![Gimlet Labs: Revolutionizing AI Inference with Multi-Silicon Solutions [2025]](https://tryrunable.com/blog/gimlet-labs-revolutionizing-ai-inference-with-multi-silicon-/image-1-1774283859919.jpg)
Introduction
Artificial Intelligence (AI) is reshaping industries, driving innovation, and offering capabilities that were once the stuff of science fiction. However, the rapid evolution of AI technologies has also ushered in significant challenges, particularly when it comes to AI inference—the process of executing an AI model to get predictions. Gimlet Labs, a pioneering startup, is addressing this bottleneck in an innovative way, unlocking new possibilities for AI applications.
In this comprehensive guide, we will explore how Gimlet Labs is solving the AI inference bottleneck with its cutting-edge multi-silicon cloud technology. We will delve into the technical intricacies, examine real-world applications, discuss best practices, and forecast future trends. Whether you're a developer, data scientist, or tech enthusiast, this article is your definitive resource for understanding the impact of Gimlet Labs' solutions.
TL; DR
- Gimlet Labs' multi-silicon cloud enables AI workloads to run across CPUs, GPUs, and high-memory systems.
- AI inference bottleneck occurs when executing AI models at scale, often limited by hardware capabilities.
- Real-world applications include autonomous vehicles, real-time analytics, and personalized healthcare.
- Best practices involve optimizing hardware allocation and utilizing Gimlet Labs' API for seamless integration.
- Future trends point to increased adoption of multi-silicon solutions and advancements in AI model efficiency.

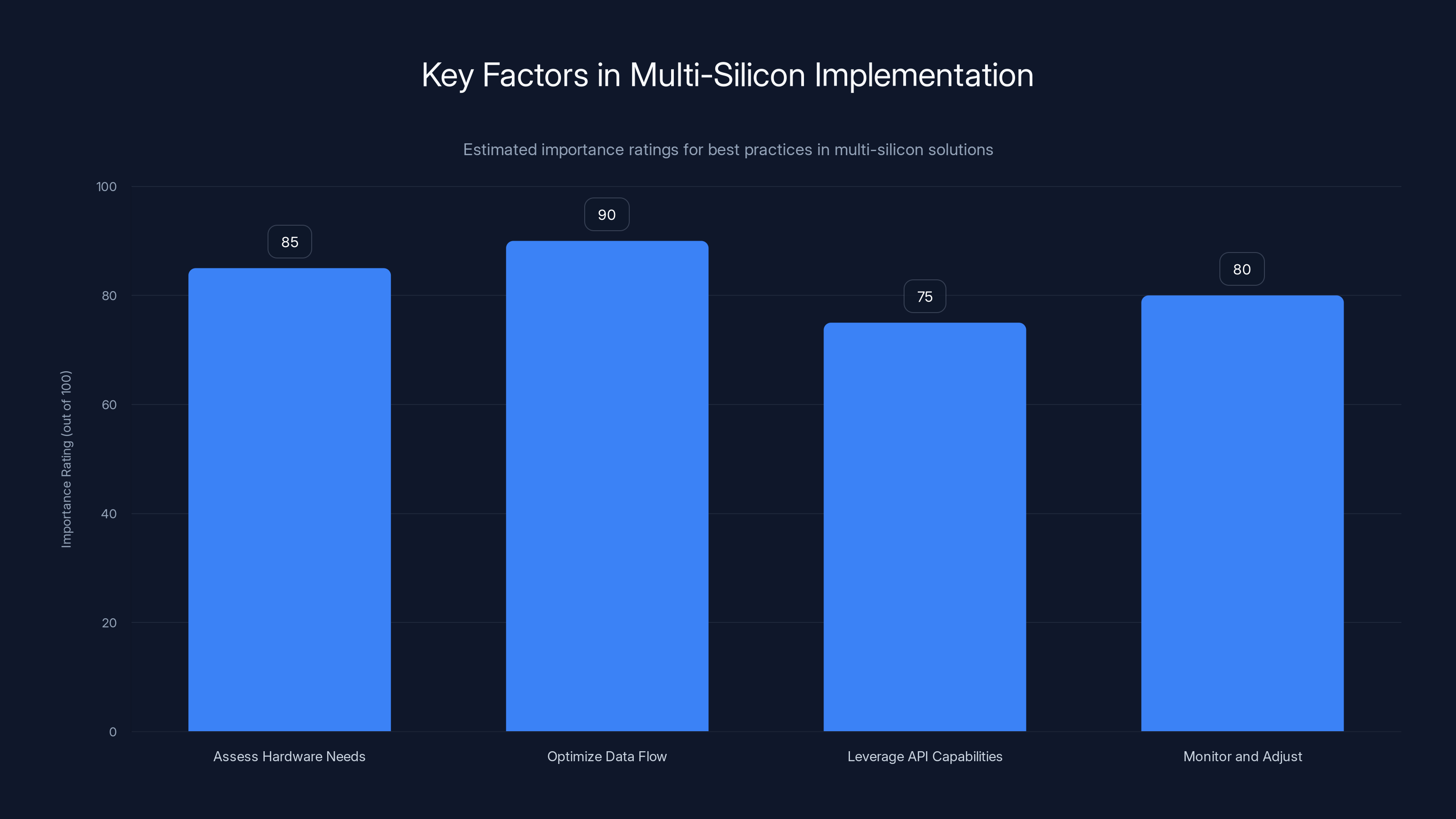
Optimizing data flow and assessing hardware needs are crucial for effective multi-silicon implementation. Estimated data.
Understanding the AI Inference Bottleneck
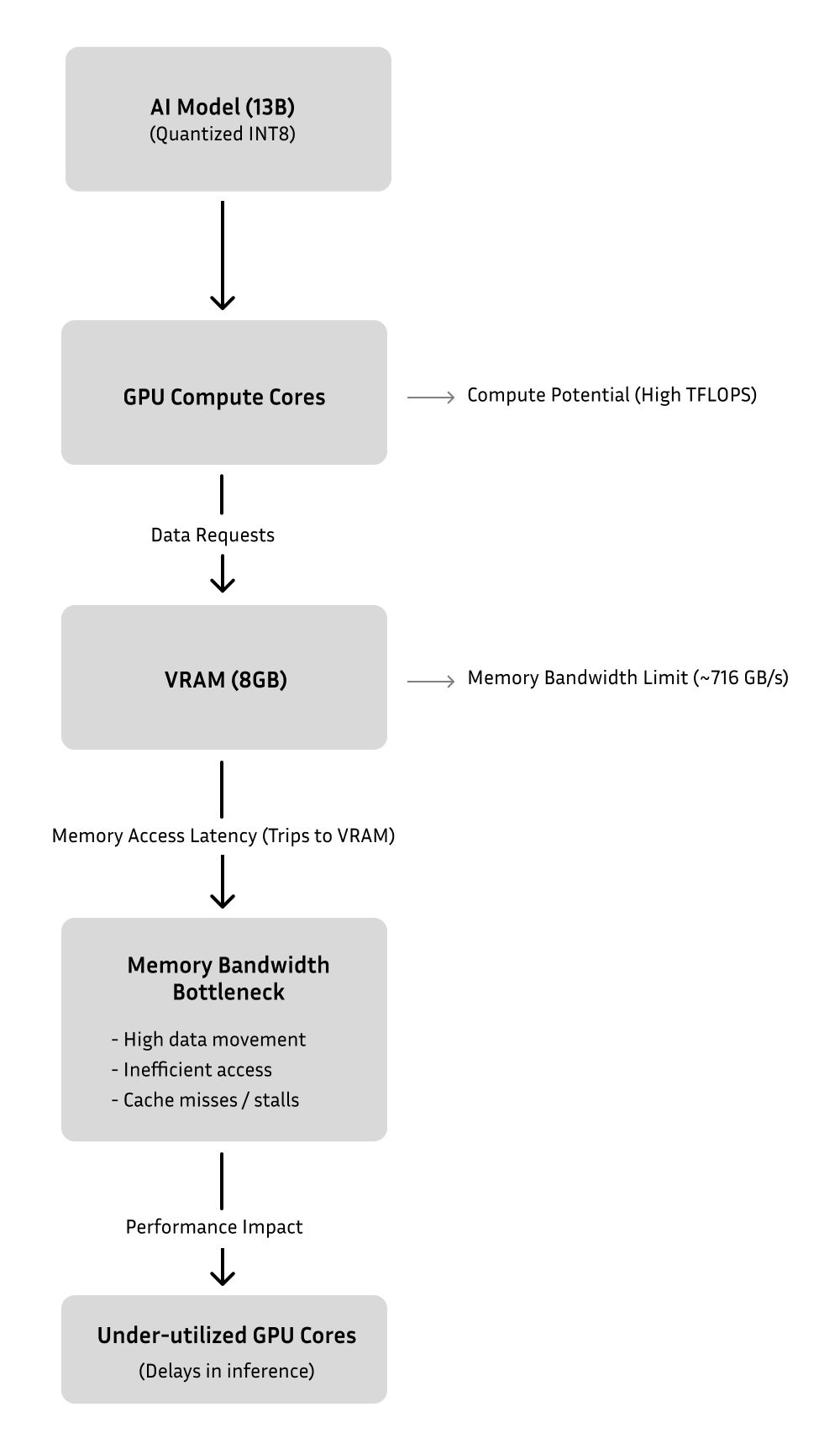
AI inference is the stage where a trained AI model is used to make predictions or decisions based on new data. While training AI models is computationally intensive, inference requires optimized hardware to deliver rapid results, often in real-time scenarios. The bottleneck arises when the available hardware cannot efficiently handle the demands of inference, leading to delays and reduced performance.
The Role of Hardware in AI Inference
Traditionally, AI inference relies on CPUs (Central Processing Units) and GPUs (Graphics Processing Units). CPUs are versatile and handle a wide range of tasks, but they may lack the specialized capabilities needed for high-speed AI inference. GPUs, on the other hand, excel at parallel processing and are ideal for tasks like deep learning.
