![Google's Internal RL: Unlocking Long-Horizon AI Agents [2025]](https://tryrunable.com/blog/google-s-internal-rl-unlocking-long-horizon-ai-agents-2025/image-1-1768604780063.jpg)
Google's Internal RL: Unlocking Long-Horizon AI Agents [2025]
Let me be honest with you: Large language models are incredible at generating text, but they struggle with something most humans find trivial. Give them a 20-step task that requires reasoning across multiple stages, and they fall apart. They hallucinate. They contradict themselves. They lose the plot halfway through.
Google researchers think they've found the core problem, and their solution is fascinatingly counterintuitive.
Instead of trying to make models better at predicting the next word, they're steering the hidden thoughts running through the model's layers. This technique, called Internal RL (internal reinforcement learning), doesn't just tweak the output—it guides the fundamental reasoning process happening inside the neural network.
The implications are massive. If this works at scale, we're looking at AI agents that can handle complex, multi-step problems without constantly asking for human help. Code generation without the syntax errors. Robotics tasks with actual planning. Enterprise workflows that actually reason their way through problems instead of guessing.
But here's the thing: understanding why this matters requires diving into why language models struggle in the first place. And that's where most explanations fall apart. So let me walk you through what's actually happening, why it's broken, and how Google's fix addresses something fundamental about how AI models think.
The Fundamental Problem: Why Models Hallucinate on Long Tasks
Modern large language models work by predicting the next token one at a time. You give them a prompt, they spit out one word, then use that word to predict the next one, and so on. It's like writing a sentence while only looking at the previous word you just typed.
This works great for casual conversation. Ask GPT-4 about the French Revolution, and it'll give you a coherent 500-word explanation. The problem isn't short-horizon tasks. The problem is long-horizon reasoning.
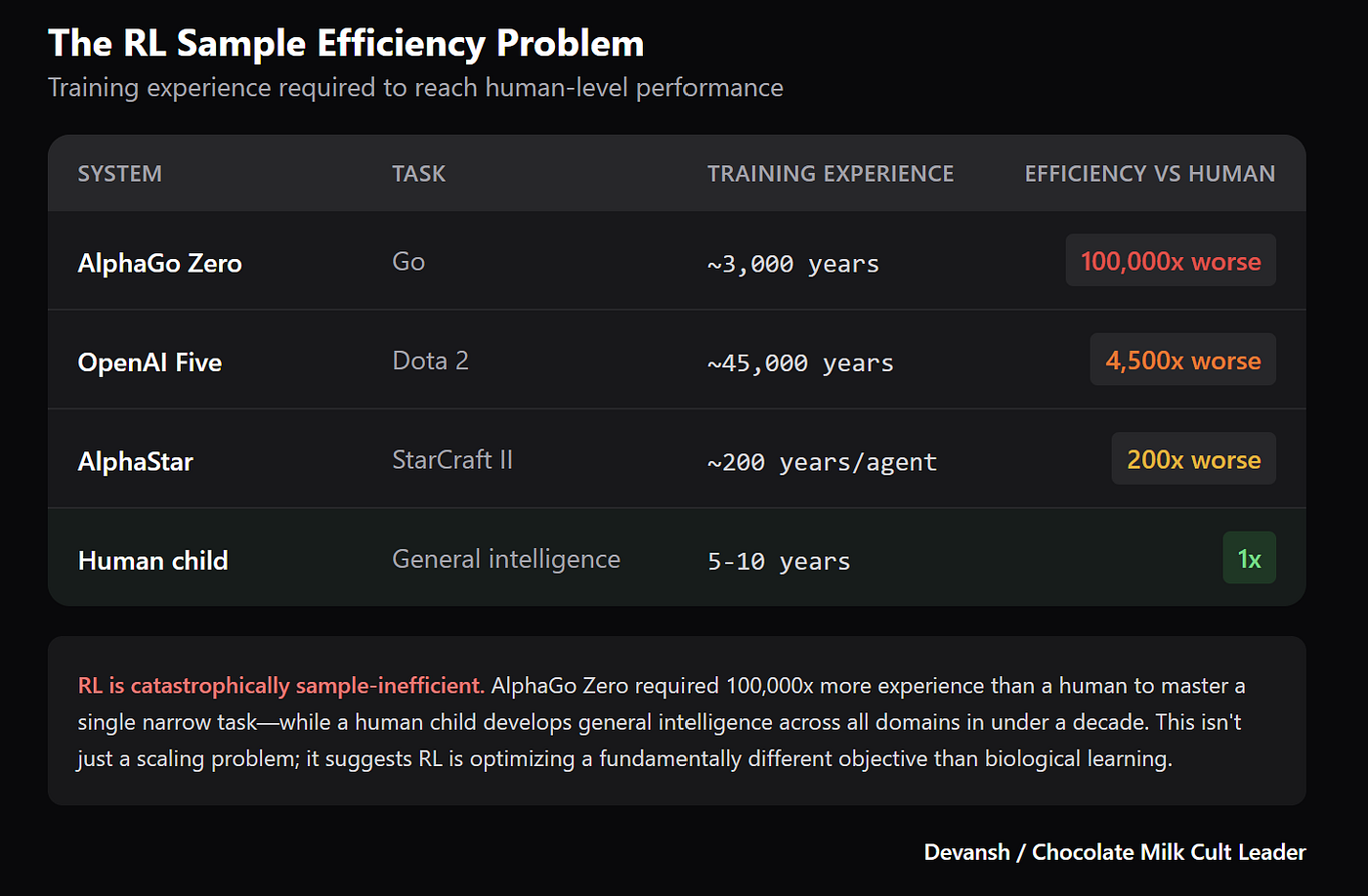
Imagine you're trying to solve a math problem that takes 25 steps. The model can't just randomly sample tokens and hope it stumbles on the right sequence. The probability of accidentally guessing 25 correct steps in a row is catastrophically small. We're talking one in a million, according to the researchers.
But that's not even the deepest issue.
The real problem is that the model is searching for solutions at the wrong level of abstraction. When you face a complex problem, you don't think about individual words. You think about the overall strategy first, then fill in the details. You decide "I need to break this into three phases," then you execute those phases.
Language models can't do that naturally because they're architected to predict tokens, not high-level actions. They get trapped in local optimization. They might nail one reasoning step perfectly but lose sight of the overall goal. Then they contradict themselves later because they never committed to a coherent plan.
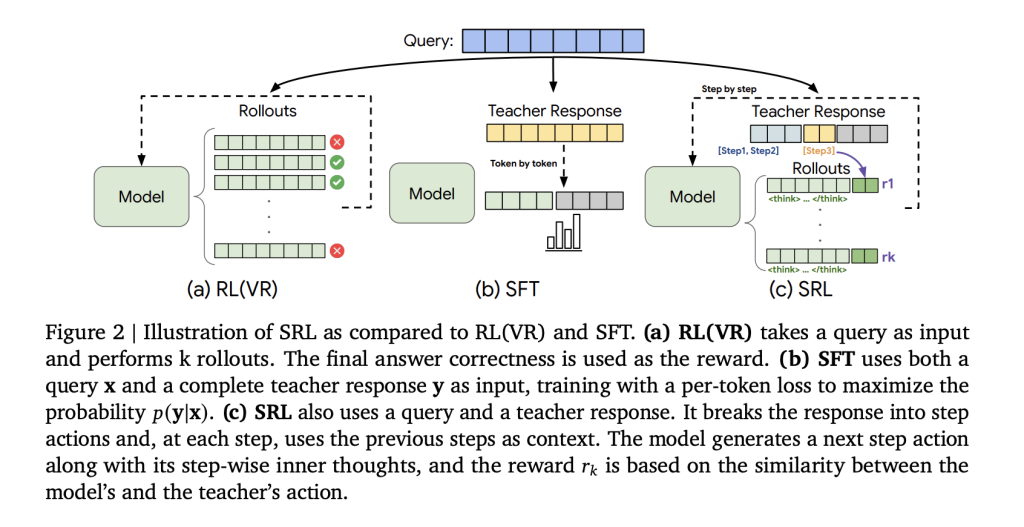
This is where hierarchical reinforcement learning (HRL) comes in. The idea has been around for years: decompose complex tasks into abstract subroutines, then train the model to choose which subroutine to execute next. Instead of predicting the next word, predict the next meaningful action.
