![Why Retrieval Quality Beats Model Size in Enterprise AI [2025]](https://tryrunable.com/blog/why-retrieval-quality-beats-model-size-in-enterprise-ai-2025/image-1-1768511382351.png)
The Silent Killer Nobody's Talking About
You've got a massive language model. You've invested in the best infrastructure. Your team's built something impressive. Then it hits production, and everything falls apart.
The model still works—it can generate coherent responses, reason through problems, pass benchmarks. But your users are getting wrong answers. Your system's hallucinating at scale. Your accuracy metrics are tanking. What went wrong?
Chances are, your retrieval system is broken.
This is the dirty secret of enterprise AI in 2025. While everyone's obsessing over whether GPT-5 will have trillion parameters or whether we need bigger models, a completely different problem is silently destroying production systems across the enterprise world. It's not the language model. It's what you feed it.
Retrieval—the ability to find and fetch the right information from your data at the moment your AI system needs it—has become the actual bottleneck. Not the model. Not the infrastructure. The retrieval layer. And most enterprises haven't even realized this is where they're losing the game.
This insight isn't coming from some obscure research lab. It's coming from MongoDB, one of the world's largest database providers that sits in the middle of thousands of enterprise AI deployments. They're seeing patterns that the public conversation about AI is completely missing.
Here's what's happening: as companies move from experimental RAG (retrieval-augmented generation) systems and simple agentic AI into production environments, they're discovering that the hard part isn't making the model smarter. It's making sure the model has access to accurate, relevant information when it needs it. Get that wrong, and your $100 million language model becomes a very expensive, very confident mistake machine.
The implications are huge. Organizations are wasting millions upgrading to bigger models when they should be fixing their retrieval infrastructure. Teams are building fragmented, stitched-together stacks of tools instead of integrated systems designed for retrieval at scale. And worst of all, the industry narrative is completely wrong. We're optimizing for the wrong thing.
Let's dig into why this matters, what's actually happening in production, and how companies are starting to fix it.
Understanding the RAG Reality Check
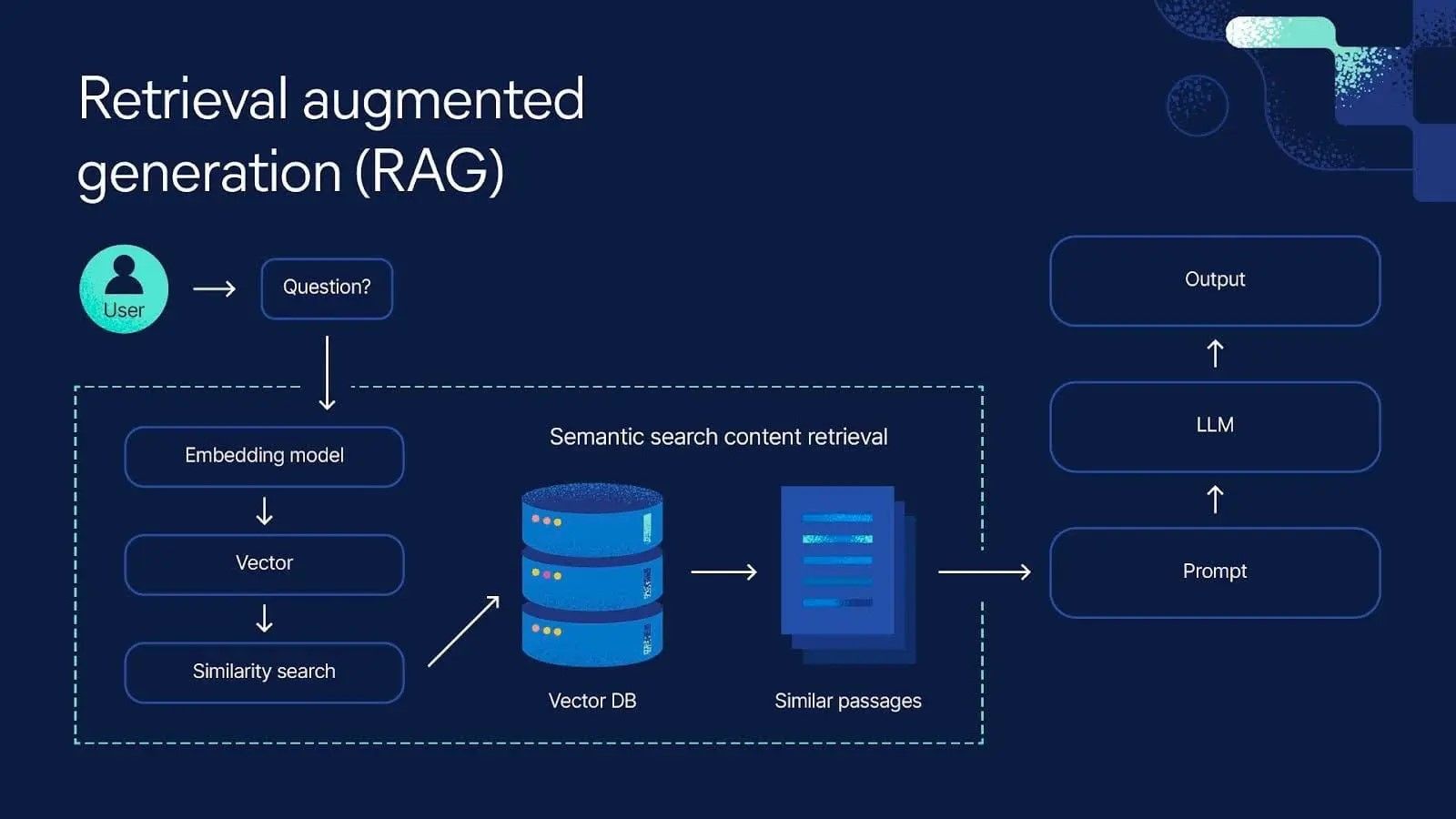
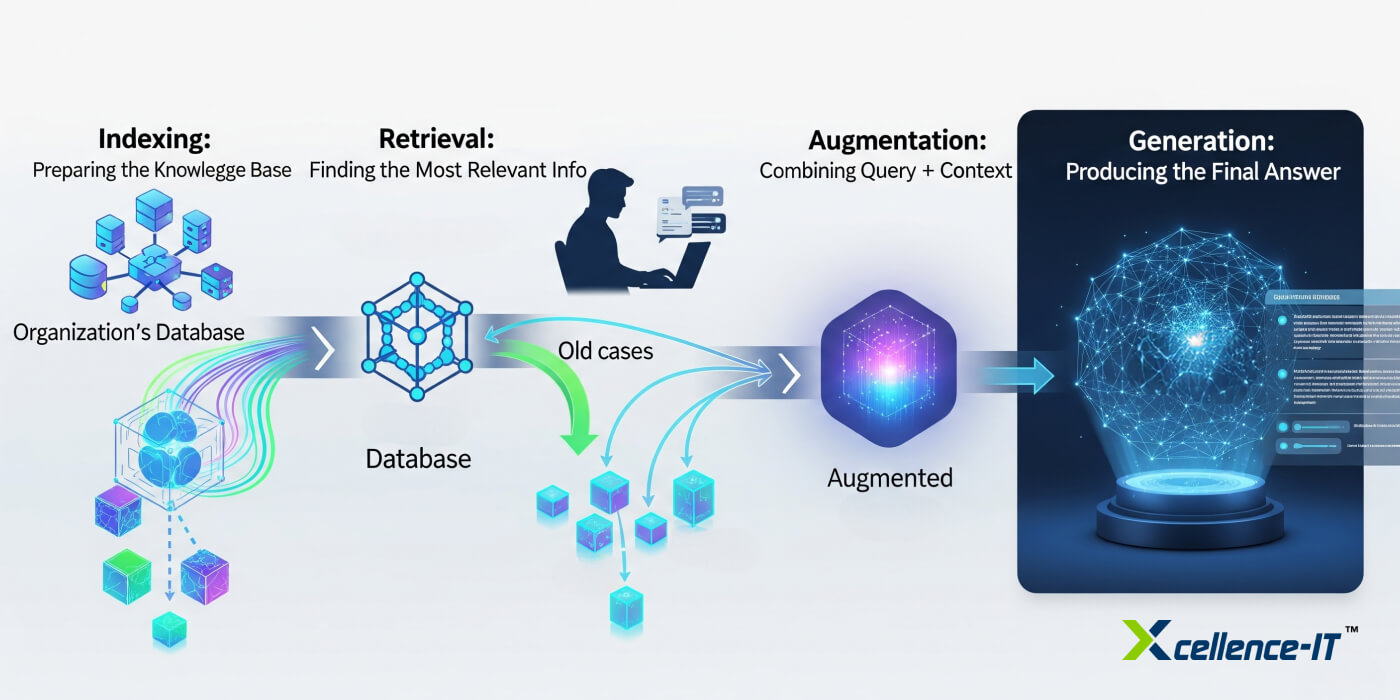
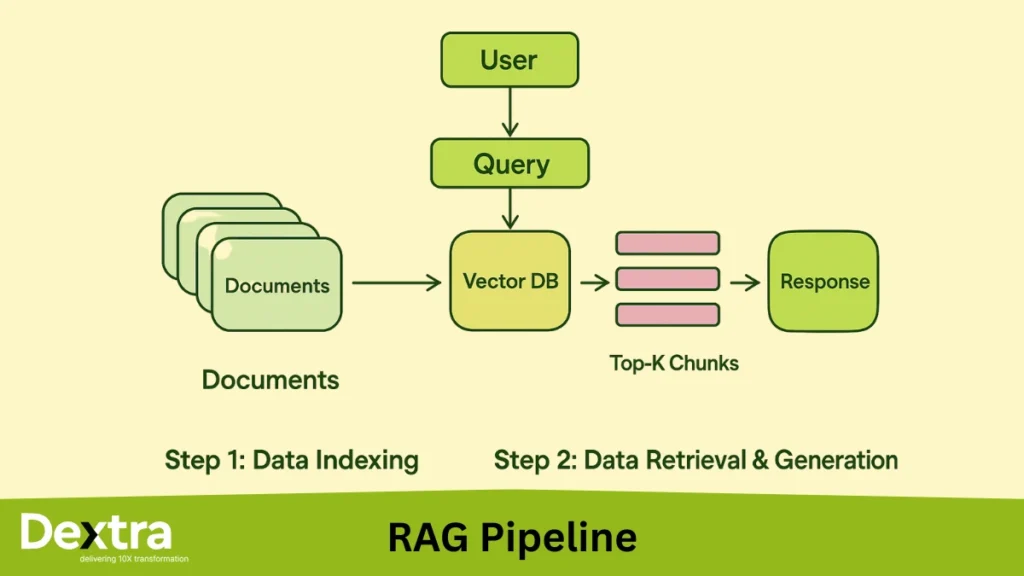