However, no single type of hardware is perfect for all aspects of AI inference. Some tasks are compute-bound, requiring fast calculations, while others are memory-bound, needing vast amounts of data storage. This diversity of requirements has led to the development of specialized hardware like TPUs (Tensor Processing Units) and FPGAs (Field-Programmable Gate Arrays), each designed to optimize specific aspects of AI workloads.
The Elegance of Multi-Silicon Solutions
Gimlet Labs introduces a revolutionary approach with its multi-silicon inference cloud. This technology allows AI workloads to seamlessly run across a variety of hardware platforms, including CPUs, GPUs, and high-memory systems. By dynamically distributing tasks based on their specific hardware needs, Gimlet Labs optimizes performance and reduces the inference bottleneck.
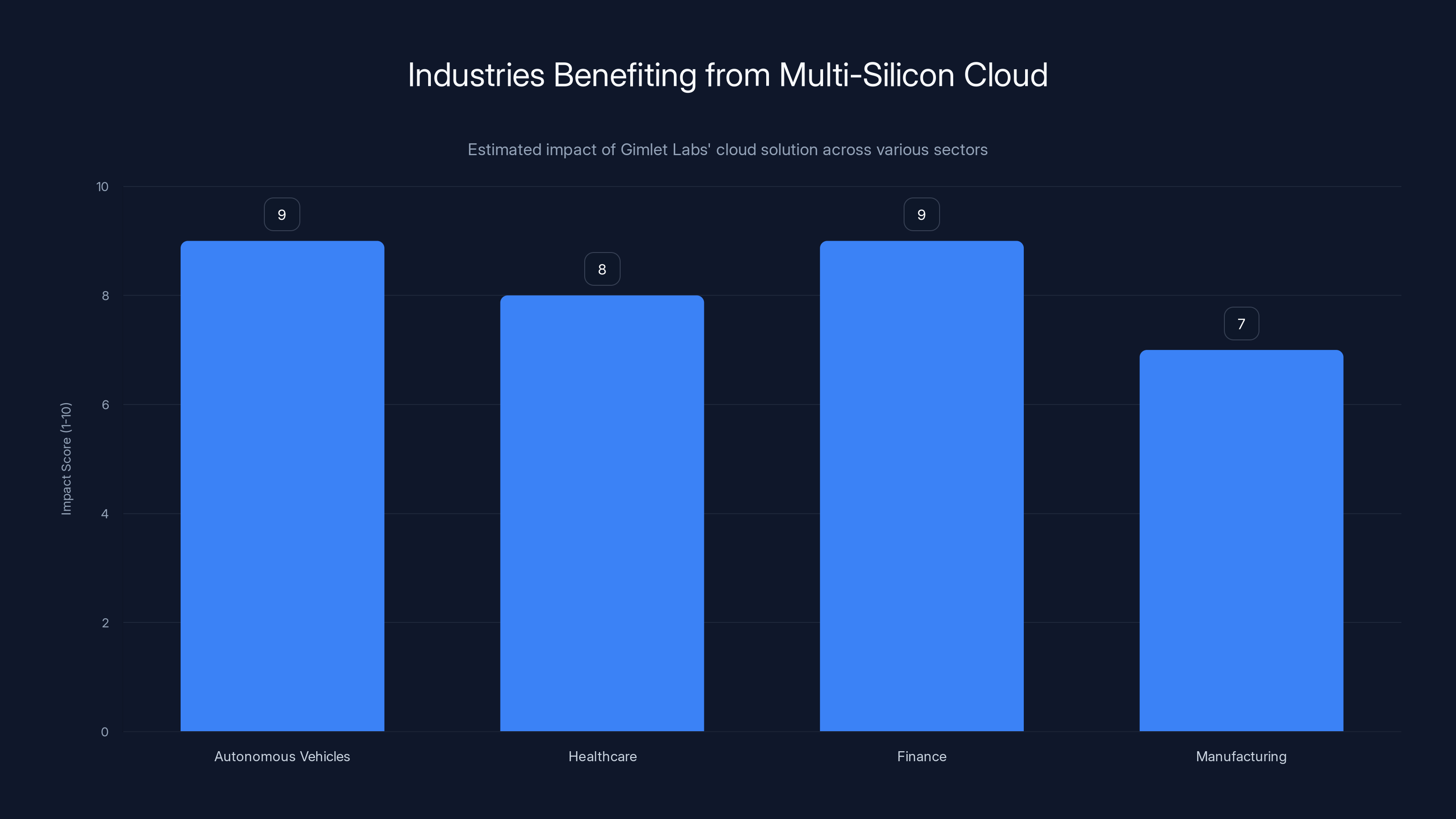
Gimlet Labs' multi-silicon cloud significantly enhances performance in autonomous vehicles, healthcare, and finance by optimizing workload distribution. (Estimated data)
How Gimlet Labs' Multi-Silicon Cloud Works
At the heart of Gimlet Labs' solution is a sophisticated orchestration layer that manages the distribution of AI workloads across different hardware types. This layer intelligently allocates resources, ensuring that each task is executed on the most suitable hardware. Let's explore how this system operates.
Dynamic Workload Allocation
Gimlet Labs' cloud architecture is designed to be highly adaptable. When an AI application is deployed, the system analyzes the workload's requirements and dynamically assigns tasks to the appropriate hardware. For example, compute-intensive tasks might be assigned to GPUs, while memory-heavy operations could utilize high-memory systems.
Seamless Integration with Existing Infrastructure
One of the standout features of Gimlet Labs' solution is its ability to integrate seamlessly with existing infrastructure. Organizations can leverage their current hardware investments while benefiting from the enhanced performance of the multi-silicon cloud. This is achieved through a comprehensive API that facilitates communication between the cloud and on-premises systems.
Real-World Applications
The multi-silicon approach is not just a theoretical concept; it has practical applications across various industries. Here are a few examples:
-
Autonomous Vehicles: Real-time decision-making is crucial for autonomous vehicles. Gimlet Labs' cloud enables efficient processing of sensor data, enhancing safety and performance.
-
Healthcare: Personalized medicine relies on rapid analysis of genetic data. The multi-silicon cloud accelerates this process, enabling tailored treatments.
-
Finance: High-frequency trading algorithms require lightning-fast execution. By distributing tasks across optimized hardware, Gimlet Labs ensures minimal latency and maximum throughput.