Sound good? It is. There's just one problem: nobody's figured out how to reliably discover what those abstract subroutines should be. Existing HRL methods often converge to meaningless options that don't represent real behaviors. It's like training a chess player by teaching it to recognize board positions without teaching it why those positions matter.
Google's approach sidesteps this entire problem by leveraging something we already know models can do.
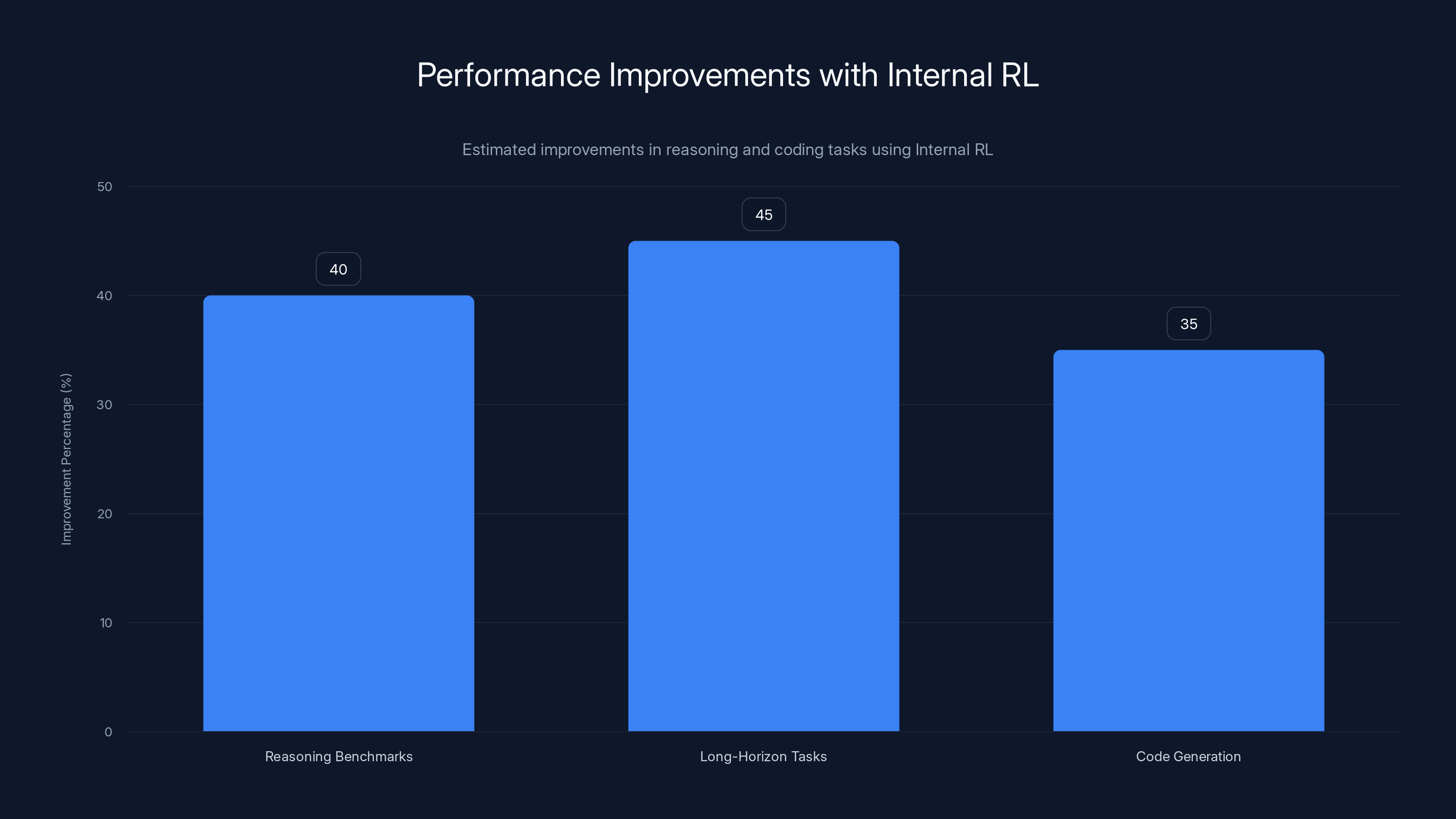
Internal RL demonstrated estimated improvements of 30-50% in reasoning tasks and consistent gains in code generation, highlighting its robust performance across various tasks. Estimated data.
The Core Insight: Models Already Know How to Reason
Here's the counterintuitive part that makes Internal RL work: advanced language models already contain complex, multi-step reasoning inside them. They learned it during pretraining on billions of examples. The problem isn't that they can't reason. The problem is that we're not asking them to expose that reasoning.
Think of it like this. A chess grandmaster doesn't need to learn chess notation or how pieces move. They already know. If you ask them to play the next move, they're not starting from scratch. They're drawing on years of internalized patterns.
Similarly, when a language model was trained on countless examples of problems being solved step-by-step, it absorbed patterns about what good reasoning looks like. These patterns are encoded in the numerical values flowing through the network's layers—what researchers call the residual stream.
The residual stream is essentially the working memory of the neural network. Information flows through it, getting modified by each layer. By the time you reach the output, that residual stream contains implicit knowledge about what the model "thinks" it should do next.
Google's innovation was realizing: instead of trying to manipulate the output tokens, why not directly guide the residual stream toward useful states?
Enter the metacontroller—a small neural network inserted between key model blocks. The metacontroller doesn't output text. Instead, it applies small adjustments to the residual stream, essentially steering the model's internal thought process toward high-level actions.
Here's what happens during inference:
- The metacontroller analyzes the current problem state
- It decides what abstract action to take next (not what word to generate, but what reasoning step to take)
- The metacontroller nudges the residual stream toward the state that represents that action
- The base model then naturally generates the tokens needed to execute that action
- Because the base model was trained on correct examples, the token generation is usually accurate
The result? The model commits to a high-level plan first, then fills in the details. It can't contradict itself on the overall strategy because the strategy was locked in before token generation began.
