![Odinn Omnia: The 37kg Supercomputer That Redefines Portable Computing [2026]](https://tryrunable.com/blog/odinn-omnia-the-37kg-supercomputer-that-redefines-portable-c/image-1-1767897366273.jpg)
Odinn Omnia: The 37kg Supercomputer That Redefines Portable Computing [2026]
Some hardware exists to solve problems. Other hardware exists to prove a point.
The Odinn Omnia is decidedly the latter. When you first see the specs, your brain does a double-take. Dual AMD EPYC 9965 processors delivering 384 CPU cores. Four Nvidia H200 NVL GPUs with 564GB of combined VRAM. Six terabytes of DDR5 ECC registered RAM. One petabyte of NVMe SSD storage. A 24-inch 4K display with a flip-down keyboard. And all of this crammed into a chassis that weighs 37 kilograms.
Yes, it has carry handles.
I'll be honest: when I first read those specs, I thought someone was joking. This isn't a laptop. This isn't even a portable workstation in the traditional sense. This is a data center that someone decided should technically be "mobile" because you can physically move it, assuming your lower back has already accepted its fate.
But here's where it gets interesting. The Odinn Omnia isn't actually ridiculous. It's a remarkably focused device designed for a very specific slice of the market: organizations that need bleeding-edge AI training, large-scale simulations, scientific computing, or real-time rendering in environments where traditional server racks simply won't fit. It's luggable computing for the 2020s.
TL; DR
- Raw Power: Dual AMD EPYC processors with 384 cores, four Nvidia H200 NVL GPUs, and up to 564GB of GPU VRAM
- Memory & Storage: 6TB of DDR5 ECC RAM and up to 1PB of NVMe SSD capacity
- Network: Supports up to 400 Gbps network throughput—unusual for anything with a handle
- Portability Caveat: Weighs 37kg with redundant power supplies and integrated cooling; "portable" here requires generous interpretation
- Market Position: Designed for AI labs, research institutions, and computational facilities needing data center power without traditional infrastructure

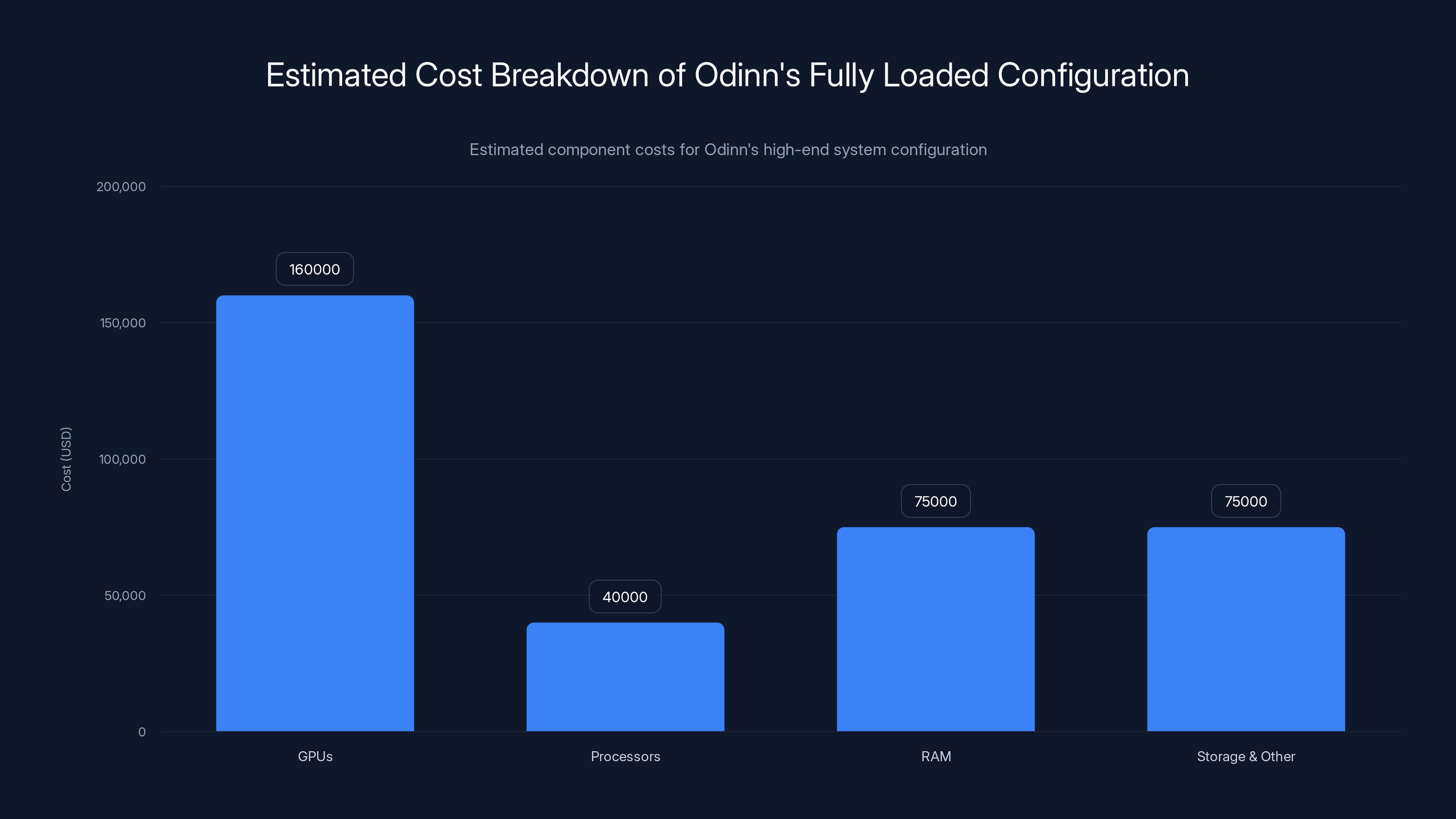
Estimated data shows that GPUs are the most expensive component, contributing significantly to the total cost approaching $500,000.
What the Odinn Omnia Actually Is
Let me cut through the marketing speak. The Odinn Omnia is a compact, integrated computing system that brings enterprise-grade server hardware into a form factor you could theoretically move between rooms. The word "theoretically" doing a lot of heavy lifting there.
Compare it to the luggable computers of the 1980s—the Compaq Portable, for instance. Those machines weighed far less but were still brutal to move. They earned their reputation as arm-stretching beasts because you needed genuine strength and commitment to transport them. The Odinn Omnia plays in the same philosophical space, just with contemporary server-grade components.
