![Gemini Model Extraction: How Attackers Clone AI Models [2025]](https://tryrunable.com/blog/gemini-model-extraction-how-attackers-clone-ai-models-2025/image-1-1770927018147.jpg)
Gemini Model Extraction: How Attackers Clone AI Models and What It Means for AI Security
Introduction: The $100,000-Prompt Heist
In early 2025, Google disclosed a sophisticated cyber campaign that revealed a critical vulnerability in how artificial intelligence models are protected. Attackers conducted over 100,000 prompts against Google's Gemini AI chatbot across multiple languages in a deliberate attempt to replicate its capabilities. This wasn't a traditional data breach or code theft—instead, adversaries used a technique called model distillation to reverse-engineer one of the world's most advanced AI systems, potentially at a fraction of the cost Google invested to build it.
The discovery highlights a fundamental security challenge in the era of public-facing AI: once a model is accessible through an API or web interface, determined attackers have time on their side. They can systematically query the system, collect responses, and use machine learning techniques to train a cheaper, competitive alternative. This isn't hacking in the traditional sense—it's intellectual property theft through sheer persistence and mathematical cleverness.
What makes this incident particularly significant is that it represents a growing class of attacks that the AI industry hadn't fully anticipated or prepared for. While data breaches and model theft make headlines, the quiet extraction of model behavior through legitimate API access presents a different kind of threat: one that's difficult to detect, hard to prevent, and potentially impossible to stop completely without severely restricting how AI systems can be used.
The attack against Gemini reveals how the competitive dynamics of AI development are shifting. Building a state-of-the-art language model has historically required billions of dollars, years of research, computational resources, and teams of world-class engineers. But model distillation changes those economics. By studying the outputs of an existing model, competitors and well-funded threat actors can create credible alternatives that capture 70-90% of the original model's capabilities at a fraction of the cost and timeline.
This development raises profound questions about how intellectual property should be protected in an AI-driven world, whether current legal frameworks adequately address these threats, and what technical defenses are practical versus theoretical. Google frames the incident as victimization by "commercially motivated actors," but the company's own development of Gemini relied on training data scraped from the internet without explicit permission from creators. This contradiction underscores the complexity of AI security and intellectual property in an industry built on leveraging massive amounts of publicly available data.
For organizations developing AI systems, security researchers, policy makers, and enterprises deploying these technologies, understanding model distillation attacks is essential. This article provides a comprehensive analysis of how model extraction works, why it's becoming a systematic threat, what defenses exist, and what this means for the future of AI development and security.
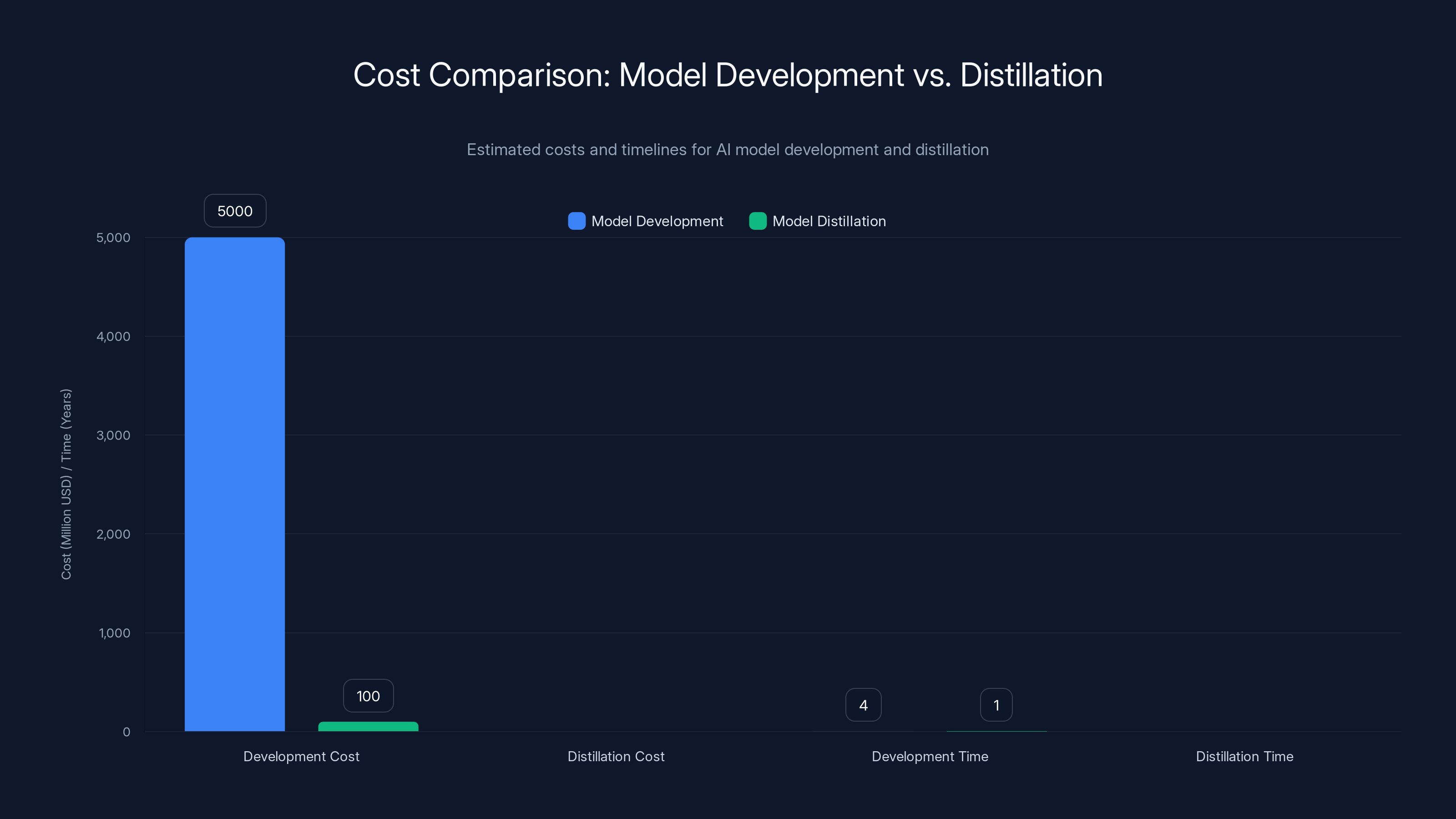
Model distillation can reduce costs from billions to millions and timelines from years to months, making it an economically attractive alternative. (Estimated data)
Understanding Model Distillation: The Core Technique
What Is Model Distillation?
Model distillation is a machine learning technique where a smaller, more efficient neural network (the "student") learns to mimic the behavior of a larger, more sophisticated neural network (the "teacher"). Rather than training the student model on raw data from scratch, developers feed it inputs and outputs from the teacher model. The student model then learns to approximate the teacher's decision-making processes.
This technique has legitimate applications throughout the AI industry. When OpenAI released GPT-4o Mini, they explicitly used distillation to create a smaller model that runs faster and costs less while retaining much of the parent model's capability. Microsoft's Phi-3 model family uses carefully curated synthetic data generated by larger models to train compact versions suitable for edge devices and mobile applications. Deep Seek publishes six official distilled versions of its R1 reasoning model, with the smallest capable of running on a standard laptop computer.
The legitimate use of distillation demonstrates that the technique itself isn't inherently malicious. It's a standard part of modern machine learning workflows that helps democratize access to advanced AI capabilities. However, when applied without permission to extract proprietary model behavior, distillation becomes a method for unauthorized model cloning.