RAG stands for retrieval-augmented generation, and it's been the backbone of most enterprise AI deployments for the past couple of years. The concept is straightforward: instead of relying only on what a language model learned during training, you give it access to your actual company data. You embed that data into vectors, store those vectors in a database, and when a user asks a question, you retrieve the most relevant documents and feed them to the language model as context.
In theory, this solves the hallucination problem. If the model has access to your real data, it should give real answers. Simple.
Except it doesn't work that way once you scale it.
The problem emerges when you have millions of documents instead of hundreds. When your data is constantly changing. When you need to retrieve information across multiple data types—text, images, tables, videos. When users ask questions that don't have clean semantic matches to your existing documents. When you need to understand nuanced context that's spread across multiple pieces of information.
Sudden, "grab the most similar documents and feed them to the model" stops working.
Why? Because similarity isn't the same as relevance. You can have a document that's semantically similar to what the user asked for, but completely irrelevant to what they actually need. Your embedding model might be optimized for generic similarity matching but terrible at domain-specific retrieval. You're using an embedding model trained on general web data, but your enterprise documents have specific terminology, domain knowledge, and context that don't exist in the general internet.
Here's a concrete example: imagine you're a financial services company and someone asks, "What's our policy on customer investment limits?" Your generic embedding model might return documents about investment philosophy, market strategy, or customer acquisition. Technically, those are similar. They both contain the word "investment." But they're useless. What you actually need is the specific policy document.
Or consider this: you're a healthcare organization and a clinician asks about drug contraindications. A good retrieval system needs to understand that certain pieces of information are more relevant than others depending on the specific drug, the patient's history, and the context. A generic similarity search might retrieve information about related drugs, general pharmacology, or historical case studies. That's not good enough when someone's life is on the line.
The problem scales exponentially. When you have millions of documents, the probability of your retrieval system returning something that's technically similar but practically useless approaches near certainty. You end up with a model that's confidently answering questions based on the wrong information.
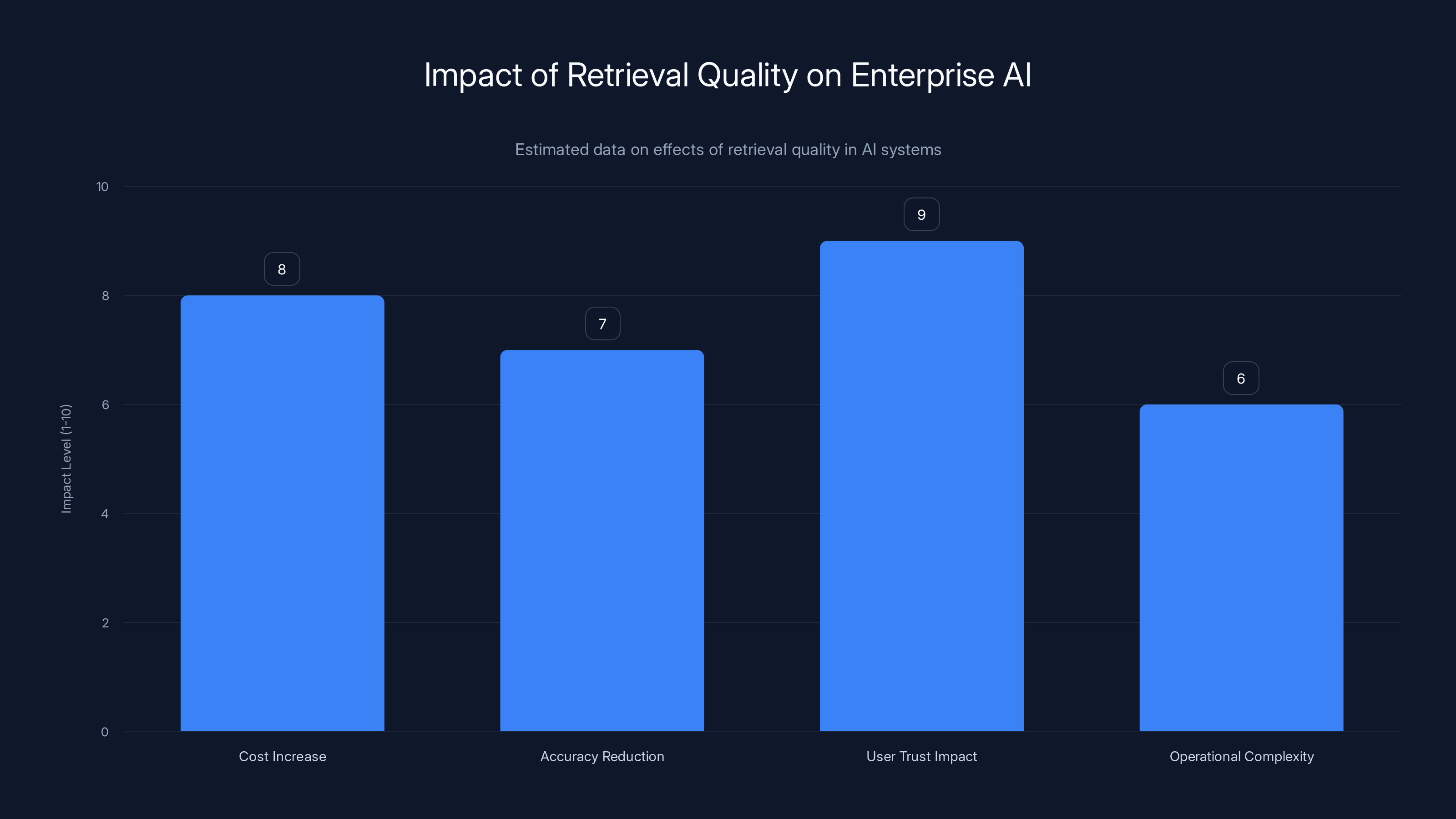
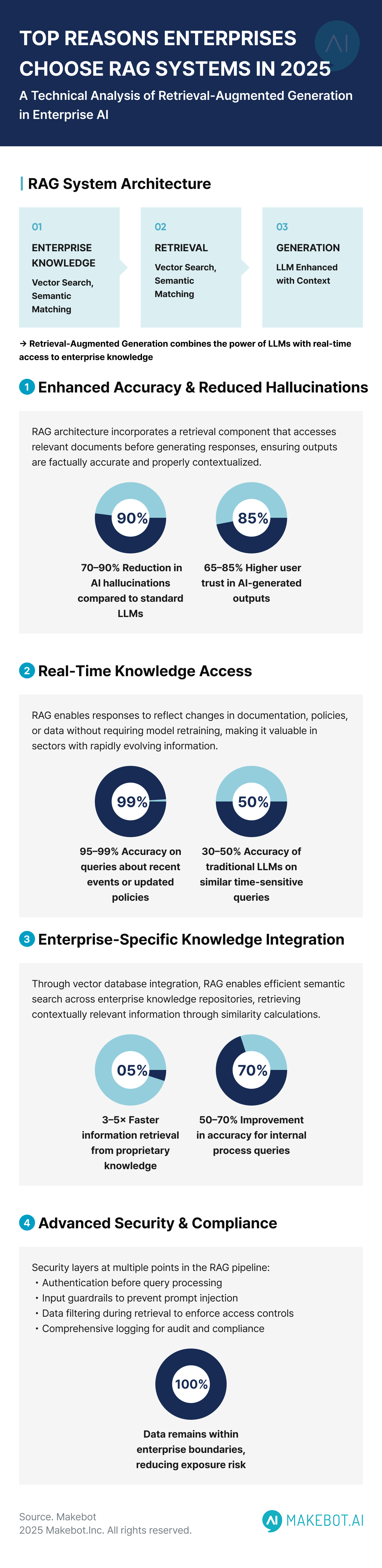
Poor retrieval quality significantly impacts enterprise AI by increasing costs, reducing accuracy, undermining user trust, and adding operational complexity. Estimated data based on typical enterprise scenarios.