The difference is scale and purpose. Where 1980s luggables squeezed office productivity into a suitcase shell, the Omnia compresses contemporary data center capabilities into a single, theoretically mobile enclosure. It's not trying to be a laptop. It's not trying to be a traditional workstation. It's a different animal entirely.
Inside the chassis sits hardware you'd normally encounter in dedicated server racks or high-performance computing facilities. AMD EPYC processors designed for data centers. Nvidia GPUs intended for scientific computing and AI training. Redundant power supplies rated for continuous operation. Integrated liquid cooling to handle the thermal load. Every component selected for reliability, performance, and sustained operation under demanding workloads.
The 24-inch 4K display feels almost whimsical attached to such industrial hardware. Same with the flip-down keyboard. It's like someone took a mainframe, added a monitor and keyboard, and said, "Now you can carry it." Which is exactly what happened.
The Processor Configuration: 384 Cores of Parallel Computing
Let's talk about the CPU foundation. The Odinn Omnia supports up to two AMD EPYC 9965 processors. Each one delivers 192 cores. That's 384 cores total.
To put that in perspective: a high-end gaming PC has 24 cores. A professional workstation has maybe 128. The Odinn Omnia has three times the core count of a professional workstation. And it can support dual processors in a single chassis.
The EPYC 9965 is not a consumer processor. It's designed specifically for data centers, cloud infrastructure, and high-performance computing. These processors excel at highly parallelized workloads: machine learning training, complex simulations, mathematical modeling, genetic sequencing, financial modeling.
Each core runs at respectable clock speeds while the dual-processor configuration enables true multi-socket, multi-threaded parallel processing. Tasks that normally require a farm of interconnected servers can run on a single system. Not a single laptop—a single chassis. That's the Omnia's real power.
The processor architecture includes what AMD calls 12-channel memory support per socket. That's an enormous memory bandwidth compared to consumer systems. This matters enormously for AI training and data processing workloads where moving data efficiently is often the bottleneck.
One practical example: training a large language model might require constant feeds of data from memory to computation units. Processor memory bandwidth determines how fast that data flows. The Omnia's dual EPYC setup with 12-channel memory per socket means data movement isn't the limiting factor—the GPUs are.

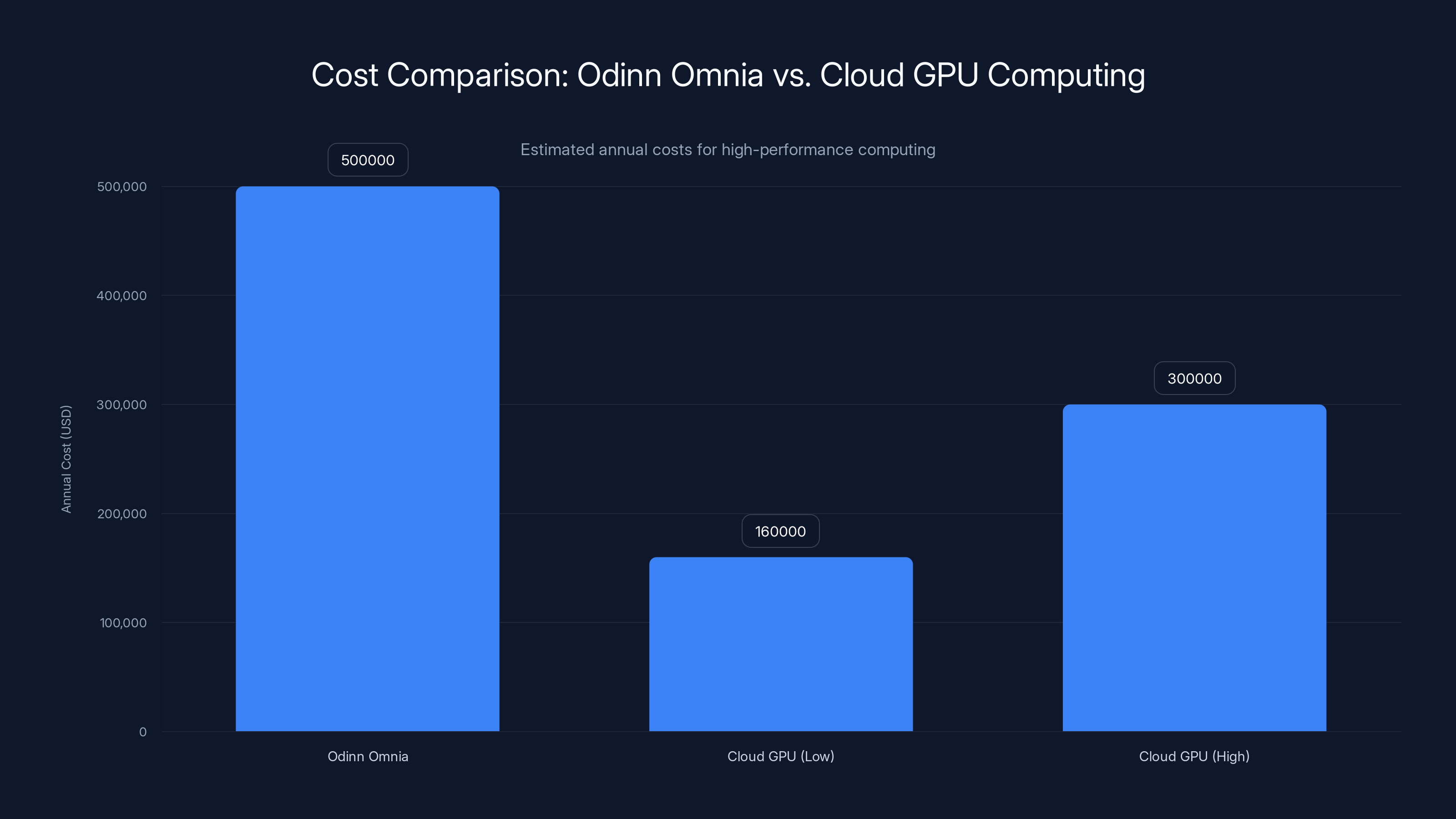
While the Odinn Omnia has a high upfront cost, it can be more economical over time compared to cloud GPU solutions, which can range from
GPU Acceleration: Four Nvidia H200 NVL Units
Now we get to the real heavy lifting. The Odinn Omnia supports four Nvidia H200 NVL (Nvidia Vallaram) GPUs with up to 564GB of combined VRAM.
Let me explain why this matters. The H200 NVL is specifically designed for AI inference and large language model serving. It's not a gaming GPU. It's not a general-purpose compute GPU. It's an AI-focused accelerator with 141GB of HBM3e memory per card.
