![Google's Gemma 4: Unlocking Speed with Speculative Decoding [2025]](https://tryrunable.com/blog/google-s-gemma-4-unlocking-speed-with-speculative-decoding-2/image-1-1778083697511.jpg)
Introduction
In the rapidly evolving world of artificial intelligence, speed and efficiency are paramount. Google's latest innovation, the Gemma 4 open AI models, promises to revolutionize the field by leveraging an advanced technique known as speculative decoding. This approach is designed to enhance processing speeds by up to 3x without sacrificing the quality of outputs. But what exactly is speculative decoding, and how does it transform AI performance?
In this comprehensive guide, we'll dive deep into the mechanics of speculative decoding, explore its integration within the Gemma 4 models, and discuss its implications for the future of AI technology. Whether you're a developer, researcher, or AI enthusiast, this article will provide valuable insights into this cutting-edge advancement.
TL; DR
- Speculative Decoding: A technique that predicts multiple future tokens to enhance processing speed.
- Gemma 4 Models: Google's latest AI models utilizing this technique to achieve up to 3x faster processing.
- Real-World Applications: Significant improvements in edge AI applications, including mobile and IoT devices.
- Implementation Tips: Practical guidelines for integrating Gemma 4 models into existing systems.
- Future Trends: Speculative decoding as a potential standard in AI model development.