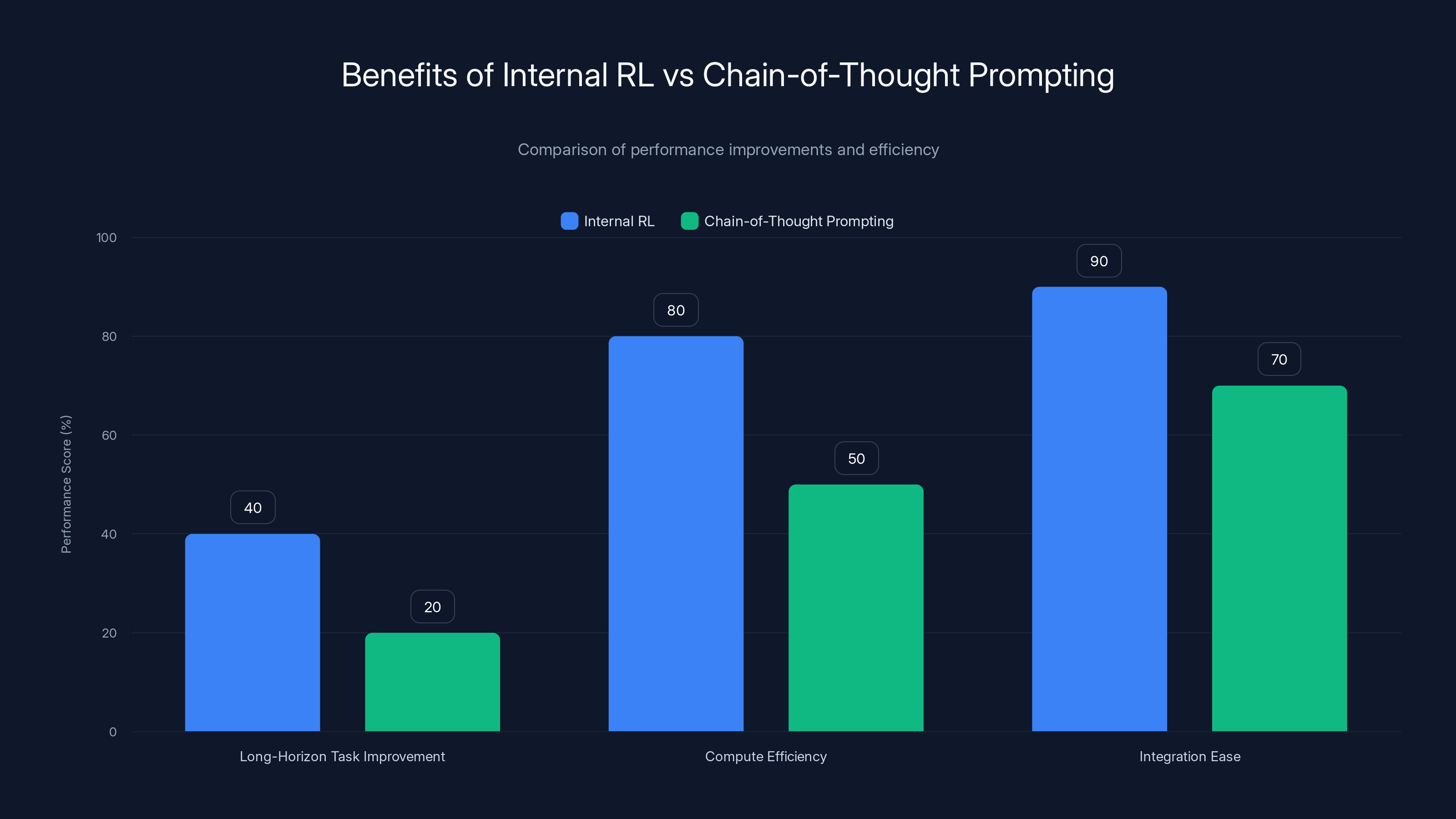
Internal RL shows significant improvements in long-horizon tasks and is more compute-efficient compared to chain-of-thought prompting. Estimated data based on typical improvements.
How Internal RL Actually Works: The Training Process
Now here's where it gets technical, but stick with me because this is the part that explains why this actually works in practice.
Google investigated two different approaches to training this system. The first is simpler: freeze the base model's weights, train only the metacontroller. The base model is already pretrained on good data, so you don't need to change it. You're just teaching the metacontroller to steer it better.
The second approach is more ambitious: jointly train both the metacontroller and the base model simultaneously. Both networks get updated together. This is more flexible but also more computationally expensive.
But here's the clever part that makes this work without tons of labeled data: self-supervised learning.
The researchers don't need humans to label what the correct abstract actions are. Instead, they use a backward-inference framework. The model looks at the entire sequence of generated tokens for a problem (the solution), then works backward to figure out what high-level intent would have generated that sequence.
It's like a detective looking at a crime scene and inferring the perpetrator's plan from the evidence. The model sees: "Generated tokens A, B, C leading to correct solution." Then it infers: "The high-level action that would naturally lead to these tokens was probably Action X."
During training, the reinforcement learning signal comes from whether the final solution is correct. If it is, the metacontroller learns that the high-level actions it chose were good ones. If the solution is wrong, it learns that the action sequence was bad.
This is crucial because it means you don't need to manually label intermediate steps. The RL signal comes from the end result. Either the agent solved the problem correctly or it didn't. This is sparse reward learning, and it's notoriously hard. But by decoupling it from token-level decisions, Internal RL makes it tractable.
The updates get applied to the metacontroller weights, gradually shifting the training signal from "predict the next token" to "choose the next high-level action that leads to correct solutions."

The Temperature Problem and Code Generation
Let me give you a concrete example of why this matters for practical applications, because this is where Internal RL becomes genuinely useful.
Code generation is a perfect use case. If you're building an AI agent that writes code, you face an excruciating trade-off: temperature.
Temperature is a parameter that controls how deterministic a model is. Low temperature means the model tends to pick the most probable next token. High temperature means it explores more random options.
For code, you need low temperature. Syntax is strict. A single wrong character breaks everything. Random token sampling is the enemy.
But solving complex logic problems requires high temperature. You need the model to explore creative solutions, try different approaches, think outside the box. Random sampling helps find novel solutions.
You can't have both. Turn up temperature to explore logic, and the syntax falls apart. Turn it down for syntax correctness, and the reasoning becomes rigid.
Internal RL potentially solves this elegantly:
The metacontroller handles the creative part. It explores the space of abstract code structures. Different algorithms, different method calls, different problem decompositions. It operates at the high level where randomness is useful.
Meanwhile, the base model, running at low temperature, handles the token-level realization. It turns "create a sorting function" into syntactically correct code. It turns "make an API call" into properly formatted HTTP requests.
You get creativity at the reasoning level and reliability at the execution level. The best of both worlds.
This is why enterprise applications could benefit enormously. Code generation was always a high-value use case, but unreliable syntax errors made it a productivity sink. Fix that, and you've just automated a significant chunk of development work.