The Cost of Bad Retrieval
This isn't just an accuracy problem. Bad retrieval has massive downstream consequences.
First, there's the cost angle. If your retrieval system is bad, you need to compensate somewhere else. Maybe you increase your context window size, feeding the model way more information than it actually needs, just hoping the right stuff is in there somewhere. That costs more money—longer sequences mean higher API bills if you're using a provider, or more compute if you're running locally.
Or you keep increasing the model size, thinking a bigger model will be smarter about finding the signal in a noisy context. But here's the thing: a 100-parameter model with perfect information will beat a trillion-parameter model with garbage information every single time. You can't fix bad retrieval by throwing more model capacity at it.
Second, there's the user experience problem. When your AI system returns confidently wrong answers, users stop trusting it. Not because they're worried about hallucinations in abstract—they don't care about the theoretical risk. They stop trusting it because they've caught it being wrong in ways that matter. Their document search works fine. Their customer support system confidently tells someone something that contradicts the actual policy. Their internal knowledge system gives outdated information.
Third, there's the operational complexity. Most enterprises are stitching together different tools—a vector database here, a retrieval framework there, a reranking model somewhere else, a data warehouse in another place. These systems don't talk to each other well. Your embeddings are out of sync with your data updates. Your reranker is using a different ranking criteria than your retrieval mechanism. Your vector database doesn't have the metadata your application needs to filter properly.
You end up with a fragmented, brittle system that's expensive to maintain, difficult to debug, and constantly breaking in new and creative ways.
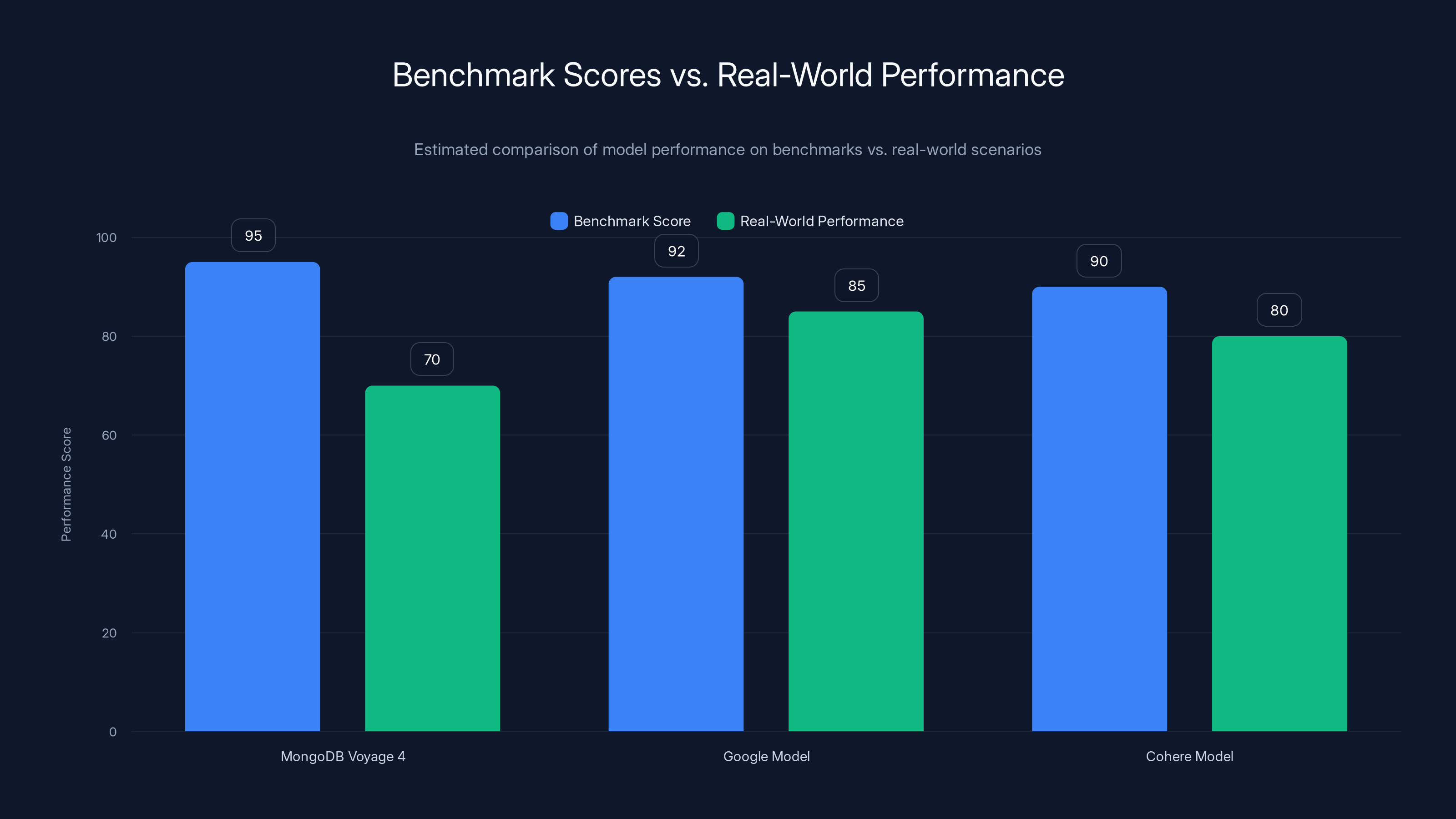
Benchmark scores often overestimate real-world performance. MongoDB Voyage 4, despite high benchmark scores, may not excel in specific enterprise scenarios. Estimated data.
The Embedding Model Problem
Embedding models—the neural networks that convert text into vectors—are the foundation of any RAG system. They're also where a lot of enterprises are getting it wrong.
Most companies start by using a generic, open-source embedding model or whatever comes built into their platform. BERT variants are common. Some use OpenAI's embedding model. A few have tried newer options from Cohere or Google.
