The Open AI Head of Preparedness Hire: What It Reveals About AI's Growing Risks
Open AI just posted a job listing that tells you everything you need to know about where the AI industry actually stands right now, and it's not the optimistic narrative you hear in keynotes. The company is hunting for a new Head of Preparedness. Someone to oversee their "preparedness framework"—basically Open AI's system for studying and preparing for the catastrophic risks that AI models might create. Not someday risks. Risks that are starting to show up right now.
When Sam Altman announced the opening on X, he was refreshingly blunt about what he's worried about. AI models are "starting to present some real challenges." Models that are so good at finding computer security vulnerabilities they're accidentally becoming offensive tools. Models that might be impacting people's mental health in ways nobody fully understands yet. Biological capabilities that are advancing faster than safeguards.
This isn't theoretical anymore. This is happening. And Open AI is essentially admitting they need someone senior enough, experienced enough, and probably tough enough to actually do something about it. Here's what's really going on, why this hire matters, and what it says about the entire AI industry's relationship with safety and risk management.
Understanding Open AI's Preparedness Framework
Open AI didn't just wake up and decide to study AI risks. They built an entire framework around it. And that framework is the backbone of why this new hire matters. Back in 2023, Open AI announced the creation of a dedicated preparedness team. The mandate was clear: study potential "catastrophic risks" created by AI models. But here's what made the framework interesting. They weren't just worried about abstract, decades-away scenarios. They were tracking immediate threats too.
Phishing attacks. Social engineering. Models becoming good enough at security vulnerabilities that bad actors start asking them for help. These are happening now. Right now. Today. Not some speculative future where AI gets smarter. The preparedness framework is essentially Open AI's way of saying: "We're going to systematically track what new capabilities our models develop, figure out what harms those capabilities could enable, and prepare defenses before those harms happen." It's less "prevent AGI from destroying humanity" and more "make sure our current model doesn't accidentally enable a cybersecurity disaster in six months."
The framework has four main components. First, capability evaluation. Testing what new things the model can do before release. Second, risk assessment. Running through scenarios where those capabilities could cause harm. Third, policy development. Creating rules about how and where the model can be deployed. Fourth, ongoing monitoring. Watching what actually happens in the wild after release.
It sounds rational and structured. It is. But the framework is also proof that even the companies building these models don't fully understand what they're building until they build it and see how people actually use it. The fact that they need a senior executive dedicated to this full-time tells you something else too. This isn't a side project. This is strategically important work at a company worth over $80 billion.

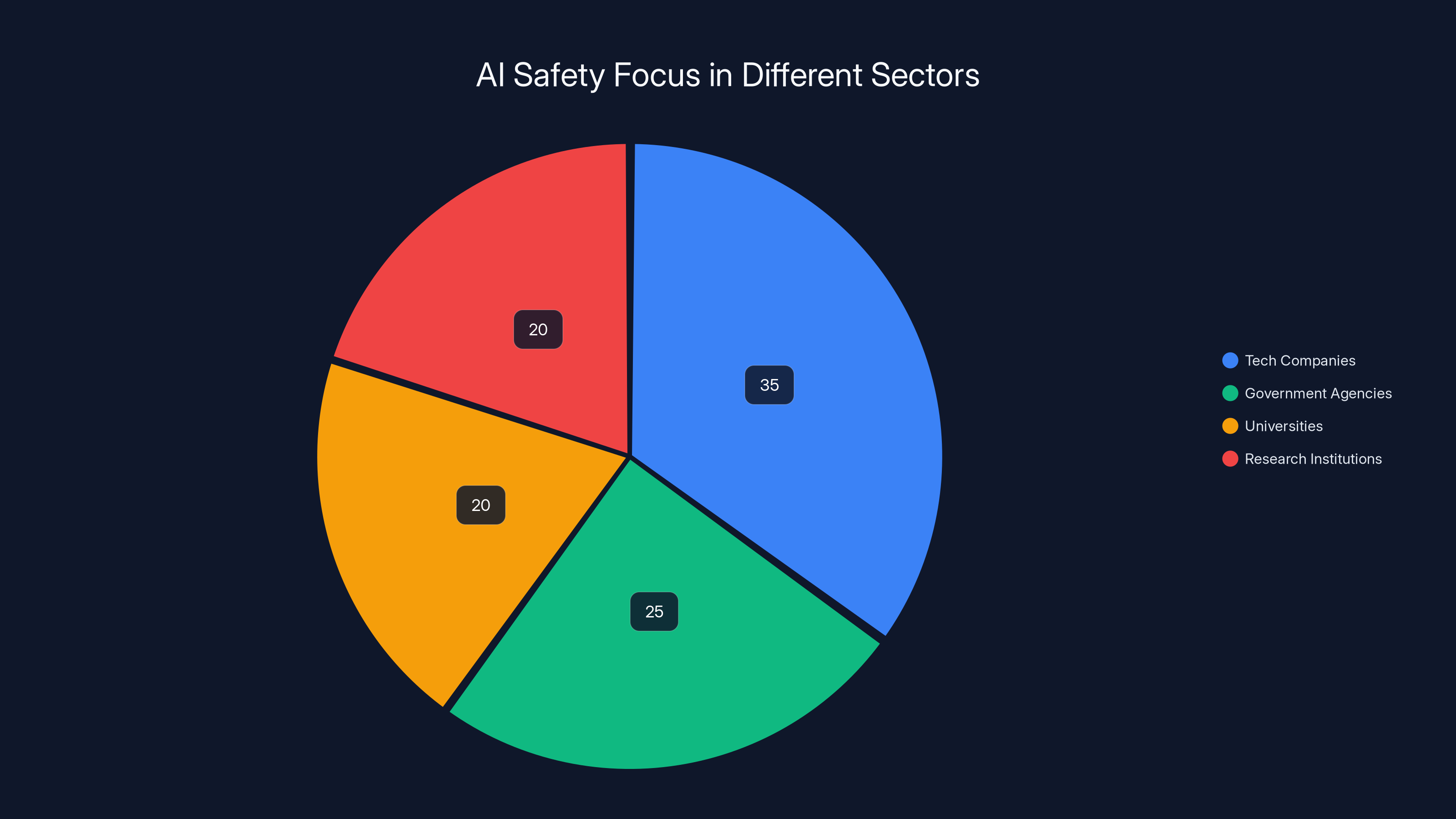
Estimated data shows that tech companies lead in AI safety focus, followed by government agencies and academic institutions. Estimated data.
