![AMD Instinct MI500: CDNA 6 Architecture, HBM4E Memory & 2027 Timeline [2025]](https://tryrunable.com/blog/amd-instinct-mi500-cdna-6-architecture-hbm4e-memory-2027-tim/image-1-1767815018376.jpg)
The AI Hardware Acceleration Race Heats Up: AMD's MI500 Challenge
The artificial intelligence infrastructure market is moving at breakneck speed, and the stakes couldn't be higher. We're talking about billion-dollar decisions that determine whether companies can train models efficiently, deploy them at scale, or fall behind competitors. At the center of this arms race sits a fundamental question: who owns the next generation of AI hardware?
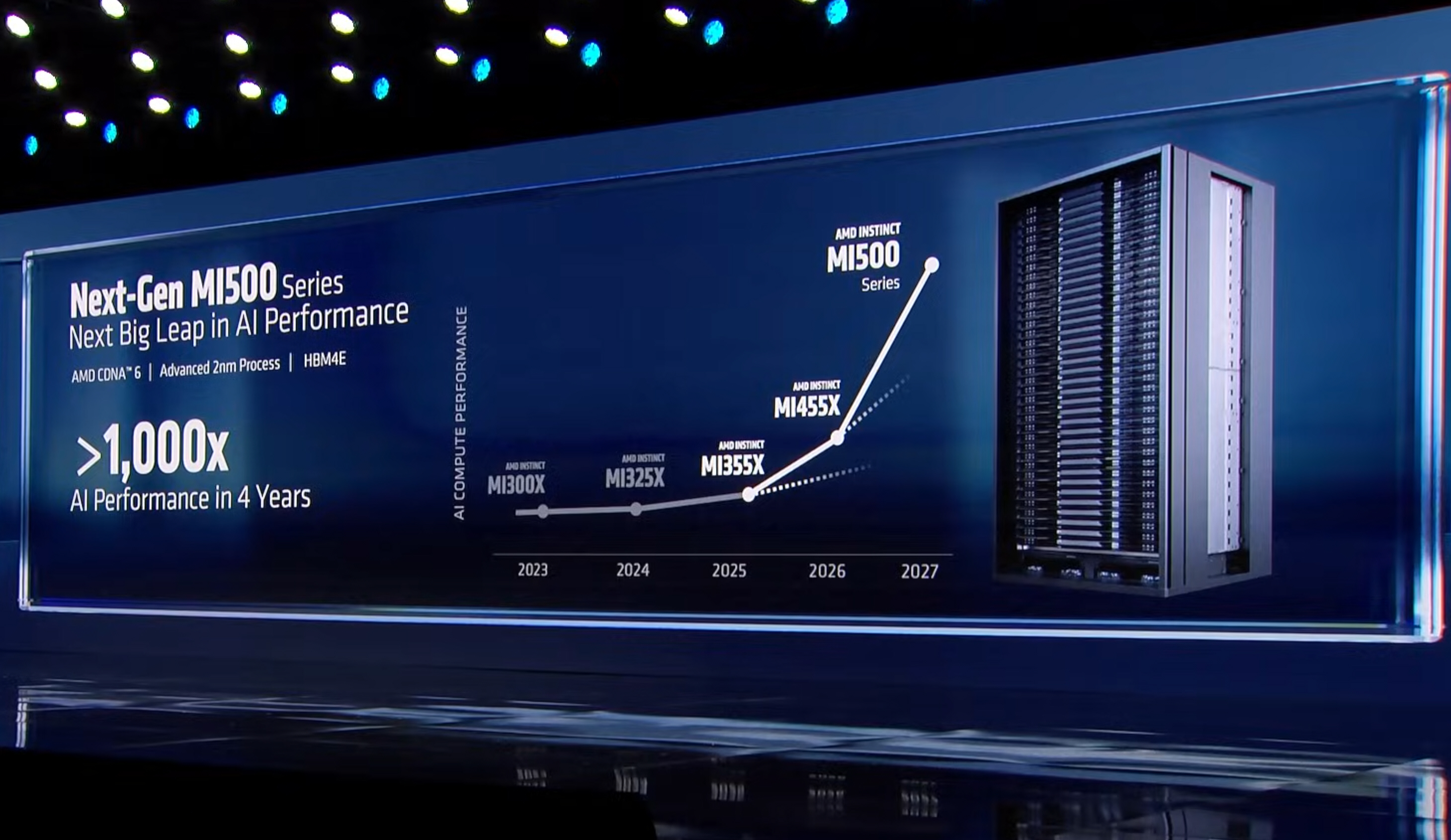
For years, Nvidia has dominated this space with overwhelming market share and an ecosystem advantage that's frankly hard to challenge. But AMD isn't backing down. At CES 2026, AMD pulled back the curtain on its ambitious timeline for next-generation AI accelerators, specifically the Instinct MI500 Series planned for 2027. The announcement was both impressive and sobering, revealing a company that's making serious engineering bets on the future while simultaneously acknowledging that Nvidia's Vera-Rubin platform will hit the market a full year earlier.
This timing gap matters tremendously. In AI hardware, a year is an eternity. It represents an entire generation of model training, refinement, and deployment. By the time AMD's MI500 arrives, Nvidia's Vera-Rubin ecosystem will already be entrenched in data centers worldwide, with optimized software stacks, established partnerships, and proven performance benchmarks.
But AMD's MI500 roadmap isn't without merit. The company is promising dramatic performance improvements over its current MI300X generation, built on a next-generation architecture that pushes memory bandwidth, compute density, and efficiency to new extremes. Let's dig into what AMD is actually building, why the timeline matters, and what this means for the broader AI infrastructure landscape.
TL; DR
- AMD MI500 launches in 2027: Built on CDNA 6 architecture, 2nm process, and HBM4E memory with expected 1,000x performance improvement over MI300X
- Nvidia moves first in 2026: Vera-Rubin platform ships mid-2026 with six new chips, NVSwitch fabric, and 10x cost reduction for Mo E model inference
- Memory bandwidth is critical: HBM4E promises substantially higher bandwidth than current HBM standards, addressing the memory bottleneck in modern LLMs
- Architecture matters: CDNA 6 represents a fundamental rethinking of compute density, cache hierarchy, and interconnect fabric compared to CDNA 5
- Ecosystem timing favors Nvidia: Earlier availability means software optimization, framework support, and customer deployments happen before MI500 even ships

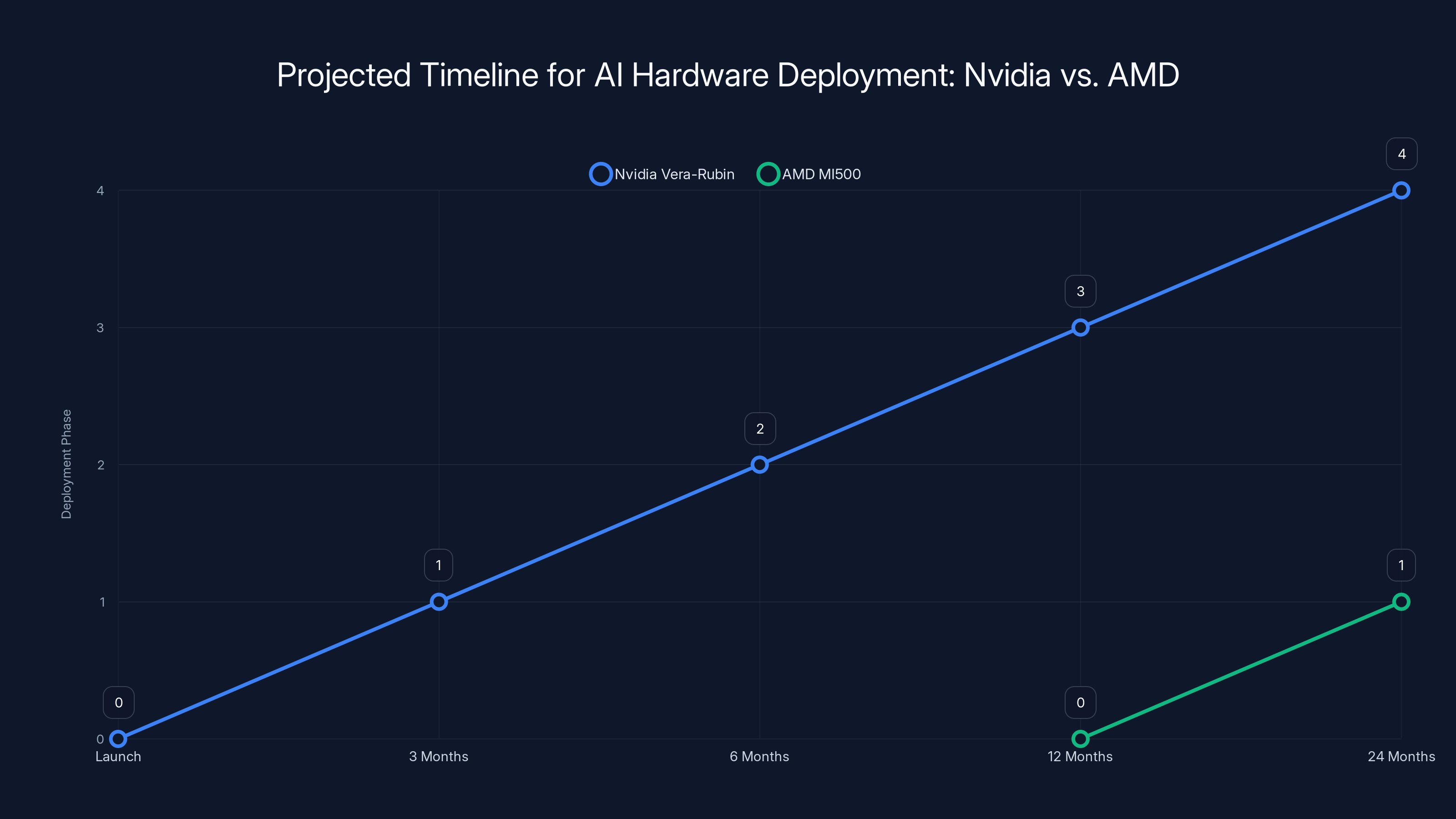
Nvidia's Vera-Rubin platform is projected to be fully integrated and optimized by the time AMD's MI500 launches, giving Nvidia a significant head start. Estimated data based on typical deployment phases.
