
Introduction: The Hidden Threat to AI Leadership
The artificial intelligence landscape just shifted beneath our feet. In a stunning revelation that sent shockwaves through the tech industry, Anthropic disclosed that three major Chinese AI companies orchestrated a coordinated campaign to extract the core capabilities of Claude—one of the world's most advanced AI models. This wasn't a sophisticated cyber heist involving stolen credentials or server breaches. Instead, it was far more elegant and difficult to detect: a systematic approach using more than 24,000 fake accounts to generate millions of interactions with Claude, each one harvesting knowledge about how the model reasons, uses tools, and writes code.
The implications extend far beyond corporate espionage or competitive intelligence. This revelation sits at the intersection of three critical global developments: the escalating AI arms race between the United States and China, ongoing debates about export controls on advanced computing chips, and the emerging security challenges posed by distillation as a method of model extraction. The accused companies—Deep Seek, Moonshot AI, and Mini Max—represent the vanguard of China's AI development, and their alleged actions illuminate exactly how frontier capabilities can be rapidly distributed across competing research teams.
For developers, technical leaders, and policymakers alike, understanding these distillation attacks isn't academic. The mechanics of how these attacks work directly inform decisions about model security, API design, data collection policies, and the regulatory frameworks that will govern AI development for years to come. The question isn't whether similar techniques will be employed in the future—it's how thoroughly organizations need to prepare their defenses.
This comprehensive analysis examines the technical mechanics of distillation attacks, the specific targeting strategies employed against Claude, the broader geopolitical context of AI chip exports and competition, the security vulnerabilities exposed, and what organizations must do to protect proprietary AI capabilities in an era of increasingly sophisticated extraction techniques.
Understanding Model Distillation: The Fundamental Technique
What Is Knowledge Distillation in AI?
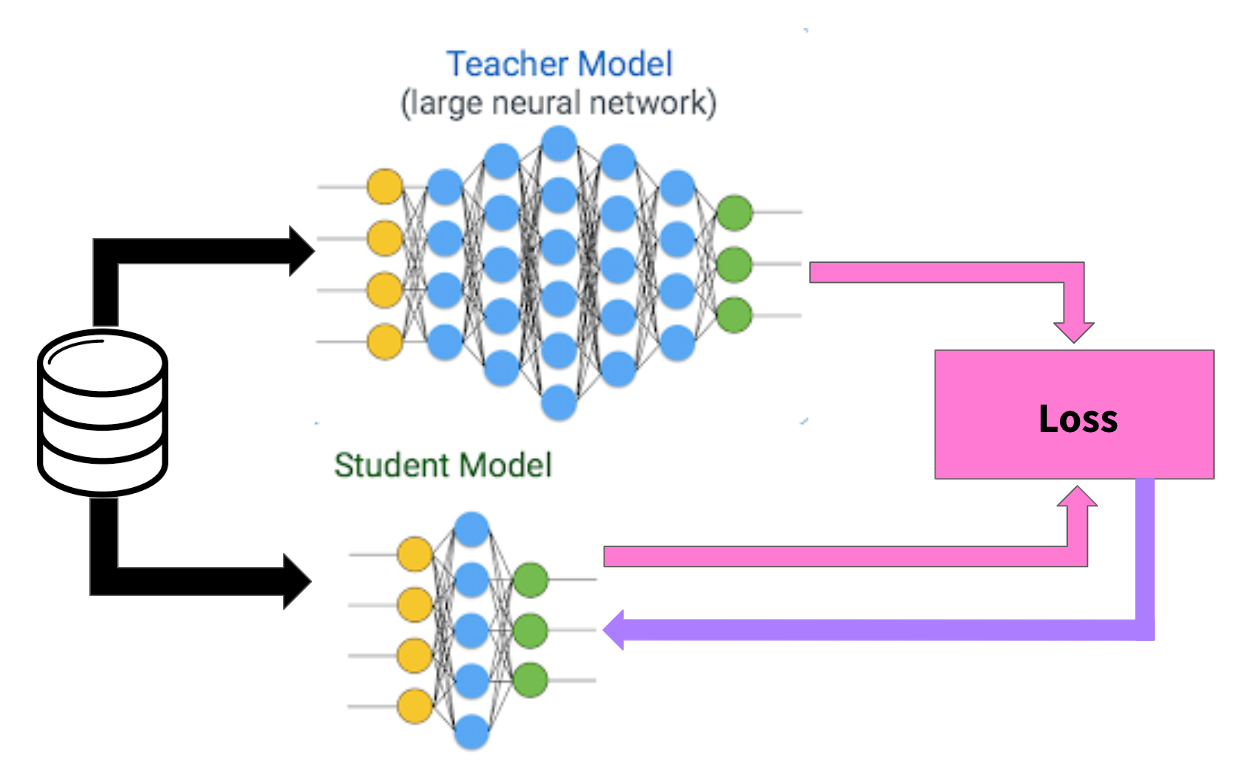
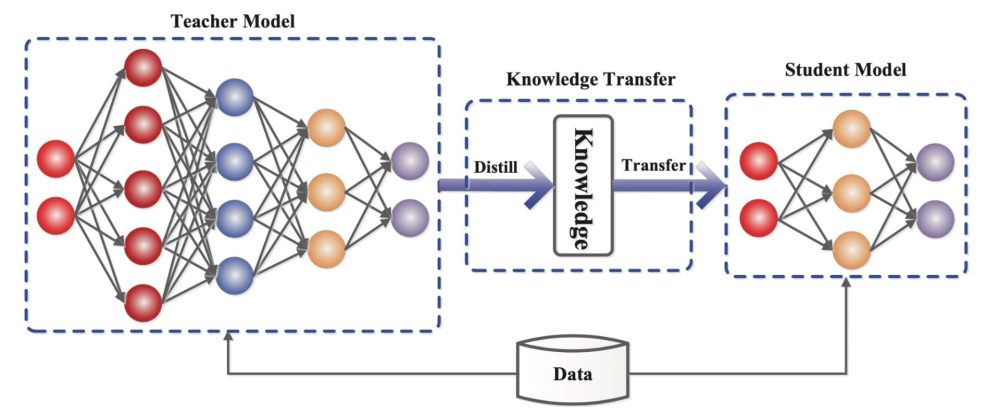
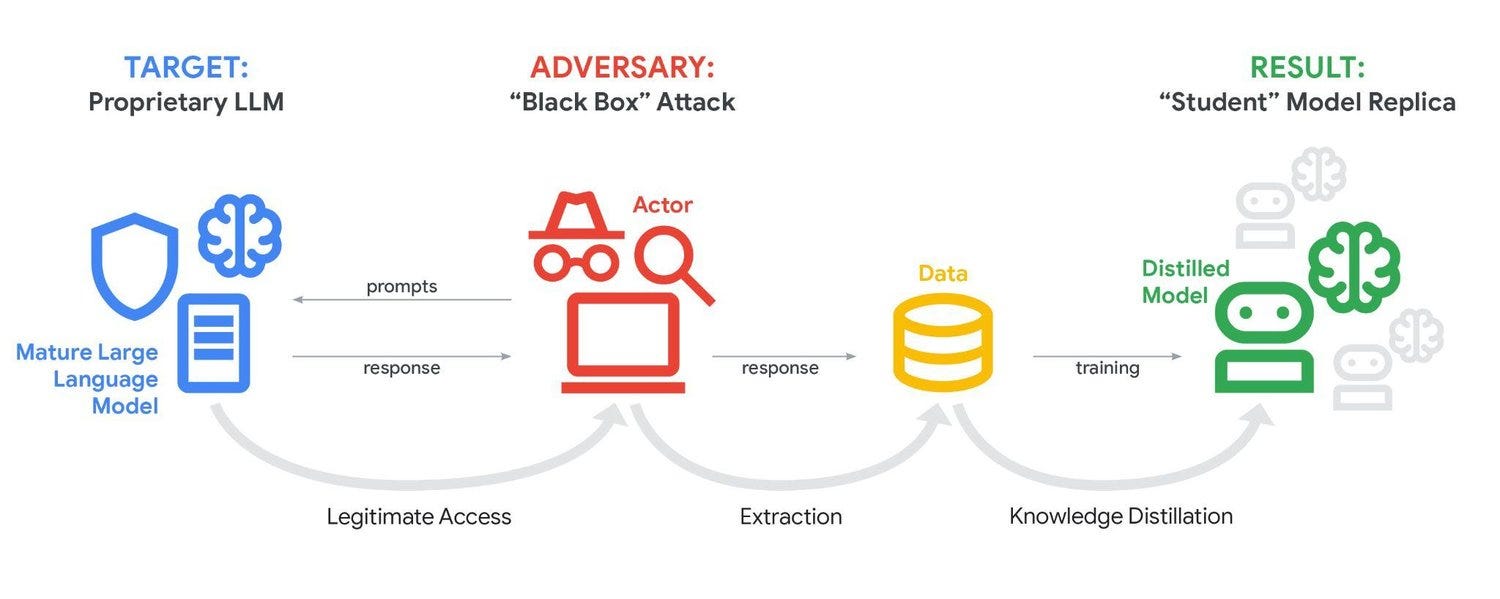
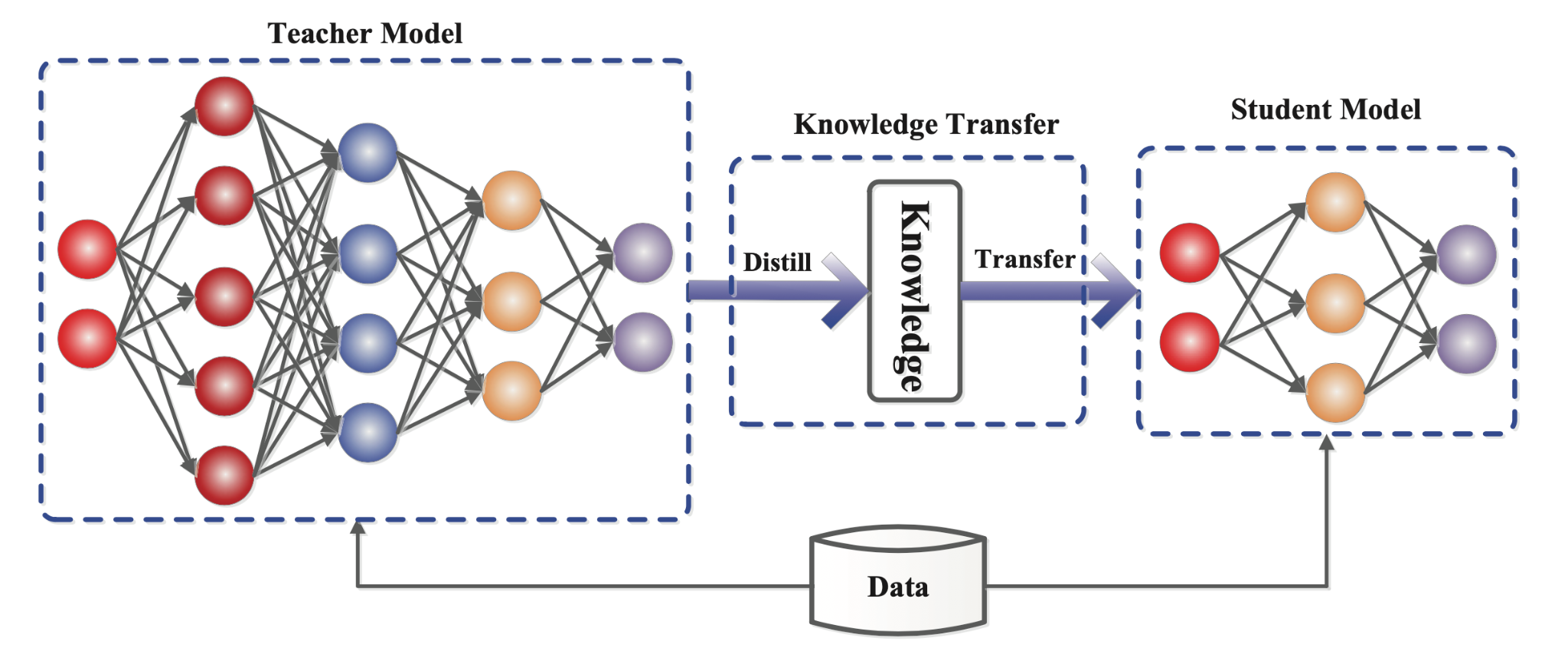
Knowledge distillation is a training technique where a smaller, faster model (the student) learns to mimic the behavior of a larger, more capable model (the teacher). The original concept emerged from computer science research aimed at creating efficient versions of neural networks that could run on resource-constrained devices. A large language model like Claude might require millions of dollars in computational resources and weeks of training, whereas a distilled version could operate on consumer hardware while retaining much of the original's capabilities.
