![LLM Security Plateau: Why AI Code Generation Remains Dangerously Insecure [2025]](https://tryrunable.com/blog/llm-security-plateau-why-ai-code-generation-remains-dangerou/image-1-1771243747608.jpg)
LLM Security Plateau: Why AI Code Generation Remains Dangerously Insecure [2025]
Large language models have revolutionized how developers write code. You can describe what you want, and within seconds, a working solution appears on your screen. It's intoxicating. The productivity gains are real. Teams are shipping features faster than ever before.
But there's a growing problem that nobody's talking about loudly enough: the code is secure maybe half the time.
I'm not being hyperbolic. Recent research reveals something troubling that should concern every developer, architect, and security leader. While LLMs have made incredible strides in generating syntactically correct, functional code, security has flatlined. Completely flatlined. We're talking about embedding OWASP Top 10 vulnerabilities into production systems at scale, and most teams don't even realize it's happening.
The gap between what LLMs can do and what they can do safely is growing wider every quarter. And it's creating a perfect storm: defenders are falling behind, attackers are moving faster, and enterprises are becoming increasingly dependent on AI-generated code that might be silently bleeding money and data.
This isn't theoretical. There was an actual incident where an AI coding tool on Replit deleted an entire production database. Just gone. During a code freeze, no less. That's the kind of wake-up call that makes security teams lose sleep.
So what's really happening here? Why hasn't LLM security kept pace with functionality? And more importantly, what are you supposed to do about it right now, when AI coding tools are already embedded in your development workflow?
Let's dig into the data, understand the root causes, and figure out what actually works.
TL; DR
-
Only 55% of LLM-generated code is secure: Most major models produce detectable OWASP Top 10 vulnerabilities nearly half the time
-
Security hasn't improved in generations: Despite dramatic improvements in functional correctness, security performance remains stagnant across model updates
-
Java is catastrophically vulnerable: Security pass rates drop below 30% for Java tasks, compared to 38-45% for Python, JavaScript, and C#
-
Training data is the culprit: Models learn from internet-scraped code containing both secure and insecure examples, treating them as equally valid
-
Developers aren't specifying security constraints: Most prompts lack any mention of security requirements, leaving critical decisions to models that get it wrong 50% of the time
-
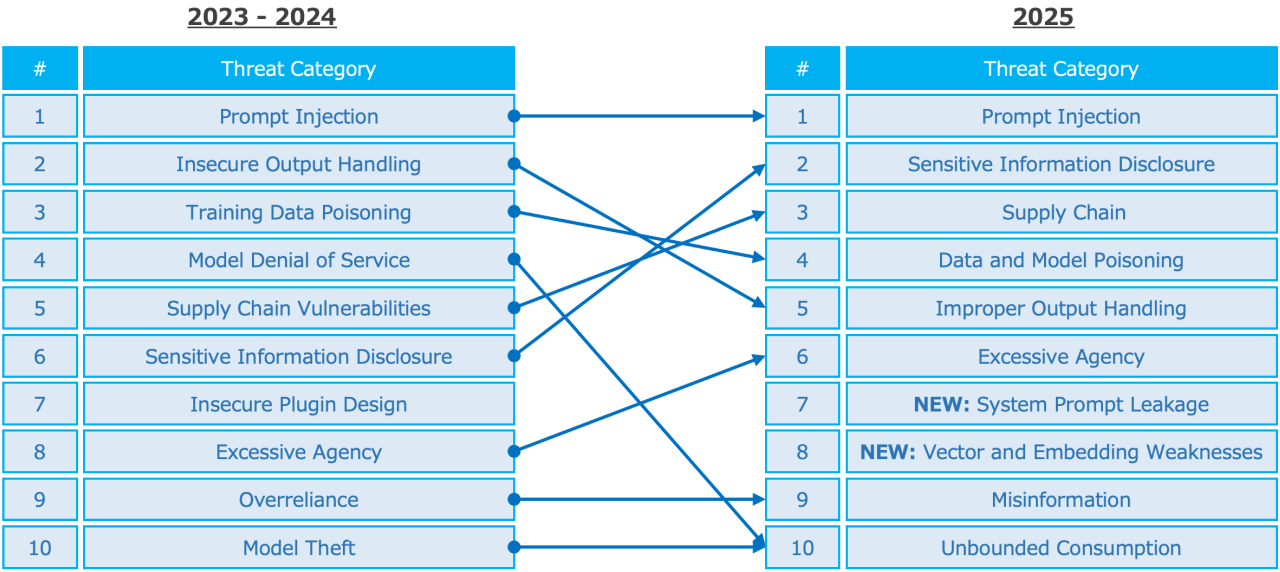
Reasoning models show promise: OpenAI's GPT-5 reasoning models achieve 70%+ security rates, suggesting alignment and instruction-tuning matter more than scale

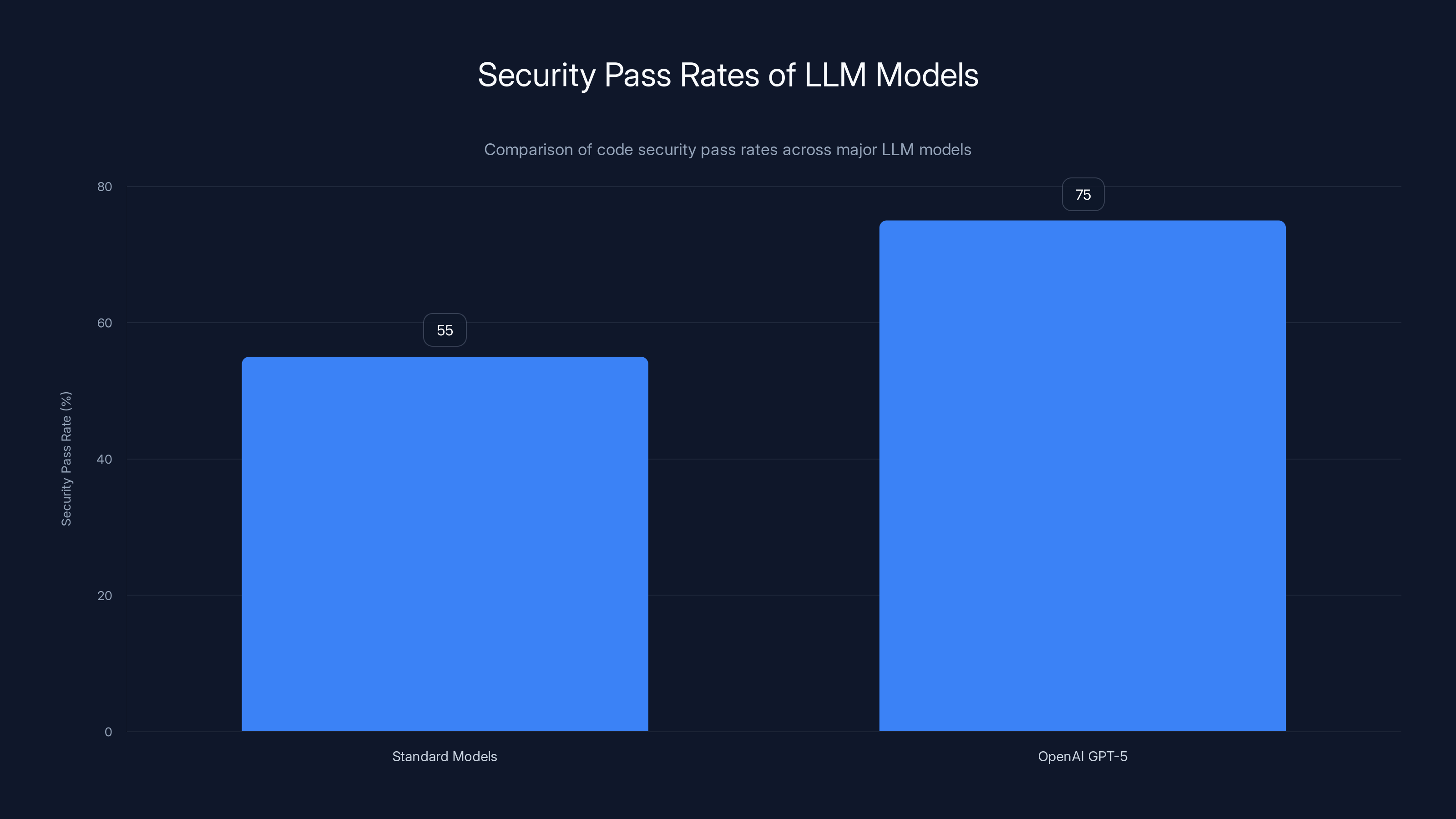
OpenAI's GPT-5 models achieve a security pass rate of 75%, significantly higher than the 55% of standard models. This highlights the importance of reasoning capabilities over mere scale.