Understanding AMD's Current MI300X Baseline
Before we can appreciate what AMD is promising with MI500, we need to understand where the company stands today with the MI300X generation. The MI300X isn't a failure by any means, but it represents the ceiling of current-generation CDNA 5 architecture married to HBM3E memory technology.
The MI300X delivers impressive raw performance numbers. Each GPU features 192 GB of HBM3E memory, providing bandwidth of around 5.3 TB/s. For certain workloads, particularly those that fit within the memory constraints, the MI300X performs admirably. We're talking about inference workloads where latency requirements are less demanding, or fine-tuning operations on moderately-sized models.
But here's where the limitations become apparent. Modern large language models like GPT-4 and Claude are pushing memory requirements to unprecedented scales. When you're running mixture-of-experts models with hundreds of billions of parameters, memory bandwidth becomes the bottleneck rather than compute throughput. Your GPUs are sitting idle, waiting for data to arrive from memory.
The MI300X also uses AMD's CDNA 5 architecture, which, while solid, hasn't closed the gap with Nvidia's H100 in many real-world scenarios. Software optimization is harder, the compiler ecosystem is smaller, and the ecosystem of pre-built models optimized for AMD is fractional compared to Nvidia's dominance.
AMD shipped MI300X systems in 2024, and we've seen limited enterprise adoption so far. Some cloud providers like Oracle and a few others have made public commitments, but the volume numbers remain small relative to Nvidia's scale. This context makes AMD's MI500 announcement both a correction and a bet on future market conditions.
The CDNA 6 Architecture: A Ground-Up Redesign
At the heart of AMD's MI500 sits CDNA 6 architecture, and this is where things get genuinely interesting. CDNA 6 isn't a minor iteration over CDNA 5. Based on AMD's communications, this represents a fundamental rethink of how to structure compute elements, memory hierarchies, and interconnect fabrics for modern AI workloads.
The specific architectural changes haven't been fully detailed yet, which is expected for a product two years out. But we can infer from industry patterns and AMD's public statements what areas likely saw the most significant engineering attention.
Compute Density and Block Structure
First, there's almost certainly been a re-optimization of compute block size and structure. CDNA 5 uses 64-core compute units with specific ratios of floating-point operations to memory operations. CDNA 6 likely adjusts these ratios specifically for modern transformer architectures. Matrix multiplication operations (matrix-matrix multiply for attention mechanisms) are probably getting dedicated hardware acceleration improvements, following the pattern Nvidia set with its Tensor Cores in recent generations.
The push toward smaller precision formats (FP8, FP6, and mixed-precision) is also embedded in hardware now. Rather than treating low-precision operations as an afterthought, CDNA 6 probably has dedicated execution paths for these formats, recognizing that most inference workloads don't need full FP32 precision and that quantization is becoming standard industry practice.
Cache Hierarchy Improvements
Second, the cache architecture is probably getting a significant overhaul. Modern AI inference is memory-bound, and the gap between compute speed and memory speed is the primary bottleneck. CDNA 6 likely features larger L2 caches and probably introduces new cache coherency mechanisms that are optimized for the access patterns typical in transformer inference.
Consider what happens during a typical attention operation in a language model. You're accessing weights in specific patterns that are somewhat predictable, but not identical to traditional high-performance computing workloads. A cache designed with this in mind can dramatically improve effective memory bandwidth without physically increasing bandwidth to off-chip memory.
Interconnect and Fabric Changes
Third, the interconnect between GPU chiplets and the rest of the system is probably getting redesigned. AMD will likely use improved versions of its Infinity Fabric, with higher bandwidth and lower latency connections between multiple MI500 GPUs. This matters because hyperscalers deploy these accelerators in large clusters. If you're running a model across 100 or 1,000 GPUs, the communication overhead between devices becomes a significant constraint.
The promise of 1,000x performance improvement over MI300X sounds hyperbolic until you realize it's probably not comparing apples to apples. It likely refers to specific workloads that are perfectly suited to the new architecture. For general-purpose AI workloads, expect improvements in the 30-50% range per generation, which is actually substantial but less sensational.

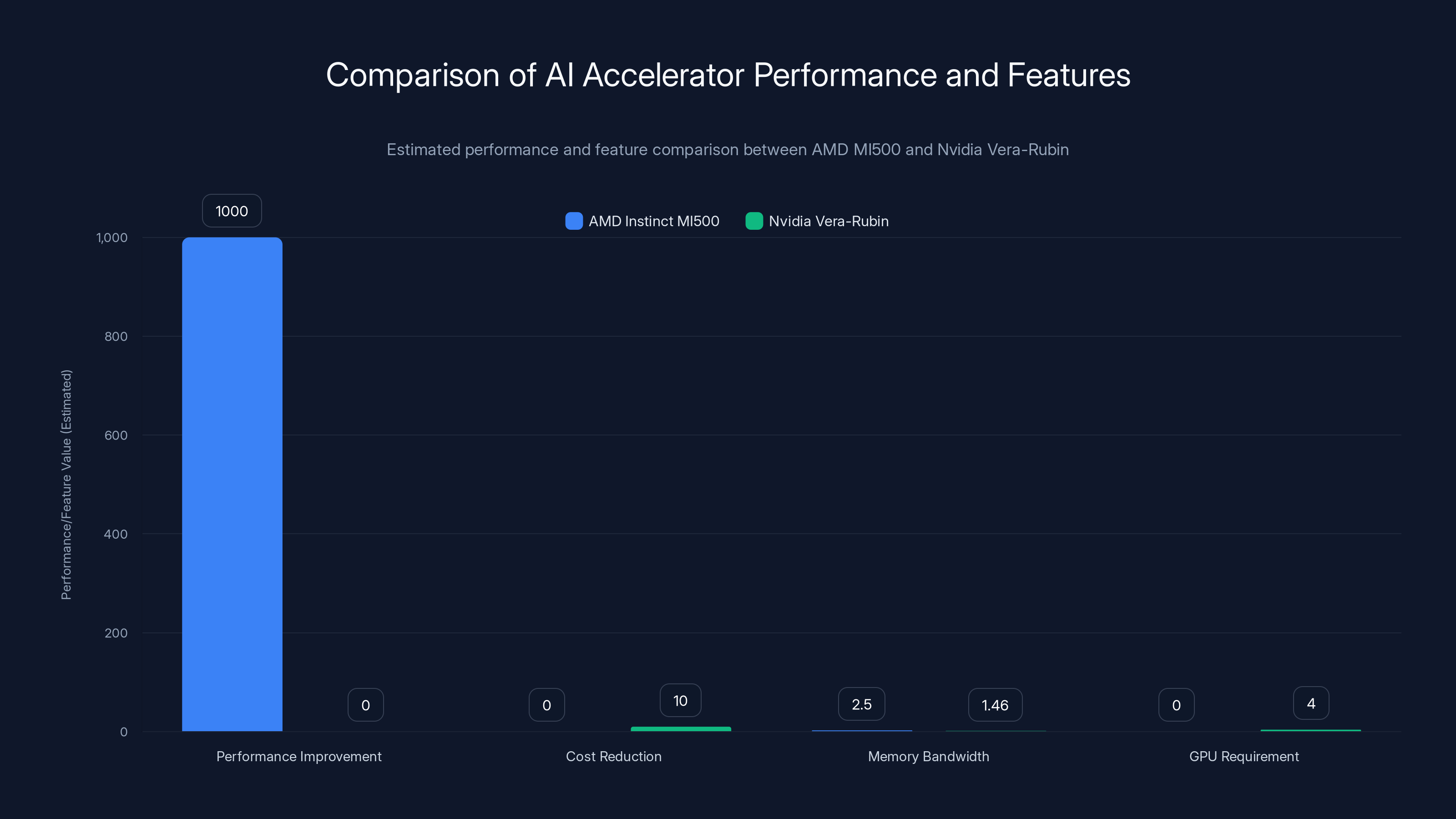
AMD's MI500 is projected to deliver up to 1,000x performance improvement in specific workloads, while Nvidia's Vera-Rubin offers significant cost and GPU requirement reductions. HBM4E memory in MI500 provides higher bandwidth.