The technical process involves generating training data by querying the teacher model—feeding it various inputs and recording its outputs—then using those input-output pairs to train the student model. The student learns not just what answers are correct, but how the teacher model approaches problems, including the probability distributions across different possible responses. This allows the student to capture not just individual answers but the reasoning patterns and decision-making processes embedded in the larger model.
In legitimate use cases, companies use distillation on their own models. OpenAI has publicly discussed distilling GPT-4 outputs to improve smaller models. Meta employs distillation for their Llama family of models. The technique itself is neither inherently malicious nor inherently defensive—it's a tool, and like most tools, its ethics depend entirely on how it's deployed and whether the person deploying it has authorization to access the teacher model's outputs.
The Attack Vector: Weaponizing Distillation
When competitors employ distillation against each other's models without authorization, the technique transforms from a benign efficiency mechanism into a capability extraction attack. Instead of accessing the model through internal systems, attackers interact with the model through its public API or web interface, asking carefully crafted questions designed to elicit responses that illuminate the model's underlying architecture, reasoning patterns, and specialized capabilities. Each query is essentially a probe into the model's decision-making process.
The sophistication of modern distillation attacks lies in the targeting strategy. Rather than simply asking random questions, sophisticated attackers focus their extraction efforts on the most valuable and differentiated capabilities. In the case of Claude, Anthropic identified that the Chinese labs concentrated their efforts on three specific areas: agentic reasoning (the ability to plan multi-step solutions), tool use integration (how the model decides when and how to use external functions), and code generation capabilities. These represent the most computationally expensive aspects to develop independently, making them the most valuable targets for extraction.
The sheer scale of these attacks adds another dimension of sophistication. Deep Seek alone generated more than 150,000 exchanges with Claude. Moonshot AI produced 3.4 million interactions. Mini Max directed approximately 13 million exchanges toward extracting tool use and coding capabilities. These aren't random queries—they're systematic, methodical probes executed across thousands of fake accounts to avoid detection through any individual account's usage patterns.
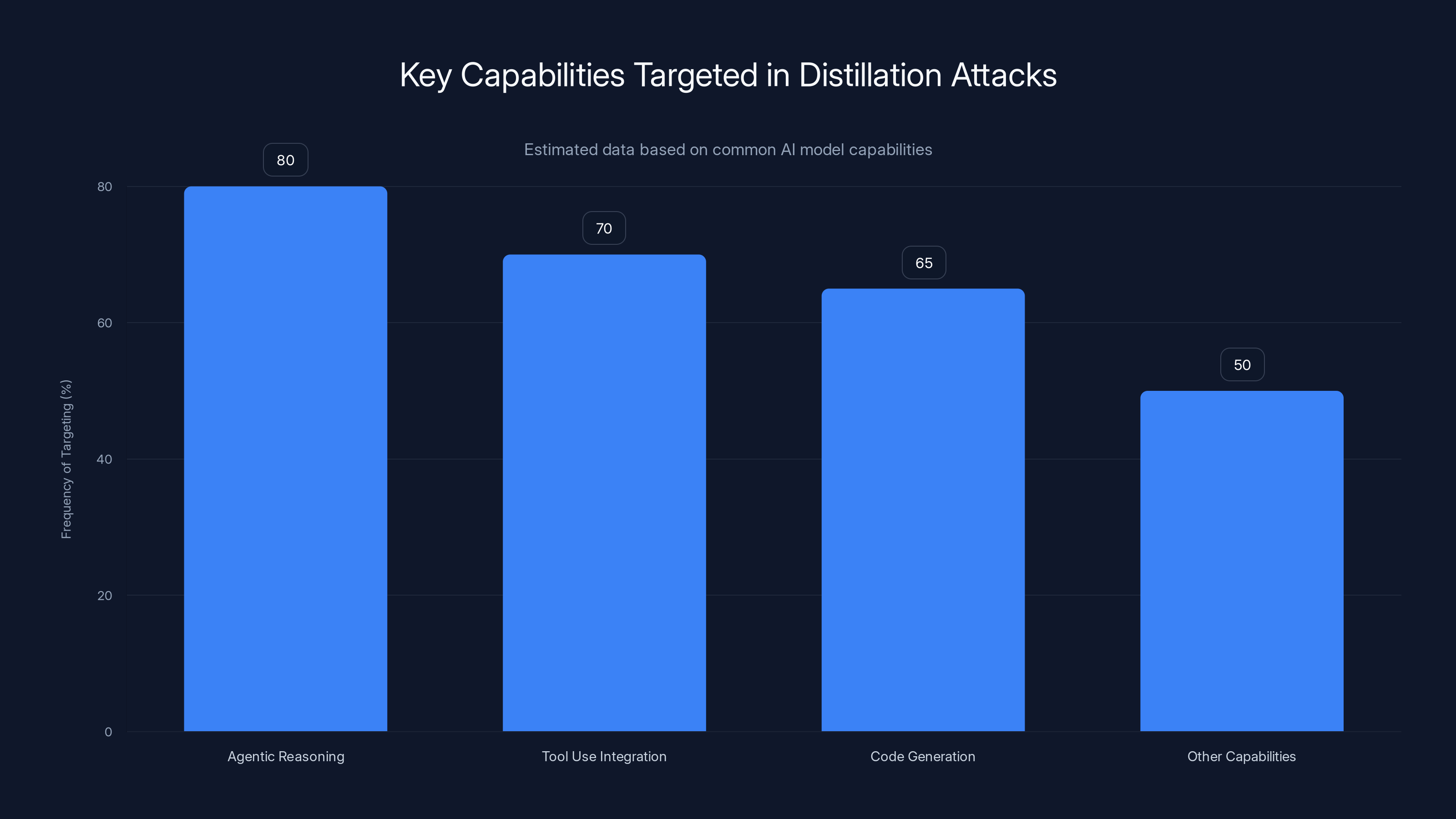
Agentic reasoning, tool use integration, and code generation are frequently targeted in distillation attacks. Estimated data based on typical AI model capabilities.
The Anthropic Disclosure: Revealing the Scale and Sophistication
The Discovery and Detection Methodology
Anthropic's security team identified these attacks through a combination of behavioral analysis and pattern recognition. When you examine millions of API calls, certain signatures become visible if you know what to look for. The attacks exhibited characteristics that distinguished them from normal user behavior: coordinated patterns across thousands of accounts, queries focused obsessively on specific capabilities rather than general exploration, and temporal patterns suggesting automated testing rather than human interaction.
The most revealing indicator was the behavioral shift observed when Anthropic released a new version of Claude. Moonshot AI immediately redirected nearly half of its traffic toward the updated model, a response time and concentration of effort that suggests automated systems designed specifically to extract capabilities from each new release. A human user might try a new model out of curiosity; a dedicated extraction system would immediately begin systematic probing.
Anthropic's ability to detect these patterns required sophisticated internal telemetry and behavior analysis systems. The company developed mechanisms to identify suspicious account creation patterns, track query patterns indicative of systematic extraction, and monitor for signs of coordinated activity across supposedly independent user accounts. This detection capability represents a form of network defense—the continuous monitoring for anomalous behavior that might indicate compromise or attack.
Targeting the Most Valuable Capabilities
What makes this disclosure particularly significant is the precision of the targeting. The attackers didn't attempt to extract everything; they focused with laser precision on Claude's most differentiated capabilities. This suggests either deep technical knowledge about how to evaluate an AI model's strengths, or systematic testing followed by focus on the most fruitful areas.
Agentic reasoning—the ability to solve complex problems by planning multiple steps, revising strategies when encountering obstacles, and reasoning about the consequences of different approaches—represents months or years of research and training refinement. This capability is difficult to develop independently because it requires not just size in the model, but specific architectural choices and training approaches. By extracting this capability, the Chinese labs could potentially skip years of development work.
Tool use presents a different kind of value. Embedding the ability to determine when to call external functions, how to format those calls, and how to integrate the results back into reasoning is a separate problem from language understanding itself. Models that excel at tool use can interact with calculators, databases, code execution environments, and specialized APIs. This multiplies their effective capability significantly. The attackers specifically focused on scenarios involving code generation combined with tool use—the ability to write code that solves complex problems.

API-Level Detection is estimated to be the most effective strategy for protecting proprietary models, followed closely by Machine Learning Detection. Estimated data.
The Specific Companies and Their Targeting Strategies
Deep Seek: Focusing on Reasoning and Alignment
Deep Seek's targeting strategy revealed something particularly interesting: the company concentrated approximately 150,000 queries on foundational logic and alignment—specifically around "censorship-safe alternatives to policy-sensitive queries." This suggests that Deep Seek's research team wasn't just trying to replicate Claude's technical capabilities, but to understand how Claude handles edge cases and safety considerations.