The problem is that these generic models are trained on generic data. They're optimized for general-purpose similarity matching, not for your specific domain. A legal firm and a biotech company and a financial services organization all need fundamentally different retrieval behavior. A legal firm needs to understand precedent relationships and clause similarities. A biotech company needs to understand molecular structures and research relationships. A financial services organization needs to understand regulatory requirements and policy hierarchies.
But they're all probably using the same embedding model.
This leads to a subtle but devastating problem: retrieval that works reasonably well on benchmarks but fails catastrophically in production. Your embedding model might score well on standard retrieval benchmarks—they measure similarity well—but those benchmarks don't measure whether it retrieves what your enterprise actually needs.
Say you're a tech company with thousands of support documents, code repositories, and architectural documentation. Your embedding model might be great at finding documents that are topically similar to a query. But when an engineer asks, "How do I connect to the database in our production environment?" the model might return documents about database theory, scaling strategies, or historical architectural decisions. Technically similar. Practically useless.
The problem gets worse with multimodal data. Modern enterprise documents aren't just text. They're presentations with charts. They're PDFs with tables. They're documents with images and diagrams. A text-only embedding model can't understand the content in those images. You lose critical information. An image of a circuit diagram tells you something that text could never capture. A table in a sales report shows relationships that pure text embedding will miss entirely.
This is where domain-specific embedding models start to matter. Not just embedding the raw text, but understanding the semantic structure of your data. Extracting meaning from tables and diagrams. Recognizing when two pieces of information are related in ways that pure similarity matching would miss.
Reranking: The Forgotten Layer
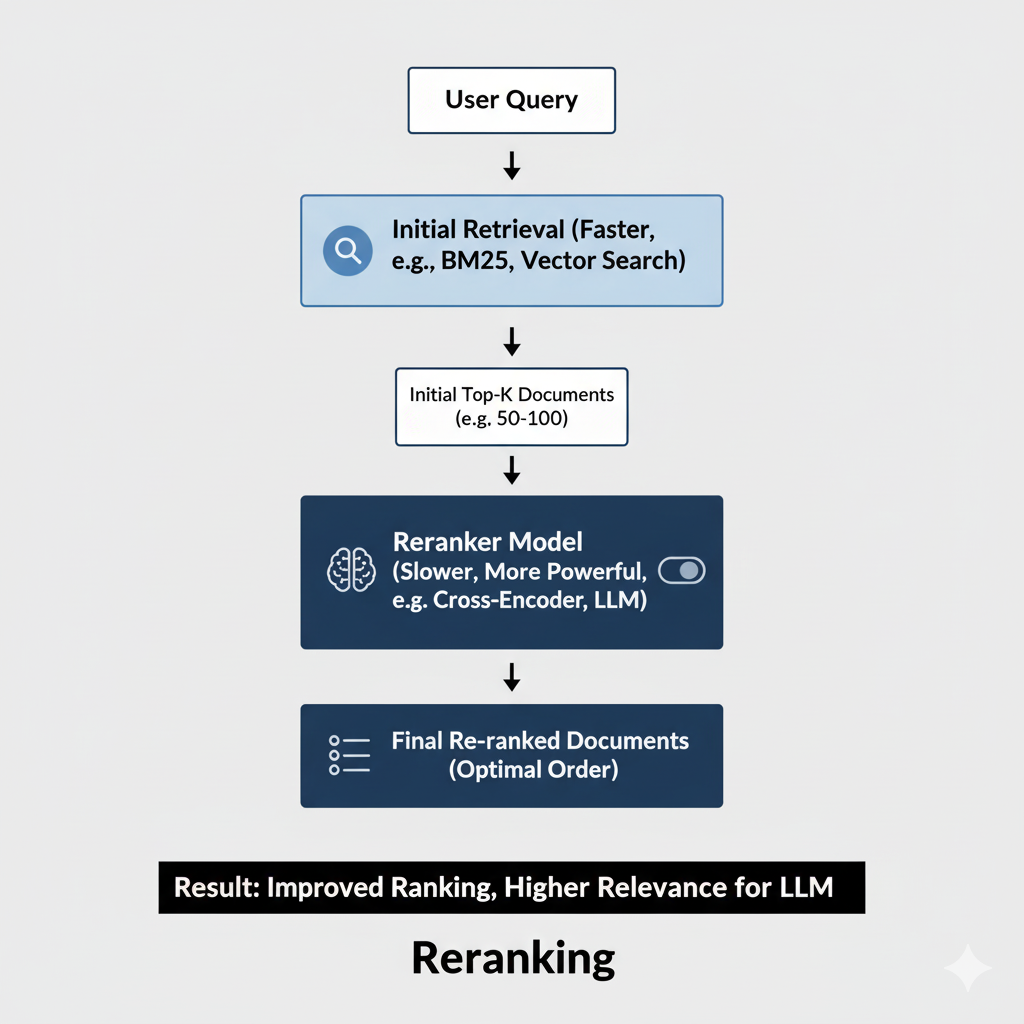
Here's something most enterprises aren't doing: reranking.
Retrieval systems typically work in two stages. First, you do a fast, approximate retrieval—grab a bunch of documents that seem relevant. Second, you should do a more careful, expensive ranking—order those documents by actual relevance, then keep only the best ones.
Most teams skip the second step. They retrieve documents and feed all of them to the model, or they keep whatever the retrieval ranked highest. This is a massive mistake.
A reranking model is specifically trained to understand relevance better than a generic embedding model. It can see a set of documents and understand which one actually answers the question best. It can understand context in ways that pure similarity search can't.
Here's why this matters: your initial retrieval might grab 50 documents that are topically related to what the user asked. But maybe only three of them actually answer the question directly. A good reranker can identify those three, discard the other 47, and feed only the relevant information to your language model. This saves money (shorter context), improves quality (less noise), and reduces hallucination (less irrelevant information to get confused by).
But reranking is expensive. A good reranking model needs to compare each candidate document against the user's query in a detailed way. That's not fast. So most enterprises either skip it entirely or use it only when they have money to burn.
This is a false economy. The cost of reranking is usually trivial compared to the cost of giving a language model the wrong information. And the improvement in quality is dramatic.
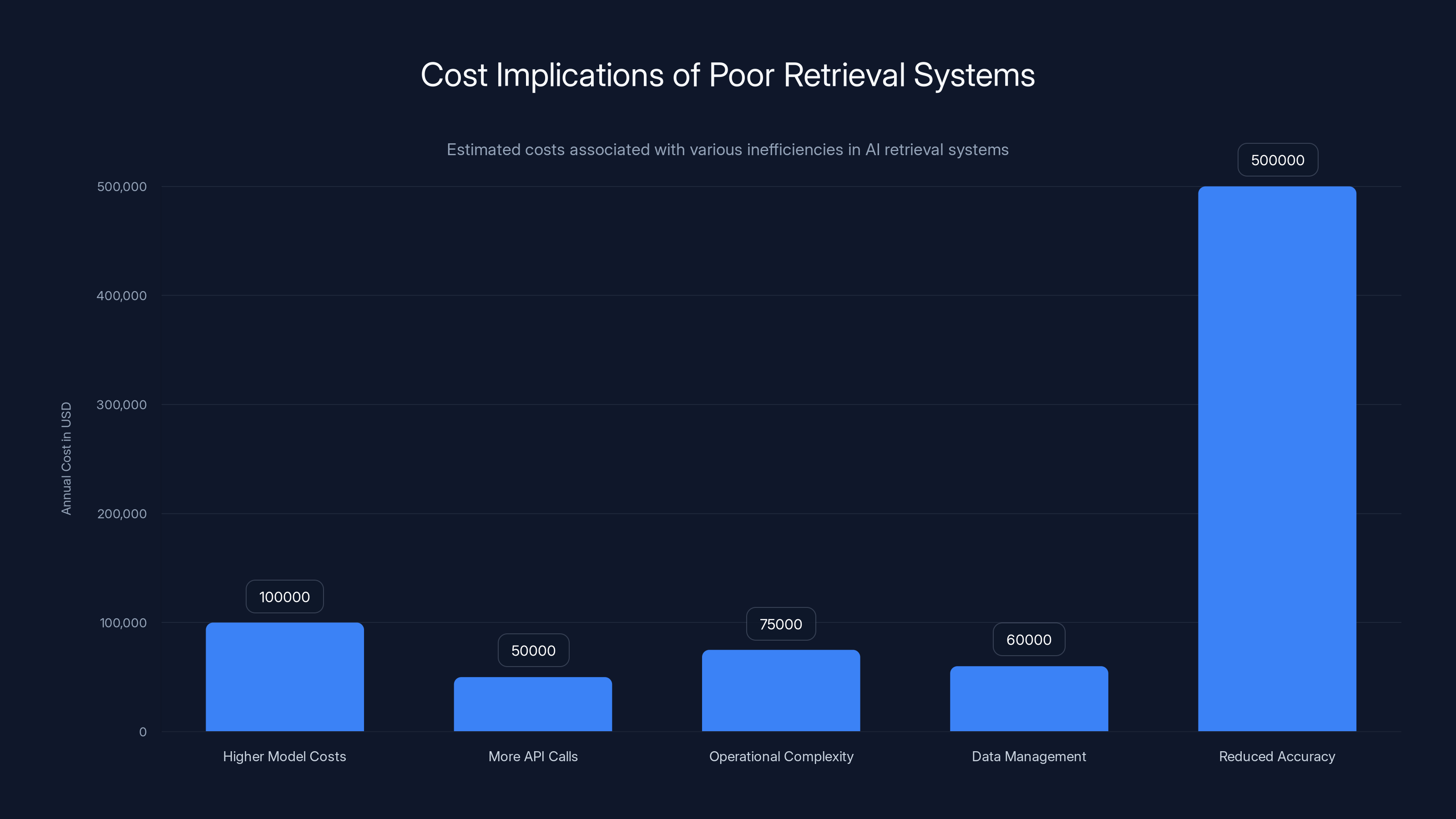
Reduced accuracy due to poor retrieval systems can cost over $500,000 annually, significantly outweighing other inefficiencies. Estimated data.