HBM4E Memory: The Bandwidth Revolution
Perhaps the most tangible improvement coming with MI500 is the adoption of HBM4E memory. This is where AMD is making physics-based performance gains that don't require architectural wizardry.
JEDEC, the standards organization that defines memory specifications, has been progressing the HBM (High Bandwidth Memory) standards roughly every two years. HBM3 launched in 2022, HBM3E in 2024, and HBM4E is expected to arrive around 2026-2027, perfectly timed for AMD's MI500 launch.
Here's the physics: HBM memory uses a 3D stacking approach where multiple DRAM dies are stacked vertically and connected through thousands of microscopic copper through-silicon vias (TSVs). Each generation increases the stack height and the density of these connections, directly translating to higher bandwidth.
HBM3E Specifications (current generation in MI300X):
- Per-channel bandwidth: ~1.46 TB/s per channel
- Typical configuration: 12 channels per GPU
- Total bandwidth: ~17-18 TB/s per GPU
- Total capacity: 192 GB per GPU (typical)
HBM4E Specifications (expected for MI500):
- Per-channel bandwidth: ~2.5+ TB/s per channel (estimated)
- Typical configuration: Likely 12 channels per GPU
- Total bandwidth: ~30+ TB/s per GPU (estimated)
- Total capacity: 256-384 GB per GPU (estimated)
The math here is straightforward: if memory bandwidth doubles or nearly doubles, you can feed your compute units data twice as fast. For memory-bound workloads (which most AI inference is), this directly translates to throughput improvements.
The challenge, of course, is power consumption. Each HBM stack consumes power, and packing more memory bandwidth into the same physical space means higher power density. This is where the 2nm manufacturing process becomes critical.
The 2nm Process Technology Advantage
AMD's commitment to building MI500 on 2nm process technology (likely from TSMC) is absolutely central to making the memory bandwidth improvements viable. You can't just keep adding HBM stacks and higher bandwidth connections without dramatically increasing power consumption. The process technology is what makes it possible.
Process Node Benefits
Moving from 5nm to 2nm brings several advantages:
- Transistor Density: Roughly 2x improvement in transistor density, meaning you can fit more compute logic into the same physical space
- Power Efficiency: Transistors are more energy-efficient at smaller nodes, reducing leakage current and dynamic power consumption
- Clock Speed: Smaller transistors can switch faster, enabling higher clock speeds with the same power budget
- Memory Interface: The physical width of interconnects can be narrower, improving signal integrity and reducing power
For a product like MI500 where you're packing 256+ GB of HBM4E memory and massive compute arrays, the power efficiency improvements are what make the architecture feasible.
Consider the practical constraints: a data center has finite power density. If you want to deploy more performance per kilowatt, you need better efficiency per transistor. A 30% reduction in power consumption per unit performance (which is roughly what moving from 5nm to 2nm delivers) is the difference between a viable product and one that can't be economically deployed at scale.
Timeline Analysis: AMD vs. Nvidia's Race
Let's talk about the elephant in the room: timing. AMD is promising MI500 in 2027. Nvidia is shipping Vera-Rubin in the second half of 2026. That's a full calendar year advantage for Nvidia, and in AI infrastructure, that's an enormous gap.
Why Timing Matters in AI Hardware
When a new GPU generation launches, several things happen in sequence:
- Months 1-3: Engineering teams at cloud providers and hyperscalers integrate the hardware, build out clusters, and begin benchmarking
- Months 3-6: Software optimization begins. CUDA frameworks, libraries, compilers get tuned. Inference engines get optimized.
- Months 6-12: Customer applications start migrating to the new hardware. Teams rewrite their inference pipelines.
- Year 2+: The ecosystem solidifies. There's extensive documentation, proven best practices, and performance benchmarks.
By the time AMD's MI500 ships in 2027, Nvidia will have already completed steps 1-2 and be well into step 3. Vera-Rubin systems will have been in production for 12+ months. The software ecosystem will be optimized. Cloud providers will have published reference architectures.
This creates a compound advantage for Nvidia that's difficult to overcome.
Nvidia's Vera-Rubin Platform
To understand the severity of this timing gap, let's look at what Nvidia is actually shipping. Vera-Rubin isn't just a GPU. It's a complete rack-scale platform consisting of six specialized components:
- Vera CPU: Specialized processor for control and coordination
- Rubin GPU: The workhorse accelerator for compute
- NVLink 6 Switch: High-speed fabric for connecting components
- Connect X-9 Super NIC: Network interface optimized for AI infrastructure
- Blue Field-4 DPU: Data Processing Unit for network offloading
- Spectrum-6 Ethernet Switch: Top-of-rack networking
This is different from AMD's approach. AMD is primarily focused on the GPU itself and how it connects to CPUs and networks. Nvidia is designing the entire system as an integrated unit, which is a different engineering challenge but potentially offers tighter optimization.
The NVL72 configuration specifically combines 72 Rubin GPUs and 36 Vera CPUs in a single shared-memory system. This is a fundamental architectural difference. Everything in the system can directly access everything else without explicit data copying. For distributed AI training, this is incredibly powerful.
Nvidia claims Vera-Rubin provides 10x cost reduction for mixture-of-experts model inference compared to current generation systems, and reduces the number of GPUs needed for training by 4x. These aren't negligible improvements.
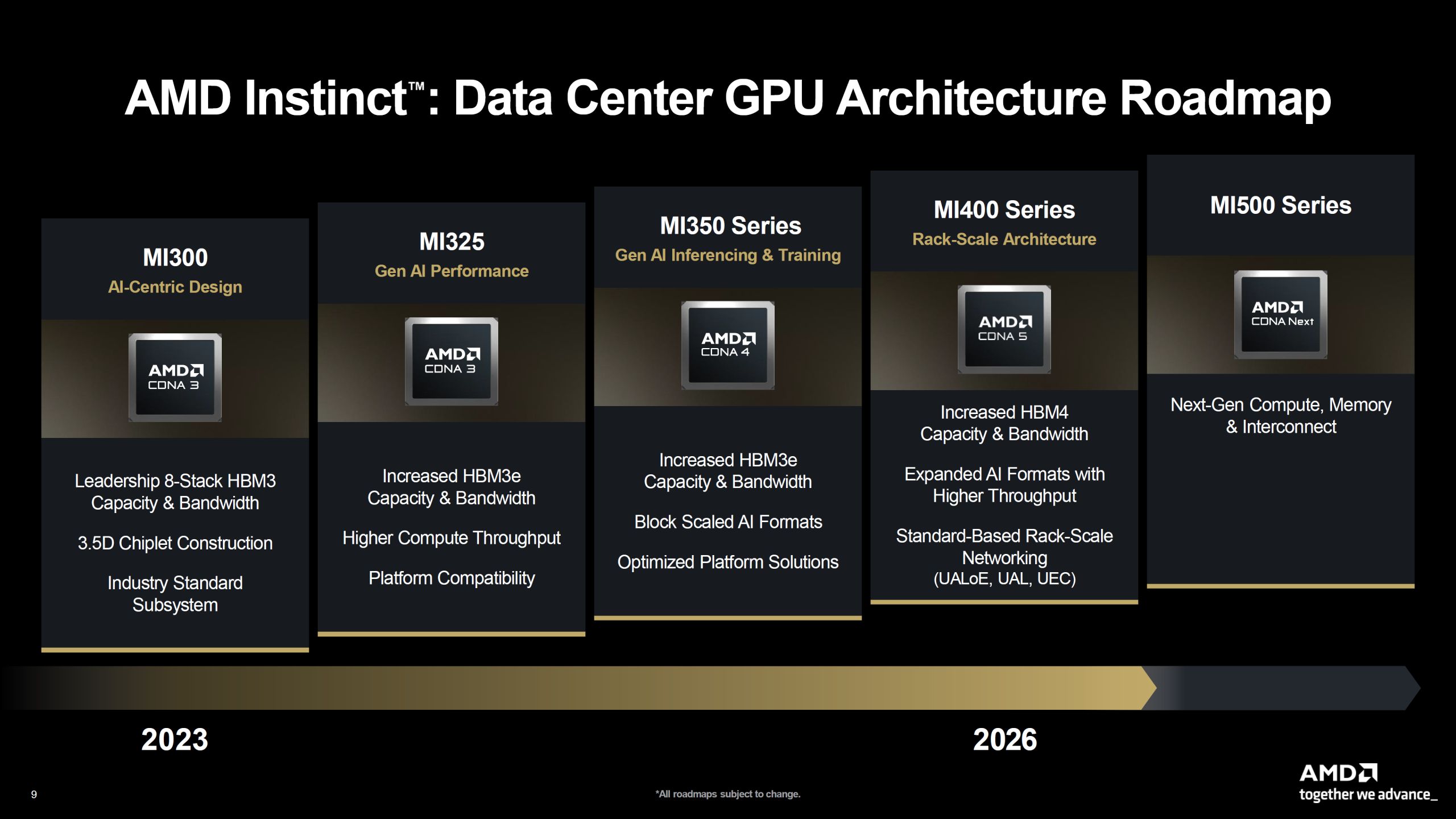
AMD's Response Strategy
AMD isn't ignoring the timing problem. The company announced the Instinct MI440X as a near-term product to maintain relevance while waiting for MI500. MI440X is positioned as an on-premises enterprise solution, aimed at organizations that want to maintain existing investments in their data center infrastructure.