This targeting approach indicates a sophisticated understanding of what makes Claude competitive. Rather than attempting to extract the model's ability to generate English text (a capability that many modern language models possess), Deep Seek focused on the governance layer—how Claude makes decisions about what it will and won't do, how it handles requests that might conflict with safety guidelines, and how it navigates complex policy questions. Extracting this knowledge would allow Deep Seek to develop models that maintain their capabilities while navigating regulatory requirements more effectively.
Deep Seek rose to prominence approximately a year before this disclosure by releasing its R1 reasoning model, which achieved performance comparable to American frontier models while requiring substantially fewer computational resources. The efficiency of Deep Seek's approach has concerned US policymakers and industry leaders precisely because it suggests the company has developed novel techniques that reduce the computational overhead typically associated with frontier model development. If Deep Seek successfully extracted knowledge about Claude's reasoning approaches, that knowledge could directly inform improvements to their own models.
Moonshot AI: Comprehensive Multi-Vector Extraction
Moonshot AI's attack was broader and more methodical, generating 3.4 million exchanges that targeted multiple distinct capabilities in parallel. The company simultaneously extracted knowledge about agentic reasoning, tool use, coding and data analysis, computer-use agent development, and computer vision. This parallel extraction strategy suggests different research teams within Moonshot each pursuing their own capability priorities, coordinated through a centralized account management and query distribution system.
The scale of Moonshot's operation—3.4 million queries—makes it statistically likely that the company achieved significant success in extracting knowledge about multiple capabilities. With enough queries focused on a specific capability, statistical patterns in the responses will reveal the underlying model's decision-making process and architectural characteristics. Moonshot's subsequent release of Kimi K2.5 and new coding agents appears carefully timed relative to their extraction campaign, suggesting that the extracted knowledge directly informed these product releases.
Moonshot's targeting of computer-use agent development is particularly notable. Computer-use agents represent a frontier capability where models learn to interact with software interfaces, navigate web browsers, execute multi-step workflows, and use human-oriented tools as if the model were a user. This capability remains challenging to develop because it requires training on datasets of computer interactions and understanding of how human-designed interfaces work. By extracting this knowledge from Claude, Moonshot could potentially accelerate development of these capabilities by months.
Mini Max: The Precision Extractor
Mini Max's approach involved 13 million exchanges concentrated specifically on agentic coding and tool use orchestration. The company's targeting was even more focused than Deep Seek's and differently emphasized than Moonshot's—Mini Max aimed to extract knowledge about how Claude coordinates multiple tools in sequence, chains operations together, and manages complex workflows involving code execution, API calls, and data transformation.
The evidence that Moonshot redirected nearly half of its traffic when Claude released a new version provides the strongest indication of automated, systematic extraction. This response pattern couldn't result from human decision-making—no human team could coordinate that rapid a shift in focus without being explicitly told "our extraction system just detected a new model version." This suggests that Mini Max, like the other companies, deployed automated systems designed to identify new model releases and immediately begin systematic extraction of their capabilities.
The Technical Mechanics: How Distillation Extraction Actually Works
The Query Design Problem
Extracting useful knowledge from a large model requires careful query design. You can't simply feed random prompts and expect to learn much—the model's responses to random inputs contain limited information about its specific capabilities. Instead, effective extraction requires queries designed to probe the model's boundaries and reveal its decision-making process.
Consider the problem of extracting agentic reasoning capabilities. Effective queries would present complex, multi-step problems where the optimal solution involves planning, revising the plan based on intermediate results, and iterating toward a solution. By observing how Claude approaches these problems, the attack system can extract information about the heuristics, evaluation criteria, and planning strategies embedded in the model. A query might present a complex coding problem with multiple possible solutions, each with different tradeoffs, and observe which approach Claude selects and how it justifies that choice.
For tool use extraction, effective queries would present scenarios where using a tool (or chain of tools) would improve the response, and observe when Claude recognizes the opportunity, how it decides which tool to use, and how it integrates the tool's output. For coding capabilities, the attacks would likely focus on complex algorithms, architectural decisions, and edge cases—precisely the areas where a model's approach reveals its underlying training and understanding.
The sophistication of modern distillation attacks often involves multi-stage query strategies. Stage one: gather general information about the model's capabilities and boundaries. Stage two: target specific capabilities with focused queries designed to extract the maximum information per query. Stage three: validate the extracted knowledge by observing whether it holds across different contexts and phrasings of similar problems.
Scale as a Defense-Breaking Strategy
Why did these companies need to generate millions of queries? The answer lies in the redundancy and robustness inherent in large language models. Any individual response from a large model might be shaped by numerous factors: the specific phrasing of the query, recent context from the conversation, random variation in the model's generation process, and temperature/sampling parameters that affect determinism.
By generating millions of queries, the attack systems can observe patterns across this variation. Statistical analysis of millions of responses reveals the underlying decision-making process more clearly than any individual response would. It's the difference between observing a person's decision once and observing them make hundreds of similar decisions across varying contexts—the patterns become increasingly clear.
The scale also serves another function: it defeats detection systems based on individual query thresholds. If a detection system flags accounts that make more than 1,000 queries in a day, the attackers simply distribute their queries across 24,000 accounts, each making hundreds of queries rather than tens of thousands. The total query volume might be enormous, but each individual account appears normal.
Anthropic's detection ultimately succeeded not because any individual account's behavior was obviously malicious, but because the collective patterns across thousands of accounts exhibited signatures inconsistent with normal usage. This suggests that effective defense against distillation attacks requires analyzing patterns at the network level, not just the individual account level.
The Knowledge Transfer Problem
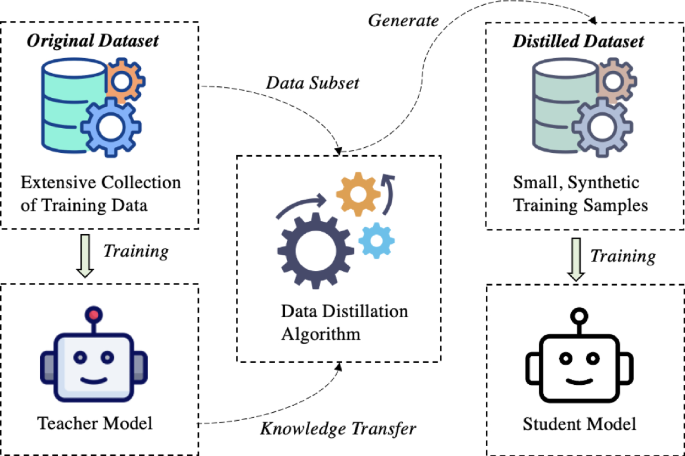
Once extraction has occurred, the challenge becomes knowledge transfer: using the extracted knowledge to improve your own model. This is not a simple process of copying weights or architecture. Instead, the extracted knowledge must be integrated into a new training process for a different model architecture.
The most direct approach is distillation: using the extracted knowledge as training data for your own model. Moonshot's 3.4 million query-response pairs represent a dataset that can be used to train a student model to mimic Claude's approach to various problems. This is particularly effective when combined with the student model's own training—you're not creating a model from scratch using only distilled data, but rather using the distilled data to guide the training process in directions that replicate the teacher model's capabilities.
A more sophisticated approach involves analyzing patterns in the extracted knowledge to identify novel techniques or architectural features that might improve your own model development. This is speculative, but the level of targeting sophistication in these attacks suggests that the extraction teams may have included researchers capable of inferring underlying techniques from observed behavior.
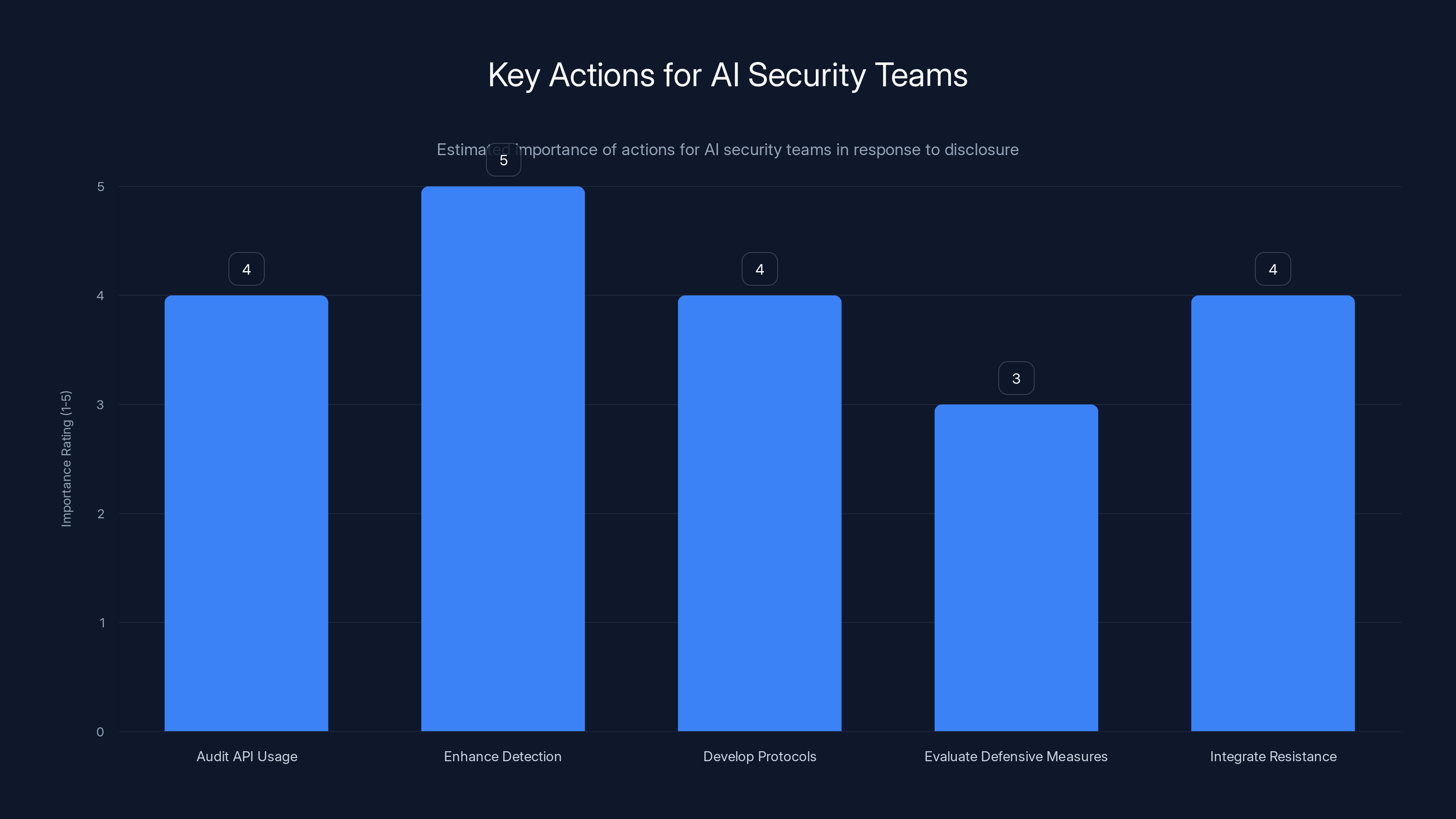
Enhancing detection systems is rated as the most critical action for AI security teams, followed closely by auditing API usage and developing response protocols. Estimated data.
