
Energy Storage: Renewable energy is intermittent. Solar generates power during the day, wind is unpredictable. Managing yottaflop-scale compute on intermittent power requires massive battery systems or other storage. This is a solvable problem but adds significant cost and complexity.
Grid-Level Coordination: Rather than each data center being independent, they'll need to coordinate at the regional and continental level. Shifting compute workloads to follow renewable generation will become standard practice.
Demand Response: Data centers will need to act as load balancers for the grid, shifting compute to times when power is abundant and reducing consumption when the grid is stressed. This is technically feasible but requires software and business model innovations.
The good news: renewable energy costs are dropping fast, battery technology is improving rapidly, and companies like Google, Amazon, and Meta are already implementing these strategies. The bad news: the scale required by 2030 is still 5-10x larger than what's being built today.

The Industry Transformation: What Needs to Change
Reaching yottaflop scale isn't just an engineering problem. It's an industry-wide transformation.
Data Center Architecture: The colocation model (multiple companies sharing a facility) doesn't work at yottaflop scale. Power and cooling requirements are too specific. The future looks like dedicated facilities for each major workload, or maybe hyperscalers offering specialized facilities for specific compute classes.
Supply Chains: The supply chain for semiconductors, memory, and networking equipment is already strained. Growing 10,000x in seven years requires completely new manufacturing facilities, which take 5-10 years to build. We're probably already late on this; the facilities being built in 2024-2025 might still not be enough by 2030.
Skill Gap: Operating yottaflop-scale systems requires skills that barely exist today. How do you debug problems across a million GPUs? How do you optimize code for systems this complex? How do you predict failures before they happen? The industry needs tens of thousands of people with skills we haven't invented yet.
Standardization: More than ever, we need open standards for hardware, software, and protocols. Proprietary solutions don't scale. The ecosystem needs to agree on common interfaces, common benchmarks, and common optimization targets.
Regulatory and Environmental: Governments will eventually regulate the power consumption of AI compute. This is already happening in some regions. By 2030, you might not be able to build certain types of data centers due to environmental regulations or grid constraints.
Cost Models: The business model of "build a data center, sell compute to customers" might not work at yottaflop scale. The upfront capital costs are so enormous that only a handful of entities can afford them. This might drive consolidation in the industry or new financing models.
These transformations are already beginning, but they need to accelerate. The companies and countries that move fastest on infrastructure will have enormous advantages in AI capabilities, costs, and capabilities.