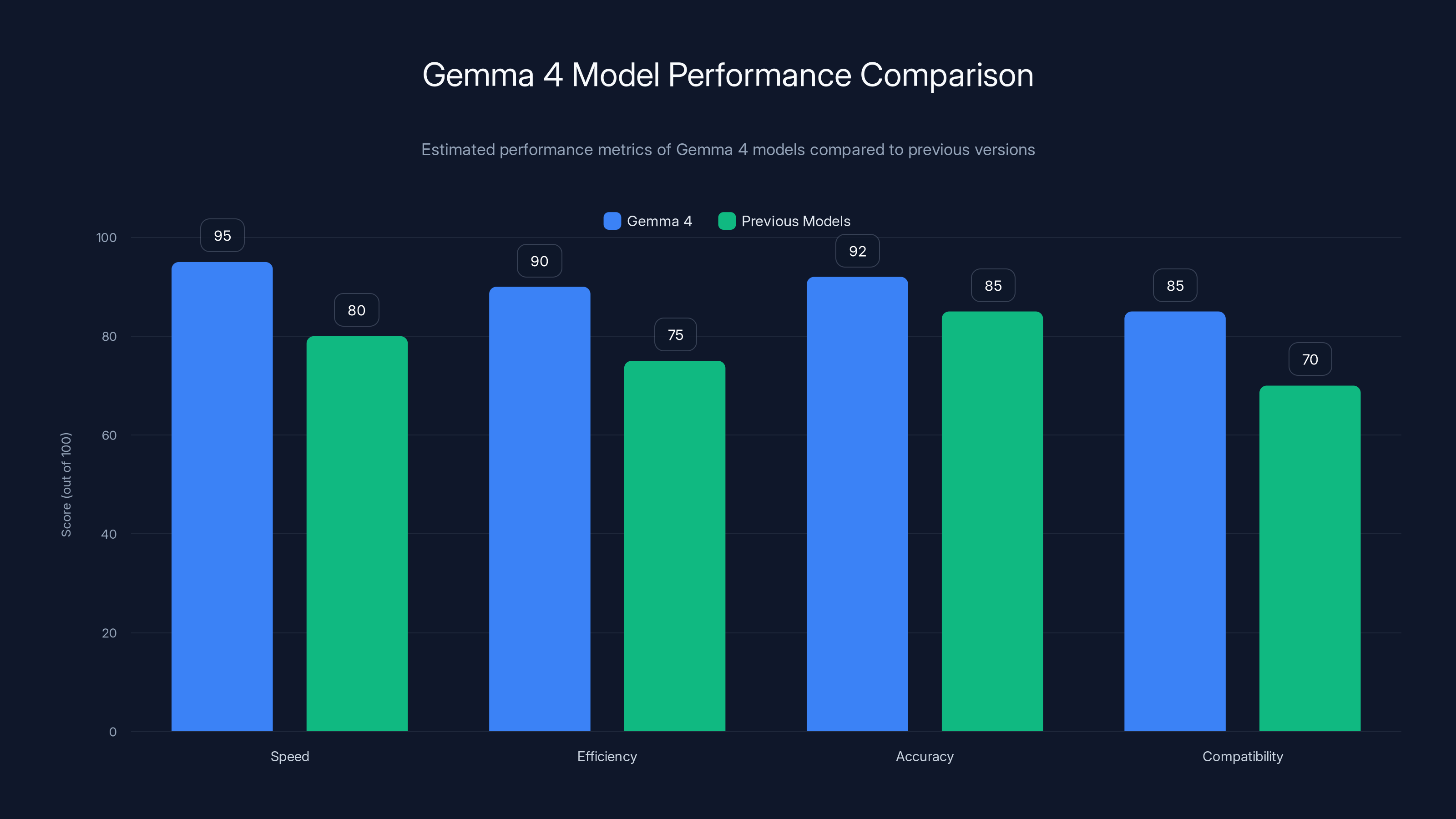
Gemma 4 models show significant improvements in speed, efficiency, and accuracy compared to previous models. Estimated data based on typical performance gains.
Understanding Speculative Decoding
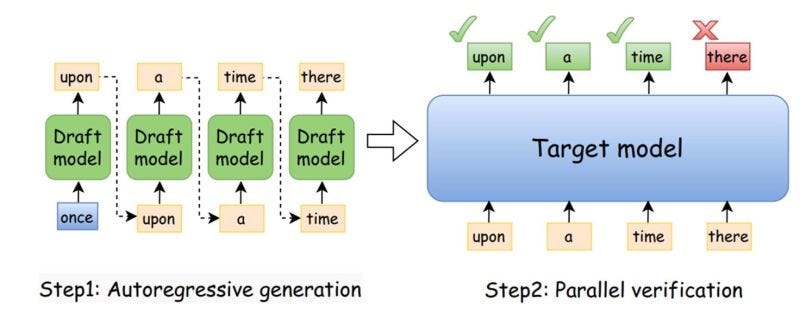
Speculative decoding is an innovative method used to enhance the speed of AI models by predicting multiple possible future outcomes. Traditional AI models generate output tokens one at a time, leading to slower processing speeds, especially in complex tasks. Speculative decoding, however, changes the game by allowing models to predict several potential tokens in advance and choose the best ones.
How it Works
Imagine you're reading a book and trying to guess the next sentence. Traditional models read word-by-word, but speculative decoding reads a few sentences ahead, makes educated guesses, and then recalibrates based on actual outcomes. This approach significantly reduces wait times during processing.
The technique involves running parallel models: a fast 'draft' model that generates multiple token predictions and a 'verifier' model that checks these predictions for accuracy. This dual-model approach ensures that the outputs are not only fast but also accurate.
Key Benefits
- Speed: By predicting multiple tokens simultaneously, processing time is dramatically reduced.
- Efficiency: Reduces computational load by optimizing the decision-making process.
- Accuracy: Maintains high output quality by verifying predictions against model standards.