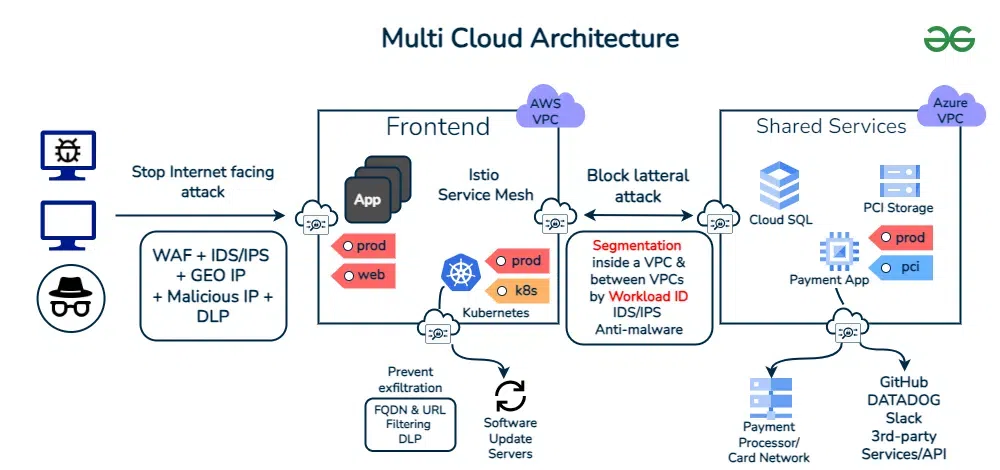
Best Practices for Implementing Multi-Silicon Solutions
Implementing multi-silicon solutions requires careful planning and execution. Here are some best practices to consider:
-
Assess Hardware Needs: Analyze your AI workload to determine the specific hardware requirements for each task. This will guide resource allocation and maximize efficiency.
-
Optimize Data Flow: Ensure that data is efficiently transferred between hardware components. This involves minimizing bottlenecks in network and memory access.
-
Leverage API Capabilities: Utilize Gimlet Labs' API to integrate the multi-silicon cloud with your existing systems. This allows for seamless data exchange and task management.
-
Monitor and Adjust: Continuously monitor the performance of your AI applications and adjust hardware allocation as needed. This ensures optimal use of resources and consistent performance.
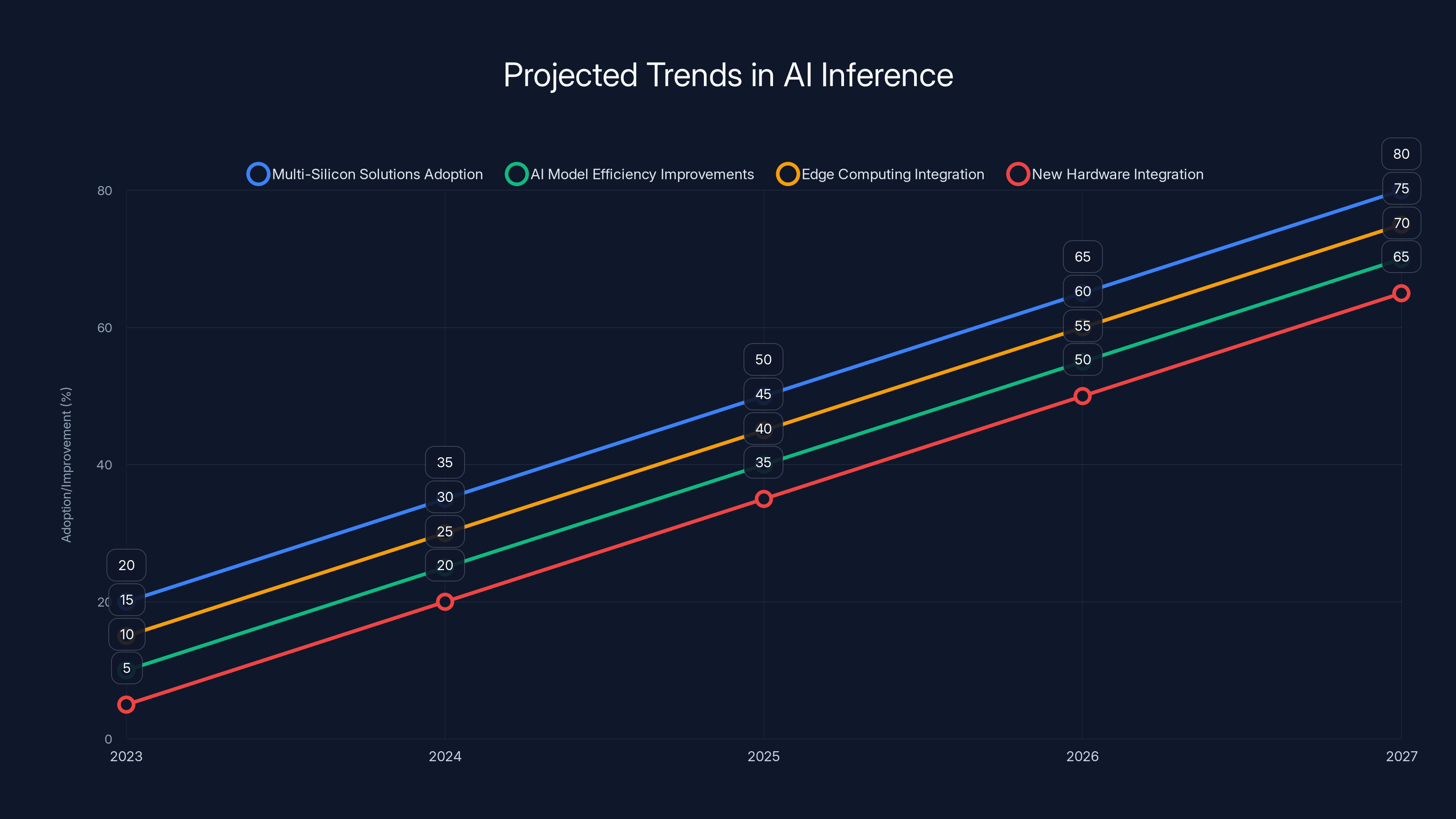
The adoption of multi-silicon solutions and integration with edge computing are projected to grow significantly, enhancing AI inference capabilities. Estimated data.
Common Pitfalls and Solutions
While the benefits of multi-silicon solutions are clear, there are potential pitfalls to be aware of. Here are some common challenges and how to address them:
-
Compatibility Issues: Not all AI models are compatible with every type of hardware. Ensure that your models are optimized for multi-silicon execution.
-
Resource Overhead: Managing multiple hardware types can introduce overhead. Use automation tools to streamline resource allocation and reduce complexity.
-
Data Security: Transferring data between different hardware platforms can pose security risks. Implement robust encryption and access controls to protect sensitive information.
Future Trends and Recommendations
The future of AI inference is bright, with several trends on the horizon:
-
Increased Adoption of Multi-Silicon Solutions: As organizations seek to optimize AI performance, multi-silicon approaches will become more widespread.
-
Advancements in AI Model Efficiency: Ongoing research will lead to more efficient AI models, reducing the hardware demands of inference tasks.
-
Integration with Edge Computing: Combining multi-silicon clouds with edge computing will enable real-time AI applications in remote and resource-constrained environments.
-
Emergence of New Hardware: As new hardware innovations emerge, they will be seamlessly integrated into multi-silicon architectures, further enhancing performance.