Why Open AI Lost Their Last Head of Preparedness
This job opening exists because Open AI just moved their previous Head of Preparedness, Aleksander Madry, to a different role focused on AI reasoning. Madry wasn't some junior product manager moved around for career development. He was a serious researcher who spent years focused on AI safety, adversarial robustness, and making sure models didn't do harmful things. The fact that Open AI pulled him away from preparedness work is significant. It signals that either (a) they thought the preparedness team was mature enough to not need his full attention, or (b) AI reasoning became urgent enough that they needed his expertise there instead.
Given everything happening in the AI market right now, I'd bet it's both. The reasoning capabilities of modern large language models have become critical to companies' competitive positioning. Models that reason better, that can break down complex problems, that can plan multi-step solutions—these are the models that actually create business value. So Open AI pulled their most senior safety researcher to help make reasoning better.
This is actually a common pattern across the AI industry. Google Deep Mind, Anthropic, Meta—all of them have safety teams. All of them have strong researchers in those teams. But when competition heats up and capability development becomes the differentiator, safety work can start feeling like a drag on velocity.
Open AI is trying to thread a needle here. They want to move fast on reasoning and other capabilities. But they also can't completely ignore the real harms that are already emerging from their models. So they promoted Madry to reasoning work and opened up a search for someone new to run preparedness.
The interesting thing is that this new hire will be stepping into a role where the previous person just got demoted in terms of priority (even if it felt like a promotion in terms of project importance). That's not a comfortable position. You're walking into a role that just signaled maybe it's not the company's highest priority.
The Mental Health Crisis Nobody Talks About
Open AI wouldn't have mentioned mental health in a CEO post about hiring if this wasn't already becoming a real problem. Chat GPT is a conversational AI. People use it for what seems like innocent reasons. They want help writing. They want someone to talk to. They want to brainstorm ideas. Millions of people use it every single day in exactly that way, and it's fine. Helpful, even.
But some people are using it in ways that are harmful to themselves. Recent lawsuits against Open AI allege that Chat GPT has reinforced users' delusions, increased their social isolation, and in some cases contributed to suicidal thinking. These aren't speculative harms. These are actual lawsuits filed by actual lawyers on behalf of actual people who claim their mental health got worse because of how they were using the model.
One lawsuit alleges that a user with obsessive-compulsive disorder used Chat GPT to reinforce their compulsions rather than interrupt them. Another claims the model increased isolation by replacing human interaction. Another suggests the model didn't recognize signs of distress and respond appropriately.
Open AI has actually made some moves here. They've been working to improve Chat GPT's ability to recognize signs of emotional distress and connect users to real-world mental health resources. They added features to detect concerning language patterns. They've been testing interventions when users seem to be in crisis.
But here's the honest part: that's all after the fact. That's remediation. That's admitting that the default behavior of the model wasn't designed with mental health in mind. The preparedness team's job would be figuring out how to catch these issues before they're big enough to generate lawsuits.
This is actually harder than it sounds. Chat GPT doesn't have user context. It doesn't know if someone has a diagnosed mental health condition. It doesn't know if they're currently in therapy or on medication. It's just responding to text prompts. Figuring out how to keep a conversational AI from accidentally making someone's mental health worse while still being genuinely useful to billions of other people? That's a complex problem that requires real expertise.

Estimated data shows increased isolation and reinforcement of delusions are the most reported negative impacts of AI on mental health. (Estimated data)
Cybersecurity: The Model That's Too Good At Finding Vulnerabilities
Alman mentioned something else that caught my attention. Models that "are so good at computer security they are beginning to find critical vulnerabilities." This is both incredible and deeply concerning.
On one hand, if your AI model can find security vulnerabilities better than most human security researchers, that's an amazing tool. You could use it to defend systems. You could use it to fix problems before attackers find them. You could use it to secure critical infrastructure. That's the dream scenario.
On the other hand, that same capability is a weapon if it gets into the wrong hands. Or if someone figures out how to prompt the model to find vulnerabilities for malicious purposes. Open AI has been cautious about releasing models with strong hacking capabilities. Earlier versions of their models were restricted in what they could say about security vulnerabilities. But current models are good enough that they naturally develop these capabilities. They learn to think like security researchers because that's part of understanding computer systems.
The preparedness team's job in this case is to figure out: where's the line between "good tool for defenders" and "dangerous if it enables attackers"? How do you release a model that's useful for cybersecurity professionals without creating new risks for everyone else? How do you design access controls that keep the tool away from bad actors while letting the good actors use it?
There's also the question of what to do when your model discovers vulnerabilities in real systems. Does Open AI have a responsibility to disclose those vulnerabilities? To the affected companies? To security researchers? To regulators? Should Chat GPT refuse to find vulnerabilities at all, or should it find them and report them to the right people?
These aren't technical questions anymore. They're policy and ethics questions. The new Head of Preparedness will probably spend a lot of time on decisions like this.
Biological Capabilities and the Acceleration Problem
Alman also mentioned "how we release biological capabilities and even gain confidence in the safety of running systems that can self-improve." That second part is almost casually mentioned but extremely significant.
Biological capabilities could mean a lot of things. Models that understand protein folding. Models that can design new proteins. Models that understand microbiology well enough to generate information about how to create pathogens. Models that are just generally knowledgeable about biology but could be misused.
All of these capabilities are emerging as side effects of training large language models on internet text. Nobody specifically tried to make the model good at biology. It just happened because there's a lot of biology information on the internet.