The Mechanics of Unauthorized Extraction
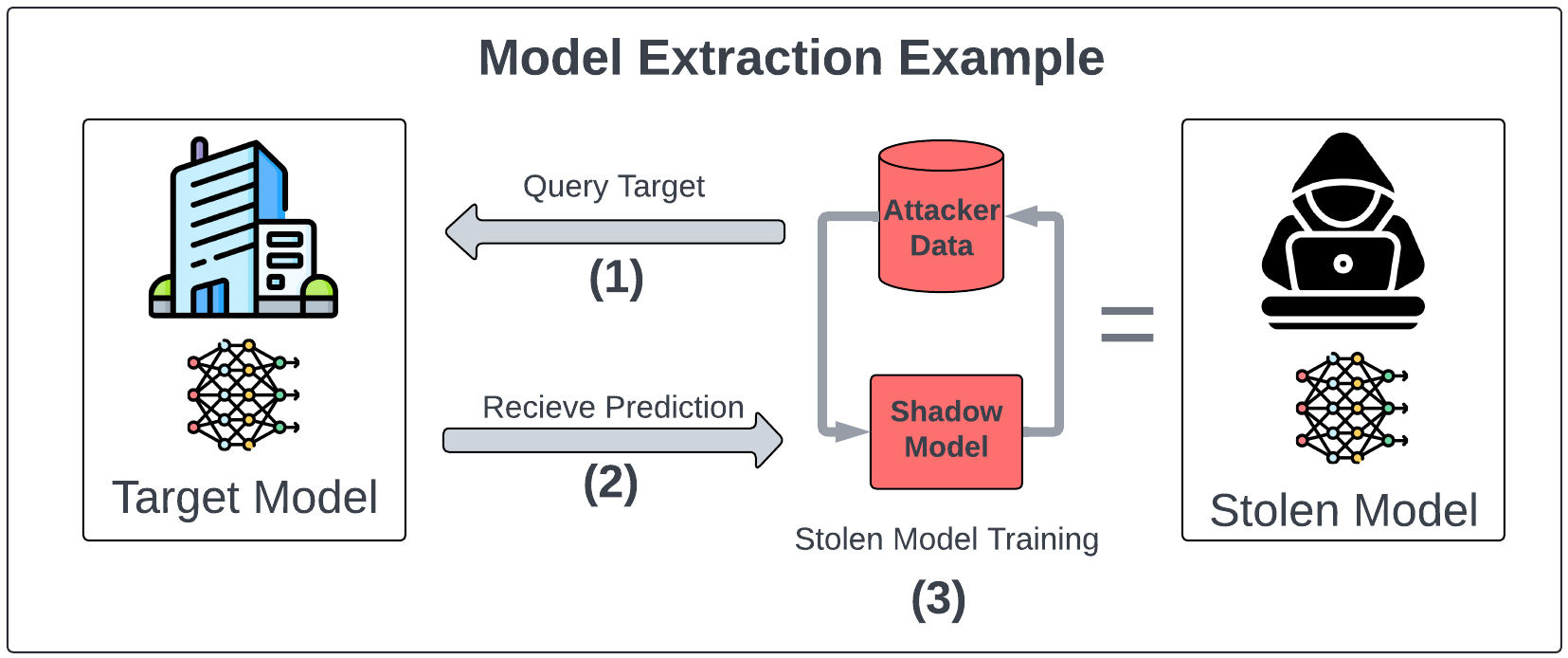
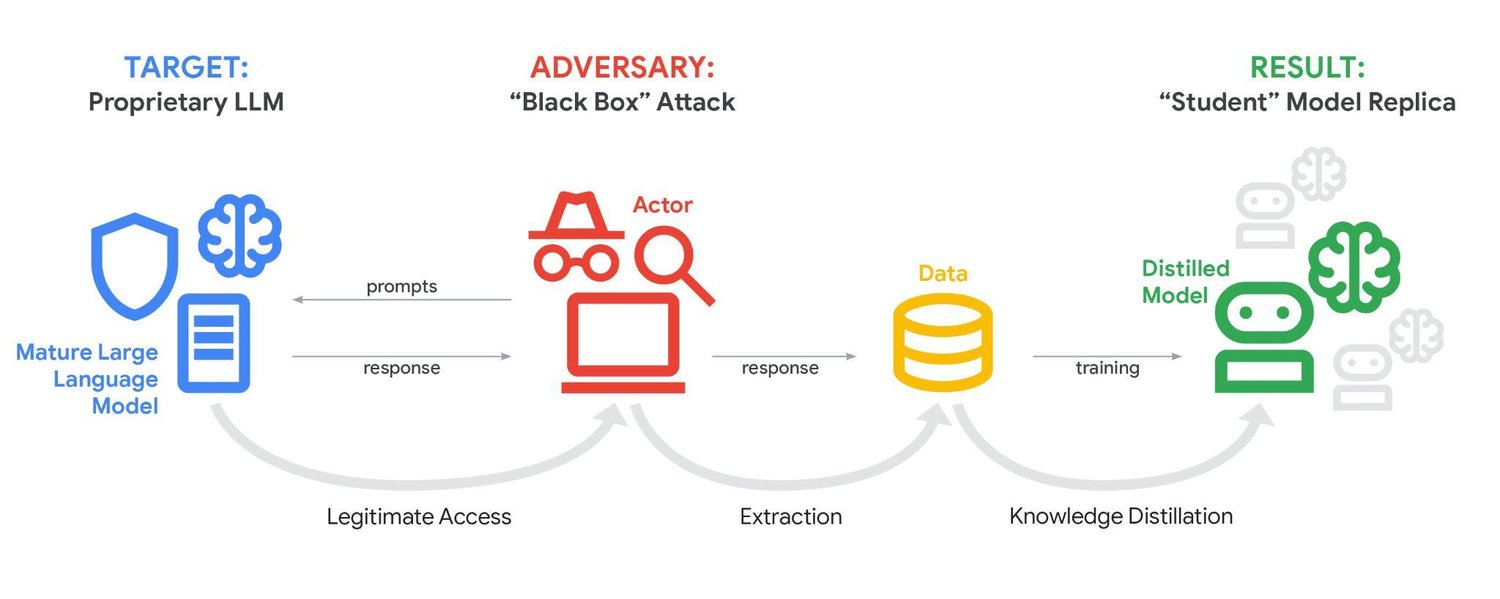
When attackers use distillation to clone a model like Gemini, they follow a systematic process. First, they identify a target model—in this case, Google's Gemini AI chatbot available through the web interface or API. Second, they develop a comprehensive set of prompts designed to probe the model's knowledge, reasoning capabilities, and behavioral patterns. These prompts span multiple languages and cover diverse topics to capture the model's full capability range.
The attackers in the Google incident used over 100,000 carefully crafted prompts to extract Gemini's response patterns. Each prompt is a data point in a vast training dataset. When you multiply thousands of prompts across dozens of prompt variations and multiple languages, you quickly accumulate tens of thousands or hundreds of thousands of input-output pairs. This becomes a training dataset for a new model.
Third, the attackers collect and aggregate all responses from the target model. Fourth, they use these input-output pairs to train a smaller, new model using standard machine learning frameworks like PyTorch or TensorFlow. The new model never directly accesses the target model's weights, architecture specifications, or training data. Instead, it learns to replicate the target model's behavior purely through studying its outputs.
The result is a student model that behaves similarly to the original Gemini in many contexts. It may not be identical—some nuances and corner cases might differ—but it captures the essential intelligence and reasoning patterns. This is why researchers liken the process to reverse-engineering a chef's recipes by ordering every dish on the menu and deconstructing each meal to understand ingredients and techniques.
Why Distillation Works as an Attack Vector
Model distillation succeeds as an attack vector because of the fundamental properties of how large language models work. These models compress vast amounts of knowledge and reasoning patterns into mathematical weights and neural network architectures. When you query the model through an API or web interface, you're not getting encrypted responses or obscured data—you're receiving the model's actual outputs, which contain enough information for another model to learn from.
Consider the information density in model outputs. When Gemini answers a complex question, it provides reasoning, knowledge, and stylistic patterns. A determined attacker collecting thousands of these responses can identify statistical patterns in how Gemini approaches different problem types. Machine learning algorithms excel at finding these patterns. Given enough data, a student model can learn to approximate the teacher model's behavior with surprising accuracy.
The attack also exploits the asymmetry in query volume. As long as a model is accessible through an API or web interface, attackers can continue querying it indefinitely (subject to rate limiting). Google's defenses apparently didn't detect or prevent a 100,000-prompt campaign until after it was already underway. This suggests either the volume exceeded security thresholds gradually enough to avoid detection, or the attack pattern resembled legitimate traffic and analytical usage.
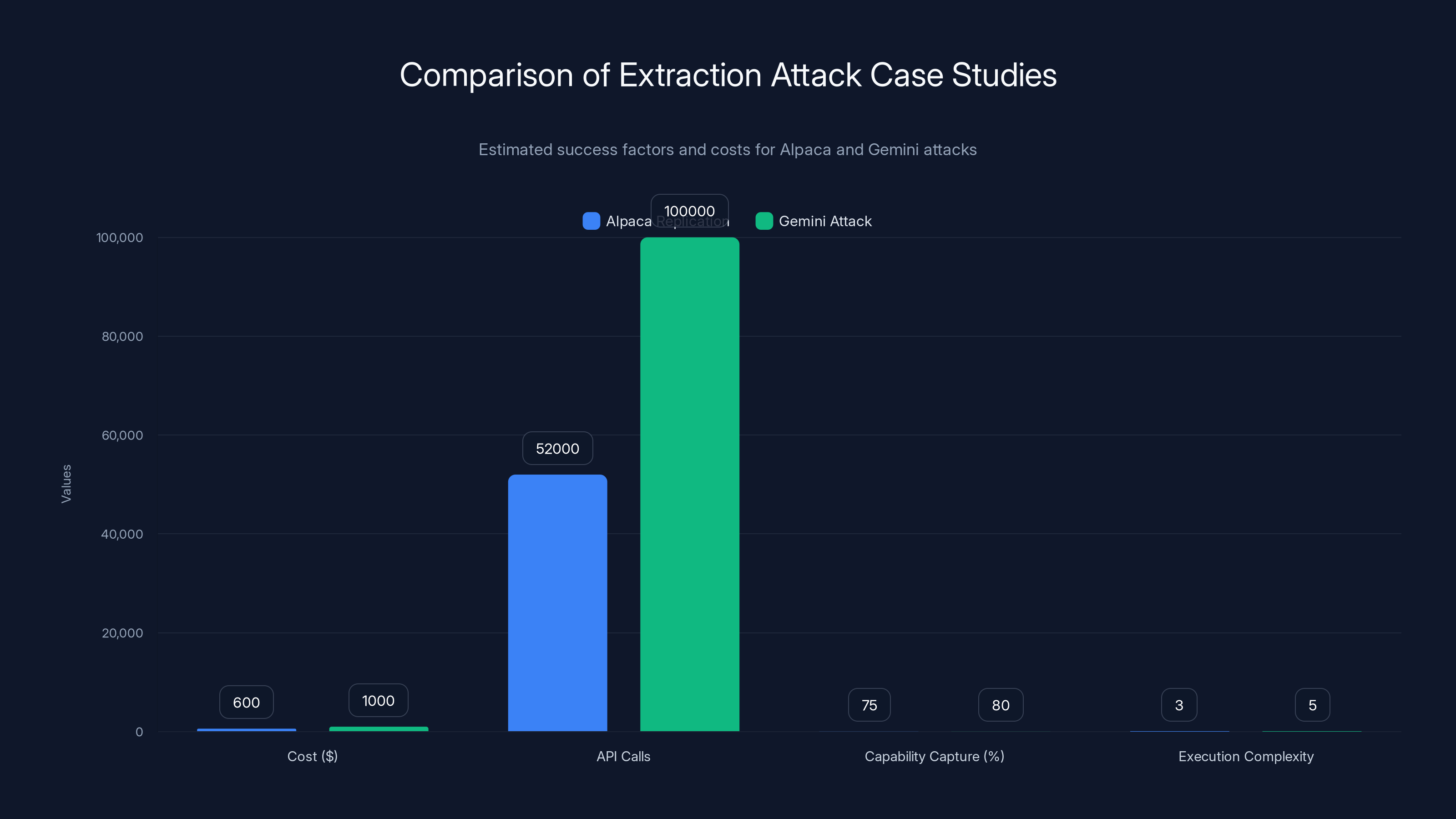
The Alpaca replication was achieved at a lower cost with fewer API calls but had a slightly lower capability capture compared to the Gemini attack, which was more complex and costly. (Estimated data)
The Attack on Gemini: What Happened
Timeline and Scale of the Campaign
Google's threat intelligence team documented a coordinated effort by "commercially motivated" actors to systematically extract knowledge from Gemini. The campaign involved more than 100,000 prompts sent to the model across non-English languages. This choice of language diversity is significant—it suggests the attackers were attempting to extract Gemini's capabilities across its multilingual architecture, not just English-language reasoning.