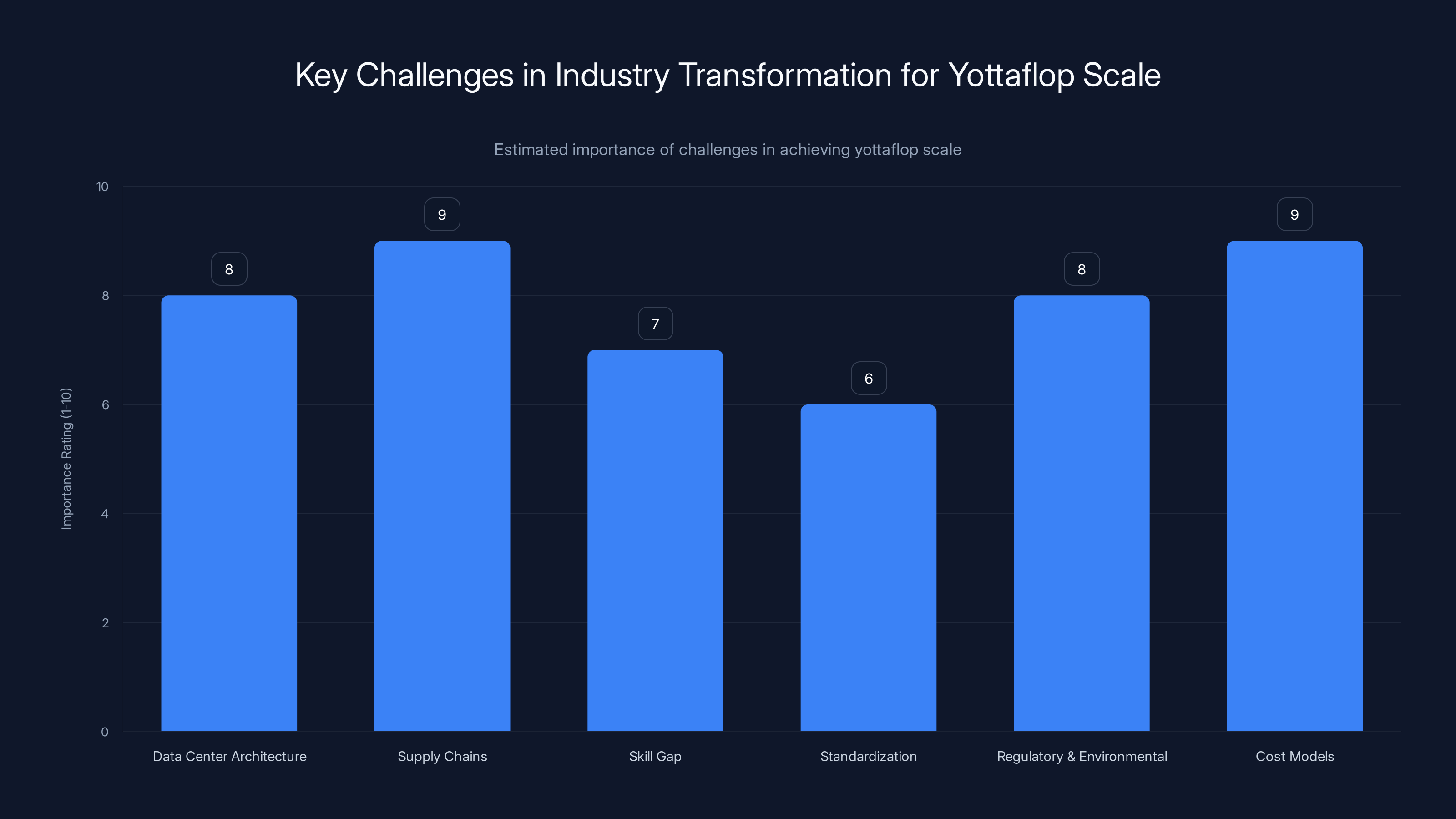
The most critical challenges in reaching yottaflop scale include supply chain constraints and cost models, both rated at 9 out of 10 in importance. Estimated data.
AMD's Competitive Position in the Yottaflop Era
Why is AMD positioning itself as the leader for yottaflop-scale computing?
Historically, AMD has competed with Nvidia in GPUs and with Intel in CPUs, but rarely dominated. However, yottaflop-scale systems require something different than what made Nvidia or Intel dominant in previous eras.
The Integrated Systems Advantage: AMD's strategy of selling integrated CPU+GPU+networking stacks (Helios) is fundamentally different from Nvidia's approach of selling GPUs and letting customers assemble systems. At massive scale, integrated systems have huge efficiency advantages. AMD is betting that these advantages will compound as scale increases.
Software Optimization: AMD's ROCm software stack has matured significantly. It's still behind Nvidia's CUDA in some ways, but the gap is narrowing. For yottaflop systems, software maturity matters more than it ever has. AMD's willingness to compete on software, not just hardware, is positioning them well.
Supply Chain Agility: AMD is willing to source components from multiple suppliers (Nvidia can't, since they control their own supply). This makes AMD's supply chain more resilient, which matters when scaling 10,000x.
Cost Positioning: AMD's systems are generally cheaper than equivalent Nvidia systems. When you're buying yottaflop-scale infrastructure, cost differences of 10-20% compound to billions of dollars in total cost.
Ecosystem Openness: AMD is more willing to work with open standards and allow ecosystem partners. Nvidia tends toward vertical integration. For yottaflop systems that require thousands of component suppliers, AMD's approach might prove superior.
That said, Nvidia still has significant advantages: enormous software ecosystem, better developer tools, and first-mover advantage in many large deployments. But for new yottaflop-scale deployments, AMD's positioning is strong.

Timeline Reality: Getting to Yottaflop Scale
Su said we need 10 yottaflops by the end of the decade. Let's break down whether that's realistic.
2025-2026: Foundation Building
- New data center designs are finalized
- Manufacturing facilities for 2030 products are being built
- Software stacks are being rewritten for massive scale
- First integrated systems like Helios are deployed at scale
- Power generation and cooling infrastructure are being added
2027-2028: Acceleration
- New chip generations hit volume production
- Second-generation integrated systems are deployed
- Data center capacity is doubling year-over-year
- Software maturity reaches acceptable levels for yottaflop systems
- Regulatory and environmental frameworks are being finalized
2029-2030: The Explosion
- Yottaflop-capable systems are available at scale
- Deployment accelerates rapidly
- By late 2030, we approach yottaflop capacity
This timeline is aggressive but not impossible. It requires:
- No major supply chain disruptions
- No regulatory blockages
- Successful execution from multiple companies in parallel
- Sustained investment in infrastructure
- Breakthroughs in power efficiency
Missing any one of these pushes yottaflop-scale availability to 2031-2032.