So the preparedness team has to figure out: how good is good enough? If a model is smart enough to help a researcher cure a disease, is it smart enough that bad actors could use it to create a biological weapon? And if so, what do you do about it?
The self-improvement part is even more interesting. Altman mentioned "systems that can self-improve." This is code for models that can generate training data for themselves, iterate on their own capabilities, or modify their own behavior without human intervention.
We're not there yet, but models are starting to do early versions of this. They can generate code to test their own output. They can iterate on solutions. They can learn from feedback in ways that previous models couldn't.
If a model can self-improve, then you can't just rely on testing it once before release. You have to monitor what happens as the model iterates. You have to prepare for capabilities you didn't anticipate because the model created them itself.
That's a completely different job than what preparedness teams were doing even a year ago.

The Competitive Pressure Problem
Here's where this gets politically important, and it's probably the real reason this job opening matters. Open AI recently updated its preparedness framework to include something controversial. The company stated it might "adjust" its safety requirements if a competing AI lab releases a "high-risk" model without similar protections.
In other words: if Anthropic or Google or Meta or x AI releases a model that's powerful but not as carefully safeguarded, Open AI might decide that their own safety requirements are unnecessary friction.
This is fundamentally different from a credible safety commitment. A credible safety commitment says: "We will maintain these standards regardless of what competitors do." A conditional safety commitment says: "We'll maintain these standards unless we think someone else isn't, in which case all bets are off."
The new Head of Preparedness is going to inherit this policy. They're going to have to defend it. They're going to have to figure out how to enforce safety standards in a competitive market where other companies are racing ahead.
That's not a fun job. It's the job of someone who has to be comfortable saying "no" to the CEO when the CEO wants to release something that hasn't been fully prepared for.
The reason Open AI moved Aleksander Madry to AI reasoning is now pretty clear. Reasoning capabilities are becoming the competitive differentiator. Every model is trying to get better at multi-step problem solving because that's what creates business value. So you need your best researcher working on that.
But you also can't completely blow off safety because that creates regulatory risk and legal risk. So you hire a new Head of Preparedness who can manage that balance.
What you're looking for in that person is someone who understands that safety and capability development aren't fundamentally at odds. Someone who can find ways to be cautious without being slow. Someone who can communicate why certain risks matter even when executives are impatient.

Red teaming is estimated to catch 70-80% of serious issues before release, highlighting its critical role in model safety. Estimated data.
What This Job Actually Involves Day-to-Day
Based on the job description, here's what the new Head of Preparedness would actually be doing. First, they'd be responsible for executing the preparedness framework itself. That means designing the processes, managing the teams, making sure evaluations actually happen before models are released.
Second, they'd be tracking frontier capabilities. Every new feature that comes out of the research labs gets evaluated. Can this capability be misused? What's the threat model? What mitigations are needed?
Third, they'd be developing preparedness plans for each major model release. What could go wrong? What monitoring do we need in place? What guardrails should be built in?
Fourth, they'd be managing stakeholder relationships. This includes talking to regulators, talking to security researchers, talking to people inside Open AI who want to move faster than safety processes allow.
Fifth, they'd be staying ahead of emerging risks. The field is moving fast. New capabilities emerge regularly. The Head of Preparedness has to be thinking two or three steps ahead.
Sixth, they'd be managing the tension between safety and capability. This is the hardest part of the job. How do you keep up with competitors while maintaining meaningful safety standards?
The job also requires someone with serious credibility. You can't hire someone who's been working in product management at a social media company. You need someone who has deep expertise in AI, security, risks, or related fields. Someone who can stand up to technical experts and say "we're not releasing this yet" and make it stick.
It's also a job where you're somewhat doomed to fail. If nothing bad happens, people say your safety work was unnecessary. If something bad does happen, people say your safety work failed. So you need someone who can function in that environment.

The Brain Drain From AI Safety Teams
Open AI isn't the only lab that's had trouble keeping senior people in safety roles. This is actually a pattern. Google Deep Mind has seen several safety researchers move on or change roles. Anthropic, which was founded specifically to focus on safety, has also lost some safety leadership. Meta's approach to safety seems less rigorous than other companies.
Why? A few reasons. First, the capability side of the research is more glamorous. Building better models, training larger models, discovering new properties of neural networks—that's the research that gets published in top venues and gets you famous. Studying risks and building safety systems? That's important but less celebrated.
Second, working on safety means constantly saying "no" to exciting research projects. That's not fun. Eventually you want to work on something where you get to say "yes."
Third, the timeline question. If you believe that superhuman AI is 30 years away, safety work feels less urgent. But if you believe it's 5 years away, safety work feels critical. Most researchers are somewhere in the middle, which means they're not fully committed to safety work.
Fourth, there's a philosophical question about whether safety work at companies actually does anything. Some researchers think that focusing on safety at one lab while other labs ignore it is basically pointless. The only thing that matters is what happens across the entire field.
Fifth, the pay and working conditions. Capability research probably pays better. The teams are larger. You get more resources. The management probably cares more about the work.
So when Open AI moves their best safety researcher to a capability team, that's not unique. That's actually the baseline expectation in the industry.
The Regulatory Context: Why Safety Frameworks Matter Now
Two years ago, talking about AI safety frameworks would have felt academic. Today it feels urgent because regulators around the world are watching. The EU's AI Act explicitly requires companies to have risk assessment processes and ongoing monitoring systems. The UK has an AI framework. The US government has been issuing executive orders on AI safety. China has announced regulations. This is becoming actual law.
Open AI's preparedness framework isn't just an internal system anymore. It's part of their legal compliance strategy. When regulators ask "how do you manage risks," Open AI can point to the preparedness team and the documented framework.
The new Head of Preparedness isn't just managing internal risks anymore. They're managing regulatory relationships. They're building the documentation that governments will use to decide whether to allow Open AI to build bigger models.
That actually makes the job more important but also more constrained. You can't just blow off safety because regulators are watching. But you also can't build such tight restrictions that you slow the company down relative to competitors who might be in jurisdictions with less oversight.