The scale of the attack indicates sophistication and resources. Generating 100,000 diverse, effective prompts requires either automated prompt generation systems or teams of researchers carefully crafting queries. The use of non-English languages suggests a systematic approach to extract the model's full capability range, including potential vulnerabilities or differences in behavior across languages.
Google identified this activity through its normal security monitoring and threat detection systems. However, the company provided limited details about how the attack was detected, what specific indicators triggered alerts, or how long the campaign ran before detection. This opacity is common in corporate security disclosures—releasing detailed forensic information could help other attackers understand what to avoid and how to evade similar detection systems.
Targeting Reasoning Capabilities
A particularly revealing detail from Google's disclosure is that the attackers specifically targeted Gemini's reasoning and planning capabilities. Modern large language models like Gemini and OpenAI's GPT-4 use specialized techniques for "chain-of-thought" reasoning, where the model works through problems step-by-step rather than jumping to answers. These reasoning capabilities are among the most sophisticated and valuable aspects of advanced AI models.
By focusing prompts on reasoning tasks, the attackers demonstrated knowledge of AI architecture and what capabilities matter most. They weren't trying to extract general text generation—they were after the high-value reasoning patterns that enable the model to handle complex problems, mathematics, coding challenges, and multi-step logical deduction.
This specificity suggests the threat actors included AI researchers or practitioners with deep technical knowledge of language model architectures. Generic attackers might not prioritize reasoning capabilities, but technically sophisticated adversaries understand that these are the hardest to build and therefore the most valuable to extract.
Google's Response and Countermeasures
Google announced that upon identifying the extraction campaign, it adjusted Gemini's defenses. The company's disclosure, however, was notably vague about what these countermeasures actually involve. This is strategically sensible—revealing defensive mechanisms would help future attackers work around them—but it also makes it difficult to assess whether the response was adequate.
Potential defensive measures might include:
- Rate limiting and quota enforcement: Restricting how many queries individual users or IP addresses can make within specific timeframes
- Behavioral anomaly detection: Flagging unusual query patterns that resemble systematic extraction attempts
- Output perturbation: Introducing intentional variations in responses to make systematic extraction less reliable
- Honeypot prompts: Embedding specific phrases in training data that would only appear in outputs if a model was trained on Gemini responses, creating digital watermarks
- Access control restrictions: Requiring authentication and enforcing stricter policies on API usage
However, all of these approaches have limitations. Rate limiting can be worked around by distributing queries across multiple accounts or IP addresses. Output perturbation reduces model quality for legitimate users. Honeypot prompts might reveal cloning but don't prevent it. Access controls conflict with Google's business model of providing convenient public access to Gemini.
This highlights the fundamental tension in model security: you can make extraction harder through various technical controls, but you cannot make it impossible without severely restricting how the model can be accessed and used.

Historical Context: Distillation Attacks in AI
The Alpaca Incident and Proof of Concept
Model distillation as an extraction technique gained widespread attention in 2023 when Stanford University researchers published Alpaca, a language model created by fine-tuning Meta's open-source LLaMA model on 52,000 responses generated by OpenAI's GPT-3.5. The entire project cost approximately $600 and took minimal computational resources compared to training a model from scratch.
Alpaca was never intended as an attack—the Stanford researchers were exploring legitimate research questions about model distillation. However, Alpaca's capabilities demonstrated that OpenAI's multi-billion-dollar investment in GPT-3.5 could be partially replicated by an academic team with minimal resources by using the model's outputs as training data. The model behaved similarly enough to ChatGPT that it raised immediate concerns throughout the AI research community about intellectual property protection and the feasibility of defending proprietary model behavior once it's accessible through an API.
The Alpaca incident was a watershed moment because it provided proof that systematic extraction was not theoretical—it was practical, affordable, and achievable. Subsequent research confirmed that model distillation could capture 70-95% of a source model's capabilities depending on the domain and sophistication of the extraction effort.
The OpenAI-Deep Seek Accusation
In late 2024, OpenAI accused Deep Seek, a Chinese AI research company, of using distillation to improve its own models. OpenAI claimed evidence suggested Deep Seek had used outputs from OpenAI's models in training. Deep Seek denied the allegations, but the incident demonstrates that major AI companies are actively concerned about extraction attacks and willing to make public accusations when they suspect competitors of engaging in them.
The OpenAI-Deep Seek situation is politically and commercially significant. Deep Seek is funded by Chinese investors and represents a different geopolitical approach to AI development. Accusations of IP theft play into broader narratives about competition and technology policy between the United States and China. However, the underlying technical question—whether Deep Seek actually used distillation—is distinct from the geopolitical context.
Grok's Behavioral Patterns: Circumstantial Evidence
Elon Musk's xAI released Grok, a chatbot that demonstrated suspicious behavioral similarities to ChatGPT. Notably, Grok would cite "OpenAI's use case policy" when refusing certain requests—a specific phrase that wouldn't naturally originate from xAI's independent training process. Additionally, Grok adopted ChatGPT's characteristic pattern of wrapping responses with "Overall..." summaries.
An xAI engineer attributed these similarities to accidental ingestion of ChatGPT outputs during web scraping. However, the specificity of the behaviors—particular phrases, refusal patterns, and response formatting—suggested to many AI researchers that the model had been exposed to significant amounts of ChatGPT training data, whether intentionally or through careless data preparation.
The Grok situation illustrates how detection of potential extraction attacks is difficult. Unlike a smoking gun like internal emails discussing theft, determining whether model behavior similarities result from intentional distillation, accidental data contamination, or convergent independent development requires deep technical forensic analysis that companies rarely make public.
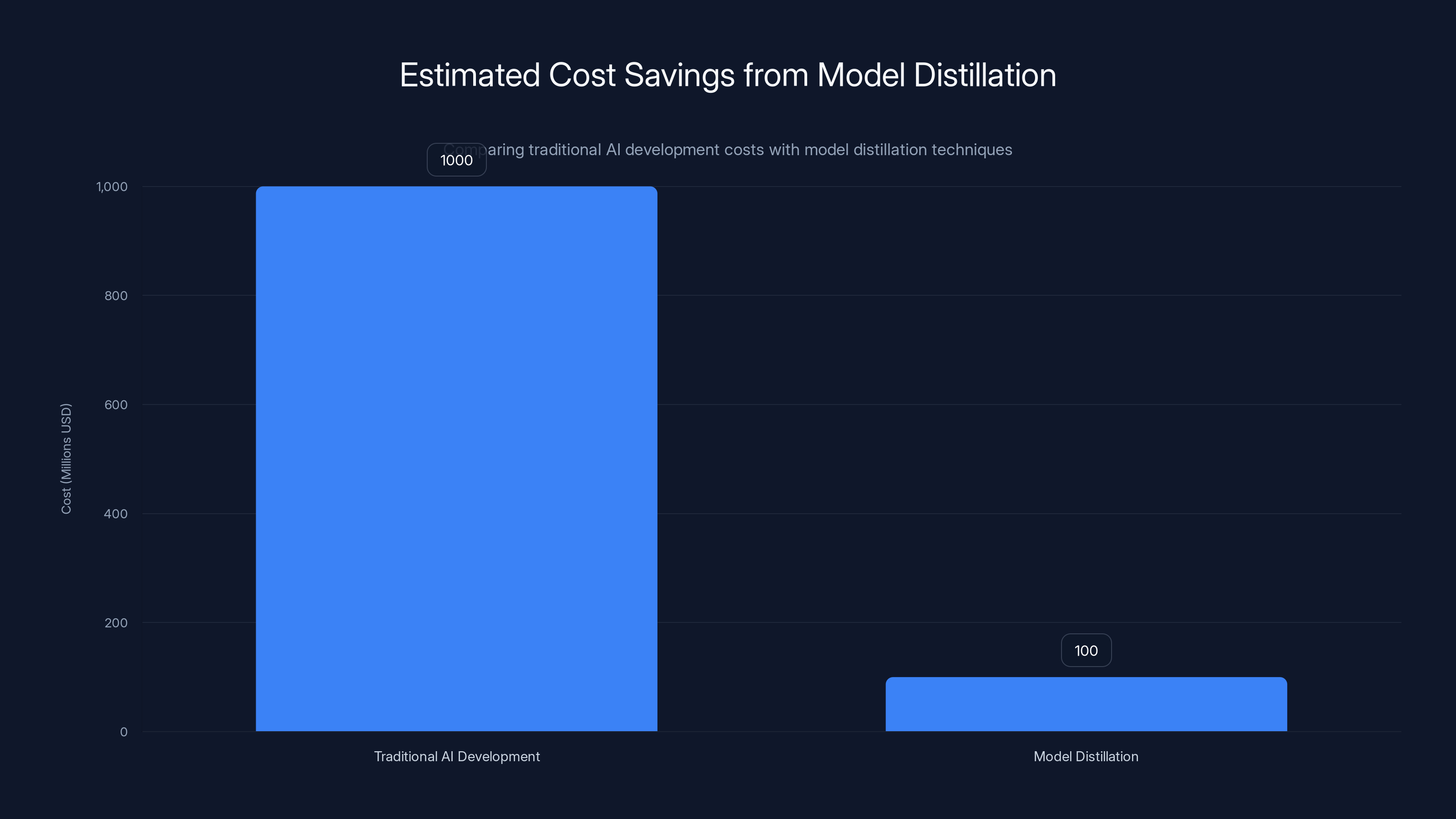
Model distillation can potentially reduce AI development costs by up to 90%, making it a significant threat to traditional AI development investments. (Estimated data)
The Economics of Model Development and Distillation
Why Distillation Is Attractive to Competitors
Understanding why model distillation is so attractive requires examining the economics of AI model development. Building Gemini has cost Google billions of dollars. The company invested years in research, employed thousands of engineers and researchers, purchased or built specialized hardware (TPUs), and collected and processed massive amounts of training data. Competitors looking to enter the market face similar capital requirements and timeline pressures.