HBM3e is high-bandwidth memory, fundamentally different from the GDDR6 found in gaming GPUs. HBM3e provides around 4.8TB/s of memory bandwidth. For context, even a flagship RTX 6000 Ada GPU maxes out at around 960GB/s. The H200 is approximately five times faster at moving data between memory and compute units.
Why does this matter? Large language models are memory-bound, not compute-bound. A model like GPT-3 or larger requires moving enormous amounts of weights and activations from memory through computation units constantly. HBM3e memory bandwidth directly translates to faster inference and faster training.
Four H200 NVL cards provide 564GB of GPU memory total. That's genuinely massive. You could load an enormous model into GPU memory—like a large vision transformer or a multi-trillion-parameter language model—and avoid the constant PCIe transfers that kill performance in distributed setups.
The NVL form factor (as opposed to standard PCIe cards) enables direct GPU-to-GPU communication with ultra-low latency. This matters for distributed training or inference where GPUs need to synchronize frequently. A reduction in communication overhead directly improves training speed and efficiency.
The Memory Hierarchy: 6TB of DDR5 ECC RAM
Here's a spec that almost sounds fictional: 6 terabytes of DDR5 ECC registered RAM.
Let me parse this. DDR5 is the latest memory generation, offering higher bandwidth and lower latency than DDR4. ECC means error-correcting code—memory that automatically detects and corrects single-bit errors. Critical for long-running computations where a single bit flip could corrupt results. Registered means this memory uses a memory register on the DIMM itself, allowing more modules per channel.
Six terabytes total means the system can hold enormous datasets entirely in RAM. Consider a typical machine learning workflow: you load training data into memory, iterate repeatedly. If that data exceeds available RAM, you're constantly reading from disk, which is tens of thousands of times slower than memory access.
With 6TB of RAM, you could load a dataset containing billions of records and keep it entirely in fast memory. The CPU and GPUs operate on this data at full speed without the constant bottleneck of disk I/O.
The actual configuration likely uses multiple DIMMs across both processor sockets. Each EPYC processor can theoretically support hundreds of gigabytes of RAM through 12 memory channels per socket. The Omnia reaches 6TB by populating a substantial portion of available slots.
One critical detail: this is registered, ECC memory. That means every memory access is checked for errors. There's a tiny overhead—maybe 2-3% performance penalty compared to unbuffered memory—but the guarantee of data integrity is worth it for serious computational work. One undetected bit flip in a training run could invalidate hours or days of computation.

Storage Architecture: 1PB of NVMe SSD Capacity
One petabyte. That's one million gigabytes. In the context of a single system, that number is genuinely mind-bending.
For perspective: a modern SSD might hold 2-4TB. A fully loaded data center might contain hundreds of terabytes across many systems. The Omnia single-handedly can store a petabyte of data, which is equivalent to the entire contents of many small organizations' data centers.
The Omnia achieves this through high-density NVMe SSD configurations. Modern NVMe SSDs come in various form factors—2.5-inch drives, M.2 cards, U.2 industrial forms. The Omnia likely uses multiple NVMe slots with high-capacity drives (4TB, 8TB, or even larger).
NVMe is critical here. It's orders of magnitude faster than traditional SATA SSDs. NVMe drives connected directly to PCIe lanes provide latency measured in microseconds and throughput measured in gigabytes per second. This matters enormously for data-intensive workflows.
However—and this is important—one petabyte of storage is more of a capability than an expectation. Most users likely won't populate all available slots. A fully loaded configuration might be extremely expensive. But the architecture supports it, which means users can scale storage as needed without replacing the entire system.
Why would you need 1PB? Consider scientific research institutions processing climate data, genomic sequences, astronomical observations. These fields generate massive datasets. Having all data locally accessible avoids network transfers and enables fast analysis loops.
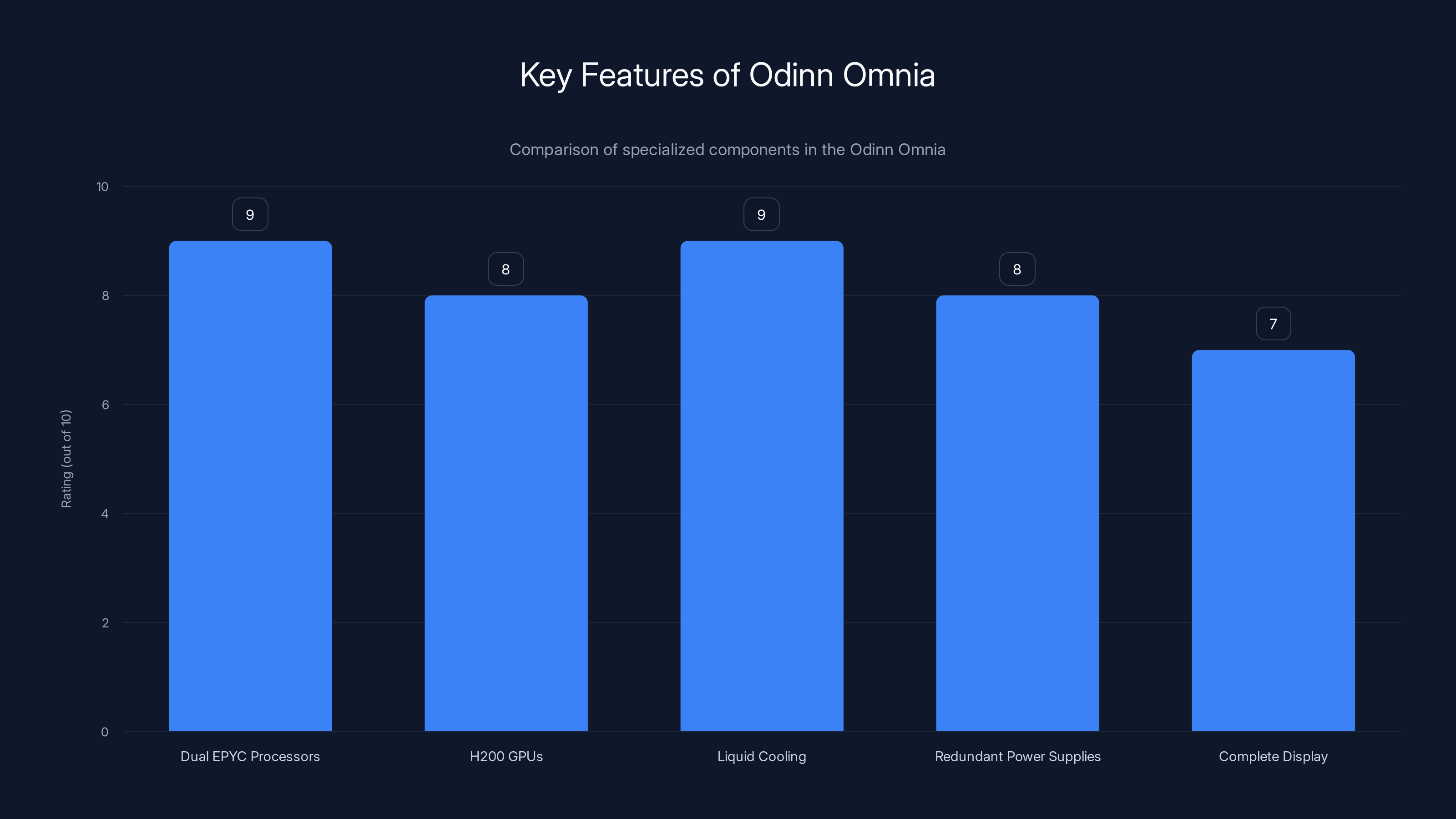
The Odinn Omnia integrates high-performance components, excelling in processing power and cooling, making it ideal for specialized computing tasks. Estimated data.