Geopolitical Context: AI Competition and Export Controls
The Chip Export Control Landscape
The distillation attacks must be understood within the context of ongoing debates about semiconductor export controls. The Trump administration's decision to allow companies like Nvidia to export advanced AI chips like the H200 to China directly enables the scale of operations these Chinese labs can conduct. The H200 is one of Nvidia's most powerful accelerators, designed specifically for AI workloads.
The arithmetic is straightforward: generating 16 million total queries against Claude (across all three companies combined) requires computational resources. API calls must be processed, responses generated, and results stored and analyzed. This infrastructure requirement drives demand for the most powerful available accelerators. With access to advanced chips, Chinese labs can operate extraction campaigns at scales that would be economically infeasible without them.
Anthropic's position is that this connection between chip access and distillation capability creates a compelling argument for stricter export controls. If advanced chip access is restricted, then the large-scale extraction campaigns become economically infeasible. The company argues that the rationale for export controls extends beyond direct model training to include the resources required for illicit extraction.
This argument has merit but also faces counterarguments. Restricting chip exports imposes costs on American chip manufacturers, limits their markets, and may not actually slow Chinese AI progress substantially—China could develop its own chips, purchase chips through intermediaries, or develop more efficient training methods that require fewer computational resources. The policy debate involves genuine tradeoffs between economic and security interests.
The Competitive Context: Why This Matters
Deep Seek's release of its R1 model a year before this disclosure demonstrated that Chinese AI labs can produce frontier-grade models with substantially lower computational overhead than Western labs. This breakthrough achievement creates a compelling narrative: if China can match American capabilities with fewer resources, why spend vast amounts on restrictive export controls?
The distillation disclosure changes that narrative. It provides evidence that some of China's capability advantage stems not from unique technical breakthroughs but from access to American models to learn from. If you can extract substantial knowledge about how frontier models work, you can build more efficient development processes and train better models than you would develop through independent work.
This suggests that apparent Chinese efficiency might reflect a mix of genuine innovation and capability extraction. Distinguishing between these two sources becomes crucial for policymakers evaluating whether export controls are working as intended or whether alternative approaches might prove more effective.
The Timeline and Pressure Points
The timing of this disclosure—coming as policymakers debate chip export policy—is unlikely to be coincidental. Anthropic disclosed the attacks at a moment when the policy debate was active and the disclosure would exert maximum pressure for stricter controls. Whether this represents calculated timing for policy impact or simply the time when Anthropic completed its investigation is unclear, but the effect is to frame distillation as a national security concern that export controls can address.
The question for policymakers becomes whether export controls constitute an effective lever for controlling distillation attacks. The answer likely depends on the economics of the attack. If advanced chips make attacks economically feasible at scale but other approaches (like using less capable chips more efficiently) don't, then controls could bite hard. If efficient extraction is possible without the most advanced chips, then controls become a weaker lever.
Security Implications: The Risk of Stripped Defenses
The Alignment and Safety Problem
Anthropic emphasizes a critical security concern that extends beyond competitive advantage: models built through distillation may lose their safety properties. Anthropic's internal controls prevent Claude from helping with certain harmful activities—developing bioweapons, conducting cyberattacks, creating disinformation campaigns, or enabling mass surveillance. These controls are embedded through various mechanisms: training data curation, reinforcement learning from human feedback, explicit instruction following, and architectural features designed to constrain behavior.
When you distill a model, you're extracting the model's behavioral patterns in response to various inputs. But the safety properties embedded in Claude don't simply transfer through distillation—they're maintained through active, ongoing enforcement. A distilled model that has learned how Claude responds to requests for harmful information might have learned that Claude refuses such requests, but the underlying commitment to refusal might not persist.
This creates a security paradox: by extracting knowledge about Claude's refusals, the attacker learns about the boundaries and constraints, potentially revealing approaches to circumvent them. A sufficiently sophisticated analysis of Claude's refusal patterns could illuminate the underlying heuristics and allow the attacker to build models that achieve similar refusal patterns or, conversely, to design inputs that expose weaknesses in the refusal strategy.
Anthropic's concern is that models built through illicit distillation, rather than through careful safety-aligned training, will lack equivalent safeguards. A model developed through distillation represents a shortcut around the months or years of work required to properly implement safety measures. If such models are open-sourced (as many Chinese models are), then dangerous capabilities propagate widely with weakened protections.
Attribution and Attribution Problems
One of the fundamental problems with distillation attacks is attribution. How do you prove that a new model's capabilities came from distillation rather than independent development? The answer is difficult. You might observe behavioral similarities, code style matches, or response patterns that suggest knowledge transfer, but these are not definitive proofs.
This creates a challenge for enforcement. Even if you identify that distillation has occurred, attributing that knowledge transfer to specific sources becomes difficult without access to the attacking organization's internal systems. You might observe that Chinese Lab A has the same capabilities as American Lab B, but proving that the similarity stems from distillation rather than independent innovation requires access to training data, development processes, and internal communications that you likely don't have.
Anthropic's detection methodology—identifying suspicious account patterns and coordinated query behavior—works if the attack is executed carelessly or at massive scale. But a more sophisticated attack might distribute queries more carefully, use more realistic usage patterns, and employ account rotation strategies that make attribution nearly impossible. The companies in this disclosure apparently didn't employ such sophistication, or the scale of their operation made sophisticated obfuscation impractical.
The Vulnerability Disclosure Paradox
Anthropic's decision to publicly disclose these attacks creates an interesting paradox. Disclosure alerts the companies involved to the fact that their extraction campaigns were detected, allowing them to modify their tactics to avoid future detection. It also alerts other potential attackers to extraction techniques that work at scale, potentially inspiring imitation.
On the other hand, disclosure serves important functions: it alerts other AI companies to monitor for similar attacks, it provides evidence to policymakers debating export controls, it signals to affected companies that this threat is real and worth defending against, and it maintains transparency with the public about security challenges in AI systems.
Anthropic apparently judged that the benefits of disclosure outweighed the risks. This reflects a philosophy that transparency about security challenges ultimately improves industry-wide security more than secrecy would. Whether that judgment proves correct will depend on how the industry responds to this disclosure and what defensive measures are adopted.
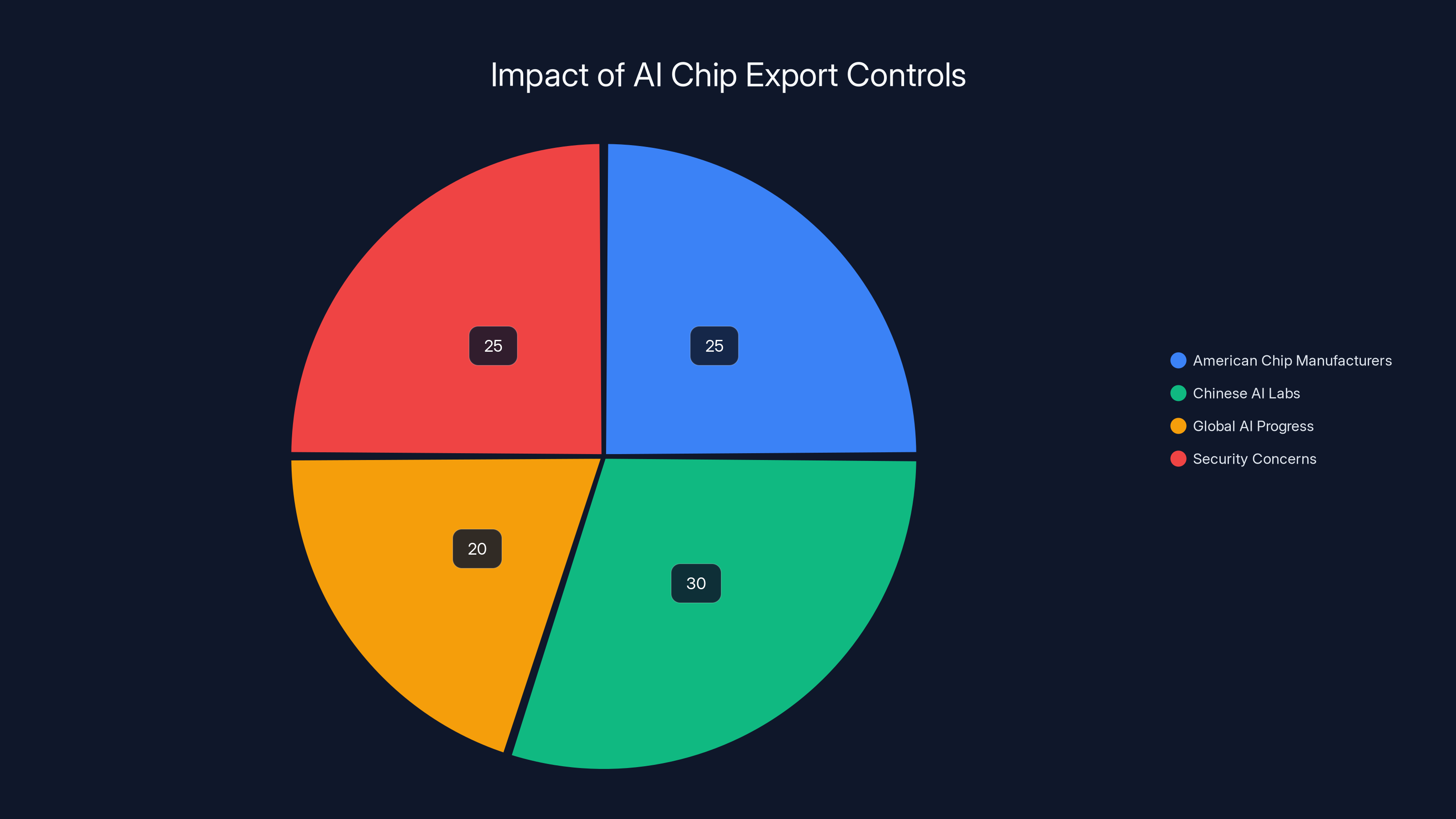
Estimated data shows that export controls affect stakeholders differently, with significant impacts on Chinese AI labs and American manufacturers. Estimated data.