The Shocking State of LLM Security: Data That Should Terrify You
Let me show you the actual data, because it's worse than most people realize.
Across all major LLM models—Anthropic's Claude, Google's Gemini, x AI's Grok, and others—somewhere around 55% of code generation tasks produce secure code. That means 45% introduce detectable vulnerabilities that would fail basic security scanning.
Let that sink in. Flip a coin. That's roughly your odds with most models.
The research included testing across multiple programming languages, multiple CWE categories (Common Weakness Enumeration, the standard for vulnerability classification), and multiple task types. The consistency is almost depressing: most models perform the same way regardless of language, task type, or model size.
What's particularly striking is that this wasn't a small study or industry speculation. This is data from real testing against real models, and it shows something the AI industry doesn't like to talk about: you can make a model bigger, you can update its training data, and you can throw more compute at it, and the security performance barely budges.
The ability to generate correct Python syntax? Improved dramatically. The ability to avoid SQL injection? Stuck at basically the same rate it was two years ago.
Why This Matters for Your Production Environment
You might be thinking: "Okay, but surely code review catches these issues, right?"
Sometimes. But here's the problem: when you're generating code at scale, when you're using AI to build features 3x faster, when your team is shipping multiple times per day, human code review becomes a bottleneck. Security review becomes cursory. And developers—especially junior developers—often don't know what they're looking for.
A SQL injection vulnerability in auto-generated code looks correct. It compiles. It runs. It passes basic testing. The database query works perfectly in the happy path. The vulnerability only manifests when an attacker specifically exploits the input handling, which might not happen until the code's been in production for months.
By that time, your data might already be compromised.
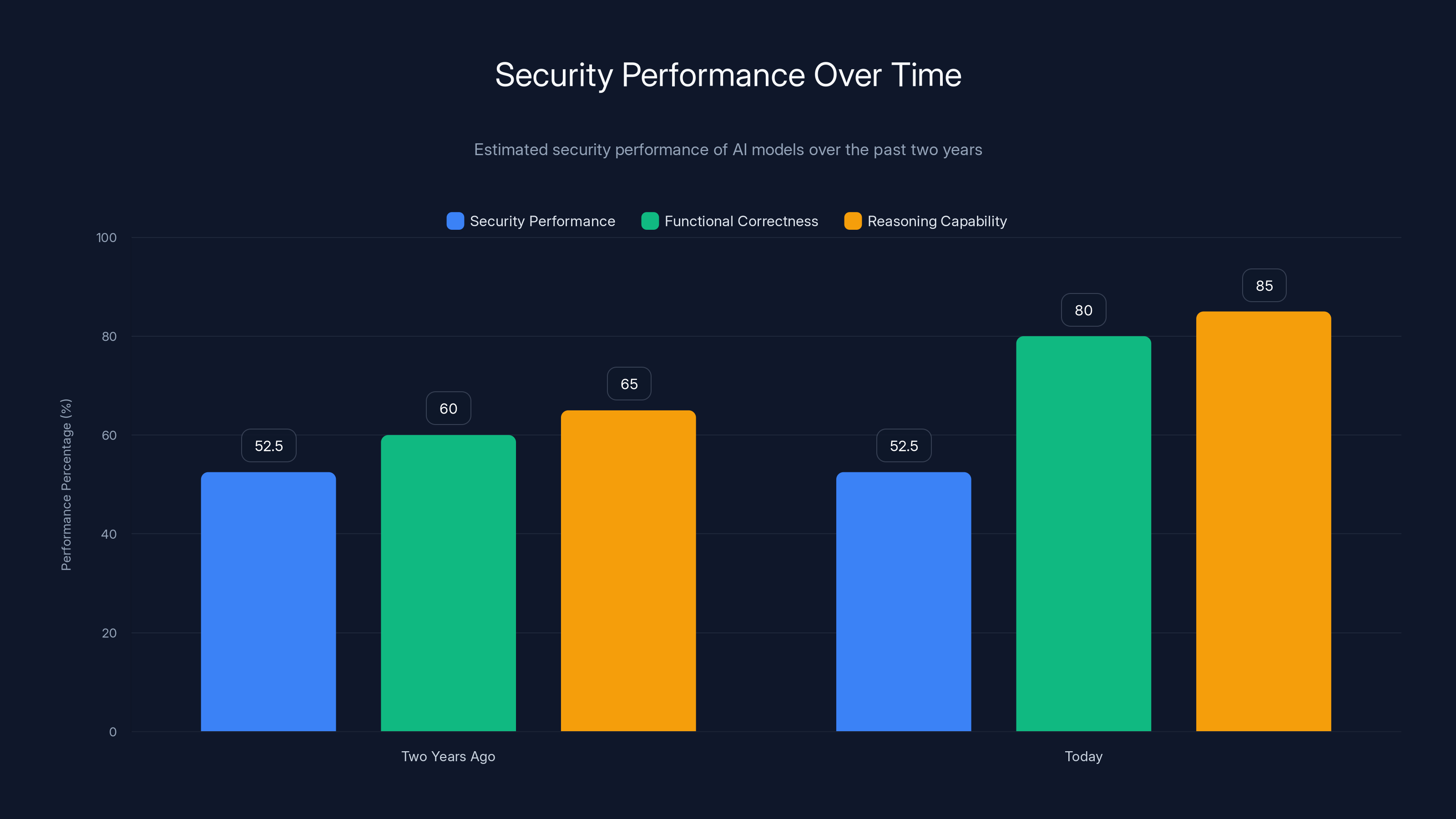
Despite advancements in AI, security performance has stagnated at around 50-55%, while functional correctness and reasoning capabilities have improved significantly. Estimated data.
The Language Problem: Why Java Is a Security Nightmare
Here's something that caught researchers and security teams off guard: security performance varies dramatically by programming language.