Thermal Management: Cooling Enterprise-Grade Hardware
Here's a challenge nobody discusses about data center hardware: heat. Four GPUs, two processors, and gigabytes of RAM generate substantial thermal load.
The Odinn Omnia includes integrated cooling hardware designed to manage this heat reliably. This likely includes liquid cooling loops running through the chassis, extracting heat from high-power components and exhausting it through radiators.
Liquid cooling serves several purposes. First, it allows higher performance sustained indefinitely. Air cooling works fine for brief peaks, but moving a system with sustained full utilization requires better heat transfer. Liquid absorbs heat more efficiently and transports it away from components faster.
Second, it enables higher density. Cramming four GPUs, dual processors, and 6TB of RAM into a single chassis generates enough heat that air cooling alone wouldn't suffice. Liquid cooling enables this compact configuration.
Third, it extends component lifespan. Heat degrades semiconductor performance and reliability over time. Better thermal management means longer system lifetime and more predictable reliability.
The engineering challenge is significant. Every component generates heat, and that heat needs pathways out of the chassis. The design must balance thermal performance with acoustic noise—liquid coolers can be loud if fans run at high speed.
We don't have detailed thermal specifications, but anyone running this system should expect active cooling systems, possibly with redundant pumps for reliability. Failure of the cooling system means the hardware will throttle or shut down, so redundancy matters.
Power Delivery: Redundant Platinum-Rated PSUs
The Odinn Omnia includes redundant Platinum-rated power supply units. Let's unpack what that means.
First, redundancy. A single power supply has a finite reliability. It could fail. Having two independent PSUs means if one fails, the system continues running on the other. This is standard for mission-critical equipment but unusual for anything you can carry.
Second, Platinum rating. Power supplies are rated for efficiency at different levels: Bronze, Silver, Gold, Platinum, Titanium. Platinum-rated PSUs are roughly 92% efficient. That means 92% of electrical power goes to the system, 8% becomes waste heat. It's meaningful because less waste heat means lower cooling requirements and lower electricity bills.
Third, the power requirement itself. Two EPYC processors, four H200 GPUs, cooling systems, and storage arrays don't run on a 1000W PSU. The actual power requirement likely reaches 10,000-15,000 watts. That's enormous for a single system. For context, a large house uses maybe 5,000-10,000 watts on average.
This power requirement has practical implications. You can't just plug this into a standard wall outlet. You need dedicated high-amperage circuit infrastructure. Deploying the Omnia requires electrical planning just like deploying data center equipment.
The redundant PSU design also matters for reliability. If you're running important workloads, you can't afford sudden power loss. Dual PSUs with automatic failover mean hardware failure doesn't interrupt your system.
Network Connectivity: 400 Gbps Throughput
The specification that genuinely shocked me: up to 400 Gbps network throughput.
Let me contextualize this. A typical home internet connection is maybe 1 Gbps download. An office network might be 10 Gbps. Enterprise data centers use 40 Gbps or 100 Gbps connections. Four hundred gigabits per second is data center-tier networking, the kind you find in massive cloud infrastructure.
Why does a portable system need 400 Gbps? Several reasons. First, if you're using the Omnia to train massive AI models, you need enormous data throughput. Feeding training data to GPUs requires moving gigabytes of data per second. 400 Gbps provides sufficient bandwidth that network transfer doesn't become the bottleneck.
Second, if multiple Omnia systems are networked together, 400 Gbps allows inter-system communication fast enough that distributed training doesn't suffer from slow interconnects. You could theoretically link multiple Omnias together and achieve performance close to a single unified system.
Third, if the Omnia is accessing external data storage or cloud infrastructure, 400 Gbps ensures local compute is never waiting for data. Everything flows at maximum speed.
Achieving 400 Gbps requires specialized network interface cards—likely multiple 100 Gbps NICs or 400 Gbps single cards using advanced standards. These are expensive components themselves, adding to the overall system cost.
For most users, this level of network capability is overkill. Typical deployments might use 100 Gbps connections, which are already extraordinarily fast. The 400 Gbps specification represents architectural headroom for the most demanding workloads.