The strategy is reasonable but faces challenges. MI440X is based on MI300X-derived technology, which means it's inherently competing with Vera-Rubin while being architecturally behind. Nvidia can position Vera-Rubin as a massive leap forward, while MI440X looks like an incremental step. That messaging advantage is real.
AMD also introduced Helios, a rack-scale platform based on MI455X GPUs and EPYC Venice CPUs. Helios is positioned as a blueprint rather than a finished product, AMD's way of saying "look, we understand system-level optimization too." But blueprints don't run inference workloads. Shipping products do.
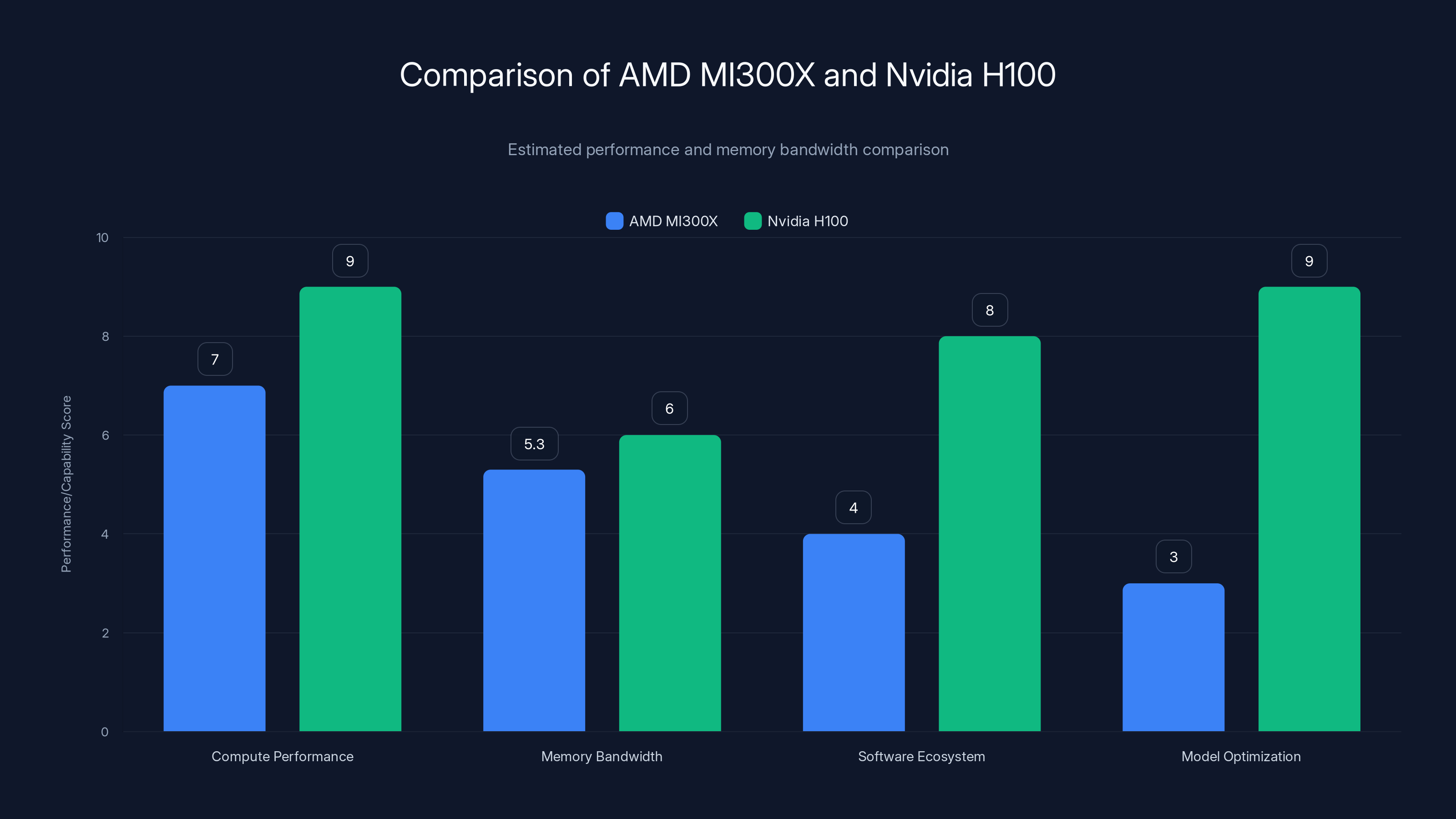
The Nvidia H100 outperforms the AMD MI300X in compute performance and software ecosystem support, while the MI300X shows competitive memory bandwidth. Estimated data based on current architecture insights.
The Broader AI Infrastructure Ecosystem
To really understand the stakes here, you need to zoom out and see how AMD's timeline interacts with the broader ecosystem of AI infrastructure companies.
Cloud Provider Commitments
Google Cloud, Microsoft Azure, and AWS have all publicly committed to supporting multiple accelerator vendors. In principle, this creates an opportunity for AMD. In practice, the engineering cost of supporting multiple hardware platforms is enormous.
For cloud providers, supporting Nvidia means integrating with CUDA ecosystem, Nvidia libraries, and Nvidia's software stack. Supporting AMD means doing the same thing for ROCm ecosystem, AMD libraries, and so on. When one vendor has 85% of the market, it's economically rational to invest most heavily in that vendor.
Cloud providers are slowly diversifying, partly due to Nvidia pricing power and partly due to real concern about dependency. But this happens at the margins. By the time MI500 ships, the economic gravity will have shifted further toward Nvidia if Vera-Rubin is genuinely superior.
Custom Silicon and Alternatives
There's also the wild card of custom silicon. Companies like Google with TPUs, Apple with Neural Engine, and various startups building specialized inference chips are nibbling away at the market. These won't displace Nvidia completely, but they create additional competition for AMD's attention.
Mostly, though, the market remains a two-horse race between Nvidia and AMD, with Nvidia holding overwhelming advantage.

Memory Architecture Deep Dive: HBM4E vs. Traditional GDDR
One dimension where AMD's MI500 will have an absolute advantage over consumer and some data center Nvidia products is the memory type. MI500 will use HBM4E. Some Nvidia solutions still use GDDR memory or older HBM standards.
Here's why this matters technically:
Bandwidth Comparison
GDDR6X memory (used in some Nvidia GeForce RTX products) provides about 960 GB/s of bandwidth per GPU. HBM3E provides 1,456 GB/s. HBM4E will provide an estimated 2,400+ GB/s.
That's a 2.5x difference between GDDR and HBM4E. In absolute terms, it's the difference between:
- Running a 70B parameter model at reasonable batch sizes (with HBM4E)
- Running it at severely reduced batch sizes or needing to shard across multiple GPUs (with GDDR)
Power Efficiency
HBM memory is also more power-efficient than GDDR for high-bandwidth access patterns because:
- Shorter signal paths mean less power per bit transferred
- Fewer IO pins for the same bandwidth
- Better integration with compute logic
For a data center operator running inference 24/7, power efficiency directly translates to operational costs.
Capacity Scaling
HBM4E will support substantially higher capacity per GPU. We're talking about potentially 384 GB per GPU vs. current 192 GB. This matters because it means you can fit larger models on individual GPUs without resorting to model sharding, which adds communication overhead.
The equation is:
Larger per-GPU capacity reduces sharding overhead, improving the denominator and therefore throughput.
Manufacturing and Supply Chain Realities
AMD's commitment to 2nm with TSMC is credible, but it's worth acknowledging the manufacturing realities and risks.
TSMC Capacity and Constraints
TSMC is ramping 2nm manufacturing in 2025-2026, with meaningful volume expected in 2027-2028. MI500 launch in 2027 is achievable, but early supply will likely be constrained. AMD will compete with Apple, Qualcomm, and others for capacity.