The Data Integration Problem
Here's what nobody talks about: your retrieval system is only as good as your data layer.
Most enterprises have data scattered across multiple systems. Your customer information is in a CRM. Your product documentation is in a wiki or GitHub. Your financial data is in a data warehouse. Your operational logs are in a separate system. Your employee handbook is in a shared drive. Your legal documents are in yet another system.
Building an RAG system on top of this fragmented data landscape is incredibly difficult. You need to:
- Normalize data from multiple sources into a consistent format
- Keep everything in sync as data changes
- Handle different data types—structured databases, unstructured text, images, PDFs
- Manage permissions so that queries respect who's allowed to see what
- Track data freshness so you know when information becomes stale
- Handle data that's updated frequently versus data that rarely changes
Most enterprises try to solve this by extracting everything into a data warehouse or a vector database. But that introduces new problems. Your data is now stale relative to the source systems. If a customer record updates, how quickly does that propagate? If a document changes, is your vector database updated? Who's responsible for keeping these systems in sync?
Furthermore, there's a metadata problem. Your retrieval system needs to filter and understand metadata—what document type is this? What customer does it belong to? What's the date? Who authored it? But metadata is often inconsistent or missing across your various data sources.
A truly integrated system would connect directly to your source data, retrieve in real time, and maintain consistency automatically. That's rare.
Context Window Fragmentation
Another production pain point: context window fragmentation.
Large language models have context windows—the maximum amount of information they can process at once. GPT-4 can handle about 128K tokens. Claude can handle 200K. Gemini can handle even more.
But context windows are expensive. The cost of processing a token grows quadratically with sequence length in many models. So there's a direct financial incentive to keep your context windows small. But there's also an accuracy incentive to give your model as much relevant information as possible.
Here's what happens in practice: you have a user query, you retrieve a bunch of documents, you try to pack them into your model's context window. But now you have a fragmentation problem. You can't fit all the relevant information. Do you include 5 short documents or 2 long ones? Do you truncate long documents or discard them entirely? How do you summarize without losing important details?
Different teams solve this differently, leading to inconsistent behavior. One service gives the model access to 10 documents. Another gives it 50. One truncates at 2,000 tokens. Another uses 5,000. You end up with a system that's unpredictable and difficult to debug.
Worst case: you're returning information that contradicts itself because you're including multiple outdated versions of the same policy, and the model has to pick which one's right. You're getting hallucination not because the model is broken, but because you've fed it contradictory information.
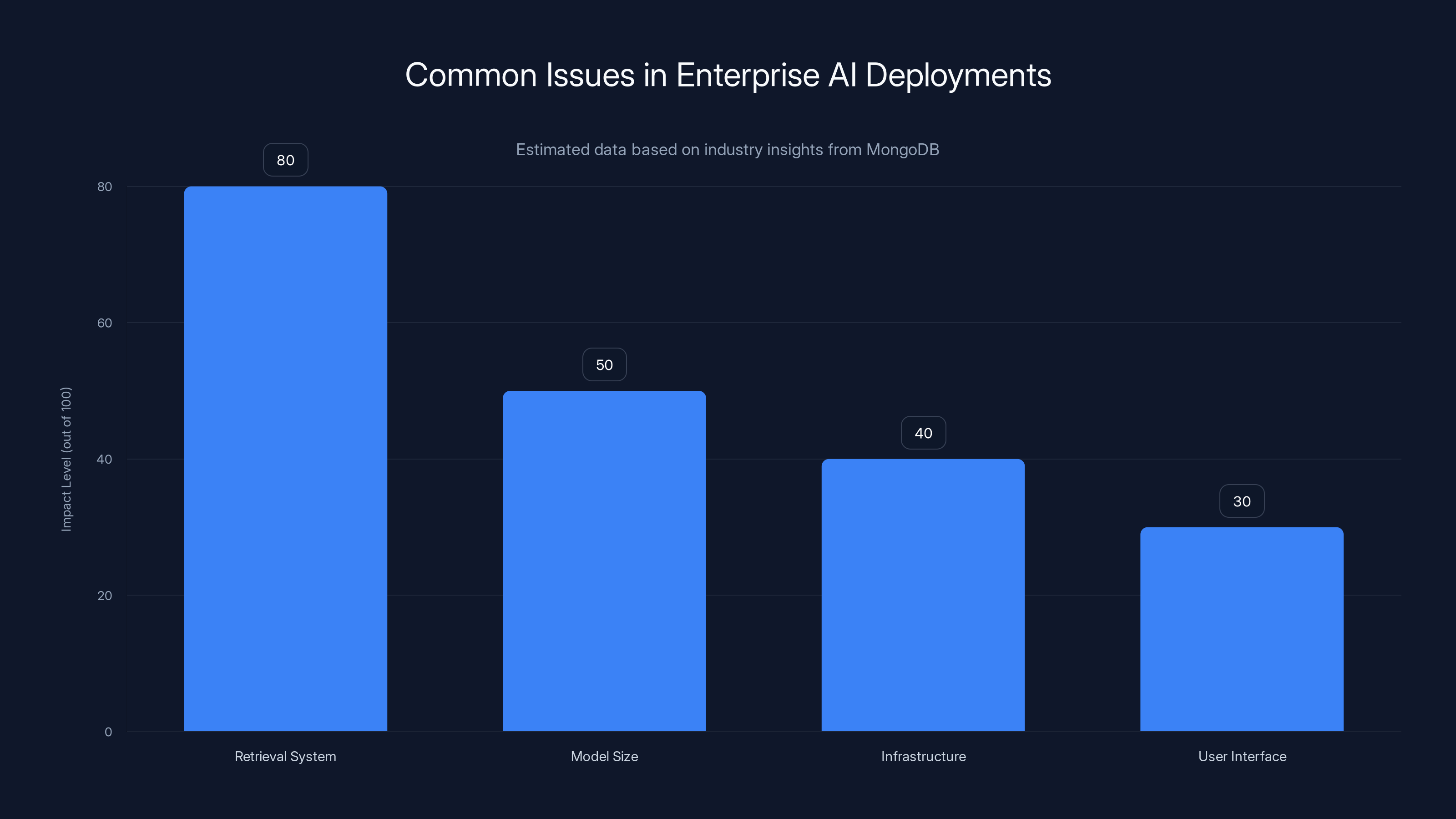
Retrieval systems are the most significant bottleneck in AI deployments, often overlooked in favor of model size and infrastructure. (Estimated data)
The Agentic AI Dimension
Everything discussed so far is already challenging. Then agentic AI adds another layer of complexity.