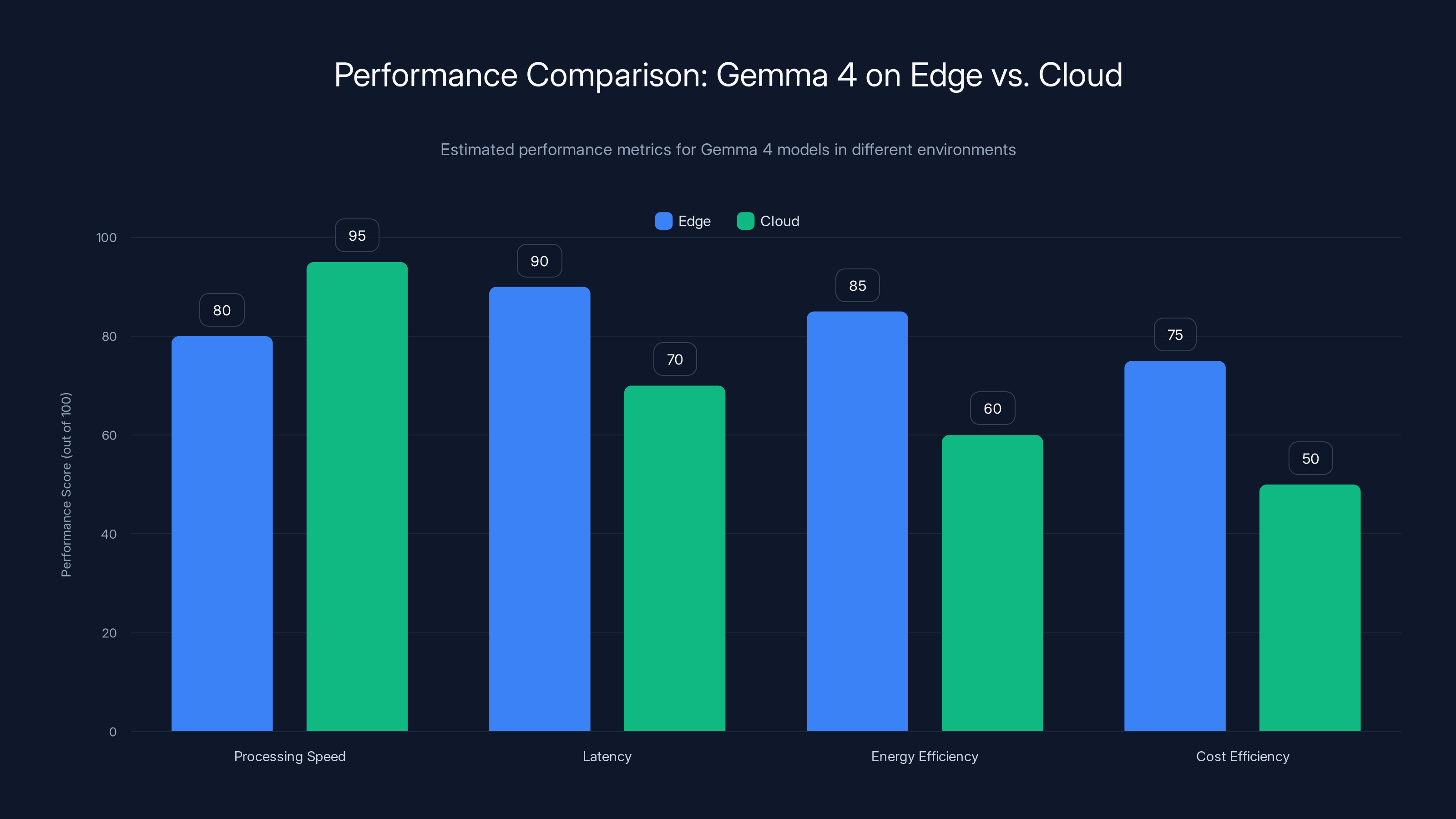
Gemma 4 models show superior latency and energy efficiency on edge devices compared to cloud execution, though cloud offers slightly higher processing speed. (Estimated data)
The Gemma 4 Advantage
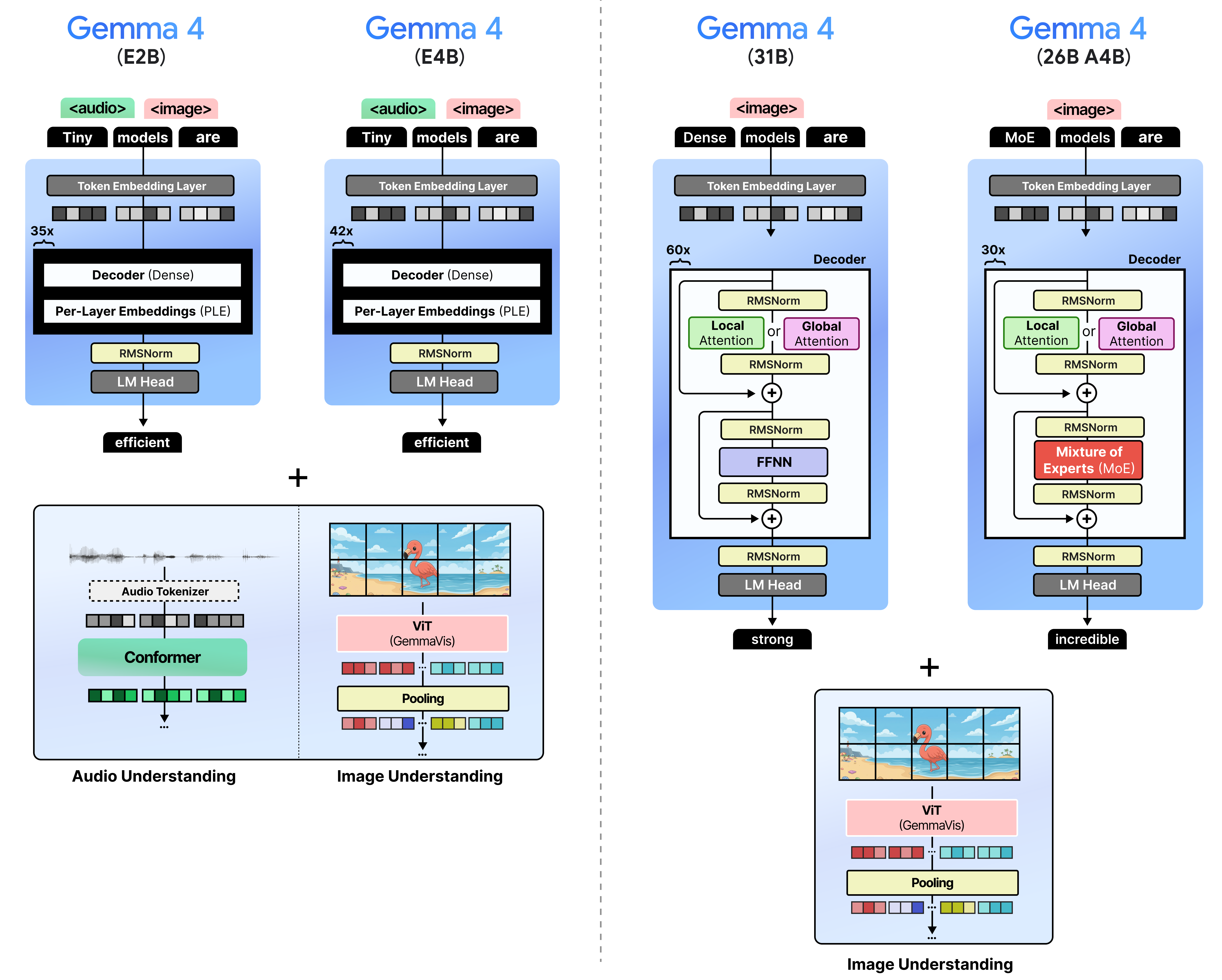
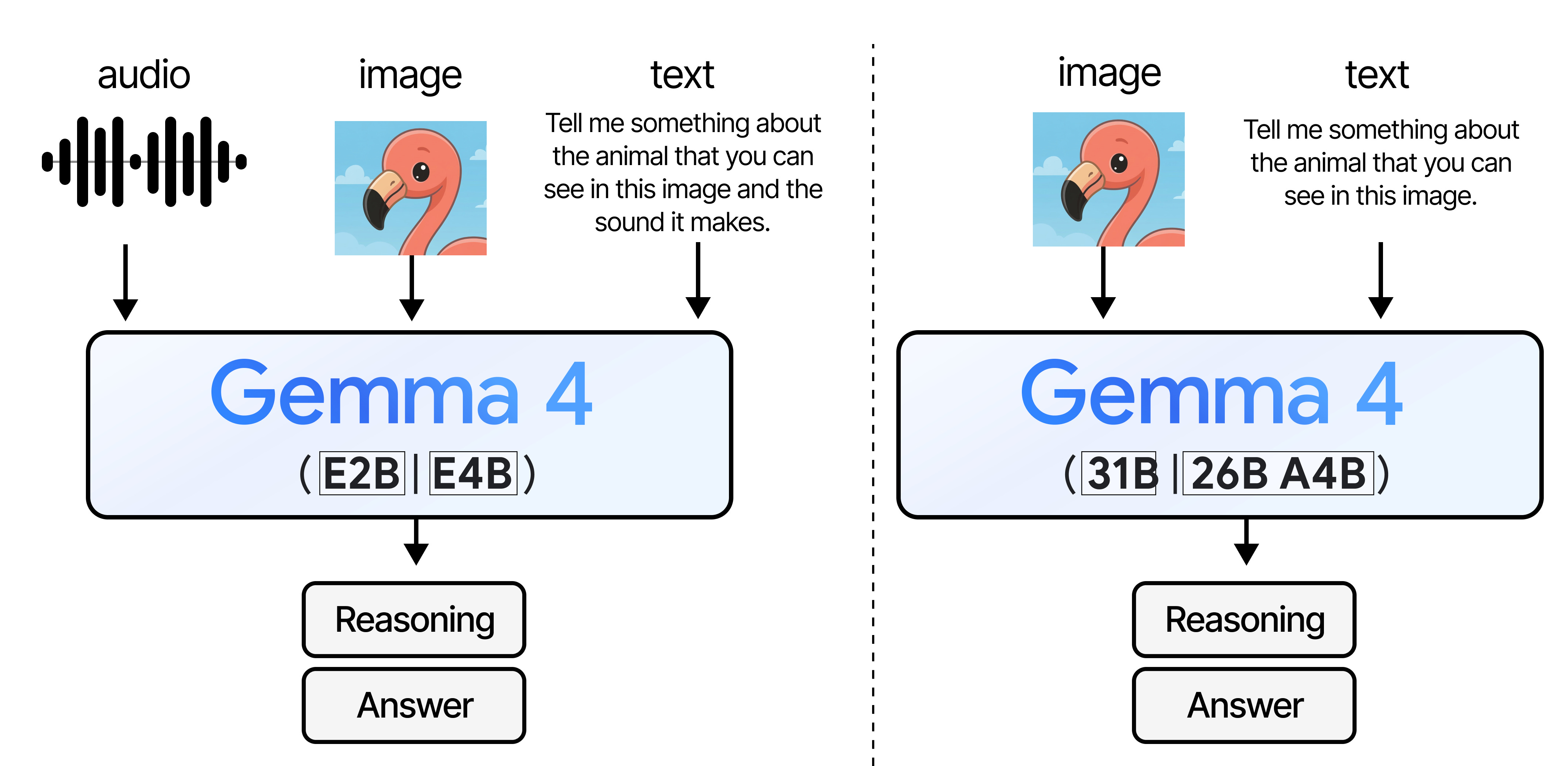
Google's Gemma 4 models incorporate speculative decoding into their architecture, providing a significant leap in AI performance. Built on the robust foundation of Google's Gemini AI, Gemma 4 models are tailored for local execution, making them ideal for edge AI applications.
Edge AI Optimization
The optimization for edge devices is a crucial aspect of Gemma 4 models. These models can run efficiently on devices with limited computational resources, such as smartphones or IoT gadgets, without relying on cloud-based processing.
Key Features
- Multi-Token Prediction: Predicts multiple tokens at once to speed up processing.
- Local Execution: Optimized for running on local hardware, reducing latency.