This means even if MI500 performance is superior, availability constraints might prevent AMD from capturing significant market share in early 2027. Nvidia, meanwhile, will have Vera-Rubin in volume production with likely better TSMC allocation.
Cost Structure
2nm wafers are expensive, and the economics are challenging. A MI500 GPU will cost more to manufacture than a MI300X, which will be reflected in pricing. If AMD prices MI500 competitively with Vera-Rubin, margins are thin. If AMD prices for margin, they lose customers to price-sensitive markets.
This is less of an issue for Nvidia, which can use its market dominance to justify premium pricing.
Risk and Yield
New manufacturing processes have yield challenges. Nvidia's Vera-Rubin is probably on established 5nm or slightly more advanced nodes. AMD's 2nm bet is higher risk. If yields are below expectations, MI500 could face production problems or higher costs than planned.
The upside is that 2nm offers genuine technical advantages. The downside is execution risk is real.

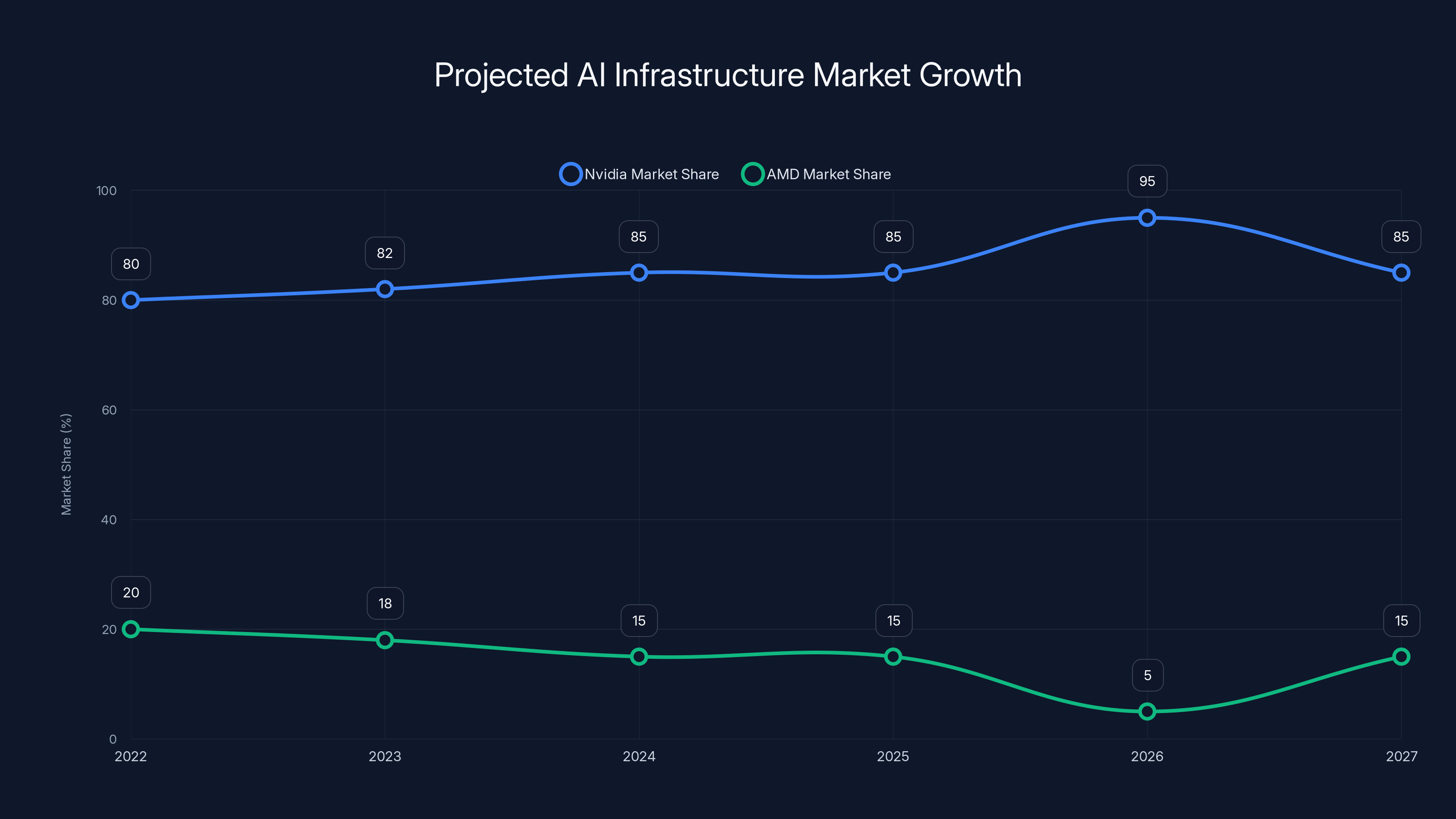
Nvidia's market share in AI infrastructure is projected to peak at 95% in 2026 before slightly decreasing as AMD's MI500 enters the market in 2027. Estimated data.
Performance Projections and Reality Checks
AMD claims MI500 will deliver up to 1,000x performance improvement over MI300X. Let's break this down honestly.
Compute Performance Scaling
From a pure compute throughput perspective, we might expect 2-3x improvement over two generations of architecture plus process technology improvements. That accounts for:
- Density improvements from 5nm to 2nm: ~1.5x
- Architecture efficiency improvements: ~1.3x
- Combined: ~2x
Memory Bandwidth Scaling
Memory bandwidth improvements from HBM3E to HBM4E represent another 1.6-1.8x improvement. So combined with compute, we're at roughly 3-4x overall.
Workload-Specific Gains
The 1,000x claim is likely cherry-picking a specific workload where MI500's architecture is particularly well-suited. For example, a small-batch inference workload with specific tensor dimensions might see dramatic throughput improvements from improved memory hierarchies and cache design.
For general-purpose workloads, expect 3-4x overall improvement.
For memory-bandwidth-limited workloads (most inference), expect 1.6-2x improvement primarily from HBM4E.
For compute-limited workloads (some training scenarios), expect 2-3x improvement.
These are substantial improvements but far short of the 1,000x claim.
Competitive Landscape: Who's Actually Competing?
Let's map out who's in this race and where they stand:
Nvidia Vera-Rubin: Ships mid-2026. Proven ecosystem. Massive software advantage. Clear path to volume production.
AMD MI500: Ships 2027. Credible architecture. HBM4E advantage. Smaller ecosystem. Supply risk.
Intel Arc A-series: Still ramping. Limited adoption. Significant ecosystem gap. Unlikely to be competitive in this timeframe.
Custom Silicon: Google TPUs, Amazon Trainium, etc. Competitive for specific use cases. Won't displace Nvidia at scale.
Really, this is a two-player game, and player one has overwhelming advantage at kickoff.

Enterprise Adoption Considerations
For enterprise customers making purchasing decisions today, the MI500/Vera-Rubin timeline creates specific strategic considerations.
Short-term (2025-2026): Enterprises deploying AI infrastructure now must choose between MI300X and Nvidia alternatives (A40, A100, H100, etc.). MI300X is viable for specific use cases but requires more software engineering work.
Medium-term (2026-2027): Vera-Rubin ships. Enterprises that waited benefit from early availability and ecosystem maturity. Those that committed to MI300X are stuck with an older generation.
Long-term (2027+): MI500 ships, but the installed base of Vera-Rubin is substantial. Enterprises rarely rip-and-replace hardware. MI500 competes for new capacity additions but struggles to dislodge Vera-Rubin that's already proven in production.
This creates a challenging situation for AMD. The company needs enterprises to take a leap of faith on MI500 before it's proven, while competitors are shipping proven alternatives.