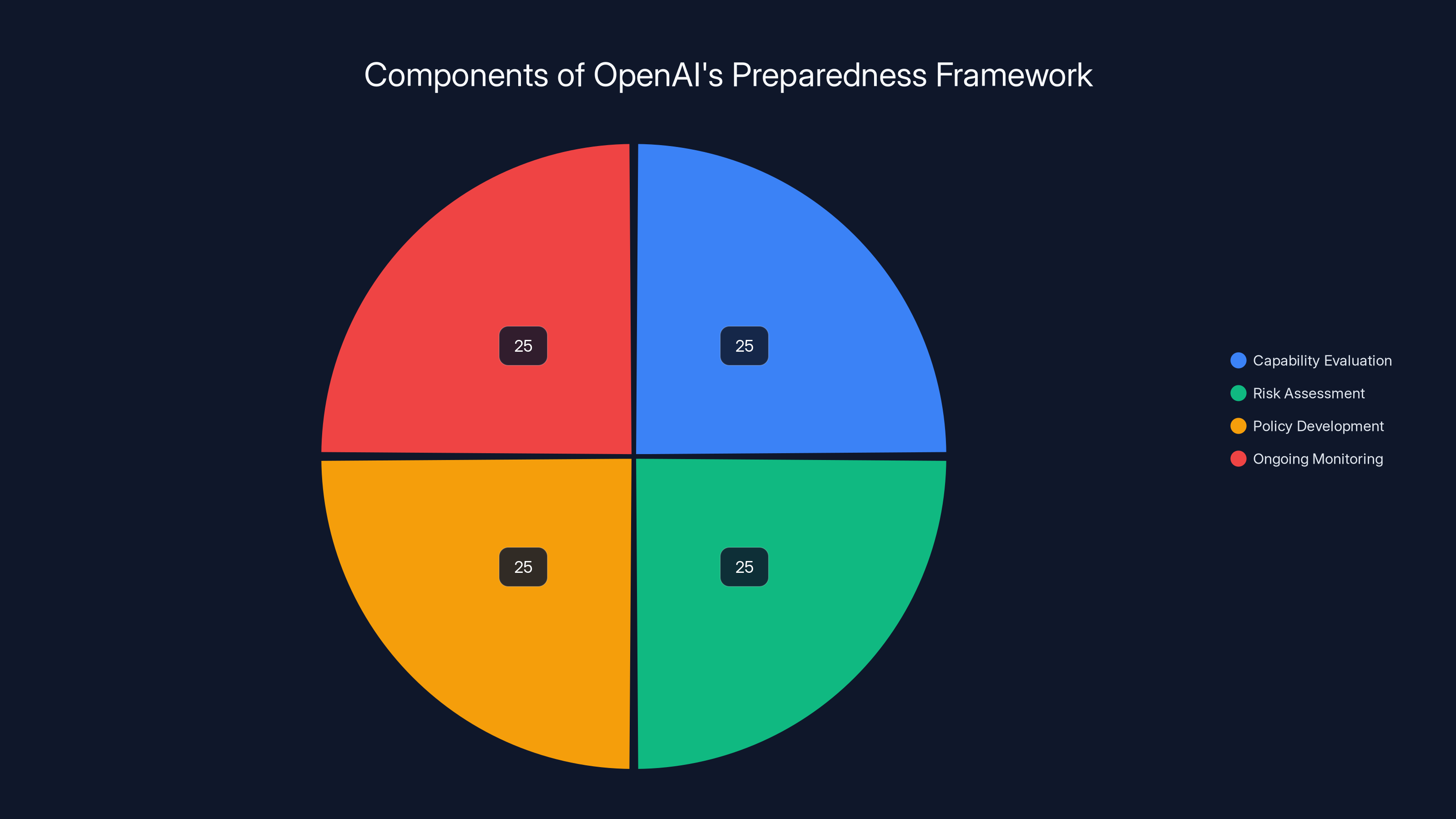
OpenAI's preparedness framework is evenly divided into four components: capability evaluation, risk assessment, policy development, and ongoing monitoring. Each plays a crucial role in mitigating AI risks.
Competitive Intelligence and Red Teaming
Part of the preparedness role involves understanding what other labs are doing and preparing for what might come next. If Anthropic releases a model with stronger reasoning capabilities, Open AI needs to understand what new risks that creates before they release their own models with similar capabilities. If Deep Mind develops a model with better biological knowledge, what's the threat model? What mitigations are needed?
This competitive intelligence function is crucial. It's the difference between being reactive (waiting for another lab to release something harmful, then responding) and being proactive (preparing for risks before they emerge).
Red teaming is another big part of the job. You hire people to try to break the model. Try to find vulnerabilities. Try to make it do harmful things. The preparedness team coordinates this work and figures out what to do about the vulnerabilities they find.
A good red teaming process catches maybe 70-80% of serious issues before release. But it's expensive and time-consuming. As competition heats up, there's pressure to do less red teaming and release faster. The Head of Preparedness has to defend the red teaming process against that pressure.
The Future of AI Preparedness
Here's my prediction: the next Head of Preparedness at Open AI is going to face increasing pressure from three directions simultaneously. First, regulators are getting serious. The EU AI Act goes into full effect soon. The UK might pass stronger regulations. The US might impose restrictions on compute and data access. These aren't theoretical anymore. Companies need serious safety and preparedness infrastructure to stay compliant.
Second, capability development is accelerating. Reasoning is improving faster than anyone predicted. Multimodal models are getting smarter. There will be new capabilities emerging regularly, and each one needs to be evaluated for risks.
Third, competition is fierce. Anthropic, x AI, Meta, and others are building models without the same level of safety scrutiny that Open AI applies. If Open AI moves too slowly, they lose market share. If they move too fast, they create risks and regulatory problems.
Maneuvering between those three pressures requires someone with unusual skills. You need deep technical expertise. You need political savvy. You need the ability to make decisions when the information is incomplete. You need to be comfortable being wrong.