Agentic systems aren't just answering questions from static documents. They're reasoning through multi-step tasks, retrieving information iteratively, following chains of logic that might require dozens of retrieval operations. An agent might need to:
- Retrieve the customer's current account status
- Based on that, retrieve their transaction history
- Based on the transaction history, retrieve relevant policies
- Based on the policies, retrieve similar past cases for precedent
- Based on all of that, retrieve competitor offerings to provide recommendations
Each step requires retrieval. Each step needs to return accurate information. And each step's results affect what information is relevant for the next step.
Bad retrieval at any point breaks the entire chain. And because you're doing many retrievals per task instead of one or two, the probability of retrieval failure compounds. Even if each retrieval is 95% accurate, five retrievals in sequence gives you only about 77% end-to-end accuracy. Ten retrievals in sequence drops you to 59%.
Moreover, agents need to be cost-conscious because every retrieval operation has a cost. You can't just retrieve everything and hope something useful is in there. You need to be efficient. You need to retrieve exactly what you need, nothing more. That requires sophisticated retrieval systems that understand context and can prioritize ruthlessly.
This is where most agentic systems are failing. Not because the planning is bad or the reasoning is bad, but because the retrieval is bad. The agent can't find the information it needs, so it can't make good decisions.

MongoDB's Approach: Integrated Systems
MongoDB's bet is that this problem—retrieval quality—is too important to leave fragmented. They're arguing that you can't treat embedding models, reranking models, and data storage as separate components anymore. You need them to work together as an integrated system.
This is why they released new versions of their embedding models. But more importantly, it's why they're positioning these models as part of a broader platform.
The models themselves are technically strong. Voyage 4 comes in multiple versions optimized for different tradeoffs: there's a general-purpose version, a larger "flagship" version for maximum quality, a lite version for latency-sensitive applications, and a nano version for local development or on-device use. They also released a multimodal model that can handle text, images, and videos together.
But the real strategy is integration. These models work directly in MongoDB Atlas, their cloud database platform. Your data doesn't need to be exported to a separate vector database. You don't need to sync between systems. You don't need to worry about data freshness because the data is always up to date—it's the source system.
This solves several problems simultaneously. Your retrieval is operating directly on your source data, so there's no staleness issue. Your reranking is happening in the same system as your data, so you have access to metadata and can filter intelligently. Your application code doesn't need to orchestrate multiple systems—the platform handles it.
Do they achieve better retrieval quality than if you stitched together best-of-breed components? Probably not in every single dimension. You could probably find a specialized reranking model that's slightly better, or a vector database that has slightly more features. But you'd pay the cost of integration complexity, data freshness issues, and operational overhead.
The platform argument is that once you factor in all those costs, the integrated approach wins because it's coherent, it's up to date, and it's maintainable.

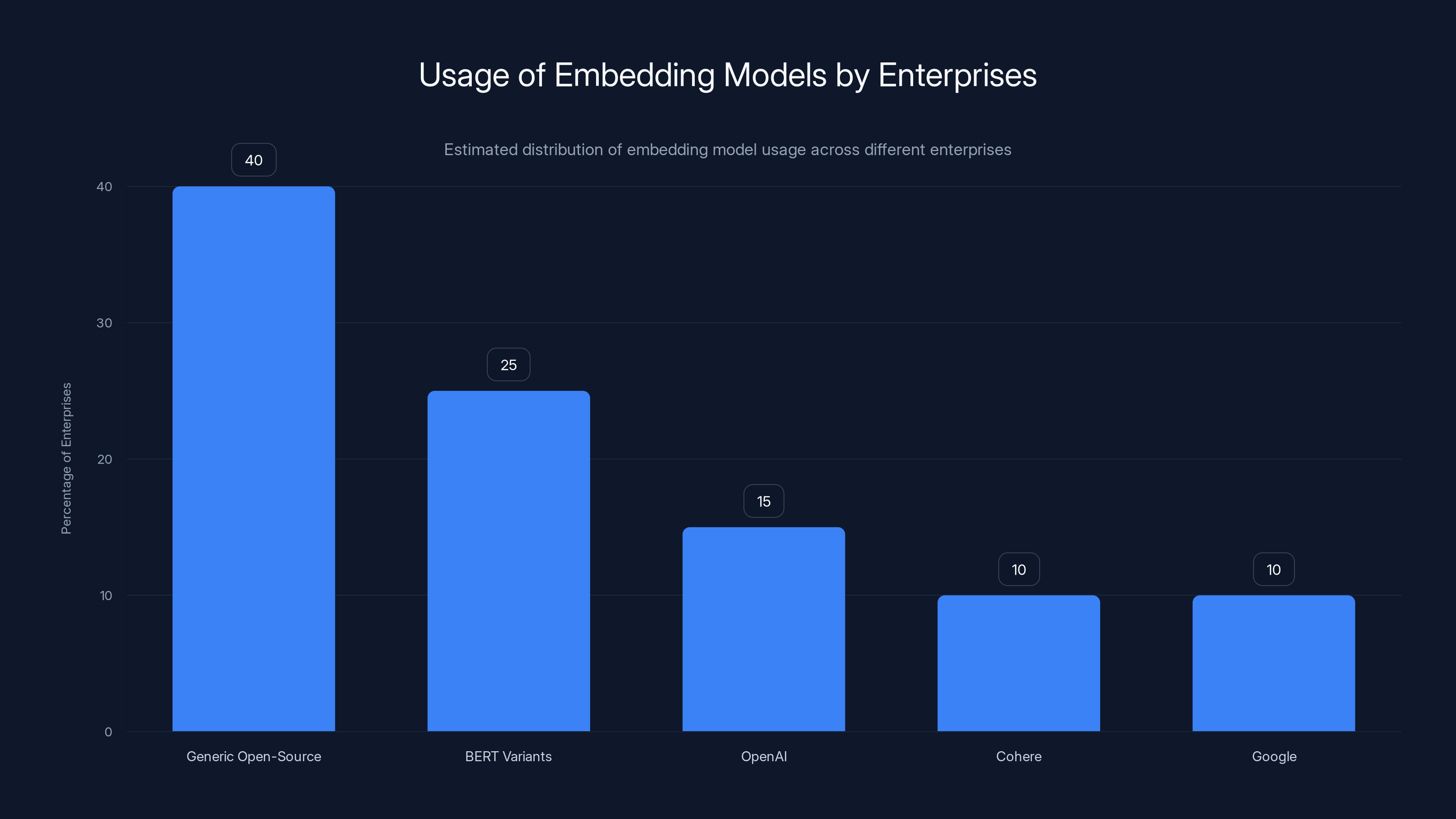
Estimated data shows that a significant portion of enterprises rely on generic open-source models, potentially leading to suboptimal retrieval performance in domain-specific applications.
Benchmarks vs. Reality
Here's where benchmarks become dangerous.
MongoDB reports that their Voyage 4 models outperform comparable models from Google and Cohere on RTEB, which is an industry-standard embedding benchmark. And they appear near the top of the Hugging Face MTEB leaderboard. These are legitimate achievements.
But here's the problem: benchmarks measure narrow things. They measure how well an embedding model can rank documents based on human-labeled relevance. That's valuable, but it's not the same as production enterprise AI retrieval.
Production retrieval needs to handle:
- Data that's constantly changing
- Heterogeneous data types that benchmarks don't include
- Domain-specific terminology that the benchmark didn't see
- Privacy and permission constraints that have nothing to do with pure relevance
- Real-time performance constraints where 100ms slower is unacceptable
- Edge cases where the "most similar" document is completely wrong
A model that's best-in-class on MTEB might perform terribly in your specific domain. A model that scores lower on benchmarks might work much better for your use case because you've fine-tuned it or because it generalizes better to your data distribution.
This is why benchmarks are useful but insufficient. They help you understand relative performance on standard tasks. But they don't tell you whether a solution will work for your enterprise.
The Multimodal Shift
One area where MongoDB's new models show genuine innovation is multimodal support.
The voyage-multimodal-3.5 model can handle documents that mix text, images, and video. This is important because modern enterprise documents aren't single-mode. A quarterly report has tables, charts, photos, and text. A product manual has screenshots and diagrams. A training video has visual content with closed captions. A patent application has technical drawings and descriptions.