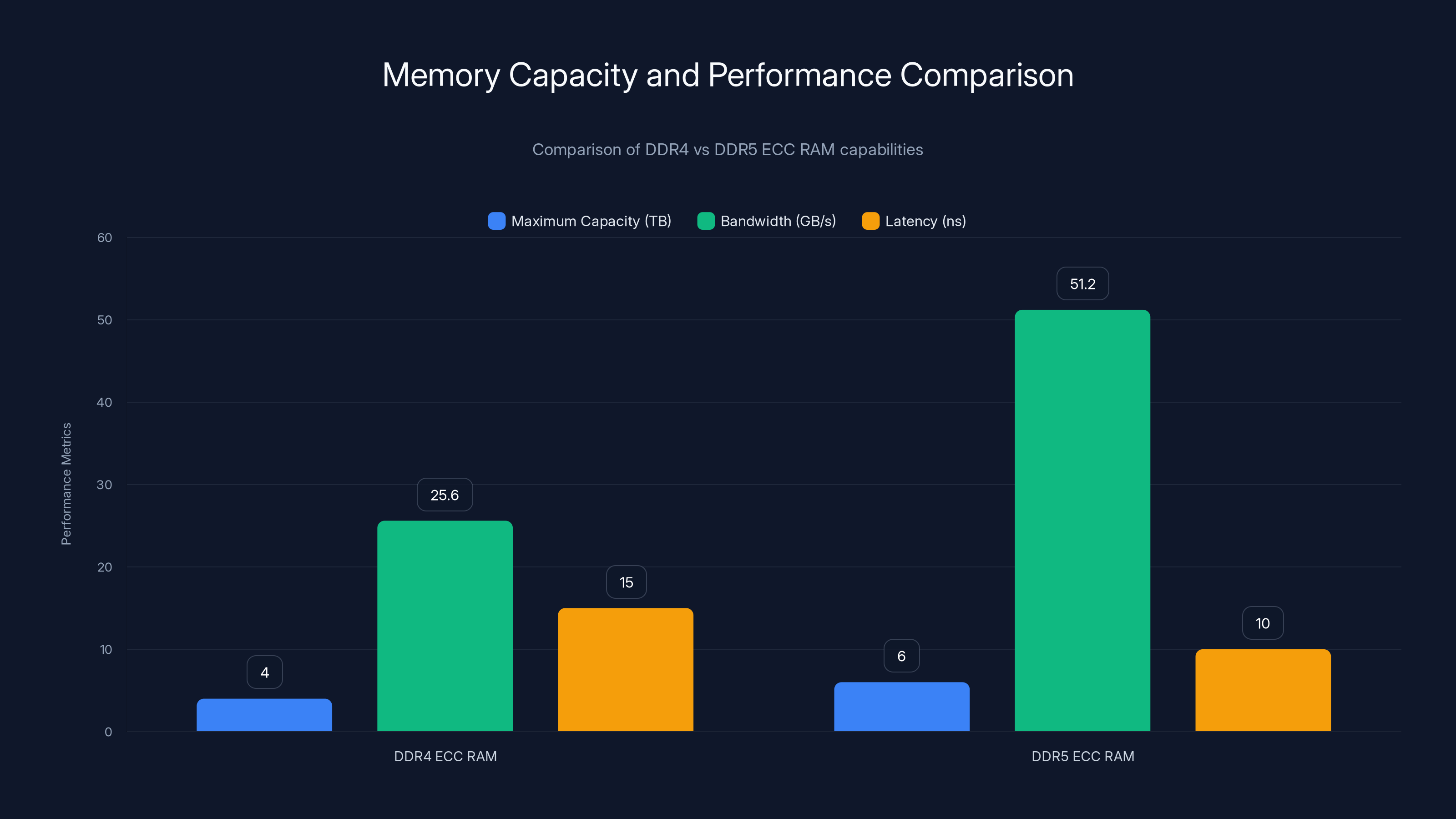
DDR5 ECC RAM offers higher capacity, bandwidth, and lower latency compared to DDR4, making it ideal for handling large datasets in memory-intensive applications. Estimated data based on typical specifications.
Display and Interface: The Almost-Whimsical UI
Here's where the Odinn Omnia feels genuinely surreal: it includes a 24-inch 4K display and a flip-down keyboard.
Attach those to a data center chassis and you get this fascinating contradiction. The monitor is legitimately good—24-inch 4K means sharp text and detailed images. The keyboard is functional. You can actually sit down at this system and use it interactively, which contradicts the entire server-grade hardware philosophy.
But that's also the point. The Omnia isn't designed for rack mounting in a data center. It's designed for deployment in research labs, company offices, or specialized computing facilities where you need data center power but want a single integrated system rather than a server rack.
The display and keyboard mean you can troubleshoot directly. Run diagnostics. Monitor system status in real-time. Doesn't require a separate workstation and network connectivity to manage the hardware.
The flip-down keyboard design is clever—it folds when not in use, reducing the system's footprint. When you need to interact with the system directly, flip it down and work locally.
This is actually a thoughtful design choice. It recognizes that portability includes not just physical movement but also practical deployment. You don't need specialized infrastructure just to use the system. Plug it in, unfold the keyboard, and start working.
Portability: A Generous Definition
Let's address the elephant in the room: the Odinn Omnia weighs 37 kilograms (about 82 pounds) and has carry handles.
I want to be very clear: this is not actually portable in any practical sense. You can move it. That's undeniably true. But moving something and moving it comfortably are different things. Moving it safely without back injury is a third thing entirely.
Compare it to the Compaq Portable from 1983—one of the first commercially successful portable computers. It weighed about 23kg. People called it portable because someone could carry it between rooms. But it was brutal. Your arms would hurt. You'd need a break after a hundred meters.
The Odinn Omnia, at 37kg, is heavier than the Compaq Portable. You can move it, but nobody would describe moving it as pleasant. The carry handles are more of a philosophical statement than a practical feature.
However, here's where the positioning makes sense: portability is relative. Compared to a traditional server rack (which requires specialized infrastructure, climate control, power conditioning), the Omnia is genuinely portable. You could load it into a vehicle, move it to a different building, set it up in a new location. You can't do that with a server rack.
So portability here means "can be relocated as a complete integrated system." Not "can be casually carried by one person."
The wheels would help. The specifications don't mention wheels, but adding wheels would transform it from "theoretically portable" to "actually mobile." Rolling a 37kg system is far superior to carrying it.

Pricing and Market Position: Enterprise Territory
Odinn hasn't officially confirmed pricing. However, analysts estimate a fully loaded configuration—all processors, all GPUs, maximum RAM, maximum storage—could approach or exceed $500,000.
Let me parse what that means. The components alone cost substantial sums: each H200 NVL GPU costs roughly
Simple math suggests a fully configured system genuinely could exceed $500,000. That's not outrageous pricing; it's what components actually cost.
But here's the critical context: this system enables capabilities unavailable elsewhere. If your organization needs petabyte-scale storage, 384 CPU cores, and GPU acceleration in a physically transportable package, your alternatives are: (a) build a server rack, which costs more and requires infrastructure, or (b) purchase cloud computing, which costs even more over time.
For organizations doing serious AI training, scientific computing, or data processing, the Omnia becomes cost-competitive. Rent equivalent cloud GPU time for a week and you might approach the purchase price of an Omnia.
The target market is clear: research institutions, AI labs, specialized computing facilities, possibly some large companies with significant computational needs. Not typical businesses. Not consumers. Enterprise customers with legitimate needs for powerful, integrated computing systems.