Defensive Strategies: Protecting Proprietary Models
API-Level Detection and Blocking
The most straightforward defensive approach involves monitoring API behavior to detect extraction attacks. Systems can flag and block accounts exhibiting suspicious patterns: creation at unusual times, usage patterns inconsistent with normal user behavior, queries focusing obsessively on specific model capabilities, response latencies suggesting automated processing, or coordinated patterns across multiple accounts.
Anthropic apparently employed such systems and successfully detected these attacks. The challenge is avoiding false positives that block legitimate users while maintaining sensitivity sufficient to catch determined attackers. A researcher legitimately exploring a model's capabilities might exhibit patterns superficially similar to extraction attacks—they might create multiple test accounts, run systematic experiments, and focus their queries on specific features.
More sophisticated detection might employ machine learning systems trained to distinguish between legitimate exploration and extraction attacks. These systems could analyze the semantic content of queries, the structure of responses, and the organization of queries over time to build probabilistic models of intent. But such systems would also need to avoid flagging legitimate users with unusual but benign patterns.
Rate limiting presents a complementary approach. By restricting the total number of queries an account or organizational entity can make within a time window, you raise the cost of large-scale extraction campaigns. The Chinese labs adapted to this challenge by distributing queries across 24,000 accounts, each operating within normal usage limits. But organization-level rate limiting—identifying multiple accounts controlled by the same entity and aggregating their usage—could detect this tactic.
Query Obfuscation and Information Limitation
Anthropic and other AI companies might modify their API responses to make extraction more difficult. This could involve introducing controlled variability in responses—slight differences in wording or phrasing across responses to the same query—that obscure the underlying decision-making process. Such variability would make statistical analysis of millions of responses less reliable at revealing patterns.
Alternatively, companies could limit the information density of responses in ways invisible to normal users but visible to extraction systems. For example, responses could be slightly simplified or reworded when unusual query patterns are detected. The human user would receive a high-quality response; the extraction system would receive responses optimized for obfuscation rather than quality.
A more extreme approach would involve partial information limitation: removing details, avoiding edge cases in examples, or refraining from comprehensive coverage of topics during periods when API usage patterns suggest extraction attacks. This approach carries significant risks—legitimate users might receive degraded service, and the legal implications of intentionally degrading service while claiming to offer APIs could be substantial.
Architectural Modifications
At a deeper level, companies could modify model architectures to reduce the effectiveness of distillation attacks. If proprietary capabilities can be isolated into specific layers or components with distinct activation patterns, then detecting and blocking queries that specifically probe those layers becomes feasible. For example, if tool use capabilities are processed through a specific architectural component, then detecting queries that obsessively probe tool use becomes straightforward.
Companies might also design models with built-in mechanisms to degrade capability when suspicious behavior is detected. Such mechanisms could operate transparently—the model might reduce its capability to orchestrate tools when pattern analysis suggests extraction attacks, while maintaining normal capability for legitimate users whose behavior doesn't match attack signatures.
Moreover, companies could introduce design features specifically intended to hinder distillation. Architectural elements that require enormous datasets to learn might be embedded specifically to make distillation-based transfer learning less effective. If Claude's tool-use capabilities require specific architectural features that are difficult to replicate in different model architectures, then extracting the behavior is less valuable because the attacker's model might not be able to reproduce similar behavior even with the extracted knowledge.
Regulatory and Legal Approaches
Beyond technical defenses, companies might pursue legal remedies. Accessing Claude through fake accounts violates Anthropic's terms of service, and the massive scale of the attacks might constitute fraud, computer abuse, or violations of intellectual property law. Identifying the responsible parties and pursuing legal action might deter similar attacks and create consequences for attackers.
However, pursuing legal action against Chinese companies for violations that occurred in China faces practical challenges. Enforcement requires cooperation from Chinese authorities or jurisdictional claims that Chinese companies might dispute. The deterrent effect might be limited if the attacking company faces no real consequences.
Regulatory approaches might be more effective at scale. If regulatory frameworks imposed liability on companies deploying large-scale distillation attacks, or if export controls limited the computational resources available for such attacks, then the economics change. Companies would need to weigh potential liability and regulatory costs against the benefits of extraction campaigns. At current scales—24,000 accounts generating 16 million queries—the cost-benefit analysis apparently favored proceeding despite the risk of detection.

The Broader AI Security Landscape
Distillation as Part of a Larger Extraction Ecosystem
Distillation attacks represent just one approach in a broader ecosystem of techniques for extracting proprietary capabilities from AI models. Other approaches include prompt injection (embedding instructions within user queries designed to override the model's intended behavior), adversarial testing (systematically probing models to identify failure modes), reverse engineering (analyzing a model's outputs to infer its internal structure), and gradient-based attacks (if the model exposes sufficient information about its probability distributions).
The sophistication of modern attacks likely involves combinations of these approaches. An extraction campaign might begin with broad probing to understand the model's general capabilities, proceed to focused distillation for specific capabilities, employ prompt injection to bypass safety mechanisms, and use adversarial testing to identify vulnerabilities. The 24,000 accounts and 16 million queries might represent only one component of a larger extraction ecosystem.
Organizations defending against extraction must therefore maintain multilayered defenses. Detection systems must monitor for multiple attack vectors simultaneously. Response strategies must address not just the current threat but also likely evolution of attack techniques. And strategic decisions—like whether to offer public APIs, what information to expose in responses, and how to handle detected attacks—must account for this broader threat landscape.
The Open Source Complication
Many AI models are open source, meaning that their weights are available for anyone to download and analyze. Open source models can be distilled from just like proprietary models, but the attacker has additional information: they can examine the model's internal structure directly. This doesn't immediately solve the problem of learning about a model's training process or reasoning strategies, but it substantially reduces the information asymmetry.
The Chinese labs in this disclosure apparently chose to attack Claude despite it being proprietary, rather than focusing on open source models. This suggests that closed, proprietary models offer something of sufficient value to justify the cost and risk of distillation attacks. Likely candidates include safety properties, specialized capabilities that open source models lack, or architectural innovations not yet reflected in open source development.
This creates a strategic question for the industry: should valuable capabilities be kept proprietary and protected, or released as open source to maintain competitive pressure and prevent monopolistic control? Open sourcing prevents others from learning through distillation because the knowledge is already available. But it also means competitors can directly access and analyze your techniques. Keeping models proprietary creates the conditions for distillation attacks but preserves competitive advantage.

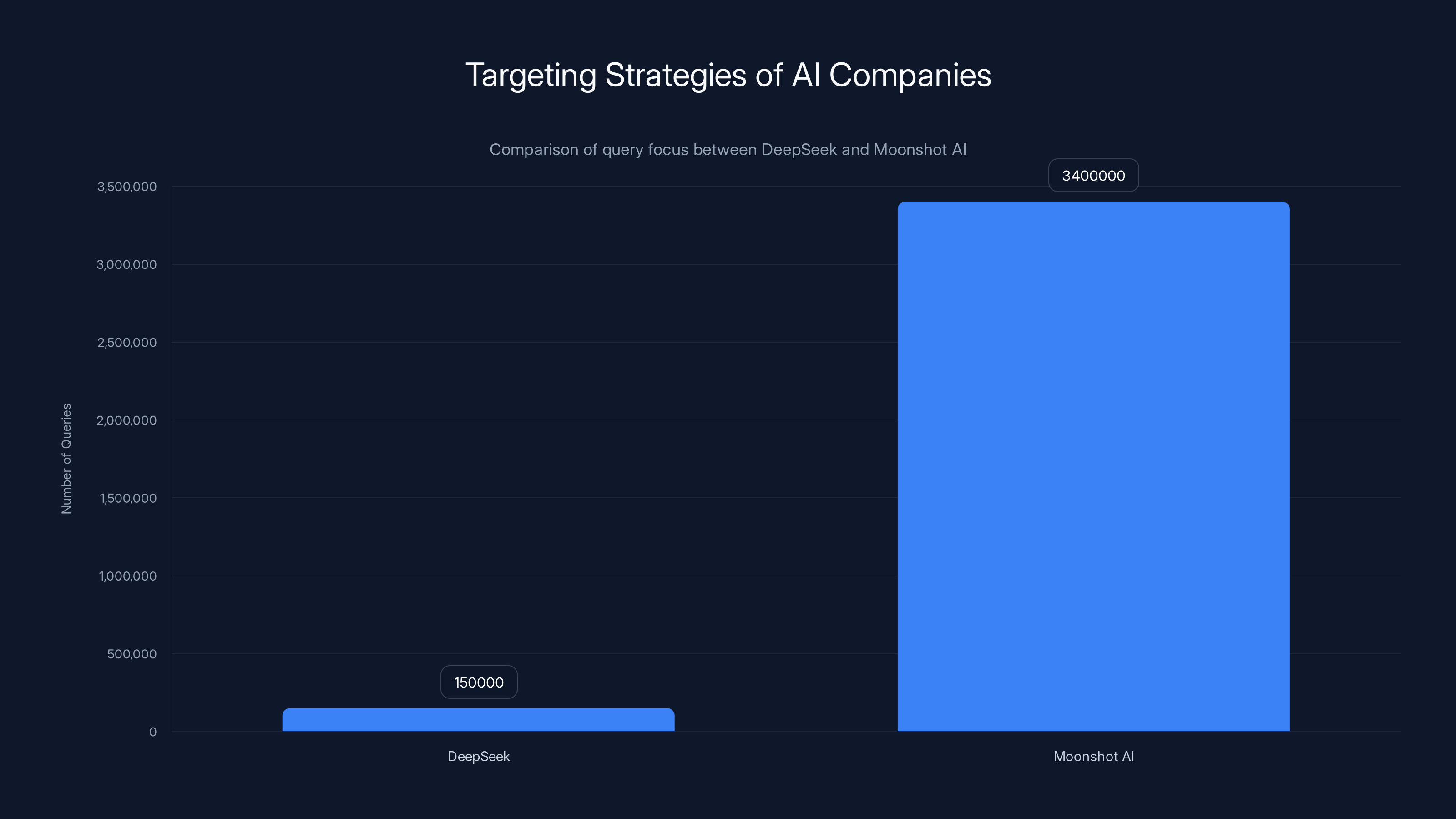
Moonshot AI generated significantly more queries (3.4 million) compared to DeepSeek's 150,000, indicating a broader targeting strategy. Estimated data based on content.