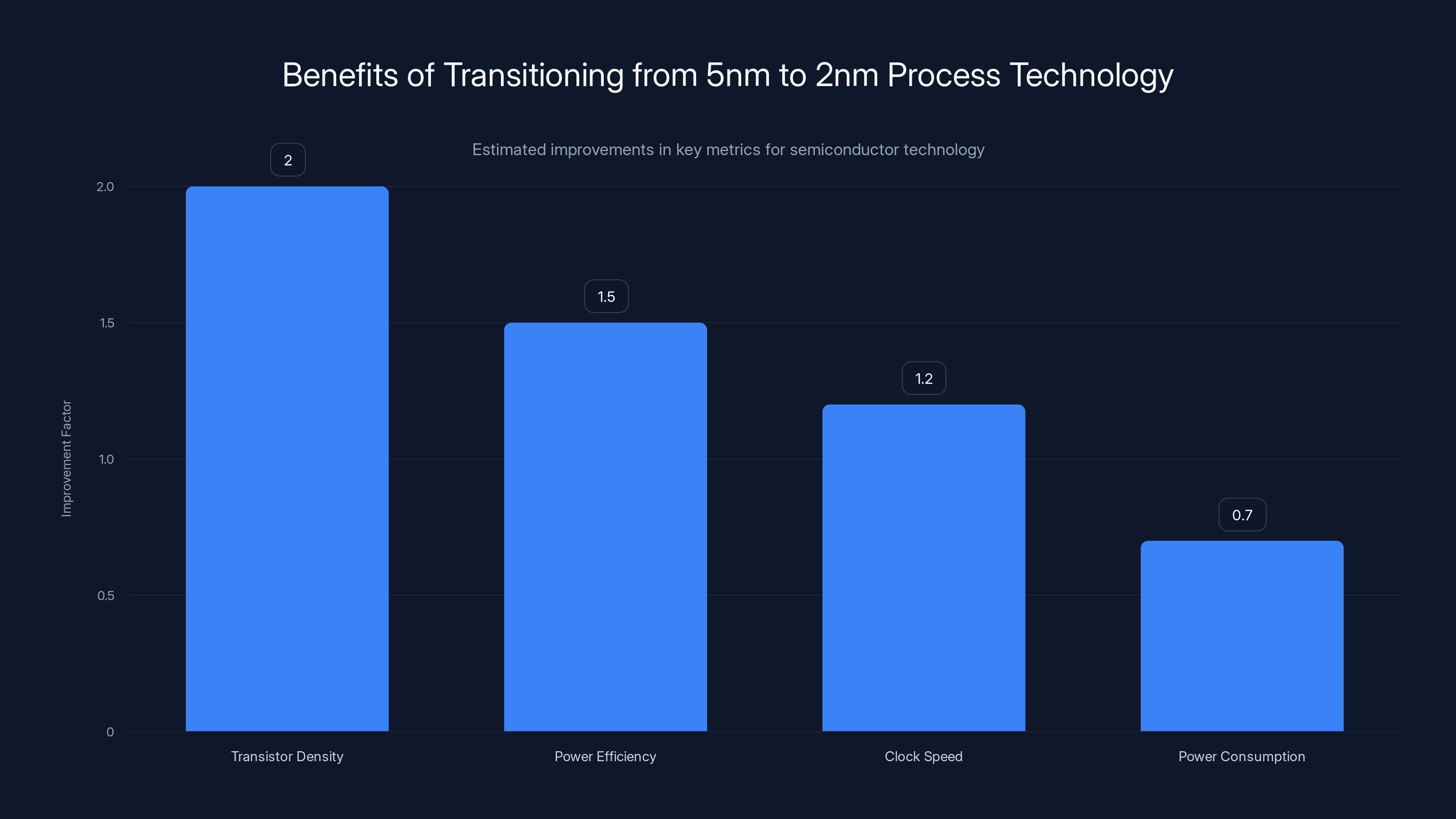
Transitioning from 5nm to 2nm technology roughly doubles transistor density and improves power efficiency by 50%, while reducing power consumption by 30%. (Estimated data)
Software Ecosystem and Developer Adoption
One advantage AMD's MI500 could theoretically have is timing for software optimization. By 2027, the ROCm ecosystem might have matured significantly.
Today, ROCm is functional but lags CUDA in:
- Library coverage and optimization
- Developer familiarity
- Third-party framework support
- Documentation quality
Two more years of development could help, but CUDA will also advance. Nvidia invests heavily in software. By 2027, CUDA will have had two more years of optimization for Vera-Rubin and newer workloads.
The fundamental problem for AMD is that software optimization is a compounding advantage. Nvidia has more developers writing CUDA code, finding optimization techniques, publishing best practices. This compounds over time.
AMD could theoretically overcome this with aggressive developer outreach and tooling investment between now and 2027. But that's a bet against historical patterns.
Power Efficiency and TCO Calculations
Where AMD might genuinely compete is power efficiency and total cost of ownership. MI500's 2nm process and HBM4E memory could deliver genuine power efficiency advantages over older Nvidia generations.
TCO Formula for Data Centers
In this equation:
- Hardware cost slightly favors Nvidia (volume discount, market maturity)
- Power consumption slightly favors MI500 (2nm advantage, HBM4E efficiency)
- Cooling favors MI500 (lower power means lower cooling requirements)
- Support favors Nvidia (larger ecosystem)
Overall, the equation probably favors Nvidia, but perhaps by a smaller margin than raw performance metrics suggest. For enterprises sensitive to power costs (particularly those in regions with high electricity prices), MI500 could be competitive.
The Helios Strategy and Rack-Scale Thinking
AMD's Helios platform deserves more analysis because it represents the company's thinking about system-level integration. Rather than just shipping a GPU, AMD is designing the whole rack.
Helios combines:
- MI455X GPUs (note: not MI500, but current generation)
- EPYC Venice CPUs
- Optimized interconnect fabric
- System-level memory hierarchy
The idea is that by designing the entire rack as a system, AMD can achieve better performance than customers building their own clusters with discrete components. This is similar to what Nvidia is doing with Vera-Rubin.
But here's the catch: Helios is described as a "blueprint" rather than a shipping product. This means customers can't immediately order Helios systems. AMD is potentially sharing designs with system integrators like HPE, Dell, and others who will build and sell systems based on it.
This is a reasonable strategy (it avoids AMD getting into the systems business), but it's slower and less direct than Nvidia's approach of having partners like NVIDIA directly sell Vera-Rubin systems.
By the time Helios-based systems are available from multiple vendors in volume, Vera-Rubin will already be in production with Supermicro, Inspur, and others.

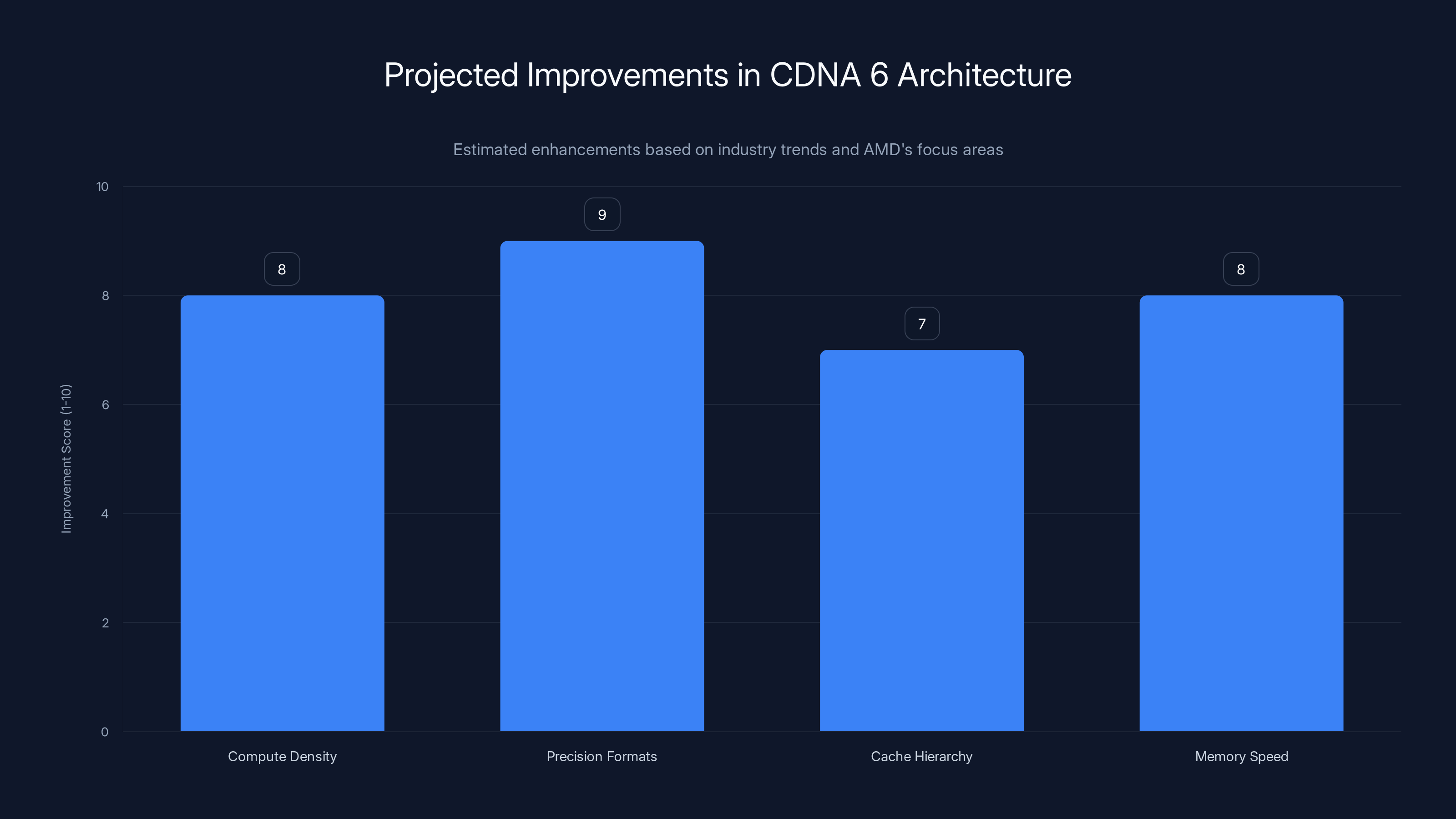
Estimated data suggests CDNA 6 will significantly enhance compute density, precision format handling, and cache hierarchy, aligning with industry trends for AI workloads.