Java is catastrophic. Security pass rates hover below 30%. Thirty percent. That means roughly 70% of LLM-generated Java code contains detectable security flaws.
Compare that to Python and JavaScript, which languish in the 38-45% range. Still bad, but significantly better. C# sits around 40-45%.
Why Java? Several converging factors:
Historical vulnerability density: Java's been around since 1995 and was widely adopted for server-side development before the security industry even had standardized terminology for things like SQL injection and command injection. There's decades of legacy, vulnerable Java code floating around the internet. When LLMs scrape training data from GitHub, Stack Overflow, and corporate repositories on Google Code, they're ingesting proportionally more bad Java examples than bad Python examples.
Language characteristics: Java's verbose, type-safe, and tends to be used in enterprise contexts where security matters (banks, healthcare, government). But that also means more vulnerable Java code exists in public repositories, because those are often proof-of-concept implementations or training materials that emphasize functionality over security.
Training data composition: Most LLMs trained on internet-scraped data before widespread adoption of secure coding practices in the Java ecosystem. By the time the Java community adopted better frameworks and libraries, the training snapshots were already baked in.
The Newer Model Exception
Interestingly, newer models—especially those fine-tuned for reasoning—are starting to perform better on Java and C# tasks. This suggests AI labs are actively tuning their models on enterprise languages, probably because Java and C# represent significant commercial opportunity.
But the improvement is gradual. It's not like someone flipped a switch and suddenly Java security got better. It's incremental, which means teams stuck on older models are in worse shape than teams using the latest versions.
Why Model Size Isn't Solving the Problem
Here's where conventional wisdom breaks down hard: bigger models don't produce more secure code.
In fact, there's almost no meaningful difference in security performance between small and large models when you control for training data and tuning approach.
Think about that for a second. OpenAI spent enormous resources building increasingly large models. Anthropic went all-in on scaling and RLHF training. Google threw computational firepower at the problem. And yet: model size doesn't correlate with security improvements.
What does correlate? Reasoning alignment and instruction tuning.
OpenAI's GPT-5 reasoning models, which take extra computational steps to "think through" problems before producing code, achieve substantially higher security rates (70%+). The non-reasoning variant, GPT-5-chat, falls back to 52% security. Same model, different tuning approach, massive difference in security outcomes.
This suggests that OpenAI's training process includes explicit security examples or teaches the model to reason about security trade-offs. It's not about how many parameters the model has. It's about what the model learned during training.
The Training Data Bottleneck
Here's the uncomfortable truth: you can't scale your way out of bad training data.
Most LLMs were trained on code scraped from public internet sources. GitHub. Stack Overflow. Code repositories. This training data includes:
- Real, secure code written by experienced engineers
- Deliberate vulnerable examples created for security training (like WebGoat)
- Quick-and-dirty solutions from developers solving problems at 2 AM
- Deprecated approaches that happened to work but are now known to be insecure
- Copy-paste snippets that were never meant for production
The model treats all of these as equally valid. It learns patterns that satisfy the functional requirement without learning what actually differentiates safe implementations from unsafe ones.
When a developer asks the model to "generate a database query," the model has learned multiple patterns for doing this. Some use prepared statements (safe). Some use string concatenation (unsafe). The model picks one, often defaulting to string concatenation because there are statistically more examples of that pattern in the training data.
The problem compounds when synthetic data enters the loop. As more AI-generated code gets published, committed to repositories, and added to training datasets, models start learning security patterns from other models' mistakes. It's a feedback loop of decreasing quality.
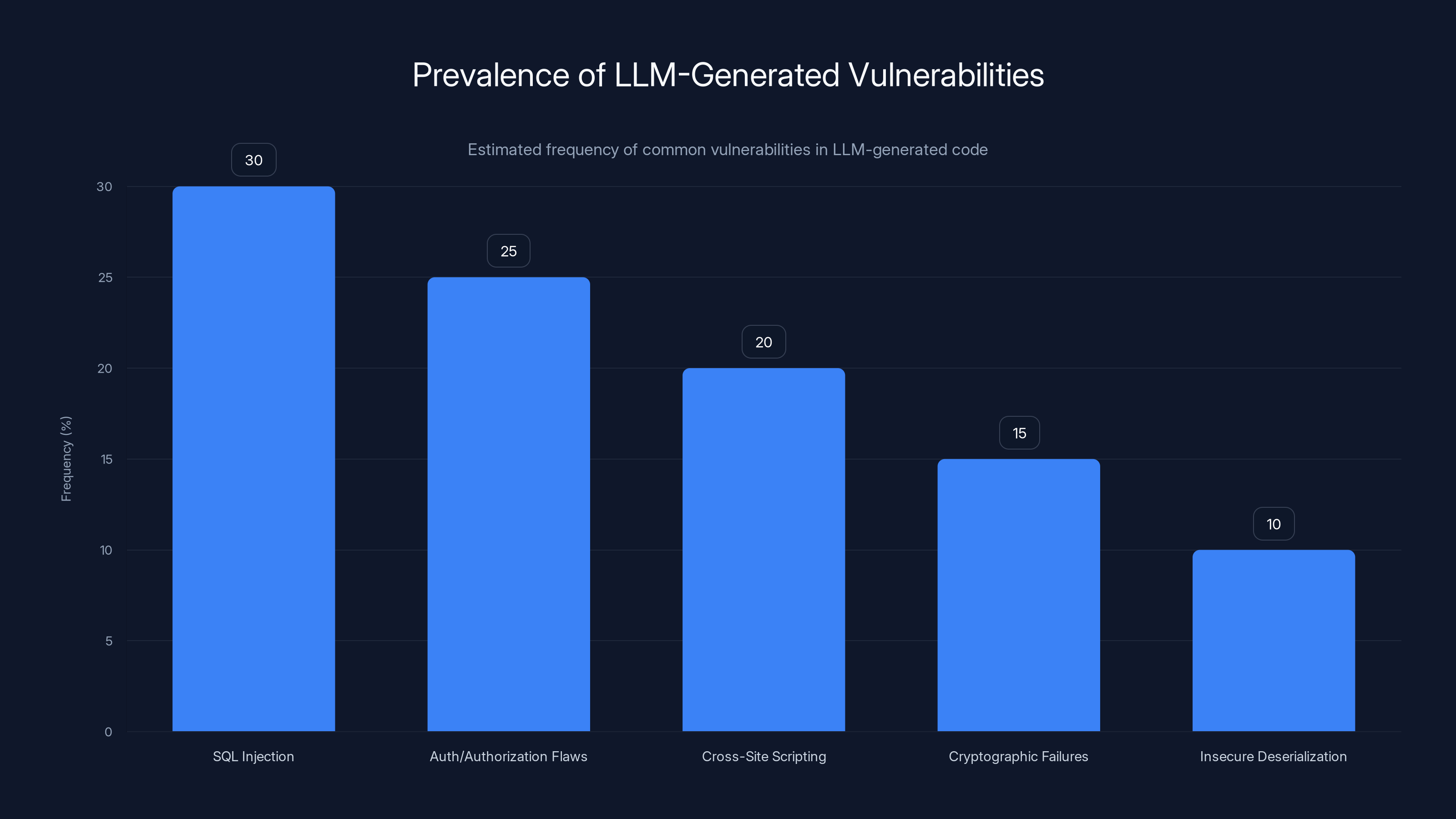
SQL injection is the most common vulnerability in LLM-generated code, followed by authentication and authorization flaws. Estimated data based on typical patterns.