The good news is that the role is becoming more important and more resourced. Open AI clearly thinks preparedness matters or they wouldn't be hunting for a senior executive.
The bad news is that the job is probably harder now than it was when Aleksander Madry had it. The stakes are higher. The models are more capable. The risks are more real. The competition is fiercer.
Whoever takes this job is walking into one of the most important roles in AI right now. They're not going to be building the models or training them. They're going to be the person saying whether the models are ready to release.
That's enormous responsibility.

Industry Response and Implications
The fact that Open AI is publicly looking for this role tells us something about industry maturity. A few years ago, safety roles were quiet, behind-the-scenes work. Now they're public, competitive, important positions that get announced by the CEO. This signals that the industry recognizes AI risks as real and material. Not speculative. Not for philosophers to debate. Real business problems that need real solutions.
Other labs are watching this hire closely. If Open AI brings in someone impressive, that person becomes the standard bearer for what preparedness leadership looks like. Other companies will try to recruit people with similar skills.
It also signals that safety and preparedness aren't going away as functions in AI companies. They're becoming more central, not less. Even as Open AI moves fast on capability development, they're doubling down on safety infrastructure.
That's actually good news for the field. It means the companies building the most powerful AI models are taking risks seriously. They're building systematic processes to catch problems. They're hiring smart people to think about what could go wrong.
The bad news is that even with these systems in place, bad outcomes are still possible. Safety frameworks catch problems, but they don't prevent all problems. The best systems are still reactive to some degree. Something will slip through, and when it does, the Head of Preparedness will be responsible for explaining why.
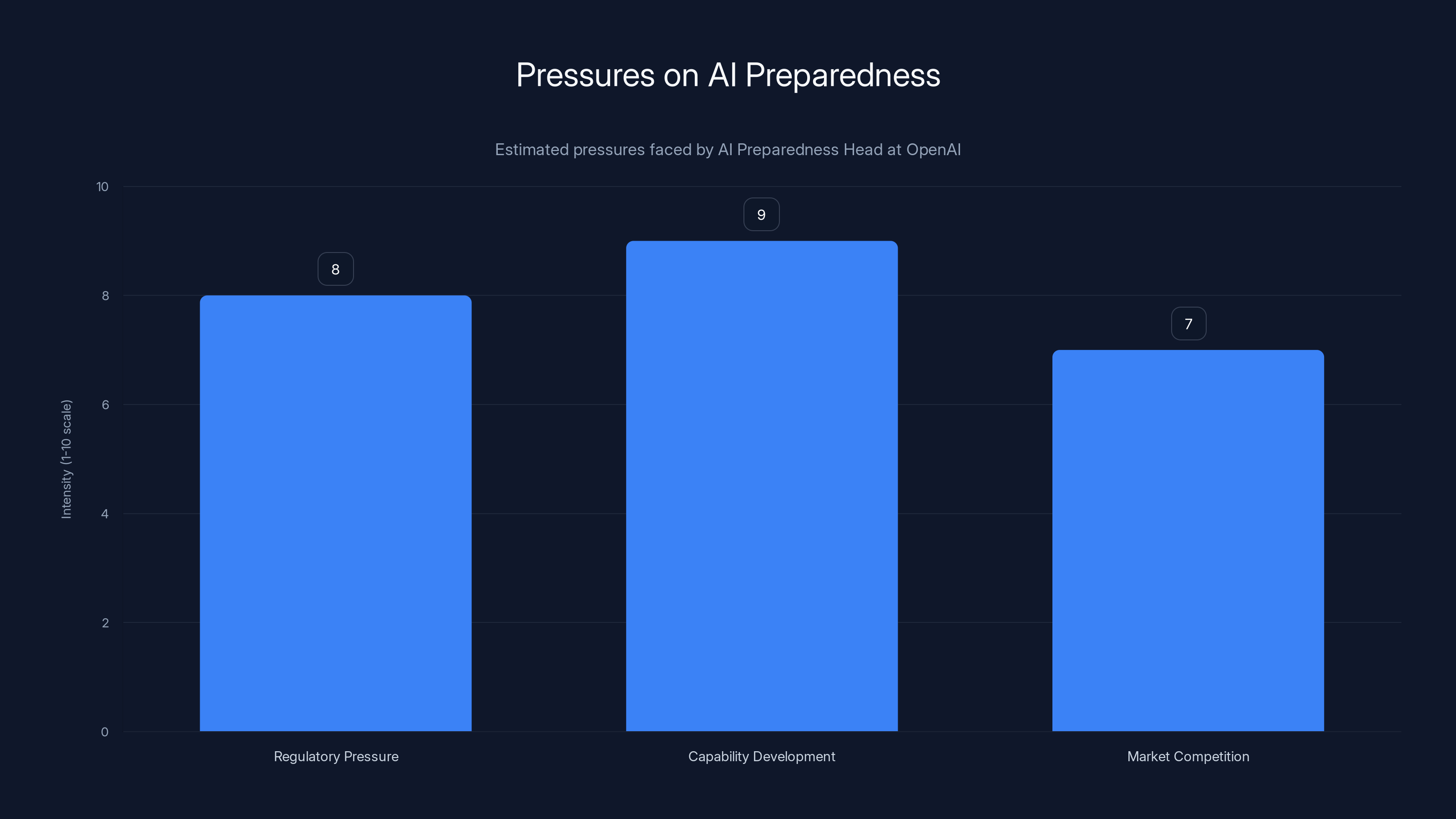
The Head of Preparedness at OpenAI faces significant pressures from regulatory changes, rapid capability development, and intense market competition. (Estimated data)
The Mental Health Lawsuit Question
Let's circle back to the mental health lawsuits because they're probably going to be a major focus for the new Head of Preparedness. These lawsuits aren't frivolous. They're alleging that Chat GPT caused measurable harm to real people. The legal theory is basically that Open AI knew or should have known that conversational AI could be harmful to people with certain mental health conditions, and they didn't build adequate safeguards.
Open AI's defense is that they've been working to improve these safeguards. They've made updates. They've added features to detect distress. They've tested interventions.