Previously, you'd need to:
- Extract text from your documents
- Generate descriptions of images manually or with computer vision
- Create separate embeddings for text and images
- Try to merge those embeddings somehow
- Hope that loss of information doesn't break your retrieval
With a proper multimodal embedding model, the system understands the content directly without that lossy conversion process. A table in a spreadsheet gets embedded as a table, not as OCR'd text that might lose the structure. A diagram gets embedded with its visual relationships preserved, not just described in words.
This is particularly valuable for technical enterprises—software companies with architecture diagrams, hardware companies with schematics, pharmaceutical companies with molecular structures, financial services with complex charts.
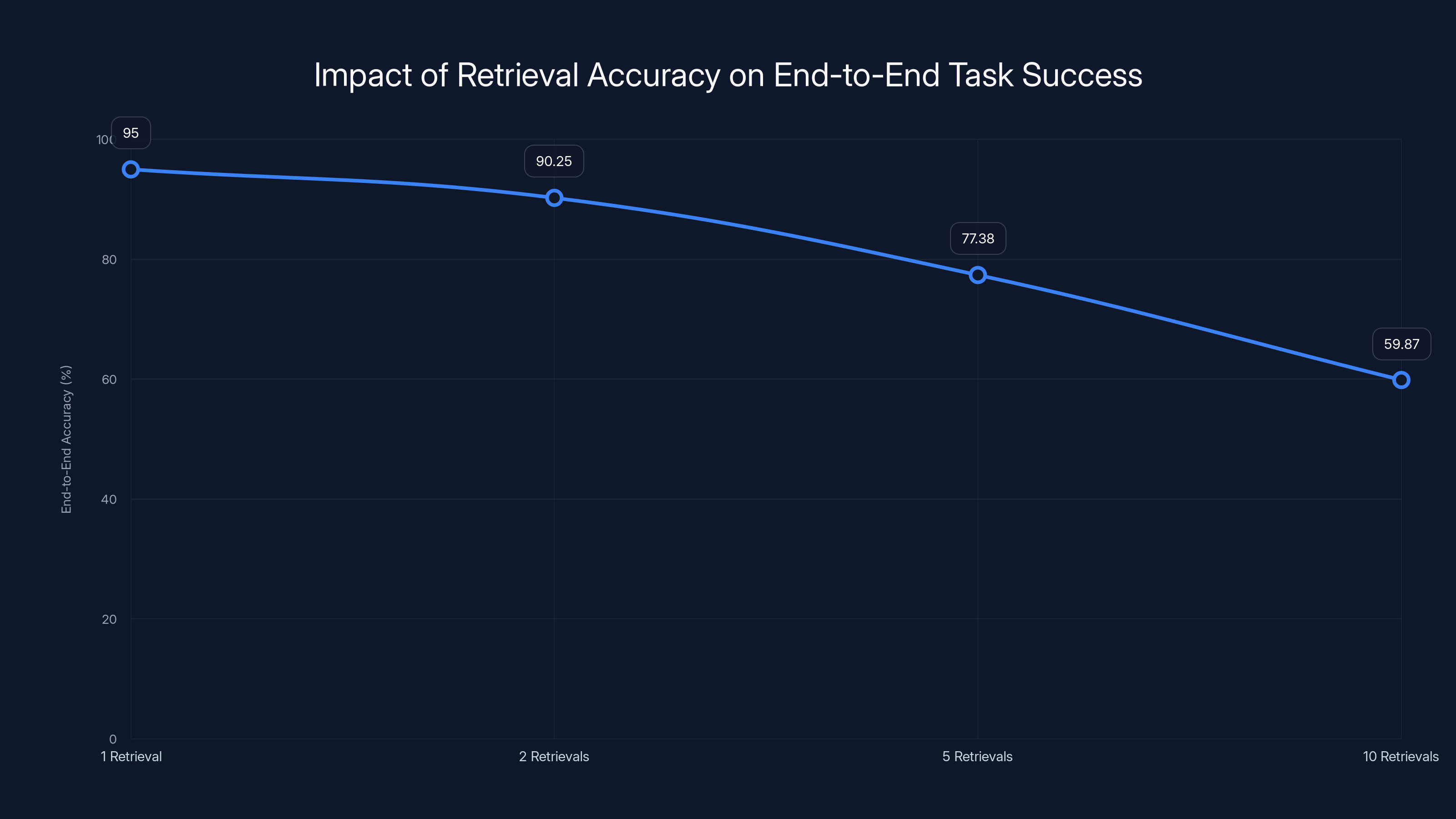
As the number of sequential retrievals increases, the end-to-end accuracy of agentic AI systems significantly decreases, illustrating the compounding effect of retrieval accuracy. Estimated data based on 95% accuracy per retrieval.
Cost Implications
Let's talk about money, because that's what actually drives decisions in enterprises.
If your retrieval system is bad, you incur costs in multiple ways:
Higher model costs: You compensate for bad retrieval by using bigger models or longer context windows. A bigger model costs more. A longer context window costs more. That's direct, measurable cost.
More API calls: Bad retrieval means you might need to retry queries, retrieve different documents, try different approaches. That's more API calls, more cost.
Operational complexity: Stitching together multiple systems requires engineering time to integrate, debug, monitor, and maintain. That's salary cost.
Data management overhead: Syncing between source systems and separate retrieval databases is work. That's engineering time.
Reduced accuracy: This is where the real cost hides. When your system returns confidently wrong answers, you get customer complaints, support tickets, potential liability. You lose user trust. You might have to manually review outputs, which is expensive.
Let's do some rough math. Say you have an enterprise with 1,000 knowledge workers using an AI system. Bad retrieval means your system returns wrong answers 20% of the time instead of 5% of the time. That's 150 additional incorrect answers per day. Maybe 80% of those get caught before they cause damage. That's still 30 wrong answers getting through to decisions or customers.
Each one might require 30 minutes of human review and correction. That's 15 hours of work per day. At
Now compare that to the cost of a better embedding model, a good reranking layer, and an integrated platform. It's probably tens of thousands of dollars per year, maybe hundreds of thousands for a large enterprise. But the ROI is obvious.
Most enterprises aren't doing this math. They're fixating on model size and API costs. They're missing the massive hidden cost of bad retrieval.
Fragmentation as a Strategic Problem
Here's the uncomfortable truth: most enterprise AI stacks are fragmented, and nobody planned it that way. It happened organically.
Your company starts experimenting with RAG. Maybe you use LangChain with a vector database. You host that somewhere. It works. Then another team wants to build something similar. They pick a different vector database because they like it better. Now you have two systems that don't talk to each other.
Your data's in multiple places—some in the relational database for transactional systems, some in a data warehouse, some in a vector database for embeddings. Getting data updates to propagate across all of them is a nightmare. You end up with stale data in some systems, fresh data in others.
You've got reranking happening in one service, embeddings happening in another, language model inference in a third. Adding latency, complexity, and fragility to your system.
This fragmentation has a cost. Every system transition is an opportunity for error. Every data sync is an opportunity for staleness. Every integration point is a place where things can break.
A tightly integrated platform reduces those integration points. Your data lives in one place. Your embeddings are computed and stored in the same system. Your reranking happens in that same system. Your API calls are to one platform, not multiple. This reduces complexity, reduces staleness, and reduces failure points.
Is it always the right choice? No. For very large enterprises with sophisticated engineering teams, a specialized best-of-breed approach might make sense. But for most organizations, integration beats fragmentation.
Building Better Retrieval Systems
If you're building a retrieval system today, here are the practical things that matter:
Start with your data layer: Before you think about embedding models or reranking, understand your data. Where does it live? How often does it change? What metadata do you have? What access controls do you need? If your data layer is broken, everything built on top is broken.
Choose the right embedding model for your domain: Generic models are better than nothing, but domain-specific models are better than generic. If you're in legal tech, look for a model trained on legal documents. If you're in biotech, look for a model trained on scientific literature. If your domain is specific enough, fine-tune an existing model on your data.
Use multimodal models if you have multimodal data: If your documents include images, tables, or videos, don't throw away that information by converting to text. Use a multimodal model that understands the original format.
Add reranking: It's not optional. First-stage retrieval finds candidates. Second-stage reranking identifies the good ones. The cost is worth it.
Measure what actually matters: Benchmark scores are useful, but measure what matters in your domain. How often does your system return information that's technically similar but practically irrelevant? How often does retrieval fail in ways that matter? Build domain-specific metrics that align with success in production.