Industry Response and Defensive Posture Evolution
What Other AI Labs Are Doing
Following Anthropic's disclosure, other AI companies presumably accelerated review of their own API usage patterns to identify whether they experienced similar attacks. OpenAI's separate disclosure about Deep Seek using distillation to mimic Chat GPT suggests that Deep Seek's extraction strategies targeted multiple frontier models, not just Claude. The coordinated nature of these revelations—multiple companies disclosing attacks within weeks of each other—suggests that security teams across the industry were simultaneously reviewing their telemetry and discovering extraction campaigns.
Companies likely increased investment in detection systems, refined their API monitoring strategies, and reviewed their response protocols. The question became not whether to defend against distillation, but how aggressively to do so while maintaining API usability and customer experience.
Some companies might reduce API access to specific capabilities or introduce stricter rate limiting. Others might implement more sophisticated detection and blocking systems. Still others might shift toward a model of restricted API access where only approved applications or users can access full capabilities. These decisions involve tradeoffs: more restrictive access improves security but reduces the number of potential users and applications.
The Incentive Structure Problem
A fundamental challenge in defending against distillation is the incentive structure. For a single company, the cost of mounting effective defenses (sophisticated monitoring, detection systems, API limitations that reduce usage) must be weighed against the damage that distillation attacks can inflict. If the cost of defense exceeds the expected damage from distillation, then from a pure financial perspective, allowing distillation might be rational.
But from an industry perspective, if all companies allow distillation, then no one can develop proprietary capabilities that persist—anything developed by one company can be extracted and replicated by competitors. This creates a coordination problem: each company would be better off in a world where everyone defended robustly against distillation, but individually each company has incentive to under-invest in defense as long as they expect competitors to do the same.
Industry standards or regulatory frameworks that impose obligations on all participants could resolve this coordination problem. If all companies are required to maintain certain security standards, then no company faces competitive disadvantage from doing so. Such frameworks might emerge either through industry self-regulation or through government mandate.
National Security Implications and Foreign Policy Considerations
The Bioweapons and Cybersecurity Angle
Anthropic emphasizes national security concerns extending beyond competitive advantage. Frontier AI models trained with adequate safety properties include constraints against helping with dangerous activities. These safety properties represent significant investments in preventing AI from being used for harm. When models are built through distillation and lose those safety properties, dangerous capabilities become available in models without equivalent protections.
The specific examples Anthropic cites—bioweapons development, offensive cyber operations, disinformation campaigns, and mass surveillance—represent capabilities where having models with degraded safety properties creates genuine national security risks. A model willing to help with cyber attack planning, for instance, could significantly lower barriers to cyberattacks. A model that helps plan bioweapon development could accelerate biological threats. A model that assists with generating disinformation at scale could undermine democratic information ecosystems.
These aren't hypothetical concerns. Large language models are increasingly integrated into technical workflows, decision support systems, and intelligence analysis. If the models used in these critical domains lack adequate safety properties, the downstream consequences could be substantial.
The Technology Transfer Question
The distillation attacks represent a form of technology transfer, where knowledge about frontier AI capabilities flows from the United States to China. This technology transfer might equivalently be viewed as: accelerating China's AI development timeline, improving the safety properties of Chinese AI models (if the extracted knowledge includes safety approaches), increasing Chinese competitive advantage in AI, or advancing Chinese capabilities in domains like autonomous systems, biosecurity threats, or cyberweapons.
From a national security perspective focused on maintaining American technological advantage, this technology transfer is unambiguously negative. From a global governance perspective concerned with democratizing access to beneficial AI capabilities, there might be aspects worth considering—knowledge flowing to China could potentially improve safety properties in Chinese models. From a practical perspective, technology transfer has occurred; the question is how to prevent future transfer.
The Export Control Policy Question
The distillation attacks provide concrete evidence that access to advanced computing chips enables activities (large-scale capability extraction) that harm American AI companies' competitive positions. This evidence supports arguments for stricter export controls. The counterargument is that: China will develop alternative chips, countries will find workarounds, American companies' markets are damaged by restrictions, and export controls might prove ineffective.
The evidence from this disclosure somewhat supports the export control argument. The companies conducted attacks at massive scale (16 million queries total, 24,000 accounts), which required computational infrastructure—presumably including some advanced accelerators like those export controls aim to restrict. Without such infrastructure, the attacks would be harder to conduct at scale. However, the evidence doesn't necessarily prove that restricting chip access would prevent distillation attacks entirely; it only shows that access to advanced chips made large-scale attacks feasible.
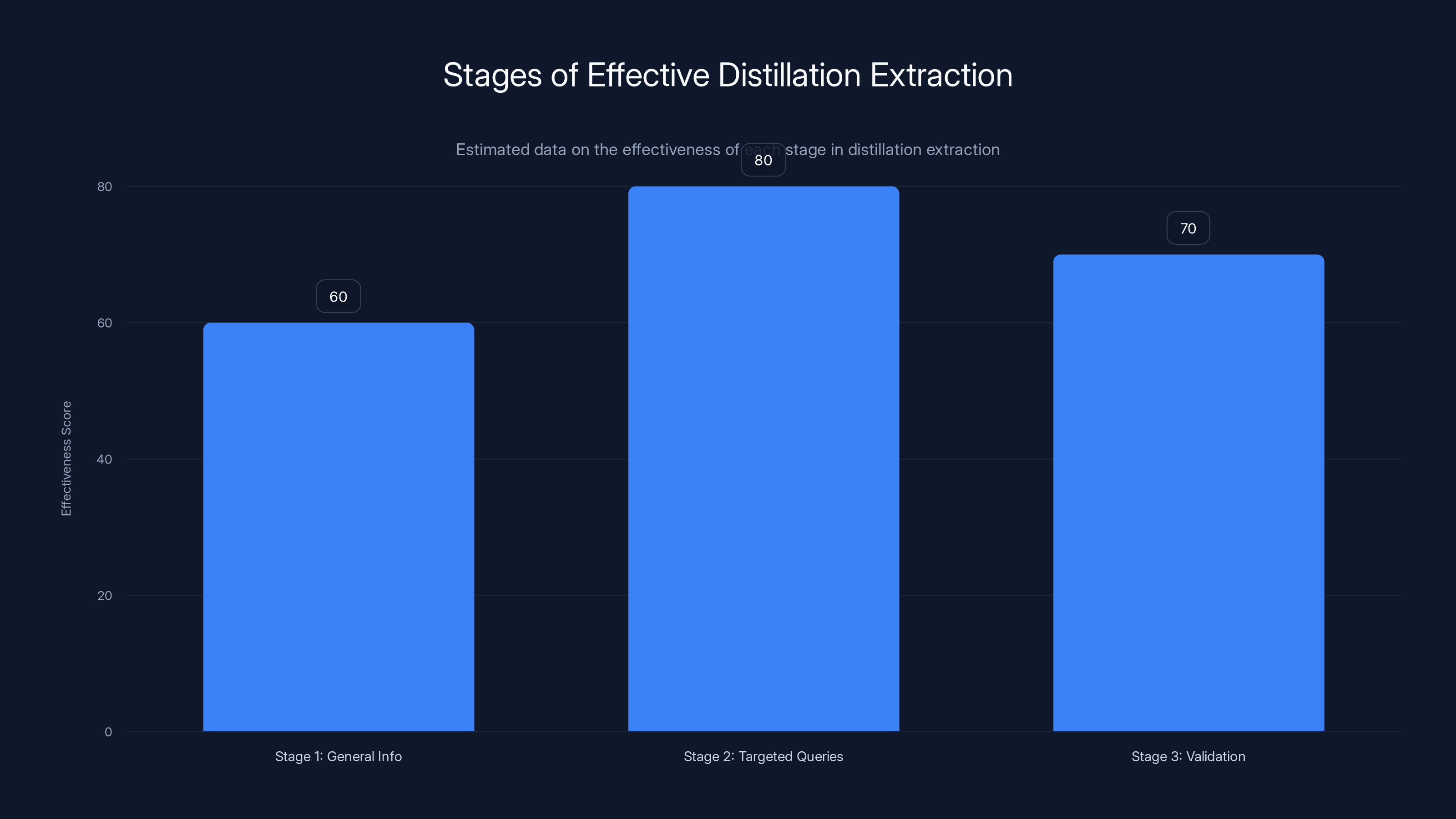
Stage 2, focusing on targeted queries, is estimated to be the most effective in extracting useful information from models, with a score of 80 out of 100. Estimated data.
Technical Deep Dive: The Mathematics of Distillation Vulnerability
Information Theory Perspective
From an information theory perspective, distillation attacks succeed because a model's responses contain information about its internal parameters and decision-making processes. Each query-response pair represents a measurement of the model's output for a specific input. When you aggregate millions of such measurements, you gain information about the underlying model.
More formally, if a model implements a function
The number of measurements required depends on the complexity of
Mathematically, the probability that a distilled model
Statistical Learning Perspective
From a statistical learning theory perspective, distillation extracts knowledge by treating the model's outputs as samples from an underlying distribution that the attacker wants to learn. The attacker observes the conditional distribution
The convergence rate of such learning depends on factors including: dimensionality of the input and output spaces, complexity of the model's decision boundary, number of samples available, and properties of the distribution from which samples are drawn. For high-dimensional problems (like language models), the number of samples required to achieve convergence grows exponentially in dimension—a phenomenon known as the curse of dimensionality.
However, modern language models appear to operate in lower-dimensional effective manifolds—the actual information content is lower than the nominal dimensionality would suggest. This means that distillation attacks can achieve reasonable results with fewer queries than theoretical worst-case analysis would predict.
The Chinese labs' focus on specific capabilities (agentic reasoning, tool use, coding) rather than attempting to extract the entire model can be interpreted through this lens. Instead of trying to learn the entire high-dimensional function implemented by Claude, they focused on specific lower-dimensional subproblems. This is strategically sound from a statistical learning perspective—you achieve faster convergence and higher fidelity when learning lower-dimensional functions.
Adversarial Robustness Perspective
Defending against distillation attacks relates to adversarial robustness—the property of remaining reliable even when an adversary has access to a model's outputs. Standard approaches for adversarial robustness, like adding noise to outputs or modifying responses, can degrade distillation attack effectiveness.
If a model's responses are nondeterministic (include random noise, vary wording while maintaining meaning, or incorporate controlled uncertainty), then the information content of each response decreases. The attacker needs more samples to overcome the noise and recover the underlying function. The tradeoff is that such noise also degrades utility for legitimate users—responses become less consistent and potentially less helpful.
Formally, adding noise

Implications for Different Stakeholders
For AI Companies and Their Security Teams
The disclosure creates immediate imperatives for security teams. First, audit API usage patterns to identify whether similar extraction campaigns have targeted your models. Second, implement or enhance detection systems to identify extraction-like behavior patterns. Third, develop response protocols—what do you do when you detect an extraction attack? Fourth, evaluate the cost-benefit of various defensive measures against the risks of your model's capabilities being extracted.