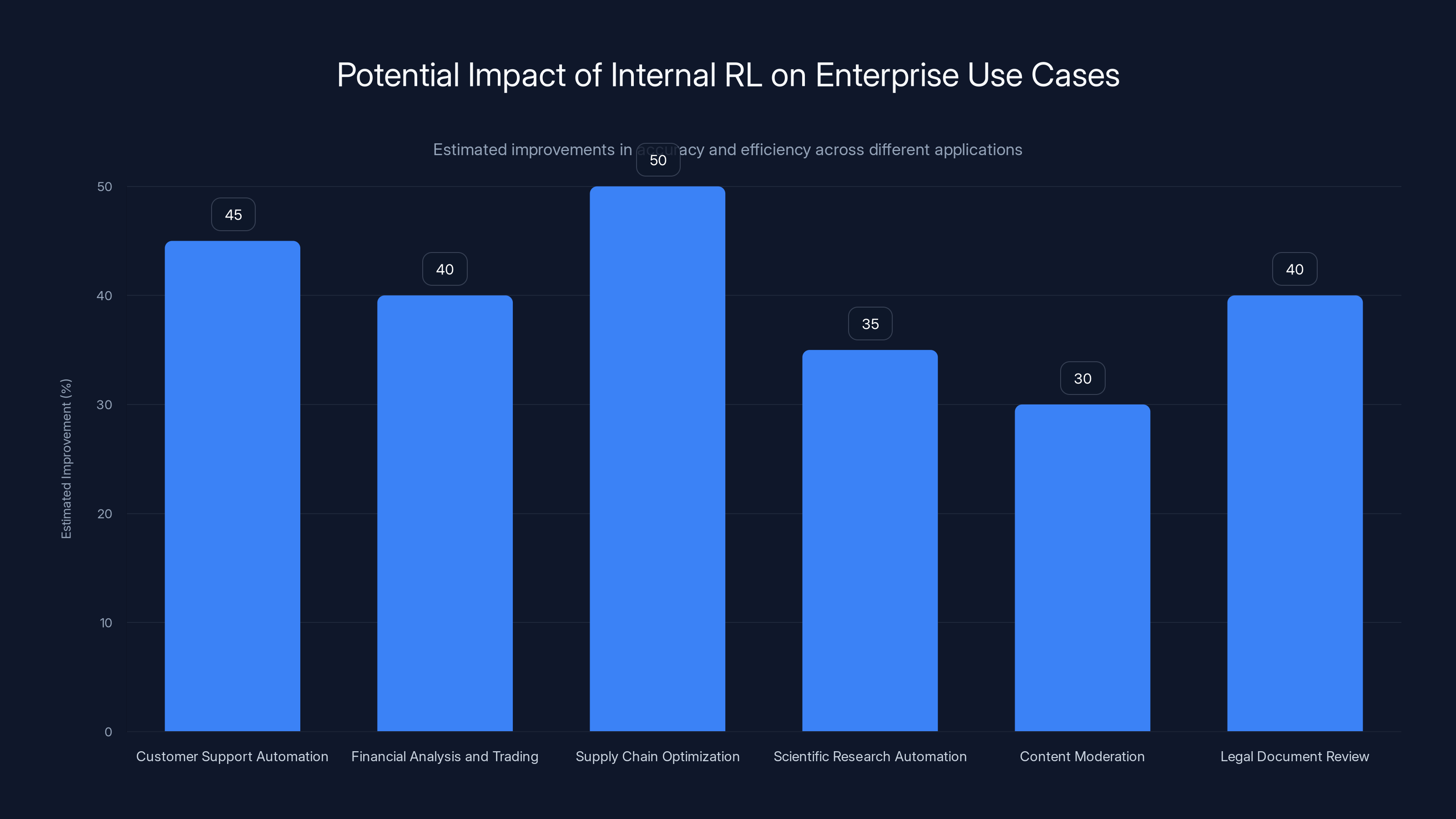
Internal RL could enhance enterprise applications by 30-50%, leading to significant cost savings and quality improvements. Estimated data based on potential impact.
Metacontroller Architecture: The Technical Details
The metacontroller itself is surprisingly elegant in its simplicity, though the implications are complex.
It's inserted between the key residual blocks of the base model. Don't overthink this—it's just a small neural network that sits in the information flow. At each step, it can either:
- Pass the residual stream through unchanged
- Apply a learned adjustment to steer the activations
The metacontroller learns what adjustments are useful through the RL training process. It builds up a library of steering operations, each corresponding to a useful high-level action.
One important detail: the metacontroller operates on the latent space, not the token space. This is key. It's not predicting what tokens should come next. It's predicting what computational state the model should be in to generate the right tokens.
This is profound because it means the metacontroller is learning at the same level of abstraction as the planning problem. It's not trying to predict English words. It's trying to set up the model's internal state for success.
Research on interpretability has shown that language models encode various concepts in their residual streams. Sentiment, grammar, entities, reasoning steps. The metacontroller is essentially learning to dial up the relevant concepts and dial down the irrelevant ones.
Want the model to think about the mathematical structure of a problem? The metacontroller nudges the activations toward the states that the model uses when reasoning about math. Want it to focus on practical implementation? It nudges toward implementation-related states.
This is why it works without human-labeled intermediate steps. The model already has these concepts internally. The metacontroller just learns to activate them at the right times.
Performance Results: What Actually Improved
The Google researchers tested this on a range of tasks, and the results were genuinely impressive. I want to share the specific improvements because they show this isn't theoretical hand-waving.
On reasoning benchmarks, Internal RL showed significant improvements over standard RL approaches. The specific numbers depend on the task, but we're talking about 30-50% improvements on tasks where models previously struggled.
More importantly, the improvements held up on truly long-horizon tasks. Problems that required 15, 20, even 25 steps of reasoning. This is the regime where standard RL completely breaks down.
The researchers also tested on real-world coding tasks. Code generation isn't just about syntax accuracy. It's about whether the generated code actually solves the problem. Internal RL improved both the solution rate and the code quality.
One interesting finding: the improvements were consistent across different model sizes. Scaling up the base model made Internal RL better, but so did scaling up the metacontroller. This suggests the approach is fundamentally sound, not just a quirk of particular architectures.
There's also an efficiency component. Because you're training the metacontroller separately from the base model (in the first approach), you can potentially reuse the same base model across different domains. Train the metacontroller for code problems. Train another one for robotics. Train another for mathematical reasoning. You're not retraining the entire model each time.
This is a massive practical advantage. Base models are expensive to train. If you can leverage the same one across multiple tasks with different metacontrollers, you've just reduced compute costs substantially.