Looking at MI440X: The Stopgap Solution
AMD's MI440X announcement shows the company understands the timing problem and is trying to maintain relevance while waiting for MI500. MI440X is built on MI455X GPU technology (similar to MI300X but with some enhancements) and positioned specifically for enterprise on-premises deployments.
The idea: enterprises that want to avoid expensive data center upgrades can deploy MI440X into their existing eight-GPU infrastructure. This is a clever positioning that acknowledges the reality that enterprises have existing hardware commitments and budgets.
But MI440X is also a defensive play. It's not creating new demand; it's trying to prevent customers from switching to Nvidia alternatives. For new, greenfield deployments, MI440X has to compete with both Vera-Rubin (superior performance) and existing MI300X (lower cost).
As a business strategy, it's reasonable. As a growth driver, it's limited.
The Vera-Rubin Technical Details Worth Understanding
To really appreciate the challenge AMD faces, let's dig into what Nvidia is actually shipping with Vera-Rubin.
The Rubin GPU Architecture
Rubin GPUs use eight stacks of HBM4 memory (vs. HBM4E that AMD is promising, but still impressive). Each Rubin GPU has a new Transformer Engine with hardware-supported adaptive compression. This compression is crucial because it lets Nvidia run larger models through the same GPU by transparently compressing data without affecting model accuracy.
Adaptive compression works by analyzing data patterns at runtime and applying the most efficient compression algorithm. During inference, this is particularly powerful because you're doing the same compute patterns repeatedly, so the compression opportunities are predictable.
NVLink 6 and Fabric Optimization
The interconnect between Rubin GPUs and Vera CPUs uses NVLink 6, Nvidia's updated high-speed interconnect. This is faster and lower-latency than previous generations. For models distributed across multiple GPUs, fabric latency is often as important as link bandwidth.
Nvidia's tight integration of the fabric into the overall system design is something AMD will have to match with equivalent Infinity Fabric improvements.
System Coherency
The shared-memory system architecture (where all 72 Rubin GPUs and 36 Vera CPUs can directly access the same memory space) is a subtle but significant advantage. Traditional systems require explicit data movement between GPU and CPU memory spaces. Vera-Rubin eliminates this, reducing code complexity and communication overhead.
This is an architectural choice that's hard to retrofit. It requires careful system design from the ground up.

Market Timing and the Cost of Being Late
There's an economic principle that applies directly to this situation: in fast-growing markets with network effects, being first matters disproportionately.
The AI infrastructure market is growing at 40-50% annually. If Nvidia captures 95% of 2026 growth (Vera-Rubin dominance) and 85% of 2027 growth (when MI500 ships), the compounding effect is enormous. Vera-Rubin's installed base becomes so large that enterprises optimize software for it, developing expertise around it, building infrastructure dependencies on it.
By the time MI500 ships, Nvidia's advantage isn't just performance or features. It's ecosystem, software maturity, expert availability, and installed base momentum.
For AMD to overcome this, MI500 would need to be demonstrably superior by some large margin. 30-50% performance improvement is significant but probably not enough to convince enterprises to rip-and-replace working Vera-Rubin systems or delay Vera-Rubin deployments for speculative MI500 promises.
What Success Looks Like for AMD
Let's be realistic about what represents success for AMD's MI500 in 2027.
Conservative scenario (20-30% market share capture): MI500 ships, is competitive with Vera-Rubin in performance, and gains adoption in:
- Chinese market (where supply chain alternatives to US companies matter politically)
- Power-sensitive data centers (where efficiency advantages matter)
- Companies with existing AMD investments
- Greenfield deployments that can afford to wait
This scenario still leaves Nvidia with 70-80% market share but represents meaningful progress for AMD.
Aggressive scenario (40-50% market share capture): MI500 significantly outperforms Vera-Rubin (unlikely given the one-year head start), or a major market dynamic shifts (unlikely but possible), or Vera-Rubin faces production problems (possible but not expected). This would require multiple things to go right for AMD and wrong for Nvidia.
Realistic scenario (10-20% market share capture): Despite competitive performance, market inertia favors Nvidia. Vera-Rubin's head start and ecosystem advantage prove decisive. AMD gains share in specific niches but doesn't fundamentally challenge Nvidia's dominance.
Historically, AMD has struggled to gain significant share against entrenched Nvidia positions despite competitive products. The fundamental dynamics haven't changed, which suggests the realistic scenario is most likely.

The Importance of Ecosystem Maturity
One dimension worth emphasizing: ecosystem maturity isn't just nice-to-have, it's often decisive.
Consider the state of ROCm versus CUDA today. CUDA has:
- 20+ years of optimization
- Thousands of pre-built libraries
- Millions of developers with expertise
- Deep integration with every major deep learning framework
- Extensive documentation and tutorials
- Tools, debuggers, and profilers that are mature
ROCm has:
- Growing but still limited library coverage
- Smaller developer community
- Good but incomplete framework support
- Improving but still less mature tools
By 2027, ROCm will have improved significantly. But CUDA will also have improved. The delta might be smaller, but Nvidia's lead is almost certainly preserved.
For AMD to win on ecosystem, the company would need to:
- Dramatically accelerate ROCm development (possible)
- Convince major framework maintainers to optimize more aggressively for ROCm (hard)
- Attract developers to learn and use ROCm when CUDA is dominant (requires incentives)
None of these are impossible, but all require execution at higher speeds than historical patterns suggest.
Process Technology Reality Check
While AMD's 2nm commitment is impressive, it's worth understanding the risks and realities.
TSMC's Capacity
TSMC has announced 2nm capacity in 2025 with meaningful scaling in 2026-2027. But TSMC's most advanced node capacity is always constrained. Apple, Qualcomm, Nvidia, AMD, and others are competing for access.
Historically, Nvidia has strong TSMC relationships and gets priority allocation. AMD might face capacity constraints that limit MI500 production even if the product is superior.
Cost Trade-offs
2nm wafers cost roughly 20-30% more than 5nm. For a high-end product like MI500, this is manageable. But if AMD needs to price aggressively to gain market share, the higher manufacturing cost eats into margins.
Yield Uncertainty
New process nodes always have yield challenges in early production. TSMC is good at managing this, but yield on 2nm won't immediately match 5nm yields. This means initial MI500 production will be smaller than planned and cost higher than expected.
Nvidia, meanwhile, is using more mature process nodes (5nm or similar) with proven yields. This gives Nvidia a production cost advantage that could persist for years.
The Customer Perspective: Why This Matters
Let's zoom out and think about this from a customer perspective. You're a major cloud provider or enterprise considering infrastructure investments in late 2026 and early 2027.
Scenario 1: Deploy Vera-Rubin in 2026
- Proven product in market
- Software ecosystem mature
- Reference architectures published
- Vendor support established
- Immediate deployment timeline
- Future upgrade path to next-gen Nvidia
Scenario 2: Wait for MI500 in 2027
- Speculative performance claims
- Software ecosystem still maturing
- First-customer problems likely
- Marketing claims unproven
- Delayed deployment timeline
- Risk of supply constraints
Rationally, most customers choose Scenario 1. The risk-adjusted value proposition favors the proven alternative.
AMD would need to convince customers that the performance advantage is so large that waiting a year and accepting higher risk is justified. Based on current information, that's a hard sell.
Long-term Competitive Dynamics
Zooming out to a 5-year horizon, what does the competitive landscape look like?
Assuming Vera-Rubin succeeds commercially (baseline expectation), Nvidia will ship next-generation platforms in 2028-2029. AMD's MI500, having launched in 2027, will be one generation behind again.
This pattern could perpetuate: Nvidia ships first, establishes ecosystem dominance, and AMD chases one generation behind. The technology gap might narrow over time, but market dynamics mean Nvidia maintains leadership.
For AMD to break this cycle, the company would need either:
- Superior technology two generations ahead (unlikely, both companies are pushing physics limits)
- Massive software ecosystem investment (requires sustained multi-billion-dollar commitment)
- Supply chain advantage (possible if Nvidia faces manufacturing constraints)
- Geopolitical tailwinds (possible, US government restrictions on Nvidia sales to China creates opportunities)
- Price competition at scale (viable if manufacturing costs drop faster for AMD)
Among these, the geopolitical angle is probably most realistic. The US government's restrictions on Nvidia sales to China and various other markets create genuine opportunities for AMD. Chinese cloud providers and tech companies might have no choice but to use AMD if Nvidia is restricted.