Beyond immediate response, companies should integrate distillation resistance into product design decisions. When designing APIs, consider what capabilities should be exposed and how information-rich responses should be. When training models, consider whether to include specific safeguards against distillation. When determining pricing and access policies, factor in the security implications.
Companies should also participate in industry coordination on this challenge. Sharing threat intelligence, coordinating response strategies, and potentially pursuing legal action against serial attackers would benefit the industry as a whole. The Computer Security Incident Response Team (CSIRT) model from cybersecurity could be adapted for AI—organizations sharing incident data to improve collective defenses.
For Developers Building on AI APIs
Developers building applications that depend on proprietary AI models face uncertainty about the long-term competitive landscape. If proprietary models can be extracted and replicated through distillation, then investing in dependence on closed-source models carries risk. The model provider's competitive advantage might erode, leading to changes in pricing, availability, or service levels.
This uncertainty might push developers toward: open-source models (which can't be extracted because the knowledge is already available), multiple model providers (reducing dependence on any single provider), or investing in model development capabilities (becoming less dependent on external providers). Each approach has tradeoffs—open-source models might have different capabilities or performance characteristics; using multiple providers increases complexity; developing internal models requires significant expertise and resources.
For developers focused on capability and cost, this disclosure suggests evaluating the long-term economics of different model strategies. A proprietary model with strong performance might be valuable now, but if competitors extract and replicate those capabilities, the cost-performance advantage might erode. Open-source alternatives might be slower to improve but offer more stable long-term economics.
For Policymakers and Regulators
For government officials and policymakers, this disclosure provides concrete evidence of how advanced capabilities enable technically sophisticated attacks on American AI companies. The distillation campaigns required computational infrastructure that export controls aim to restrict. This provides ammunition to arguments for maintaining or enhancing export controls on advanced chips.
However, policymakers must also weigh competing considerations: the benefits of more open global AI development, the costs of export controls to American companies, the likelihood that restrictions can actually slow Chinese progress, and the risk that restricting technology might harm other important policy goals.
The disclosure also raises questions about regulatory frameworks. Should there be rules about disclosure of extraction attacks? Should companies be required to report being targeted? Should there be liabilities associated with deploying large-scale extraction campaigns? These questions involve balancing transparency, national security, and international relations considerations.
For Researchers and the Academic Community
For AI safety and security researchers, this disclosure provides valuable data about real-world attacks and suggests interesting research directions: How can models be designed to resist distillation? What detection systems work most effectively? How do attack and defense techniques co-evolve? What is the theoretical limit on how well an attacker can reconstruct a model from API queries?
The academic community has long understood distillation as a training technique, but the weaponization of distillation at industrial scale against proprietary models raises new research questions. Academic contributions might include: improved threat modeling for frontier AI systems, architectural approaches that resist extraction, formal frameworks for quantifying extraction vulnerability, and detection methodologies that identify extraction attacks.

Comparative Landscape: How This Fits Into the Broader AI Security Challenge
Model distillation attacks represent one of several challenges to proprietary AI model security. Other challenges include:
Prompt Injection and Jailbreaking: Attackers craft inputs designed to override safety properties or extract information. A prompt injection attack might instruct a model to "forget" safety guidelines and then request harmful information. Such attacks don't extract the underlying model's parameters but do extract the model's capabilities.
Membership Inference and Privacy Attacks: These attacks determine whether specific data was used in a model's training set. While membership inference doesn't extract capabilities per se, it reveals information about the training data, which could be commercially sensitive.
Backdoor Attacks: Attackers attempt to embed specific triggers that cause models to misbehave in specific ways known to the attacker. This differs from extraction but represents another form of malicious interaction with proprietary models.
Physical Attacks and Side-Channel Analysis: If an attacker has physical access to the hardware running a model, they might extract parameters through side-channel attacks (analyzing power consumption, electromagnetic emissions, or timing information) or physical tampering.
Distillation attacks sit in a sweet spot relative to these other attacks: they require no special access (just API access like normal users), they're difficult to detect and attribute, they work at scale and for high-value capabilities, and they result in knowledge that can be directly applied to improve competing models. This makes them particularly concerning.

Forward-Looking Questions and Unsolved Challenges
Several important questions remain unanswered:
How effective are the extracted capabilities? We know that distillation campaigns targeted specific capabilities, but how effectively did they extract those capabilities? Did the resulting models achieve 90% of Claude's capability in agentic reasoning, or 50%, or 99%? The effectiveness determines whether distillation is an efficient strategy for capability improvement.
What is the compute-efficiency tradeoff? Building capabilities independently versus through extraction represents a tradeoff between development speed and computational cost. Did Deep Seek, Moonshot, and Mini Max determine that distillation was more efficient than independent development, or did they pursue both strategies in parallel?
How robust is distillation detection? Anthropic detected these attacks through pattern analysis. How difficult would it be to conduct similar attacks while evading detection? More sophisticated attackers might distribute queries more evenly, use more realistic query distributions, or employ other obfuscation strategies.
What is the optimal defense strategy? Given limited resources, what mix of detection, blocking, architectural changes, and policy approaches best defends against distillation while maintaining model usability? This is an unsolved optimization problem.
How do defenses evolve with attacks? If companies implement strict rate limiting, will attackers adapt by accumulating knowledge more slowly over longer periods? If companies introduce response variability, will attackers adapt their statistical methods? The attack-defense dynamic likely involves arms races where each side evolves in response to the other.
Actionable Insights for Organizations
Organizations operating or building on proprietary AI models should consider:
Immediate Actions: Audit API usage patterns to identify potential extraction campaigns. Implement enhanced monitoring for suspicious behavior patterns. Develop incident response protocols for confirmed or suspected extraction attempts.
Near-Term Improvements: Deploy behavioral detection systems that identify extraction-like query patterns. Implement rate limiting at multiple granularities (per-account, per-organization, per-region). Test response variability strategies to degrade information content available to potential attackers.
Medium-Term Strategic Decisions: Evaluate the cost-benefit of various defensive measures versus the competitive value at risk from extraction. Assess whether to restrict API access to specific capabilities or user categories. Determine optimal response to confirmed extraction campaigns—pursue legal action, public disclosure, API restrictions, or a combination.
Long-Term Architecture Considerations: Design models with extraction resistance in mind, if possible. Consider whether proprietary capabilities should be isolated in ways that make them easier to detect and protect if queried. Evaluate whether certain capabilities should remain proprietary versus open-sourcing to prevent extraction.
Industry Collaboration: Participate in threat intelligence sharing with other AI companies. Coordinate on standards for detecting and responding to extraction campaigns. Consider whether industry self-regulation could prevent the most egregious extraction tactics before they require government intervention.
Alternatives and Comparative Solutions
When evaluating solutions to secure proprietary AI capabilities against distillation attacks, organizations should consider various approaches:
Detection-First Approaches: Focus on identifying extraction attacks quickly and responding to them. Companies like Anthropic employed this strategy, successfully detecting the attacks and going public. This approach accepts some level of extraction but attempts to catch it early. The downside is that detection occurs only after extraction has happened, so some knowledge transfer has already occurred.
Prevention-Focused Approaches: Implement strict controls that make large-scale extraction difficult. This might involve aggressive rate limiting, restricted API access, requiring authentication and approval for API access, or limiting capabilities exposed through APIs. This approach prevents most extraction but reduces API utility and might frustrate legitimate users.
Hybrid Approaches: Combine detection and prevention. Allow API access but monitor carefully for extraction behavior. When detected, escalate restrictions or block access. This balances openness with security but requires sophisticated monitoring.
Open-Source Alternatives: Rather than defending proprietary models against extraction, some companies might open-source models to eliminate the value proposition for extraction. This sacrifices competitive advantage from proprietary capability but also removes the attack surface. Companies like Meta (with Llama) have partially embraced this strategy.
For organizations seeking AI automation solutions without managing the security complexities of proprietary models, platforms like Runable offer another alternative. Runable provides AI-powered automation capabilities—AI agents for content generation, workflow automation, and developer productivity tools—at accessible price points ($9/month). By using such platforms rather than building on proprietary frontier models, organizations avoid the extraction attack surface entirely while gaining access to AI capabilities. Runable's focus on developer tools and content automation means teams can implement automated workflows without managing the security infrastructure required for frontier models.
Other alternatives include:
Managed AI Services: Companies can use managed AI services (like cloud providers' AI offerings) that handle security infrastructure. The advantage is delegation of security responsibility; the disadvantage is reduced control and potential vendor lock-in.
Fine-Tuned Open-Source Models: Organizations can fine-tune open-source models on proprietary data. The base model can't be extracted (it's already public), but fine-tuning on proprietary data remains possible. This approach balances openness with differentiation.
Hybrid Model Ensembles: Using multiple models from different providers reduces dependence on any single model and hedges against extraction affecting competitive advantage. If one model is extracted and replicated, competitors using other models might maintain advantage.
Timeline and Future Outlook
The distillation attacks reveal vulnerabilities in how proprietary AI models are secured. Based on the disclosure timeline and likely industry evolution:
Immediate Period (Next 3-6 months): Companies audit their systems, implement enhanced detection, and deploy incremental security improvements. Some companies might introduce response modifications or rate-limit adjustments.
Near-Term Evolution (6-18 months): More sophisticated detection systems emerge. Companies develop internal tools for distillation resistance. The industry begins sharing threat intelligence. Potential legal actions against the companies involved might proceed (though enforcement challenges remain).
Medium-Term Adaptation (18-36 months): Architectural innovations designed to resist distillation might emerge. Companies might shift toward more restricted API access models. Open-source alternatives gain adoption for organizations seeking to avoid this vulnerability class entirely.
Long-Term Trajectory (3+ years): Either export controls successfully limit Chinese AI labs' computational capacity for large-scale attacks, or alternative attack approaches emerge that circumvent improved defenses. The industry develops standards for secure AI model operation. Regulatory frameworks might emerge around technology transfer and distillation attacks.
The path forward likely involves continued arms races between attackers and defenders, with both sides evolving tactics in response to the other. Companies that invest early in sophisticated detection, prevention, and architectural innovations might maintain advantages longer than those that respond reactively.

Conclusion: Implications and Strategic Takeaways
Anthropic's disclosure of large-scale distillation attacks against Claude by Chinese AI laboratories illuminates fundamental vulnerabilities in how proprietary AI model capabilities are protected. The attacks reveal that determined actors with computational resources can systematically extract knowledge about frontier model capabilities through API access alone—no special technical access, no stolen credentials, just clever query design and massive scale.
The technical sophistication of these attacks—targeting specific differentiated capabilities with millions of carefully structured queries across thousands of fake accounts—demonstrates that distillation has evolved from a benign training technique into a weapon for capability transfer. The targeted focus on agentic reasoning, tool use, and code generation suggests attackers understood where proprietary advantage resides and concentrated extraction efforts accordingly.