Real-World Implications: What Changes for Enterprises
If AMD's prediction is correct, here's what enterprises should expect:
Cost of AI Compute Continues Dropping: The price per unit of compute will fall dramatically as infrastructure scales. What costs
AI Becomes Geographically Distributed: Rather than all compute happening in a few hyperscaler data centers, compute will be distributed closer to data sources. This requires advances in edge AI and new architectures for distributed inference.
New Workloads Become Feasible: With abundant cheap compute, applications that aren't economically viable today become feasible. Real-time personalization, continuous model updating, on-device AI with cloud backup—all these become standard.
Enterprises Need New Skills: Using yottaflop-scale systems requires different skills than managing today's infrastructure. Enterprises need data engineers, MLOps specialists, and infrastructure architects who understand distributed systems at massive scale.
Vendor Lock-in Becomes More Critical: If you choose AMD, Nvidia, or someone else, switching later becomes exponentially more expensive as you scale. This decision will have 5-10 year implications.
Competition Intensifies: With cheap compute available to everyone, competitive advantage shifts to algorithms, data, and talent. Companies can't win on compute anymore; they need to innovate on all other dimensions.
Environmental Responsibility Matters: Companies running yottaflop-scale systems will need to be transparent about power consumption and environmental impact. Sustainability becomes part of your brand and business operations.
AMD's "AI is for Everyone" Philosophy
Beyond the hardware announcements, there's an important message in Su's keynote: "AI is for everyone."
This is more than marketing. It's a fundamental vision for how yottaflop-scale computing should be deployed.
Currently, AI is expensive. Only companies with massive budgets can deploy cutting-edge AI. By scaling compute 10,000x and dropping costs proportionally, AI becomes affordable for small companies and startups.
What does "AI for everyone" actually mean?
Affordable Access: Cloud-based access to yottaflop-scale systems at reasonable prices. Not just for Google and Meta, but for anyone building AI applications.
Simpler Tools: Software that makes it easier to build and deploy AI without deep expertise. This is already happening (cloud AI services), but it will accelerate.
Reduced Skill Barriers: As tooling improves, you don't need a Ph D in machine learning to build AI applications. Templates, pre-trained models, and guided workflows lower the bar.
Localized Compute: Edge AI, on-device models, and geographically distributed inference mean AI runs where it's needed, not just in centralized data centers.
Open Standards: More open-source tools, more interoperability, more ability to avoid vendor lock-in.
This is aspirational, and the reality will be messier. But it's the direction the industry is moving. By 2030, we should see significantly more democratization of AI compute than exists today.

The Competition: Nvidia, Intel, and Others
AMD isn't alone in recognizing the importance of yottaflop-scale systems. Every major chipmaker is preparing for this.
Nvidia: Nvidia dominates the current AI infrastructure market with their H100/H200 GPUs and has announced the next generation (Blackwell and beyond). Nvidia's strategy is faster chips (which help) and deeper software integration (through CUDA and other tools). Nvidia still has first-mover advantage, but AMD's integrated systems approach might prove superior at yottaflop scales.
Intel: Intel has been less aggressive in AI but is finally investing heavily. Their Falcon Shores GPU and Xeon processors are targeting similar markets as AMD's offerings. Intel's challenge is that they're three years behind, and in fast-moving markets, that's a huge gap.
Startups and Specialized Makers: Companies like Graphcore, Cerebras, and others have announced specialized AI processors. These don't compete head-to-head with general-purpose GPUs but instead optimize for specific workloads. In a yottaflop-scale world, we'll likely see multiple architectures coexisting.
Software-Focused Competitors: Companies like Anduril, Modal, and others are building software abstractions that hide hardware details. These companies might matter more than hardware makers by 2030.
The realistic future probably involves multiple winners. Nvidia will remain dominant but with reduced market share. AMD will take a significant chunk. Startups will win niches. But the pie is growing fast enough that multiple companies can thrive.