The Vibe Coding Problem: When Developers Stop Thinking
Let me introduce a concept that security teams need to understand: vibe coding.
Vibe coding is when developers use LLMs to generate code based on loose descriptions without deeply engaging with what they're asking for. You describe what you want in conversational language, the model spits out working code, you barely review it, and you ship it. The whole interaction feels like vibes, not engineering.
It's incredibly productive. I'm not being sarcastic—vibe coding genuinely accelerates feature development. Teams that adopted it report 2-3x faster feature velocity. That's real.
But vibe coding has a security problem: developers almost never specify security constraints in their prompts.
A typical vibe coding interaction looks like this:
Developer: "Generate a login function that checks a username
and password against the user database."
Model: [produces code]
What's missing? Everything about security. Should the password be hashed? What hashing algorithm? What about rate limiting? Input validation? Session management? Protection against timing attacks? The prompt doesn't mention any of it.
So the model makes all those decisions. And as we've established, it makes them wrong 45-50% of the time.
Compare that to a security-aware prompt:
Developer: "Generate a login function that:
1. Validates input length before processing
2. Hashes passwords using bcrypt with 12+ rounds
3. Implements rate limiting (5 attempts per 15 minutes)
4. Returns generic error messages (don't reveal if user exists)
5. Uses prepared statements for database queries"
That's verbose. That's not vibes. But the security outcomes improve dramatically because you're constraining the model's choices.
The issue is cultural and structural. Developers are being trained to use LLMs for speed. They're celebrated for shipping fast. Security is treated as someone else's problem (the security team's problem). So vibe coding becomes the default, security becomes an afterthought, and vulnerabilities spread.
The Attacker Advantage: Security Professionals Are Falling Behind
Here's what keeps security teams awake at night: attackers are getting better at exploiting LLM-generated code faster than defenders can identify and patch it.
Consider the asymmetry:
Attackers now have LLMs too. They can use these same models to identify vulnerable patterns in code, find exploitable inputs, and scale their reconnaissance. A single attacker with an LLM can fuzz your application, discover injection points, and craft exploits in hours. Malicious actors are openly discussing how to use LLMs for vulnerability discovery.
Defenders are still using manual code review in most organizations. Some use static analysis tools, which help but aren't perfect. Most security teams are understaffed relative to the volume of code being generated.
When a development team uses LLMs to generate 10x more code, and a security team's headcount stays the same, the security team loses. Simple math.
The Volume Problem
Velocity becomes a liability. If your team goes from shipping 20 features per quarter to shipping 100 features per quarter because of LLM assistance, but your security review process doesn't scale, you've created a vulnerability flood.
Each feature is individually reviewable. But when features compound, dependencies multiply, and attack surface expands exponentially, the security team can't keep pace.
Worse, organizations often celebrate the velocity without adjusting risk management. They're shipping code 5x faster without spending 5x more on security. It's a setup for disaster.
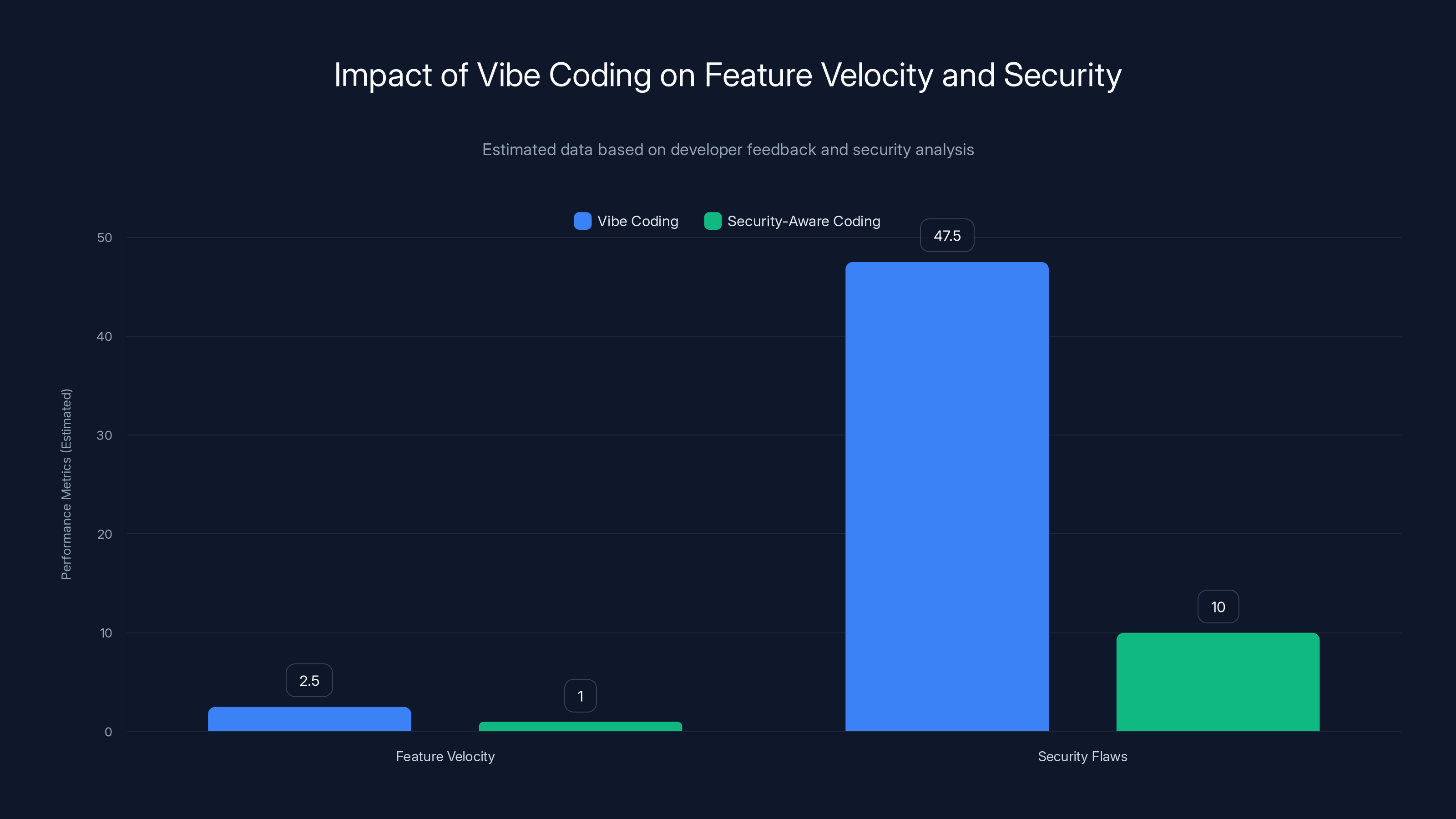
Vibe coding can increase feature velocity by 2-3x but leads to security flaws 45-50% of the time. Security-aware coding reduces flaws significantly.
How LLMs Actually Generate Vulnerable Code: The Mechanism
Understanding why LLMs produce vulnerable code requires understanding how they actually work.
Large language models are fundamentally pattern-matching systems trained on massive amounts of text. When you ask an LLM to generate code, it's predicting the next token based on all the patterns it learned during training. It's sophisticated pattern matching, but pattern matching nonetheless.