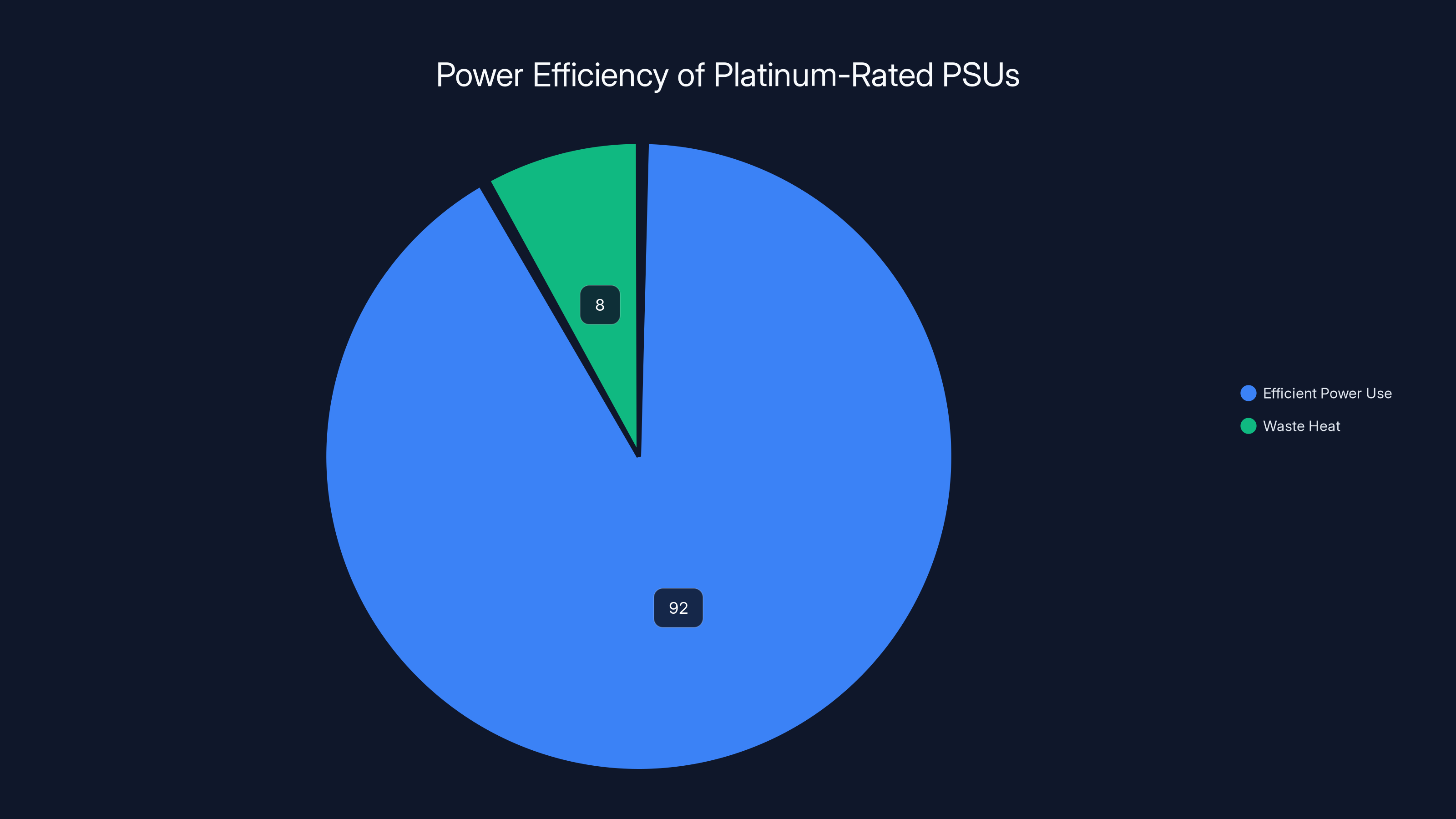
Platinum-rated PSUs are 92% efficient, meaning most power is used effectively, with only 8% lost as waste heat. This high efficiency reduces cooling needs and electricity costs.
Real-World Use Cases: Where the Omnia Makes Sense
Let's get concrete about where this system actually solves problems.
AI Model Training
Training large language models requires enormous compute and memory. A model like GPT-3 requires months of training on thousands of GPUs. The Omnia can't replace a massive training cluster, but it can serve specialized purposes. Fine-tuning models. Domain-specific training. Rapid experimentation.
The combination of GPU memory and DDR5 RAM means you can load models entirely into fast memory and iterate rapidly. Compression techniques, quantization experiments, architecture modifications—all benefit from being able to keep large models in memory.
Scientific Computing
Physics simulations, climate modeling, molecular dynamics—all these fields benefit from high core count processors and GPU acceleration. The Omnia provides research teams with serious computational capability on a single system.
Data Processing
Analyzing massive datasets requires fast storage, abundant RAM, and parallel processing. The Omnia's combination—1PB storage, 6TB RAM, 384 CPU cores—enables processing datasets that might otherwise require a cluster.
Real-time Inference
Serving large models to many users requires sufficient GPU memory to hold entire models and handle multiple requests simultaneously. The Omnia's 564GB of GPU memory and 400 Gbps networking enables serving large models with low latency.
Mobile Research
For organizations doing fieldwork or temporary deployments, the Omnia avoids cloud dependency. Bring it to a remote location, set it up, run computations locally without network dependency.

Competitive Context: How Does Omnia Compare?
The Omnia doesn't directly compete with traditional workstations or data center servers because it occupies a unique position—it's both and neither.
Versus traditional server racks: The Omnia is more expensive per component but offers complete integration and portability. Server racks are cheaper if you already have infrastructure, but they require dedicated space, power conditioning, and cooling infrastructure. The Omnia self-contains everything.
Versus cloud GPU compute: Renting equivalent GPU time from AWS, Google Cloud, or Azure costs roughly
Versus portable workstations: High-end portable workstations with dual GPUs and 256GB RAM cost $30,000-50,000. But they're fundamentally different animals. They're optimized for professional work (rendering, simulation) but lack the memory, storage, and core count of the Omnia.
The Omnia fills a gap that nothing else quite occupies. It's for organizations that need serious computing power, want integrated systems without infrastructure complexity, and can justify the cost through either heavy usage or time-sensitive work.
Manufacturing and Availability
Odinn showed the Omnia at CES 2026, generating significant buzz. But public availability remains limited. The company has released primarily a video demonstration rather than widespread hands-on access.
This makes sense for a system at this price point and complexity. Manufacturing isn't simple. Each system requires integration of components, testing, thermal tuning. You can't mass-produce the Omnia like consumer laptops.