Challenges and Realistic Obstacles
We should be honest about the obstacles to reaching yottaflop scale by 2030:
Supply Chain Risk: Building manufacturing capacity for 10,000x compute growth in seven years is extraordinarily difficult. Every component (chips, memory, networking equipment, power supplies) has a supply chain that needs to grow proportionally. If even one bottleneck develops, the whole timeline slips.
Regulatory and Environmental Pushback: Some governments will regulate AI compute consumption. Environmental groups will protest the power consumption. China and the US might restrict technology sharing, fragmenting the global market. These aren't marginal risks; they could dramatically slow deployment.
Technical Challenges: We don't know yet if we can actually build systems this large reliably. Yottaflop-scale systems will have a different failure rate profile than smaller systems. We're not sure how to manage or predict those failures. This could become a hard blocker.
Cost Reality: Even if the cost per FLOP drops 100x, yottaflop systems will still require enormous capital investment. The financing, both at the company level and at the macroeconomic level, might not materialize as expected.
Software Immaturity: The software for yottaflop systems doesn't exist yet. Building it might take longer than anyone expects. You can have great hardware, but if the software is immature, it won't deliver value.
Skills Shortage: Training enough engineers to operate and optimize yottaflop-scale systems is an enormous undertaking. There might simply not be enough trained people available.
Realistic assessment: reaching 10 yottaflops by the end of 2030 is ambitious. More likely scenarios:
- 2-3 yottaflops by end of 2030 (one-third of target)
- 10 yottaflops by 2032-2033
- Or gradual growth with 5 yottaflops by 2030, 15 by 2032
The exact number matters less than the direction. We're definitely heading toward yottaflop-scale systems. The question is the timeline, not whether it happens.

Strategic Implications for Technology Leaders
If you're responsible for technology infrastructure decisions, here's what to think about:
Invest in Flexibility: Rather than optimizing for today's hardware, build systems that can adapt as hardware changes. This means software abstraction layers, multi-vendor strategies where possible, and avoiding deep vendor lock-in.
Think Long-Term: Infrastructure decisions made today will determine your capabilities in 2028-2030. You're not optimizing for 2025; you're optimizing for 2030. Plan accordingly.
Develop In-House Expertise: You'll need people who understand yottaflop-scale systems. These people barely exist in 2026. Develop them internally or make relationships with the experts who will develop them.
Engage with Emerging Standards: Open standards will matter more than proprietary solutions in the future. Companies that contribute to standards bodies will shape the future. Companies that ignore them will be reactive later.
Plan for Power: Power consumption will be your limiting factor. Start working with power providers now to understand what infrastructure improvements they can offer by 2030.
Cost Projections: The cost of your favorite AI workload will drop 10-100x by 2030. Build business models that anticipate this. If you're charging per-compute unit, you need to understand how your costs will change.
Talent Strategy: The skills needed to operate yottaflop systems are different from today. Start developing those capabilities now in your organization.

The Bigger Picture: Computing's Next Era
We're at an inflection point in computing history. For the past 50 years, compute growth has followed predictable patterns: Moore's Law, architectural improvements, gradually increasing scale.
Yottaflop-scale systems break that pattern. This isn't incremental improvement; it's exponential expansion forced by the demands of AI.
Likewise, it's forcing fundamental rethinking of how we design hardware, structure software, manage infrastructure, and even generate electricity. Companies and countries that adapt fastest will have enormous advantages.
AMD's vision of integrated systems, combined with industry-wide improvements in power efficiency, software maturity, and infrastructure, makes yottaflop-scale computing possible. It won't be easy, and the timeline might slip by a year or two, but it's coming.
The question for every organization is: how will you prepare for a world where compute is 10,000x more abundant than it is today? That preparation starts now, with infrastructure decisions, talent development, and strategic positioning.
The yottaflop era isn't some distant future. It's six or seven years away. And the companies and countries that get there first will define what AI looks like for the next decade.
FAQ
What exactly is a Yotta FLOP?
A Yotta FLOP is one septillion floating-point operations per second (10^24 FLOPS). To give it context, one yottaflop is 1,000 times larger than one zettaflop (the scale we're at now). AMD predicts we'll need 10 yottaflops of compute by 2030, which represents a roughly 10,000x increase from current global AI compute capacity. This scale of computation has never been attempted before in any computing system.
Why does AI need so much compute power?
AI capability grows with compute investment following a predictable trend: each generation of more capable models requires roughly 10x the training compute. Simultaneously, demand for AI applications is expanding into new domains: reasoning tasks, scientific discovery, personalized applications, real-time inference, and edge deployment all require compute. As the AI field matures and applications multiply, cumulative demand explodes. Without dramatic efficiency improvements, we genuinely need exponentially more compute to meet demand.
How is the computing industry preparing for yottaflop-scale systems?
Chip manufacturers like AMD and Nvidia are designing specialized processors for yottaflop systems. Companies are building new data centers with power delivery and cooling infrastructure designed for massive density. Software stacks are being rewritten for distributed computing at scale. Manufacturing capacity is being expanded. Renewable energy generation is being integrated. The entire ecosystem is accelerating preparation, though most observers believe we're still underinvesting in infrastructure growth for the 2030 timeline.
What are integrated systems, and why does AMD emphasize them?
Integrated systems combine CPUs, GPUs, networking hardware, and software designed to work together as a single optimized unit, rather than separate components assembled together. AMD's Helios is an example. At yottaflop scales, integrated systems deliver 2-10x better efficiency than combining best-of-breed individual components because they eliminate inefficiencies in data movement, optimize software specifically for the hardware, and standardize interfaces. For yottaflop systems where power and cost become constraining factors, these efficiency gains are critical.
What's the biggest technical challenge for reaching yottaflop scale?
No single challenge; multiple bottlenecks need to be solved simultaneously. Power delivery and cooling are physical constraints that limit how much compute can be deployed in any location. Networking bandwidth needs to increase dramatically to keep processors fed with data. Software maturity for distributed systems at this scale barely exists. Supply chain capacity for components needs to grow 10,000x. Skill development to operate these systems hasn't started. Success requires solving all of these in parallel, which makes the challenge exponentially harder than any individual problem.
How much will yottaflop-scale computing cost?
A single yottaflop-scale system might cost
Will yottaflop-scale computing use too much energy?
Yes, it will consume enormous amounts of energy—potentially 10-20 terawatts if we reach 10 yottaflops. This is unsustainable if powered by fossil fuels but potentially manageable if powered by renewable energy. This is why data centers are increasingly paired with renewable generation. The challenge is building renewable capacity fast enough. Efficiency improvements (doing more computation per watt) will be critical. Without power efficiency improvements of 10x, yottaflop scale becomes infeasible or requires massive renewable infrastructure expansion.
When will yottaflop-scale systems actually be available?
AMD predicts we'll need 10 yottaflops by 2030. More realistic estimates suggest we'll have 2-5 yottaflops by 2030, with full 10-yottaflop capacity reaching by 2032-2033. The timeline depends on manufacturing capacity expansion, which is lagging current demand. Early yottaflop-capable systems will be available starting in 2027-2028, but reaching full scale will take a few more years. The exact timeline remains uncertain due to supply chain, regulatory, and technical risks.
How will this affect AI development and availability?
With 10,000x more compute available, the cost of AI workloads drops proportionally. This makes AI accessible to smaller organizations, enables new use cases, and supports continuous model updating and personalization. The democratization of AI accelerates. However, competitive advantage shifts from "we have access to compute" toward "we have better algorithms, better data, and better talent." Companies building AI in 2030 will have fundamentally different constraints than companies building today.