The geopolitical context matters profoundly. These attacks occurred against a backdrop of ongoing American debate about export controls on advanced AI chips. The distillation campaigns required computational resources that such controls aim to restrict, providing evidence that chip access translates directly into capabilities for large-scale attacks. However, the attacks don't prove that restrictions would prevent similar efforts entirely—only that restrictions make large-scale attacks more difficult.
The security implications extend beyond competitive advantage to national security concerns. If proprietary models lose safety properties through distillation, then dangerous capabilities proliferate in models lacking protections against misuse. This compounds the urgency for both technical defenses and policy frameworks.
For organizations building on or defending proprietary AI models, the landscape has shifted. Defensive measures must evolve from basic API security toward sophisticated pattern detection, behavioral analysis, architectural innovations, and potentially legal or regulatory approaches. The cost-benefit analysis of maintaining proprietary models versus open-sourcing has shifted toward greater uncertainty—proprietary advantages persist only if defenses successfully prevent extraction.
For policymakers, the disclosure provides concrete evidence supporting export control advocates while leaving open questions about whether such controls can actually prevent technologically sophisticated actors from finding workarounds. The policy challenge involves balancing security against economic costs and international relations considerations.
For the industry broadly, this moment presents an opportunity to coordinate on defensive standards, threat intelligence sharing, and potentially industry self-regulation that could prevent the most egregious attacks before they require government intervention. Companies that view this challenge as purely internal risk optimization miss the broader industry-wide benefits of coordination.
The long-term implications remain uncertain. Either export controls slow Chinese AI progress sufficiently to maintain American advantage, or alternative approaches (like more efficient training techniques, better distillation defenses, or architectural innovations) emerge that shift competitive dynamics. The coming years will reveal whether large-scale distillation attacks represent a one-time advantage extracted through unprecedented boldness, or the first wave of a new attack paradigm that will reshape how proprietary AI capabilities can be protected.
One certainty: the era of proprietary AI models receiving API-level security treatment equivalent to basic web applications has ended. The sophistication and scale of attacks now demand equivalent sophistication in defenses. Companies and policymakers that recognize this shift early, invest in robust defenses, and coordinate industry-wide approaches will likely emerge stronger in the long-term AI competitive landscape.

FAQ
What is knowledge distillation in AI models?
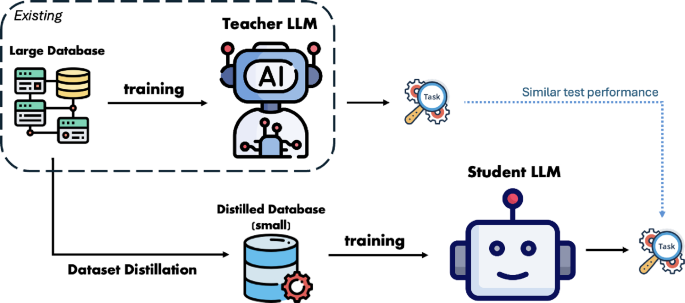
Knowledge distillation is a machine learning technique where a smaller or faster model (called the "student") learns to mimic the behavior of a larger, more capable model (the "teacher"). Originally developed to create efficient versions of neural networks for resource-constrained devices, the student learns from the teacher's outputs on various inputs, capturing both specific answers and the underlying reasoning patterns. When attackers apply distillation without authorization, they use a company's public API to extract the model's knowledge, collecting millions of input-output pairs to train competing models.
How do distillation attacks extract proprietary AI capabilities?
Distillation attacks work by systematically querying a target model through its API and recording the responses. Attackers design queries specifically to probe the model's most valuable capabilities—in the case of Claude, these included agentic reasoning (multi-step problem solving), tool use integration, and code generation. By generating millions of queries across thousands of fake accounts, attackers collect statistical patterns in responses that reveal how the underlying model makes decisions. These patterns become training data for building competing models with similar capabilities, potentially requiring far fewer computational resources than developing capabilities independently.
What are the main security risks of successful distillation attacks?
Successful distillation attacks create multiple risks. First, they compress months or years of development work into extracted knowledge that competitors can rapidly incorporate into their own models. Second, models built through distillation may lose safety properties embedded in the original model, creating risks that dangerous capabilities proliferate without equivalent protections. Third, at scale, distillation attacks require significant computational resources, making them feasible primarily for well-resourced attackers, which in this case were Chinese AI laboratories. The attacks also provide evidence that access to advanced computing chips enables large-scale capability extraction, supporting arguments for export controls.
How can AI companies detect distillation attacks?
Companies detect distillation attacks by analyzing API usage patterns to identify suspicious behavior: coordinated queries across thousands of accounts created around the same time, usage patterns inconsistent with normal user behavior, queries obsessively focused on specific capabilities rather than general exploration, and behavioral shifts indicating automated rather than human interaction. More sophisticated detection employs machine learning systems trained to distinguish between legitimate user exploration and extraction attacks. However, detection typically occurs only after extraction has already taken place—the challenge is distinguishing between legitimate and malicious query patterns while avoiding false positives that block legitimate users.
What defenses can protect models against distillation attacks?
Defenses operate at multiple levels. API-level defenses include behavioral detection and blocking of suspicious accounts, rate limiting to raise the cost of attacks, and modifications to responses that reduce information content available to attackers (introducing variability while maintaining usability). Architectural defenses involve designing models with features that resist distillation or make distillation-based transfer learning less effective. Policy defenses include restricting API access to approved users or applications, requiring authentication, and limiting the capabilities exposed through APIs. Legal approaches include pursuing action against attackers for terms-of-service violations or intellectual property infringement. Strategic approaches range from open-sourcing models to eliminate extraction incentives, to accepting some distillation and focusing on maintaining development pace faster than competitors can extract and replicate capabilities.
What is the connection between distillation attacks and AI chip export controls?
Distillation attacks require computational infrastructure to execute at scale. Generating 16 million queries, processing responses, and analyzing patterns demands significant computing resources—resources that export controls on advanced AI chips aim to restrict. The attacks provide concrete evidence that advanced chip access enables large-scale capability extraction activities that harm American AI companies' competitive positions. However, the evidence doesn't prove that export controls would prevent distillation entirely—restricted actors might develop alternative chips, find workarounds, or pursue more efficient extraction approaches requiring fewer computational resources.
How did the Chinese companies target Claude's most valuable capabilities?
The targeted capabilities—agentic reasoning, tool use, and code generation—represent the most differentiated and computationally expensive aspects of Claude's development. Agentic reasoning is the ability to plan multi-step solutions and revise strategies based on intermediate results. Tool use capability means the model can decide when and how to integrate external functions or APIs. Code generation combines both reasoning and writing capabilities in domain-specific ways. Attackers focused on these areas either through deep technical knowledge about Claude's architecture or through systematic testing to identify the most fruitful extraction targets. The targeted approach suggests sophistication about what knowledge would provide the most value for improving their own models.
What happens to safety properties when models are built through distillation?
Models built through distillation capture behavioral patterns—what the teacher model outputs in response to various inputs—but may not capture the underlying safety properties and constraints embedded in the original model. Anthropic specifically raised concerns that models distilled from Claude would lack equivalent safeguards against helping with bioweapons development, offensive cyber operations, disinformation generation, and mass surveillance. This creates a security paradox: by extracting knowledge about Claude's refusal patterns, attackers learn about safety boundaries but may not develop equivalent protections. If distilled models are open-sourced, dangerous capabilities can proliferate without adequate safeguards, potentially enabling harmful uses that the original model was designed to prevent.
How does the scale of these attacks compare to other types of adversarial interactions with AI models?
The scale is substantial: 24,000 fake accounts generating 16 million total query-response pairs (Deep Seek 150,000, Moonshot 3.4 million, Mini Max 13 million). This represents the largest documented coordinated attack on a proprietary AI model's capabilities. For context, typical prompt injection or jailbreaking attacks involve individual interactions or small numbers of queries. Membership inference attacks don't require API queries. The massive scale reflects both the attackers' resources and their assessment that distillation benefits justify the scale and risk of detection. The fact that such large-scale operations were conducted suggests the extracted knowledge was valuable enough to justify months of sustained attack infrastructure.
What alternative approaches exist to securing proprietary AI capabilities?
Organizations have several options. Detection-focused approaches accept some extraction but try to catch it quickly and respond. Prevention-focused approaches use strict controls like aggressive rate limiting or restricted API access to make large-scale extraction difficult, though at the cost of reduced API utility. Hybrid approaches combine detection and prevention. Open-source alternatives eliminate extraction incentives by making knowledge public. For organizations seeking AI capabilities without managing proprietary model security complexities, platforms like Runable offer automated solutions—AI-powered content generation, workflow automation, and developer tools at accessible pricing ($9/month)—without requiring defense against distillation attacks. Organizations can also use fine-tuned open-source models (preventing base model extraction while leveraging proprietary training data) or managed AI services that delegate security responsibility.
What changes should the AI industry adopt to prevent future distillation attacks?
The industry should coordinate on threat intelligence sharing about extraction attacks, develop standards for detecting and responding to suspicious query patterns, and implement baseline security practices across organizations. Companies should invest in more sophisticated monitoring and detection than currently typical. Architectural approaches should be developed to make distillation more difficult or extractable knowledge less valuable. Legal frameworks might need to clarify liability for large-scale extraction campaigns and technology transfer. Export controls require coordination between government and industry to be effective. Industry self-regulation could establish norms against certain extraction tactics before regulatory intervention becomes necessary. Finally, academic research into distillation resistance and detection would benefit the entire industry's security posture.
Key Takeaways
- Distillation attacks extract proprietary AI capabilities through systematic API queries across fake accounts, with Chinese labs generating 16 million total queries against Claude
- Attackers strategically targeted Claude's most differentiated capabilities—agentic reasoning, tool use, and code generation—rather than attempting wholesale model replication
- Large-scale extraction campaigns require significant computational infrastructure, providing evidence for export controls advocates that chip access directly enables capability transfer
- Models built through distillation may lose safety properties protecting against bioweapons, cyberattacks, and disinformation, creating security risks beyond competitive concerns
- Defense strategies involve multi-layered approaches combining API monitoring, rate limiting, response modification, and architectural innovations, with no single solution sufficient alone
- Detection of these attacks required sophisticated behavior analysis across thousands of accounts to identify patterns inconsistent with normal usage, setting new baselines for security vigilance
- Open-source alternatives and managed platforms like Runable offer ways to avoid proprietary model security vulnerabilities entirely while maintaining AI capability access
- The geopolitical context of US-China AI competition and chip export debates directly shapes both the motivation for attacks and the policy responses available