But this represents market share in specific geographies, not broad global dominance.

AMD's Strengths and Advantages
To be fair, AMD isn't starting from zero. The company has real advantages:
Manufacturing Relationship: AMD's relationship with TSMC is strong and long-standing. The company has proven ability to execute on advanced process nodes.
CPU Integration: With EPYC Venice and next-generation Zen CPUs, AMD can design tightly integrated systems that combine CPU and GPU performance. This is an advantage over Nvidia's CPU-GPU separation model.
Price Positioning: AMD could potentially price MI500 more aggressively than Nvidia prices competing products. This won't win on performance, but could win on value.
Open Ecosystem: ROCm is more open than CUDA in certain respects. For organizations building custom stacks, this can be an advantage.
Enterprise Relationships: Some large enterprises have existing AMD relationships and commitments. These customers might be predisposed to AMD solutions.
These advantages are real but not decisive against Nvidia's market dominance and ecosystem advantage.
Investment Thesis and Risk Factors
For investors evaluating AMD versus Nvidia based on MI500 prospects, key risk factors include:
AMD Risks:
- Later market arrival (one year)
- Smaller ecosystem and software maturity gap
- Supply chain constraints on 2nm capacity
- Unproven architecture at scale
- Possible yield issues on 2nm
- Difficult pricing dynamics (can't compete on performance, can only compete on price)
Nvidia Risks:
- Antitrust scrutiny (small probability, but real)
- Overconfidence leading to Vera-Rubin missteps (low probability, Nvidia executes well)
- Geopolitical restrictions on China sales (real but already priced in)
- Alternative custom silicon from cloud providers (limited impact)
- Supply constraints (low probability, Nvidia has TSMC priority)
On a risk-adjusted basis, Nvidia remains the lower-risk investment for 2026-2027. AMD MI500 is a reasonable bet for 2027+ upside, but current momentum and ecosystem advantages favor Nvidia.

Conclusion: Managing Expectations
AMD's MI500 announcement is genuinely impressive from a technical standpoint. CDNA 6 architecture, 2nm manufacturing, and HBM4E memory represent serious engineering work. The company is making real bets on next-generation technology.
But impressive technology doesn't always win in the market. Market timing, ecosystem maturity, and competitive positioning matter enormously. On these dimensions, Nvidia's Vera-Rubin has significant advantages despite being first to market.
For customers and investors, the realistic expectation is that MI500 will be competitive but won't dislodge Vera-Rubin from market leadership. AMD will gain share in specific use cases and geographies, but Nvidia's dominance persists.
For AMD shareholders, MI500 success (defined as meaningful share gains and competitive positioning) is the company's best shot at challenging Nvidia in the current business cycle. If MI500 underperforms expectations or misses timelines, the company's prospects in AI infrastructure become dimmer.
The 2027 launch is credible and achievable. The technology is credible. But the market dynamics are stacked against AMD, and no amount of superior engineering can fully overcome that without corresponding software ecosystem and business execution advantages.
AMD executives publicly acknowledge that they're taking the long view on AI infrastructure, recognizing that 2027 doesn't solve the competitive challenge but represents necessary progress. That's honest strategic thinking. Now the company needs to execute the engineering and ecosystem building work to back it up.
FAQ
What is the AMD Instinct MI500?
The AMD Instinct MI500 is a next-generation AI accelerator planned for launch in 2027, built on AMD's CDNA 6 architecture with 2nm manufacturing and HBM4E memory. AMD claims it will deliver up to 1,000x performance improvement over the current MI300X generation, though this figure likely refers to specific workloads rather than general-purpose performance.
When will the AMD MI500 be available?
AMD has committed to a 2027 launch for the Instinct MI500 Series. The company announced this timeline at CES 2026, positioning the product one year after Nvidia's Vera-Rubin platform (which ships mid-2026). Early production in 2027 is expected, with volume availability likely ramping through 2027-2028.
How does the MI500 compare to Nvidia's Vera-Rubin?
Vera-Rubin ships one year earlier (mid-2026) with an established ecosystem and software maturity advantage. Nvidia claims Vera-Rubin provides 10x cost reduction for mixture-of-experts inference and 4x reduction in GPUs needed for training. MI500 will likely offer competitive performance in certain workloads, particularly those sensitive to memory bandwidth. However, Vera-Rubin's earlier availability and larger ecosystem give Nvidia significant advantages.
What are the key advantages of HBM4E memory?
HBM4E memory provides substantially higher bandwidth than current HBM3E (estimated 2.5+ TB/s vs. 1.46 TB/s per channel), enabling faster data delivery to compute units. This addresses memory bandwidth bottlenecks in modern AI workloads. HBM4E also enables higher per-GPU capacity (potentially 256-384 GB vs. current 192 GB) and operates more efficiently than GDDR memory, reducing power consumption and cooling requirements.
What is CDNA 6 architecture and how does it improve on CDNA 5?
CDNA 6 is AMD's next-generation compute architecture for AI workloads, representing a ground-up redesign from CDNA 5. Expected improvements include optimized compute block structures for transformer operations, enhanced cache hierarchies for inference workloads, improved interconnect fabric for multi-GPU systems, and better support for low-precision formats (FP8, FP6). Specific architectural details remain confidential until closer to launch.
Why is the 2nm process important for MI500?
The 2nm process enables greater transistor density (approximately 2x improvement over 5nm), reducing power consumption per unit of compute while enabling higher clock speeds. This is critical because MI500 combines high-bandwidth HBM4E memory with increased compute density, which would be power-prohibitive on older process nodes. 2nm manufacturing essentially makes the design physically and economically feasible for data center deployment.
What is AMD's strategy with the MI440X and Helios products?
MI440X is positioned as a near-term product for enterprises with existing on-premises infrastructure, designed to fit into standard eight-GPU systems for training and inference. Helios is a rack-scale platform combining MI455X GPUs and EPYC Venice CPUs, positioned as a blueprint for system integrators rather than a direct consumer product. Both are defensive plays to maintain market presence while waiting for MI500, acknowledging the one-year timing gap with Vera-Rubin.
What are the risks that could delay MI500 or impact its success?
Key risks include TSMC capacity constraints on 2nm manufacturing (competing with Apple, Qualcomm, and others), potential yield challenges on the new process node, possible supply chain delays, ecosystem maturity gaps in ROCm software, and the compounding competitive advantage Vera-Rubin gains through a year of market presence and software optimization. Additionally, customer inertia favoring proven Nvidia solutions represents an adoption barrier.
How does memory bandwidth affect AI inference performance?
Memory bandwidth is often the bottleneck in AI inference workloads. The equation is: Effective Throughput = Compute Performance / (Memory Latency + Data Transfer Time). If memory bandwidth is insufficient, GPUs sit idle waiting for data. MI500's HBM4E memory (estimated 2.5+ TB/s per GPU) directly addresses this bottleneck, enabling higher effective throughput for inference workloads without requiring model sharding across multiple GPUs.
What does the 1,000x performance improvement claim mean?
AMD's claim of up to 1,000x performance improvement likely refers to specific workload scenarios where MI500's architecture is particularly well-suited, rather than general-purpose performance. For actual implementation, expect 3-4x overall improvement from combined architecture enhancements, process technology benefits, and memory bandwidth increases. Memory-bandwidth-limited workloads will see 1.6-2x improvement, while compute-limited training scenarios might see 2-3x improvement. The 1,000x figure should be interpreted with appropriate skepticism until detailed benchmarks are published.

Key Takeaways
- AMD's MI500 launches in 2027 with CDNA 6 architecture, 2nm manufacturing, and HBM4E memory, promising up to 1,000x performance improvement over MI300X
- Nvidia's Vera-Rubin ships mid-2026, one year earlier, with established ecosystem and software maturity advantages that create compounding market leadership
- HBM4E memory provides estimated 70% higher bandwidth than HBM3E, addressing critical memory bottlenecks in modern AI inference workloads
- 2nm process technology is essential for achieving power efficiency required to deploy high-bandwidth GPU designs economically in data centers
- CUDA ecosystem dominance and software maturity give Nvidia significant advantages regardless of MI500's technical competence; adoption barriers remain substantial
- MI500's realistic success looks like 15-30% market share capture in specific use cases and geographies, not broad displacement of Vera-Rubin's market leadership
- Timing disadvantage and one-year delay mean Vera-Rubin establishes installed base, customer optimization, and ecosystem momentum before MI500 even ships
Related Articles
- Nvidia's Vera Rubin Chips Enter Full Production [2025]
- The YottaScale Era: How AI Will Reshape Computing by 2030 [2025]
- Nvidia Rubin Chip Architecture: The Next AI Computing Frontier [2025]
- AI Isn't a Bubble—It's a Technological Shift Like the Internet [2025]
- CES 2026: Everything Revealed From Nvidia to Razer's AI Tools
- xAI's $20B Series E: What It Means for AI Competition [2025]