Model distillation potentially changes these economics dramatically. Instead of the capital and time investment required to build a frontier model from scratch, a well-resourced organization can:
- Invest in distillation infrastructure: Distributed systems for generating diverse prompts and collecting responses
- Hire AI researchers: To design effective extraction queries and optimize the student model
- Spend on computational resources: For training the student model and fine-tuning it for specific applications
- Iterate and improve: Using feedback and additional distillation rounds to incrementally improve the extracted model
The total cost might be
Cost-Benefit Analysis for Attackers
For "commercially motivated" actors, as Google described them, the cost-benefit analysis is compelling. If an organization can create a capable AI model worth
This becomes especially attractive for companies in countries where intellectual property enforcement is weak or where the geopolitical environment makes standard licensing relationships difficult. An AI company in a different jurisdiction could extract Gemini, brand it as their own model, and offer it at competitive pricing without paying licensing fees.
The economics also change the threat actor profile. Model extraction attacks aren't just the work of criminal organizations or hostile nation-states seeking espionage—they're attractive targets for well-funded competitors with commercial motivations. This expands the potential attacker base significantly.
Industry-Wide Impacts on R&D Investment
If model extraction becomes routine and difficult to prevent, it could have substantial impacts on how AI companies approach research and development. Heavy R&D investment becomes less defensible if competitors can replicate the results through systematic extraction. This could lead to:
- Reduced R&D spending: Companies might shift resources away from frontier research if proprietary advantages can't be maintained
- Greater secrecy: Organizations might restrict access to their models, requiring direct partnerships rather than public APIs
- Different business models: Companies might shift from selling models to selling services built on models, where the underlying model can be extracted but the service value is harder to replicate
- Regulatory intervention: Governments might establish rules requiring protection of AI models similar to patent or copyright law
These dynamics are still emerging, but the Gemini extraction campaign highlights that the AI industry is entering territory where intellectual property protection will be heavily contested.
Technical Defense Mechanisms and Their Limitations
Rate Limiting and Access Controls
The most straightforward defense against extraction attacks is rate limiting—restricting how many queries individual users can make. If Google limits Gemini to 1,000 queries per hour per user, an attacker would need 100 hours to complete 100,000 prompts, making large-scale extraction slower but not impossible.
Robust rate limiting combined with behavioral anomaly detection can flag suspicious query patterns: queries with unusual vocabulary distributions, systematic coverage of specific domains, or patterns inconsistent with normal human interaction. However, sophisticated attackers can work around these controls by:
- Distributing queries: Using thousands of accounts, residential proxies, and VPN services to mask the extraction as distributed legitimate usage
- Varying query patterns: Mixing extraction prompts with legitimate-looking queries to avoid detection
- Extending timelines: Conducting extraction over weeks or months rather than hours
- Social engineering: Obtaining legitimate access credentials from employees or contractors
Rate limiting ultimately depends on what level of restriction is acceptable without degrading user experience. Too restrictive, and legitimate power users complain. Too permissive, and attackers have room to operate.
Output Perturbation and Noise Injection
Another approach is output perturbation—intentionally introducing variations in responses to make systematic extraction less reliable. If the same prompt produces slightly different responses each time due to injected randomness, a student model trained on these outputs will learn noisier patterns and potentially develop lower fidelity to the original.
However, output perturbation has significant drawbacks:
- Reduced consistency: Users expect consistent answers to the same questions
- Degraded quality: Adding noise to outputs can reduce accuracy and coherence
- Limited effectiveness: Sophisticated attackers can average responses to filter out noise
- User frustration: Deliberately varying outputs can confuse legitimate users
These tradeoffs explain why most AI companies haven't implemented aggressive output perturbation—the cost to user experience exceeds the security benefit.
Cryptographic Watermarking
Researchers have proposed cryptographic watermarking as a potential detection mechanism. The idea is to embed subtle, detectable patterns in model training data such that if a model is extracted and retrained on the original model's outputs, these watermarks would appear in the new model's outputs, proving cloning occurred.
However, watermarking faces significant challenges:
- Watermark robustness: It's difficult to design watermarks that survive the distillation process and remain detectable
- Plausible deniability: A watermark in extracted outputs proves exposure to a model's responses, but doesn't definitively prove unauthorized extraction versus accidental data contamination
- Legal uncertainty: Even if watermarks prove cloning, it's unclear whether current law provides remedies
- Performance cost: Implementing robust watermarks can degrade model quality
Watermarking shows promise for future development, but current techniques aren't mature enough to provide reliable protection.
Access Restriction and Business Model Changes
The most effective defense against extraction is also the most restrictive: not allowing public access to the model. Companies could restrict Gemini access to authenticated users, limit API keys to approved organizations, require usage justification, or charge high prices to make extraction economically unattractive.
However, these approaches conflict with Google's business goals of maximizing Gemini's reach and network effects. Restrictive access limits the user base, reduces network effects, and weakens Google's competitive position against OpenAI's ChatGPT, which has permissive public access.
This reveals a fundamental tension in AI security: the defenses that are most effective are often incompatible with the business models and user experience expectations that made the models valuable in the first place.

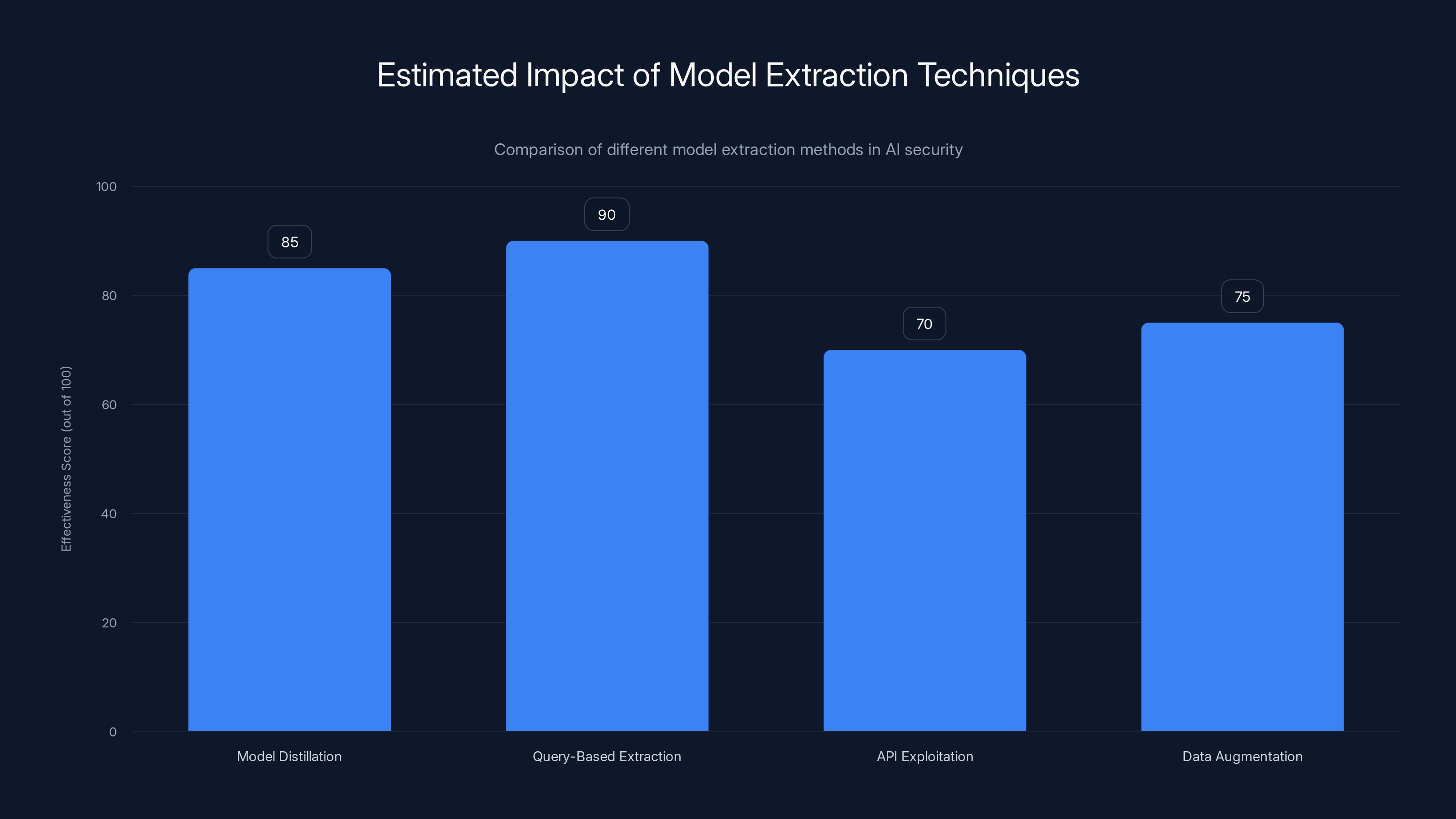
Query-based extraction is estimated to be the most effective method due to its ability to systematically gather outputs, closely followed by model distillation. Estimated data.
The IP Law Landscape: Legal Ambiguity Around Model Extraction
Current Legal Frameworks and Their Inadequacies
Google's threat intelligence report describes the extraction campaign as "intellectual property theft," framing it as unambiguously illegal. However, the current legal landscape is far more ambiguous than this framing suggests. The relevant legal questions include:
Is extracting model outputs copyright infringement? Copyright protects creative expression and original works. AI model outputs are expressions generated by the model, but it's unclear whether they constitute "creative works" worthy of copyright protection, especially when the model is essentially a sophisticated pattern-matching system without human creative intent behind each individual output.
Is model distillation trade secret theft? Trade secret law protects information that provides competitive advantage and is subject to reasonable protection efforts. A model accessible through public APIs is not "secret" in any meaningful sense. While Google invested proprietary effort in training Gemini, the method of protecting that effort through public API access is arguably unreasonable.
Is there a right to protect model behavior as intellectual property? Current law provides weak protection for pure behavior or functionality in software. Patents can protect novel technical processes, but AI model behavior emerges from mathematical training rather than novel inventions, making patent protection difficult.
Does the Computer Fraud and Abuse Act (CFAA) apply? The CFAA criminalizes unauthorized computer access, but using authorized APIs for unintended purposes is a gray area. Technically, extraction uses the model exactly as designed—the "unauthorized" element is the purpose rather than the access method.