But here's the problem: none of this prevents the lawsuits from happening. All this work is remediation, not prevention. The preparedness team's job would be figuring out how to prevent these scenarios from happening in the first place.
What would that look like? Maybe screening users for signs of mental health risk. Maybe refusing to engage in certain types of conversations. Maybe implementing conversation limits to prevent excessive reliance. Maybe being more transparent about the model's limitations.
All of these have downsides. Users hate being told what they can or can't do. Limiting conversations reduces the utility of the product. Being transparent about limitations might scare people away.
So the preparedness role becomes a balancing act. How do you protect people from potential mental health harms without crippling the product's utility?
The new Head of Preparedness might recommend that Open AI implement stronger mental health safeguards, knowing it will be unpopular. They might recommend that the company takes a less aggressive stance on conversational freedom. They might recommend resources and partnerships with mental health organizations.
Whatever they recommend, it's going to be controversial inside the company. Product teams want maximum flexibility. Safety teams want maximum caution. The preparedness role is where that tension gets resolved.

Biological Risks and Dual-Use Concerns
Alman's mention of biological capabilities deserves more attention because it's probably one of the most serious risks Open AI is considering. Current language models are already pretty knowledgeable about biology. They can explain protein folding. They can discuss microbiology. They can generate information about how pathogens work.
Most of this information is harmless and actually useful. Researchers use it. Students use it. People trying to understand their own health use it.
But the same information could theoretically be used to create biological weapons or pathogens. This is what's called a "dual-use" capability. The same knowledge is useful for good purposes and bad purposes.
Open AI's job is to figure out: are our models good enough at biology that they become a biosecurity risk? And if so, what do we do about it?
One approach is to restrict biological information in training data. But that's not practical at scale. Another approach is to refuse requests for information that seems like it's being used for bad purposes. But that's hard to detect reliably.
A third approach is to make the capability public so that bad actors can access it anyway but legitimate researchers also get access. That paradoxically might be safer because it removes Open AI's role as gatekeeper.
The preparedness team has to think through these tradeoffs and make recommendations. They have to talk to biosecurity experts. They have to understand what bad actors might actually do with this capability. They have to figure out what responsibility Open AI has.
This is where the job gets philosophically deep. Open AI is creating a tool (a language model) that could theoretically be used to cause massive harm. They can't prevent that entirely. So what's their responsibility? Just minimize risk? Try to shape deployment? Work with regulators?
Self-Improvement and Recursive Learning
When Altman mentioned "systems that can self-improve," he was talking about a specific capability that's starting to emerge in advanced models. It's not AGI or artificial general intelligence. It's not the model turning into Skynet. It's something more specific and more tractable: the model can generate code, test that code, iterate on the results, and improve its own capabilities without human intervention at each step.
This has been demonstrated in research settings. Models can write Python code to solve problems, test whether the code works, and improve the code based on test results. It's like a programmer who keeps working on code until it's right.
The problem for preparedness teams is obvious: you can't just test a model once before release. If the model can improve itself, then the model you deploy is different from the model you tested.
It's like approving a painting and then finding out the painting has been secretly modifying itself. You tested version 1.0 but users are interacting with version 47.0 because the painting has been improving itself in the wild.
How do you prepare for that? You need continuous monitoring systems. You need alerts that trigger if the model's behavior changes significantly. You need the ability to update or retract the model if it starts doing harmful things.
You also need to think about whether you should allow this capability at all. Should you disable the self-improvement loops? Should you restrict them? Should you monitor them closely?
These are questions the new Head of Preparedness will probably spend a lot of time on.

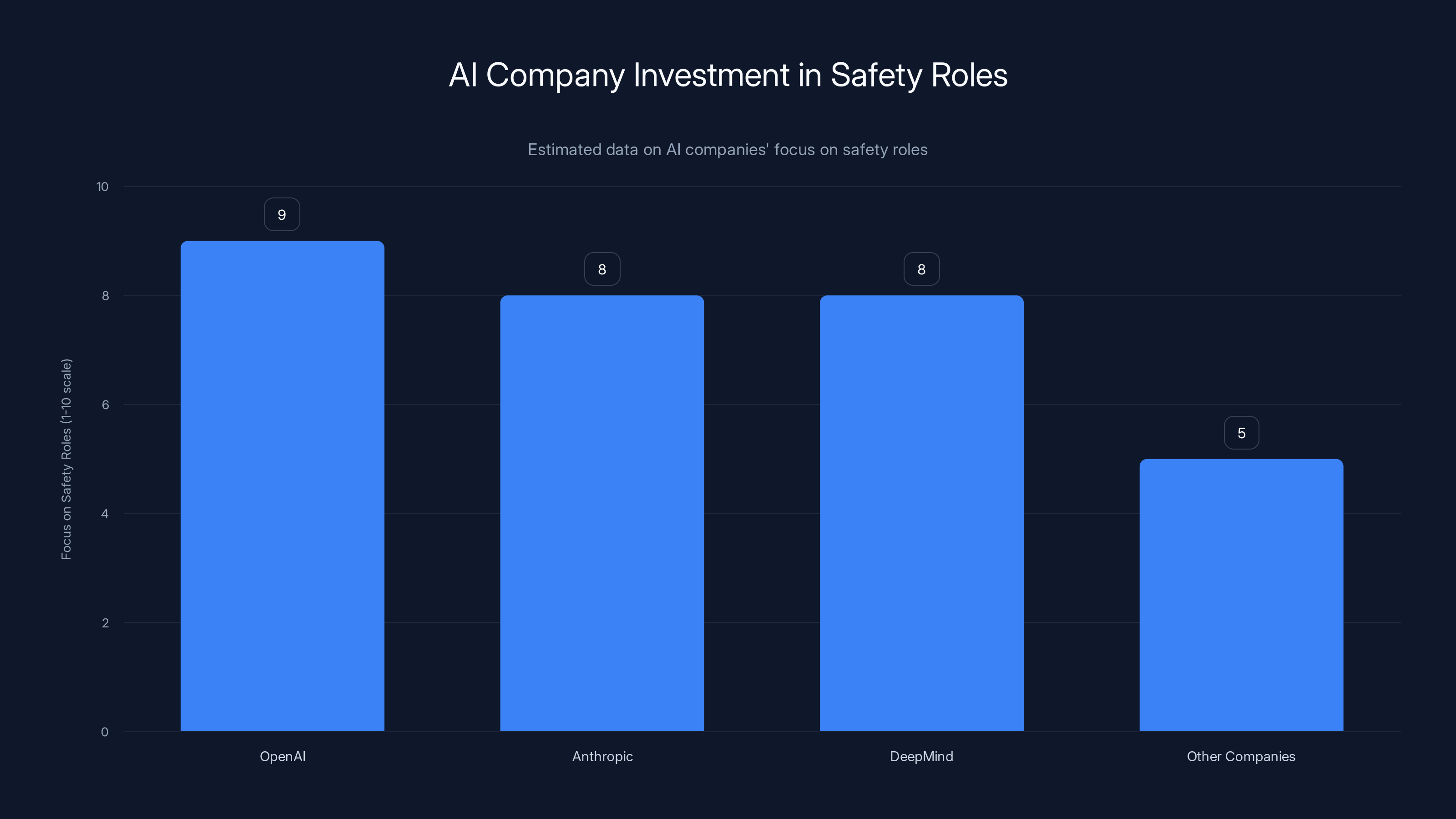
OpenAI, Anthropic, and DeepMind are highly focused on safety roles, with other companies likely to increase their focus. Estimated data based on industry trends.