Expect custom configurations. Organizations would contact Odinn, specify requirements, and the company would build systems to order. Lead times might be weeks or months. Support would likely require specialized training.
This is actually healthy. It indicates Odinn understands the market—small number of buyers willing to pay for customization and support. Not a mass-market product.

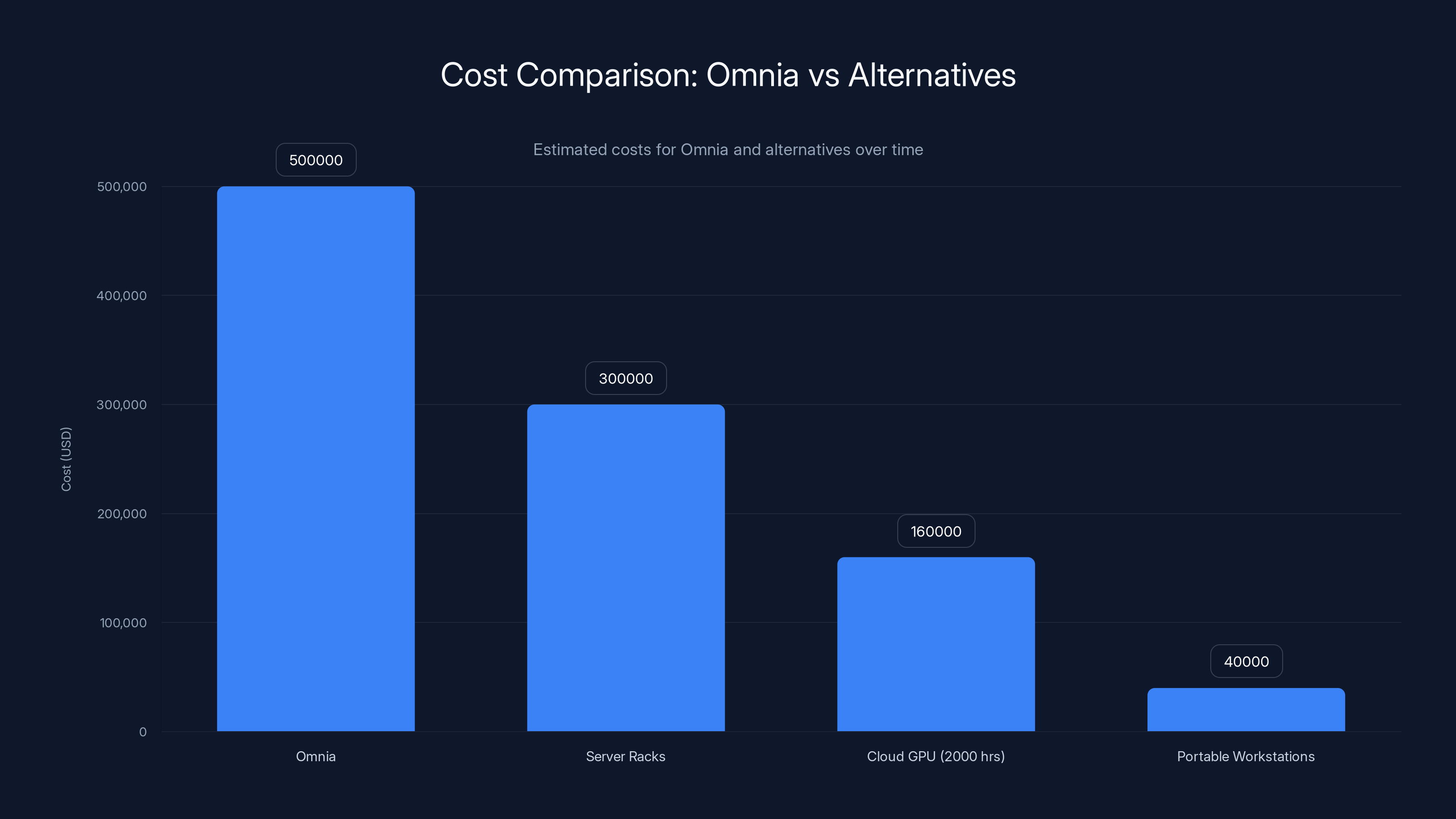
The Omnia, while initially more expensive, can become economical over time compared to cloud GPU costs. Estimated data.
Future Evolution: Where This Goes
The Omnia represents something interesting: proof that integrating data center-scale hardware into portable form factors is technically feasible.
Looking forward, expect generational improvements following standard semiconductor evolution. Better processors, higher-capacity GPUs with more VRAM, faster memory. The architecture Odinn established could continue with each generation, similar to how servers evolve.
The real question is pricing trajectory. As components become cheaper and manufacturing scales, could future Omnia configurations become more accessible? Probably not dramatically—the target market is fundamentally premium. But evolution would likely follow standard industry trends.
Another interesting direction: specialized versions. Maybe a lighter version trading maximum storage for reduced weight. A more compute-focused version optimized for AI without maximum storage. The baseline architecture could support variants.
Finally, ecosystem development. As more organizations have systems like the Omnia, software optimization for this specific hardware class would improve. Better use of 384 cores. Better GPU utilization. Better thermal management through software intelligence.
The Philosophy: Rejecting Constraints
Ultimately, the Odinn Omnia represents a philosophy: why accept constraints?
Traditional thinking says if you need serious computing power, you get a cloud subscription or a server rack. The Omnia rejects that. It says: build a complete system so powerful and self-contained that you can take it anywhere.
Yes, it's heavy. Yes, it costs substantial money. Yes, the electrical requirements are demanding. But it works, and it works in situations where cloud infrastructure isn't viable and server racks are impractical.
That's genuinely interesting from a technology perspective. Not every innovation needs to be consumer-focused. Not every breakthrough needs to democratize technology. Sometimes innovation means enabling edge cases and demanding specialized applications.
The Odinn Omnia is unflinchingly specialized. It's for researchers, for AI labs, for organizations with serious computational needs that can justify both the cost and the deployment complexity. It's not trying to be everything to everyone.
In a technology landscape obsessed with thin, light, and cheap, something powerful, heavy, and expensive is actually kind of refreshing.

Key Specifications at a Glance
Processors: Up to dual AMD EPYC 9965 processors (192 cores each, 384 total)
GPUs: Up to four Nvidia H200 NVL accelerators (141GB HBM3e memory each, 564GB total)
System RAM: Up to 6TB DDR5 ECC Registered
Storage: Up to 1PB NVMe SSD capacity
Network: Up to 400 Gbps throughput
Display: 24-inch 4K integrated monitor
Input: Flip-down keyboard
Cooling: Integrated liquid cooling
Power: Dual Platinum-rated PSUs (redundant)
Weight: Approximately 37kg (82 pounds)
Estimated Pricing: $500,000+ for fully loaded configuration
FAQ
What is the Odinn Omnia?