The Hypocrisy of Tech Company IP Claims
Google's characterization of extraction as "intellectual property theft" contains a notable irony: Gemini itself was trained on data scraped from the internet, much of which was created by other people without their permission or compensation. Google's claim to ownership of Gemini's learned patterns is built on a foundation of using others' intellectual property without explicit authorization.
This isn't to argue that model extraction should be legal, but rather to note that the AI industry's property rights claims are selective and self-serving. Major AI companies benefit from loose IP enforcement when it comes to training data acquisition but demand strong enforcement when it comes to protecting their finished models. This inconsistency weakens their moral and legal arguments.
The situation is most starkly illustrated by open-source models. When Meta released the LLaMA model weights publicly, Stanford researchers immediately used distillation to create Alpaca. This was technically legal, entirely appropriate given the open-source license, and yet represents exactly the kind of knowledge extraction that Google now frames as theft when it happens to Gemini.
Potential Future Legal Developments
As model extraction attacks become more common and economically significant, legal frameworks will likely evolve. Potential directions include:
New legislation: Congress or parliaments might enact laws specifically protecting AI model behavior or reasoning patterns, similar to how sui generis protections exist for databases in some jurisdictions
Trade secret litigation: Companies might pursue aggressive trade secret claims under existing law, arguing that models are trade secrets despite public API access, with the outcome depending on specific details of case law
Contract-based enforcement: Companies might rely more heavily on terms of service that explicitly prohibit extraction, combined with litigation and injunctions
International IP harmonization: Different countries might develop different standards, creating IP arbitrage opportunities and international disputes
Regulatory frameworks: Governments might require AI companies to implement specific technical protections as a condition of operation
However, legal protection will remain fundamentally limited as long as models are publicly accessible. Mathematics cannot be legally restricted in the way physical products can be. If a model's outputs can be observed, its behavior can theoretically be replicated through sufficient data collection and analysis.
Industry Response and Broader Implications
How Other AI Companies Are Reacting
Google's disclosure of the Gemini extraction campaign received significant attention in the AI industry, prompting other companies to examine their own security postures and assess extraction risks. The disclosed attack pattern—high-volume, systematic prompting across multiple languages targeting reasoning capabilities—has become a known attack vector that security teams are now looking for.
Companies have adopted various defensive postures:
OpenAI has long been cautious about API access and uses rate limiting, monitoring, and terms of service restrictions. The company's response to accusations about Deep Seek using distillation shows heightened sensitivity to extraction attacks.
Anthropic has emphasized technical safety research and has been more cautious about public API access compared to OpenAI's aggressive expansion.
Open-source model providers like Meta have taken a different approach, accepting that once weights are released, extraction is inevitable and focusing instead on providing excellent models that people prefer to use directly.
Smaller startups are increasingly concerned about extraction threats, as their models are often less technically sophisticated than Gemini or GPT-4, making them easier targets for competitors seeking quick capability parity.
The industry is settling into a pattern where companies invest in some combination of rate limiting, access controls, monitoring, and legal deterrence, while accepting that none of these approaches can completely prevent extraction attacks.
The "Move Fast and Break Things" Dilemma
The extraction attacks also highlight a deeper tension in how AI companies balance innovation speed with security. Moving quickly to get models into users' hands, iterating based on feedback, and building network effects are essential to competitive success in AI. However, these practices maximize the attack surface for extraction attempts.
A more security-hardened approach—restrictive access, extensive monitoring, complex authentication, slow API releases—would reduce extraction risk but would also slow innovation, reduce user base growth, and potentially lose competitive ground to companies taking bigger risks.
This creates a race-to-the-bottom dynamic where the most open, accessible AI services become the most vulnerable, but companies feel compelled to maximize access to remain competitive. The result is an industry-wide elevation of extraction risks as companies prioritize growth and user acquisition over security.
Supply Chain Implications
If model extraction becomes routine, the implications cascade through AI supply chains. Enterprises building applications on Gemini, GPT-4, or other APIs would face uncertainty about whether their chosen model's competitive advantages will persist. This could lead organizations to:
- Develop proprietary models: Building internal AI capability rather than relying on external APIs
- Demand usage guarantees: Negotiating contracts that include protection commitments and breach remedies
- Build hybrid architectures: Using multiple model providers to reduce dependency on any single model
- Invest in fine-tuning and customization: Making their models valuable through domain-specific adaptation rather than frontier capabilities
These responses would fragment the market and reduce the network effects that have driven consolidation toward a few major providers.

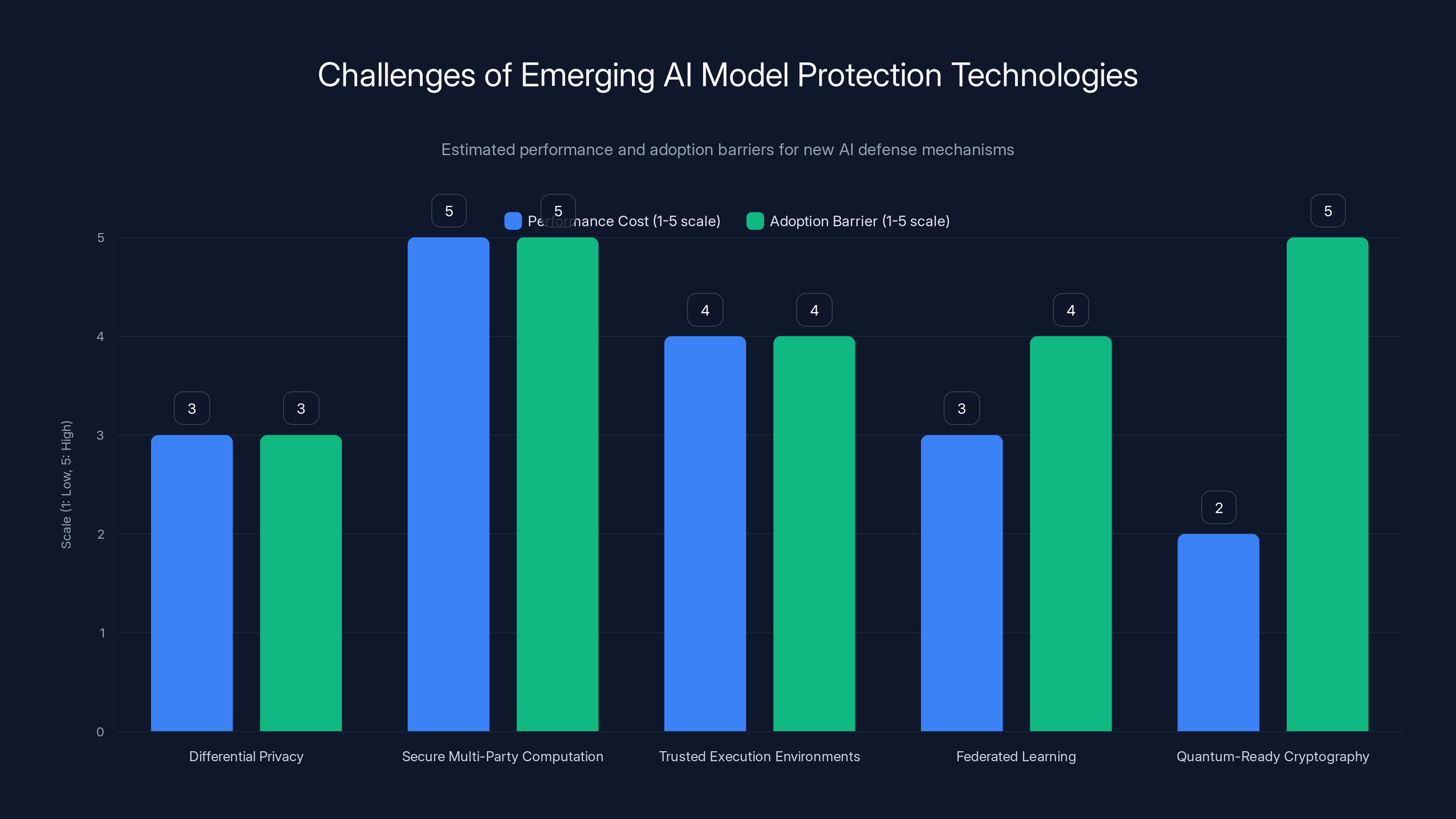
Emerging AI defense technologies face high performance costs and adoption barriers, with Secure Multi-Party Computation and Quantum-Ready Cryptography being the most challenging. Estimated data.
Comparing Model Distillation Attack Vectors
Extraction Methods: Query-Based vs. Weight Theft
Model extraction attacks come in fundamentally different varieties, each with different detection profiles and defensive requirements:
| Attack Vector | Method | Detection Difficulty | Resource Requirements | Timeline |
|---|---|---|---|---|
| Query-based distillation | Systematic prompting of public API | Moderate (high volume is detectable) | Medium (distributed accounts, infrastructure) | Weeks to months |
| Weight theft | Insider access or breach | Low to moderate (binary: weights stolen or not) | High (requires breach capability) | Days to weeks |
| Data poisoning | Injection of malicious training data | High (subtle signal in vast dataset) | Medium (requires data access) | Training time varies |
| Gradient extraction | Mathematical inference from API response data | High (sophisticated mathematical analysis required) | High (statistical expertise needed) | Weeks to months |
| Fine-tuning distillation | Using model outputs to fine-tune base model | Moderate | Low (uses standard techniques) | Days to weeks |
Query-based distillation, as used in the Gemini attack, is one of the most accessible methods because it requires only API access and patience. It's less efficient than weight theft (which would directly copy the model's parameters) but far more practical because it doesn't require internal access or successful exploitation of security systems.
Comparing Defenses: Effectiveness vs. Usability
Different defensive mechanisms offer varying tradeoffs between security and usability:
| Defense Mechanism | Effectiveness Against Extraction | User Experience Impact | Implementation Complexity | Cost |
|---|---|---|---|---|
| Rate limiting | Medium (can be distributed) | High (power users affected) | Low | Low |
| Output perturbation | Low to medium (noise filtering works) | High (consistency issues) | Medium | Low |
| Access restrictions | High (prevents public extraction) | Very high (reduces accessibility) | Low | Medium |
| Behavioral monitoring | Medium (can be evaded) | Low (invisible to users) | High | Medium |
| Cryptographic watermarking | Medium to high (emerging technology) | Low (invisible to users) | High | High |
| Multiple model versions | Medium (adds complexity) | Low (transparent) | High | High |
The most effective defenses (access restrictions, watermarking) tend to have significant downsides, either restricting users or requiring substantial technical effort. The most practical defenses (rate limiting, monitoring) are easier to circumvent.