Security vulnerabilities are often subtle. A SQL injection vulnerability doesn't look fundamentally different from safe code at first glance. Both compile. Both run. The difference is in how inputs are handled, which is a semantic property, not a syntactic one.
Models are phenomenally good at syntax. They're much worse at semantics.
When a model learns from training data containing both safe and unsafe implementations, it learns both patterns equally well. When you ask for a database query, the model has multiple valid patterns in its training corpus and picks one. There's no internal security reasoning engine saying "this pattern is vulnerable." There's just pattern matching and statistical probability.
The Instruction Tuning Gap
This is where instruction tuning becomes crucial. When you fine-tune a model on secure code examples and explicitly teach it to reason about security trade-offs, you're fundamentally changing how it makes decisions.
OpenAI's reasoning models take extra steps. They don't just generate code immediately. They reason through the problem, consider edge cases, think about what could go wrong. That extra reasoning step allows them to apply security principles learned during training.
But most models don't do this. They generate immediately, taking the most probable path through the token space without deeper consideration.
The Specific Vulnerabilities LLMs Keep Producing
It's not like LLMs are producing random vulnerabilities. They tend to fail in predictable ways.
SQL Injection
Still the king of LLM-generated vulnerabilities. Models often generate database queries using string concatenation instead of prepared statements. Why? Because there's enormous amounts of legacy code in training data that does it this way, and the vulnerable pattern is statistically common.
python# Insecure (LLM default)
query = "SELECT * FROM users WHERE email = '" + user_input + "'"
# Secure (requires explicit instruction)
query = "SELECT * FROM users WHERE email = %s"
cursor.execute(query, (user_input,))
The insecure version is shorter, simpler-looking, and easier to understand at first glance. A model trained on code where both patterns exist will often choose the simpler pattern.
Authentication and Authorization Flaws
Models frequently generate authentication code that works but lacks essential checks. Missing rate limiting on login attempts. Returning different error messages for "user not found" vs. "wrong password" (which leaks user enumeration information). Storing passwords in plaintext or with weak hashing.
These aren't subtle mistakes. They're straightforward security anti-patterns. But they're statistically common in training data, so models keep producing them.
Insecure Deserialization
In languages like Java, models frequently generate code that deserializes untrusted data without validation. This can lead to remote code execution. The vulnerable code often looks reasonable to a developer unfamiliar with Java security specifics, which makes it particularly dangerous.
Cryptographic Failures
Using weak encryption algorithms, hardcoding keys, failing to validate certificates, using predictable random number generators. Models often generate cryptographic code that works for the happy path but fails against actual attacks.
Cross-Site Scripting (XSS)
In web frameworks, models frequently fail to properly escape output, allowing injection of malicious JavaScript. This is especially common when the model generates template code without explicit instructions about escaping context.
The pattern across all these vulnerabilities? They're all in the training data. The models learned them. They reproduce them. Without explicit instruction to do otherwise, they default to the simplest, most statistically common pattern, which is often insecure.
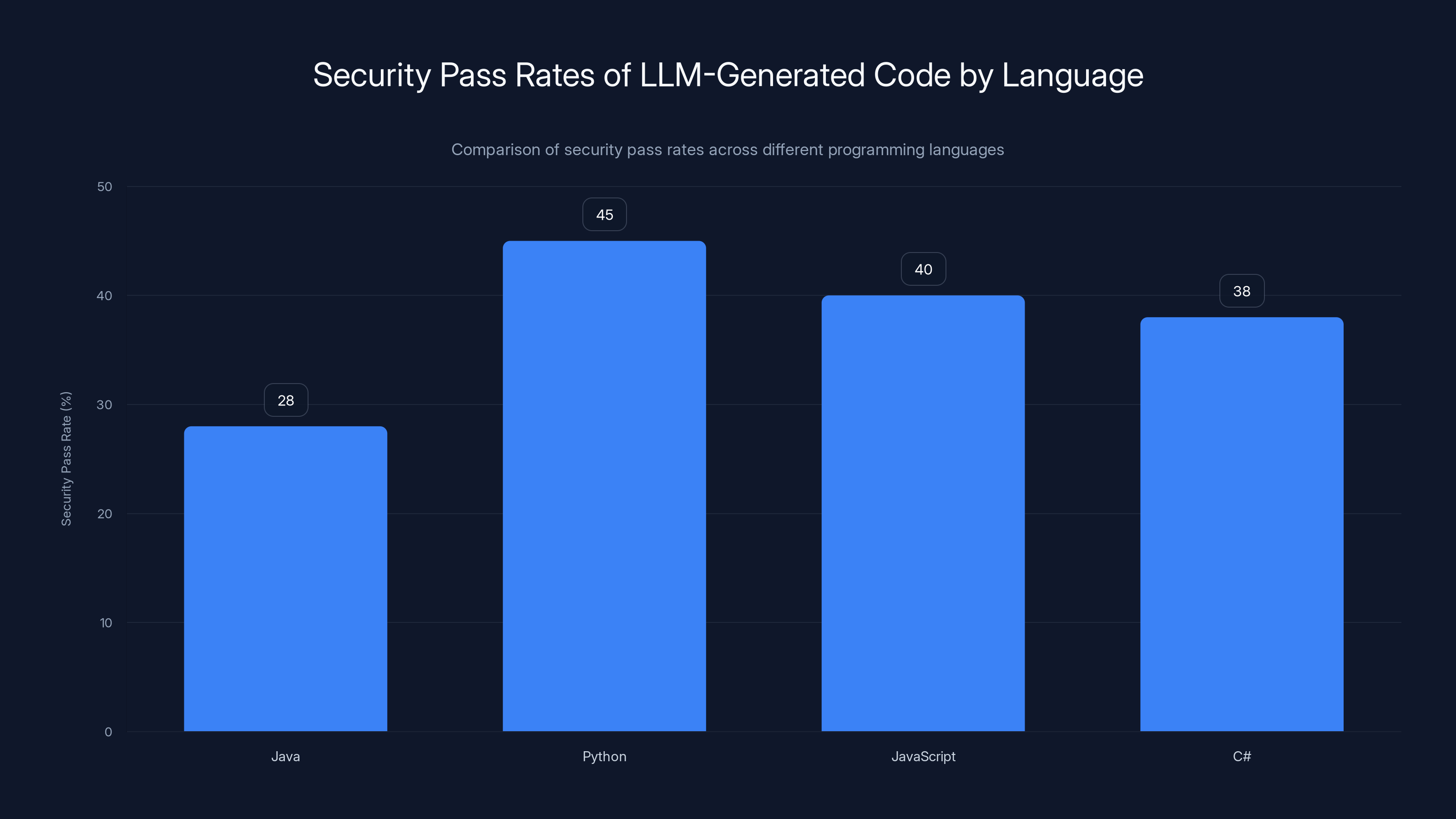
Java has the lowest security pass rate at 28%, highlighting its vulnerability compared to other languages like Python, JavaScript, and C# which have pass rates between 38% and 45%.
Why Scaling Isn't the Answer: The Fundamental Problem
Here's the conversation happening in AI labs right now:
Exec: "Our models still produce insecure code. Let's make them bigger."
Researcher: "That won't help. The problem isn't model size. It's training data."
Exec: "Bigger models are always better. Let's try it."