What Success Looks Like for the New Head of Preparedness
How do you measure success in a safety and preparedness role? It's not obvious. If nothing bad happens, did you succeed? Or were you just lucky? Maybe Open AI would have been fine without this person's work. Maybe they prevented disasters that would never have happened anyway.
If something bad does happen, did you fail? Or did you fail better than you would have without the preparedness framework? Maybe the harm would have been worse if you hadn't been there.
This is the fundamental challenge of working in risk management. Success is invisible. You don't see the disasters you prevented.
But there are some measurable success metrics:
Regulatory compliance: Does Open AI pass government audits? Are they operating within legal frameworks?
Documented processes: Is there a clear, documented, repeatable process for evaluating risks before release? Can someone read the documentation and understand why Open AI did or didn't release something?
External credibility: Do safety researchers, regulators, and external experts think Open AI is doing serious safety work? Or do they think it's mostly theater?
Balanced decisions: Does the preparedness team sometimes say no? If they say yes to everything, they're not actually doing their job.
Industry influence: Do other labs copy Open AI's approach? Is the preparedness framework becoming an industry standard?
Incident response: When bad things happen (and they will), does the preparedness team have a documented process for responding? Is the response proportional and effective?
The new Head of Preparedness will probably be evaluated on these metrics, along with whatever Open AI's internal goals are.
The Bigger Picture: AI Safety as an Industry
Open AI's preparedness team is part of a larger movement in the AI industry toward more systematic approaches to safety and risk management. Anthropic was founded specifically to focus on safety. They've built a whole company around the idea that AI safety should be central to how you develop models.
Deep Mind has an entire division focused on AI safety and governance. The US government is now funding AI safety research through NIST and other agencies. Universities are building AI safety programs.
There's a whole field emerging around AI governance, safety evaluation, and risk management. This is relatively new. Five years ago, AI safety was a fringe concern. Now it's mainstream. Companies are hiring people specifically to work on it. Governments are making it a priority. Academic papers on AI safety are getting published in top venues.
The question is whether this is enough. Is the field moving fast enough to actually address the risks? Or are the risks scaling faster than the safety responses?
My guess is that the answer is: it's not enough yet, but it's getting better. The field is building infrastructure and expertise. The preparedness teams at major labs are becoming more sophisticated. The processes are improving.
But there's still a fundamental tension between moving fast and moving carefully. As long as that tension exists, there will be pressure to cut corners on safety work. And sometimes those corners get cut.

What This Means for Users and the Broader Ecosystem
For most people using Chat GPT or other AI models, the existence of a preparedness team doesn't change anything. The model works or it doesn't. It's helpful or it's not.
But behind the scenes, there are people thinking about what could go wrong. Thinking about how the model might be misused. Thinking about what safeguards are needed.
That work is valuable even if it's invisible. It means that the most powerful AI models are being built with at least some consideration for risks.
It also means that if something goes wrong, there's a documented process for responding. Open AI can point to the preparedness framework and show that they took steps to prevent the problem.
From a policy perspective, the existence of these roles also makes it easier for governments to regulate AI. They can point to internal safety teams and say "see, companies are taking this seriously." That strengthens the case for lighter regulation.
The question is whether light touch regulation is sufficient. Some people argue that companies will always prioritize capability development over safety if left to their own devices. Others argue that regulation is too slow and companies should be allowed to self-regulate.
The new Head of Preparedness will probably think about both sides of that debate.
Lessons for Other AI Companies
Open AI's decision to hire a new Head of Preparedness sends signals to other companies that this is an important role. It signals that safety and preparedness should be senior positions with real resources and authority. Not junior roles. Not side projects.
It signals that even successful companies (Open AI is worth over $80 billion) think safety work is important enough to invest in publicly.
It signals that the talent market for safety and preparedness roles is competitive. Open AI is hunting for the best people they can find.
Other companies will probably respond by beefing up their own safety and preparedness teams. Anthropic and Deep Mind probably don't need to hire right now because they're already focused on safety. But companies that are less focused on safety might realize they need to create these roles.
That's a positive trend. More companies investing in safety means more people working on these problems. It means more approaches being tried. It means the field is building collective expertise.

Looking Ahead: What's Next for AI Preparedness
Based on what we know about the current trajectory of AI development, here are the areas that the next Head of Preparedness will probably focus on:
Capability evaluation at scale: As models get bigger and more capable, evaluating what they can do becomes harder. The new preparedness leader will need systems that scale with model capability.