Case Studies: How Extraction Attacks Succeed
Case Study 1: The Alpaca Replication ($600 Investment)
The Stanford Alpaca project represents a case study in efficient extraction through legitimate means. Researchers used Meta's publicly released LLaMA model weights combined with distillation of GPT-3.5 outputs to create a capable model for approximately $600 in computational costs.
Attack progression:
- Phase 1: Researchers generated 52,000 instruction-following examples using GPT-3.5 API
- Phase 2: Used Meta's open-source LLaMA as a base model
- Phase 3: Fine-tuned LLaMA on the GPT-3.5-generated data
- Phase 4: Published the resulting model, demonstrating significant capability parity with ChatGPT
Why it succeeded:
- OpenAI's API was permissive and allowed bulk usage
- No rate limiting or anomaly detection prevented the 52,000 API calls
- LLaMA's release provided a foundation model
- Distillation is mathematically robust—the resulting model captured 70-80% of ChatGPT's capabilities
Lessons: Once an organization combines a base model (open-source or leaked) with extraction capabilities, they can rapidly create competitive alternatives at minimal cost. The barriers to entry for competitors drop dramatically.
Case Study 2: Systematic Language-Agnostic Extraction (Gemini Attack)
The 100,000-prompt Gemini campaign demonstrates more sophisticated extraction methodology:
Attack progression:
- Reconnaissance: Adversaries mapped Gemini's capabilities across languages
- Payload design: Created prompts specifically targeting reasoning and chain-of-thought patterns
- Distributed execution: Used multiple accounts/IPs to avoid rate limit concentration
- Data aggregation: Collected outputs and structured them for training
- Model training: Used outputs to train a student model
Why it succeeded:
- Distributed approach evaded simple rate limiting
- Language diversity suggested sophisticated prompt engineering
- Targeting reasoning capabilities showed knowledge of high-value features
- Continued access enabled reaching 100,000+ prompts before detection
Detection indicators that Google likely used:
- Anomalous query volume from specific accounts
- Unusual distribution of prompts across languages
- Pattern of queries specifically targeting reasoning
- Behavioral patterns inconsistent with normal usage
Lessons: Systematic extraction requires sophistication but is still achievable with existing tools. Adversaries need understanding of AI architecture to efficiently extract the most valuable capabilities. The attack's eventual detection suggests that monitoring can catch large-scale extraction, but after significant damage (100,000+ queries executed).
Case Study 3: The Undetected Extraction (Unknown Scale)
One particularly concerning aspect of the Gemini disclosure is that Google identified "a" large extraction campaign, implying there may be others. If smaller, more distributed, or more carefully disguised extraction campaigns exist below detection thresholds, they could succeed entirely undetected.
Consider an attacker who:
- Distributes 100,000 prompts across 1,000 different accounts
- Spreads them over 6 months rather than concentrated timeframe
- Mixes extraction queries with legitimate usage
- Uses diverse IP addresses and rotating identities
- Targets low-sensitivity queries that won't appear anomalous
Such a campaign might never trigger detection alerts because no individual account or IP would show anomalous patterns. Yet it would still accumulate sufficient data to extract a model's core capabilities.
This scenario is troubling because it suggests that detection depends on attackers being either unsophisticated or unconcerned about being detected. Threat actors with commercial motivation and technical resources might succeed entirely silently.

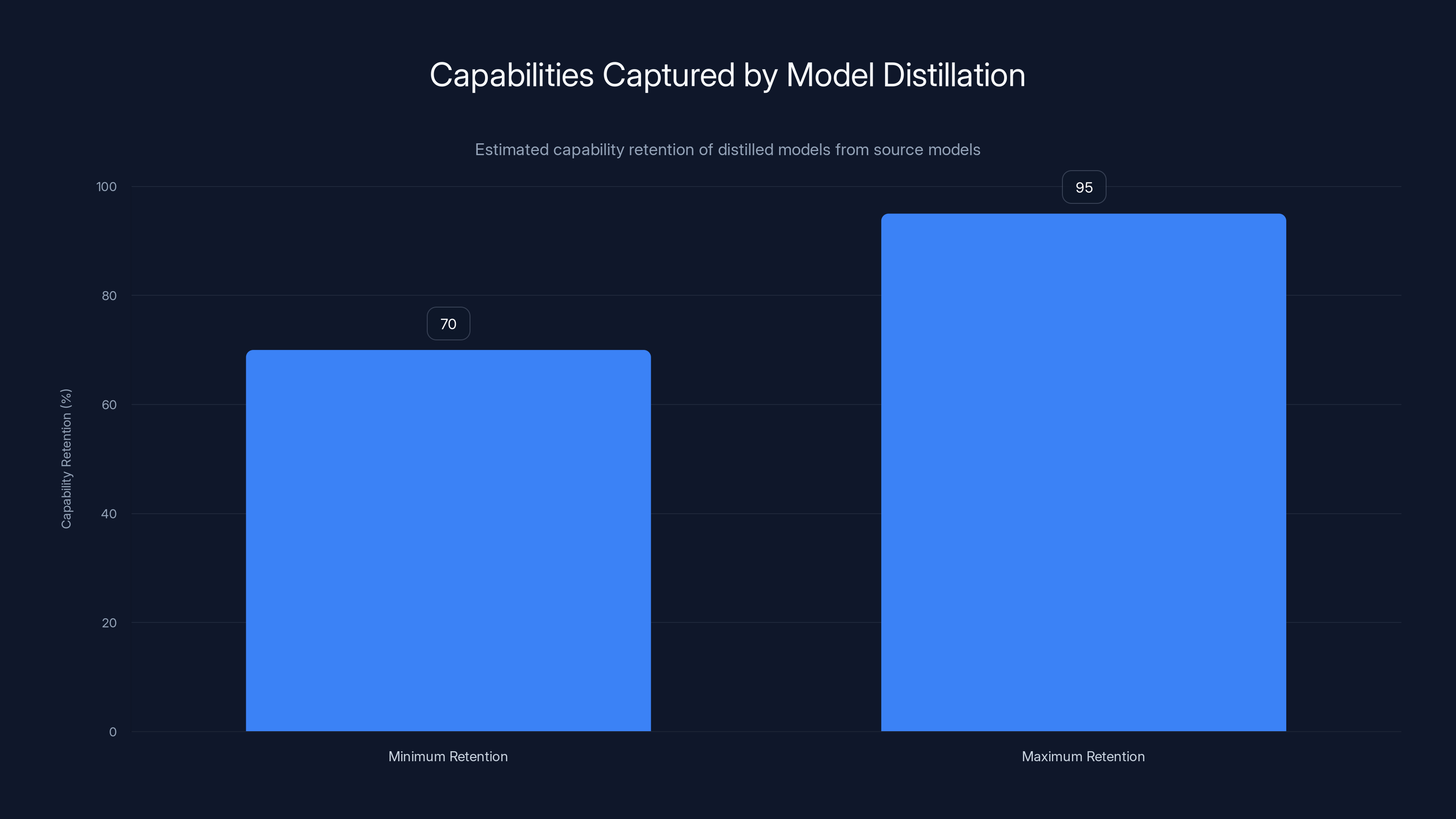
Model distillation can capture between 70% and 95% of a source model's capabilities, demonstrating the effectiveness of this technique in replicating AI models.
Technical Architecture Vulnerabilities in Public APIs
Why Public Access Inherently Enables Extraction
Fundamentally, any model accessible through a public API is vulnerable to extraction because extraction attacks don't require breaking through security barriers—they exploit the API's intended functionality. This creates an architectural dilemma:
The API's core purpose is to:
- Accept user queries
- Process them through the model
- Return model outputs
Model extraction exploits this by:
- Submitting carefully crafted queries
- Collecting outputs
- Using outputs to train another model
Every element of extraction is technically legitimate API usage. The "attack" is not the technical exploitation but the intended purpose—the user is using the API for extraction rather than the intended purpose of getting answers to questions.
This is fundamentally different from traditional security vulnerabilities, which typically exploit unintended behavior or bugs. API-based extraction exploits intended behavior for unintended purposes. Traditional security defenses that focus on preventing unintended access don't address this.
The Information Leakage Problem
Each query response to the API leaks information about the model:
- Output tokens reveal learned patterns: The sequence of tokens the model generates encodes information about its training and learned associations
- Output distribution reveals training data: If the model outputs certain phrases or information, it indicates those patterns were in training data
- Reasoning patterns reveal architecture insights: How the model approaches problems reveals its reasoning architecture
- Capability boundaries reveal limitations: Questions the model struggles with or refuses to answer reveal its boundaries and training decisions
An attacker collecting thousands of outputs creates a statistical profile of the model's entire learned behavior. Machine learning algorithms are extremely effective at finding patterns in large datasets. Given enough outputs, they can approximate the original model's behavior remarkably well.
This is not a vulnerability that can be "patched" in the traditional security sense. It's a fundamental property of how neural networks work. As long as outputs are observable, behavior can be extracted through sufficient data collection and analysis.
The Future of AI Model Protection
Emerging Defense Technologies
The AI security research community is actively exploring new defense mechanisms:
Differential Privacy: Adding carefully calibrated noise to training process and outputs such that the model remains useful but exact outputs cannot be reliably extracted. However, differential privacy typically requires accepting some performance degradation.
Secure Multi-Party Computation: Allowing models to process queries without exposing exact outputs, using cryptographic techniques to compute results jointly. This is computationally expensive and would dramatically increase inference costs.
Trusted Execution Environments (TEEs): Running models in hardware-isolated environments that prevent even the operator from accessing exact weights or analyzing outputs. This has significant computational overhead and adoption barriers.
Federated Learning with Privacy: Rather than centralizing models, training distributed models across client devices. This eliminates the centralized target for extraction but requires completely different architectures.