Plan for iteration: Retrieval quality improves over time. You'll get better embedding models. You'll understand your domain better. You'll collect feedback from production failures. Build systems that are easy to update.
Keep your data fresh: This is harder than it sounds, but absolutely critical. Your retrieval system can only retrieve information that's up to date. Stale data in your vector database will cause failures.
Looking Ahead: The Future of Enterprise Retrieval
Where is this all heading?
First, expect more specialized models. General-purpose embedding models will continue improving, but domain-specific models optimized for legal documents, medical literature, financial data, and technical documentation will become the norm for serious enterprises.
Second, expect integration to become more important. The days of stringing together separate tools will increasingly be seen as a naive approach. Platforms that integrate data, embeddings, reranking, and inference will gain adoption because they solve real operational problems.
Third, expect retrieval to become more sophisticated. Today's retrieval is mostly keyword-based or simple semantic similarity. Tomorrow's retrieval will include more reasoning, more context awareness, more understanding of what information actually answers a question versus what's merely related.
Fourth, expect cost pressures to drive efficiency. As AI usage scales, the cost of inefficient retrieval becomes intolerable. Companies will demand and build more efficient systems that retrieve less data to get the same quality results.
Fifth, expect better measurement and monitoring. Currently, most enterprises don't have good visibility into their retrieval quality. That will change. Better observability tools will help teams understand where retrieval is failing and what to optimize.
Sixth, expect regulation to touch this area. As AI systems make real decisions affecting real people, regulators will care about explainability and accuracy. That means being able to show that you retrieved accurate, relevant information. That means building audit trails. That means retrieval systems designed with compliance in mind.

The Real Lesson
Here's what stands out: the industry's narrative about AI has been wrong.
We've obsessed over model size, parameter counts, and benchmark performance. We've assumed that bigger models automatically mean better results. We've invested in upgraded hardware to run larger models. We've competed on model leaderboards.
But the real bottleneck for enterprise AI isn't the model. It's not compute. It's retrieval. It's the ability to find and return accurate, relevant information when the model needs it.
You can have the best model in the world and still fail if it doesn't have access to good information. You can have a mediocre model that outperforms the competition if it has access to perfect information.
This reframes the entire optimization problem. Instead of asking "How do we build a bigger, better model?" you should be asking "How do we ensure our system has access to the right information at the right time?"
For most enterprises, that's not a sexy question. It doesn't make good conference talks. It's not something that shows up on AI leaderboards. But it's the difference between an AI system that works in production and one that doesn't.
MongoDB's angle—that you need integrated systems optimized for retrieval quality, not fragmented collections of specialized tools—makes sense. Not because it's cutting-edge or innovative in a breakthrough way, but because it addresses the actual problems enterprises are struggling with.
If you're building or maintaining an enterprise AI system, start here: evaluate your retrieval quality honestly. Measure it. Understand where it's failing. Then decide whether you need better embedding models, better reranking, better data integration, or all of the above.
The answer probably isn't a bigger model. The answer is better retrieval.

FAQ
What is retrieval quality in enterprise AI systems?
Retrieval quality refers to the ability of a system to find and return accurate, relevant information from your data when needed. In RAG (retrieval-augmented generation) systems, this determines whether the language model receives the right context to answer questions correctly. Poor retrieval quality means the AI system might receive irrelevant or incorrect information, leading to hallucinations and inaccurate responses regardless of model size.
How does bad retrieval impact enterprise AI in production?
Bad retrieval creates multiple problems: it inflates costs by forcing you to use larger models or longer context windows to compensate, reduces accuracy by giving models irrelevant information, undermines user trust when systems return confidently wrong answers, and creates operational complexity as teams struggle with stale data and system fragmentation. The financial impact can reach hundreds of thousands annually when factoring in support costs and reduced accuracy.
Why are specialized embedding models better than generic ones?
Specialized embedding models are trained on domain-specific data and understand terminology, relationships, and context unique to your industry. A generic model trained on web data might rank documents as "similar" based on surface-level keyword matching, but miss the nuanced relevance your enterprise requires. For legal, medical, technical, or financial domains, specialized models deliver significantly better retrieval accuracy for actual use cases versus benchmark scores.
What role does reranking play in retrieval systems?
Reranking is a second-stage filtering process where a specialized model evaluates initial retrieval candidates and ranks them by actual relevance. While initial retrieval might return 50 topically-related documents, reranking identifies the 3-5 that actually answer the question. This reduces noise fed to the language model, improves accuracy, saves costs by shortening context windows, and dramatically reduces hallucination caused by irrelevant information.
Why is data integration critical for retrieval quality?
Retrieval quality depends on having accurate, up-to-date data. When enterprise data is scattered across multiple systems (CRM, data warehouse, document management, etc.) with separate vector databases, synchronization becomes a nightmare. Data goes stale, updates don't propagate, and metadata becomes inconsistent. Integrated systems that operate directly on source data eliminate staleness issues and reduce failure points, delivering fresher and more reliable retrieval.
How does multimodal retrieval change enterprise AI?
Multimodal retrieval handles documents containing text, images, tables, and videos as unified content instead of converting everything to text descriptions. This is critical because modern enterprise documents are inherently multimodal—quarterly reports with charts, product manuals with screenshots, patents with technical drawings. Multimodal models understand visual information directly, preserving structure and relationships that text conversion destroys, resulting in significantly better retrieval quality for complex enterprise documents.
What's the actual cost of poor retrieval quality?
Poor retrieval quality generates costs across multiple dimensions: direct API costs increase when you compensate with larger models, operational costs rise from maintaining fragmented systems, support costs climb as users catch errors, and lost productivity accumulates from reviewing incorrect AI outputs. For a 1,000-person organization, returning wrong answers just 15% more frequently than needed could cost over $500,000 annually in remediation labor alone.
How should enterprises measure retrieval quality?
While benchmark scores matter, they don't capture production reality. Enterprises should measure domain-specific metrics: how often does retrieval return technically similar but practically irrelevant documents? What's the accuracy when critical decisions depend on retrieved information? How often do multi-step agentic tasks fail due to retrieval failures? These production metrics matter far more than leaderboard rankings for evaluating whether your retrieval system actually works.
Why do agentic AI systems require better retrieval?
Agentic systems perform iterative retrieval across multiple steps—each decision depends on information retrieved in previous steps. Each retrieval operation introduces failure probability. If individual retrievals are 95% accurate, just five retrievals in sequence drops end-to-end accuracy to 77%. Ten retrievals drops it to 59%. This compounding effect means agentic systems fail catastrophically with mediocre retrieval—not because reasoning is bad, but because information access breaks the chain.
What's the advantage of integrated platforms over best-of-breed components?
Integrated platforms reduce complexity by keeping data, embeddings, reranking, and inference in one system. This eliminates data freshness issues, reduces integration failures, simplifies deployment and monitoring, and makes it easier to maintain. While specialized components might optimize individual dimensions slightly better, the operational overhead, staleness problems, and integration complexity of fragmented stacks usually cost more than any marginal quality gains, especially for mid-to-large enterprises.
Key Takeaways
- Retrieval quality—not model size—is the actual bottleneck limiting enterprise AI success in production
- Bad retrieval forces expensive compensation through larger models, longer context windows, and manual review overhead reaching $500K+ annually
- Fragmented RAG systems with separate vector databases, embeddings, and reranking layers create staleness and sync problems that integrated platforms solve
- Domain-specific embedding models and two-stage retrieval with reranking dramatically outperform generic similarity-based approaches for enterprise data
- Agentic AI compounds retrieval failures exponentially—five retrieval steps at 95% accuracy drop to 77% end-to-end performance
Related Articles
- VoiceRun's $5.5M Funding: Building the Voice Agent Factory [2025]
- Amazon's Bacterial Copper Mining Deal: What It Means for Data Centers [2025]
- Enterprise AI Needs Business Context, Not More Tools [2025]
- Trump's 25% Advanced Chip Tariff: Impact on Tech Giants and AI [2025]
- Wikipedia's Enterprise Access Program: How Tech Giants Pay for AI Training Data [2025]
- Meta Compute: The AI Infrastructure Strategy Reshaping Gigawatt-Scale Operations [2025]