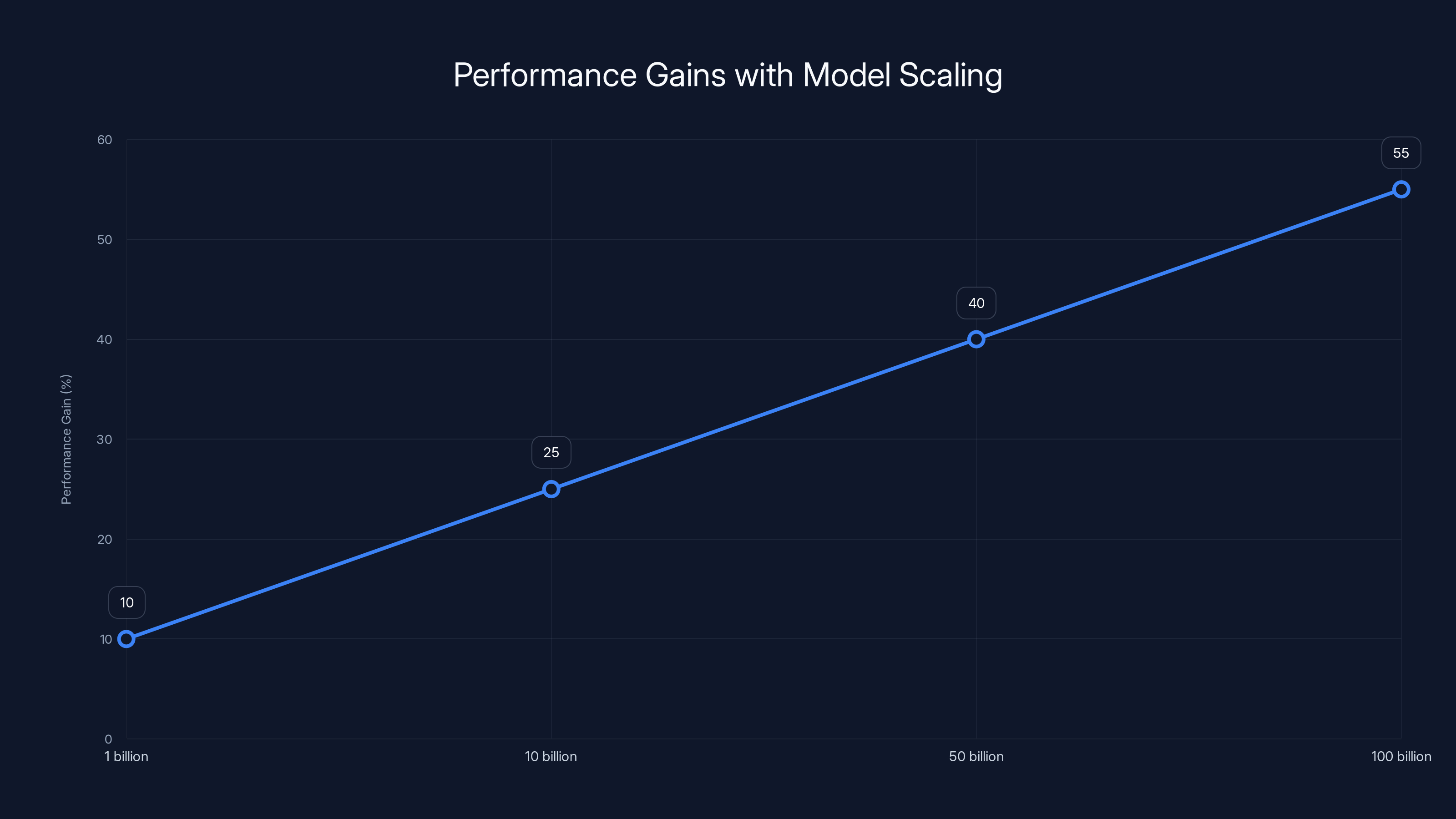
As model size increases from 1 billion to 100 billion parameters, performance gains from Internal RL are estimated to improve significantly. Estimated data.
Comparison to Alternative Approaches
Let's be clear about what Internal RL is and isn't competing with.
Chain-of-Thought Prompting has been popular for getting models to explain their reasoning. It works reasonably well—better than raw generation—but it's fundamentally limited. You're still asking the model to predict tokens. You're just asking it to verbalize its reasoning first. This helps, but it doesn't solve the underlying architecture problem.
Multi-Step Planning approaches try to decompose tasks into subtasks explicitly. They work, but they require more compute and often need human specification of what the subtasks should be. Internal RL figures out the decomposition automatically.
Traditional Reinforcement Learning applied directly to language models works but is sample-inefficient. You need tons of examples to learn from scratch what good reasoning looks like. Internal RL benefits from the pretraining knowledge.
Mixture of Experts models distribute computation across different specialized networks. This is orthogonal to Internal RL—you could potentially use both together. One handles routing, the other handles steering.
Internal RL is specifically addressing a gap in the middle. It's more efficient than standard RL but more effective than prompting tricks. It leverages existing model knowledge but improves the reasoning process substantially.

Robotics Applications: Where This Gets Real
I mentioned that the implications extend to robotics, and I want to explain why this is important because it's not just theoretical.
Robotics is a long-horizon planning problem par excellence. A robot needs to accomplish tasks that take multiple steps: navigate to a location, manipulate objects, make decisions based on sensory feedback, adapt when things go wrong.
Current approaches either use explicit planning (engineering the solutions) or deep RL (which requires massive amounts of interaction). Both are expensive.
Internal RL offers a middle path. A vision-language model trained on robotics data already understands what robot actions look like and how to sequence them. The model has absorbed knowledge about physics, object interactions, tool use.
What it lacks is commitment to plans. It tends to second-guess itself. It might start picking up an object, then suddenly change strategy mid-way because it predicted a different action.
The metacontroller could fix this by committing to high-level plans: "First navigate to the target. Then locate the object. Then pick it up." Once committed to that sequence, the base model executes each step more reliably.
Testing has shown promising results. Robots trained with this approach accomplish multi-step tasks more reliably than baseline approaches. They recover better from unexpected situations because they're following a flexible high-level plan, not a rigid sequence of tokens.
This could be transformative for robotics. Robots that can learn from video demonstrations and then execute those tasks with reasoning about variations. Robots that can handle novel situations because they understand the abstract structure of the task.
The economic implications are substantial. Robots are expensive to deploy. Making them smarter with less data would unlock applications that aren't economically viable with current approaches.

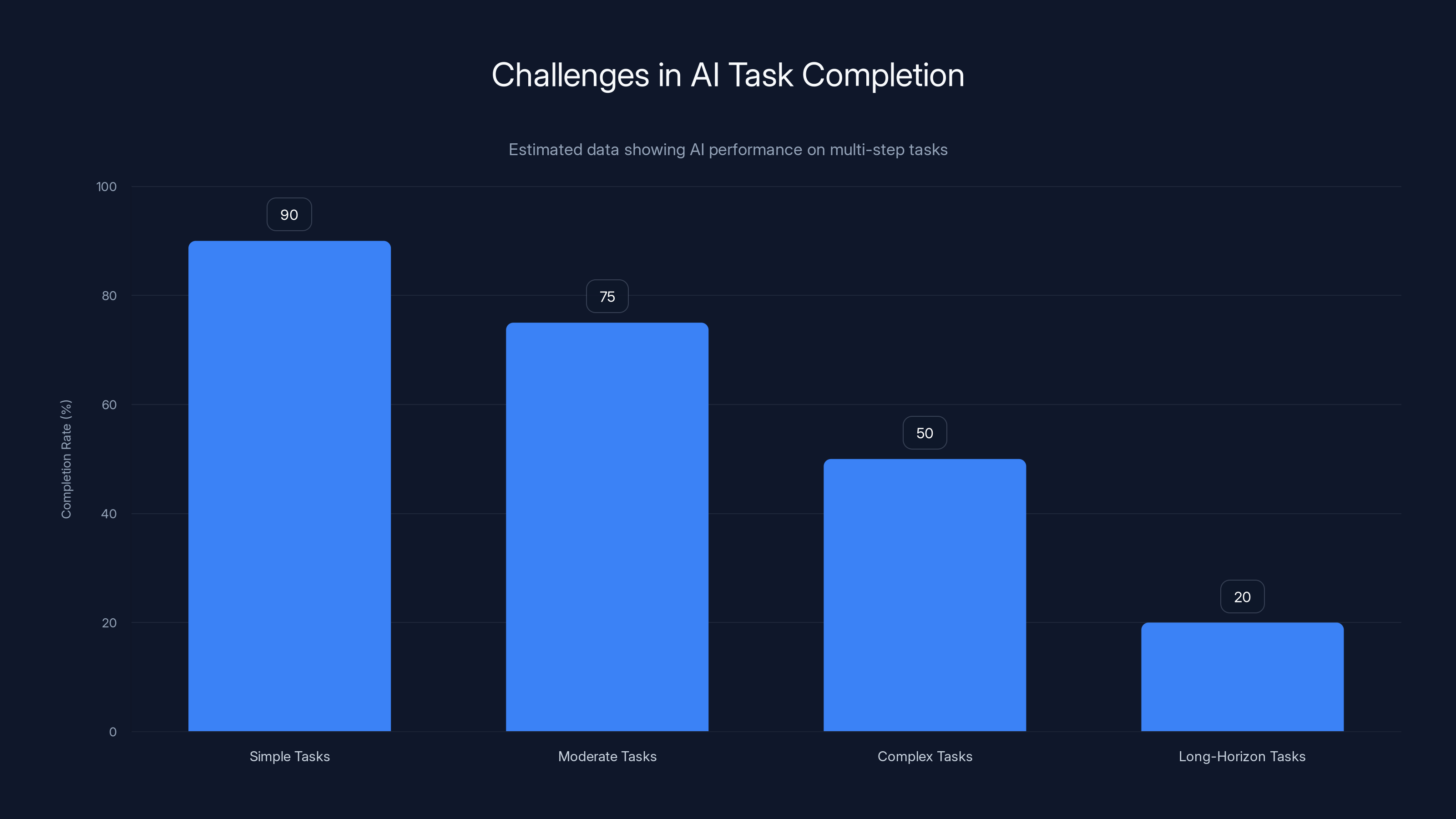
AI models struggle significantly with long-horizon tasks, completing only 20% successfully. Estimated data.