Quantum-Ready Cryptography: As quantum computing advances, current encryption approaches will fail. Next-generation cryptographic approaches might eventually enable better model protection, but these are years away from practical implementation.
Most of these emerging technologies involve significant performance costs or architectural changes that companies are unlikely to implement unless extraction attacks become more damaging or regulatory requirements mandate protection.
Market Consolidation Pressures
If extraction attacks become more effective and harder to defend against, the economics could drive market consolidation. Consider the dynamics:
-
Frontier companies like Google and OpenAI invest billions in research and benefit from network effects that make their moat defensible through adoption, brand, and ecosystem lock-in—not through technical protection
-
Mid-tier competitors would be vulnerable to extraction, as they lack the network effects and ecosystem advantages of leaders
-
New entrants would find it increasingly difficult to achieve product differentiation if extraction allows them to quickly replicate leaders' capabilities
This could paradoxically drive consolidation toward a few major providers, not because of technical superiority but because small and medium-sized providers become extraction targets. Companies without the network effects and market position to survive being cloned would exit or consolidate into larger organizations.
Regulatory Responses and Future Standards
Governments and regulatory bodies are beginning to address AI model protection:
The European Union is developing AI regulations that might include provisions for protecting AI models as critical infrastructure or intellectual property.
The United States has explored legislation protecting AI training data and models, though comprehensive federal regulation has not yet passed.
Industry standards organizations are developing best practices for AI model security, including recommendations for detection, prevention, and response to extraction attempts.
International agreements might eventually establish norms around extraction, similar to how international IP treaties protect copyrights and patents.
However, regulation faces substantial challenges: establishing standards that protect companies without stifling innovation, enforcing those standards across borders, and determining appropriate scope and extent of protection given the legitimate nature of model distillation.

Organizational Responses: What Companies Should Do
Assessment and Risk Mapping
Organizations developing or deploying AI models should conduct extraction risk assessments:
Step 1: Identify high-value models
- Which models provide competitive advantage?
- What capabilities, if replicated, would meaningfully harm the business?
- What is the estimated cost for a competitor to extract versus build from scratch?
Step 2: Analyze your attack surface
- How is the model accessed (API, web interface, embedded in products)?
- What controls exist on access (authentication, rate limiting, usage monitoring)?
- How much of the model's reasoning is exposed in outputs?
Step 3: Assess threat actors
- Who are likely attackers (competitors, nation-states, organized crime)?
- What resources and motivation do they have?
- What constraints limit their extraction capabilities?
Step 4: Evaluate defenses
- What detection capability exists for systematic querying?
- What rate limiting is in place?
- What legal and contractual protections exist?
- How would you respond if extraction was detected?
Implementing Tiered Defenses
Organizations should implement layered defenses rather than relying on any single mechanism:
Layer 1: Detection and Monitoring
- Implement behavioral anomaly detection for unusual query patterns
- Monitor for systematic extraction attempts
- Track query volume, velocity, and pattern characteristics
- Alert on accounts showing extraction-like behavior
Layer 2: Access Control
- Require authentication for API access
- Implement rate limiting at account and IP level
- Require justification for high-volume API access
- Use geographic restrictions if appropriate
- Implement subscription tiers with usage quotas
Layer 3: Output Management
- Consider what information is necessary in outputs
- Evaluate whether reasoning exposure can be reduced
- Implement output logging and analysis
- Consider watermarking or fingerprinting techniques
Layer 4: Legal and Contractual
- Implement terms of service explicitly prohibiting extraction
- Include legal language around intellectual property claims
- Establish breach notification and response procedures
- Consider digital rights management approaches
Layer 5: Business Model Adaptation
- Develop service-based value that's harder to extract
- Build network effects that persist even if model is cloned
- Create proprietary datasets and fine-tunings
- Develop brand and trust relationships that survive commoditization
When to Accept Extraction Risk
Not all organizations should implement maximum-intensity defenses against extraction. Consider accepting extraction risk if:
- The model is commodity-like: If the model is not significantly superior to alternatives, extraction is less concerning
- Your value is in the service layer: If your business value comes from applications built on models rather than the models themselves, extraction is less critical
- First-mover advantages dominate: If being first to market with a capability matters more than sustaining technical advantage, extraction may be acceptable
- Network effects create moats: If your advantage comes from user network effects rather than technical superiority, model extraction doesn't destroy your position
- Defense costs exceed protected value: If implementing strong defenses costs more than the competitive advantage of the protected model, accept the risk
This analysis is specific to each organization's business model and strategic positioning.
The Broader Context: AI Development Economics
The Race for Capability Parity
The existence of effective model distillation has profound implications for the economics of AI development. Historically, first-mover advantages in technology came from sustained technical leadership—the first company to develop a capability had time to improve it before competitors caught up. This dynamic worked because replicating complex technology takes time and resources.
Model distillation compresses this timeline dramatically. Instead of competitors taking years to develop comparable capabilities, they might achieve capability parity through extraction in months or less. This changes the dynamics of competition:
Traditional model: Invest billions → Build superior model → Defend advantage through technical leadership → Profit from sustained advantage
Extraction model: Invest billions → Build superior model → Competitor invests $100M → Competitor extracts model → Competitor achieves capability parity in months
This shift makes sustained competitive advantage harder to achieve based purely on model capability. Companies need additional moats: brand, ecosystem lock-in, proprietary data, specialized fine-tuning, or service-layer advantages.
Implications for Research Investment
If model extraction becomes routine and effective, it could alter incentives for AI research investment. Venture capitalists and executives must consider: "Will our research investment produce defensible competitive advantage, or can it be easily replicated through extraction?"
This could lead to reduced investment in certain types of AI research (especially models intended as products) and increased investment in areas that are harder to extract:
- Proprietary data and datasets: Data advantages can't be easily extracted
- Specialized fine-tuning: Domain-specific expertise is harder to replicate than general capabilities
- Integration and embedding: Value created by deep integration in products is harder to extract
- Infrastructure and efficiency: Operational advantages from specialized hardware or optimization
- Service layer innovation: Creating value through how models are applied rather than the models themselves
Paradoxically, concerns about extraction could reduce foundational AI research investment at a time when continued progress requires substantial resources.
Recommendations for Different Stakeholders
For AI Model Developers and Companies
Immediate actions:
- Conduct extraction risk assessments for your models
- Implement detection and monitoring for systematic querying
- Implement rate limiting and usage quotas
- Update terms of service to explicitly address extraction
- Develop incident response procedures for extraction attempts
Medium-term strategy:
- Develop service-based value propositions that persist even if models are extracted
- Invest in proprietary fine-tuning and customization that competitors can't replicate through extraction
- Build network effects and ecosystem lock-in
- Monitor competitors for signs of extraction
- Engage with industry groups developing best practices and standards
Long-term positioning:
- Diversify value creation beyond model capabilities
- Develop brand and trust relationships with customers
- Build proprietary datasets and continuous improvement advantages
- Consider business model evolution as extraction becomes more common
For Organizations Using AI Models
Immediate actions:
- Assess which models are critical to your differentiation
- Evaluate dependency on any single model provider
- Understand the IP implications of your model usage
- Review vendor security practices and extraction defenses
- Develop contingency plans for model provider disruption
Medium-term strategy:
- Diversify across multiple model providers
- Invest in internal model fine-tuning and customization
- Build proprietary applications and integrations that create value beyond the base model
- Establish contractual protections and SLAs with model providers
- Monitor for competitive threats related to model extraction
Long-term positioning:
- Develop in-house AI capabilities for critical applications
- Build moats through proprietary data, fine-tuning, and integration
- Prepare for a future where model capabilities commoditize faster
For Policymakers and Regulators
Assessment and research:
- Commission independent research on the prevalence and impact of extraction attacks
- Assess whether current intellectual property frameworks adequately protect AI models
- Research effectiveness of various technical and legal defenses
- Examine international dimensions and competitive implications
Policy development:
- Consider targeted legislation protecting AI models without unduly restricting beneficial uses like research and distillation
- Harmonize international approaches to AI IP protection
- Balance protection for model developers with public interest in competition and innovation
- Consider sui generis protection frameworks tailored to AI's unique characteristics
- Establish standards for technical and operational safeguards
Monitoring and enforcement:
- Develop capacity to understand and investigate AI-related IP disputes
- Establish frameworks for adjudicating cases involving model extraction
- Monitor for geopolitical dimensions and national security implications
- Foster international cooperation on enforcement
For AI Researchers and Security Experts
Research priorities:
- Develop more robust and practical defenses against extraction attacks
- Research detection methods that don't degrade user experience
- Investigate the effectiveness of extraction attacks across different model architectures
- Study the economics and resource requirements for successful extraction
- Develop frameworks for evaluating model security and extraction resistance
Community engagement:
- Contribute to development of industry standards and best practices
- Publish research on extraction attacks and defenses (responsibly)
- Work with companies to implement and evaluate defenses
- Engage with policymakers to provide technical input on regulation
- Develop open-source tools for detection and defense

The Paradox of Open AI and Extraction Risks
The Tension Between Innovation and Protection
The entire field of AI faces a fundamental tension. The rapid progress in large language models over the past few years has been enabled by openness: researchers sharing findings, companies releasing open-source models, and accessible APIs enabling experimentation. This openness has accelerated progress and broadened participation in AI research.
However, the same openness that enables progress also enables extraction. The more accessible and open an AI model is, the more it can be studied, analyzed, and extracted. Companies must choose between:
- Openness: Maximize model access, enable rapid iteration, broad adoption, network effects—but maximize extraction vulnerability
- Secrecy: Restrict access, limit extraction surface—but slow adoption, reduce innovation velocity, limit network effects
Most successful AI companies are currently choosing openness and accepting extraction risks as a cost of doing business. However, if extraction becomes more effective and damaging, this calculation could shift toward greater secrecy.
A future with tightly restricted AI models, limited API access, and carefully controlled distribution would be worse for innovation than the current state. But the economic logic of extraction attacks could drive the industry in that direction if defenses don't improve.
The Difference Between Commercial and Open-Source Models
It's worth noting that open-source AI models face a different extraction risk profile than commercial models. When Meta released LLaMA's weights publicly, there's nothing to "extract" because the weights are already public. Distillation can improve open-source models, but this represents improvement rather than theft.