- AI Accelerator Compatibility: Designed to operate with Google's custom TPU chips for enhanced performance.
Practical Implementation Guide
Integrating Gemma 4 models into your AI projects can provide substantial benefits in terms of speed and efficiency. Here's a step-by-step guide to implementing these models effectively.
Step 1: System Requirements
Ensure your hardware is compatible with Gemma 4 models. Devices with AI accelerators like Google's TPU chips are preferred for optimal performance.
Step 2: Model Integration
- Download the Gemma 4 Model: Access the model from Google's AI platform.
- Install Necessary Libraries: Ensure your system has all required libraries for model execution.
- Set Up the Environment: Configure your development environment to support speculative decoding.
Step 3: Testing and Validation
Run initial tests to validate model performance. Use benchmark datasets to compare the efficiency and accuracy against prior models.
Step 4: Deployment
Deploy the optimized model in your application. Monitor performance metrics to ensure the model meets speed and accuracy expectations.
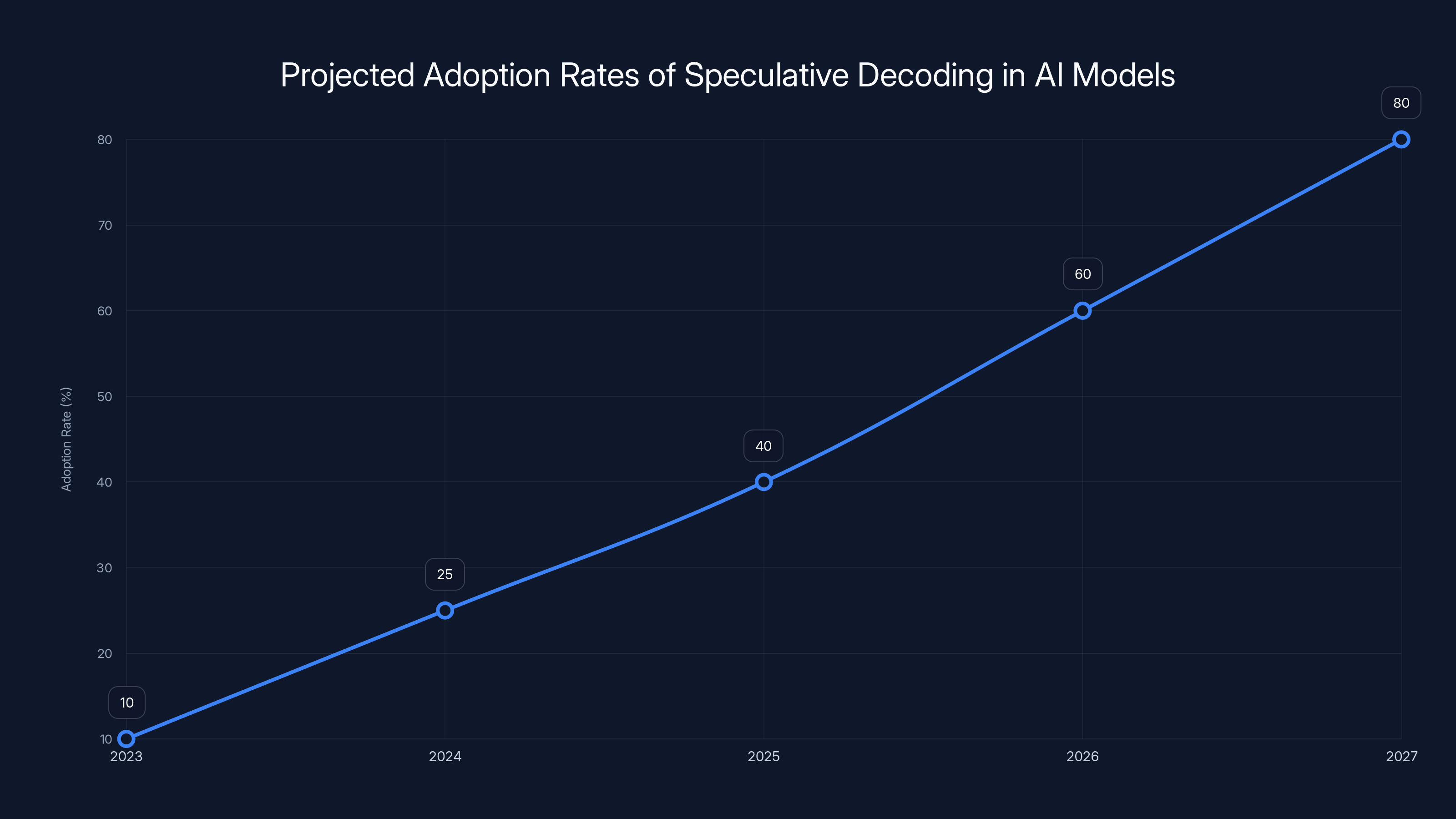
Speculative decoding is expected to see a significant increase in adoption, reaching an estimated 80% by 2027. Estimated data reflects anticipated growth in AI model capabilities.