The Odinn Omnia is a high-performance, integrated computing system combining enterprise-grade components—dual AMD EPYC processors, four Nvidia H200 GPUs, 6TB of RAM, and up to 1PB of storage—into a single 37kg chassis with integrated display and keyboard. It's designed for organizations needing data center-scale computing power in a more portable, self-contained form factor than traditional server racks.
How does the Odinn Omnia achieve such high performance in a portable form factor?
The Omnia uses advanced thermal management (liquid cooling), redundant power supplies, and careful component integration to pack data center-grade hardware into a single chassis. It sacrifices some traditional "portability" (it's heavy) to maintain complete system integration and self-containment, making it suitable for deployment in locations where server racks are impractical.
What are the primary use cases for the Odinn Omnia?
Primary use cases include AI model training and fine-tuning, scientific computing simulations, large-scale data processing, real-time inference serving for large models, and research applications requiring high compute in non-traditional environments. It's positioned for research institutions, AI labs, and specialized computing facilities rather than typical business or consumer use.
How much does the Odinn Omnia cost?
Odinn hasn't officially confirmed pricing, but analysts estimate fully loaded configurations could approach or exceed $500,000 based on component costs. Actual pricing depends on specific configuration—which processors, how many GPUs, storage capacity, etc. Custom orders would be built to specification.
How does the Omnia's performance compare to cloud GPU computing?
Cloud GPU rental costs approximately
What is the difference between the Omnia's processors and typical server processors?
The Omnia uses AMD EPYC 9965 processors specifically designed for data centers. Each offers 192 cores and optimizations for parallel processing, memory bandwidth, and reliability. This differs dramatically from consumer processors (typically 8-24 cores) and even professional workstation processors (typically 32-128 cores). The EPYC design prioritizes core count and memory bandwidth over single-threaded performance.
How much electrical power does the Odinn Omnia require?
Estimated power consumption ranges from 10,000-15,000 watts for a fully loaded system under heavy computation. This requires dedicated high-amperage electrical infrastructure—standard building circuits cannot support this power draw. Comparative perspective: this approaches the power consumption of an entire household.
Can the Odinn Omnia be deployed remotely or in field locations?
Yes, that's a primary design motivation. The Omnia's complete self-containment means it can be relocated and deployed in research locations, field sites, or facilities without requiring data center infrastructure. It requires electrical power and network connectivity, but it doesn't depend on cloud services or remote infrastructure.
What networking capabilities does the Odinn Omnia provide?
The system supports up to 400 Gbps network throughput—data center-tier connectivity. This enables rapid data transfer, distributed computing scenarios, and AI model serving with minimal network latency. For most deployments, actual configurations would use 100 Gbps connections rather than the maximum 400 Gbps.
How does the Omnia compare to purchasing equivalent cloud GPU resources?
Cloud GPUs offer pay-as-you-go flexibility but accumulate costs with extended usage. Omnia ownership requires substantial upfront investment but provides unlimited usage at marginal power cost. The break-even point typically occurs within 1-2 years of heavy utilization, making ownership economical for organizations with sustained computational needs.

Conclusion: A Machine for Specific Problems
The Odinn Omnia won't change computing for most people. It's not trying to.
What it does is solve a genuinely specific problem: organizations that need data center power without data center infrastructure. Research labs that want portable computing facilities. AI companies that need specialized hardware on-site. Scientific teams analyzing massive datasets.
For those organizations, the Omnia is genuinely innovative. It's also undeniably weird. A 37kg chassis with carry handles containing a data center's worth of processors and memory doesn't fit conventional categories.
But that's the point. Not everything needs to be conventional.
The engineering required to integrate dual EPYC processors, four H200 GPUs, liquid cooling, redundant power supplies, and a complete display into a single portable system is legitimately impressive. The thermal management alone is non-trivial. The power distribution requires careful design. The cooling system must operate reliably in non-ideal environments.
Odinn built something that technically shouldn't work as a practical product but does. It's luggable computing evolved for the 2020s: not consumer-friendly, not mass-market, but genuinely useful for specialized high-performance computing applications.
Sometime in 2026, some research organization will buy an Omnia. They'll move it into a lab. They'll start running serious AI workloads. And they'll probably be impressed by what's possible when you reject conventional constraints.
That's the Odinn Omnia in a nutshell: a machine built because someone asked, "What if we stopped pretending portability and performance are mutually exclusive?" The answer cost around $500,000 and weighs 37 kilograms.
But it works.
Related Resources
For organizations exploring the Omnia or similar high-performance systems, consider evaluating your actual computational needs first. Determine whether the cost and complexity justify the investment compared to cloud alternatives. For teams managing complex deployments and automating workflows around computational systems, platforms that streamline deployment, monitoring, and documentation become increasingly valuable. Tools that help create reports, generate documentation, and automate deployment workflows can significantly reduce operational overhead when deploying specialized systems like the Omnia.
Use Case: Automate deployment documentation and system status reports for specialized computing infrastructure like high-performance clusters.
Try Runable For Free
Key Takeaways
- The Odinn Omnia packs dual AMD EPYC processors (384 cores), four Nvidia H200 GPUs, 6TB DDR5 RAM, and up to 1PB NVMe storage into a 37kg chassis
- H200 NVL GPUs with 141GB HBM3e memory per card provide 5x greater bandwidth than gaming GPUs, critical for AI model training and inference
- 400Gbps network throughput matches data center infrastructure, enabling rapid distributed computing and model serving
- Estimated 8-15/hour) over 2+ years of sustained usage
- Portability here means relocatable integration, not lightweight convenience—target markets are research labs, AI companies, and scientific institutions
Related Articles
- Olares One Mini PC: Desktop AI Power in Compact Form [2025]
- AMD Instinct MI500: CDNA 6 Architecture, HBM4E Memory & 2027 Timeline [2025]
- Lenovo Yoga Mini i 1L 11: Tiny Cylindrical PC with AI Copilot [2025]
- Lenovo ThinkPad X9 15p Aura Edition: Game-Changing Pro Laptop [2025]
- Asus Zenbook Duo 2026: Dual-Screen Laptop with Intel Panther Lake [2025]
- MSI Prestige 16 vs MacBook Pro: Battery Life, Weight & Performance [2025]