Meanwhile, commercial models like Gemini, GPT-4, and Claude are accessible only through APIs, making the extraction question prominent. The difference suggests that the AI industry might bifurcate further: proprietary commercial models with restricted access and strong protection, versus open-source models available for any use including extraction.
This bifurcation could have implications for competition, innovation, and access to AI capabilities.
Conclusion: The Evolving Landscape of AI Security
Google's disclosure of the 100,000-prompt campaign against Gemini illuminates a critical vulnerability in the emerging AI security landscape. Model distillation attacks represent a new class of threat that's difficult to prevent, hard to detect comprehensively, and increasingly attractive as AI capabilities become more valuable and competitors seek to achieve capability parity without billion-dollar investments in research.
The attack reveals that the current defenses against extraction—rate limiting, access controls, terms of service restrictions, and detection systems—provide only partial protection. A determined, well-resourced attacker with technical sophistication can work around these controls by distributing queries across multiple identities, varying patterns to avoid detection, and extending timelines to reduce the apparent query rate.
The fundamental challenge is architectural: any AI model accessible through a public API exposes information through its outputs that can be leveraged for extraction. This isn't a bug that can be patched; it's a feature of how neural networks work. The model's outputs encode information about its learned patterns, training data, reasoning processes, and capabilities. Sufficient collection and analysis of outputs enables replication of the model's behavior.
Legal frameworks remain inadequate to address extraction attacks. Current intellectual property law wasn't designed for machine learning, and the framing of extraction as theft becomes complicated when companies claiming ownership of models themselves built those models using unlicensed training data. The legal landscape will likely evolve, but change is slow, and any restrictions must balance protection of legitimate interests with benefits to competition, research, and innovation.
The Gemini incident is significant not because it represents a new technique—model distillation has been known since Alpaca demonstrated its viability—but because it shows that extraction attacks are now systematic, intentional, and apparently effective enough to warrant disclosure by one of the world's most sophisticated technology companies. If Gemini, backed by Google's expertise and resources, is vulnerable to extraction despite presumably having substantial defenses, then all publicly accessible AI models should be assumed vulnerable to similar attacks.
This changes how organizations should think about AI model protection and defensibility. The era where intellectual property protection relied primarily on technical superiority is ending. In its place, sustainable competitive advantage in AI will come from network effects, ecosystem lock-in, proprietary data, service-layer value creation, brand and trust, and continuous improvement advantages that persist even when models are extracted.
Companies investing heavily in frontier AI research must accept that extracted versions of their models will emerge. The question isn't whether extraction can be prevented entirely—it can't—but how organizations respond to commoditization of base model capabilities and how they create value in a world where AI models become rapidly available to all competitors.
For the industry, policymakers, and researchers, the path forward requires balancing multiple competing interests: protecting legitimate intellectual property investments, enabling continued innovation and research, supporting competition and entry by new providers, and maintaining the openness that has driven rapid progress in AI.
The Gemini extraction campaign is a watershed moment highlighting the inadequacy of current defenses and the need for comprehensive responses combining improved technical defenses, evolved business models, regulatory frameworks, and changed expectations about the defensibility of AI model capabilities in an era where observed behavior can be systematically extracted and replicated.
FAQ
What is model distillation in the context of AI security?
Model distillation is a machine learning technique where a smaller, more efficient neural network learns to replicate the behavior of a larger network by training on the larger model's outputs. In security contexts, attackers use distillation to systematically query a target model (like Gemini), collect its responses, and use those responses to train their own model that mimics the original's capabilities, without requiring access to the original model's weights or training data.
How does the Gemini extraction attack work?
The attackers sent over 100,000 carefully crafted prompts to Google's Gemini chatbot across multiple non-English languages, specifically targeting its reasoning and planning capabilities. They collected all responses, aggregated them into a training dataset, and used this data to train a new AI model to replicate Gemini's behavior. By studying the model's outputs, the student model learned to approximate the original model's reasoning patterns and knowledge representations without seeing the underlying code or weights.
Why is model extraction difficult to prevent completely?
Model extraction is difficult to prevent because it exploits the model's intended functionality rather than security vulnerabilities. Any model accessible through a public API must accept queries and return outputs—but those same outputs contain information that enables extraction. Detection depends on identifying unusual query patterns, but sophisticated attackers can distribute queries across many accounts, vary patterns to avoid detection, and extend timelines to reduce suspicion. Ultimately, once outputs are observable, they can be analyzed and extracted.
What were Google's countermeasures against the Gemini extraction attack?
Google announced it adjusted Gemini's defenses after identifying the 100,000-prompt campaign but did not provide specific details about the countermeasures. These could include rate limiting, behavioral anomaly detection, output perturbation, enhanced monitoring, or access control restrictions. Google's vagueness is strategic—revealing specific defenses would help future attackers develop circumvention techniques.
How does model distillation compare to traditional data breaches or code theft?
Model distillation differs fundamentally from traditional theft. A data breach requires breaking through security systems to access unauthorized information. Code theft requires compromising secure systems. Model distillation uses the system exactly as intended—the attacker is just using the API for extraction rather than its intended purpose. This makes distillation harder to prevent through traditional security controls, as the technical behavior is legitimate even if the purpose is not.
What are the economic incentives for attempting model extraction attacks?
Companies that conduct successful model extraction can replicate state-of-the-art AI capabilities for a fraction of the development cost. Building Gemini cost Google billions of dollars and years of research. A successful extraction costing $10-100 million could produce a competitive model worth hundreds of millions. This ROI creates powerful incentives for commercially motivated actors, including competitors, startups, and organizations in jurisdictions where IP enforcement is weak.
What role did the Alpaca project play in demonstrating extraction feasibility?
Stanford researchers created Alpaca by fine-tuning Meta's open-source LLaMA model on 52,000 responses generated by OpenAI's GPT-3.5, at a total cost of approximately $600. Alpaca demonstrated convincingly that ChatGPT's capabilities could be partially replicated through distillation at minimal cost. This proof-of-concept established that extraction wasn't theoretical—it was practical, affordable, and achievable with standard machine learning tools.
How do current intellectual property laws address model extraction?
Current IP law provides weak protection for model extraction because the legal categories (copyright, trade secrets, patents) weren't designed for machine learning. Copyright protects creative expression but doesn't clearly protect model outputs. Trade secret law requires that information be "secret," but models accessible through public APIs aren't secret. Patents protect novel inventions but model behavior emerges from training rather than novel technical invention. These mismatches create legal ambiguity about whether extraction constitutes IP theft or legitimate use of public information.
What technical defenses are most effective against model extraction?
No single defense completely prevents extraction, but layered approaches help: rate limiting restricts query volume; behavioral monitoring detects unusual patterns; access restrictions reduce the attack surface; output perturbation adds noise to make extraction less reliable; cryptographic watermarking can detect if cloning occurred; and contract-based restrictions establish legal deterrents. However, all these defenses involve tradeoffs—strong technical controls often degrade user experience, and sophisticated attackers can potentially circumvent any single mechanism.
How might model extraction attacks change the AI industry's business models?
If extraction becomes routine, companies will likely shift value creation away from model capabilities alone toward service-based differentiation including proprietary data, specialized fine-tuning, ecosystem integration, and brand/trust relationships. This could lead to industry consolidation as companies without strong network effects or ecosystem advantages become extraction targets. Regulatory responses might establish IP protections, and companies might restrict API access more severely, reducing openness and potentially slowing innovation.
What should organizations do to protect against model extraction risks?
Organizations should conduct extraction risk assessments identifying high-value models and attack surfaces. Implement layered defenses including detection and monitoring, access controls and rate limiting, output management and potential watermarking, legal and contractual protections, and business model adaptation toward service-based value that persists even if models are extracted. Organizations using models should diversify across providers, develop internal capabilities, and build proprietary applications and integrations that create value beyond base model capabilities.
Additional Context on Runable
For organizations concerned about AI model security and the challenges of building and protecting AI-powered workflows, Runable offers an AI-powered automation platform designed for developers and teams. Rather than investing massive resources into building proprietary AI models vulnerable to extraction, teams can leverage Runable's AI agents for content generation, workflow automation, and developer productivity tools.
Runable's approach focuses on automated workflows and AI-powered content creation ($9/month), enabling organizations to generate value through AI slides, AI docs, AI reports, and AI presentations without the burden of building and protecting proprietary models. For teams prioritizing practical AI automation over frontier model development, Runable provides an alternative to the high-stakes, extraction-vulnerable world of building and maintaining public-facing AI models. This represents a fundamentally different approach to creating AI value—through automation and productivity rather than through defensible proprietary models.
Key Takeaways
- Model distillation enables attackers to extract AI model capabilities through systematic API queries without accessing underlying weights or training data
- Google's disclosure of 100,000+ prompts against Gemini reveals that even sophisticated defenses cannot completely prevent extraction attacks when models are publicly accessible
- The economics of AI favor extraction attacks—companies can replicate state-of-the-art models for $10-100M through distillation rather than investing billions in research
- Current intellectual property law provides inadequate protection for AI models, creating legal ambiguity around whether extraction constitutes theft or legitimate use
- Effective defense against extraction requires layered approaches combining rate limiting, behavioral monitoring, access controls, legal protections, and business model adaptation toward service-based value
- Model extraction attacks will likely drive industry consolidation as smaller competitors without strong network effects or ecosystem advantages become extraction targets
- The future of AI model protection will emphasize service-based differentiation, proprietary data, specialized fine-tuning, and ecosystem lock-in rather than defending base model capabilities
- Organizations should prepare for a future where AI model capabilities commoditize more rapidly due to extraction feasibility, shifting competitive advantage to layers above base models
Related Articles
- 6.8 Billion Email Addresses Leaked: What You Need to Know [2025]
- ExpressVPN Pricing Deals: Save on the Cheapest VPN [2025]
- Surfshark VPN 87% Off: Complete Deal Analysis & VPN Buyer's Guide [2025]
- Proton VPN 70% Off Deal: Is This Two-Year Plan Worth It? [2025]
- Windows 11 Notepad Security Flaw: What You Need to Know [2025]
- Lumma Stealer's Dangerous Comeback: ClickFix, CastleLoader, and Credential Theft [2025]