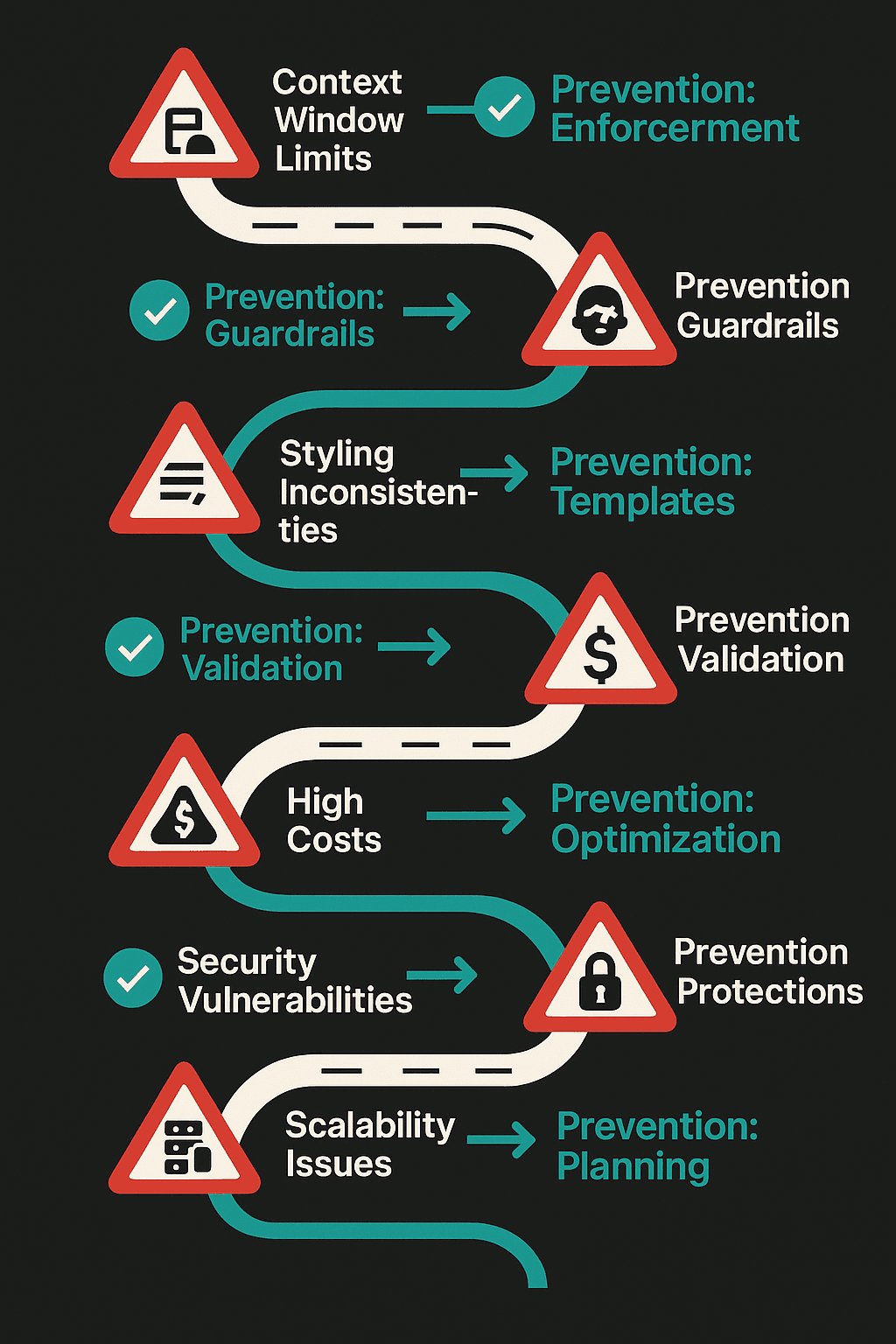
Common Pitfalls and Solutions
While speculative decoding offers numerous advantages, there are potential challenges you might encounter. Here are common pitfalls and how to address them.