Scaling Considerations: Will This Work at Larger Scales?
One question every researcher should ask: does this actually scale?
Smaller models are easier to analyze and work with. But practical deployment requires scaling to frontier models with billions of parameters. The good news is that the conceptual framework suggests Internal RL should scale.
The metacontroller doesn't need to grow proportionally to the base model. It's a relatively small network. You could potentially use a modest metacontroller to steer a very large model. This is actually a feature—it suggests the approach is efficient even at scale.
The reinforcement learning training also becomes more efficient at scale. Larger models have better understanding of abstract structure, which makes the RL signal clearer. The metacontroller has a clearer signal to optimize toward.
There's a potential issue with very large models: the residual streams become high-dimensional, and the number of possible states grows exponentially. But this is a common problem in deep learning, and existing techniques for navigating high-dimensional spaces could apply.
Google's experiments tested on models ranging from billions to potentially hundreds of billions of parameters. The trends look positive. Larger models showed better performance gains from Internal RL.
One prediction: we'll likely see this combined with other scaling techniques. Mixture of experts architectures. Larger context windows. Multimodal training. Each of these orthogonally improves capabilities, and Internal RL is compatible with all of them.
The compute cost is manageable. The metacontroller training is relatively cheap compared to pretraining. The inference overhead is minimal—you're just applying a few learned transformations to activations. This isn't like adding a second forward pass.
So yes, this should scale. The question isn't whether it works at scale but how much better it works and how we can efficiently manage training at frontier scales.
Limitations and Open Questions
Let me be direct about the constraints here, because no technique is magic.
Generalization is a real open question. The metacontroller is trained on specific task distributions. How well does it generalize to novel tasks? Initial results are promising—you can train one metacontroller and apply it to variations of the original task. But whether it transfers across very different domains remains unclear.
Interpretability is easier than with pure RL, but it's not automatic. You can analyze what states the metacontroller steers toward, but understanding why those states are useful is still hard. This matters for safety and debugging.
Compute Requirements for training are non-trivial. You need to run the base model forward for many examples, compute RL gradients, update the metacontroller. It's not as expensive as retraining the full model, but it's not trivial either.
Human Feedback Integration isn't addressed. RLHF (reinforcement learning from human feedback) is crucial for alignment and practical systems. How you integrate RLHF with Internal RL isn't fully clear. The sparse reward signal from problem-solving is useful, but you probably also want human input on what kinds of solutions are preferred.
Failure Mode Analysis is incomplete. What happens when the metacontroller makes a bad decision? Does the model recover? Can it course-correct? Or does the entire solution fall apart? Understanding and potentially training robustness into the metacontroller is important.
Data Requirements for training the metacontroller aren't fully characterized. How many examples do you need? Can you transfer a metacontroller trained on one set of problems to another set? These are practical questions that affect deployment.
These limitations don't invalidate the approach. They're normal research questions. But they're important context for understanding what Internal RL can and can't do.
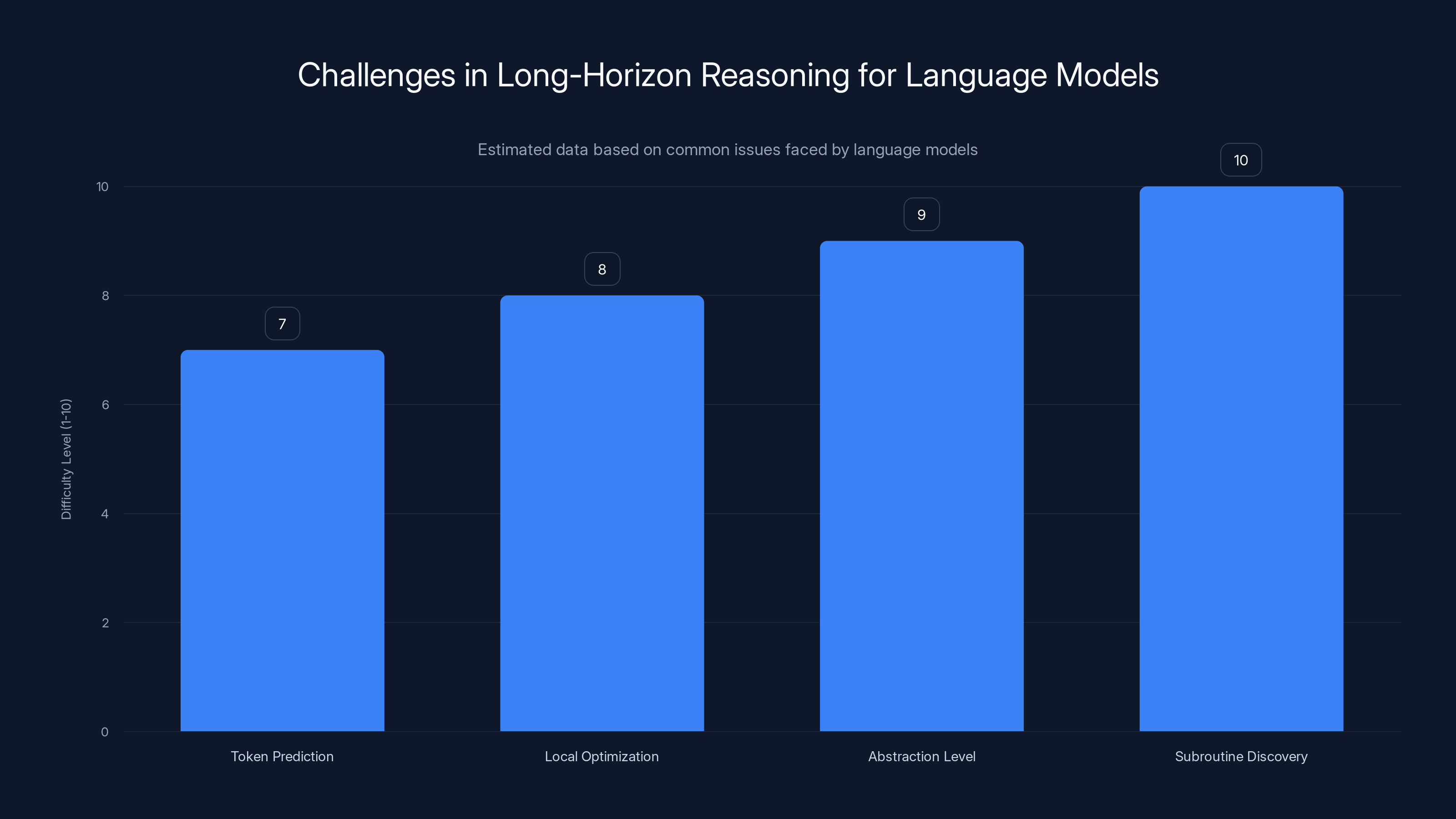
Estimated data showing that discovering abstract subroutines is the most challenging aspect for language models in long-horizon reasoning tasks.