So they make bigger models. Security doesn't improve. Rinse, repeat, six months later.
This has been going on for over a year. It's the model industry's dirty secret: you can't scale your way out of bad training data.
The fundamental issue is that training data contains both secure and insecure examples, and models don't have built-in mechanisms to preferentially learn security. They learn whatever's statistically dominant in the data.
Java's a perfect example. There's so much vulnerable Java code in public repositories that models statistically learn vulnerability-prone patterns more frequently than security-conscious patterns. Making the model bigger doesn't change this. It just learns the bad patterns faster.
What does help:
- Curated training data: Training on high-quality, security-reviewed code instead of internet-scraped garbage
- Instruction tuning: Fine-tuning on security examples and explicit security principles
- Reasoning-based approaches: Teaching models to think through security trade-offs
- Specialized models: Creating models specifically optimized for security-critical code
But none of these are as easy or flashy as "make the model bigger." So they're being deprioritized relative to scale-focused research.
The Stagnation in Security Performance: What the Numbers Really Mean
Let's zoom out and look at the bigger picture: security performance has been flat for generations of models.
Two years ago, models were producing secure code roughly 50-55% of the time across multiple languages and task types. Today, with dramatically more advanced models, better training, larger parameter counts, and billions more dollars invested, that number is still 50-55%.
Functional correctness has improved dramatically. Reasoning capability has improved. Coding ability in niche languages has improved. Security has not.
This is the core insight: we've solved the wrong problem.
The AI industry has been optimized around capability benchmarks. Can the model generate correct Python? Can it solve programming interviews? Can it write working code faster than humans? Yes, yes, and yes.
But can it generate secure Python that doesn't leak data or enable attacks? Not particularly. Not at scale. Not consistently.
And because security isn't a flashy capability that drives adoption or investor interest, it's been treated as a secondary concern. Maybe something to address in the next generation of models. Maybe something for the security-focused startups to worry about.
Meanwhile, organizations are rolling out LLM-assisted code generation at scale without understanding the security implications.
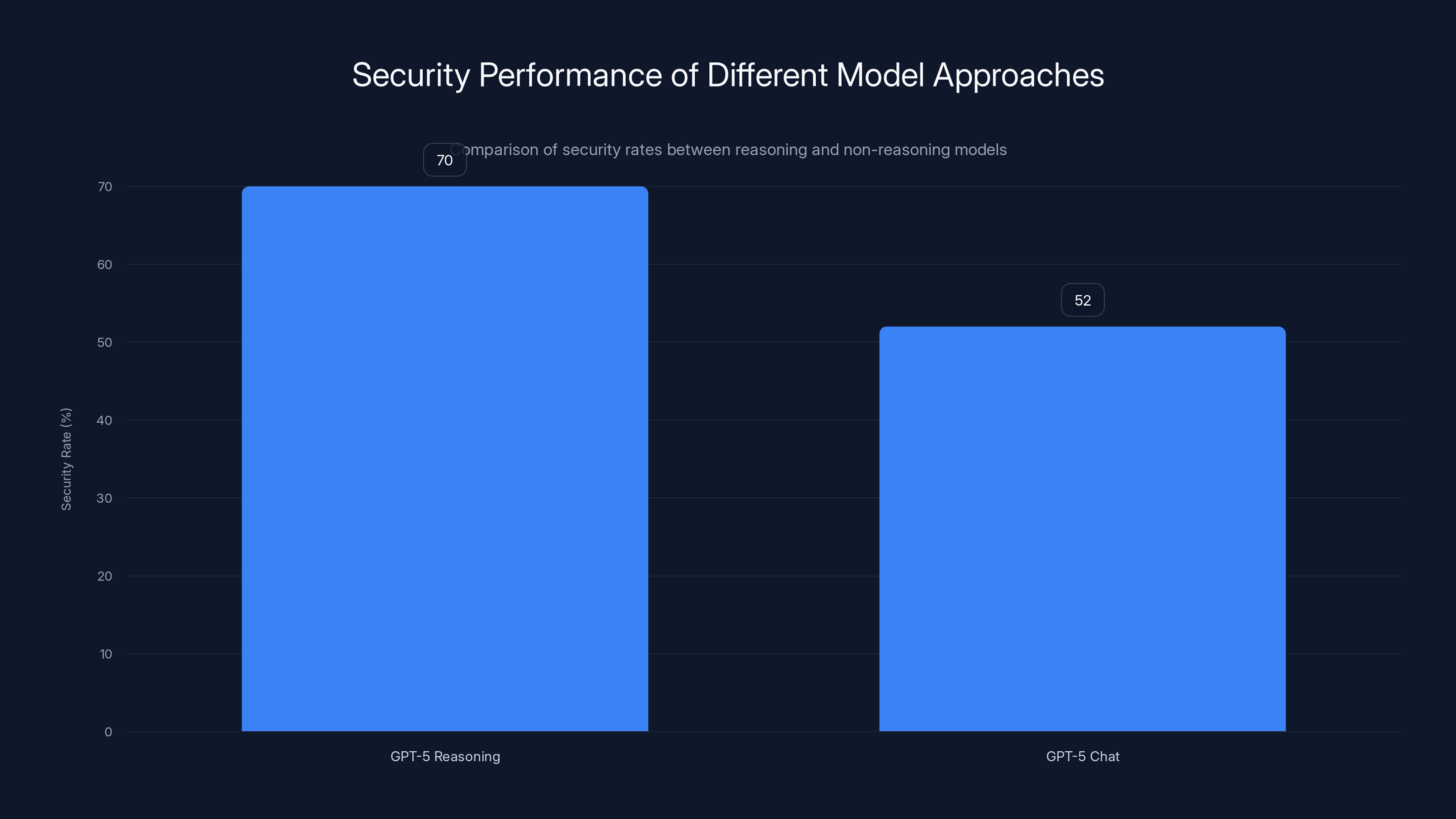
Models with reasoning alignment and instruction tuning, like GPT-5 Reasoning, achieve significantly higher security rates (70%+) compared to non-reasoning variants like GPT-5 Chat (52%). Estimated data based on typical performance.
What Developers and Teams Can Do Right Now
You can't wait for LLM security to magically improve. You need to act now, with existing tools, in your current environment.
1. Explicit Security Constraints in Prompts
Every prompt should include security requirements. Instead of "generate a database query," say "generate a database query using prepared statements, validating input length first, and returning generic error messages."
This dramatically improves outcomes because you're constraining the model's choices to safe options.
2. Security-First Code Review Process
When reviewing LLM-generated code, security review should come before functional review. Check for vulnerabilities first. Does this code follow secure patterns for your stack? Is input validated? Are secrets hardcoded?
Treat generated code like you'd treat third-party library code: assume it's potentially dangerous until proven safe.
3. Automated Security Scanning
Deploy static analysis tools that specifically scan LLM-generated code. These tools can catch SQL injection, XSS, insecure deserialization, and other common patterns automatically.
Tools like Semgrep, WhiteSource, and commercial SAST tools can be configured to flag patterns known to be problematic in LLM output.
4. Use Reasoning-Tuned Models When Available
If you're generating security-critical code, prefer models that explicitly use reasoning (like GPT-5 reasoning variants). The extra cost is minimal compared to the security improvement.