Pitfall 1: Overfitting
Solution: Regularly update your model with new data to prevent overfitting to outdated datasets.
Pitfall 2: Hardware Limitations
Solution: Upgrade to devices with compatible AI accelerators or optimize model settings for existing hardware.
Pitfall 3: Integration Complexity
Solution: Utilize Google's support resources and community forums for troubleshooting and best practice advice.
Future Trends and Recommendations
As AI technology continues to evolve, speculative decoding is poised to become a standard feature in model development. Here's what to expect in the coming years.
Trend 1: Increased Adoption
More AI frameworks are likely to integrate speculative decoding to enhance model performance across various applications.
Trend 2: Enhanced Models
Future models will likely offer even more sophisticated speculative decoding capabilities, further improving speed and accuracy.
Trend 3: Broader Application
Expect to see speculative decoding applied beyond traditional AI tasks, including real-time data processing and autonomous systems.

Conclusion
Google's Gemma 4 models mark a significant advancement in AI technology by introducing speculative decoding. This technique not only accelerates processing speeds but also maintains high-quality outputs, making it a valuable tool for developers and businesses alike.
As speculative decoding becomes more prevalent, staying ahead of the curve by understanding and implementing these models will be crucial for those looking to capitalize on the next wave of AI innovation.
FAQ
What is speculative decoding?
Speculative decoding is a technique used in AI models to predict multiple future tokens simultaneously, enhancing processing speed without compromising output quality.
How does speculative decoding benefit AI models?
It allows AI models to process information faster and more efficiently by reducing computational load and optimizing decision-making processes.
What are Gemma 4 models?
Gemma 4 models are Google's AI models that utilize speculative decoding to enhance performance, particularly in edge AI applications.
How can I implement Gemma 4 models in my project?
Ensure your hardware is compatible, integrate the model using Google's AI platform, and validate performance through testing before deployment.
What challenges might I face with speculative decoding?
Common challenges include overfitting, hardware limitations, and integration complexity, which can be mitigated with appropriate updates and optimizations.
What is the future of speculative decoding?
Speculative decoding is expected to become a standard feature in AI model development, with broader applications and improved capabilities.
Key Takeaways
- Speculative Decoding enhances AI speed.
- Gemma 4 Models optimize edge AI performance.
- Implementation requires compatible hardware.
- Future Trends include broader adoption.
- Challenges involve hardware and integration.
Related Articles
- Scaling AI into Production: The New Frontier in Enterprise Infrastructure [2025]
- Google's Gemini: Revolutionizing File Organization on Mac [2025]
- Chrome's 4GB AI Download Controversy: Unpacking User Consent and Privacy Implications [2025]
- Why 42% of Business AI Projects Are Failing: A Deep Dive [2025]
- Maximize Your Impact at TechCrunch Disrupt 2026: Last Chance for 50% Off [2025]
- Google AI Search Summaries Now Quote Reddit [2025]