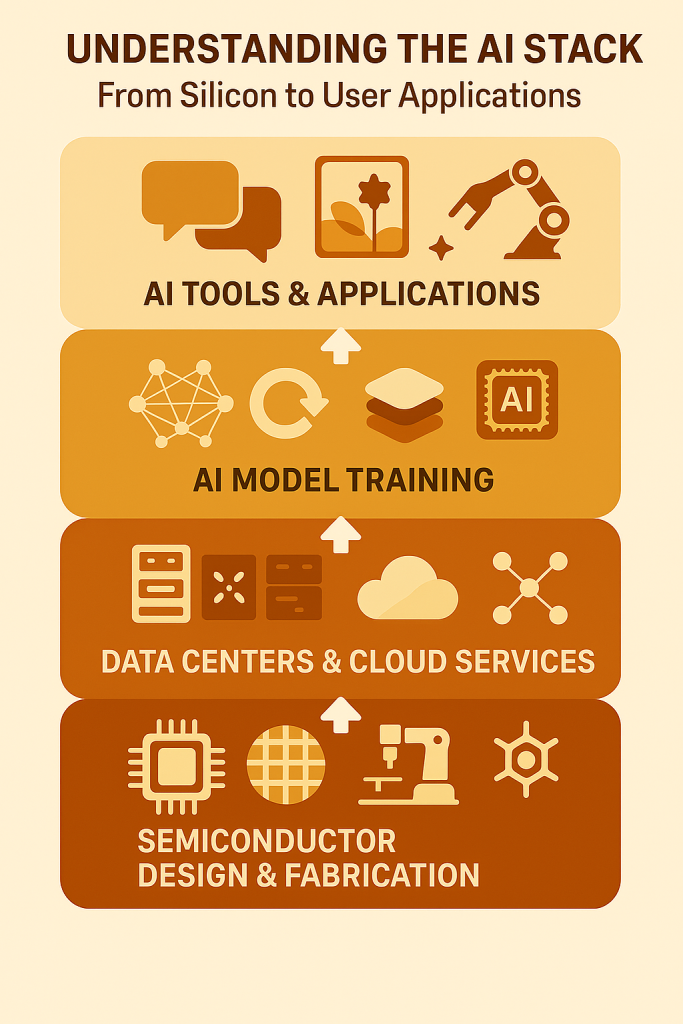
Conclusion
Gimlet Labs is at the forefront of solving the AI inference bottleneck with its innovative multi-silicon cloud. By intelligently distributing workloads across diverse hardware types, Gimlet Labs is enabling faster, more efficient AI applications. As the technology landscape continues to evolve, the adoption of multi-silicon solutions will play a critical role in shaping the future of AI.
For those looking to harness the power of AI, embracing multi-silicon architectures offers a pathway to enhanced performance and new possibilities. Stay ahead of the curve by exploring the potential of Gimlet Labs' solutions and preparing for the next wave of AI advancements.
Key Takeaways
- Gimlet Labs' multi-silicon cloud optimizes AI inference by utilizing diverse hardware.
- AI inference bottlenecks occur when hardware cannot meet computational demands.
- Successful AI implementation requires optimized hardware allocation and API integration.
- Future AI trends include increased multi-silicon adoption and edge computing integration.
- Common pitfalls include compatibility issues and data security challenges.
Related Articles
- Testing Autonomous Agents: Embrace Chaos [2025]
- AI Startups Are Revolutionizing the Venture Industry: A Deep Dive [2025]
- Is Marc Andreessen a Philosophical Zombie? [2025]
- Ultimate Guide to Ergonomic Office Chairs: Comfort, Features, and Future Trends [2025]
- How UK Businesses Can Bolster AI Crisis Management in 2025
- In-Depth Review: GE Profile Smart Grind and Brew Coffee Maker [2025]
FAQ
What is Gimlet Labs: Revolutionizing AI Inference with Multi-Silicon Solutions [2025]?
Artificial Intelligence (AI) is reshaping industries, driving innovation, and offering capabilities that were once the stuff of science fiction
What does tl; dr mean?
However, the rapid evolution of AI technologies has also ushered in significant challenges, particularly when it comes to AI inference—the process of executing an AI model to get predictions
Why is Gimlet Labs: Revolutionizing AI Inference with Multi-Silicon Solutions [2025] important in 2025?
Gimlet Labs, a pioneering startup, is addressing this bottleneck in an innovative way, unlocking new possibilities for AI applications
How can I get started with Gimlet Labs: Revolutionizing AI Inference with Multi-Silicon Solutions [2025]?
In this comprehensive guide, we will explore how Gimlet Labs is solving the AI inference bottleneck with its cutting-edge multi-silicon cloud technology
What are the key benefits of Gimlet Labs: Revolutionizing AI Inference with Multi-Silicon Solutions [2025]?
We will delve into the technical intricacies, examine real-world applications, discuss best practices, and forecast future trends
What challenges should I expect?
Whether you're a developer, data scientist, or tech enthusiast, this article is your definitive resource for understanding the impact of Gimlet Labs' solutions