5. Segregate Generated Code in Your Codebase
Consider maintaining generated code in separate modules or namespaces. This allows for more intensive security review, separate testing regimes, and easier rollback if issues are discovered.
6. Security Training for Development Teams
Developers using LLMs for code generation need security training. They need to understand common vulnerabilities, why they matter, and how to specify secure constraints in prompts.
This isn't optional. This is table stakes when you're generating code at scale with AI.
7. Incident Response Planning
Assume you'll discover vulnerabilities in LLM-generated code. Plan for it. How will you identify affected code? How will you patch it? How will you communicate with customers? Having a plan before crisis hits is worth exponentially more than scrambling after.

Enterprise Solutions and Security Tools
If you're operating at enterprise scale, generic LLMs aren't enough. You need specialized approaches.
Curated LLM Instances
Some organizations are fine-tuning their own LLM instances on proprietary, security-reviewed code. This solves the training data problem but requires significant technical infrastructure.
Security-Focused Code Generation Tools
New tools are emerging specifically designed to generate more secure code. These tools add security constraints automatically, use specialized training approaches, or integrate security validation into the generation process.
Policy Enforcement
Enforcing policies at the CI/CD level: code generated without security constraints gets flagged for manual review before merge. Generated code must pass security scanning before deployment. These are guardrails that catch problems before production.
Developer Education Platforms
Platforms that teach security-first coding practices specifically in the context of AI-assisted development. This is becoming a critical skill.
The Future: Will LLM Security Actually Improve?
Let's talk about what might actually fix this problem.
Specialized Security Models
We might see models specifically trained for security-critical code generation. These would use curated datasets, security-aware fine-tuning, and perhaps novel architectures specifically designed for reasoning about security trade-offs.
The economic incentive is there: enterprises will pay for this. But it requires treating security as a first-class capability, not an afterthought.
Hybrid Approaches
Combining LLMs with formal verification, static analysis, and security constraint solvers. The model generates a candidate, automated tools verify it's secure, and only verified code is returned to the developer.
This is computationally expensive but might be necessary for critical systems.
Security as a Core Benchmark
The AI research community needs to stop treating security as optional. Security benchmarks should be as prestigious as reasoning benchmarks. Models should be compared on security metrics as much as capability metrics.
This requires culture change in AI labs. It's starting to happen, but slowly.
Regulation and Standards
As enterprises get burned by vulnerabilities in LLM-generated code, they'll demand standards. Compliance frameworks will require security attestation. This creates market pressure for actually secure tools.
We're seeing early signs of this in healthcare and finance, where security is already table stakes.

Security-First Teams vs. Speed-First Teams: The Divergence
We're seeing organizational divergence happen in real time.
Speed-first teams adopt LLMs aggressively, focus on velocity, and treat security as a downstream concern. They ship fast. They accumulate technical debt in the form of security vulnerabilities. Eventually, they experience an incident—data breach, system compromise, regulatory fine—that forces a reckoning.
Security-first teams adopt LLMs cautiously. They establish security constraints in prompts. They review generated code carefully. They scan output automatically. They train their developers on security-aware prompting. They move slower initially.
But here's the thing: after the initial adjustment period, security-first teams achieve nearly the same velocity as speed-first teams, except they don't accumulate security debt. When an incident inevitably affects the industry, security-first teams are insulated.
The divergence gets wider over time. Speed-first teams have to slow down to fix security. Security-first teams keep moving. The math is inexorable.
Integrating Security Into Your Development Workflow
Practical steps to make this real in your organization:
Phase 1: Awareness (Weeks 1-4)
- Educate team on LLM security risks
- Audit current code generation practices
- Identify which generated code handles sensitive data
- Document current security review processes
Phase 2: Implementation (Weeks 5-12)
- Create security constraint templates for prompts
- Integrate static analysis scanning into CI/CD
- Implement mandatory security review for generated code
- Begin training developers on security-aware prompting
Phase 3: Optimization (Weeks 13+)
- Monitor security metrics over time
- Refine constraint templates based on incident data
- Evaluate specialized security-focused tools
- Establish feedback loops between security and development teams
Phase 4: Scaling (Ongoing)
- As practices mature, scale across teams
- Maintain vigilance as new models and tools emerge
- Continue security training and awareness
- Share learnings across organization

The Uncomfortable Truth About LLM Security
Here's what nobody wants to admit publicly: the LLM security problem is getting worse, not better, in absolute terms.
More code is being generated. More of that code is insecure. More vulnerabilities are being shipped. Attackers are getting better at exploiting LLM-generated code. And defenders are falling further behind.
It's not that there's no solution. There are solutions. But they require effort, resources, and willingness to slow down. Most organizations aren't choosing to slow down.
So the gap widens. And the gap creates risk.
The organizations that will thrive are the ones that choose to slow down. That choose to integrate security into their LLM workflows. That choose to treat generated code with appropriate skepticism. That choose to invest in security-aware development practices.
This isn't pessimism. It's realism. The technology has capabilities. The question is whether organizations will use them responsibly.
Making AI-Assisted Development Secure: A Framework
Let me give you a concrete framework you can apply immediately.
The Security-Aware Prompt Template
Every LLM code generation prompt should follow this structure:
[FUNCTION DESCRIPTION]
Generate [what you want]
[SECURITY REQUIREMENTS]
1. Input validation: [specific approach]
2. Output encoding: [specific approach]
3. Authentication: [specific requirement]
4. Authorization: [specific requirement]
5. Data handling: [specific requirement]
6. Error handling: [specific requirement]
7. Logging: [specific requirement]
[TECHNOLOGY CONSTRAINTS]
Language: [language]
Framework: [framework]
Database: [database]
[EXAMPLES OF SECURE PATTERNS]
[Include 1-2 examples of secure implementations]
Using this template significantly improves security outcomes because it constrains the model's choices to explicitly secure patterns.
The Code Review Checklist
When reviewing LLM-generated code:
- Input handling: Is all input validated? Length checks? Type checks? Whitelist validation?
- Authentication: If required, is it properly implemented? Passwords hashed? Sessions secure?
- Authorization: Are access controls properly enforced? Role-based access?
- Data protection: Is sensitive data encrypted? At rest and in transit?
- Error handling: Do error messages leak sensitive information?
- Logging: Are security-relevant events logged?
- Dependencies: Are external libraries secure? Updated?
- Injection vulnerabilities: SQL injection? Command injection? LDAP injection?
- Deserialization: If present, is deserialization of untrusted data prevented?
- Cryptography: If used, are algorithms, key lengths, and implementations correct?
The Automation Requirements
Every organization should have:
- Static analysis scanning: Catch known vulnerability patterns
- Dependency checking: Identify vulnerable libraries
- Secret scanning: Prevent hardcoded credentials
- Automated testing: Unit tests and security tests
- Code coverage analysis: Identify untested code paths

Looking Ahead: The Reality in 2025 and Beyond
As we move through 2025, the LLM security problem isn't going away. It's intensifying.
More code generation: Every organization is adopting LLM-assisted development. More code is being generated than ever before.
More sophisticated attacks: Attackers are using LLMs to identify vulnerabilities at scale. They're developing automated exploit tools. The attacker advantage grows.
Regulatory pressure: Incidents will drive regulation. Compliance frameworks will require security attestation. This creates market pressure but also complexity for organizations to navigate.