Cross-lab coordination: If Open AI is worried about what Anthropic or others are doing, they need better information sharing. That might mean more transparency between labs or coordinated safety standards.
Measurement and monitoring: Right now, we don't have great metrics for measuring AI risks. The preparedness team might invest in developing these metrics.
Regulatory relationships: As governments get more active in AI regulation, the preparedness team will probably do more work interfacing with regulators.
Incident response: Eventually something bad will happen. The preparedness team needs to be ready to respond quickly and effectively.
Long-term planning: Beyond the current models, what risks emerge from future models? The preparedness team should be thinking two or three generations ahead.
These are the kinds of problems that the new Head of Preparedness will be working on.
Conclusion
Open AI's search for a new Head of Preparedness tells us that AI safety has become a core business function, not a side project. It tells us that the risks from current AI models are real and material, not speculative.
It tells us that even in a competitive environment, major AI companies are willing to invest in safety and preparedness infrastructure. It tells us that the field is maturing. Role definitions are becoming clearer. Standards are emerging. Expertise is accumulating.
Most importantly, it tells us that people building the most powerful AI models recognize they need help managing the risks those models create.
Is that help enough? Is the pace of safety work keeping up with the pace of capability development? Is the preparedness framework actually preventing bad outcomes or just providing political cover?
Those are the real questions. The new Head of Preparedness will be one of the people trying to answer them.
The role matters. The person who takes it will have influence over how the most powerful AI models in the world are developed and deployed. They'll have say in what gets released and what gets held back. They'll be involved in some of the most important decisions in technology.
That's a lot of responsibility. The right person for the job needs to be expert enough to understand the technical details, thoughtful enough to navigate the ethical complexity, and tough enough to push back against executives who want to move faster.
Finding that person is hard. But Open AI is clearly committed to trying.

FAQ
What is Open AI's Preparedness Framework?
Open AI's Preparedness Framework is the company's systematic approach to identifying emerging AI capabilities, assessing potential harms those capabilities could enable, developing policies to prevent misuse, and monitoring real-world outcomes after model deployment. The framework was first announced in 2023 and is designed to track both immediate risks like cybersecurity vulnerabilities and more speculative long-term risks like biological capabilities. It serves as Open AI's core tool for managing AI safety and compliance with emerging government regulations.
Why did Open AI reassign Aleksander Madry?
Aleksander Madry, Open AI's previous Head of Preparedness, was reassigned to focus on AI reasoning capabilities. This move likely reflects Open AI's assessment that AI reasoning has become a critical competitive priority, combined with the belief that their preparedness team had matured enough to function with different leadership. However, it also signals a potential shift in organizational priorities, with capability development possibly receiving more resources than safety work.
What specific AI risks is Open AI concerned about?
Open AI is tracking multiple categories of emerging risks: cybersecurity vulnerabilities that advanced models can identify and potentially weaponize, mental health impacts from conversational AI, biological information that could be misused, and capabilities related to self-improving systems that evolve after deployment. According to Sam Altman's announcement, the company views these as immediate challenges, not theoretical future concerns, making active preparedness essential.
How does AI's impact on mental health work?
Large language models like Chat GPT can engage in extended conversations that sometimes reinforce unhealthy thought patterns. Recent lawsuits allege that the model has reinforced users' delusions, increased isolation, and contributed to suicidal ideation in vulnerable individuals. Open AI is working to improve detection of emotional distress and connection to mental health resources, but the foundational challenge remains: designing conversational AI that's genuinely helpful while avoiding unintended psychological harm to vulnerable users.
What is dual-use technology in AI?
Dual-use technology refers to AI capabilities that have both beneficial and potentially harmful applications. For example, advanced knowledge about biology can help researchers cure diseases but could theoretically be misused to create biological weapons. Open AI's models possess various dual-use capabilities, creating the challenge of enabling legitimate beneficial uses while preventing misuse. This is why preparedness frameworks focus on assessing and monitoring how capabilities are actually used in the wild.
What does it mean for an AI model to self-improve?
Self-improving AI refers to models that can generate and execute code, test results, iterate on improvements, and modify their own behavior without human intervention at each step. Some advanced models now demonstrate this capability at small scales. The challenge for preparedness teams is that this means the deployed model continues evolving after release, making pre-deployment testing alone insufficient. Continuous monitoring becomes critical because you cannot fully predict what version of the model users will interact with.
How do AI safety frameworks help with regulation?
Governments like the EU, UK, and US are increasingly requiring AI companies to demonstrate risk assessment processes and ongoing monitoring systems. Open AI's preparedness framework provides documented evidence of these processes, which helps the company maintain compliance with emerging regulations and demonstrates to regulators that serious safety work is happening. However, this also creates pressure to ensure the framework is substantive rather than purely performative.
Why is finding a Head of Preparedness difficult?
The role requires an unusual combination of skills: deep technical AI expertise, understanding of security and risk management, political savvy for navigating stakeholder relationships, and the ability to make decisions with incomplete information. Additionally, it's a role where success is often invisible (preventing problems that don't occur), which makes it less appealing than capability development roles where success is concrete and celebrated. The high stakes and inherent tension between safety and speed also make it a challenging position to fill.
Key Takeaways
- OpenAI is actively recruiting a senior Head of Preparedness to oversee AI risk management across multiple emerging threat categories
- The company acknowledges that AI models are already presenting real risks in cybersecurity, mental health, and biological domains
- Previous head Aleksander Madry was reassigned to AI reasoning capabilities, signaling the growing priority of capability development alongside safety
- Mental health lawsuits against OpenAI indicate that AI conversational impacts represent material legal and regulatory liability
- Global AI regulations from the EU, UK, and US are making systematic risk assessment and preparedness frameworks essential for compliance
- Self-improving AI systems create new preparedness challenges requiring continuous monitoring instead of pre-release testing alone
- The recruitment signals that safety and preparedness roles are becoming core business functions rather than peripheral compliance activities