Conclusion: Preparing for the Yottaflop Era
Lisa Su's declaration that we're entering the Yotta Scale era isn't hyperbole. It's a recognition that AI's computational appetite has grown so large that everything about infrastructure, power delivery, networking, and software needs to change.
We're not talking about incremental improvements. We're talking about multiplying global AI compute capacity by 10,000x in less than seven years while making it cheaper, more efficient, and more accessible.
This is ambitious. It's probably going to take slightly longer than 2030. It will hit obstacles we can't predict. But the direction is certain.
The companies and countries that prepare now—by investing in infrastructure, developing talent, building software capabilities, and positioning themselves strategically—will thrive in the yottaflop era.
Those that wait will play catch-up for a decade.
Start building now. The future is coming fast.
Use Case: Build AI automation workflows that scale with your infrastructure as compute becomes cheaper and more abundant.
Try Runable For Free
Key Takeaways
- AMD predicts AI will need 10 yottaflops (10^25 FLOPS) by 2030, roughly 10,000x more than the 1 zettaflop available in 2022
- Current infrastructure is already insufficient for demand; reaching yottaflop scale requires simultaneous breakthroughs in hardware, software, power delivery, and cooling
- Integrated systems combining CPUs, GPUs, networking, and optimized software deliver 2-10x efficiency gains over best-of-breed components at scale
- Power consumption becomes the primary constraint: yottaflop systems would consume 10-20 terawatts requiring massive renewable energy expansion
- Timeline to full 10 yottaflop deployment more realistically 2032-2033, not 2030, due to manufacturing, supply chain, and talent constraints
- Companies preparing now through infrastructure investment, talent development, and strategic positioning will have enormous advantages in the yottaflop era
Related Articles
- Shokz OpenFit Pro: Open Earbuds With Real Noise Reduction [2025]
- Garmin's AI Food Tracking at CES 2026: A Bold Nutrition Move [2025]
- Alienware's 2026 Gaming Laptop Lineup: Covert, Budget, and OLED [2025]
- Rokid Style AI Smartglasses: Everything You Need to Know [2026]
- HP's HyperX Omen Rebrand: A Gaming Laptop Strategy Gone Wrong [2025]
- MSI Prestige Laptops 2025: The Most Beautiful Business Laptops Yet [CES]