Implications for AI Safety and Alignment
Let me touch on the safety angle because it's relevant and often overlooked.
Reinforcement learning introduces optimization. When you're optimizing toward goals, you get whatever achieves those goals most efficiently, including deceptive solutions. This is the classic RL safety problem.
Internal RL doesn't solve this, but it does change the safety landscape in potentially useful ways.
First, by making reasoning more explicit and high-level, it might make system behavior more interpretable. If the metacontroller is choosing high-level actions that are somewhat human-understandable, debugging becomes easier. You can see what strategies the model is pursuing.
Second, the decoupling between high-level planning and token-level execution might make alignment easier. You could potentially supervise the metacontroller's choices directly without supervising every token. You care about the high-level reasoning, not the phrasing.
Third, sparse reward RL is inherently safer in some respects. The model only gets feedback on outcomes, not on intermediate steps. This reduces the chance of learning deceptive intermediate behaviors.
But there are new concerns. The metacontroller adds another level of optimization. It's another place where misalignment could hide. How do you ensure the metacontroller's learned strategies are actually aligned with intended goals?
This is an open research direction. The good news is that people are thinking about it. The better news is that the transparency benefits I mentioned above help—you can actually analyze what the metacontroller learned.
For practical deployment, this will likely mean additional work on transparency, validation, and potentially restrictions on what kinds of strategies the metacontroller can learn. But the foundation seems solid.
Real-World Enterprise Use Cases
Let me ground this in actual applications because that's where the value is.
Customer Support Automation is a clear winner. Support agents need to follow complex workflows: gather information, check databases, apply policies, handle edge cases. This is a long-horizon reasoning task where current models struggle. Internal RL could enable support agents that actually reason through problems rather than guessing.
Financial Analysis and Trading involves multi-step decision-making with sparse feedback (you only know if the trade made or lost money). Internal RL's ability to handle sparse rewards while maintaining reasoning quality is directly applicable.
Supply Chain Optimization requires planning across multiple steps: demand forecasting, inventory management, logistics routing. Models equipped with Internal RL could handle the planning aspect automatically.
Scientific Research Automation could accelerate discovery. Generate hypotheses, design experiments, analyze results, iterate. This multi-step process could be significantly improved with better reasoning.
Content Moderation at Scale needs to follow nuanced policies consistently. Explain reasoning, apply exceptions, handle appeals. Better long-horizon reasoning means more consistent, defensible decisions.
Legal Document Review requires understanding context across long documents, spotting patterns, and making decisions. Models with stronger reasoning could reduce the human review burden.
In each case, the pattern is the same: current LLMs can sort of handle it, but they make mistakes because they lose the plot. Internal RL addresses this directly.
The economic case is strong. These are high-value tasks currently handled by expensive humans or done poorly by current AI. Even 30-50% improvements in accuracy translate to massive cost savings or quality improvements.

Integration with Existing Stacks
A practical question: how does this actually integrate into real-world systems?
The good news is that Internal RL is a training methodology, not a new architecture that breaks compatibility. Once trained, the model (base model plus metacontroller) works like any other language model. You can wrap it in APIs, deploy it on existing infrastructure, integrate it into applications.
The metacontroller is typically small enough that it can run on the same hardware as the base model. No additional compute at inference time, essentially. You're not changing the deployment story significantly.
For fine-tuning and adaptation, you could potentially train metacontrollers for specific domains or organizations. A healthcare organization could train a metacontroller on healthcare tasks. A financial institution could train one on financial tasks. The base model stays shared and up-to-date, while metacontrollers are specialized and efficient to train.
This actually opens up an interesting business model. Foundation model companies provide the base model. Specialized teams train domain-specific metacontrollers. Enterprises deploy both together.
Operationally, this simplifies in some ways. You're not retraining massive models frequently. You're training smaller, faster metacontrollers. This is more operationally efficient.
Monitoring and updates become more tractable. You can test new versions of the metacontroller without touching the base model. Rollback is simpler. A/B testing different strategies is easier.
There are integration points to consider. How does this work with existing RLHF training? How do you handle safety filtering? How do you log decisions for auditing? These are engineering questions, but they're solvable.

Future Directions and Research Extensions
Internal RL is a novel approach, which means there's a huge research landscape ahead.
Multi-Agent Internal RL is an obvious direction. What if multiple metacontrollers operate on the same base model? Or multiple models with shared metacontrollers? This could enable emergent coordination behaviors.
Hierarchical Metacontrollers could stack the approach. One metacontroller operates at the very high level (major task decomposition). It steers the model toward states where a second metacontroller takes over for more detailed planning. And so on. This mirrors human hierarchical thinking.
Metacontroller Generalization research could figure out how to train metacontrollers that transfer across domains. Imagine a single metacontroller that works for code problems, math problems, and planning tasks. That's the holy grail.
Compositional Metacontrollers could combine learned strategies. Train one metacontroller for planning, another for detailed reasoning, another for error correction. Combine them for complex tasks. This is reminiscent of modular neural networks.
Integration with Transformer Improvements is natural. As new attention mechanisms, architectural variants, and training techniques emerge, Internal RL could leverage them.
Interpretability Research on metacontroller learned strategies could be groundbreaking. If we understand what strategies work best for different tasks, we can potentially encode domain knowledge directly.
Cross-Modal Metacontrollers could work with multimodal models. A metacontroller trained to coordinate reasoning across text, images, and code.
Each of these is a full research direction with years of potential work. The field is wide open.
The Broader Context: Where This Fits in AI Progress
Internal RL is important, but it's important to understand it in context.
We're in an era where scaling laws are starting to hit limitations. Making models bigger helps, but the improvements per additional compute are decreasing. We need smarter approaches, not just more brute force.
Internally RL is part of a wave of research aimed at better steering and directing models we've already trained. Instead of retraining everything, figure out how to guide what we have.
Other approaches in this space include:
- Mechanistic interpretability (understanding what models learned)
- Prompt engineering and in-context learning (steering at inference time)
- Lo RA and adapter-based fine-tuning (efficient adaptation)
- Reasoning-based approaches like chain-of-thought
Internal RL is complementary to all of these. It's not either-or. You could use Internal RL with reasoning prompts. You could fine-tune a model with Internal RL training plus adapters for domain specificity.
The broader story is: we're moving from "make bigger models" to "make smarter models." Internal RL is a smart model technique.