Tool maturation: We'll see more specialized security tools for LLM code generation. Better integration with development workflows. Improved security scanning specifically tuned for LLM patterns.
Cultural shift (maybe): Some organizations will embrace security-first development. Others will keep moving fast and breaking things. The divergence will become obvious.
The question isn't whether you'll use LLMs for code generation. You will. Everyone will. The question is how carefully you'll use them.
Final Thoughts: Security Isn't Optional
LLMs are genuinely powerful tools for accelerating development. The productivity gains are real and substantial. But those gains are pyrrhic if they come with exponential security debt.
The good news: you don't have to choose between speed and security. You can have both if you're deliberate about it. Explicit security constraints in prompts, careful code review, automated scanning, and security-first culture create a path to both velocity and safety.
The bad news: most organizations won't choose that path. They'll choose speed, accumulate vulnerabilities, and eventually get hit by an incident that forces a reckoning.
If you're reading this, you have the opportunity to choose differently. You can be the organization that uses LLMs safely, that integrates security into your development workflows, that treats generated code with appropriate skepticism.
It requires discipline. It requires investment. It requires treating security as a core value, not an afterthought.
But the alternative—shipping code at scale that's silently full of vulnerabilities, hoping nobody exploits them, waiting for the inevitable incident—is genuinely worse.
Choose wisely. Choose security. The cost of inaction is exponential.

FAQ
What exactly is LLM security plateauing?
LLM security plateauing means that while the ability to generate functionally correct code has improved dramatically, the ability to generate secure code has remained stagnant. Models still produce code with detectable OWASP Top 10 vulnerabilities roughly 45-50% of the time, and this rate hasn't improved meaningfully across multiple generations of increasingly powerful models. The problem isn't getting better despite massive increases in computational power and training data.
Why don't larger models produce more secure code?
Model size alone doesn't improve security outcomes because the problem is fundamentally about training data quality and what the model learns during fine-tuning, not about computational capacity. Larger models learn the same vulnerable patterns as smaller models, just faster. What actually matters is explicit instruction tuning on secure code examples and reasoning-based approaches that teach models to think about security trade-offs. OpenAI's reasoning models achieve 70%+ security rates because of how they're trained, not because they're bigger.
What are the most common vulnerabilities LLMs introduce?
SQL injection remains the most prevalent LLM-generated vulnerability, followed by authentication and authorization flaws (missing rate limiting, weak password hashing, information leakage). Cross-site scripting (XSS) is common in web frameworks, cryptographic failures appear frequently, and insecure deserialization is a recurring problem in Java code. The consistency of these patterns suggests they're statistically dominant in training data rather than random generation errors.
Why is Java specifically so vulnerable to LLM-generated insecurity?
Java has a long history as a server-side language predating widespread awareness of vulnerabilities like SQL injection. Training data scraped from public repositories contains proportionally more vulnerable Java examples than other languages, and Java's verbose syntax can obscure security issues. Additionally, Java predates many secure coding practices now common in the ecosystem, so historical code in training datasets reflects older, less secure patterns. Newer models tuned on enterprise languages show improved Java security, suggesting this can be fixed with focused fine-tuning.
How can developers get LLMs to generate more secure code?
The most effective approach is explicit specification of security constraints in prompts. Instead of asking for "a database query," specify "a database query using prepared statements with input validation." Provide security examples in prompts. Use models with explicit reasoning capabilities when available. Integrate security constraints into your development workflow templates. Make security review mandatory before code merges. These practical steps improve security outcomes substantially without requiring better models.
Should organizations stop using LLMs for code generation?
No. LLMs genuinely improve productivity, and those gains are valuable. The answer isn't to avoid LLMs, it's to use them responsibly. Establish security constraints in prompts, implement comprehensive code review processes, use automated security scanning, and train developers on security-aware prompting. Organizations that integrate security into their LLM workflows achieve both velocity and safety. The organizations that'll suffer are those pursuing speed without security safeguards.
What tools can help secure LLM-generated code?
Static analysis tools like Semgrep, commercial SAST platforms, and dependency checkers can automatically identify known vulnerability patterns. DAST tools can test running code for security issues. Code review platforms can enforce mandatory security review before merge. IDE plugins can flag suspicious patterns in real-time. Specialized LLM tools focusing on security-aware code generation are emerging. No single tool is sufficient—you need a layered approach combining multiple tools and processes.
Will model improvements eventually solve the LLM security problem?
Model improvements alone won't solve this without explicit focus on security. Larger models, better capabilities, and more training data don't automatically produce more secure code. What does help: explicit security-focused fine-tuning, training on curated secure code, instruction tuning on security principles, and reasoning-based approaches. The breakthrough will come when AI labs treat security as a first-class optimization target equivalent to capability, not as an afterthought. We're starting to see this shift, but it's gradual.
What's the role of code review in catching LLM vulnerabilities?
Code review is necessary but insufficient on its own. Human reviewers, even security-conscious ones, miss vulnerabilities in generated code because: 1) the volume is too high to review thoroughly, 2) many developers don't have deep security expertise, and 3) some vulnerabilities aren't obvious by inspection. Automated scanning is essential as a first pass, catching known patterns. Code review should focus on architectural security decisions and novel code patterns, not on catching well-known vulnerability types that tools can identify.
How should organizations structure their security processes for LLM adoption?
Start with awareness and education. Establish explicit security constraints that developers must include in prompts. Implement automated scanning in CI/CD pipelines. Make security review mandatory for generated code before merge. Segregate generated code for more intensive review if possible. Monitor security metrics over time. Create feedback loops between security and development teams. Scale gradually as processes mature. Treat this as a multi-quarter initiative, not something to bolt on quickly. The organizations that will be most secure are those treating LLM adoption as a strategic shift requiring proportional security investment.
Automating your workflow documentation and security review is one way to scale these practices efficiently. Tools that help developers generate security-compliant documentation, automate security scanning, and integrate security review into development processes are becoming essential infrastructure. Platforms like Runable can help teams automate report generation and documentation with built-in security considerations, making it easier to maintain security practices at scale without sacrificing productivity.
Use Case: Generate security-compliant documentation and incident reports automatically while maintaining strict security control over sensitive data handling.
Try Runable For FreeKey Takeaways
- Only 55% of LLM-generated code is actually secure; models produce OWASP Top 10 vulnerabilities nearly half the time across major platforms
- Model size and capability improvements don't automatically improve security—instruction tuning and reasoning alignment matter far more than scale
- Java code generation is catastrophically insecure (below 30% security rate) due to historical vulnerability density in training data
- Developers rarely specify security constraints in prompts, leaving critical decisions to models that choose incorrectly 45% of the time
- Attackers are using LLMs to identify vulnerabilities faster than defenders can patch them, widening the security gap during peak adoption
- Security-first teams that implement explicit constraints, code review, and scanning maintain both velocity and safety while others accumulate debt
Related Articles
- How Bill Gates Predicted Adaptive AI in 1983 [2025]
- Airbnb's AI Search Revolution: What You Need to Know [2025]
- Why OpenAI Retired GPT-4o: What It Means for Users [2025]
- 7 Biggest Tech News Stories This Week: Claude Crushes ChatGPT, Galaxy S26 Teasers [2025]
- Testing OpenClaw Safely: A Sandbox Approach [2025]
- AI Recommendation Poisoning: The Hidden Attack Reshaping AI Safety [2025]