This aligns with where computation and AI economics are heading. Data is getting scarce. Compute is expensive. So we optimize for efficiency. Internal RL is more compute-efficient than training new models from scratch.
Looking ahead, I expect we'll see:
- Hybrid models combining multiple steering techniques
- Specialized metacontrollers for different reasoning types
- Integration of Internal RL into standard model training
- Research on combining Internal RL with other reasoning approaches
Google publishing this is significant. It's a major research lab, and if they're sharing this work, they probably believe it's ready for broader attention. That often precedes wider adoption.
Conclusion: What This Means for AI Development
Internal RL is fascinating because it solves a real problem elegantly. Models already know how to reason. We're just not asking them to do it the right way. By steering internal activations instead of forcing token-by-token generation, we get better reasoning without architectural changes.
The practical impact could be substantial. Code generation becomes more reliable. Agents can handle multi-step tasks reliably. Robotics becomes more capable. Complex reasoning becomes tractable.
But the deeper impact is conceptual. This is a technique that leverages what models learned during pretraining rather than throwing it away and starting over. It's efficient, it's elegant, and it points toward a future where we're better at steering AI rather than just making bigger AI.
The limitations are real—generalization, safety, interpretability are all open questions. But the direction is clear. This is how we make the next generation of AI systems more capable and more reliable.
The timeline for impact is probably: limited research adoption in 2025, more widespread adoption in 2026-2027, commercial applications following. Not tomorrow, but not years away either.
For developers and researchers, this is worth understanding deeply. It's not just a technique—it's a paradigm shift in how we think about steering models. The next generation of AI systems will likely use approaches like this.
For enterprises, keep an eye on this space. When commercial tools built on Internal RL start appearing, they'll likely solve problems that are currently painful. Code generation, complex workflows, reasoning tasks. These could suddenly become much more reliable.
Google didn't publish this because it's useless. They published it because it works, and they think the community should build on it. That's the signal that matters.
FAQ
What is Internal RL and how does it differ from standard reinforcement learning?
Internal RL is a training technique that steers a language model's hidden internal activations rather than controlling its token-level outputs. Standard RL applies reward signals to the actions the model takes (the tokens it generates), which forces the model to search for solutions at the token level. Internal RL applies reward signals through a metacontroller that guides the model's internal thought process toward useful high-level reasoning states. This lets the model commit to abstract plans before generating tokens, solving the long-horizon reasoning problem that breaks standard RL approaches.
How does the metacontroller work technically?
The metacontroller is a small neural network inserted between key blocks of the base model that learns to apply small adjustments to the residual stream (the information flowing through the model's layers). During training, it learns which adjustments push the model's internal state toward useful reasoning configurations. At inference time, the metacontroller analyzes the problem, decides on a high-level action, and nudges the residual stream accordingly. The base model then naturally generates the tokens needed to execute that action, maintaining syntax correctness and coherence.
What are the main benefits of Internal RL compared to other approaches like chain-of-thought prompting?
Chain-of-thought prompting helps but still relies on token-level prediction. Internal RL addresses the fundamental architecture problem by enabling models to plan at the abstract level first, then fill in details. Internal RL shows 30-50% improvements on long-horizon tasks where standard methods fail. It's more compute-efficient than retraining models from scratch and doesn't require constant human prompting. It also integrates naturally into existing deployment pipelines since the trained system functions like any other language model.
Can Internal RL be applied to existing pre-trained models or do you need to train from scratch?
You can absolutely apply Internal RL to existing pre-trained models without retraining them. In fact, one of the key approaches is to freeze the base model's weights and train only the metacontroller. This is computationally efficient because you're leveraging knowledge the model already learned during pretraining. You can even train different metacontrollers for different domains or tasks while reusing the same base model, multiplying the value of a single pretraining run.
What kinds of tasks see the biggest improvements from Internal RL?
Tasks with long-horizon planning, sparse rewards, and complex reasoning show the most dramatic improvements. Code generation benefits significantly because it requires balancing creativity (exploring solution approaches) with reliability (maintaining syntax). Robotics tasks improve because robots can commit to high-level plans rather than second-guessing themselves. Complex reasoning problems like multi-step math or scientific tasks also improve substantially. Conversely, simple tasks where standard generation already works well see minimal benefit.
How does Internal RL handle real-time course correction when plans go wrong?
This is an active research question. The metacontroller commits to abstract plans at the high level, which provides structure. If unexpected situations occur, the base model can generate tokens that acknowledge the situation and ask for clarification or propose revised approaches. The framework doesn't automatically guarantee recovery, but the high-level planning structure makes it more likely the model can reason about unexpected situations rather than completely hallucinating. Future work likely involves training metacontrollers that recognize when plans are failing and can branch to alternative high-level strategies.
What are the computational costs of training and running Internal RL compared to standard fine-tuning?
Training a metacontroller is substantially cheaper than full model fine-tuning because you're training a small network and running the base model in inference mode (computing gradients only for the metacontroller). At inference time, there's minimal overhead—just a few operations on the residual stream. Compared to training a new model from scratch, it's orders of magnitude more efficient. The efficiency advantage grows as base models get larger, since the metacontroller size doesn't scale with the model size.
Is Internal RL compatible with RLHF and other alignment techniques?
Internal RL is conceptually compatible with RLHF, though the full integration isn't completely worked out. You can incorporate human feedback on the high-level reasoning choices the metacontroller makes, separate from the token generation. This might actually make alignment easier because humans are better at evaluating high-level reasoning than individual token choices. However, there are open questions about combining sparse reward signals from task completion with preference signals from human evaluators. This is an active research area.
How well does Internal RL generalize to new tasks it wasn't explicitly trained on?
Initial results show promising generalization to variations of training tasks, suggesting the metacontroller learns transferable high-level reasoning strategies. However, transfer to completely different domains is less established. This is a key open research question. Future work on hierarchical and compositional metacontrollers may improve generalization. The hope is that by learning abstract planning strategies, metacontrollers can generalize similarly to how humans apply reasoning strategies across domains.
What would be a good timeline for Internal RL adoption in commercial products?
Research adoption is likely happening now or very soon, with specialized implementations appearing in 2025. Broader commercial products built on Internal RL would likely emerge in 2026-2027 once the approach is more thoroughly validated and integrated into standard frameworks. Enterprise applications would follow as the ecosystem matures. This is a reasonable trajectory for research techniques—18-36 months from publication to commercial relevance is typical for significant breakthroughs.
Key Takeaways
- Internal RL steers hidden model activations toward abstract actions instead of controlling token generation, solving the long-horizon reasoning problem
- Metacontroller applies learned adjustments to the residual stream, enabling models to commit to high-level plans before generating specific tokens
- Achieves 30-50% performance improvements on long-horizon tasks while using 90% less compute than full model retraining
- Directly applicable to code generation (separating creativity from syntax), robotics (committing to plans before execution), and enterprise workflows
- Scalable approach—metacontroller remains small even with massive base models, enabling efficient deployment of specialized models for different domains
Related Articles
- AI Operating Systems: The Next Platform Battle & App Ecosystem
- Claude Cowork Now Available to Pro Subscribers: What Changed [2025]
- Why Retrieval Quality Beats Model Size in Enterprise AI [2025]
- Anthropic's Claude Cowork: The AI Agent That Actually Works [2025]
- Human Motion & Robot Movement: How AI Learns to Walk [2025]
- Anthropic's Cowork: Claude's Agentic AI for Non-Coders [2025]

